

Abstract
Gaussian latent factor models are routinely used for modeling of dependence in continuous, binary, and ordered categorical data. For unordered categorical variables, Gaussian latent factor models lead to challenging computation and complex modeling structures. As an alternative, we propose a novel class of simplex factor models. In the single-factor case, the model treats the different categorical outcomes as independent with unknown marginals. The model can characterize flexible dependence structures parsimoniously with few factors, and as factors are added, any multivariate categorical data distribution can be accurately approximated. Using a Bayesian approach for computation and inferences, a Markov chain Monte Carlo (MCMC) algorithm is proposed that scales well with increasing dimension, with the number of factors treated as unknown. We develop an efficient proposal for updating the base probability vector in hierarchical Dirichlet models. Theoretical properties are described, and we evaluate the approach through simulation examples. Applications are described for modeling dependence in nucleotide sequences and prediction from high-dimensional categorical features.
Keywords: Classification, Contingency table, Factor analysis, Latent variable, Nonparametric Bayes, Nonnegative tensor factorization, Mutual information, Polytomous regression
1. INTRODUCTION
Multivariate unordered categorical data are routinely encountered in a variety of application areas, with interest often in inferring dependencies among the variables. For example, the categorical variables may correspond to a sequence of A, C, G, T nucleotides or responses to questionnaire data on race, religion, and political affiliation for an individual. We shall use yi = (yi1, …, yip)T to denote the multivariate observation for the ith subject, with yij ∈ {1, …, dj}.
Complicated dependence can potentially be expressed in terms of simpler conditional independence relationships via graphical models (Dawid and Lauritzen 1993). Such models have been used for continuous (Lauritzen 1996; Dobra et al. 2004), categorical (Whittaker 1990; Madigan and York 1995), and mixed-scale variables (Pitt, Chan, and Kohn 2006; Dobra and Lenkoski 2011). Although graphical models are popular due to their flexibility and interpretability, computation is daunting since the size of the model space grows exponentially with p. Even with highly efficient search algorithms (Jones et al. 2005; Carvalho and Scott 2009; Dobra and Massam 2010; Lenkoski and Dobra 2011, among others), it is only feasible to visit a tiny subset of the model space even for moderate p. Accurate model selection in this context is difficult when p is moderate to large and the number of samples is not enormous because, in such cases, even the highest posterior probability models receive very small weight and there will typically be a large number of models having essentially identical performance according to any given model selection criteria (Akaike information criterion [AIC], Bayesian information criterion [BIC], etc). Dobra and Lenkoski (2011) advocated model averaging to avoid the inferences to depend explicitly on the choice of the underlying graph.
In parallel to the development of graphical models, factor models (West 2003; Carvalho et al. 2008) have been widely used for modeling of high-dimensional variables and dimension reduction. While Gaussian graphical models work with the precision matrix, factor models provide a framework for regularized covariance matrix estimation. Factor models and generalizations such as structural equation models (Bollen 1989) can accommodate mixtures of continuous, binary, and ordered categorical data through an underlying Gaussian latent factor structure (Muthén 1983). Such models link each observed yij to an underlying continuous variable zij, with ordinal yij arising via thresholding of zij. For multivariate binary yi, a multivariate Gaussian distribution on zi = (zi1, …, zip)T induces the multivariate probit model (Ashford and Sowden 1970; Chib and Greenberg 1998; Ochi and Prentice 1984). Multivariate probit models can accommodate nominal data with dj > 2 by introducing a vector of variables zij = (zij1, …, zijdj)T underlying yij, with yij = l if zijl = max zij (Aitchison and Bennett 1970; Zhang, Boscardin, and Belin 2008). The latent zi’s are usually modeled as -dimensional Gaussian with covariance Σ, with at least p diagonal elements of Σ constrained to be one for identifiability. This constraint makes sampling from the full conditional posterior of Σ difficult. Zhang, Boscardin, and Belin (2006) used a parameter-expanded Metropolis–Hastings algorithm to obtain samples from a correlation matrix for multivariate probit models. Zhang, Boscardin, and Belin (2008) extended their algorithm to multivariate multinomial probit models. An alternative to probit models is to define a generalized linear model for each of the individual outcomes, while including shared normal latent traits to induce dependence (Sammel, Ryan, and Legler 1997; Dunson 2000, 2003; Moustaki and Knott 2000).
For unordered categorical variables, the data could be alternatively presented in the form of a p-way contingency table of dimension d1 × ··· × dp. There is a vast literature on analysis of contingency tables dating back to the nineteenth century. Fienberg and Rinaldo (2007) provided an excellent chronological overview of the development of log-linear models, maximum likelihood estimation, and asymptotic tests for goodness of fit. While log-linear models (Bishop, Fienberg, and Holland 1975) have been extensively used to model interactions among related categorical variables, asymptotic tests based on log-linear models face multiple difficulties in the case of sparse contingency tables—refer to the discussion in Section 3 of Fienberg and Rinaldo (2007). In a Bayesian framework, such problems can be avoided by specifying priors of the log-linear model parameters; Massam, Liu, and Dobra (2009) provided a detailed study of a useful class of conjugate priors. Posterior model search in log-linear models using traditional Markov chain Monte Carlo (MCMC) methods tends to bog down quickly as dimensionality increases. Dobra and Massam (2010) proposed a mode-oriented stochastic search method to more efficiently explore high posterior probability regions in decomposable, graphical, and hierarchical log-linear models.
Each of the above-mentioned methods are flexible and have their own distinct advantages. Graphical log-linear models are often preferred for ease of interpretation, while the underlying variable methods are useful for mixed data types, which commonly arise in social science applications. However, these methods face major computational challenges for large contingency tables. Dunson and Xing (2009) developed a nonparametric Bayes approach using Dirichlet process (Ferguson 1973, 1974) mixtures of product multinomials to directly model the joint distribution of multivariate unordered categorical data. They assumed that (yi1, …, yip)T are conditionally independent, given a univariate latent class index zi ∈ {1, 2, …, ∞}. The prior specification is completed by assuming a stick-breaking process prior on the distribution of zi and independent Dirichlet priors for the component-wise position-specific probability vectors. Marginalizing over the distribution of zi induces dependence among the p variables. This approach extends latent structure analysis (Lazarsfeld and Henry 1968; Goodman 1974) to the infinite mixture case and is conceptually related to nonnegative tensor decompositions (Shashua and Hazan 2005; Kimand Choi 2007). The direct modeling of the joint distribution of the category probabilities in a sparse manner enables efficient posterior computation, thereby allowing their method to efficiently scale up to high dimensions.
Although the Dunson and Xing (2009) approach can handle large contingency tables, the assumption of conditional independence, given a single latent class index, seems restrictive. Although their prior has full support and hence they can flexibly approximate any joint distribution of yi, in practice, even relatively simple dependence structures may require allocation of individuals to different classes, leading to a large effective number of parameters. Hence, in applications involving moderate to large p and modest sample size n, the Dunson and Xing (2009) approach may face difficulties.
In this article, we propose a new class of simplex factor models for multivariate unordered categorical data in which the dependence among the high-dimensional variables is explained in terms of relatively few latent factors. This is akin to Gaussian factor models, but factors on the simplex are more natural for nominal data. Methods for factor selection are discussed and the proposed approach is shown to have large support and to lead to consistent estimation of joint or conditional distributions for categorical variables. The Dunson and Xing (2009) model is obtained as a particular limiting case of the proposed model, as is the product multinomial model. The joint distribution of the multivariate nominal variables induced from the simplex factor model is shown to correspond to a multilinear singular value decomposition (SVD) (or higher-order SVD [HOSVD]) (De Lathauwer, De Moor and Vandewalle 2000) of probability tensors, which is regarded as a natural generalization of the matrix SVD in the tensor literature. A simple-to-implement data-augmented MCMC algorithm is proposed for posterior computation that scales well to higher dimensions. The methods are illustrated through simulated and real-data examples.
2. MODEL AND PRIOR SPECIFICATION
2.1 The Simplex Factor Model
Let yi = (yi1, …, yip)T denote a vector of responses and/or predictors. If yi ∈ ℜp, then a common approach is to jointly model the yi’s via a normal linear factor model:
| (1) |
where μ ∈ ℜp is an intercept term, Λ is a p × k factor loadings matrix, ηi ∈ ℜk are latent factors, and εi is an idiosyncratic error with covariance . When ηi ~ Nk(0, Ik), marginally, yi ~ Np(μ, Ω), with Ω = ΛΛT + Σ, a decomposition which uses at most p(k + 1) free parameters instead of the p(p + 1)/2 parameters in an unstructured covariance matrix.
Now consider the case in which yij ∈ {1, …, dj} for j = 1, …, p, and the different observations are unordered categorical variables. Let ηi = (ηi1, …, ηik)T ∈
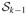 , with
the (k − 1)-dimensional simplex. The ηi’s will play the role of the latent factors but they lie on the simplex instead of being in ℜk. In addition, for each j, let
be a probability vector for h = 1, …, k. The
’s can be interpreted as loadings for factor h and outcome j, but we have a vector instead of a single element, as we would have in the case in which yij ∈ ℜ. With these components, we let:
, with
the (k − 1)-dimensional simplex. The ηi’s will play the role of the latent factors but they lie on the simplex instead of being in ℜk. In addition, for each j, let
be a probability vector for h = 1, …, k. The
’s can be interpreted as loadings for factor h and outcome j, but we have a vector instead of a single element, as we would have in the case in which yij ∈ ℜ. With these components, we let:
| (2) |
| (3) |
where . We refer to the model defined in Equations (2) and (3) as a simplex factor model. The formulation is conceptually related to mixed membership models (Pritchard, Stephens, and Donnelly 2000; Barnard et al. 2003; Blei, Ng, and Jordan 2003; Erosheva, Fienberg, and Joutard 2007), which have found widespread applications in text modeling, population genetics, and machine learning. In particular, the latent Dirichlet allocation (LDA) model (Blei et al. 2003) for text modeling arises as a special case of our model when p = 1. We can think of as the vector of probabilities of yij = 1, 2, …, dj, respectively, in ancestral population or pure species h, with none of the individuals being pure and ηih being the weight on the hth component for the ith individual. When k = 1, the simplex factor model reduces to the product multinomial model representing global independence. As k increases, the complexity of the model increases.
To obtain further insight, we represent the simplex factor model in the following hierarchical form, which will also be used for posterior computation:
| (4) |
Clearly, marginalizing out zij in (4) gives (2). The zij’s can be considered as local latent class indices for the jth variable and the ith subject. The simplex factor model allows these local indices zij’s to vary across j for a particular subject, resulting in a more flexible and parsimonious (in terms of number of components k) specification compared with that in Dunson and Xing (2009), where a univariate latent class index is used.
Marginalizing out ηi in Equation (3) induces dependence among the yij’s. Letting πc1…cp = pr(yi1 = c1, …, yip = cp | Λ), one has
| (5) |
with
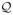 denoting the distribution of ηi and gh1,…,hp = E(ηih1, …, ηihp).
denoting the distribution of ηi and gh1,…,hp = E(ηih1, …, ηihp).
2.2 Relationship With Tensor Decompositions
It is useful at this point to consider relationships between (5) and the literature on tensor decompositions, which shall be used in particular to illustrate the differences between our model and the Dunson and Xing (2009) model. Let
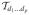 denote the set of all tensors of dimension d1 × ··· × dp, and Πd1…dp ⊂
denote the set of probability tensors so that π ∈ Πd1…dp implies
denote the set of all tensors of dimension d1 × ··· × dp, and Πd1…dp ⊂
denote the set of probability tensors so that π ∈ Πd1…dp implies
A decomposed tensor (Kolda 2001) is a tensor D ∈
such that D = u(1) ⊗ u(2), …, ⊗u(p), where u(j) ∈ ℜdj and ⊗ denotes the outer product so that
. One notion of the rank of a tensor is the minimal r such that D can be expressed as a sum of r decomposed (or rank 1) tensors. Such a decomposition is often referred to as a PARAFAC decomposition (Harshman 1970), which is one way of generalizing the matrix SVD. Tucker (1966) proposed a different decomposition for three-way data, which was later extended to arbitrary tensors by De Lathauwer et al. (2000). The Tucker decomposition or HOSVD aims to decompose a tensor D ∈
as
| (6) |
where G = {gh1…hp} ∈
is called a core tensor and its entries control interaction between the different components. Wang and Ahuja (2005) and Kim and Choi (2007) empirically noted that the HOSVD achieves better data compression and requires fewer components compared with the PARAFAC model as it uses all combinations of the mode vectors
’s, h = 1, …, k.
The product multinomial mixture model of Dunson and Xing (2009) induces a decomposition of a probability tensor π as
| (7) |
where νh = pr(zi = h) and . Note that (7) is different from a usual PARAFAC decomposition because of the nonnegativity constraints on ν and the ’s. In the subsequent discussion, a nonnegativity matrix/tensor has all entries nonnegativity. The classical nonnegativity matrix factorization (NMF) problem seeks the best approximation of a nonnegative matrix as a product of nonnegative matrices and for some k ≤ min{m, n}. Gregory and Pullman (1983) were among the first to consider NMF and introduced the notion of nonnegative rank of a matrix, which is the minimal r such that a nonnegative matrix can be written as a sum of rank 1 nonnegative matrices. Cohen and Joel (1993) generalized many properties of the usual rank to the case of nonnegative rank. Along the lines of NMF, one can similarly envision nonnegative versions of the PARAFAC and HOSVD decompositions for tensors (Shashua and Hazan 2005; Kimand Choi 2007).
We note that (7) is a form of nonnegative PARAFAC decomposition, while the simplex factor model in (5) induces a nonnegative HOSVD on the space of probability tensors. Let
be a nonnegative tensor. Define the nonnegative PARAFAC rank
of π to be the minimum k such that π admits a decomposition as in (7)with
and ν ∈ ℜk. Similarly, define the nonnegative HOSVD rank
of π to be the minimum k such that π can be expressed as in (5) with
and
. In considering a nonnegative decomposition, assuming
is not restrictive since we can always scale nonnegative weights to lie to the simplex and adjust the scale in ν or G. In the special case when π is a probability tensor, ν ∈
is a probability vector and G is a probability tensor.
If we start with
in (7), then we can clearly express π as in (5) using the same k by simply letting gh1…hp = νh1(h1 = h, …, hp = h). Conversely, suppose we start with a nonnegative HOSVD of π as in (5) with
and the core tensor G ∈ Πk…k having
. Then, there exist
, l = 1, …, r and q ∈
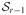 such that
. Substituting this expression for gh1…hp in (5), one has
such that
. Substituting this expression for gh1…hp in (5), one has
| (8) |
where . Thus, starting with a nonnegative HOSVD of π, we have expanded it in nonnegative PARAFAC form. Clearly, r ≥ k; otherwise, the minimality of k is contradicted. Moreover, very little is known about upper bounds on PARAFAC ranks of tensors. The most general result is for third-order tensors where the upper bound is O(k2); hence, r can potentially be much larger than k, requiring very many parameters for the PARAFAC expansion compared with the HOSVD. We summarize the above facts in the following theorem.
Theorem 2.1
Let π ∈ Πd1…dp and let . Then, , where G is a core tensor in the minimal HOSVD expansion of π. Moreover, among all such minimal expansions in k components, if G has minimal nonnegative PARAFAC rank, then .
From a statistical perspective, the decomposition in (8) shows that the simplex factor model can provide sparser solutions in scenarios where the Dunson and Xing (2009) model may require many components to adequately explain the dependence structure. The Dunson and Xing (2009) model induces a global clustering phenomenon by forcing all the variables for a particular subject to be allocated to the same cluster. This can lead to introduction of too many clusters to accommodate small idiosyncracies within the variables or the subjects might be inappropriately grouped together, obscuring local differences. The simplex factor model instead allows the different variables to be allocated to different clusters via the dependent local cluster indices zij.
2.3 Prior Specification and Properties
To complete a Bayesian specification of the simplex factor model, a natural choice is to draw the ηi’s and the different
’s from independent Dirichlet priors. We let ηi ~ Diri(αν1, …, ανk), where α > 0 and ν = (ν1, …, νk)T = E(ηi) ∈
is a vector of probabilities. To obtain a parsimonious representation in which the first few components (subpopulations) tend to be assigned most of the weight, we let
with
and place a beta(1, β) prior on
, h = 1, …, k − 1. This corresponds to the stick-breaking formulation (Sethuraman 1994) of the Dirichlet process truncated to the first k terms and is widely used for posterior computation in Dirichlet process mixture models (Ishwaran and James 2001). In this case, k can be viewed as an upper bound on the number of components as higher-indexed components will tend to have νh ≈ 0, so one obtains ηih ≈ 0 with high probability for all i and the k-component model adaptively collapses on a lower-dimensional model. In practice, such collapsing will be driven by the extent to which the data support a model with fewer components. The model can be expressed in hierarchical form as
| (9) |
The hierarchical prior specification on ηi has similarities to a finite-dimensional version of the hierarchical Dirichlet process (Teh et al. 2006), although the motivation here is slightly different. Essentially, we have a Dirichlet random-effects model with an unknown mean for the subject-specific random effects ηi’s, with dependence being induced by marginalizing out the ηi’s.
The Dirichlet latent factor distribution allows evaluation of gh1…hp = E(ηih1 … ηihp) in (5) analytically
| (10) |
where τh(h1, …, hp) = {#j: hj = h} for h = 1, …, k. When evident from the context, we shall drop the arguments and use τh. Clearly, .
With and , one has
| (11) |
| (12) |
Now let us consider a few limiting cases; the main results are summarized below.
Proposition 2.2
For any fixed k, (i) in the limit as α → ∞, the simplex factor model (9) simplifies to a product multinomial model with independently for j = 1, …, p; and (ii) in the limit as α → 0, model (9) simplifies to the Dunson and Xing (2009) model.
Thus, by putting a hyperprior on α, we can allow the data to inform about α and the posterior to concentrate near either of these two simplifications in cases where the simple structure is warranted. Next, we show that the proposed prior has large support on the space of probability tensors, so any dependence structure can be accurately approximated.
Theorem 2.3
Let
denote the prior induced on Πd1…dp through the k-component simplex factor model in (9) and
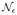 (π0) denote an L1 neighborhood around an arbitrary probability tensor π0 ∈ Πd1…dp. Then, for any π0 ∈ Πd1…dp and ε > 0, there exists k such that
.
(π0) denote an L1 neighborhood around an arbitrary probability tensor π0 ∈ Πd1…dp. Then, for any π0 ∈ Πd1…dp and ε > 0, there exists k such that
.
Since the space of probability tensors is isomorphic to a compact Euclidean space, a straightforward extension of theorem 4.3.1 of Ghosh and Ramamoorthi (2003) ensures that the posterior concentrates in arbitrary small neighborhoods of any true data-generating distribution π0 with increasing sample size.
3. POSTERIOR COMPUTATION AND INFERENCE
3.1 MCMC Algorithm for Posterior Computation
Let y = (yij), η = (ηi), and z = (zi). We use a combination of Gibbs sampling and independence chain Metropolis–Hastings sampling to draw samples from the posterior distribution of (Λ, z, η, ν*,α) for the hierarchical model specified in (9). We place a gamma(aα, bα) prior on α to allow the data to inform more strongly about sparsity in the ηi vectors. In particular, for small α, the tendency will be to assign one element of ηi to a value close to 1, while for larger α, the ηi vectors will be closer to ν for different subjects. We recommend aα = bα = 1 as a default value favoring high weights on few components. In addition, we let aj1 = ··· = ajdj= 1, for j = 1, …, p, to induce a uniform prior for the category probabilities in each class for each outcome type. This default prior specification can be modified in cases in which one has prior information on the category probabilities and/or the number of subpopulations.
The conditional posteriors for all the parameters other than ν* and α can be derived in closed form using standard algebra and the sampler cycles through the following steps:
-
Step 1For h = 1, …, k, update from the following Dirichlet full conditional posterior distribution
-
Step 2Update zij from the multinomial full conditional posterior distribution, with
-
Step 3Update ηi from the Dirichlet full conditional posterior:
-
Step 4
Update α using a Metropolis random walk on log(α).
-
Step 5Update { } using the following approach. Let and nls = {#i: mil > s} for nonnegative integers s. Letting , one has nls = 0 for . Further, let and for l > h, and define . The conditional posterior of marginalizing out the ηi’s is given by
(13) We assume the default choice β = 1. Since the expression for νl contains for l = h and ( ) for l > h, the conditional posterior of in (13) is an analytically intractable mixture of beta densities. However, we show that can be accurately approximated by a single beta distribution. One can thus use an appropriate beta density as a proposal in a Metropolis–Hastings step, with the beta parameters estimated numerically on a fine grid via moment matching. However, the grid-based method is computationally costly, since the expression in (13) needs to be computed at every point on the grid. We propose an approach to provide analytic expressions for the parameters of the approximating beta density. The analytic solution produces high acceptance rates, and there is a dramatic gain in computational time, whose effect is increasingly pronounced with large n and/or p. We mention below the choices of the parameters of the approximating beta density in the different cases, with justification provided in the Appendix.
If mh > 0 and mh+ = 0, we use a beta(â, 1) density with
| (14) |
to approximate . Similarly, if mh = 0 and mh+ > 0, a beta(1, b̂) density with
| (15) |
is used to approximate .
If mh > 0 and mh+ > 0, we prove the following fact.
Proposition 3.1
If mh > 0 and mh+ > 0, then is unimodal and .
We approximate by a beta(â, b̂) density in this case, where â = max(ã + 1, 1), b̂ = max(b̃ + 1, 1), and ã, b̃ are obtained by solving a 2 × 2 linear system E(ã, b̃)T = (d1, d2)T, with e11 = 1/2, e12 = −1/2, e21 = 1/6, e22 = −1/3 and
A one-step improvement is obtained next by running a mode search of the log posterior from the estimated (ã, b̃) pair above and subsequently adjusting those values to have the right mode. Since is unimodal in this case, the mode search can be done very efficiently using the Newton–Rapson algorithm.
3.2 Adaptive Selection of the Number of Factors
In practical problems, one typically expects a small number of factors k relative to the number of outcomes p. The stick-breaking prior on ν induces a sparse formulation a priori, so relatively few components with high weights are encouraged. Accordingly, one can start with a conservative upper bound k* on the number of factors and the sparsity favoring prior ensures that the posterior will concentrate on a few components if the truth is approximately sparse. However, an overly conservative upper bound wastes substantial computational time. For Gaussian factor models, Lopes and West (2004) compared a number of alternatives to select the number of factors, recommending a reversible-jump MCMC approach that requires a preliminary run for each choice of the number of factors, which is very computationally intensive. Since we are not interested in inference on the number of factors and our sole consideration is computational efficiency, we outline below a simple adaptive scheme to discard the redundant factors in a tuning phase and continue with a smaller number of factors for the remainder of the chain. This results in considerable computational gains in high dimensions; however, for moderate values of p (e.g., p ≤ 20), one can set p to be the truncation level and ignore the adaptive scheme.
We reserve Ttune many iterations at the beginning of the chain for tuning. At iteration t, letting to denote the unique values among the zij’s, one clearly has mh > 0 if and only if . We define the effective number of factors k̃(t) as | |. The inherent sparse structure of the simplex factor model favors small values of k̃(t). Starting with a conservative guess for k, we monitor the value of k̃(t) every 50 iterations in the tuning phase. If there are no redundant factors, that is, mh > 0 for all h, we add a factor and initialize the additional parameters for η, Λ, ν* from the prior. Otherwise, we delete the redundant components and retain the elements of η, Λ, ν* corresponding to . In either case, we normalize the samples for η and ν* to ensure they lie on the simplex. We continue the chain with the updated number of factors and the modified set of parameters for the next 50 iterations before making the next adaptation. At the end of the tuning phase, we fix the number of factors for the remainder of the chain at the value corresponding to the last adaptation. In all our examples, we let Ttune = 5000 and choose the initial number of factors as 20 or 10.
3.3 Inference
One can estimate the marginal distribution of the yij’s and conduct inferences on the dependence structure based on the MCMC output and using the expressions for the lower-dimensional marginals in Equations (11) and (12). To conduct inference on dependence between yij and yij′ for j ≠ j′ ∈ {1, …, p}, we consider the pairwise normalized mutual information matrix M = (mjj′), with mjj′ = Ijj′/{HjHj′}0.5 and
The mutual information Ijj′ is a general measure of dependence between a pair of random variables (YJ, Yj′), with Ijj′ = 0 if and only if Yj and Yj′ are independent. Using our Bayesian approach, one can obtain samples from the posterior distribution of mjj′ for all j ≠ j′ pairs. In particular, posterior summaries of the p × p association matrix can be used to infer on the association between pairs of variables accounting for uncertainty in other variables. Dunson and Xing (2009) pointed out that in large model spaces, it is more computationally tractable to consider pairwise marginal dependencies as compared with learning the entire graph of conditional dependencies. Dunson and Xing (2009) and Dobra and Lenkoski (2011) used the pairwise Cramer’s V association matrix as a measure of dependence. We also computed the pairwise Cramer’s V association matrix for all our examples and obtained similar dependence structures as found by the mutual information criterion. In the analysis of the Rochdale data in Section 4, we present results for both measures of association and in the subsequent simulated and real-data examples, we only provide the results for the mutual information criterion as the conclusions were similar.
In many practical examples, one routinely encounters a high-dimensional vector of nominal predictors yi along with nominal response variables ui, with interest in building predictive models for ui given yi. For example, yi might correspond to a nucleotide sequence, with ui being the existence/nonexistence of some special feature within the gene sequence. By using a simplex factor model for the joint distribution of the response and predictors, one obtains a very flexible approach for classification from categorical predictors that may have higher-order interactions. Such a joint model also trivially allows imputation of missing values under the missing at-random assumption or any other informative missingness.
4. ANALYSIS OF ROCHDALE DATA
Dobra and Lenkoski (2011) used copulas to extend traditional Gaussian graphical models to allow mixed outcomes. They applied their general class of copula Gaussian graphical models (CGGM) to analyze the Rochdale data, a 28 contingency table popular in the social science literature. In this section, we illustrate various aspects of making inference with the simplex factor model on this well-known dataset and compare our results with the CGGM.
The Rochdale dataset was previously analyzed in Whittaker (1990). It is a social survey dataset aimed to assess the relationship among factors influencing women’s economic activity. The dataset consists of eight related binary variables coded a, b, …, h for n = 665 women. A detailed account of the different variables can be found in Dobra and Lenkoski (2011). The resulting 28 contingency table is sparse, with 165 cell counts of zero. The top 10 cell counts are all greater than 20.
Whittaker (1990) used log-linear models to analyze this dataset and argued against using higher-order interactions involving more than two variables. He considered two log-linear models, one being the all two-way interaction model, and the minimal sufficient statistics for the other one consisted of 14 two-way marginals in equation 5.1 of Dobra and Lenkoski (2011). Dobra and Lenkoski (2011) analyzed this dataset using their proposed CGGM and also compared it with a copula full model where the underlying graph was not updated and was fixed at the full graph.
The simplex factor model was run for 50,000 iterations, with the first 30,000 iterations discarded as burn-in and every fifth sample post burn-in was collected. We started with 10 factors and the adaptive algorithm selected four factors, with more than 85% acceptance rate for all elements of ν*. The posteriormean of α was 0.10, with a 95% credible interval of (0.03–0.20).
According to Whittaker (1990), the strongest pairwise interaction in this dataset is for the pair (b, d), followed by (b, h), (e, f), and (a, g). Dobra and Lenkoski (2011) obtained strongest associations for the pairs (b, d), (b, h), (a, g), (e, f), and (c, g) according to Cramer’s V statistic. They also noted that conditioning on the full graph in the copula full model leads to severe underestimation of all the pairwise Cramer’s V associations. From the MCMC output, we obtained posterior samples for the pairwise normalized mutual information and the pairwise Cramer’s V. Figure 1 shows posterior summaries of the pairwise associations for these two measures. From Figure 1, it is evident that both measures obtained a similar dependence structure and the top four pairs according to either of the two measures were (b, d), followed by (b, h), (a, g), and (c, g). The posterior means of the Cramer’s V values in Figure 1(e) for these four pairs were 0.21, 0.10, 0.09, and 0.09, respectively, which are very similar to those obtained by the CGGM (Dobra and Lenkoski 2011, table 5.5). The variable a denotes wife’s economic activity and is of interest in determining the variables that share association with a. The variables having largest Cramer’s V association to a were g, c, and d, with the posterior means for the pairs (a, g), (a, c), and (a, d) given by 0.09, 0.08, and 0.04, respectively. Again, the same ordering was discovered by the CGGMs. Overall, our results were very much in agreement with those obtained by the CGGMs, with the only notable difference being (a, c) ranking over (e, f) for both the measures in our case.
Figure 1.
Results for Rochdale data—posterior means (second column), and 2.5 and 97.5 percentiles (first and third column, respectively) of the pairwise normalized mutual information matrix (top row) and the pairwise Cramer’s V association matrix (bottom row). (The online version of this figure is in color.)
The MCMC was also run with the set of 10 factors for the entire length of the chain with a beta(1, 1) prior on β. The results were robust, with the same ordering of the pairwise Cramer V’s obtained as in the previous case. As discussed before, the stick-breaking prior on the drives the νh’s for the redundant components close to zero, thereby making the procedure robust with respect to the choice of the number of factors as long as there are sufficiently many factors.
5. SIMULATION STUDY
We considered two simulation scenarios to assess the performance of the simplex factor model. We simulated yij ∈ {A, C, G, T} at p = 50 locations and a nominal response ui having two and three levels in the two simulation cases, respectively. We considered two pure species (k = 2) and simulated the local subpopulation indices zij as in (9) to induce dependence among the response and a subset of locations J = (2, 4, 12, 14, 32, 34, 42, 44)T. The eight locations in J had different A, C, G, T probabilities in the two pure species, while the phenotype probabilities at the remaining 42 locations were chosen to be the discrete uniform distribution on four points in each species.
In the first simulation scenario, we considered n = 100 sequences and two randomly chosen subpopulations of sizes 60 and 40, respectively. All the zij’s were assigned a value of 1 in the first subpopulation, and 2 in the second one. Within each subpopulation, the nucleotides were drawn independently across locations, with the jth nucleotide having phenotype probabilities . The binary response (ui ∈ {1, 2}) had category probabilities (0.92, 0.08) and (0.08, 0.92) in the two subpopulations, respectively.
The second scenario had a more complicated dependence structure. We considered 200 sequences and three subpopulations of sizes 80, 80, and 40, respectively, with all the local indices zij assigned a value of 1 and 2, respectively, in the first two subpopulations. In the third subpopulation, the zij’s for the first 30 locations were assigned a value of 1 (zij = 1, j = 1, …, 30), and the remaining 20 locations a value of 2 (zij = 2, j = 31, …, 50). The response variable had three categories in this case, with category probabilities (0.90, 0.05, 0.05), (0.05, 0.90, 0.05), and (0.05, 0.05, 0.90) in the three subpopulations, respectively. The third subpopulation is biologically motivated as a rare group that has local similarities with each of the other groups, and thus, is difficult to distinguish from the other two.
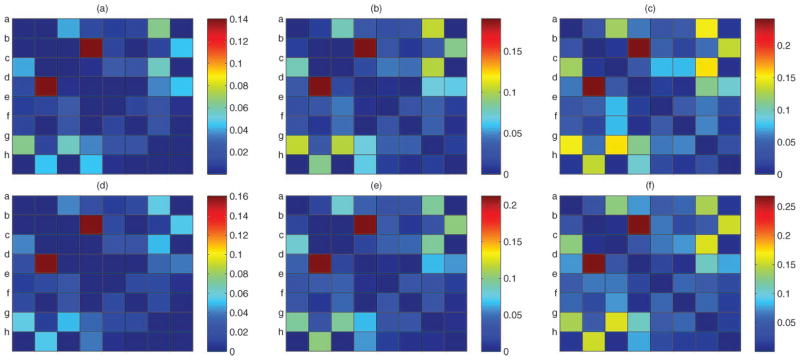
For each case, we generated 50 simulation replicates and the simplex factor model was fitted separately to each dataset using the MCMC algorithm mentioned in Section 3.1. The sampler was run for 30,000 iterations, with a burn-in of 10,000 and every fifth sample was collected. We obtained good mixing and convergence for the elements of the pairwise mutual information matrix based on examination of trace plots. Figure 2 shows the posterior means of the pairwise normalized mutual information matrix mjj′ averaged across simulation replicates in the two simulation scenarios, with the last row/column corresponding to the response variable. The posterior means corresponding to all dependent location pairs are clearly well separated from the remaining nondependent pairs. We also provide kernel density plots of the posterior means and upper 97.5 percentiles of the mjj′ across the 50 replicates for the two simulation cases in Figure 3. For the first simulation case (top row), the density plot for the posterior means in Figure 3(a) is bimodal, with a tall spike near zero and a very heavy right tail, thus showing a clear separation between the dependent and the nondependent pairs. The second simulation also had a very heavy tail for the posterior means in Figure 3(c), and the second mode is visible for the upper quantile in Figure 3(d).
Figure 2.
Simulation results—posterior means of the pairwise normalized information matrix of the nominal variables in simulation cases 1 and 2. Dependence between locations (2, 4, 12, 14, 32, 34, 42, 44) and the response (last row/column). (The online version of this figure is in color.)
Figure 3.

Simulation results—density plots of the posterior means (first column) and upper 97.5 percentiles (second column) of the p.w. normalized mutual information mjj ′’s across simulation replicates in the two simulation cases.
Next, we aim to assess out-of-sample predictive performance for the simplex factor model. Since the subpopulations were chosen in a random order, we chose the first 20 samples in simulation case 1 and the first 30 samples in simulation case 2 as training sets within each replicate. We compared our approach with the Dunson and Xing (2009) method, a tree classifier built in MATLAB, and the random forest ensemble classifier (Breiman 2001), which was implemented using the RandomForest package (Liaw and Wiener 2002) in R. We did not consider a fully Bayesian graphical modeling approach, such as Dobra and Lenkoski (2011), because such methods do not scale computationally to the sized contingency tables we are considering. Figure 4 shows box plots of the overall and group-specific misclassification proportions for the different methods across the simulation replicates. As expected, the misclassification rates for simulation case 2 are higher than simulation case 1. The misclassification percentages corresponding to the second category are slightly larger than those for the first category in simulation case 1, which is explained by the relative sizes of the two subpopulations. It is clear from Figure 4 that the simplex factor model had better performance than the tree classifier and the random forest classifier in both cases. The overall misclassification percentage and category-specific misclassification percentages for the simplex factor model and random forest in the two simulation scenarios are provided in Table 1.
Figure 4.

Box plots for misclassification proportions across simulation replicates for the different methods. TREE = tree-based classifier, RF = random forest classifier, DX = Dunson–Xing method, SF = simplex factor model. The top row corresponds to simulation case 1, bottom row to simulation case 2. The first column corresponds to overall misclassification proportion, the remaining columns indicate group-specific misclassification proportions. (The online version of this figure is in color.)
Table 1.
Misclassification percentages in the two simulation cases for the simplex factor model and random forest
| Simulation case 1
|
Simulation case 2
|
|||
|---|---|---|---|---|
| Simplex factor | Random forest | Simplex factor | Random forest | |
| Best | (2.50, 0, 3.03) | (2.50, 0, 3.03) | (6.47, 1.54, 0, 8.10) | (8.82, 0, 0, 13.89) |
| Average | (7.55, 5.45, 10.39) | (9.90, 5.84, 15.51) | (14.08, 7.15, 6.80, 37.07) | (16.67, 9.30, 9.18, 41.03) |
| Worst | (16.25, 12.00, 28.57) | (35.00, 16.32, 77.77) | (34.12, 14.49, 13.89, 100) | (34.70, 27.14, 31.74, 100) |
NOTE: Each vector represents overall and category-specific misclassification percentages, with the categories arranged according to their index. Best-, average-, and worst-case performances across replicates are reported.
Simulation case 1 was designed to comply with the Dunson and Xing (2009) model, since all of the variables for a particular subject were assigned to the same subpopulation. Accordingly, the Dunson and Xing (2009) method had very similar performance compared with the simplex factor model in the first case and did better than the other two methods. However, the performance of the Dunson and Xing (2009) method deteriorated in simulation case 2. In this case, the subjects in the third group had mixed membership for the different variables and the misclassification rates for this group were particularly high for the Dunson and Xing (2009) method.
6. NUCLEOTIDE SEQUENCE APPLICATIONS
We first applied our method to the p53 transcription factor-binding motif data (Wei et al. 2006). The data have n = 574 DNA sequences consisting of A, C, G, T nucleotides (dj = 4) at p = 20 positions. Transcription factors are proteins that bind to specific locations within DNA sequences and regulate copying of genetic information from the DNA to them RNA. p53 is a widely known tumor suppressor protein that regulates expression of genes involved in a variety of cellular functions. It is of substantial biological interest to discover positional dependence within such DNA sequences.
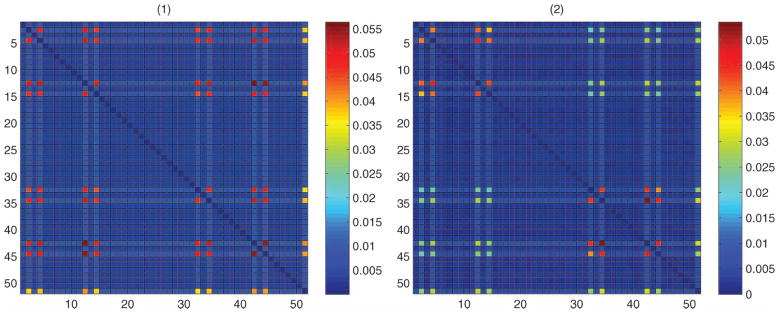
We ran the MCMC algorithm for 25,000 iterations after the tuning phase, with a burn-in of 10,000 and collected every fifth sample. The adaptive algorithm selected four factors and we obtained acceptance rates greater than 90% for all the elements of ν* using our proposed independence sampler. Using a gamma(0.1, 0.1) prior for α, the posterior mean of α was 0.11, with a 95% credible interval of (0.08–0.16). From Proposition 2.2, the small value of α indicates that the model favors a simpler dependence structure, as in Dunson and Xing (2009). We actually obtained very similar results to the Dunson and Xing (2009) method for this particular dataset. Figure 5(a)–(c) shows the posterior means and quantiles for the simplex factor model. Figure 5(d)–(f) shows the same for the Dunson and Xing (2009) method. Clearly, the dependence structure is sparse and the strongest dependence are found near the center of the sequence, with position pairs (11, 12) and (9, 11) having the largest normalized mutual information using both methods. The Xie and Geng (2008) approach flagged all 190 pairs as dependent using a p-value of 0.01 or 0.05 for edge inclusion; such overfitting can typically occur for Bayes Nets unless the threshold on edge inclusion is very carefully chosen.
Figure 5.
Results for the p53 data—posterior means (second column), and 2.5 and 97.5 percentiles (first and third column, respectively) of the normalized mutual information matrix. The top row corresponds to the simplex factor model, the bottom row is for the Dunson and Xing (2009) method. (The online version of this figure is in color.)
We next applied our method to the promoter data (Frank and Asuncion 2010) publicly available at the UCI Machine Learning Repository. The data consist of A, C, G, T nucleotides at p = 57 positions for n = 106 sequences, along with a binary response indicating instances of promoters and nonpromoters. There are 53 promoter sequences and 53 nonpromoter sequences in the dataset. We selected six training sizes as 20%, 30%, 40%, 50%, 60%, and 70% of the sample size n. For each training size, we randomly selected 10 training samples and evaluated the overall misclassification percentage and misclassification percentages specific to the promoter and nonpromoter groups. We compared out-of-sample predictive performance with the Dunson and Xing (2009) method, random forest, and a tree classifier. The MCMC algorithm for the simplex factor model was run for 30,000 iterations, with five factors selected. Our proposed approach for updating the ’s again produced high acceptance rates; the mean acceptance rates averaged across all replicates for were 0.85, 0.92, 0.96, and 0.97, respectively. The posterior means for α across all replicates within each training size was greater than 1; we have provided box plots for the posterior samples of α across the 10 replicates corresponding to the smallest training size in Figure 6.
Figure 6.

Results for the promoter data—box plots for posterior samples of α for the 10 replicates in the first case, where training size is 20% of the sample size. The red line denotes the posterior median, and the edges of the box denote posterior 25th and 75th percentiles. (The online version of this figure is in color.)
The simplex factor model had superior performance compared with the other three methods across all training sizes. In particular, for the training size = 20, the average misclassification percentages (overall, promoters, nonpromoters) for the Dunson and Xing (2009) method and random forest were (23.41, 26.24, 19.69) and (25.53, 29.92, 19.30), respectively, while the same for our method were (14.35, 15.41, 12.16). Table 2 provides the average-, best-, and worst-case misclassification percentages for the simplex factor model and random forest corresponding to the smallest and largest training sizes. From Table 2, the misclassification percentage for the nonpromoter group was smaller compared with that of the promoter group. For the smallest training size of 21, the simplex factor model provides an improvement of more than 14% in terms of the misclassification percentages for the promoter group. We also plot the average-, best-, and worst-case overall misclassification proportions across different training sizes for the competing methods in Figure 7 and the average misclassification proportions specific to the promoter and nonpromoter groups in Figure 8. It is clearly seen from Figures 7 and 8 that the simplex factor model provides the best performance across all training sizes.
Table 2.
Results for the promoter data—misclassification percentages (overall, among promoters, among nonpromoters) for the smallest and largest training sizes for the simplex factor model and random forest
| Training size = 21
|
Training size = 74
|
|||
|---|---|---|---|---|
| Simplex factor | Random forest | Simplex factor | Random forest | |
| Best | (8.24, 0, 0) | (15.29, 0, 0) | (0, 0, 0) | (6.25, 0, 0) |
| Average | (14.35, 15.41, 12.16) | (25.53, 29.92, 19.30) | (7.81, 10.14, 4.79) | (12.50, 17.84, 6.37) |
| Worst | (30.59, 53.32, 35.56) | (44.71, 80.85, 64.44) | (15.62, 21.05, 17.65) | (15.62, 33.33, 23.53) |
NOTE: Best-, average-, and worst-case performances across 10 training samples for each training size are reported.
Figure 7.

Results for the promoter data—misclassification proportions (overall) for the different methods versus training size (ranging from 20% to 70% of the sample size n = 106). The rows correspond to average-, worst- and best-case performances, respectively, across 10 training sets for each training size. (The online version of this figure is in color.)
Figure 8.
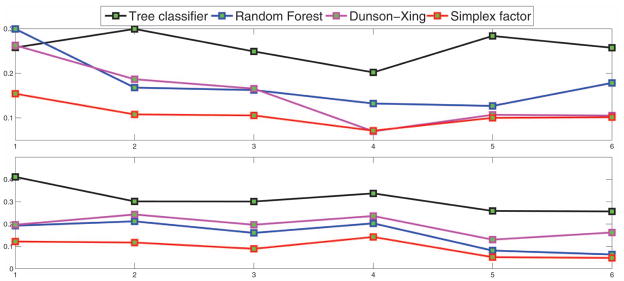
Results for the promoter data—average misclassification proportions (for the promoter and nonpromoter group, respectively) for the different methods versus training size (ranging from 20% to 70% of the sample size n = 106). (The online version of this figure is in color.)
We performed sensitivity analysis for the prior on α by choosing a gamma(1, 1) prior instead of gamma(0.1, 0.1), with the results unchanged. We also multiplied and divided the prior mean by a factor of 2 and did not observe any notable changes. For , the uniform prior was found to be a reasonable default choice, as in most practical cases, one expects to have few dominant components in the case of contingency tables. That said, one can alternatively place a beta(1, β) prior on , with a gamma prior assigned to β.
The additional flexibility of our model over the nonparametric Bayes method of Dunson and Xing (2009) produces improved performance in classification for the promoter data, and our approach also does better than sophisticated frequentist methods such as the tree classifier and random forest. We also applied our classification method to the splice data (publicly available at the UCI Machine Learning Repository) and obtained similar conclusions.
7. DISCUSSION
In a variety of problems, one now encounters data where the dimensionality of the outcome is comparable or even larger than the number of subjects. In such scenarios, one needs to make sparsity assumptions for meaningful inference. For continuous outcomes, one might consider sparse modeling of the covariance matrix via factor models or alternatively use Gaussian graphical models for sparse modeling of the precision matrix. However, the scope of either of these two frameworks is not solely limited to continuous variables. In more general terms, graphical models aim to model conditional dependencies among the variables, while factor models model marginal dependence relationships. In this article, we have proposed a sparse Bayesian factor modeling approach for multivariate nominal data that aims to explain dependence among high-dimensional nominal variables in terms of few latent factors that reside on a simplex. Posterior computation is straightforward and scales linearly with n and p. The proposed method can be thus used in high-dimensional problems, which is an advantage over graphical model-based approaches, which face computational challenges in scaling up to high dimensions.
An interesting extension of our proposed approach is joint modeling of a vector of nominal predictors and a continuous response, and more generally mixtures of different data types, as such situations are often encountered in biological and social sciences. To elaborate, let yi = (yi1, …, yip)T denote a vector of observations as before, where the yij’s now are allowed to be of different types, such as binary, count, ordinal, continuous, etc. Letting γi = (γi1, …, γip)T ∈ {1, 2, …,∞}p denote a multivariate latent class index for subject i, one can let
| (16) |
where G is the joint distribution of the multivariate categorical variable γi. The different yij’s are assumed to be conditionally independent, given the latent class index γi, and a prior Π on the distribution G of the latent class indices induces dependence among the yij’s. In a Dirichlet process mixture modeling framework, one usually has a single cluster index γi for the different data types, which forces individuals to be allocated to the same cluster across all data types. This often leads to blowing up of the number of clusters and degraded performance; see, for example, Dunson (2009). We can instead allow for separate but dependent clustering across the different domains by letting Π correspond to the simplex factor prior. One can also include covariate information by stacking together the covariates xi and the response yi in a vector zi = (yi, xi) and jointly model zi as above, with inference based on the induced conditional distribution of yi | xi obtained from the joint model. Müller, Erkanli, and West (1996) considered such joint models in a nonparametric Bayes frame work using Dirichlet process mixtures.
There has been a recent surge of interest in developing flexible Bayesian density regression models where the entire conditional distribution of the response y, given the predictors x, is allowed to change flexibly with x; see, for example, Griffin and Steel (2006); Dunson, Pillai, and Park (2007); Dunson and Park (2008); Chung and Dunson (2009); Rodriguez and Dunson (2011). It would be interesting to consider extensions of these models for multivariate categorical response variables by allowing predictor-dependent weights, for example, using the probit stick-breaking process (Chung and Dunson 2009; Rodriguez and Dunson 2011). Pati and Dunson (2011) developed theoretical tools for studying posterior consistency with a broad class of predictor-dependent stick-breaking priors; see also Norets and Pelenis (2011). Along those lines, one can envision extensions of our baseline posterior consistency results to the uncountable collection of probability tensors {π(x): x ∈
 }.
}.
Acknowledgments
The authors thank Adrian Dobra for sharing the Rochdale data and providing insightful comments. This research was partially supported by grant number R01 ES017240-01 from the National Institute of Environmental Health Sciences (NIEHS) of the National Institutes of Health (NIH).
APPENDIX
Proof of Proposition 2.2
From Equation (10), one has
Dividing the numerator and the denominator in the above expression by αp, it is evident that , which corresponds to the product multinomial model.
On the other hand,
Clearly, limα→0 gh…h = νh, and thus in the limit, . As G is a probability tensor for every value of α, the nondiagonal elements must converge to 0 as α → 0. Hence, in this limiting case, G becomes super-diagonal and thus corresponds to the Dunson and Xing (2009) model.
Proof of Theorem 2.3
Fix π0 ∈ Πd1…dp and ε > 0. For π ∈ Πd1…dp, the L1 distance between π and π0 is defined as
Suppose π0 has nonnegative PARAFAC rank k, so π0 can be expressed as:
where ν0 ∈
and
are probability vectors of dimensions d1, …, dp for each h ∈ {1, …, k}. The prior probability assigned to an ε-sized L1-neighborhood
(π0) of π0 by a k-component simplex factor model is given by:
| (A.1) |
where
with gh1…hp, as in Equation (10). Using Proposition 2.2 and standard algebra, it can be shown that for any ε > 0, there exist α̃ > 0 and ε̃ > 0 such that
implies that ||π − π0||1 < ε. Hence, to prove that (A.1) is positive, it suffices to show that 12501000:
which immediately follows from the prior specification in (9).
Updating ν
We drop the h superscript in for notational convenience. Let
| (A.2) |
denote the unnormalized conditional posterior, and define . When mh > 0 and mh+ = 0,
so , and is convex. Similarly, if mh = 0 and mh+ > 0, then , and is convex. In both these cases, the conditional posterior of can be approximated by a single beta density.
When mh > 0 and mh+ > 0,
As converges to a finite limit. Since mh > 0, nh0 > 0 and thus , implying . Similarly, , since mh+ > 0 implies that there exists h′ > h such that nh′s > 0. Hence, and thus .
We now show that has a unique mode by considering the first and second derivatives of φ. We have
| (A.3) |
and
| (A.4) |
Once again, using the fact that nh0 > 0 and there exists h′ > h such that nh′0 > 0, one can prove that and . One can then find ε > 0 such that for and for . Since φ′ is a continuous function, by the intermediate value theorem, there exists such that . Since on (0, 1), φ′ is monotonically decreasing and hence is the unique mode of .
Next, we discuss an approach to avoid the grid approximation and obtain analytic expressions for the parameters of the approximating beta distribution. When mh > 0 and mh+ = 0, we want to find a ≥ 1 such that a beta(a, 1) approximates . Define so that f̃(1) = 1. Hence, the above problem can be equivalently posed as approximating by . Since , we let , where φ(x) = log f̃(x), which leads to the expression in (14). Observe that log(1 + ch/s) ≤ ch/s; hence, â ≥ 1. The analysis for the case where mh = 0 and mh+ > 0 proceeds along similar lines, where we define and find b̂ so that .
When mh > 0 and mh+ > 0, the analysis proceeds slightly differently. We want a, b ≥ 1 such that . Comparing the first three moments of to the log beta(a, b) density, we build the 2 × 2 linear system mentioned in Section 3.1 to estimate a, b. The formulas for d1, d2 can be obtained from the following expressions
where
Contributor Information
Anirban Bhattacharya, Email: ab179@stat.duke.edu, Department of Statistical Science, Duke University, NC 27708.
David B. Dunson, Email: dunson@stat.duke.edu, Department of Statistical Science, Duke University, NC 27708.
References
- Aitchison J, Bennett J. Polychotomous Quantal Response by Maximum Indicant. Biometrika. 1970;57(2):253–262. [Google Scholar]
- Ashford JR, Sowden RR. Multivariate Probit Analysis. Biometrics. 1970;26:535–546. [PubMed] [Google Scholar]
- Barnard K, Duygulu P, Forsyth D, De Freitas N, Blei D, Jordan M. Matching Words and Pictures. Journal of Machine Learning Research. 2003;3:1107–1135. [Google Scholar]
- Bishop Y, Fienberg S, Holland P. Discrete Multivariate Analysis: Theory and Practice. New York: Springer; 1975. [Google Scholar]
- Blei D, Ng A, Jordan M. Latent Dirichlet Allocation. Journal of Machine Learning Research. 2003;3:993–1022. [Google Scholar]
- Bollen K. Structural Equations With Latent Variables. New York: Wiley; 1989. [Google Scholar]
- Breiman L. Random Forests. Machine Learning. 2001;45(1):5–32. [Google Scholar]
- Carvalho C, Lucas J, Wang Q, Nevins J, West M. High-Dimensional Sparse Factor Modelling: Applications in Gene Expression Genomics. Journal of the American Statistical Association. 2008;103:1438–1456. doi: 10.1198/016214508000000869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carvalho C, Scott J. Objective Bayesian Model Selection in Gaussian Graphical Models. Biometrika. 2009;96(3):1–16. [Google Scholar]
- Chib S, Greenberg E. Analysis of Multivariate Probit Models. Biometrika. 1998;85:347–361. [Google Scholar]
- Chung Y, Dunson D. Nonparametric Bayes Conditional Distribution Modeling With Variable Selection. Journal of the American Statistical Association. 2009;104(488):1646–1660. doi: 10.1198/jasa.2009.tm08302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen JE, Rothblum UG. Nonnegative Ranks, Decompositions, and Factorizations of Nonnegative Matrices. Linear Algebra and Its Applications. 1993;190:149–168. [Google Scholar]
- Dawid A, Lauritzen S. Hyper Markov Laws in the Statistical Analysis of Decomposable Graphical Models. The Annals of Statistics. 1993;21(3):1272–1317. [Google Scholar]
- De Lathauwer L, De Moor B, Vandewalle J. A Multilinear Singular Value Decomposition. SIAM Journal on Matrix Analysis and Applications. 2000;21(4):1253–1278. [Google Scholar]
- Dobra A, Hans C, Jones B, Nevins J, Yao G, West M. Sparse Graphical Models for Exploring Gene Expression Data. Journal of Multivariate Analysis. 2004;90(1):196–212. [Google Scholar]
- Dobra A, Lenkoski A. Copula Gaussian Graphical Models. The Annals of Applied Statistics. 2011;5:969–993. [Google Scholar]
- Dobra A, Massam H. The Mode Oriented Stochastic Search (MOSS) Algorithm for Log-Linear Models With Conjugate Priors. Statistical Methodology. 2010;7(3):240–253. [Google Scholar]
- Dunson DB. Bayesian Latent Variable Models for Clustered Mixed Outcomes. Journal of the Royal Statistical Society, Series B. 2000;62(2):355–366. [Google Scholar]
- Dunson DB. Dynamic Latent Trait Models for Multidimensional Longitudinal Data. Journal of the American Statistical Association. 2003;98(463):555–563. [Google Scholar]
- Dunson DB. Nonparametric Bayes Local Partition Models for Random Effects. Biometrika. 2009;96(2):249. doi: 10.1093/biomet/asp021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunson DB, Park J. Kernel Stick-Breaking Processes. Biometrika. 2008;95(2):307. doi: 10.1093/biomet/asn012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunson DB, Pillai N, Park J. Bayesian Density Regression. Journal of the Royal Statistical Society, Series B. 2007;69(2):163–183. [Google Scholar]
- Dunson DB, Xing C. Nonparametric Bayes Modeling of Multivariate Categorical Data. Journal of the American Statistical Association. 2009;104(487):1042–1051. doi: 10.1198/jasa.2009.tm08439. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Erosheva E, Fienberg S, Joutard C. Describing Disability Through Individual-Level Mixture Models for Multivariate Binary Data. The Annals of Applied Statistics. 2007;1(2):502–537. doi: 10.1214/07-aoas126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferguson TS. A Bayesian Analysis of Some Nonparametric Problems. The Annals of Statistics. 1973;1:209–230. [Google Scholar]
- Ferguson TS. Prior Distributions on Spaces of Probability Measures. The Annals of Statistics. 1974;2:615–629. [Google Scholar]
- Fienberg S, Rinaldo A. Three Centuries of Categorical Data Analysis: Log-Linear Models and Maximum Likelihood Estimation. Journal of Statistical Planning and Inference. 2007;137(11):3430–3445. [Google Scholar]
- Frank A, Asuncion A. UCI Machine Learning Repository. Irvine, CA: School of Information and Computer Science, University of California; 2010. available at http://archive.ics.uci.edu/ml. [Google Scholar]
- Ghosh J, Ramamoorthi R. Bayesian Nonparametrics. New York: Springer-Verlag; 2003. [Google Scholar]
- Goodman LA. Explanatory Latent Structure Assigning Both Identifiable and Unidentifiable Models. Biometrika. 1974;61:215–231. [Google Scholar]
- Gregory D, Pullman N. Semiring Rank: Boolean Rank and Nonnegative Rank Factorizations. Journal of Combinatorics, Information & System Sciences. 1983;8(3):223–233. [Google Scholar]
- Griffin J, Steel M. Order-Based Dependent Dirichlet Processes. Journal of the American Statistical Association. 2006;101(473):179–194. [Google Scholar]
- Harshman R. UCLA Working Papers in Phonetics. 1. Vol. 16. Los Angeles, CA: UCLA; 1970. Foundations of the PARAFAC Procedure: Models and Conditions for an ‘Explanatory’ Multi-Modal Factor Analysis; p. 84. [Google Scholar]
- Ishwaran H, James L. Gibbs Sampling Methods for Stick-Breaking Priors. Journal of the American Statistical Association. 2001;96(453):161–173. [Google Scholar]
- Jones B, Carvalho C, Dobra A, Hans C, Carter C, West M. Experiments in Stochastic Computation for High-Dimensional Graphical Models. Statistical Science. 2005;20(4):388–400. [Google Scholar]
- Kim Y, Choi S. Nonnegative Tucker Decomposition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2007—CVPR’07; 2007. pp. 1–8. [Google Scholar]
- Kolda T. Orthogonal Tensor Decompositions. SIAM Journal on Matrix Analysis and Applications. 2001;23(1):243–255. [Google Scholar]
- Lauritzen S. Graphical Models. Oxford: Oxford University Press; 1996. [Google Scholar]
- Lazarsfeld P, Henry N. Latent Structure Analysis. Boston, MA: Houghton Mifflin; 1968. [Google Scholar]
- Lenkoski A, Dobra A. Computational Aspects Related to Inference in Gaussian Graphical Models With the G-Wishart Prior. Journal of Computational and Graphical Statistics. 2011;20(1):140–157. [Google Scholar]
- Liaw A, Wiener M. Classification and Regression by Random Forest. R News. 2002;2(3):18–22. [Google Scholar]
- Lopes H, West M. Bayesian Model Assessment in Factor Analysis. Statistica Sinica. 2004;14(1):41–68. [Google Scholar]
- Madigan D, York J. Bayesian Graphical Models for Discrete Data. International Statistical Review. 1995;63(2):215–232. [Google Scholar]
- Massam H, Liu J, Dobra A. A Conjugate Prior for Discrete Hierarchical Log-Linear Models. The Annals of Statistics. 2009;37(6A):3431–3467. [Google Scholar]
- Moustaki I, Knott M. Generalized Latent Trait Models. Psychometrika. 2000;65(3):391–411. [Google Scholar]
- Müller P, Erkanli A, West M. Bayesian Curve Fitting Using Multivariate Normal Mixtures. Biometrika. 1996;83(1):67. [Google Scholar]
- Muthén B. Latent Variable Structural Equation Modeling With Categorical Data. Journal of Econometrics. 1983;22(1–2):43–65. [Google Scholar]
- Norets A, Pelenis J. Technical report. Princeton, NJ: Princeton University; 2011. Posterior Consistency in Conditional Density Estimation by Covariate Dependent Mixtures. [Google Scholar]
- Ochi Y, Prentice R. Likelihood Inference in a Correlated Probit Regression Model. Biometrika. 1984;71(3):531–543. [Google Scholar]
- Pati D, Dunson D. Working Paper. Durham, NC: Department of Statistical Science, Duke University; 2011. Posterior Consistency in Conditional Distribution Estimation. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pitt M, Chan D, Kohn R. Efficient Bayesian Inference for Gaussian Copula Regression Models. Biometrika. 2006;93(3):537–554. [Google Scholar]
- Pritchard J, Stephens M, Donnelly P. Inference of Population Structure Using Multilocus Genotype Data. Genetics. 2000;155(2):945. doi: 10.1093/genetics/155.2.945. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rodriguez A, Dunson D. Nonparametric Bayesian Models Through Probit Stick-Breaking Processes. Bayesian Analysis. 2011;6:145–178. doi: 10.1214/11-BA605. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sammel M, Ryan L, Legler J. Latent Variable Models for Mixed Discrete and Continuous Outcomes. Journal of the Royal Statistical Society, Series B. 1997;59(3):667–678. [Google Scholar]
- Sethuraman J. A Constructive Definition of Dirichlet Priors. Statistica Sinica. 1994;4(2):639–650. [Google Scholar]
- Shashua A, Hazan T. Non Negative Tensor Factorization With Applications to Statistics and Computer Vision. Proceedings of the 22nd International Conference on Machine Learning; 2005. p. 799. [Google Scholar]
- Teh Y, Jordan M, Beal M, Blei D. Hierarchical Dirichlet Processes. Journal of the American Statistical Association. 2006;101(476):1566–1581. [Google Scholar]
- Tucker L. Some Mathematical Notes on Three-Mode Factor Analysis. Psychometrika. 1966;31(3):279–311. doi: 10.1007/BF02289464. [DOI] [PubMed] [Google Scholar]
- Wang H, Ahuja N. Rank-R Approximation of Tensors: Using Image-as-Matrix Representation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2005—CVPR’05; 2005. pp. 346–353. [Google Scholar]
- Wei C, Wu Q, Vega V, Chiu K, Ng P, Zhang T, et al. A Global Map of p53 Transcription-Factor Binding Sites in the Human Genome. Cell. 2006;124(1):207–219. doi: 10.1016/j.cell.2005.10.043. [DOI] [PubMed] [Google Scholar]
- West M. Bayesian Factor Regression Models in the ‘Large p, Small n’ Paradigm. Bayesian Statistics. 2003;7(2003):723–732. [Google Scholar]
- Whittaker J. Graphical Models in Applied Multivariate Statistics. New York: Wiley; 1990. [Google Scholar]
- Xie X, Geng Z. A Recursive Method for Structural Learning of Directed Acyclic Graphs. Journal of Machine Learning Research. 2008;9:459–483. [PMC free article] [PubMed] [Google Scholar]
- Zhang X, Boscardin WJ, Belin TR. Sampling Correlation Matrices in Bayesian Models With Correlated Latent Variables. Journal of Computational and Graphical Statistics. 2006;15(4):880–896. [Google Scholar]
- Zhang X, Boscardin WJ, Belin TR. Bayesian Analysis of Multivariate Nominal Measures Using Multivariate Multinomial Probit Models. Computational Statistics & Data Analysis. 2008;52:3297–3708. doi: 10.1016/j.csda.2007.12.012. [DOI] [PMC free article] [PubMed] [Google Scholar]