

Abstract
We propose a semiparametric marginal modeling approach for longitudinal analysis of cohorts with data missing due to death and non-response to estimate regression parameters interpreted as conditioned on being alive. Our proposed method accommodates outcomes and time-dependent covariates that are missing not at random with non-monotone missingness patterns via inverse-probability weighting. Missing covariates are replaced by consistent estimates derived from a simultaneously solved inverse-probability-weighted estimating equation. Thus, we utilize data points with the observed outcomes and missing covariates beyond the estimated weights while avoiding numerical methods to integrate over missing covariates. The approach is applied to a cohort of elderly female hip fracture patients to estimate the prevalence of walking disability over time as a function of body composition, inflammation, and age.
Keywords: gerontology, longitudinal data, missing data, missing not at random, sensitivity analysis
1. Introduction
Our goal is to estimate semiparametric marginal regression models for longitudinal studies with non-monotone missing outcomes and covariates, where missingness may be due to non-response or death. To accommodate deaths, we specify models to estimate associations that are conditioned on being alive [1]. That is, the target of inference is the mean outcome at a particular time conditioned on being alive at that time. Cohorts with data missing due to death are called ‘mortal cohorts,’ and another term for analysis conditioned on being alive, where missingness due to death and non-response is distinguished, is mortal cohort analysis [2]. In contrast, ‘immortal cohort’ analysis does not distinguish between the two reasons for missingness [2]. An analysis approach for mortal cohorts has previously been proposed for continuous outcomes and one time-dependent covariate, where missing data are integrated out of a normal working model [3]. We extend this approach to handle (1) marginal means that are non-linear functions of covariates and (2) a general number of time-dependent covariates with non-monotone missingness. If the model includes continuous covariates with missing data, then integrating over the missing data is intractable, requiring a numerical approach [4]. To avoid computationally intensive methods, we propose a computationally simple extension of weighted estimating equations (WEE). WEE involve multiplying the estimating equation for each observation by the inverse probability of being observed [5, 6]. Motivated by score equations of likelihood-based models for continuous [3, 7] and binary [8] outcomes, we circumvent the integration by replacing missing covariates with simultaneously estimated values.
WEE extends generalized estimating equations (GEE) [9] to better handle the missing data. When there is no selection bias, i.e. data are missing completely at random (MCAR) [10], GEE produces unbiased results. However, GEE produces biased estimates if outcomes are missing not at random (MNAR), i.e. missingness depends on variables that are not fully observed, or are missing at random (MAR), i.e. missingness only depends on fully observed variables [10]. GEE may also be biased if covariates’ missingness depends on outcome data or auxiliary variables (variables not included in the analysis model) that are related to the outcome [5]. An important auxiliary variable in mortal cohorts is survival time. As described in the previous literature [1, 3], MAR-S is a mechanism similar to MAR, except that the probability of missingness at a particular time point depends on (future) time of death. WEE can produce unbiased results if the missingness mechanism is correctly specified [11, 12]. However, the challenge in using WEE to handle the missing data is that the missingness mechanism cannot be identified solely by observed data. Rather, unverifiable assumptions are needed for analyses. Conclusions may not be robust across ranges of assumptions, thus a formal sensitivity analysis is advocated [11–15]. Eliciting assumptions from subject-matter experts about missingness can improve studies by promoting communication between statistical and substantive experts and performing sensitivity analyses over scientifically plausible assumptions.
When using WEE to address the missing data, it is important to distinguish between data that are missing due to death and data that are missing due to non-response (e.g. refusal or missed visits). WEE was originally developed to handle missing covariates [5] and missing outcomes [6, 11] due to non-response. To produce estimates interpreted as conditioned on being alive, weights at each time point are estimated using only data from participants who are alive [1, 3].
The aforementioned data structure and analysis goal are exemplified by longitudinal studies of injured older adults. In one such study, the Baltimore Hip Studies 3 (BHS-3), 205 Caucasian women aged ≥65 years were followed for 1 year after experiencing a hip fracture, with follow-up visits scheduled for 2, 6, and 12 months post-fracture. Our motivating example is an analysis that aims to estimate the associations of interleukin-6 (IL-6), an inflammatory cytokine, and percentage of body fat, a measure of body composition, with self-reported walking disability (defined as inability or requiring human or equipment assistance to walk one block), an activity of daily living (ADL), controlling for age at hip fracture. Body fat and IL-6 are two time-dependent continuous covariates, and walking disability is a binary outcome. Owing to the missing data, unweighted GEE only includes 67, 79, and 68 observations at 2, 6, and 12 months post-fracture, respectively, and data from 110 unique individuals, of whom only 30 had complete data at all three visits. To produce estimates that are conditioned on being alive, WEE only uses information at each visit on the participants who are alive via the estimated weights (inverse probability of being observed among those who are alive) [1, 3]. IL-6, body fat, and ADL information do not have the same missingness pattern at a given visit, and all three variables have non-monotone missing-data patterns. Frequencies of missing-data patterns are found in Table I. Those who miss visits or who refuse to provide serum for measuring IL-6, to undergo dual-energy X-ray absorptiometry (DXA) evaluations for measuring the body composition, or to respond to the questions about ADLs may have greater functional or cognitive decline or may be sicker than those who attend visits and provide complete data; therefore, it is not plausible to assume that data are MAR. MAR-S conditioned on age at hip fracture may be a plausible missingness mechanism, because age at hip fracture is associated with the post-fracture ADL disability, high IL-6 levels, and low body fat. That is, it is plausible that missingness may be independent of unobserved ADL, IL-6, and body fat conditioned on age and time of death.
Table I.
Missing data patterns from BHS-3 by variable and by time of visit.
| Variable pattern
|
Number with variable pattern, by time
|
||||||
|---|---|---|---|---|---|---|---|
| RY |
|
|
2 months | 6 months | 12 months | ||
| 1 | 1 | 1 | 67 | 79 | 68 | ||
| 1 | 1 | 0 | 6 | 6 | 5 | ||
| 1 | 0 | 1 | 23 | 18 | 16 | ||
| 0 | 1 | 1 | 21 | 14 | 8 | ||
| 0 | 0 | 1 | 10 | 5 | 8 | ||
| 0 | 1 | 0 | 1 | 2 | 0 | ||
| 1 | 0 | 0 | 17 | 10 | 23 | ||
| 0 | 0 | 0 | 53 | 56 | 50 | ||
| D | D | D | 7 | 15 | 27 | ||
| Time pattern
|
Number with time pattern, by variable
|
||||
|---|---|---|---|---|---|
| R2months | R6months | R12months | Y | XIL-6 | XFat |
| 1 | 1 | 1 | 66 | 51 | 79 |
| 1 | 1 | 0 | 20 | 19 | 18 |
| 1 | 0 | 1 | 10 | 3 | 4 |
| 0 | 1 | 1 | 17 | 20 | 13 |
| 0 | 0 | 1 | 18 | 8 | 4 |
| 0 | 1 | 0 | 5 | 8 | 2 |
| 1 | 0 | 0 | 8 | 15 | 11 |
| 0 | 0 | 0 | 34 | 54 | 47 |
| 1 | 1 | D | 4 | 2 | 4 |
| 1 | 0 | D | 4 | 2 | 2 |
| 0 | 1 | D | 1 | 1 | 0 |
| 0 | 0 | D | 3 | 7 | 6 |
| 1 | D | D | 1 | 3 | 3 |
| 0 | D | D | 7 | 5 | 5 |
| D | D | D | 7 | 7 | 7 |
Y = Walking dependence; XIL-6 = Interleukin 6; XFat = Body fat percentage; 1= Observed; 0= Missing; D= Death.
2. Data, models, and estimation
In this section, we describe the data structure, missing-data and analysis models, and estimation procedures for the proposed approach.
2.1. Data
Let Yi j be an outcome at visit j, j = 1, …, J, for participant i, i = 1, …, N, where J is the number of planned follow-up visits, and N is the sample size. Let t j denote the time of the jth visit, let Xi j = {Xi jk, k = 1, …, K} be a vector of K incomplete time-dependent covariates in an arbitrary order for participant i, and let Vi be a vector of fully observed baseline covariates for participant i. To handle missing data, let be the response indicator for Xijk, and let be the response indicator for Yi j. Let Si be time from baseline until death (e.g. first scheduled study visit after death in the BHS-3 cohort) for participant i. Let Ai j be an indicator that participant i is alive at visit j. Lastly, let Wi = {Si, Vi, Xi, Yi} denote all relevant data for participant i until death, except for response indicators.
2.2. Models
Consider the expected value of Yi j, given covariates of interest, partly conditioned on being alive [1, 3, 16]:
Our goal is to estimate the regression equation
| (1) |
where g(·) denotes a link function. Estimating survival, f (Si), is not a primary analysis goal; thus, we aim to estimate the parameters in equation (1) using semiparametric models.
To accommodate the missing data, let be the vector of response indicators for Xi j. Also, specifying and to be degenerate, let denote the history of response indicators for Yi up through visit j − 1; let denote the history of response indicators for Xi up through visit j −1. We consider the following general model for the joint response probabilities at visit j given the history of response probabilities and Wi for participants who are alive (Ai j = 1):
where
| (2) |
| (3) |
For example, if K = 2 like in the BHS-3 study, then at the first scheduled post-baseline visit (j = 1), the joint probability of observing the outcome and both covariates is
The probabilities at j = 2 can condition on the response pattern at j = 1, etc. Conditioning on Ai j = 1 implies that equations (2) and (3) are response probabilities only among those who are alive at visit j. As a result, the increasing number of deaths over time will not explicitly diminish response probabilities at later times. Equations (2) and (3) exemplify MNAR mechanisms, because missingness depends on variables with the missing data. Further simplification depends on assumptions about the missing-data mechanism [11]. Also, although the ordering of the K components of Xi j is arbitrary for calculating joint response probabilities at visit j, study design aspects may help to simplify the response probability model and inform the ordering (e.g. covariates with a monotone missing-data pattern at visit j) [17].
Let , where and . That is is the collection of relevant observed data for participant i up through visit j − 1, plus survival. The missing-data mechanisms
| (4) |
| (5) |
are examples of MAR-S, because the probabilities at time j are functions of observed histories of Yi and Xi up until j −1 and survival time Si, an auxiliary variable. If and in equations (4) and (5), respectively, were conditionally independent of Si, given the fully observed covariates, the equations would simplify to an MAR mechanism.
2.3. Estimation
To estimate the parameters in equation (1), we adapt GEE to accommodate mortality. However, in order for the parameters to be interpreted as partly conditional on being alive, an independence working correlation structure must be specified. A non-independence correlation structure would require specifying pairwise correlations between all visits up until the last visit prior to death. Thus, the parameters in equation (1) would depend on the time of death when Si ≤ tJ, not just on being alive (Ai j = 1) [1, 3, 16]. In the absence of the missing data due to non-response, the independence estimating equation (IEE) to be fit is
| (6) |
where VarY |X(Yi j) is the j, j term, , of the J × J diagonal working variance–covariance matrix VarY |X(Yi). In the presence of missing data due to non-response, the missing-data mechanism can be incorporated into equation (6) via simple inverse-probability-weighted independence estimating equations (simple W-IEE) using
| (7) |
In most cases, and are not known and need to be estimated. In addition, equation (7) does not efficiently use observations for which at least one of Yi j or Xi jk, k = 1, …, K, but not all, are missing. Thus, we consider an estimating equation that can utilize observations with missing variables beyond the estimated weights.
The proposed approach extends equation (7) to utilize observations where X is observed and Y is missing beyond the weights for general models for Y. We first describe the equations for estimating and and then introduce the proposed estimating equation for β.
Let and , k =1, … K, denote the vectors of variables associated with and , respectively. Let and denote the regression parameters for and , respectively. Unbiased estimating equations for and are
| (8) |
| (9) |
The summands in equations (8) and (9) are multiplied by Ai j to ensure that the estimated response probabilities only use data from participants who are alive at visit j. When Yi j (Xijk) is missing, the summand in equation (8) (equation (9)) simplifies to . Thus, equation (8) can accommodate MNAR Yij via user-specified values for the coefficient of Yij. Similarly, MNAR Xijk in equation (9) can be specified via the coefficient of Xijk.
To estimate β in our proposed method, we utilize observations with missing components of X by plugging in consistent estimates of the missing variables conditioned on the observed covariates. We assume that the mean of Xi jk conditioned on being alive, tj, and fully observed baseline covariates Vi is
Let be the K-vector of . To estimate αk = {α0k, α1k, α2k}, we posit a weighted independence estimating equation. Let Var(Xi) be the JK × JK block-diagonal working variance–covariance matrix of Xi, which has jth K × K block Var(Xi j). Consistent estimates of Xijk conditioned on Vi, tj, and observed components of Xij will be functions of α= {αk : k = 1, …, K} and components of Var(Xi j), with k, k′ component .
Let denote the collection of all possible K-vector missing-data patterns at visit j, , for . Thus, for missing-data patterns in indicates Xjk is observed, and for missing-data patterns in indicates Xjk is missing. For example, in the BHS-3 study, K = 2, and all covariate response patterns are possible at all visits; therefore, for all j. Let the terms and refer, respectively, to the conditional mean and variance of Yi j, with Xi jk replaced by when . If K = 2 then if, for example, participant i at visit j has observed Xi j1 and missing Xi j2 then and Xi j2 is replaced by , which equals , in :
Also, let denote the subvector of excluding when . Similarly, is the submatrix of Var(Xij) excluding Xijk when . Let σ denote the vector of and for j =1, …, J and k, k′ = 1, …, K. Let φ= {β, α, σ}. We consider the following estimating equation for φ:
| (10) |
| (11) |
where
and
corresponds to the score equation for multivariate normal , with specified to be degenerate (i.e. when ). Although and components of can be set to 0 by convention when Aij = 0 their values do not affect estimates of , and φ, because equations (8–11) only use observations where Ai j = 1. We show in the Appendix that equations (10) and (11) are unbiased so long as the summands are unbiased.
To understand equations (10) and (11), consider the special case of K = 2. Thus, summing equation (10) over produces four terms because there are four possible covariate response vectors:
| (12) |
where , and VarY|X(1,1)(Yij)=VarY|X(Yij); therefore the fourth term in equation (12) equals simple W-IEE in equation (7).
Thus, all data points with Yij observed contribute information to at least one term in equation (12). However, data points with Xi j1 and Xi j2 both observed contribute information to all four terms and are the only data points that contribute information to the fourth term. In contrast, data points with Xi j1 and Xi j2 both missing only contribute information to the first term in equation (12).
For general K, equation (10) can be split into 2K terms (unless some patterns are precluded by study design). Individual i at visit j can contribute information to a particular term if and . Similarly, equation (11) can be split into 2K − 1 terms (the term with is degenerate; hence, 1 is subtracted). As a result, when K = 2, equation (11) is equal to
| (13) |
where Xij(0,1), Xij(1,0), and Xij(1,1) are just Xij2, Xij1, and Xi j, respectively. Similarly, , and are just , and , respectively.
As written, equations (10) and (11) only accommodate MNAR mechanisms where RY depends on Y, but not components of X and where depends on Xk, but not Y or X−k. However, equations (10) and (11) can be adapted to handle these mechanisms. For example, for components of RX that depend on Y, the summand in equation (11) is multiplied by . An implication of this approach is that equation (11) does not use observations with missing Y beyond the weights; thus, more complicated MNAR mechanisms may lead to less efficient estimates. We consider this mechanism and approach in the simulation study and when analyzing the BHS-3 data. When the response probabilities are unknown, the π are replaced with estimates derived from equations (8) and (9).
3. Simulation study
We performed simulation studies to explore the performance of our proposed method and several popular alternatives. We considered K = 1, J = 4, one baseline covariate V, and binary Y. Each study consisted of N = 200 or N = 500 individuals and Nsim = 1000 iterations. Appropriate robust standard errors can be calculated via the information sandwich; however these estimates are not quite correct [2]. Additionally, it has been shown [3] that bootstrap standard errors outperform robust standard errors for WEE; thus the former were calculated with Nbs = 150 bootstrap simulations.
Two different MNAR missing-data mechanisms were explored in this study. The first mechanism, which we call MNAR1, was specified such that the only incomplete variable on which RX and RY depended was X and Y, respectively. In the second mechanism, which we call MNAR2, both RX and RY depended on Y, but only RX depended on X. To implement estimation assuming MNAR2, the summand in equation (11) was multiplied by . Both MNAR1 and MNAR2 depended on S.
The simulation proceeded as follows. First, the baseline covariate, V, was simulated from a Normal(1, 4) distribution. We operationalized S as a discrete survival time interpreted as the first visit after death, S ∈ {2, …, J +1}, where all individuals are alive at the first visit, and S = J +1 denotes survival past the end of follow up. S was simulated from a multinomial distribution with a continuation ratio model where logit[P(Si = s|Si≥s)]= δ0s + δ1Vi, s = 2, 3, 4, δ0 = {−1.65, −2.00, −2.25}, and δ1 = −0.25. The time-dependent covariate, X, was simulated from a normal distribution with variance 1, exchangeable correlation 0.5, and mean
| (14) |
where tj = j (visit number) here.
A Bernoulli distribution assuming a mixed-effects logistic model was specified for Y such that a vector of random effects was simulated from a multivariate normal distribution with mean vector 0, variances 1, and pair-wise correlations 0.5. Y was then simulated, conditional on the simulated random effects, V, X, t, and S. Let bi denote the random model component. The subject-specific logistic model was
| (15) |
where bi = bi0 + bi1 Xi j + bi2Vi + bi4(t j − 1)+ Si [bi5 + bi6 Xi j + bi7Vi + bi8(tj − 1)], and bi0, …, bi8 are the random effects. Equation (15) was not the target of estimation, because it is not partly conditioned on being alive. True values of β in equation (1) were found by solving equation (6):
Lastly, among those who are alive, the response indicators were simulated. For both MNAR mechanisms, when Ai j = 1, was simulated from a Bernoulli distribution with logistic model , where γRX|Y = 0 for MNAR1 and γRX|Y = 0.75 for MNAR2. In both mechanisms, γRX|X = −0.10. For both MNAR mechanisms, when Ai j = 1, was simulated from a Bernoulli distribution with logistic model , where γRY|Y = 0.75. We analyzed the data using the proposed method (W-IEE; equations (10) and (11) with K = 1), simple inverse-probability weighting (simple W-IEE; equation (7)), unweighted logistic regression (IEE), and weighted GEE (W-GEE) using an exchangeable correlation matrix.
The MNAR1 model resulted in 21(j = 1) to 51 per cent (j = 4) missing data for X, 22 (j = 1) to 46 per cent (j = 4) missing data for Y, and 37 (j = 1) to 71 per cent (j = 4) missing data for X or Y. The MNAR2 model resulted in 20 (j = 1) to 47 per cent (j = 4) missing data for X, 21(j = 1) to 48 per cent (j = 4) missing data for Y, and 36 (j = 1) to 57 per cent (j = 4) missing data for X or Y. The average cumulative incidences of death at j = 2, 3, 4 specified by the model were 18, 28, and 32 per cent, respectively.
Table II shows results comparing W-IEE, simple W-IEE, W-GEE, and IEE for N = 200 and N = 500. Overall, bias using W-IEE and simple W-IEE was smaller than that when using IEE or W-GEE for both sample sizes. Under the MNAR1 assumption, when α can be estimated using observations with missing Y, W-IEE produced smaller standard errors than simple W-IEE; however, when MNAR2 was assumed, the differences in standard errors were negligible. This result was expected because, under MNAR2, equation (11) only uses observations with Y observed, whereas under MNAR1, inclusion in equation (11) does not depend on whether Y is observed. For both MNAR mechanisms, standard errors using W-GEE and IEE tended to be smaller than those using W-IEE and simple W-IEE. This result for W-GEE was due to the implicit imputation that occurs when specifying GEE to have a non-independence correlation structure in the presence of incomplete data. IEE reflected the MCAR assumption, and observations with Y and X observed varied less than those from the population distribution.
Table II.
Simulation study results (Nsim = 1000, Nbs = 150); percent bias of β̂ 100(β̂ − β)/β (Bias), bootstrap standard error for β̂ (SE), empirical standard error for β̂ (ESE), relative efficiency with simple W-IEE as referent (Rel. Eff.), and 95 per cent confidence interval coverage percent (95 per cent CI Cov.).
| Effect | β | N | Method | MNAR1
|
MNAR2
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | SE | ESE | Rel. eff. | 95 per cent CI cov. | Bias | SE | ESE | Rel. eff. | 95 per cent CI cov. | ||||
| Intercept | 0.066 | 200 | W-IEE | −12 | 0.189 | 0.190 | 1.3 | 95.0 | 14 | 0.189 | 0.189 | 1.0 | 95.4 |
| Simple W-IEE | −14 | 0.217 | 0.218 | 1.0 | 95.0 | 13 | 0.192 | 0.190 | 1.0 | 95.7 | |||
| IEE | 109 | 0.197 | 0.199 | 1.2 | 93.9 | 252 | 0.192 | 0.189 | 1.0 | 88.1 | |||
| W-GEE | −239 | 0.208 | 0.196 | 1.2 | 89.7 | −492 | 0.196 | 0.189 | 1.0 | 65.2 | |||
| 500 | W-IEE | −2 | 0.117 | 0.119 | 1.3 | 95.2 | 2 | 0.116 | 0.117 | 1.0 | 95.8 | ||
| Simple W-IEE | −5 | 0.134 | 0.136 | 1.0 | 94.7 | 1 | 0.118 | 0.119 | 1.0 | 95.7 | |||
| IEE | 114 | 0.124 | 0.124 | 1.2 | 92.0 | 256 | 0.120 | 0.123 | 0.9 | 72.0 | |||
| W-GEE | −234 | 0.121 | 0.126 | 1.2 | 76.7 | −490 | 0.120 | 0.123 | 0.9 | 27.0 | |||
| I(tj=2) | 0.238 | 200 | W-IEE | 2 | 0.186 | 0.190 | 1.6 | 94.8 | −1 | 0.185 | 0.182 | 1.0 | 96.2 |
| Simple W-IEE | 3 | 0.245 | 0.244 | 1.0 | 96.3 | −1 | 0.186 | 0.182 | 1.0 | 96.2 | |||
| IEE | −10 | 0.167 | 0.178 | 1.9 | 94.3 | −18 | 0.156 | 0.163 | 1.2 | 93.4 | |||
| W-GEE | −17 | 0.184 | 0.169 | 2.1 | 94.7 | −27 | 0.152 | 0.151 | 1.4 | 93.8 | |||
| 500 | W-IEE | −2 | 0.113 | 0.110 | 1.7 | 95.4 | <1 | 0.113 | 0.112 | 1.0 | 95.2 | ||
| Simple W-IEE | −1 | 0.149 | 0.145 | 1.0 | 96.4 | 1 | 0.113 | 0.112 | 1.0 | 95.3 | |||
| IEE | −13 | 0.105 | 0.110 | 1.7 | 93.0 | −20 | 0.098 | 0.099 | 1.3 | 91.5 | |||
| W-GEE | −19 | 0.102 | 0.100 | 2.1 | 91.7 | −29 | 0.093 | 0.091 | 1.5 | 89.0 | |||
| I(tj=3) | 0.304 | 200 | W-IEE | 1 | 0.233 | 0.230 | 1.4 | 96.1 | −1 | 0.232 | 0.232 | 1.0 | 94.4 |
| Simple W-IEE | <1 | 0.288 | 0.277 | 1.0 | 96.0 | −1 | 0.233 | 0.232 | 1.0 | 94.6 | |||
| IEE | −9 | 0.179 | 0.183 | 2.3 | 94.1 | −19 | 0.167 | 0.179 | 1.7 | 91.7 | |||
| W-GEE | −17 | 0.197 | 0.173 | 2.6 | 96.3 | −30 | 0.165 | 0.166 | 2.0 | 91.0 | |||
| 500 | W-IEE | <1 | 0.142 | 0.138 | 1.4 | 95.2 | 2 | 0.142 | 0.141 | 1.0 | 96.0 | ||
| Simple W-IEE | 1 | 0.175 | 0.166 | 1.0 | 96.1 | 2 | 0.142 | 0.141 | 1.0 | 96.1 | |||
| IEE | −11 | 0.113 | 0.112 | 2.2 | 94.9 | −19 | 0.105 | 0.110 | 1.6 | 89.3 | |||
| W-GEE | −19 | 0.110 | 0.106 | 2.4 | 92.8 | −30 | 0.101 | 0.100 | 2.0 | 84.1 | |||
| I(tj=4) | 0.313 | 200 | W-IEE | <1 | 0.289 | 0.288 | 1.4 | 95.6 | <1 | 0.285 | 0.280 | 1.0 | 95.3 |
| Simple W-IEE | 1 | 0.339 | 0.345 | 1.0 | 95.9 | <1 | 0.286 | 0.280 | 1.0 | 95.4 | |||
| IEE | −9 | 0.199 | 0.208 | 2.8 | 94.1 | −17 | 0.185 | 0.192 | 2.1 | 91.7 | |||
| W-GEE | −17 | 0.224 | 0.198 | 3.0 | 95.6 | −29 | 0.185 | 0.177 | 2.5 | 93.0 | |||
| 500 | W-IEE | <1 | 0.175 | 0.170 | 1.3 | 95.6 | <1 | 0.175 | 0.169 | 1.0 | 96.6 | ||
| Simple W-IEE | 1 | 0.206 | 0.195 | 1.0 | 97.0 | <1 | 0.175 | 0.169 | 1.0 | 96.7 | |||
| IEE | −12 | 0.125 | 0.123 | 2.5 | 94.6 | −18 | 0.116 | 0.118 | 2.0 | 91.2 | |||
| W-GEE | −20 | 0.122 | 0.118 | 2.7 | 92.0 | −30 | 0.113 | 0.108 | 2.4 | 85.6 | |||
| X | 0.045 | 200 | W-IEE | <1 | 0.142 | 0.149 | 1.0 | 94.2 | −2 | 0.139 | 0.136 | 1.0 | 95.4 |
| Simple W-IEE | <1 | 0.142 | 0.150 | 1.0 | 94.3 | −2 | 0.139 | 0.136 | 1.0 | 95.4 | |||
| IEE | −2 | 0.087 | 0.094 | 2.5 | 93.6 | 10 | 0.082 | 0.085 | 2.6 | 95.3 | |||
| W-GEE | 7 | 0.099 | 0.090 | 2.8 | 96.0 | 14 | 0.084 | 0.079 | 3.0 | 97.0 | |||
| 500 | W-IEE | 2 | 0.086 | 0.087 | 1.0 | 96.0 | <1 | 0.085 | 0.086 | 1.0 | 94.9 | ||
| Simple W-IEE | 3 | 0.087 | 0.088 | 1.0 | 96.0 | 1 | 0.086 | 0.086 | 1.0 | 94.9 | |||
| IEE | 4 | 0.055 | 0.055 | 2.6 | 95.9 | 2 | 0.052 | 0.056 | 2.4 | 93.4 | |||
| W-GEE | 12 | 0.054 | 0.053 | 2.8 | 96.2 | 8 | 0.051 | 0.052 | 2.7 | 94.8 | |||
| V | 0.092 | 200 | W-IEE | 8 | 0.109 | 0.106 | 1.2 | 96.2 | 7 | 0.109 | 0.108 | 1.1 | 94.8 |
| Simple W-IEE | 7 | 0.118 | 0.115 | 1.0 | 96.0 | 8 | 0.114 | 0.114 | 1.0 | 94.5 | |||
| IEE | 25 | 0.106 | 0.106 | 1.2 | 95.2 | 26 | 0.105 | 0.107 | 1.1 | 94.3 | |||
| W-GEE | 36 | 0.122 | 0.114 | 1.0 | 96.8 | 61 | 0.113 | 0.114 | 1.0 | 94.7 | |||
| 500 | W-IEE | 2 | 0.067 | 0.066 | 1.2 | 95.9 | 3 | 0.067 | 0.067 | 1.1 | 95.6 | ||
| Simple W-IEE | 3 | 0.072 | 0.074 | 1.0 | 95.1 | 4 | 0.070 | 0.070 | 1.0 | 94.9 | |||
| IEE | 21 | 0.066 | 0.066 | 1.2 | 95.2 | 20 | 0.065 | 0.066 | 1.1 | 94.5 | |||
| W-GEE | 31 | 0.070 | 0.069 | 1.2 | 94.0 | 55 | 0.069 | 0.070 | 1.0 | 90.1 | |||
Comparing estimated standard errors to empirical standard errors shows that the bootstrap with Nbs = 150 performed well. Overall, coverage was slightly closer to the nominal 95 per cent using W-IEE and simple W-IEE compared with IEE or W-GEE. The small decrease in empirical coverage for W-GEE when N = 200 compared with the nominal coverage reflected that the overestimated standard errors using W-GEE (compared with the empirical standard errors) compensated for the large bias. We also explored W-GEE using an unstructured covariance matrix, which resulted in non-convergence problems for N = 200 and little improvement in performance when N = 500 (not shown).
Figure 1 shows the true and estimated proportions (P(Y = 1)), when Vi = 1, its mean, and Xi = (0.65, 1.15, 1.65, 2.15), the means from equation (14), for both MNAR1 and MNAR2 mechanisms when N = 200. In both cases, IEE overestimated the proportion, whereas W-GEE underestimated the proportion, and W-IEE and simple W-IEE produced unbiased estimates.
Figure 1.
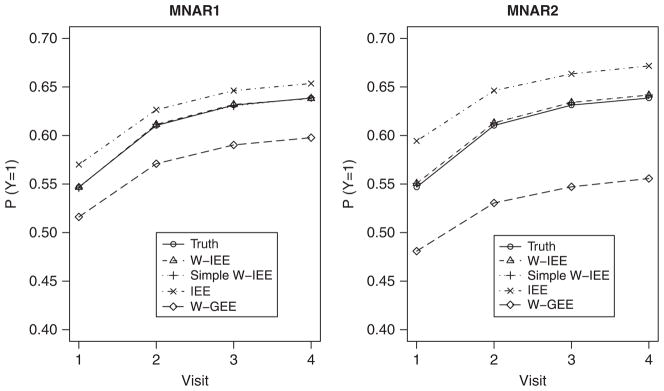
Simulation results, N = 200, Nsim = 1000. Estimated proportions (P(Y = 1)) under two MNAR mechanisms and four estimation methods.
4. BHS-3 data analysis: a sensitivity analysis approach
Our goal was to quantify the association of IL-6 (pg/mL) (XIL-6) and body composition (XFat) (operationalized as fat mass as a percentage of total mass assessed via DXA evaluations) with prevalence of walking disability (Y) measured at the same time among older women (aged ≥65 years) who experienced a hip fracture, after controlling for age at hip fracture and time since fracture, conditioned on being alive. For this target of inference (i.e. cross-sectional means at time j partly conditional on time-dependent variables at time j, time, and baseline covariates, for j = 1, …, J), independence estimating equations are an appropriate estimation method [18]. Seven, 15, and 27 women died by the 2-, 6-, and 12-month evaluations, respectively. Thus, the impact of deaths on the interpretation of regression coefficients should be considered. One option was to model Y as a trichotomous variable, treating death as a response state of Y as in Miller et al. [19]. However, death was not the primary outcome of interest (if it were, it could be more appropriately handled as a continuous time-to-event variable); thus, we used estimating equations to partly condition on being alive.
In addition to deaths, only 30 participants provided information about Y, XIL-6, and XFat at all three visits. All 23 possible missing-data patterns between the three variables were observed during at least one visit (Table I). Within a visit, the variable most commonly missing was IL-6, perhaps because it required the most invasive collection procedure of the three variables; the pattern with only IL-6 collected was the least common. Only 51 participants provided serum at all three visits, compared with 66 and 79 participants who self-reported ADLs and underwent DXA evaluations, respectively, at all three visits. Although less common than longitudinal monotone patterns within a variable, 10, 3, and 4 women provided information at only 2 and 12 months post-fracture (missing at six months) for ADLs, IL-6, and body composition, respectively. Similarly, 5, 8, and 2 women provided information at six months only for ADLs, IL-6, and body composition, respectively. Monotone patterns whereby women missed early visits, but returned at later visits were almost as common as drop outs. We assumed that those with missing observations were in worse physical condition than those providing information. Therefore, these patterns may reflect the competing forces of recovery post-fracture and aging-related physical decline.
We analyzed the BHS-3 data using the proposed W-IEE approach (equations (10) and (11) with K = 2), simple W-IEE (equation (7)), W-GEE, and IEE (logistic regression). Weights were estimated using the following MNAR2 models:
| (16) |
| (17) |
| (18) |
Arbitrarily assigning k = 1 for IL-6, and k = 2 for body fat, we did not include or in equation (17) due to sparseness. MNAR1 was specified by excluding Yi j from equations (16) and (17). Both MNAR1 and MNAR2 depended on S. For both MNAR mechanisms, assumptions were needed about and γRY|Y, the coefficients for Xi j(IL-6), Xi j(Fat), and Yi j in equations (16)–(18), respectively, because these parameters were not identifiable by observed data. To address this issue, ranges of parameter values were elicited from two subject-matter experts, a geriatrician (RRM) and geriatric physical therapist (GEH), to perform a sensitivity analysis. The experts were interviewed separately (by MS) about their beliefs regarding the parameters. The experts were asked the following set of three questions: (1) ‘Holding all else constant, who is more likely to provide responses about ADLs: those who can independently walk one block, or those who cannot independently walk one block?’, (2) ‘What is a plausible range of values for the odds ratio of providing a response, comparing (group chosen in question 1) to (group not chosen in question 1)?’, and (3) ‘What is your rationale for these beliefs?’ The questions were repeated to compare women whose IL-6 levels differed by 10 pg/mL about providing serum, and to compare women whose body fat levels differed by 5 per cent about undergoing DXA evaluations.
The experts were in agreement about the directions of associations and rationale, but opinions differed regarding the magnitudes of associations. After reaching a consensus by connecting the elicited ranges, the experts believed that those without walking disability (those who could independently walk one block) had 1.0 to 2.0 times greater odds of providing a response compared with those with walking disability. The reasons for this belief were that those without walking disability would be proud to admit so, and those with walking disability would feel embarrassed to admit it. Also, walking independence requires cognitive ability, and those lacking the cognitive ability to walk independently may also lack the cognitive ability to respond to interview questions [20]. Comparing women whose IL-6 levels differed by 10 pg/ml, women with lower IL-6 were thought to have 1.0 to 2.5 times greater odds of providing serum than women with higher IL-6. IL-6 levels tended to be highest in the most frail patients. Also, elevated IL-6 is a marker for lingering adverse effects of the hip fracture; thus, those in worse general health were thought more likely to refuse the needle venopuncture required for providing serum [21, 22]. Lastly, the experts assumed that women would have 1.0 to 1.5 times greater odds of undergoing DXA when compared with women with 5 per cent less body fat. Both experts mentioned that elderly hip fracture patients are rarely overweight, and that those with the lowest fat percentage were most likely underweight, a marker of frailty. Given that DXA evaluations required travel from home or hospital to a location with DXA equipment, those who were most frail were thought most likely to refuse. In summary, those who were in better physical health were thought more likely to provide data than those in worse physical health.
We performed sensitivity analysis using the elicited expert information by assuming MCAR and six MNAR assumptions. We defined MNAR1-Min, MNAR1-Mid, and MNAR1-Max, as MNAR1 mechanisms assuming odds ratios that were the minimum, midpoint, and maximum elicited departures from the null, 1.0. MNAR2 mechanisms were analogously named. For example, elicited values of ranged from 1.0 to 1.5; thus, the odds ratios corresponding to the minimum, midpoint, and maximum departures from 1.0 were 1.0, 1.25, and 1.5, respectively. The ranges of elicited odds ratios for all three parameters included 1.0; thus, MNAR1-Min simplified to the MAR-S mechanism. Analyses were performed using W-IEE, simple W-IEE, W-GEE, and IEE.
The estimated model parameters are shown in Table III. With the exception of the coefficient for body fat assuming MNAR2-Max using W-IEE, directions of parameters were robust to estimation method or missing-data mechanism. In general, higher levels of IL-6 and body fat and older age were associated with walking disability, adjusted for time since hip fracture and conditioned on being alive. After controlling for IL-6, body fat, and age, estimated prevalence of walking disability using W-IEE for all assumptions except MNAR1-Max was highest at 2 months and lowest at 6 months post-fracture among those who were alive.
Table III.
BHS-3 study results (N = 205, Nbs = 150); estimated coefficients (β̂) and standard errors (SE) relating walking disability (Y = 1) to time since hip fracture, IL-6, body fat, and age. Min, Mid, and Max of , (−log(1.50), −log(1.75), log(1.25)), and (−log(2.00), −log(2.50), log(1.50)), respectively.
| Effect | Assumption | IEE
|
W-IEE
|
Simple W-IEE
|
W-GEE
|
||||
|---|---|---|---|---|---|---|---|---|---|
| β̂ | SE | β̂ | SE | β̂ | SE | β̂ | SE | ||
| Intercept | MCAR | −8.04 | 2.94 | ||||||
| MNAR1-min | −8.05 | 3.44 | −10.44 | 4.48 | −10.96 | 4.62 | |||
| MNAR1-mid | −8.95 | 3.65 | −11.75 | 4.05 | −12.35 | 4.44 | |||
| MNAR1-max | −8.16 | 3.86 | −13.13 | 4.89 | −13.66 | 5.08 | |||
| MNAR2-min | −8.81 | 3.27 | −10.04 | 3.45 | −10.99 | 3.65 | |||
| MNAR2-mid | −7.26 | 3.27 | −12.01 | 4.47 | −12.52 | 4.76 | |||
| MNAR2-max | −6.13 | 2.96 | −10.70 | 4.38 | −11.14 | 4.48 | |||
| 6 months | MCAR | −1.41 | 0.40 | ||||||
| MNAR1-min | −1.49 | 0.48 | −1.49 | 0.61 | −1.24 | 0.54 | |||
| MNAR1-mid | −1.64 | 0.64 | −1.49 | 0.73 | −1.43 | 0.61 | |||
| MNAR1-max | −1.49 | 0.67 | −1.32 | 0.86 | −1.35 | 0.73 | |||
| MNAR2-min | −1.89 | 0.61 | −2.04 | 0.64 | −1.82 | 0.56 | |||
| MNAR2-mid | −1.68 | 0.76 | −1.82 | 0.84 | −1.77 | 0.80 | |||
| MNAR2-max | −1.60 | 0.71 | −1.75 | 0.81 | −1.70 | 0.73 | |||
| 12 months | MCAR | −1.33 | 0.41 | ||||||
| MNAR1-min | −1.45 | 0.50 | −1.15 | 0.53 | −1.07 | 0.41 | |||
| MNAR1-mid | −1.50 | 0.55 | −1.72 | 0.72 | −1.65 | 0.65 | |||
| MNAR1-max | −1.57 | 0.64 | −2.06 | 0.96 | −2.03 | 0.87 | |||
| MNAR2-min | −1.60 | 0.53 | −2.03 | 0.64 | −1.89 | 0.57 | |||
| MNAR2-mid | −1.46 | 0.65 | −1.65 | 0.72 | −1.61 | 0.70 | |||
| MNAR2-max | −1.46 | 0.50 | −1.75 | 0.60 | −1.71 | 0.57 | |||
| IL-6 (per 10 pg/mL) | MCAR | 0.08 | 0.10 | ||||||
| MNAR1-min | 0.11 | 0.08 | 0.12 | 0.08 | 0.16 | 0.09 | |||
| MNAR1-mid | 0.14 | 0.07 | 0.14 | 0.09 | 0.16 | 0.15 | |||
| MNAR1-max | 0.11 | 0.07 | 0.12 | 0.09 | 0.13 | 0.10 | |||
| MNAR2-min | 0.12 | 0.18 | 0.15 | 0.17 | 0.18 | 0.15 | |||
| MNAR2-mid | 0.14 | 0.08 | 0.12 | 0.08 | 0.13 | 0.09 | |||
| MNAR2-max | 0.15 | 0.07 | 0.16 | 0.08 | 0.18 | 0.08 | |||
| Body fat (per 5 per cent) | MCAR | 0.20 | 0.17 | ||||||
| MNAR1-min | 0.14 | 0.20 | 0.18 | 0.27 | 0.18 | 0.26 | |||
| MNAR1-mid | 0.10 | 0.19 | 0.22 | 0.22 | 0.23 | 0.22 | |||
| MNAR1-max | 0.02 | 0.16 | 0.32 | 0.20 | 0.34 | 0.20 | |||
| MNAR2-min | 0.14 | 0.20 | 0.08 | 0.22 | 0.08 | 0.23 | |||
| MNAR2-mid | 0.02 | 0.21 | 0.18 | 0.24 | 0.18 | 0.26 | |||
| MNAR2-max | −0.01 | 0.20 | 0.04 | 0.24 | 0.04 | 0.24 | |||
| Age (years) | MCAR | 0.11 | 0.03 | ||||||
| MNAR1-min | 0.12 | 0.04 | 0.15 | 0.04 | 0.15 | 0.05 | |||
| MNAR1-mid | 0.14 | 0.04 | 0.16 | 0.04 | 0.17 | 0.05 | |||
| MNAR1-max | 0.13 | 0.04 | 0.18 | 0.06 | 0.18 | 0.06 | |||
| MNAR2-min | 0.14 | 0.03 | 0.16 | 0.04 | 0.18 | 0.04 | |||
| MNAR2-mid | 0.13 | 0.03 | 0.18 | 0.05 | 0.19 | 0.05 | |||
| MNAR2-max | 0.12 | 0.03 | 0.18 | 0.04 | 0.18 | 0.04 | |||
Magnitudes of parameters were sensitive to estimation method for a given missing-data mechanism. For example, the coefficient for IL-6 assuming MNAR2-Min ranged from 0.12 (W-IEE) to 0.18 (W-GEE). The parameters were also sensitive to assumptions about the missing-data mechanism for a given method. The coefficient for body fat using W-IEE varied from −0.01 (MNAR2-Max) to 0.14 (MNAR1-Min and MNAR2-Min). Overall, estimates using W-GEE and simple W-IEE fluctuated across assumptions about missing data more than those using W-IEE, perhaps because the former methods used fewer observations than W-IEE. This reason is also a plausible explanation why estimated associations for IL-6 and body fat were stronger more often using simple W-IEE and W-GEE than those using W-IEE. Among those for whom , the prevalences of walking disability at 2, 6, and 12 months post-fracture were 0.90, 0.72, and 0.72, respectively, whereas the analogous prevalences among those for whom (data only used by W-IEE beyond the weights) were 1.00, 0.82, and 0.84. Similarly, the means of IL-6 among those with at 2, 6, and 12 months post-fracture were 21.0, 16.6, and 17.5 pg/mL, whereas the means of those with (data only used by W-IEE beyond the weights) were 17.8, 22.1, and 12.0 pg/mL. Finally, the means of body fat percentage among those with at 2, 6, and 12 months post-fracture were 29.5, 30.2, and 31.4 per cent, whereas the means among those with (data only used by W-IEE beyond the weights) were 28.7, 29.1, and 29.5 per cent. These estimates cannot be interpreted as time-specific prevalences of walking disability owing to the missing data; however, with the exception of 2- and 12-month IL-6, these descriptive statistics correspond with the assumption that healthier participants were more likely to provide observations.
Estimates in general fluctuated more across MNAR2 assumptions than MNAR1 assumptions. This result was expected because weights for RX assuming MNAR2, unlike MNAR1, depended on assumptions about Y, and fewer observations were used in MNAR2 than in MNAR1. Estimated adjusted time-specific prevalences of walking disability are shown in Figure 2 Panel A for IEE and W-IEE for a hypothetical participant with IL-6, age, and body fat at the observed time-specific mean levels. The lowest estimated prevalences of walking disability were derived using IEE, reflecting the MCAR assumption that those providing data were representative of those with missing data. Estimated prevalences were higher assuming MNAR2 than when assuming the analogous MNAR1 mechanism due to the dependence of RX on Y. Despite the sensitivity of parameter estimates on assumptions about the missing data, all mechanisms except MNAR1-max suggested some recovery from walking disability by 6 months post-fracture followed by incident disability at twelve months, perhaps due to advancing age. Panel B of Figure 2 compares the estimated prevalence of walking disability and 95 per cent confidence intervals between W-IEE and simple W-IEE for MNAR1-mid and MNAR2-mid mechanisms. For MNAR1-mid, the 95 per cent confidence interval was wider when using simple W-IEE than when using W-IEE, but the confidence intervals were of similar width between the two methods under MNAR2-mid. Also, when assuming MNAR2-mid, the estimated prevalences of walking disability were higher when using simple W-IEE than when using W-IEE at each time point.
Figure 2.

BHS-3 results. Panel A: estimated prevalence of walking disability (P(Y = 1)) at 2, 6, and 12 months post-fracture for MCAR (IEE) and six MNAR (W-IEE) mechanisms. Panel B: estimated prevalence and 95 per cent confidence interval of walking disability (P(Y = 1)) at 2, 6, and 12 months post-fracture for MNAR1-mid and MNAR2-mid mechanisms from W-IEE and simple W-IEE. Min, mid, and max of , (−log(1.50), −log(1.75), log(1.25)), and (−log(2.00), −log(2.50), log(1.50)), respectively.
5. Discussion
We proposed a computationally simple approach to marginal modeling of longitudinal studies with deaths and non-monotone missing outcomes and covariates partly conditioned on being alive. This approach is flexible enough to handle a general number of missing covariates and data that are MNAR, and it does not require performing numerical integration over missing covariates. Also, the simulation study shows that the proposed method performs well for sample sizes as small as N = 200 and results in more efficient estimates than when using simple W-IEE assuming MNAR1. If the missing-data mechanism of each incomplete variable is specified to depend on Y and all components of X, then the proposed method simplifies to simple W-IEE. Otherwise, the proposed simultaneous estimating equations can provide some efficiency benefits by using more data than simple W-IEE for deriving estimates.
The simulation study and example focused on the scenario when all components of X are continuous to motivate use of a multivariate normal working model for X. When some incomplete covariates are categorical, this model is not correct. However, so long as π, μY | A,X, and μX|A are correctly specified, the proposed estimating equation is unbiased. Previous empirical research focusing on continuous outcomes also suggests that WEE performs well when a normal working model for X is incorrectly specified [7]. Although the simulation study shows no bias for both W-IEE and simple W-IEE, the BHS-3 analysis shows that results from a particular study may vary between the two methods; thus, it is preferable to use as many observations as possible.
An important limitation of our method is that the number of parameters to estimate can become large when several incomplete covariates are included in the model or when there are many follow-up visits. However, this limitation can be overcome by making plausible assumptions to control the number of parameters, for example by assuming that for j, j′ ∈ {1, …, J}, j ≠ j′. Also, as is always the case for missing data, the missing-data mechanism cannot be identified from the observed data; thus, untestable assumptions are required for performing the analysis. No statistical method accommodating missing data is more beneficial than data collection methods that can minimize the missing data. Therefore, efforts should be made to reschedule missed appointments and obtain responses to interview questions. If missing data remain, a sensitivity analysis should be performed to assess the impact of assumptions about the missing-data mechanism on scientific conclusions. Such an analysis can be facilitated by collecting information to understand the reasons for missingness. For example, those who miss visits due to poor health conditions may differ from those who miss visits due to inclement weather. Additionally, missingness may be due to reasons that are not related to the study participants. For example, some variables may be collected from clinicians as part of the standard clinical care, whereas others may only be collected as part of a research protocol. Thus, reasons for missingness should also be collected from clinicians. This information can be used when estimating weights. Finally, the method is only appropriate for studies with prescheduled visits (i.e. discrete time). Otherwise, data should be analyzed within the framework of informative observation times [23].
The analysis goal that motivated the proposed method was to estimate cross-sectional marginal prevalence of walking disability generalized to those who are alive as a function of simultaneously measured body fat percentage and IL-6, at 2, 6, and 12 months post-fracture. In this case, a W-IEE analysis can provide unbiased estimates if the missing-ness mechanism is correctly specified. However, if the investigator is interested in whether body fat percentage and IL-6 causally affect walking disability, the proposed W-IEE method needs to be adapted to handle time-dependent confounders. For example, if body fat percentage or IL-6 are endogenous (walking disability affects body fat percentage or IL-6 at later times), then previous walking disability is a time-dependent confounder. To address this issue, our proposed method can easily be adapted by using inverse probability of treatment weights (IPTW) [24]. In the BHS-3 example, this would involve multiplying the summand in equation (10) by the inverse joint density of body fat percentage and IL-6 conditional on previous walking disability and other time-dependent confounders. Also, if the investigator is interested in generalizing inferences to the whole cohort, not just those who are alive, then methods for estimating survivor average causal effects are needed to address healthy survivor bias [25]. Additional considerations regarding the use of IPTW can be found elsewhere [24, 26].
One challenge for performing a sensitivity analysis is determining a plausible range of assumptions to explore. The best sources for these assumptions are subject-matter experts. In the BHS-3 example, a geriatrician and a physical therapist were interviewed to obtain plausible assumptions about why hip-fracture patients may refuse to respond to interview questions, provide serum, or undergo DXA evaluations. Although estimates varied, weak to marginal evidence was found across assumptions about the relationship of IL-6 and body fat with walking disability conditioned on being alive, controlling for age and time since hip fracture.
Our proposed method is an example of a selection model, where the probability of response conditional on potentially missing variables and fully observed variables is modeled [27]. Eliciting information interpreted as odds ratios of response for selection models from subject-matter experts may be difficult. An alternative approach, which may be easier for subject-matter experts to interpret, is to specify missing-data mechanisms using pattern-mixture models, where means of a variable are specified separately for those with missing and observed data [13, 15, 27]. However, the pattern-mixture model would require parameterizing models conditional on response pattern. Future research involves marginalized pattern-mixture models conditioned on being alive to retain the benefits of both selection and pattern-mixture models. Additionally, the proposed method was motivated by mortal cohorts where survival status is known for all participants during the study period. Thus, future research involves extending the method to handle possible censoring of mortality. In this case, assumptions about the censoring mechanism would be needed to account for missing values of vital status.
Acknowledgments
This research was supported in part by National Institutes of Health grants K12HD043489, K12HD055931, K23AG027746, R37AG009901, R01AG09902. Support to perform assays was provided by an intramural grant from the University of Maryland School of Medicine.
Contract/grant sponsor: National Institutes of Health; contract/grant numbers: K12HD043489, K12HD055931, K23AG027746, R37AG009901, R01AG09902
Appendix
In this Appendix, we establish that equations (10) and (11) are unbiased if , and are correctly specified, irrespective of the missing-data mechanism. Let , where . Using iterated expectations on equation (10),
because
Next,
where is the indicator that is the member of where for k = 1, …, K because
Finally, , where is for .
Similarly, we use iterated expectations to show that equation (11) has mean 0. First,
Next, . Thus, equations (10) and (11) are unbiased so long as , and are correctly specified, even if the distributions of Xi j and Yi j are not correctly specified.
References
- 1.Kurland BF, Heagerty PJ. Directly parameterized regression conditioning on being alive: analysis of longitudinal data truncated by deaths. Biostatistics. 2005;6:241–258. doi: 10.1093/biostatistics/kxi006. [DOI] [PubMed] [Google Scholar]
- 2.Dufouil C, Brayne C, Clayton D. Analysis of longitudinal studies with death and drop-out: a case study. Statistics in Medicine. 2004;23:2215–2226. doi: 10.1002/sim.1821. [DOI] [PubMed] [Google Scholar]
- 3.Shardell M, Miller RR. Weighted estimating equations for longitudinal studies with death and non-monotone missing time-dependent covariates and outcomes. Statistics in Medicine. 2008;27:1008–1025. doi: 10.1002/sim.2964. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ibrahim JG, Chen MH, Lipsitz SR. Monte Carlo EM for missing covariates in parametric regression models. Biometrics. 1999;55:591–596. doi: 10.1111/j.0006-341x.1999.00591.x. [DOI] [PubMed] [Google Scholar]
- 5.Robins JM, Rotnitzky A, Zhao LP. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association. 1994;89:846–866. [Google Scholar]
- 6.Robins JM, Rotnitzky A, Zhao LP. Analysis of semiparametric regression models for repeated outcomes in the presence of missing data. Journal of the American Statistical Association. 1995;90:106–121. [Google Scholar]
- 7.Parzen M, Lipsitz SR, Ibrahim JG, Lipshultz S. A weighted estimating equation for linear regression with missing covariate data. Statistics in Medicine. 2002;21:2421–2436. doi: 10.1002/sim.1195. [DOI] [PubMed] [Google Scholar]
- 8.Xie F, Paik MC. Generalized estimating equation model for binary outcomes with missing covariates. Biometrics. 1997;53:1458–1466. [PubMed] [Google Scholar]
- 9.Liang KY, Zeger SL. Longitudinal data analysis using generalized linear models. Biometrika. 1986;73:13–22. [Google Scholar]
- 10.Rubin DB. Inference and missing data. Biometrika. 1976;63:581–592. [Google Scholar]
- 11.Rotnitzky A, Robins JM, Scharfstein DO. Semiparametric regression for repeated outcomes with nonignorable nonresponse. Journal of the American Statistical Association. 1998;93:1321–1339. [Google Scholar]
- 12.Scharfstein D, Rotnitzky A, Robins JM. Adjusting for nonignorable dropout using semiparametric nonresponse models. Journal of the American Statistical Association. 1999;94:1096–1146. [Google Scholar]
- 13.Minini P, Chavance M. Sensitivity analysis of longitudinal binary data with non-monotone missing values. Biostatistics. 2004;5:531–544. doi: 10.1093/biostatistics/kxh006. [DOI] [PubMed] [Google Scholar]
- 14.Rotnitzky A, Scharfstein DO, Su TL, Robins JM. Methods for conducting sensitivity analysis of trials with potentially nonignorable competing causes of censoring. Biometrics. 2001;57:103–113. doi: 10.1111/j.0006-341x.2001.00103.x. [DOI] [PubMed] [Google Scholar]
- 15.Wilkins KJ, Fitzmaurice GM. A marginalized pattern-mixture model for longitudinal binary data when nonresponse depends on unobserved responses. Biostatistics. 2007;8:297–305. doi: 10.1093/biostatistics/kxl010. [DOI] [PubMed] [Google Scholar]
- 16.Pepe MS, Couper D. Modeling partly conditional means with longitudinal data. Journal of the American Statistical Association. 1997;92:991–998. [Google Scholar]
- 17.Little RJA. Regression with missing X’s: a review. Journal of the American Statistical Association. 1992;87:1227–1237. [Google Scholar]
- 18.Pepe MS, Anderson GA. A cautionary note on inference for marginal regression models with longitudinal data and general correlated response data. Communications in Statistics—Simulation. 1994;23:939–951. [Google Scholar]
- 19.Miller ME, Ten Have TR, Reboussin BA, Lohman KK, Rejeski WJ. A marginal model for analyzing discrete outcomes from longitudinal surveys with outcomes subject to multiple-cause nonresponse. Journal of the American Statistical Association. 2001;96:844–857. [Google Scholar]
- 20.Dolan MM, Hawkes WG, Zimmerman SI, Morrison RS, Gruber-Baldini AL, Hebel JR, Magaziner J. Delirium on hospital admission in aged hip fracture patients: prediction of mortality and 2-year functional outcomes. Journals of Gerontology Series A: Biological Sciences and Medical Sciences. 2000;55:M527–M534. doi: 10.1093/gerona/55.9.m527. [DOI] [PubMed] [Google Scholar]
- 21.Miller RR, Cappola AR, Shardell MD, Hawkes WG, Yu-Yahiro JA, Hebel JR, Magaziner J. Persistent changes in interleukin-6 and lower extremity function following hip fracture. Journals of Gerontology Series A: Biological Sciences and Medical Sciences. 2006;61:1053–1058. doi: 10.1093/gerona/61.10.1053. [DOI] [PubMed] [Google Scholar]
- 22.Miller RR, Shardell MD, Hicks GE, Cappola AR, Hawkes WG, Yu-Yahiro JA, Magaziner J. Association of interleukin-6 with lower extremity function following hip fracture-the role of muscle mass and strength. Journal of the American Geriatrics Society. 2008;56:1050–1056. doi: 10.1111/j.1532-5415.2008.01708.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Lin H, Scharfstein DO, Rosenheck RA. Analysis of longitudinal data with irregular, informative follow-up. Journal of the Royal Statistical Society Series B. 2004;66:791–813. [Google Scholar]
- 24.Robins JM, Greenland S, Hu FC. Estimation of the causal effect of a time-varying exposure on the marginal mean of a repeated binary outcome. Journal of the American Statistical Association. 1999;94:687–712. [Google Scholar]
- 25.Egleston BL, Scharfstein DO, MacKenzie E. On estimation of the survivor average causal effect in observational studies when important confounders are missing due to death. Biometrics. 2009;65:497–504. doi: 10.1111/j.1541-0420.2008.01111.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Diggle PJ, Heagerty P, Liang KY, Zeger SL. Analysis of Longitudinal Data. 2. Oxford; New York: 2002. [Google Scholar]
- 27.Little RJA. Pattern-mixture models for multivariate incomplete data. Journal of the American Statistical Association. 1993;88:125–134. [Google Scholar]