

Abstract
Controlling complex systems is a fundamental challenge of network science. Recent advances indicate that control over the system can be achieved through a minimum driver node set (MDS). The existence of multiple MDS's suggests that nodes do not participate in control equally, prompting us to quantify their participations. Here we introduce control capacity quantifying the likelihood that a node is a driver node. To efficiently measure this quantity, we develop a random sampling algorithm. This algorithm not only provides a statistical estimate of the control capacity, but also bridges the gap between multiple microscopic control configurations and macroscopic properties of the network under control. We demonstrate that the possibility of being a driver node decreases with a node's in-degree and is independent of its out-degree. Given the inherent multiplicity of MDS's, our findings offer tools to explore control in various complex systems.
The need to control is ubiquitous in many complex systems. For example, a cellular system controls a series of chemical reactions during its division to guarantee sufficient genetic materials in each daughter cell1,2,3. A company controls the dynamics of information flow for efficient task execution or innovation4. In a supply chain, cost is reduced by controlling the commodity flow5. Therefore there is an increasing need to understand the control principles of complex systems.
Recent advances in applying control theory6,7,8 to complex networks9,10 shed new light on this problem11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28. According to control theory, a dynamical system is controllable if it can be driven from any initial state to any desired final state within finite time6,7. Obviously, when we influence every element in the system, we obtain full control. However, control in general can be achieved through the control of only a subset of nodes that we call driver nodes. In a linear time-invariant system, the minimum driver node set (MDS) can be efficiently identified, representing the minimum set of nodes through which we can yield control over the whole system12. It has been shown that the number of driver nodes necessary for control (ND) is fixed in a given network and primarily determined by the underlying degree distribution. Yet, there are often multiple control configurations with the same ND24. For example, in the six-node network shown in Fig. 1a ND = 4, but control can be achieved via five different MDS's: {1, 2, 4, 6}, {1, 2, 4, 5}, {1, 2, 3, 6}, {1, 2, 3, 5} and {1, 2, 3, 4}.
Figure 1.
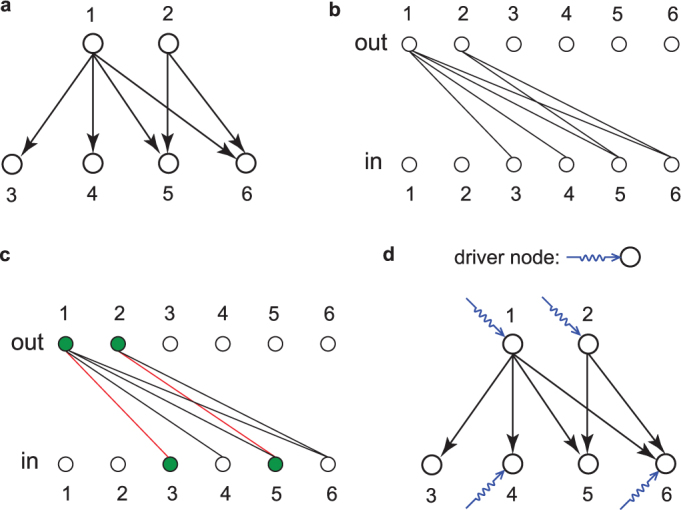
(a) An example of a directed network with six nodes. (b) The bipartite representation of the directed network in (a) where nodes are represented as two disjoint sets of nodes out and in. A directed link from node 1 to node 3 in (a) corresponds to a connection between node 1 in the out set and node 3 in the in set. (c) One maximum matching configuration of the bipartite graph (b) where one node can maximumly match another node through one link. Colored nodes and links are matched nodes and links respectively. (d) One choice of minimum driver node set (MDS) to control the network based on the maximum matching in (c), i.e. controlling nodes 1, 2, 4 and 6 to control the whole system.
The existence of multiple MDS's indicates that not all nodes participate in control equiprobability, prompting us to quantify the role of each node in control. Here we introduce the concept of control capacity φ(i), defined as the fraction of MDS's in which node i is included. This quantity measures the participation of node i in MDS's, hence gives the likelihood that node i is a driver node when the network is under control via a random control configuration. For example, in Fig. 1a, the control capacity of each node is φ(1) = φ(2) = 1, φ(3) = φ(4) = 0.6 and φ(5) = φ(6) = 0.4. In connection with previous work that classifies nodes into three categories24, a node with φ = 1 is critical as it always acts as a driver node, φ = 0 is redundant as it never participates in MDS's whereas 0 < φ < 1 is intermittent as it plays as a driver node in some control configurations but not all.
In spite of its direct relevance control capacity is difficult to measure, as only nodes with φ = 0 and φ = 1 can be identified in polynomial time24. Intuitively control capacity is readily obtained once all MDS's are known. However, enumeration of all MDS's in an arbitrary network is in the class of #P problem and computationally prohibitive for large networks. Indeed, the number of MDS's can grow exponentially with networks size, hence a network with only hundreds of nodes often leads to millions of MDS's29. To cope with this difficulty we propose a random sampling algorithm, allowing us to measure the control capacity within a limited number of MDS's, drawn randomly from all MDS's. In the following we show that our algorithm yields a random pick of MDS and provides reliable statistical estimation of control capacity of nodes in arbitrary networks.
Results
Random sampling algorithm
We start by briefly reviewing the process in identifying ND and MDS for an arbitrary directed network. First, a directed network is converted to a bipartite graph with two disjoint sets of nodes out and in. The out nodes can be considered as “superiors” that influence others internally. The in nodes are “subordinates” that need to be controlled. A directed link from node i to j corresponds to a connection between node i in the out set and node j in the in set in the bipartite graph (Fig. 1a, b). By performing the maximum matching in the bipartite graph12,30, the minimum driver nodes are unmatched nodes in the in set (Fig. 1c, d).
The method provides a direct connection between a maximumly-matched set (MMS) and a MDS, as the complementary set of a MMS yields a MDS. One can use different algorithms to find the maximum matching in a bipartite graph, such as Hopcroft-Karp algorithm30, FordFulkerson algorithm31 and Hungarian algorithm32. All these algorithms aim to increase the matching size in each iteration via the augmenting path that starts at a matched node, end on a unmatched node and alternates between unmatched and matched links on the path17. Because there is no randomness in identifying an augmenting path, these algorithms will locate only one MMS for a given initial condition hence they are not appropriate for sampling purposes. Two simple modifications can be applied to bring randomness: one is to randomize the initial matching and the other is to randomly choose possible augmenting paths. However, sampling based on these methods are not guaranteed to be uniform among all MMS's and can be typically biased.
Here we propose a novel algorithm that performs unbiased random sampling among all MMS's, which equivalently samples all MDS's and estimates the control capacity. The steps are as follows: 0. For simplicity, remove the always matched nodes in the in set and their links (the algorithm to identify always matched nodes is introduced in reference24). Denote by G the bipartite graph obtained after node removal.
Obtain one MMS (denoted by M).
Randomly pick an element in M (denoted by node i).
Enumerate all alternative MMS's that include all other elements of M except node i. (see Methods)
Randomly pick one of these alternative MMS as the current MMS M.
Repeat step 2.
Now we prove that the above steps randomly samples MMS's. Considering each MMS as one state, our algorithm maps to a Markov chain characterized by a transition matrix P with the element pi,j that equals the probability of transition from state i to j. Without loosing generality, assume two MMS as sets of m nodes {n1, n2, …, na, …, nm} and {n1, n2, …, nb, …, nm}, denoted by M1 and M2 respectively. Suppose that there are totally z other MMS's that include n1, n2, …, nm except na or nb and consider the MMS M1 and M2 as two state i and j in the Markov chain that our algorithm maps to. The transition from state i to j requires the pick of element na out of m elements with probability 1/m and the pick of set M2 out of z + 1 alternative sets with probability 1/(z + 1). Therefore 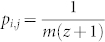 . Similarly, from state j to i, the probability to pick element nb is 1/m. As the number of alternative MMS's including n1, n2, …, nN except nb is also z + 1,
. Similarly, from state j to i, the probability to pick element nb is 1/m. As the number of alternative MMS's including n1, n2, …, nN except nb is also z + 1, 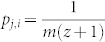 . Hence pi,j = pj,i and the transition matrix P is symmetric. For Markov chain with symmetric transition matrix, the steady state distribution is with equal probabilities for all states33. This means that in the long run, each MMS is picked with the same probability as all others.
. Hence pi,j = pj,i and the transition matrix P is symmetric. For Markov chain with symmetric transition matrix, the steady state distribution is with equal probabilities for all states33. This means that in the long run, each MMS is picked with the same probability as all others.
To verify the result, we construct a small network with 244 MDS's, perform our sampling algorithm 48,800 iterations and count the time that each MDS is picked. We find that each MDS is sampled approximately 200 times (Fig. 2a), which is the expected count a random sampling yields. The distribution of the counts follows a Gaussian distribution (Fig. 2b) centered at 200, implying the difference between actual and expected counts are due to random fluctuation.
Figure 2.

(a) The count on each of 244 MDS's is around the expected value 200 when taking 48800 samples. (b) The distribution of the counts that is centered at 200 and can be well fitted by a Gaussian distribution. (c) The time evolution of φt(i)/φ(i) of 33 nodes with 0 < φ < 1. φt(i) is the control capacity of node i at time-step t based on the samples collected up to t and φ(i) is the expected control capacity of node i that is explicitly measured through the enumeration of all 153,123 MDS's. Control capacity starts to converge at the characteristic time-step T. (d) The time evolution of the mean absolute percentage error MAPE = Σi|φt(i) − φ(i)|/n, where n is the number of nodes with 0 < φ < 1. MAPE drops quickly after T time-steps.
One important attribute of a sampling method is the rate of convergence, capturing how fast the estimate converges to the actual value. Typically the rate of convergence is not known exactly unless an analytical solution can be found for the sampling process34. Via numerical tests, we find that the sampling results converges to the actual value after T = N ln N iterations in a network with N nodes. The interpretation of T is intuitive: as our algorithm randomly draws the original elements in the MMS and replaces it with the new ones, the measure will not converge until we have the original MMS completely shuffled. Assuming that the size of the MMS is m, the expected number of iterations to obtain the first element replaced is 1, second element replaced is m/(m − 1) and the nth element replaced is m/(m − n). Therefore for m elements the expected iteration is 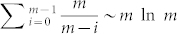 . As m varies but is proportional to network size N, we replace m by N and hence have the characteristic time-step T.
. As m varies but is proportional to network size N, we replace m by N and hence have the characteristic time-step T.
The characteristic time-step provides the minimum number of iterations necessary for sampling, therefore capturing the complexity in quantifying control capacity. The time needed to find one maximum matching can be as small as 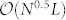 with the Hopcroft-Karp algorithm in a network with N nodes and L links30. To find one alternative MMS with one node replaced, a breadth first search is needed with
with the Hopcroft-Karp algorithm in a network with N nodes and L links30. To find one alternative MMS with one node replaced, a breadth first search is needed with 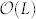 time. As the number of alternative MMS is capped by N, the complexity of one sampling is
time. As the number of alternative MMS is capped by N, the complexity of one sampling is 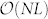 . As the sampling time needed is proportional to T, the control capacity can be estimated in polynomial time as
. As the sampling time needed is proportional to T, the control capacity can be estimated in polynomial time as 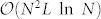 .
.
To test our proposition, we construct a network with 100 nodes. We explicitly enumerate all 153,123 MDS's (see Methods) and exactly measure the control capacity of all 33 nodes with 0 < φ < 1. Then we apply the random sampling and estimate the capacity φt(i) of each node i at time-step t based on the samples collected up to t. It is observed that φt(i) quickly converges to the expected value in T = N ln N steps (Fig. 2c,d). It is also noteworthy that in 3000 iterations, which cover fewer than 2% of all MDS's, the mean absolute percentage error (MAPE) of the estimated control capacity is less than 3% (Fig. 2d), indicating the efficiency of utilizing random sampling in estimating the control capacity that significantly reduces the computational complexity.
Control capacity in model and real networks
We check the relationship between a node's topological property and its role in control. On the one hand, we find that a node's out-degree does not affect its control capacity (Fig. 3b). This is because the outgoing links serve as means to control other nodes, which does not affect how this node itself would be controlled. On the other hand, control capacity does depend on in-degree. Particularly φ = 1 when kin = 0, indicating that nodes without incoming links need to be always controlled, in line with our previous finding24. As in-degree increases, φ decays rapidly (Fig. 3a), indicating that a node with more incoming links are less likely to be a driver node as they are more likely to be influenced internally.
Figure 3. Dependency between control capacity φ and nodes' in- and out-degree.
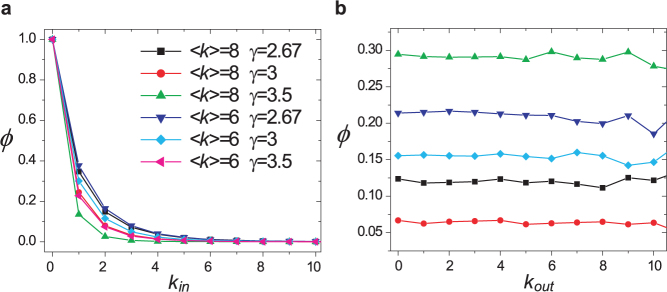
(a) φ decays rapidly with in-degree kin, suggesting that nodes with more incoming links are less likely to be a driver node. φ = 0 when kin = 0, indicating that nodes without incoming links are always driver nodes. (b) For the same networks in (a), φ does not vary with out-degree kout, indicating control capacity is independent of out-degree. Networks analyzed are generated by static model (see Methods) with size N = 10,000 where 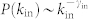 ,
, 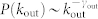 , γin = γout = γ and
, γin = γout = γ and 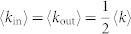 .
.
We extend the analysis to real systems and check the relationship between 〈kD〉 and 〈k〉, which are the average degree of the driver nodes and all nodes, respectively (Table 1). With control capacity, 〈kD〉 can be explicitly expressed as 〈kD〉 = Σiφ(i)k(i)/ND where k(i) is the degree of an arbitrary node i. One would expect 〈kD〉 < 〈k〉 in real networks since φ decreases with kin. However, while the fact that the average in-degree of driver nodes is less than that of the network (〈kD,in〉 < 〈kin〉) reflects the relationship between φ and kin, average out-degree of driver nodes (〈kD,out〉) can be affected by the in- and out-degree correlation21,35,36,37,38 featuring in real systems and the finite size effect39,40. Indeed several networks are found with 〈kD,out〉 > 〈kout〉 (e.g. Seagrass in food web and TRN-Yeast-2 in regulatory networks of Table 1) and in one network we even observe that 〈kD〉 is slightly higher than 〈k〉 (TRN-EC-2 in regulatory networks of Table 1). But for majority of real networks the average degree of driver nodes are less than that of the whole network, leading to the conclusion that hubs are less likely to be driver nodes12.
Table 1. Real networks Analyzed. For each network, we show its type, name; number of nodes (N) and links (L); average degree 〈k〉; average degree of driver nodes 〈kD〉 and average in- and out-degree of driver nodes (〈kD,in〉 and 〈kD,out〉), respectively.
| Type | Name | N | L | 〈k〉 | 〈kD〉 | 〈kD,in〉 | 〈kD,out〉 |
|---|---|---|---|---|---|---|---|
| Regulatory | TRN-Yeast-147 | 4,441 | 12,873 | 5.80 | 5.74 | 2.82 | 2.92 |
| TRN-Yeast-248 | 688 | 1,079 | 3.14 | 3.13 | 1.31 | 1.82 | |
| TRN-EC-149 | 1,550 | 3,340 | 4.31 | 4.30 | 2.09 | 2.22 | |
| TRN-EC-248 | 418 | 519 | 2.48 | 2.61 | 1.06 | 1.55 | |
| Trust | College student50,51 | 32 | 96 | 6 | 3.5 | 0.17 | 3.33 |
| Prison inmate50,51 | 67 | 182 | 5.43 | 3.98 | 1.43 | 2.55 | |
| Food Web | Ythan52 | 135 | 601 | 8.90 | 4.17 | 0.28 | 3.89 |
| Little Rock53 | 183 | 2,494 | 27.26 | 25.87 | 10.03 | 15.84 | |
| Grassland52 | 88 | 137 | 3.11 | 2.30 | 0.29 | 2.00 | |
| Seagrass54 | 49 | 226 | 9.22 | 6.05 | 0.55 | 5.51 | |
| Power Grid | TexasPowerGrid55 | 4,889 | 5,855 | 2.40 | 1.9 | 0.81 | 1.09 |
| Metabolic | E. coli56 | 2,275 | 5,763 | 5.07 | 3.64 | 1.76 | 1.88 |
| S. cerevisiae56 | 1,511 | 3,833 | 5.07 | 3.71 | 1.79 | 1.92 | |
| C. elegans56 | 1,173 | 2,864 | 4.88 | 3.60 | 1.72 | 1.88 | |
| Electronic | s83848 | 512 | 819 | 3.20 | 2.40 | 0.87 | 1.54 |
| Circuits | s42048 | 252 | 399 | 3.17 | 2.43 | 0.84 | 1.59 |
| s20848 | 122 | 189 | 3.10 | 2.49 | 0.79 | 1.70 | |
| Neuronal | C. elegans57 | 297 | 2,345 | 15.79 | 8.09 | 2.69 | 5.40 |
| Internet | p2p-158 | 6301 | 20777 | 6.59 | 5.48 | 2.29 | 3.19 |
| p2p-258 | 8,846 | 31,839 | 7.20 | 6.27 | 2.73 | 3.53 | |
| p2p-358 | 8,717 | 31,525 | 7.23 | 6.28 | 2.79 | 3.49 | |
| Social | UCIonline59 | 1,899 | 20,296 | 21.38 | 5.89 | 3.37 | 2.52 |
| Communication | Email-epoch60 | 3,188 | 39,256 | 24.63 | 7.13 | 2.70 | 4.43 |
Finally, we check how control capacity is distributed among nodes with 0 < φ < 1 in Erdös-Rényi networks41, scale-free networks42 (see Methods) and some real networks (Fig. 4). The distributions are found to depend on specific network configurations and there seems no simple universal function for the distribution. But as a common feature, φ typically displays multi-modal distribution, implying that several clusters of nodes share about the same chance of being driver nodes. Recent work24 discovered that dense networks with identical degree distribution can stay in one of the two control modes, centralized or distributed, depending on the fraction of nodes that can participate in MDS's. The distributions of control capacity corresponding to networks in the two control modes also show distinct features. For networks in distributed mode, a significant fraction of nodes are with control capacity close to zero (Fig. 4(b), (e)). This indicates that while many nodes can participate in MDS's, their participation is not frequent compared with the huge number of MDS's in distributed mode. For networks in centralized mode, the number of nodes with 0 < φ < 1 is small, but the distribution of capacity among these nodes is similar to that when 〈k〉 is small (Fig. 4(c), (f)).
Figure 4. Distribution of control capacity φ among nodes with 0 < φ < 1 in Erdős-Rényi networks ((a)–(c)), scale-free networks ((d)–(f)) and real networks ((g)–(i)).

Dense networks with identical degree distribution in centralized ((c) and (f)) and distributed ((b) and (e)) control modes are labeled. For Erdős-Rényi and scale-free networks, network size N = 10,000. For scale-free networks, γin = γout = 3. The information for the three real networks is listed in Table 1.
Discussion
In summary, uncovering the role of individual nodes in controlling a network requires us to understand control capacity, a centrality measure quantifying a node's likelihood of being a driver node. While a network's control can be achieved via different MDS's and each may give rise to different outcomes, we lack a tool to average the effect of different MDS's or statistically analyze the consequences driven by different MDS's over the network. In this paper we propose a random sampling algorithm, allowing us to efficiently measure control capacity in arbitrary networks. The proposed algorithm bridges the gap between multiple microscopic control configurations and macroscopic properties of the network under control. One important example of its application is the study of 〈kD〉, which can not be properly addressed without the random sampling method12.
The results presented have many potential applications in future works. For example, recent work on the controllability of bank systems investigated the time correlation of nodes' roles in control25,27. The measure of control capacity could be crucial in such tasks, especially in temporal networks where a node's role in control varies with time43,44,45. The relationship between control capacity and the efficiency or energy cost in control15,28 are also important issues for further investigations. The random sampling method is useful in problems when an overall measure of a network is needed. As an example, when estimating the control robustness of a network, the random sampling algorithm has to be considered as different MDS's may facing different failure risks. Finally, links do not participate in control in an equal manner, allowing multiple link combinations to spread the control signal. Our approach can offer insights for future work exploring the participation of links in control. Given the inherent multiplicity feature in control, our findings offer fundamental tools to explore control in various complex systems.
Methods
Enumerating all alternative MMS's with one node replaced
Suppose the maximum matching is obtained in a bipartite graph and denote M by the current maximumly-matched set (MMS) of nodes in the in set. Assume node i is an element of the set M. The following procedures can provide all MMS's that contain all other elements of M except node i. (0) Set node i as the removal node. (1) Identify the node in the out set that matches the removal node (denoted by node j). (2) Keep the current matched nodes and links unchanged, remove the removal node with all its links. (3) Check if there is an augmenting path that starts from node j, ends at an unmatched node and alternates between unmatched and matched links on the path. (4) If so, we obtain a new MMS with node i replaced. Update the matched links and nodes correspondingly. Set the new matched node in the in set as the removal node and repeat step (1). (5) If not, there is no new MMS with node i replaced and all of them are enumerated already.
Enumerating all MDS's
For a given bipartite graph, we first remove all the always matched nodes in the in set and their links (algorithm discussed in reference24). Define Si as a set of nodes that a out node i can reach. For example, in Fig. 1b there are S1 = {3, 4, 5, 6} and S2 = {5, 6}. Effectively Si is the set of nodes that node i can match. In the bipartite graph with no always matched nodes in the in set, a MMS of in nodes is a set of nodes without duplication, each drawn from one set S. Therefore, we can repeatedly test all possible combinations to enumerate all MMS's that equivalently provides all MDS's. Note that nodes chosen from different S's can sometimes give rise to the same MMS. For example, in Fig. 1b picking node 5 from S1 and node 6 from S2 yields the same MMS as picking node 6 from S1 and node 5 from S2. All MMS's need to be recored. Once a valid node combination is found, it needs to be checked with previously found MMS to avoid double count.
Generating a scale free network
The scale-free networks42 analyzed are generated via the static model46. We start from N disconnected nodes indexed by integer number i (i = 1, … N). The weight 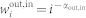 is assigned to each node in the out and the in set, with αout,in a real number in the range [0, 1). Randomly selected two nodes i and j respectively from the out set and the in set, with probability proportional to
is assigned to each node in the out and the in set, with αout,in a real number in the range [0, 1). Randomly selected two nodes i and j respectively from the out set and the in set, with probability proportional to 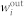 and
and 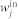 . Connect node i and j if there is no connection between them, corresponding to a directed link from node i to node j in the digraph. Otherwise randomly choose another pair. Repeated the procedure until 〈kin〉 = 〈kout〉 = 〈k〉/2 links are created. The degree distribution under this construction is
. Connect node i and j if there is no connection between them, corresponding to a directed link from node i to node j in the digraph. Otherwise randomly choose another pair. Repeated the procedure until 〈kin〉 = 〈kout〉 = 〈k〉/2 links are created. The degree distribution under this construction is 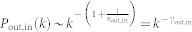 in the large k limit.
in the large k limit.
Author Contributions
T.J. and A.-L.B. designed the research. T.J. performed numerical simulation and analyzed the empirical data. T.J. and A.-L.B. prepared the manuscript.
Acknowledgments
We thank Y.-Y. Liu, M. Pósfai, E. Csóka, J.-J. Slotine, C. Song and D. Wang for discussions. This work was supported by the Network Science Collaborative Technology Alliance sponsored by the US Army Research Laboratory under Agreement Number W911NF-09-2-0053; the Defense Advanced Research Projects Agency under Agreement Number 11645021; the Defense Threat Reduction Agency award WMD BRBAA07-J-2-0035; and though the generous support of Lockheed Martin.
References
- Warren G. Membrane partitioning during cell division. Annual review of biochemistry 62, 323–348 (1993). [DOI] [PubMed] [Google Scholar]
- Birky C. W. Jr et al. The partitioning of cytoplasmic organelles at cell division. International review of cytology. Supplement 15, 49 (1983). [DOI] [PubMed] [Google Scholar]
- Huh D. & Paulsson J. Random partitioning of molecules at cell division. Proceedings of the National Academy of Sciences 108, 15004–15009 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Georgakopoulos D., Hornick M. & Sheth A. An overview of workflow management: from process modeling to workflow automation infrastructure. Distributed and parallel Databases 3, 119–153 (1995). [Google Scholar]
- Beamon B. M. Supply chain design and analysis: Models and methods. International journal of production economics 55, 281–294 (1998). [Google Scholar]
- Kalman R. E. Mathematical description of linear dynamical systems. J. Soc. Indus. and Appl. Math. Ser. A 1, 152–192 (1963). [Google Scholar]
- Slotine J.-J. & Li W. Applied Nonlinear Control (Prentice-Hall, 1991). [Google Scholar]
- Lin C.-T. Structural controllability. IEEE Trans. Auto. Contr. 19, 201–208 (1974). [Google Scholar]
- Albert R. & Barabási A.-L. Statistical mechanics of complex networks. Reviews of Modern Physics 74, 47–97 (2002). [Google Scholar]
- Newman M. E. The structure and function of complex networks. SIAM review 45, 167–256 (2003). [Google Scholar]
- Wang X. F. & Chen G. Pinning control of scale-free dynamical networks. Physica A: Statistical Mechanics and its Applications 310, 521–531 (2002). [Google Scholar]
- Liu Y.-Y., Slotine J.-J. & Barabási A.-L. Controllability of complex networks. Nature 473, 167–173 (2011). [DOI] [PubMed] [Google Scholar]
- Rajapakse I., Groudine M. & Mesbahi M. Dynamics and control of state-dependent networks for probing genomic organization. Proceedings of the National Academy of Sciences 108, 17257–17262 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nepusz T. & Vicsek T. Controlling edge dynamics in complex networks. Nature Physics 8, 568–573 (2012). [Google Scholar]
- Yan G., Ren J., Lai Y.-C., Lai C.-H. & Li B. Controlling complex networks: How much energy is needed? Physical Review Letters 108, 218703 (2012). [DOI] [PubMed] [Google Scholar]
- Liu Y.-Y., Slotine J.-J. & Barabási A.-L. Control centrality and hierarchical structure in complex networks. PLoS ONE 7, e44459 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang W.-X., Ni X., Lai Y.-C. & Grebogi C. Optimizing controllability of complex networks by minimum structural perturbations. Physical Review E 85, 026115 (2012). [DOI] [PubMed] [Google Scholar]
- Tang Y., Gao H., Zou W. & Kurths J. Identifying controlling nodes in neuronal networks in different scales. PloS one 7, e41375 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cowan N. J., Chastain E. J., Vilhena D. A., Freudenberg J. S. & Bergstrom C. T. Nodal dynamics, not degree distributions, determine the structural controllability of complex networks. PloS one 7, e38398 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gutiérrez R., Sendiña-Nadal I., Zanin M., Papo D. & Boccaletti S. Targeting the dynamics of complex networks. Scientific reports 2, 396 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pósfai M., Liu Y.-Y., Slotine J.-J. & Barabási A.-L. Effect of correlations on network controllability. Scientific Reports 3, 1067 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu Y.-Y., Slotine J.-J. & Barabási A.-L. Observability of complex systems. Proceedings of the National Academy of Sciences 110, 2460–2465 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nacher J. C. & Akutsu T. Structural controllability of unidirectional bipartite networks. Scientific Reports 3, 1647 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jia T. et al. Emergence of bimodality in controlling complex networks. Nature Communications 4, (2013). [DOI] [PubMed] [Google Scholar]
- Delpini D. et al. Evolution of Controllability in Interbank Networks. Scientific reports 3, (2013) 10.1038/srep01626 . [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caldarelli G., Chessa A., Pammolli F., Gabrielli A. & Puliga M. Reconstructing a credit network. Nature Physics 9, 125–126 (2013). [Google Scholar]
- Galbiati M., Delpini D. & Battiston S. The power to control. Nature Physics 9, 126–128 (2013). [Google Scholar]
- Sun J. & Motter A. E. Controllability transition and nonlocality in network control. Physical Review Letters 110, 208701 (2013). [DOI] [PubMed] [Google Scholar]
- Zdeborová L. & Mézard M. The number of matchings in random graphs. Journal of Statistical Mechanics: Theory and Experiment 05, P05003 (2006). [Google Scholar]
- Hopcroft J. E. & Karp R. M. An n5/2 algorithm for maximum matchings in bipartite graphs. SIAM Journal on computing 2, 225–231 (1973). [Google Scholar]
- Ford L. R. & Fulkerson D. R. Maximal flow through a network. Canadian Journal of Mathematics 8, 399–404 (1956). [Google Scholar]
- Kuhn H. W. The hungarian method for the assignment problem. Naval research logistics quarterly 2, 83–97 (1955). [Google Scholar]
- Norris J. R. Markov chains. 2008 (Cambridge university press, 1998). [Google Scholar]
- Bishop C. M. et al. Pattern recognition and machine learning, vol. 1, (springer New York, 2006). [Google Scholar]
- Ravasz E., Somera A. L., Mongru D. A., Oltvai Z. N. & Barabási A.-L. Hierarchical organization of modularity in metabolic networks. Science 297, 1551–1555 (2002). [DOI] [PubMed] [Google Scholar]
- Pastor-Satorras R., Vázquez A. & Vespignani A. Dynamical and correlation properties of the internet. Physical Review Letters 87, 258701 (2001). [DOI] [PubMed] [Google Scholar]
- Maslov S. & Sneppen K. Specificity and stability in topology of protein networks. Science 296, 910–913 (2002). [DOI] [PubMed] [Google Scholar]
- Lee J.-S., Goh K.-I., Kahng B. & Kim D. Intrinsic degree-correlations in the static model of scale-free networks. The European Physical Journal B-Condensed Matter and Complex Systems 49, 231–238 (2006). [Google Scholar]
- Boguná M., Pastor-Satorras R. & Vespignani A. Cut-offs and finite size effects in scale-free networks. The European Physical Journal B-Condensed Matter and Complex Systems 38, 205–209 (2004). [Google Scholar]
- Lü L., Zhang Z.-K. & Zhou T. Zipf's law leads to heaps' law: analyzing their relation in finite-size systems. PloS one 5, e14139 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Erdős P. & Rényi A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 5, 17–60 (1960). [Google Scholar]
- Barabási A.-L. & Albert R. Emergence of scaling in random networks. Science 286, 509–512 (1999). [DOI] [PubMed] [Google Scholar]
- Holme P. & Saramäki J. Temporal networks. Physics reports 519, 97–125. [Google Scholar]
- Perra N., Gonçalves B., Pastor-Satorras R. & Vespignani A. Activity driven modeling of time varying networks. Scientific reports 2 (2012) 10.1038/srep00469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu S.-Y., Baronchelli A. & Perra N. Contagion dynamics in time-varying metapopulation networks. Physical Review E 87, 032805 (2013). [Google Scholar]
- Goh K.-I., Kahng B. & Kim D. Universal behavior of load distribution in scale-free networks. Physical Review Letters 87, 278701 (2001). [DOI] [PubMed] [Google Scholar]
- Balaji S., Madan Babu M., Iyer L., Luscombe N. & Aravind L. Principles of combinatorial regulation in the transcriptional regulatory network of yeast. Journal of molecular biology 360, 213–227 (2006). [DOI] [PubMed] [Google Scholar]
- Milo R. et al. Network motifs: Simple building blocks of complex networks. Science 298, 824–827 (2002). [DOI] [PubMed] [Google Scholar]
- Gama-Castro S. et al. Regulondb (version 6.0): gene regulation model of escherichia coli k-12 beyond transcription, active (experimental) annotated promoters and textpresso navigation. Nucleic Acids Research 36, D120–D124 (2008). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van Duijn M. A. J., Huisman M., Stokman F. N., Wasseur F. W. & Zeggelink E. P. H. Evolution of sociology freshmen into a friendship network. Journal of Mathematical Sociology 27, 153–191 (2003). [Google Scholar]
- Milo R. et al. Superfamilies of designed and evolved networks. Science 303, 1538–1542 (2004). [DOI] [PubMed] [Google Scholar]
- Dunne J. A., Williams R. J. & Martinez N. D. Food-web structure and network theory: The role of connectance and size. Proceedings of the National Academy of Sciences 99, 12917–12922 (2002). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martinez N. Artifacts or attributes? effects of resolution on the little rock lake food web. Econological Monographs 61, 367–392 (1991). [Google Scholar]
- Christian R. R. & Luczkovich J. J. Organizing and understanding a winter's seagrass foodweb network through effective trophic levels. Ecological Modelling 117, 99–124 (1999). [Google Scholar]
- Bianconi G., Gulbahce N. & Motter A. E. Local structure of directed networks. Physical Review Letters 100, 118701 (2008). [DOI] [PubMed] [Google Scholar]
- Jeong H., Tombor B., Albert R., Oltvai Z. N. & Barabási A.-L. The large-scale organization of metabolic networks. Nature 407, 651–654 (2000). [DOI] [PubMed] [Google Scholar]
- Watts D. J. & Strogatz S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998). [DOI] [PubMed] [Google Scholar]
- Leskovec J., Kleinberg J. & Faloutsos C. Graph evolution: Densification and shrinking diameters. ACM Transactions on Knowledge Discovery from Data (TKDD) 1, 2 (2007). [Google Scholar]
- Opsahl T. & Panzarasa P. Clustering in weighted networks. Social Networks 31, 155 (2009). [Google Scholar]
- Eckmann J.-P., Moses E. & Sergi D. Entropy of dialogues creates coherent structures in e-mail traffic. Proceedings of the National Academy of Sciences 101, 14333–14337 (2004). [DOI] [PMC free article] [PubMed] [Google Scholar]