

Abstract
Benefits to speech intelligibility can be achieved by enhancing a listener’s ability to decipher it. However, much remains to be learned about the variables that influence the effectiveness of various listener-based manipulations. This study examined the benefit of providing listeners with the topic of some phases produced by speakers with either hypokinetic or ataxic dysarthria. Total and topic word accuracy, topic-related substitutions, and lexical boundary errors were calculated from the listener transcripts. Data were compared with those who underwent a familiarization process (reported by Liss, Spitzer, Caviness, & Adler, 2002) and with those inexperienced with disordered speech (reported by Liss Spitzer, Caviness, & Adler, 2000). Results revealed that listeners of ataxic speech provided with topic knowledge obtained higher intelligibility scores than naïve listeners. The magnitude of benefit was similar to the familiarization condition. However, topic word and word substitution analyses revealed different underlying perceptual mechanisms responsible for the observed benefit. No differences attributable to listening condition were discovered in lexical segmentation patterns. Overall, the results support the need for further study of listener-based manipulations to elucidate the mechanisms responsible for the observed perceptual benefits for each dysarthria type.
Keywords: intelligibility, lexical segmentation, hypokinetic dysarthria, ataxic dysarthria, perceptual learning, signal-complementary information
INTRODUCTION
Intelligibility of dysarthric speech often is compromised by the underlying neuromuscular condition of the speaker. The vast majority of treatment strategies for improving intelligibility focus on speech modifications (e.g., Lee Silverman Voice Treatment [LSVT®], rate reduction) (Duffy, 1995). However, intelligibility depends not only on the quality of the acoustic speech signal but also on factors that are independent of the signal, known as signal-complementary information (Lindblom, 1990a). This information includes the listener’s experience or knowledge about a specific speaker or topic of conversation, as well as semantic, syntactic, and phonotactic probabilities; lexical knowledge; and word frequency (e.g., Luce, Goldinger, Auer, & Vitevitch, 2000; Luce & Large 2001). The perceptual benefits offered by the presence of signal-complementary information in difficult listening environments, such as in understanding dysarthric speech, have been exploited both therapeutically (e.g., alphabet boards and other augmentative and alternative communication devices) and experimentally (e.g., perceptual learning paradigms, semantic and syntactic priming). The idea is that the intelligibility of a degraded signal can be augmented without modifying the degraded signal at all; rather, the manipulations are listener based.
Therapeutic interventions that manipulate signal-complementary information are attractive options, particularly when traditional treatments that target the speaker are not indicated. This is often the case because of the degenerative nature of many of the diseases that cause dysarthria. For example, priming lexical candidates to facilitate word recognition can be accomplished through a variety of manipulations, including alphabet cuing, topic cuing, and word likeliness based on semantic and syntactic probabilities (Hustad, Auker, Natale, & Carlson, 2003a; Hustad, Jones, & Daily, 2003b; Luce et al., 2000; Luce & Pisoni, 1998). When given relevant cues, the pool of lexical candidates is narrowed, and the activation threshold of likely lexical candidates is decreased, mitigating the detrimental effects that result from the loss of reliable acoustic information (Beliveau, Hodge, & Hagler, 1995; Dongilli, 1994; Garcia & Dagenais, 1998; Jones, Mathy, Azuma, & Liss, 2004; Yorkston, Strand, & Kennedy, 1996). Hustad and her colleagues (2003b) have reported alphabet cuing to improve listener performance, and sentence and word-level improvements in intelligibility have been reported when listeners were presented with a semantically related cues (Dongilli, 1994; Hammen, Yorkston, & Dowden, 1991) or sentence topic (Jones et al., 2004). Familiarizing the listener with the speaker or the type of dysarthria also has been found to produce intelligibility benefits (Hustad & Cahill, 2003; Liss et al., 2002; Tjaden & Liss, 1995a, 1995b).
Despite the therapeutic and experimental import of signal-complementary information, very little is known about the mechanisms underlying the perceptual benefits of different forms of this information. For example, an alphabet board presumably primes words in the cohort of options that begin with the same letter, allowing the listener to narrow the field of lexical candidates. This facilitates the processes of lexical activation (Cole & Jakimik, 1978; Nooteboom, 1981). A similar mechanism for improved listener performance can be proposed for providing the listener with knowledge of the topic of the degraded utterance (semantic priming). This facilitates lexical activation and lexical competition (Luce & Pisoni, 1998; Luce et al., 2000), thereby improving the listener’s chance of mapping the degraded acoustic cues onto the intended word. In contrast, providing a listener with guided experience in deciphering a particular pattern of degraded speech (i.e., familiarization procedure) does not serve to narrow the field of lexical candidates or facilitate lexical competition. Instead, the mechanism for improved listener performance is presumed to be perceptual learning, in which the exposure and feedback allows listeners to recognize segmental or suprasegmental regularities (or both) that may be useful for subsequent deciphering. This is regarded as a signal-complementary process because nothing changes with the speech signal, only with the listeners’ ability to map the degraded acoustic information onto their existing canonical acoustic-phonetic representations or more accurately identify word boundaries in the degraded acoustic stream (Clarke & Garrett, 2004; DePaul & Kent, 2000; Dupoux & Green, 1997; Liss et al., 2002; Mattys, White, & Melhorn, 2005; Tjaden & Liss, 1995a, 1995b).
It may be expected, then, that different manipulations have different magnitudes of beneficial effect. Indeed, there are reports of differential benefits of topic knowledge (TK) and alphabet cuing depending on the dysarthria severity and the listener’s age (c.f., Hustad et al., 2003a, 2003b; Jones et al., 2004) and differential benefits of familiarization depending on dysarthria subtype (Liss et al., 2002). It remains to be determined whether there is a predictive relationship between the nature of the speech degradation and the type of manipulation used, such that some forms of signal- complementary information may be more beneficial for certain degradation patterns. Understanding how listeners deploy their cognitive-perceptual processes is not only of basic science import in developing models of intelligibility deficits but also in optimally exploiting signal-complementary information to enhance perceptual performance therapeutically.
In a previous investigation (Liss et al., 2002), we reported significant benefits of a brief listener familiarization procedure on intelligibility of ataxic speech and to a much lesser degree on hypokinetic dysarthric speech. Furthermore, there was a significant benefit when listeners were familiarized with one type of dysarthria and tested on the other, although less impressive than the same- dysarthria condition. Finally, there was no evidence that the familiarization procedure improved intelligibility by way of an improved ability to segment the phrases into discrete words (lexical segmentation), but the patterns of lexical boundary errors (LBEs) again differed by dysarthria type. This led us to wonder whether the ataxic speech samples used in that study were offering information not available from the hypokinetic samples. If the source of perceptual benefits of familiarization lies in learning about the acoustic signal, we would expect the differential improvements for dysarthria types to disappear if listeners were offered signal- complementary information that serves to narrow the field of lexical candidates by way of semantic priming (topic knowledge). We examined error patterns for three groups of listeners: a control group (who were neither familiarized with dysarthric speech nor provided knowledge of topic), a familiarization group (who followed along with a written transcript while listening to either ataxic or hypokinetic speech), and a topic knowledge group (TK) who were not familiarized but told that some of the words in the phrases would be political in nature. Data from the control and familiarization groups were taken from Liss et al. (2002), and those from the TK condition have not been previously reported.
The following hypotheses were set forth: (1) TK will result in an increase in overall intelligibility relative to the control group, as well as a higher percentage of correctly identified topic-related words and higher number of topic-related word substitutions compared with the control and familiarization conditions; (2) the order of magnitude of improved intelligibility will be similar for the two dysarthria groups, unlike the pattern elicited by the previously reported familiarization data; and (3) TK LBEs will mirror the control group because the knowledge is not expected to allow listeners to “learn” about the acoustic signal to facilitate the use of syllabic strength in segmenting the acoustic stream.
METHOD
Study Overview
A between-groups design was selected to compare listener performance for the two dysarthria types (hypokinetic and ataxic). This was necessary to minimize the opportunity for cross- contamination, or the effects of implicit familiarization that may have occurred during the transcription task. Previous research has shown that evidence of perceptual learning are present even with brief exposure to different patterns of degraded speech, but the effects are not as robust (Liss et al., 2002). Therefore, although it is preferable to use a within-subjects design, establishing the isolated effects for a given group is imperative. After receiving knowledge of the topic of some of the phrases in the task, two groups of 40 listeners transcribed 60 phrases produced by speakers with either hypokinetic or ataxic dysarthria, allowing us to explore main and interaction effects of speaker type in this condition, and compared it with previously published control and familiarization data.
Participants
The data from 200 participants were analyzed in the present study. All listeners had normal hearing; standard American English as their native language; and little to no experience with dysarthric speech, as per self-report. The listener groups contained equal numbers of Arizona State University undergraduate men and women whose ages ranged from 18 to 50 years old. All were compensated for their participation in this study. Data from two groups of 40 individuals were collected for this investigation (TK group; n = 80). Data were compared with those of two control groups of 20 listeners unaware of the target topic and received no additional familiarization to disordered speech (control group; n = 40) (reported in Liss et al., 2000) and with those of two groups of 40 listeners who underwent a familiarization process (reported in Liss et al., 2002) (familiarization group; n = 80). The study protocol and consent procedures were approved by the Institutional Review Board of Arizona State University.
Speech Stimuli
Details on the creation of the stimulus sets are described in previous reports (Liss, Spitzer, Caviness, Adler, & Edwards, 1998; Liss et al., 2000). Briefly, phrases were recorded from six speakers with hypokinetic dysarthria and six speakers with ataxic dysarthria. The perceptual characteristics of the phrases for each speaker group were consistent with our operational definitions, derived from the Mayo Classification System (Darley, Aronson, & Brown, 1969; Duffy, 1995). All speakers were deemed to have moderate to severe impairments in intelligibility by certified speech-language pathologists and were selected to create relatively homogenous groups for each dysarthria type, with highly similar segmental and suprasegmental characteristics. The characteristics of speakers classified with hypokinetic dysarthria included a perceptually rapid speaking rate with monopitch and monoloudness; imprecise articulation, leading to a perceived blurring of phonemes and syllables; and a breathy, hoarse, or harsh voice. Speakers classified with ataxic dysarthria were noted to have an equal and even syllable duration pattern, perceptually slow rate, and excessive loudness variation.
The perceptual impressions were supported by acoustic measures of phrase duration, strong-to-weak vowel duration calculations, vowel formant frequencies and point-vowel quadrilateral areas, as well as fundamental frequency and amplitude variation (see Liss et al., 2000, Tables I and II). Briefly, the hypokinetic phrases were significantly shorter in duration and had a significantly smaller range of fundamental frequency variation than those of the speakers with ataxic dysarthria. These characteristics correspond with the perceived rapid rate and monotone speech of hypokinetic speech. The vowel durations for ataxic speech were similar for those within adjacent strong and weak syllables. This corroborated the perception of slow, equal, and even speech. The vowel quadrilateral areas for both hypokinetic and ataxic speakers were approximately 50% smaller than those of the neurologically normal control speakers (see Figure 3 in Liss et al., 1998). As reported in Liss et al. (2000), the phrases recorded for the two dysarthria samples were of equivalent intelligibility by design. The intelligibility (as measured by mean words-correct score) for the ataxic set was 43.2%, and the mean for the hypokinetic set was 41.8%.
The phrases, modeled after Cutler and Butterfield (1992), were designed for the assessment of the quality of lexical segmentation using patterns of LBEs. The phrases each consisted of six syllables that alternated in phrasal strength patterns, with strong syllables identified as containing full vowels of relatively longer duration, that may or may not receive prosodic stress, and weak syllables identified as containing reduced vowels, and do not receive prosodic stress1 (Cutler & Carter, 1987). Half of the phrases alternated strong– weak (SWSWSW), and the other half alternated weak–strong (WSWSWS). The phrases ranged in length from three to five words, and all words were one or two syllables in length. The phrases contained all English words but were of low interword predictability to reduce the contribution of contextual information to word activation and recognition. None of the words in the phrases was repeated, with the exception of articles and auxiliary verbs. The complete list of test phrases can be found in Spitzer, Liss, and Mattys (2007).
The stimulus sets consisted of 60 phrases, with 10 productions from each of the six speakers in each group. A neurologically healthy female speaker stated the phrase number immediately before each phrase. After each phrase, there was 12 seconds of silence during which the listeners transcribed the phrase. Of the 60 phrases, 36 phrases contained one target word that was political in nature (e.g., caucus, voter), henceforth referred to as topic words. The phrases containing political words were developed in a series of pilot studies to eliminate ambiguous words.
PROCEDURE
The listeners were seated in individual cubicles. The audiotapes were presented via the Tandberg Educational sound system in the ASU Language Laboratory over high-quality Tandberg supra-aural headphones. Equivalent sound pressure levels across headphones were verified with a headphone coupler sound level meter (Quest 215 Sound Level Meter). Listeners were instructed to adjust the loudness to a comfortable listening level in 4-dB increments up or down during the preliminary instructions. They were told not to alter the loudness after the stimulus phrases had begun. The listeners transcribed three practice phrases, which were read by a neurologically normal female speaker. No listeners made more than one word error in the practice transcriptions.
Before the transcription task, all listeners in the TK condition were informed that some of the phrases contained words that are political in nature. They were told that all phrases consisted of real words in the English language produced by several different male and female speakers and that some of the phrases may be difficult to understand but that they should guess if they did not know what the speaker was saying.
ANALYSES
The TK corpus consisted of 4800 phrase transcriptions (80 listeners × 60 phrases). The following dependent measures were analyzed.
Intelligibility
To determine overall intelligibility, a words- correct score (number of words correct divided by total words) was calculated for each listener. A word was counted as correct when it exactly matched the target or when it differed only by tense (-ed) or plural (-s) without changing its syllabic structure. Substitutions between “a” and “the” were also regarded as correct. A 2 × 3 between-groups analysis of variance (ANOVA) was conducted. The first factor was speaker group (ataxic or hypokinetic dysarthria), and the second factor was condition (control, familiarization, or TK). Post-hoc pairwise multiple comparisons, with Bonferroni’s adjustment, were conducted to detect differences in mean intelligibility scores between speaker groups and listening conditions.2
Topic Words Correct
Topic words (i.e., words that are political in nature) appeared in 36 of the 60 phrases. The percentage of topic words correctly identified was calculated for each listener and subjected to a 2 × 3 between-groups ANOVA. The first factor was speaker group (ataxic or hypokinetic dysarthria), and the second factor was condition (control, familiarization, or TK). To evaluate the specific effects of speaker group and listening condition on the percentage of topic words correct, post-hoc pairwise multiple comparisons were conducted. Bonferroni’s adjustment was used to correct for the number of comparisons made.
Topic-Related Substitutions
Word substitutions that were political in nature (e.g., civil for simple) were tabulated and summed independently by two trained judges, for which interrater reliability (Cronbach’s alpha) was computed to be 98.9%. The tabulations of the first judge (RU) were used in the remaining analyses. The proportion of political substitutions to total words incorrectly identified was calculated for each listener. Evidence of lexical priming is supported by a larger proportion of political word substitutions in the TK condition relative to the other listening conditions. A 2 × 3 between-groups ANOVA was conducted. The first factor was speaker group (ataxic or hypokinetic dysarthria), and the second factor was condition (control, familiarization, or TK). Post-hoc pairwise multiple comparisons were also made, with Bonferroni’s adjustment, to evaluate this potential relationship.
Lexical Boundary Errors
Two trained judges independently coded the listener transcripts for the presence and type of LBEs to obtain the quantity of agreed upon errors. Lexical boundary violations were defined as erroneous insertions or deletions of lexical boundaries. Four error types were possible: insert boundary before a strong syllable (IS), insert boundary before a weak syllable (IW), delete boundary before a strong syllable (DS), and delete boundary before a weak syllable (DW). Each phrase had the possibility of containing more than one LBE (for examples, see Table 1). If syllabic strength is an important cue for segmenting the speech stream, we expect to see a larger proportion of LBE insertions before strong syllables and deletions before weak syllables because most English words begin with a strong syllable (Cutler & Carter, 1987). A χ2 test of independence was conducted to determine the presence of this dependency structure between LBE type (insertion or deletion) and syllabic strength (strong or weak) for each dysarthria group.
TABLE 1.
Examples of Lexical Boundary Errors
| Before Strong Syllable | Before Weak Syllable | |
|---|---|---|
| Insertion | IS | IW |
| Target → Error | Amend → Come in | Friendly → Man that |
| Deletion | DS | DW |
| Target → Error | Slower page → Novocaine | Catch it → Catchy |
DS = delete boundary before a strong syllable; DW = delete boundary before a weak syllable; IS = insert boundary before a strong syllable; IW = insert boundary before a weak syllable.
To measure the overall quality of lexical segmentation for each condition, the metrical segmentation strategy (MSS) ratio, the number of predicted errors divided by total LBEs (IS + DW/Total LBEs), was calculated for each listener. An MSS ratio greater than 0.50 is taken as evidence of strength-based segmentation. To evaluate the effects of speaker group and listening conditions on the MSS ratio, a 2 × 3 between-groups ANOVA was conducted. To further elucidate the relationship between syllabic strength and LBE type in the TK condition, IS/IW and DW/DS ratios were calculated for each dysarthria group. These ratios permitted a comparison with previously published data regarding the strength of adherence to predicted error patterns. Ratio values of 1 indicate that insertions and deletions occur equally as often before strong and weak syllables. Therefore, the greater the positive distance from 1, the greater the strength of adherence to the predicted pattern. These descriptive data were not treated statistically but were calculated to complement the results of the χ2 tests of independence and the ANOVA.
RESULTS
Intelligibility
Results of the 2 × 3 between-groups ANOVA revealed significant main effects for both the dysarthria group [F (1, 195) = 32.75; P < .005; ηp2 = .144] and listening condition [F (2, 195) = 16.548; P < .005; ηp2 = .145]. The interaction effect was not significant [F (2, 195) = 2.872; P = .059; ηp2 = .029]. Planned comparisons revealed a significant difference between the TK and control conditions (P < .005). Intelligibility scores from the TK and familiarization conditions did not differ significantly (P = .537), indicating that both methods of training produced similar magnitudes of facilitative effects. Planned comparisons of dysarthria type by condition revealed both speaker groups were of equivalent intelligibility in the control conditions, confirming the design of the speech stimuli. However, greater perceptual benefit to intelligibility was revealed for ataxic than for hypokinetic speakers for both listener manipulations (see Figure 1 for group means). Although there was some variability among listeners, there was no noticeable difference in this variability among conditions (see Table 2 for descriptive statistics of listener variability).
Figure 1.
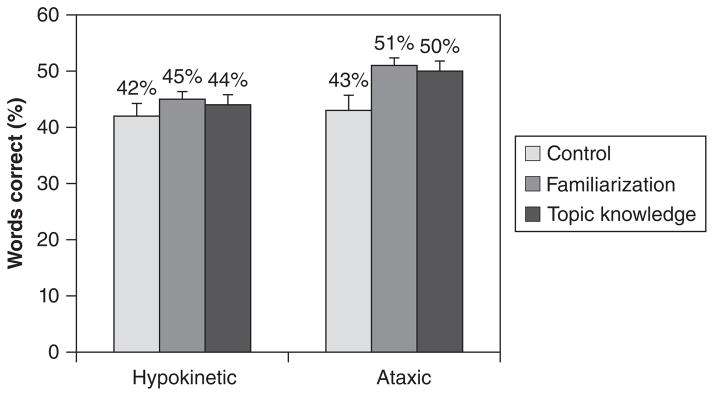
Mean intelligibility (with standard error) for all listening conditions.
TABLE 2.
Descriptive Statistics of Average Listener Performance Within Each Condition
| Intelligibility (% Words Correct) | Topic Words Correct (%) | |||||
|---|---|---|---|---|---|---|
|
| ||||||
| Minimum | Maximum | SD | Minimum | Maximum | SD | |
| Control | ||||||
| Hypokinetic | 31 | 51 | 5 | 14 | 42 | 8 |
| Ataxic | 30 | 55 | 6 | 17 | 36 | 7 |
| Familiarization | ||||||
| Hypokinetic | 35 | 55 | 5 | 14 | 39 | 7 |
| Ataxic | 41 | 60 | 5 | 17 | 53 | 7 |
| TK | ||||||
| Hypokinetic | 35 | 53 | 5 | 17 | 42 | 6 |
| Ataxic | 36 | 60 | 6 | 22 | 53 | 8 |
SD = standard deviation; TK = topic knowledge.
Topic Words Correct
The 2 × 3 between-groups ANOVA revealed significant main effects of speaker group [F (1, 194) = 16.803; P < .005; ηp2 = .080] and listening condition [F (2, 194) = 16.155; P < .005; ηp2 = .143], as well as a significant interaction [F (2, 194) = 7.357; P < .005; ηp2= .071]. Planned comparisons, with Bonferroni’s correction (alpha set at P < .005), revealed significant differences between the control and both the TK and familiarization groups. The difference between the TK and familiarization conditions failed to reach significance (P = .025). In the ataxic listening group, significant differences were revealed between the percentage of topic words correctly identified between the TK condition relative to the control (t(58) = −6.214; P < .005) and familiarization (t(78) = −3.157; P < .005) conditions and between the familiarization and control conditions (t(58) = −4.082; P < .005). In the hypokinetic listening group, the percentage of topic words correctly identified did not differ significantly between the TK condition relative to control (t(58) = −1.362; P = .178) or familiarization (t(78) = −.475; P = .636) conditions or between control and familiarization (t(58) = −.966; P = .338) conditions. See Figure 2 for group means. Again, there was no noticeable difference in variability of listener performance among conditions (see Table 2 for descriptive statistics of listener variability).
Figure 2.
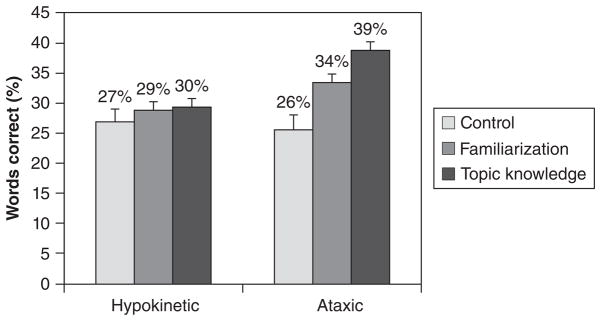
Mean topic words correct (with standard error) for all listening conditions.
Topic-Related Substitutions
The proportion of substitutions to total number of incorrectly transcribed words was calculated, revealing a larger proportion of topic-related substitutions in the TK condition for both speaker groups relative to the control and familiarization conditions (Figure 3). Results of the 2 × 3 between-groups ANOVA revealed a significant main effect for dysarthria group [F (1, 195) = 13.311; P < .005; ηp2=0.064] and listening condition [F (2, 195) = 25.433; P < .005; ηp2=0.208] and a nonsignificant interaction [F (2, 195) = 2.631; P = .075; ηp2= .026]. Planned comparisons demonstrated that listeners of hypokinetic speech made significantly higher proportions of political word substitutions in the TK condition than in the control condition (t(58) = −3.44; P < .005) or familiarization condition (t(78) = −4.362; P < .005). There was no difference between the control and familiarization conditions (t(58)= −.484; P = .630). However, the findings for listeners of ataxic speech were somewhat different. Listeners made significantly higher proportions of political word substitution errors in the TK condition than in the familiarization condition (t(58) = −5.517; P <.005) but not in the control condition (t(58) = −1.863; P = .067).
Figure 3.

Mean proportion of topic-related substitutions to total incorrect words (with standard error).
Lexical Boundary Errors
Chi-Square Procedures
A χ2 test of independence revealed significant dependency between error type and syllabic strength for the hypokinetic dysarthria group (contingency coefficient = .255; P < .005) but not for the ataxic dysarthria group (contingency coefficient = .006; P = .825).
Metrical Segmentation Strategy Ratio
The average MSS ratio for each condition can be found in Table 3. The results of a 2 × 3 between-groups ANOVA demonstrated a significant main effect for dysarthria group [F (1, 194) = 142.514; P < .005; ηp2 = .424]. The main effect of listening condition [F (2, 194) = .628; P = .535; ηp2 = .006] and the interaction between the variables [F (2, 194) = 2.156; P = .119; ηp2 = .022] were not significant. 3 The results indicate that listeners of hypokinetic speech used more strength-based segmentation strategies in all conditions in contrast to listeners of ataxic speech, who did not appear to rely on such strategies for segmentation.
TABLE 3.
Lexical Boundary Errors for Each Condition
| % IS | % IW | % DS | % DW | Median IS/IW | Median DW/DS | Median MSS Ratio | |
|---|---|---|---|---|---|---|---|
| Control | |||||||
| Hypokinetic | 47.1 | 27.4 | 9.0 | 16.5 | 1.72 | 1.82 | .631 |
| Ataxic | 40.5 | 34.4 | 12.3 | 12.8 | 1.18 | 1.04 | .536 |
| Familiarization | |||||||
| Hypokinetic | 44.9 | 27.2 | 10.3 | 17.6 | 1.65 | 1.70 | .618 |
| Ataxic | 36.0 | 34.0 | 14.5 | 15.4 | 1.06 | 1.06 | .511 |
| TK | |||||||
| Hypokinetic | 45.5 | 25.8 | 10.0 | 18.7 | 1.76 | 1.88 | .650 |
| Ataxic | 33.4 | 34.8 | 15.4 | 16.5 | 0.96 | 1.07 | .481 |
DS = delete boundary before a strong syllable; DW = delete boundary before a weak syllable; IS = insert boundary before a strong syllable; IW = insert boundary before a weak syllable; MSS = metrical segmentation strategy; TK = topic knowledge.
Descriptive Statistics
Descriptive statistics including proportions of LBE types and IS/IW and DW/DS ratios were calculated per dysarthria group and can be seen in Table 3. Proportions of LBE types and IS/IW and DW/DS ratios from the control and familiarization conditions are also included in Table 3 to permit cross-listening condition comparisons. The percentages and proportions of error types remain stable for each speaker group across listening conditions, further demonstrating that the listeners’ reliance on a strength-based segmentation strategy were not appreciably altered by either listener manipulation. Furthermore, the proportions of IS/IW and DW/DS support that listeners of hypokinetic speech used a strength-based segmentation strategy, with larger ratios indicating predicted errors are occurring more frequently than nonpredicted errors for each error type. Listeners of this ataxic speech made equal amounts of predicted and nonpredicted errors, as demonstrated by ratio values near 1, suggesting that syllabic strength information likely is not assisting these listeners in segmenting the acoustic stream.
DISCUSSION
The present study indicates that many critical questions remain to be answered before signal-complementary manipulations can be rationally applied to different forms and severities of degraded speech. We show that different manipulation types may provide similar magnitudes of benefit but for different reasons. Also, dysarthria-specific effects shown in this and previous studies further suggest a complex relationship between signal characteristics and signal- complementary information. The issue of dose was not addressed in this investigation but may account for some of the present findings (e.g., see Hustad & Cahill, 2003).
Initially, we offered the intuitive prediction that informing listeners of the topic would cause an increase in overall intelligibility and a higher percentage of correctly identified topic-related words relative to the control condition. This prediction was confirmed for listeners of ataxic speech. It was also speculated that a higher proportion of topic-related word substitutions would be present in the TK condition compared with control and familiarization conditions. This was the case for listeners of hypokinetic speech. These results provide support for the presumption that the mechanisms of semantic priming and delimitation of lexical candidates underlie perceptual benefits of this manipulation but perhaps differently for each speaker group. Listeners of ataxic dysarthria are more accurate at recognizing political words. Listeners of hypokinetic dysarthria show a greater tendency to guess or mishear a word as political.
These results are not surprising given previous work in this area. Most relevantly, Hustad (2007) reported significant changes to intelligibility of eight speakers with dysarthria (secondary to cerebral palsy) by experimentally manipulating two sources of listener knowledge: (1) semantic predictability of the speech stimuli and (2) use of alphabet cues. In short, listeners who transcribed predictable sentences and were provided alphabet cues outperformed those who transcribed unpredictable sentences and were given no cues. Despite differing methodology and cue type, the results of the present study seem consistent with Hustad’s work. Although the superficial results of this investigation support cue usage to improve intelligibility of dysarthric speech, a closer look at the dysarthria-specific findings reveals a different story.
Our key prediction was that the magnitude of benefit of TK should be similar for the two dysarthria groups. This was based on the theoretical premise that informing listeners of topic should not exert differential benefits for two groups of speech that are of equivalent intelligibility, unlike the previous familiarization procedure, which depends on the listener learning something about the speech signal. That is, priming lexical candidates for two groups of people listening to speech of similar intelligibility should provide similar magnitude of benefit. This prediction was not supported by the data: The magnitude of the TK effect was much larger for the listeners who transcribed ataxic speech relative to those who transcribed hypokinetic speech. This pattern closely mirrored the effects for familiarization in the previous report (Liss et al., 2002). In fact, based on the intelligibility measures alone (both percent words and topic-words correct), there seems to be no evidence that TK benefited the listeners of hypokinetic dysarthric speech. However, evidence of lexical priming for these listeners is found in the word substitution data, with a significantly higher proportion of political word substitutions revealed in the TK condition than in the other two listening conditions. Thus, the mechanism of TK benefits (i.e., semantic priming and lexical candidate delimitation) were observed for both types of dysarthric speech, but the magnitudes of benefit were smaller for hypokinetic dysarthria, and neither group differed from that of the previous familiarization condition.
The findings of the present study suggest that listeners are faced with a different set of perceptual challenges depending on the dysarthria type and that these challenges may not be ameliorated by any one form of signal-complementary information. Klasner and Yorkston (2005) qualitatively outlined the barriers to intelligibility of hyperkinetic and mixed flaccid-spastic speech and the strategies used by naïve listeners to mitigate these effects. They concluded that both the hurdles to intelligibility and the strategies employed by listeners varied as a function of dysarthria type. In the present study, the dysarthria-specific discrepancy was exhibited for both forms of listener manipulation. This is further supported by the qualitative findings of Klasner and Yorkston’s (2005) study and calls for a more systematic investigation of the cause. Perhaps a systematic manipulation of perceptual features (e.g., speech rate, pitch variability, loudness variability), in tandem with controlled tests of listener manipulations, will further inform the underlying mechanisms used by listeners.
The benefits to lexical segmentation, or lack thereof, offered by the two forms of listener manipulation are also deserving of further discussion. We predicted that LBEs in the TK condition would be equivalent to those of the control condition because the manipulation should not allow listeners to “learn” about the acoustic signal to facilitate the use of strength in segmenting the acoustic stream. Instead the LBEs of the TK condition resembled those of both control and familiarization, in which listeners of hypokinetic speech appeared to more actively exploit syllabic strength information for segmentation than did listeners of ataxic speech. In our previous paper (Liss et al., 2000), we postulated that the relatively equal and even rhythmic pattern of the ataxic speech prevented an efficient exploitation of acoustic cues to syllabic strength (Cutler & Norris, 1988). Thus, LBEs occurred rather equally between predicted and nonpredicted errors. In contrast, the hypokinetic speech contained diminished but relatively preserved syllabic strength cues, offering more reliable landmarks for the use of metrical segmentation strategies. We were surprised that this pattern persisted after a brief familiarization phase because listeners might have benefited from learning about the suprasegmental patterns and applied that knowledge to guide lexical segmentation. However, the absence of differences in LBE error patterns—both in terms of magnitude and in dysarthria-specific patterns—might be interpreted as an absence of effect on lexical segmentation of these two signal-complementary manipulations. A possible explanation may lie in the dose and specificity effect, in which the exposure for the familiarization condition was brief, and no explicit attention to suprasegmental information was invoked. Future work that varies the dose and specificity of familiarization training may provide insight to this signal-complementary variable.
In summary, these results highlight the importance of continuing to explore the interface between the acoustic signal and the cognitive-perceptual processes used by listeners to understand the nature of intelligibility deficits and improvement (Davis & Johnsrude, 2007; Lindblom, 1990b; Weismer, 2008). Manipulating signal-complementary information as an intervention strategy to improve intelligibility of dysarthric speech is common (Duffy, 1995; Hustad & Weismer, 2007; Yorkston, Beukelman, & Bell, 1988; Yorkston et al., 1996), yet there is little information upon which clinicians can base their strategic decisions. Future research must explicate how different forms of signal-complementary information access different entry points for improving intelligibility (e.g., learning something about how to decipher the degraded signal versus learning something about the content of the message). It is likely that when one mechanism is activated, it allows for others to be used; however, it is yet to be determined how these entry points can be best accessed and exploited for a given dysarthria type. Knowing the perceptual benefits offered by these individual techniques will allow for exploration of synergistic effects from combining multiple pieces of signal-complementary information with one another and other therapeutic techniques.
Acknowledgments
This work was supported by National Institute on Deafness and Other Communicative Disorders Grants 5 R01 DC 6859 and 5 R29 DC 02672, awarded to J. M. Liss. A portion of this research was presented before the Conference on Motor Speech Conference, Savannah, Georgia, in March 2010. The authors thank David Ingram for his comments on an earlier version of this manuscript. Gratitude is extended to Angela Davis for her assistance with data analysis.
Footnotes
This definition of syllabic strength is distinguished from that of prosodic phonology, which holds that all strong syllables are stressed and weak syllables are unstressed (Halle & Keyser, 1971). The relative importance of vowel quality versus prosodic stress in the perceptual designation of syllabic strength remains to be determined (Fear, Cutler, & Butterfield, 1995; Gow & Gordon, 1995).
Recognizing the unmatched size of the groups with 40 listeners in the TK and familiarization groups and 20 listeners in the control groups, a conservative alpha of 0.005 was selected. This was intended to minimize the potential for an overpowered study in which small between-group differences may attain statistical significance without being clinically or perceptually relevant.
Significant results of Levene’s test for equality of variances showed that the data were of unequal variance, likely secondary to unequal sample sizes, and the data were transformed to normalize the distribution. However, results obtained in parametric testing on the transformed data and nonparametric equivalents (Welch’s ANOVA) mirrored those obtained in the ANOVA reported above.
References
- Beliveau C, Hodge M, Hagler P. Effects of supplemental linguistic cues on the intelligibility of severely dysarthric speakers. AAC: Augmentative and Alternative Communication. 1995;11:176–186. [Google Scholar]
- Cole RA, Jakimik J. Understanding speech: how words are heard. In: Underwood G, editor. Strategies of information processing. London: Academic Press; 1978. [Google Scholar]
- Clarke CM, Garrett MF. Rapid adaptation to foreign-accented English. Journal of the Acoustical Society of America. 2004;116:3647–3658. doi: 10.1121/1.1815131. [DOI] [PubMed] [Google Scholar]
- Cutler A, Butterfield S. Rhythmic cues to speech segmentation: Evidence from juncture misperception. Journal of Memory and Language. 1992;31:218–236. [Google Scholar]
- Cutler A, Carter DM. The predominance of strong initial syllables in the English vocabulary. Computer Speech & Language. 1987;2:133–142. [Google Scholar]
- Cutler A, Norris D. The role of strong syllables in segmentation for lexical access. Journal of Experimental Psychology: Human Perception and Performance. 1988;14:113–121. [Google Scholar]
- Darley FL, Aronson AE, Brown JR. Differential diagnostic patterns of dysarthria. Journal of Speech and Hearing Research. 1969;12:246–269. doi: 10.1044/jshr.1202.246. [DOI] [PubMed] [Google Scholar]
- Davis MH, Johnsrude IS. Hearing speech sounds: Top-down influences on the interface between audition and speech perception. Hearing Research. 2007;229:132–147. doi: 10.1016/j.heares.2007.01.014. [DOI] [PubMed] [Google Scholar]
- DePaul R, Kent R. A longitudinal case study of ALS: Effects of listeners’ familiarity and proficiency on intelligibility judgments. American Journal of Speech Language Pathology. 2000;9:230–240. [Google Scholar]
- Dongilli P. Semantic context and speech intelligibility. In: Till J, Yorkston K, Beukelman D, editors. Motor speech disorders: Advances in assessment and treatment. Baltimore: Paul H. Brookes; 1994. pp. 175–191. [Google Scholar]
- Duffy JR. Motor speech disorders. St. Louis: Mosby; 1995. [Google Scholar]
- Dupoux E, Green K. Perceptual adjustment to highly compressed speech: Effects of talker and rate changes. Journal of Experimental Psychology: Human Perception and Performance. 1997;23:914–927. doi: 10.1037//0096-1523.23.3.914. [DOI] [PubMed] [Google Scholar]
- Fear BD, Cutler A, Butterfield S. The strong/weak syllable distinction in English. Journal of the Acoustical Society of America. 1995;97:1893–1904. doi: 10.1121/1.412063. [DOI] [PubMed] [Google Scholar]
- Garcia JM, Dagenais P. Dysarthric sentence intelligibility: Contribution of iconic gestures and message predictiveness. Journal of Speech Language and Hearing Research. 1998;41:1282–1293. doi: 10.1044/jslhr.4106.1282. [DOI] [PubMed] [Google Scholar]
- Gow DW, Gordon PC. Lexical and prelexical influences on word segmentation: Evidence from priming. Journal of Experimental Psychology. 1995;21:344–359. doi: 10.1037//0096-1523.21.2.344. [DOI] [PubMed] [Google Scholar]
- Halle M, Keyser SJ. English stress: Its form, its growth, and its role in verse. New York: Harper and Row; 1971. [Google Scholar]
- Hammen V, Yorkston K, Dowden P. Index of contextual intelligibility: Impact of semantic context in dysarthria. In: Moore C, Yorkston K, Beukelman D, editors. Dysarthria and apraxia of speech: Perspectives on management. Baltimore: Paul H. Brookes; 1991. [Google Scholar]
- Hustad KC, Auker J, Natale N, Carlson R. Improving intelligibility of speakers with profound dysarthria and cerebral palsy. Augmentative and Alternative Communication. 2003a;19:187–198. [Google Scholar]
- Hustad KC, Jones T, Dailey S. Implementing speech supplementation strategies: Effects on intelligibility and speech rate of individuals with chronic severe dysarthria. Journal of Speech Language and Hearing Research. 2003b;46(2):462–474. [PubMed] [Google Scholar]
- Hustad KC, Cahill MA. Effects of presentation mode and repeated familiarization on intelligibility of dysarthric speech. American Journal of Speech-Language Pathology. 2003;12:198–208. doi: 10.1044/1058-0360(2003/066). [DOI] [PubMed] [Google Scholar]
- Hustad KC. Contribution of two sources of listener knowledge to intelligibility of speakers with cerebral palsy. Journal of Speech Language and Hearing Research. 2007;50(5):1228–40. doi: 10.1044/1092-4388(2007/086). [DOI] [PubMed] [Google Scholar]
- Hustad KC, Weismer G. A Continuum of interventions for individuals with dysarthria: Compensatory and rehabilitative treatment approaches. In: Weismer G, editor. Motor speech disorders. San Diego: Plural Publishing; 2007. [Google Scholar]
- Jones W, Mathy P, Azuma T, Liss JM. The effect of aging and synthetic topic cues on the intelligibility of dysarthric speech. Augmentative and Alternative Communication. 2004;20(1):22–29. [Google Scholar]
- Klasner ER, Yorkston K. Speech intelligibility in ALS and HD dysarthria: The everyday listener’s perspective. Journal of Medical Speech- Language Pathology. 2005;13:127–139. [Google Scholar]
- Lindblom B. Explaining phonetic variation: A sketch of the H and H theory. In: Hardcastle W, Marchal A, editors. Speech production and speech modeling. Dordrecht: Kluwer Academic Publishers; 1990a. pp. 403–439. [Google Scholar]
- Lindblom B. On the communication process: Speaker–listener interaction and the development of speech. Augmentative and Alternative Communication. 1990b;6:220–230. [Google Scholar]
- Liss JM, Spitzer SM, Caviness JN, Adler C. LBE analysis in hypokinetic and ataxic dysarthria. Journal of the Acoustical Society of America. 2000;107:3415–3424. doi: 10.1121/1.429412. [DOI] [PubMed] [Google Scholar]
- Liss JM, Spitzer SM, Caviness JN, Adler C. The effects of familiarization on intelligibility and lexical segmentation of hypokinetic and ataxic dysarthria. Journal of the Acoustical Society of America. 2002;112:3022–3031. doi: 10.1121/1.1515793. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liss JM, Spitzer S, Caviness JN, Adler C, Edwards B. Syllabic strength and lexical boundary decisions in the perception of hypokinetic dysarthric speech. Journal of the Acoustical Society of America. 1998;104:2457–2466. doi: 10.1121/1.423753. [DOI] [PubMed] [Google Scholar]
- Luce PA, Goldinger SD, Auer ET, Vitevitch MS. Phonetic priming, neighborhood activation, and PARSYN. Perception & Psychophysics. 2000;62:615–625. doi: 10.3758/bf03212113. [DOI] [PubMed] [Google Scholar]
- Luce PA, Large NR. Phonotactics, density, and entropy in spoken word recognition. Language and Cognitive Processes. 2001;16:565–581. [Google Scholar]
- Luce PA, Pisoni DB. Recognizing spoken words: The Neighborhood Activation Model. Ear & Hearing. 1998;19:1–36. doi: 10.1097/00003446-199802000-00001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mattys SL, White L, Melhorn JF. Integration of multiple speech segmentation cues: A hierarchical framework. Journal of Experimental Psychology: General. 2005;134(4):477–500. doi: 10.1037/0096-3445.134.4.477. [DOI] [PubMed] [Google Scholar]
- Nooteboom SG. Lexical retrieval from fragments of spoken words: Beginnings vs. endings. Journal of Phonetics. 1981;9:407–424. [Google Scholar]
- Spitzer S, Liss JM, Mattys S. Acoustic cues to lexical segmentation: A study of resynthesized speech. Journal of the Acoustical Society of America. 2007;122(6):3678–3687. doi: 10.1121/1.2801545. [DOI] [PubMed] [Google Scholar]
- Tjaden KK, Liss JM. The role of listener familiarity in the perception of dysarthric speech. Clinical Linguistics and Phonetics. 1995a;9:139–154. [Google Scholar]
- Tjaden KK, Liss JM. The influence of familiarity on judgments of treated speech. American Journal of Speech-Language Pathology. 1995b;4(1):39–47. [Google Scholar]
- Weismer G. Speech intelligibility. In: Ball M, Perkins M, Muller N, Howard S, editors. The handbook of clinical linguistics. Oxford, UK: Blackwell; 2008. [Google Scholar]
- Yorkston KM, Beukelman DR, Bell KR. Clinical management of dysarthric speakers. Boston: Little, Brown; 1988. [Google Scholar]
- Yorkston K, Strand E, Kennedy M. Comprehensibility of dysarthric speech: Implications for assessment and treatment planning. American Journal of Speech Language Pathology. 1996;5(1):55–66. [Google Scholar]