

Abstract
We investigate the consequences of adopting the criteria used by the state of California, as described by Myers et al. (2011), for conducting familial searches. We carried out a simulation study of randomly generated profiles of related and unrelated individuals with 13-locus CODIS genotypes and YFiler® Y-chromosome haplotypes, on which the Myers protocol for relative identification was carried out. For Y-chromosome sharing first degree relatives, the Myers protocol has a high probability (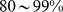 ) of identifying their relationship. For unrelated individuals, there is a low probability that an unrelated person in the database will be identified as a first-degree relative. For more distant Y-haplotype sharing relatives (half-siblings, first cousins, half-first cousins or second cousins) there is a substantial probability that the more distant relative will be incorrectly identified as a first-degree relative. For example, there is a
) of identifying their relationship. For unrelated individuals, there is a low probability that an unrelated person in the database will be identified as a first-degree relative. For more distant Y-haplotype sharing relatives (half-siblings, first cousins, half-first cousins or second cousins) there is a substantial probability that the more distant relative will be incorrectly identified as a first-degree relative. For example, there is a 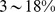 probability that a first cousin will be identified as a full sibling, with the probability depending on the population background. Although the California familial search policy is likely to identify a first degree relative if his profile is in the database, and it poses little risk of falsely identifying an unrelated individual in a database as a first-degree relative, there is a substantial risk of falsely identifying a more distant Y-haplotype sharing relative in the database as a first-degree relative, with the consequence that their immediate family may become the target for further investigation. This risk falls disproportionately on those ethnic groups that are currently overrepresented in state and federal databases.
probability that a first cousin will be identified as a full sibling, with the probability depending on the population background. Although the California familial search policy is likely to identify a first degree relative if his profile is in the database, and it poses little risk of falsely identifying an unrelated individual in a database as a first-degree relative, there is a substantial risk of falsely identifying a more distant Y-haplotype sharing relative in the database as a first-degree relative, with the consequence that their immediate family may become the target for further investigation. This risk falls disproportionately on those ethnic groups that are currently overrepresented in state and federal databases.
Introduction
DNA databases have unquestionably assumed a vital role in the American criminal justice system. Genetic evidence has served to bolster the evidence in existing cases and to identify suspects through “cold hit” database matches [1]. Typically, investigative queries in DNA databases have been limited to searches intended to find the source of the crime-scene sample. However, increasing attention has been given to the question of whether law enforcement should also be able to search for partial matches, that is, DNA searches intended to find the source by identifying a relative in the database [1], [2]. Such searches are commonly called “kinship” or “familial” searches.
The concept of familial searching is not particularly new. In fact, familial searches fueled some of the earliest illustrations of the investigative power of DNA typing [3]. In 2002, investigators in the United Kingdom identified a serial rapist in part through a database search that led them to the perpetrator via the DNA profile of his son [4]. In another widely cited case, UK investigators recovered DNA from a brick thrown off an overpass that landed on a truck, leading to the driver's fatal heart attack, and found the source through a database search that located a relative [5]. More recently, California authorities used a familial search to identify the putative son of a serial killer nicknamed the “Grim Sleeper,” and arrested the suspect after a sting operation in which police collected a discarded pizza crust [5].
Familial searches by no means dominate the use patterns of DNA databases, in part because they are difficult to conduct, require access to a sizeable database, are subject to various clear or unclear legal restrictions, and raise ethical concerns [6]. Because familial searches are by design inexact, the most effective methods typically employ several steps beyond a simple database search. To find a lead, one commonly used approach, which may entail additional rounds of testing, relies on examining the Y haplotype of all significant partial matches. Even if a partial match is identified, law enforcement still must investigate the relatives of that person to determine if any are likely to be the crime scene sample source.
Nevertheless, familial searches are presently conducted by a number of jurisdictions and continue to garner interest. The UK is the most prominent and longstanding advocate of the technique: from 2004 to 2011, 179 cases were submitted for search [7]. As of 2009, New Zealand had conducted 12 familial searches in serious cases [8]. The Netherlands recently passed legislation authorizing familial searches [9], [10]. Japan, Australia and Canada have robust DNA collection programs, but only Canada has explicitly rejected familial searches on what appear to be privacy grounds [11].
With regard to Europe, it is worth noting that adoption may be slowed by the December 2008 judgment by the European Court of Human Rights that declared the retention of DNA profiles and samples from unconvicted persons a violation of Article 8 of the Convention for the Protection of Human Rights and Fundamental Freedoms. That opinion, (S. & Marper v. United Kingdom), invoked the provision of the Convention that safeguards its members' “private life” [12]. Although the influence of the ruling beyond its immediate holding is unclear, the Marper decision does represent the first substantial curtailment of DNA expansion programs by a legal entity. Moreover, Marper may be used by privacy advocates and opponents to widespread DNA typing to bolster their legal claims to circumscribe such programs.
In the United States, the push to expand DNA testing has intensified. Originally, United States national database administrators prohibited the disclosure of identifying information for partial matches made across state lines [5]. As a result, although many states either legally authorized or informally permitted partial match (“moderate stringency”) reporting and/or familial searches [13], investigators could not obtain informational leads on profiles generated out of state. In 2006, however, the FBI modified its policy and now permits interstate sharing [14]. As of May 2012, a bill was pending before Congress that would allow the FBI to conduct familial searches in federal and state investigations [15].
Because the rules governing familial search methods in the United States consist of a patchwork of state law, state and local regulation, and even internal laboratory policies [5], [6], it is impossible to relate a precise legal picture. In June of 2013, the U.S. Supreme Court in Maryland v. King [16] upheld DNA collection from arrestees for serious offenses. Although the Court noted that Maryland forbids familial searches, that observation did not seem central to its holding, and no lower courts have ruled on the issue. Assessment is further complicated by the slim line that differentiates unintentional and intentional partial match searches, because some jurisdictions allow the former but not the latter. Nevertheless, some clarity is possible.
At the state level, both Maryland and Washington, D.C. have laws expressly forbidding familial searching [17], [18], although the language of both statutes could be interpreted to permit reporting of unintentional partial matches. As a matter of either written or unwritten policy, roughly nine states expressly forbid both partial matching and familial searching: Alaska, Nevada, Utah, New Mexico, Michigan, Vermont, Massachusetts, and Georgia [19]. At least another seven states prohibit familial searches, but allow reporting of inadvertent partial matches [19]. Fifteen states allow both forms of partial matching, although all of them rely upon formal or informal policies rather than express statutory authorization [19].
The states most actively pursuing familial matches are California, Colorado, Virginia, and Texas; Pennsylvania, Minnesota, and Tennessee are considering legislation. In April 2008, California became the first state to formally endorse and adopt explicit rules for conducting intentional familial searches [20].
The burgeoning interest in familial searching has reignited a national conversation about the propriety of the method that focuses on legal and ethical issues [21], [22]. The major concerns are two-fold: first, is familial searching actually efficacious, and second, does it adequately respect privacy and equality interests?
With regard to efficacy, the challenges of familial searching are reflected in its reported success rates, albeit based on limited data. The UK reports the greatest effectiveness with a 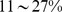 success rate) [23]. California has conducted 29 searches, with 2 reported successes (
success rate) [23]. California has conducted 29 searches, with 2 reported successes (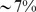 success rate) [24].
success rate) [24].
With regard to the ethical issues, familial searches raise privacy, equality, and democratic accountability concerns [1], [2], [5], [6], [25], [26]. In the United States, the most common critique is that the method is likely to have a discriminatory effect because DNA databases contain the profiles of certain racial minorities in disproportion to their presence in the population. To date there have been only a handful of efforts to quantify the impact of familial searches, and all have been undertaken without reference to a specific search policy [1]–[3]. Only one study, by a multidisciplinary team of researchers, attempted to calculate the general discriminatory impact and concluded that roughly “four times as much of the African-American population as the U.S. Caucasian population would be ‘under surveillance’ as a result of family forensic DNA” [2]. It is this estimation that scholars, policymakers and the popular press have latched upon as a means of quantifying the racial impact of familial searching [21], [27]–[29], and while helpful, it is nonetheless an approximation reached before any specific policy was in place to be examined.
Answering the efficacy and ethical concerns raised by familial search methods in part requires addressing complex statistical questions. The articulation of the first formal familial search policy by California [30], an American state with the world's fourth largest DNA database (nearly 2 million profiles) and a large and diverse general population [31], affords an opportunity to gain valuable insight into the question of whether and under what circumstances familial searching should be allowed. The racial and ethnic diversity of the California database roughly mirrors the racial and ethnic diversity of the United States national database [32], [33]. Moreover, as a bellwether of criminal justice policy, California has already wielded influence both nationally and internationally as other jurisdictions contemplate various approaches.
Methods
Here we implement the Myers et al. familial identification procedure used for familial searching in California [30] to estimate power and false positive rate in addition to estimating the rates of misidentification of distant relatives as first-degree relatives. As detailed more below, in the Myers et al. method, both parent-offspring and sibling relationships are considered by first calculating each likelihood ratio using autosomal data between the unknown sample and each entry in the state database. Of these, the database samples with the highest likelihood ratios are considered in a secondary likelihood ratio analysis using Y-chromosome haplotypes. The cumulative likelihood ratios are calculated under three population genetic assumptions and if they pass particular thresholds, the individual is considered a suspect. This method is detailed in our descriptions below.
All the analyses described were coded in c and R in scripts that are available at github.com/rrohlfs/familial_searching.
Allele frequency data
Autosomal data
In this study, we use allele frequency estimates to investigate identification procedures that are contingent on racially defined population sample allele frequency calculations. For the autosomal STR allele frequencies, we rely upon estimates from a published survey of five population samples consisting of 182–213 individuals each and classified according to socially-identified race [33]. The groups are described in the study as ‘Vietnamese,’ ‘African American,’ ‘Caucasian,’ ‘Hispanic,’ and ‘Navajo.’ Any labeling scheme introduces questions and classifies groups in different ways not independent of the social construction of these groups. In this study we use the labels Vietnamese American, African American, European American, Latino American, and Native American.
The consent and population grouping procedures used to obtain these data are not clear. Since these data were collected, the customary ethical standards regarding informed consent processes have changed considerably, driven by several cases of severe misuse of samples provided by Indigenous communities [34]–[42]. We use these data because of their public availability and utility to investigate error rates and efficacy in familial searching. We look forward to working with data collected using transparent informed consent methodology.
The California state database consists of some entries with the 13 core CODIS loci and some with 15 loci [30]. To maintain manageable complexity, in this study we only consider the core 13 loci. Similar analyses can be performed with 15 locus profiles.
Y-chromosome data
For the Y-haplotypes, we consider data released by ABI consisting of YFiler® haplotypes genotyped in individuals grouped according to social labels ‘Vietnamese,’ ‘African American,’ ‘Caucasian,’ ‘Hispanic,’ and ‘Native American’, with sample sizes of 103, 1918, 4102, 1594, and 105 individuals, respectively (Applied Biosystems®, Foster City, CA) [43]. Again, we refer to these groups as Vietnamese American, African American, European American, Latino American, and Native American.
Individuals were genotyped and categorized into population labeling schemes differently for the autosomal and Y-chromosome markers. In this study, we use samples with the same labels in both the autosomal and Y chromosome data to get our combined population sample allele frequencies for the Vietnamese American, African American, European American, and Latino American groups. Accordingly, the group we call Native American is created from ‘Navajo’ autosomal marker allele frequencies and ‘Native American’ Y-chromosome allele frequencies. This inconsistency brings to question the relevance of these results for highly specified populations. However, this degree of inconsistency in population labeling is not remarkable when considering the wide variation typical to categorizing population groups (social identity-based labels like ‘Hispanic’, ‘African American,’ or ‘Caucasian’). The results of the analysis of these data should be confirmed and augmented by similar analyses of more transparent data.
Simulation scheme
Simulating relatives
To investigate the power and false positive rate of relative identification procedures, pairs of related individuals were simulated. Specifically, 100,000 pairs of parent-offsprings, siblings, half-siblings, cousins, half-cousins (individuals sharing a single grandparent), and second cousins (individuals sharing a set of great-grand parents) were simulated using allele frequency distributions for each of the five populations described above. The relative pairs were simulated to share a Y-haplotype by descent, and we refer to this sort of relationship as Y-sharing. The autosomal markers for all of the individual pairs were simulated with a population background relatedness parameter 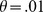 , in accordance with the lower recommended correction in identification likelihood ratio estimations [44].
, in accordance with the lower recommended correction in identification likelihood ratio estimations [44].
Simulating unrelated individuals
Since unrelated individuals very rarely share enough alleles to resemble genetic relatives, more simulations are needed to accurately estimate the rates of positive relative identification between unrelated individuals. To this end, 200,000,000 pairs of unrelated individuals were simulated based on allele frequencies from each pair of population samples.
Because of the immense polymorphism of Y-chromosome haplotypes, accurate estimates of background Y-chromosome relatedness (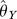 ) require greater sample sizes. To simulate Y-haplotypes of unrelated individuals with realistic levels of background relatedness, haplotypes were independently drawn from the data. This way, rates of coincidentally shared Y-haplotypes correspond with those observed in the available data. Note that simulated rates of coincidentally shared Y-chromosome haplotypes are greatly influenced by the available data, which for some population samples is based on small numbers of individuals.
) require greater sample sizes. To simulate Y-haplotypes of unrelated individuals with realistic levels of background relatedness, haplotypes were independently drawn from the data. This way, rates of coincidentally shared Y-haplotypes correspond with those observed in the available data. Note that simulated rates of coincidentally shared Y-chromosome haplotypes are greatly influenced by the available data, which for some population samples is based on small numbers of individuals.
Relative identification procedure
Parent-offspring and sibling identification protocols were followed with the method implemented in California which incorporates autosomal and Y-chromosome haplotype data [30]. These calculations were performed on pairs of individuals simulated with different genetic relationships, using the allele frequencies from each population sample.
Autosomal likelihood ratio
Using autosomal data, the standard likelihood ratio (LR) comparing the probabilities of the observed genotypes (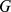 ) assuming a particular genetic relationship (parent-offspring or sibling) and assuming the individuals are unrelated is defined as [1], [45]
) assuming a particular genetic relationship (parent-offspring or sibling) and assuming the individuals are unrelated is defined as [1], [45]
| (1) |
where 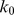 ,
, 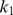 , and
, and 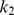 are parameters describing the probabilities that individuals with the specified relationship share 0, 1, or 2 alleles identical by descent (IBD) [46]. As specified by Myers et al., this LR is estimated under three conditions using allele frequency distributions from African American, European American, and Latino American population samples with no
are parameters describing the probabilities that individuals with the specified relationship share 0, 1, or 2 alleles identical by descent (IBD) [46]. As specified by Myers et al., this LR is estimated under three conditions using allele frequency distributions from African American, European American, and Latino American population samples with no  -correction for population substructure, as practiced in California [30].
-correction for population substructure, as practiced in California [30].
Y-haplotype likelihood ratio
Ignoring mutation, the probability that two Y-sharing relatives have the same haplotype of population frequency 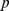 is
is 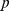 . On the other hand, the probability that two unrelated male individuals each have that same haplotype is
. On the other hand, the probability that two unrelated male individuals each have that same haplotype is 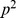 . So, the Y-haplotype likelihood ratio
. So, the Y-haplotype likelihood ratio 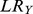 is
is 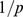 . In the Myers et al. procedure [30],
. In the Myers et al. procedure [30], 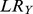 was estimated as the inverse of the upper
was estimated as the inverse of the upper 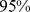 confidence limit of the haplotype frequency, obtained using the data pooled across populations excluding the sampled haplotype [30], [47]. Specifically, after exclusion, if the Y-haplotype is observed with sample frequency
confidence limit of the haplotype frequency, obtained using the data pooled across populations excluding the sampled haplotype [30], [47]. Specifically, after exclusion, if the Y-haplotype is observed with sample frequency 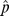 in the database,
in the database,
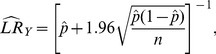 |
(2) |
whereas if the Y-haplotype is not observed in the database,
| (3) |
where  denotes the total number of Y-haplotypes in the database.
denotes the total number of Y-haplotypes in the database.
Combined result
The combined test statistic defined by Myers et al.
[30] is the product of the autosomal marker and Y-haplotype LR estimates, divided by the database size (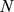 ):
):
| (4) |
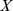 is calculated for each of the three population samples described above. In this study we consider a database of size
is calculated for each of the three population samples described above. In this study we consider a database of size 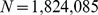 , the size of the California state database as of January 2012 [48].
, the size of the California state database as of January 2012 [48].
An investigative positive identification (called simply a positive identification here) is called when 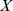 is greater than 0.1 under all three assumed population samples, and greater than 1.0 for at least one population sample [30].
is greater than 0.1 under all three assumed population samples, and greater than 1.0 for at least one population sample [30].
Results
False positive rates of relative identification
Unrelated individuals were simulated based on allele frequency data from five population samples to investigate false positive rates of parent-offspring and sibling identification. Autosomal and Y-chromosome LRs were estimated using (1)–(3), and the combined test statistic 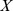 defined in (4) was calculated for unrelated pairs of individuals simulated from all pairs of population samples. Using the procedure described by Myers et al. [30], false positive rates were estimated for parent-offspring (Table 1) and sibling (Table 2) identifications.
defined in (4) was calculated for unrelated pairs of individuals simulated from all pairs of population samples. Using the procedure described by Myers et al. [30], false positive rates were estimated for parent-offspring (Table 1) and sibling (Table 2) identifications.
Table 1. False positive parent-offspring identification rates between pairs of unrelated individuals simulated from all pairs of population samples.
| Vietnamese | African | European | Latino | Native | |
| American | American | American | American | American | |
| Vietnamese American | 8.2×10−7 | 5.0×10−9 | 1.5×10−8 | <5.0×10−9 | <5.0×10−9 |
| African American | 6.5×10−8 | <5.0×10−9 | <5.0×10−9 | <5.0×10−9 | |
| European American | 1.5×10−7 | 1.5×10−8 | 1.0×10−8 | ||
| Latino American | 1.3×10−7 | 5.0×10−9 | |||
| Native American | <5.0×10−9 |
Table 2. False positive sibling identification rates between pairs of unrelated individuals simulated from all pairs of population samples.
| Vietnamese | African | European | Latino | Native | |
| American | American | American | American | American | |
| Vietnamese American | 1.1×10−5 | <5.0×10−9 | 1.0×10−8 | 5.0×10−9 | <5.0×10−9 |
| African American | 1.7×10−7 | <5.0×10−9 | 5.0×10−9 | 1.0×10−8 | |
| European American | 1.7×10−7 | 1.5×10−8 | 4.0×10−8 | ||
| Latino American | 4.3×10−7 | 2.0×10−8 | |||
| Native American | <5.0×10−9 |
Even though false positive rates are low, on the order of 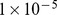 to
to 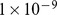 , across population sample pairs, there is some variation (Tables 1 and 2). In particular, the false positive rates for unrelated pairs of individuals simulated with Vietnamese American and with Native American allele frequencies are relatively high and low, respectively (Tables 1 and 2). In sibling identification, the Vietnamese American sample shows a comparatively high false positive rate of
, across population sample pairs, there is some variation (Tables 1 and 2). In particular, the false positive rates for unrelated pairs of individuals simulated with Vietnamese American and with Native American allele frequencies are relatively high and low, respectively (Tables 1 and 2). In sibling identification, the Vietnamese American sample shows a comparatively high false positive rate of 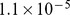 , while no false positives are observed in the Native American sample (Table 2). This can be explained by the particular Y-haplotype patterns considered for these population samples. False positive identifications were observed only when unrelated individuals coincidentally share a Y-haplotype. In the available Vietnamese American population sample of Y-haplotypes (
, while no false positives are observed in the Native American sample (Table 2). This can be explained by the particular Y-haplotype patterns considered for these population samples. False positive identifications were observed only when unrelated individuals coincidentally share a Y-haplotype. In the available Vietnamese American population sample of Y-haplotypes (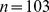 ), several pairs of individuals share Y-haplotypes, while in the Native American population sample (
), several pairs of individuals share Y-haplotypes, while in the Native American population sample (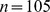 ), no individuals share Y-haplotypes. In the other population samples, Y-haplotypes are shared at frequencies intermediate to those in the Vietnamese American and Native American population samples. Given the small sizes for these population samples, it is not clear if varying rates of coincidental Y-haplotype sharing are due to population genetic differences, or stochasticity of small samples.
), no individuals share Y-haplotypes. In the other population samples, Y-haplotypes are shared at frequencies intermediate to those in the Vietnamese American and Native American population samples. Given the small sizes for these population samples, it is not clear if varying rates of coincidental Y-haplotype sharing are due to population genetic differences, or stochasticity of small samples.
To examine the validity of the total lack of observed false positive relative identifications for unrelated individuals simulated from the Native American population sample, we consider the possibility of observing complete Y-haplotype diversity (as observed) by chance. Using simulations, 100,000 subsamples of 105 (the Native American sample size) Y-haplotypes were randomly chosen from the larger African American, European American, and Latino American samples. Of the subsamples, 0.67, 0.57, 0.37 of the African American, European American, and Latino American samples, respectively, consisted of all unique haplotypes, as observed in the Native American sample. This indicates the plausibility that a small sample from a group with the intermediate degree of Y-haplotype diversity observed in these larger population samples could all have unique Y-haplotypes by chance. Larger Y-haplotype samples are required to confidently estimate false positive rates between unrelated individuals across population samples.
False positives in the database context
Our results agree with previous work, showing that with the prescribed methodology, false positive rates of parent-offspring and sibling identification are low, on the order of 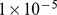 to
to 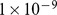 (Tables 1 and 2) [30]. But even with these low false positive rates, differences were observed between population samples, raising the question of how these differences in false positive rates interact with distortions in DNA database representation.
(Tables 1 and 2) [30]. But even with these low false positive rates, differences were observed between population samples, raising the question of how these differences in false positive rates interact with distortions in DNA database representation.
To investigate this question, California census and prison population proportions of Asian, African American, European American, Latino American, and Native American individuals were normalized to fit the assumption that all individuals are described by exactly one of these categories (Table S1 in File S1) [49], [50]. In combining census and population genetic data, groups labeled as ‘Vietnamese’ and ‘Asian’ were equated to each other. Clearly, these simplifications limit the applicability of the population sample-specificity of this analysis, however it provides a first approach.
Using each of the census and prison demographics, the proportion of false positive parent-offspring and sibling identifications that involve at least one member of each population group were estimated (Tables S2 and S3 in File S1). As expected, in the demographic context of a prison system in which African Americans are drastically over-represented (Table S1 in File S1, exact binomial test 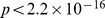 ), the rates of false identification of individuals in this groups is much higher, roughly two orders of magnitude higher (Tables S2 and S3 in File S1). Nevertheless, the overall rate of false identification of unrelated individuals remains low.
), the rates of false identification of individuals in this groups is much higher, roughly two orders of magnitude higher (Tables S2 and S3 in File S1). Nevertheless, the overall rate of false identification of unrelated individuals remains low.
Spurious identification of distant relatives
The simulations of unrelated individuals showed low false positive rates of parent-offspring and sibling identification. However, distant Y-sharing relatives may be more often mistaken for parent-offsprings or siblings. To investigate this, individuals with various Y-sharing relationships (parent-offspring, siblings, half-siblings, cousins, half-cousins, and second cousins) from population sample backgrounds were simulated and used in the same relative identification procedure. Note that when considering Y-sharing relatives, the 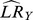 calculation is greatly influenced by the database size, as opposed to the Y-haplotype reference frequency.
calculation is greatly influenced by the database size, as opposed to the Y-haplotype reference frequency.
The observed distributions of the test statistic 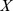 for second-degree and distant relatives is shifted left of those for first-degree relatives, but still has significant mass greater than
for second-degree and distant relatives is shifted left of those for first-degree relatives, but still has significant mass greater than  (Figure 1). So as relatedness decreases, the
(Figure 1). So as relatedness decreases, the 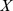 more effectively distinguishes first-degree from distant Y-sharing relatives. Concordant with a previous study [51], distinguishability is also higher with appropriately-specified allele frequencies in population samples with higher polymorphism at the markers considered. By considering these distributions, it is clear that regardless of the exact decision procedure, distant Y-sharing relatives show elevated
more effectively distinguishes first-degree from distant Y-sharing relatives. Concordant with a previous study [51], distinguishability is also higher with appropriately-specified allele frequencies in population samples with higher polymorphism at the markers considered. By considering these distributions, it is clear that regardless of the exact decision procedure, distant Y-sharing relatives show elevated 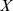 values.
values.
Figure 1. Distributions of the test statistic 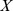 , defined in (4), for sibling test for individuals who are siblings (solid red), parent-offsprings (solid black), half-sibs (dashed black), cousins (dashdot black), and second cousins (dotted black).
, defined in (4), for sibling test for individuals who are siblings (solid red), parent-offsprings (solid black), half-sibs (dashed black), cousins (dashdot black), and second cousins (dotted black).

The population sample individuals are sampled from is along the top and the assumed pop sample is along the side.
Positive rates vary across true relationships, population samples, and tests of parent-offspring versus sibling relationships (Figure 2, Tables 3 and 4). The power of the parent-offspring test varies from 0.94 to 0.99 and the sibling test varies from 0.68 to 0.85 for various population samples. Of course, a different threshold procedure could raise the power of these tests, but will simultaneously raise the false positive rates. Regardless of the particular threshold procedure, the relative trends observed across true relationships, population samples, and tests of parent-offspring versus sibling relationships will hold for LR-based methods.
Figure 2. Positive identification rates across different true relationships of individuals simulated from different sample populations Vietnamese American (red circles), African American (orange triangles), European American (purple pluses), Latino American (blue exes), and Native American (green diamonds); left plot is for sibling test, right for parent test.

Table 3. Parent-offspring test identification rates for different Y-sharing relatives and population samples.
| Vietnamese | African | European | Latino | Native | |
| American | American | American | American | American | |
| parent-offspring | 0.997458 | 0.989336 | 0.987365 | 0.988130 | 0.998809 |
| sibling | 0.263659 | 0.244048 | 0.255853 | 0.248439 | 0.348373 |
| half-sib | 0.056135 | 0.045746 | 0.050528 | 0.047072 | 0.105056 |
| cousin | 0.009311 | 0.006451 | 0.007765 | 0.007039 | 0.027139 |
| half-cousin | 0.003337 | 0.002019 | 0.002506 | 0.002095 | 0.012716 |
| second cousin | 0.001971 | 0.000997 | 0.001423 | 0.001145 | 0.008580 |
Table 4. Sibling test identification rates for different Y-sharing relatives and population samples.
| Vietnamese | African | European | Latino | Native | |
| American | American | American | American | American | |
| sibling | 0.891566 | 0.819365 | 0.793025 | 0.798273 | 0.925786 |
| parent-offspring | 0.907037 | 0.813399 | 0.767383 | 0.777360 | 0.942995 |
| half-sib | 0.303888 | 0.163525 | 0.138446 | 0.140161 | 0.423558 |
| cousin | 0.099529 | 0.033460 | 0.028376 | 0.027985 | 0.181687 |
| half-cousin | 0.044457 | 0.010445 | 0.009258 | 0.008978 | 0.100643 |
| second cousin | 0.027139 | 0.004934 | 0.004582 | 0.004332 | 0.070761 |
When implementing the full Myers et al. procedure to call putative relatives, Y-sharing relatives are frequently mistakenly identified as parent-offsprings or siblings (Table 4). Second degree Y-sharing relatives like half-siblings are called as siblings in 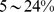 of simulations (Table 4). The frequency of relative identification decreases with the degree of relatedness (or equivalently, those with higher kinship coefficients), but even Y-sharing half-cousins are called as siblings in
of simulations (Table 4). The frequency of relative identification decreases with the degree of relatedness (or equivalently, those with higher kinship coefficients), but even Y-sharing half-cousins are called as siblings in 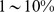 of simulations, depending on the population sample (Table 4).
of simulations, depending on the population sample (Table 4).
Positive identification between distant Y-sharing relatives occurs more often when considering sibling relationships rather than parent-offspring because of the less stringent allele sharing requirements. For example, Y-sharing half-siblings are called as siblings in 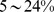 of simulations and called as parent-offspring in
of simulations and called as parent-offspring in 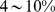 of simulations (Tables 3 and 4). Sharing at least one allele at each locus, as required for parent-offspring relationships, is less likely by chance than sharing on average one allele at each locus, as expected for sibling relationships.
of simulations (Tables 3 and 4). Sharing at least one allele at each locus, as required for parent-offspring relationships, is less likely by chance than sharing on average one allele at each locus, as expected for sibling relationships.
Higher rates of positive identification are observed for individuals simulated with Native American or Vietnamese American allele frequencies (Figure 2, Tables 3 and 4). This is likely due to allele frequency misspecification inherent in the method, which calculates the test statistic 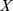 under African American, European American, and Latino American allele frequencies only, and due to varying population sample gene diversity, as found in a study of autosomal loci [51]. For relatives simulated from African American, European American, or Latino American population samples, the method correctly specifies their allele frequencies, so they show comparatively lower identification rates (Figures 2 and 1, Tables 3 and 4).
under African American, European American, and Latino American allele frequencies only, and due to varying population sample gene diversity, as found in a study of autosomal loci [51]. For relatives simulated from African American, European American, or Latino American population samples, the method correctly specifies their allele frequencies, so they show comparatively lower identification rates (Figures 2 and 1, Tables 3 and 4).
To show that these differences in identification rates across population samples are not driven by differing sample sizes, the same rates were estimated with a reduced Y-haplotype reference of 103 haplotypes per population sample. Again, we see the same trends across population samples, confirming that they are not caused by varying reference Y-haplotype sample sizes (Tables S4 and S5 in File S1). Note that the absolute false identification rates differ in the full and subsample analysis because the estimated Y-haplotype frequency a function of the pooled sample size.
Discussion
We have investigated by computer simulation the consequences of using a familial search policy similar to that described by Myers et al. [30], which is the policy currently used by the state of California for conducting familial searches. Our simulations assumed that allele frequencies at the 13 CODIS loci and the Y haplotypes for five ethnic groups are as given in Budowle et al. and the ABI reference database [33], [43]. We reach three main conclusions. First, if the profile of a first-degree relative of a randomly generated profile is in the database searched, there is a relatively high probability of identifying the relative as such. Thus we agree with Myers et al. [30], Bieber et al. [1], and Curran and Buckleton [3] that familial searching can be an effective way to identify first-degree Y-sharing relatives of an individual who left a crime scene sample. However, note that the simulation study of Bieber et al. [1] suggests higher identification efficiency than observed in an empirical study by Curran and Buckleton [3], possibly due to population structure in the empirical dataset [51]. Slooten and Meester [52] have also shown that there may be high variability in power to identify relatives when considering profiles of varying rareness in specific databases.
Second, we found that the probability of identifying an unrelated Y-chromosome-carrying individual as a first-degree relative is quite low, agreeing with the results of Myers et al. [30]. However, our ability to obtain precise estimates of this probability for different ethnic groups is limited by the relatively small samples sizes available to estimate Y haplotype frequencies, especially for the Vietnamese American and Native American samples. For population samples other than those, the probabilities are so low that we could reasonably expect at most one unrelated individual would be incorrectly identified as a first-degree relative even in a database as large as California's, which is approaching 2 million profiles. The high false positive rate in the Vietnamese American population sample is subject to sampling error with the relatively low number of Y-haplotypes for this group (103 haplotypes), so we hesitate to put great confidence behind that particular rate.
Our third conclusion is that there is a previously unrecognized risk from conducting familial searches created by the possibility that a more distant relative whose profile is in a database will be incorrectly identified as a first-degree relative of the person who left the crime-scene sample. With the data considered here (13 autosomal loci and 17-locus Y-haplotypes), even with other decision procedures, distinguishability of first-degree and distant genetic relatives may be limited (Figure 1). This is especially troubling when contemplating the possibility that familial searches may be conducted in the national database, which contains over ten million profiles. Widening the geographic scope of a search is likely to result in more of the source's distant relatives having a presence in the database.
To be clear, our concerns arise only with respect to inadvertent erroneous identification of distant relatives as first-degree leads. Familial searches are ineffective if secondary relatives are intentionally sought. Indeed, the Myers protocol targets first-degree relationships only because actively seeking more remote connections ordinarily returns too many leads to investigate. Yet familial searches also cannot be configured to assure that only first-degree relatives of the crime scene sample source are identified as leads. As our and other research has shown, the tailored approach of the Myers et al. protocol has the advantage of returning few spurious leads – if a lead is generated, it is almost certainly a relative of the crime scene sample source. Our findings, however, suggest that the closeness of the lead to the source is an open question. Significantly, our research does not reveal the percentage of cases in which a lead returned will be a distant relative, as opposed to a first degree relative. Such an estimation requires a different set of simulations including complex demographic estimates.
In our simulations, we set the coancestry coefficient 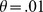 , which aligns with the less conservative parameter value suggested for direct identification [44]. The currently implemented familial searching methodology in California assumes
, which aligns with the less conservative parameter value suggested for direct identification [44]. The currently implemented familial searching methodology in California assumes 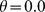 . This discrepancy contributes to elevated rates of positive identifications observed between both unrelated individuals and distant Y-sharing relatives. In addition, our simulation parameter value
. This discrepancy contributes to elevated rates of positive identifications observed between both unrelated individuals and distant Y-sharing relatives. In addition, our simulation parameter value 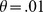 may be an underestimate for some population samples [44]. For these cases, we have underestimated the amount of coincidental relatedness, and thus, estimated power and false positive rate. This is particularly relevant for some population samples with higher
may be an underestimate for some population samples [44]. For these cases, we have underestimated the amount of coincidental relatedness, and thus, estimated power and false positive rate. This is particularly relevant for some population samples with higher  including some Native American groups.
including some Native American groups.
In our analysis, we estimate the Y-haplotype frequency upper 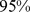 confidence limit asymptotically, rather than exactly, as indicated in the Myers et al. method. This estimate may be sufficient, but has greater error than the exact confidence limit. For very low Y-haplotype frequencies, the asymptotic estimate may be lower than the true confidence limit, which would lead to inflated (anti-conservative)
confidence limit asymptotically, rather than exactly, as indicated in the Myers et al. method. This estimate may be sufficient, but has greater error than the exact confidence limit. For very low Y-haplotype frequencies, the asymptotic estimate may be lower than the true confidence limit, which would lead to inflated (anti-conservative) 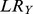 . A study of the affect of different confidence limit estimates on final outcomes would inform method choice.
. A study of the affect of different confidence limit estimates on final outcomes would inform method choice.
In this study, we have considered only complete genotypes with no errors or allelic dropout. It is not clear how allelic dropout would affect familial searching results, but this must be explored before considering extention to low-template samples.
The probabilities we estimated with our simulations are necessarily approximate. Autosomal allele and Y-haplotype frequencies for various population samples are poorly known because publicly available databases are of limited size and are unavailable for many population groups. Nevertheless, the groups for which we have data include African Americans, who have relatively high genetic diversity at the considered loci, and Native Americans, who have relatively low diversity, which suggests that our results are applicable to other populations for which data are unavailable.
A difference between our analysis and the implemented Myers et al. method is the one or two-stage design. In the Myers et al. method, first an analysis is performed using only autosomal data and the top 168 matches are genotyped for Y-haplotype and the cumulative statistic 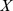 is computed only for these samples [30]. In our analysis we simply computed the cumulative
is computed only for these samples [30]. In our analysis we simply computed the cumulative 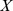 for all samples considered. An additional study of positive identification of distant relatives using the two-stage method in the context of a realistic database would provide more realistic rate estimates, however this sort of analysis is hindered by lack of access to forensic databases [53]. Such a study is unlikely to show substantially different results than those presented here since the pairs of individuals we positively identify as first degree relatives are likely to appear related and rank above the 168 person threshold.
for all samples considered. An additional study of positive identification of distant relatives using the two-stage method in the context of a realistic database would provide more realistic rate estimates, however this sort of analysis is hindered by lack of access to forensic databases [53]. Such a study is unlikely to show substantially different results than those presented here since the pairs of individuals we positively identify as first degree relatives are likely to appear related and rank above the 168 person threshold.
We also note that in this analysis we only consider the familial searching method of Myers et al.. To our knowledge, at the writing of this manuscript, the Myers et al. method is the only explicit protocol available and the current standard in the field [54], [55]. Although the absolute rates of identification will change according to the method used, when considering LR-based approaches, which have been shown to be more effective than allele-sharing methods [56], the trends we observed across population samples and close and distant relatives will hold.
Implications of spurious identification of distant relatives
Our findings confirm that familial searches carried out according to the Myers protocol do a good job of locating a relative if one is in the database. They also affirm that a search is unlikely to return a false lead – in other words, a match that appeared to be related to the crime scene source, but in fact was not. However, we have shown that if there is a more distant relative in the database, that person may have up to a 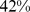 chance of being returned as a lead and erroneously labeled as a first degree relative of the crime scene source (Table 4).
chance of being returned as a lead and erroneously labeled as a first degree relative of the crime scene source (Table 4).
The possibility that the lead is a more remote relative of the source might not be a concern if investigators could easily ascertain what kind of lead they had been given. But the Myers protocol can do no more than alert investigators that the source may be a relative of the individual in the database; it does not tell investigators which relative or the closeness or kind of relation. In any case, once a search returns a lead, law enforcement must undertake further investigation to locate the actual source. It is the scope and impact of the follow-up investigation that, in light of our results, may be troubling.
Before our research identified the possibility that a familial search might identify distant relatives and erroneously label them as first degree relatives of the source, it may be that law enforcement simply assumed that all leads were to a first degree relative, because that is what the search is structured to find. Accordingly, if further investigation did not identify a source from among the lead's first degree relatives, then officers likely assumed that the problem was the lead, rather than the depth of their investigation. In light of our results, however, law enforcement may now recognize that a lead that fails to reveal a source among first degree relatives may still be a good lead, it is only that the investigation must extend to more remote branches of the family tree.
To illustrate, suppose that law enforcement conducts a familial search to find a burglar. Following the Myers protocol, the search returns a lead to the profile of K, a known offender in the database. Conventional wisdom holds that the burglar is likely a brother or the father of K, and so law enforcement officers initiate their investigation accordingly. They ascertain the identify of K's father and any brothers, and check their ages and criminal records. They determine whether the father or brothers were in the area of the burglary at the time it occurred, used cell phones or credit cards around that area, or otherwise engaged in suspicious behavior. Ultimately, they might surreptitiously attempt to obtain DNA samples for testing from members of K's immediate family – say by posing as restaurant personnel or collecting up a half-eaten lunch. In some number of cases, one of those immediate family members will match, and the burglar will be found.
But if no match is made, then investigators aware of our research may conclude three things: that the familial search was almost certainly effective, that the probability that the lead was a bad lead is low, and that leads that do not initially pan out are likely to have faltered only because the source is a more distant relative than investigators presumed. In other words, the source is not a brother or father, but instead is a cousin, second cousin, uncle, half-sibling, or even half-cousin. At that point the officers have two choices. They may limit themselves to the follow-up they have already conducted with the first degree relatives and simply stop their investigation or, more likely, they may simply widen the scope of their investigation, and start pursuing all second-degree relatives of the lead.
Our research thus suggests two unanticipated likely outcomes of familial search policies. First, investigations may wrongly target the immediate families of known offenders, because officers mistakenly believe that their lead is a first-degree relative. Second, investigations may ultimately probe far more deeply than initially imagined, because once officers are convinced that the source cannot be found among first degree relatives, they will widen their net of investigation to include more distant relations. Both of these consequences exacerbate the numerous ethical problems presented by familial searching.
First, familial searches will affect a greater number of persons. There is no way for investigators to know from the start that a lead is a distant, rather than immediate, relative of the source. Thus suspicion may no longer be restricted to a father and small number of siblings – one of whom is likely to be the crime scene sample source – but instead will fall upon innocent immediate family members and a much larger number of second-degree relatives. The greater the number of persons involved, and the less likely that one of them is in fact the perpetrator, the more such investigations may begin to feel like a fishing expedition rather than a reasonable search. This is particularly true given that any investigated family member is, by design, a member of the family whose DNA is not already in the database as a result of wrongdoing.
Second, follow-up investigations may prove more intrusive and yet less effective. Identification of more distant relatives requires more complicated investigation than does determining a lead's immediate family members. For instance, the known offender will likely have provided information about immediate relatives in the course of the criminal case that is readily available, such as in a bail report, corrections dossier, or probation file. But such sources are much less likely to contain information about secondary relatives, and thus simply composing the list of potential suspects could require more aggressive investigation. Moreover, the difficulty in accurately mapping more distant familial relations might lower the already low success rate of familial searches. Although a lead may in fact be a relative, it may simply be too difficult to locate the actual source if that person is a half-cousin or other distant relation.
Third, widening the pool intensifies the threat that familial searching poses to our understandings of families as constructions of social, not biological, realities. A person may have hundreds of “cousins” but only a handful of biological cousins. Investigators may either ignore the difference and unnecessarily investigate those non-biological relations, or else engage in potentially intrusive questioning or activity (such as DNA sampling) to differentiate between proffered and actual relations. Probing secondary biological relationships might also dredge up painful family experiences of death, unknown biological ties, or previous partners. And, to the extent that some advocates of familial searching have justified the practice on grounds akin to “crime runs in families,” such arguments may be less defensible when more remote connections are involved.
Finally, to the extent that our findings suggest that familial searches may in fact necessitate investigating a greater number of people with a greater degree of intrusiveness, that consequence is particularly troubling in that it will be specially visited on certain racial groups. It has been well documented that familial searching is apt to disproportionately affect African American families, due to the greater representation of those groups in DNA databases and the high rate of intra-racial procreation. Limiting investigations to the immediate family members of known offenders at least minimizes the intrusion on innocent relatives within those racial groups. But if more distant relations are included, the web of potential “genetic suspects” becomes still broader, and may effectively encompass entire communities. It takes only one member of a large and varied family tree to render every father, brother, half-brother, cousin, half-cousin, uncle, nephew and so on vulnerable to scrutiny and surreptitious sampling by law enforcement officers.
Of course, it is always possible to limit, for practical or ethical reasons, the range of permissible follow-up investigation to first degree relatives in familial search cases as a matter of policy. Such an approach might be sensible from a practical perspective in light of the difficulty in identifying and investigating more remote relatives, and the heightened ethical concerns. It would also ensure that any spurious leads – of which, granted, there are expected to be few – would not first generate highly invasive and costly investigations. Whatever the case, our research suggests that as states and localities debate the virtues of familial searching and craft policies to govern law enforcement, it would be wise to consider terms delimiting the scope of potential follow-up investigation with regard to degree of relatedness.
Supporting Information
Tables S1–5.
(PDF)
Acknowledgments
We are immensely grateful to the individuals whose DNA samples were used in this study, without which none of this work would be possible. We thank Kirk Lohmueller for his valuable discussions on these topics.
Funding Statement
This work was supported in part by National Institutes of Health grant R01-GM40282, National Science Foundation award 1103767 and CAREER Grant DBI-0846015, a Packard Fellowship for Science and Engineering, and the Filomen D'Agostino and Max E. Greenberg Research Fund. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Bieber F, Brenner C, Lazer D (2006) Finding criminals through DNA of their relatives. Science 312: 1315–1316. [DOI] [PubMed] [Google Scholar]
- 2. Greely H, Riordan D, Garrison N, Mountain J (2006) Family ties: The use of DNA offender databases to catch offenders' kin. Journal of Law, Medicine, and Ethics 34: 248–262. [DOI] [PubMed] [Google Scholar]
- 3. Curran J, Buckleton J (2008) Effectiveness of familial searches. Science and Justice 48: 164–167. [DOI] [PubMed] [Google Scholar]
- 4. Williams R, Johnson P (2005) Inclusiveness, effectiveness and intrusiveness: Issues in the developing uses of dna profiling in support of criminal investigations. The Journal of Law, Medicine, and Ethics 33: 545–558. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Murphy E (2011) Relative doubt: Familial searches of DNA databases. Michigan Law Review 109: 291–349. [Google Scholar]
- 6. Gershaw C, Schweighardt A, Rourke L, Wallace M (2011) Forensic utilization of familial searches in DNA databases. Forensic Science International: Genetics 5: 16–20. [DOI] [PubMed] [Google Scholar]
- 7.O'Connor K, Butts E, Hill C, Butler J, Vallone P (2010) Evaluating the effect of additional forensic loci on likelihood ratio values for complex kinship analysis. In: 21st International Symposium on Human Identification, Familial Search Workshop. Citing Chris Maguire, formerly of the Forensic Science Service.
- 8.Rushton S (2010) Familial searching and predictive DNA testing for forensic purposes: A review of laws and practices. Available: http://dnaproject.co.za/new_dna/wp-content/uploads/2011/03/Report-Familial-Searching-and-Predictive-DNA-Testing-2010.pdf.
- 9.Netherlands Ministry of Security and Justice. (2011) Senate agrees to DNA relationship test. Available: http://www.government.nl/documents-and-publications/press-releases/2011/11/23/senate-agrees-to-dna-relationship-test.html.
- 10.Netherlands Ministry of Security and Justice. (2012) Overview of acts that will enter into effect on 1 april 2012. Available: http://www.government.nl/documents-and-publications/press-releases/2012/04/02/overview-of-acts-that-will-enter-into-effect-on-1-april-2012.html.
- 11.Statements of Lisa Campbell & Constable Derek Egan, before Standing Committee on Public Safety and National Security, with reference to the statutory review of the DNA Identification Act. Available: http://www2.parl.gc.ca/HousePublications/Publication.aspx?DocId=3702024&Language=E&Mode=1&Parl=40&Ses=2#Int-2620184. (Discussing inability to make familial matches, pressure to do so, and privacy-related concerns against) Canadian investigators did solve one case by evaluating two samples offered voluntarily and determining that a relative was the likely perpetrator. There have been some recent efforts to authorize familial searches in Canada.
- 12.S. & Marper v. United Kingdom, Eur. Ct. H.R. 1581 (2008) Available: http://www.bailii.org/eu/cases/ECHR/2008/1581.html.
- 13. Ram N (2011) Fortuity and forensic familial identification. Stanford Law Review 63: 751. [Google Scholar]
- 14.(2006) Interim plan for release of information in the event of a ‘partial match’ at ndis.
- 15.H.R. 3361, Utilizing DNA Technology to Solve Cold Cases Act of 2011.
- 16.(2013) S.Ct., 2013 WL 2371466, No.12–207.
- 17.(2010) Md. Code Ann., Pub. Safety s 2–506(d).
- 18.(2010) D.C. Code s 22–4151.
- 19.Council for Responsible Genetics. State rules on partial/familial searching. Available: http://www.councilforresponsiblegenetics.org/dnadata/usa/usa2.html. Although the map does not show New York in the inadvertent match category, the state has recently authorized only that form of reporting.
- 20.California Department of Justice, Division of Law Enforcement, Information bulletin no. 2008-BFS-01, DNA partial match (crime scene DNA profile to offender) Policy (2008)
- 21. Rosen J (2009) Genetic surveillance for all. Slate [Google Scholar]
- 22. Nakashima E, Hsu S (17 April 2008) U.S. to expand collection of crime suspects' DNA: Policy adds people arrested but not convicted. Washington Post [Google Scholar]
- 23.Butler J (2012) Advanced Topics in Forensic DNA Typing: Methodology. Academic Press.
- 24.Konzak K (2011) Familial searching: A practical & effective approach: Californias experience. In: 22nd International Symposium on Human Identification, Familial Search Workshop.
- 25. Hicks T, Taroni F, Curran J, Buckleton J, Castella V, et al. (2010) Use of DNA profiles for investigation using a simulated national DNA database: Part II. Statistical and ethical considerations on familial searching. Forensic Science International: Genetics 4: 316–322. [DOI] [PubMed] [Google Scholar]
- 26. Garrison N, Rohlfs R, Fullerton S (2013) Forensic familial searching: Scientific and social implications. Nature Reviews Genetics 14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Reid T, Baird M, Reid J, Lee S, Lee R (2008) Use of sibling pairs to determine the familial searching efficiency of forensic databases. Forensic Science International: Genetics 2: 340–342. [DOI] [PubMed] [Google Scholar]
- 28. Grimm D (2007) The demographics of genetic surveillance: Familial DNA testing and the Hispanic community. Columbia Law Review 107: 1164–1194. [Google Scholar]
- 29.Minutes (2007) A not so perfect match. Available: http://www.cbsnews.com/stories/2007/03/23/60minutes/main2600721.shtml.
- 30. Myers S, Timken M, Piucci M, Sims G, Greenwald M, et al. (2011) Searching for first-degree familial relationships in California's offender DNA database: Validation of a likelihood ratio-based approach. Forensic Science International: Genetics 5: 493–500. [DOI] [PubMed] [Google Scholar]
- 31. Steinberger E, Sims G (2009) Finding criminals through the DNA of their relatives – Familial searching of the California offender DNA database. Prosecutor's Brief 31: 28. [Google Scholar]
- 32.West H, Sabol W (2008) Prisoners in 2007. Technical Report 3, Bureau of Justice Statistics.
- 33. Budowle B, Moretti TR (1998) Examples of STR population databases for CODIS and casework. 9th International Symposium on Human Identification 1: 64–73. [Google Scholar]
- 34. Dalton R (2002) Tribe blasts ‘exploitation’ of blood samples. Nature 420: 111. [DOI] [PubMed] [Google Scholar]
- 35.Wiwchar D (16 December 2004) Nuu-chah-nulth blood returns to west coast. Ha-Shilth-Sa.
- 36. Mello M, Wolf L (2010) The Havasupai Indian tribe case – lessons for research involving stored biologic samples. The New England Journal of Medicine 363: 204–207. [DOI] [PubMed] [Google Scholar]
- 37.Asociación ANDES (May 2011) Genographic project hunts the last of the Incas. ANDES Communiqué.
- 38. Arbour L, Cook D (2006) DNA on loan: Issues to consider when carrying out genetic research with Aboriginal families and communities. Community Genetics 9: 153–160. [DOI] [PubMed] [Google Scholar]
- 39. Goering S, Holland S, Fryer-Edwards K (2008) Transforming genetic research practices with marginalized communities: A case for responsive justice. Hastings Center Report 38: 43–53. [DOI] [PubMed] [Google Scholar]
- 40. Anderson J (2009) Commentary on implications of the Genographic Project. International Journal of Cultural Property 16: 213–217. [Google Scholar]
- 41. Kaye J, Heeney C, Hawkins N, de Vries J, Boddington P (2009) Data sharing in genomics – re-shaping scientific practice. Nature Reviews Genetics 10: 331–335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. McIness R (2011) 2010 presidential address: Culture: The silent language geneticists must learn –genetic research with Indigenous populations. American Journal of Human Genetics 88: 254–261. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Applied Biosystems. YFiler haplotype database. Available: http://www6.appliedbiosystems.com/yfilerdatabase/.
- 44.National Research Council: Committee on DNA forensic science (1996) The evaluation of forensic DNA evidence. National Academy Press.
- 45.Buckleton J, Triggs C (2005) Forensic DNA Evidence Interpretation, CRC Press, chapter Relatedness.
- 46. Weir B, Anderson A, Helper A (2006) Genetic relatedness analysis: modern data and new challenges. Nature Reviews Genetics 7: 771–780. [DOI] [PubMed] [Google Scholar]
- 47. ScientificWorking Group on DNA Analysis Methods (SWGDAM) (2009) Y-chromosome short tandem repeat (Y-STR) interpretation guidelines. Forensic Science Communications 11: 1–5. [Google Scholar]
- 48.FBI (January 2012) CODIS-NDIS statistics. Available: http://www.fbi.gov/about-us/lab/codis/ndis-statistics.
- 49. California Department of Corrections and Rehabilitation (2008) Total institution population, offenders by ethnicity and gender. Prison Census Data [Google Scholar]
- 50.United States Census Bureau.State and county QuickFacts. Available: http://quickfacts.census.gov/qfd/states/06000.html.
- 51. Rohlfs R, Fullerton S, Weir B (2012) Familial identification: Population structure and relationship distinguishability. PLoS Genetics 8: e1002469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Slooten K, Meester R (2012) Forensic identification: Database likelihood ratios and familial DNA searching. arXiv 1201: 4261v3. [Google Scholar]
- 53. Krane D, Bahn V, Balding D, Barlow B, Cash H, et al. (2009) Time for DNA disclosure. Science 326: 1631–1632. [DOI] [PubMed] [Google Scholar]
- 54.O'Connor K (2011) Introduction to familial searching. Available: www.cstl.nist.gov/strbase/pub_pres/OConnor_Promega2011.pdf.
- 55.Global Privacy and Information Quality Working Group (QPIQWG) (2011) An introduction to familial DNA searching for state, local, and tribal justice agencies. Available: http://www.it.ojp.gov/docdownloader.aspx?ddid=1698.
- 56. Balding D, Krawczak M, Buckleton J, Curran J (2012) Decision-making in familial database searching: KI alone or not alone? Forensic Science International: Genetics 7: 52–54. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Tables S1–5.
(PDF)