

Summary
We introduce a novel stochastic process that we term the multivariate beta process. The process is defined for modelling-dependent random probabilities and has beta marginal distributions. We use this process to define a probability model for a family of unknown distributions indexed by covariates. The marginal model for each distribution is a Polya tree prior. An important feature of the proposed prior is the easy centring of the nonparametric model around any parametric regression model. We use the model to implement nonparametric inference for survival distributions. The nonparametric model that we introduce can be adopted to extend the support of prior distributions for parametric regression models.
Keywords: Dependent random probability measures, Multivariate beta process, Polya tree distribution
1. Introduction
We introduce a stochastic process that we call the multivariate beta process; this is not related to the process introduced in Hjort (1990). The multivariate beta process {Yx}x∈X is defined on a Euclidean space X ⊂ k, for every x in X, the random variable Yx has a beta distribution and, for every pair of points (x1, x2) in X, the random variables Yx1 and Yx2 are positively dependent. Moreover, the degree of dependence becomes stronger as x1 approches x2. In the first part of this article, the multivariate beta process is studied and a relation with the Dirichlet process (Ferguson, 1974) is illustrated. In the second part, a Bayesian model for a family 𝒫 = {𝒫x; x ∈ X} of dependent random probability measures 𝒫x indexed by covariates x is defined by using the multivariate beta process. The model is an extension of the Polya tree model (Lavine, 1992).
Many important applications naturally lead to statistical inference based on dependent random distributions. Typical examples are MacEachern (1999), De Iorio et. al. (2004) and Dunson & Park (2008). We use the proposed model to implement a nonparametric extension of a parametric proportional hazards model.
The stochastic process 𝒫 is indexed by the points of the set {X × }, where X is the covariate space and is the usual Borel σ-field of the real line. It is assumed that X ⊂ k, for a given positive integer k: covariates can be continuous or discrete. We summarize a few salient properties of the model. For any x ∈ X, the marginal process {𝒫x (B)}B∈ is a random probability measure with a Polya tree distribution. The process can a priori be centred around a given regression model {Fx}x∈X. The model {Fx}x∈X can include unknown hyperparameters θ. For example, in an application to survival data, we use a Weibull model with unknown regression parameters θ for prior centring. Another relevant property of the model is that for every measurable subset B ∈ , point x ∈ X and sequence {xi ∈ X}i⩾1 such that the Euclidean distances {‖ xi − x ‖}i⩾1 vanish, the random sequence {𝒫xi (B)}i⩾1 converges in probability to 𝒫x (B). We also illustrate that, for every finite subset of the covariate space {x1, …, xm}, the law of the random probability measures (𝒫x1, …, 𝒫xm) has full support with respect to the weak convergence topology. We call the outlined extension of the Polya tree model 𝒫 the multivariate Polya tree.
2. The multivariate beta process
2.1. Definition
We define a random process {Yx}x∈X with beta marginal distributions, Yx ∼ Be(α0, α1) for every x ∈ X. Constructions of dependent beta random variables have been studied in Olkin & Liu (2003), Nadarajah & Kotz (2005) and Nieto-Barajas & Walker (2007). Olkin & Liu (2003) define a bivariate beta distribution by ratios of gamma random variables. We build on a similar construction; the definition of the process {Yx}x∈X is a natural extension of the following specification of a bivariate random vector (Y1, Y2) with beta marginal distributions:
| (1) |
where the equality is in distribution and G1, …, G6 are independent gamma random variables with a fixed common scale parameter. Consider the kernels centred at x1 and x2 in Fig. 1(a). The kernels create six non-overlapping regions A1, …, A6. Let X denote the covariate space, represented as the horizontal axis in Fig. 1(a). We define the gamma random variables G1, …, G6 as the random weights assigned to A1 through A6 by a gamma process on X × . The kernels centred at x1 and x2 are used to specify the distribution of the random vector (Y1, Y2). We extend the construction to {Yx}x∈X by expanding from kernels centred at x1 and x2 to a family of kernels with location parameters in X. The extension exploits the fact that a beta random variable can be represented as the ratio of two gamma distributed random variables and the infinite divisibility property of the gamma distribution.
Fig. 1.

Construction of a multivariate beta process. (a) Kernels α0qx1(·), α0qx2(·), −α1qx1(·) and −α1qx2(·), centred at two covariate values, x1 and x2. The areas indicated by A1 through A6 are used to define the dependent random variables Y1 and Y2 in (1). (b) Correlation corr(Yx, Yx+d) as a function of d. Here X = , {Yx}x∈X ∼ mbp(α0, α1, Q), α0 = α1 = 1, μ is the Lebesgue measure and {qx}x∈ are Gaussian kernels with mean x and variance equal to 1.
Let X be endowed with a σ-field 𝒳 and a σ-finite measure μ. Lebesgue measure and counting measure are natural candidates for μ in continuous and discrete covariate cases, respectively. Let Q = {Qx}x∈X be a location family of probability measures, absolutely continuous with respect to μ and with derivatives {qx}x∈X. Throughout the article such derivatives will be assumed to be unimodal; for example Gaussian, qx (·) = N(·; x, σ). Let {G(A)}A∈{𝒳×} be a gamma process indexed by the sets of the product σ-field 𝒳 × . For every m ⩾ 1 and non-overlapping A1, …, Am, the random variables G(A1), …, G(Am) are independently gamma distributed with a fixed-scale parameter and shape parameters ν(Aj), where ν is the product measure on X × of μ and Lebesgue measure. Note that {G(A)}A∈{𝒳×} is a positive random measure on X × . Finally, for every x, let = {(z, y) ∈ X × : 0 < y < α0qx (z)} and symmetrically = {(z, y) ∈ X × : −α1qx (z) < y < 0}, where α0 and α1 are positive parameters. The sets and are the regions bounded by the kernels α0qx (·) and −α1qx (·). We will use the notation . In Fig. 1 we illustrate the case X = , with qx (·) = N(· ; x, σ). The regions and , for i ∈ {1, 2}, are bordered by the two kernels centred at xi. We can now define, for every x ∈ X, the beta random variable Yx as a function of the gamma process {G(A)}A∈{𝒳×}:
We call the constructed process {Yx}x∈X the multivariate beta process with parameters (α0, α1, Q) and use the notation {Yx}x∈X ∼ mbp(α0, α1, Q).
For later reference, we note an alternative construction for the finite-dimensional distributions of {Yx}x∈X. Consider a set of covariate values x1, …xn. Define νx1,…,xn as the ν measure restricted to
If Dx1,…,xn is a Dirichlet process parameterized by the positive measure νx1,…,xn, then
| (2) |
where the equality is in distribution. The identity between the two definitions of the process {Yx}x∈X follows from the fact that a Dirichlet process can be represented as a normalized gamma process.
2.2. Sampling from a multivariate beta process prior
We exploit (2) for sampling binary variables when their joint distribution is specified by means of a multivariate beta process. Consider a vector of binary random variables Z = (Z1, …, ZN), with covariates xi (i = 1, …, N), and assume
| (3) |
The urn scheme in Blackwell & MacQueen (1973) can be used to sample Z, marginalizing over {Yx}x∈X. Let {(lij, hij) ∈ X × ; i = 1, …, N, j ⩾ 1} be an array of exchangeable random vectors with random distribution Dx1,…,xN. Let (j1, …, jN) be a vector of integers defined as ji = inf{j : (lij, hij) ∈ Sxi}. The vector (ji; i = 1, …, N) selects N pairs {(lij, hij); (i, j) = (1, j1), …, (N, jN)} that belong to the areas contoured by the curves α0qxi and −α1qxi. The set of variables {(lij, hij); i = 1, …, N, j = 1, …, ji} can be generated by the Polya urn. The binary random vector {I (hij > 0); (i, j) = (1, j1), …, (N, jN)} has the same distribution as Z. The equality in distribution follows from the fact that the random probabilities of the binary vector {I (hij > 0); (i, j) = (1, j1), …, (N, jN)} are exactly the right-hand side of (2) and have the same distribution as the random variables (Yxi; i = 1, …, N) that define the probability distribution of Z.
We will use this construction for the implementation of posterior simulation in §4. The augmented model with the latent variables {(lij, hij); i = 1, …, N + 1, j ⩾ 1} can be used to sample from the predictive distribution for a future ZN+1 with covariate xN+1 and, more generally, to implement posterior inference.
2.3. Assessing the correlation function of a multivariate beta process
The correlation function of the process {Yx}x∈X ∼ mbp(α0, α1, Q) can be computed using a result in Olkin & Liu (2003), who studied the bivariate beta distribution of a random vector (Y1, Y2) defined by the equality
where G1, G2 and G3 are independent gamma random variables with shape parameters a, b and c. Olkin & Liu (2003) show that
| (4) |
Consider {Yx}x∈X ∼ mbp(α0, α1, Q) and two points x1 and x2 in X. For i ∈ {1, 2} and j ∈ {0, 1}, let , , , and D = x1,x2. We note that
| (5) |
The equalities follow from representation (2) and from the tail-free property of the Dirichlet process (Doksum, 1974). The right-hand side of the equation allows us to compute E(Yx1 Yx2) using the identity (4). This is possible since the law of the random vector
belongs to the family studied in Olkin & Liu (2003). Figure 1(b) illustrates the correlation function of a specific multivariate beta process.
The parameters have a clear interpretation: α0 and α1 characterize the univariate marginal distributions while the correlation function can be flexibly chosen through a suitable specification of Q. A simple example helps to clarify the relationship between Q and the correlation function. Let Q be the location family of normal distributions on the real line with common variance σ2. The correlation function of the process {Yx}x∈ depends on the choice of σ2; the larger the variance the larger the correlations of the bivariate marginal distributions. The triple α0, α1, ν (Sx1 ∩ Sx2) parameterizes the joint distribution of (Yx1, Yx2). For fixed values of α0 and α1, the correlation between Yx1 and Yx2 is an increasing function of ν (Sx1 ∩ Sx2). See Proposition A1 in the Appendix. It follows that, in the example, the map (σ, x1, x2) ↦ corrσ2 (Yx1, Yx2) is decreasing with respect to |x1 − x2|/σ. The elicitation of the multivariate beta process includes the choice of the parameter Q; this family of distributions defines the positive definite function
| (6) |
The right-hand of (6) is identical to the correlations corr{G( ), G( )} and corr{G( ), G( )}. The mapping in (6) provides an easily interpretable representation of the dependence between the random variables Yx1 and Yx2. Moreover, for fixed values of α1 and α2, expression (5) allows us to evaluate the correlation function (x1, x2) ↦ corr(Yx1, Yx2) corresponding to any specific choice of the map (6). Positive definite functions as in (6) arise from integrating suitably chosen indicator functions with respect to infinitely divisible processes and have been studied in the literature (Mittal, 1976; Berman, 1978; Gneiting, 1999).
We conclude this section with a proposition on the distribution of (Yx1, Yx2) when the distance between x1 and x2 becomes infinitesimal.
Proposition 1. For every x ∈ X, if {xi ∈ X}i⩾1 is a sequence such that supB∈ |Qxi(B) − (Qx (B)| → 0, then the random variables {Yxi}i⩾1 converge in probability to Yx.
The proofs of this and subsequent propositions are given in the Appendix.
3. Multivariate Polya trees
3.1. The Polya tree model
For later reference, we recall the definition of the Polya tree prior (Lavine, 1992, 1994). Let Π = (B⊘ = Ω; B0, B1; B00, B01, …) be a binary tree of nested partitions of a separable measurable space Ω such that (B⊘; B0, B1; B00, …) generate the measurable sets. Let 𝒜 = (α0, α1, α00, …) be a sequence of nonnegative numbers. Finally, let denote the index set of 𝒜.
Definition 1. A random probability measure 𝒫 on Ω is said to have a Polya tree distribution, with parameter (Π, 𝒜), written 𝒫 ∼ PT (Π, 𝒜), if there exist independent random variables 𝒴 = (Yε; ε ∈ ∪ ⊘) such that, for every ε ∈ ∪ ⊘, Yε ∼ Be(αε1, αε0) and 𝒫(Bε1)/𝒫(Bε) = Yε.
For extensive discussion of the properties of the Polya tree model, we refer to Mauldin et al. (1992).
3.2. The multivariate Polya tree
We introduce the multivariate Polya tree distribution. The idea formalized in the following definition is to replace the beta random variables that characterize the Polya tree model with random processes indexed by the points of a covariate space. We will use multivariate beta processes {Yε,x}x∈X, independent across ε, to generate beta-distributed random variables that define Polya tree random measures 𝒫x for each x.
In the sequel (B0, B1; B00, …) = {(0, 1/2], (1/2, 1]; (0, 1/4], …} is fixed as the standard dyadic tree of partitions of the unit interval. The proposed model is parameterized by (𝒜, Q, F) defined as follows. Let 𝒜 = (αε; ε ∈ ∪ ⊘) denote a sequence of positive numbers. For a σ-finite measure μ on (X, 𝒳), let Q = {Qx}x∈X denote a location family of probability measures absolutely continuous with respect to μ. Finally, F = {Fx}x∈X is a class of continuous distribution functions.
Definition 2. A class of random probability measures on the real line {𝒫x}x∈X has a multivariate Polya tree distribution, with parameters (𝒜, Q, F), if there exist random processes 𝒴 = {{Yε,x}x∈X; ε ∈ ∪ ⊘} such that the following hold: the random processes in 𝒴 are independent across ε; for every ε ∈ ∪ ⊘, {Yε,x}x∈X ∼ mbp(αε, αε, Q); for every m = 1, 2, …and every ε ∈ {0, 1}m
| (7) |
where the first factor in the products is interpreted as Y⊘,x or as 1 − Y⊘,x and, for every a ∈ (0, 1], F−1(a) = inf{b ∈ : F(b) > a}.
We write {𝒫x} ∼ mpt(𝒜, Q, F). The parameter F defines the prior mean, 𝒜 specifies the variability, and Q defines the strength of dependence.
The following proposition asserts that the defined class of random probability measures {Px}x∈X can be centred on an arbitrary model {Fx}x∈X.
Proposition 2. For every x ∈ X and every Borel subset B, if {𝒫x}x∈X ∼ mpt(𝒜, Q, F), then the expected value of the random variable 𝒫x (B) is equal to Fx (B).
For data analysis, it is important that the prior can be centred on a prior guess and that the degree of variability of the random probability measure can be controlled to reflect the strength of the available prior information. The Polya tree prior is a flexible probability model that can achieve both of these objectives. See for example Lavine (1992).
In the multivariate Polya tree model, a third aspect enters the prior elicitation. The investigator can specify the degree of dependence between the jointly modelled random probability measures {𝒫x}x∈X. For example, consider a covariate space X = {x1, x2} consisting of two points. The higher the degree of dependence between the two random probability measures, the more borrowing of strength will occur between the two groups defined by the two covariates. In the extreme cases, if the random measures are independent, the observations with covariate x2 are not used to estimate the unknown distribution 𝒫x1, while if the random measures are almost surely identical, then all data are pooled to carry out inference about the one common random probability measure.
The degree of dependence between jointly modelled random distributions is most easily characterized by the correlations of the random probabilities. For an exhaustive motivation of this approach, we refer to Walker & Muliere (2003). They study the joint law of two Dirichlet processes, D1 and D2, such that the quantity corr{D1(B), D2(B)} is a fixed positive constant independent of the specific Borel subset B. In our case, the correlations of interest can easily be evaluated for a rich class of Borel subsets. Given the covariate points x1 and x2, for every ordered pair of integers (i1, i2), consider
Using (7), the computation of the correlation coefficients can be reduced to the previously discussed problem of evaluating second-order moments of bivariate marginal distributions of independent multivariate beta processes. Figure 2 illustrates, for a specific multivariate Polya tree parametrization, some of the correlations that can be computed following the outlined procedure. As desired, the closer the two covariates, the stronger the dependence between the corresponding random measures. The parameters (𝒜, F) characterize the marginal distribution of a single random measure 𝒫x. If (𝒜, F) is fixed, then the choice of Q allows flexible modelling of the strength of dependence between the random measures. Consider, for example, the parametrization adopted in Fig. 2. Following the same arguments used earlier to discuss the relationship between Q and the correlation function of {Yx}x∈X ∼ mbp(α0, α1, Q), it can be shown that the ratio |x1 − x2|/σ determines the degree of dependence between 𝒫x1 and 𝒫x2.
Fig. 2.

Correlation between 𝒫x1(0, t] and 𝒫x2(0, t]. Here{𝒫x}x∈X ∼ mpt(𝒜, Q, F), X = , αε = 2 for every ε, Fx is the uniform distribution function on [0, 1] for every x and (qx; x ∈ X) is the family of Gaussian kernels with variance σ2 = 2.
The next proposition asserts that, for a sequence of covariate points {xi}i⩾1 converging to x, the differences between the associated random distributions, 𝒫xi and 𝒫x, become negligible.
Proposition 3. For every x ∈ X, if {xi ∈ X}i⩾1 is a sequence such that supB∈ | Qxi(B) − Qx (B)|→ 0 and supB∈ | Fxi(B) − Fx (B)| → 0, then, for every Borel subset B of the real line, the random variables {𝒫xiB)}i⩾1 converge in probability to 𝒫x (B).
Proposition 4 describes the support of the prior {𝒫x}x∈X. For every x ∈ X, the support of the random probability measure 𝒫x includes all probability distributions that are absolutely continuous with respect to Fx. If the support of Fx is the real line, then the law has full weak support, which remains the same even under restrictions on neighbouring random probability measures. Specifically, let x1, …, xm denote distinct covariate points. The random probability measure 𝒫x still has full support, even conditional on 𝒫x1, …, 𝒫xm belonging to m, arbitrarily chosen, open sets (Δ1, …, Δm) with respect to the weak convergence topology.
This property distinguishes the multivariate Polya tree from many other Bayesian models for heterogeneous populations. Consider, for example, a Bayesian proportional hazards model F. If the covariate space X is a subset of the real line, then, for any monotone bounded continuous function f, the map x ↦ ∫ f d Fx is monotone. In contrast, assume that a multivariate Polya tree 𝒫 is centred on a proportional hazards model; if x1 < x2 < x3 belong to the covariate space, then the probability of the event ∫ f d𝒫x2 > max(∫ f d𝒫x1, ∫ f d𝒫x3) is strictly positive.
Proposition 4. For every strictly positive δ, for every m = 1, 2, …, distinct x1, …, xm ∈ X, and for any family of probability measures 𝒮1, …, 𝒮m such that the absolute-continuity relations 𝒮1 ≪ Fx1, …, 𝒮m ≪ Fxm are satisfied, the following holds. If {V1, …, Vk} is a partition of the real line into intervals Vj, then the event
has strictly positive probability.
The proposition guarantees that for any finite sequence of continuous and bounded real functions {f1, …, fl}, and for every positive ξ, the event
has a priori strictly positive probability.
3.3. Mixtures of multivariate Polya trees
We introduce to hierarchical extension to the multivariate Polya tree model. The extension is similar to mixtures of Polya tree models. Mixtures of Polya trees have been studied by authors including Hanson (2006), Hanson & Johnson (2002) and Berger & Guglielmi (2001). An important advantage of the mixture of Polya tree models compared with the Polya tree prior is discussed in Lavine (1994). The awkward sensitivity of the inference with respect to the choice of the partitions is mitigated, and predictive distributions are smoother than under a Polya tree prior; see Hanson (2006) and Hanson & Johnson (2002).
A mixture of multivariate Polya trees is a natural extension to the mixture of Polya tree models. We consider a class of random probability measures {𝒫x}x∈X indexed by covariates x such that conditionally on a random parameter θ the process {𝒫x}x∈X is a multivariate Polya tree centred on Fθ,
| (8) |
The parameter θ indexes a regression model Fθ. For example, in the following discussion, {𝒫x}x∈X will be centred on a parametric survival regression model. Simple modifications allow one to adapt the framework to other regression problems.
In §5 we will use the following nonparametric Bayesian model for event time data. Let denote survival times, possibly censored from the right, of a sample of subjects with covariates . We assume that the censoring times are independently distributed with respect to the survival times. Let Hθ1 (·) be a continuous cumulative hazard function with parameter θ1 ∈ Θ1. Let Lθ2(·) denote a link function with parameter θ2 ∈ Θ2. Define the cumulative distribution functions Fθ1,θ2,x(·) = 1 − exp{−Hθ1(·) Lθ2(x)} and Fθ = {Fθ1,θ2,x (·)}x∈X. We use the prior (8) with θ = (θ1, θ2) and conditionally independent survival times, Wi | {𝒫x}x∈X ∼ 𝒫xi for i = 1, …, n. We will specify Fθ in the hierarchical prior as a Weibull proportional hazards model: θ1 = (θ11, θ12) and Lθ2(x)Hθ1(t) = exp(θ2x) θ11θ12tθ12. A vague prior is adopted for the regression parameter θ2, which is normally distributed with zero mean and large variance, while θ11 and θ12 are exponentially distributed.
4. Posterior inference
4.1. Posterior inference with multivariate Polya trees
Posterior inference in the proposed model can be implemented by Markov chain Monte Carlo simulation.
Consider posterior inference conditional on data , under the sampling model Wi ∼ 𝒫xi and {𝒫x}x∈X ∼ mpt(𝒜, Q, F). We explain two key concepts that allow the construction of posterior Markov chain Monte Carlo simulation, the independence of the processes {Yε,x}x∈X across ε, both a priori and a posteriori, and the Polya urn scheme with latent variables {(lij, hij); i = 1, …, N, j ⩾ 1} introduced in §2.2. Throughout the sequel, we use finite Polya trees as approximations. Let m be a positive integer, M = 2m and let ε1, …, εM denote the indices of the partitioning subsets Bε at level m of the multivariate Polya tree construction. Posterior inference on 𝒫x { (Bεj)}, j = 1, …, M, provides an approximation of the conditional law of the random probability measure 𝒫x. Let 𝒴m = {Yε,x ; , x ∈ X} denote all random branching probabilities up to level (m − 1). Given the data W, a sufficient statistic for updating 𝒴m consists of the array of indicators
The sampling model for Im, conditionally on 𝒴m, can be conveniently factored using (7). We rearrange the likelihood such that all factors related to a single multivariate beta process {Yε,x}x∈X are grouped together and observe that the multivariate beta processes that define the multivariate Polya tree are both a priori and a posteriori independent. It thus suffices to discuss posterior inference of {Yε,x}x∈X for a fixed ε. Let and, without loss of generality, assume that Fxi(Wi) ∈ Bε for i = 1, …, N. The next paragraph describes a Gibbs sampler algorithm that allows posterior inference for {Yε,x}x∈X given a sample Z = (Z1, …, ZN) of binary variables with covariates x1, …, xN, characterized as in (3). The variables Zi, for i = 1, …, N, coincide with the indicator functions I {Fxi(Wi) ∈ Bε1}.
Recall the definitions of Dx1…xN, {(lij, hij); i = 1, …N, j ⩾ 1} and {j1, …, jN} in the sampling algorithm described in §2.2. The posterior distribution of the truncated sequences {(lij, hij); i = 1, …, N, j = 1, …, ji}, conditionally on the binary random variables Z = {I (h1j1 > 0), …, I (hNjN > 0)}, with regression function {Yx}x∈X ∼ mbp(α0, α1, Q), can be approximated by iteratively sampling from the full conditionals
| (9) |
Without loss of generality we assume that u = N. A minor modification to the algorithm in §2.2 can be used for sampling from (9). We sample {(lNj, hNj); j = 1, …, jN} from Dx1…xN conditional on {(lij, hij); i = 1, …, N − 1, j = 1, …, ji} using the updated Polya urn. So far we are following the sampling scheme illustrated in §2.2. An additional accept–reject step is introduced. If hjN >0 and ZN = 1 or, symmetrically, hiN < 0 and ZN = 0, then the realization is saved. Otherwise, sampling is repeated until the condition is satisfied. Using the latent random variables {(lij, hij); i = 1, …, N, j = 1, …, ji}, we can generate a predictive sample for ZN+1. It suffices to exploit the conjugacy property of the Dirichlet process in (2) with respect to the random variables {(lij, hij); i = 1, …, N, j = 1, …, ji} and, if xN+1 does not belong to {x1, …, xN}, the tail free property of the Dirichlet process.
4.2. Posterior inference with mixtures of multivariate Polya trees
In this subsection we consider mixtures of truncated multivariate Polya trees: for j ⩾ m. We write {𝒫x}x∈X ∼ mptm(𝒜, Q, F) to denote a truncated multivariate Polya tree, truncated at level m. Consider the model
Below we give Markov chain transition probabilities that can be used to define Markov chain Monte Carlo posterior simulation for the model.
Consider again the array {(lij, hij); i = 1, …, n, j ⩾ 1} defined in §2, (j1, …, jn), Dx1,…,xn and the binary vector (Z1, …, Zn) with Zi = I (hiji > 0). Let k be an arbitrarily chosen positive integer, say k = 30. We define two more latent quantities, ki and Hi. Let ki = max(k, ji). We will later condition on {(lij, hij); j = 1, …, ki}. Also, we define the unsorted set Hi = {(lij, hij), j = 1, …, ki}. It will be important that Hi is an unsorted set rather than a sequence. We repeat this construction for each of the {Yε,x}x∈X in the construction of {𝒫x}x∈X ; we define arrays {(lijε, hijε); i = 1, …, n, j ⩾ 1}, vectors (j1ε, …, jnε), binary variables (Z1ε, …, Znε) and sets (Hiε, …, Hnε). The use of the random sets Hiε is motivated by the following fact: if the parameter θ and the arrays {(lijε, hijε); i = 1, …, n, j ⩾ 1} are iteratively sampled from the full conditional distributions, then we only obtain a random sequence of θ values that preserve the classes Bε to which {Fθ,x1(W1), …, Fθ,xn(Wn)} belong. That is, the random sets Hiε are introduced in order to define an irreducible Markov chain. The Markov chain Monte Carlo algorithm exploits the identities
We use three transition probabilities and adopt the notation (x | y, z) to indicate that the random quantity x is updated conditional on currently imputed values for y and z. In the following description Liε is the ith row of Lε = {(lijε, hijε); i = 1, …, n, j = 1, …, jiε} and H denotes the random sets Hiε.
The first transition is (Liε | θ, W, H). This step is carried out separately for all i and all ε, exploiting independence across i and ε, conditional on θ, W and H. Conditioning on (θ, W) could determine Ziε and the indicator I (hjiε ⩾ 0). A simple example clarifies that sampling from the conditional distribution reduces to a combinatorial exercise. Consider A1,…, A6 and Dx1,x2, as in Fig. 1(a). Let k = 3, ε = ⊘ and i = 1. Assume H1⊘ is constituted by three points, respectively, in A1, A5 and A6. If Fθ,x1(W1) > 0.5 and Z1⊘ = 1, then, simply counting the permutations of the elements in H1⊘ that satisfy hj1 > 1 we find pr(L1⊘∈ A6 × A1 | θ, W, H) = 1/3. By similar arguments, we generate Liε.
The second transition is (H | Lε, θ, W). This step is carried out separately for each ε, exploiting conditional independence. It is implemented by sampling, from the updated Polya urn, the random variables {(lijε, hijε); i = 1, …, n, j = jiε + 1, …, kiε} conditional on Lε.
Finally, the third transition is (θ | H, θ, W). We include θ also in the conditioning subset since the proposed Metropolis–Hastings transition probability also depends on the currently imputed value of θ. Propose a transition θ → θ′ and accept or reject the proposed value on the basis of the standard Metropolis–Hastings rule. The acceptance probability requires the evaluation of
| (10) |
where p{Fθ,xi(Wi) | H} denotes the conditional density function of Fθ,xi(Wi) and F′θ,xi is the derivative of Fθ,xi. The right-hand side of (10) is evaluated using a simple combinatorial argument, which is best explained with an example. For simplicity, assume m = 1 and focus on i = 1. Consider A1, …, A6 and Dx1,x2 as in Fig. 1(a), k =3 and H1⊘ constituted by three points, respectively, in A1, A2 and A5. Then
Only two out of the six possible permutations of A1, A2, A5 imply (lj1, hj1) ∈ A5 and Z1 = 0.
Censored data are handled by imputing the missing event times and sampling them conditionally on θ and H; a similar approach is discussed in Walker & Mallick (1999).
5. Examples
5.1. Simulation example
The first example illustrates the flexibility of the multivariate Polya tree model. We consider a simulated dataset generated from the following model:
The density p(Wi ∈ dw | xi) is a truncated normal density. The covariates xi are uniformly sampled from the unit interval. The simulation model includes censoring times {Ci}i⩾1 that are independent of {Wi}i⩾1. The censoring times are exponentially distributed with mean equal to 5.7; the resulting censoring probability pr(Ci < Wi) is approximately equal to 0.15. We generated a sample of n = 300 observations and estimated the underlying distributions. We use a mixture of multivariate Polya trees truncated at m = 5. The hierarchical prior (8) is centred on a Weibull model. The dashed lines in Fig. 3 show the simulation truth for two covariate values x1 = 0.25 and x2 = 0.75. The distribution functions associated with x1 and x2 cross. The sampling model violates the proportional hazards assumption. The simulation results show how the dependent branching probabilities allow posterior inference to adapt to the data when the assumptions of the centring model are violated. Figure 3 shows the corresponding posterior estimates and point-wise credibility intervals. Posterior inference appears to achieve a balance between borrowing strength across covariate levels versus reporting meaningful covariate effects. These two goals are in conflict with each other. Excessive prior dependence diminishes the flexibility of the posterior inference to adapt to the model structure. On the other hand, in the absence of prior dependence we would not borrow any strength across x.
Fig. 3.

Simulation example. The dashed lines represent the true survival functions, pr(Wi > wi | xi), for xi = 0.25 and xi = 0.75. The solid lines illustrate the posterior estimates of the two survival functions. The shaded bands show 90% credible intervals.
The estimates are based on 30 000 iterations of the Markov chain Monte Carlo algorithm described in §4.2 after a burn in of 10 000 iterations. Convergence of the Markov chain Monte Carlo simulations has been validated by simulating six independent Markov chains starting from distinct values of the hyperparameter θ. We also evaluated the convergence diagnostic proposed by Raftery & Lewis (1992). This method requires a single Markov chain realization, which is used to verify the accuracy of the computed predictive probabilities of the events {Wn+1 > w} for a grid of values of w. We found no evidence of lack of convergence. The computational time required for computing the estimates in Fig. 3 with a laptop computer was less than 9 minutes.
We compare the proposed mixture of multivariate Polya trees with a recent proposal for modelling dependent random distributions (Dunson & Park, 2008). This approach extends the Dirich-let mixture model by introducing a kernel stick breaking process which defines dependent discrete random distributions. The random distributions are then used for specifying dependent mixtures indexed by covariates. In our comparison we used mixtures of lognormal densities. This modelling approach extends the density regression method introduced in Dunson et al. (2007). We add a simple imputation step for censored data to the algorithm discussed in Dunson & Park (2008). We carried out 100 simulations of the inferential procedure described in the previous paragraphs. In Table 1 we summarize the simulation results by reporting mean absolute errors of the posterior estimates of pr(Wn+1 > w | xn+1) for several values of w and xn+1. The results show the overall comparable errors under the two models.
Table 1.
Monte Carlo approximations of mean absolute errors for point estimates of pr(Wn+1 > w | xn+1) for some values of xn+1 and w: a comparison between mixtures of multivariate Polya trees and dependent mixtures of log-normal densities specified with kernel stick breaking processes (Dunson, 2008). Covariate values are 0.25, 0.50 and 0.75. For each value of xn+1 we consider w equal to the 25th, 50th and 75th percentile of the corresponding truncated normal distribution.
| Mean absolute errors | ||||
|---|---|---|---|---|
| xn+1 | w = 25th percentile | w = 50th percentile | w = 75th percentile | |
| mmpt | 0.25 | 0.044 | 0.049 | 0.041 |
| 0.50 | 0.042 | 0.046 | 0.040 | |
| 0.75 | 0.047 | 0.049 | 0.042 | |
| ksbp | 0.25 | 0.042 | 0.050 | 0.045 |
| 0.50 | 0.043 | 0.051 | 0.042 | |
| 0.75 | 0.045 | 0.047 | 0.046 | |
mmpt, mixtures of multivariate Polya trees; ksbp, kernel stick breaking process.
5.2. A lung cancer trial
We apply the proposed mixture of multivariate Polya tree models to the analysis of survival data from a clinical trial performed by the Lung Cancer Study Group (Lad et. al., 1980). The objective of the trial was to determine the potential benefit of adjuvant chemotherapy for patients with incompletely resected non-small-cell lung cancer. Patients were randomly assigned to either radiotherapy, or radiotherapy plus chemotherapy. The trial demonstrated the benefit of adjuvant chemotherapy in addition to the radiotherapy. The survival data are published in Piantadosi (1997); 164 patients were enrolled in the trial and 28 were alive at the end of the follow-up period.
The most relevant prognostic factors are cancer histology and performance status at enrollment. Histology is coded as X1 = 0 for squamous and X1 = 1 for non squamous. Performance status is coded as X2 = 0 for Karnofsky indicator ⩾ 7 and X2 = 1 otherwise; we use the dichotomized Karnofsky measurements provided in Piantadosi (1997). The third covariate is the treatment assignment; we use X0 = 1 for treatment and X0 = 0 for control.
Observed survival times in the treatment and control arms are shown in Fig. 4(a). The Kaplan–Meier survival functions for treatment and control cross at around w = 1000 days. For a while after the crossing, the differences are negligible. At the end of the third year, the Kaplan–Meier estimate of the survival function for the treatment group is above the corresponding curve for controls.
Fig. 4.
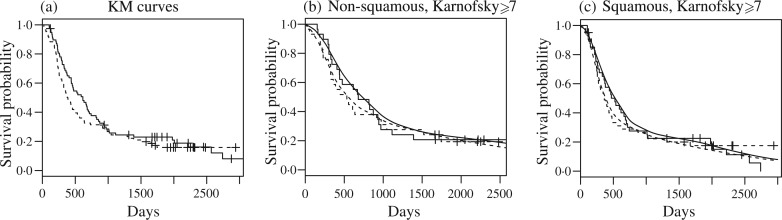
Lung cancer trial. (a) Kaplan–Meier estimates of survival functions. Solid lines refer to treatment and dashed lines refer to the control group. (b) and (c) The model-based estimates of survival curves arranged by cancer histology. For comparison, the corresponding Kaplan–Meier estimates are also included.
The prior is parameterized by αε = 4 for every ε. The kernels qx in this case are multivariate normal densities with diagonal covariance matrix and the three standard deviations equal to 3.
As this example demonstrates the proposed multivariate Polya tree can easily be implemented for a moderate number of covariates. In fact, the computational effort of posterior inference scales only with the sample size, not with the number of covariates. Here the estimates of the survival curves have been obtained on the basis of 25 000 iterations of the proposed algorithm, after a burn in of 7000 iterations. The only concern limiting the number of covariates is the ability to define meaningful kernels to induce the desired correlation. For practical implementations, we see no problem with using the model with up to ten or so covariates.
Figure 4 summarizes some aspects of posterior inference under the proposed model. The model-based estimates identify crossing survival functions. The corresponding Kaplan–Meier curves are shown for comparison. Despite prior centring around the proportional hazards structure, posterior inference correctly identifies the intersecting curves. In contrast to the proportional hazards model, the proposed mpt model allows posterior inference to violate the structure of the prior centring family if the data so indicate.
6. Discussion
The construction of probability models for dependent random measures has been studied by several authors in recent years. Among these, MacEachern (1999) and De Iorio et. al. (2004) explore the idea of defining dependent random probability measures by means of an extension of the Dirichlet process mixture model while Dunson & Park (2008) discuss an extension of the stick-breaking representation.
The two main guiding principles in the proposed construction of dependent random probability measures are the need to specify prior distributions with a clear interpretation and the aim of constructing a probability model with large support.
One of the main strengths of the proposed approach is the use of marginal Polya tree priors, which allows one to restrict the model to continuous random distributions. Posterior inference under the finite multivariate Polya tree model allows easy interpretation as essentially a random histogram method. Some of the remaining limitations are computational challenges of higher dimensional extensions, requiring the manipulation of higher dimensional partitioning subsets, and the sensitivity of posterior inference on partitioning boundaries. The latter is greatly mitigated by the hierarchical extension of the multivariate Polya tree model to a mixture of multivariate Polya trees with a hyperprior for the centring model.
The multivariate beta process has interesting applications beyond the multivariate Polya tree model. The multivariate beta process provides a flexible construction to define dependent random probabilities indexed by covariates; the proposed approach can be generalized for defining dependent random vectors on a finite-dimensional simplex or dependent discrete random distributions. For example, it could be used to define priors for finite mixtures by formalizing a regression of mixture weights on covariates.
A natural continuation to the above line of research is the study of the asymptotic properties of Bayesian inferential procedures based on the proposed class of dependent random probability measures. We hope that the strict similarities of the multivariate Polya tree model with the tail free prior distributions could prove helpful in future research for exploring its asymptotic behaviour.
Acknowledgments
The authors thank the editor, the associate editor and two referees for helpful comments. This article was written while the first author was a visiting student at the Department of Biostatistics, University of Texas M. D. Anderson Cancer Center. The second author was partially supported by the National Institutes of Health, U.S.A., and the National Cancer Institute.
Appendix.
Proposition A1. Let α0 and α1 be two strictly positive real values. If
where a ∈ (0, 1), and ( , , , , , ) are independent gamma random variables with same scale parameter and shape parameters ( , , , , , ), then the function
is monotone increasing.
Proof. The vector
is Dirichlet distributed with parameter ( , , , , , ). Consider a Blackwell–McQueen random sequence {lk}k⩾1 from an urn with initial weights ( , , , , , ) and colours ( , , , , , ). Let S be the first ball from the Blackwell–McQeen urn whose colour belongs to the set ( , , , ) and let V be the first ball, subsequent to S, whose colour belongs to the set ( , , , ). Then
| (A1) |
For each component of the sum, the first product term equals
and the second equals
The following inequalities can be verified with simple algebra. If a, a* and a** belong to the interval (0, 1) and a** > a*, then ∑m⩾j p′(a**, m) ⩽ ∑m⩾j p′(a*, m) for every j and, for every m, p″(a**, m) > p″(a*, m) and p″(a, m) > p″(a, m + 1). These inequalities and the equality ∑m⩾1 p′(a**, m) = ∑m⩾j p′(a*, m) imply that
The last inequality completes the proof, indeed the two terms are equivalent to the expected value in (A1) under different parameterizations of , …, .
Proof of Proposition 1. For every i, let
We observe that , and
The hypotheses imply that ν{(z, y) ∈ X × : 0 < y < qxi(z), qx (z) > y} → 0, and it follows that var( ) → 0. We can similarly define , and , and verify that . Finally, the convergences in mean square of {G( )}i⩾1 and {G( )}i⩾1 imply that, for every ε > 0, pr(| Yxi − Yx |> ε) → 0.
Proof of Proposition 2. For every , E[𝒫x{ (Bε)}] = λ (Bε), where λ denotes the Lebesgue measure. The same equality holds for the elements of the algebra of finite unions of Bε sets. The class (B ⊆ (0, 1] : λ(B) = E[𝒫x{ (B)}]) is monotone. The monotone class theorem implies that for every Borel subset B of (0, 1], E[𝒫x{ (B)}] = λ(B). Finally, if a distribution p satisfies the equality p{ (B)} = λ(B) for every Borel subset B of (0, 1] then p = Fx.
Proof of Proposition 3. Proposition 1 implies that, for every , the sequence 𝒫xi{ (Bε)} (i = 1, 2 …) converges in probability to 𝒫x{ (Bε)}. Similarly, if a measurable set B belongs to the algebra generated by {Bε; }, then the random variables 𝒫xi{ (B)} converge in probability to 𝒫x{ (B)}. Let B ⊂ [0, 1] be a measurable set. Let B1, B2, …be an increasing sequence such that ∪j⩾1 Bj = B and assume that, for every j ⩾ 1, the random variables 𝒫xi{ (Bj)} converge in probability to 𝒫x{ (Bj)}. We observe that, for every pair (i, j), 𝒫xi{ (B)} − 𝒫xi{ (Bj)} ⩾ 0 almost surely. We also observe that E[𝒫xi{ (B)} − 𝒫xi{ (Bj)}] = λ (B\Bj), where λ denotes the Lebesgue measure. It follows, using the Markov inequality, that, for every δ > 0 and ξ > 0, there exists m such that
Moreover, there exists k ⩾ 1 such that, for every j > k,
For every j > k, pr[|𝒫xj{ (B)} − 𝒫x{ (B)}| > ξ] < δ. Similarly, if the sequence B1, B2, …decreases to B and, for every j ⩾1, the random variables 𝒫xi{ (Bj)} converge in probability to 𝒫x{ (Bj)}, then the sequence 𝒫xi{ (B)} converges in probability to 𝒫x{ (B)}. It follows, using the monotone class theorem, that for every Borel subset B ⊂ [0, 1] the sequence 𝒫xi{ (B)} converges in probability to 𝒫x{ (B)}.
Assume that the pair (a, b) satisfies c = Fx (a). The cumulative distribution functions Fxi and Fx are continuous. Therefore, the variables |𝒫xi{(−∞, (c)]} − 𝒫x{(−∞, a]}| and |𝒫xi{ (0, c]} − 𝒫x{ (0, c]}| are almost surely identical. The random sequence |𝒫xi{ (0, c]} − 𝒫x{ (0, c]}| converges in probability to zero. Note that E[|𝒫xi{(− ∞, (c)]} − 𝒫xi{−∞, a]}|] =|c − Fxi(a)| and |c − Fxi (a)|→ 0. It follows that the random sequences |𝒫xi{(−∞, (c)]} − 𝒫xi{(−∞, a]}| and |𝒫xi{(−∞, a]} − 𝒫x{(−∞, a]}| converge in probability to zero. Finally, through monotone class arguments and exploiting the convergence in total variation of {Fxi}i⩾1 to Fx, we verify that, for every Borel subset B, the sequence 𝒫xi(B) converges in probability to 𝒫x(B).
Proof of Proposition 4. Assume that {Yx}x∈X ∼ mbp(α0, α1, Q). We prove that for every ξ > 0, for every m = 1, 2, …, for every distinct x1, …, xm ∈ X and a1, …, am ∈ [0, 1] the event {|Yxi − ai | < ξ; i =1, …m} has strictly positive probability.
There exist strictly positive numbers ( , ) such that | − a1| < ξ/2. Given and , there exist strictly positive numbers ( , ) such that, if and , then − a2| < ξ/2. Similarly, for any fixed value of and , there exist positive numbers ( , ) such that, if and , then − ai+1|< ξ/2. The quantities , , are strictly positive, indeed {qx}x∈X is a location family of unimodal densities. It follows that the density function of [ , , ] in an adequate neighbourhood of ( , is strictly positive. This fact proves our assertion.
For every positive ξ and every integer j the event
has strictly positive probability. Finally, for any positive δ and partition (V1, …, Vk) constituted of intervals, the absolute continuity hypothesis Si ≪ Fxi ≪ λ, where λ denotes the Lebesgue measure, implies that, if j and ξ are suitably chosen, then this event becomes a subset of {|𝒮i (Vl) − 𝒫xiVl)| < δ; l = 1, …, k, i = 1, …, m}.
References
- Berger JO, Guglielmi A. Bayesian testing of a parametric model versus nonparametric alternatives. J Am Statist Assoc. 2001;96:174–84. [Google Scholar]
- Berman M. A class of isotropic distributions in Rn and their characteristic functions. Pac J Math. 1978;78:1–9. [Google Scholar]
- Blackwell D, MacQueen JB. Ferguson distributions via Polya urn schemes. Ann Statist. 1973;1:353–5. [Google Scholar]
- De Iorio M, Muller P, Rosner GL, MacEachern S. An ANOVA model for dependent random measures. J Am Statist Assoc. 2004;99:205–15. [Google Scholar]
- Doksum K. Tailfree and neutral random probabilities and their posterior distributions. Ann Prob. 1974;2:183–201. [Google Scholar]
- Dunson DB, Park BK. Kernel stick-breaking processes. Biometrika. 2008;95:307–23. doi: 10.1093/biomet/asn012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dunson DB, Pillai N, Park BK. Bayesian density regression. J. R. Statist. Soc. B. 2007;69:163–83. [Google Scholar]
- Ferguson TS. Prior distributions on spaces of probability measures. Ann Statist. 1974;4:615–29. [Google Scholar]
- Gneiting T. Radial positive definite functions generated by Euclid’s hat. J Mult Anal. 1999;69:88–19. [Google Scholar]
- Hanson T. Inference for mixtures of finite Polya tree models. J Am Statist Assoc. 2006;101:1548–65. [Google Scholar]
- Hanson T, Johnson W. Modeling regression error with a mixture of Polya trees. J Am Statist Assoc. 2002;97:1020–33. [Google Scholar]
- Hjort NL. Nonparametric Bayes estimators based on Beta processes in models for life history data. Ann Statist. 1990;18:1259–94. [Google Scholar]
- Lad T, Rubinstein L, Sadeghi A. The benefit of adjuvant treatment for resected locally advanced non-small-cell lung cancer. J Clin Oncol. 1988;6:9–17. doi: 10.1200/JCO.1988.6.1.9. [DOI] [PubMed] [Google Scholar]
- Lavine M. Some aspects of Polya tree distributions for statistical modelling. Ann Statist. 1992;20:1222–35. [Google Scholar]
- Lavine M. More aspects of Polya tree distributions for statistical modelling. Ann Statist. 1994;22:1161–76. [Google Scholar]
- MacEachern S. ASA Proc Sec Bayesian Statist Sci. Alexandria, VA: American Statistical Association; 1999. Dependent nonparametric processes; pp. 50–5. [Google Scholar]
- Mauldin RD, Sudderth WD, Williams SC. Polya trees and random distributions. Ann Statist. 1992;20:1203–21. [Google Scholar]
- Mittal Y. A class of isotropic covariance functions. Pac. J. Math. 1976;64:517–38. [Google Scholar]
- Nadarajah S, Kotz S. Some bivariate beta distributions. Statistics. 2005;39:457–66. [Google Scholar]
- Nieto-Barajas LE, Walker SG. Gibbs and autoregressive processes. Statist Prob Lett. 2007;77:1479–85. [Google Scholar]
- Olkin I, Liu R. A bivariate beta distribution. Statist Prob Lett. 2003;62:407–12. [Google Scholar]
- Piantadosi S. Clinical Trials: A Methodologic Perspective. New York: Wiley; 1997. [Google Scholar]
- Raftery AE, Lewis SM. How many iterations in the Gibbs sampler? In: Bernardo JM, Berger JO, Dawid AP, Smith AFM, editors. Bayesian Statist 4. Oxford: Oxford University Press; 1992. pp. 763–73. [Google Scholar]
- Walker S, Mallick BK. A Bayesian semiparametric accelerated failure time model. Biometrics. 1999;55:477–83. doi: 10.1111/j.0006-341x.1999.00477.x. [DOI] [PubMed] [Google Scholar]
- Walker S, Muliere P. A bivariate Dirichlet process. Statist Prob Lett. 2003;64:1–7. [Google Scholar]