

Abstract
This article describes a pattern classification algorithm for pediatric epilepsy using fMRI language‐related activation maps. 122 fMRI datasets from a control group (64) and localization related epilepsy patients (58) provided by five children's hospitals were used. Each subject performed an auditory description decision task. Using the artificial data as training data, incremental Principal Component Analysis was used in order to generate the feature space while overcoming memory requirements of large datasets. The nearest‐neighbor classifier (NNC) and the distance‐based fuzzy classifier (DFC) were used to perform group separation into left dominant, right dominant, bilateral, and others. The results show no effect of age, age at seizure onset, seizure duration, or seizure etiology on group separation. Two sets of parameters were significant for group separation, the patient vs. control populations and handedness. Of the 122 real datasets, 90 subjects gave the same classification results across all the methods (three raters, LI, bootstrap LI, NNC, and DFC). For the remaining datasets, 18 cases for the IPCA‐NNC and 21 cases for the IPCA‐DFC agreed with the majority of the five classification results (three visual ratings and two LI results). Kappa values vary from 0.59 to 0.73 for NNC and 0.61 to 0.75 for DFC, which indicate good agreement between NNC or DFC with traditional methods. The proposed method as designed can serve as an alternative method to corroborate existing LI and visual rating classification methods and to resolve some of the cases near the boundaries in between categories. Hum Brain Mapp 35:1446–1460, 2014. © 2013 Wiley Periodicals, Inc.
Keywords: fMRI, language networks, PCA, eigensystem, eigenvectors, lateralization index, visual rating system, nearest neighbor classifier, distance‐based fuzzy classifier
INTRODUCTION
The functional anatomy of language processing networks has been extensively studied through fMRI [Binder et al., 1995; Bookheimer, 2002; Cabeza and Nyberg, 2000; Just et al., 1996]. For normal healthy persons, language activation is typically left dominant, but there are known variants (bilateral or right dominance) in right handed populations and left handed populations: 4% right handed and 24% left handed in Pujol et al., 1999; 4% right handed and 30% left handed in Rasmussen and Milner, 1977; 6% right handed in Springer et Al., 1999; and 22% left handed in Szaflarski et al., 2002. Furthermore, patients with localization‐related epilepsy (LRE) exhibit a higher incidence of atypical language activations (20–30%) based either on quantitative region of interest (ROI) analysis [Frost et al., 1999; Gaillard et al., 2007; Woermann et al., 2003] at hemisphere [Binder et al., 1996], sub region levels [Abbott et al., 2010; Gaillard et al., 2002; Ramsey et al., 2001; Spreer et al., 2002], or visual rating [Fernandez et al., 2001; Gaillard et al., 2002, 2004]. The reorganization of language networks from canonical areas (i.e., Broca's and Wernicke's areas) to distinct locations either in the same or in the contra lateral hemisphere is a consequence of underlying structural lesions (e.g., stroke) or the functional processes of epilepsy [Gaillard, 2004; Liegeois et al., 2004; Szaflarski et al., 2006]. We have implemented data driven methods free of a priori assumptions and limitations of ROI and visual methods, to achieve subgroup classification and characterization [Mbwana et al., 2009; You et al., 2011].
One such method, principal component analysis (PCA), is a valuable mathematical method used for exploring and analyzing multidimensional datasets. It enables computation of a linear transformation that maps data from a high dimensional space to a lower dimensional orthogonal space, maximizing variance as a consequence [Jolliffe, 2002]. These characteristics of the PCA are incorporated in our method to transform the fMRI activation map from its spatial space into the eigenvector feature space, which we use as the feature space for classification. Previous studies have shown that this feature space facilitates classification by means of different algorithms including the K‐means approach [Mbwana et al., 2009], neural networks [Samanwoy and Adeli, 2008], and nonlinear decision functions [Cabrerizo et al., 2011; Tito et al., 2010, 2009] to name a few.
Another advantage of the PCA feature space is its independence of a priori assumptions and biases inherent to ROI and visual rating. In our previous study [You et al., 2011], we performed PCA on 122 fMRI activation maps with regional masking, and identified three primary activation pattern groups or clusters: left dominant with higher intensity, left dominant with lower intensity, and right dominant. Then, through a Euclidean distance method, we associated the remaining undecided subjects to the primary clusters that were previously determined. This study aims to overcome limitations identified during our previous study, namely the need (1) to include bilateral activation and (2) to resolve those challenging activation patterns that are at the boundaries in between categories and are therefore difficult to classify.
DATA AND SUBJECTS
A multisite consortium with pediatric epilepsy programs at five children's hospitals: Miami Children's Hospital (MCH), Children's National Medical Center (CNMC), Hospital for Sick Children (HSC), British Columbia Children's Hospital(BCCH), and Children's Hospital of Philadelphia (CHOP) built a repository for pediatric epilepsy data (http://mri-cate.fiu.edu) to investigate the effects of epilepsy on brain function and structure [Lahlou et al., 2006]. Procedures were followed in accordance with local institutional review board requirements; all parents gave written informed consent and children gave assent. The control subjects were right handed, determined by clinical assessment or handedness inventories such as the Harris tests of lateral dominance or the modified Edinburgh inventory [Harris, 1974; Oldfield, 1971], and free of any current or past neurological or psychiatric disease. Since demographic and clinical information are required for statistical analysis, the requirements for the usable data include: (1) at least two of the three variables (gender, age, and handedness) in demographic information are available; (2) at least two of the three variables (age at seizure onset, seizure focus, and seizure etiology) are also available. With these requirements, 64 controls and 58 patients were included in the study. Among all subjects, the following are the number of missing cases for variables: 0 in gender, 2 in age, 4 in handedness, 9 in seizure onset, 9 in duration of epilepsy, 8 in seizure focus, and 11 in seizure etiology.
Each participant performed an auditory description decision task‐ADDT (a word definition task) which was designed to activate both temporal (Wernicke's area) and inferior frontal (Broca's area) cortex [Gaillard et al., 2007]. The task required comprehension of a phrase, semantic recall, and a semantic decision. The block design paradigm is consisted of 100 (TR = 3 s) or 150 (TR = 2 s) time‐points, with experimental and baseline periods alternating every 30 s for five cycles, totaling 5 min.
To perform the group analysis of datasets collected from several sites, datasets were matched into Neuroimaging Informatics Technology Initiative (NIFTI) format using the transversal view and radiology convention, and were registered into the standard Montreal Neurological Institute (MNI) [Burgund et al., 2002; Faria et al, 2010; Muzik et al., 2000] brain with 3 × 3 × 3 (mm3) in voxel size and 61 × 73 × 61 (axial × coronal × sagittal) in resolution. The fMRIB software Library (FSL) was used to perform the pre‐processing required for obtaining the 3D activation maps [Jenkinson et al., 2002; Jenkinson and Smith, 2001; Woolrich et al., 2001].
Of the 64 control datasets and 58 children with focal epilepsy (patient population) included in this study, 63.79% of the patients and 54.69% of the controls are males. Moreover, 19% of the patients had atypical handedness (left or mixed). The mean age of patients was 13.86 years (standard deviation 3.37 years, age range 4.5–19 years), and the mean age of controls was 8.65 years (standard deviation 2.65, range 4.2–12.9). The patients had mean age seizure onset of 8.23 years (standard deviation 4.28, range 1–18 years). There were 26 left localized patients; 17 (65%) had a temporal focus and the rest an extra‐temporal focus. There were 18 right localized patients; seven (39%) had a temporal focus and the rest had an extra‐temporal focus. Three patients had bilateral seizure focus. Twenty‐two patients had abnormal MRIs: seven tumors, five mesial temporal sclerosis, four focal cortical dysplasia, one vascular malfunction, three focal gliosis, and two atrophy. Of the 45 patients with seizure etiology information, 21 had remote symptomatic seizure cause, three an acute symptomatic cause, and 21 no known cause. Eleven patients (out of the 54 available) had atypical handedness (left or mixed).
METHODS
Artificial Data Generation and Validation
In this study, artificial activation patterns were generated based on different combinations of activations in the typical language related areas of Broca's and Wernicke's. These artificial patterns are created as the training data to classify the 122 real datasets in the testing phase. First, we obtained left and right Broca's [BA: 44, 45, 47] and Wernicke's [BA 21, 22, 39] masks separately from BA templates provided by MRIcro (Rorden and Brett, 2000). In accordance with the clinical notion of typical and atypical language patterns (Fig. 1), the top five combinations of Broca's and Wernicke's masks were regarded as typical (left dominant if both regions are left, or one region is left and the other is bilateral or with no activity), and the rest were considered atypical (bilateral for both bilateral or lateralized in opposite sides; or right dominant when both regions are right lateralized, or when one is right and the other is bilateral or with no activity). Moreover, activation patterns which are considered as “others” (nondiagnostic) include null activation and noise.
Figure 1.
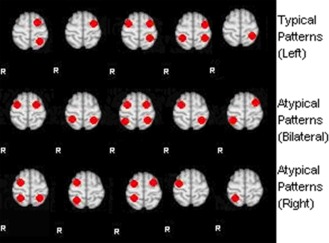
Suggested standard fMRI language activation patterns: Anterior and lateral dots represent expressive language areas (Broca); posterior and lateral dots represent receptive language areas (Wernicke). Note: Null‐activation and noise (pseudo activation) are not displayed in this figure. [Color figure can be viewed in the online issue, which is available at http://wileyonlinelibrary.com.]
Activations are then generated randomly within the four ROIs (left and right Brocas' and Wernicke's) in accordance to the following rules:(i) the center of activation must be within the ROI; (ii) the covariance matrix is randomly generated, and the number of activations is randomly chosen from 1 to 10. (iii) the generated clusters satisfy the Gaussian distribution; These datasets were generated taking into consideration only the extent of volume and masked regions, while disregarding any demographic or clinical information of the real data. The reason is to remove any inference to the available real data, so that the classification method as designed can be generalized in its use to other real fMRI data. The procedure for generating artificial data consists of the following steps:
Generate related parameters following the set rules.
Resample the original volume size 61*73*61 into 244*292*244.
Randomly generate points in the resampled volume (2500 points in this case is generated for each activation pattern).
Accumulate the number of points on each voxel as the value of that voxel.
Resample the volume back to its original size 61*73*61.
Apply the mask to obtain the artificial data.
Four hundred activation samples within each of the four basic masks (left Broca, right Broca, left Wernicke, and right Wernicke) were generated initially for a total of 1,600. Random combinations from those basic activation patterns were thereafter generated yielding 580 artificial datasets. Since the goal is to classify the data into four categories: left dominant, right dominant, bilateral, and others (noise and NA), the artificial datasets which satisfy the characteristics of the three main categories (left dominant, right dominant, and bilateral) were generated with close numbers in volumes in each category for a balanced analysis. In order to focus on activation region differences instead of activation intensity as we did in our previous study [You et al., 2011], the intensity of all artificial activation maps was normalized. The intensity normalization was achieved by changing the range of pixel intensity values to range between 0 and 1. More specifically, we divide each pixel by the maximum value of the whole volume.
Incremental PCA‐Based Method and Feature Space for Classification
Feature space generation has been studied extensively with different applications in medical imaging, as well as for object recognition and pattern classifications problems [Joliffe and Morgan, 1992; Turk and Pentland, 1991]. With the due consideration to the concept and merit of subject loading [Alexander and Moeller, 1994], we intended to perform the PCA on the artificial datasets to obtain the eigenvectors for projecting the data into a dimensionally reduced feature space. However, the number of artificial datasets considered initially in this study was too large to be loaded into the program at once. Consequently, the Incremental PCA was used instead. Implementation details of the IPCA are provided in the Appendix.
The inputs for the classifiers are the basis projections of the data into the IPCA leading eigenvector feature space.
Nearest Neighbor Classifier
The nearest neighbor classifier (NNC) searches for the minimum distance in the Eigen space or feature space between a testing dataset and the training datasets. Suppose the projection of one testing activation data is y t and the projection of the p th training activation data is y p. Then the distance between projections of the two data is determined as d p=||y t − y p||. The index of minimum(d) gives the recognition result in the training data for the given test data.
Distance‐Based Fuzzy Classifier
Clinical decisions or rating of activation patterns that fall at or near the boundary in between categories are difficult to make. In the case of the four categories considered here, it may be important to know such matters as this data has 0.56 similarity to left dominant patterns and 0.44 similarity to bilateral patterns to facilitate the decision making or at least proceed at scrutinizing the activation patterns of that particular subject or patient. To achieve this goal, a distance‐based fuzzy classifier (DFC) for this specific study was introduced, which is based on the K‐nearest neighbor algorithm [Dasarathy, 1991; Shakhnarovish et al., 2008].
This DFC follows the same steps as the NNC until the distance vector is obtained between all the training data and the testing dataset. In this case, we consider the nearest m distances (d i with i = 1, 2,…,m where d 1 < d 2 < …< d m) instead of the nearest distance. For this particular implementation, we opted for the nearest 3 distances (m = 3). The statistical analysis for other m will be discussed in the result section.
For the nearest m distances, different weights are given according to their nearest order following Eq. (3):
| (1) |
where i is the index of the nearest m distances. For example, when m = 3, the nearest distance d 1 is given the weight 1/6, the second nearest distance d 2 is given the weight 2/6 and the third nearest distance d 3 is given the weight 3/6, and so on for other nearest distances if considered. The reason for the choice of weights is because in Eq. (4), the smaller is the weight (i.e., distance) the higher is the similarity.
The similarity for the ith distance (i = 1, 2, …, m) is given by the following relation:
| (2) |
Then to determine the percentage similarity of a given real dataset to any one of the four categories, the following equation was used:
| (3) |
Assume a real dataset is now to be categorized after we determined the 3 nearest distances d 1, d 2 and d 3. Assume further as an example that it was determined that d 1 and d 3 are computed from artificial patterns in category L, and that d 2 on the other hand is from an artificial pattern in category B. Equation (4) is then used to compute the similarity percentage S 1, S 2, S 3 based on d 1, d 2 and d3, respectively. Then according to equation (5), S 1 and S3 are summed together to yield the similarity percentage for category L, and similarity S 2 alone will the similarity percentage for category B and the similarity percentages for the remaining categories will be 0. In this case, only such similarity percentages will be tabulated as will be detailed in the Results section. The larger similarity percentage for the category means the test data has a higher probability of belonging to that category. A special case that should be considered is when one of the d i is very small or near zero in contrast to the other d is, then the category similarity gives 1 to the pattern corresponding to the near zero d i. For example if d 1 ≤ 0.01 with d 2 ≥10d 1, then a similarity of 100% is given to the category nearest to the pattern corresponding to d 1.
Visual Rating System
We used a visual rating system to categorize each subject's activation map into the dominance patterns used for LI assignment. An access‐based tool was used to score images to a predetermined set of language network patterns representing the differing combinations of activations in canonical frontal and temporal regions. Each subject's activation map interpreted using set threshold, Z > 2.3 with P = 0.05 cluster corrected [Forman et al., 1995; Friston et al., 1994; Worsley et al., 1992], and then overlaid on top of the brain template. Three clinical raters, blinded to subject identity, categorized the laterality of activation in language related areas, and provided the level of confidence in the rating (confidence scale was from 1 to 5: 5 being most confident, 1 least (i.e., not) confident of rating). Comments on observations when there was concern about noise or null activation were noted [Guillen et al., 2009]. Raters were instructed to rate each subject's map independently and categorize the map into one of the 20 available activation patterns present in the tool (Fig. 2), and mark their selection, if necessary, with personal comments.
Figure 2.
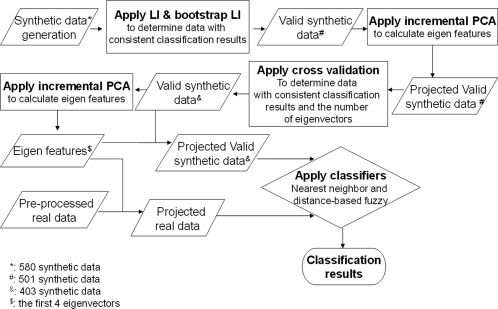
Structure of the classification process combining synthetic and real data.
Laterality Indices
For quantitative assessments, we used two approaches to calculate regional LIs: (1) a fixed threshold (the threshold at which visual rating was performed) [Adcock et al., 2003; Holland et al., 2001; Liegeois et al., 2004; Price, 2000] and (2) a bootstrap method with the weighted mean measure with the option “no optional steps” [Wilke and Schmithorst, 2006] (postulated to be more versatile than a fixed threshold). With these measures we then categorized the regional activation maps into a specific laterality category using these following criteria: LI ≥ 0.2 is deemed left; LI ≤ −0.2 is deemed right; |LI | < 0.2 is deemed bilateral [Gaillard et al., 2002; Wilke and Schmithorst, 2006].We defined typical language related area Broca's (BA: 44, 45, 47) and Wernicke's (BA 21, 22, 39) areas as our two ROIs. These specific regions were extracted from BA templates provided by MRIcro [Rorden and Brett, 2000].
The LI measure was derived using the following equation:
| (4) |
where V denotes either the activation magnitude to yield LImagnitude or voxel count to yield LIvoxel. Average LI that accounts for both voxel and magnitude can be obtained as follows:
| (5) |
Once the two LIs from the Broca's and Wernicke's areas were calculated (for fixed threshold and bootstrap methods) we then used the following criteria for determining hemispheric language dominance: (1) left dominance when activation patterns in both Broca's and Wernicke's areas are left lateralized, or when one region is deemed left and the other bilateral or with no activity (NA); (2) right dominance when both regions of the activation patterns are right, or one region is right and the other is bilateral or with NA; (3) bilateral if both regions of the activation patterns are bilateral, or one is bilateral and the other is with NA, or one is left and the other is right; (4) “other,” when both regions of the activation patterns are with NA or noise/artifact.
Post‐Processing for Artificial Data
Artificial datasets were post‐processed to determine which ones were to be used as training data in the classification process. The following steps are considered:
Calculate LI and bootstrap LI to re‐group the artificial data.
Collect the data that match the group in both LI and bootstrap‐LI.
Perform the cross validation for the data through nearest neighbor classifier based on the PCA dimensionally‐reduced decision space. In this test, the repeated random sub‐sampling validation is used (50% for training and 50% for testing). A total of twenty trials were performed.
Determine the number of eigenvectors by the most frequent number of eigenvectors that gives the highest recognition rate.
Examine the number of eigenvectors that will be used in order to exclude the wrongly classified testing data from the final artificial data group which is used for classification of real data.
A null activation data is added into the artificial data.
The artificial null activation data is used to classify the null activation data in the real datasets. And for the artificial datasets, we know where the activation should be located, therefore wrongly classified artificial datasets means that the classified category of the datasets is not the one initially assigned to it (after verification of two LI methods). Therefore, there should be four categories in the classification results.
Processing Procedure
Randomly generated artificial data were utilized in this study to complement the classification process of the 122 real datasets used in study. To validate these artificial datasets, LI based on a fixed threshold at which visual ratings was determined, and a LI based on a bootstrap threshold was performed. The two LIs served as a first filter to keep, for further consideration, only those artificial datasets that yielded consistent classification results from both methods. Cross validation was then applied to the IPCA using the nearest neighbor classifier to determine the optimal number of eigenvectors (optimal feature space) that would yield the highest classification accuracies in different trials. Once the number of components was determined, wrongly classified artificial datasets in the optimal feature space were excluded from further consideration. In this selection process, we started with 580 artificial datasets, which were reduced to 501 after the LI and bootstrap LI classification consistency test, and then further reduced to 403 after the cross validation test in the IPCA feature space [Wang et al., 2011]. Then the NNC and DFC were both implemented, and the latter addressed those activation patterns that were located in the boundaries between categories. Also, for comparable assessments, we also used fixed LI, bootstrap LI, and visual rating to categorize the activation maps.
Figure 2 illustrates the overall classification process as it is implemented. In this figure, projected data (i.e., validated artificial data and real data) are the data that are projected into the reduced 4‐D feature space determined through the IPCA method.
Methods Used for Statistical Analysis
Because of the limited sample size, Fisher's exact test was applied to analyze the association of categorical factors with the group distribution, while continuous numerical factors are analyzed by Friedman or Mann‐Whitney U test as nonparametric alternatives to the ANOVA and independent t‐test. And the agreement between the LI, visual rating and the IPCA results were quantified using Kappa coefficient κ [Belle et al., 2004; Cohen, 1960]. The interpretation from the Kappa value follows: >0.81 as “excellent agreement”, 0.61–0.80 as “good agreement,” 0.41–0.60 as “moderate agreement,” 0.21–0.40 as “fair agreement,” <0.20 as “poor agreement”.
RESULTS
Artificial Data
For the artificial data considered, there were initially 580 datasets generated with 190 volumes for left dominant, 190 volumes for right dominant and 200 volumes for bilateral, with no duplicate basic activation patterns. After the LI and bootstrap LI validation, 501 out of 580 data were kept for further consideration. Of these 182 were found to be left dominant, 196 were right dominant and 123 were bilateral.
With the cross validation using the IPCA, in 16 out of the 20 trials among 1–10 eigenvectors, the highest accuracy values ranged from 91.1% to 95.1% when four eigenvectors were used. Therefore, four eigenvectors were deemed sufficient as a feature space for deploying the classification process. After this cross validation, and using the four‐dimensional feature space, 403 out of 501 data were classified correctly using the nearest neighbor classifier. Of these, 140 were left dominant, 158 were right dominant and 105 were bilateral. Comparing to left dominant and right dominant patterns, bilateral patterns are more likely to be eliminated as shown in the results. Since the first three patterns from the left in middle row of Figure 1 could be considered as ambiguous cases. While for left and right dominant patterns, there are only two such ambiguous cases (left dominant: third and fourth patterns from the left in top row; right dominant: first and third patterns from the left in the bottom row in Fig. 1).
Figure 3 shows the plots for the recognition accuracy rate in the cross validation based on the 20 trials and across one through ten eigenvectors. In this figure, each plot represents the recognition accuracy rate of a single trial as the accuracy changes from using one eigenvector up to ten eigenvectors. Each “cross” in the graph represents the highest value found for each trial.
Figure 3.
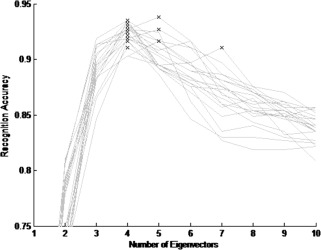
Plots of the recognition accuracy rate for the 20 trials in the cross validation across 1 through 10 eigenvectors.
Assessment of IPCA Results and Key Cases
Of the 122 real datasets, 90 subjects (81 left, 5 right, 3 bilateral, and 1 others) had the same classification results across all the methods (three raters, LI, bootstrap LI, NNC, DFC). For the remaining datasets, there were 18 cases for the IPCA‐NNC and 21 cases for the IPCA‐DFC that agreed with the majority of the five classification results, including three visual ratings and two LI results. For example, if there were three classification results identified as bilateral, bilateral became the majority choice of the classification results.
The categorization results of IPCA‐NNC, comparing with other methods, are shown in Table 1 with L, left dominant, R, right dominant, B, bilateral, and O, others.
Table 1.
Categorization results between each method and the IPCA‐based method
| Rater1 | Rater2 | Rater3a | LI | LI | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Fixed threshold) | (Bootstrap) | |||||||||||||||||||
| IPCA | L | R | B | O | L | R | B | O | L | R | B | O | L | R | B | O | L | R | B | O |
| L | 90 | 0 | 5 | 4 | 92 | 0 | 4 | 3 | 88 | 1 | 5 | 4 | 88 | 2 | 9 | 0 | 90 | 3 | 6 | 0 |
| R | 0 | 9 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 8 | 0 | 1 | 0 | 7 | 2 | 0 | 0 | 8 | 1 | 0 |
| B | 1 | 2 | 5 | 0 | 2 | 3 | 3 | 0 | 3 | 2 | 3 | 0 | 0 | 3 | 5 | 0 | 0 | 0 | 8 | 0 |
| O | 1 | 0 | 0 | 5 | 1 | 0 | 0 | 5 | 1 | 1 | 0 | 5 | 2 | 1 | 0 | 3 | 2 | 0 | 0 | 4 |
There is a special case for rater 3 in the others category.
For the IPCA‐DFC which relies on the similarity percentage to a given category, the highest similarity percentage determines the category to which the activation pattern belongs. The following categorization results were obtained:
Considering the ten cases that the IPCA‐DFC did not agree with the majority results, four cases were found to be special cases, where more than one category was designated as a majority choice. For example, two results claimed the activation pattern was left dominant, two other results determined that the same activation pattern was bilateral, and one result identified the activation as others (NA, noise). Two out of these four cases can thus be considered as an agreement with the majority.
Some of these results are exemplified in Table 3 for comparative purposes (in this table, four‐category classification was considered). Moreover, the similarity for the DFC is shown as a percentage number. Among the highlighted cases (Table 3 and Figs. 4–11, representative slices), the first three illustrate examples where all results were in agreement throughout the methods. The next two cases illustrate examples where the discrepancy happened between LI methods or among LI methods and the other methods. Another set of three cases demonstrates examples where the inconsistency existed among the three visual raters.
Table 3.
Example results from LI, visual rating, nearest neighbor classifier and distance‐based fuzzy classifier
| Case # | Fixed LI | Bootstrap LI | Rater 1 | Rater 2 | Rater 3 | PCA | |
|---|---|---|---|---|---|---|---|
| NNC | Fuzzy | ||||||
| 1 | L | L | L | L | L | L | 100%:L |
| 2 | R | R | R | R | R | R | 100%:R |
| 3 | B | B | B | B | B | B | 100%:B |
| 4 | B | B | L | L | L | L | 100%:L |
| 5 | B | R | R | R | R | R | 100%:R |
| 6 | L | L | L | L | B | L | 100%:L |
| 7 | L | L | L | O | L | O | 65.5%:L |
| 34.5%:O | |||||||
| 8 | L | L | L | R | B | L | 100%:L |
| 9 | R | B | R | R | R | B | 68.7%:B |
| 31.3%:R | |||||||
Figure 4 shows examples where the proposed method and all other methods agreed and classified the given activation patterns into the same category.
Figure 4.
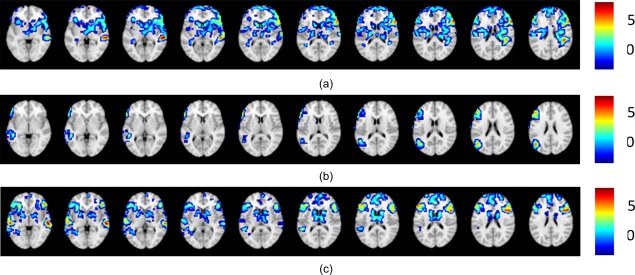
Cases where agreement is reached among all methods. (a) Left dominant case; (b) right dominant case; (c) bilateral case.
For Case 4 (Fig. 5), both LI methods resulted in a left dominant classification, while all the other methods classified this activation as bilateral. By comparing the original data in Figure 5a and the masked data in Figure 5b, the mismatch is believed to be due to the predefined regional mask selected and potentially relevant to (or irrelevant) activation adjacent to the Broca's area.
Figure 5.
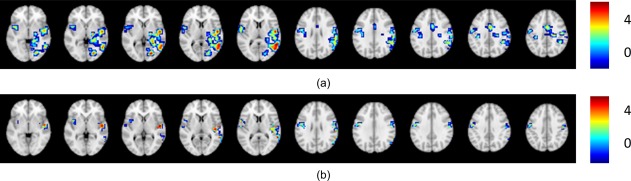
Case 4, illustrating activation pattern yielding the same results for all other methods, except for the two LI methods: (a) original data; (b) masked data.
For case 5 (Fig. 6a), only the LI method yielded bilateral language classification; all the other methods classified as left dominant. It is likely that this misclassification is largely due to the fixed threshold of the LI algorithm, since the bootstrap LI correctly classified this pattern as left dominant. The LI value for the Wernicke's area is 0.18, which is close to the boundary in between the categorical determination of left dominant and bilateral.
Figure 6.
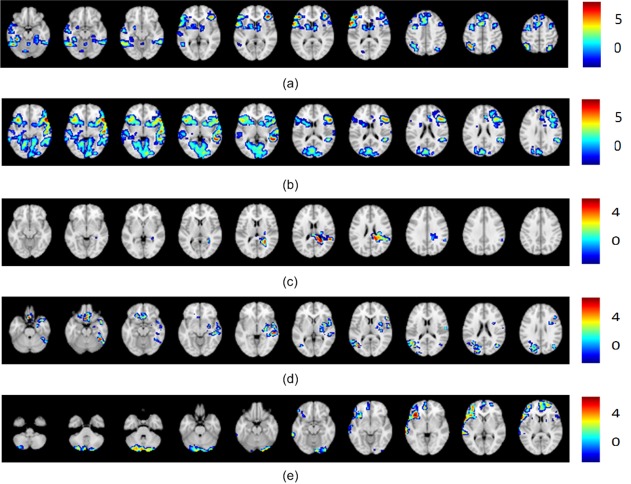
Other interesting cases: (a) Case 5 illustrating activation pattern slices where only the fixed LI method yielded the bilateral classification and all the other methods classified the activation as right dominant. (b) Case 6 illustrating an activation pattern where all the results agree on left dominant except for the classification of one rater as bilateral. (c) Case 7 illustrating slices of an activation pattern that received a majority classification for left dominant with the rest of the classifications being null activation, and with the IPCA‐Fuzzy method reflecting in percentages the similarities of this pattern to both classifications. (d) Case 8 illustrating slices of activation pattern where there is complete disagreement among the raters (three of them give three different classification results), and yet the data driven methods, IPCA‐NNC and IPCA‐Fuzzy, as well as both LI methods come in support of one of the rater that classified this pattern as left dominant. (e) Case 9 illustrating an activation pattern where fixed LI and all the raters identified it as right dominant disagreeing with the data driven methods and bootstrap LI who identified it as bilateral.
For case 6 (Fig. 6b), one rater scored bilateral classification while the two other raters, and the other methods classified this activation as left dominant. This result from one rater highlights subjective judgment and motivates the development of a data driven method to augment the decision making and minimize misclassifications. Raters varied in the confidence in their classification (scored 3,4,2) perhaps made problematic by low intensity activation in the right Broca's ROI.
Case 7 (Fig. 6c) provides slices of an activation pattern that has different classifications, including the “others” category. All slices that exhibit activation are shown. Both LI methods as well as two of the three raters classified the pattern as left dominant, one of the raters as well as the IPCA‐NNC method classified the pattern as null activation. However, the IPCA‐Fuzzy method provided a 65.5% similarity to the left dominant classification and 34.5% similarity to the null activation, which reflects the trend in the way the different methods classified the pattern and indicates that the pattern is more likely to be left dominant. Raters had low confidence in their assignment (scored 2,3,2). In this case, the results of our method sided with 65.5% similarity with the majority classification results for left dominant. It did however provide a 34.5% similarity for other which is compatible with the low confidence ratings.
The activation pattern in Figure 6d (case 8) also shows disagreement in the visual rating results—each rater gave a different classification result. Both LI methods as well as both IPCA‐NNC and IPCA‐Fuzzy methods agree with a left dominant classification. The IPCA‐Fuzzy gave a 100% similarity to both LI methods and thus augment the decision making process. All three raters gave the lowest confidence rating (scored 1,1,1).
The activation patterns of case 9 (Fig. 6e) show the limitation of the proposed IPCA‐NNC and IPCA‐Fuzzy methods, where IPCA–NNC and the IPCA‐DFC disagreed with the majority classification for right dominant language. All three raters and the fixed threshold LI agreed on right dominant classification, while the bootstrap LI agreed with the IPCA‐NNC and the high similarity provided by the IPCA‐DFC method for bilateral classification (68.7%).We believe that this may have been caused by the nature of the generated artificial data, where there may not have been a pattern in category R generated that was closer to the test data. Although more artificial data means more variability, a fixed amount of artificial data that is large enough should be sufficient. It is important to note however that the IPCA‐DFC did provide a similarity 31.3% to the right dominant classification. Such limitation is unavoidable even in data driven method even when a sizable number of artificial datasets was considered.
Statistical Analysis for Group Separation
The statistical analysis related to group separation is performed on the basis of the aforementioned four groups. Since intensity normalization is performed, scanner and site effects on group separation are also examined.
Demographic and Clinical Variables
Previous studies have examined the association between demographic data and clinical variables with the laterality of the language activation patterns; however, the participants in those studies were not restricted to pediatric populations [Gaillard et al. 2007; Springer et al., 1999; Woermann et al., 2003]. In this study, we seek to investigate such associations within a pediatric population.
Patients versus control populations affected significantly results of group separation (Fisher's Exact test, P = 0.0029). Furthermore, handedness also affected significantly the results of group separation (with right handedness considered typical and the rest as atypical, with a Fisher's Exact test, P = 1.25e‐5 for all subjects and P = 0.013 for patients only). The results also show that the patient population and atypical handedness have more cases classified into the right dominant category. Excluding the right dominant category, the same tests were carried out with the patient vs. control populations (Fisher's Exact test, P = 0.67) and handedness (Fisher's Exact test, P = 0.086 for all subjects and P = 0.12 for patient only), and the results show no difference. There was no association for gender with the group separation (Fisher's Exact test, P = 0.59 for all, P = 1 for controls, and P = 0.51 for patients), or for age (Friedman Test, χ2(3)=3.048, P = 0.384 for all subjects, and χ2(3) = 0.624, P = 0.891 for patients only).
We found no effects of age at seizure onset (Friedman Test, χ2(2) = 0.401, P = 0.818), duration of epilepsy (Friedman Test, χ2(2) = 0.638, P = 0.727), seizure focus (Fisher's Exact test, P = 0.90), seizure etiology (Fisher's Exact test, P = 0.87) on group separation.
Comparison to Results of Traditional Methods
According to the results in Table 1, the three raters revealed good inter‐rater agreement with IPCA in the four categories (Kappa 0.61–0.71). Furthermore, the ROI LI showed good inter‐rater agreement with IPCA in the four categories (Kappa 0.59 from LI and 0.73 from bootstrap LI). The special case is one noise activation map, which is correctly recognized as belonging to the bilateral category.
As shown in Table 2, the three raters exhibited good inter‐rater agreement with the IPCA‐DFC (Kappa 0.63–0.73). The LIs also showed good inter‐rater agreement with IPCA‐DFC (Kappa 0.61 from LI and 0.75 from bootstrap LI).
Table 2.
Categorization results between each method and the IPCA‐DFC
| Rater1 | Rater2 | Rater3a | LI | LI | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (Fixed threshold) | (Bootstrap) | |||||||||||||||||||
| PCA | L | R | B | O | L | R | B | O | L | R | B | O | L | R | B | O | L | R | B | O |
| L | 91 | 0 | 5 | 4 | 93 | 0 | 4 | 3 | 89 | 1 | 5 | 4 | 89 | 2 | 9 | 0 | 91 | 3 | 6 | 0 |
| R | 0 | 9 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 8 | 0 | 1 | 0 | 7 | 2 | 0 | 0 | 8 | 1 | 0 |
| B | 1 | 2 | 5 | 0 | 2 | 3 | 3 | 0 | 3 | 2 | 3 | 0 | 0 | 3 | 5 | 0 | 0 | 0 | 8 | 0 |
| O | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 5 | 0 | 1 | 0 | 5 | 1 | 1 | 0 | 3 | 1 | 0 | 0 | 4 |
There is a special case for rater 3 in other category.
As mentioned previously, 90 cases exhibited agreement, and 32 cases exhibited disagreement among all results (obtained from all methods). Results of rater 1 shows no difference in confidence rating between agree and disagree groups at significant level of 0.017 based on Bonferroni correction (Mann‐Whitney U test, P = 0.43). However for the other two raters, there are significant differences in confidence rating (Mann‐Whitney U test, P = 0.012 for rater 2 and P = 1.47e‐5 for rater 3), and we can further conclude that the mean confidence rating in the agreed upon cases is higher than in the disagreed upon cases. Also for LI and bootstrap LI, we compared the differences between the boundary values (−0.2 and 0.2) and the LI values of the Broca's area and Wernicke's area respectively. Differences are calculated between the LI value and its nearest boundary value, and shows differences between the agreed upon cases and disagreed upon cases at significant level of 0.025 based on Bonferroni correction (Mann‐Whitney U test, P = 0.02 for LI Broca's area, P = 0.02 for LI Wernicke's area). However, the results show no differences for bootstrap LI in both Broca's and Wernicke's areas (Mann‐Whitney U test, P = 0.04 for bootstrap LI Broca's area; and P = 0.61 in Wernicke's area). The results show that it is statistically significant for fixed LI that the values of disagreed upon cases are closer to these boundary values. However, the bootstrap LI shows no such significance possibly due to the weighted mean results based on only 50% of the data points at the central part of the histogram or the stringency of the Bonferroni correction process.
Comparison Among Different in DFC
The aforementioned results are based on in DFC. In our case, we use different values in the DFC to do the group separation on the samples, and perform the test on the results when respectively to examine if there is difference among different values of . We find that the value has no significant effects on the group separation (Friedman Test, χ2(4) = 6.4, P = 0.171). The result shows that the model is insensitive to the value of , and a probable reason for this may be related to the generated artificial data and the weight values chosen.
DISCUSSION
This study extended our previous work (1) from a 2D feature space to a 4D feature space (number of eigenvectors by using the incremental PCA method); (2) from a two‐category (left dominant and right dominant) classification to a four‐category classification (left dominant, right dominant, bilateral, and others); (3) from using only the real data to including a large number of artificial data that was integrated in the classification process; (4) from using solely the nearest neighbor classifier to including the distance‐based fuzzy classifier to resolve cases near the boundary in between categories; and (5) examining the relation between the classified groups and demographic and clinic information.
Another important contribution of this work is in the way the artificial data was generated then reassessed for inclusion. The main purpose for using synthetic data is based on increasing certainty in defining the different data patterns as defined in Figure 1. When we generate the data according to these patterns, steps used to remove specific synthetic data are taken in order to reduce the error in the training phase, as the initial label used for the synthetic data might be the wrong one to begin with. It is important to know that through this procedure, we did not affect any information related to the real‐world data but only strengthened the process for classifying it, since the synthetic data used in the classification process reflect the four categories (L, R, B, and O) in a more meaningful way. As more patients and control subjects are included in the collaborative repository, the more thorough the IPCA analysis will become; eventually recourse to artificial data may not be necessary.
There are several methods for determining language dominance, qualitative/subjective by visual rating, or by quantitative LI based whether on hemisphere or regions [Seghier, 2008]. There is no agreed upon method; there is some evidence the regional LI rather than hemispheric LI is better [Seghier, 2008], the former is based on a priori assumptions. Some investigators use a generous regional ROI [Jansen et al., 2006] others more restricted [Fernandez, et al., 2001, 2003]. In practice when one rates visually, one focuses on activation in classical (canonical) areas. Here we are using a data driven method to overcome these obstacles. For these reasons we have compared our results with commonly used methods. For most patients all methods agree; we are able to comment on when, and how they partially disagree. These limitations are important and informative. In retrospect, this is both a strength and a limitation as visual analysis allows looking outside canonical areas [Fernandez et al., 2001] obtained the visual rating results from six senior neurologists, and achieved fully concordant results except for one patient. And [Gaillard et al., 2002] also proved that clinical visual interpretation of language lateralization is comparable to quantitative ROI analysis.
At this juncture of data availability, and for this particular study, the inclusion of the artificial data allowed the proposed IPCA‐based methods to encompass the four‐category classification, including bilateral and others categories. For the large majority of cases (90 out of 122), there is agreement across all methods; the small minority (32 out of 122) occasions where one or other methods do not agree are illustrative of the limitations of current methods as well as the approach proposed here. As reported by others, it is rare to have overt disagreement; most differences are where one method is lateralized and another is bilateral. When the LI is near 0.2, the boundary between typical and atypical language, there is rare disagreement between the LI methods as activation is known to change according to threshold used (fixed vs. bootstrap, case 4). Similarly, when activation maps are poor or LI is close to 0.2, there may be subjective differences among raters (cases 6‐8) or with objective LI assessment differences including the extent of regional mask employed (cases 4‐5). These differences also highlight the clinical use of rigid criteria that in fact rests on a continuum. With the parceling methods proposed here, differences, when they occur, are also found at boundaries (case 9).Knowing the circumstances where uncertainties may occur, allows for more judicious use of fMRI data. We found that the confidence rating in the agreed upon cases is higher than in the disagreed upon cases (mean confidence rating of agreed upon cases is higher than that of the disagreed upon cases). The values of disagreed upon cases are closer to these boundary values.
There are few comparison studies of which we are aware that examine the different rating system (in [Gaillard et al., 2002], we compared visual rating at several thresholds and a LI at several thresholds). The boot strap method is designed to effectively examine data at several thresholds and select the optimal threshold for that person, and this is what we now use in practice. However some centers and reviewers prefer to use a single threshold, therefore we have provided a range of assessments and we believe this helps contribute to the literature in this way. In the absence of invasive tests (Wada procedure), which are also imperfect, we thought it best to provide comparison to commonly used assessments. The LI method provided by [Fernandez et al., 2001, 2003] uses an adjusted threshold to identify the activated pixels based on inter‐subjects variability in general activation levels. On the other hand, [Adcock et al., 2003, Branco et al., 2006, Suarez et al., 2009, and Pillai and Zaca, 2011] all included weighted voxels to calculate the LI value. Yet, different weighting functions were adopted and compared. As discussed in [Arora et al., 2009], it showed that proper consideration of midline exclusion was necessary due to the higher concordance with WADA test.
The merits of the proposed data driven methods include artificial data generation, as a means to overcome the subjective nature of visual rating, and the shortcomings of ROI‐based LI methods. Furthermore, corollary contributions can be derived from the observation that the DFC can give the similarity percentage to the categories for better representation of the pattern, especially for those patterns near the boundaries in between categories, where raters may disagree and LI methods (fixed LI and bootstrap LI) may not converge on classification.
Although some mismatches were observed among the IPCA‐based algorithms, the visual rating and LI‐based methods, the IPCA‐based algorithm in most cases classified the activation pattern in the same category as the one found in the majority results across all methods. Furthermore, when disagreement happened, the IPCA‐DFC method provided similarity percentages that always included the majority category across methods (visual rating and LI methods). It is useful for the cases that have close similarity percentages in more than one category. For those cases, verification process may be utilized such as visual rating by the physician to assure proper category assignment. Unfortunately, there is no golden standard that would allow us to assess which method is better. Conventional ratings have excellent but not complete agreement with invasive methods [Gaillard et al., 2002; Pouratian et al., 2002]. Moreover, there are clear limitations to the use of invasive methods – the Wada test or electrocorticography — as “gold standards”, like fMRI, may be flawed and under various circumstances yield faulty information [Gaillard et al., 2011]. Finally, recent clinical practice [De Ribaupierre et al., 2012; Szaflarski et al., 2012; Wilke et al., 2011] in most pediatric epilepsy centers, especially for younger patients, has de‐emphasized the Wada test. As the standard is not established we present data for commonly used methods and report our observations on their concordance, not their “correctness.” Further, we have made some observations about when and how partial discordance arises. We find they are mostly boundary issues hence our efforts to seek data driven means to segregate and classify datasets. As there are few such comparison studies, IPCA‐based methods could thus serve as an alternative method to corroborate existing LI and visual rating classification methods.
The fuzzy classifier for group separation is empirically proven to improve classification and may overcome human rating errors as well as the limitation of a priori assumptions upon re‐evaluation. Furthermore, instead of a blind clustering of the given real datasets, the idea of using artificial activation patterns helps the method to be language patterns‐oriented. Since both classifiers of the proposed data driven methods (IPCA‐NNC and IPCA‐DFC) were distance based, the generation of the artificial data does affect the results as we have indicated in at least one of the cases. Such is the limitation in the inclusion of artificial data in terms of the way it is generated and in determining how large such a dataset should be to make the classification process more effective. With all these issues in mind, the proposed approach to classify pediatric fMRI datasets could promote objective assessments of large datasets and can serve to interrogate data for a multitude of clinical variables.
We observed no effect of age, age at seizure onset, duration of epilepsy, seizure focus, or seizure etiology to the group separation. However, based on the clinical information, these results are taken with some caution as the sample size, although coming from five different hospitals, is still limited. We intend to pursue this type of analysis as more data is collected within our consortium of hospitals. It is also important to note that just as reported in other reported studies, we found patient/control populations as well as handedness to have significant effect on group separation, with patient population and atypical handedness as having more cases being classified as right dominant. Also, some of our patients had a very diverse range of problems, including brain tumors and vascular malformations, which might affect the functional MRI. However, the data from previous studies suggests this may be so for larger lesions, generally absent in this study [Liegeois, 2004], evidence is mixed for smaller lesions but likely small [Duke et al., 2012; Wellmer et al., 2009]. In addition data from 15O water and FDG PET suggests these abnormalities do not disrupt the BOLD signal [Duke et al, 2012; Gaillard et al, 2011].
This study also emphasizes that a single site is unlikely to evaluate a sufficient number of patients to identify the array of variant activation patterns; the consortium of imaging epilepsy centers provides the necessary collaborative effort to overcome this limitation to optimizing the role of advanced technologies for improved clinical care. Thus, with a large sample, inter‐subject variability can be more reliably characterized for control populations as well as heterogeneous patient groups. With the growing data source from the consortium, more meaningful classifications and statistical analysis can be expected. New associations between the demographic as well as clinic information and the activation maps are expected to be discovered. Moreover, with the proposed IPCA, which progressively includes more eigenvectors without re‐computing the entire Eigen system, there is an opportunity to break down the three classes into more specific categories to include, perhaps, all the 15 patterns shown in Figure 1, at least in theory, which are needed to describe more fully the lateralization of brain activation related to language tasks.
ACKNOWLEDGMENTS
The authors are also very thankful for the philanthropic support provided through the Ware Foundation and the joint Neuro‐Engineering Program with Miami Children's Hospital.
INCREMENTAL PCA ALGORITHM
Each volume was transformed into a 1D vector with q elements where q is defined as the product M* N* L, where M, N, and L are the resolutions of the activation map in the x, y, and z axes, respectively. The i th subject is represented by a specific column x i in matrix X. The mean matrix is composed of n column‐wise mean , which means the mean vector is composed of the mean voxels on every row of matrix X. Consequently, the centered matrix is obtained by . Suppose there are two matrices A and B and that M An1 and MBn2 are their mean matrices, respectively. To compute the eigenvector of matrix C which concatenates matrices A and B, denoted as C = [A, B] where C is now too large to be loaded, the largest k eigenvectors and eigenvalues of matrix C, will be computed following the procedural steps given in Table AI.
The core of the algorithm is based on partitioning the Singular Value Decomposition (SVD) of a large matrix. Suppose we already performed the SVD of the centered matrix A denoted by , where . The goal is to now compute the SVD of matrix , where k 1 and k 2 are the number of columns in A and B respectively and .Only and are considered for efficient storage and fast computing since is no longer saved as it is no longer needed in the decomposition of . Note that if we use directly, we will lose this computational gain. Therefore, an alternative of defined as , which has been proven to have the same covariance matrix as , is utilized instead for implementing this particular incremental algorithm.
Given that (step 5 in the Table IV), then (it should be noted that 0 in the equation means a nested matrix where all its elements are zero). Also, (step 6 through 8 in the Table IV). Let , on which we perform the SVD to get . Then we obtain (step 9 through 12 in the Table IV). It should be noted that if only the first k largest eigenvectors are considered, those parameters such as U, V will only contain the first k largest eigenvectors and eigenvalues instead of all.
REFERENCES
- Abbott DF, Waites AB, Lillywhite LM, Jackson GD (2010): fMRI assessment of language lateralization: An objective approach,Neuroimage 50:1446–1455. [DOI] [PubMed] [Google Scholar]
- Adcock JE, Wise RG, Oxbury JM, Oxbury SM, Matthews PM (2003): Quantitative fMRI assessment of the differences in lateralization of language‐related brain activation in patients with temporal lobe epilepsy. NeuroImage 18:423–438. [DOI] [PubMed] [Google Scholar]
- Alexander GE, Moeller JR (1994): Application of the scaled subprofile model to functional imaging in neuropsychiatric disorders: A principal component approach to modeling brain function in disease. Hum Brain Mapp 2:79–94. [Google Scholar]
- Arora J, Pugh K, Westerveld M, Spencer S, Spencer DD, Todd Constable R (2009): Language lateralization in epilepsy patients: fMRI validated with the Wada procedure. Epilepsia 50:2225–2241. [DOI] [PubMed] [Google Scholar]
- Belle GV, Fisher LD, Heagerty PJ, Lumely T (2004):Biostiatistics: A Methodology for the Health Sciences, 2nd ed. Hoboken, New Jersey:Wiley. [Google Scholar]
- Berl MM, Mayo J, Parks EN, Rosenberger LR, VanMeter J, Ratner NB, Vaidya CJ, Gaillard WD (2012): Regional differences in the developmental trajectory of lateralization of the language network. Hum Brain Mapp, DOI:10.1002/hbm.22179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder JR, Rao SM, Hammeke TA, Frost JA, Bandettini PA, Jesmanowicz A et al., (1995): Lateralized human brain language systems demonstrated by task subtraction functional magnetic resonance imaging. Arch Neurol 52:593–601. [DOI] [PubMed] [Google Scholar]
- Binder JR, Swanson SJ, Hammeke TA, Morris GL, Mueller WM, Fischer M et al., (1996): Determination of language dominance using functional MRI: A comparison with the Wada test. Neurology 46:978–984. [DOI] [PubMed] [Google Scholar]
- Bookheimer S (2002): Functional MRI OF LANGUAGE: New approaches to understanding the cortical organization of semantic processing. Annual Rev Neurosci 25:151–188. [DOI] [PubMed] [Google Scholar]
- Branco DM, Suarez RO, Whalen S, O'shea JP, Nelson AP, da Costa JC, Golby AJ (2006): Functional MRI of memory in the hippocampus: Laterality indices may be more meaningful if calculated from whole voxel distributions. NeuroImage 32:592–602. [DOI] [PubMed] [Google Scholar]
- Burgund ED, Kang HC, Kelly JE, Bucker RL, Snyder AZ, Petersen SE, Schlaggar BL (2002): The feasibility of a common stereotactic space for children and adults in fMRI studies of development. Neuroimage 17:184–200. [DOI] [PubMed] [Google Scholar]
- Cabeza R, Nyberg L (2000): Imaging cognition II: An empirical review of 275 PET and fMRI studies. J Cogn Neurosci 12:1–47. [DOI] [PubMed] [Google Scholar]
- Cabrerizo M, Ayala M, Jayakar P, Adjouadi M (2011): Classification and medical diagnosis of scalp EEG using artificial neural networks. Int J Innovative Computing Information Control 7:6905–6918. [Google Scholar]
- Cohen J (1960): A coefficient of agreement for nominal scales. Educational Psychological Measurement 20:37–46. [Google Scholar]
- Dasarathy BV (1991): Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques.
- De Ribaupierre S, Wang A, Hayman‐Abello S (2012): Language mapping in temporal lobe epilepsy in children: Special considerations. Epilepsy Res Treat 2012:1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Duke ES, Tesfaye M, Berl MM, Walker JE, Ritzl EK, Fasano RE, Conry JA, Pearl PL, Sato S, Theodore WH, Gaillard WD (2012): The effect of seizure focus on regional language processing areas. Epilepsia 53:1044–1050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Faria AV, Zhang J, Oishi K, Li X, Jiang H, Akhter K, Hermoye L, Lee SK, Hoon A, Stashinko E, Miller MI, van Zijl PC, Mori S (2010): Atlas‐based analysis of neurodevelopment from infancy to adulthood using diffusion tensor imaging and applications for automated abnormality detection. Neuroimage 52:415–428. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernandez G, de Greiff A, von Oertzen J, Reuber M, Lun S, Klaver P, Ruhlmann J, Reul J, and Elger C.E. (2001): Language mapping in less than 15 minutes: Real‐time functional MRI during routine clinical investigation. Neuroimage 14:585–594. [DOI] [PubMed] [Google Scholar]
- Fernandez G, Specht K, Weis S, Tendolkar I, Reuber M, Fell J, Klaver P, Ruhlmann J, Reul J, and Elger C.E. (2003): Intrasubject reproducibility of presurgical language lateralization and mapping using fMRI. [DOI] [PubMed]
- Forman S, Cohen J, Fitzgerald M, Eddy W, Mintun M, Noll D (1995): Improved assessment of significant activation in functional magnetic resonance imaging (fMRI): Use of a cluster‐size threshold. Magn Resonance Med 33:636–647. [DOI] [PubMed] [Google Scholar]
- Friston K, Worsley K, Frackowiak R, Mazziotta J, Evans A (1994): Assessing the significance of focal activations using their spatial extent. Hum Brain Mapp 1:210–220. [DOI] [PubMed] [Google Scholar]
- Frost JA, Binder JR, Springer JA, Hammeke TA, Bellgowan PS, Rao SM et al., (1999): Language processing is strongly left lateralized in both sexes. Evidence from functional MRI. Brain 122( Part 2):199–208. [DOI] [PubMed] [Google Scholar]
- Gaillard WD (2004): Functional MR imaging of language, memory, and sensorimotor cortex. Neuroimaging Clin N Am 14:471–485. [DOI] [PubMed] [Google Scholar]
- Gaillard WD, Balsamo L, Xu B, Grandin CB, Braniecki SH, Papero PH et al., (2002): Language dominance in partial epilepsy patients identified with an fMRI reading task. Neurology 59:256–265. [DOI] [PubMed] [Google Scholar]
- Gaillard WD, Balsamo L, Xu B, McKinney C, Papero PH, Weinstein S et al., (2004): fMRI language task panel improves determination of language dominance. Neurology 63:1403–1408. [DOI] [PubMed] [Google Scholar]
- Gaillard WD, Berl MM, Moore EN, Ritzl EK, Rosenberger LR, Weinstein SL et al., (2007): Atypical language in lesional and nonlesional complex partial epilepsy. Neurology 69:1761–1771. [DOI] [PubMed] [Google Scholar]
- Gaillard WD, Cross JH, Duncan JS, Stefan H, Theodore WH (2011): Task force on practice parameter imaging guideline for the international league against epilepsy, commission for diagnostics, “epilepsy imaging study guideline criteria: Commentary on diagnostic testing study guidelines and practice parameters. Epilepsia, 52:9, 1750–1756. [DOI] [PMC free article] [PubMed]
- Guillen MR, Adjouadi M, Bernal B, Ayala M, Barreto A, Rishe N, Lizarraga G, You X, Gaillard W (2009): A knowledge‐based database system for visual rating of fMRI activation patterns for brain language networks InThe Fifth Richard Tapia Celebration of Diversity in Computing Conference: Intellect, Initiatives, Insight, and Innovations, TAPIA '09 (pp.1–6). New York, NY, USA:ACM. [Google Scholar]
- Holland SK, Plante E, Byars A, Strawsburg RH, Schmithorst VJ, Ball WS Jr. (2001),Normal fMRI brain activation patterns in children performing a verb generation task. NeuroImage 14:837–843. [DOI] [PubMed] [Google Scholar]
- Jansen A, Menke R, Sommer J, Förster AF, Bruchmann S, Hempleman J, Weber B et al., (2006): The assessment of hemispheric lateralization in functional MRI–robustness and reproducibility. NeuroImage 33:204–217. [DOI] [PubMed] [Google Scholar]
- Jenkinson M, Bannister P, Brady M, Smith S (2002): Improved optimization for the robust and accurate linear registration and motion correction of brain images. Neuroimage 17:825–841. [DOI] [PubMed] [Google Scholar]
- Jenkinson M, Smith S (2001): A global optimisation method for robust affine registration of brain images. Med Image Anal 5:143–156. [DOI] [PubMed] [Google Scholar]
- Jolliffe IT (2002):Principal Component Analysis, 2nd ed. New York:Springer. [Google Scholar]
- Joliffe IT, Morgan BJ (1992): Principal component analysis and exploratory factor analysis. Stat Methods Med Res 1:69–95. [DOI] [PubMed] [Google Scholar]
- Just MA, Carpenter PA, Keller TA, Eddy WF, Thulborn KR (1996): Brain activation modulated by sentence comprehension. Science 274:114–116. [DOI] [PubMed] [Google Scholar]
- Kraemer HC, Periyakoil VS, Noda A (2005):Agreement Statistics: Kappa Coefficients in Medical Research, in Tutorials in Biostatistics: Statistical Methods in Clinical Studies, Volume1, Chichester, UK:Wiley. [Google Scholar]
- Lahlou M, Guillen MR, Adjouadi M, Gaillard WD (2006):An online web‐based repository site of fMRI medical images and clinical data for childhood epilepsy. The 11th world congress on internet in medicine Ontario, Canada:Mednet: pp120–127. [Google Scholar]
- Liegeois F, Connelly A, Cross JH, Boyd SG, Gadian DG, Vargha‐Khadem F et al., (2004): Language reorganization in children with early‐onset lesions of the left hemisphere: An fMRI study. Brain 127:1229–1236. [DOI] [PubMed] [Google Scholar]
- Mbwana J, Berl MM, Ritzl EK, Rosenberger L, Mayo J, Weinstein S et al., (2009): Limitations to plasticity of language network reorganization in localization related epilepsy. Brain 132:347–356. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muzik O, Chugani DC, Juhász C, Shen C, Chugani HT (2000): Statistical parametric mapping: Assessment of application in children. Neuroimage 12:538–549. [DOI] [PubMed] [Google Scholar]
- Pillai JJ, Zaca D (2011): Relative utility for hemispheric lateralization of different clinical fMRI activation tasks within a comprehensive language paradigm battery in brain tumor patients as assessed by both threshold‐dependent and threshold‐independent analysis methods. NeuroImage 54(Suppl 1):S136–S145. [DOI] [PubMed] [Google Scholar]
- Pouratian N, Bookheimer SY, Rex DE, Martin NA, Toga AW (2002): Utility of preoperative functional magnetic resonance imaging for identifying language cortices in patients with vascular malformations. J Neurosurg 97:21–32. [DOI] [PubMed] [Google Scholar]
- Price C (2000): The anatomy of language: Contributions from functional neuroimaging. J Anat 197:335–359. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pujol J, Deus J, Losilla JM, Capdevila A (1999): Cerebral lateralization of language in normal left‐handed people studied by functional MRI. Neurology 52:1038–1043. [DOI] [PubMed] [Google Scholar]
- Ramsey NF, Sommer IE, Rutten GJ, Kahn RS (2001): Combined analysis of language tasks in fMRI improves assessment of hemispheric dominance for language functions in individual subjects. Neuroimage 13:719–733. [DOI] [PubMed] [Google Scholar]
- Rasmussen T, Milner B (1977): The role of early left‐brain injury in determining lateralization of cerebral speech functions. Ann NY Acad Sci 299:355–369. [DOI] [PubMed] [Google Scholar]
- Rorden C, Brett M (2000): Stereotaxic display of brain lesions. Behav Neurol 12(191–200):191–200. [DOI] [PubMed] [Google Scholar]
- Ross D, Lim J, Lin R, Yang M (2008): Incremental learning for robust visual tracking. Int J Comp Vis, special issue: Learning for Vision. [Google Scholar]
- Samanwoy G, Adeli H (2008): Principal component analysis‐enhanced cosine radial basis function neural network for robust epilepsy and seizure detection. IEEE Trans Biomed Eng 55:512–518. [DOI] [PubMed] [Google Scholar]
- Seghier ML (2008): Laterality index in function MRI: Methodological issues. Magn Reson Imaging 26:594–601 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shakhnarovish G, Darrell T, Indyk T (2008): Nearest‐Neighbor Methods in Learning and Vision. IEEE Transactions on Neural Networks, 19:2, 377–377.
- Spreer J, Arnold S, Quiske A, Wohlfarth R, Ziyeh S, Altenmuller D et al., (2002): Determination of hemisphere dominance for language: comparison of frontal and temporal fMRI activation with intracarotid amytal testing. Neuroradiology 44:467–474. [DOI] [PubMed] [Google Scholar]
- Springer JA, Binder JR, Hammeke TA, Swanson SJ, Frost JA, Bellgowan PS et al., (1999): Language dominance in neurologically normal and epilepsy subjects: A functional MRI study. Brain 122( Part 11):2033–2046. [DOI] [PubMed] [Google Scholar]
- Suarez RO, Whalen S, Nelson AP, Tie Y, Meadows M‐E, Radmanesh A, Golby AJ (2009): Threshold‐independent functional MRI determination of language dominance: A validation study against clinical gold standards. Epilepsy Behav 16:288–297. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Szaflarski JP, Binder JR, Possing ET, McKiernan KA, Ward BD, Hammeke TA (2002): Language lateralization in left‐handed and ambidextrous people: fMRI data. Neurology 59:238–244. [DOI] [PubMed] [Google Scholar]
- Szaflarski JP, Schmithorst VJ, Altaye M, Byars AW, Ret J, Plante E et al., (2006): A longitudinal functional magnetic resonance imaging study of language development in children 5 to 11 years old. Ann Neurol 59:796–807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Szaflarski JP, Rajagopal A, Altaye M, Byars AW, Jacola L, Schmithorst VJ, Schapiro MB et al., (2012): Left‐handedness and language lateralization in children. Brain Res 1433:85–97. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tito M, Cabrerizo M, Ayala M, Jayakar P, Adjouadi M (2010): A comparative study of intracranial EEG files using nonlinear classification methods. Annals Biomed Eng 38:187–199. [DOI] [PubMed] [Google Scholar]
- Tito M, Cabrerizo M, Ayala M, Jayakar P, Adjouadi M (2009): Seizure detection: An assessment of time‐ and frequency‐based features in a unified 2‐D decisional space using nonlinear decision functions. J Clin Neurophysiol 26:381–391. [DOI] [PubMed] [Google Scholar]
- Turk M, Pentland A (1991): Eigenfaces for recognition. J Cogn Neurosci 3:71–86. [DOI] [PubMed] [Google Scholar]
- Wang J, Barreto A, Rishe N, Andrian J, Adjouadi M. A fast incremental multilinear principal component analysis algorithm. Int J Innovative Computing Inform Control. 7:6019–6040. [Google Scholar]
- Wellmer J, Weber B, Urbach H, Reul J, Fernandez G, Elger CE (2009): Cerebral lesions can impair fMRI‐based language lateralization. Epilepsia 50:2213–2224. [DOI] [PubMed] [Google Scholar]
- Wilke M, Schmithorst VJ (2006): A combined bootstrap/histogram analysis approach for computing a lateralization index from neuroimaging data. Neuroimage 33:522–530. [DOI] [PubMed] [Google Scholar]
- Wilke M, Pieper T, Lindner K, Dushe T, Staudt M, Grodd W, Holthausen H et al., (2011): Clinical functional MRI of the language domain in children with epilepsy. Hum Brain Mapp 32:1882–18893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Woermann FG, Jokeit H, Luerding R, Freitag H, Schulz R, Guertler S et al., (2003): Language lateralization by Wada test and fMRI in 100 patients with epilepsy. Neurology 61:699–701. [DOI] [PubMed] [Google Scholar]
- Woods RP, Dodrill CB, Ojemann GA (1988): Brain injury, handedness, and speech lateralization in a series of amobarbital studies. Ann Neurol 23:510–518. [DOI] [PubMed] [Google Scholar]
- Woolrich MW, Ripley BD, Brady M, Smith SM (2001): Temporal autocorrelation in univariate linear modeling of FMRI data. Neuroimage 14:1370–1386. [DOI] [PubMed] [Google Scholar]
- Worsley K, Evans A, Marrett S, Neelin P (1992): A three‐dimensional statistical analysis for CBF activation studies in human brain. J Cerebral Blood Flow Metabolism 12:900–900. [DOI] [PubMed] [Google Scholar]
- You X, Adjouadi M, Guillen MR, Ayala M, Barreto A, Rishe N, Sullivan J, Dlugos D, VanMeter J, Morris D, Donner E, Bjornson B, Smith ML, Bernal B, Berl M, Gaillard WD (2010): Sub‐patterns of language network reorganization in pediatric localization related epilepsy: A multisite study. Hum Brain Mapp 32:4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- You X, Adjouadi M, Wang J, Guillen MR, Bernal B, Sullivan J, Donner E, Bjornson B, Berl M, Gaillard WD (2012): A decisional space for fmri pattern separation using the principal component analysis–A comparative study of language networks in pediatric epilepsy. Hum Brain Mapp. DOI: 10.1002/hbm.22069. [DOI] [PMC free article] [PubMed] [Google Scholar]