

Abstract
Purpose
The contributions of voice onset time (VOT) and fundamental frequency (F0) were evaluated for the perception of voicing in syllable-initial stop consonants in words that were low-pass filtered and/or masked by speech-shaped noise. It was expected that listeners would rely less on VOT and more on F0 in these degraded conditions.
Method
Twenty young normal-hearing listeners identified modified natural speech tokens that varied by VOT and F0 in several conditions of low-pass filtering and masking noise. Stimuli included /b/-/p/ and /d/-/t/ continua that were presented in separate blocks. Identification results were modeled using mixed-effects logistic regression.
Results
When speech was filtered and/or masked by noise, listeners’ voicing perceptions were driven less by VOT and more by F0. Speech-shaped masking noise exerted greater effects on the /b/-/p/ contrast, while low-pass filtering exerted greater effects on the /d/-/t/ contrast, consistent with the acoustics of these contrasts.
Conclusion
Listeners can adjust their use of acoustic-phonetic cues in a dynamic way that is appropriate for challenging listening conditions; cues that are less influential in ideal conditions can gain priority in challenging conditions.
Keywords: speech perception, noise, voicing contrast, bandwidth
INTRODUCTION
Consonant voicing contrasts are very common in the world’s languages (Ladefoged & Maddieson, 1996) and the perception of acoustic cues underlying these contrasts has been explored thoroughly for normal hearing listeners and other listeners in quiet conditions. Much less is known about how voicing is perceived by individuals who rely on low-frequency hearing (i.e. individuals with hearing impairment [HI]) or individuals listening in background noise. It is clear that perception of voicing remains accurate across a wide range of signal degradations, including high or low-pass filtering (Miller & Nicely, 1955), masking noise (Miller & Nicely, 1955; Wang and Bilger, 1973; Phatak & Allen, 2007; Phatak, Lovitt and Allen, 2008), hearing impairment (Bilger & Wang, 1976), spectral degradation (Shannon, Zeng, Kamath, Wygonski & Ekelid 1995; Xu, Thompson & Pfingst, 2005) or cochlear implantation (Friesen, Shannon, Başkent & Wang 2001). It is thus often stated that the amount of “information transfer” is high for the voicing feature relative to other consonant features. This finding is so consistent that some studies dispense with potential voicing confusions in the very design of the experiment (Dubno & Levitt, 1981). Despite this generalized high level of success, the constraints that face listeners in noise and/or those who rely on low-frequency hearing (e.g. listeners with hearing loss) are likely to change the means by which voicing is perceived. That is, the voice information could be recovered via different cues in varied listening conditions. In the current study, we show that in some degraded conditions, the role of voice onset time decreases and the role of fundamental frequency (F0) increases for the perception of word-initial voicing in stop consonants.
Cues for voicing in stop consonants
Although perception of voicing in word-initial stop consonants has been largely attributed to VOT (the duration between consonant release and the onset of voicing for the following vowel; Lisker & Abramson, 1964), F0 plays a role as well. F0 is higher after voiceless stops than after voiced stops (House & Fairbanks, 1953), and this difference generally lasts roughly 100 ms into a vowel (Hombert, 1975). While F0 is not a very potent cue for stop sounds with canonical voiced or voiceless VOTs (Abramson & Lisker, 1985), it can exert potent influence under certain conditions, such as for sounds with ambiguous VOTs (Haggard, 1970, Abramson & Lisker, 1985). When F0 contour conflicts with VOT, reaction time is slowed (Whalen, Abramson, Lisker & Mody, 1993), suggesting that listeners are sensitive to F0 information even when identification curves suggest otherwise.
Another acoustic cue that may be useful to voicing perception is F1. Word-initial stop sounds are followed by transitioning formants, the first of which begins at a low frequency (e.g. 300 Hz) and ascends to its target frequency for the following sound. As VOT grows longer, that rising transition becomes increasingly de-voiced, resulting in a higher F1 frequency at the onset of voicing; long VOT values yield higher F1 onsets, while low F1 onsets are characteristic of short VOT values (Lisker, 1975). An exception to this trend is for high vowels (e.g. /i/, /u/), whose voicing-related F1 perturbations are minimal because F1 begins and ends at low frequencies; F1 is thus not thought to aid the voicing contrast in high vowel environments. In this experiment, we focus on the contributions of VOT and F0, and hence rely on the /i/ vowel to provide an environment in which VOT perception can be measured without confounding changes in F1.
Low-pass filtering and masking noise both should affect VOT and F0 disproportionately. The aspiration noise that characterizes the VOT cue contains considerable energy in the high-frequency regions, particularly for the /t/ consonant (see Figure 2). Eliminating high-frequency energy from the signal would render the aspiration less audible while maintaining lower-frequency harmonics in the vowel that drive F0 perception. Competing noise should more effectively mask the VOT than the vowel because the aspirated portion of the word is less intense than the vowel portion; the F0 is recovered from the vowel and should thus be relatively less affected by the noise.
Figure 2.
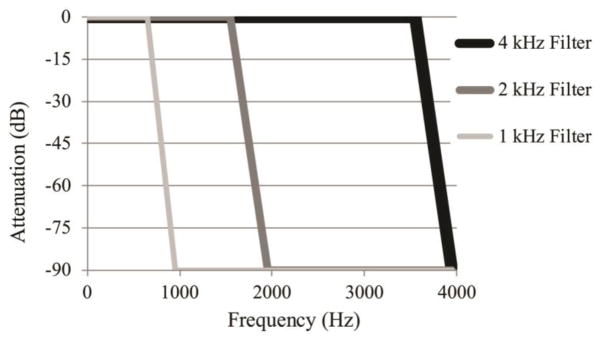
Illustration of low-pass filters used in this experiment, implemented using the Praat software.
The effect of low-pass filtering
Exploring the effect of limited bandwidth in terms of a low-pass filter (LPF) has particular relevance for understanding the experience of people with hearing impairment (HI). High-frequency hearing loss can render some phonetic cues inaudible, potentially compelling HI listeners to rely on different cues than those used by people with normal hearing. Furthermore, the lack of access to high-frequency auditory filters is likely to compromise temporal resolution because the wideband high-frequency filters are considerably superior in the temporal domain compared to the narrowband low-frequency filters (Eddins, Hall and Grose, 1992). For example, noise gap detection thresholds become smaller as bandwidth grows wider (Eddins, et al, 1992, Grose, 1991, Eddins and Green, 1995). For this reason, it is likely that listeners who rely solely on low-frequency energy have poorer ability to use temporal cues (such as voice onset time) but remain receptive to residual information that should include F0.
The role of F0 in noise
Previous research has shown that F0 is a useful cue for listening to speech in noise (Brokx & Nooteboom, 1982; McAdams, 1989). When the F0 contours of masked sentences are flattened or inverted around the mean, intelligibility decreases (Binns and Culling, 2007), and self-reported difficulty increases (Laures & Wiesmer, 1999) particularly when the masker is competing speech. It is likely that the F0 contour can help direct listeners’ attention to the timing of target words to aid in intelligibility (Cutler and Foss, 1977). While the utility of a natural F0 contour is well-established at the sentence level, relatively little is known about the contributions of F0 contour to the intelligibility of individual segments or phonetic features. Fogerty and Humes (2012) showed that the flattening of F0 contours or the removal of F0 information (i.e. whisper-like speech) resulted in deficits for both vowels and consonants. Therefore, while vowels are the primary periodic element in the speech signal, consonant sounds stand to benefit from natural F0 contours as well.
Objectives and hypothesis
The present study was designed to test whether F0 would become a more prominent cue for voicing in word-initial stop consonants in conditions of low-pass filtering and/or masking by speech-shaped noise. Unlike aspiration noise that characterizes the VOT cue, F0 should be perceptible even without high-frequency information. F0 has been previously shown to be a beneficial cue for listening to sentences in noise, but its use at the segmental level has not been fully understood. We hypothesized that in the aforementioned degraded signal conditions, listeners’ voicing judgments would be driven more heavily by F0 and less by VOT.
Method
Participants
Participants included 20 adult listeners (mean age: 24.3 years, 15 females) with normal hearing, defined as having pure-tone thresholds <20 dB HL from 250–8000 Hz in both ears (ANSI, 2010). All participants were native speakers of American English and were screened for self-reported unfamiliarity with tonal languages (e.g. Mandarin, Cantonese, Vietnamese, etc.) to ensure that no participant entered with a priori increased bias towards using F0 as a lexical/phonetic cue. Informed consent was obtained for each participant, and the experimental protocol was approved by the Institutional Review Board at the University of Maryland. Participants were reimbursed for their participation.
Stimuli
Two sets of stimuli were created using modified natural speech. The words Pete, Beat, Teen and Dean spoken by a male native speaker of English were recorded in a double-walled sound-treated room with a 44.1 kHz sampling rate. We sought to measure the contribution of VOT without the added complementary cue of F1, so a high vowel /i/ was used for all consonant environments. Stimuli varied by VOT (in 7 or 8 steps for /b/-/p/ and /d/-/t/, respectively) and F0 (in 8 steps). Following the method used by Andruski, Blumstein and Burton (1994), onset portions of words with /b/ or /d/ onsets were progressively replaced with equivalently long portions of onset aspiration from /p/ or /t/, respectively, in 10 ms increments from the onsets (bound at the closest zero-crossing) to create continua of voice onset time. Thus, the vowel from each stimulus item came from the /b/ or /d/-initial tokens. For the /d/-/t/ continuum, the VOT range spanned from 0ms to 70ms, and the range for the /b/-/p/ continuum spanned from -10ms (pre-voicing) to 50ms, as suggested by previous studies (Lisker & Abramson, 1964; Abramson & Lisker, 1970).
Intensity of items in the /b/-/p/ series varied within 2.7 dB, and all items in the /d/-/t/ series varied within 1 dB; overall RMS intensity was affected by VOT step because lower-intensity aspiration noise progressively replaced higher-intensity phonated vowel onsets. Volume was calibrated such that the endpoint “voiced” stimulus of each series in the optimal (full-spectrum, in quiet) condition was 65 dBA.
The F0 contour of each stimulus was manipulated using the pitch synchronous overlap-add (PSOLA) method in Praat (Boersma & Weenik, 2011). Steps in the F0 continuum were interpolated in 8 steps along a log scale ranging from 94 – 142 Hz, which reflects the general range for male speech indicated by previous work (Ohde, 1984; Abramson & Lisker, 1985; Whalen et al., 1993). F0 was kept steady over the first two pitch periods of the vowel, and fell (or rose) linearly until returning to the original contour at the 100 ms point in the vowel (the time indicated by Hombert, 1975). Following the 100 ms timepoint, all F0 contours were equal within each continuum.
Masking Noise
Speech-shaped noise (SSN) was extracted offline from the iCAST program (Fu, 2006). Its spectrum was strongest in the 200–600 Hz region, and decreased by roughly 6 dB per octave (see Figure 2). This noise was chosen to reflect the long-term average spectrum (LTAS) of conversational speech rather than the LTAS of our stimuli (the presence of only one vowel in our stimuli would yield a LTAS of only very limited utility with regard to everyday experience). Stimulus timing within the noise was roved so that there was 280–360 ms of noise before the stimulus and 380–450 ms of noise after the stimulus. To present varying signal-to-noise ratios (SNRs), noise levels varied while speech signals were kept at constant amplitude within each condition. Noise levels were set relative to the vowel onset so that SNR was not affected by intensity differences stemming from VOT continuum steps or by syllable type (stop-final or nasal-final). As most studies do not reference one particular point in a syllable to calculate SNR, caution is encouraged when comparing SNR levels in the current study to those from other publications. For example, the SNR at vowel onset for “Pete” is roughly 4 dB greater than that calculated from the entire word, resulting in greater masking to reach equivalent SNR.
Low-Pass Filtering
Stimuli were low-pass filtered using the Hann band filter function in Praat (Boersma & Weenik, 2011), illustrated by the filter responses in Figure 1. Cutoff frequencies of 4 kHz, 2 kHz and 1 kHz were used to investigate various degrees of residual acoustic information. Filtering was done after the addition of background noise, to model the order of signal degradations encountered by a listener with hearing impairment. Therefore, the level of noise (and hence the overall signal) for conditions at poorer SNRs was more intense than those at better SNRs, and signals with higher LPF cutoffs were more intense that those with lower LPF cutoffs. It should be noted that while the vowels and final consonants in all speech stimuli were degraded by the masking noise and filtering, these segments were already identified by the visual word choices.
Figure 1.
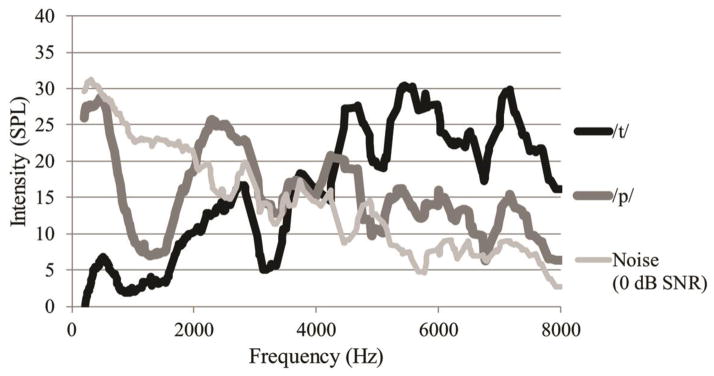
Illustration of frequency spectra for /t/ (black) and /p/ (gray) aspiration noises, and the masking noise (hollow gray) at 0 dB SNR.
Conditions
The levels of low-pass filtering and SNR in this experiment were chosen to measure specific effects highlighted below in Table 1.
Table 1.
Listening conditions tested for each comparison, defined by spectral bandwidth and SNR.
| Initial exploration of bandwidth and noise effects | ||||
| Bandwidth | Full | 1000 Hz | Full | 1000 Hz |
| SNR | Quiet | Quiet | 0 dB | 0 dB |
| Effect of bandwidth in 0 dB SNR noise | ||||
| Bandwidth | Full | 4000 Hz | 2000 Hz | 1000 Hz |
| SNR | 0 dB | 0 dB | 0 dB | 0 dB |
| Effect of SNR with 1000 Hz low-pass filter | ||||
| Bandwidth | 1000 Hz | 1000 Hz | 1000 Hz | 1000 Hz |
| SNR | Quiet | +10 dB | +5 dB | 0 dB |
Note: Rows are organized by the specific purpose of comparison, stated in italic text. Note that the 1000 Hz, 0 dB SNR condition is present in all three rows.
The arrangement of conditions was inspired by preliminary experiments (Table 1 top row) that suggested that either 0 dB SNR or a 1 kHz low-pass filter (LPF) permitted use of the VOT cue, but the combination of these factors promoted the use of F0 nearly exclusively. The combination of the 1 kHz LPF and the 0 dB SNR condition could be improved by either ameliorating the LPF settings or making the SNR more favorable. Thus, questions following this pilot testing included 1) (middle row) What LPF cutoff is necessary to facilitate the use of VOT when the SNR is 0 dB? and 2) (bottom row) What SNR is needed to facilitate the use of VOT when the LPF is 1 kHz? Each of these conditions was tested for the /b/-/p/ stimuli and for the /d/-/t/ stimuli, resulting in a total of 16 conditions (note that some conditions above are used for multiple comparisons, but were tested just once).
Procedure
All testing was conducted in a double-walled sound-treated booth. Stimuli were presented in the free field through a single Tannoy Reveal studio monitor loudspeaker (frequency response: 65 Hz – 20 kHz, +/− 3 dB) at a distance of 1 – 2 feet placed in front of the listener at eye level. Listeners responded to these stimuli by clicking a button on a computer screen labeled with two word choices (either Pete/Beat or Teen/Dean). There was no time limit on their response, and they were permitted to enable stimulus repetitions up to three times; stimulus repetitions were very rare.
Conditions were defined by SNR and LPF cutoff (e.g. [0 dB SNR, 4 kHz], [+10 dB SNR, 1 kHz], see Table 1). There were 56 items (7 VOT x 8 F0) for the /b/-/p/ blocks and 64 items (8 × 8) for the /d/-/t/ blocks; stimuli within each block were presented in random order. Each block was presented 5 times, which resulted in well-defined psychometric functions along the stimulus parameters. Each participant began with at least one block of the optimal (quiet, no LPF) condition before hearing any masked/LPF conditions. Because of the large number of conditions, participants generally did not volunteer enough time to complete five blocks of each condition; condition selection and ordering was constrained within participants’ scheduling availability. Listeners heard a variable subset of the conditions (that were not necessarily limited to one contrast), depending on their scheduling availability; most completed between 5 and 10 different conditions. The final data set included at least ten listeners for each condition, for a total of over 800 tested blocks. Each repetition of a single block took roughly 3 – 5 minutes.
Before performing the group analyses, individual listeners’ response functions were initially fit to a simple logistic model using Sigmaplot 9.01 (Systat, 2004). When listeners’ data for a particular condition did not reach satisfactory convergence to the model, 1 or 2 more repetitions of that condition were conducted to smooth the function to allow a better fit. This was done for 5 of 20 listeners in some of the more challenging conditions (i.e. those where signal degradations were harsh enough to inhibit consistent use of the cues).
Analysis
Listeners’ responses were fit using generalized linear (logistic) mixed-effects models (GLMMs). This was done in the R software interface (R Development Core Team, 2010), using the lme4 package (Bates & Maechler, 2010). A random effect of participant was used, and the fixed effects were the stimulus factors described above (Consonant place, VOT, F0, LPF, SNR). The binomial family link function was used. The models included each main factor and all possible interactions (the four-way interactions were significant, necessitating the inclusion of all nested factors and interactions) The goal of these models was similar to that used by Peng, Lu and Chatterjee (2009) and Winn, Chatterjee and Idsardi (2012); the models tested whether the coefficient of the resulting parameter estimate for an acoustic cue was different from 0 and, crucially, whether the coefficient was different across conditions of LPF and SNR levels. Changes in this coefficient represent changes in the log odds of voiceless perceptions resulting from the condition or cue level change. Following previous studies (Morrison & Kondaurova, 2009; Winn et al., 2012), we interpreted the factor estimate from the GLMM as an indication of the strength of the factor (i.e. a higher estimate indicates higher perceptual weight).
Results
Averaged group responses to the continua of VOT and F0 are displayed in the tiled grids in Figures 3, 4, and 5. Grayscale intensity represents the proportion of voiced responses. Listeners who solely use VOT to distinguish these contrasts would yield grids with rows of different grayscale intensity, while listeners who solely used F0 would yield grids with columns of different grayscale intensity; each grid reflects the use of both cues in varying proportions. Sharper grayscale contrasts in successive rows and columns are akin to steeper psychometric functions.
Figure 3.

Tiled grid showing the proportion of voiced or voiceless responses at each level of the VOT and F0 continua for the first comparison (initial exploration of filtering and noise).
Figure 4.

Tiled grid showing the proportion of voiced or voiceless responses at each level of the VOT and F0 continua for the second comparison (exploration of LPF effects in 0 dB SNR noise).
Figure 5.

Tiled grid showing the proportion of voiced or voiceless responses at each level of the VOT and F0 continua for the third comparison (exploration of SNR effects with 1 kHz LPF).
Three GLMMs were used to describe listeners’ responses for each of the three planned comparisons. Model terms along with the intercept and parameter estimates are in Tables 2, 3 and 4. Simplified parameter estimates from the GLMMs are summarized in the supplemental table of coefficients and are illustrated in Figure 6.
Table 2.
GLMM results for the first comparison (Initial exploration of bandwidth and noise)
| Effect | Estimate | z | p value | |
|---|---|---|---|---|
| Intercept | 1.109 | 11.15 | < 0.001 | |
| /b/-/p/ | LPF | −1.184 | −10.07 | < 0.001 |
| 0 dB SNR | −1.338 | −11.31 | < 0.001 | |
| LPF:0 dB SNR | 1.476 | 10.40 | < 0.001 | |
| /d/-/t/ | POA | −1.788 | −13.33 | < 0.001 |
| POA:LPF | 1.756 | 10.95 | < 0.001 | |
| POA:0 dB SNR | 0.954 | 5.76 | < 0.001 | |
| POA:LPF:0 dB SNR | −1.262 | −6.38 | < 0.001 | |
|
| ||||
| VOT | 0.302 | 21.94 | < 0.001 | |
| /b/-/p/ | VOT:LPF | −0.169 | −11.62 | < 0.001 |
| VOT:0 dB SNR | −0.191 | −13.22 | < 0.001 | |
| VOT:LPF:0 dB SNR | 0.070 | 4.55 | < 0.001 | |
| /d/-/t/ | VOT:POA | −0.067 | −3.98 | < 0.001 |
| VOT:POA:LPF | 0.054 | 3.02 | < 0.01 | |
| VOT:POA:0 dB SNR | 0.081 | 4.53 | < 0.001 | |
| VOT:POA:LPF:0 dB SNR | −0.072 | −3.75 | < 0.001 | |
|
| ||||
| F0 | 0.027 | 4.18 | < 0.001 | |
| /b/-/p/ | F0:LPF | 0.028 | 3.69 | < 0.001 |
| F0:0 dB SNR | 0.037 | 4.85 | < 0.001 | |
| F0:LPF:0 dB SNR | −0.019 | −2.02 | < 0.05 | |
| /d/-/t/ | F0:POA | 0.044 | 5.19 | < 0.001 |
| F0:POA:LPF | −0.039 | −3.81 | < 0.001 | |
| F0:POA:0 dB SNR | −0.023 | −2.16 | < 0.05 | |
| F0:POA:LPF:0 dB SNR | 0.058 | 4.49 | < 0.001 | |
|
| ||||
| VOT:F0 interaction | 0.000 | −0.50 | n.s. | |
| /b/-/p/ | VOT:F0:LPF | 0.000 | −0.06 | n.s. |
| VOT:F0:0 dB SNR | −0.002 | −2.15 | < 0.05 | |
| VOT:F0:LPF:0 dB SNR | 0.002 | 2.26 | < 0.05 | |
| /d/-/t/ | VOT:F0:POA | 0.000 | −0.33 | n.s. |
| VOT:F0:POA:LPF | 0.001 | 0.84 | n.s. | |
| VOT:F0:POA:0 dB SNR | 0.002 | 2.16 | < 0.05 | |
| VOT:F0:POA:LPF:0 dB SNR | −0.003 | −2.24 | < 0.05 | |
Note: The default (intercept) condition was full-spectrum in Quiet. POA refers to place of articulation; corresponding numbers reflect the difference between factor estimates for the /b/-/p/ and /d/-/t/ series.
Table 3.
GLMM results for the second comparison (Effects of bandwidth in 0 dB SNR noise)
| Effect | Estimate | z | p value | |
|---|---|---|---|---|
| Intercept (full spectrum) | −0.503 | −3.99 | < 0.001 | |
| /b/-/p/ | 4kHz | 0.267 | 3.04 | < 0.01 |
| 2kHz | 0.553 | 6.57 | < 0.001 | |
| 1kHz | 0.562 | 6.59 | < 0.001 | |
| POA | −0.708 | −7.01 | < 0.001 | |
| /d/-/t/ | POA:4kHz | 0.774 | 6.20 | < 0.001 |
| POA:2kHz | 0.419 | 3.45 | < 0.001 | |
| POA:1kHz | 0.415 | 3.42 | < 0.001 | |
|
| ||||
| VOT | 0.114 | 25.08 | < 0.001 | |
| /b/-/p/ | VOT:4kHz | −0.040 | −7.40 | < 0.001 |
| VOT:2kHz | −0.100 | −19.92 | < 0.001 | |
| VOT:1kHz | −0.102 | −20.15 | < 0.001 | |
| VOT:POA | 0.017 | 2.68 | < 0.01 | |
| /d/-/t/ | VOT:POA:4kHz | −0.061 | −8.46 | < 0.001 |
| VOT:POA:2kHz | −0.021 | −3.03 | < 0.01 | |
| VOT:POA:1kHz | −0.020 | −2.93 | < 0.01 | |
|
| ||||
| F0 | 0.065 | 15.59 | < 0.001 | |
| /b/-/p/ | F0:4kHz | 0.009 | 1.64 | n.s. |
| F0:2kHz | 0.005 | 1.06 | n.s. | |
| F0:1kHz | 0.010 | 1.82 | < 0.1 | |
| F0:POA | 0.023 | 3.75 | < 0.001 | |
| /d/-/t/ | F0:POA:4kHz | 0.034 | 4.08 | < 0.001 |
| F0:POA:2kHz | 0.039 | 4.80 | < 0.001 | |
| F0:POA:1kHz | 0.020 | 2.47 | < 0.05 | |
|
| ||||
| VOT:F0 interaction | −0.002 | −9.30 | < 0.001 | |
| /b/-/p/ | VOT:F0:4kHz | 0.001 | 3.10 | < 0.01 |
| VOT:F0:2kHz | 0.003 | 8.46 | < 0.001 | |
| VOT:F0:1kHz | 0.002 | 7.00 | < 0.001 | |
| VOT:F0:POA | 0.002 | 5.81 | < 0.001 | |
| /d/-/t/ | VOT:F0:POA:4kHz | −0.001 | −2.38 | < 0.05 |
| VOT:F0:POA:2kHz | −0.002 | −4.32 | < 0.001 | |
| VOT:F0:POA:1kHz | −0.002 | −4.14 | < 0.001 | |
Note: The default (intercept) condition was full-spectrum in 0 dB SNR noise. POA refers to place of articulation; corresponding numbers reflect the difference between factor estimates for the /b/-/p/ and /d/-/t/ series.
Table 4.
GLMM results for the third comparison (Effects of SNR using 1 kHz low-pass filter)
| Effect | Estimate | z | p value | |
|---|---|---|---|---|
| Intercept | −0.075 | −1.16 | n.s. | |
| /b/-/p/ | +10 dB SNR | 0.604 | 7.52 | < 0.001 |
| +5 dB SNR | 0.442 | 5.49 | < 0.001 | |
| 0 dB SNR | 0.138 | 1.76 | < 0.1 | |
| /d/-/t/ | POA | −0.032 | −0.36 | n.s. |
| POA:+10 dB SNR | −0.451 | −4.06 | < 0.001 | |
| POA:+5 dB SNR | −0.525 | −4.61 | < 0.001 | |
| POA:0 dB SNR | −0.309 | −2.84 | < 0.01 | |
|
| ||||
| VOT | 0.133 | 27.96 | < 0.001 | |
| /b/-/p/ | VOT:+10 dB SNR | −0.083 | −15.40 | < 0.001 |
| VOT:+5 dB SNR | −0.105 | −19.61 | < 0.001 | |
| VOT:0 dB SNR | −0.121 | −23.14 | < 0.001 | |
| /d/-/t/ | VOT:POA | −0.013 | −2.07 | < 0.05 |
| VOT:POA:+10 dB SNR | −0.025 | −3.54 | < 0.001 | |
| VOT:POA:+5 dB SNR | −0.002 | −0.33 | n.s. | |
| VOT:POA:0 dB SNR | 0.009 | 1.36 | n.s. | |
|
| ||||
| F0 | 0.055 | 13.24 | < 0.001 | |
| /b/-/p/ | F0:+10 dB SNR | 0.006 | 1.23 | n.s. |
| F0:+5 dB SNR | 0.041 | 7.43 | < 0.001 | |
| F0:0 dB SNR | 0.018 | 3.51 | < 0.001 | |
| /d/-/t/ | F0:POA | 0.005 | 0.93 | n.s. |
| F0:POA:+10 dB SNR | 0.066 | 8.55 | < 0.001 | |
| F0:POA:+5 dB SNR | 0.051 | 6.14 | < 0.001 | |
| F0:POA:0 dB SNR | 0.035 | 4.71 | < 0.001 | |
|
| ||||
| VOT:F0 | 0.000 | −1.70 | < 0.1 | |
| /b/-/p/ | VOT:F0:+10 dB SNR | −0.001 | −2.12 | < 0.05 |
| VOT:F0:+5 dB SNR | 0.001 | 1.72 | < 0.1 | |
| VOT:F0:0 dB SNR | 0.000 | 0.69 | n.s. | |
| /d/-/t/ | VOT:F0:POA | 0.001 | 1.59 | n.s. |
| VOT:F0:POA:+10 dB SNR | 0.001 | 1.89 | < 0.1 | |
| VOT:F0:POA:+5 dB SNR | −0.001 | −1.51 | n.s. | |
| VOT:F0:POA:0 dB SNR | 0.000 | −0.63 | n.s. | |
Note: The default (intercept) condition was 1 kHz low-pass filtered in 0 dB SNR noise. POA refers to place of articulation; corresponding numbers reflect the difference between factor estimates for the /b/-/p/ and /d/-/t/ series.
Figure 6.
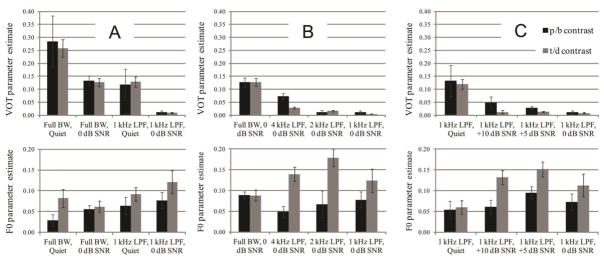
Parameter estimates (coefficients) for the logistic models for the three comparisons: A) Initial exploration of LPF and noise effects; B) Effects of LPF with 0 dB SNR; (C: effects of SNR with 1 kHz low-pass filter. Greater bar height indicates greater influence of the cue in the model. Black and gray bars represent estimates for the /b/-/p/ and /d/-/t/ contrasts, respectively. The upper and lower panels illustrate estimates for the VOT and F0 cues, respectively. Error bars reflect ± 1 standard error of the mean of the coefficients across participants.
In the first comparison (initial exploration of LPF and noise; Figure 3; Table 2), there were significant main effects of VOT, F0, SNR and LPF (all p <0.001). Alveolar consonants were less likely to be heard as voiced (consistent with acoustics of these consonants; Lisker & Abramson, 1964). F0 was a stronger cue for the /d/-/t/ contrast (p <0.001). The effect of VOT was significantly reduced when the signal was either low-passed (p <0.001 for both contrasts) or in noise (p <0.001 for both contrasts), and significantly reduced further in the presence of both filtering and noise (p < 0.001). The effect of F0 was significantly stronger for both contrasts when the signals were masked by noise (p <0.001); when signals were low-passed, F0 became stronger only for the /b/-/p/ contrast. When the signal was both low-passed and in noise, the use of F0 significantly increased for both contrasts compared to either degradation alone (p <0.001).
In the second comparison (effects of LPF in 0 dB SNR noise; Figure 4; Table 3), the effect of VOT significantly decreased for both contrasts with each successive reduction in LPF cutoff (p <0.001), with the exception of the 1 kHz condition, which was not significantly different from the 2 kHz condition. The use of VOT for the /d/-/t/ contrast was greater than that for the /b/-/p/ contrast when the full spectrum was available, but in any LPF condition, there was a significant advantage for the /b/-/p/ contrast for the use of VOT (all p <0.001). The effect of F0 was significantly stronger for the /d/-/t/ contrast in all low-pass filtered conditions (p <0.001 for 4 kHz and 2 kHz; p <0.05 for 1 kHz). The effect of F0 for the /b/-/p/ contrast did not significantly increase in any LPF condition.
In the third comparison (effects of SNR with a 1 kHz LPF; Figure 5; Table 4), the use of VOT significantly decreased with each successive reduction in SNR for both contrasts (all p <0.001). The use of F0 increased for the /b/-/p/ contrast for +5 and 0 dB SNR (both p <0.001), while it increased for the /d/-/t/ contrast in all conditions with noise (all p <0.001).
A question that remains from the results presented thus far is whether a listener can achieve the same or similar level of accuracy for voicing recognition via F0 as with VOT. Because the analyses presented thus far do not speak to correctness per se, a final analysis was conducted to evaluate the identification of stimuli where both the VOT and F0 cues cooperated at typical “voiceless” or “voiced” values. Figure 7 illustrates performance levels for these endpoint stimuli by listeners in all conditions. Voicing was correctly identified with 80% accuracy or greater in all conditions except for /b/ in the 1 kHz LPF with 0 dB SNR noise condition. The cue estimate for VOT showed a significant positive correlation with accuracy for endpoint accuracy (r = 0.76 for /b/-/p/, r = 0.74 for /d/-/t/; p < 0.05 for each). The cue estimate for F0 showed a significant negative correlation with endpoint accuracy for the /d/-/t/ contrast (r = −0.68, p < 0.05), but did not show a significant correlation with accuracy for the /b/-/p/ contrast. Thus, while listeners were able to mostly compensate for the degraded VOT cue via the F0 cue, they performed better when relying on VOT.
Figure 7.
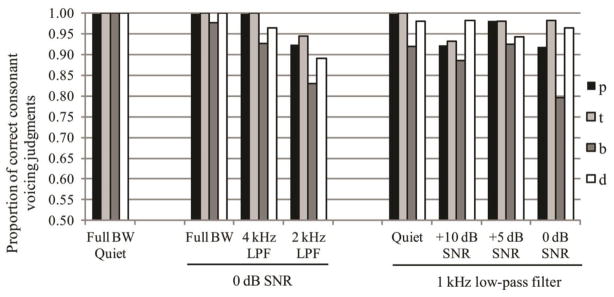
Mean accuracy in identification of consonant voicing at continuum endpoints by different listener groups. Voiceless and voiced items for this analysis were limited to those where both the VOT and F0 cues cooperated appropriately (i.e. long VOT & high F0 or short VOT & low F0) at continuum endpoints to signal the same feature.
IV. DISCUSSION
In this experiment, listeners perceived voicing contrasts in signals that were low-pass filtered and/or masked by SSN. These two signal degradations generally yielded a decline in the use of VOT that was accompanied by an increase in the use of F0. Thus, as acoustic degradations compromised the availability of the VOT cue, listeners did not simply guess at the words – they recruited appropriate information from a different acoustic cue. The one condition common to all three comparisons (0 dB SNR, 1 kHz LPF; the most challenging condition) was theoretically the most challenging in the experiment. It was distinct because while the use of VOT decreased, the use of F0 was less than that for some other more favorable masked and/or filtered conditions. For the most challenging condition, it appears that the acoustic signal is so degraded that even F0 is difficult to perceive in a useful way.
Speech-shaped masking noise and low-pass filtering had disproportionate effects on the /b/-/p/ and /d/-/t/ contrasts. To the extent that voicing perception can be framed as detection of aspiration noise, these disproportionate effects can be explained by the acoustics of labial and alveolar stop sounds in this study. The use of cues for labial sounds was influenced more by the level of masking noise, presumably because the spectrum of SSN competes more directly with the /p/ burst and aspiration (see Figure 2). Low-pass filtering the sounds had little effect on the use of cues for labial sounds, presumably because the spectrum of the /p/ aspiration contains sufficient low-frequency components that remain after filtering. Conversely, the use of VOT for the /d/-/t/ contrast was heavily reduced by low-pass filtering. Consistent with earlier literature on the acoustics and perception of /t/ (Régnier & Allen, 2008), the audibility of energy above 4 kHz is essential for the perception of /t/ aspiration; all conditions that used a LPF of 4 kHz or lower saw dramatic reductions in VOT use along with increased use of F0 for alveolar sounds, even for modest SNRs. Table 5 shows that the SNR advantage of /p/ compared to /t/ is evident in the lower frequency regions (i.e. from 0 – 4 kHz), while in higher frequency regions (i.e. between 4 and 8 kHz), /t/ has an advantage (all relative to the masking noise used in this experiment). The pronounced asymmetry in energy at the upper and lower regions for labial and alveolar aspiration noise helps to explain differences in cue-weighting across these two places of articulation and accords with previous reports of individual consonant advantages in speech-shaped noise (Phatak and Allen, 2007).
Table 5.
SNRs for /p/ and /t/ aspiration relative to masking noise in the 0 dB SNR condition, in different frequency bands.
| Low frequency | High Frequency | /p/ SNR (dB) | /t/ SNR (dB) | Relative Advantage (dB) (stronger consonant) | |
|---|---|---|---|---|---|
| 0 | 1000 | −10.2 | −20.9 | 10.7 | /p/ |
| 0 | 2000 | −14.6 | −21.0 | 6.4 | /p/ |
| 0 | 4000 | −9.6 | −13.9 | 4.3 | /p/ |
| 0 | 8000 | −6.0 | −0.8 | 5.2 | /t/ |
| 4000 | 8000 | −2.4 | 12.3 | 14.7 | /t/ |
Other types of noise may have different effects than those shown in this study. With the entire spectrum available and audible, the SNR of stimuli in white noise may affect the /t/-/d/ contrast more heavily than the /p/-/b/ contrast. Amplitude-modulated noise or competing speech might momentarily provide a favorable SNR for these cues via a dip in amplitude concurrent with the onset of the target words; there is no reason to think that modulation would differentially affect /p/ versus /t/. It should be noted that listeners with hearing loss are less able to capitalize on short-term valleys of a masker, (Carhart & Tillman, 1970; Festen & Plomp, 1990) and may thus not recover segmental information in such conditions.
Although listeners were able to reliably identify the voicing of the most natural (i.e. “endpoint”) stimuli (Figure 7), it is not yet known whether the signal degradation requires listeners to use greater cognitive resources to perceive voicing. Given listeners’ general tendency to rely on VOT rather than F0 (Abramson and Lisker, 1985), conditions driven by F0 could have been more difficult than those driven by VOT, despite similar accuracy scores. Accuracy for endpoint stimuli in this experiment was significantly correlated to the strength (i.e. factor estimate) of VOT. Thus, scores in phoneme identification tasks may tell only part of the story; similar scores could have arisen because of different perceptual strategies. Pupillometry during speech perception tasks suggests that extra effort is required to maintain equal intelligibility of speech in the presence of different types of maskers (Koelewijn, Zekveld, Festen & Kramer, 2012) or if listeners have hearing loss (Kramer, Kapteyn, Festen & Kuik, 1997). It is not yet known whether alternative phonetic cue-weighting strategies would elicit similar signs of increased listening effort.
In this experiment, the role of F1 was minimized via the use of the high vowel /i/. Jiang, Chen and Alwan (2006) showed that F1 can play a role in the perception of voicing in noise for non-high vowels, confirming a prediction by Hillenbrand, Ingrisano, Smith and Flege (1984). It is not yet known whether F1 or F0 is more dominant in compensating for degradations of VOT in masked and/or filtered conditions.
The motivation for this experiment was to model potential listening strategies that could arise when a person experiences hearing impairment. Because hearing impairment is more complex than a simple low-pass filter, the results of this study should be interpreted with caution. There are supra-threshold deficits in the spectral and temporal domains that might limit a listener’s ability to utilize either of the acoustic cues explored in this study. These deficits are frequently attributed to poor frequency resolution and/or temporal fine structure coding (Bernstein & Oxenham, 2006; Lorenzi, Gilbert, Carn, Garnier & Moore, 2006). Turner and Brus (2001) showed that while the amplification of low-frequency energy (including F0) provided benefit for listeners with hearing impairment, this benefit was smaller than that observed for those with normal hearing. Grant (1987) suggested that HI listeners are not able to detect subtle F0 contrasts, and would therefore benefit from F0 contours only if they were exaggerated by roughly 1.5 to 6 times those observed in natural speech. Thus, it remains unclear whether listeners with cochlear hearing loss can capitalize on F0 cues in noise to the same extent as the participants in this study. Further difficulties might be experienced by older listeners, who have been shown to experience deficiencies in auditory temporal processing in basic psychophysical tasks (Gordon-Salant and Fitzgibbons, 1993; 1999), and tasks involving perception of temporal phonetic cues in isolated words (Gordon-Salant, Yeni-Komshian, Fitzgibbons & Barrett, 2006) and in sentence contexts (Gordon-Salant, Yeni-Komshian & Fitzgibbons, 2008).
The use of F0 as a segmental cue in this study may partly explain the benefit of a natural F0 contour of sentences presented in noise (Laures & Wiesmer, 1999; Binns and Culling, 2007, Miller, Schlauch & Watson, 2010). It is not known whether the segmental use of F0 cues in this study would generalize to longer utterance contexts, where F0 contrast is likely constrained by other sources of variability (e.g. intonation) and phonetic reduction. It should be noted that the current experiment used a 2-alternative forced choice task that assessed only voicing perception in single words; it is likely that these stimuli would be confused with other consonants (but perhaps not with consonants of different voicing) if a larger response set were used. On the other hand, the influence of sentence context and other top-down factors may compensate for the added difficulty of an open response set (McClelland, Mirman & Holt, 2006).
Emergent models of phonetic perception and categorization increasingly acknowledge the integration of multiple co-varying acoustic cues in the speech signal (McMurray, Tanenhaus & Aslin, 2002; Toscano & McMurray, 2010; McMurray & Jongman, 2011). The presence of multiple cues for voicing can at least partly explain why voicing is such a robust feature in phoneme identification tasks in adverse listening conditions like low-pass filtering and masking noise. Listeners are capable, without any explicit instructions, of increasing reliance upon residual cues in a speech signal when otherwise stronger cues have been degraded.
Acknowledgments
This work was supported by NIH grant R01 DC 004786 to Monita Chatterjee and NIH grant 7R01DC005660-07 to David Poeppel and William Idsardi. Matthew Winn was supported by the University of Maryland Center for Comparative and Evolutionary Biology of Hearing Training Grant (NIH T32 DC000046-17 PI: Arthur N. Popper). We are grateful to Ewan Dunbar for his assistance with the statistical analysis.
Contributor Information
Matthew B. Winn, Department of Hearing and Speech Sciences, University of Maryland, College Park, 0100 Lefrak Hall, College Park, Maryland 20742.
Monita Chatterjee, Department of Hearing and Speech Sciences, University of Maryland, College Park, 0100 Lefrak Hall, College Park, Maryland 20742.
William J. Idsardi, Department of Linguistics, University of Maryland, College Park, 1401 Marie Mount Hall, College Park, Maryland 20742
References
- Abramson A, Lisker L. Discriminability along the voicing continuum: Cross language tests. Proceedings of the 6th International Congress of Phonetic Sciences; Prague. Prague: Academia; 1970. pp. 569–573. [Google Scholar]
- Abramson A, Lisker L. Relative power of cues: F0 shift versus voice timing. In: Fromkin V, editor. Phonetic linguistics: Essays in Honor of Peter Ladefoged. New York, NY: Academic Press; 1985. pp. 25–33. [Google Scholar]
- Andruski J, Blumstein S, Burton M. The effect of subphonetic differences on lexical access. Cognition. 1994;52:173–187. doi: 10.1016/0010-0277(94)90042-6. [DOI] [PubMed] [Google Scholar]
- ANSI. American National Standard Specification for Audiometers. American National Standards Institute; New York: 2010. S3.6-2010. [Google Scholar]
- Bates D, Maechler M. lme4: Linear mixed-effects models using S4 classes. R package version 0.999375-37. 2010 [Software package]. Available from http://CRAN.R-project.org/package=lme4.
- Bernstein J, Oxenham A. The relationship between frequency selectivity and pitch discrimination: Sensorineural hearing loss. Journal of the Acoustical Society of America. 2006;120:3929–3945. doi: 10.1121/1.2372452. [DOI] [PubMed] [Google Scholar]
- Bilger R, Wang M. Consonant confusions in patients with sensorineural hearing loss. Journal of Speech and Hearing Research. 1976;19:738–748. doi: 10.1044/jshr.1904.718. [DOI] [PubMed] [Google Scholar]
- Binns C, Culling J. The role of fundamental frequency contours in the perception of speech against interfering speech. Journal of the Acoustical Society of America. 2007;122:1765–1776. doi: 10.1121/1.2751394. [DOI] [PubMed] [Google Scholar]
- Boersma P, Weenink D. Praat: doing phonetics by computer. 2011 [Software]. Version 5.1.23, Available from http://www.praat.org/
- Brokx J, Nooteboom S. Intonation and the perceptual separation of simultaneous voices. Journal of Phonetics. 1982;10:23–36. [Google Scholar]
- Carhart R, Tillman TW. Interaction of competing speech signals with hearing losses. Archives of Otolaryngology. 1970;91:273–279. doi: 10.1001/archotol.1970.00770040379010. [DOI] [PubMed] [Google Scholar]
- Cutler A, Foss D. On the role of sentence stress in sentence processing. Language and Speech. 1977;20:1–10. doi: 10.1177/002383097702000101. [DOI] [PubMed] [Google Scholar]
- Dubno J, Levitt H. Predicting consonant confusions from acoustic analysis. Journal of the Acoustical Society of America. 1981;69:249–261. doi: 10.1121/1.385345. [DOI] [PubMed] [Google Scholar]
- Eddins D, Hall J, Grose J. The detection of temporal gaps as a function of frequency region and absolute noise bandwidth. Journal of the Acoustical Society of America. 1992;91:1069–1077. doi: 10.1121/1.402633. [DOI] [PubMed] [Google Scholar]
- Eddins D, Green D. Temporal integration and temporal resolution. In: Moore B, editor. Hearing. San Diego: Academic; 1995. [Google Scholar]
- Festen J, Plomp R. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. Journal of the Acoustical Society of America. 1990;88:1725–1736. doi: 10.1121/1.400247. [DOI] [PubMed] [Google Scholar]
- Fogerty D, Humes L. The role of vowel and consonant fundamental frequency, envelope, and temporal fine structure cues to the intelligibility of words and sentences. Journal of the Acoustical Society of America. 2012;131:1490–1501. doi: 10.1121/1.3676696. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friesen L, Shannon R, Başkent D, Wang X. Speech recognition in noise as a function of the number of spectral channels: Comparison of acoustic hearing and cochlear implants. Journal of the Acoustical Society of America. 2001;110:1150–1163. doi: 10.1121/1.1381538. [DOI] [PubMed] [Google Scholar]
- Fu Q-J. Internet-Based Computer-Assisted Speech Training (iCAST) by TigerSpeech Technology (version 5.04.02) 2006 [Computer program]. Available from http://www.tigerspeech.com/tst_icast.html.
- Gordon-Salant S, Fitzgibbons P. Temporal factors and speech recognition performance in young and elderly listeners. Journal of Speech and Hearing Research. 1993;36:1276–85. doi: 10.1044/jshr.3606.1276. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Fitzgibbons P. Profile of auditory temporal processing in older listeners. Journal of Speech Language and Hearing Research. 1999;42:300–311. doi: 10.1044/jslhr.4202.300. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Yeni-Komshian G, Fitzgibbons P, Barrett J. Age-related differences in identification and discrimination of temporal cues in speech segments. Journal of the Acoustical Society of America. 2006;119:2455–2466. doi: 10.1121/1.2171527. [DOI] [PubMed] [Google Scholar]
- Gordon-Salant S, Yeni-Komshian G, Fitzgibbons P. The role of temporal cues in word identification by younger and older adults: Effects of sentence context. Journal of the Acoustical Society of America. 2008;124:3249–3260. doi: 10.1121/1.2982409. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grant K. Identification of intonation contours by normally hearing and profoundly hearing-impaired listeners. Journal of the Acoustical Society of America. 1987;82:1172–1178. doi: 10.1121/1.395253. [DOI] [PubMed] [Google Scholar]
- Grose J. Gap detection in multiple narrow bands of noise as a function of spectral configuration. Journal of the Acoustical Society of America. 1991;90:3061–3068. doi: 10.1121/1.401780. [DOI] [PubMed] [Google Scholar]
- Haggard M, Ambler A, Callow M. Pitch as a voicing cue. Journal of the Acoustical Society of America. 1970;47:613–617. doi: 10.1121/1.1911936. [DOI] [PubMed] [Google Scholar]
- Hillenbrand J, Ingrisano D, Smith B, Flege J. Perception of the voiced-voiceless contrast in syllable-final stops. Journal of the Acoustical Society of America. 1984;76:18–26. doi: 10.1121/1.391094. [DOI] [PubMed] [Google Scholar]
- Hombert J. Unpublished doctoral dissertation. University of California; Berkely: 1975. Towards a theory of tonogenesis: An empirical, physiologically and perceptually-based account of the development of tonal contrasts in language. [Google Scholar]
- House A, Fairbanks G. The influence of consonant environment upon the secondary acoustical characteristics of vowels. Journal of the Acoustical Society of America. 1953;25:105–113. [Google Scholar]
- Jiang J, Chen M, Alwan A. On the perception of voicing in syllable-initial plosives in noise. Journal of the Acoustical Society of America. 2006;119:1092–1105. doi: 10.1121/1.2149841. [DOI] [PubMed] [Google Scholar]
- Koelwijn T, Zekveld A, Festen J, Kramer S. Pupil dilation uncovers extra listening effort in the presence of a single-talker masker. Ear and Hearing. 2012;33:291–300. doi: 10.1097/AUD.0b013e3182310019. [DOI] [PubMed] [Google Scholar]
- Kramer S, Kapteyn D, Festen J, Kuik D. Assessing aspects of auditory handicap by means of pupil dilatation. Audiology. 1997;36:155–164. doi: 10.3109/00206099709071969. [DOI] [PubMed] [Google Scholar]
- Ladefoged P, Maddieson I. The sounds of the world’s languages. Oxford: Blackwell; 1996. [Google Scholar]
- Laures J, Weismer G. The effects of a flattened fundamental frequency on intelligibility at the sentence level. Journal of Speech Language and Hearing Research. 1999;42:1148–1156. doi: 10.1044/jslhr.4205.1148. [DOI] [PubMed] [Google Scholar]
- Lisker L. Is it VOT or a first-formant transition detector? Journal of the Acoustical Society of America. 1975;57:1547–1551. doi: 10.1121/1.380602. [DOI] [PubMed] [Google Scholar]
- Lisker L, Abramson A. A cross-language study of voicing in stops: Acoustical measurements. Word. 1964;20:384–422. [Google Scholar]
- Lorenzi C, Gilbert G, Carn H, Garnier S, Moore B. Speech perception problems of the hearing impaired reflect inability to use temporal fine structure. Proceedings of the National Academy of Sciences. 2006;103:18866–18869. doi: 10.1073/pnas.0607364103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McAdams S. Segregation of concurrent sounds I: Effects of frequency modulation coherence. Journal of the Acoustical Society of America. 1989;86:2148–2159. doi: 10.1121/1.398475. [DOI] [PubMed] [Google Scholar]
- McClelland J, Mirman D, Holt L. Are there interactive processes in speech perception? Trends in Cognitive Science. 2006;10:363–369. doi: 10.1016/j.tics.2006.06.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McMurray B, Jongman A. What information is necessary for speech categorization? Harnessing variability in the speech signal by integrating cues computed relative to expectations. Psychological Review. 2011;118:219–246. doi: 10.1037/a0022325. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McMurray B, Tanenhaus M, Aslin R. Gradient effects of within-category phonetic variation on lexical access. Cognition. 2002;86:B33–B42. doi: 10.1016/s0010-0277(02)00157-9. [DOI] [PubMed] [Google Scholar]
- Miller S, Schlauch R, Watson P. The effects of fundamental frequency contour manipulations on speech intelligibility in background noise. Journal of the Acoustical Society of America. 2010;128:435–443. doi: 10.1121/1.3397384. [DOI] [PubMed] [Google Scholar]
- Miller G, Nicely P. An analysis of perceptual confusions among some English consonants. Journal of the Acoustical Society of America. 1955;27:338–352. [Google Scholar]
- Morrison G, Kondaurova M. Analysis of categorical response data: Use logistic regression rather than endpoint-difference scores or discriminant analysis. Journal of the Acoustical Society of America. 2009;126:2159–2162. doi: 10.1121/1.3216917. [DOI] [PubMed] [Google Scholar]
- Ohde R. Fundamental frequency as an acoustic correlate of stop consonant voicing. Journal of the Acoustical Society of America. 1984;75:224–230. doi: 10.1121/1.390399. [DOI] [PubMed] [Google Scholar]
- Peng SC, Lu N, Chatterjee M. Effects of cooperating and conflicting cues on speech intonation recognition by cochlear implant users and normal hearing listeners. Audiology and Neurotology. 2009;14:327–337. doi: 10.1159/000212112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Phatak S, Allen J. Consonant and vowel confusions in speech-weighted noise. Journal of the Acoustical Society of America. 2007;121:2312–2316. doi: 10.1121/1.2642397. [DOI] [PubMed] [Google Scholar]
- Phatak S, Lovitt A, Allen J. Consonant confusions in white noise. Journal of the Acoustical Society of America. 2008;124:1220–1233. doi: 10.1121/1.2913251. [DOI] [PubMed] [Google Scholar]
- R Development Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing; Vienna, Austria: 2010. [Computer software]. Available from http://www.R-project.org/ [Google Scholar]
- Régnier M, Allen J. A method to identify noise-robust perceptual features: Application for consonant /t/ Journal of the Acoustical Society of America. 2008;123:2801–2814. doi: 10.1121/1.2897915. [DOI] [PubMed] [Google Scholar]
- Shannon R, Zeng FG, Kamath V, Wygonski J, Ekelid M. Speech recognition with primarily temporal cues. Science. 1995;270:303–304. doi: 10.1126/science.270.5234.303. [DOI] [PubMed] [Google Scholar]
- Systat. SigmaPlot (version 9.01) San Jose, CA: 2004. [Computer program] [Google Scholar]
- Toscano J, McMurray B. Cue integration with categories: Weighting acoustic cues in speech using unsupervised learning and distributional statistics. Cognitive Science. 2010;34:434–464. doi: 10.1111/j.1551-6709.2009.01077.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Turner C, Brus S. Providing low-and mid-frequency speech information to listeners with sensorineural hearing loss. Journal of the Acoustical Society of America. 2001;109:2999–3006. doi: 10.1121/1.1371757. [DOI] [PubMed] [Google Scholar]
- Wang M, Bilger RC. Consonant confusions in noise: a study of perceptual features. Journal of the Acoustical Society of America. 1973;54:1248–1266. doi: 10.1121/1.1914417. [DOI] [PubMed] [Google Scholar]
- Whalen D, Abramson A, Lisker L, Mody M. F0 gives voicing information even with unambiguous voice onset times. Journal of the Acoustical Society of America. 1993;93:2152–2159. doi: 10.1121/1.406678. [DOI] [PubMed] [Google Scholar]
- Winn M, Chatterjee M, Idsardi W. The use of acoustic cues for phonetic identification: Effects of spectral degradation and electric hearing. Journal of the Acoustical Society of America. 2012;131:1465–1479. doi: 10.1121/1.3672705. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu L, Thompson K, Pfingst B. Relative contributions of spectral and temporal cues for phoneme recognition. Journal of the Acoustical Society of America. 2005;117:3255–3267. doi: 10.1121/1.1886405. [DOI] [PMC free article] [PubMed] [Google Scholar]