

Abstract
We investigate architectures for time encoding and time decoding of visual stimuli such as natural and synthetic video streams (movies, animation). The architecture for time encoding is akin to models of the early visual system. It consists of a bank of filters in cascade with single-input multi-output neural circuits. Neuron firing is based on either a threshold-and-fire or an integrate-and-fire spiking mechanism with feedback. We show that analog information is represented by the neural circuits as projections on a set of band-limited functions determined by the spike sequence. Under Nyquist-type and frame conditions, the encoded signal can be recovered from these projections with arbitrary precision. For the video time encoding machine architecture, we demonstrate that band-limited video streams of finite energy can be faithfully recovered from the spike trains and provide a stable algorithm for perfect recovery. The key condition for recovery calls for the number of neurons in the population to be above a threshold value.
Keywords: Faithful representation, neural circuit architectures, spiking neurons, time encoding, visual receptive fields
I. INTRODUCTION
TIME encoding machines (TEMs) [1] are asynchronous signal processors that encode analog information in the time domain. TEMs play a key role in the representation of analog waveforms by silicon-based information systems and in sensing the natural world by biological sensory systems. There is also substantial amount of interest in TEMs as front ends of brain-machine interfaces, i.e., as building blocks connecting biological and silicon-based information systems.
Intuitively, TEMs encode a (input) band-limited time signal into a multidimensional time sequence. For applications in the visual space, however, the input is a space-time function. TEMs encoding space-time analog waveforms that are of interest in silicon-based information systems and in early biological vision systems are discussed below.
Early hardware implementations of space-time encoding mechanisms include silicon retinas for spike-based vision systems [2], [3]. Applications of silicon retinas include, among others, spatial-contrast image encoding [4], motion detection [5], and real-time 2-D convolutions [6]. The question of implementing silicon retinas that faithfully represent video streams in the time domain and the associated design of perfect recovery algorithms has not been addressed in the literature. In neuromorphic engineering practice, the recovery of real-time video streams has shown substantial aliasing effects [7].
Decoding of stimuli encoded by early biological visual systems is a grand challenge in neuroengineering. A number of encoding models exist in the literature including computational models for the retina, lateral geniculate nucleus (LGN), and V1 of mammals. However, the representation power of these circuits in unknown. In [8], we initially addressed the use of neurons modeled akin to simple V1 cells having Gabor-like spatial receptive fields and a non-leaky integrate-and-fire (IAF) spiking mechanism. However, a general methodology for building arbitrary neural circuits with feedback and arbitrary receptive fields is not available.
In this paper, we introduce for the first time a general architecture of space-time video TEMs. The architecture is inspired by models of the early visual system; it applies as a template architecture for silicon-based TEMs. The basic TEM architecture is based on a flexible set of interconnected building blocks. The key building blocks are filters modeling receptive fields and single-input multiple-output (SIMO) neural circuits with feedback representing analog information akin to neuronal circuits in the early visual system.
For each SIMO neural circuit, neuron spike generation is based on a threshold-and-fire (TAF) or an IAF mechanism. The circuit models employed here include general feedback connections within and in-between neurons. For each of the encoding neural circuits, we study the representation of the input analog signal and its recovery from the output spike train. As we shall demonstrate, these circuits project the input signal on a set of functions determined by the spike sequence. Under appropriate conditions, these functions span the space of band-limited signals, and, consequently, the encoded stimulus can be recovered from these projections. We devise algorithms that faithfully recover the stimulus and investigate changes in encoding due to feedback. We also demonstrate that encoding circuits based on TAF and IAF mechanisms can be operationally treated in a similar manner.
For the overall video TEM architecture, we derive conditions for the faithful representation of the analog input stream as a multidimensional time (spike train) sequence. We also provide a stable algorithm for recovery of the video input from spike times. The key condition for recovery comes from the mathematical theory of frames [9] and requires that the population spike density as well as the number of neurons is above the Nyquist rate.
This paper is organized as follows. In Section II, we present SIMO neural circuits that map an analog signal into a multidimensional time sequence. We show how these circuits encode information and establish invertibility conditions. In Section III, the problem of time encoding of analog video streams is posed in a general setting. We shall derive a time decoding algorithm that faithfully recovers the video signal from the multidimensional spike train in Section IV. Detailed examples are given in Section V. Finally, Section VI concludes our work and discusses future directions.
II. Time Encoding with Neural Circuits with Feedback
In this section, we analyze the representation power of a number of encoding circuits based on models of neurons of the early visual system as well as models of neurons arising in silicon retina and related neuromorphic hardware. The basic encoding circuit investigated here is a SIMO neural circuit with feedback that maps an analog input signal into a multidimensional time sequence (see Fig. 1).
Fig. 1.
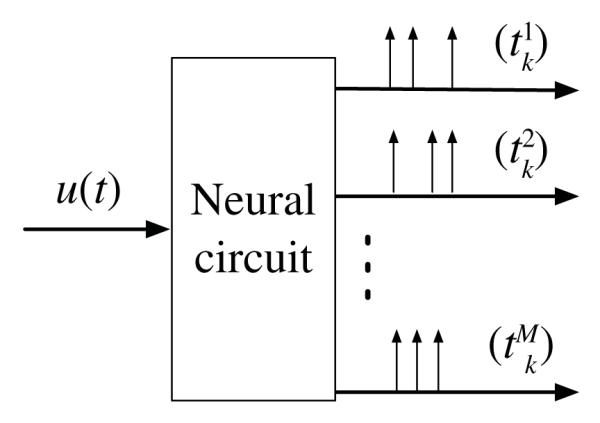
SIMO neural circuit with feedback.
All analog input signals of interest u = u(t), t ∈ ℝ, in this section live in the space of band-limited functions with finite energy and with spectral support in, the [−Ω, Ω]. We denote this space with letter Ξ. In Section II-A, single-input single-output (SISO) neural circuits are investigated, in Section II-B and II-C single-input two-output neural circuits are considered. We shall show that existing models of retinal ganglion cells (RGCs) and LGN neurons [10] and simple neural circuits arising in frame-free cameras [5] have the same representation properties. They are simple instantiations of the neural circuit model with feedback (see Fig. 1).
We demonstrate that information contained at the input of the neural encoding circuit can be recovered by a decoder provided the average number of spikes is above the Nyquist rate. For each TEM, we will show how to build a time decoding machine (TDM) that perfectly recovers the encoded signal. The structure of the decoders is the same and consists of a low-pass filter (LPF) whose input is a train of weighted spikes derived from those generated by the neural circuit.
The theoretical framework presented in this section was first developed in [11]. It has only been formally applied, however, to the decoding of stimuli encoded with a population of unconnected IAF neurons without feedback. Here we show how to apply it to stimuli encoded with fully pulse-connected neural circuits and extend it to circuits with neurons with TAF with feedback. Moreover, by explicitly calculating the spike density of all the neural circuits of interest, we greatly improve on the bounds presented in [11]. Examples are given in Section II-D.
A. Time Encoding with a Single Neuron
The object of this section is the analysis of SISO TEMs with feedback (see Fig. 2). We will refer to these circuits as single neuron TEMs. Fig. 2(a) shows the spiking mechanism of a time encoding neural circuit consisting of a single neuron with feedback. The structure of the circuit is inspired by a neuron model that was first proposed in [10]. The neuron fires whenever its membrane potential reaches a fixed threshold value δ. After a spike is generated, the membrane potential is reset through a negative feedback mechanism that gets triggered by the just emitted spike. The feedback mechanism is modeled by a filter with impulse response h(t).
Fig. 2.
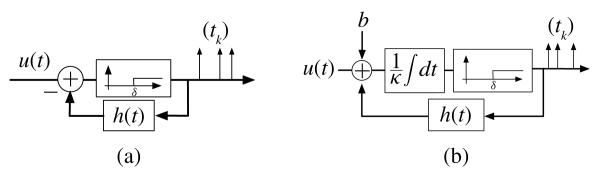
Single neuron TEMs with feedback. (a) TAF with feedback. (b) IAF with feedback.
The encoding is quantified with the t-transform [1] that, given the input stimulus, describes in mathematical language the sampling process. Let (tk), k ∈ ℤ, be the set of spike times at the output of the neuron. Then the t-transform of the TEM depicted in Fig. 2(a) can be written for all k, k ∈ ℤ, as
| (1) |
Equation (1) can be written in inner product form as
| (2) |
where qk = δ + Σl<k h(tk−tl), χk(t) = g(t−tk), k ∈ ℤ, and g(t) = sin(Ωt)/πt, t ∈ ℤ, is the impulse response of a LPF with cutoff frequency Ω. The impulse response of the filter in the feedback loop is causal, and in widely adopted models it is decreasing with time (e.g., exponential decay) [10].
Fig. 2(b) depicts a time encoding neural circuit consisting of an IAF neuron with feedback. IAF neurons have been used to model RGCs and LGN neurons in [12]. The t-transform of the encoding circuit can be written as
| (3) |
or in inner product form as
| (4) |
where and χk = g *1[tk, tk+1], for all k, k ∈ ℤ (* denotes the convolution).
It is easy to see that both encoding circuits described above have a similar operational structure. Both encode the signal u by projecting it on a set of sampling functions (χk), k ∈ ℤ. A decoder with observations (tk), k ∈ ℤ, can readily evaluate the inner product (projection) sequence (qk), k ∈ ℤ. Assuming that the spike density of the observations is above a threshold value, the following proposition provides a representation of the stimulus that is stable. The spike density intuitively formalizes the notion of average number of spikes in an arbitrarily large time interval. Appendix A provides a detailed methodology for computing the spike density of the simple neurons models employed in this paper.
Proposition 1: The band-limited input stimulus u, encoded with a single neuron TEM (Fig. 2), can be recovered as
| (5) |
where ηk (t) = g(t−tk), provided that the spike density of the single neuron TEM is above the Nyquist rate Ω/π. Moreover, with [c]k = ck, the vector of coefficients c is given by
| (6) |
where G+ denotes the pseudoinverse of G, [q]k = qk and [G]kl = 〈χk, ηl〉, for all k, l ∈ ℤ.
Proof: The representation result (5) holds and it is stable if the sequences of sampling functions χ = (χk), k ∈ ℤ, and representation functions η = (ηk), k ∈ ℤ, form frames for the space of band-limited functions Ξ. From the theory of frames for complex exponentials [13], the sequence η is a frame if the spike density is above the Nyquist rate. For the TAF with feedback TEM of Fig. 2(a), χk = ηk, for all k ∈ ℤ, and therefore, the sequence χ is a frame. For the IAF with feedback TEM of Fig. 2(b), the sequence η can be mapped to χ by a bounded operator with closed range, and thus, the frame property is preserved [9]. The interested reader can find a more detailed technical discussion in [11] and [14].
Equation (6) can be obtained by substituting the representation of u in (5) into the equation of the t-transform in (2) or (4), respectively. Since the sequence η, is a frame for Ξ, (5) and (6) are guaranteed to give a stable reconstruction [15].
B. Time Encoding with ON-OFF Neurons
In this section, we analyze single-input two-output TEMs with feedback (see Fig. 3). Two different circuits are shown. Each circuit consists of two neurons with the same spike triggering mechanism and feedback. We will refer to these circuits as ON-OFF TEMs.
Fig. 3.

ON-OFF TEMs with feedback. (a) TAF with feedback. (b) IAF with feedback.
Fig. 3(a) shows a circuit consisting of two interconnected ON-OFF neurons each with its own feedback. Each neuron is endowed with a level crossing detection mechanism with a threshold that takes a positive value δ1 and a negative value −δ2, respectively. Whenever a spike is generated, the feedback mechanism resets the corresponding membrane potential. In addition, the firing of each spike is communicated to the other neuron through cross-feedback. In general, the cross-feedback brings the other neuron closer to its firing threshold and thereby increases its spike density. The two neurons in Fig. 3(a) arise as models of ON and OFF bipolar cells in the retina and their connections through the non-spiking horizontal cells [16].
With (), k ∈ ℤ, the set of spike times of the neuron j, j = 1, 2, the t-transform of the ON-OFF TEM amounts to
| (7) |
for all k, k ∈ ℤ. Equation (7) can be written in inner product form , where is the right side of (7) and , k ∈ ℤ, j = 1, 2, are the sampling functions.
Fig. 3(b) shows a circuit consisting of two interconnected ON-OFF neurons each with its own feedback. The neurons are IAF. The t-transform of the neural circuit can be written as
| (8) |
or in inner product form , with the right side of (8), and the sampling functions are , for k ∈ ℤ, and j = 1, 2.
Proposition 2: The input stimulus u, encoded with an ON-OFF TEM (Fig. 3), can be recovered as
| (9) |
where the representation functions are given by , j = 1, 2, provided that the spike density of the ON-OFF TEM is above the Nyquist rate Ω/π. Moreover, with c = [c1; c2] and , the vector of coefficients c can be computed as
| (10) |
where q = [q1; q2] with , and
for all i, j = 1, 2, and k, l ∈ ℤ.
Proof: It is similar to the proof of Proposition 1.
C. Time Encoding with Silicon ON-OFF TEMs
ON-OFF spiking mechanisms have been used in various neuromorphic hardware applications [2], [5]. In this section, we present simplified versions of the ON-OFF neurons presented in Section II-B that have been implemented in silicon. We will refer to these circuits as silicon ON-OFF TEMs.
Fig. 4(a) depicts the silicon neuron implemented in [5]. A spike is generated whenever a positive or negative change of magnitude δ is detected. Immediately thereafter, the input to the thresholding blocks is reset to zero through a simple feedback mechanism. The encoding circuit in Fig. 4(a) can be obtained from the ON-OFF TEM depicted in Fig. 3(a) by setting δ1 = δ2 = δ and h11(t) = h22(t) = h12(t) = h21(t) = δ · 1[t>0]. The input to both the ON and OFF branch is
where τ(t) is the last spike before time t.
Fig. 4.
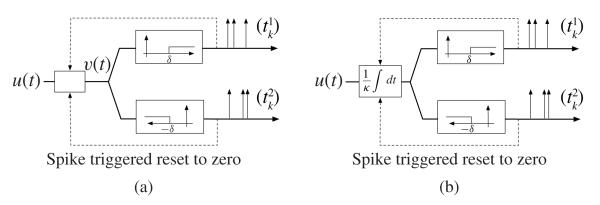
Encoding with a silicon ON-OFF TEM. (a) TAF with feedback. (b) IAF with feedback.
For arbitrary n ∈ ℤ and k ∈ ℕ, the t-transform of the silicon TEM amounts to
| (11) |
As in the previous examples, the above equalities can also be expressed in inner product form.
The circuit in [17, Fig. 4(b)] can be obtained by simplifying the ON-OFF TEM shown in Fig. 3(b) with δ1 = δ2 = δ, κ1 = κ2 = κ and h11(t) = h22(t) = h12(t) = h21(t) = κδ · 1[t>0]. We finally note that Proposition 2 holds for the silicon ON-OFF TEMs briefly sketched above, thus establishing conditions for perfect recovery.
D. Example
We illustrate the recovery algorithms for the TEMs presented above with an example using a band-limited function with Ω = 2π · 100 rad/s on the time interval [0, 0.2] s. For simplicity in presentation, we restrict ourselves to neuron models based on TAF spiking mechanism. In order to simplify the comparison of the performance of recovery algorithms for signals encoded with different neural circuits, the circuit parameters were chosen so that all TEMs approximately generated the same number of spikes.
For the single neuron TEM, the threshold was δ = 0.01 and the feedback filter h(t) = 0.1 exp(−100t)1[t>0] For the ON-OFF TEM, δ1 = δ2 = 0.47, h11(t) = h22(t) = 0.1 exp(−100t)1[t>0], and h12(t) = h21(t) = 0.075 exp(−t/0.015)1[t>0]. For the silicon ON-OFF TEM δ = 0.21. The results are shown in Fig. 5.
Fig. 5.

Recovery of signals encoded with TAF with feedback TEMs. Top row: Encoding mechanisms. Single neuron TEM (left), ON-OFF TEM (middle), and silicon ON-OFF TEM (right). Middle row: Encoding mechanisms zoomed in, in the time interval [0.024, 0.038 s. Bottom row: Comparison between the encoded and the recovered signals.]
The single neuron TEM fired a total of 87 spikes, fired in clusters when the input signal is greater than the threshold and the stimulus is increasing. The neuron does not fire any spikes when the input is negative. In theory, this does not create problems as long as the spike density is above the Nyquist rate. In practice, however, signals have finite time support. As a result, in negative signal regions the recovery might be poor.
The situation improves with the ON-OFF TEM which also fired a total of 87 spikes (51 for the ON part and 36 for the OFF part). Trigger times occur again in clusters but sample the stimulus at both positive and negative values. Note that the signal entering the thresholding block has a reduced range when compared to the encoded stimulus. In general, for the same number of trigger times, the ON-OFF TDM tends to lead to better recovery results than the single neuron TDM. For example, in the time interval [0.025, 0.175] s the single neuron TDM had a signal-to-noise ratio (SNR) = 13.87 [dB] whereas the ON-OFF TDM recovered the stimulus with SNR = 54.04 [dB].
Finally, the silicon ON-OFF TEM produced a similar number of spikes (84 spikes, 42 for each branch). The spikes were more uniformly distributed when compared to the spikes of the single neuron TEM and the ON-OFF TEM, both of which occur in clusters. This resulted in a better stimulus recovery with SNR = 64.2 [dB] in the time interval [0.025, 0.175] s. The improved performance is primarily due to the precision in representing the signal samples as integer multiples of the threshold value. In the case of the ON-OFF TEM, numerical errors are introduced through the feedback current. The latter is dependent on the previous spike times that are measured with a finite temporal resolution.
III. Architecture of Video TEMs
In this section, we introduce a model architecture for video TEMs (see Fig. 6). The architecture consists of a bank of N spatiotemporal filters and N neural circuits. The neural circuits are SIMO TEMs. Each filter is connected to a single neural circuit and represents its spatiotemporal receptive field (STRF). The input video stream is considered to be band-limited in time and continuous in space.
Fig. 6.

Architecture of the video TEM.
By establishing the t-transform of the video TEM, we show how an analog video stream is represented in the time domain. In Section IV, we shall prove that under mild conditions the video stream can be perfectly recovered by only knowing the encoder parameters and the spike times and derive perfect recovery algorithms.
Let denote the space of (real) analog video streams I = I (x, y, t), (x, y, t) ∈ ℝ3, that are band-limited in time and continuous in space, and have finite energy. It is clear that the space is a Hilbert space, when endowed with the inner product defined by
In full generality, we assume that each neural circuit j has an STRF described by the function Dj = Dj (x, y, t), (x, y, t) ∈ ℝ3, j = 1, 2, …, N. In what follows, we assume that the filters describing the STRFs are bounded-input bounded-output stable. Filtering the video stream with the receptive field of the neural circuit j gives the receptive field output vj(t). The latter serves as the main input to neural circuit j and amounts to
| (12) |
Following the discussion of Section II, the t-transform of ith branch of the jth neural circuit is described by
| (13) |
where the sampling functions and the inner products , for all k ∈ ℤ, i = 1, 2, …, M, and all j = 1, 2, …, N. Depending on the spiking mechanism of the neural circuit, the sampling functions are of the form or , t ∈ ℤ, where (), k ∈ ℤ, i = 1, 2, …, M, and j = 1, 2, …, N, is the spike sequence generated by the video TEM. Therefore, the t-transform of the video TEM is given by
| (14) |
where for all k ∈ ℤ, i = 1, 2, …, M, and j = 1, 2, …, N (D̃j(x, y, t) = Dj (x, y, −t)).
The t-transform in (14) quantifies the projection of the video stream I onto the sequence of sampling functions , j = 1, 2, …, N, i = 1, 2, …, M, k ∈ ℤ. If the sequence ϕ is a frame for , then I can be perfectly recovered from this set of projections. Furthermore, the recovery is stable. Our goal in the next section is to find sufficient conditions on the sequence ϕ to be a frame for and to provide a recovery algorithm.
IV. Time Decoding and Perfect Recovery
In this section, we present the conditions on the set of receptive fields that guarantee a faithful representation of video stimuli and provide an algorithm for perfect signal recovery.
A. Conditions for Perfect Stimulus Recovery
Theorem 1: The input video stream I can be perfectly recovered from the set of spike times (), j = 1, 2, …, N, i = 1, 2, …, M, k ∈ ℤ, provided that the spike density of the neural circuits is sufficiently large, and for every ωt ∈ [−Ωt, Ωt]
| (15) |
is a frame for the space of spatially band-limited images. Here, and denote the 2-D and 3-D Fourier transforms, respectively.
Proof: The proof is presented in Appendix B. Note that an explicit sufficient density condition is to have the spike density of every neural circuit above the temporal Nyquist rate Ωt/π. Note also that a necessary condition for (15) to hold is to have the number of neurons at least equal to the number of independent spatial components of the input video stimulus. The latter is in full generality equal to Ωx · Ωy/π2 per unit area, where Ωx and Ωy denote the spatial bandwidth along the x and y directions, respectively. In practice, although the video streams are defined on a finite spatial aperture, the spatial bandwidths are assumed to be finite.
Remark 1: The assumption of finite spatial bandwidth is supported in practice. In the visual system, the maximum spatial resolution is finite and depends (among others) on the density of the photoreceptor rods and cones [18].
Remark 2: Space-time separable receptive fields of the form
| (16) |
are of particular interest in systems neuroscience. For such receptive fields, the frame condition for perfect recovery becomes
where denotes the (1-D) Fourier transform of . This holds, for example, when the temporal components of the receptive fields have full frequency support, i.e., , and the spatial receptive fields form an overcomplete wavelet filterbank. Such filterbanks arise as a model of receptive fields in the primate retina [19]. For more information, see the examples in Section V or [8].
The required conditions of Theorem 1 are rather abstract. These conditions are satisfied, however, for a number of practical applications with STRFs that:
are space-time separable and the spatial components form an overcomplete spatial filterbank (see Remark 2);
form an overcomplete space-time wavelet filterbank. Such a case can be useful for tracking applications [20];
are chosen randomly according to a known distribution (e.g., Gaussian). The latter case, briefly explored in example V-C, arises in analog-to-information conversion for compressed sensing [21].
Remark 3: The result of Theorem 1 along with the above discussion has a simple evolutionary interpretation. If every neuron responds to the stimulus with a positive, nonvanishing, spike rate, then visual stimuli can be faithfully represented in the spike domain using a finite number of neurons.
B. Perfect Recovery Algorithm
In order to devise a general recovery algorithm for the infinite dimensional case, we use the sequence of representation functions k ∈ ℤ, j = 1, 2, …, N, i = 1, 2, …, M, k ∈ ℤ, with
| (17) |
where , t ∈ ℤ. We have the following.
Algorithm 1: If the assumptions of Theorem 1 hold, then for a sufficiently large N, the video stream I, encoded with a video TEM (Fig. 6), can be recovered as
| (18) |
where , j = 1, 2, …, N, i = 1, 2, …, M, k ∈ ℤ, are suitable coefficients. With c = [c1, c2, …, cN]T, cj = [cj1, cj2, …, cjM]T and , the coefficients c can be computed as
| (19) |
where T denotes the transpose, q is a vector with entries , and G+ denotes the pseudoinverse of G. G is a N × N block matrix. Each block Gij is in turn a M × M block matrix with entries given by
| (20) |
for all i, j = 1, 2, …, N; k, l ∈ ℤ and m, n = 1, 2, …, M.
Proof: Equation (19) can be obtained by substituting the representation of I in (18) into thet-transform equation (14).
The video TDM pertaining to Algorithm 1 is depicted in Fig. 7.
Fig. 7.

Architecture of the video TDM.
V. Examples
In this section, we present examples of encoding of synthetic and natural video scenes with various video TEM architectures and analyze the performance of the associated decoding algorithms. The examples highlight the versatility of video TEMs for modeling purposes and the generality of their underlying structure. A note of caution, the video TEMs are clockless. In order to simulate them on Turing machines, however, only frame-based digital video sequences can be used. Consequently, in all our examples we employed natural scenes with a high frame rate. The high frame rate allowed us to load an approximation of the analog waveforms into our computation platform.
In Section V-A and V-B, we consider video TEMs with receptive fields used in models of RGCs and simple cells in V1. In Section V-C, the STRFs are randomly drawn and are space-time nonseparable. An encoding example of natural video scenes is presented in Section V-D.
A. Video TEM with Spatial Gabor Filterbank
The video TEM in this section consists of a spatial Gabor filter bank and neural circuits using four different firing mechanisms. Such encoding circuits are encountered in modeling simple cells and their receptive fields in the area V1 of the visual cortex in mammals [22].
The signal at the input of the video TEM is a synthetically generated space-time separable video stream of the form I (x, y, t) = S(x, y)u(t). The stream has the following characteristics. The temporal component has an equivalent bandwidth of 20 Hz in the time interval 𝕋 = [0, 250] ms. A temporal bandwidth of 20 Hz (Ω = 2π · 20 rad/s) has been reported to contain almost all the information for natural video streams [23]. The spatial component is defined on the domain (aperture) ⅅ = [−4, 4] × [−4, 4]. One hundred and twenty-eight pixels were used for the spatial discretization in each direction. This spatial resolution supports stimuli with spatial bandwidth of up to 8 Hz in each direction. In our case, the spatial bandwidth was 2.5 Hz in each spatial direction (2π · 2.5 rad/degree).
The architecture of the video TEM consists of a spatial Gabor filterbank in cascade with a population of neural circuits. The (Gabor) mother wavelet employed here was originally proposed by Lee [24] based on a number of mathematical and biological constraints. It is given by
with κ/2π = 0.75 Hz. For (real) video streams, the mother wavelet decomposes into two wavelets corresponding to its real and imaginary part, respectively. To construct a spatial filterbank, one performs the operations of rotations, dilations, and translations on the mother wavelet. More information can be found in [8]. On both wavelet components, operations on three scales, three rotations, and 5 × 5 translations along both dimensions were used to generate a spatial Gabor filterbank consisting of a total of N = 2 × 3 × 3 × 5 × 5 = 450 filters.
Four different firing mechanisms for the neural circuits were considered, single neuron TEMs (with TAF, IAF with bias and feedback, and IAF with feedback without bias) and ON-OFF TAF TEM. In each case, the 450 SIMO TEMs were chosen to be the same. By appropriately choosing certain parameters, the four different video TEMs realizations approximately generated the same number of spikes. More specifically, the parameters of the neurons were chosen as follows. For every single neuron TEM with TAF, δ = 0.06 and h(t) = 0.055 exp(−t/0.03) · 1(t ≥ 0). For every single neuron TEM with IAF with bias, b = 1.1, δ = 2.7, κ = 0.01, and h(t) = 0.055 exp(−t/0.03) · 1(t ≥ 0), and finally, for the IAF without bias, b = 0, δ = 0.068, κ = 0.01, and h(t) = 0.055 exp(−t/0.03) · 1(t ≥ 0). For every ON-OFF TEM δ1 = −δ2 = 0.085, h11(t) = h22(t) = 0.08 exp(−t/0.06) · 1(t ≥ 0) and h12(t) = h21(t) = 0 (time in seconds).
To quantify the quality of the recovery, we used the peak-SNR (PSNR) for the spatial component (PSNR[S]) and for the entire video stream (PSNR[I]) and, SNR for the temporal component (SNR[u]). The performance of the various architectures under these metrics is summarized in Table I, where we also provide the total number of spikes for each architecture and the number of neurons that fired spikes out of the total 450. All the quality metrics are measured in dB.
TABLE I.
Performance of the Various Video TEM Realizations
| PSNR[S] | SNR[u] | PSNR[I] | Spikes | # fired | |
|---|---|---|---|---|---|
| TAF | 26.67 | 28.21 | 29.25 | 4667 | 259 |
| IAF w bias | 44.36 | 44.44 | 40.90 | 4409 | 450 |
| IAF w/o bias | 20.17 | 28.83 | 25.69 | 4543 | 215 |
| ON-OFF TAF | 32.63 | 42.3 | 35.11 | 4258 | 239 |
From Table I, we conclude that the best results were achieved by the video TEM realized with IAF neurons with bias, followed by the video TEM realized with ON-OFF TAF TEMs. The bias term in the former TEM forces every neuron to fire and, thereby, provides a “more uniform” sampling of the video stream. Consequently, information about all the projections of the video stream onto the elements of the filterbank is obtained. This leads to improved performance in recovery.
For the remaining cases, it is clear that the video TEM built with ON-OFF TAF TEMs significantly outperforms the other two. The reasons are similar to the ones mentioned in the example of Section II. It is important to note that for the spatial component, the largest errors appear at the spatial boundaries of the video stream. This is of course expected since the finite aperture stream fails to be spatially band-limited. By excluding the boundaries (5 pixels on each side), the spatial component PSNR[S] and of the video stream PSNR[I] significantly increases in all four cases (2–3.5 [dB]).
For the ON-OFF TAF-based video TEM, we also examined the quality of signal recovery as a function of the number of spikes that the neurons produced. In order to do so, we changed the feedback parameters of the ON-OFF TEMs while leaving the rest of the parameters (receptive fields, thresholds) unchanged. The plot of the three quality measures (PSNR[S], SNR[u], and PSNR[I]) as a function of the number of spikes is shown in Fig. 8. As shown, with an increase in the number of spikes, the quality of the recovery also increases.
Fig. 8.

Performance of the video TEM as a function of the number of spikes. Each neuron is realized as an ON-OFF TEM.
B. Video TEM with Spatial Isotropic Wavelet Filterbank
The methodology presented in the previous example can also be applied to video TEMs with spatial receptive fields constructed from other mother wavelets. For example, a filter bank with a difference-of-Gaussians (DoG) mother wavelet has been used to model the spatial receptive fields of RGCs [25], [26].
As above, we used a space-time separable video stream with the same bandwidth, duration of 200 ms, spatial domain ⅅ = [−2, 2] × [−2, 2], and 128 pixels in each direction. To eliminate the boundary effects, the spatial domain was extrapolated to [−2.5, 2.5] × [−2.5, 2.5] (with 160 pixels per direction). The spatial filterbank had a wavelet structure generated from an isotropic wavelet given by a DoG
with α2 = 0.5, α1 = α2/1.6. Since the DoG wavelet is isotropic, the filterbank was constructed by performing only dilations and translations. Six different scales were used, m = −2, −1, …, 3, and , and a different number of translations was performed for each scale. For each scale , the number of translations in each direction was given by , with resolution , where b0 = 0.55. Here nint(x) denotes the nearest integer of x. In total, 622 filters were constructed. The ON-OFF TEM had a TAF with feedback spiking mechanism and parameters δ1 = −δ2 = 0.7, h12(t) = h21(t) = 0.01 exp(−t/0.01)1[t>0] and h11(t) = h22(t) = 0.65 exp(−t/0.015)1[t>0]. Overall, 554 neuron pairs fired at least one spike amounting to a total of 5660 spikes. The input and the recovered components of the stimuli are shown in Fig. 9. The performance of the stimulus recovery was PSNR[S] = 34.57 dB, PSNR[I] = 30.26 dB, and SNR[u] = 39.37 dB.
Fig. 9.
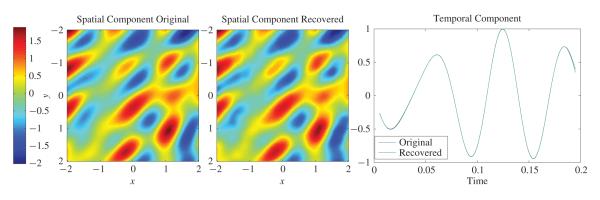
Performance of a video TEM based on a DoG wavelet. Each neuron is realized as an ON-OFF TEM.
The results of Fig. 9 suggest that any possible mother wavelet (or in general x-let structure) can be used as long as the set of wavelets is “dense enough” so that it can faithfully represent the required spatial characteristics of the input video stream. Consequently, the optimal choice of the mother wavelet largely depends on the desired application.
C. Video TEM with Nonseparable STRFs
In this section, we highlight the versatility of the theoretical framework and the generality of the decoding algorithms presented in this paper. From a technical standpoint, both the input video stimulus I and the set of STRFs are nonseparable.
The input video stream belongs to a discretized version of , the space of trigonometric polynomials (see Appendix B) with Mx = My = 3, Mt = 5, and bandwidth Ωx = Ωy = 2π · 2 rad/degree, Ωt = 2π · 7.5 rad/s. The STRFs also belong to the same space of trigonometric polynomials. Their line frequency response was randomly chosen, for each frequency, from a standard normal distribution. One hundred STRFs were constructed in this way. Since the frequency responses were picked randomly, all the necessary rank conditions (required rank = 49) were satisfied with high probability. The neural circuits consisted of ON-OFF neuron pairs with TAF with feedback spiking mechanism. These neurons produced a total of 1150 spikes.
The video synthetic stream was reconstructed using Algorithm 2 (see Appendix C). The encoded and recovered synthetic video stream are shown for three different time instances in Fig. 10. The embedding of the videos and the STRFs into the finite-dimensional space of trigonometric polynomials enables the closed form evaluation of the dendritic outputs vj [see (30)] as well as the entries of the matrix F. As such, there are no numerical errors introduced during the encoding and reconstruction phase beyond finite precision considerations of the spike times. This leads to a practically perfect reconstruction of the input stimulus. The performance of the reconstruction algorithms speaks for itself: SNR [I] = 74.78 [dB] and PSNR 86.96 [I] = [dB]. Note that random filters have been used as analog-to-information converters for compressed sensing applications [21].
Fig. 10.

Performance of a video TEM based on filters with random STRFs. The upper row shows three of the encoded frames and the lower one the corresponding recovered ones.
D. Natural Video Scene Example
The most experimentally demanding case pertains to the encoding and decoding of natural scenes. As already mentioned, we used high-frame-rate video sequences captured with special cameras. The high computational demands were met by employing a computational platform based on GPUs.
The video TEM architecture consisted of 2744 neurons with spatial receptive fields drawn from a Gabor filterbank. Seven different scales and four different orientations were used. On average, for each pair of orientation/scale 49 different translations along the both axes were employed, more translations were used for finer scales and less for coarser ones. For m = 0 and m = −1, three translations were used in each direction, for m = −2 five, for m = −3 and m = −4 seven, for m = −5 nine and finally for m = −6 eleven translations were used.
All the neurons had an IAF spiking mechanism with bias b = 0.25, threshold δ = 0.04, and integration constant κ = 0.01. The input video, showing a fly taking off, had a duration 20 ms with a frame rate of 6000 frames/s, resulting in an effective temporal bandwidth of 3 kHz. Ninety-six pixels were used in each direction giving a total of 9216 pixels. The neurons fired a total of 33 713 spikes, giving an average of 12.3 spikes per neuron, and 615 spikes per neuron per second. Note that this number is one order of magnitude less than the 6-kHz frame rate of the video stream. The recovered video had PSNR[I] = 31.28 [dB].
Three of the recovered video, along with the corresponding encoded ones, are shown in Fig. 11. Note that the number of neurons used to encode the video is significantly lower than the number of pixels that are used to display the video stream. This highlights one of the potential advantages of the video TEMs when compared to past silicon retina implementations.
Fig. 11.

Encoding of a natural video scene with a video TEM. The upper row shows three of the encoded frames and the lower one the corresponding recovered frames. The PSNR for each of these three frames is also displayed.
VI. Discussion and Conclusion
Stringent requirements for extremely low-power information processing systems are one of the main drivers for information representation in the time domain. Due to the ever-decreasing size of integrated circuits and the attendant low voltage, in traditional silicon-based information systems amplitude-domain high precision quantizers are more and more difficult to implement. By representing information in the time domain, SISO TEMs leverage the phenomenal device speeds that a temporal code can take advantage of [27]. Consequently, next-generation encoders in silicon are expected to represent information in the time domain [28]. Widely used modulation circuits such as asynchronous sigma/delta modulators and FM modulators in cascade with zero-crossing detectors have been shown to be instances of TEMs [1]. These advances served as a basis for (1-D) TEM implementations in hardware [29]-[35]. These implementations exhibit extremely low power requirements, see [34] for an extensive discussion on SISO TEMs meeting these power requirements.
Video TEMs realized in silicon are a natural extension of SISO information systems that represent analog waveforms in the time domain. They are highly versatile for modeling purposes, since they enable different combinations of filters/receptive fields and spiking mechanisms. Unlike asynchronous silicon retina implementations, which assign to every pixel a neuron, video TEMs use a bank of STRFs to map the incoming video streams into a train of spikes. Thus, video TEMs provide a more compact representation of information in the time domain and can serve as templates for future neuromorphic hardware applications. In quantized form, the spike sequence generated by video TEMs can be used for transmission and for further processing with any digital communications and/or signal processing system.
The interest in temporal encoding in systems neuroscience is closely linked with the natural representation of sensory stimuli (signals) as a sequence of action potentials (spikes) in early olfaction, audition, and vision. TEMs based on single-neuron models such as IAF neurons [36] and more general Hodgkin–Huxley neurons with multiplicative coupling, feedforward, and feedback have also been investigated [37]. Video TEMs can be used to represent analog information residing in the visual world as a multidimensional time (spike) sequence. They are versatile encoding circuits for modeling information representation in the early visual system.
From a theoretical point of view, video TEMs realize two operators in cascade. The first, which is a filter bank or receptive field, is a vector linear operator. The second, which is population of neural circuits, is a vector nonlinear operator. The task of decoding, which is a key challenge both in silicon-based information systems and in systems neuroscience, calls for finding the inverse of the composition of these two operators. We formally investigated conditions for the existence of the inverse, i.e., for the faithful representation of analog band-limited video streams using the sequence of spikes. We examined a variety of neuron spiking mechanisms, such as level-crossing detection and IAF with feedback, and combined these with models of receptive fields that arise in the early visual system. Our investigations demonstrated that the visual world can be faithfully represented with a population of neurons, provided that the size of the population is beyond a critical value. Based on the characteristics of the input signal, we showed that this estimate is substantially smaller than the total number of pixels.
Finally, we note that the formal representation of spatiotemporal information as a set of projections in the Hilbert space of band-limited functions may serve as a theoretical foundation for future asynchronous stimulus encoding algorithms. The work presented here raises a number of issues regarding the encoding efficiency of video TEMs. These and other issues will be investigated elsewhere.
ACKNOWLEDGMENT
The authors would like to thank Y. Zhou for coding the natural video scene example. They also thank the anonymous reviewers for their comments and suggestions for improving this paper.
This work was supported in part by the National Institutes of Health under Grant R01 DC008701-01 and in part by the Air Force Office of Scientific Research under Grant FA9550-09-1-0350. The work of E. A. Pnevmatikakis was supported by the Onassis Public Benefit Foundation, Athens, Greece.
Biography

Aurel A. Lazar (S’77–M’80–SM’90-F’93) is a Professor of electrical engineering at Columbia University, New York, NY. In the mid-1980s and 1990s, he pioneered investigations into networking games and programmable networks (www.ee.columbia.edu/~aurel/networking.html). His current research interests (www.bionet.ee.columbia.edu) are at the intersection of computational, systems and theoretical neuroscience. In silico, his focus is on neural encoding, systems identification of sensory systems, and spike processing and neural computation in the cortex. In this work, he pioneered rigorous methods of encoding information in the time domain, functional identification of spiking neural circuits, and massively parallel neural computation algorithms in the spike domain. In vivo, his focus is on the olfactory system of the Drosophila. His current work primarily addresses the nature of odor signal processing in the antennal lobe of the fruit fly.

Eftychios A. Pnevmatikakis (S’08-M’11) received the Diploma degree in engineering from the School of Electrical and Computer Engineering, National Technical University of Athens, Athens, Greece, in 2004. He received the M.Sc. and Ph.D. degrees from Columbia University, New York, NY, both in electrical engineering, in 2006 and 2010, respectively. He was an Adjunct Assistant Professor with the Department of Electrical Engineering, Columbia University, in 2010. Since May 2010, he has been a Post-Doctoral Researcher with the Department of Statistics and the Center for Theoretical Neuroscience, Columbia University. His current research interests include theoretical neuroscience, signal processing, brain inspired computation, and methods for statistical analysis of neural data. Dr. Pnevmatikakis received the Jury Award from the Department of Electrical Engineering, Columbia University, in 2010, for outstanding achievement by a graduate student in the area of systems, communications, and signal processing.
appendix A
Spike Density of Spiking Neural Circuits
In this section, we present a formal definition of the notion of spike density and a general methodology for its computation for spiking neural circuits. The methodology to evaluate the spike density for spiking neurons was first developed in [38] for the case of a single IAF neuron without feedback.
Definition 1: A real sequence is called separated if infk≠l |λk − λl| > 0 and relatively separated if it is a finite union of separated sequences.
Definition 2: Let be a sequence of real numbers that is relatively separated. Let N(a, b) the number of elements of Λ that are contained in the interval (a, b). The upper and lower (Beurling) densities of Λ are defined as
| (21) |
A. Spike Density of Ideal IAF Neural Circuits
Lemma 1: The interspike time interval generated by an IAF neuron (wlog without feedback) with input and bias b > 0 is bounded.
Proof: Let t1 be a spike time and assume that the neuron did not fire another spike until time t2, (t2 > t1). Then
where the first inequality follows from the Cauchy–Schwartz inequality. Solving for t2 − t1 we obtain the bound
| (22) |
Note that this bound is presented here for the first time.
Let [a1, a2] be an arbitrary time interval and let t1 denote the first spike time immediately after a1 and t2 denote the last spike time just before a2. The average number of spikes in the interval [a1, a2], D(a1, a2), of the IAF neuron is given by
| (23) |
Assume that |a2 − a1| → ∞. From Lemma 1, we have (t1−α1)/(α2−α1) → 0(t2−α2)/(α2−α1) → 0 and therefore the integration interval [t1, t2] in (23) can be replaced with [a1, a2].
Proposition 3: For all inputs u, u ∈ Ξ, the spike density of an ideal IAF neuron with feedback is equal to
| (24) |
Proof: We will compute the lower and upper densities D−, D+ defined above. Let I denote the whole current due to feedback. Proceeding as above
Using again the Cauchy-Schwarz inequality, we get
| (25) |
For the feedback current we have
provided that since each spike produces enough feedback current to elicit another spike with a continuously increasing frequency. Otherwise
and the result of (24) is a lower bound for D−. Repeating the procedure for the upper density D+ we can show that the right side of (24) is an upper bound and the general result follows.
Remark 4: Note that the result of (24) is asymptotic in the sense that the instantaneous firing rate of the neuron converges to the value of the density.
Using similar arguments, one can also derive the spike density of the IAF ON-OFF TEM as follows.
Proposition 4: Consider the IAF ON-OFF TEM of Fig. 3(b) and let , i, j = 1, 2. Assume that Hij > −κiδi, i = 1,2 and that
The spike density of the IAF ON-OFF TEM is given by
| (26) |
If one of the inequality conditions is not satisfied, then the spike density is infinite.
Proof: Similar to the proof of Proposition 3.
B. Spike Density of TAF Neural Circuits
For completeness, we present the evaluation of the spike density of neurons with TAF with feedback spiking mechanism. We assume that the neuron exhibits a bias b. This bias was absent in our analysis in Section II since in applications stimuli have finite time support and therefore the neural circuits do not fire infinitely often.
Proposition 5: The spike density D of the single neuron TEM with TAF with feedback spiking mechanism and external bias b is 0 for b ≤ δ. For b > δ, the spike density is the solution of the equation
| (27) |
where ℕ is the set of positive integers.
Proof: In the absence of a time-varying external input, the neuron will not fire at all if b < δ. If b > δ, then the neuron will fire periodically with period T at times tk = kT, k ∈ ℤ. From (1), we have that
Since u = 0, the result follows. If the feedback mechanism is of the form h(t) = h(0) exp(−t/τ) · 1[t≥0], with h(0) > 0, then the spike density becomes
| (28) |
Appendix B
Proof of Theorem 1
In this section, we first present the proof of Theorem 1 for band-limited video streams that belong to the finite-dimensional space of trigonometric polynomials. Subsequently we shall extend these results to the infinite-dimensional case.
Let the set of functions (emx, my, mt (x, y, t)) for all mx = −Mx, …, Mx, my = −My, …, My, and mt = −Mt, …, Mt, be defined as
with and emy, emt similarly defined. The space spanned by this set consists of the band-limited and periodic video streams, with space-time bandwidth (Ωx, Ωy, Ωt) and period (2πMx/Ωx, 2πMy/Ωy, 2πMt/Ωt), respectively. The band-limited and periodic video streams are elements of a Hilbert space endowed with the usual (sesquilinear) inner product and with (emx, my, mt (x, y, t)) as its orthonormal basis.
The elements of the space represent a natural discretization of band-limited functions in the frequency domain. The functions in the Hilbert space have a discrete spectrum at frequencies (my(Ωx/Mx), my(Ωy/My), mt(Ωt/Mt). By letting Mx, My, Mt → ∞, the spectrum becomes dense in [−Ωx, Ωx] × [−Ωy, Ωy] × [−Ωt, Ωt] and these functions converge to band-limited functions.
Let the input video I and the STRFs Dj be expressed by
| (29) |
Let a = [a1; … ; amt], denote the column vector of coefficients, with
Similarly, let for all j, j = 1, 2, …, N, denote the set of coefficients for every STRF. To simplify the notation we assume that i = 1, i.e., all neurons have a single component (this can easily be generalized). The problem is to recover the vector a.
We assume here that the spike density of every neural circuit j, j = 1, 2, …, N, is above the temporal Nyquist rate Ωt/π. Based on Propositions 1 and 2, for each j, j = 1, 2 …, N, the set of sampling functions (), forms a frame for Ξ. Therefore, all the dendritic outputs (vj), j = 1, 2, …, N, can be perfectly recovered. Equation (12) can be rewritten as
where the coefficients are given by
| (30) |
For a fixed mt ∈ [−Mt, …, Mt] we can write (30) for all neurons in the matrix form
| (31) |
where , , for each mt, mt = −Mt, …, Mt. For these equations to be solvable, we need the matrices Dmt to have full row rank (2Mx + 1)(2My + 1) for all mt. A necessary condition to achieve full row rank is to have the number of neurons N at least equal to the number of independent spatial components (2Mx + 1)(2My + 1). Note that this full row rank condition is equivalent with having the columns of the matrix form a frame for the space of images spanned by the set of basis functions (emx, my) [9]. Moreover, each vector represents the Fourier transform of the receptive field Dj at the temporal frequency mtΩt/Mt. Therefore, the rank condition on the matrices Dmt calls for the set of STRFs to form a frame for the space of spatial images when restricted to each and every temporal frequency mtΩt/Mt, mt = −Mt, …, Mt.
In order to extend the above results to the infinite dimensional case, let Mx, My, Mt → ∞. Then the set {mxΩx/Mx}, mx = −Mx, …, Mx becomes dense in the interval [−Ωx, Ωx], and
where denotes the 3-D Fourier transform. Let also denote the 2-D (spatial) Fourier transform. In the limit, the rank condition becomes a frame condition for every ωt ∈ [−Ωt, ωt], the set of spatial receptive fields (), j = 1, …, N, is a frame for the set of spatially band-limited images.
Appendix C
Finite-Dimensional Recovery Algorithm
We now present an algorithm that faithfully recovers a video stimulus with a finite-dimensional representation in the space of trigonometric polynomials.
Algorithm 2: If the assumptions of Theorem 1 hold, then for a sufficiently large N, the finite dimensional video stream I, encoded with a video TEM (Fig. 6), can be recovered as
| (32) |
where the vector of coefficients c is given by
| (33) |
with q = [q1; q2; … qN]T, qj = [qj1, qj2, …, qjM]T and and F+ denotes the pseudoinverse of F. The matrix F has dimensions NT × (2Mx + 1)(2My + 1)(2Mt + 1), where NT is the total number of spikes (measurements). If the lth entry of the vector q corresponds to the spike at time , then the lth row of F is given by
with mx = −Mx, ’, Mx, my = −My, …, My, mt = −Mt, …, Mt.
Proof: By considering (14) for all spike times and substituting the finite-dimensional representations of the sampling functions and of the input video stream, we obtain
If the rows of F form a frame for the finite-dimensional video space, then the inversion is stable. A necessary condition is to have F of rank (2Mx + 1)(2My + 1)(2Mt + 1). This can be guaranteed by increasing the number of neurons and appropriately chosing their receptive fields (e.g., randomly).
Algorithm 2 assumes that the input stimulus belongs to a known space of trigonometric polynomials, i.e., has a discrete spectrum with a known structure. This assumption leads to an algorithm that can be fully discretized and implemented without numerical errors, thereby exhibiting very high accuracy (see for example, V-C). In practice, however, this information may not be available.
Contributor Information
Aurel A. Lazar, Department of Electrical Engineering, Columbia University, New York, NY 10027 USA (aurel@ee.columbia.edu)..
Eftychios A. Pnevmatikakis, Department of Electrical Engineering, Columbia University, New York, NY 10027 USA. He is now with the Department of Statistics, Columbia University, New York, NY 10027 USA (eftychios@stat.columbia.edu)..
REFERENCES
- [1].Lazar AA, Tóth LT. Perfect recovery and sensitivity analysis of time encoded bandlimited signals. IEEE Trans. Circuits Syst. I. 2004 Oct.51(10):2060–2073. [Google Scholar]
- [2].Zaghloul KA, Boahen KA. Optic nerve signals in a neuromorphic chip I: Outer and inner retina models. IEEE Trans. Biomed. Eng. 2004 Apr.51(4):657–666. doi: 10.1109/tbme.2003.821039. [DOI] [PubMed] [Google Scholar]
- [3].Shimonomura K, Yagi T. Neuromorphic VLSI vision system for real-time texture segregation. Neural Netw. 2008 Oct.21(8):1197–1204. doi: 10.1016/j.neunet.2008.07.003. [DOI] [PubMed] [Google Scholar]
- [4].Costas-Santos J, Serrano-Gotarredona T, Serrano-Gotarredona R, Linares-Barranco B. A spatial contrast retina with on-chip calibration for neuromorphic spike-based AER vision systems. IEEE Trans. Circuits Syst. I. 2007 Jul.54(7):1444–1458. [Google Scholar]
- [5].Lichtsteiner P, Posch C, Delbruck T. A 128 × 128 120 dB 15 μs latency asynchronous temporal contrast vision sensor. IEEE J. Solid-State Circuits. 2008 Feb.43(2):566–576. [Google Scholar]
- [6].Serrano-Gotarredona R, Serrano-Gotarredona T, Acosta-Jimenez A, Serrano-Gotarredona C, Perez-Carrasco JA, Linares-Barranco B, Linares-Barranco A, Jimenez-Moreno G, Civit-Ballcels A. On real-time AER 2-D convolutions hardware for neuromorphic spike-based cortical processing. IEEE Trans. Neural Netw. 2008 Jul.19(7):1196–1219. [Google Scholar]
- [7].Zaghloul KA, Boahen K. A silicon retina that reproduces signals in the optic nerve. J. Neural Eng. 2006;3(4):257–267. doi: 10.1088/1741-2560/3/4/002. [DOI] [PubMed] [Google Scholar]
- [8].Lazar AA, Pnevmatikakis EA. Proc. 15 th IEEE Int. Conf. Image Process. San Diego, CA: Oct. 2008. A video time encoding machine; pp. 717–720. [Google Scholar]
- [9].Christensen O. An Introduction to Frames and Riesz Bases (Applied and Numerical Harmonic Analysis) Birkhäuser; Basel, Switzerland: 2003. [Google Scholar]
- [10].Keat J, Reinagel P, Reid RC, Meister M. Predicting every spike: A model for the responses of visual neurons. Neuron. 2001 Jun.30(3):803–817. doi: 10.1016/s0896-6273(01)00322-1. [DOI] [PubMed] [Google Scholar]
- [11].Lazar AA, Pnevmatikakis EA. Faithful representation of stimuli with a population of integrate-and-fire neurons. Neural Comput. 2008 Nov.20(11):2715–2744. doi: 10.1162/neco.2008.06-07-559. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Pillow JW, Paninski L, Uzzell VJ, Simoncelli EP, Chichilnisky EJ. Prediction and decoding of retinal ganglion cell responses with a probabilistic spiking model. J. Neurosci. 2005 Nov.25(47):11003–11013. doi: 10.1523/JNEUROSCI.3305-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Seip K. On the connection between exponential bases and certain related sequences in L2(−π, π) J. Funct. Anal. 1995 May;130(1):131–160. [Google Scholar]
- [14].Pnevmatikakis EA. Ph.D. dissertation. Dept. Elect. Eng., Columbia Univ.; New York, NY: Sep. 2010. Spikes as projections: Representation and processing of sensory stimuli in the time domain. [Google Scholar]
- [15].Eldar YC, Werther T. General framework for consistent sampling in Hilbert spaces. Int. J. Wavelets, Multiresolution Inf. Process. 2005;3(4):497–509. [Google Scholar]
- [16].Masland RH. The fundamental plan of retina. Nature Neurosci. 2001;4(9):877–886. doi: 10.1038/nn0901-877. [DOI] [PubMed] [Google Scholar]
- [17].Sanchez JC, Principe JC, Nishida T, Bashirullah R, Harris JG, Fortes JAB. Technology and signal processing for brain-machine interfaces. IEEE Signal Process. Mag. 2008 Jan.25(1):29–40. [Google Scholar]
- [18].Campbell FW, Green DG. Optical and retinal factors affecting visual resolution. J. Physiol. 1965 Dec.181(3):576–593. doi: 10.1113/jphysiol.1965.sp007784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Field GD, Chichilnisky EJ. Information processing in the primate retina: Circuitry and coding. Annu. Rev. Neurosci. 2007;30(1):1–30. doi: 10.1146/annurev.neuro.30.051606.094252. [DOI] [PubMed] [Google Scholar]
- [20].Antoine J-P, Murenzi R, Vandergheynst P, Ali ST. 2-D Wavelets and Their Relatives. Cambridge Univ. Press; Cambridge, U.K.: 2004. [Google Scholar]
- [21].Laska J, Kirolos S, Massoud Y, Baraniuk R, Gilbert A, Iwen M, Strauss M. Proc. IEEE Dallas/CAS Design Appl., Integr. Softw. Richardson, TX: Oct. 2006. Random sampling for analog-to-information conversion of wideband signals; pp. 119–122. [Google Scholar]
- [22].Jones JP, Palmer LA. An evaluation of the 2-D Gabor filter model of simple receptive fields in cat striate cortex. J. Neurophysiol. 1987 Dec.58(6):1233–1258. doi: 10.1152/jn.1987.58.6.1233. [DOI] [PubMed] [Google Scholar]
- [23].Butts DA, Weng C, Jin J, Yeh C-I, Lesica NA, Alonso J-M, Stanley GB. Temporal precision in the neural code and the timescales of natural vision. Nature. 2007 Sep.449(7158):92–95. doi: 10.1038/nature06105. [DOI] [PubMed] [Google Scholar]
- [24].Lee TS. Image representation using 2-D Gabor wavelets. IEEE Trans. Pattern Anal. Mach. Intell. 1996 Oct.18(10):959–971. [Google Scholar]
- [25].Rodieck RW. Quantitative analysis of cat retinal ganglion cell response to visual stimuli. Vis. Res. 1965 Dec.5(122):583–601. doi: 10.1016/0042-6989(65)90033-7. [DOI] [PubMed] [Google Scholar]
- [26].Van Rullen R, Thorpe SJ. Rate coding versus temporal order coding: What the retinal ganglion cells tell the visual cortex. Neural Comput. 2001 Jun.13(6):1255–1283. doi: 10.1162/08997660152002852. [DOI] [PubMed] [Google Scholar]
- [27].Roza E. Analog-to-digital conversion via duty-cycle modulation. IEEE Trans. Circuits Syst. II: Analog Digital Signal Process. 1997 Nov.44(11):907–914. [Google Scholar]
- [28].Lazar AA, Simonyi EK, Tóth LT. An overcomplete stitching algorithm for time decoding machines. IEEE Trans. Circuits Syst. I. 2008 Oct.55(9):2619–2630. [Google Scholar]
- [29].Hernandez L, Prefasi E. Analog-to-digital conversion using noise shaping and time encoding. IEEE Trans. Circuits Syst. I. 2008 Aug.55(7):2026–2037. [Google Scholar]
- [30].Garcia-Tormo A, Alarcon E, Poveda A, Guinjoan F. Proc. IEEE Int. Symp. Circuits Syst. Seattle, WA: May, 2008. Low-OSR asynchronous Σ-Δ modulation high-order buck converter for efficient wideband switching amplification; pp. 2198–2201. [Google Scholar]
- [31].Gouveia LC, Koickal TJ, Hamilton A. Proc. IEEE Int. Symp. Circuits Syst. Seattle, WA: May, 2008. An asynchronous spike event coding scheme for programmable analog arrays; pp. 1364–1367. [Google Scholar]
- [32].Harris JG, Xu J, Rastogi M, Singh-Alvarado A, Garg V, Principe JC, Vuppamandla K. Proc. IEEE Int. Symp. Circuits Syst. Seattle, WA: May, 2008. Real time signal reconstruction from spikes on a digital signal processor; pp. 1060–1063. [Google Scholar]
- [33].Kościelnik D, Miśkowicz M. Asynchronous sigma-delta analog-to-digital converter based on the charge pump integrator. Analog Integr. Circuits Signal Process. 2008 Jun.55(3):223–238. [Google Scholar]
- [34].Ng SY. Ph.D. dissertation. Dept. Elect. Comput. Eng., Ohio State Univ.; Columbus: 2009. A continuous-time asynchronous sigma delta analog to digital converter for broadband wireless receiver with adaptive digital calibration technique. [Google Scholar]
- [35].Serrano-Gotarredona R, Oster M, Lichtsteiner P, Linares-Barranco A, Paz-Vicente R, Gómez-Rodríguez F, Camuñas-Mesa L, Berner R, Rivas M, Delbrück T, Liu SC, Douglas R, Hafliger P, Jimenez-Moreno G, Ballcels AC, Serrano-Gotarredona T, Acosta-Jimenez AJ, Linares-Barranco B. CAVIAR: A 45k neuron, 5M synapse, 12G connects/s AER hardware sensory–processing–learning–actuating system for high-speed visual object recognition and tracking. IEEE Trans. Neural Netw. 2009 Sep.20(9):1417–1438. doi: 10.1109/TNN.2009.2023653. [DOI] [PubMed] [Google Scholar]
- [36].Lazar AA. Time encoding with an integrate-and-fire neuron with a refractory period. Neurocomputing. 2004 Jun.58–60:53–58. [Google Scholar]
- [37].Lazar AA. Time encoding machines with multiplicative coupling, feedforward, and feedback. IEEE Trans. Circuits Syst. II. 2006 Aug.53(8):672–676. [Google Scholar]
- [38].Lazar AA, Pnevmatikakis EA, Tóth LT. Dept. Elect. Eng., Columbia Univ., New York, NY, BNET Tech. Rep. #4-07. Dec. 2007. On computing the density of the spike train of a population of integrate-and-fire neurons. [Google Scholar]