

Abstract
Repetition of the same stimulus leads to a reduction in neural activity known as repetition suppression (RS). In functional magnetic resonance imaging (fMRI), RS is found for multiple object categories. One proposal is that RS reflects locally based “within-region” changes, such as neural fatigue. Thus, if a given region shows RS across changes in stimulus size or view, then it is inferred to hold size- or view-invariant representations. An alternative hypothesis characterizes RS as a consequence of “top-down” between-region modulation. Differentiating between these accounts is central to the correct interpretation of fMRI RS data. It is also unknown whether the same mechanisms underlie RS to identical stimuli and RS across changes in stimulus size or view. Using fMRI, we investigated RS within a body-sensitive network in human visual cortex comprising the extrastriate body area (EBA) and the fusiform body area (FBA). Both regions showed RS to identical images of the same body that was unaffected by changes in body size or view. Dynamic causal modeling demonstrated that changes in backward, top-down (FBA-to-EBA) effective connectivity play a critical role in RS. Furthermore, only repetition of the identical image showed additional changes in forward connectivity (EBA-to-FBA). These results suggest that RS is driven by changes in top-down modulation, whereas the contribution of “feedforward” changes in connectivity is dependent on the precise nature of the repetition. Our results challenge previous interpretations regarding the underlying nature of neural representations made using fMRI RS paradigms.
Introduction
Repetition of the same stimulus produces a reduction in neural activity known as repetition suppression (RS) and is observed for both low-level perceptual properties (e.g., orientation, color) and complex-object categories (e.g., faces, bodies, inanimate objects) (Grill-Spector et al., 2006; Taylor et al., 2010). In functional magnetic resonance imaging (fMRI), RS manifests as a reduction in the blood oxygenation level-dependent (BOLD) response, also known as fMRI adaptation (Grill-Spector and Malach, 2001). It extends across changes in object size and viewpoint, although evidence for the latter is mixed (Vuilleumier et al., 2002; Andrews and Ewbank, 2004). Different neural accounts of repetition-related reductions in BOLD signal have been proposed, and its underlying mechanisms are unclear (Grill-Spector et al., 2006). Moreover, whether the same mechanisms underlie RS to identical stimuli and RS across size/view changes is unknown.
RS is frequently used to probe the response properties of neuronal populations. Reduced BOLD signal after stimulus repetition is thought to indicate the presence of a neural population tuned to that stimulus. Furthermore, how changing different properties of the stimulus affects RS has been used to infer the nature of the underlying representation (Grill-Spector and Malach, 2001; Naccache and Dehaene, 2001). For example, a given brain region is inferred to show size- or view-invariant coding if RS in this region persists across changes in stimulus size or view. However, this inference only holds if RS reflects local, “within-region” changes, such as neuronal fatigue (Grill-Spector et al., 2006). Alternative theories propose that RS is the consequence of “top-down” modulation, whereby reduced activity in region X reflects a modulatory influence of a “higher-level” region Y (Henson, 2003; Friston, 2005). In this case, inferences that can be drawn from RS about local neural representations are not as simple as outlined above. Identifying the precise neural mechanism for BOLD RS is therefore central to the accurate interpretation of fMRI RS data.
To address this, we used a form of effective connectivity analysis known as dynamic causal modeling (DCM) (Friston et al., 2003). We focused on two areas implicated in the visual processing of human bodies: the extrastriate body area (EBA) and the fusiform body area (FBA) (Fig. 1A). EBA is thought to perform a relatively early (part-based) visual analysis of bodies, whereas FBA is proposed to hold more holistic representations (Peelen and Downing, 2007). The use of body images enabled us to explore the effects of RS within a highly specific, simple, but plausible network model rather than a more complex network, such as that implicated in face processing (Haxby et al., 2000).
Figure 1.
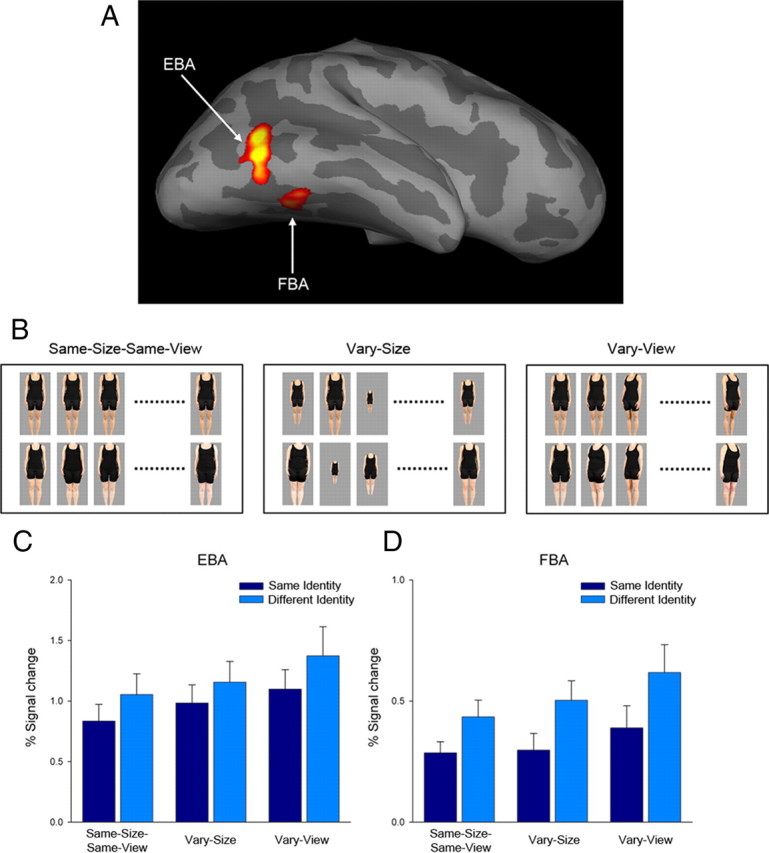
A, Body-sensitive EBA and FBA in occipitotemporal cortex of a representative participant rendered on an inflated standardized brain (p < 0.05, whole-brain corrected). B, Example stimuli from same-identity (top) and different-identity (bottom) blocks for each of the three RS conditions (same-size–same-view, vary-size, and vary-view). C, D, Mean percentage signal change across all participants in EBA (C) and FBA (D) during each of the three conditions.
We defined RS in EBA and FBA to repetitions of identical images of the same body identity compared with different body identities and determined how this was affected by changes in body size and view. If RS reflects changes in top-down modulation, then DCM should identify changes in backward connectivity (FBA-to-EBA) during RS. However, alternate accounts, such as the fatigue model, would predict that RS is driven by locally based changes, such as changes in the self-connections within a region.
Materials and Methods
Participants.
Twenty healthy volunteers (11 male, all right-handed, aged 19–32 years old, mean age of 23 years) with normal or corrected-to-normal vision participated in this study. No participants had a history of neurological disease or head injury or were currently on medication affecting the CNS. The data from one participant were excluded because of scanner malfunction. The study was approved by Cambridgeshire Psychology Research Ethics Committee. All volunteers provided written informed consent and were paid for participating.
Task design.
Participants lay supine in the magnet bore and viewed images projected onto a screen visible via an angled mirror placed above the participant's head. The body stimuli comprised pictures of 12 different individual bodies. Color photographs of human bodies were obtained from real-life models and depicted 12 females of different identities, ages, and body shapes. Female models were chosen to maximize differences between individual models, while at the same time ensuring that differences between same and different identity blocks were not confounded with the gender of the bodies. Each body image subtended a visual angle of ∼9° × 2.5°. Presentation of images was controlled using E-Prime software (Psychology Software Tools). In the same-size–same-view condition, all bodies were shown from a frontal viewpoint. In the vary-size condition, frontal view images were presented either at full size or at 66% and 33% of the original image size and were presented in a random sequence throughout the block. In the vary-view condition, body images were rotated via a series of 15° increments from a frontal viewpoint (0°) through to 45° left and right of center (i.e., 0°, −15°, −30°, −45°, −30°, −15°, 0°, +15°, +30°, +45°, +30°, and +15°) (Fig. 1B).
The images were presented using a block design. Each block lasted for 14.4 s and contained 12 images. Each image was presented for 1000 ms, followed by a 200 ms blank screen. Participants performed a target detection task and responded, via a button press, whenever they saw a green dot appear on the body. One or two images in each block contained a green dot. Reaction time and accuracy data were recorded. At the end of each block, participants responded, via a button press, according to whether they thought the block contained images of the same body or different bodies (performance of this task was close to ceiling, with a mean accuracy of 96%).
There were three stimulus conditions in total (1) same-size–same-view, (2) vary-size, and (3) vary-view, each with two levels of (1) same identity and (2) different identity. Each condition comprised eight same-identity blocks and eight different-identity blocks, giving a total of 48 stimulus blocks. Blocks of images were separated by periods of fixation when an equiluminant gray screen was viewed for 8 s. Individual identities of all bodies were shown an equal number of times in the same- and different-identity blocks. In this way, we were able to control for any change in neural activity that may be attributable to differences in the response to particular bodies.
Localizer scan.
A localizer scan was also performed to define the body-sensitive EBA and FBA. Participants were required to perform a one-back matching task on images of bodies, chairs, houses, faces, and images of implied motion. Regions of interest (ROIs) were identified using the contrast of bodies > chairs (Downing et al., 2001). The face, house and implied motion conditions were included for use in another experiment and were not analyzed in the current study. Images were presented using a block design, consisting of four 16 s blocks for each condition; a block contained 16 images, with each shown for 800 ms, followed by a 200 ms fixation. Blocks were separated by a rest block (fixation) of equal duration. Body images differed from those used in the main experiment. Body and chair images were identical to those used previously to identify body-sensitive regions (Downing et al., 2001) and were obtained from the Downing Laboratory website (http://pages.bangor.ac.uk/∼pss811/page7/page7.html).
In the same scanning session, we also performed a motion-localizer scan to identify motion-sensitive area visual cortical area 5 (V5)/middle temporal area (MT). This consisted of 10 16-s blocks (five containing moving-dot stimuli and five containing static-dot stimuli), with participants required to fixate on a cross in the center of the screen throughout all blocks. The motion localizer was included for use in another experiment not reported here.
Imaging parameters.
MRI scanning was performed on a Siemens Tim Trio 3 Tesla MR scanner. Whole-brain data were acquired with T2*-weighted echo-planar imaging sensitive to BOLD signal contrast. Each image volume consisted of 32 3-mm-thick slices (gap, 25%; field of view, 192 × 192 mm; voxel size, 3 × 3 × 3 mm; flip angle, 78°; echo time, 30 ms; repetition time, 2 s). Slices were acquired in an axial orientation. The first three volumes were discarded to allow for the effects of magnetic saturation. T1-weighted structural images were acquired at a resolution of 1 × 1 × 1 mm.
Image analysis.
Data were analyzed using SPM 5 software (Wellcome Trust Centre for Neuroimaging, London, UK). Standard preprocessing was applied, including correction for slice timing and head motion. Each participant's scans were normalized to the Montreal Neurological Institute (MNI)–Instituto de Ciencias Biomedicas average 152, T1-weighted template using 2 mm isotropic voxels and smoothed with a Gaussian kernel of 8 mm full-width half-maximum. For both the localizer scan and the RS scan, blocks of each condition were modeled by sustained epochs of neural activity (boxcars) convolved with a canonical hemodynamic response function. Realignment parameters were also included as effects of no interest to account for motion-related variance. A high-pass filter of 128 s was used to remove low-frequency noise.
Analysis of regional effects.
To determine the effect of RS on body-sensitive regions, mean parameter estimates were extracted from an 8 mm sphere centered on the maximal voxel in each participant's individually defined EBA and FBA ROIs using MarsBar (Brett et al., 2002). In this way, identical ROIs were used in the DCM analysis (see below) and RS analysis. Mean parameter estimates for each region were then entered into two separate 2 × 3 ANOVAs including identity (same, different) and RS condition (same-size–same-view, vary-size, vary-view) as within-participant factors. To determine whether regions outside of the body-sensitive ROIs showed RS, a group-based whole-brain analysis was performed in which individual images of parameter estimates were entered into a repeated-measures ANOVA, including all 19 participants.
Dynamic causal modeling.
DCM explains regional effects in terms of changing patterns of connectivity among regions during experimentally induced contextual modulation (Friston et al., 2003). Here, the contextual modulation was RS (same-identity > different-identity). The principal advantage of DCM is the ability to make inferences about the direction of causal connections. A standard model with a set of regions and connections is defined. DCM then optimizes the parameters of this model including neuronal interactions and a hemodynamic forward model of neurovascular coupling in each region. The endogenous connections (DCM matrix A) represent the fixed coupling between and within regions in the absence of experimental manipulation. Responses in a dynamic model network can be changed in one of two ways. First, inputs can elicit responses through direct influences on specific regions, called the driving input of the network. Here, the driving input (DCM matrix C) represented all body images relative to fixation, regardless of condition. Any low-level visual processing (e.g., activation to body images in V1 spreading up the cortical hierarchy) is modeled implicitly by the functions that serve as direct inputs to the network. Second, there can be contextual modulation of the coupling between regions and also within regions, according to stimulus type or epoch. “Repetition suppression” was included as the modulatory context (DCM matrix B) defined as greater change during same-identity blocks compared with vary-identity blocks and vice versa.
We specified a large set of 59 models, including all plausible models, with systematic variations in structure. All models were composed of the two body-sensitive regions—identified in the localizer scan—EBA and FBA. No other body-sensitive regions were consistently identified in >50% of participants. In all models, both EBA and FBA had at least one input (specified by DCM matrix A and/or C), at least one of which could be traced back, possibly via the other region, to a driving input (DCM matrix C). Models were grouped into a number of different families based on shared structure and direction of modulation. The families were grouped in three “meta-families,” X, Y, and Z, based on differences in the location of the driving input. This could enter the system via EBA only (Meta-family X), FBA only (Meta-family Y), or parallel inputs into both EBA and FBA (Meta-family Z). Each meta-family comprised four families. This grouping reflected differences in the effect of RS on connectivity. RS could modulate (1) forward connectivity only (EBA-to-FBA), (2) backward connectivity only (FBA-to-EBA), (3) both forward and backward connectivity, or (4) neither forward nor backward connectivity. All families included models with and without modulation of within-region connections (i.e., within-EBA, within-FBA). A modulation of a within-region inhibitory autoconnection by RS would reflect an increase in the rate of exponential decay of neural activity (above and beyond any saturation attributable to hemodynamics) (Friston et al., 2003). Other differences in the members of families related to systematic differences in the direction of endogenous connectivity: forward only, backward only, or both forward and backward (DCM matrix A). All 59 models are shown in supplemental Figures S1–S3 (available at www.jneurosci.org as supplemental material).
Model fitting is achieved by adjusting the model parameters to maximize the free-energy estimate of the model evidence (F) for a given dataset (Friston et al., 2003). This ensures that the model fit uses the free parameters in a parsimonious way, i.e., the estimate of model evidence is adjusted for complexity and dependencies among parameters. After model inversion, the maximized negative F is a lower bound on the model log evidence, namely the probability of the data given the model (Stephan et al., 2009). Bayesian model selection (BMS) was used to identify the preferred model (i.e., that with the largest negative free energy). Note that the absolute value of the log evidence for a model depends on the dataset fitted; what matters for BMS are the differences in log evidence across different models. Furthermore, as any other measure of model “goodness,” a result obtained using BMS is a relative statement that is conditional on the space of models tested.
After estimating all 59 models for each participant, we then computed the group evidence for all models using a fixed-effects (FFX) BMS as implemented in SPM 8 software (Wellcome Trust Centre for Neuroimaging). An FFX analysis is optimal when there is no a priori reason to predict different cortical organization across participants (Stephan et al., 2010). However, an FFX analysis is also susceptible to outliers in model evidence. To address these concerns, we also used a random-effects (RFX) BMS, which also explicitly compared families of models (Penny et al., 2010). In an FFX analysis, model selection is based on the difference in sum of log evidences (F), which equates to the log Bayes factor (BF). Given two models, A and B, the BF comparing model A with model B is defined as the ratio of model evidences, such that the log BF corresponds to the difference in F. By convention (Raftery, 1995), a BF above 3 (ΔF > 1.1) indicates positive evidence for the winning model, a BF between 20 and 150 (ΔF > 3) indicates strong evidence, and a BF above 150 (ΔF > 5) indicates very strong evidence. An FFX analysis also reports the posterior model probability (between 0 and 1) for each model, i.e., the likelihood that the given model generated the observed group data. Thus, a posterior probability of 1 represents an extremely high likelihood.
An RFX approach does not assume that the optimal model will be same across all participants and is therefore less susceptible to outliers than an FFX approach (Stephan et al., 2009). It should be noted that FFX and RFX approaches allow slightly different inferences. Rather than F, RFX analysis reports the exceedance probability, i.e., the extent to which each model is more likely than any other model to have generated the data from a randomly selected participant. Instead of posterior model probability, RFX reports the expected posterior probability, which reflects the probability of a model generating the observed data, allowing for a distribution of different generative models across the study population. This means that the exceedance probability and expected posterior probability will be reduced as the model space increases, such that including multiple models with shared features means that one model is less likely to dominate. Because of the relative nature of BMS, it is also possible that higher evidence for a given model may be the result of other implausible models. Because of the large number of models included in the analysis, we therefore adopted the family inference method, as implemented in SPM 8 (Penny et al., 2010), whereby models were divided into groups/families (outlined previously) to identify the model family with the preferred intrinsic structure. Models from the most likely family were then entered into a second BMS. Restricting the model space to plausible models (i.e., the winning family) provides a more stringent test of models.
The data for the model nodes (or ROIs) were extracted by taking the first eigenvariate across voxels within an 8 mm sphere centered on the peak voxel in each participant's right EBA and right FBA as defined in the localizer scan. The first eigenvariate reflects the first component of the time course of the response of a region (i.e., the principal source of variance within a region). Unlike the mean MR signal, the first eigenvariate does not assume that all voxels contribute to the same extent; instead, it weights each voxel according to their contribution to the first component. Thus, the eigenvariate should be relatively de-noised compared with the raw MR signal. In the current study, the first component of the EBA explained 88% of the variance in that region, whereas the first component of the FBA explained 78% of the variance.
Because we were interested in determining how RS would modulate connectivity across image changes (i.e., size and view), we performed model selection for three different contrasts, selecting the model that best explained the observed data during (1) RS to same-size–same-view images, (2) RS across size, and (3) RS across view. The parameters for the winning model were then obtained using Bayesian parameter averaging (BPA) (Stephan et al., 2009). In DCM, parameter values reflect exponential rate constants, i.e., how activity changes as a function of time (Friston et al., 2003). Because BPA is only considered valid when using an FFX approach (Stephan et al., 2010), parameter values and posterior model probabilities shown in Figure 3 refer to the FFX analysis only.
Figure 3.

Preferred models identified using Bayesian model selection. A, In the same-size–same-view condition, identity repetition (RS) modulated both forward and backward connectivity (red arrows) between EBA and FBA. B, C, In the vary-size (B) and vary-view (C) conditions, RS modulated backward connectivity only. Parameter A represents endogenous connectivity regardless of RS, parameter B represents modulation during RS, and parameter C represents driving input. Conditional probability of parameter values are shown in parentheses.
Results
Localizer scan
Right EBA was identified in all 19 subjects. Four of the participants showed no activation in the right FBA at the minimum threshold (p < 0.05, uncorrected) and were excluded from the ROI analysis and the DCM analysis. Because a relatively small number of participants showed activation in the left FBA (n = 5), we restricted the analysis to right-hemisphere regions only. Mean ± 1 SE MNI coordinates for the two regions were as follows: EBA, +53 ± 1.0, −67 ± 1.3, 4 ± 1.5; FBA, +44 ± 0.9, −46 ± 1.2, −18 ± 0.8. Apart from EBA and FBA, no other regions were consistently identified in >50% of participants using the contrast of bodies > chairs.
Behavioral data
Accuracy rates for the dot-detection task were close to ceiling; mean ± 1 SD accuracy rate was 96.9 ± 4.9% and were therefore not analyzed further. Response times (RTs) were entered into a 2 × 3 ANOVA including identity (same, different) and RS condition (same-size–same-view, vary-size, vary-view) as repeated-measures factors. This revealed no effect of identity (p > 0.11), but there was an effect of RS condition (F(1,14) = 8.53, p < 0.005), with participants fastest to respond in the same-size–same-view condition. Importantly, RS condition showed no interaction with identity (p > 0.43), i.e., there was no evidence that RT differed as a function of the type of repetition. Means and SDs of accuracy rates and RTs for all RS conditions can been found in supplemental Table 1 (available at www.jneurosci.org as supplemental material).
Univariate imaging analysis
Mean parameter estimates from EBA and FBA ROIs were entered into two separate 2 × 3 ANOVAs analogous to those used for the behavioral data above. For the EBA (Fig. 1C), we found a main effect of identity (F(1,14) = 9.87, p < 0.01), with participants showing a reduced response to same-identity blocks compared with different-identity blocks. There was also a main effect of RS condition (F(1,14) = 6.54, p < 0.01), with a greater response observed in the vary-view blocks. There was no RS condition × identity interaction (p > 0.63), indicating that RS effects were not modulated by changes in size or view.
The ANOVA for FBA also revealed main effects of identity (F(1,14) = 16.43, p < 0.005) and RS condition (F(1,14) = 6.21, p < 0.01) (Fig. 1D). Again, we found a reduced response in same-identity blocks compared with different-identity blocks and an increased response in the vary-view blocks. Similar to EBA, there was no identity × RS condition interaction (p > 0.68), indicating that RS to identity was invariant to changes in body size or view.
In addition, a whole-brain analysis revealed no significant reduction in activation to repetition of identity outside of body-sensitive EBA and FBA that survived correction for multiple comparisons (or even that survived p < 0.001, uncorrected).
Finally, to test the possibility that image changes during the vary-size and vary-view blocks may have led to the percept of transformational apparent motion (Tse and Logothetis, 2002), we examined activity in area V5/MT, an area sensitive to this (Tse, 2006). Cluster-based ROIs corresponding to bilateral area V5/MT were obtained using the motion-localizer scan (see above). A 2 × 3 ANOVA revealed no effect of RS condition in either left or right V5/MT (p values >0.32, small volume corrected), indicating that activity in this area did not differ between conditions. Thus, differences in patterns of connectivity between conditions are unlikely to be explained by differences in apparent motion.
DCM Results
FFX analysis
BMS was used to select the most likely model for each of three RS conditions. For the same-size–same-view condition, BMS found strong evidence favoring model X34 (Fig. 2A), with a posterior model probability of 0.91. The structure of model X34 has driving input entering EBA only (DCM C connections), whereas RS affects both forward and backward between-region connectivity, as well as within-region self-connectivity (DCM B connections). The winning model belonged to family X3, in which RS modulated both forward and backward connectivity. The second most likely model, X33, also belonged to the same family, only differing in absence of changes in within-region EBA connectivity. Thus, as evident in Figure 2A, models from family X3 had a combined posterior model probability of 0.99.
Figure 2.

Log evidence (top) and posterior model probability (bottom) obtained using FFX BMS across all participants for each of 59 models for same-size–same-view condition (A), vary-size condition (B), and vary-view condition (C).
Next, we determined the favored model for the vary-size condition. BMS found positive evidence for model X24, with a posterior model probability of 0.68 (Fig. 2B). In this model, RS modulates within-region and backward (FBA-to-EBA) connectivity but not forward between-region connectivity. The second favored model X22 (posterior model probability of 0.22), differed from model X24 only in the absence of modulation of FBA within-region connectivity. Both models belonged to family X2, characterized by modulation of backward between-region connectivity only. Together, models for family X2, in which RS modulated backward between-region connectivity only during the vary-size condition, had a combined posterior model probability of 0.90.
For the vary-view condition, BMS found very strong evidence favoring model X24, with a posterior model probability of 1.0 (Fig. 2C). This was the same winning model as identified for the vary-size condition, again belonging to family X2, characterized by modulation of backward between-region connectivity only. Thus, from a total of 59 possible models, the identical model was favored in both the vary-size and vary-view conditions. For both conditions, RS was found to modulate backward, but not forward, between-region connectivity, as well as within-region connectivity for both FBA and EBA. In contrast, in the same-size–same-view condition, RS modulated both forward and backward between-region connectivity, as well as within-region changes. The structure of the preferred models for each condition and average parameter values are shown in Figure 3.
RFX analysis
For the same-size–same-view condition, RFX BMS indicated that the winning family was model family X3, the same family as identified by FFX analysis, with an exceedance probability of 0.76 (supplemental Fig. S4A, available at www.jneurosci.org as supplemental material). The shared structure underlying family X3 is that driving input enters the EBA only, whereas RS modulates both forward and backward connectivity. All four models from family X3 were then entered into a second RFX BMS (supplemental Fig. 4B, available at www.jneurosci.org as supplemental material). Again, in agreement with the FFX analysis, we found the strongest evidence in favor of model X34, with an exceedance probability of 0.66.
Next, we determined the winning model during RS in the vary-size condition. As for the FFX analysis, BMS indicated that the winning family was model family X2, with an exceedance probability of 0.47 (supplementary Fig. 5A, available at www.jneurosci.org as supplemental material). Models in this family all have driving input entering the EBA, whereas RS modulates backward but not forward between-region coupling. All four models from family X2 were entered into an additional BMS. Here, models X22 and X24 were favored above the other models, but unlike the FFX analysis, RFX was unable to determine the superior model. Exceedance probabilities for models X22 and X24 were 0.39 and 0.38, respectively (supplemental Fig. 5B, available at www.jneurosci.org as supplemental material). However, these two models share an almost identical structure, with backward, but not forward, between-region connectivity (FBA-to-EBA) being modulated by RS. The only difference between the two models was the absence of RS effects on FBA within-region connectivity in model X22.
Finally, we determined the favored model structure underlying RS in the vary-view condition. BMS indicated that the favored model family was X2 with an exceedance probability of 0.88 (supplemental Fig. 6A, available at www.jneurosci.org as supplemental material); again, this accorded with the FFX BMS. An additional model comparison restricted to family X2 models revealed strongest evidence in favor of model X24, with an exceedance probability of 0.79 (supplemental Fig. 6B, available at www.jneurosci.org as supplemental material). Therefore, there was concordance between RFX and FFX methods in model selection for all three RS conditions. From a total of 59 possible models, both methods clearly identified models in family X3, which included changes in backward and forward connectivity, as most likely in the same-size–same-view condition. In contrast, models in family X2, which included changes in backward connectivity alone, were identified as most likely in the vary-size and vary-view conditions.
Discussion
Our findings suggest that changes in top-down between-region connectivity contribute to fMRI repetition suppression in the ventral visual pathway. These findings contrast with existing neural models proposing that RS is driven purely by locally based changes, such as neuronal fatigue. Moreover, we show for the first time that RS to identical images (same-size–same-view) and RS across changes in image size or view require different neural accounts.
Consistent with recent work (Aleong and Paus, 2010; Taylor et al., 2010), a contrast of parameter estimates obtained from a multiple regression analysis of each voxel—the conventional analysis used in RS paradigms—revealed reduced activation to the same image of the same body relative to images of different bodies (same-size–same-view condition) in two regions of the ventral visual pathway, the EBA and FBA. Most importantly, this type of analysis did not reveal statistically distinguishable patterns of RS between repetitions of the same image of the same body and repetitions of the same body across changes in size or view. In contrast, dynamic causal modeling revealed that the mechanisms underlying RS to identical images and RS across size/view changes were qualitatively different. For all conditions, RS modulated backward connectivity (FBA-to-EBA), whereas only RS with identical stimuli changed forward connectivity (EBA-to-FBA).
The change in backward connectivity found for all three conditions accords with models of predictive coding, which propose that RS reflects the match between higher-level prediction and perceptual input, with inferences in higher-level areas serving to suppress responses (or errors) to incoming sensory information in lower areas (Rao and Ballard, 1999; Henson, 2003; Friston, 2005). Thus, consecutive occurrence of the same body should lead to a reduction in “prediction error,” and a subsequent reduction in neural activity; consistent with this, expected repetitions enhance RS (Summerfield et al., 2008). A change in within-region connectivity during RS was also observed in all three conditions and represents an increased rate of exponential decay, consistent with the an additional contribution of local causes [e.g., neuronal fatigue (Grill-Spector et al., 2006)] or altered within-region inhibition resulting from between-region connectivity (Friston, 2005; Garrido et al., 2009).
Notably, for the vary-size and vary-view conditions, backward changes occurred in the absence of altered forward connectivity and therefore cannot be a consequence of the latter. This suggests that RS effects in the EBA, across changes in image size and view, are attributable to modulatory input from FBA. In contrast, altered forward connectivity was restricted to the same-size–same-view condition, suggesting that repetitions of an identical body image can produce repetition-related changes in EBA during a “first pass” through the ventral visual pathway. This accords with magnetoencephalogram and electroencephalogram research showing that RS to identical images of objects and faces occurs as early as 160 ms (Schendan and Kutas, 2003; Ewbank et al., 2008), whereas RS across view is found after 400 ms (Schendan and Kutas, 2003). These different patterns of connectivity (i.e., forward changes during repetition of identical images and backward modulation alone across image changes) are also consistent with the functional asymmetry of forward and backward connections found in sensory cortex. Forward connections are characterized as driving, and elicit an obligatory response in higher levels, whereas backward connections are more modulatory in their effects (Felleman and Van Essen, 1991; Sherman and Guillery, 1998).
The effect of repetition on backward but not forward connectivity for the vary-size and vary-view conditions may reflect a different nature of coding in EBA (image-dependent) and FBA (image-invariant). In other words, when the same body is shown from two or more different views or image sizes, it activates a different neuronal population in image-sensitive EBA but the same neuronal population in FBA; thus, forward connectivity (EBA-to-FBA) is not altered although the identity remains constant. In contrast, the change in forward connectivity during repetition of an identical image (same-size–same-view) may be attributable to repeated activation of the same neuronal population, resulting in neuronal fatigue (Faber and Sah, 2003). Figure 4 illustrates the mechanisms by which RS to same-size–same-view images and RS across size and view might operate, with bodies shown from different sizes or views activating different neural populations within EBA for both the same- and different-identity conditions. Although Figure 4 portrays RS as a reduction in the response of the neuronal population selective for a particular identity, RS may also be the consequence of changes in nonselective neuronal populations (i.e., sharpening) (Desimone, 1996; Wiggs and Martin, 1998). Thus, we cannot discount the possibility that stimulus repetition leads to a sparser representation and fewer responsive neurons overall.
Figure 4.

Possible mechanisms underlying repetition suppression within body-sensitive regions to images of human bodies. EBA and FBA are proposed to hold differently tuned neural representations of body identity, EBA holds relatively fine-tuned image-dependent representations (A1, A2, B1, B2, etc.), and FBA contains more broadly tuned image-independent representations (A, B, etc.) that are invariant to changes in body size or view. Both regions have reciprocal connections between neuronal populations coding the same identity (data not shown). Red circles indicate neuronal populations showing RS. Red arrows indicate the direction of change in connectivity during RS. A, Top, After repeated presentation of the identical image of the same body (A1), neurons responding to image A1 show neuronal fatigue resulting in a change in forward connectivity. A, Bottom, Neuronal populations in EBA coding identity A are suppressed as the result of modulatory input from FBA, manifested as a change in backward connectivity. B, Top, When the same body is shown from different views (A1, A2, A3), they activate different neuronal populations in view-sensitive EBA; thus, forward connectivity is not changed during identity repetition (black arrows). B, Bottom, Neuronal populations in EBA coding identity A are suppressed as the result of modulatory input from FBA, manifested as a change in backward connectivity.
As discussed, our findings accord with models of predictive coding that emphasize the role of top-down modulation in RS. Thus, a possible interpretation of these findings, within a predictive coding model, is that repetition of the same identity changes the predictions from FBA about activity in EBA (presumed to reflect short-term synaptic changes between these regions), so that they become more tuned toward activity associated with a specific identity. However, during blocks of changing size/view, top-down predictions only provide guidance regarding body identity and not accurate predictions of image size/view (Fig. 4B, bottom). Therefore, despite repetition of identity, prediction errors still occur in the vary-size and vary-view blocks, and consequently repetition does not change forward connectivity. In addition, it is possible that, in the same-size–same-view condition, FBA accurately predicts not only identity but view/size as well. However, the issue cannot be resolved using DCM data.
The change in forward connectivity in the same-size–same-view condition might reflect a reduction in prediction error originating from “lower” regions that feed into EBA (i.e., because neurons in EBA can now better predict low-level visual features, e.g., the prediction error from V1/V2 that drives EBA is reduced). The current study found no RS in such early visual regions, but it should be noted that RS to complex objects in V1 is consistently less robust than that found in higher-level areas (Krekelberg et al., 2006), possibly because V1 neurons are more sensitive to transient stimuli (Dragoi et al., 2002) rather than the long stimulus presentations used here.
The additional change in self-connections (which model evidence suggests is necessary above any concomitant changes in forward/backward connectivity) might reflect local neuronal changes within EBA and FBA, perhaps as a result of overlap in the tuning curves of view/size-dependent neurons within EBA or even changes in inhibitory, within-region synapses between such neurons. Alternatively, in a more detailed neuronal model, the change in inhibitory self-connections (as defined in dynamical terms by DCM) might actually be a consequence of changes in forward and/or backward synapses between regions.
RS is used in functional neuroimaging studies of healthy participants, clinical populations, and developmental disorders (Williams et al., 2007; Pihlajamäki et al., 2008; Steeves et al., 2009). Hence, an understanding of its neurophysiological basis has important implications for multiple areas of research. As discussed previously, RS has been used to infer the nature of complex-object representations across different stages of the visual processing stream (Kourtzi and Kanwisher, 2000; Ewbank et al., 2005; Rotshtein et al., 2005). Specifically, reductions in BOLD signal in a given region following stimulus repetition have been used to infer the nature of the underlying neural representation in that region. Our findings indicate that, across changes in higher-level stimulus properties, such as size and view, reduction in BOLD signal after stimulus repetition may be the consequence of modulation from higher-level regions rather than reflecting locally driven changes alone. Thus, although a comparison of parameter estimates revealed size- and view-invariant RS in EBA, this does not necessarily imply that EBA contains neural populations holding size- and view-invariant representations of body identity. Instead, our results indicate that RS in EBA across changes in image size and view is the consequence of changes in top-down (FBA-to-EBA) connectivity. Our findings are therefore consistent with a size- and view-dependent representation of body identity within EBA, despite the fact that size- and view-invariant RS is observed in this region using a standard contrast analysis (Fig. 4).
In conclusion, using three conditions within the same paradigm, DCM revealed a critical role for top-down modulation in RS and suggested that distinct neural accounts underlie different forms of RS. These findings contrast with existing neural models characterizing RS as a purely local phenomenon (Grill-Spector et al., 2006). Although repetition of the same-body identity affected self-connections within EBA and FBA, suggesting a local mechanism, it also affected backward connections from FBA to EBA in all three conditions. Furthermore, only repetition of the same size and view produced additional changes in forward (EBA-to-FBA) connectivity. These results suggest that RS is driven by both local and between-region changes, and importantly, the relative contribution of these mechanisms depends on the nature of the conditions, such as changes in image size or view. By highlighting the role of top-down modulation in RS, our findings challenge previous interpretations made using RS paradigms regarding the underlying nature of neural representations in multiple sensory modalities. Indeed, the demonstration of a critical role for top-down cortical feedback in RS necessitates a reevaluation of numerous studies that have been interpreted in terms of the locally-based hypothesis.
Footnotes
This research was funded by the Medical Research Council (United Kingdom) under Projects U.1055.02.001.0001.01 (A.J.C.) and U.1055.05.012.00001.01 (R.N.H.). J.B.R. is supported by Wellcome Trust Grant 077029. We are grateful to Simon Strangeways for his assistance in generating the stimuli and figures and Niko Kreigeskorte for his helpful comments on this manuscript.
References
- Aleong R, Paus T. Neural correlates of human body perception. J Cogn Neurosci. 2010;22:482–495. doi: 10.1162/jocn.2009.21211. [DOI] [PubMed] [Google Scholar]
- Andrews TJ, Ewbank MP. Distinct representations for facial identity and changeable aspects of faces in the human temporal lobe. Neuroimage. 2004;23:905–913. doi: 10.1016/j.neuroimage.2004.07.060. [DOI] [PubMed] [Google Scholar]
- Brett M, Anton J, Valabregue R, Poline JB. Region of interest analysis using an SPM toolbox. Neuroimage. 2002;16:2. [Google Scholar]
- Desimone R. Neural mechanisms for visual memory and their role in attention. Proc Natl Acad Sci U S A. 1996;93:13494–13499. doi: 10.1073/pnas.93.24.13494. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Downing PE, Jiang Y, Shuman M, Kanwisher N. A cortical area selective for visual processing of the human body. Science. 2001;293:2470–2473. doi: 10.1126/science.1063414. [DOI] [PubMed] [Google Scholar]
- Dragoi V, Sharma J, Miller EK, Sur M. Dynamics of neuronal sensitivity in visual cortex and local feature discrimination. Nat Neurosci. 2002;5:883–891. doi: 10.1038/nn900. [DOI] [PubMed] [Google Scholar]
- Ewbank MP, Schluppeck D, Andrews TJ. fMR-adaptation reveals a distributed representation of inanimate objects and places in human visual cortex. Neuroimage. 2005;28:268–279. doi: 10.1016/j.neuroimage.2005.06.036. [DOI] [PubMed] [Google Scholar]
- Ewbank MP, Smith WA, Hancock ER, Andrews TJ. The M170 reflects a viewpoint-dependent representation for both familiar and unfamiliar faces. Cereb Cortex. 2008;18:364–370. doi: 10.1093/cercor/bhm060. [DOI] [PubMed] [Google Scholar]
- Faber ES, Sah P. Calcium-activated potassium channels: multiple contributions to neuronal function. Neuroscientist. 2003;9:181–194. doi: 10.1177/1073858403009003011. [DOI] [PubMed] [Google Scholar]
- Felleman DJ, Van Essen DC. Distributed hierarchical processing in the primate cerebral cortex. Cereb Cortex. 1991;1:1–47. doi: 10.1093/cercor/1.1.1-a. [DOI] [PubMed] [Google Scholar]
- Friston K. A theory of cortical responses. Philos Trans R Soc Lond B Biol Sci. 2005;360:815–836. doi: 10.1098/rstb.2005.1622. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friston KJ, Harrison L, Penny W. Dynamic causal modelling. Neuroimage. 2003;19:1273–1302. doi: 10.1016/s1053-8119(03)00202-7. [DOI] [PubMed] [Google Scholar]
- Garrido MI, Kilner JM, Stephan KE, Friston KJ. The mismatch negativity: a review of underlying mechanisms. Clin Neurophysiol. 2009;120:453–463. doi: 10.1016/j.clinph.2008.11.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grill-Spector K, Malach R. fMR-adaptation: a tool for studying the functional properties of human cortical neurons. Acta Psychologica (Amst) 2001;107:293–321. doi: 10.1016/s0001-6918(01)00019-1. [DOI] [PubMed] [Google Scholar]
- Grill-Spector K, Henson R, Martin A. Repetition and the brain: neural models of stimulus-specific effects. Trends Cogn Sci. 2006;10:14–23. doi: 10.1016/j.tics.2005.11.006. [DOI] [PubMed] [Google Scholar]
- Haxby JV, Hoffman EA, Gobbini MI. The distributed human neural system for face perception. Trends Cogn Sci. 2000;4:223–233. doi: 10.1016/s1364-6613(00)01482-0. [DOI] [PubMed] [Google Scholar]
- Henson RN. Neuroimaging studies of priming. Prog Neurobiol. 2003;70:53–81. doi: 10.1016/s0301-0082(03)00086-8. [DOI] [PubMed] [Google Scholar]
- Kourtzi Z, Kanwisher N. Cortical regions involved in perceiving object shape. J Neurosci. 2000;20:3310–3318. doi: 10.1523/JNEUROSCI.20-09-03310.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krekelberg B, Boynton GM, van Wezel RJ. Adaptation: from single cells to BOLD signals. Trends Neurosci. 2006;29:250–256. doi: 10.1016/j.tins.2006.02.008. [DOI] [PubMed] [Google Scholar]
- Naccache L, Dehaene S. The priming method: imaging unconscious repetition priming reveals an abstract representation of number in the parietal lobes. Cereb Cortex. 2001;11:966–974. doi: 10.1093/cercor/11.10.966. [DOI] [PubMed] [Google Scholar]
- Peelen MV, Downing PE. The neural basis of visual body perception. Nat Rev Neurosci. 2007;8:636–648. doi: 10.1038/nrn2195. [DOI] [PubMed] [Google Scholar]
- Penny WD, Stephan KE, Daunizeau J, Rosa MJ, Friston KJ, Schofield TM, Leff AP. Comparing families of dynamic causal models. PLoS Comput Biol. 2010;6:e1000709. doi: 10.1371/journal.pcbi.1000709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pihlajamäki M, DePeau KM, Blacker D, Sperling RA. Impaired medial temporal repetition suppression is related to failure of parietal deactivation in Alzheimer disease. Am J Geriatr Psychiatry. 2008;16:283–292. doi: 10.1097/JGP.0b013e318162a0a9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Raftery A. Bayesian model selection in social research. In: Marsden P, editor. Sociological methodology. Cambridge, MA: Wiley-Blackwell; 1995. pp. 111–196. [Google Scholar]
- Rao RP, Ballard DH. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat Neurosci. 1999;2:79–87. doi: 10.1038/4580. [DOI] [PubMed] [Google Scholar]
- Rotshtein P, Henson RN, Treves A, Driver J, Dolan RJ. Morphing Marilyn into Maggie dissociates physical and identity face representations in the brain. Nat Neurosci. 2005;8:107–113. doi: 10.1038/nn1370. [DOI] [PubMed] [Google Scholar]
- Schendan HE, Kutas M. Time course of processes and representations supporting visual object identification and memory. J Cogn Neurosci. 2003;15:111–135. doi: 10.1162/089892903321107864. [DOI] [PubMed] [Google Scholar]
- Sherman SM, Guillery RW. On the actions that one nerve cell can have on another: distinguishing “drivers” from “modulators”. Proc Natl Acad Sci U S A. 1998;95:7121–7126. doi: 10.1073/pnas.95.12.7121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steeves J, Dricot L, Goltz HC, Sorger B, Peters J, Milner AD, Goodale MA, Goebel R, Rossion B. Abnormal face identity coding in the middle fusiform gyrus of two brain-damaged prosopagnosic patients. Neuropsychologia. 2009;47:2584–2592. doi: 10.1016/j.neuropsychologia.2009.05.005. [DOI] [PubMed] [Google Scholar]
- Stephan KE, Penny WD, Daunizeau J, Moran RJ, Friston KJ. Bayesian model selection for group studies. Neuroimage. 2009;46:1004–1017. doi: 10.1016/j.neuroimage.2009.03.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephan KE, Penny WD, Moran RJ, den Ouden HE, Daunizeau J, Friston KJ. Ten simple rules for dynamic causal modeling. Neuroimage. 2010;49:3099–3109. doi: 10.1016/j.neuroimage.2009.11.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Summerfield C, Trittschuh EH, Monti JM, Mesulam MM, Egner T. Neural repetition suppression reflects fulfilled perceptual expectations. Nat Neurosci. 2008;11:1004–1006. doi: 10.1038/nn.2163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JC, Wiggett AJ, Downing PE. fMRI-adaptation studies of viewpoint tuning in the extrastriate and fusiform body areas. J Neurophysiol. 2010;103:1467–1477. doi: 10.1152/jn.00637.2009. [DOI] [PubMed] [Google Scholar]
- Tse PU. Neural correlates of transformational apparent motion. Neuroimage. 2006;31:766–773. doi: 10.1016/j.neuroimage.2005.12.029. [DOI] [PubMed] [Google Scholar]
- Tse PU, Logothetis NK. The duration of 3-d form analysis in transformational apparent motion. Percept Psychophys. 2002;64:244–265. doi: 10.3758/bf03195790. [DOI] [PubMed] [Google Scholar]
- Vuilleumier P, Henson RN, Driver J, Dolan RJ. Multiple levels of visual object constancy revealed by event-related fMRI of repetition priming. Nat Neurosci. 2002;5:491–499. doi: 10.1038/nn839. [DOI] [PubMed] [Google Scholar]
- Wiggs CL, Martin A. Properties and mechanisms of perceptual priming. Curr Opin Neurobiol. 1998;8:227–233. doi: 10.1016/s0959-4388(98)80144-x. [DOI] [PubMed] [Google Scholar]
- Williams MA, Berberovic N, Mattingley JB. Abnormal FMRI adaptation to unfamiliar faces in a case of developmental prosopamnesia. Curr Biol. 2007;17:1259–1264. doi: 10.1016/j.cub.2007.06.042. [DOI] [PubMed] [Google Scholar]