

Abstract
Several studies have shown that blind humans can gather spatial information through echolocation. However, when localizing sound sources, the precedence effect suppresses spatial information of echoes, and thereby conflicts with effective echolocation. This study investigates the interaction of echolocation and echo suppression in terms of discrimination suppression in virtual acoustic space. In the ‘Listening’ experiment, sighted subjects discriminated between positions of a single sound source, the leading or the lagging of two sources, respectively. In the ‘Echolocation’ experiment, the sources were replaced by reflectors. Here, the same subjects evaluated echoes generated in real time from self-produced vocalizations and thereby discriminated between positions of a single reflector, the leading or the lagging of two reflectors, respectively. Two key results were observed. First, sighted subjects can learn to discriminate positions of reflective surfaces echo-acoustically with accuracy comparable to sound source discrimination. Second, in the Listening experiment, the presence of the leading source affected discrimination of lagging sources much more than vice versa. In the Echolocation experiment, however, the presence of both the lead and the lag strongly affected discrimination. These data show that the classically described asymmetry in the perception of leading and lagging sounds is strongly diminished in an echolocation task. Additional control experiments showed that the effect is owing to both the direct sound of the vocalization that precedes the echoes and owing to the fact that the subjects actively vocalize in the echolocation task.
Keywords: auditory, binaural hearing, temporal processing, reverberation
1. Introduction
Echolocation is usually attributed to bats and toothed whales, which analyse the echoes of self-generated sounds to navigate and hunt. But blind humans also produce sounds to evaluate their environments; some individuals even have perfected this skill for orientation: by clicking their tongue, objects are ensonified and the reflections can be analysed to create acoustic snapshots of the environment [1].
Reports of blind people using a special sense to orient and to locate obstacles in front of them go back to the eighteenth century [2]. However, it took until the 1940s to show that they actually do not feel remote obstacles with their facial skin but unconsciously evaluate echoes to gain information about their spatial surroundings [3,4]. Since then, several studies have demonstrated that human auditory processing is precise enough for echo-acoustic localization of sound-reflecting surfaces [5–8]. Recent reports of blind human echolocation experts even raise the possibility that traditionally visual functions like scene recognition or navigation might be available based on echo-acoustic cues, with spatial resolution as high as in the peripheral visual field [9]. Yet, the auditory processes that are crucial for such outstanding performance remain unclear—however important this information would be for rehabilitation and mobility training in blind people.
There are hints that echolocation performance may be correlated with high sensitivity to echo signals in general: Dufour et al. [10] found that blind people were more accurate than sighted ones in localizing objects by echolocation, but also that they were more disturbed by reflected sounds in auditory localization tasks. For external sound sources, the issue of directing auditory attention in reverberant environments has been studied in terms of a phenomenon called ‘precedence effect’ [11]: when two coherent sound signals are presented from different locations with a brief delay, the human auditory system gives precedence to the first-arriving directional information and suppresses the later-arriving one. However, certain situations can induce a break-down or build-up of the precedence effect [12–14]. In an echolocation context, one would expect echo suppression to cause a loss of important information, and therefore the precedence effect to interfere with echolocation, unless the precedence effect is inhibited during echolocation. This has been demonstrated successfully for echolocating bats, which do not suppress spatial information of a second echo by default [15]. Yet for humans, a formal quantification of the influence of the precedence effect on echolocation is not available to date.
The first aim of this study was to quantify the ability of sighted human subjects to discriminate positions of a single reflective surface, the nearer (i.e. leading) and the farther (i.e. lagging) of two reflective surfaces, respectively, by evaluating echoes generated in real time from self-produced vocalizations. The second aim was to quantify the precedence effect in an echolocation context. To that end, the asymmetry between lead- and lag-discrimination performances was assessed as a measure for the influence of the precedence effect in the ‘Echolocation’ experiment. To benchmark results, all subjects performed another, ‘Listening’, version of the experiment, which was identical to the Echolocation experiment except that the sound reflectors were replaced by sound sources, as in past studies on the precedence effect. To control the occurrence of perceptual cues, all experiments were transferred into virtual echo-acoustic space (VEAS) and conducted in an anechoic chamber.
2. Material and methods
(a). Apparatus and stimuli for the Listening experiment
In the Listening experiment, subjects were required to discriminate between the positions of sound sources. All sound sources were presented in virtual acoustic space (VAS, see below) and radiated the same signal, namely a periodic train of Dirac impulses with a repetition rate of 2.5 Hz.
VAS was created by convolving the signal with individually measured head-related impulse responses (HRIRs) which incorporate the azimuth-dependent binaural properties of a sound radiated in anechoic space, both in terms of interaural level- and time differences as a function of frequency.
To gather their HRIRs, the subjects sat on a chair in the middle of an anechoic chamber with the dimensions 2.0 × 2.0 × 2.2 m. An array of 19 loudspeakers (Canton Plus XS.2, Canton Elektronik GmbH & Co. KG, Weilrod, Germany) was placed at 0° elevation in a frontal hemicircle with a radius of 1 m, arranged in equidistant steps of 10°. The loudspeakers were individually calibrated, in magnitude and phase, to provide a flat frequency spectrum between 100 and 20 000 Hz and a linear phase spectrum. The speakers successively presented white noise, which was recorded via binaural in-ear microphones (type 4101, Brüel & Kjær, Nærum, Denmark) in the ear canals of the subjects. The HRIRs for all 19 loudspeaker positions were calculated by cross correlation of the emitted and the recorded signals. The HRIRs were interpolated (by linear interpolation of the linear magnitude spectra and unwrapped phase spectra) to increase the angular resolution from the original angle step size of 10° to a resolution of 0.2°.
To simulate a sound source at a certain azimuth in VAS, the periodic impulse train was convolved with the subject's HRIR corresponding to that azimuth, and the resulting signal was presented via a professional audio interface (Fireface 400, RME, Haimhausen, Germany) and earphones (ER-4S, Etymotic research, Grove Village, USA). To add a lagging sound, a second HRIR, corresponding to the lag azimuth, was added to the leading HRIR with a delay of 2 ms.
The actual experiments took place in an anechoic chamber with the dimensions 1.2 × 1.2 × 2.4 m. The walls of the chamber were lined with 10 cm acoustic wedges, which decrease the level of echoes by at least 40 dB at frequencies higher than 500 Hz. Stimulus generation and experimental control were implemented using Matlab v. 7.5.0 (The Mathworks, Natick, MA, USA) and Soundmexpro v. 1.4.3 (Hoertech, Oldenburg, Germany).
(b). Procedure of the Listening experiment
Using an adaptive two-alternative, two-interval, forced-choice (2AIFC) paradigm with audio feedback, subjects were trained to discriminate between azimuthal positions of a single sound source, the leading of two sources or the lagging of two sources, respectively. Whenever several sources were presented, the sound coming from the lagging source reached the subject with a time delay of 2 ms relative to the sound coming from the leading source. The positions of the target sound source, which were to be discriminated, were always centred around an azimuth of 40° to the right; the other sound source was fixed at 40° to the left (cf. figure 1).
Figure 1.
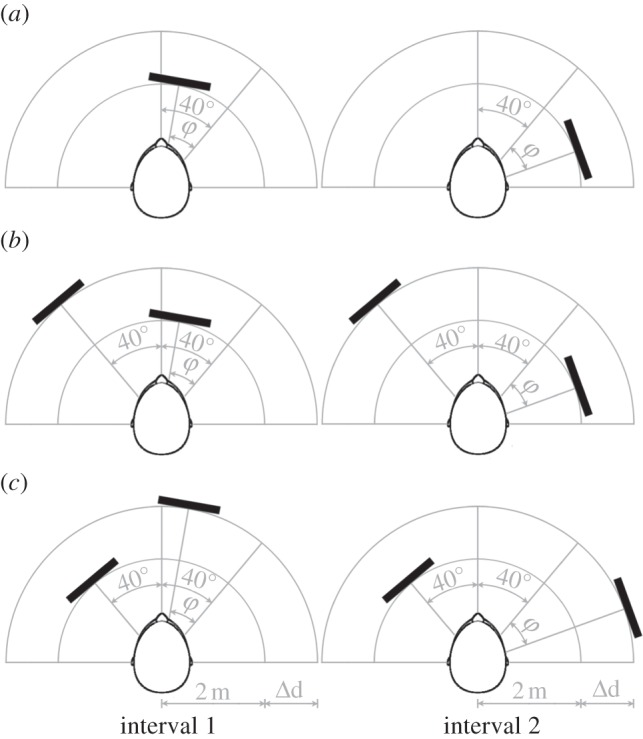
Illustration of the Echolocation experiment. In a 2AIFC paradigm, subjects were asked to discriminate between azimuthal positions of a single sound reflector (a), the leading of two reflectors (b), and the lagging of two reflectors (c), respectively. The same paradigm with sound sources instead of sound reflectors was used for the Listening experiment. The temporal delay between leading and lagging sound was 2 ms at the subjects’ ears, which corresponds to a simulated physical distance of Δd = 34 cm in the Echolocation experiment and Δd = 68 cm in the Listening experiment.
Each experimental trial started with a 50 ms, 1 kHz tone pip to indicate the beginning of a 2 s exploration interval. During the exploration interval, a stimulus was presented as described above. The ending of the exploration interval was signalled by a 2 kHz tone pip. After a 500 ms pause, the second exploration interval was presented in the same way, but with a different stimulus. Subsequently, the subjects had to respond whether the first or the second exploration interval had contained the target sound source at the more rightward azimuthal position, using a game pad. Subjects were given audio feedback by a 250 ms frequency chirp which was upward modulated for positive feedback and downward modulated for negative feedback.
Azimuthal separation of the target sound source positions (which is illustrated in figure 1 as twice the angle φ) was adapted with a three-down-one-up procedure: it was decreased after three correct responses in a row and increased after one incorrect response, which yields threshold estimates at the 79.4% correct level [16]. Until the third reversal of the adaptive track, φ was changed by 100% (i.e. it was halved or doubled), it was changed by 20% for reversals four and five and by 10% from the sixth reversal on. The experimental run was stopped at the 11th reversal and the minimum audible angle (MAA) was calculated as the mean of the azimuthal separation in degrees at the last six reversals of the run. All subjects were trained until their performance in terms of MAA stabilized over runs. The criterion for stable performance was fulfilled when the standard deviation across the last three runs was less than 25% of the mean across these runs. On average, it took about 26 runs per condition for a subject to fulfil the stability criterion (the standard deviation was 13 runs). The mean duration per run was about 5 min with a standard deviation of 1.5 min.
The method of VAS presentation guarantees that there were no visual cues to the experimental set-up. Moreover, the experiments took place in complete darkness and subjects were asked to close their eyes.
(c). Subjects
Six sighted adults (two females, four males) aged 20–30 years participated in the study. In each subject, both ears were individually tested for hearing deficits by pure-tone audiometry for the frequencies 0.5, 1, 2, 4, 6, 8 and 12 kHz. All subjects showed normal hearing thresholds. Participation was paid at an hourly rate.
(d). Apparatus and stimuli for the Echolocation experiment
In the Echolocation experiment, the subjects gained spatial information about their environment by producing sounds with their mouths and evaluating computer-generated echoes of these sounds presented via headphones. Building on the VAS technique of the Listening experiment, we conducted the Echolocation experiment in VEAS.
To produce virtual echoes from the subjects’ vocalizations, several stages of filtering are necessary that represent the different stages a signal runs through on its way from the subjects’ mouth via one or several reflections to the subjects’ eardrums. The first stage is the emission of the signal out of the mouth into free field. The human mouth is not a perfectly omnidirectional sound emitter, especially for high frequencies. The vocal impulse response (VIR) describes the individual sound emission characteristics of the subject's mouth as a function of frequency and azimuth.
To measure the individual VIRs, the subjects sat on a chair in the middle of an anechoic chamber with the dimensions 2.0 × 2.0× 2.2 m (Industrial Acoustics Company GmbH, Niederkrüchten, Germany) and were equipped with a headset microphone (HS2-EW, Sennheiser, Wedemark, Germany). Subjects had to produce a broadband hissing sound for at least 5 s. Using a half inch measuring microphone (B&K 4189, Brüel & Kjær, Nærum, Denmark) at 0° azimuth and elevation and 1 m distance in front of the subjects’ mouths as reference, the headset microphone was first calibrated in terms of power spectra. Afterwards, the vocalization recording was repeated with the headset microphone and 19 identical measuring microphones (SM420, BSWA Technology Co., Ltd., Peking, China) placed at 0° elevation in a hemicircle with a radius of 1 m in front of the subjects, arranged in equidistant azimuth steps of 10°. The difference between the spectrum recorded by the calibrated headset microphone and the spectrum recorded by the measuring microphones was taken as the magnitude of the VIR for the respective azimuth. VIRs were interpolated to increase the angular resolution from the original angle step size of 10° to a resolution of 0.2°.
A virtual echo from a surface at a specific azimuth was generated in the following steps: first, the sound was picked up by the headset microphone. Second, the spectrum of the sound was compensated both for the calibration of the headset microphone and the VIR for the specific azimuth. These steps create the sound as it would impinge on a reflective surface at this azimuth. The distance of the surface is incorporated both in terms of a time delay and geometric attenuation, i.e. an increase in distance led to a decrease in sound level. A leading echo was generated at a distance of 2 m (echo delay = 11.7 ms); a lagging echo was generated at a distance of 2.34 m (echo delay = 13.7 ms, cf. figure 1). The digital delay applied to the sounds was shorter than these delays because of the additional input–output delay of the real-time convolution engine (see below), which was 4.95 ms. Finally, the (binaural) echo was calculated by convolving this filtered and delayed sound with the HRIR.
Apparatus for the actual experiments was the same as in the Listening experiment, except that subjects were equipped with the headset microphone. In the audio interface, the signal was routed via a direct path and an indirect (echo) path. In the direct path, the signal was sent directly from the microphone input to the headphone amplifier via ‘Asio direct monitoring’ to simulate the part of the sound that reaches the ears directly from the mouth without any reflections. In the following, this part of the sound will be referred to as ‘direct sound’ (DS). The level of the direct path was experimentally adjusted such that self-produced vocalizations in anechoic space sounded most similar with and without ear phones. The input–output delay of this path was only 1.7 ms.
The indirect path contained a real-time convolution engine (using a custom-made soundmexpro VST Plugin, Hoertech, Oldenburg, Germany), which performed in real time the echo calculations described above at a sampling rate of 48 kHz.
(e). Procedure of the Echolocation experiment
The same 2AIFC adaptive paradigm as in the Listening experiment was used to train subjects to discriminate between azimuthal positions of a single sound reflector, the leading of two reflectors and the lagging of two reflectors, respectively. But within each interval, the subjects had to produce vocalizations and listen to real-time generated echoes to evaluate the spatial layout of the different reflectors in the VEAS. Performance and stability were measured in the same way as in the Listening experiment.
Subjects were allowed to choose any kind of vocalization, as long as they produced it with the mouth. In each experimental run including echolocation, the subjects’ vocalizations were recorded.
(f). Analysis and statistics
Conditions were trained successively in ascending order of the level of difficulty. According to Litovsky et al. [17] this means that first, single object discrimination was trained until the stability criterion was fulfilled. Then lead discrimination was trained and finally lag discrimination. The Listening and Echolocation experiments were trained simultaneously. After the subjects had fulfilled the stability criterion for all three conditions and acquisition was completed, they were tested again on single object discrimination to verify that the results really are asymptotic thresholds. The obtained MAAs were in accordance with the previous performance, which confirms that our results are not contaminated by long-term learning effects.
The non-parametric Wilcoxon rank-sum test was used to test whether two datasets are independent samples from identical continuous distributions with equal medians. Results are presented in terms of p-value and the rank-sum statistic WM,N, where M and N denote the number of elements in the two datasets. To compare lead- and lag-discrimination performance across the Listening and the Echolocation experiments, the discrimination deterioration factors (DDFs) were calculated according to Litovsky [18] and Tollin & Henning [19]: DDFs are defined as ratio of lead/single, lag/single and lag/lead thresholds.
(g). Control experiments
As the Listening and the Echolocation experiments differ with respect to the acoustic properties of the stimuli, two control experiments were conducted to disambiguate the effects of these differences. As in the two original experiments, six sighted subjects with normal hearing participated in the control experiments, four of that (S1–S4) had also participated in the main experiments.
The first control experiment is identical to the Listening experiment beside the fact that the stimuli were not derived from Dirac impulses, but from pre-recorded vocalizations: for each trial and interval, an individual vocalization was randomly picked from a database containing all recorded vocalization of the respective subject and the respective condition in the Echolocation experiment. These were also available for the two new subjects that had taken part in other Echolocation experiments. The level of the stimuli was matched to the level of the echoes that were presented in the Echolocation experiment. The purpose of the first control experiment was to determine whether any differences between the Echolocation and Listening experiments could be explained by differences in acoustic properties of the stimuli.
The second control experiment is also a Listening experiment with pre-recorded vocalizations, but, unlike in the first control experiment, stimuli are preceded with a third copy of the vocalization. This third copy matches the auditory representation of the DS in the Echolocation experiment. Hence, this second control experiment matches most closely the auditory excitation in the Echolocation experiment. As the only difference between the Echolocation experiment and the second control experiment was the active vocalization, this control experiment enabled us to determine the role played by the active generation of the click during echolocation.
3. Results
All six subjects were successfully trained to perform single object-, lead- and lag-discrimination conditions in both the Listening and the Echolocation experiments. During training, subjects improved both the precision of their auditory analysis and, in the Echolocation experiment, optimized their vocalizations for the echo-acoustic task. Analysing changes of call parameters over time revealed that after less than five training sessions, all subjects ended up emitting short broadband clicks and continued to do so during the whole data acquisition.
(a). The Listening experiment
In the single-source condition of the Listening experiment, most subjects could detect a change in the azimuth of less than 3.3° (cf. figure 2a). Subject S3 performed the best with an MAA of 2.3°. Only subject S2 had a markedly worse MAA of 7.0°. This subject performed worse than average in all three listening conditions. Averaging over the performance of all six subjects yields a mean MAA of 3.4°. Without underperforming subject S2, the mean MAA would be 2.7°, and therefore still around 3°.
Figure 2.

Results of the azimuth discrimination experiments for all six subjects. (a,d,g) MAAs for sound source discrimination, (b,e,h) MAAs for sound reflector discrimination, and (c,f,i) MAAs for the control experiment without and with DS. The rows represent the three conditions, single object, lead and lag discrimination, respectively.
Lead-discrimination performance was slightly worse than the performance in the single-source discrimination task (W6,6 = 26, p = 0.041). The average MAA in this condition was 5.4°, as shown in figure 2d. Most subjects had similar MAAs, only subject S2 again performed much worse than the average with an MAA of 11.9°.
In the lag-discrimination condition, performance deteriorated strongly compared with lead discrimination: the average MAA was 27.5°, but the individual MAAs ranged from 17.5° (S6) to 43.5° (S1), as shown in figure 2g. A Wilcoxon rank-sum test was performed on the logarithmically transformed MAAs to provide homoscedasticity and revealed with high significance that values for lag discrimination are larger than those for lead discrimination (W6,6 = 21, p = 0.0022). These results show a strong asymmetry between lead- and lag-discrimination performances, which means that the precedence effect had considerable influence in the Listening experiment.
(b). The Echolocation experiment
In the single-reflector condition of the Echolocation experiment, MAAs ranged from 4.8° (S6) to 9.2° (S1) with an average of 6.7° (cf. figure 2b). There were no obvious outliers among the subjects’ performances in this condition.
In contrast to the Listening experiment, performance worsened markedly in the Echolocation experiment when the lagging sound reflector was introduced (W6,6 = 21, p = 0.0022). Here, subjects could detect changes of the lead azimuth of 29.7° on average, MAAs are shown in figure 2e. Individual MAAs ranged from 24.1° for subject S6 to 37.4° for subject S5.
While introducing a lagging reflector significantly increased difficulty in lead discrimination relative to single-reflector discrimination, there was no significant additional decline in performance when the roles of the leading and the lagging reflectors were interchanged (cf. figure 2h): in the Echolocation experiment, lag-discrimination performance was not significantly worse than lead-discrimination performance (W6,6 = 28, p = 0.093). The mean MAA was 39.5°. Therefore, in the Echolocation experiment, there was no significant asymmetry between lead- and lag-discrimination performances.
(c). Comparison of Listening and Echolocation results
As described in the material and methods, the DDF allows comparison of the performances across the Listening and Echolocation experiments. For the Listening experiment, the average lead/single DDF was 1.60 (cf. figure 3a), which means that lead-discrimination performance deteriorated only by this relatively small factor compared with single-source discrimination. In the Echolocation experiment, however, the average lead/single DDF was 4.75 (cf. figure 2b), which is significantly higher (W6,6 = 57, p = 0.0022).
Figure 3.

Normalized results in terms of DDFs. (a,b,c) Lead-discrimination performance was significantly better in the Listening experiment and in the control experiment without DS than in the Echolocation experiment and the control experiment with DS, (d,e,f) while lag-discrimination performance was significantly better in the Echolocation experiment than in all other experiments. (g,h,i) The asymmetry between lead and lag discriminations as the defining factor for the precedence effect was significantly weaker in the Echolocation experiment than in all other experiments.
While lead/single DDFs were significantly lower in the Listening experiment than in the Echolocation experiment, the situation for lag discrimination was the other way around. As shown in figure 3d, lag/single DDFs for the Listening experiment amounted 8.58 on average. In the Echolocation experiment, lag/single DDFs were significantly lower (W6,6 = 52, p = 0.041), with an average of 6.06 (cf. figure 3e).
Calculating lag/lead DDFs allows for a direct quantification of the asymmetry between the lag and the lead in their efficiency to suppress spatial information of one another. Figure 3g,h clearly shows that in the Listening experiment this asymmetry was very strong (DDF = 5.53), whereas in the Echolocation experiment, it was almost absent (DDF = 1.35). This asymmetry difference is highly significant (W6,6 = 21, p = 0.0022).
Lead/single and lag/single DDFs were tested for main and interaction effects of conditions and experiments using an analysis of variance (ANOVA) with two within-subject variables. It revealed no significant main effect of the type of experiment (F1,20 = 0.22, p = 0.65), which means that subjects did not generally perform better in either of the experiments. However, both the main effect of condition (F1,20 = 37.52, p < 0.001) and the interaction effect of condition and experiment (F1,20 = 17.56, p < 0.001) are highly significant. Hence, the precedence effect did influence performance in both experiments, but its strength was significantly smaller in the Echolocation experiment than in the Listening experiment.
A two-way ANOVA was performed on the 24 lag/lead DDFs (including DDF comparisons across the Listening and Echolocation experiments) with two factors, namely the version of the lag-discrimination experiment (Listening versus Echolocation) and the version of the lead-discrimination experiment. The ANOVA revealed that a majority of 60% of the variance in lag/lead DDFs between the Listening and the Echolocation experiments can be explained by higher lead/single DDFs in the Echolocation experiment (F1,20 = 29.61, p < 0.001), whereas the lower lag/single DDFs in the Echolocation experiment are responsible for 20% of the variance (F1,20 = 4.90, p = 0.039).
(d). Results from the control experiments
Results from the first control experiment showed no significant difference to the original Listening experiment in any condition (cf. figure 3). The asymmetry between lead- and lag-discrimination performance in terms of lag/lead DDFs was 4.69 on average, which is quite similar to the average lag/lead DDF in the original Listening experiment (5.53). As for the original Listening experiment, results were significantly different from the Echolocation experiment in terms of lead/single DDFs (W6,6 = 57, p = 0.0022), lag/single DDFs (W6,6 = 24, p = 0.015) and lag/lead DDFs (W6,6 = 21, p = 0.0022). This shows that the acoustic properties of the stimuli are not responsible for the differences between the Listening and the Echolocation experiments.
In the second control experiment, the asymmetry between lead- and lag-discrimination performances in terms of lag/lead DDFs was significantly lower than for the Listening experiment (W6,6 = 57, p = 0.0022), with a mean lag/lead DDF of 2.02 (cf. figure 3). The difference in this asymmetry between the second control experiment and the Echolocation experiment is much less pronounced but still significant (W6,6 = 24, p = 0.015). This shows that the presence of the DS is appropriate to explain most of the variance in lag/lead DDF between the Listening and the Echolocation experiments. The reduced asymmetry between lead and lag discrimination in the Echolocation experiment when compared with the other experiments, and in particular when compared with the second control experiment, also shows that there is a significant effect of whether subjects are actively vocalizing or not.
Specifically, lead discrimination was significantly impaired both in the Echolocation experiment and in the second control experiment. By contrast, lead discrimination was virtually unaffected in the original Listening experiment and in the first control experiment: the average lead/single DDF in the second control experiment was 3.79, which is significantly higher than that in the Listening experiment (W6,6 = 21, p = 0.0022), but not significantly different from the original Echolocation experiment (W6,6 = 45, p = 0.39). This shows that the observed impairment in lead discrimination in the Echolocation experiment is owing to the presence of the DS.
Lag discrimination, however, was significantly better in the Echolocation experiment than in all other experiments: lag/single DDFs for the Echolocation experiment were significantly lower than that for the original Listening experiment (W6,6 = 52, p = 0.041), the first control experiment (W6,6 = 24, p = 0.015) and the second control experiment (W6,6 = 26, p = 0.041). This shows that the observed improvement in lag discrimination in the Echolocation experiment is not related to the acoustic properties of the stimulation. Instead, it must be owing to the fact that the subjects were actively producing vocalizations.
4. Discussion
(a). Single-object discrimination
Previous studies on the spatial acuity of the human auditory system have shown that performance in localization and lateralization tasks strongly depends on the experimental set-up. Using stimuli delivered via headphones, Klumpp & Eady [20] found that the threshold interaural time difference is 28 μs for single clicks of 1 ms duration, which corresponds to an MAA of 2.4°. This threshold is quite similar to the current MAA of 3.4° in the single-source condition of the Listening experiment. Note that the 2.4° threshold is obtained for a frontal position of the clicks. In this study, the single sources were presented not in front but 40° to the right. Several studies have shown that MAAs deteriorate when the overall position of the sound sources is shifted towards one hemisphere [21,22]. These findings are likely to explain the residual differences between the current single-source MAAs and the data from Klumpp & Eady [20]. Thus, the current single-source MAAs provide evidence for the validity of our implementation of VAS.
Comparing the current single-source MAAs to the single-reflector MAAs in the Echolocation experiment demonstrates that very high levels of spatial acuity can be reached by training echolocation: MAAs for a single reflector were around 6.7°, i.e. Echolocation performance was less than 4° worse than Listening performance. Teng & Whitney [23] trained 11 sighted but blindfolded subjects to detect a lateral displacement between two 20.3 cm circular discs vertically mounted above each other. The two best-performing sighted subjects could detect a lateral displacement of 4.1° and 6.7°, respectively. Again, these data are well comparable to the current single-reflector MAAs with an average of 6.7°.
In this context, it must be pointed out that in the Echolocation experiment with the single reflector, subjects always had to evaluate the spatial information of the second sound they received, namely the echo from the reflector; the first sound was always the DS from the mouth to the ear. This DS preceded the echo from the reflector by 10 ms. The low single MAA data indicate that the subjects’ judgments were not much impaired by the presence of the DS in the single-reflector discrimination task, which suggests that the delay between DS and echoes was beyond echo threshold. The small but significant MAA increase from the single-source to the single-reflector condition may result from residual forward masking elicited by the DS onto the echo.
This finding is consistent with published echo thresholds for similar sounds: Schubert & Wernick [24] reported an echo threshold of 5.5 ms for 20 ms high-pass noise bursts with a cut-off frequency of 1 kHz. These stimuli are roughly comparable to the sounds produced by our subjects in the Echolocation experiment.
However, it has been shown that processing of the second click can be good when only two sounds are presented, but adding a third click may impair the processing of the second one [19,25,26]. Hence, the finding that performance in the single-source condition was not much impaired by the DS cannot be directly generalized to the lead- and the lag-discrimination conditions, which is discussed below.
(b). Lead discrimination
In the lead-discrimination condition, a second sound source or sound reflector was introduced at a fixed azimuth of 40° to the left, which was delayed by 2 ms relative to the lead. In such a situation, perceptual fusion between lead and lag is known to be strong and the location of the lead dominates the localization of the fused perception [19,27,28]. Therefore, localizing the leading object should not be impaired much by the lagging object. Indeed, Litovsky [18] reports a small but significant lead/single DDF of 1.47. The current results from the Listening experiment confirm these data with a lead/single DDF of 1.60.
In contrast to the Listening experiment, we observed a pronounced increase in MAAs for lead discrimination relative to single-reflector discrimination in the Echolocation experiment. Here, the performance worsened markedly for all subjects when the lagging sound reflector was introduced. This indicates that first, the lead was not as dominant as in the Listening experiment, second, lag suppression was weaker and third, localization was highly affected by both reflectors.
(c). Lag discrimination
In the lag-discrimination condition, subjects had to detect changes in the lag, which was centred around 40° to the right and delayed by 2 ms relative to the lead. This kind of configuration is known to create a strong precedence effect such that the lead dominates perception. Therefore, one would expect that changes in the lag are extremely difficult to discriminate, which is reflected in the finding that lag-discrimination MAAs are higher than lead-discrimination MAAs [18,29–32]. Hence, the precedence effect produces an asymmetry between lead- and lag-discrimination performances. The strength of this asymmetry in terms of lag/lead DDFs can be used as a quantitative measure for the influence of the precedence effect [18,19].
This effect could be observed clearly in the current Listening experiment: compared to the lead-discrimination condition, the subjects’ performance deteriorated dramatically. The observed strong asymmetry between lead- and lag-discrimination performances reveals a considerable influence of the precedence effect in the Listening experiment. However, in the Echolocation experiment, the subjects’ performance deteriorated only slightly. This indicates that here, the leading and lagging reflection received almost equivalent perceptual weights. The strong asymmetry between lead- and lag-discrimination performances as the defining factor of the precedence effect was clearly observed in the Listening experiment, but not in the Echolocation experiment.
Saberi & Perrott [33] observed a ‘substantial drop’ in lag/single DDFs after ‘sufficient practice on the lateralization task’. They concluded that their data show a release from precedence owing to training. In our study, lag/single DDFs were significantly lower in the Echolocation experiment than that in the Listening experiment, i.e. our data also show a ‘release from precedence’ in this sense.
(d). Do echolocators ‘untrain’ the precedence effect?
As there are contradictory reports as to whether the precedence effect can be unlearned [33] or not [34], it is interesting to discuss why the perceptual imbalance between lead and lag underlying the classical precedence effect was much less pronounced in the Echolocation experiment than in the Listening experiment.
The effect observed in our data essentially differs from the release from precedence that was reported by Saberi & Perrott [33]. In their study, the precedence effect was not characterized by lag/lead DDFs, but by lag/single DDFs. In our study, lag/single DDFs were significantly lower in the Echolocation experiment than in the Listening experiment, i.e. our data do show a ‘release from precedence’ in this sense, too. However, our data also show a new precedence-like effect of lead-discrimination suppression in the Echolocation experiment, which is absent in the Listening experiment. In the Listening experiment, the presence of the leading source affected discrimination of lagging sources much more than vice versa. In the Echolocation experiment, however, the presence of the lag affected discrimination of leading reflectors almost as strongly as vice versa. Thus, the lower lag/lead DDFs in the Echolocation experiment—which we use as a quantitative measure for the strength of the precedence effect in consistence with e.g. Litovsky [18,19]—is mainly owing to the decline in lead-discrimination performance and only to a much smaller extent owing to the enhancement in lag-discrimination performance.
Our Listening and Echolocation experiments differ with respect to the acoustic properties of the stimuli: in the Listening experiment, transformed Dirac impulses are presented via the earphones, whereas in the Echolocation experiment, transformed tongue clicks are presented. Moreover, in the Listening experiment, two sounds were presented (lead and lag), whereas in the Echolocation experiment, the subject perceived three sounds, namely, the DS and the two reflections from the leading and lagging reflectors. In the following, these two aspects are discussed with respect to their potential to explain the observed performance differences in the Listening and the Echolocation experiments.
(e). Dirac impulses versus tongue clicks
First, subjects could have produced vocalizations with a frequency range that is minimally affected by the precedence effect. It has been shown that localization dominance as one of the main aspects of precedence depends on the spectral content of stimuli [35] and is most pronounced at low frequencies around 750 Hz [26]. However, the sound analysis (which is available in the electronic supplementary material) showed that our subjects did not adjust the frequency content of their calls in the double-reflector tasks: subjects S3 and S4 even produced calls with lower peak frequencies for lag-discrimination than for single-reflector discrimination.
Second, subjects could have adjusted the number of their vocalizations to exploit build-up and break-down effects of precedence. Not all aspects of the precedence effect seem to be ‘hard wired’ phenomena, as described by Tollin [36] or Hartung & Trahiotis [37], but they at least partly depend on high-level cognitive processes: Clifton [13] showed that the precedence effect breaks down temporarily when the acoustical conditions are changed, and therefore contradicts the listeners’ expectations. Freyman et al. [14] found that the precedence effect can take some time to build up, i.e. it strengthens with acoustic experience about the echo-encoded spatial information. Several studies provide further evidence that echo suppression is enhanced when the echoes match the listeners’ expectations about the environment based on previous experience [38–41]. Clearly, these cognitive components are a likely candidate to tune auditory processing for echolocation as opposed to echo suppression. Most of our subjects produced five or more clicks per 2 s interval. This relatively high number of repetitions would facilitate a build-up of precedence, and hence impair the performance in the lag-discrimination condition. It appears that nevertheless, most subjects chose to produce this relatively high number of clicks both for single-reflector discrimination and for lead- and lag-discrimination conditions. This provides circumstantial evidence that our subjects did not suffer from a build-up of precedence.
In addition to the sound analysis, the first control experiment provides conclusive evidence that none of the different acoustic properties of Dirac impulses versus tongue clicks is responsible for the performance differences between the Listening and the Echolocation experiments.
(f). Influence of the direct sound
In the Listening experiment, the leading and lagging sounds were always the first and second sounds heard by the subjects, whereas in the Echolocation experiment they were the second and third. It has been shown by Tollin & Henning [19,26] and Saberi & Perrott [25] that the precedence effect can be strongly affected by a sound preceding or following the judged pair, even if the delay is at or beyond the echo threshold.
Indeed, the second control experiment shows that the presence of the DS explains most of the variance between the Listening and the Echolocation experiments. Specifically, the DS is responsible for impaired lead discrimination in the Echolocation- and in the second control experiment. However, there is still a small but significant effect of whether subjects were actively vocalizing or not, which cannot be related to the acoustic properties of the stimulation. This effect is responsible for improved lag discrimination in the Echolocation experiment relative to all other experiments.
5. Conclusion
The current experiments show first that sighted subjects can learn to discriminate reflective surfaces echo-acoustically in VEAS with very high accuracy. Second, the perceptual imbalance between lead and lag underlying the classical precedence effect was much less pronounced in the Echolocation experiment than in the Listening experiment: in the Listening experiment, the presence of the leading source affected discrimination of lagging sources much more than vice versa, whereas in the Echolocation experiment, the presence of both a lead and a lag strongly affected discrimination. Two control experiments show that the observed difference is mainly owing to the presence of the DS, which impairs lead-discrimination performance in the Echolocation experiment. Moreover, there is a smaller but significant effect of whether subjects are actively vocalizing or not, which is responsible for improved lag-discrimination performance in the Echolocation experiment. These data show that the classically described asymmetry in the perception of leading and lagging sounds is diminished in a context of trained echolocation practice, which may allow for a more unbiased assessment of spatially distributed reflective surfaces.
The current psychophysical experiments have been ethically approved by the Ethikkommission der Medizinischen Fakulta¨t der LMU München.
Funding statement
This work was funded by the Bernstein Center for Computational Neuroscience in Munich, the ‘Studienstiftung des deutschen Volkes’ (stipend to L.Wallmeier) and the German Research Foundation (Wi 1518/9 to L.Wiegrebe).
References
- 1.Stoffregen TA, Pittenger JB. 1995. Human echolocation as a basic form of perception and action. Ecol. Psychol. 7, 181–216 (doi:10.1207/s15326969eco0703_2) [Google Scholar]
- 2.Diderot D. 1749. Letter on the blind for the use of those who see. In Diderot's early philosophical works (ed. Jourdain M.), pp. 68–141 New York, NY: Burt Franklin [Google Scholar]
- 3.Supa M, Cotzin M, Dallenbach KM. 1944. ‘Facial vision’: the perception of obstacles by the blind. Am. J. Psychol. 57, 133–183 (doi:10.2307/1416946) [Google Scholar]
- 4.Kohler I. 1964. Orientation by aural clues. Am. Found. Blind Res. Bull. 4, 14–53 [Google Scholar]
- 5.Kellogg WN. 1962. Sonar system of the blind. Science 137, 399–404 (doi:10.1126/science.137.3528.399) [DOI] [PubMed] [Google Scholar]
- 6.Rice CE. 1967. Human echo perception. Science 155, 656–664 (doi:10.1126/science.155.3763.656) [DOI] [PubMed] [Google Scholar]
- 7.Schenkman BN, Nilsson ME. 2010. Human echolocation: blind and sighted persons’ ability to detect sounds recorded in the presence of a reflecting object. Perception 39, 483–501 (doi:10.1068/p6473) [DOI] [PubMed] [Google Scholar]
- 8.Thaler L, Arnott SR, Goodale MA. 2011. Neural correlates of natural human echolocation in early and late blind echolocation experts. PLoS ONE 6, e20162 (doi:10.1371/journal.pone.0020162) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Teng S, Puri A, Whitney D. 2012. Ultrafine spatial acuity of blind expert human echolocators. Exp. Brain Res. 216, 483–488 (doi:10.1007/s00221-011-2951-1) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Dufour A, Despres O, Candas V. 2005. Enhanced sensitivity to echo cues in blind subjects. Exp. Brain Res. 165, 515–519 (doi:10.1007/s00221-005-2329-3) [DOI] [PubMed] [Google Scholar]
- 11.Wallach H, Newman EB, Rosenzweig MR. 1949. The precedence effect in sound localization. Am. J. Psychol. 62, 315–336 (doi:10.2307/1418275) [PubMed] [Google Scholar]
- 12.Thurlow WR, Parks TE. 1961. Precedence suppression effects for two-click sources. Percept. Mot. Skills 13, 7–12 (doi:10.2466/pms.1961.13.1.7) [Google Scholar]
- 13.Clifton RK. 1987. Breakdown of echo suppression in the precedence effect. J. Acoust. Soc. Am. 82, 1834–1835 (doi:10.1121/1.395802) [DOI] [PubMed] [Google Scholar]
- 14.Freyman RL, Clifton RK, Litovsky RY. 1991. Dynamic processes in the precedence effect. J. Acoust. Soc. Am. 90, 874–884 (doi:10.1121/1.401955) [DOI] [PubMed] [Google Scholar]
- 15.Schuchmann M, Hubner M, Wiegrebe L. 2006. The absence of spatial echo suppression in the echolocating bats Megaderma lyra and Phyllostomus discolor. J. Exp. Biol. 209, 152–157 (doi:10.1242/jeb.01975) [DOI] [PubMed] [Google Scholar]
- 16.Levitt HL. 1970. Transformed up-down methods in psychophysics. J. Acoust. Soc. Am. 49, 467–477 (doi:10.1121/1.1912375) [PubMed] [Google Scholar]
- 17.Litovsky RY, Colburn HS, Yost WA, Guzman SJ. 1999. The precedence effect. J. Acoust. Soc. Am. 106, 1633–1654 (doi:10.1121/1.427914) [DOI] [PubMed] [Google Scholar]
- 18.Litovsky RY. 1997. Developmental changes in the precedence effect: estimates of minimum audible angle. J. Acoust. Soc. Am. 102, 1739–1745 (doi:10.1121/1.420106) [DOI] [PubMed] [Google Scholar]
- 19.Tollin DJ, Henning GB. 1998. Some aspects of the lateralization of echoed sound in man. I. The classical interaural-delay based precedence effect. J. Acoust. Soc. Am. 104, 3030–3038 (doi:10.1121/1.423884) [DOI] [PubMed] [Google Scholar]
- 20.Klumpp RG, Eady HR. 1956. Some measurements of interaural time difference thresholds. J. Acoust. Soc. Am. 28, 859–860 (doi:10.1121/1.1908493) [Google Scholar]
- 21.Stevens SS, Newman EB. 1936. The localization of actual sources of sound. Am. J. Psychol. 48, 297–306 (doi:10.2307/1415748) [Google Scholar]
- 22.Tonning FM. 1970. Directional audiometry. I. Directional white-noise audiometry. Acta Otolaryngol. 69, 388–394 (doi:10.3109/00016487009123383) [PubMed] [Google Scholar]
- 23.Teng S, Whitney D. 2011. The acuity of echolocation: spatial resolution in the sighted compared to expert performance. J. Vis. Impair Blind 105, 20–32 [PMC free article] [PubMed] [Google Scholar]
- 24.Schubert ED, Wernick J. 1969. Envelope versus microstructure in the fusion of dichotic signals. J. Acoust. Soc. Am. 45, 1525–1531 (doi:10.1121/1.1911633) [DOI] [PubMed] [Google Scholar]
- 25.Saberi K. 1996. Observer weighting of interaural delays in filtered impulses. Percept. Psychophys. 58, 1037–1046 (doi:10.3758/BF03206831) [DOI] [PubMed] [Google Scholar]
- 26.Tollin DJ, Henning GB. 1999. Some aspects of the lateralization of echoed sound in man. II. The role of the stimulus spectrum. J. Acoust. Soc. Am. 105, 838–849 (doi:10.1121/1.426273) [DOI] [PubMed] [Google Scholar]
- 27.Zurek PM. 1980. The precedence effect and its possible role in the avoidance of interaural ambiguities. J. Acoust. Soc. Am. 67, 953–964 (doi:10.1121/1.383974) [DOI] [PubMed] [Google Scholar]
- 28.Gaskell H. 1983. The precedence effect. Hear. Res. 12, 277–303 (doi:10.1016/0378-5955(83)90002-3) [DOI] [PubMed] [Google Scholar]
- 29.Perrott DR, Strybel TZ, Manligas CL. 1987. Conditions under which the Haas precedence effect may or may not occur. J. Aud. Res. 27, 59–72 [PubMed] [Google Scholar]
- 30.Perrott DR, Marlborough K, Merrill P, Strybel TZ. 1989. Minimum audible angle thresholds obtained under conditions in which the precedence effect is assumed to operate. J. Acoust. Soc. Am. 85, 282–288 (doi:10.1121/1.397735) [DOI] [PubMed] [Google Scholar]
- 31.Perrott DR, Pacheco S. 1989. Minimum audible angle thresholds for broadband noise as a function of the delay between the onset of the lead and lag signals. J. Acoust. Soc. Am. 85, 2669–2672 (doi:10.1121/1.397764) [DOI] [PubMed] [Google Scholar]
- 32.Litovsky RY, Macmillan NA. 1994. Sound localization precision under conditions of the precedence effect: effects of azimuth and standard stimuli. J. Acoust. Soc. Am. 96, 752–758 (doi:10.1121/1.411390) [DOI] [PubMed] [Google Scholar]
- 33.Saberi K, Perrott DR. 1990. Lateralization thresholds obtained under conditions in which the precedence effect is assumed to operate. J. Acoust. Soc. Am. 87, 1732–1737 (doi:10.1121/1.399422) [DOI] [PubMed] [Google Scholar]
- 34.Litovsky RY, Hawley ML, Fligor BJ, Zurek PM. 2000. Failure to unlearn the precedence effect. J. Acoust. Soc. Am. 108, 2345–2352 (doi:10.1121/1.1312361) [DOI] [PubMed] [Google Scholar]
- 35.Shinn-Cunningham BG, Zurek PM, Durlach NI, Clifton RK. 1995. Cross-frequency interactions in the precedence effect. J. Acoust. Soc. Am. 98, 164–171 (doi:10.1121/1.413752) [DOI] [PubMed] [Google Scholar]
- 36.Tollin DJ. 1998. Computational model of the lateralization of clicks and their echoes. In Proc. of the NATO Advanced Study Institute on Computational Hearing, IL Ciocco, Italy, 1–12 July (eds Greenberg S, Slaney M.), pp. 77–82 Amsterdam, The Netherlands: IOS Press. [Google Scholar]
- 37.Hartung K, Trahiotis C. 2001. Peripheral auditory processing and investigations of the ‘precedence effect’ which utilize successive transient stimuli. J. Acoust. Soc. Am. 110, 1505–1513 (doi:10.1121/1.1390339) [DOI] [PubMed] [Google Scholar]
- 38.Clifton RK, Freyman RL, Litovsky RY, McCall D. 1994. Listeners’ expectations about echoes can raise or lower echo threshold. J. Acoust. Soc. Am. 95, 1525–1533 (doi:10.1121/1.408540) [DOI] [PubMed] [Google Scholar]
- 39.Blauert J. 1997. Spatial hearing: the psychophysics of human sound localization. Cambridge, MA: MIT Press [Google Scholar]
- 40.Clifton RK, Freyman RL. 1997. The precedence effect: beyond echo suppression. In Binaural and spatial hearing in real and virtual environments (eds Gilkey R, Anderson T.), pp. 233–255 Hillsdale, NJ: Erlbaum [Google Scholar]
- 41.Hartmann WM. 1997. Listening in a room and the precedence effect. In Binaural and spatial hearing in real and virtual environments (eds Gilkey R, Anderson T.), pp. 191–210 Hillsdale, NJ: Erlbaum [Google Scholar]