

Abstract
The utterance planning processes allowing speakers to produce agreement between subjects and verbs (the catspl arepl asleep) have been the topic of extensive study as a window into language production mechanisms. A key question has been the extent to which agreement processing is influenced by semantic and phonological factors. Most prior studies have found limited effects of non-syntactic, particularly phonological factors, leading to conclusions that agreement is computed by a process influenced strongly by syntactic factors and with only a minor contribution of semantics. This conclusion may have been influenced by use of agreement error data as the main dependent variable, because errors are rare, potentially reducing sensitivity to the interaction of several factors. Two studies investigate agreement processing in Serbian, which allows both singular and plural verb forms to agree with plural nouns in some constructions. We use these constructions to further investigate the contribution of semantic factors to agreement, by manipulating levels of individuation of the members of a set. In addition, we investigate the effect of morphophonological homophony onto the participants’ productions of agreeing forms. The findings are discussed in the context of three models of agreement (Marking & Morphing, competition and controller misidentification), which differ in the extent to which they allow the influence of non-syntactic factors on agreement. We also compare the behavioral findings with the predictions of four computational implementations of the Marking & Morphing account. We discuss the implications of the behavioral and computational findings for models of agreement and the language production more broadly.
Rosemary: Some biscuits or a piece of cake… ‘goes’ or ‘go’ better with an afternoon tea?
In this quote, the speaker expresses indecisiveness about whether the verb should be singular (goes) or plural (go) for the subject noun phrase biscuits or cake. Her utterance is a relatively rare example of a conscious contemplation of subject-verb agreement, which usually proceeds rapidly and without reflection during language production. Despite the typical speed and accuracy with which agreement is computed, the mapping between a subject noun phrase and its agreeing verb is a complex one in many languages, and language production researchers have repeatedly studied this relationship as a window into sentence production processes.
Within this research, there are two general views on the nature of the cognitive processes that compute agreement. One approach assumes that the mechanisms governing agreement are primarily syntactic in nature, with some early and constrained input from non-syntactic information. On this view, agreement computations are a process of reconciliation of the conceptual number of a noun phrase (NP) and grammatical number specifications of morphemes that constitute the phrase (Bock, Eberhard, Cutting, Meyer, & Schriefers, 2001; Eberhard, Cutting, & Bock, 2005), the results of which are then transmitted to agreeing elements (e.g. verbs). This transmission process is sometimes referred to as hierarchical feature passing (e.g. Gillespie & Pearlmutter, 2011; Solomon & Pearlmutter, 2004), reflecting the view that abstract grammatical features are transmitted through a hierarchical syntactic structure. In the Marking and Morphing account of these processes (Eberhard et al., 2005), agreement computation starts with an evaluation of the notional number of the NP, and through marking the resulting number feature is transmitted to the root of the subject noun phrase. To use a simple example, in the clause the cats are asleep this process would involve an evaluation of whether the message refers to single or multiple entities, and in the case of multiple feline animals it would result in marking the NP as plural. During morphing, which is the process of activating representations supporting phonological encoding, the number features resulting from marking are reconciled with number specifications of the NP morphemes in the lexicon (catspl) and then transmitted to agreeing elements. Hence in the above example, the plural feature of the morpheme s would support the conceptually plural marking of the noun phrase, and during morphing the plural feature would be transmitted to the verb, resulting in the cats arepl. On this view, conceptual properties influence number information on the NP (marking), but in the subsequent morphing process, computing agreement on the verb is a syntactic operation, via hierarchical feature passing. The Marking & Morphing account keeps a clear distinction between syntax and the lexicon, and describes agreement computations as operating over abstract syntactic features. The computational implementation of the account (Eberhard et al., 2005) models agreement as essentially a constraint satisfaction process (e.g. MacDonald, Pearlmutter, & Seidenberg, 1994; McRae, Spivey-Knowlton, & Tanenhaus, 1998; Spivey, Tanenhaus, et al., 1998; Trueswell & Tanenhaus, 1994), and it embodies the theoretical account in implementing syntactic features as the strongest constraint.
A second approach views agreement computations as emerging from competition between alternative forms during the process of mapping between the message and its phonological form. This type of account is generally consistent with linguistic approaches that do not draw such a clear distinction between the lexicon and syntax as is held in the Marking and Morphing view (e.g. Bybee & McClelland, 2005; Goldberg, 2006), and it is also consistent with linguistic treatments of agreement that emphasize the influence of semantic factors (e.g. Corbett, 2000; Pollard & Sag, 1988). In competition accounts, different sources of information, including non-syntactic factors, influence the choice of agreeing elements to the extent that they are correlated with the agreeing form (Haskell & MacDonald, 2003; Thornton & MacDonald, 2003). For example, conceptually plural but grammatically singular nouns such as family will promote the use of plural verbs because conceptual plurality in English is correlated with plural verb form use (Haskell & MacDonald, 2003). On this view, the conceptual and grammatical information together influence agreement computations; agreement is not viewed as a process of first using conceptual information in marking and later transmitting grammatical features in morphing. Further, the competition account predicts that conflicting information from different sources will increase processing time and/or variability of responses. For example, the conflicting information from conceptually plural but grammatically singular collective nouns (family, gang, cast) produces longer initiation latencies relative to both conceptually and grammatically singular nouns, which is attributed to the competition between alternative verb forms which are supported by the two different sources of information (Haskell & MacDonald, 2003). The competition account also shares features with constraint satisfaction models in psycholinguistics, particularly in the hypothesis that several different factors simultaneously influence agreement computations (MacDonald et al., 1994; Trueswell & Tanenhaus, 1994). Furthermore, this account also emphasizes the role of learning from previous experiences with distributional patterns in the language. For example, previous encounters with the phrases such as a trio of violinists and a committee of opera directors paired with plural verbs increase the likelihood of producing plural verbs with other collective (e.g. a class of children) but also non-collective, singular noun-headed, NPs, e.g. a pencil in the gift bags (Haskell, Thornton, & MacDonald, 2010). According to the competition account, the varying amounts of experience with distributional patterns of a language influence the strength of activation of competing forms in agreement.
A similar competitive mechanism, proposed by Badecker and Kuminiak (2007), emphasizes the role of memory encoding and retrieval in agreement processing (see also Gillespie & Pearlmutter, 2011, for a related account). This proposal focuses on the process of identifying the agreement controller i.e. the sentence subject, because agreement-relevant morpho-syntactic features of the verb crucially depend on the morpho-syntactic features of the subject noun. Badecker and Kuminiak (2007) suggest that during utterance planning in working memory, morpho-syntactic features involved in identifying the sentence subject serve as its retrieval cues. If the message contains elements with similar features they can interfere with each other which can result in the retrieval of an incorrect element, i.e. lead to a misidentification of the agreement controller. For example, in a study by Hartsuiker, Schriefers, Bock, and Kikstra (2003) German speakers made more agreement errors with NPs with number and case ambiguous local NPs than with number but not case ambiguous NPs (e.g. number and case ambiguous: die Stellungnahmesg gegen dienom,acc;sg,pl Demonstrationenpl - the position against the demonstrations, vs. number but not case ambiguous: die Stellungnahmesg zu dendat;sg,pl Demonstrationenpl - the position on the demonstrations). According to the controller misidentification account, the local NP is more likely to be misidentified as the agreement controller when it shares features used in identifying the sentence subject (e.g. nominative case). The controller misidentification account thus focuses on the morpho-syntactic processes involved in identifying the agreement controller, and also suggests that the relevance of different morpho-syntactic features will depend on the type of agreement. For example, features involved in identifying the sentence subject (e.g. case) will play a more prominent role in subject-verb agreement than in pronoun-antecedent agreement (Badecker & Kuminiak, 2007).
Because these accounts differ in the extent to which non-syntactic information is thought to influence the agreement process, attempts to distinguish them have naturally focused on assessing the degree to which agreement production is influenced by semantic, phonological, and other non-syntactic factors. Several modest non-syntactic effects have been observed in prior studies, including effects of morphophonology (e.g. Haskell & MacDonald, 2003; Vigliocco, Butterworth, & Semenza, 1995), linear order of NPs and verbs (Gillespie & Pearlmutter, 2011; Haskell & MacDonald, 2005), semantic integration between nouns (Solomon & Pearlmutter, 2004), and semantic relationships between nouns and verbs (Thornton & MacDonald, 2003). If these non-syntactic influences do shape agreement computations, then they provide evidence against accounts in which the computation is purely syntactic in nature. However, the impact of these findings to date has been mixed, because these non-syntactic effects appear to be very subtle in comparison to syntactic influences (Ferreira & Slevc, 2007), and some studies have failed to find them altogether (e.g. Bock & Eberhard, 1993; Vigliocco & Nicol, 1998). As a result, the role of non-syntactic factors in grammatical agreement has remained controversial.
Both the competition and the Marking & Morphing accounts of agreement assume a semantic component in which the notional number in the message influences the linguistic form, but there has been little systematic investigation of this process. For example, there is little understanding of how similar messages (e.g. two cats, some cats, many cats, a colony of cats) may differ in their notional number, and how those differences may affect representations of nouns and their agreeing forms. In the studies below we investigate one aspect of notional number, individuation, which refers to the degree to which entities within a set (e.g. many cats) are perceived as unique individuals vs. an undifferentiated whole. The goal is not necessarily to distinguish between current agreement accounts, but rather to push all accounts to consider semantic effects more fully.
One reason why non-syntactic effects on agreement have been difficult to document is that their existence is typically inferred from the rate and pattern of agreement errors that speakers produce. Because the vast majority of utterances have correct agreement, the error data are often very sparse and will therefore tend to be an insensitive domain in which to compare conditions. One alternative is to use a measure other than errors, and some researchers have had success in collecting speech initiation latencies in picture naming tasks in languages that exhibit determiner agreement (Spalek & Schriefers, 2005), but the fragment completion tasks that are commonly used to study subject-verb agreement are not readily amenable to reaction time measures (though see Haskell & MacDonald, 2003). A second approach is to examine areas in which several different agreeing forms may be acceptable, because subtle influences on agreement production may be more evident in speakers’ implicit choices of alternative grammatical forms than in rates of actual errors. Examples in English of forms with several grammatical options include number agreement with collective expressions, such as the group of senators is/are meeting, and with disjunctive noun phrases, such as either the biscuits or cake go/goes well with afternoon tea, as well as existential constructions, such as there was/were always two films on (Tagliamonte & Baayen, 2012). Studies of these forms have shown more robust effects of non-syntactic influences on which agreeing form is produced (Haskell & MacDonald, 2003; Haskell & MacDonald, 2005; Haskell et al., 2010), which suggests that the strategy of studying correct production is a promising one.
Here we continue this tradition of examining production of alternative correct agreement forms and report studies in Serbian1, a language where both singular and plural verb agreement are grammatical with some noun phrases. As we describe in more detail below, this property allows us to investigate the distribution of agreement forms across two grammatically correct alternatives, which could potentially reveal more subtle effects on agreement production processes than may be possible in cases with only one grammatical option. We investigate the effects of notional number variation, which are relevant to every account of agreement and to message-language mapping more generally, and also other non-syntactic properties of agreement computations, with the goal of shedding light on different accounts of agreement production processes.
Quantified Noun Phrases in Serbian
Serbian is a south Slavic language with rich morphology and a complex agreement system. Nouns are marked inflectionally for number (singular, plural), gender (masculine, feminine, neuter) and case (nominative, genitive, dative, accusative, vocative, instrumental, locative). Verbs are marked inflectionally for tense, person and number, and in some forms gender. Modifiers agree with nouns in number, gender and case, and verb predicates in number and in some cases gender.
The studies presented here make use of quantified noun phrases (QNPs). The QNPs of interest contain a noun and either a number such as five, or a quantified expression such as mnogo – many, nekoliko – several, a few, većina – most, malo – some, a little. The noun in the QNP takes different case/number forms depending on the quantifier (see Table 1). In all instances using the quantifiers many, several, most, and numbers larger than four, the noun is in the plural (genitive) form (the quantifier is unmarked). Pronoun agreement with the QNPs using these quantifiers is always plural, but interestingly, when these phrases appear as sentence subjects, both singular and plural verb forms are grammatical (Mrazovic & Vukadinovíc, 1991; Stanojčić, Popović, & Micić, 1989). Thus, both Pet lisica skaču, a pored njih trči zec. – Five foxes jump, and a rabbit runs by them, and Pet lisica ska ce, a pored njih tr ci zec. – Five foxes jumps and a rabbit runs by them, are considered grammatical in Serbian. This property of Serbian, which also appears in several other Slavic languages (Corbett, 2000), permits us to examine the choice of agreeing verb form among two grammatical alternatives.
Table 1.
Examples of quantified noun phrases in Serbian
| Quantifier | Noun | Verb | ||||
|---|---|---|---|---|---|---|
| Feminine | Masculine | Case | Number | Number | ||
| 1 | lisica (fox) | vuk (wolf) | nominative | singular | trči (run) | singular |
| 2, 3, 4 | lisice | vuka | genitive | singular | trče | plural |
| larger than 41, several, many, most, some, (a) few | lisica | vukova | genitive | plural | trči/trče | singular/plural |
but excluding numbers ending in 1, 2, 3, or 4, e.g. 22
Traditional Serbian grammars suggest that verb number agreement with the QNPs with numbers five and larger, as well as with many, several and other quantified expressions can be governed either by form or by meaning: form-based agreement assumes that the quantifier is a neutral word and similar to the use of other neutral (non-nominative) constructions it requires a singular verb2 (Mrazović & Vukadinović, 1991; Stanojčić et al., 1989). Meaning-based agreement requires plural verbs. While grammar books agree that both types of agreement are possible, some suggest that singular verb forms may be used more often (e.g. Mrazović & Vukadinović, 1991).
There is considerable disagreement in formal linguistic accounts of subject-verb agreement with this type of QNPs, acknowledging the variation in agreement patterns (for discussion, see Zlatić, 1997). For example, the analysis by Zlatić (1997) suggests that uninflected quantifiers such as the numbers five and larger, and quantifiers many and several are the head of the QNP. Because these quantifiers are uninflected they require singular verb forms. Zlatić (1997) acknowledges the occasional use of the QNPs with plural verbs by some speakers, suggesting that those speakers’ representations of the QNP are somewhat different. Specifically, in these speakers’ structural representations the quantifier is marked as nominative, and this allows it to inherit some of the noun’s syntactic features (e.g. number and gender) and agree with plural verb forms. One implication of this account is that if the differences in the structural representations of QNPs drive the use of different verb forms, then the choice of the singular vs. the plural verb should not vary depending on non-structural factors, for example, meaning or morphophonology.
In the studies reported below, we use Serbian QNPs to investigate the influence of two non-syntactic factors on agreement processes, individuation (Experiments 1 and 2) and morphophonology (Experiment 2). The manipulation of morphophonological factors involved homophony between inflectional forms, roughly equivalent to English noun phrases such as the sheep, which has the same form in both its singular and plural meanings. Establishing whether homophony has an effect on agreement production is important because the effect is not expected under strict syntactic approaches, in which subject-verb agreement is computed using the abstract number marking assigned to the subject noun phrase, and the fact that the final form of this noun phrase happens to be homophonous with some other interpretation should be irrelevant to these syntactic computations. Effects of homophony have previously been shown to influence agreement production in some circumstances (Antón Mendéz & Hartsuiker, 2010; Badecker & Kuminiak, 2007; Hartsuiker et al., 2003) but not others (e.g. Bock & Eberhard, 1993). Our investigation here using correct productions rather than errors could clarify the nature of these effects.
Individuation refers to the semantics of the QNP, specifically the extent to which the group described in the noun phrase is perceived as a set of distinct individuals or an undifferentiated whole. A similar effect of the semantics of the NP on agreement processes was first demonstrated in the Romance languages Spanish, Italian, and French (Vigliocco, Butterworth, & Garrett, 1996; Vigliocco et al., 1995; Vigliocco, Hartsuiker, Jarema, & Kolk, 1996). These studies used distributive noun phrases such as the label on the bottles which, although grammatically singular and thus agreeing with a singular verb, denote multiple entities. In a series of studies using the fragment completion paradigm, in which participants were given a sentence fragment (e.g. the label on the bottles) and asked to repeat it and complete the sentence, Vigliocco and colleagues found that speakers made more agreement errors (used more plural verb forms) with distributive noun phrases relative to phrases referring to single entities (e.g. the church near the hills). Subsequent studies found this effect in English (Eberhard, 1999). In collective noun phrases (e.g. gang on/near the motorcycles), which are also grammatically singular but refer to a group of entities, Humphreys and Bock (2005) further found that the degree to which the group members are perceived as individuals affects the rate of plural verb usage. In one condition, Humphreys and Bock used a preposition that promoted a spatial distribution of elements in the message (gang on the motorcycles), and they compared this condition to one that did not promote this more individuated message (gang near the motorcycles). Humphreys and Bock (2005) argued that this latter condition promoted the focus on the group, the singular set of a gang when it is near the motorcycles, but in the first case, the focus is more on the individuals constituting the set when they (the individual members) are on the motorcycles. As predicted, participants produced more plural verbs when conveying messages with the more individuated group members than for the less individuated groups.
These individuation effects are interesting because they suggest that aspects of the message beyond sheer numerosity (e.g., that a gang refers to more than one individual) can affect singular vs. plural usage in language. This result parallels similar effects reported in the numerical cognition literature, where different representational systems for numerical processing seem to crucially depend on the level of individuation of elements within a set (see Feigenson, Dehaene, & Spelke, 2004, for a review; see also Piazza, Fumarola, Chinello, & Melcher, 2011). The influence of these differences in numerical aspects of message-level representations on the message-language mapping has received little attention in the language production literature. Our investigation of individuation here could thus inform all accounts of agreement production, independent of whether individuation effects are one of several constraints used to converge on an agreeing form (Haskell & MacDonald, 2003; Thornton & MacDonald, 2003), whether the effect of semantic factors such as individuation is more limited (e.g. to the marking process (Eberhard et al., 2005)), or whether it influences the identification of the agreement controller (Badecker & Kuminiak, 2007).
Our investigation of individuation in QNPs in Serbian differs in several respects from the previous studies. First, unlike the studies described above in which the head noun of the subject NP (e.g. label, gang) was grammatically singular, we investigate a construction in which the noun takes an unambiguously grammatically plural form. Second, we manipulated two factors that contributed to the degree of individuation in the QNP. One of these was contained within the QNP, in the contrast between the quantifiers many and several, both referring to groups consisting of multiple entities. However, many typically refers to a numerically larger group than several (e.g. Borges & Sawyers, 1974). Group members in smaller sets are often perceived as more individuated (e.g. Feigenson et al., 2004; Hyde & Wood, 2011), and hence many may be promoting less individuated readings than several. Thus in a construction in which either singular or plural verbs are grammatical, we predict that descriptions of larger groups (using many) but with less individuated members may actually result in more singular verb agreement than descriptions that identify a smaller group of more individuated members (e.g. using several). This result could shed light on the relationship between conceptual properties such as individuation and group size, and grammatical plurality.
The third difference from previous studies of distributivity and individuation is that we manipulated properties of the whole event to be conveyed, in contrast to studies that have focused on directly manipulating properties of the event participants, such as the gang on the motorcycles. If broader event properties, manipulated by presenting a verb along with a preamble NP, can strongly affect individuation of the entities conveyed by the NP, then the competition account proposed by Haskell and MacDonald (2003) predicts that they should affect agreement processes, because any factor that correlates with a particular verb form use will influence agreement (see also Thornton & MacDonald, 2003). Within the Marking & Morphing account, event properties affecting individuation should affect the process of marking, in that messages with some events may have more individuated event participants than with other events. However, accounts that attribute non-syntactic agreement effects to ambiguity in identifying the agreement controller among several nouns (e.g. Badecker & Kuminiak, 2007) may have difficulty accounting for event/verb effects on individuation, given that there is only a single noun in our fragment preambles (in the QNP) and thus no ambiguity about the identity of the agreement controller. Thus this type of manipulation of individuation should illuminate the nature of the mapping from the message to linguistic form, potentially informing all accounts of agreement, and may also be able to provide evidence for some accounts over others.
We begin our investigation of the use of Serbian QNPs with a corpus analysis, to establish distributional patterns in the native speakers’ experience. We analyzed the use of the QNPs with the quantified expressions mnogo (many) and nekoliko (several) in a corpus of Serbian written language. The corpus contains approximately 1 million words from samples of literary prose (Kostić, 2001), tagged for grammatical properties (e.g. part of speech, number, gender, case, tense, person). We extracted all occurrences of the quantifiers mnogo and nekoliko in instances where they were in the subject NP and thus co-varied with verb number. We counted verb forms only when they were unambiguously marked for number. There were 73 occurrences of the two quantifiers, and 79% (58) of them were used with singular verbs. Interestingly, among the 18 occurrences of the quantifier mnogo (many) there were no plural verbs, while with the quantifier nekoliko (several) 27% were plural. Although this analysis is based on a relatively small number of occurrences of the QNPs, it suggests that in the experience of native speakers this notionally plural phrase with nouns with grammatically plural inflections is most often used with singular verbs. However, while the singular verb is the most frequent form, there is considerable variation, which seems to depend on the type of the quantifier. In the studies below, we further explore one possible reason for this finding, the variation in the amount of individuation of the referents of the QNP.
Experiment 1: Semantic factors
The goal of Experiment 1 was to explore the extent to which semantic factors influence grammatically correct agreement production. We focused on two factors: quantifier meaning, which modulates notional number within the noun phrase, and verb meaning, which affects the event to be described in the utterance. Quantifiers can change the interpretation of the noun phrase through individuation: quantifiers denoting smaller quantities (e.g. several) may promote interpretation of the entities denoted by the NP as a collection of distinct individuals i.e. promote more individuated readings, whereas quantifiers denoting larger quantities (e.g. many) may promote perceiving the entities as a group of non-distinct entities. This in turn can have consequences for the choice of the verb number form, with less individuated construals promoting the use of singular verbs, as observed in the small corpus analysis described above.
Several linguists and psycholinguists have argued that different types of verbs (or the events they describe) also promote individuation to different degrees (e.g. Barner, Wagner, & Snedeker, 2008; Robblee, 1993). For example, Robblee (1993) suggested that the less distinctive the property that the verb denotes, the less likely the verb is to promote individuation. For example, existential verbs (e.g. be) can be used with semantically diverse nouns (animate and inanimate, concrete and abstract), and thus they are interpreted as representing non-distinctive properties. By contrast, agentive verbs (e.g. jump, read, fly) are thought to promote individuation as they are used with a limited set of semantically coherent nouns (e.g., animate entities) and thus denote more distinctive properties. Robblee (1993) investigated this claim in a text corpus in Russian (another language in which both singular and plural verb forms are grammatical with QNP subjects) and found that existential verbs were more likely to appear in singular forms with QNPs, whereas agentive verbs were more likely to appear in plural forms. This result is consistent with the view that event semantics can influence subject-verb number agreement by modifying individuation of the referents of the NP.
Quantifier meaning and verb meaning represent two sources of information that can promote or reduce the degree of individuation in the event participants (see Table 2). Although most studies of agreement have investigated notional effects via direct manipulation of the subject NP in the preamble (though see Thornton & MacDonald, 2003), the effect of verb meaning can also be accounted for as influencing aspects of the message representation (and thus the marking portion of the Marking & Morphing). Specifically, the properties of the event encoded by the verb can influence the construal of event participants encoded by the NP (e.g. Ferretti, McRae, & Hatherell, 2001). Thus we would expect that producers’ use of singular vs. plural verb number form will be influenced by verb type, with existential verbs promoting the use of singular forms by promoting less individuated construals of the NP referents, in comparison to the condition with the agentive (individuation-promoting) verbs.
Table 2.
Possible sources of information influencing notional number
| Individuation | ||
|---|---|---|
| Promoted | Reduced | |
| Quantifier | nekoliko | mnogo |
| several | many | |
| Verb Meaning | skakati | opstajati |
| to jump | to survive | |
Method
Participants
Fifty-three participants form the University of Belgrade, Serbia, completed the experiment for a course credit. All were native speakers of Serbian.
Materials
The materials consisted of 40 sets of sentence preambles, 16 of which were experimental stimuli. Each preamble contained a verb in the infinitive form (e.g. tr cati –to run; unmarked for number, tense or person) and an NP. Experimental NPs consisted of a quantifier (mnogo [many] or nekoliko [several]) and a noun (Appendix A). All 16 experimental nouns were masculine, in a case-unambiguous genitive plural form; as shown in Table 1, the genitive plural is the only grammatical form for these QNPs. Filler preambles contained an NP consisting of a head noun and an adjective that agreed with it in number and gender (e.g. beli orlovi [white eagles]), half of which were masculine, and half feminine. Half of the filler NPs were singular, and a half plural, and none contained quantifiers. Examples of stimuli and possible responses in different conditions are shown in Table 3.
Table 3.
Examples of the stimuli in Experiment 1.
| Preamble | Possible responses | ||
|---|---|---|---|
|
| |||
| Verb | QNP | singular verb / plural verb | |
| Existential Verb | |||
| opstajati | mnogo vukova | Mnogo vukova opstaje / opstaju. | |
| to survive | many wolves | Many wolves survives / survive. | |
| opstajati | nekoliko vukova | Nekoliko vukova opstaje / opstaju. | |
| to survive | several wolves | Several wolves survives / survive. | |
| Agentive Verb | |||
| skakati | mnogo vukova | Mnogo vukova skače / skaču. | |
| to jump | many wolves | Many wolves jumps / jump. | |
| skakati | nekoliko vukova | Nekoliko vukova skače / skaču. | |
| to jump | several wolves | Several wolves jumps / jump. | |
Note: The verb forms in the last column represent possible participant responses, both of which are grammatical.
There were eight experimental verbs, four existential (opstajati [to survive], radjati se [to be born], nalaziti se [to be located, to be], razvijati se [to develop]), and 4 agentive (tr cati [to run], skakati [to jump], jesti [to eat], ići [to go, to walk]). The two types of verbs were matched in total frequency, as well as the singular and plural form frequency (Kostić, 1999). Half of the filler verbs were existential, half were agentive. The verbs were chosen based on the classification of English verbs (Levin, 1993) with the corresponding meaning in Serbian.
Given that the meaning of the utterance that participants produce necessarily changes across the quantifier and verb conditions in this study, it is important to assess the nature of these changes. Two norming studies were conducted with these stimulus items, using raters who did not participate in the main experiment. First, the noun-verb combinations were matched for plausibility across the two verb conditions. Twenty-two native Serbian speakers rated how likely it was for a particular entity (e.g., a wolf) to perform the action denoted by the verb (e.g., to jump) on a 7-point scale, where 7 indicated highly likely (veoma moguće) and 1 indicated little likely (malo moguće). Two lists of items were created, such that across the lists each item was paired with an existential and an agentive verb, and half of the items in each list was with agentive, and a half with existential verbs. Participants were assigned to one of the lists, and thus they were presented with only one version of each item. The average likeliness for the experimental items was high (M = 6.01, SD = 0.55), and there was no significant difference between existential (M = 6.11, SD = 0.43) and agentive (M = 5.99, SD = 0.66) verbs.
The second rating study assessed the effects of the quantifiers on individuated vs. group interpretation of the QNPs. Thirty-two native speakers rated how likely they were to perceive the entities denoted by the QNP as an agglomeration/collection, versus as a group of distinct individuals. A 7-point scale was used, where 7 indicated perceived more as an agglomeration/collection (opažam više kao gomilu) and 1 indicated perceived more as individual entities (opažam više kao pojedinacne objekte). Each item consisted of a quantifier and a noun. The experimental items contained the quantifiers many (mnogo) and several (nekoliko). Two lists of items were created, such that across the lists each item was paired with both quantifiers, and half of the items in each list was paired with many, and a half with several. Participants were assigned to one of the lists, and thus they were presented with only one version of each item. The filler items contained quantifiers that would be expected to span the full range of this scale, all, most, six, four, and one. The experimental items with the quantifier several were rated as less likely to be perceived as a collection of things, i.e. more likely to be perceived as individual entities (M = 2.05, SD = 0.69) than the experimental items with the quantifier many (M = 4.75, SD = 0.86), F(1, 30) = 253.15, p < .001.
There were four counterbalanced lists of stimuli. Within each list, the 16 experimental nouns were paired with a quantifier and a verb, so that within a list each verb was presented twice, and each quantifier was presented in eight trials. Over the four lists, all nouns were paired with both quantifiers and a verb from each condition.
Procedure
The experiment was run using Psyscope (Cohen, MacWhinney, Flatt, & Provost, 1993). The preambles were presented in the 24pt Chicago CE font (Cyrillic alphabet). All responses were digitally recorded and subsequently transcribed by a native speaker blind to the conditions of the experiment.
A variation of the fragment completion method was used to elicit responses, where first the verb in the infinitive form was presented, followed by the noun phrase. Participants were instructed to produce a sentence starting with the noun phrase, and to continue with the verb. In order to avoid giving explicit instructions about the agreement between the verb and the noun, an example was used where the noun phrase was the subject of the sentence and the verb was the predicate (so they agreed in number). A modifier + noun phrase was used in the example (Dobar u cenik piše [domaći zadatak] – A good student is writing [the homework]).
At the beginning of each trial, a row of asterisks was presented at the center of the screen for 600 ms. It was followed by the presentation of the infinitive verb for 1000 ms. The verb was replaced by the noun phrase which remained on the screen until the participant started speaking or for 2000 ms, whichever happened first. The experimenter started the next trial. The session started with a practice block of 5 stimuli. The entire session took approximately 10 minutes.
Responses were transcribed and were scored as correct if the participant repeated the full NP correctly and used the correct verb in a form marked for number3. Both imperfective (e.g., skakati – to jump) and perfective variants of the verb (e.g., sko citi – to jump) were scored as correct. Using these criteria, 4.24% of responses were excluded from the analysis. These included verb omissions or errors (e.g. use of an incorrect verb), NP errors (e.g. use of an incorrect noun or quantifier), and other errors (no response, or use of the QNP as sentence object).
Results and Discussion
The arcsine transformed proportion of singular verbs (out of all correct responses) was used as the dependent variable. As shown in Figure 1 and Table 4, singular responses were overall more common but the rate varied across conditions. Participants produced fewer singular responses with agentive verbs, and they also produced fewer singular responses with the quantifier several, relative to the quantifier many (verb type: F1(1, 52) = 11.49, p = .001; F2(1,15) = 22.17, p < .001; quantifier: F1(1, 52) = 7.4, p = .009; F2(1,15) = 3.36, p = .04 (one tailed); the verb type x quantifier interaction was not significant). Participants were more likely to use singular verb forms when the QNP was perceived more as denoting a group of non-distinct entities, and when the verb denoted less distinctive events. These effects were not concentrated in a few participants who preferably used one verb form over the other, and thus the effect cannot be attributed to individual differences in speakers’ grammar, as suggested by some formal linguistic accounts (e.g. Zlatić, 1997).
Figure 1.

Proportion of singular verbs as a function of verb type and quantifier (untransformed).
Table 4.
Counts of responses across scoring categories in Experiment 1.
| Preamble | Response Categories | |||||
|---|---|---|---|---|---|---|
| Verb Type | QNP | Correct | ||||
|
| ||||||
| Plural | Singular | Verb Error | NP Error | Other | ||
| existential | many | 15 | 189 | 7 | 0 | 1 |
| existential | several | 21 | 174 | 12 | 3 | 2 |
| agentive | many | 29 | 179 | 2 | 0 | 2 |
| agentive | several | 41 | 164 | 3 | 1 | 3 |
Note: Verb and NP errors include omissions and errors (e.g. use of an incorrect word), and Other responses include the use of the QNPs as sentence objects, and no responses.
These findings are interesting in several respects. First, they show that the distribution of forms across two grammatical alternatives can provide a sensitive measure of agreement production processes, consistent with prior results in other constructions in English (Haskell & MacDonald, 2003; Haskell & MacDonald, 2005). Second, they shed light on the nature of the conceptual factors that affect plurality, in that the subject NPs containing the quantifier many, which identified large groups of less distinct individuals, yielded more singular verb responses than the smaller but more individuated groups denoted by several. This effect of the quantifier is consistent with studies of agreement errors suggesting that increased individuation in the message promotes the use of plural verbs (Humphreys & Bock, 2005), and further suggests that it is the degree of individuation, and not the sheer number of individuals referenced, that affects grammatical plurality. This result is particularly interesting in Serbian, where grammatical number marking diachronically incorporated the size of the group (with three levels of number agreement – singular, dual, and plural, for greater than two entities). While the dual form is now archaic and not in current usage in Serbian, some Slavic languages still retain the two vs. more distinction (e.g. Slovene, Upper Sorbian), and some Austronesian and Oceanic languages also include a two vs. three vs. more, or a two vs. a few vs. more distinction (Corbett, 2000). The existence of distinctions found in these languages suggests that size of a group can in principle be a conceptual property influencing agreement processes, and yet this property, if it has any effect in modern Serbian, is dwarfed by individuation, at least in the context of this experiment.
The third interesting result concerns the effects of the event semantics. The effect of quantifiers can be accommodated by all accounts of agreement which incorporate a role for conceptual representations of the subject NP in subject noun plurality, but the effects of event semantics are perhaps more surprising. These effects suggest that in principle the properties of the whole message, and in particular the properties of different events, to the extent that they influence number-relevant properties of the NP referents, can influence agreement.
The fourth interesting finding is that agreement patterns were modulated in NPs using a single noun, in contrast to all other studies of subject-verb agreement of which we are aware. This result presents a challenge for models which attribute variation in agreement patterns to the misidentification of the agreement controller (e.g. Badecker & Kuminiak, 2007). All NPs in this experiment consisted of a quantifier and a noun, which had the same morpho-syntactic features across conditions. Moreover, the manipulation of verb meaning was repeated across items. Hence if there were any ambiguity in identifying the agreement controller (e.g. between the quantifier and the noun) it would have been the same across the two quantifiers and the two types of verbs. The overall pattern of results in this experiment thus seems incompatible with the controller misidentification accounts. Both the Marking & Morphing and competition frameworks can account for these results with the differences at the message level representations.
The final finding of note is that the majority of responses for these grammatically unambiguously plural NPs contained singular verbs, consistent with the corpus results reported above. English and other languages contain many examples of notionally plural entities that take singular agreement, e.g. each girl jumps, in which there are multiple girls in the event, and yet the verb jumps is singular. These patterns appear to reflect the importance of the morpho-syntactic form of the noun – girl is singular, and as a result, so is its verb. The Serbian QNP cases are different, in that the subject NPs are both notionally and grammatically plural. The Serbian speakers in the study strongly favored the equivalent of many/several girls jumps, whereas in English and many other languages, a plural verb is required for a plural subject NP, e.g. many/several girls jump. The Serbian preference for singular verbs here is surprising within all accounts of agreement, though for different reasons in each account. Within Marking & Morphing, the combination of notionally and grammatically plural NPs should yield plural verbs, not singular ones: Even if the quantifier itself were identified as the NP head, the noun is clearly morpho-syntactically plural, and it and the whole NP are notionally plural. This NP plurality should yield plural verb agreement in this account. Within controller misidentification accounts, there is also no basis for different agreement patterns without competing NPs, as we have noted, and certainly no mechanism for dominantly singular verbs. Within the competition account, it is also not clear why the dominant response would be singular in an environment that clearly reflects the effects of conceptual properties (individuation) on agreement. We address the implications of this issue for models of agreement in the General Discussion following further investigation of non-syntactic effects in Experiment 2.
Experiment 2: Morphophonological and semantic factors
In our discussion of individuation we suggested that preamble manipulations, as in the gang on vs. near the motorcycles, the contrast between the quantifiers several vs. many, and manipulations of agentive vs. existential verbs, are having their effects entirely via the message level representations. On this view, the particular word forms themselves have no direct effect on agreement production; the effect is entirely due to these words’ establishing a more vs. less individuated message for the speaker, which then has consequences for agreement production. There are, however, some suggestions in the literature that the actual form of the words could directly affect agreement, via statistical learning in which co-occurrences between the quantifier several (say) becomes correlated with plural agreement forms, thereby boosting subsequent agreement production above and beyond any message-level effects (see Haskell et al., 2010, for discussion of the role of statistical learning in agreement). In practice, it seems impossible to distinguish message-level and more direct (learning of co-occurrences) effects for the individuation manipulations in Experiment 1, because every manipulation is both the message (more vs. less individuated) and a word form (e.g. many vs. several). There are other word form manipulations, however, in which it is possible to tease apart message-level from word form effects, to which we turn next.
Conceptions of agreement computations as hierarchical feature passing naturally do not incorporate the word form entering into the agreement relation, as this information is not thought to play a major part in agreement (Eberhard et al., 2005). Word form effects on agreement are also not expected in memory-based approaches in which agreement errors are thought to emerge from a misidentification of the agreement controller based on morpho-syntactic features (Badecker & Kuminiak, 2007; Gillespie & Pearlmutter, 2011). The effect of word form factors on what is assumed to be a syntactic process would pose a major challenge to these views of agreement in particular and language production in general, as it would provide evidence of feedback from word form (phonological, orthographic) processing to grammatical encoding (Bock & Levelt, 1994).
Previous evidence about the effects of word form factors on subject-verb number agreement in behavioral studies is mixed. The majority of studies to date have investigated effects of morphophonological properties of the noun. For example, using the fragment completion paradigm with prepositional phrases such as the X-ray of the teeth, Bock and Eberhard (1993) explored the extent to which the proportion of incorrect plural verb responses is reduced by irregular local nouns (teeth) relative to regular, plural-sounding, local nouns (mouths). They found no evidence for any effect of the regular vs. irregular plural form within the prepositional phrase, and they concluded that the agreement process is not affected by morphophonological properties of this type. Haskell and MacDonald (2003) replicated this study but used collective NPs (e.g. a row of teeth/toes) and did find fewer plural verb responses with irregular relative to regular local nouns. However, it was unclear whether this effect was phonological or conceptual in nature (or both), because phrases with irregular local nouns were rated as conceptually less plural than phrases with regular local nouns.
The influence of regularity of the plural marking on subject-verb agreement was also investigated in Italian. Vigliocco et al. (1995) showed that incorrect plural verb forms are more likely with invariant nouns which use the same form in the singular and the plural (similar to sheep in English). For example, Italian speakers produced more agreement errors with sentence fragments like il camion sulle strade – the truck on the roads (camion = truck, trucks), relative to fragments where the head noun had distinct singular and plural forms, e.g la scoperta degli scienzati – the discovery of the scientists (scoperta = discovery, scoperte = discoveries). (Note that in the invariant case the determiner was unambiguously marked for number (singular).) Similar effects were reported in Dutch and German using determiner homophony (Antón Mendéz & Hartsuiker, 2010; Hartsuiker et al., 2003): determiners with homophonous singular and plural forms (e.g. German: diesg,pl Frausg = woman; Dutch: desg,pl straatsg = street) induced more (incorrect) plural verb responses relative to number-unambiguous determiners (German: dersg Mannsg = man; Dutch: hetsg pleinsg = square).
These results span several different languages, syntactic constructions, and forms of agreement, any of which could play a part in modulating researchers’ ability to detect any influences of word form on agreement production. It is also possible that one reason for the mixed evidence for the effect of such factors is the reliance on relatively rarely occurring agreement errors. Thus in Experiment 2 we investigated whether correct production of subject-verb agreement is influenced by morphophonological factors, again using the QNP construction from Experiment 1 for which both singular and plural verb forms are grammatical. We again included the semantic manipulation of individuation via quantifier meaning, with several promoting more individuated readings relative to many, thereby affording an opportunity to replicate the quantifier effect obtained in Experiment 1. As in Experiment 1 (and unlike in most prior studies of subject-verb agreement), the preamble NPs in Experiment 2 consisted of a quantifier and a noun with the same morpho-syntactic features across conditions, thus equating them for opportunities for controller misidentification. We manipulated inflectional form homophony on the noun: in feminine nouns, the genitive plural form, used with the QNPs with the quantifiers many and several, is homophonous with the nominative singular form (see Table 5). Masculine nouns use two distinctive forms in these two cases, but some masculine nouns have homophony between the genitive plural and the genitive singular case forms (Table 5). Thus both types of nouns have the same amount of grammatical number ambiguity, but only the feminine nouns are homophonous specifically with the nominative case, which is typically associated with the subject function. (Note that this ambiguity should be absent at the morpho-syntactic level because the quantifier governs the noun’s genitive case.) This produces a distributional co-occurrence pattern in which nominative singular-marked nouns co-occur with singular verbs. Thus, if native speakers’ prior experience with the morphophonological patterns of the language affects their subsequent agreement computations, then we should see different rates of singular and plural verbs as a function of the noun’s gender. Specifically, if prior experience in which nominative marked nouns co-vary in number with their verbs affects subsequent agreement, then there should be more singular verb uses with feminine nouns, which have the singular-promoting homophony, than with masculine nouns. In the competition account proposed by Haskell and MacDonald (2003) this would occur because singular noun forms are correlated with singular verb form use in speakers’ prior experiences. According to the Marking & Morphing account, this effect should be negligible, because the process of morphing involves the abstract plural marker, not a phonological form. The controller misidentification framework could account for this result only if it is assumed that there is feedback from the phonological form to the morpho-syntactic level, which would activate the nominative singular features for the feminine but not for the masculine nouns.
Table 5.
Inflectional forms of nouns krompirmasc (potato) and kajsijafem (apricot)
| case | number | masculine | feminine | case | number | masculine | feminine |
|---|---|---|---|---|---|---|---|
| nom | sing | krompir | kajsija | nom | plur | krompiri | kajsije |
| gen | sing | krompira | kasije | gen | plur | krompira | kajsija |
| dat | sing | krompiru | kasiji | dat | plur | krompirima | kajsijama |
| acc | sing | krompir | kajsiju | acc | plur | krompire | kajsije |
| inst | sing | kormpirom | kajsijom | inst | plur | krompirima | kajsijama |
| loc | sing | krompiru | kajsiju | loc | plur | krompirima | kajsijama |
| voc | sing | krompiru | kajsijo | voc | plur | krompiri | kajsije |
nom = nominative, gen = genitive, dat = dative, acc = accusative, inst = instrumental, loc = locative, voc = vocative, sing = singular, plur = plural
Method
Participants
Thirty-two Serbian native speakers from the University of Belgrade completed the experiment for a course credit.
Materials
The materials consisted of a total of 64 NPs. Sixteen NPs constituted the experimental stimuli, containing a quantifier (mnogo [many] or nekoliko [several]) and a noun; in contrast to Experiment 1, there was no verb manipulation. There were 8 masculine nouns (in the genitive plural non-homophonous with the nominative singular form), and 8 feminine nouns (in the genitive plural form homophonous with the nominative singular). Nouns were matched for total frequency (singular + plural), total frequency of singular forms, total frequency of plural forms as well as genitive plural frequency, and genitive plural form frequency (for feminine nouns: genitive plural + nominative singular, for masculine: genitive plural + genitive singular) (Kostić, 1999). All nouns were inanimate, and masculine and feminine pairs were drawn from similar semantic categories, within the constraints of the frequency matching. There were two counterbalanced lists, such that half of the nouns in each gender were paired with many, and half with several in each list. Sixteen fillers were NPs with modifiers (e.g. veliki kamioni – big trucks) and 32 prepositional phrases (e.g. staza pored klupe – a path by the bench). Half of the filler items unambiguously required a singular verb form, and a half required a plural verb form. Examples of the stimuli in the experimental conditions are presented in Table 6 and all items are presented in Appendix A.
Table 6.
Examples of the stimuli in Experiment 2.
| Quantifier | Noun | |
|---|---|---|
| homophonous with nominative singular | non-homophonous with nominative singular | |
| nekoliko | kajsijafem | krompiramasc |
| several | apricots | potatoes |
| mnogo | kajsijafem | krompiramasc |
| many | apricots | potatoes |
Norming
The items were also normed for the individuated vs. group readings of the quantifiers, using a scale from 1 to 7, where 1 indicated perceiving the stimulus item as a collection of things, and 7 as individual entities. The norming included a total of 110 items, 16 of which were experimental stimuli. The filler items contained quantifiers spanning the whole range of the scale (all, most, six, four, and one). The norming with 34 native Serbian speakers confirmed that the items with the quantifier several were rated as more likely to be perceived as individual entities (M = 4.16, SD = 1.09) relative to the items with the quantifier many (M = 2.02, SD = 1.05), F(1, 33) = 126.08, p < .001. The effect of the quantifier did not vary with gender (no significant quantifier x gender interaction, F(1, 33) = .83, n.s.), nor were there significant differences between items in the two genders (no main effect of gender, F(1, 33) = .02, n.s.).
Procedure
The experiment was run using Psyscope (Cohen et al., 1993). The stimuli were presented in the 24pt Chicago CE font (Cyrillic alphabet). All responses were digitally recorded and subsequently transcribed by a native speaker blind to the conditions of the experiment.
At the beginning of each trial, a row of asterisks was presented at the center of the screen for 600 ms. It was followed by the NP, which remained on the screen until the participant started speaking or after 1500 ms, whichever came first. Participants were instructed to produce a sentence starting with the noun phrase and continue in any way they wished. They were encouraged to start the production as soon as possible after stimulus onset. Each session started with a block of six practice items. The whole session lasted approximately ten minutes.
Responses were coded from transcriptions and scored as correct if there were no errors in either the quantifier or the noun, a number marked verb was produced, and the QNP was used as the subject of the produced utterance. Using these criteria 15.04% of responses were excluded from the analysis. The proportion of excluded responses in this experiment is larger than in Experiment 1, partly due to the less constraining preamble including only an NP, which allowed participants to use the QNP as a direct object4. Excluded responses were coded as: verb form not inflected for number (e.g. future tense), NP used as sentence object, and other (e.g. no verb produced, no responses, disfluencies). Arcsine transformed proportion of singular verbs out of all correct responses was used as the dependent variable.5
Results
As in Experiment 1, singular responses were overall more common, but the rate varied across conditions (Table 7). Again, fewer singular verbs were produced with the quantifier several, promoting individuated readings of the NP, as confirmed by the significant main effect of the quantifier, F1(1, 31) = 9.90, p = .004; F2(1,14) = 9.51, p = .008. Further, there were more singular responses with the nouns homophonous with the nominative singular form (main effect of homophony: F1(1, 31) = 10.21, p = .003; F2(1,14) = 8.40, p = .012). In addition, as shown in Figure 2, the effect of the quantifier was reduced in the nouns homophonous with the nominative singular form, as shown by a homophony x quantifier interaction6, which was reliable only in the by-participant analyses (F1(1, 31) = 5.17, p = .03, F2(1,14) = 1.05, n.s.).7
Table 7.
Counts of responses across scoring categories in Experiment 2.
| Preamble | Response Categories | |||||
|---|---|---|---|---|---|---|
| NOM. SG. homophony | Quantifier | Correct | Miscellaneous | |||
|
| ||||||
| Plural | Singular | Verb | NP | Other | ||
| homophonous | many | 0 | 103 | 14 | 8 | 3 |
| homophonous | several | 4 | 103 | 6 | 9 | 6 |
| non-homophonous | many | 3 | 106 | 11 | 2 | 6 |
| non-homophonous | several | 17 | 98 | 4 | 8 | 1 |
Note: In the miscellaneous category, Verb responses include verb forms uninflected for number, NP responses include the use of the QNPs as sentence objects, and Other include no responses, no verb produced, and disfluencies.
Figure 2.

Proportion of singular verbs as a function of homophony with the nominative singular and quantifier.
Discussion
These findings indicate that in correct productions, the choice of the verb form is influenced by morphophonological properties of the head noun: the homophony of feminine nouns with the nominative singular increased the proportion of singular verbs, even though within the QNP construction the noun is unambiguously grammatically plural (Table 1). The increase in the agreement with singular verbs seems to be driven not by the grammatical number marking, as the masculine nouns were also homophonous with a grammatically singular form (genitive), but by the homophony with the noun form which in the experience of the speakers co-varies with (singular) verb number. This effect is robust, and while it may be difficult to compare across studies, grammatical constructions, and languages, it is worth noting that the grammaticality of both the singular and plural verb forms with this construction may be one of the factors that has contributed to the ability to detect a morphophonological effect here where other studies have found a more marginal effect.
Experiment 2 also replicated the effect of the quantifier obtained in Experiment 1, with the quantifier several, promoting more individuated readings, decreasing the use of singular verb forms. Moreover, relative to masculine nouns, the quantifier effect was reduced in feminine nouns, which were homophonous with the nominative singular form. As in Experiment 1, these effects were not due to the individual differences between participants, with some preferably using one verb form over the other. Together, these findings indicate that the choice of the verb form is indeed influenced by the morphophonological properties of the noun, and specifically their homophony with the form that in the speakers’ experience co-varies with verb number. This challenges models of subject-verb agreement that assume that agreement is not (or is very weakly) influenced by word form factors.
Antón Mendéz and Hartsuiker (2010) recently reported a similar study where the interactivity in the language production system was explored in agreement errors in Dutch, using number-ambiguous determiners and a distributivity manipulation. They contrasted agreement errors in four conditions analogous to the conditions in our study above, and they reported an effect of distributivity (more agreement errors in NPs with distributive readings) and determiner number-ambiguity (more agreement errors in NPs with number-ambiguous determiners). However, there was no significant contribution of the interaction between distributivity and morphophonological ambiguity. Antón Mendéz and Hartsuiker (2010) interpreted these results as supporting the Marking & Morphing model in that even though agreement errors were influenced by both notional (distributivity) and morphophonological factors, these effects were independent, suggesting non-interactivity in the language production system. Their conclusion was further strengthened by the results of the computational implementation of the Marking & Morphing model, which could fit the experimental findings well.
Some of the findings of our Experiment 2 are in agreement with the results reported by Antón Mendéz and Hartsuiker (2010), in that we also found an effect of both notional number and morphophonology (homophony between different inflectional forms). However, our results differ in that we also found a marginally significant interaction between these two factors: in nouns homophonous with the nominative singular the notional effect was reduced. This interaction may suggest some level of interactivity in the language production system. Within the competition account this can be interpreted as an example of an interaction pattern in which one factor exerts a strong influence on performance and the effects of other factors are consequently reduced (Haskell & MacDonald, 2003). To further evaluate our findings, we compared them to the predictions of the computational implementation of the Marking & Morphing model (Eberhard et al., 2005).
Testing the Extension of Marking & Morphing to Serbian
The main aim of the computational implementation of the Marking & Morphing model (Eberhard et al., 2005) was to provide quantitative predictions of the proportion of plural verbs produced in empirical studies typically using the fragment completion paradigm. The existence of this implementation adds significant specificity to the Marking & Morphing account, and it gives this approach a real advantage over the other accounts we have discussed, competition and controller misidentification, which are not computationally implemented. The computational implementation allows more precise testing of the theory than with the other accounts.
In its original form (Eberhard et al., 2005), the Marking & Morphing implementation assessed the contribution of different sources of number information in the NP to agreement production, incorporating some of the basic principles of the Marking & Morphing account, and particularly the emphasis on the strong role of syntactic properties of the NP. The implementation was developed using the data from agreement production studies in English, but it was also successfully extended to other languages (e.g Antón Mendéz & Hartsuiker, 2010; Eberhard et al., 2005). Here we will first briefly describe the original implementation, and then explore its application to the Serbian QNPs.
To facilitate description of the Marking & Morphing implementation and our testing of new parameter values, we have provided a visual display of the components of the model in Figure 3, along with the equations and original parameter values from Eberhard et al. (2005). In this model, the proportion of plural verbs is calculated as a logistic function of the total amount of evidence for singular and plural at the root of the NP, represented by Sr (Equation 1, also displayed on the top in Figure 3):
| (1) |
where
Figure 3.

Computational implementation of the Marking & Morphing model.
| (2) |
The main parameters included in the model are:
Sn, representing information about notional number (shown in the rectangle on the left in Figure 3). The model uses single-value parameters to capture conceptual number, where extremes represent unambiguous multitudes (Sn = 1) and cases of specific individuation, as in one apple, or John (Sn = −1). Notionally ambiguous phrases (e.g. distributive NPs and NPs with different levels of individuation) are also captured by a single-value parameter, with an intermediate value of .48 (this specific value was obtained in model fitting procedures, Eberhard et al., 2005).
Sm, representing lexical specification of the grammatical number of the morphemes constituting the NP (the large box in the middle of Figure 3). For nouns, this parameter is a combination of the relative frequency of the noun’s singular and plural forms (Cfreq = log10(frequencysingular + frequencyplural)/log10frequencyplural), and the noun’s type as reflected in its Specification values (Equation 2). Count nouns are assumed to have fixed values for this parameter: 0 for singular forms, 1 for plural forms. For other types of nouns this parameter is estimated from corpus analyses. For example, for English uninflected collectives (e.g. team, government) the Specification value is estimated at .07, which is the proportion of plural verb targets for these nouns in the Wall Street Journal corpus (Bock et al., 2006).
wj, representing the weight associated with NP constituents, reflecting the relative contribution of grammatical number information depending on the position in the structural representation of the phrase. The three parameter values in the original implementation are shown above the large box in Figure 3. These values show that a head noun contributes significantly more than a determiner, as reflected in the weight value of 18.31 for the head noun and 0.28 for the determiner (Eberhard et al., 2005). Complements, e.g. local nouns, are assumed to provide a stronger contribution than determiners, but weaker than head nouns, and thus have a value of 1.39 (Eberhard et al., 2005).
The resulting value of the parameter Sr (the evidence for singular and plural at the root of the NP, shown with an oval in Figure 3) is transformed to the proportion of plural verbs (in the hexagon) using a logistic function (Equation 5 in Eberhard et al., 2005), with the bias parameter b = −3.42:
| (3) |
The nature of the logistic function is that any value of Sr larger than 3.42 results in a majority of plural responses (a proportion larger than .5, Eberhard et al., 2005).
The mathematical formulation of the Marking & Morphing model incorporates the main assumptions of the theoretical account. First, syntactic information such as the position in the structural representation of the NP or the grammatical number specification of the NP morphemes are weighted more heavily in their contributions than notional properties. For example, the weighting parameters, reflecting positional information, are multiplicative (in Figure 3: large equation above the figure, wj * Smj; values above the thick line of the large box) and range from 0.28 to 18.3, whereas the notional parameter is only additive and has a much narrower range (−1 to 1, in the small rectangle, which is added to the weighted result of the grammatical number calculation in the large box). Second, specification values of 0 for singular and 1 for plural (the diamond on the left) mean that grammatical number either has no influence on the total evidence for singular and plural (oval on the right) when the noun is grammatically singular with a multiplicative value of 0, or, when the noun is marked as plural and has a Specification value of 1, grammatical number marking has up to 18 times more influence than the notional parameter (the multiplicative value of the Specification = 1 and wH = 18.31, Equations 1 and 2). Further, due to the logistic function transforming the NP information into the proportion of plural verbs, a grammatically singular head, even if maximally notionally plural (Sn = 1), will yield singular verbs (dashed line on the left in the graph in Figure 3) whereas a grammatically plural head, even if maximally notionally singular (Sn = −1), will result in plural verbs (dashed line on the right in the graph in Figure 3). These outcomes are modified by smaller contributions from complements (e.g. local nouns). Together, these equations instantiate the view that grammatical number is a much stronger constraint than notional number.
The computational implementation of the Marking & Morphing model based on the above assumptions and the parameter values obtained in model fitting procedures based on 17 agreement studies successfully predicted data from several other studies, both in English and in other languages (Eberhard et al., 2005). Here we test the model’s predictions for the Serbian QNPs with the quantifiers many and several and the verb and homophony manipulations used in Experiments 1 and 2. Because the Specification value for the heads in Serbian might be calculated in several different ways, we report four different implementations below.
All four implementations were based on the analysis of quantifiers in Zlatić (1997), in which Serbian uninflected quantifiers (such as many and several used in Experiments 1–2) are considered the head of the NP, and the noun the complement. If instead we had considered the noun the head (e.g. foxes in several foxes), this plural-marked head noun would have yielded essentially 100% plural verb agreement, which clearly does not correspond to agreement usage in this construction in Serbian and other Slavic languages. Based on the quantifier-head analysis, the evidence for singular and plural at the root of the NP in the Serbian QNP many/several foxes would be calculated in the following way (cf. Equations 3 and 4 in Eberhard et al., 2005):
| (4) |
This includes notional contributions (Sn), grammatical specification of the quantifier (SmQ), specification and frequency information of the noun (SpecificationLN, CfreqLN), and weighting parameters for the head (wH), and the complement (wL).
The parameter values are provided in Table 8. The four implementations differ only in terms of how the Specification value for the quantifier head (SmQ) was specified (see below). The implementations were identical in all other ways. In addition to treating the quantifier as the NP head, the other differences from the original Eberhard et al., 2005 implementation were to a) represent notional number ambiguity as a graded rather than a single-value parameter, based on the quantifier and event type, and b) take into account form homophony when calculating relative frequencies of singulars and plurals of complement nouns.
Table 8.
Model parameters for the Serbian QNPs used in Experiments 1 and 2. Different Specification values for the quantifiers (SmQ) were used in the four model implementations (M&M 1–4).
| Sn | wH | SmQ | wL | SpecLN | CfreqLN | ||||
|---|---|---|---|---|---|---|---|---|---|
| M&M 1 | M&M 2 | M&M 3 | M&M 4 | ||||||
| Experiment 1 | |||||||||
| many + verb: | |||||||||
| agentive | 0.32 + 0.17 | 18.31 | 0 | 0.063 | −1 | 0 | 1.39 | 1 | 1.22 |
| existential | 0.32 + 0.09 | 18.31 | 0 | 0.063 | −1 | 0 | 1.39 | 1 | 1.22 |
| several + verb: | |||||||||
| agentive | 0.71 + 0.17 | 18.31 | 0.27 | 0.127 | −1 | 0 | 1.39 | 1 | 1.22 |
| existential | 0.71 + 0.09 | 18.31 | 0.27 | 0.127 | −1 | 0 | 1.39 | 1 | 1.22 |
| Experiment 2 | |||||||||
| many + noun: | |||||||||
| homophonous with nom.sg. | 0.29 | 18.31 | 0 | 0.063 | −1 | 0 | 1.39 | 1 | 1.40 |
| non-homophonous with nom.sg. | 0.29 | 18.31 | 0 | 0.063 | −1 | 0 | 1.39 | 1 | 1.73 |
| several + noun: | |||||||||
| homophonous with nom.sg. | 0.59 | 18.31 | 0.27 | 0.127 | −1 | 0 | 1.39 | 1 | 1.40 |
| non-homophonous | |||||||||
Notional number
In the original implementation, the contribution of notional number ambiguity was modeled using a single-value parameter (Eberhard et al., 2005). However, the findings presented in Experiments 1–2 suggest that notionally ambiguous elements may vary systematically in the extent to which they promote notional plurality. For example, greater individuation of entities in the quantified NP several foxes is more likely to promote notional plurality relative to many foxes, where the referents are perceived as a single collection of less individuated entities. Thus to model notional plurality of the quantifiers we used the norming results presented earlier. Specifically, keeping within the range of the parameter encoding notional ambiguity in the original implementation, the means on the norming scale (1 to 7) for each quantifier were converted to the 0 to 1 scale, with larger values indicating greater notional plurality (Table 8). To approximate notional contributions from different types of events we used the average proportion of plural responses for agentive and existential verbs obtained in Experiment 1 (Table 8).
Grammatical number parameter values for nouns
In all four implementations, the Specification value for the nouns in all conditions was 1 as they were all plural count nouns such as foxes. In implementing the Experiment 1 data, contrastive frequency (Cfreq) was calculated from the total frequency of singular and plural forms (Kostić, 1999). For Experiment 2, however, contrastive frequency was calculated taking into account form homophony: in feminine nouns, which were homophonous with the nominative singular, the summed singular and plural frequency was the sum of the frequency of the genitive plural and the nominative singular, whereas in masculine nouns (homophonous with the genitive singular form) it was the sum of the genitive plural and the genitive singular form8 (Table 8).
Specification value of quantifiers in the grammatical number calculation
The main difference between our four model implementations is the Specification value of the quantifiers, affecting the degree to which they are grammatically plural. In Implementations 1–3 these values were calculated as suggested in the original implementation of the Marking & Morphing model: as in Bock et al. (2006), in Implementations 1 and 2 they were based on corpus counts of plural targets (we used the data from the small corpus analysis presented earlier in Implementation 1, and behavioral responses across both experiments in Implementation 2), and in Implementation 3 we tested the hypothesis that the quantifiers mark the NP as syntactically singular (Specification = −1), similar to the quantifiers each and every in English (Table 5 in Eberhard et al., 2005 and Eberhard, 1997). Finally, in Implementation 4 the value of 0 was assigned as the quantifier Specification. As discussed above, because of the multiplicative contribution of this parameter, computationally this value cancels the contribution of grammatical information from the quantifiers. Theoretically, this value can be interpreted in different ways, including as the absence of grammatical number specification on the quantifier (see Corbett, 2000, for discussion of unspecified, or general number).
In all four implementations, the predicted proportion of singular verbs was calculated by subtracting the predicted proportion of plural verbs (Equation 3) from 1 (Psing = 1 - Pplur). The resulting predictions for all manipulations in Experiments 1 and 2 are plotted against human data in Figure 4.
Figure 4.
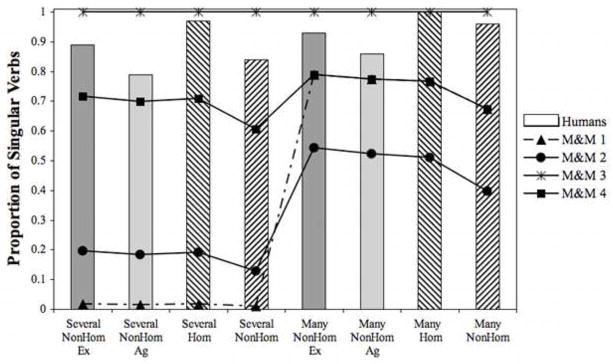
Proportions of singular verbs predicted by four different implementations of the Marking & Morphing model (lines) plotted against human data (Experiment 1: grey-shaded bars; Experiment 2: zebra-style bars). In Implementation 1 (M&M 1), Specification values for the quantifiers were determined based on the corpus analysis, in Implementation 2 (M&M 2) based on the behavioral data. In Implementation 3 (M&M 3) the quantifiers were assumed to be syntactically marked as singular, and in Implementation 4 (M&M 4) they were assumed to be unmarked for grammatical number. The first four bars represent conditions with the quantifier several, the last four bars conditions with the quantifier many. NonHom = non-homophonous with the nominative singular form; Hom = homophonous with the nominative singular; Ex = existential verb; Ag = agentive verb.
In accordance with the main assumptions of the Marking & Morphing model regarding the strong influence of grammatical information, different ways of implementing Specification values for the quantifier heads result in major differences in predictions across the four implementations. In Implementation 1, with Specification values for the quantifiers based on the corpus analysis, the correlation between predicted and obtained proportions of singular verbs is 0.47, and the prediction error (RMSE) is 0.62. These values should be considered in the context of the prediction error of 0.032 in the original implementation (Eberhard et al., 2005), as well as its extensions with RMSE values between 0.038 and 0.077 (Eberhard et al., 2005). Thus the overall prediction error for the Serbian data in Implementation 1 is eight to twenty times higher than other extensions of the model. One of the reasons for this outcome is the contribution the model assigns to grammatical information: Specification values larger than 0, particularly in the head, will produce larger Sr values, resulting in a high proportion of plural verbs. Thus with the Specification value of 0.27 for the quantifier several the model incorrectly predicts the majority of plural responses, because of the larger weighting of the grammatical information relative to other information included in the model. The large contribution assigned to grammatical information is also evident in the conditions with the quantifier many (Specification = 0) where the model predicts the majority of singular responses. Specifically, even without any numerical contribution from the quantifier grammar (with the Specification value of 0 all grammatical information from the quantifier equals 0), the model predicts an average of 25% of plural responses, due to the plural marking (Specification = 1) of the noun complement. This result compares to the average of 6% of plural responses produced by the participants in the behavioral studies presented above.
An alternative to using Specification values based on the relatively small corpus presented earlier would be to use Specification values for the quantifiers based on the average proportion of plural responses obtained in the experiments. These values were used in Implementation 2 (many = 0.0625, several = 0.127). The new Specification values, however, do not improve the model’s predictions: both the correlation between the predicted and obtained proportion of singular verbs and the RMSE remain similar to Implementation 1 (r = .45, RMSE = .59). In Implementation 2, the model slightly improves the predictions for the proportion of singular verbs for several but further overestimates the proportion of plural verbs for many (Figure 4).
In sum, in both Implementations 1 and 2, the model predicts a large effect of the quantifier but with predominantly plural responses for the quantifier several, which is unlike the pattern obtained in behavioral experiments. The analysis of the model suggests that this effect is driven not by the (small) notional difference between the quantifiers, but rather it is due to the strong effect of their different grammatical specifications, calculated based on corpus counts of plural targets (Bock et al., 2006). The model also predicts a small effect of verb type (with more singular forms with existential than agentive verbs), as well as noun-form homophony (with more singular forms with nominative singular homophonous nouns). We further discuss the verb type and noun homophony effects after presenting two additional implementations.
In Implementation 3 we provide an alternative specification of both quantifiers as syntactically singular, with the Specification value of −1 (cf. Table 5 in Eberhard et al., 2005; see also Eberhard, 1997), which conforms with the linguistic analysis of Serbian QNPs (Zlatić, 1997). In this implementation, the model predicts almost exclusively singular responses across all conditions (Figure 4), and the error between the predicted values and obtained data increases to 0.69.
Finally, in Implementation 4 we used the Specification value of 0 for both quantifiers. Computationally, this value completely cancels grammatical contributions from the quantifiers. Theoretically, this value could be interpreted as the quantifiers being neither singular nor plural but rather unspecified for number (e.g. Corbett, 2000), or alternatively as being specified as lexically unmarked/default singular. The prediction error for this implementation fared much better than in Implementations 1–3 (for Implementation 4 RMSE = 0.40), although the error rate was still five to ten times higher than the other extensions of the model in Eberhard et al. (2005). The main source of the error is the strong effect of the plural specification of the noun, leading the model to predict about 28% plural verb responses compared to the 10% found in Experiments 1–2. Nonetheless, an improvement over Implementations 1–3 is that the notional influences become more apparent: now the only contribution to the quantifier difference, and different verb types, is the parameter reflecting notional effects. In this implementation, the model correctly predicts a higher proportion of singular verbs for the quantifier many (75%) than the quantifier several (69%), and slightly more for existential (75%) than agentive (74%) verbs.
Given the improved performance of Implementation 4 compared to the other three implementations, we considered whether further refinements of the notional parameter values could improve model fit. Manipulations of the notional parameter could improve the difference in the extent to which notionally ambiguous elements promote plurality relative to each other (e.g. agentive vs. existential verbs), but they would not improve the overall predictions regarding the proportion of plural verbs. For example, even when the notional parameter is set to 0, the model predicts an average of 19% of plural responses where humans produce 10%, reflecting the contribution from the grammatical information of the complement noun. In sum, the Specification value of 0 for the quantifier head improves the overall model fit, and it allows for notional effects to emerge. However, due to the globally strong effect of grammatical information, and specifically grammatical plurality of the complement noun, the model is restricted in the extent to which it can match the overall dominance of singular verb forms in the behavioral data.
We also investigated further the effect of noun from homophony. It is interesting to note that across all four implementations when the predicted values are not at floor or ceiling levels, the model predicts a larger proportion of singular verbs for the nouns homophonous vs. non-homophonous with the nominative singular form (Figure 4), similar to the participants in our studies. The reason for this in the model is a small difference in the contrastive frequency of the homophonous singular and plural forms in the two types of nouns (Table 8). When the contrastive frequency is equated by excluding 2 items in each gender9, across all implementations the model predicts no differences in the proportion of singular verbs across the two types of nouns (Figure 5). However, with the same subset of items in the behavioral data there is still a significant effect of the homophony with the nominative singular form, with a larger proportion of singular verbs produced with nouns homophonous with the nominative singular: F1(1, 31) = 11.22, p = .002; F2(1,10) = 4.99, p = .049 (the rest of the findings in Experiment 2 remain unchanged: main effect of the quantifier: F1(1, 31) = 10.54, p = .003; F2(1,10) = 17.59, p = .002; quantifier x homophony interaction: F1(1, 31) = 6.26, p = .018; F2(1,10) = 1.73, p = .2). This suggests that in the behavioral data contrastive frequency is not the driving force behind the difference in the items homophonous vs. non-homophonous with the nominative singular form. Thus, with contrastive frequency as the only parameter in the model to account for word form effects, the Marking & Morphing model is limited in its ability to account for the effect of noun form homophony found in Experiment 2. As suggested above, an alternative proposed by the competition account would be to include a parameter encoding distributional co-occurrence of the nouns homophonous with the nominative singular form which in the native speakers’ experience co-occurs with singular verbs.
Figure 5.
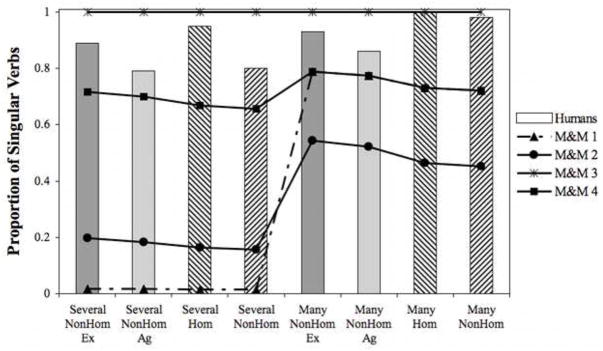
Proportion of singular verbs predicted by the computational implementation of the Marking & Morphing model (lines) plotted against human data (Experiment 1: grey-shaded bars; Experiment 2: zebra-style bars) with the subset of items equated for contrastive frequency. In Implementation 1 (M&M 1), Specification values for the quantifiers were determined based on the corpus analysis, in Implementation 2 (M&M 2) based on the behavioral data. In Implementation 3 (M&M 3) the quantifiers were assumed to be syntactically marked as singular, and in Implementation 4 (M&M 4) they were assumed to be unmarked for grammatical number. The first four bars represent conditions with the quantifier many, the last four bars conditions with the quantifier several. NonHom = non-homophonous with the nominative singular form; Hom = homophonous with the nominative singular; Ex = existential verb; Ag = agentive verb.
Together, the findings from the four implementations of the Marking & Morphing account provide evidence that the model can be extended with some success to a language from a different family, and a more intricate agreement system, than the languages studied so far. Further, even though the four implementations differ in the specification of only one parameter, the dramatic differences in their predictions demonstrate the strong role attributed to the grammatical information in the NP, which captures one of the basic principles of the Marking & Morphing model (agreement as a syntactic process). However, this strong role of grammar was also one of the features that limited the model’s ability to fully account for the Serbian data: it was only when the influence of grammatical information of the quantifier head was reduced (Implementation 4) that the notional effects started to emerge. With the reduced influence of grammar the model was able to capture the general pattern of effects of notional number variation induced by the quantifiers and different event types. Importantly, these effects were captured by a graded, rather than a single-value, parameter encoding notional number ambiguity. Finally, the modeling results indicate that morphophonological effects such as homophony remain a challenge for the Marking & Morphing account. Further refinements of the model may require the inclusion of additional parameters, including perhaps information about distributional co-occurrence, as suggested by the competition account.
General Discussion
The findings from the two behavioral studies suggest that correct agreement production in Serbian is influenced by several non-syntactic factors – the semantic properties of the NP manipulated via quantifier and event semantics, as well as morphophonological properties of the head noun. In Experiment 1 the proportion of singular verbs decreased with more individuated readings of the NP due to the quantifier, as well as due to event type. In Experiment 2 the proportion of singular verbs increased with the homophony of the noun with the nominative singular form, and this decreased the effect of the quantifier meaning. These findings suggest that both semantic and morphophonological factors influence correct subject-verb agreement production. Beyond strengthening the evidence for non-syntactic effects obtained in the agreement error paradigm, these results go farther by demonstrating that the semantic effects extend to include properties of whole events, rather than only properties encoded as NP modifiers. In addition, the influence of morphophonological properties of the head noun on correct agreement suggests that they may play a more important role than previously suggested. An additional novel finding is that in both studies, the majority of responses were singular verb forms despite the grammatically unambiguous plural marking in the NP.
We also provided evidence that the computational implementation of the Marking & Morphing model can be extended to Serbian, and specifically to the types of QNPs investigated in the behavioral experiments. The results of the modeling suggest that with a reduction of the role of grammatical information the Marking & Morphing implementation could account for the notional effects induced by quantifier and event type, if the notional parameter is allowed to vary based on their semantic properties. However, the effect of form homophony remains a challenge for the model.
Cross-linguistic research in agreement production
What are the possible implications of findings in an understudied language for general models of agreement production? All three models discussed here assume a universal architecture of the language production system and common processing mechanisms, and both the Marking & Morphing and the controller misidentification accounts were either developed (Badecker & Kuminiak, 2007) or extended (Eberhard et al., 2005) to languages other than English. However, what remains a possibility is that the extent to which various factors influence agreement may vary cross-linguistically. Specifically, it has been suggested that susceptibility to notional effects may vary with morphological richness, such that morphologically richer languages may be more susceptible to notional effects (e.g. Vigliocco et al., 1996). Recent comparisons of inflectionally rich and inflectionally impoverished languages suggest otherwise. For example, in a study directly comparing the effect of distributivity in Spanish (inflectionally rich) and English (inflectionally impoverished) Bock, Carreiras, and Meseguer (2012) found no difference in the size of the effect in the two languages. They suggested instead that morphological richness may have the opposite effect, where richer morphology may reduce notional effects, both cross-linguistically but also within the same language. In a study of notional effects in Russian, an inflectionally rich language, Lorimor, Bock, Zalkind, Sheyman, and Beard (2008) found that the rate of attraction errors, used as a measure of notional effects, was a third of that found in English. Similar effects were found by Foote and Bock (2012) when comparing a morphologically poorer with a morphologically richer dialect of Spanish. Further, in the same study, when the morphological constraints were reduced by using null subjects, Foote and Bock (2012) reported a notional effect of equal size in both dialects.
Our results in Serbian are in accordance with the hypothesis that inflectional richness of a language does not prevent notional effects to emerge: we found strong and reliable notional effects in subject-verb number agreement in both experiments, despite the rich inflectional morphology in both nouns and verbs. However, we also found that these effects may be modulated by morphophonological factors: with a strong morphophonological cue in feminine nouns in Experiment 2 there was a tendency for notional effects to be reduced. Our findings suggest that indeed cross-linguistically, as well as within the same language, the same factors influence agreement production.
Implications for models of subject-verb agreement
Together, the findings of Experiment 1 and Experiment 2 are important in that they pose three challenges for accounts of agreement processing, which we discuss in turn.
The first important challenge for agreement accounts concerns the overall bias for singular verb forms found in both Experiment 1 and 2, which is surprising in light of past research on agreement patterns in other languages. A number of studies have demonstrated some tendency for plural verbs to appear with singular subject NPs (Haskell et al., 2010), but the opposite case, singular verbs with plural subject NPs, as we obtained here, has generally been found to be very rare (Bock & Miller, 1991; Bock, Nicol, & Cutting, 1999). Given this past research, it is important to note that the bias toward singular verbs for a plural NP subject obtained in our studies is clearly not limited to our items or experimental manipulations. Corbett (2000) reports a corpus analysis of agreement patterns in quantified phrases in Serbian using numerals greater than four, all of which require a noun in the genitive plural form: out of 1161 instances of QNPs with these numerals, 93% occurred with singular agreement. This result attests to the overall bias to singular verbs for this construction, beyond the particular quantifiers and nouns used in our studies. The effects are not even limited to Serbian, as this same agreement pattern with quantified noun phrases is also found in other Slavic languages, including Czech, Slovak, Polish, and Russian (Corbett, 2000). It is not clear why this exceptional agreement pattern exists, but it is clear that the singular response bias with the QNPs used in our experiments reflects broader patterns in Serbian and other Slavic languages.
None of the agreement accounts that we have discussed here are particularly well-equipped to handle this bias toward singular verb usage with QNPs in many Slavic languages. As we saw in the computational implementation of the Marking & Morphing model, this account strongly over-predicts the rate of plural verbs in our studies, except in Implementation 3, in which the NP was explicitly marked as singular, which yielded 100% singular responses and eliminated any ability of the model to account for other aspects of the data. The only case when the model came close to the overall majority of singulars was when the grammatical contributions from the quantifier head were completely excluded (Implementation 4). However, even in this case the model overpredicted the rate of plural verbs. A key reason why the Marking & Morphing model has limitations in providing a full account of the overall singular verb bias is that it is inherently tuned to produce plural verb biases. That is, the model parameters reflect the view that the singular is the unmarked default, which can be overridden by the explicitly marked plural feature (e.g. Bock & Eberhard, 1993; Eberhard, 1997). This assumption is a central component of the model’s account of subject-verb agreement error asymmetries in NPs containing an embedded prepositional phrase, such as the key(s) to the cabinet(s), in which a plural noun in the prepositional phrase (cabinets) interferes with the computation of singular subject-verb agreement (the key…is), while a singular prepositional phrase noun has little effect on plural subject-verb agreement (see Haskell et al., 2010). Thus commitment to a specifically architectural property (plural markedness) to account for production biases favoring plurals in some languages inherently limits the model’s ability to provide a full account for singular biases in Serbian and other Slavic languages.
Haskell et al. (2010) offered a non-architectural account for the plural bias in agreement errors in English and some other languages, in that they suggested the error asymmetry came from statistical learning over prior language use with constructions that promoted the (correct) use of plural verbs with singular noun phrases, such as a trio of violinists are playing. On this account, the competition process to select agreeing forms is shaped by prior statistics of subject-verb agreement. The competition account of the Serbian singular bias should be similar, in that the use of the alternative verb forms for the QNP phrases should be strongly shaped by people’s prior experiences with the frequent use of singular verbs with QNPs. Generalization from other constructions would also be expected, as in the Haskell et al. (2010) data, in that biases toward the singular verb should increase when the materials contain a homophonous form that is associated with singular verb usage in other constructions, as was observed in Experiment 2 here. What is not clear, however, is what broader experiences in the language promote singular agreement in QNPs, given that in other constructions, plural noun subjects agree with plural verbs. One possibility comes from the fact that the quantifiers are uninflected, and uninflected forms in Serbian often take singular agreement. This tendency might be viewed as an example of Plan Reuse in MacDonald (in press) account of how production processes contribute to typological variation. These possibilities await future research. Thus at this point, the competition account offers some promise in accounting for producers’ sensitivity to prior experiences in their production of agreement, but it needs (indeed, all accounts need) a deeper understanding of why the language has these patterns.
The controller misidentification proposals (e.g. Badecker & Kuminiak, 2007) could account for the majority of singular responses by assuming that the whole NP is marked as nominative singular. However, as the results of the implementation of the similar assumption in the Marking & Morphing model show (Implementation 3), the challenge would be to explain the variation of agreement patterns with the changes in quantifier and verb meaning, and noun morphophonology.
The effects of individuation on agreement processes are the second challenge of the findings presented above that all accounts of agreement need to consider. Linguists have long noted the important role for individuation on utterance form, beyond the QNPs in Slavic languages. In many dialects of Arabic, for example, the degree of individuation of a group affects not only agreement but choice of determiner and the case in which the head noun appears (Brustad, 2000). Humphreys and Bock (2005) previously identified a role of individuation of the members of a group, with effects for agreement production, in that NPs emphasizing the individual nature of the group yielded more plural agreement than NPs emphasizing the group as a whole. The quantifier results in Experiments 1 and 2 here build on this result and show that when individuation and group size are placed in opposition, the NPs with the quantifier many, which names a large but less individuated group, yielded more singular verbs than NPs with the quantifier several, which typically identifies a smaller but more individuated group. Together these results indicate that “number” agreement computations are influenced not (only) by the sheer number of entities being referred to, but also the extent to which they are perceived as individuated.
The existence of joint effects of individuation and number on subject-verb agreement raises several questions, including the extent to which these two factors have similar effects cross-linguistically. This question forms an obvious opportunity for subsequent research, but the evidence to date suggests that there is substantial cross-linguistic variation in the relative influence of these factors. First, there is variation in the existence and nature of subject-verb number agreement. Some languages, such as Japanese, have none, others, like English and modern day Serbian, distinguish a singular (one entity) from more than one (plural), with some influence of individuation, and some other languages have different agreement paradigms for one entity vs. small numbers vs. larger numbers. Second, languages may admit exceptions; for example, Serbian QNPs with the numbers two, three, and four (as in two foxes) must take plural verb agreement, whereas numbers greater than four and quantifiers such as several and many admit either singular or plural verbs, as seen in the current studies. Other Slavic languages, including Bulgarian and Macedonian, take plural agreement with all numerals larger than 1 (Corbett, 2000). Third, there appear to be variations within dialects: Brustad (2000) describes cross-dialect variation on the extent to which individuation affects the form of utterances in Arabic. Similarly, American vs. British English dialects vary in the extent to which collective nouns such as family take plural agreement (Bock et al., 2006). Thus while there may be broad cross-linguistic tendencies to consider the number and individuation of subjects when computing the morphological form of verbs, the degree of cross-linguistic variation suggests that substantial agreement information must be learned from experience with the language in question.
The results of the computational instantiation of the Marking & Morphing model show that the original version of the model could account for the differences induced by different levels of individuation only if it allowed for the reduced influence of the grammatical number marking and simultaneously provided a more fine-grained consideration of notional effects. Specifically, while both the quantifier and verb meaning effects can be conceptualized as properties of the entire message which influence the construal of the NP referents, the original implementation of the model only encoded message properties that influenced its ambiguity regarding notional number relative to clear cases of units and multitudes. Indeed, the challenge for all models of agreement is to elaborate on the various properties of the entire message relevant for grammatical agreement, including sheer number, levels of individuation, and type-token ambiguity, which may require additional parameters. The Haskell and MacDonald competition account could build on the effect of semantic features correlated with verb number, such that more individuated semantics correlates with the use of plural verbs. Evidence that individuation information is subject to statistical learning is clearly needed to elaborate this account, as is a more detailed model of the competition process. Notional effects, including levels of individuation, seem incompatible with the controller misidentification account given its focus on morpho-syntactic features relevant for subject identification, and this model would need broader adjustments to account for semantic effects. Thus there are paths by which several different accounts of agreement might be elaborated to make predictions about the effects of individuation, but there is not yet sufficient empirical data on the range of individuation effects, nor about the message or linguistic elements, such as quantifiers and verbs, that contribute to these effects. To this aim all accounts may benefit from links with models of (non-linguistic) numerical representations, where similar issues regarding numerosity and individuation are relevant (e.g. Feigenson et al., 2004; Hyde & Wood, 2011; Piazza et al., 2011).
The third challenge to models of agreement is the effect of homophony observed in Experiment 2. Eberhard et al. (2005) implicitly included a small amount of morphophonological information in their implemented model via the parameter encoding the relative frequency of singular and plural noun forms. In the current Experiment 2, however, the contrastive frequencies of homophonous (feminine) and non-homophonous (masculine) nouns did not seem to be the source of the difference in the proportion of singular verbs, as when they were equated this difference didn’t disappear, which is unlike what the computational implementation of Marking & Morphing predicted.
The competition account proposed by Haskell and MacDonald (2003) could account for the homophony effect through statistical learning of distributional information via past experience with the language, i.e. the prior strong co-occurrence of the nominative singular nominal form with singular verb forms. In Serbian, and other languages with case markings, the nominative singular form of the noun frequently co-occurs with singular verb forms, because the nominative case is typically used to mark subjecthood. This will be a strong cue in the language, and with the further support of the majority of singular responses with QNPs (Corbett, 2000) it may explain the high proportion of singular responses and the weaker effect of quantifier meaning with the homophonous feminine forms (Haskell & MacDonald, 2003).
In the controller misidentification account proposed by Badecker and Kuminiak (2007) the homophony effect could be explained by feedback from the phonological form to morpho-syntactic features. In feminine nouns this would activate the nominative singular feature, which could result in an increase in singular verb forms relative to masculine nouns. However, this proposal would need a second mechanism to account for the effect of the different quantifiers, as the activation of the nominative singular feature does not depend on the quantifier.
While the competition model could account for the effect of homophony and the majority of singular responses via distributional learning, both the Marking & Morphing and the competition account need further elaboration of semantic representations relevant for subject-verb agreement. The challenge remains for the competition account to also provide more detailed and possibly computational implementations that would in turn enable quantitative comparisons of different models and consequently a more detailed understanding of the agreement phenomena. The competition account proposed by Haskell and MacDonald (2003) is close in spirit to connectionist models of inflectional morphology, in particular in terms of the role attributed to the probabilistic information present in the language (e.g. Haskell et al., 2010). Connectionist models of inflectional morphology develop sensitivity to morphological structure by encoding probabilistic regularities that exist between the words’ semantic and phonological/orthographic properties (e.g. Joanisse & Seidenberg, 1999; Mirković, Seidenberg, & Joanisse, 2011; Plaut & Gonnerman, 2000; Rueckl & Raveh, 1999; Woollams, Joanisse, & Patterson, 2009). Both noun (e.g. Mirković et al., 2011; Plaut & Gonnerman, 2000) and verb morphology (e.g. Joanisse & Seidenberg, 1999; Woollams et al., 2009) have been modeled using these systems. Similar models have also been used to simulate the use of distributional co-occurrence information (e.g. Elman, 1990). Thus these models have the potential to capture some of the agreement phenomena discussed here within the competition framework. However, they also have the challenge to account for the same wealth of data as the current Marking & Morphing model does.
More broadly, the Marking & Morphing and the competition accounts share general properties with other constraint-satisfaction models in psycholinguistics (e.g. MacDonald et al., 1994; Trueswell & Tanenhaus, 1994), and in this way they both differ from the controller misidentification account. For example, both Marking & Morphing and the competition account suggest that several factors shape the agreement process, including semantic and syntactic properties of the noun phrase. They differ in the proposed relative contribution of each factor, with a strong emphasis on the syntactic properties in the Marking & Morphing model, and an assumption that syntactic properties are represented as abstract features in the lexicon. An alternative is to view grammatical properties of words as properties emerging out of semantic, phonological and distributional regularities learned through language use (e.g Elman, 1990; McClelland et al., 2010; Seidenberg, 1997). Agreement between words, in this view, will similarly be shaped by all factors that shape the word’s grammatical properties, and the relative weighting of different factors will depend on the consistency of different cues between agreeing elements. This principle would apply both within a language (e.g. when morphological factors are weak, notional factors will play a stronger role, as in collective noun agreement, Haskell & MacDonald, 2003; nouns with irregular plural morphology will induce fewer agreement errors than regular nouns, e.g. Haskell & MacDonald, 2003), as well as cross-linguistically (e.g. notional effects will have a weaker effect in languages with richer morphology and stronger morphophonological cues to agreement, e.g. Foote & Bock, 2012). This is perhaps the place where the two models may meet, in emphasizing the role of learning in shaping the representations and processes supporting agreement. Learning appears to be critical to agreement production at a number of levels, including properties of individual lexical items (e.g., learning that pasta is singular but noodles is plural in English), properties of entire word classes (e.g. the extent to which collectives like family are given singular vs. plural agreement in different dialects of English, Bock et al., 2006), or constructions (e.g. learning that most quantified noun phrases, despite their conceptual and grammatical plurality, co-occur with singular verb forms in Serbian), the extent to which semantic factors such as individuation affect case marking and other aspects of utterance form (Brustad, 2000), and homophony effects observed here and elsewhere (Antón Mendéz & Hartsuiker, 2010; Haskell & MacDonald, 2003; Vigliocco et al., 1995). Learning processes are becoming increasingly central to accounts of language production more broadly (e.g. Bock & Griffin, 2000; Chang, Dell, & Bock, 2006; Dell, Reed, Adams, & Meyer, 2000), and their extension to agreement is a natural one.
We examine grammatical encoding in language production using subject-verb number agreement.
We use Serbian quantified noun phrases where both singular and plural verb agreement are grammatical in two fragment completion studies.
We show that verb number varies with levels of individuation, manipulated via quantifier and verb meaning, and with morphophonological homophony of the NP noun with the nominative singular form.
We present four computational implementations of the Marking & Morphing model to try to account for the behavioral data.
We discuss the behavioral and computational findings in the context of Marking & Morphing, competition and controller misidentification accounts of agreement, and discuss the role of learning in agreement and language production.
Acknowledgments
This research was supported by R01-HD047425 to the University of Wisconsin-Madison. Portions of this research were submitted in partial fulfillment of the requirements for the PhD degree submitted to the University of Wisconsin-Madison by JM. We thank Aleksandar Kostić, Jelena Morača, and the members of the Laboratory for Experimental Psychology, University of Belgrade, Serbia, for their help with data collection. We also thank Kathryn Bock and two anonymous reviewers for their comments.
Appendix A: Experimental Items
Table 9.
Experimental NPs in Experiment 1
| Quantifier (many/several) | Noun (genitive plural) | English gloss |
|---|---|---|
| mnogo/nekoliko | kitova | whale |
| mnogo/nekoliko | ovnova | ram |
| mnogo/nekoliko | lavova | lion |
| mnogo/nekoliko | galebova | seagull |
| mnogo/nekoliko | zeceva | rabbit |
| mnogo/nekoliko | vukova | wolf |
| mnogo/nekoliko | nojeva | ostrich |
| mnogo/nekoliko | bikova | bull |
| mnogo/nekoliko | volova | ox |
| mnogo/nekoliko | ježeva | hedgehog |
| mnogo/nekoliko | golubova | pigeon |
| mnogo/nekoliko | miševa | mouse |
| mnogo/nekoliko | petlova | rooster |
| mnogo/nekoliko | pasa | dog |
| mnogo/nekoliko | slonova | elephant |
| mnogo/nekoliko | tigrova | tiger |
Table 10.
Experimental NPs in Experiment 2
| Gender | Quantifier (many/several) | Noun (genitive plural) | English gloss |
|---|---|---|---|
| Masculine | |||
| mnogo/nekoliko | kreveta | bed | |
| mnogo/nekoliko | balona | balloon | |
| mnogo/nekoliko | simbola | symbol | |
| mnogo/nekoliko | kaveza | cage | |
| mnogo/nekoliko | paketa | package | |
| mnogo/nekoliko | šešira | hat | |
| mnogo/nekoliko | krompira | potato | |
| mnogo/nekoliko | crteža | drawing | |
| Feminine | |||
| mnogo/nekoliko | stolica | chair | |
| mnogo/nekoliko | figura | figurine | |
| mnogo/nekoliko | ideja | idea | |
| mnogo/nekoliko | violina | violin | |
| mnogo/nekoliko | kutija | box | |
| mnogo/nekoliko | haljina | dress | |
| mnogo/nekoliko | kajsija | apricot | |
| mnogo/nekoliko | stranica | page | |
Footnotes
Languages referred to as Serbian, Croatian and Bosnian were previously referred to as Serbo-Croatian.
Hladno je. – It is cold. [cold is-sg]; Smrkava se. – It is getting dark. [to get dark - sg.]
Serbian is a relatively free-word order language, but with a canonical SVO structure. Sentence final subject NPs are possible, however the participants complied with the instructions and only produced NP-initial structures.
Serbian is a (relatively) free word order language, so the QNP can be used as a direct object at the beginning of the sentence, e.g. Nekoliko paketa (several packages) doneo je (brought) poštar (postman). – The postman brought several packages.
The filler items with prepositional phrases allowed us to estimate the rate of attraction errors in Serbian. As in other Slavic languages (e.g. Lorimor et al., 2008), we found it to be low: the verb was unambiguously specified as plural in only 4 out of 160 occurrences (2.5%) of the filler PPs with a singular head and a plural local noun, relative to 3 out of 224 occurrences (1.3%) of the singular head/singular local noun PPs.
The interaction may be partly due to the ceiling effect in the maximally singular-promoting condition (many + nom.sg. homophonous noun).
Participants mostly produced existential verbs (e.g. to be located) in this study: across all four conditions, only 38% of verbs were agentive. However, when only considering plural responses, this overall pattern was reversed: the majority of verbs here were agentive (67%). While this pattern conforms to the one from Experiment 1, we were not able to test the finding statistically due to the overall low proportion of plural verbs.
There is little change in these values when they are calculated over all singular and plural forms, and not just the homophonous cases: for feminine nouns Cfreq = 1.24, for masculine nouns Cfreq = 1.48.
ideja and stranica in feminine, and krompir and kavez in masculine; the resulting relative frequencies are: Cfreqfem = 1.54, Cfreqmasc = 1.57.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Jelena Mirković, University of York.
Maryellen C. MacDonald, University of Wisconsin - Madison
References
- Antón Mendéz I, Hartsuiker R. Morphophonological and conceptual effects on Dutch subject-verb agreement. Language and Cognitive Processes. 2010;25:728–748. [Google Scholar]
- Badecker W, Kuminiak F. Morphology, agreement and working memory retrieval in sentence production: Evidence from gender and case in Slovak. Journal of Memory and Language. 2007;56:65–85. [Google Scholar]
- Barner D, Wagner L, Snedeker J. Events and the ontology of individuals: Verbs as a source of individuating mass and count nouns. Cognition. 2008;106:805–832. doi: 10.1016/j.cognition.2007.05.001. [DOI] [PubMed] [Google Scholar]
- Bock K, Butterfield S, Eberhard K, Cutler A, Humphreys K, Cutting J. Number agreement in British and American English: Disagreeing to agree collectively. Language. 2006;82:64–113. [Google Scholar]
- Bock K, Carreiras M, Meseguer E. Number meaning and number grammar in English and Spanish. Journal of Memory and Language. 2012;66:17–37. [Google Scholar]
- Bock K, Eberhard KM. Meaning, sound, and syntax in English number agreement. Language and Cognitive Processes. 1993;8:57–99. [Google Scholar]
- Bock K, Eberhard KM, Cutting CJ, Meyer AS, Schriefers H. Some attractions of verb agreement. Cognitive Psychology. 2001;43:83–128. doi: 10.1006/cogp.2001.0753. [DOI] [PubMed] [Google Scholar]
- Bock K, Griffin Z. The persistence of structural priming: Transient activation or implicit learning? Journal of Experimental Psychology: General. 2000;129:177–192. doi: 10.1037//0096-3445.129.2.177. [DOI] [PubMed] [Google Scholar]
- Bock K, Levelt W. Language production: Grammatical encoding. In: Gernsbacher MA, editor. Handbook of psycholinguistics. Academic Press; 1994. pp. 945–984. [Google Scholar]
- Bock K, Miller CA. Broken agreement. Cognitive Psychology. 1991;23:45–93. doi: 10.1016/0010-0285(91)90003-7. [DOI] [PubMed] [Google Scholar]
- Bock K, Nicol J, Cutting CJ. The ties that bind: Creating number agreement in speech. Journal of Memory and Language. 1999;40:330–346. [Google Scholar]
- Borges MA, Sawyers BK. Common verbal quantifiers: usage and interpretation. Journal of Experimental Psychology. 1974;2:335–338. [Google Scholar]
- Brustad KE. The syntax of spoken Arabic: A comparative study of Moroccan, Egyptian, Syrian and Kuwaiti dialects. Washington, DC: Georgetown University Press; 2000. [Google Scholar]
- Bybee J, McClelland J. Alternatives to the combinatorial paradigm of linguistic theory based on domain general principles of human cognition. The Linguistic Review. 2005;22:381–410. [Google Scholar]
- Chang F, Dell G, Bock K. Becoming syntactic. Psychological Review. 2006;113:234. doi: 10.1037/0033-295X.113.2.234. [DOI] [PubMed] [Google Scholar]
- Cohen JD, MacWhinney B, Flatt M, Provost J. Psyscope: a new graphic interactive environment for designing psychological experiments. Behavioral Research Methods, Instruments, & Computers. 1993;25:257–271. [Google Scholar]
- Corbett GG. Number. Cambridge: Cambridge University Press; 2000. [Google Scholar]
- Dell GS, Reed KD, Adams DR, Meyer AS. Speech errors, phonotactic constraints, and implicit learning: A study of the role of experience in language production. Journal of Experimental Psychology: Learning, Memory and Cognition. 2000;26:1355–1367. doi: 10.1037//0278-7393.26.6.1355. [DOI] [PubMed] [Google Scholar]
- Eberhard KM. The marked effect of number on subject-verb agreement. Journal of Memory and Language. 1997;36:147–164. [Google Scholar]
- Eberhard KM. The accessibility of conceptual number to the processes of subject-verb agreement in English. Journal of Memory and Language. 1999;41:560–578. [Google Scholar]
- Eberhard KM, Cutting JC, Bock K. Making syntax of sense: Number agreement in sentence production. Psychological Review. 2005;112:531–559. doi: 10.1037/0033-295X.112.3.531. [DOI] [PubMed] [Google Scholar]
- Elman JL. Finding structure in time. Cognitive Science. 1990;14:179–211. [Google Scholar]
- Feigenson L, Dehaene S, Spelke E. Core systems of number. Trends in Cognitive Sciences. 2004;8:307–314. doi: 10.1016/j.tics.2004.05.002. [DOI] [PubMed] [Google Scholar]
- Ferreira VS, Slevc LR. Grammatical encoding. In: Gaskell G, editor. Oxford handbook of psycholinguistics. Oxford, UK: Oxford University Press; 2007. [Google Scholar]
- Ferretti TR, McRae K, Hatherell A. Integrating verbs, situation schemas, and thematic role concepts. Journal of Memory and Language. 2001;44(4):516–547. [Google Scholar]
- Foote R, Bock K. The role of morphology in subject-verb number agreement: A comparison of Mexican and Dominican Spanish. Language and Cognitive Processes. 2012 (in press) [Google Scholar]
- Gillespie M, Pearlmutter N. Hierarchy and scope of planning in subject-verb agreement production. Cognition. 2011;118:377–397. doi: 10.1016/j.cognition.2010.10.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goldberg A. Constructions at work: The nature of generalization in language. Oxford University Press; USA: 2006. [Google Scholar]
- Hartsuiker RJ, Schriefers HJ, Bock K, Kikstra G. Morphophonological influences on the construction of subject-verb agreement. Memory & Cognition. 2003;31:1316–1326. doi: 10.3758/bf03195814. [DOI] [PubMed] [Google Scholar]
- Haskell T, Thornton R, MacDonald MC. Experience and grammatical agreement: Statistical learning shapes number agreement production. Cognition. 2010;114:151–164. doi: 10.1016/j.cognition.2009.08.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haskell TR, MacDonald MC. Conflicting cues and competition in subject-verb agreement. Journal of Memory and Language. 2003;48:760–778. [Google Scholar]
- Haskell TR, MacDonald MC. Constituent structure and linear order in language production: Evidence from subject-verb agreement. Journal of Memory and Language. 2005;31:891–904. doi: 10.1037/0278-7393.31.5.891. [DOI] [PubMed] [Google Scholar]
- Humphreys KR, Bock K. Notional number agreement in English. Psychonomic Bulletin and Review. 2005;12:689–695. doi: 10.3758/bf03196759. [DOI] [PubMed] [Google Scholar]
- Hyde D, Wood J. Spatial attention determines the nature of nonverbal number representation. Journal of Cognitive Neuroscience. 2011;23:307–314. doi: 10.1162/jocn.2010.21581. [DOI] [PubMed] [Google Scholar]
- Joanisse MF, Seidenberg MS. Impairments in verb morphology following brain injury: A connectionist model. Proceedings of the National Academy of Sciences, USA. 1999;96:7592–7597. doi: 10.1073/pnas.96.13.7592. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kostić Đ. Frekvencijski rečnik savremenog srpskog jezika. [Frequency dictionary of the contemporary Serbian language]. Yugoslavia: Institute for Experimental Phonetics and Speech Pathology and Laboratory for Experimental Psychology, University of Belgrade; 1999. [Google Scholar]
- Kostić Đ. Korpus srpskog jezika. [Corpus of Serbian language]. Yugoslavia: Institute for Experimental Phonetics and Speech Pathology and Laboratory for Experimental Psychology, University of Belgrade; 2001. [Google Scholar]
- Levin B. English verb classes and alternations: a preliminary investigation. Chicago: Univeristy of Chicago Press; 1993. [Google Scholar]
- Lorimor H, Bock K, Zalkind E, Sheyman A, Beard R. Agreement and attraction in Russian. Language and Cognitive Processes. 2008;23:769–799. [Google Scholar]
- MacDonald MC. Frontiers in Language Sciences. How language production shapes language form and comprehension. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- MacDonald MC, Pearlmutter NJ, Seidenberg MS. Lexical nature of syntactic ambiguity resolution. Psychological Review. 1994;101:676–703. doi: 10.1037/0033-295x.101.4.676. [DOI] [PubMed] [Google Scholar]
- McClelland J, Botvinick M, Noelle D, Plaut D, Rogers T, Seidenberg M, Smith L. Letting structure emerge: connectionist and dynamical systems approaches to cognition. Trends in Cognitive Sciences. 2010;14:348–356. doi: 10.1016/j.tics.2010.06.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McRae K, Spivey-Knowlton MJ, Tanenhaus MK. Modeling the influence of thematic fit (and other constraints) in on-line sentence comprehension. Journal of Memory and Language. 1998;38:283–312. [Google Scholar]
- Mirković J, Seidenberg MS, Joanisse MF. Rules vs. statistics: Insights from a highly inflected language. Cognitive Science. 2011;35:638–681. doi: 10.1111/j.1551-6709.2011.01174.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mrazović P, Vukadinović Z. Gramatika srpskohrvatskog jezika za strance. [Serbo-Croatian grammar for foreigners]. Sremski Karlovci: Izdavacka knjižarnica Zorana Stojanovića; 1991. [Google Scholar]
- Piazza M, Fumarola A, Chinello A, Melcher D. Subitizing reflects visuo-spatial object individuation capacity. Cognition. 2011;121:147–153. doi: 10.1016/j.cognition.2011.05.007. [DOI] [PubMed] [Google Scholar]
- Plaut DC, Gonnerman LM. Are non-semantic morphological effects incompatible with distributed connectionist approach to lexical processing? Language and Cognitive Processes. 2000;15:445–485. [Google Scholar]
- Pollard C, Sag IA. An information-based theory of agreement. In: Brentari D, Larson G, MacLeod L, editors. Papers from the 24th annual regional meeting of the Chicago Linguistics Society: Parasession on agreement in grammatical theory. Chicago: Chicago Linguistics Society; 1988. [Google Scholar]
- Robblee KE. Individuation and Russian agreement. Slavic and East-European Journal. 1993;37:423–441. [Google Scholar]
- Rueckl JG, Raveh M. The influence of morphological regularities on the dynamics of a connectionist network. Brain and Language. 1999;68:110–117. doi: 10.1006/brln.1999.2106. [DOI] [PubMed] [Google Scholar]
- Seidenberg MS. Language acquisition and use: Learning and applying probabilistic constraints. Science. 1997;275:1599–1604. doi: 10.1126/science.275.5306.1599. [DOI] [PubMed] [Google Scholar]
- Solomon E, Pearlmutter N. Semantic integration and syntactic planning in language production. Cognitive Psychology. 2004;49(1):1–46. doi: 10.1016/j.cogpsych.2003.10.001. [DOI] [PubMed] [Google Scholar]
- Spalek K, Schriefers H. Dominance affects determiner selection in language production. Journal of Memory and Language. 2005;52:103–119. [Google Scholar]
- Spivey MJ, Tanenhaus MK, et al. Syntactic ambiguity resolution in discourse: Modeling the effects of referential context and lexical frequency. Journal of Experimental Psychology: Learning, Memory and Cognition. 1998;24:1521–1543. doi: 10.1037//0278-7393.24.6.1521. [DOI] [PubMed] [Google Scholar]
- Stanojčić Ž, Popović L, Micić S. Savremeni srpskohrvatski jezik i kultura izražavanja. [Contemporary Serbo-Croatian grammar and style manual]. Belgrade, Novi Sad: Zavod za udžbenike i nastavna sredstva; 1989. [Google Scholar]
- Tagliamonte SA, Baayen RH. Models, forests, and trees of York English: Was/were variation as a case study for statistical practice. Language Variation and Change. 2012;24:135–178. [Google Scholar]
- Thornton R, MacDonald MC. Plausibility and grammatical agreement. Journal of Memory and Language. 2003;48:740–759. [Google Scholar]
- Trueswell JC, Tanenhaus MK. Toward a lexicalist framework of constraint-based syntactic ambiguity resolution. In: Clifton CJ, Frazier L, Rayner K, editors. Perspectives on sentence processing. Hillsdale, NJ: Lawrence Erlbaum Associates; 1994. pp. 155–179. [Google Scholar]
- Vigliocco G, Butterworth B, Garrett MF. Subject-verb agreement in Spanish and English: Differences in the role of conceptual constraints. Cognition. 1996;61:261–298. doi: 10.1016/s0010-0277(96)00713-5. [DOI] [PubMed] [Google Scholar]
- Vigliocco G, Butterworth B, Semenza C. Constructing subject-verb agreement is speech: The role of semantic and morphological factors. Journal of Memory and Language. 1995;34:186–215. [Google Scholar]
- Vigliocco G, Hartsuiker RJ, Jarema G, Kolk HHJ. One or more labels on the bottles? Notional concord in Dutch and French. Language and Cognitive Processes. 1996;11:407–442. [Google Scholar]
- Vigliocco G, Nicol J. Separating hierarchical relations and word order in language production: Is proximity concord syntactic or linear? Cognition. 1998;68:B13–B29. doi: 10.1016/s0010-0277(98)00041-9. [DOI] [PubMed] [Google Scholar]
- Woollams A, Joanisse M, Patterson K. Past-tense generation from form versus meaning: Behavioural data and simulation evidence. Journal of Memory and Language. 2009;61:55–76. doi: 10.1016/j.jml.2009.02.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zlatić L. PhD Thesis. Austin: University of Texas; 1997. The Structure of the Serbian Noun Phrase. [Google Scholar]