

Abstract
Visual search in real life involves complex displays with a target among multiple types of distracters, but in the laboratory, it is often tested using simple displays with identical distracters. Can complex search be understood in terms of simple searches? This link may not be straightforward if complex search has emergent properties. One such property is linear separability, whereby search is hard when a target cannot be separated from its distracters using a single linear boundary. However, evidence in favor of linear separability is based on testing stimulus configurations in an external parametric space that need not be related to their true perceptual representation. We therefore set out to assess whether linear separability influences complex search at all. Our null hypothesis was that complex search performance depends only on classical factors such as target-distracter similarity and distracter homogeneity, which we measured using simple searches. Across three experiments involving a variety of artificial and natural objects, differences between linearly separable and nonseparable searches were explained using target-distracter similarity and distracter heterogeneity. Further, simple searches accurately predicted complex search regardless of linear separability (r = 0.91). Our results show that complex search is explained by simple search, refuting the widely held belief that linear separability influences visual search.
Keywords: similarity, shape, perception
Introduction
Our everyday visual experience frequently involves searching for a target object among a complex clutter of other objects. This phenomenon of visual search has been studied in the laboratory using simplified displays containing a single target among either one or two types of distracters (Nakayama & Martini, 2011). Indeed, studying visual search on these simple displays has yielded several important insights into the features that make search easy or difficult (Wolfe & Horowitz, 2004). However, the approach of using simple displays is based on the belief that understanding simple search will directly elucidate complex, real-life search. This is possible if complex search (i.e., search with a target among multiple types of distracters) can be explained using simple searches (i.e., searches with a target among one type of distracter). Alternatively, complex search might involve additional emergent phenomena that cannot be explained using simple search alone.
Existing theories of visual search contain several qualitative predictions regarding complex search. First, all theories agree that search becomes hard when the target is similar to its distracters (Metzger, 1936; Duncan & Humphreys, 1989; Wolfe, Cave, & Franzel, 1989) and when the distracters are heterogeneous (Duncan & Humphreys, 1989) but do not offer quantitative predictions about their relative contributions. Second, it is widely believed that search becomes hard when a target cannot be separated from its distracters using a single linear boundary in feature space (Bauer, Jolicoeur, & Cowan, 1996a, 1996b, 1998, 1999; Arguin & Saumier, 2000; Hodsoll & Humphreys, 2001; Saumier & Arguin, 2003; Blais, Arguin, & Marleau, 2009; Nakayama & Martini, 2011). This property, known as linear separability, is thus an emergent phenomenon arising from the configuration of target and distracters that cannot be explained using target-distracter or distracter-distracter similarity. However, the target-distracter configurations deemed linearly separable (LS) or linearly nonseparable (LNS) in these studies were based on coordinates defined in an external parametric space (Bauer et al., 1996a, 1996b, 1998, 1999) or using shape-matching experiments (Arguin & Saumier, 2000; Saumier & Arguin, 2003), neither of which may reflect their true perceptual configuration. This problem is compounded by the fact that targets in LS configurations are generally further away from their distracters (resulting in easier search) compared to LNS configurations. Thus, it is not clear whether linear separability influences search difficulty above and beyond that expected from increased target-distracter similarity or distracter heterogeneity alone (Navalpakkam & Itti, 2006).
Here, we set out to investigate the relationship between complex search and simple search in three experiments. According to the above theories, the ease of finding a target T among distracters D1 and D2 depends on the dissimilarity of T with D1 and D2 the similarity between the D1 and D2 as well as their linear separability. To measure these similarities, we set up simple search displays involving these items and took the similarity between two items A and B to be the average time taken by subjects to search for A among Bs (or vice versa). To assess the impact of linear separability, we asked whether differences between LNS and LS configurations could be explained by target-distracter or distracter-distracter similarities alone. As in previous studies, we sought to identify the impact of linear separability over and above the contributions expected from similarity relations alone.
The above similarity measurements have the advantage that they are directly based on visual search itself rather than subjective similarity ratings or external parametric differences between stimuli. We were further able to use these similarity measurements to visualize the underlying representation using multidimensional scaling (see Methods). This allowed us to explicitly visualize the underlying perceptual representation, which we term as visual search space. We observed important differences between distances in external parametric space and distances in visual search space. For instance, in Experiment 1, we found that orientations related through vertical mirror reflection (e.g., −20° and 20°) are more similar to each other than unrelated orientations (e.g., 0° and 40°) in visual search space even though they are equally distinct in externally defined orientation space.
In Experiment 1, we tested complex searches involving a simple one-dimensional feature, namely orientation. Here, a search for an intermediate orientation (e.g., 0° among −20° and 20°) is LNS whereas search for an extreme orientation (e.g., −20° among 0° and 20°) is LS. We found that some LNS searches are harder than comparable LS searches as expected, but we also found some LNS searches to be easier than their comparable LS searches. Upon examining the corresponding simple searches, we found that the harder search (whether LS or LNS) always involved larger target-distracter similarity and smaller distracter homogeneity—in keeping with the similarity-based theories. Thus, at least for a one-dimensional feature like orientation, differences between LNS and LS searches were explained using similarity relations as measured in simple search. However, testing linear separability for one-dimensional features is problematic because it co-varies with similarity: An intermediate orientation will always, by definition, be closer to two flanking orientations compared to an extreme orientation. Another problem with orientation is that if it is taken as a clock variable (e.g., a vertical line can be taken as either 0° or 180°), defining linear separability becomes problematic because even two orientations are LNS in that two linear boundaries are required to separate them. Nonetheless, we have chosen orientation because it is widely studied, and we treat it as varying along a line at least for the small range of orientations used here.
In Experiment 2, we tested complex shapes varying along two dimensions (curvature and thickness) used in previous studies (Arguin & Saumier, 2000; Saumier & Arguin, 2003). As in these studies, we found LNS searches to be harder than LS searches, but we were able to explain these differences using target-distracter similarity or distracter heterogeneity. Thus, even for shapes varying along two dimensions, differences between complex searches attributed in previous studies to linear separability can be explained instead using similarity relations alone. However, this still leaves open the possibility that linear separability might play a role if tested on perceptually LNS configurations.
In Experiment 3, we set out to quantitatively characterize the relationship between complex search and simple search by fitting a model that uses simple search to predict complex search across a wide variety of shapes. We looked for possible effects of linear separability by asking whether the model, being based solely on similarity relations, would become less accurate for LNS compared to LS searches. This still left us with the problem of detecting LNS configurations in search space. To this end, we devised an independent measure to assess the degree to which any target-distracter configuration (T, D1, D2) is LS and used this method to compare LS and LNS configurations. Using this measure, we were able to show that model predictions were equally accurate for LS and LNS target-distracter configurations, suggesting that the linear separability has no impact on visual search.
In Experiment 3, we tested two categories of models, both of which can capture the relationship between complex search and simple search. The first category consisted of models based on linear combinations of search times, which measure search similarity. These models, although based on the more direct measure of search reaction time (RT), have no straightforward mechanistic interpretation because it is not clear why or how search times should be summed linearly to produce a complex search time. The second category comprised models based on linear combinations of the reciprocal of search time (1/RT), which measures dissimilarity or distance in visual search. The reciprocal of search time, although an indirect measure, is a plausible quantity for explaining complex search because (a) it varies linearly with target-distracter differences whereas search time is nonlinear (Arun, 2012), (b) it has a plausible interpretation as the underlying discriminative signal that accumulates to a decision threshold in visual search, and (c) it is conceivable that complex search is driven by independent contributions from target-distracter similarity and distracter-distracter dissimilarity that sum linearly to produce a global discriminative signal that drives visual search. We tested both types of models and found that models based on search distance provide quantitatively better fits to the data compared to models based on search times.
Taken together, our results show that (a) previous evidence in favor of linear separability at least for two-dimensional shapes can be parsimoniously explained using similarity relations and (b) across a wide variety of shapes, complex search is accurately predicted by simple search regardless of linear separability.
Experiment 1: Oriented bars
In Experiment 1, we investigated the relationship between complex and simple search using simple stimuli varying along a single feature dimension, namely orientation. We measured search times for three different set sizes (16, 24, and 32 items) for LS and LNS searches involving oriented bars. For each complex search that involved finding T among D1 and D2, we also measured search performance across set sizes for T among D1, T among D2, and D1 among D2 (or vice versa).
Methods
Subjects
A total of six subjects, aged 20–30 years, with normal or corrected-to-normal vision participated in this experiment. All participants were naïve to the purpose of the experiment and gave written consent to a protocol approved by the Institutional Human Ethics Committee of the Indian Institute of Science.
Subjects were seated approximately 90 cm from a computer monitor that was under control of custom Matlab programs written using Psychtoolbox (Brainard, 1997), running on a Dell workstation.
Stimuli
Stimuli in this experiment consisted of bars measuring 0.7° × 0.2° of visual angle oriented at −40°, −20°, 0°, 20°, and 40° measured clockwise relative to the vertical.
Target-distracter configurations
We tested a total of 20 target-distracter configurations, which consisted of 10 pairs of LNS and matched LS configurations (Table 1). For each LNS configuration (say −20° among 0° and −40°), we identified a comparable LS configuration using the same three orientations but with the target interchanged with one of the distracters (e.g., 0° among −20° and −40°).
Table 1.
Target-distracter configurations tested in Experiment 1. Notes: Each LNS and LS pair shared the same three orientations but differed in the identity of the target. The third column represents the direction of the effect observed in the data. Conditions 1 through 5, marked LNS > LS, represent cases in which the LNS search was significantly harder than the LS search as assessed by a significant main effect of condition (LNS/LS) in an ANOVA on the search times with subject, condition, and set size as factors (p < 0.05). Conditions 6 through 9 represent cases in which LNS were easier than LS searches. Condition 10 showed no significant difference.
| No. |
LNS configuration |
LS configuration |
Observed effect direction (LNS vs. LS) |
||||
| T |
D1 |
D2 |
T |
D1 |
D2 |
||
| 1 | −20° | 0° | −40° | 0° | −20° | −40° | LNS > LS |
| 2 | −20° | −40° | 20° | −40° | −20° | 20° | LNS > LS |
| 3 | 0° | 20° | −20° | 20° | 0° | −20° | LNS > LS |
| 4 | 20° | 40° | −20° | 40° | 20° | −20° | LNS > LS |
| 5 | 20° | 0° | 40° | 0° | 20° | 40° | LNS > LS |
| 6 | −20° | −40° | 40° | −40° | −20° | 40° | LNS < LS |
| 7 | 0° | 20° | −40° | 20° | 0° | −40° | LNS < LS |
| 8 | 0° | 40° | −40° | 40° | 0° | −40° | LNS < LS |
| 9 | 0° | −20° | 40° | −20° | 0° | 40° | LNS < LS |
| 10 | 20° | 40° | −40° | 40° | 20° | −40° | n.s. |
Visual search task
Each subject performed randomly interleaved trials of either complex search or simple search in which they located a previewed target. In the complex search displays, there were two types of distracters whereas in the simple search displays there was one type of distracter (see Figure 1 for example 24-item displays). In a given trial, the search display contained a total number of 16, 24, or 32 items (chosen randomly each time). Prior to starting the task, subjects performed practice search trials using natural objects not used in the experiment.
Figure 1.

An example LNS search that is harder than a LS search. Search for a −20° target among 0° and −40° (A) is LNS because −20° lies in between 0° and −40° and cannot be separated from the two distracters using a single linear boundary. In contrast, the search for 0° among −20° and −40° (E) is LS because 0° can be separated from −20° and −40° using a single linear boundary. Here, the LNS search (A) is harder than the LS search (E). The remaining panels in each row indicate the simple searches corresponding to the LNS (panels B, C, and D) and LS searches (panels F, G, and H). These show that the LNS target is less similar to one distracter compared to LS (−20° among 0° is easier than 0° among −20°; B vs. F), but it is more similar to its distracters than LS (−20° among −40° is harder than 0° among −40°; C vs. G), and the distracters in the LNS search are less similar than the LS distracters (0° among −40° is easier than −20° among −40°; D vs. H). Thus, the LNS search has a target that is more similar to its distracters and has more heterogeneous distracters, making it harder than the LS search. The numbers at the bottom of each panel represent the average search times ± SEM across subjects.
In each trial of the task, subjects saw a fixation cross (0.35° × 0.35°) presented for 500 ms, followed by a preview of the target, presented in isolation for 500 ms at fixation, which was then replaced by a blank screen for 500 ms. This was then followed by the search display, which was a 6 × 6 array consisting of 16, 24, or 32 items with their locations chosen at random (but with the constraint that exactly half the items would be shown on each side). Target location was chosen uniformly at random within the central 4 × 4 region to minimize effects of target eccentricity. The array measured 15° × 15°. Item locations were chosen from a uniform distribution centered at each array location with a maximum deviation of 0.25° from the center. The display stayed on until the subject made a response, and the trial timed out after 15 s of display onset. Reaction times greater than 10 s for complex searches and greater than 4 s for the simple searches were excluded from our analyses (∼5% of the data in each search type). Subjects were asked to hit a key (M for right, Z for left) to indicate the side on which the target appeared. A vertical red bar (17° × 0.2°) was displayed at the center of the screen along with the search array to facilitate left/right judgments.
Search displays
In the complex search displays, the target side of the 6 × 6 array contained seven, 11, or 15 distracters (depending on set size), which were split into four, six, or eight instances of one distracter and three, five, or seven of the other. The other side of the array contained equal numbers of distracters of each type. The two types of distracter placements (more D1 or more D2 on the target side) were crossed with two possible target locations (left/right) to yield four unique conditions for a given target-distracter triplet (T, D1, D2). These conditions were repeated two times to yield a total of eight trials of each triplet, which resulted in 480 complex search trials (20 triads × 8 repetitions × 3 set sizes).
In the simple search displays, there were six possible simple searches corresponding to each triplet (T, D1, D2) in the complex search task: These were T among D1, T among D2, and D1 among D2 or vice versa. Because there were 20 triplets in the complex search task (Table 1) involving only five orientations, there were only 10 unique simple searches (5C2). Each of these simple searches was repeated four times each with the target randomly located on the left or right side and two times with each orientation in the pair as target. As a result, there were eight trials at each set size for each image pair (T, D) in which T or D could be the target, giving rise to 240 trials (10 triads × 2 pairs × 4 repetitions × 3 set sizes).
Results
To assess the consistency in the search times between subjects, we separated the subjects randomly into two groups and calculated the correlation between the average search times across conditions between the two groups. We found a high correlation between subjects in both blocks, suggesting that subjects were extremely consistent (r = 0.83, p < 0.00005 for complex search; r = 0.77, p < 0.00005 for simple search). We compared the performance of subjects on LNS versus LS configurations and how this related to their performance on the corresponding simple searches.
Among the LNS and LS configurations tested, we found some instances in which LNS search was harder than the LS searches but others in which LS searches were harder. Figure 1 depicts an example LNS search (−20° among 0° and −40°; Figure 1A) that is harder than its LS counterpart (0° among −20° and −40°; Figure 1E). Note that both searches contain the same three orientations and differ only in the identity of the target.
We then analyzed subjects' performance on simple searches involving all possible pairs of these orientations (i.e., 0° among −20°, 0° among −40°, and −20° among −40°). For the LNS search (−20°, 0°, −40°), the corresponding simple searches are (−20°, 0°), (−20°, −40°), and (0°, −40°). Of these, the first two represent target-distracter similarity and the last one represents distracter homogeneity (Figure 1B through 1D, top row). For the LS search (0°, −20°, −40°), the corresponding simple searches are (0°, −20°), (0°, −40°), and (−20°, −40°) (shown in Figure 1F through 1H, bottom row). According to similarity-based accounts, search should be hard when target-distracter similarity is high or when distracter-distracter similarity is low (i.e., distracters are heterogeneous).
It can be seen that the LNS and LS configurations have significant differences also in their corresponding simple searches: The LNS search target was slightly less similar to one of the distracters compared to the LS search (i.e., −20° among 0° took 0.11 s less than 0° among −20°, a well-known search asymmetry; Figure 1B vs. 1F), which predicts that the LNS search should be easier. However, the LNS search target was considerably more similar to the second distracter compared to the LS search (i.e., −20° among −40° took 0.5 s longer than 0° among −40°; Figure 1C vs. 1G). Likewise, distracter heterogeneity was greater in LNS compared to LS; in other words, the distracter-distracter search was easier (i.e., 0° among −40° took 0.5 s less than −20° among −40°; Figure 1D vs. 1H). The last two comparisons predict that LNS should be harder than LS and outweighed the first effect. Thus, taken together, the similarity factors predict that the LNS search should be harder than the LS search.
Figure 2 depicts an LNS search (0° among 20° and −40°; Figure 2A) that is easier than an LS search (20° among 0° and −40°; Figure 2E) along with the associated simple searches. It can be seen that one of the target-distracter similarities is slightly higher in the LNS compared to the LS search (i.e., 0° among 20° took 0.2 s longer than 20° among 0°, an asymmetry; Figure 2B vs. 2F) and lower target-distracter similarity for the second distracter (e.g., search for 0° among −40° took 0.3 s less than 20° among −40°; Figure 2C vs. 2G). Here the second effect was stronger than the first, suggesting that overall, the LS search had greater target-distracter similarity. In addition, the distracters in the LNS search are more homogeneous (20° among −40° took 0.3 s longer than 0° among −40°; Figure 2D vs. 2H), causing the LNS search to be easy. Thus, differences between LNS and LS search performance are again easily explained using similarity relations measured in simple search.
Figure 2.

An example LNS search that is easier than an LS search. The LNS search for a 0° target among 20° and −40° (A) is easier than an LS search for 20° among 0° and −40° (E). The related simple searches show that although the LNS target is slightly more similar to one of the distracters compared to LNS (0° among 20° is harder than 20° among 0°; B vs. F), the other distracter is less similar for LNS over LS (0° among −40° is easier than 20° among −40°; C vs. G), and the two distracters in LNS are more similar than the two distracters in LS (20° among −40° is harder than 0° among −40°; D vs. H). Thus, the LNS search has a target that is less similar to its distracters and has more homogeneous distracters, making it easier than the LS search.
These examples illustrate that LNS searches are harder than LS searches in some cases but easier than LS searches in other cases, but more importantly, these effects can be understood in terms of the corresponding simple searches. We next investigated the presence of these effects across different set sizes for each LNS and LS pair. To assess the presence of a significant difference between each LS and LNS pair, we performed an ANOVA on the search RTs with subject (six levels), condition (two levels, LS and LNS), and set size (three levels) as factors. We selected LS and LNS pairs that differed significantly as assessed by the presence of a significant main effect of condition (α < 0.05, indicated in Table 1).
We then averaged separately across pairs in which LNS was harder than LS or vice versa. For the five complex searches in which LNS was harder than LS, the LNS slopes (mean = 43 ms/item) were larger than the LS slopes (mean = 20 ms/item), and this difference approached statistical significance (paired t test, p = 0.12). For the four complex searches in which LNS was easier than LS, the slopes did not differ significantly (mean slopes: 28 ms/item for LNS, 19 ms/item for LS, p = 0.72, paired t test). The resulting RT versus set size plots are shown in Figure 3. Across pairs, we observed effects similar to the example displays in Figure 1, namely that the harder complex search (whether LNS or LS) was always associated with differences in target-distracter similarity relations as measured using simple searches. For the harder complex searches (whether LNS or LS), the target was less similar to one of the distracters—a relatively weak effect that did not reach significance in one group (Figure 3B; p = 0.7 for main effect of LS vs. LNS in an ANOVA with subject, configuration, search triple, and set size as factors) and reached significance in the other group (Figure 3F; p = 0.0001 for main effect of LS vs. LNS as before). This effect, which is in the opposite direction, was outweighed by the fact that the target in the harder search was significantly more similar to one of the distracters in both groups of conditions (LS vs. LNS main effect p < 0.00001; Figure 3C and 3G). The harder complex search was also associated with significantly smaller distracter-distracter similarity in both groups of conditions (LS vs. LNS main effect p < 0.00001; Figure 3D and 3H). Again, two of these simple searches predicted the direction of the effect (whether LNS was harder or easier than LS), and these two appeared to have dominated the third. We conclude that differences between LNS and LS searches, at least for oriented lines, can be accounted for using similarity relations as measured using simple searches.
Figure 3.

Search reaction times as a function of set size for complex searches and their associated simple searches. LNS searches and their associated simple searches are indicated using red lines, and LS searches and their associated simple searches use blue lines. Search times are averaged across conditions in which LNS searches were harder than LS searches (top row, panels A through D) and vice versa (bottom row, panels E through H). The first two simple searches measure target-distracter similarity (panels B and F for TD1; C and G for TD2, middle panels), and the last simple search (panels D and H) measures distracter-distracter similarity or distracter homogeneity (D1D2). The green asterisk in each panel denotes a statistically significant main effect (p < 0.0001) of search configuration (LS vs. LNS) (see text).
Although differences between complex searches were explained by differences in the corresponding simple searches, this was true of search times in general but not necessarily for search slopes. It can be seen (Figure 3) that complex searches had large and positive search slopes whereas the corresponding simple searches had near-zero or negative slopes. We take up the possible reasons for this discrepancy in the General discussion.
Discussion
The above results demonstrate that the differences between LS and LNS configurations as defined in orientation space can be parsimoniously explained using differences in target-distracter similarity and distracter-distracter similarity. We note however that for a one-dimensional feature space such as orientation, it is impossible to manipulate linear separability while keeping target-distracter and distracter-distracter distances constant. In other words, if orientation A were intermediate between orientations B and C, then the LNS search for A among B and C would be hard because A is close to both B and C in orientation whereas the LS search for B among A and C would be automatically easier because B is close to A but far from C. However, this argument implies that all LNS searches should be harder than their LS counterparts, which was not the case in our data: There were four LS/LNS conditions in which LS was, in fact, harder than LNS (Table 1). Why might this be so?
To investigate this issue further, we compared the simple searches corresponding to the conditions in which LNS search was easier than LS search (Table 1). Consider, for example, the orientations 0°, 20°, and −40° shown in Figure 2. If larger orientation differences resulted in easy search, then search for 20° among −40° (a 60° difference) should be easier than search for 0° among −40° (a 40° difference). Instead we found the opposite (Figure 2C vs. 2G). Similarly, search for 40° among −40° (an 80° difference in orientation) was as easy as search for 0° among 40° (data not shown). Thus, distances in visual search space do not have a straightforward relationship with differences in orientation.
To explicitly visualize the similarity relations that govern search for orientation, we performed a multidimensional scaling analysis on the reaction times for the 32-item displays (we obtained similar results for the 16-item and 24-item displays). Specifically, we took the search time for each pair of orientations in the experiment and took its reciprocal as a measure of dissimilarity or distance in search space (Arun, 2012). On the set of distances obtained in this manner between all pairs of orientations, we performed multidimensional scaling. This technique finds the best-fitting two-dimensional coordinates of each orientation such that their distances match the observed pair-wise distances. In the resulting plot, therefore, nearby orientations represent hard searches and distant orientations represent easy searches. The resulting plot (Figure 4) shows that orientations on one side of the vertical (0°, 20°, 40°) are systematically mapped in search space (e.g., the distance between 0° and 20° is roughly equal to the distance between 20° and 40°). In contrast, distances between orientations spanning the vertical midline (e.g., −20° and 20°, distance d2 in Figure 4) are far smaller than distances between orientations on the same side of the vertical (e.g., 0° and 40°, distance d1 in Figure 4) despite having the same angular separation. This is consistent with the perceptual tendency to confuse mirror-related shapes (Gross & Bornstein, 1978; Wolfe & Friedman-Hill, 1992; Rollenhagen & Olson, 2000). Likewise, the distance d3 between 40° and −40°—an orientation difference of 80°—is slightly smaller than the distance d1 between 0 deg and 40 deg even though the latter involves only a 40° difference (Figure 4).
Figure 4.
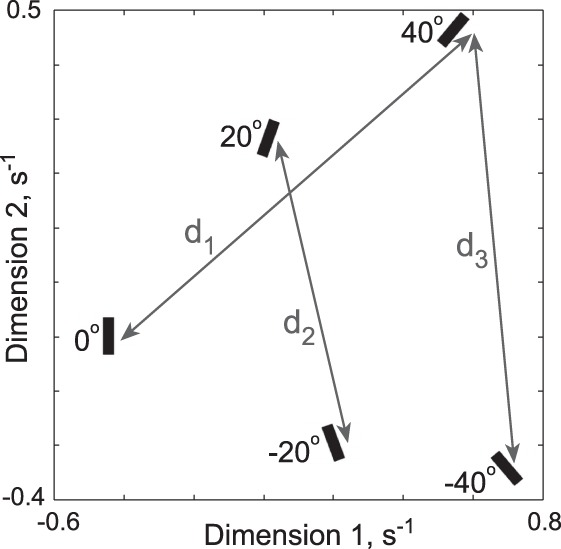
Representation of orientations in visual search space obtained using multidimensional scaling. Distances between pairs of orientations in this plot are roughly equal to the reciprocal of the average search time involving one orientation among the other for the 32-item displays. Similar plots were obtained for 16- and 24-item displays. Observed search distances and distances in this plot are closely related (r = 1.00, p < 0.00005). However, the observed search distances are not proportional to the angular differences: for instance, despite having the same difference in orientation, the distance d1 between 0° among −40° is larger than the distance d2 between −20° and 20°. Likewise, the distance d3 between 40° and −40°—an orientation difference of 80°—is slightly smaller than d1 even though the latter involves only a 40° difference.
Although the above distortions are interesting in their own right, of particular relevance here is the fact that LS searches become harder than LNS searches for certain orientations spanning across the vertical and that these differences can be explained using target-distracter similarity and distracter homogeneity as measured in simple search. We conclude that differences between complex searches involving orientations can be explained using similarity relations measured using simple search without invoking any linear separability.
Our results also provide an alternative explanation for previous findings on complex search for orientations (Wolfe, Friedman-Hill, Stewart, & O'Connell, 1992). In the Wolfe et al. (1992) study, for instance, the authors find that search for −10° among −50° and 50° is easy, but search for 10° among −30° and 70° is hard. Based on this, the authors argue for categorical representations of orientation such as “steep,” “shallow,” etc. In contrast, our findings on orientation space suggest that all orientation differences are not equal; the latter search is easy because the distracters −50° and 50° are more similar to each other than the distracters −30° and 70° despite having the same angular difference because they are mirror-related. The more homogeneous distracters, in turn, result in an easier search.
In the above experiment, it was difficult to manipulate linear separability without influencing other factors because the underlying feature was only one-dimensional. In the next experiment, we used shapes varying along two dimensions, so it was possible to manipulate linear separability while keeping target-distracter similarity and distracter homogeneity constant. Specifically, we replicated previously reported differences between LS and LNS configurations and showed that these differences can be accounted for again using similarity considerations without invoking any notion of linear separability.
Experiment 2: Shapes varying along two dimensions
In Experiment 2, we tested search performance of subjects on LS and LNS configurations consisting of shapes varying along two dimensions: curvature and thickness. Differences between these configurations have previously been attributed to linear separability (Arguin & Saumier, 2000; Saumier & Arguin, 2003). However, performances on simple searches were not measured in these studies. We therefore set out to test whether differences between LNS and LS configurations could be explained by differences in target-distracter similarity and distracter homogeneity.
Methods
Subjects
A total of six subjects performed this experiment. All other details are identical to Experiment 1.
Stimuli
The stimuli were identical to those used by the Arguin and Saumier studies (Arguin & Saumier, 2000; Saumier & Arguin, 2003), and the full stimulus set is shown in Figure 7A. Stimuli were scaled so that they measured 0.7° of visual angle along the longer dimension. The set of shapes varied in two dimensions—aspect ratio and curvature—and the method of generation is described in detail elsewhere (Arguin, Bub, & Dudek, 1996).
Figure 7.
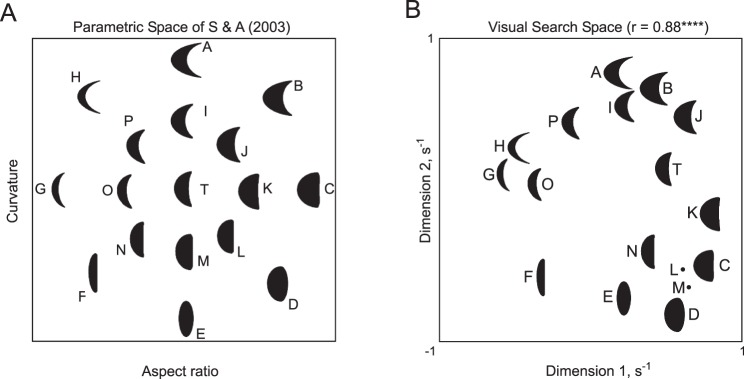
Parametric space versus search space in Experiment 2. (A) Stimuli shown in the parameter space used by Saumier and Arguin (2003). (B) A two-dimensional representation of these stimuli obtained from multidimensional scaling performed on the set of experimentally measured pair-wise search distances. Distances between pairs of shapes in this plot are roughly equal to the reciprocal of the average search time involving one shape among the other for 6 × 6 search displays. Stimuli L and M are depicted using filled dots for clarity. The original configuration in parameter space is considerably distorted in visual search space (compare panels A and B). These distortions explain the difference observed between LS and LNS searches (see text).
Target-distracter configurations
The target-distracter configurations were identical to those used in previous studies of linear separability on shapes (Arguin & Saumier, 2000; Saumier & Arguin, 2003) as summarized in Table 2. The target shape was always the item “T” (Figure 7A), but the distracters were chosen in these studies to make the overall configuration LS or LNS. In the complex search block, there were 384 trials (16 complex searches × 8 repetitions × 3 set sizes). In the simple searches, there were a total of 768 trials (32 unique searches × two pairs with A or B as the target × 4 repetitions × 3 set sizes).
Table 2.
LNS and LS target-distracter configurations used by Saumier and Arguin (2003). Notes: The letters refer to shapes in Figure 7A. The fifth column represents the direction of the effect observed in the data. In all but one LNS and LS pair, we found that LNS searches were significantly harder (p < 0.05) than the corresponding LS search, using analyses identical to those described in Table 1. For the remaining pair, the LNS and LS searches were not significantly different.
| Condition |
No. |
LNS configuration |
LS configuration |
Effect direction (LNS vs. LS) |
||||
| T |
D1 |
D2 |
T |
D1 |
D2 |
|||
| Similar distracters | 1 | T | J | N | T | N | L | LNS > LS |
| 2 | T | K | O | T | K | M | LNS > LS | |
| 3 | T | I | M | T | I | O | LNS > LS | |
| 4 | T | L | P | T | P | N | n.s. | |
| Dissimilar distracters | 5 | T | B | F | T | D | F | LNS > LS |
| 6 | T | D | H | T | F | H | LNS > LS | |
| 7 | T | A | E | T | A | G | LNS > LS | |
| 8 | T | C | G | T | C | E | LNS > LS | |
Visual search task
All aspects of the experiment were identical to Experiment 1. Extreme reaction times greater than 10 s in complex search and those greater than 4 s in simple search were excluded from the analyses (∼6% of the data).
Results
Subjects were highly consistent in their responses as evidenced by a high correlation between the average RTs of one half of the subjects and that of the other half for both tasks (r = 0.91, p < 0.00005 for complex search; r = 0.94, p < 0.00005 for simple search). Subjects searched for the target faster in LS configurations compared to LNS configurations (p < 0.0005 for the main effect of linear separability, ANOVA on search times with subject, linear separability, similarity, and set size as factors). There were also significant main effects of subject, set size, and similarity (p < 0.00005) but no significant interaction effects. These results are similar to the effects reported by Saumier and Arguin (2003).
An example LNS and LS search pair is shown in Figure 5. According to the Saumier and Arguin studies (Arguin & Saumier, 2000; Saumier & Arguin, 2003) (and also confirmed in this study), the LNS search T among N and J (Figure 5A) is harder than the LS search T among N and L (Figure 5E). In previous studies, the target-distracter and distracter-distracter similarities were never tested. On testing them, we found that the LNS search had greater target-distracter similarity (T among J is harder than T among L, Figure 5C vs. 5G) and lower distracter-distracter homogeneity (N among J is easier than N among L, Figure 5D vs. 5H).
Figure 5.

Examples of complex searches involving complex shapes used in previous studies and their associated simple searches. The LNS search T among N and J (A) is harder than the LS search for T among N and L (E). The related simple searches show one common search (T among N, panels B and F). For the other two searches, the LNS target is more similar to the distracter (TJ is harder than TL, panels C vs. G), and the LNS distracters are more heterogeneous (NJ is easier than NL, panels D vs. H). These two effects cause the LNS search to be harder than the LS search.
The trend shown in these example displays was true for most of the LNS and LS pairs tested. To assess the presence of a significant difference between each pair of LNS and LS conditions, we performed an ANOVA as before on the search times with subject, condition (LNS vs. LS), and set size as factors (Table 2). We then averaged the LNS and LS search times at each set size for the similar and dissimilar distracter conditions separately for conditions in which we observed a significant effect. We also averaged the corresponding simple search times (target-distracter and distracter-distracter) for each set size. The resulting plots are shown in Figure 6. LNS searches were harder in general than LS searches (Figure 6A and 6E) and had larger slopes compared to the LS searches (mean slopes across all similar and dissimilar distracter conditions: 57 ms/item for LNS, 17 ms/item for the corresponding LS searches, p = 0.007, paired t test). This difference was also significant for the dissimilar distracter conditions (Figure 6E; mean slopes: 48 ms/item for LNS, 18 ms/item for LS, p = 0.02, paired t test) and approached significance for the similar distracters (Figure 6A; mean slopes: 78 ms/item for LNS and 15 ms/item for LS, p = 0.08, paired t test). These results replicate the findings of previous studies using the same LNS and LS searches. However, the target-distracter and distracter-distracter similarities were never explicitly tested in previous studies.
Figure 6.

Search RTs as a function of set size for complex searches and their associated simple searches in Experiment 2. Search times are averaged across conditions in which LNS searches differed significantly from LS searches for the similar distracter conditions (panels A through D, top row) and the dissimilar distracter conditions (panels E through H, bottom row). LNS searches and their associated simple searches are indicated using red lines, and LS searches and their associated simple searches using blue lines. The leftmost column depicts complex searches whereas the remaining columns depict the corresponding simple searches. The first two simple searches measure target-distracter similarity (TD1 and TD2, middle panels), and the last simple search (panels D and H) measures distracter-distracter similarity or distracter homogeneity (D1D2). Green asterisks represent statistical significance as before.
To compare the target-distracter or distracter-distracter similarity between the LS and LNS groups of conditions, we performed an ANOVA on the corresponding search times with subject, configuration (LS vs. LNS), search condition, and set size as factors. We found that LNS searches had slightly larger target-distracter similarity, which approached statistical significance (p > 0.1 for main effect of configuration; Figure 6C and 6G). The LNS searches, however, had significantly larger distracter-distracter similarity (p < 0.00001 for the main effect of configuration; Figure 6D and 6H) compared to LS searches. Thus, similarity relations as measured in simple search predict the greater difficulty of the LNS searches compared to the LS searches. We conclude that LNS searches are harder than LS searches because they have greater target-distracter similarity or greater distracter homogeneity. Thus, we again found no evidence of an effect of linear separability over and above that expected out of purely similarity considerations alone.
Discussion
The results of Experiment 2 show that previously reported differences between LNS and LS configurations (Arguin & Saumier, 2000; Saumier & Arguin, 2003) can be attributed to similarity relations without invoking linear separability. LNS searches had greater target-distracter similarity and smaller distracter-distracter similarity; both factors are known to make search difficult. In previous studies using these shapes, these factors were controlled by asking subjects to manipulate shapes until they established a subjective equivalence in similarities between shapes, which were then used in visual search. Our results imply that subjective similarity ratings do not correspond directly to similarities in search space.
To explicitly visualize similarity relations between these shapes, we performed an additional experiment in which subjects performed simple searches involving all 136 (17C2) pairs of the shapes used in this experiment using a separate set of 12 subjects with methods identical to that used in Experiment 3. We then performed a multidimensional scaling analysis on the data as before. Distances between stimuli in the multidimensional scaling plot were in close correspondence with the experimentally measured distances (r = 0.88, p < 0.00001). But the original configuration of these stimuli in parametric space (Figure 7A) was strongly distorted in visual search space wherein the stimuli appear to form clusters of thin/thick and curved/flat stimuli (Figure 7B).
Importantly, these distances in visual search space can be used to explain the difference in search performance between LNS and LS configurations. For instance, consider the LNS configuration (T, B, F), which is harder in search compared to the LS configuration (T, D, F). Saumier and Arguin (2003) have argued these two configurations have exactly the same target-distracter and distracter-distracter similarities and only differ in linear separability, but this argument is based on externally defined parametric space. The picture in visual search space is quite different: First of all, (T, B, F) is no longer LNS in visual search space; both (T, B, F) and (T, D, F) are linearly separable (Figure 7B). Secondly, the pair-wise distances are quite different for the two configurations: The distance TB is smaller than TD (i.e., the LNS target is closer to its distracters), and BF is larger than DF (i.e., the LNS distracters are more heterogeneous). Thus, the greater difficulty of the LNS search can be explained entirely using similarity relations. We conclude that, at least for the shapes tested in the previous studies, differences between LNS and LS configurations can be explained entirely using similarity relations. Thus, linear separability does not seem to matter in complex search.
The above results show that similarity relations are a more parsimonious account of previously reported evidence in favor of a linear separability effect. However, it could still be argued that, with proper control of target and distracter distances in visual search space, linear separability might actually influence complex search. Further, we also wondered whether linear separability could be tested for arbitrary shapes. Experiment 3 is aimed at addressing these issues.
Experiment 3: Arbitrary shapes
The results of Experiments 1 and 2 show that previously reported differences between LS and LNS configurations can be explained using similarity relations in search space. It is therefore critical to assess the linear separability of a target/distracter configuration in visual search space rather than in an arbitrary parametric space. The above results also show that target-distracter similarity and distracter-distracter similarity can exert independent and sometimes competing influences on complex search difficulty. Determining which of these factors will cause one complex search to be harder than another becomes difficult in the absence of a quantitative framework.
In Experiment 3, we investigated whether complex search could be quantitatively explained using simple searches and tested for the presence of a linear separability effect on arbitrary target-distracter configurations. To this end, we measured search times in complex search and their corresponding simple searches across a wide variety of shapes (Figure 8). We then tested a number of possible quantitative relationships between search times for complex search and search times for the corresponding simple searches. To identify the contribution of linear separability, we devised a novel method to assess the linear separability of arbitrary target-distracter configurations. For an LNS configuration, we reasoned that the target and the distracters must lie along a straight line in search space. We therefore compared, for every complex search (T, D1, D2), the sum of the target distracter distances with the distracter-distracter distance; the distance is measured using the reciprocal of search time (Arun, 2012). Thus, LNS configurations must have the sum of the target-distracter distances roughly equal the distracter-distracter distance. We then reasoned that if linear separability has any effect on complex search, then models that do not incorporate it as a factor should produce poorer predictions on LNS compared to LS searches.
Figure 8.
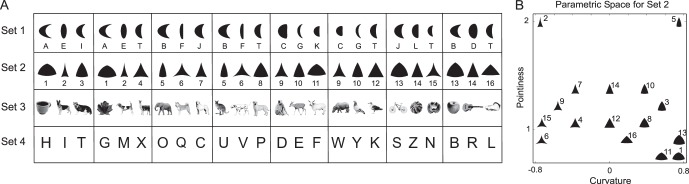
Stimuli used in Experiment 3. (A) Stimuli used in the complex and simple search tasks, depicted to scale (stimuli were white against a black background). Each set was composed of eight subsets of three shapes each. For each subset, subjects performed three complex searches in which each of the three shapes could be a target and the remaining two were the distracters. They also performed six simple searches, which consisted of all possible pair-wise searches involving the three shapes. (B) Parametric space for Set 2, which consisted of isosceles triangles that varied in curvature (convex-concave) and pointiness (ratio of height to width).
Methods
Subjects
A total of 12 subjects performed this experiment. All other details are identical to Experiment 1.
Stimuli
Stimuli in this experiment consisted of four sets of abstract and natural shapes (Figure 8A). We chose eight target-distracter triads within each set with the guiding principle that two shapes in the triad should appear perceptually similar. This ensured that visual search would vary in difficulty from easy to hard.
The first set consisted of crescent-like shapes varying in curvature and thickness (Figure 8A) and were identical to stimuli used in previous studies of linear separability (Arguin & Saumier, 2000; Saumier & Arguin, 2003).
The second set of shapes consisted of triangular shapes varying in pointiness and curvature (Figure 8B). These shapes were created by first defining an isosceles triangle with a fixed ratio of isosceles side to base. This ratio was denoted as pointiness. Using the end points of each side of this triangle, circular arcs of a fixed radius were drawn to create convex or concave triangles. The radius of the arcs on the isosceles part of the triangle was set to r = p2b/c where b was the length of the triangle base, and p and c were the two free parameters, pointiness (which had to be at least 0.5) and curvature (which could range from −1 to 1), respectively. The radius of the arc on the base of the triangle was set to rb = b/c. The sign of the curvature parameter determined whether the arc was convex (positive values) or concave (negative values). The radii, sides, and curvature then uniquely determined the location of the center of the corresponding circles, and the corresponding arcs were drawn to define the shape.
The third set of shapes consisted of grayscale images of natural objects (largely from Hemera Photo Objects; Figure 8A) in which the subsets were chosen so that the searches within a subset would range from easy to hard. The fourth set contained letters of the English alphabet (Figure 8A); here some of the subsets were chosen because they were known to produce search asymmetries (e.g., C, Q, O).
Target-distracter configurations
For each triad, we chose all three possible complex searches in which one was target and the others were distracters. Thus, there were a total of 96 complex searches performed by each subject (4 sets × 8 subsets × 3 targets per subset). For each triad of stimuli, we also performed six corresponding simple searches consisting of all pairs of stimuli as target and distracter. Although in principle this would require 192 simple searches (4 sets × 8 subsets × 6 pairs per subset), there were only 88 unique simple searches across the triads. This resulted in a total 352 trials of simple search (88 triads × 2 pairs × 2 repetitions). Each subject also performed a total of four trials of each complex search condition, resulting in a total of 384 complex search trials (96 triads × 4 repetitions). Note that the organization of the stimuli into sets was purely for the sake of subsequent analysis; in the actual experiment, search displays derived from all sets occurred in random order in both the complex and simple search tasks.
Visual search task
Each subject performed a complex search task and a simple search task in which they saw 36-item (6 × 6) search arrays. The two tasks were identical in all respects except that in the complex search task there were two types of distracters whereas in the simple search task there were multiple identical distracters. Task order was counterbalanced across subjects. Before starting each task, subjects performed 24 practice trials of each search type (using novel natural objects not used in the main experiment).
In each trial of either task, subjects saw a fixation cross (0.35° × 0.35°) presented for 500 ms, followed by a preview of the target presented in isolation for 500 ms at fixation, which was then replaced by a blank screen for 500 ms. This was then followed by the search display, which was a 6 × 6 array with the target location chosen uniformly at random within the central 4 × 4 region to minimize effects related to target eccentricity. The array size was 15° × 15° and individual items were 1.4° along the longer dimension. Item locations were chosen from a uniform distribution centered at each array location with a maximum deviation of 0.25° from the center. The display stayed on until the subject made a response, and the trial timed out after 7.5 s of display onset. Subjects were asked to hit a key to indicate the side (M for right, Z for left) on which the target appeared. A vertical red bar (17° × 0.2°) was displayed at the center of the screen along with the search array to facilitate left/right judgments.
Search displays
In the complex search task, the target appeared at a random location within the central 4 × 4 part of the 6 × 6 array. The target side of the 6 × 6 array contained 17 distracters, which were split into eight of one distracter type and nine of the other (the other side of the array contained nine distracters of each type). The two types of distracter placements (eight or nine instances of D1 on the side of the target) were crossed with two possible target locations (left/right) to yield four trials for a given target-distracter triplet (T, D1, D2). Distracter identity at each location was chosen at random in each trial while preserving these constraints. In addition to this, to ensure that the immediate vicinity of the target also contained equal proportions of distracters, four distracters of each type were placed in the 3 × 3 array surrounding the target with locations chosen at random on each trial.
In the simple search task, the target again appeared at a random location within the central 4 × 4 part of the 6 × 6 array. There were six possible simple searches corresponding to each triplet (T, D1, D2) in the complex search task; these were T among D1, T among D2, and D1 among D2 (and vice versa). Each simple search was repeated twice with the target either on the left or right side of the array with the result that there were four trials for each image pair in which either could be the target.
Model fitting
We denoted each complex search of the form T among D1 and D2 as (T, D1, D2) and the corresponding average reaction time (averaged across trials and across subjects) as RT(T, D1, D2). The corresponding simple searches are T among D1 and T among D2, which are related to target-distracter similarity. We denoted the corresponding average RTs as RT(T, D1) and RT(T, D2), respectively. Because the ordering of the distracters was arbitrary, we sorted the data such that RT(T, D1) was the larger of the two search times. In other words, D1 was always the harder of the two distracters. A third factor that may influence complex search performance is distracter homogeneity, which we measured using the average time taken to search for D1 among D2 or vice versa. Note that, in general, RT(A, B) may not equal RT(B, A) if there is a search asymmetry. In subsequent analyses (see Results) we found search asymmetry to have only a minor impact on complex search.
We tested several linear models that depict possible relationships between complex search time and its corresponding simple search times (Table 3). For each model, the observed complex search data (the 96 search times or search distances) were concatenated into a 96 × 1 vector (denoted as y). The observed simple search data were likewise concatenated to form a 96 × 3 matrix (denoted as X) in which the three columns corresponded to the TD1, TD2, and D1D2 effects (search times or distances). We then sought to find the linear contributions of the three simple search factors (a 3 × 1 vector b) that could predict the complex search. This was done using linear regression (regress function in Matlab, Natick, MA), which finds the best-fitting coefficients as
 |
Table 3.
Performance of various models relating complex search to simple search. Notes: For each model, we used simple search times to predict complex search time (Models 1 through 3) or simple search distance to predict complex search distance (Models 4 through 6). All correlations were statistically significant (p < 0.005).
| Model type |
# |
Model interpretation |
Correlation with data (n = 96) |
Model coefficients |
|||
| a |
b |
c |
d |
||||
| Models based on search times (RT) | 1 | Complex search time is determined entirely by the search time for the harder distracter. | 0.76 | - | - | - | - |
| RT(T, D1D2) = max RT(T, D1), RT(T, D2) | |||||||
| 2 | Complex search time depends on both the easy and hard distracters. | 0.79 | 0.88 | 0.94 | –0.11 | - | |
| RT(T, D1D2) = a × RT(T, D1) + b × RT(T, D2) + c | |||||||
| 3 | Complex search time depends on the easy and hard distracters as well as on distracter-distracter similarity. | 0.82 | 0.81 | 1.29 | –0.39 | 0.07 | |
| RT(T, D1D2) = a × RT(T, D1) + b × RT(T, D2) + c × RT(D1, D2) + d | |||||||
| Models based on search distance (1/RT) | 4 | Complex search distance is determined entirely by the hard (nearer) distracter. | 0.84 | - | - | - | - |
| d(T, D1D2) = 1/RT(T, D1D2) = min (1/RT(T, D1), 1/RT(T, D2)) | |||||||
| 5 | Complex search distance depends on both the hard and easy distracters. | 0.85 | 0.73 | 0.16 | –0.22 | - | |
| d(T, D1D2) = 1/RT(T, D1D2) = a × d(T, D1) + b × d(T, D2) + c | |||||||
| 6 | Complex search distance depends on hard and easy distracters as well as on distracter-distracter dissimilarity. | 0.91 | 0.60 | 0.45 | –0.35 | –0.05 | |
| d(T, D1D2) = 1/RT(T, D1D2) = a × d(T, D1) + b × d(T, D2) + c × d(D1, D2) + d | |||||||
The model predictions could then be obtained simply as ypred = XTb. To compare model predictions with the observed data, we calculated the Pearson's correlation between the two vectors.
Results
There were 96 complex searches in this experiment, and each complex search was associated with three simple searches. Subjects were highly consistent in their responses as evidenced by a high correlation between the average RTs of one half of the subjects and that of the other half for both tasks (r = 0.94, p < 0.00001 for complex search; r = 0.79, p < 0.00001 for simple search). Thus, the underlying features and/or task strategies did not vary across subjects. We then set out to investigate whether complex search times could be explained using simple search times.
For each search (complex or simple), we took the average search time across subjects and repetitions. For every complex search time involving (say) T among D1 and D2, we selected the corresponding average search times for T among D1 and T among D2. Note that we did not consider D1 or D2 among T for these calculations, thereby respecting possible search asymmetries that might be present in these displays (however, see below for an analysis of asymmetry). In contrast, the complex search displays contained equal numbers of D1 and D2, so we took as a measure of distracter homogeneity the average search time for finding D1 among D2 or D2 among D1. Because distracter identity was arbitrary, we always denoted the harder distracter to be D1 (i.e., the one among which the target was harder to find on average) and the other one as D2.
To illustrate how complex search might be related to simple search, we sorted the 96 complex search times (averaged across trials and subjects) in ascending order and separated them into two groups (easy and hard), each containing data from 48 complex search conditions. Search times were significantly different between these two groups (p < 0.00001, unpaired t test on average RTs for each condition). For these easy and hard complex searches, we calculated the average search times for the corresponding simple searches (Figure 9A). It can be seen that, compared to the hard complex searches, the easy ones had smaller search times for (T, D1) and (T, D2) (p < 0.00001, unpaired t test) but larger search times for (D1, D2) (p = 0.02, unpaired t test). Thus, just as in Experiments 1 and 2, similarity between the target and either distracter increases complex search time whereas distracter homogeneity reduces complex search time, exactly as predicted by similarity theories of search.
Figure 9.

(A) The 96 complex search times in Experiment 3 were sorted into 48 easy and 48 hard complex searches. For these two groups, the average complex search times and their corresponding simple search times are shown. Error bars represent SEM of the subject-averaged search times across conditions. It can be seen that easy complex searches involve smaller search times for (T, D1) and (T, D2) but larger search times for (D1, D2); this illustrates the opposite effect of distracter homogeneity. (B) Observed complex search distances (averaged across subjects) plotted against model predictions based on simple searches for Model 6. There were 24 complex searches in each set (eight subsets × three targets per subset). Model predictions were strongly correlated with the observed data and explained 83% of the total variance. Asterisks represent statistical significance (***** is p < 0.00005).
To quantitatively assess the contributions of these factors, we tested six plausible models that capture different relationships between complex search and simple search as described below. We have implicitly assumed that factors such as similarity between the target and the hard and easy distracters and distracter-distracter similarity all may have potentially unequal contributions. If these factors contributed equally, the corresponding model coefficients would be equal. All models included a constant term, which accounts for a possible constant offset in RTs between simple and complex searches (due to practice effects or top-down factors). We also tested models in which the baseline motor RT for each subject (calculated as the average time taken to respond to a single target disk that appeared on the left or right of the screen) was subtracted from their search times in order to factor out the contribution of motor responses; the results from these analyses were qualitatively similar to analyses done without removal of motor RTs. We therefore present below all analyses based on the raw, observed search times for simplicity.
The performance of all six models is summarized in Table 3. The first model is based on the idea that complex search time for T among D1 and D2 is dominated entirely by the time taken to search for the harder of the two distracters. The predictions of this model were positive and significant (r = 0.76, p < 0.00001), but this correlation was relatively small in comparison to the other models. The second model was based on the idea that the time taken for complex search depends on both the time taken to search for the target among the easy as well as among the hard distracters. For this model, the correlation between the predicted and observed search times was higher than Model 1 (r = 0.79, p < 0.00001). Although an increase in quality of fit is expected because this model has an extra free parameter, there is a standard statistical test (partial F test) that estimates the expected increase in the quality of fit due to the extra degrees of freedom and returns the probability that the two models are equivalent. We found that Model 2 predictions were significantly better than Model 1 over and above that expected from the extra degree of freedom, F(2, 3) = 9.47, p = 0.003, partial F test. The third model instantiated the idea that the time taken for complex search depends not only on the time taken to search for the target among the two distracters, but also on the similarity between the distracters themselves. For this model, the correlation between the predicted and observed complex search times was even higher than the previous two models (r = 0.82, p < 0.00001). This increase in quality of fit over Model 2 was significantly greater than expected from the addition of an extra degree of freedom, F(3, 4) = 15.6, p = 0.001, partial F test.
We tested an additional three models that contain the same elements as the models above except that, instead of directly using simple search times (which measure similarity), they are based on the reciprocal of the search time (which measures dissimilarity; see Discussion). These models performed better than the models based on search time. This dissimilarity or search distance used in these models can be interpreted as the discriminative signal that accumulates in visual search to produce a response upon reaching a threshold (Purcell et al., 2010; Sripati & Olson, 2010; Schall, Purcell, Heitz, Logan, & Palmeri, 2011; Arun, 2012). Note that because taking the reciprocal is a nonlinear transformation, the predictions of these models will be distinct from models based on search time.
The first of these models (Model 4) is based on the idea that search distance in complex search depends solely on the distance between the target and the nearest (i.e., hardest) distracter. The search distances predicted by this model were strongly correlated with the observed search distances (r = 0.84, p < 0.00001). The next model (Model 5) was based on the idea that search distances in complex search depend on the distances between the target and the nearest as well as the farthest distracters. The predictions of this model were slightly better (r = 0.85, p < 0.00001), but this increase barely reached statistical significance (F(2, 3) = 3.82, p = 0.053, partial F test).
The last model (Model 6) instantiated the idea that search distances in complex search are driven not only by the distance between the target and the distracters, but also by the distance between the distracters. The predictions of this model were strongly and significantly correlated with the observed search distances (r = 0.91, p < 0.00001, Figure 9B). The improvement in the quality of fit in this model was significantly greater than expected from the extra degree of freedom in Model 6 compared to Model 5, F(3, 4) = 59.7, p < 0.00001, partial F test. The correlation between the observed and predicted data for Model 6 was significantly larger than the correlations for all other models (p < 0.05 for all comparisons, Fisher's z test). Finally, when search distance predictions in Model 6 were converted back into RTs (by taking their reciprocal), they too were strongly correlated with the observed complex search times (r = 0.86, p < 0.00001).
The high degree of fit of Model 6 persisted even on individual sets (Figure 9B), and model parameters and fits did not vary by much when the model was fit separately on the individual sets (Table 4). The coefficients of Model 6 offer additional insights into the contributions of the different factors driving complex search. First, it shows that the hard distracter (weight = 0.6) has a slightly larger contribution than the easy distracter (weight = 0.45). Second, search distance in complex search reduces with increasing distance between the distracters as evidenced by a negative weight in the model (weight = −0.35). Third, the contribution of target-distracter similarity to complex search is stronger than that of distracter heterogeneity.
Table 4.
Variation in model performance across shape sets. Notes: To investigate whether the contribution of the simple searches vary across stimuli, the best model (Model 6) was fit separately to each stimulus set, and the resulting correlations and regression coefficients are given above. Statistical significance was p < 0.00001.
| Correlation with data |
Model coefficients |
||||
| Hard distracter |
Easy distracter |
Distracter heterogeneity |
Constant term |
||
| All sets (n = 96) | 0.91**** | 0.60 | 0.45 | −0.35 | −0.05 |
| Set 1 (n = 24) | 0.95**** | 0.52 | 0.40 | −0.40 | 0.13 |
| Set 2 (n = 24) | 0.89**** | 0.50 | 0.47 | −0.48 | 0.17 |
| Set 3 (n = 24) | 0.93**** | 0.69 | 0.45 | −0.26 | −0.29 |
| Set 4 (n = 24) | 0.93**** | 0.44 | 0.73 | −0.45 | −0.07 |
Based on the above analyses, we conclude that a large fraction (r2 = 83%) of the variance in complex search can be accounted for by pair-wise dissimilarities or simple searches. The striking match between complex search and predictions based solely on simple searches places strong limits on the influence of emergent properties such as linear separability. In the subsequent analyses, we present results based on Model 6, and we take up the issue of linear separability in greater detail.
Does search asymmetry influence complex search?
The above results show that search for a target T among distracters D1 and D2 is driven by simple searches T among D1, T among D2, and D1 among D2 (or vice versa). As formulated here, this model already takes into account possible visual search asymmetries because it uses, for instance, the search for T among D1 but not D1 among T. However, this framework allowed us to ask, what is the contribution of search asymmetries toward complex search? To address this issue, we set up a variant of the model (Model 6) in which we took the simple search times to be the average of the times taken to search for T among D1 and D1 among T and so on. For each of the 96 complex searches in our data, we also performed a statistical test to determine which of the simple searches (T, D1) and (T, D2) were asymmetric (ANOVA with subject and asymmetry as factors, criterion of p < 0.05 for main effect of asymmetry). We separated the complex searches into those in which the simple searches had no asymmetry (n = 46), those in which one simple search (i.e., T among D1 or T among D2) had an asymmetry (n = 40), and those in which both simple searches had asymmetries (n = 10). For these three groups of searches, we compared the correlation with the observed data of the models with and without asymmetry (Table 5). As expected, there was virtually no difference in the quality of fit of the two variants of Model 6 when neither simple searches had an asymmetry. However, when one of the simple searches had a search asymmetry, the model that incorporated asymmetry had a slightly higher quality of fit (r = 0.84 vs. r = 0.90 for without and with asymmetry), but this difference in correlation was not significant (p = 0.23, Fisher's z test). When both simple searches had asymmetries, the model with asymmetry again outperformed the model without asymmetries (r = 0.79 vs. r = 0.85), but again, the difference in correlations was not significant (p = 0.40, Fisher's z test). However, in both cases, there was a slight increase in the quality of fit when the model incorporated search asymmetry. We conclude that search asymmetries play a relatively minor role in determining complex search.
Table 5.
Performance of Model 6 with and without search asymmetry. Asterisks represent statistical significance (***** is p < 0.00005, * is p < 0.05, ** is p < 0.005).
| Type of complex search |
Model performance (correlation with data) |
|
| Without asymmetry |
With asymmetry |
|
| No asymmetric pairs (n = 46) | 0.89***** | 0.90***** |
| 1 asymmetric pair (n = 40) | 0.84***** | 0.90***** |
| 2 asymmetric pairs (n = 10) | 0.79* | 0.85** |
Does linear separability influence complex search?
The above results suggest that complex search can be explained largely by simple search without recourse to additional factors such as linear separability. However, it may be entirely possible that most target-distracter configurations tested here were LS to start with and therefore do not reveal any effect of linear separability. This is a nontrivial issue because there is no obvious way to assess the linear separability of a target-distracter configuration when the underlying feature space is unknown.
To address this problem, we devised a novel method to measure the extent to which an arbitrary target-distracter configuration is LS in visual search space (Figure 10A). For a given target-distracter configuration (T, D1, D2), the distances between the three stimuli in visual search space can be measured using the reciprocal of the pair-wise search times. In other words, the distance d(TD1) is the reciprocal of the average time taken to search for T among D1 (and vice versa). For any three points, given the distances d(TD1), d(TD2), and d(D1D2), we reasoned that if the target T lies along a straight line between D1 and D2 (i.e., it is LNS), then the distance between the distracters d(D1D2) must equal the sum of the distances d(TD1) and d(TD2); this is illustrated in Figure 10A. The extent of deviation from equality is therefore a measure of how LS this configuration is. For each of the 96 complex search configurations in Experiment 3 (8 subsets × 4 sets × 3 targets per subset), we plotted the sum of d(TD1) and d(TD2) against d(D1D2) (Figure 10B). In this plot, points close to the unit line (y = x) represent configurations that fall along a line and are, by definition, LNS. Points that fall far away from the unit line represent triangle-like configurations that are clearly LS. Of the 96 complex search configurations, we chose two equal subsets for comparison: the LNS configurations, which were defined as those that fell within 0.41 distance units of the unit line (n = 29), and the LS ones, which were defined as those that fell beyond 1.28 distance units of the unit line (n = 29). We then compared model fits for the LS and LNS configurations (Figure 10C). The correlation between model predictions and the observed complex search distances was slightly lower for the LNS than the LS configurations (r = 0.68 for LNS, r = 0.72 for LS configurations), but this difference did not reach significance (p = 0.76, Fisher's z test). This subtle and insignificant drop in correlation is hardly the impact expected of a linear separability effect. We obtained qualitatively similar results upon varying the threshold distances used to define the two configurations. We therefore conclude that linear separability is unlikely to play a role in complex visual search.
Figure 10.

Analysis of linear separability for arbitrary target-distracter configurations in search space. (A) Schematic of the method used to assess linear separability for arbitrary configurations in search space; (T, D1, D2) depicts an arbitrary target-distracter configuration in which the target (T) is linearly nonseperable from its distracters (i.e., cannot be separated from the distracters using a single linear boundary). In this case, the target must fall along a straight line connecting the two distracters, implying that the sum of the two target-distracter distances will equal the distance between the distracters. The same target (T), however, is linearly separable from D1 and D3 (i.e., can be separated from the distracters using a linear boundary; right panel); in which case the sum of the target-distracter distances will exceed the distracter-distracter distance. The degree to which the sum exceeds the distracter-distracter distance can be taken as a measure of the degree to which the configuration is LS. (B) Taking the perceived distance between two objects to be the reciprocal of the corresponding search time, the distance between the distracters is plotted against the sum of the distances between the target and the two distracters. Search configurations that fall close to the unit line (y = x) in this plot were deemed LNS (plus symbols) whereas those that fall far from the unit line were deemed LS (triangles). Configurations that fall between these two groups are represented by circles. (C) Observed complex search distances against the model predictions—same y-axis data as in Figure 9B—but now with searches relabeled as LS (blue triangles) and LNS search configurations (red crosses) based on the method in (B). Model predictions were strongly correlated with the data in both groups, and the difference in correlation was not significant (LS, r = 0.72; LNS, r = 0.68; p = 0.76, Fisher's z test). Asterisks represent statistical significance (***** is p < 0.00005).
The above approach hinges on using simple search times to assess linear separability and then using it again to predict complex search times. Although unlikely, this “double-dipping” might have somehow biased the analyses away from finding a linear separability effect. To address this concern, we repeated the above analyses after separating the data into two independent halves (containing half the number of subjects). Using one half of the data, we identified LS and LNS configurations as before, and then we fit the model to the data from the second half of the subjects. We again found no significant differences in the ability of the model to explain LS over LNS configurations.
To further address this concern, we reanalyzed the data from Experiment 2 that contained LNS and LS configurations as defined by previous studies and fit the model to both LNS and LS search data for 32-item displays (we obtained similar results for the other set sizes). Model predictions were strongly correlated with observed search distances, regardless of whether the target was LS (r = 0.82, p < 0.05) or LNS from the distracters (r = 0.86, p < 0.005). This difference between correlation was again statistically insignificant (p = 0.81, Fisher's z test). Thus, even for LNS and LS configurations defined independently of our distance criterion, differences in search performance were predicted by the model. We conclude that complex search is largely explained using simple searches and that linear separability has no impact on visual search at least for the shapes tested here.
General discussion
We set out to investigate an important missing link between simple search (finding a target among many identical distracters) and complex visual search (finding a target among multiple types of distracters): Can complex search be understood in terms of simple searches? For each complex search for a target T among distracters D1 and D2, we characterized its corresponding simple searches, i.e., T among D1, T among D2, and D1 among D2 (and D2 among D1). The first two searches measure the similarity between the target and the distracters. The last one (D1 among D2 or vice versa) measures distracter similarity or homogeneity. The main finding of this study is that, at least for a wide variety of shapes, complex search is quantitatively explained by simple search and that this holds true regardless of the linear separability of the target and distracters. It is consistent with classical similarity theories, which posit that complex search is influenced by target-distracter similarity and distracter homogeneity. This finding however refutes the widely held belief that linear separability influences visual search. We examine below the relationship between these findings and previous studies in this regard.
Relationship to theories of visual search
Many accounts of visual search acknowledge that target-distracter similarity and distracter homogeneity influence the difficulty of complex search (Metzger, 1936; Duncan & Humphreys, 1989; Wolfe et al., 1989). These factors have previously been modeled using image features to predict eye movement guidance (Navalpakkam & Itti, 2006; Hwang, Higgins, & Pomplun, 2009). However, to our knowledge, our study is the first to explicitly measure these factors and use them to elucidate complex search. Our model elucidates the relative contributions of these factors and generates testable predictions for what should happen when these factors compete with each other: For instance, we show that the most important determinant of complex search is the distracter nearest to the target and that distracter dissimilarity has a somewhat smaller contribution whose effect is opposite to that of target-distracter similarity.
Search dissimilarity versus search similarity
Classical theories of search have made no distinction between accounts based on similarity or dissimilarity. In other words, complex search could equally well be said to depend on the similarity or dissimilarity between (a) the target and distracters and (b) between the different distracters. However, we have found a surprising distinction between models based on dissimilarity (i.e., search distance) and models based on similarity (i.e., search time): The former were far more effective in predicting complex search. Why might this be so?
There are several lines of reasoning that make dissimilarity or search distance a more plausible quantity than search time for explaining complex search. First, search distance varies linearly with target-distracter differences whereas search time does not (Arun, 2012). Second, search distance has a straightforward mechanistic interpretation: It is proportional to the discriminative signal that accumulates until it reaches a response threshold. Indeed, search distance is proportional to neuronal discriminability in visual cortex (Sripati & Olson, 2010). Third, our model based on search distance has a straightforward interpretation: It implies that the discriminative signal in complex search arises from a linear combination of signals arising from target-distracter and distracter-distracter differences. Precisely how these discriminative signals arise in the brain is not clear in general although they have been observed even in early visual areas (Lee, Yang, Romero, & Mumford, 2002) and are speculated to arise from contrast-enhancing lateral interactions (Sripati & Olson, 2010). It is difficult to imagine an equally plausible interpretation of the search time–based models that explain how simple search times combined to drive complex search. Our results provide empirical support for models based on search distance by showing that they outperform models based on search times.
Search time versus search slopes
The main finding of our study is that complex search distances can be explained using simple search distances. In separate analyses, we have found that the relationship between complex and simple search distances remains qualitatively similar at all set sizes (data not shown). Does a similar relationship hold for search slopes? Our results show that hard complex searches (with large positive search slopes) are frequently associated with simple searches with near-zero slopes, which tend to differ in their intercept (e.g., Figures 3 and 6). Thus, there appears to be no systematic relationship between the search slopes in complex search and simple search. How do we explain this discrepancy?
One possibility is that there may, in fact, be a systematic relationship in search slopes, which may have been obscured by the fact that simple search slopes, being relatively small, are more prone to noise. This is because search slopes are calculated from differences in search times, which double their variance, making smaller slopes harder to distinguish from zero. To further evaluate this possibility, we calculated the search slopes for all 36 search conditions in both Experiments 1 and 2 for both complex and simple search slopes. We found that complex search slopes were significantly and positively correlated with target-distracter search slopes (r = 0.33, p = 0.05) and were positively but not significantly correlated with distracter-distracter search slopes (r = 0.18, p = 0.29). These correlations are far lower than those obtained between complex and simple search times (r = 0.91 across all sets, Figure 9), which may reflect the greater noise in search slopes compared to search times. Understanding the relationships between search slopes will require systematic measurements involving fewer conditions but many more trials per condition to obtain reliable slope estimates.
Another possibility is that search slopes may reflect two additional factors that differ between complex and simple searches. The first factor is perceptual grouping: Simple search displays have multiple identical elements that may facilitate grouping whereas complex search displays consist of multiple types of distracters, which interfere with grouping. As a result, simple searches may be more efficient in terms of per-item processing, resulting in small search slopes. We also note that the negative search slopes observed for oriented bars (Experiment 1) may reflect grouping effects. The second factor is top-down knowledge: Changing the identity of the target and distracters from one trial to another (as in our experiments) introduces a fixed RT cost and also influences search slopes (Hodsoll & Humphreys, 2001; Wolfe, Butcher, Lee, & Hyle, 2003). Importantly, however, grouping and target foreknowledge do not reverse the relative difficulty of one search over another. In particular, target foreknowledge affects LNS searches more than LS searches, which may reflect greater speeding up of difficult searches, but LNS searches remain harder than LS in either condition (Hodsoll & Humphreys, 2001). Because these factors influence but do not reverse search difficulty at a given set size, we propose that they modulate but do not fundamentally influence the relationship between complex and simple search. The fact remains that differences in complex search are explained largely by differences in simple searches, which calls into question the presence of other emergent factors such as linear separability.
Relationship to other studies of linear separability
Our results contradict the widely held view that search becomes hard when a target cannot be separated from the distracters using a single linear boundary (Bauer et al., 1996a, 1996b, 1998, 1999; Arguin & Saumier, 2000; Saumier & Arguin, 2003; Nakayama & Martini, 2011). Instead, we have shown that a model based on simple searches with no information about linear separability predicts complex search with a high degree of accuracy.
It could be argued that, in accounting for complex searches (T, D1, D2), our model implicitly incorporates a linear separability term of the form TD1 + TD2 – D1D2. Because this is a linear term, any model containing this term will produce predictions that are identical to a model based on a linear combination of TD1, TD2, and D1D2. The resulting model will be indistinguishable from a model based on similarity alone. Thus, as several others have correctly argued (Bauer et al., 1996a, 1996b, 1998), any real contribution of linear separability must be substantially larger than predictions based on similarity.
Because there are no quantitative models of linear separability, we sought to reveal the contribution of linear separability by comparing model predictions for LS and LNS configurations. We reasoned that if linear separability truly played a role, it would degrade the quality of fit of any model based on target-distracter similarity alone. We searched for this effect in two ways: First, we replicated previously reported differences in search performance between LS and LNS configurations (Arguin & Saumier, 2000; Saumier & Arguin, 2003) and showed that these effects arise from differences in target-distracter similarity as measured using simple searches (Experiments 2 and 3). Second, we devised a novel method to assess whether any configuration of target and distracters is LS using pair-wise measurements of search times in simple search. In both cases, we found no significant differences in the quality of fit between LS and LNS searches.
Importance of perceived similarity in assessing linear separability
The contradiction between our results and previously reported evidence in favor of linear separability arises from a critical methodological difference. In previous studies of linear separability, target and distracter items were generated in a parametric space and were deemed LS (or not) in this space. It was implicitly assumed that these configurations were close to the perceived target-distracter configuration in visual search space. In studies using color targets, target and distracters in color space were chosen such that all pair-wise distances in CIE color space were identical for the LS and LNS configurations (Bauer et al., 1996a, 1996b, 1998, 1999). However distances in CIE space do not necessarily correspond to those in visual search space (Lindsey et al., 2010). Assessing this possibility will require careful manipulations of color space.
In studies using abstract shapes, LS versus LNS configurations were compared while choosing targets and distracters matched for similarity in a subjective rating task involving single items (Arguin & Saumier, 2000; Saumier & Arguin, 2003). However, these similarity measurements clearly do not correspond to similarity in visual search. Our data shows that the original representation of stimuli in parametric space (Figure 7A) is strongly distorted in visual search space (Figure 7B). More importantly, these distortions explain the differences between LS and LNS searches. Thus, it is critical to assess linear separability using perceived similarity in search space rather than other indirect measures.
Relationship to more complex visual search
Here we have proposed that the linear separability of any target-distracter configuration in search space can be assessed by measuring all pair-wise dissimilarities. This idea can be tested easily for the simple case of a target among two types of distracters, for which we devised a simple formula based on the triangle inequality. Can this be generalized for more complex searches involving multiple types of distracters? For multiple types of distracters, the condition of linear separability is equivalent to testing whether the target falls within a convex hull formed by the distracters (Bauer et al., 1999). It is critical to test this possibility in visual search space. One possibility is that the underlying search space configuration can be visualized using multidimensional scaling, and the resulting coordinates can then be used to assess the convex hull condition. A more direct approach would involve reducing the convex hull condition to an equivalent mathematical condition involving pair-wise distances.
Conclusions
Taken together, our results reveal a surprising regularity in visual search: Complex search can be accurately predicted using dissimilarities as measured using simple searches. For a wide variety of shapes, including those tested in previous studies, we have found that differences between LS and LNS configurations can be explained using pairwise dissimilarities. This finding calls into question the widely held belief that linear separability influences visual search.
A generalization of the present study would be to investigate whether more complex search involving a target among multiple types of distracters can be explained using pair-wise dissimilarities. A positive outcome would imply that pair-wise relationships alone can explain all complex search. A negative outcome does not necessarily mean that complex search is irreducible. Rather, it might be accounted for by pair-wise searches as well as other lower-order complex searches. Either outcome would be interesting and will further our understanding of visual search. We speculate that, at least in natural scenes containing salient objects clearly distinguishable from the background, real-life search with multiple types of distracters in varying numbers can be understood entirely in terms of pair-wise dissimilarities between these objects in visual search space.
Acknowledgments
We thank Zhivago Kalathupiriyan for assistance with programming. This research was funded by a startup grant from the Indian Institute of Science and an Intermediate Fellowship from the Wellcome Trust - DBT India Alliance (both to S. P. A.).
Commercial relationships: none.
Corresponding author: S. P. Arun.
Email: sparun@cns.iisc.ernet.in.
Address: Centre for Neuroscience, Indian Institute of Science, Bangalore, India.
Contributor Information
T. Vighneshvel, Email: vighnesh@cns.iisc.ernet.in.
S. P. Arun, Email: sparun@cns.iisc.ernet.in.
References
- Arguin M., Bub D., Dudek G. (1996). Shape integration for visual object recognition and its implication in category-specific visual agnosia. Visual Cognition , 3, 221–275 [Google Scholar]
- Arguin M., Saumier D. (2000). Conjunction and linear non-separability effects in visual shape encoding. Vision Research , 40 (22), 3099–3115 [DOI] [PubMed] [Google Scholar]
- Arun S. P. (2012). Turning visual search time on its head. Vision Research , 74, 86–92 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bauer B., Jolicoeur P., Cowan W. (1996a). Distractor heterogeneity versus linear separability in visual search. Perception , 25, 1281–1293 [Google Scholar]
- Bauer B., Jolicoeur P., Cowan W. B. (1996. b). Visual search for colour targets that are or are not linearly separable from distractors. Vision Research , 36 (10), 1439–1465 [DOI] [PubMed] [Google Scholar]
- Bauer B., Jolicoeur P., Cowan W. B. (1998). The linear separability effect in color visual search: Ruling out the additive color hypothesis. Perception & Psychophysics , 60 (6), 1083–1093 [DOI] [PubMed] [Google Scholar]
- Bauer B., Jolicoeur P., Cowan W. B. (1999). Convex hull test of the linear separability hypothesis in visual search. Vision Research , 39 (16), 2681–2695 [DOI] [PubMed] [Google Scholar]
- Blais C., Arguin M., Marleau I. (2009). Orientation invariance in visual shape perception. Journal of Vision, 9(2); 14, 1–23, http://www.journalofvision.org/content/9/2/14, doi:10.1167/9.2.14. [PubMed] [Article] [DOI] [PubMed] [Google Scholar]
- Brainard D. H. (1997). The psychophysics toolbox. Spatial Vision , 10, 433–436 [PubMed] [Google Scholar]
- Duncan J., Humphreys G. W. (1989). Visual search and stimulus similarity. Psychological Review , 96 (3), 433–458 [DOI] [PubMed] [Google Scholar]
- Gross C. G., Bornstein M. (1978). Left and right in science and art. Leonardo , 11, 29–38 [Google Scholar]
- Hodsoll J., Humphreys G. W. (2001). Driving attention with the top down: The relative contribution of target templates to the linear separability effect in the size dimension. Perception & Psychophysics , 63 (5), 918–926 [DOI] [PubMed] [Google Scholar]
- Hwang A. D., Higgins E. C., Pomplun M. (2009). A model of top-down attentional control during visual search in complex scenes. Journal of Vision , 9 (5): 25, 1–18, http://www.journalofvision.org/content/9/5/25, doi:10.1167/9.5.25. [PubMed] [Article] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee T. S., Yang C. F., Romero R. D., Mumford D. (2002). Neural activity in early visual cortex reflects behavioral experience and higher-order perceptual saliency. Nature Neuroscience , 5 (6), 589–597 [DOI] [PubMed] [Google Scholar]
- Lindsey D. T., Brown A. M., Reijnen E., Rich A. N., Kuzmova Y. I., Wolfe J. M. (2010). Color channels, not color appearance or color categories, guide visual search for desaturated color targets. Psychological Science , 21 (9), 1208–1214 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Metzger W. (1936). Laws of seeing. Cambridge, MA: MIT Press; [Google Scholar]
- Nakayama K., Martini P. (2011). Situating visual search. Vision Research , 51 (13), 1526–1537 [DOI] [PubMed] [Google Scholar]
- Purcell B. A., Heitz R. P., Cohen J. Y., Schall J. D., Logan G. D., Palmeri T. J. (2010). Neurally constrained modeling of perceptual decision making. Psychological Review , 117 (4), 1113–1143 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rollenhagen J. E., Olson C. R. (2000). Mirror-image confusion in single neurons of the macaque inferotemporal cortex. Science , 287 (5457), 1506–1508 [DOI] [PubMed] [Google Scholar]
- Saumier D., Arguin M. (2003). Distinct mechanisms account for the linear non-separability and conjunction effects in visual shape encoding. Quarterly Journal of Experimental Psychology , 56 (8), 1373–1388 [DOI] [PubMed] [Google Scholar]
- Schall J. D., Purcell B. A., Heitz R. P., Logan G. D., Palmeri T. J. (2011). Neural mechanisms of saccade target selection: Gated accumulator model of the visual-motor cascade. European Journal of Neuroscience , 33 (11), 1991–2002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sripati A. P., Olson C. R. (2010). Global image dissimilarity in macaque inferotemporal cortex predicts human visual search efficiency. Journal of Neuroscience , 30 (4), 1258–1269 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolfe J. M., Butcher S. J., Lee C., Hyle M. (2003). Changing your mind: On the contributions of top-down and bottom-up guidance in visual search for feature singletons. Journal of Experimental Psychology: Human Perception & Performance , 29 (2), 483–502 [DOI] [PubMed] [Google Scholar]
- Wolfe J. M., Cave K. R., Franzel S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception & Performance , 15 (3), 419–433 [DOI] [PubMed] [Google Scholar]
- Wolfe J. M., Friedman-Hill S. R. (1992). On the role of symmetry in visual search. Psychological Science , 3 (3), 194–198 [Google Scholar]
- Wolfe J. M., Friedman-Hill S. R., Stewart M. I., O'Connell K. M. (1992). The role of categorization in visual search for orientation. Journal of Experimental Psychology: Human Perception & Performance , 18 (1), 34–49 [DOI] [PubMed] [Google Scholar]
- Wolfe J. M., Horowitz T. S. (2004). What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience , 5 (6), 495–501 [DOI] [PubMed] [Google Scholar]