

Abstract
The projected normal distribution is an under-utilized model for explaining directional data. In particular, the general version provides flexibility, e.g., asymmetry and possible bimodality along with convenient regression specification. Here, we clarify the properties of this general class. We also develop fully Bayesian hierarchical models for analyzing circular data using this class. We show how they can be fit using MCMC methods with suitable latent variables. We show how posterior inference for distributional features such as the angular mean direction and concentration can be implemented as well as how prediction within the regression setting can be handled. With regard to model comparison, we argue for an out-of-sample approach using both a predictive likelihood scoring loss criterion and a cumulative rank probability score criterion.
Keywords: bivariate normal distribution, circular data, concentration, latent variables, Markov chain Monte Carlo, mean direction
1. Introduction
Directional data arise naturally in many scientific fields where observations are recorded as directions or angles relative to a system with a fixed orientation. Examples of circular data include wind directions, wave directions or directions of animal movement. A different type of circular data arises from converting periodic time data to angular measurements, for example, time data measured on a 24 h clock can be converted with 0:00 corresponding to 0 and 24:00 to 2π. The circular nature of such data creates difficulties in applying ordinary statistical methods used for inline data. For example, with angular observations 1°, 0° and 359°, it is inappropriate to use the arithmetic mean, which is 120°. (Of course, the variance and other linear features suffer from similar problems.) A more sensible measurement is the angular mean direction (formally defined in Section 2) which is 0°. Over the last fifty years, substantial techniques and methods have been developed paralleling those for linear data [12, 14, 7, 1]. Lee [11] gives a recent review of statistical methods for analyzing circular data.
Corresponding to the usual parametric distributions for linear variables, there are several parametric distributions for circular variables. The most commonly used circular distribution is the von Mises distribution (also known as circular normal distribution). The von Mises distribution is the maximum entropy distribution on the circle for a fixed mean direction and dispersion and can be considered as an analogue of the normal distribution on the real line. The von Mises distribution M (μ, κ) has two parameters: the mean direction μ and the concentration parameter κ. It is unimodal and symmetric about its mode which is the same as the mean direction μ. The mean resultant length has the expression I1(κ)/I0(κ), where Iv is the modified Bessel function of the first kind of order v.
Circular distributions can also be obtained by radial projection of bivariate distributions on the plane. For any random vector Y ∈ ℜ2 with Pr(Y = 0) = 0, U = Y/‖Y‖ is a random point on the unit circle. The angle between the unit vector to this point and, say the x-axis becomes a random angle. An important distribution within this family is the projected normal distribution, where Y follows a bivariate normal distribution N2(μ, Σ). The projected normal distribution, denoted as PN2(μ, Σ), is also referred to as an offset normal distribution [12, 7] or an angular Gaussian distribution [22]. The projected normal distribution with identity covariance matrix, also known as the displaced normal[10], has attracted some work in the literature; see references below. However, like the von Mises, it suffers the limitation of symmetry and unimodality. For general Σ, the projected normal distribution will be asymmetric and can be bimodal, and is thus a more flexible family compared to the von Mises distribution. However, due to the unwieldy expression for the density function (see (1) below), the general version has received little attention in the literature.
The contribution of this paper is to demonstrate how to handle circular data using the general projected normal distribution PN2(μ, Σ). We show how to implement flexible circular regression modeling with linear covariates under the assumption of a general projected normal distribution. We work in a fully Bayesian framework and provide full inference including mean direction, concentration, regression coefficients, and predictive distributions with highest posterior density (HPD) arcs to produce credible sets. We also argue for the use of out-of-sample model comparison, employing a log likelihood scoring rule, a continuous rank probability score rule, and the mean length of HPD intervals of the predictive distribution.
The regression model with circular response and linear covariates is referred to as Linear-Circular regression [7]. Previously proposed circular regression models are mostly based on the assumption of the von Mises distribution [4, 8, 2]. Gould [4] sets and κi = κ for i = 1, …, n, allowing the mean of von Mises distribution to vary by levels of covariates. Johnson and Wehrly [8] consider only one covariate and propose the location model and concentration model, where a link function is used to convert the covariate to a value between 0 and 1. The location model takes μi = μ0 + 2π F(xi) and κi = κ, where F is chosen to be a known cumulative distribution function. Fisher and Lee [2] further generalize the Johnson-Wehrly models by a monotone link function g(·) mapping the linear predictor to (−π, π), with g(0) = 0. (A common choice for g(·) is the arctan function.) Their location model takes and κi = κ. However, computational difficulty arises when fitting a Fisher-Lee model with more than one covariate due to the multimodality of the likelihood.
Returning to the projected normal model with identity covariance matrix, Presnell et al. [17] introduce the spherically projected multivariate linear model based on the assumption of a projected normal distribution. Their paper demonstrates that the projected normal distribution has convenient regression specification and obtains the maximum likelihood estimates for the circular regression model using the EM algorithm. Extending Presnell et al. [17], Nuñez-Antonio and Gutiérrez-Peña [15] and Nuñez-Antonio et al. [16] show how to fit the projected normal distribution in a Bayesian framework using a Gibbs sampler, without and with covariates, respectively. Hernandez-Stumpfhauser et al. [6] build a mixed effect model based on the projected normal distribution by including the factors into the mean vector μ. Again, the above papers set the covariance matrix of the projected normal Σ to be I, arguing that this avoids an identifiability issue, that it is a rich enough model, and that it provides computational convenience. Again, our goal is to demonstrate the benefits of working with the more general Σ.
The format of the paper is as follows. Section 2 illustrates the general projected normal distribution and its properties. Section 3 demonstrates how to implement model fitting, inference and prediction and proposes the criteria for model comparison. Section 4 provides simulation examples and real data examples on directions of animal movements. Section 5 offers a summary and future directions.
2. The general projected normal model
In the sequel, we shall use ϕr and Φr to denote the pdf and cdf of a r-dimensional standard normal distribution. Assume a random vector Y = (Y1, …, Yr)′ follows an r ≥ 2-dimensional multivariate normal distribution, with mean μ and covariance matrix Σ. The corresponding random unit vector U = Y/‖Y‖ is said to follow a projected normal distribution [18, 14] with the same parameters, denoted as PNr(μ, Σ). Here, we confine ourselves to the circular projected normal distribution, the special case when r = 2. Let ϕ2(y1, y2; μ, Σ) be the density function of the bivariate normal distribution with mean vector μ = (μ1, μ2)′ and covariance matrix Σ. Let and be the variances of Y1 and Y2 and ρ denote the correlation between the two variables. The corresponding covariance matrix has the expression,
In this case, we convert Y, equivalently U to a random angular variable Θ through U1 = cos Θ and U2 = sin Θ whence tan Θ = Y2/Y1 = U2/U1 which exists with probability 1. Inversion for Θ requires care since the period for the tan function is only π. The usual choice is the arctan* function1. The resulting density function, f(θ; μ1, μ2, σ1, σ2, ρ), is [12, pp. 52],
| (1) |
where ϕ and Φ are defined at the beginning of this section, and
Because of the complicated form of this density function, the general version of the projected normal has only been considered theoretically. Data analysis and inference in the literature has been confined to the case of the projected normal PN2(μ, I) [17, 15, 6, 16]. In this case, a = 1, C(θ) = 1 and D(θ) = μ1 cos θ + μ2 sin θ.
With the identity covariance matrix, the corresponding density function is symmetric and unimodal. Thus PN2(μ, I) and the von Mises distribution M(μ, κ) each have two parameters and they can be aligned by matching the mean direction and the mean resultant length. When μ1 = μ2 = 0, the distribution reduces to the uniform distribution on the circle.
The mean direction for the projected normal is the unit vector, E(U)/‖E(U)‖ and the associated mean resultant length, γ = ‖E(U)‖ ≤ 1, provides a concentration. The angular mean direction, ω, arises from E(U) = (E cos Θ, E sin Θ)′. That is, cos ω = E cos Θ/γ, sin ω = E sin Θ/γ and tan ω = E sin Θ/E cos Θ = E(U2)/E(U1). Thus, since Y1 = ‖Y‖ cos Θ and Y2 = ‖Y‖ sin Θ, we can see that, in general,
In Appendix A we show that when Σ = I, tan ω = μ2/μ1 but that this is not true for general Σ. For instance, with Σ = I, for μ1 = 0 and μ2 ≠ 0, the angular mean direction is π/2 if μ2 is positive and is 3π/2 if μ2 is negative. When μ1 ≠ 0 and μ2 = 0, the angular mean direction is 0 if μ1 is positive and is π if μ1 is negative. To our knowledge, a closed form expression for the angular mean direction in the general case μ1 ≠ 0 and μ2 ≠ 0 is not available. When Σ = I, Kendall [10] provides a formula for the mean resultant length (or concentration), γ = ‖μ‖, i.e., γ = (πζ/2)1/2exp(−ζ)(I0(ζ) + I1(ζ)) where ζ = γ2/4, and Iv is the modified Bessel function of the first kind of order v. Again, a closed form expression in the general case is not available. However, both mean direction and mean resultant length can be computed using numerical integration or Monte Carlo methods. Below, we obtain these in a regression context using Monte Carlo methods.
Special cases of PN2(μ, I) with varying parameter μ1 are shown in Figure 1. In general, with increasing γ, the density becomes increasingly peaked.
Figure 1.
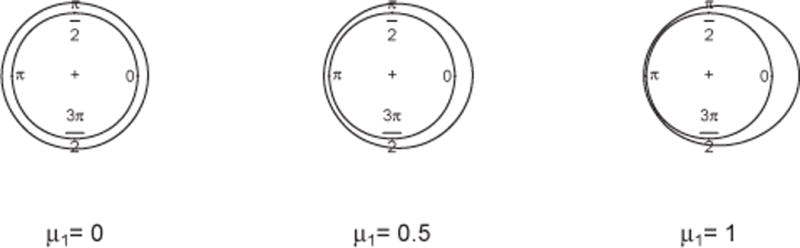
Density of PN2 with μ2 = 0, Σ = I for different values of μ1
Another special case of a general projected normal distribution is the angular central Gaussian distribution PN2(0, Σ). The angular central Gaussian is symmetric and antipodal, with two equal modes in exactly opposite directions. When σ1 = σ2 = σ, the density reduces to
revealing symmetry relative to the increasing 45°-line when ρ > 0, relative to the decreasing 45°-line when ρ < 0. Equivalently, f(θ|0, 0, σ, −ρ) = f(θ + π/2|0, 0, σ, ρ).
Let Σ = VΛV′ be an eigen-decomposition of Σ with V the matrix of unit eigenvectors and Λ the diagonal matrix of eigenvalues. Thus the bivariate random vector Y ~ V Λ½ N(0, I), where V is the rotation matrix. For any ρ > 0 and σ1 = σ2, the rotation matrix is and the modes occur at π/4 and 5π/4; for any ρ < 0 and σ1 = σ2, the rotation matrix is and the modes occur at 3π/4 and 7π/4. In the case of σ1 = σ2, the parameter ρ changes the concentration of the circular density, but not the modal axis (see Figure 2(a)). When σ1 ≠ σ2, no simple rotations are available (see Figure 2(b)). The angular central Gaussian distribution always produces a symmetric and antipodal density, except in the uniform case where σ1 = σ2 and ρ = 0.
Figure 2.
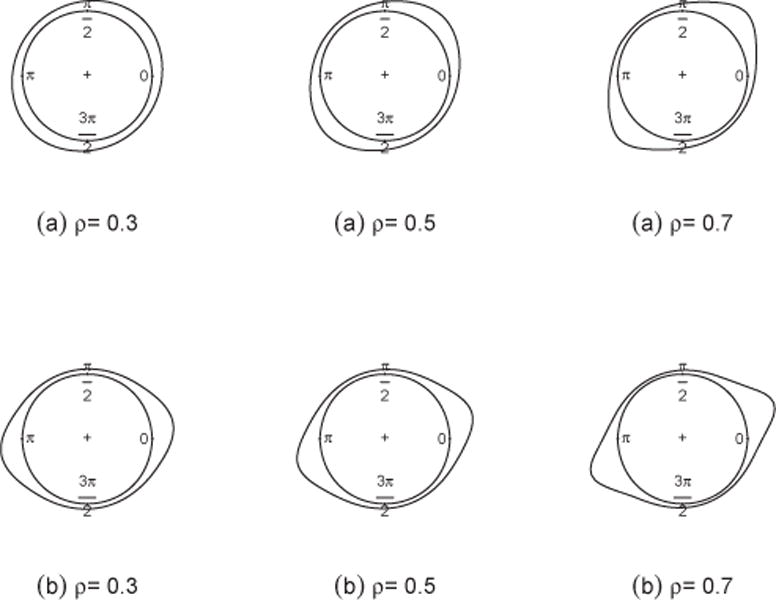
Density of PN2 with μ1 = μ2 = 0, (a) σ1 = σ2, (b) σ1 = 2σ2 for different values of ρ
In general, the shape of the PN2(μ, Σ) density with μ ≠ 0 and Σ ≠ I can be asymmetric or possibly bimodal (antipodality with different amplitudes or more general bimodality but no more than two modes) (see Figure 3). The five parameters μ1, μ2, σ1, σ2 and ρ together determine the shape of the density. However, unlike in the previous special cases, it is not clear how changing a single parameter affects the shape of the density. This suggests that, in the general case, interpretation of the parameters can be difficult. However, if the goal is flexibility and prediction, this specification can be attractive.
Figure 3.

Shapes for the general projected normal distribution
Since the distribution of U, hence, Θ does not change if the random vector Y is scaled by any a > 0, a further constraint on the parameters is needed for identifiability. To fix the scale of Σ, without loss of generality, we set σ2 = 1, so that the covariance matrix Σ becomes , and thus, we have a four parameter (μ1, μ2, τ and ρ) distribution.
In many applications, one encounters asymmetric circular data so that fitting them with a unimodal and symmetric model may result in misleading conclusions. In Section 4 below, we revisit the classical turtle movement dataset [14]; this dataset, shown in Figure 6, provides an example of circular data where an assumption of symmetry and unimodality does not seem appropriate. Asymmetry and bimodality can also be obtained by mixing two von Mises distributions, with directly interpretable parameters. However, such mixtures need to be identified and parameter estimation can be difficult if the component modes are not well-separated; see Jones and James [9] and Spurr and Koutbeiy [19] for parameter estimation based on numerical optimization. Moreover, if the goal is to capture asymmetry, it is not clear that a two-component mixture model is an appropriate specification. The general projected normal distribution provides an alternative which is straightforward to fit (within a Bayesian framework) and allows assessment of departure from symmetry and unimodality through departure of Σ from I.
Figure 6.
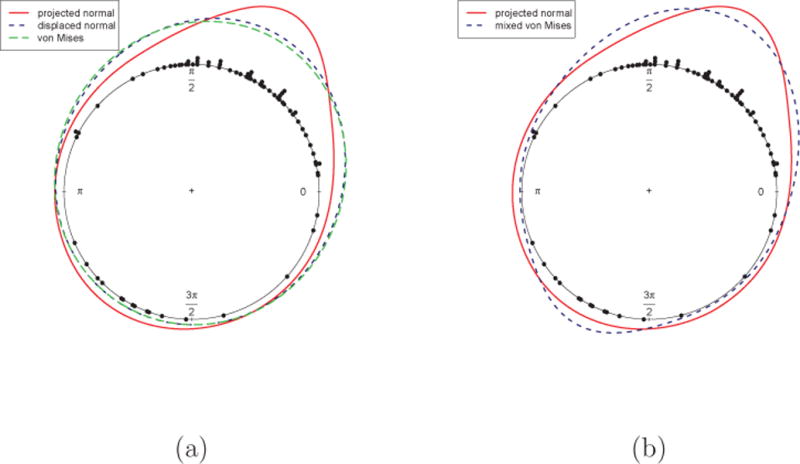
Turtle data example
The regression specification under the general projected model is , with regression coefficient matrix and covariates Xi = (1, Xi,1, …, Xi,p−1)′. In this model, changing the levels of the covariates is equivalent to changing the mean vector μi. With a fixed covariance matrix, different levels of the covariates can result in very different predictive distributions. However, smoothness of X in μ1(X) and μ2(X) induces smoothness in PN2(BTX, Σ) over X and thus smoothness in the mean directions and concentrations, as we illustrate in Section 4.3 below.
3. Bayesian inference for the general PN
With conditionally independent observations, fitting a general projected normal model in the Bayesian framework is straightforward; we illustrate both without and with covariates.
3.1. Model fitting
As discussed in the previous section, the covariance matrix is set to be , so that, with no covariates, we have four parameters to estimate: μ1, μ2, τ and ρ. For data θ = (θ1, θ2, …, θn), the likelihood is , where f(θi) has the expression shown in (1). A prior is added for μ1, μ2, τ and ρ. In implementing MCMC to fit the model, it is easiest to introduce a latent realization ri associated with θi, whence a vector r = (r1, r2, …, rn). The joint density of (Θ, R) can be obtained by changing variables from Y = (Y1, Y2)′ to (R, Θ)′. The likelihood under this data augmentation is:
| (2) |
where ui = (cos θi, sin θi)′. Conjugacy for μ arises under a bivariate normal prior, e.g., μ ~ N(0, λ0 I). However, there is still no closed form for the full conditional posteriors of τ2, ρ and the augmented parameter r. For τ2, we choose the prior as an inverse Gamma IG(aτ, bτ) with mean bτ/(aτ − 1) = 1; for ρ, a uniform distribution between −1 and 1. For the MCMC implementation, the full conditional distributions are given in Appendix B.
For the PN regression model with p − 1 covariates, the parameters to infer about are the regression coefficients , along with τ2 and ρ. The likelihood under the data augmentation becomes:
| (3) |
where xi = (1, xi,1, …, xi, p−1)′. For convenience, we partition the coefficient matrix as BT = (β1, …, βp), with βj ∈ ℜ2, j = 1, …, p. Again, a Gaussian prior is chosen for βj, e.g., βj ~ N(0, λ0I). The full conditionals are again provided in Appendix B.
3.2. Inference
Using MCMC model fitting, we obtain posterior samples for the parameters μ and Σ, or B and Σ for the density estimation or regression model, respectively.
In the “no covariates” case, the posterior density estimate is f(θ|data) = ∫f(θ|Ψ)f(Ψ|data) dΨ, where Ψ = {μ, Σ}. As a mixture of general PN densities, its form is very flexible. Posterior samples of the parameters provide the usual Rao-Blackwellized estimator. That is, given a posterior sample of the parameters , , , and ρ(g), g = 1, …, G, we evaluate f(θ|μ(g), Σ(g)) (expression (1)) on a uniform grid of points on [0, 2π). Then, averaging over g yields an estimate of the posterior at the resolution of the grid points.
As previously indicated, closed form expressions for the mean direction and the mean resultant length of the projected normal distribution are only available for the special case PN2(μ, I). MCMC Bayesian model fitting enables inference for the mean direction and mean resultant length without requiring analytical forms; in fact, we obtain posterior samples. According to the definition, the mean direction is and the resultant length is , where α = E cos Θ and β = E sin Θ. Thus, for each posterior draw, , , and ρ(g), we obtain α(g) and β(g) by Monte Carlo integration. Therefore, we obtain the posterior samples ω(g) and γ(g) as arctan*(β(g)/α(g)) and , respectively. Illustrative posterior distributions are provided below.
It is worth noting that ω and γ are parametric functional associated with f(θ|μ, Σ) and we are obtaining the posterior distribution associated with these functionals. If we wanted ω and γ associated with f(θ|data), we are seeking constants and it would be easiest to obtain sample estimates by taking draws from this distribution. This would be done by drawing θ(g) from f(θ|μ(g), Σ(g)) created as above. In fact, we would draw Y(g) from N(μ(g), Σ(g)) and convert to θ(g). We recall the usual method-of-moments estimates, i.e., for each θ(g), obtain (cos θ(g), sin θ(g)). Compute and . Then, and .
For the PN regression model, besides estimation of the regression coefficients, we are also interested in prediction at new levels of the covariates say, x*. However, given the posterior sample of parameters and the covariates, the values of the density function f(θ|x*, B(g), Σ(g)) are calculated on a uniform grid over [0, 2π). By taking the average of the density values on each grid over the samples, we obtain the predictive distribution given the covariates x*. Again, as a mixture of general PN densities, its shape is very flexible. In particular, equal tail credible intervals may be inappropriate; HPD credible intervals are more sensible. In general, the HPD arc is not trivial to calculate but it can be obtained numerically.
3.3. Model comparison using proper scoring rules
For the PN regression model, we focus on the the performance of out-of-sample prediction. We fit models using the training data θ = (θ1, …, θn)′, and evaluate models using a holdout set . As previously discussed, given the covariate levels, x*, we can calculate the length of the HPD credible interval and also see whether the holdout value θ* falls in this HPD region.
However, if predictive distributions are a goal, then model performance should be judged with regard to the entire predictive distribution. We need to compare the predictive distribution at x* with the held out θ*. Two proper scoring rules for doing this are the predictive log scoring loss (PLSL) [3] and the continuous ranked probability score (CRPS) as in [5]. Using posterior samples under (3), for the former, we calculate the quantity
As a model comparison criterion, the model with smaller PLSL is favored.
For the latter, Grimit et al. [5] developed the continuous ranked probability score (CRPS) for circular variables,
where F is the circular predictive distribution, θ* is the holdout value, α is the angular distance 2 and Θ and Θ′ are independent copies of a circular random variable with distribution F. Although we do not have an explicit expression for the predictive distribution, F, the CRPS is readily approximated in the Bayesian framework. With posterior samples from , the CRPS associated with the i-th holdout value can be approximated by
Finally, we compare the models by taking average CRPS over holdout samples. Again, the model with the smaller CRPS is favored. Both criteria are utilized in Section 4.
4. Examples
Having shown how to fit a general PN model in the Bayesian framework using MCMC, we now present several illustrations. In Section 4.1 we consider simulated examples while in Sections 4.2 and 4.3 we consider two real datasets. The first is the classic turtle movement dataset (mentioned in Section 2), which we use to illustrate density estimation; the second dataset concerns butterfly orientations [21, 17], which we use to illustrate circular regression with linear covariates.
4.1. Simulation: Density estimation and PN regression
First, we illustrate the density estimation using samples generated from a skewed PN distribution. The parameter values used in this example are μ1 = −0.19, μ2 = 1.25, σ1 = 1.58, σ2 = 1.4 and ρ = −0.84; the distribution is shown as the solid line in Figure 4. Four different sample sizes were used, n = 200, 500, 1000 and 2000. We fit the general projected normal and displaced normal (Σ = I) as described in Section 3 and display the posterior estimates, using a set of grid points, in Figure 4 (only shown for n = 200 and 2000). In addition, we fit a two component mixture of von Mises by utilizing the movMF function in the R package “movMF”. The result is also shown in Figure 4. We see that the projected normal recovers the true distribution quite well, even for the smaller sample size. The displaced normal and the von Mises mixture are not adequate. Posterior samples of the mean direction and mean resultant length for all four sample sizes are obtained, following Section 3.2, and the resultant posterior density plots are shown in Figure 5.
Figure 4.
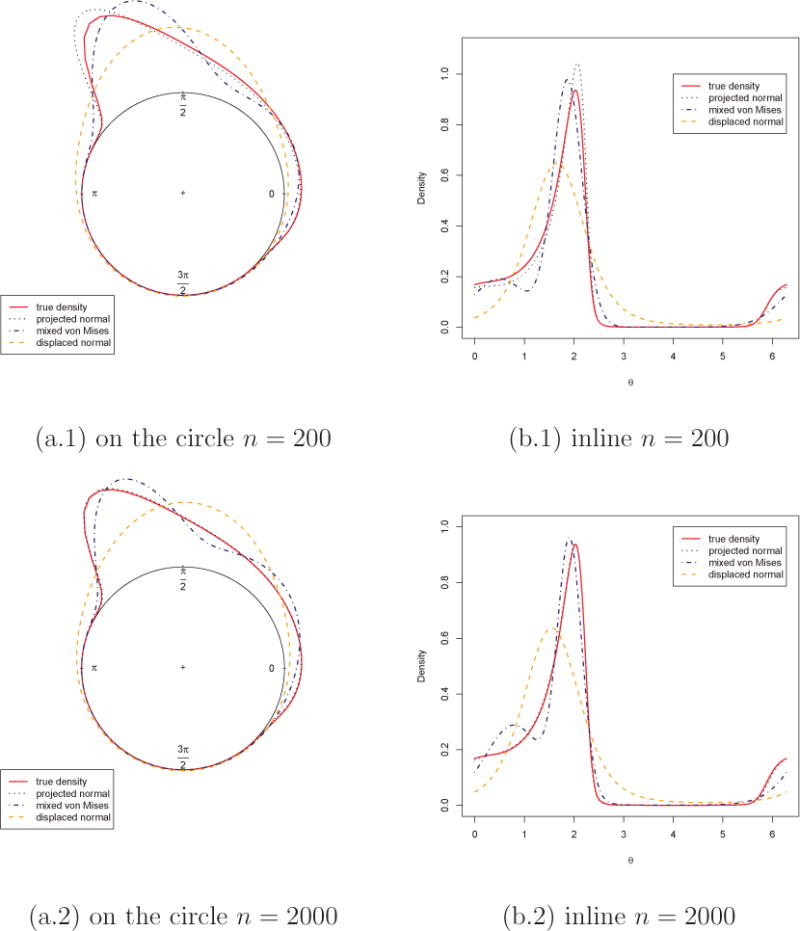
Simulation results of density estimation
Figure 5.
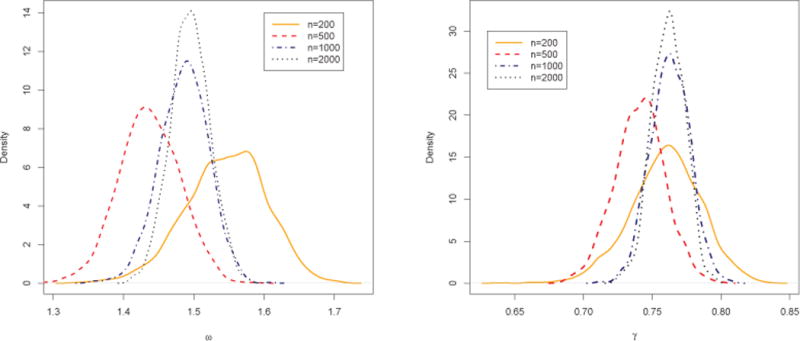
Posterior distributions of mean direction ω and mean resultant length γ
Next, we turn to the regression problem, employing simulation examples with focus on prediction and model comparison. We simulate θi, i = 1, …, n + m, from a general projected normal distribution PN2(BT xi, Σ), where xi = (1, xi,1, …, xi, p−1)′. From many simulation examples we have run, to illustrate here, we choose two τ2 values, 1 and 2.56, keeping ρ = .4 with n = 60 and 200. We take p = 3 where the covariates xi,1 and xi,2 are generated uniformly on (−1, 1) and the regression coefficients are set to be β1 = (2, −2)′, β2 = (1, −1)′ and β3 = (1, 1)′. From Section 3, the prior for τ2 is IG(5, 4) and for the β’s, λ0 = 0.5. The performance of prediction is evaluated on a validation set of size m = 100. We run Metropolis-Hastings within the Gibbs sampler for 25000 iterations with a burn-in of 5000, thinning the remainder by collecting every 5th sample.
For each of the four cases, both the general projected normal regression PN(BT xi, Σ) and the displaced normal regression PN(BT xi, I) are fitted for comparison. The posterior summaries for the parameters are shown in Table 1. As we would expect, the general PN outperforms the displaced PN. The latter gives point estimates that are less well-centered with credible intervals that are too tight. It performs relatively worse for the larger τ2 and for the larger training sample size. We see the benefit of using Σ ≠ I when this is the case.
Table 1.
Simulation Results of PN regression (n, τ2, ρ): posterior mean, lower and upper bounds of 95% credible interval for parameters τ2, ρ and βj = (βj1, βj2)′ (j = 1, 2, 3)
|
n = 60, τ2 = 1, ρ = 0.4
|
n = 200, τ2 = 1, ρ = 0.4
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Σ ≠ I | Σ = I | Σ ≠ I | Σ = I | ||||||||||
| par. | true | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% |
| β11 | 2 | 1.66 | 1.27 | 2.22 | 1.81 | 1.41 | 2.23 | 1.69 | 1.51 | 1.95 | 1.50 | 1.32 | 1.70 |
| β21 | 1 | 1.14 | 0.36 | 1.86 | 1.32 | 0.64 | 2.09 | 0.58 | 0.28 | 0.86 | 0.34 | 0.05 | 0.61 |
| β31 | 1 | 0.88 | 0.27 | 1.56 | 0.85 | 0.22 | 1.42 | 1.21 | 0.91 | 1.49 | 0.84 | 0.56 | 1.14 |
| β12 | −2 | −1.78 | −2.28 | −1.39 | −1.90 | −2.31 | −1.49 | −1.78 | −2.01 | −1.54 | −1.58 | −1.76 | −1.40 |
| β22 | −1 | −0.55 | −1.26 | 0.19 | −0.70 | −1.45 | −0.05 | −0.61 | −0.92 | −0.31 | −0.38 | −0.65 | −0.10 |
| β32 | 1 | 0.89 | 0.26 | 1.58 | 0.96 | 0.38 | 1.56 | 0.59 | 0.28 | 0.90 | 0.58 | 0.29 | 0.84 |
| τ2 | 1 | 0.91 | 0.49 | 1.55 | – | – | – | 0.76 | 0.56 | 1.04 | – | – | – |
| ρ | 0.4 | 0.23 | −0.15 | 0.62 | – | – | – | 0.42 | 0.12 | 0.68 | – | – | – |
|
n = 60, τ2 = 2.56, ρ = 0.4
|
n = 200, τ2 = 2.56, ρ = 0.4
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Σ ≠ I | Σ = I | Σ ≠ I | Σ = I | ||||||||||
| par. | true | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% |
| β11 | 2 | 1.41 | 0.96 | 1.98 | 1.18 | 0.86 | 1.49 | 1.61 | 1.27 | 1.91 | 1.22 | 1.03 | 1.40 |
| β21 | 1 | 0.58 | −0.37 | 1.46 | 0.41 | −0.20 | 1.00 | 0.81 | 0.43 | 1.20 | 0.41 | 0.12 | 0.71 |
| β31 | 1 | 1.03 | 0.25 | 1.90 | 0.74 | 0.15 | 1.36 | 0.65 | 0.26 | 1.07 | 0.49 | 0.22 | 0.76 |
| β12 | −2 | −1.79 | −2.27 | −1.06 | −1.52 | −1.22 | −0.65 | −1.67 | −1.88 | −1.43 | −1.25 | −1.43 | −1.08 |
| β22 | −1 | −0.44 | −1.20 | 0.56 | −0.39 | −1.00 | 0.21 | −0.64 | −0.94 | −0.27 | −0.28 | −0.54 | −0.02 |
| β32 | 1 | 0.93 | 0.26 | 1.65 | 0.66 | 0.04 | 1.30 | 0.60 | 0.29 | 0.91 | 0.35 | 0.12 | 0.60 |
| τ2 | 2.56 | 2.03 | 1.10 | 3.29 | – | – | – | 1.83 | 1.15 | 2.53 | – | – | – |
| ρ | 0.4 | 0.58 | 0.15 | 0.83 | – | – | – | 0.62 | 0.47 | 0.75 | – | – | – |
To compare predictive performance, we look at the average length of predictive 95% credible intervals over all holdout samples and also the percentage of holdout values falling into their corresponding 95% credible intervals. We also compute the predictive log scoring loss (PLSL) and the average predictive CRPS. The results are summarized in Table 2. For the smaller training set, the results are a bit mixed, perhaps not surprising. However, for the larger sample size, PLSL and average CRPS (which is known to be conservative) favor the general version; so does the average length of the predictive interval. We also see that the PLSL and average CRPS decrease with sample size and increase as the concentration decreases.
Table 2.
Model comparison of PN regression under each combination of (n, τ2, ρ): general PN Σ ≠ I (left column) and displaced normal Σ = I (right column)
| (n, τ2, ρ) | (60, 1, 0.4) | (60, 2.56, 0.4) | ||
|---|---|---|---|---|
|
|
|
|||
| PLSL | 121.89 | 122.70 | 183.65 | 171.45 |
| average CRPS | 0.2511 | 0.2531 | 0.3124 | 0.3129 |
| average length of predictive CI | 1.88 | 1.92 | 2.20 | 3.74 |
| percentage (%) | 98 | 94 | 95 | 98 |
| (n, τ2, ρ) | (200, 1, 0.4) | (200, 2.56, 0.4) | ||
|---|---|---|---|---|
|
|
|
|||
| PLSL | 106.64 | 117.09 | 148.35 | 164.50 |
| average CRPS | 0.2421 | 0.2444 | 0.2997 | 0.3072 |
| average length of predictive CI | 1.68 | 2.15 | 2.08 | 2.94 |
| percentage (%) | 98 | 100 | 96 | 100 |
4.2. Turtle Movement
We consider a turtle dataset due to Dr. E. Gould of the Johns Hopkins School of Hygiene. The data are the directions of turtle movements after a certain treatment and can be found in Stephens [20, pp. 27] or Mardia and Jupp [14, pp. 9]. The circular plot of the raw data is given in Figure 6. We can see that, while most of the turtles moved in one main direction, a small portion of them moved in another, almost opposite direction. We fit the general PN and displaced normal and report the posterior mean of the density in Figure 6(a). The prior used here follows Section 3.1: IG(5, 4) for τ2 and N(0, 0.5I) for μ. We also fit a single von Mises using the mle.vonmises function of R package “circular”, which is also shown in Figure 6(a). It is clear that the data can not be adequately described by a single symmetric and unimodal distribution.
Stephens [20] fit a special case of a two component von Mises, with the same concentration and modes π radians apart. Mardia [13] later fit a general two component mixture with different concentrations and modes. In Figure 6(b), we plot the posterior mean density estimate from our PN model together with the density based on the parameter estimates of Mardia [13]. The general PN distribution provides density estimation comparable with the mixture of two von Mises distributions. The latter does have five parameters, compared with four for the general PN, and also introduces potential identifiability problems. As noted in Section 2, interpretation of the parameters in the general projected normal is difficult, hence, less clear than in the case of the mixture of two von Mises distributions. But again, with the goal of capturing departure from symmetry, it is not apparent that a two-component mixture model is an appropriate specification.
4.3. Butterfly Migration
Finally, we illustrate the PN regression model using data from a study by T. J. Walker and J. J. Whitesell of migratory butterflies entering northern Florida. More detail regarding the biological background and data collection methods can be found in Walker and Littell [21]. For illustration, we only use the data for the species cloudless sulphur. One purpose of this study is to examine the effect of distance from the coast on the direction of butterfly migration. Therefore, we include the standardized distance to the coast (in kilometers) as a covariate in the regression model. We also include the standardized temperature. So, for the i-th observation, xi = (1, distcoasti, tempi)′. The total number of observations is 233 and we hold out 40, chosen at random, as a validation set. Again, we fit the general PN and the displaced PN, adding to the priors of the previous subsection for τ2 and ρ a normal prior with λ0 = 0.5 for the β’s. The posterior estimates and uncertainties are reported in Table 3. The percentage of hold out values falling into the 95% HPD predictive intervals is 100% for both; the average lengths of the predictive intervals for the holdout set are 2.09 and 2.56, respectively. The average CRPS for the general version is 0.1987; for the identity version it is 0.2044. The mean PLSLs are 34.55 and 40.10, respectively. All these criteria suggest that the general PN regression is a preferable model for this dataset. Also, we provide predictive density plots for two illustrative holdout observations in Figure 7. We see shorter HPD credible intervals for the general PN, revealed by highlighting the lengths at the bottom.
Table 3.
Butterfly data example: posterior summaries of parameters
| Σ ≠ I
|
Σ = I
|
|||||
|---|---|---|---|---|---|---|
| par. | mean | 2.5% | 97.5% | mean | 2.5% | 97.5% |
| β10 | −1.95 | −2.10 | −1.80 | −1.81 | −1.97 | −1.63 |
| β11 | 0.10 | −0.08 | 0.27 | −0.04 | −0.20 | 0.11 |
| β12 | 0.22 | 0.01 | 0.40 | 0.11 | −0.11 | 0.30 |
| β20 | 0.53 | 0.38 | 0.68 | 0.43 | 0.24 | 0.59 |
| β21 | 0.22 | 0.05 | 0.40 | 0.33 | 0.17 | 0.48 |
| β22 | −0.94 | −1.11 | −0.76 | −0.82 | −0.98 | −0.66 |
| τ2 | 0.82 | 0.66 | 1.02 | – | – | – |
| ρ | −0.21 | −0.37 | −0.04 | – | – | – |
Figure 7.
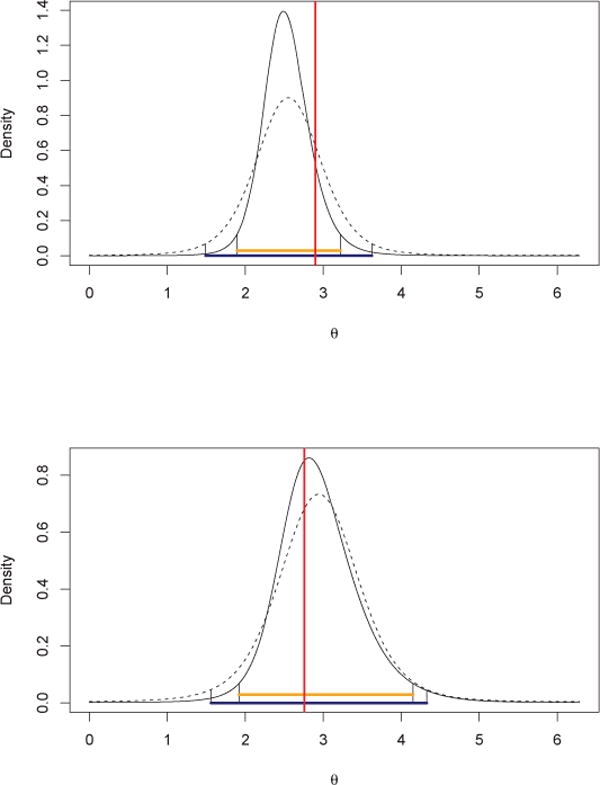
Predictive density and its 95% HPD credible intervals for two hold out observations: the solid line is the predictive density for the general PN regression and the dotted line is for the identity version. The vertical line shows the true hold out value θ*.
Finally, in order to see how the mean direction ω and the concentration γ respond to changes in the X’s, we present Figure 8. Here, we show the change in mean direction and mean resultant length with respect to change in the temperature, while fixing the value of the standardized distance to the coast (distcoasti = 1). We allow the standardized temperature X2 to range from −2 to 2 and obtain posterior estimates of ω(X2) and γ(X2) associated with f(θ|data) by Monte Carlo methods. In Figure 8, we can observe that change in temperature leads to smooth change in the mean direction of the butterfly migration, while also resulting in smooth change in the mean resultant length. As the temperature increases, the butterfly migration direction shifts and is relatively less concentrated in the mean direction.
Figure 8.
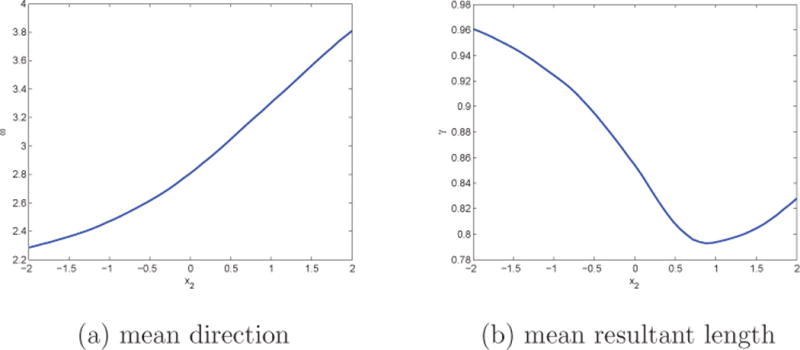
Change in mean direction ω and mean resultant length γ with changing temperature x2 under the general PN regression for the butterfly data
5. Summary and future work
We have argued that the flexibility of the general PN model as well as the convenient regression linkage to linear explanatory variables makes it an attractive model for angular data. In particular, we have shown how to straightforwardly fit these models within a Bayesian framework, obtaining full posterior inference. Using both PLSL and CRPS, we have demonstrated that the general PN outperforms the displaced PN (Σ = I) using simulated data when the former is true and with two real datasets. Finally, in the Bayesian context, we have shown how we can see the response of the mean direction and concentration to change in covariate level.
As in the turtle data example, it may be asserted that, for independent observations on a sphere, mixtures of von Mises distributions can achieve comparable flexibility to the general PN. In this regard, we note that we are currently investigating mixing with PN’s, both discrete and continuous mixtures. The former leads to a dense class theorem, the latter leads to projected t-distributions. PN’s also offer convenient multivariate extension to dependent observations, each on a circle or, more generally, on a sphere, through suitable multivariate normal distributions; the von Mises does not easily extend beyond two or three dimensions in this case. Of particular interest for space and space-time directional data is a spatial and spatiotemporal projected Gaussian process which we will report on in a forthcoming manuscript.
Acknowledgments
The authors thank Giovanna Jona Lasinio for useful conversations and Ramon Littell for help in obtaining the butterfly data in Section 4.3. The work of the authors was supported in part by NSF CMG 0934595 and NSF CDI 0940671.
Appendix A. Mean direction calculation for PN2(μ, I) from Section 2
Assume X1 and X2 are two independent variables, X1 ~ N(μ1, 1) and X2 ~ N(μ2, 1). The joint density of X1 and X2 is
Change variables (X1, X2) to (R, Θ), i.e., X1 = R cos Θ, X2 = R sin Θ and |J| = R. Let , where μ1 = μ0 cos α and μ2 = μ0 sin α, ∀α.
Use the result,
where ϕ1(·) and Φ1(·) are the standard univariate normal pdf and cdf, respectively. Let g(x) = ϕ1(x) + xΦ1(x), then
Under careful calculation,
According to the definition of mean direction, when μ1 ≠ 0.
Appendix B. Posterior Computation
The full conditionals for the parameters of the projected normal model without covariates are:
f(μ|θ, r, τ2, ρ) ~ N(μ̃, Σ̃), where and Σ̃ = (nΣ−1 + I/λ0)−1.
.
. Use the truncated normal kernel (τ2)* ~ N+(τ2, c2) and ρ* ~ T N(ρ, c3, −1, 1).
The full conditionals for the parameters of the PN regression model are:
βj ~ B N(μ̃j, Σ̃j), where and .
, where .
. Use the truncated normal kernel (τ2)* ~ N+(τ2, c2) and ρ* ~ T N(ρ, c3, −1, 1).
Footnotes
From Jammalamadaka and SenGupta [7, pp. 13], arctan*(S/C) is formally defined as arctan(S/C) if C > 0, S ≥ 0; π/2 if C = 0, S > 0; arctan(S/C) + π if C < 0; arctan(S/C) + 2π if C ≥ 0, S < 0; undefined if C = 0, S = 0.
From Grimit et al. [5, pp. 2939], the angular distance α(θ, θ*) is formally defined as |θ − θ*| if |θ − θ*| ≤ π; 2π − |θ − θ*| if π ≤ |θ − θ*| < 2π.
References
- 1.Fisher NI. Statistical Analysis of Circular Data. Cambridge University Press; 1993. [Google Scholar]
- 2.Fisher NI, Lee AJ. Regression models for an angular response. Biometrics. 1992;48:665–677. [Google Scholar]
- 3.Gneiting T, Raftery AE. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association. 2007;102:359–378. [Google Scholar]
- 4.Gould AL. A regression technique for angular variates. Biometrics. 1969;25:683–700. [PubMed] [Google Scholar]
- 5.Grimit E, Gneiting T, Berrocal V, Johnson N. The continuous ranked probability score for circular variables and its application to mesoscale forecast ensemble verification. Quarterly Journal Royal Meteorological Society. 2006;132:2925–2942. [Google Scholar]
- 6.Hernandez-Stumpfhauser D, Breidt JF, Opsomer JD. Technical Report. Colorado State University; 2010. Hierarchical Bayesian Small Area Estimation for Circular Data. [Google Scholar]
- 7.Jammalamadaka SR, SenGupta A. Topics in Circular Statistics. World Scientific; 2001. [Google Scholar]
- 8.Johnson RA, Wehrly T. Some angular-linear distributions and related regression models. Journal of the American Statistical Association. 1978;73:602–606. [Google Scholar]
- 9.Jones TA, James WR. Analysis of bimodal orientation. Mathematical Geology. 1969;1:129–135. [Google Scholar]
- 10.Kendall DG. Pole-seeking brownian motion and bird navigation. (Series B (Methodological)).Journal of the Royal Statistical Science. 1974;36:365–417. [Google Scholar]
- 11.Lee A. Circular data. Wiley Interdisciplinary Reviews: Computational Statistics. 2010;2:477–486. [Google Scholar]
- 12.Mardia KV. Statistics of Directional Data. Academic Press; London and New York: 1972. [Google Scholar]
- 13.Mardia KV. Statistics of directional data. (Series B (Methodological)).Journal of the Royal Statistical Society. 1975;37:349–393. [Google Scholar]
- 14.Mardia KV, Jupp PE. Directional Statistics. John Wiley & Sons; 2000. [Google Scholar]
- 15.Nuñez-Antonio G, Gutiérrez-Peña E. A bayesian analysis of directional data using the projected normal distribution. Journal of Applied Statistics. 2005;32:995–1001. [Google Scholar]
- 16.Nuñez-Antonio G, Gutiérrez-Peña E, Escarela G. A bayesian regression model for circular data based on the projected normal distribution. Statistical Modeling. 2011;11:185–201. [Google Scholar]
- 17.Presnell B, Morrison SP, Littell RC. Projected multivariate linear models for directional data. Journal of the American Statistical Association. 1998;93:1068–1077. [Google Scholar]
- 18.Small CG. The Statistical Theory of Shape. Springer; 1996. [Google Scholar]
- 19.Spurr BD, Koutbeiy MA. A comparison of various methods for estimating the parameters in mixtures of von mises distributions. Communications in Statistics – Simulation and Computation. 1991;20:725–741. [Google Scholar]
- 20.Stephens MA. Technical Report. Stanford University; 1969. Techniques for Directional Data. [Google Scholar]
- 21.Walker TJ, Littell RC. Orientation of fall-migrating butterflies in north peninsular florida and source areas. Ethology. 1994;98:60–84. [Google Scholar]
- 22.Watson GS. Statistics on Spheres. John Wiley & Sons; 1983. [Google Scholar]