

Abstract
Dementia is one of the most common neurological disorders among the elderly. Identifying those who are of high risk suffering dementia is important to the administration of early treatment in order to slow down the progression of dementia symptoms. However, to achieve accurate classification, significant amount of subject feature information are involved. Hence identification of demented subjects can be transformed into a pattern recognition problem with high-dimensional nonlinear datasets. In this paper, we introduce trace ratio linear discriminant analysis (TR-LDA) for dementia diagnosis. An improved ITR algorithm (iITR) is developed to solve the TR-LDA problem. This novel method can be integrated with advanced missing value imputation method and utilized for the analysis of the nonlinear datasets in many real-world medical diagnosis problems. Finally, extensive simulations are conducted to show the effectiveness of the proposed method. The results demonstrate that our method can achieve higher accuracies for identifying the demented patients than other state-of-art algorithms.
Index Terms: Dimensionality reduction, feature extraction, medical diagnosis
I. Introduction
Dementia, which causes a progressive decline in cognitive functions, is one of the most common neurolog-population, its prevalence is expected to increase [1]. However, there exists considerable regional variation in diagnosis practice because of the differences in available resources even within a country, e.g. lack of trained general practitioners and/or time to administer and analyze full cognitive function assessments. For example, it was approximated that only a third of people who were actually suffering dementia in the US ever received a formal medical diagnosis. Thus, limited patients suffering dementia are offered appropriate medical treatment or care, which can potentially slow down the progression of symptoms. To separate probably or possibly demented patients from normal subjects, a large amount of data with features for describing symptoms are currently required [1]. In that way, the identification of demented subjects can be transformed into a pattern recognition problem with a high-dimensional dataset.
But dealing with high-dimensional data has always been a major problem in pattern recognition. Hence finding a low-dimensional representation of high-dimensional data, namely dimensionality reduction is thus of great practical importance. Among the dimensionality reduction methods, linear discriminant analysis (LDA) [10] is the most popular method, which is to find the optimal low-dimensional presentation by maximizing the between-class scatter matrix while minimizing the within-class scatter matrix. Several variants of LDA have been proposed during the past decades, and trace ratio LDA (TR-LDA) is one of the most widely used variants [2], [11], [12]. TR-LDA is based on the trace ratio criterion, which can directly reflect Euclidean distances between data points of inter- and intra-classes. In addition, the optimal projection obtained by TR-LDA is orthogonal. As described in [2], when evaluating the similarities between data points based on Euclidean distance, the orthogonal projection can preserve such similarities without any change. Thus, TR-LDA tends to perform empirically better than the classical LDA and other variants of LDA in many problems.
In this paper, improved ITR algorithm (iITR), an efficient algorithm is proposed for solving TR-LDA problem, which can handle nominal attributes and missing values in many real-world medical diagnosis problems. To validate the effectiveness of the proposed method to assist medical screening, the performance of TR-LDA with iITR and other state-of-art dimensionality reduction methods will be compared here by a case study in the screening of demented subjects using only demographic data, medical history, and behavioral attributes, without the use of cognitive function assessment data. In our current study, results show that TR-LDA method can assist the identification of demented patients with higher accuracies even with less training data comparing to other state-of-art dimensionality reduction methods. The proposed dimensionality reduction method can be incorporated into computational screening program to identify probable or possible patients such that general practitioners can refer these subjects to specialists for full diagnosis.
II. Trace Ratio Linear Discriminant Analysis
A. Review of Linear Discriminant Analysis
LDA uses the within-class scatter matrix Sw to evaluate the compactness within each class and between-class scatter matrix Sb to evaluate the separability of different classes. The goal of LDA is to find a linear transformation matrix W ∈ RD×d, for which the between-class scatter matrix is maximized, while the within-class scatter matrix is minimized. Let X = {x1, x2, … Xl} ∈ RD×l be the training set, each xi belongs to a class ci = {1, 2, … c}. Let li be the number of data points in the ith class and l be the number of data points in all classes. Then, the between-class scatter matrix Sb, within-class scatter matrix Sw, and total-class scatter matrix St are defined as follows:
| (1) |
where μi = 1/li Σxi∈ci xi is the mean of the data points in the ith class, and is the mean of the data points in all classes. The original formulation of LDA, called Fisher LDA [10], can only deal with binary classification. Two optimization criteria can be used to extend Fisher LDA to solve the multi-class classification problem. The first one is in the ratio trace form (we refer it as LDA):
| (2) |
and the second one is in the trace ratio form (we refer it as TR-LDA):
| (3) |
The optimal solution of LDA can be formed by the top eigenvectors of . On the other hand, the optimization problem of TR-LDA in (3) has no close-form solution and has to calculate it by an Iterative Trace Ratio method (ITR) [7]. Specifically, if Wt denotes the solution at the tth iteration, then at the (t + 1)th solution, Wt+1 can be formed by the top eigenvectors of Sb − λtSw, where . This procedure can be proved to converge to the globally optimal solution given any initialization W0 [2].
B. A More Efficient Algorithm for Solving the TR Problem
Though the ITR algorithm works well for solving the TR problem, it has its own drawback. The ITR algorithm method has chosen d eigenvectors corresponding to the d largest eigenvalues of Sb − λ*Sw to form W*. These eigenvectors can only maximize the trace difference value Tr(WT(Sb − λ*Sw)W), but these eigenvectors cannot maximize trace ratio value . Thus, how to find eigenvectors to maximize the trace ratio value is an important question. Motivated by this issue, we then, in this subsection, propose a more efficient algorithm, called improved ITR algorithm (iITR), which can solve this problem.
Given any initial λt, by performing the eigen-decomposition of Sb − λtSw, we can obtain the D eigenvectors of SbλtSw. The problem is then to choose the d eigenvectors Wt = {wi1, wi2, …, wiD} maximizing , where i = {i1, i2, …, id} is a certain permutation chosen from {1, 2, …, D}. Here, if we define f = {f1, f2, …, fD} ∈ R1×D, g = {g1, g2, …, gD} ∈ R1×D with each element satisfying and , the above problem can be converted to find the optimal selection vector b = {b1, b2, … bD} ∈ R1×D as:
| (4) |
Note that the above problem is a linear fractional programming (LFP) problem [4], [9], [14]. It can be solved by Dinkelbach’s algorithm which is a general algorithm for optimizing γ = Φ(b)/Ψ(b) with Ψ(b) > 0. In Dinkelbach’s algorithm, it converts the problem to a sequence of sub-problems for optimizing Φ(b) − γΨ(b). Hence in our case, by initializing γ0 = λt and let f, g be defined as above, the optimal selection vector b* can then be obtained by iteratively solving the following sub-problem:
| (5) |
After b* is obtained, we can output Wt by choosing the d eigenvectors with . The basic steps of the algorithm are listed in Table I.
TABLE I.
iITR Algorithm for Solving the Trace Ratio Problem
|
C. Convergence Analysis of iITR Algorithm
Here the convergence of the proposed iITR algorithm is also analyzed. In fact, as pointed in [3], [13], the algorithm of TR-LDA is Newton method, hence the convergence rate is quadratic and the very fast convergence of the algorithm of TR-LDA is theoretically guaranteed. It has been rigorously proved that for ITR algorithm, given any initial λt, the updated λt+1 satisfying 1) and 2) . Hence we only need to prove that for the proposed iITR algorithm, the updated is no smaller than . Following (5), this can be equivalent to prove that given the initial γ0 = λt, the updated γk+1 satisfying i) γk+1 ≥ γk and ii) γk+1 ≤ γ*. We next prove the two inequalities.
Proof
Let h(γk) = maxb b(f − γkg)T, since γk+1 = bkfT/bkgT, we have bkfT − γk+1bkgT = 0 → bk (f − γk+1g)T = 0. In addition, since bk+1 = arg maxb b(f − γk+1g)T, it follows h(γk+1) = bk+1 (f − γk+1g)T ≥ bk (f − γk+1g)T = 0. This indicates that h(γk+1) ≥ 0. We then have h(γk+1) ≥ 0 → bk+1 fT/bk+1gT ≥ γk+1 → γk+2 ≥ γk+1. By simply performing the notation substitution, i.e. k + 1 → k, we thus prove the first inequality γk+1 ≥ γk. We next prove the second inequality. Recall that γ* = maxb bfT/bgT = b*fT/b*gT, it follows b*fT − γ*b*gT = 0 → b*(fT − γ*g)T = 0. Since h(γ*) = max b(f − γ* g)T = b*(f − γ* g) = 0, it can be rewritten as h(γ*) = h(γk+1) + (γk+1 − γ*)gT = 0. Note that h(γk+1) ≥ 0 and g is a semi-positive vector, the equality can only holds as γk+1 ≤ γ*, hence we prove the second inequality, i.e. γk+1 ≤ γ*.
III. Identifying Demented Patients via TR-LDA
A. Data Descriptions
The proposed method will be used to screen the demented subjects which meet the criteria for dementia in accordance with standard criteria for dementia of the Alzheimer’s type or other non-Alzheimer’s demented disorders in their first visits to Alzheimer disease Centers (ADCs) throughout the United States. Data from 289 demented subjects and 9611 controls collected by approximately 29 ADCs from 2005 to 2011 are studied. These data are organized and made available by the US National Alzheimer’s Coordinating Center (NACC). Among the demented patients studied, 97% of them were classified as probable or possible Alzheimer’s disease (AD) patients. Those with dementia and with neither probable AD nor possible AD have other types of dementia such as Dementia with Lewy Bodies, and Frontotemporal Lobar Degeneration. 5 nominal, 142 ordinal, and 9 numerical attributes of the subjects are included in the study. These attributes include demographic data, medical history, and behavioral attributes, with 5% being missing values. To make the classification problem more difficult, no cognitive assessment variable, such as Mini-Mental State Examination score, is included as attribute.
B. Prediction Stage
The next step is to apply TR-LDA in identifying demented patients from normal persons. Note that NACC dataset includes nominal attributes and missing values. It should be transferred to a numerical data before performing dimensionality reduction. To handle this problem, we use kernel method to map NACC dataset to a high-dimensional Hilbert space. We then use the data in such space to perform dimensionality reduction. The kernel function used is the radial basis function (RBF) defined by Kij = exp(−||xi − xj||2/σ2). Here, to construct the kernel function, we use VDM (Value difference Metric) [8] to calculated the distance between xi and xj instead of only relying Euclidean distance. In detail, given two samples xi and xj, suppose the first j attributes of them are nominal, the following k ones are numeric and normalized to [0,1], and the remaining D − j − k ones are missing if either xi or xj lacks the values in these attributes, the distance between xi and xj can be calculated by:
| (6) |
Here, the VDM distance between two values z1 and z2 on nominal attribute Z can be calculated by:
| (7) |
where NZ,z denotes the number of training examples holding value z on Z, NZ,z,k denotes the number of training examples belonging to the kth class and holding value z on Z, c denotes the number of classes. Hence after we define the distance as in (6), we can either use it to construct the kernel function or to train a nearest neighbor classifier for evaluating the accuracies of test set.
IV. Simulations
This simulation aims at differentiating normal persons from demented persons by using TR-LDA and compares it with other state-of-the-art methods such as PCA, LPP, MMC and LDA. In this simulation, we randomly choose 500, 1000 and 2000 samples in AD data as training set and the remaining as test set. The data is preliminarily processed with KPCA operator to eliminate the null space of training set [7]. Then, each method uses the training set in the reduced output space to train a nearest neighborhood classifier to classify the demented and non-demented persons in test set.
The average accuracies over 20 random splits under different dimensionalities are in Table II and Fig. 2. As shown in Table II, the classification accuracies of all methods change greatly with the increase in the number of labeled samples. Another important observation is that the supervised methods such as LPP [6], MMC [5], LDA [10], TR-LDA outperform the unsupervised methods such as PCA and LPP. Among all the supervised methods, the proposed TR-LDA performs the best due to the trace ratio criterion. We also compare the convergence between ITR and iITR algorithms as in Fig. 1. From Fig. 1, we can see both algorithms can converge to the optimal trace ratio value. The iITR algorithm converges faster than ITR algorithm due to reason as in Section II-C.
TABLE II.
The Average Accuracies Over 20 Random Splits
| Method | 500 samples | 1000 samples | 1500 samples | 2000 samples | ||||
|---|---|---|---|---|---|---|---|---|
|
| ||||||||
| mean ± var | dim | mean ± var | dim | mean ± var | dim | mean ± var | dim | |
| 1NN | 71.76 ± 3.89 | - | 73.09 ± 1.68 | - | 75.45 ± 1.26 | - | 77.32 ± 1.14 | - |
| KPCA+1NN | 72.08 ± 4.09 | 23 | 73.35 ± 2.14 | 25 | 75.26 ± 2.37 | 24 | 80.02 ± 2.05 | 23 |
| KPCA+LPP+1NN | 71.94 ± 3.65 | 24 | 75.09 ± 2.35 | 33 | 77.12 ± 2.23 | 30 | 80.55 ± 1.50 | 32 |
| KPCA+MMC+1NN | 79.56 ± 3.50 | 1 | 82.46 ± 2.00 | 1 | 84.63 ± 2.56 | 1 | 87.90 ± 1.22 | 1 |
| KPCA+LDA+1NN | 79.94 ± 3.86 | 1 | 82.09 ± 2.41 | 1 | 84.82 ± 2.29 | 1 | 87.46 ± 1.02 | 10 |
| KPCA+TR-LDA+1NN | 81.12 ± 3.29 | 10 | 84.35 ± 2.10 | 7 | 86.83 ± 2.52 | 15 | 90.01 ± 1.25 | 15 |
Fig. 2.
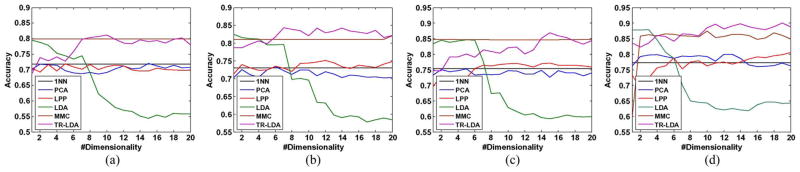
Average accuracies under different dimensionalities: (a) 500 samples; (b) 1000 samples; (c) 1500 samples; (d) 2000 samples.
Fig. 1.
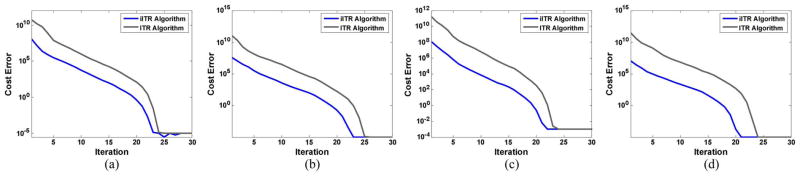
Convegence between ITR and iITR algorithms: (a) 500 samples; (b) 1000 samples; (c) 1500 samples; (d) 2000 samples.
V. Conclusion
Dementia is one of the most common neurological disorders among the elderly. Identification of demented patients from normal subjects can be transformed into a pattern recognition problem with high-dimensional nonlinear datasets. In this paper, we introduce trace ratio linear discriminant analysis (TR-LDA) for dementia diagnosis and propose an improved ITR algorithm (iITR) to solve the TR-LDA problem. The new proposed algorithm can handle nominal attributes and missing values in many real-world medical diagnosis problems. Finally, extensive simulations are presented to show the effectiveness of the proposed algorithms. The results demonstrate that our proposed algorithm can achieve higher accuracies for identifying the demented patients than other state-of-art algorithms.
Acknowledgments
The authors thank L. M. Besser for database support.
The NACC database was supported by NIA Grant UO1 AG016976.
Footnotes
The associate editor coordinating the review of this manuscript and approving it for publication was Prof. Kjersti Engan.
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
Contributor Information
Mingbo Zhao, Email: mzhao4@cityu.edu.hk, Electrical Engineering Department, City University of Hong Kong, Kowloon, Hong Kong SAR.
Rosa H. M. Chan, Email: rosachan@cityu.edu.hk, Electrical Engineering Department, City University of Hong Kong, Kowloon, Hong Kong SAR
Peng Tang, Email: rollegg@gmail.com, Electrical Engineering Department, City University of Hong Kong, Kowloon, Hong Kong SAR.
Tommy W. S. Chow, Email: eetchow@cityu.edu.hk, Electrical Engineering Department, City University of Hong Kong, Kowloon, Hong Kong SAR
Savio W. H. Wong, Email: savio@ied.edu.hk, Psychological Studies, Hong Kong Institute of Education, N.T., Hong Kong SAR
References
- 1.Beekly DL, et al. The national alzheimer’s coordinating center (NACC) database: The uniform data set. Alzheimer Dis Assoc Disord. 2007;21(3):249–258. doi: 10.1097/WAD.0b013e318142774e. [DOI] [PubMed] [Google Scholar]
- 2.Wang H, Yan S, Xu D, Tang X, Huang T. Trace ratio vs. ratio trace for dimensionality reduction. Proc CVPR. 2007 [Google Scholar]
- 3.Jia Y, Nie F, Zhang C. Trace ratio problem revisited. IEEE Trans Neural Netw. 2009;20(4):729–735. doi: 10.1109/TNN.2009.2015760. [DOI] [PubMed] [Google Scholar]
- 4.Zhou L, Wang L, Shen CH. Feature selection with redundancy-constrained class separability. IEEE Trans Neural Netw. 2010;21(5) doi: 10.1109/TNN.2010.2044189. [DOI] [PubMed] [Google Scholar]
- 5.Li H, Jiang T. Efficient and robust feature extraction by maximum margin criterion. IEEE Trans Neural Netw. 2006;17(1):157–165. doi: 10.1109/TNN.2005.860852. [DOI] [PubMed] [Google Scholar]
- 6.He X, Yan S, Hu Y, Niyogi P, Zhang H. Face recognition using Laplacianfaces. IEEE Trans Patt Anal Mach Intell. 2005;27(3):328–340. doi: 10.1109/TPAMI.2005.55. [DOI] [PubMed] [Google Scholar]
- 7.Zhang C, Nie F, Xiang S. A general kernelization framework for learning algorithms based on kernel PCA. Neurocomputing. 2010;73(4–6):959–967. [Google Scholar]
- 8.Stanfill C, Waltz D. Toward memory-based reasoning. Commun ACM. 1986;29(12) [Google Scholar]
- 9.Matsui T, Saruwatari Y, Shigeno M. An Analysis of Dinkelbach’s Algorithm for 0–1 Fractional Programming Problems. Dept. Math. Eng. Inf. Phys., Univ; Tokyo, Japan: 1992. METR92-14. [Google Scholar]
- 10.Fukuaga K. Introduction to Statistical Pattern Classification. New York, NY, USA: Academic; 1990. [Google Scholar]
- 11.Nie F, Xiang S, Zhang C. Neighborhood MinMax projections. IJCAI. 2007 [Google Scholar]
- 12.Xiang S, Nie F, Zhang C. Learning a Mahalanobis distance metric for data clustering and classification. Patt Recognit. 2008;41(12):3600–3612. [Google Scholar]
- 13.Nie F, Xiang S, Jia Y, Zhang C. Semi-supervised orthogonal discriminant analysis via label propagation. Patt Recognit. 2009;42(11):2615–2627. [Google Scholar]
- 14.Nie F, Xiang S, Jia Y, Zhang C, Yan S. Trace ratio criterion for feature selection. AAAI. 2008 [Google Scholar]