

Abstract
Individuals influence each others’ decisions about cultural products such as songs, books, and movies; but to what extent can the perception of success become a “self-fulfilling prophecy”? We have explored this question experimentally by artificially inverting the true popularity of songs in an online “music market,” in which 12,207 participants listened to and downloaded songs by unknown bands. We found that most songs experienced self-fulfilling prophecies, in which perceived—but initially false—popularity became real over time. We also found, however, that the inversion was not self-fulfilling for the market as a whole, in part because the very best songs recovered their popularity in the long run. Moreover, the distortion of market information reduced the correlation between appeal and popularity, and led to fewer overall downloads. These results, although partial and speculative, suggest a new approach to the study of cultural markets, and indicate the potential of web-based experiments to explore the social psychological origin of other macro-sociological phenomena.
In markets for books, music, movies, and other cultural products, individuals often have information about the popularity of the products from a variety of sources: friends, bestseller lists, box office receipts, and, increasingly, online forums. Consistent with the psychological literature on social influence (Sherif 1937; Asch 1952; Cialdini and Goldstein 2004), recent work has found that consumers’ decisions about cultural products can be influenced by this information (Hanson and Putler 1996; Senecal and Nantel 2004; Huang and Chen 2006; Salganik et al. 2006) in part because people use the popularity of products as a signal of quality—a phenomenon that is sometimes referred to as “social” or “observational learning” (Hedström 1998)—and in part because people may benefit from coordinating their choices; that is, listening to, reading, and watching the same things as others (Adler 1985).
The influence that individuals have over each other’s behavior, moreover, can have important consequences for the behavior of cultural markets. In a recent study of an artificial music market, for example, when participants were aware of the previous decisions of others, the popularity of songs was determined in part by a “cumulative advantage” process where early success lead to future success (Salganik et al. 2006). These observed dynamics naturally raise the question of whether perceived success alone is sufficient to generate continued success. Can success in cultural markets, in other words, arise solely as a “self-fulfilling prophecy”—a phrase coined by Robert Merton to mean “a false definition of the situation evoking a new behavior which makes the original false conception come true” [emphasis in original] (Merton 1948).1 Merton illustrated his idea with a hypothetical bank run—describing how depositors’ initially false belief that a bank was going to fail might lead them to withdraw their money causing an actual failure—but the concept was intended to be extremely broad. The bulk of Merton’s seminal paper, for example, was devoted to analyzing race-based differences in academic and professional achievement as a self-fulfilling prophecy.
Since Merton, moreover, social scientists have considered the possibility of self-fulfilling prophecies in a wide variety of domains, and these studies can be classified according to the unit of analysis at which the self-fulfilling dynamics are thought to take place: namely, individual, dyadic, and collective (Biggs 2008). At the level of the individual, for example, a substantial body of work has explored the placebo effect on health outcomes; that is, whether, and under what conditions, individuals experience improved health outcomes that are attributable to receiving a specific substance, but that are not due to the inherent powers of the substance itself (Stewart-Williams and Podd 2004). Moving up to the level of the dyad, researchers have explored the effects of teacher expectations on student outcomes (Rosenthal and Jacobson 1968; Jussim and Harber 2005) and physician prognosis on patient health (Christakis 1999). Finally, at the collective level (i.e., situations involving more than two individuals), sociologists have explored the “performativity” of economic theory (Callon 1998), including whether the predictions of economic models lead people to change their behavior in such a way as to make the original prediction come true (MacKenzie and Millo 2003). A separate body of work by economists, meanwhile, has explored self-fulfilling prophecies with regard to financial panics (Calomiris and Mason 1997), investment bubbles (Garber 1989), and even business cycles (Farmer 1999).
At face value, these studies suggest that over a wide range of scales and domains, the belief in a particular outcome may indeed cause that outcome to be realized, even if the belief itself was initially unfounded, or even false. Skeptics, however, remain unconvinced that expectations or beliefs should be treated as fundamental elements of the social environment, on a par, say, with individual preferences (Rogerson 1995), and much of the empirical evidence that might persuade them is mixed or ambiguous (Biggs 2008). One reason that skeptics remain is that with observational data alone it is virtually impossible to prove that any given real-world event was caused by the self-fulfillment of false beliefs. This difficulty arises because the strongest support for such a claim would require comparing outcomes in the presence or absence of false beliefs, but in almost all cases only one of these outcomes is observed (Holland 1986; Sobel 1996; Winship and Morgan 1999).
Given these limits of observational data, it is no surprise that our best understanding of self-fulfilling prophecies in cultural markets comes from experimental and quasi-experimental methods. For example, by exploiting errors in the construction of the New York Times bestseller list, Sorensen (2007) found that books mistakenly omitted from the list had fewer subsequent sales than a matched set of books that correctly appeared on the list, but the effects were only modest. Rather than attempting to exploit a natural experiment, Hanson and Putler (1996) performed field experiment in which they directly intervened in a real market by repeatedly downloading randomly chosen software programs to inflate their perceived popularity. The authors found that software that received the artificial downloads went on to earn substantially more real downloads than a matched set of software. While these studies offer insight, they may overstate the possibility for self-fulfilling prophecies because the manipulations employed were rather modest and therefore only loosely decoupled perceived success from actual success. Further, these studies lacked a measure of the pre-existing preferences of participants, and therefore cannot shed any light on how the “quality” of the products involved either amplifies or dampens the effect of initially false information.
In this paper we address the question of self-fulfilling prophecies in cultural markets by means of a web-based experiment where 12,207 participants were given the chance to listen to, rate, and download 48 previously unknown songs from unknown bands. Using a “multiple-worlds” experimental design (Salganik et al. 2006), described more fully below, we were able to simultaneously measure the “quality” of the songs and measure the effect of initially false information on subsequent success. When deciding what intiaily false information to provide participants, we opted for an extreme approach, namely complete inversion of perceived success. This extreme approach is not meant to model an actual marketing campaign (which would likely focus on fewer songs), but rather to completely decouple perceived and actual success so as to explore self-fulfilling prophecies in a natural limiting case. While proponents of self-fulfilling prophecies might suspect that perceived success would overwhelm pre-existing preferences and lead the market to lock-in to the inverted state, skeptics might suspect that pre-existing preferences would overwhelm the false information and return the songs to their original ordering. Our results were more complex then either of these extreme predictions suggesting the need for addition theoretical and empirical work.
Experimental Set-up
Participants for our experiment were recruited by sending emails to participants from a previous, unrelated experiment (Dodds et al. 2003). These emails, and the additional web-postings they generated, yielded 12,207 participants, the majority of which lived in the United States and were between the ages of 18 and 34 (Table 1). Our experiment ran from March 14, 2005 to August 10, 2005 (21 weeks), and during that time we recorded a slight increase in the fraction of female participants and an increase in the proportion of participants from Brazil; however, it does not appear that either of these demographic shifts affected our results. Because the experiment was web-based, we had less control over participant recruitment and behavior than in lab-based experiments (Skitka and Sargis 2006). As such we took a number of specific steps, described more fully in the appendix, to account for potential data quality problems.
Table 1.
Descriptive statistics of participants
| Category | Before inversion (n=2,211) (% of participants) | After inversion (n=9,996) (% of participants) |
|---|---|---|
| Female | 37.9 | 43.9 |
| Broadband connection | 91.3 | 89.4 |
| Has downloaded music from other sites | 69.4 | 65.3 |
| Country of Residence | ||
| United States | 68.1 | 54.7 |
| Brazil | 1.2 | 12.5 |
| Canada | 6.8 | 4.9 |
| United Kingdom | 6.6 | 6.9 |
| Other | 17.3 | 21.0 |
| Age | ||
| 17 and younger | 6.8 | 7.9 |
| 18 TO 24 | 29.6 | 26.6 |
| 25 TO 34 | 35.8 | 33.9 |
| 35 and older | 27.8 | 31.7 |
Upon arriving at our website, participants were presented with a welcome screen informing them that they were about to participate in a study of musical tastes and that in exchange for participating they would be given a chance to download some free songs by up-and-coming artists. Next, subjects provided informed consent,2 filled out a brief survey, and were shown a page of instructions. Finally, subjects were presented with a menu of 48 songs presented in a vertical column, similar to the layout of popular music sites (Figure 1A).3 Having chosen to listen to a song, they were asked to rate it on a scale of 1 star (“I hate it”) to 5 stars (“I love it”) (Figure 1B), after which they were offered the opportunity to download the song (Figure 1C). Because of the design of our site, participants could only download a song after listening to and rating it. However, they could listen to, rate, and download as many or as few songs as they wished.
Figure 1.
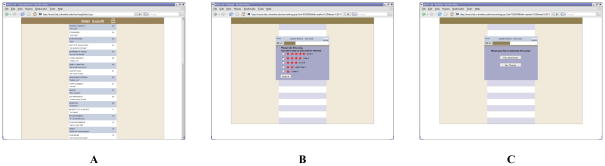
Screenshots from the experiment. Participants in the social information condition were presented the songs in a single column format sorted by previous number of downloads (A). In the independent world, the songs were presented without any measure of popularity and were randomly ordered for each participant (not shown). Having chosen to listen to a song, the participant was asked to rate it on a scale of 1 star (“I hate it”) to 5 stars (“I love it”) (B). After rating the song, the participant was offered a chance to download the song (C). After making the download decision, the participant was returned to the song menu (A) and was able to listen to, rate, and download additional songs.
Upon arrival to the website, subjects were randomly assigned into one of a number of experimental groups. During an initial set-up phase, 2,211 participants were assigned to one of two “worlds”4—independent and social influence—which differed in the available information about the behavior of other participants that was presented with the songs. In the social influence world, the songs were sorted from most to least popular and accompanied by the number of previous downloads for each song. In the independent world, however, the songs were randomly reordered for each participant and were not accompanied by any measure of popularity. Thus, although the presence or absence of download counts was not emphasized, the choices of participants in the social influence condition could clearly be influenced by the choices of previous participants, whereas no such influence was possible in the independent world.
After this set-up period, during which the popularity ordering of the songs, as measured by download counts, reached an approximate steady-state, we continued to assign subjects to the social influence and independent world, but also created two new social influence worlds (the reason we created two will become clear shortly). In these new worlds we explored the possibility of self-fulfilling prophecies by inverting the popularity order from the original social influence world. For example, at the time of the inversion “She Said” by Parker Theory had the most downloads, 128, and “Florence” by Post Break Tragedy had the fewest, 9. To construct the initial conditions for the inverted worlds, we swapped these counts, giving subsequent participants the false impression that “She Said” had 9 downloads and “Florence” had 128. As detailed in Table 2, we also swapped download counts for the 47th and 2nd songs, the 46th and 3rd songs, and so on. The task of inverting the songs was slightly complicated by the fact that there were a large number of songs that had the same number of downloads; for example three different songs were tied with 13 downloads (Table 2). During the inversion these ties were broken randomly. After this one-time intervention, we updated all download counts honestly as 9,996 new participants listened to and downloaded songs in the four worlds—one unchanged social influence world, two inverted social influence worlds, and one independent world.
Table 2.
The 48 songs used in the experiment along with their download count before and after inversion
| Band Name | Song Name | Actual downloads before inversion | Apparent downloads immediately after inversion |
|---|---|---|---|
| Parker Theory | She Said | 128 | 9 |
| Simply Waiting | Went with the Count | 83 | 9 |
| Not for Scholars | As Seasons Change | 81 | 9 |
| Shipwreck Union | Out of the Woods | 66 | 9 |
| Sum Rana | The Bolshevik Boogie | 52 | 9 |
| Dante | Life’s Mystery | 48 | 9 |
| Ryan Essmaker | Detour_(Be Still) | 45 | 9 |
| Hartsfield | Enough is Enough | 39 | 9 |
| By November | If I Could Take You | 36 | 9 |
| Star Climber | Tell Me | 35 | 9 |
| 52metro | Lockdown | 31 | 10 |
| Stranger | One Drop | 30 | 10 |
| Forthfading | Fear | 27 | 10 |
| Silverfox | Gnaw | 26 | 10 |
| Selsius | Stars of the City | 23 | 10 |
| Hydraulic Sandwich | Separation Anxiety | 22 | 10 |
| Undo | While the World Passes | 18 | 10 |
| Hall of Fame | Best Mistakes | 17 | 10 |
| The Thrift Syndicate | 2003 a Tragedy | 17 | 10 |
| Unknown Citizens | Falling Over | 16 | 11 |
| Beerbong | Father to Son | 14 | 11 |
| The Fastlane | Til Death do us Part (I don’t) | 14 | 12 |
| Evan Gold | Robert Downey Jr. | 13 | 12 |
| Ember Sky | This Upcoming Winter | 13 | 13 |
| Miss October | Pink Aggression | 13 | 13 |
| Silent Film | All I have to Say | 12 | 13 |
| Stunt Monkey | Inside Out | 12 | 14 |
| Far from Known | Route 9 | 11 | 14 |
| Moral Hazard | Waste of my Life | 11 | 16 |
| Nooner at Nine | Walk Away | 10 | 17 |
| Sibrian | Eye Patch | 10 | 17 |
| Drawn in the Sky | Tap the Ride | 10 | 18 |
| Art of Kanly | Seductive Intro, Melodic Breakdown | 10 | 22 |
| Fading Through | Wish me Luck | 10 | 23 |
| Benefit of a Doubt | Run Away | 10 | 26 |
| Salute the Dawn | I am Error | 10 | 27 |
| Cape Renewal | Baseball Warlock v1 | 10 | 30 |
| Go Mordecai | It Does What Its Told | 10 | 31 |
| The Broken Promise | The End in Friend | 9 | 35 |
| Summerswasted | A Plan Behind Destruction | 9 | 36 |
| Secretary | Keep Your Eyes on the Ballistics | 9 | 39 |
| The Calefaction | Trapped in an Orange Peel | 9 | 45 |
| A Blinding Silence | Miseries and Miracles | 9 | 48 |
| Up Falls Down | A Brighter Burning Star | 9 | 52 |
| This New Dawn | The Belief Above the Answer | 9 | 66 |
| Up for Nothing | In Sight Of | 9 | 81 |
| Deep Enough to Die | For the Sky | 9 | 83 |
| Post Break Tragedy | Florence | 9 | 128 |
Although extremely simple in comparison with real cultural markets, our experimental design (illustrated schematically in Figure 2) offered us greater control than would be possible in real markets (Willer and Walker 2007) and exhibits several advantages over previous studies in this area (Hanson and Putler 1996; Sorensen 2007). First, the “multiple-worlds” (Salganik et al. 2006) feature of the design allows us to isolate the causal effect of an extreme manipulation—in this case complete inversion—by allowing us to compare participant-level, product-level, and collective-level outcomes in unchanged and inverted worlds; previous studies explored only modest manipulations and product-level outcomes. Second, the popularity of songs in the independent world provides a natural measure of the pre-existing preferences of the participant population that can then be compared to outcomes in the social influence worlds allowing us to determine the extent to which market information can overwhelm pre-existing preferences; previous studies lack such a measure of participant preferences and thus could not address this important issue. Third, the two inverted worlds capture purely random variations in outcomes of the same intervention;5 previous studies examined only one such outcome. A final benefit of our framework is that its dynamic nature allows us to track not just the response of individuals to the inversion, but the response of the entire system, and this response can be observed over time, thus avoiding the need to choose some arbitrary point at which to measure an effect.
Figure 2.
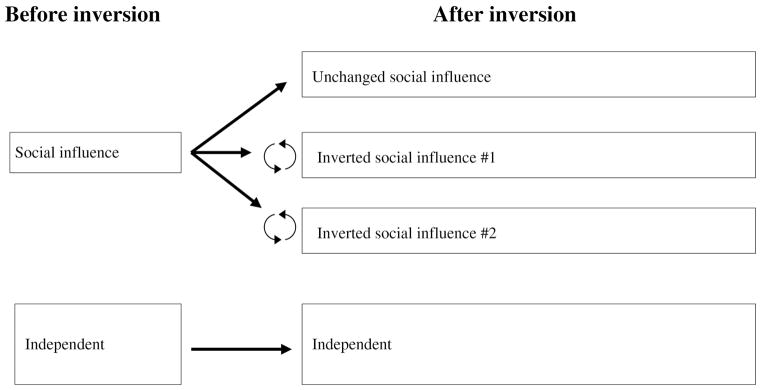
Schematic of the experimental design.
Results
Descriptive statistics of participant behavior for the pre and post inversion periods are presented in tables 3 and 4. Overall, the experiment involved 87,175 song-listens and 15,168 song-downloads meaning that, on average, participants listened to about 7 songs each, of which they downloaded 1. This ratio of listens to downloads suggests that the download decision was indeed viewed by participants as a consequential one. Moreover, the download decision was strongly related to participants’ rating decision; the more stars a participant gave a song, the more likely they were to download that song (Figure 3).
Table 3.
Descriptive statistics of subject behavior before the inversion
| Social influence (n=752) | Independent (n=1,459) | Total (n=2,211) | |
|---|---|---|---|
| Listens | 5,628 | 11,844 | 17,472 |
| Mean per subject | 7.5 | 8.1 | 7.9 |
| Downloads | 1,133 | 1,691 | 2,824 |
| Mean per subject | 1.5 | 1.2 | 1.3 |
| Pr[download | listen] | 0.201 | 0.143 | 0.162 |
| Mean rating (# of stars) | 2.70 | 2.55 | 2.62 |
Table 4.
Descriptive statistics of subject behavior after the inversion
| Unchanged (n=2,015) | Inverted #1 (n=2,014) | Inverted #2 (n=1,970) | Independent (n=3,997) | Total (n=9,996) | |
|---|---|---|---|---|---|
| Listens | 14,430 | 12,498 | 12,633 | 30,142 | 69,703 |
| Mean per subject | 7.2 | 6.2 | 6.4 | 7.5 | 7.0 |
| Downloads | 2,898 | 2,197 | 2,160 | 5,089 | 12,344 |
| Mean per subject | 1.4 | 1.1 | 1.1 | 1.3 | 1.2 |
| Pr[download | listen] | 0.201 | 0.176 | 0.171 | 0.169 | 0.178 |
| Mean rating (# of stars) | 2.71 | 2.64 | 2.60 | 2.63 | 2.64 |
Figure 3.

Probability that a participant downloaded a song as a function of how that participant rated the song. The consistency between participants’ self-reported ratings and download decisions suggests that the download decision was indeed meaningful to participants.
At the time each subject participated, every song in his or her “world” had a specific download count and market rank (i.e. the song with the most downloads had a market rank of 1). Figures 4A–C plot the probability that participants listened to the song of a given market rank. These plots show that participants who were aware of the behavior of others were more likely to listen to songs that they believed were more popular. There was also a slight reversal of this pattern for the least popular songs—for example, a subject in a social influence world was about 6 times more likely to listen to the most popular song and 3 times more likely to listen to the least popular song, than to listen to a song of middle popularity rank. The tendency for the subjects to favor the least popular songs, which at first may appear surprising, is consistent with previous work (Salganik et al. 2006) and could simply be an artifact of our experimental set-up—just as the top spot on a list is salient, so too is the bottom. Alternatively, this behavior could represent a desire for some subjects to compare their preferences with their peers or could be a form of anti-conformist behavior (Simmel 1957; Heath et al. 2006); further experimental work would be required to adjudicate between these possibilities.
Figure 4.

Probability of listening to a song as a function of its popularity in the four worlds.
A related question is to what extent the observed effect of popularity on individual listening decisions is a consequence of informational versus normative influence (Deutsch and Gerard 1955). In this experiment we suspect that the bulk of the effect was informational; that is, we suspect that most participants interpreted the popularity of songs as a quality signal regardless of their preference for listening to the same songs as others. We do not know for sure, however, because our experiment was not designed to differentiate between these two kinds of influence because this differentiation was not necessary to address the main questions raised in this paper. Regardless of the precise mechanism involved, that is, we can observe that the behavior of participants in the social influence worlds—both the unchanged (Figure 4A) and inverted worlds (Figures 4B and 4C)—differed from behavior in the independent world (Figure 4D) where, given our design, song popularity could have no effect on participants’ listening decisions.
Given that the subjects were influenced by the behavior of others (when they were made aware of it), it is natural to explore the implications of the inversion on the subsequent success of specific songs. Figure 5 displays the number of downloads over time both in the unchanged (solid lines) and inverted (dashed lines) worlds for two pairs of songs: Figure 5A compares song 1, defined as the most popular song at the end of the set-up period, with song 48, defined as the least popular song; and Figure 5B compares song 2 with song 47. In both cases, download trajectories in the unchanged world were similar before and after the inversion.
Figure 5.

Popularity dynamics before and after the inversion for the most popular song during the set-up period (song 1: “She Said” by Parker Theory) and the least popular (song 48: “Florence” by Post Break Tragedy) (A) and popularity dynamics for the second most popular song during the set-up period (song 2: “Went with the Count” by Simply Waiting) and second least-popular (song 47: “For the Sky” by Deep Enough to Die) (B). The vertical line at subject 752 shows the moment of the inversion.
The trajectories in the inverted worlds, however, were quite different. In Figure 5A, song 48 earned downloads at a faster rate as a consequence of the inversion (i.e. the slopes of the two dashed lines for song 48 are steeper than the corresponding solid line), while the pattern is reversed for song 1, which suffered from the inversion. A similar pattern is displayed in Figure 5B for song 47, which also benefited from the inversion, and song 2, which also suffered. Thus for all four songs, the initially false perception of their popularity, arising from the inversion, caused their real popularity to change in the direction of the false belief.
It is impossible to say with certainty, however, whether these dynamics would have lead to permanent effects on the popularity of the songs, or whether the observed effects were merely transitory. The problem is that although large, our pool of participants proved insufficient for either inverted world to reach a new steady state; note, for example, that in Figure 5A (dashed lines) song 1 still appears to be gaining on song 48 in both inverted worlds, where, interestingly, this does not seem to be the case for song 2 (Figure 5B, dashed lines). Even thought the inverted worlds didn’t reach a steady-state, we were nevertheless able to estimate the “final” rank of each song (i.e., the rank that would have been achieved if the experiment had run for many more participants), by linearly extrapolating the download trajectories for all 48 songs in each world.6 Figure 6A shows that ranks before the inversion and projected final ranks were highly correlated in the unchanged world (r = 0.84); whereas by contrast Figures 6B and 6C show they had a very weak relationship in the inverted worlds (r = 0.16 in both worlds)7. Figures 6B and 6C also confirm our intuition about Figure 5; that is, it appears that in both inverted worlds song 1 will eventually return to the top spot, but that song 2 will not return to the second spot.
Figure 6.
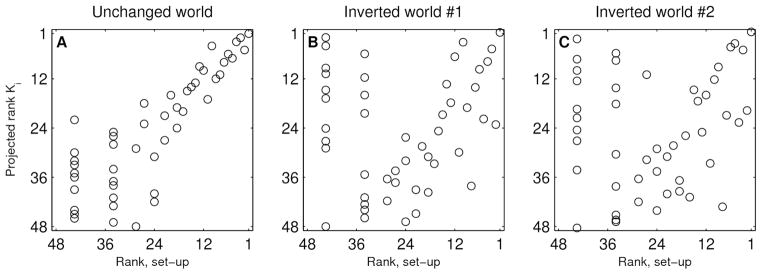
Projected final rank Ki in the unchanged world (A) and the inverted worlds (B and C) as a function of market rank at the end of the set-up period. The initial and projected final ranks were highly correlated in the unchanged world (r = 0.84), but had a very weak relation in the inverted worlds (r = 0.16 in both worlds). The vertical banding in the figures is caused by the large number of songs that had the same market rank at the end of the set-up period (see Table 2).
Further, given the projected outcomes of each song, we can compare the projected final rank in the unchanged and inverted worlds to estimate the long-term impact of the inversion on the popularity of individual songs. More specifically, the impact of the inversion on a specific song, Δi, is defined to be the difference between the projected final rank in the unchanged world and the projected final rank in an inverted world (Ki,unc–Ki,inv). Since we have two inverted worlds, moreover, we have two estimates of our impact measure Δi. Figure 7 shows the impact of inversion as a function of the rank during the set-up period and reveals, for example, that the most popular song during the set-up period was projected to finish at the same rank in the inverted and unchanged worlds; thus the impact of inversion for this song was 0.8 The second most popular song during the set-up period, however, was projected to finish higher in the unchanged world than in the inverted worlds (5th vs 20th and 23rd), so for this song the impact of the inversion was negative (i.e., it was hurt by the inversion). Overall, the final rankings of almost all songs seem to be permanently affected by the inversion, where songs that were “promoted” by the inversion tended to do better in the long run, and songs that were initially demoted tended to do worse. Thus, in our experiment, the manipulation of market information, combined with a process of social influence, seemed to lead to long-term changes in the popularity of songs.
Figure 7.

Relationship between estimated impact of inversion, Δ, and market rank at the end of the set-up period (both estimates presented on the same axis). The vertical banding in the figure is caused by the large number of songs that had the same market rank at the end of the set-up period (see Table 2).
Whereas Figures 6 and 7 show the outcomes experienced by individual songs, Figure 8 shows the outcome experienced by the entire “market”—specifically, it shows the Spearman rank correlation ρ(t) between popularity at the end of the set-up period and popularity in the three social influence worlds as a function of time.9 During the set-up period (to the left of the vertical line) the initial social influence world quickly converged to an approximate steady state, as evidenced by the continuing high value of ρ(t)≈ 1 for the unchanged world (solid line) after the inversion (i.e. to the right of the vertical line). By contrast, the two inverted worlds (dashed lines) started, by definition, with ρ(t) =−1, after which both increased monotonically towards what appears to be an asymptotic limit around zero. In other words, popularity in the inverted worlds moved to a state that had, in effect, no relationship with the popularity before the inversion. Figures 7 and 8 therefore represent slightly different perspectives on the effect of the inversion: whereas Figure 7 suggests that almost all songs, considered individually, did experience some effect on long-term popularity as a consequence of the inversion, Figure 8 suggests that these effects were not strong enough for the inversion to lock-in at the level of the entire market.
Figure 8.

Spearman rank correlation, ρ(t), between the popularity at the end of the set-up period and popularity in the unchanged and inverted worlds. The vertical line at subject 752 shows the moment of the inversion.
The role of appeal
An obvious explanation for the failure of the inversion to lock-in is that the songs themselves were of different quality, and that these differences were more salient than the perception of popularity. Previous theoretical work by economists has indeed emphasized the importance of intrinsic “quality” on outcomes (Rosen 1981), and attempts have been made to measure the quality of cultural products (Hamlen Jr. 1991; Krueger 2005). Unfortunately, no generally agreed-upon measure of quality exists, in large part because “quality” is largely, if not completely, a social construction (Gans 1974; Becker 1982; Bourdieu 1984; DiMaggio 1987; Cutting 2003; Frith 2004). Fortunately, our experimental design permits us to proceed without resolving these conceptual difficulties by measuring instead the intrinsic “appeal” of the songs to our pool of participants. Because the behavior of the participants in the independent condition reflects their true preferences (i.e. they were not subject to social influence), the appeal ai of each song i can be defined as the market share of downloads that that song earned in the independent condition, , where di is the number of downloads for song i in the independent condition (Salganik et al. 2006).10
We emphasize that our measure of appeal is not truly a measure of “quality,” in part because it is specific to our subject pool. Were we to re-run the experiments with a new population of participants, say senior citizens from Japan, our procedure would almost certainly result in a different measure of appeal. Further, because the measure of appeal is based on market share, it is constrained to sum to 1; thus if we added another song to our experiment, the measured appeal of the other songs would decrease. While these characteristics limit the general applicability of our measure, fortunately they do not affect the current analysis.
Figure 9 compares our measure of appeal to our estimates of the impact of the inversion, Δi, and shows that “bad” songs benefited from the inversion, while the “good” songs suffered. Moreover, Figure 9 shows that the success of the very “best” songs was essentially unaffected, even though these were typically the most severely penalized by the inversion. This tendency for the highest appeal songs to recover their original ranking coupled with the tendency for lower appeal songs to maintain at least some the benefits of the inversion prevented the songs from either locking-in to their inverted ordering or returning to their pre-inversion state.
Figure 9.

Relationship between estimated impact of inversion, Δ, and song appeal (both estimates presented on the same axis). The dashed line is a loess fit to the data (α = 0.6, λ = 2) and is intended as a visual aid (Cleveland 1993) In general, the “worst” songs were helped by the inversion, the “good” songs were hurt by it, and the success of the “best” songs was largely unaffected.
We can also use our measure of appeal to see how closely the projected outcomes in the social influence worlds reflect the “true” preferences of our population, as revealed by their choices in the independent condition. In the unchanged social influence world, the projected outcomes were strongly, but not completely, related to appeal (rank correlation = 0.82). Therefore, even in the absence of manipulation, the presence of social influence produced outcomes that did not perfectly reflect the true preferences of the participant population (Salganik et al. 2006). The inverted worlds, however, were much less reflective of population preferences (rank correlation = 0.42), suggesting—perhaps not surprisingly—that markets in which perceived popularity has been manipulated will in general be less revealing of true preferences than markets in which popularity is allowed to emerge naturally.
The consequences for participants
A final and unexpected consequence of the inversion was a substantial reduction in the overall number of downloads. As shown in Figure 4, subjects in all social influence worlds tended to listen to the songs that they thought were more popular. In the inverted worlds, however, the songs that appeared to be more popular tended to be of lower appeal; thus, subjects in the inverted world were more exposed to lower appeal songs. For example, in the unchanged world, the 10 highest appeal songs had about twice as many listens as the 10 lowest appeal songs, but in the inverted worlds this pattern was reversed with the 10 lowest appeal songs having twice as many listens. As a consequence, subjects in the inverted worlds left the experiment after listening to fewer songs and were less likely to download the songs to which they did listen (Table 4). Together, these effects led to a substantial reduction in downloads: 2,197 and 2,160 in the inverted worlds, compared with 2,898 in the unchanged world.
The combination of increased success for some individual songs (Figure 7) on the one hand, and decreasing overall downloads, on the other hand, suggests that the choice to manipulate market information may resemble a social dilemma, familiar in studies of public goods and common-pool resources (Dawes 1980; Yamagishi 1995; Kollock 1998), but less evident in market-oriented behavior. Specifically, Figure 7 suggests that any individual band could expect to benefit by artificially inflating their perceived popularity, regardless of their true appeal or the strategies of the other bands; thus all bands have a rational incentive to manipulate information. When too many bands employ this strategy, however, the correlation between apparent popularity and appeal is lowered, leading to the unintended consequence of the market as a whole contracting, thereby causing all bands to suffer collectively (Dellarocas 2006).11
Discussion and conclusion
Although Merton’s concept of the self-fulfilling prophecy is appealing both for its elegance and its generality, social scientists have encountered difficulty in demonstrating empirically that self-fulfilling prophecies actually occur, and that observed outcomes do not instead reflect exogenous factors like intrinsic differences in quality or convergence to rational equilibria. In particular, convincingly rejecting alternative explanations in favor of a self-fulfilling prophecy requires one to compare the outcomes of otherwise identical “versions” of history, some of which include the false perception of reality, and others of which do not—clearly an impossibility for most social processes of interest. Moreover, in many cases of interest, including cultural markets, the identification of self-fulfilling prophecies is complicated by the presence of multiple “scales” in the dynamics; that is, the decisions required to render the false belief true are made by individuals, but the false belief itself concerns some collective property, like aggregate number of downloads, over which no one individual has much control. Causal explanations of collective social phenomena that invoke self-fulfilling prophecies are therefore rendered problematic not only by the absence of counterfactuals in most observational data, but by the analytical complexity of the micro-macro problem (Schelling 1978; Coleman 1990; Hedström 2005).
By conducting an experiment on a large enough scale that we can observe both individual choices and collective dynamics simultaneously, our study sidesteps these difficulties, allowing us not only to identify the presence of self-fulfilling prophecies—when they occur—but also to begin to quantify their effects. We are able to show, for example, that although inversion of market information can lead to substantial differences in the success of individual songs, the effect on the overall market ranking was not as dramatic as we had anticipated—many “good” songs recouped much of their original popularity in spite of our manipulation. Our experiment therefore provides some ammunition both for proponents of self-fulfilling prophecies, and also for skeptics, by suggesting that cultural markets can exhibit self-fulfilling prophecies, but that their effects may be limited by pre-existing individual preferences.
Naturally, our experiment is unlike real cultural markets in a number of respects that render our results more suggestive than conclusive. For example, unlike in our experiment, where popularity was manipulated at a single time, and in a highly artificial manner (i.e. total inversion), distortion in the real world may occur repeatedly, and may also exhibit considerable subtlety and variety. As an extreme example of manipulation, total inversion seems a natural first case to consider; but there are of course many other possible manipulations that one could explore, even within our simplified experimental framework. Moreover, whereas our subjects were exposed to only a single source of influence—download counts—information in real cultural markets exhibits richer content (Chevalier and Mayzlin 2006) and comes from a variety of sources (Katz and Lazarsfeld 1955). Also, because our experiment had only 48 songs, the average participant listened to about one-seventh of the music in our market and some participants listened to almost all the songs—a feat that would be impossible in real cultural markets where the number of products is overwhelming (Caves 2000). Finally, by focusing exclusively on consumer decisions, we did not account for the decisions of institutional actors such as music executives, radio stations, and cultural critics; actors who can have important effects on outcomes as has been demonstrated by numerous scholars working in the “production of culture” school (Hirsch 1972; Peterson 1976; Frith 1978; DiMaggio 2000; Peterson and Anand 2004; Dowd 2004).
Precisely how our results would change under more realistic conditions is difficult to predict. We suspect, for example, that our finding that the highest appeal songs tend to succeed regardless of interference may derive from the relatively small number of songs, which prevented the “best” songs from escaping notice even in the inverted worlds. Thus this finding may not generalize to more realistic scenarios in which the number of songs is much greater. Moreover, because we only performed one type of manipulation on one set of songs, it is unclear how our findings would be affected either by less severe distortions or by using a set of songs that are more (or less) similar in terms of appeal. Nor is it obvious how the results would have differed had our subjects been exposed to a stronger (or weaker) form of social influence.
In spite of these ambiguities, which we hope will be addressed with additional experiments or simulations, we believe that our findings are likely to have applicability beyond the specific scope of the experiment itself, and thereby add to our general understanding of self-fulfilling prophecies in cultural markets. We also believe this experiment may have implications for experimental sociology and social psychology more generally by showing the potential for web-based experiments to operate on a scale that is not possible in a physical lab (Skitka and Sargis 2006). Our experiment involved more than 12,000 participants—a number which, to place in the context of traditional psychology experiments, is larger than the total enrollment of many universities. Even larger experiments are practical today, and likely to become increasingly so as web-related technology continues to develop. Although there are a number of important issues to consider when conducting web-based experiments—some of which are shared with laboratory experiments, and some of which are novel—we suspect that the ability to run experiments involving tens, or even hundreds, of thousands of participants will open exciting new areas of theory development and testing.
For example, both sociologists (DiMaggio 1997) and psychologists (Schaller and Crandall 2003) have recently taken an interest in the psychological foundations of culture, arguing that “Individuals’ thoughts, motives, and other cognitions govern how they interact with and influence one another; these interpersonal consequences in turn govern the emergence, persistence, and change of culture” (Schaller and Crandall: 4). Economists, sociologists, and physicists, moreover, have proposed numerous mathematical and simulation models that purport to represent how interpersonal influence—a micro-level phenomenon—aggregates to produce macro-level phenomena like information cascades, winner-take-all markets, and the successful diffusion of innovations.
Although these modeling exercises have led to some intriguing and even counterintuitive insights, they have also been confounded by the difficulty of reconciling models either with micro-level or macro-level empirical data. At the micro-level, empirical difficulties arise because social influence experiments are not generally designed to differentiate between the different “rules” governing individual behavior that are assumed, sometimes implicitly, in various models. And at the macro-level, empirical verification is plagued by ambiguities of cause and effect; that is, very different individual-level rules can sometimes generate very similar collective outcomes, while at other times very different collective outcomes can be generated by indistinguishable rules (Granovetter 1978; Watts 2002). By dramatically increasing the scale at which controlled experiments can be conducted, while still retaining the ability to measure individual-level responses, web-based experiments, of which the one described here is merely illustrative, can therefore help address the micro-macro problem inherent in understanding the psychological foundations of cultural markets and other macro-sociological phenomena (Hedström 2006).
Appendix
In all experiments researchers must take steps to ensure that data are generated by the appropriate set of subjects in situations that match the experimental design. While difficult in all experiments, these problems can be particularly challenging in web-based experiments where researchers have less control over subject recruitment and behavior than they would have in a standard laboratory-based experiment. Instead of preventing inappropriate data generation, and hence giving subjects incentive to provide us with false information, we allowed all subjects to participate in all situations, but excluded questionable data from our analysis. This “collect and exclude” approach, which we believe has general utility in web-based social research, is best illustrated by example.
Our experimental design required that a subject’s information about the behavior of others be limited to what we did or did not provide them. One of our concerns, therefore, was that information would somehow “leak” across worlds. As such we attempted to exclude from our analysis all subject behavior that might have been affected by this outside information. The first step in our process of flagging data for exclusion was based on the survey that all subjects completed during the registration process. On this survey subjects were asked to select, from a list of choices, all of the ways that they heard about the experiment. If a subject reported “friend told me about a specific song” or “friend told me about a specific band” all data generated by that subject were excluded from the analysis because it could have been influenced by information from a different world. However, data generated by subjects who reported “friend told me about the experiment in general” were included. We also excluded all data generated after either the subject clicked “log-off” or 2 hours had passed since the subject registered in order to exclude data where the subject could have participated, discussed the music with friends, and then returned with outside information.
In addition, to prevent the same subject from participating in different worlds, we placed several cookies—small pieces of information—into the subject’s web browser. These cookies ensured that if a subject returned to the experiment, the subject would be placed in the same world without having to re-complete the registration process. Further, we used the cookies to prevent subjects who participated before inversion from also participating after it.
In additional to excluding potentially inappropriate data, we also took a number of steps to guard against malicious subjects who might have attempted to disrupt the experiment. This problem, while not limited to web-based experiments, is perhaps a larger issue in this experiment than in most. For example, members of one of the bands might have tried to artificially inflate the download count of their song. To prevent this behavior, each subject was allowed to download a specific song as many times as they wished, but could only add one to the displayed download count for that song. Members of the bands might have also tried to manipulate the results by sending their fans to the experiment. As such, we excluded all data generated by people who reported on our survey that they heard about the experiment from “one of the bands.” We also checked our web-server log to ensure that we were not receiving subjects from the websites of any of the bands. During this experiment, no such links were found.
An additional class of malicious subjects could have simply wished to disrupt the experiment for no specific reason. To prevent against these subjects, the experiment was run with appropriate security precautions using the latest software at the time (Apache 2.0, MySQL 4.0, and Tomcat 5.0) with strict firewall settings. Despite all of our security precautions it was still possible for a subject to manipulate our results. For example, there is no way that we could prevent the same person from registering from several different computers and providing us with false information each time. Given that subjects have little incentive to undertake this behavior, however, we do not think that it occurred frequently. Taken together, our data-quality measures give us confidence that our data are reasonably clean. Of course we cannot rule out all possible problems, but we have not seen any patterns in the data that indicate contamination or malicious behavior.
Footnotes
We thank Peter Hausel and Peter S. Dodds for help in designing and developing the MusicLab web site, and Peter S. Dodds and members of the Collective Dynamics Group for many helpful conversations. We also thank Hana Shepherd and Amir Goldberg for helpful comments on this manuscript. This research was supported in part by an NSF graduate research fellowship (to MJS), NSF grants SES-0094162 and SES-0339023, the Institute for Social and Economic Research and Policy at Columbia University, and the James S. McDonnell Foundation.
Merton’s work on self-fulfilling prophecies was heavily influenced by Thomas and Thomas (1928) who wrote what Merton later called the Thomas Theorem: “if men define situations as real, they are real in their consequences.” For a complete review of the intellectual history, see Merton (1995).
The research protocols used were approved by the Columbia University Institutional Review Board (protocol numbers: IRB-AAAA5286 and IRB-AAAB1483).
The songs were collected by sampling bands from the music website www.purevolume.com. These bands and songs were then screened to insure that they would be essentially unknown to experimental participants. A list of band names and song names is presented later in this paper (Table 2), and additional details on the sampling and screening of the bands are available in Salganik, Dodds, and Watts (2006) and Salganik (2007).
In this paper we will use the term “world” rather than the more standard “condition” to emphasize that the fact that although there were two different conditions—independent and social influence—there were a number of different groups to which participants could be assigned (see Figure 2).
Previous work has found that artificial markets, such as the one employed here, can have multiple, stable outcomes (Salganik et al. 2006). Therefore, we wanted to observe as many inverted worlds as possible to get a sense of the range of possible steady-states that could result from a specific manipulation. At the same time, however, we wanted to have sufficient numbers of participants in each world to allow them to actually reach steady-state after our exogenous shock (Strogatz 1994). The ultimate choice of two inverted worlds was an attempt to balance the conflicting desires for many worlds and many participants per world.
The extrapolation of the download trajectories is based on a linear-least squares fit over the last 1,000 subjects in each world. Conclusions based on these projections are robust to the particular number of subjects used in the fitting (Salganik 2007). It is also the case that the projected final rank was highly correlated with the ranking at the end of the experiment (r = 0.92 in the unchanged world and r = 0.83 and 0.84 in the inverted worlds).
The vertical banding in Figure 6 is caused by the large number of songs that had the same market rank at the end of the set-up period (see Table 2).
The vertical banding in Figure 7 is caused by the large number of songs that had the same market rank at the end of the set-up period (see Table 2).
We used the Spearman rank correlation instead of the more familiar Pearson product-moment correlation (r) because the former is non-parametric measure of monotonic association, rather than just linear association (Kendall and Gibbons 1990).
An alternate measure of the appeal of a song is the probability of downloading that song given a listen (see, for example, Aizen et al. 2004). We chose not to use this measure, however, because it does not include a measure of the attractiveness of the song and band names, something that was found to vary across songs. Our proposed measure, because it is based on the probability of listen and the probability of download given listen, includes both the attractiveness of the song itself and the attractiveness of the song and band name.
The dilemma faced by the bands appears to be more similar to common-pool resource situations than public goods situations because the benefit that a band receives may be related their proportion of the total contribution, not just to the total contribution (Apesteguia and Maier-Rigaud 2006). However, this statement is hard to make precise because the payoff functions for the bands are unknown. For more on the difference between common-pool resource and public goods situations see Apesteguia and Maier-Rigaud (2006).
Contributor Information
Matthew J. Salganik, Email: mjs3@princeton.edu, Department of Sociology and Office of Population Research, 145 Wallace Hall, Princeton, NJ 08544
Duncan J. Watts, Email: djw@yahoo-inc.com, djw24@columbia.edu, Yahoo! Research, 111 W. 40th Street, 17th Floor, New York, NY 10018, Sociology Department, 411 Fayerweather Hall, Columbia University, New York, NY 10027
References
- Adler Moshe. Stardom and Talent. American Economic Review. 1985;75(1):208–12. [Google Scholar]
- Aizen Jonathan, Huttenlocher Daniel, Kleinberg Jon, Novak Antal. Traffic-based feedback on the web. Proceedings of the National Academy of Sciences, USA. 2004;101(Supp 1):5254–60. doi: 10.1073/pnas.0307539100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Apesteguia Jose, Maier-Rigaud Frank P. The Role of Rivalry: Public Goods Versus Common-Pool Resources. Journal of Conflict Resolution. 2006;50(5):646–63. [Google Scholar]
- Asch Solomon E. Social Psychology. Englewood Cliffs, NJ: Prentice-Hall; 1952. [Google Scholar]
- Becker Howard S. Art Worlds. Berkeley: University of California Press; 1982. [Google Scholar]
- Biggs Michael. Self-Fulfilling Prophecies. In: Bearman P, Hedström P, editors. The Oxford Handbook of Analytical Sociology. Oxford: Oxford University Press; 2008. [Google Scholar]
- Bourdieu Pierre. In: Distinction. Nice R, translator. Cambridge, MA: Harvard University Press; 1984. [Google Scholar]
- Callon Michel., editor. The Laws of the Markets. Oxford: Blackwell; 1998. [Google Scholar]
- Calomiris Charles W, Mason Joseph R. Contagion and Failures During the Great Depression: The June 1932 Chicago Banking Panic. American Economic Review. 1997;87(5):863–83. [Google Scholar]
- Caves RE. Creative Industries: Contracts between Art and Commerce. Cambridge, MA: Harvard University Press; 2000. [Google Scholar]
- Chevalier Judith A, Mayzlin Dina. The Effect of Word of Mouth on Sales: Online Book Reviews. Journal of Marketing Research. 2006;43:345–54. [Google Scholar]
- Christakis Nicholas A. Death Foretold: Prophecy and Prognosis in Medical Care. Chicago: University of Chicago Press; 1999. [Google Scholar]
- Cialdini Robert B, Goldstein Noah J. Social Influence: Compliance and Conformity. Annual Review of Psychology. 2004;55:591–621. doi: 10.1146/annurev.psych.55.090902.142015. [DOI] [PubMed] [Google Scholar]
- Cleveland William S. Visualizing Data. Summit, NJ: Hobart Press; 1993. [Google Scholar]
- Coleman James S. Foundations of Social Theory. Cambridge, MA: Harvard University Press; 1990. [Google Scholar]
- Cutting James E. Gustave Caillebotte, French Impressionism, and mere exposure. Psychonomic Bulletin & Review. 2003;10(2):319–43. doi: 10.3758/bf03196493. [DOI] [PubMed] [Google Scholar]
- Dawes Robyn M. Social Dilemmas. Annual Review of Psychology. 1980;31:169–93. [Google Scholar]
- Dellarocas Chrysanthos. Strategic Manipulation of Internet Opinion Forums: Implications for Consumers and Firms. Management Science. 2006;52(10):1577–93. [Google Scholar]
- Deutsch M, Gerard HB. A Study of Normative and Informative Social Influences Upon Individual Judgement. Journal of Abnormal Social Psychology. 1955;51:629–36. doi: 10.1037/h0046408. [DOI] [PubMed] [Google Scholar]
- DiMaggio Paul. Classification in Art. American Sociological Review. 1987;52(4):440–55. [Google Scholar]
- DiMaggio Paul. Culture and Cognition. Annual Review of Sociology. 1997;23:263–87. [Google Scholar]
- DiMaggio Paul. The Production of Scientific Change: Richard Peterson and the Institutional Turn in Cultural Sociology. Poetics. 2000;28:107–36. [Google Scholar]
- Dodds PS, Muhamad R, Watts DJ. An experimental study of search in global social networks. Science. 2003;301(5634):827–9. doi: 10.1126/science.1081058. [DOI] [PubMed] [Google Scholar]
- Dowd Timothy J. Production perspectives in the sociology of music. Poetics. 2004;32:235–46. [Google Scholar]
- Farmer Robert EA. Macroeconomics of Self-fulfilling Prophecies. Cambridge, MA: MIT Press; 1999. [Google Scholar]
- Frith Simon. The sociology of rock. London: Constable; 1978. [Google Scholar]
- Frith Simon. What is bad music? In: Derno CWaM., editor. Bad Music. New York: Routledge; 2004. [Google Scholar]
- Gans Herbert. Popular Culture and High Culture. New York: Basic Books; 1974. [Google Scholar]
- Garber Peter M. Tulipmania. Journal of Political Economy. 1989;97(3):535–60. [Google Scholar]
- Granovetter Mark. Threshold Models of Collective Behavior. American Journal of Sociology. 1978;83(6):1420–43. [Google Scholar]
- Hamlen William A., Jr Superstardom in Popular Music: Empirical Evidence. The Review of Economics and Statistics. 1991;73(4):729–33. [Google Scholar]
- Hanson Ward A, Putler David S. Hits and Misses: Herd Behavior and Online Product Popularity. Marketing Letters. 1996;7(4):297–305. [Google Scholar]
- Heath Chip, Ho Ben, Berger Jonah. Focal points in coordinated divergence. Journal of Economic Psychology. 2006;27:635–47. [Google Scholar]
- Hedström Peter. Rational Imitation. In: Hedström P, Swedberg R, editors. Social Mechanisms: Analytical Approach to Social Theory. Cambridge: Cambridge University Press; 1998. [Google Scholar]
- Hedström Peter. Dissecting the Social. Cambridge, UK: Cambridge University Press; 2005. [Google Scholar]
- Hedström Peter. Experimental Macro Sociology: Predicting the Next Best Seller. Science. 2006;311:786–7. doi: 10.1126/science.1124707. [DOI] [PubMed] [Google Scholar]
- Hirsch Paul M. Processing Fads and Fashions: An Organization-Set Analysis of Cultural Industry Systems. American Journal of Sociology. 1972;77(4):639–59. [Google Scholar]
- Holland Paul W. Statistics and Causal Inference. Journal of the American Statistical Association. 1986;81:945–60. [Google Scholar]
- Huang Jen-Hung, Chen Yi-Fen. Herding in Online Product Choice. Psychology & Marketing. 2006;23(5):413–28. [Google Scholar]
- Jussim Lee, Harber Kent D. Teacher Expectations and Self-Fulfilling Prophecies: Knowns and Unknows, Resolved and Unresolved Controversies. Personality and Social Psychology Review. 2005;9(2):131–55. doi: 10.1207/s15327957pspr0902_3. [DOI] [PubMed] [Google Scholar]
- Katz Elihu, Lazarsfeld Paul F. Personal Influence. Glencoe, IL: Free Press; 1955. [Google Scholar]
- Kendall Maurice, Gibbons Jean Dickinson. Rank Correlation Methods. London: Edward Arnold; 1990. [Google Scholar]
- Kollock Peter. Social Dilemmas: The Anatomy of Cooperation. Annual Review of Sociology. 1998;24:183–214. [Google Scholar]
- Krueger Alan B. The economics of real superstars: The market for rock concerts in the material world. Journal of Labor Economics. 2005;23(1):1–30. [Google Scholar]
- MacKenzie Donald, Millo Yuval. Constructing a Market, Performing Theory: The Historical Sociology of a Financial Derivatives Exchange. American Journal of Sociology. 2003;109(1):107–45. [Google Scholar]
- Merton Robert K. The Self-Fulfilling Prophecy. Antioch Review. 1948;8:193–210. [Google Scholar]
- Merton Robert K. The Thomas Theorem and The Matthew Effect. Social Forces. 1995;74(2):379–424. [Google Scholar]
- Peterson Richard A. The Production of Culture. The American Behavioral Scientist. 1976;19:669–84. [Google Scholar]
- Peterson Richard A, Anand N. The Production of Culture Perspective. Annual Review of Sociology. 2004;30:311–34. [Google Scholar]
- Rogerson Richard. Book Review: The Macroeconomics of Self-Fulfilling Prophecies by Roger E. A. Farmer. Journal of Economic Literature. 1995;33(2):841–2. [Google Scholar]
- Rosen Sherwin. The Economics of Superstars. American Economic Review. 1981;71(5):845–58. [Google Scholar]
- Rosenthal Robert, Jacobson Lenore. Pygmalion in the Classroom: Teacher Expectations and Pupils’ Intellectual Development. New York: Holt, Rinehart and Winston; 1968. [Google Scholar]
- Salganik Matthew J. PhD Thesis. Department of Sociology, Columbia University; New York: 2007. Success and failure in cultural markets. [Google Scholar]
- Salganik Matthew J, Dodds Peter Sheridan, Watts Duncan J. Experimental Study of Inequality and Unpredictability in an Artificial Cultural Market. Science. 2006;311:854–6. doi: 10.1126/science.1121066. [DOI] [PubMed] [Google Scholar]
- Schaller Mark, Crandall Chrstian S., editors. The Psychological Foundations of Culture. Mahwah, NJ: Lawrence Erlbaum; 2003. [Google Scholar]
- Schelling Thomas C. Micromotives and Macrobehavior. New York: W. W. Norton; 1978. [Google Scholar]
- Senecal Sylvain, Nantel Jacques. The influence of online product recommendations on consumers’ online choices. Journal of Retailing. 2004;80:159–69. [Google Scholar]
- Sherif Muzafer. An Experimental Approach to the Study of Attitudes. Sociometry. 1937;1(1):90–8. [Google Scholar]
- Simmel Georg. Fashion. American Journal of Sociology. 1957;62(6):541–58. [Google Scholar]
- Skitka Linda J, Sargis Edward G. The Internet as Psychological Laboratory. Annual Review of Psychology. 2006;57:529–55. doi: 10.1146/annurev.psych.57.102904.190048. [DOI] [PubMed] [Google Scholar]
- Sobel Michael E. An Introduction to Causal Inference. Sociological Methods and Research. 1996;24:353–79. [Google Scholar]
- Sorensen Alan T. Bestseller Lists and Product Variety. Journal of Industrial Economics. 2007;LV(4):715–38. [Google Scholar]
- Stewart-Williams Steve, Podd John. The Placebo Effect: Disolving the Expectancy Versus Conditioning Debate. Psychological Bulletin. 2004;130(2):324–40. doi: 10.1037/0033-2909.130.2.324. [DOI] [PubMed] [Google Scholar]
- Strogatz Steven H. Nonlinear Dynamics and Chaos. Reading, MA: Perseus; 1994. [Google Scholar]
- Thomas WI, Thomas Dorothy Swaine. The Child in America: Behavior Problems and Programs. Knopf; 1928. [Google Scholar]
- Watts Duncan J. A Simple Model of Global Cascades in Random Networks. Proceedings of the National Academy of Sciences, USA. 2002;99(9):5766–71. doi: 10.1073/pnas.082090499. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Willer David, Walker Henry A. Building Experiments: Testing Social Theory. Stanford: Stanford University Press; 2007. [Google Scholar]
- Winship Christopher, Morgan Stephen L. The Estimation of Causal Effects from Observational Data. Annual Review of Sociology. 1999;25:659–706. [Google Scholar]
- Yamagishi Toshio. Social Dilemmas. In: Cook KS, Fine GA, House JS, editors. Sociological Perspectives on Social Psychology. Boston: Allyn and Bacon; 1995. [Google Scholar]