

Abstract
Objective
This study examined how frequency lowering affected sentence intelligibility and quality, for adults with postlingually acquired, mild-to-moderate hearing loss.
Method
Listeners included adults aged 60–92 years with sloping sensorineural loss and a control group of similarly-aged adults with normal hearing. Sentences were presented in quiet and babble at a range of signal-to-noise ratios. Intelligibility and quality were measured with varying amounts of frequency lowering, implemented using a form of frequency compression.
Results
Moderate amounts of compression, particularly with high cutoff frequencies, had minimal effects on intelligibility. Listeners with the greatest high-frequency hearing loss showed the greatest benefit. Sentence intelligibility decreased with more compression. Listeners were more affected by a given set of parameters in noise. In quiet, any amount of compression resulted in lower speech quality for most listeners, with the greatest degradation for listeners with better high-frequency hearing. Quality ratings were lower with background noise, and in noise the effect of changing compression parameters was small.
Conclusions
The benefits of frequency lowering in adults were affected by the compression parameters as well as individual hearing thresholds. Data are consistent with the idea that frequency lowering can be viewed in terms of an improved audibility vs increased distortion tradeoff.
Keywords: frequency lowering, hearing, intelligibility, quality
Over the past decade, a number of sophisticated hearing aid processing strategies have become available. These include multichannel wide-dynamic range compression; various implementations of within-channel noise reduction, including suppression of feedback or impulse noise; and most recently, frequently lowering. In general, such strategies are aimed at improving audibility of essential speech cues, and thus are expected to improve speech intelligibility while maintaining speech quality. However, they can also introduce nonlinear distortion (e.g., (Arehart, Kates, & Anderson, 2010; Jenstad & Souza, 2005, 2007). For appropriate application of these technologies, we should consider whether there are circumstances under which the benefits of improved audibility are offset by distortion of acoustic information.
Consider frequency-lowering amplification as an example. Use of frequency lowering is increasing, with at least five manufacturers currently implementing this technology for some or all wearers. The impetus for incorporating frequency lowering into the audiologists’ toolbox is obvious: many individuals with hearing loss cannot receive and/or discriminate high-frequency speech sounds. Although that deficit can be addressed by providing high-frequency gain, some speech cues may be poorly perceived even with amplification. Degraded perception of high-frequency speech cues will occur for listeners with severe high-frequency loss who do not have sufficient residual hearing to receive these cues even with high-gain hearing aids. More recently, there has been interest in providing frequency lowering to listeners with moderate high-frequency loss (Ricketts & Mueller, 2012; Ross, 2010). This trend has already penetrated clinical practice--in a recent survey, three-quarters of audiologists were fitting frequency-lowering technology, with nearly half of those respondents indicating that they would consider frequency lowering for any configuration of high-frequency loss (Teie, 2012). The rationale is that such processing might improve perception of phonemes which, although not completely outside the absolute audible bandwidth, cannot be heard optimally because of elevated thresholds combined with the high-frequency roll-off of the hearing aid. For example, fricative consonants spoken by female and child talkers may occur at frequencies well above 4 kHz (Pittman, Stelmachowicz, Lewis, & Hoover, 2003; Stelmachowicz, Pittman, Hoover, & Lewis, 2002). However, recent work by McDermott (2011) demonstrated that when implemented using frequency compression, frequency lowering can also reduce spacing between harmonics, modify spectral peak levels, and alter spectral shape for phonemes within the processor dynamic range. Because those cues are important to phoneme perception, the benefits of frequency lowering need to outweigh the (potential) disadvantage of those concomitant distortions.
The following review focuses on frequency lowering implemented via frequency compression (an alternative strategy, frequency transposition, is also available in some hearing aids). There have been several population studies on use of frequency compression for listeners with mild-to-moderate hearing loss, but much of that work has focused on pediatric fitting. Two recent papers (Glista, Scollie, & Sulkers, 2012; Wolfe et al., 2011) tested only children. Two additional papers (Simpson, Hersbach, & McDermott, 2005, 2006) focused on adults, but with severe-to-profound high-frequency loss. Most relevant to the current study is a paper by Glista et al. (2009) which included both adults and children with mild-to-moderate loss. Those data suggest that children may show greater benefit with frequency compression, in that 7 of 11 children (64%) performed better with frequency compression on at least one task, compared to 4 of 14 adults (28%). Given the small cohort tested in previous studies, the child-adult difference is not conclusive, and some children do not seem to receive any benefit (Glista et al., 2009; Glista et al., 2012; Wolfe et al., 2011). Nonetheless, the idea that frequency lowering should be attempted in children makes sense if we consider that phonemes like /s/ are important linguistic cues for speech recognition and language acquisition in young children (Moeller et al., 2007; Moeller et al., 2010), and may not be adequately amplified with conventional amplification. For children, then, the available data hints that the potential benefits of frequency lowering are more likely than not to outweigh any (potential) disadvantages.
For older adults with late-acquired hearing loss, the picture is not as clear. Consider the following issues relevant to this population. First, in contrast to children who require consistent and phoneme-specific audibility for language acquisition, older adults with acquired mild-to-moderate hearing loss have long experience with language. Accordingly, they can use linguistic constraints and context as alternative cues to phoneme identification (Pichora-Fuller, 2008; Pichora-Fuller & Souza, 2003). This idea is supported by work which shows that even when given only partial audibility, adults with sloping, mild-to-moderate loss can recognize high-frequency phonemes when children with similar hearing loss cannot (Stelmachowicz, Pittman, Hoover, & Lewis, 2001). The age difference is not apparent when nonwords are used (McCreery & Stelmachowicz, 2011), suggesting that the adult-child differences may be tied to lexical knowledge. Differences in use of top-down processing can explain why improvements in high-frequency phoneme detection using frequency compression did not always improve speech recognition in adults (Glista et al., 2009).
Second, frequency compression can demonstrably improve audibility of high-frequency phonemes (Glista et al., 2009), but also alters the frequency spacing of those phonemes within the bandwidth of the received signal. The consequences of that change are not clear. Some adults preferred frequency compression over no frequency compression (Glista et al., 2009), but we do not know whether that preference was based on intelligibility, on quality, or some other component, because preference may be determined by different signal dimensions (Meister, Lausberg, Walger, & von Wedel, 2001; Versfeld, Festen, & Houtgast, 1999). Adults with acquired hearing loss consider speech quality to be a critical factor affecting use of hearing aids (Kochkin, 2010). Accordingly, there is a need for research which directly measures the perceived quality of frequency-lowered speech. As a starting point, it would be useful to understand under what circumstances frequency lowering affects quality, as well as to define the relationship between quality and intelligibility.
Third, an important consideration is that adults’ daily listening environments usually contain background noise (Olsen, 1998). Although there are some published data which considered a limited number of noisy conditions (Simpson et al., 2006), most studies of frequency compression for adults have been obtained with quiet speech. Because frequency compression may improve high-frequency audibility at the expense of spectral alteration, and because noise also affects both audibility and availability of spectral cues, it seems likely that noise level and frequency compression may interact. However, that relationship has not been described.
A reasonable approach to understanding the consequences of frequency lowering for adult listeners with mild-to-moderate loss would be to define the effect of frequency lowering parameters on speech intelligibility and quality. The present study aimed to (1) describe how frequency lowering using a form of frequency compression affects sentence intelligibility and quality across a wide range of frequency compression parameters, using typical speech (sentences), as well as to (2) describe effects of frequency lowering in background noise. We focused on adults with mild-to-moderate hearing loss as potential users of this technology. We hypothesize that effects for these adults would differ from the benefit shown by previous data for children with similar audiograms.
Method
Listeners
The test group (referred to here as the hearing-impaired group) consisted of 26 individuals with moderate high-frequency loss (Fig 1, left panel). Four members of this group were bilateral hearing-aid wearers and one was a unilateral hearing aid wearer. None of those hearing aids used frequency lowering. The mean age of the group was 74.9 years (range 62–92 years). As a control, we also tested 14 individuals (Fig 1, right panel) with pure-tone thresholds of 25 dB HL or better through 4 kHz. Although some members of the control group had thresholds outside the normal range at 6 and/or 8 kHz, these individuals would not be considered hearing-aid candidates in most clinics. This group was included to examine effects of signal distortion caused by frequency lowering in situations where the auditory system was relatively intact. For example, we wished to understand whether the reduced spacing of spectral components caused by frequency compression might have a larger effect on listeners with hearing loss (and poorer ability to resolve spectral detail) than on listeners with good spectral resolution (Souza, Wright, & Bor, 2012). The control listeners had a mean age of 66.4 years (range 60–78 years). Although both groups were representative samples of older adults, the control group was slightly younger than the hearing-impaired group (between-group t38=−3.67, p=.001).
Figure 1.
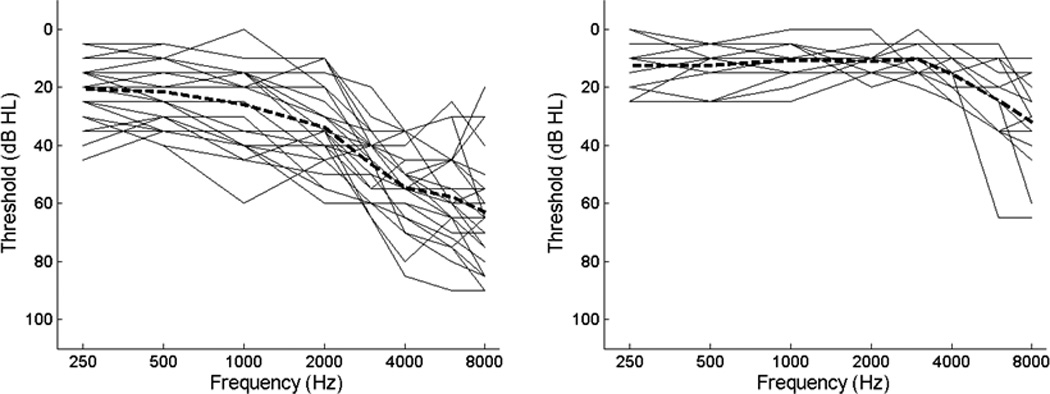
Audiograms (test ear) for listeners with hearing loss (left panel) and for the control group (right panel). Individual audiograms are plotted as thin solid lines. The thick dashed line shows the mean audiogram within each group.
All listeners had symmetrical hearing thresholds (pure-tone average difference between ears less than 10 dB), air-bone gaps of 10 dB or less at octave frequencies from 0.25–4 kHz, and normal tympanometric peak pressure and static admittance in both ears (Wiley et al., 1996). Mean QuickSIN scores (Killion, Niquette, Gudmundsen, Revit, & Banerjee, 2004) obtained using insert earphones at a presentation level of 70 dB HL were 4.97 dB (SD=3.44) for the hearing-impaired group and 2.07 dB (SD=1.45) for the control group. QuickSIN scores were significantly different across groups (t38=−2.81, p=.008). One ear was randomly selected as the test ear and all results presented here refer to that ear. All listeners spoke English as their first or primary language. All listeners passed the Mini-Mental Status Exam (MMSE) (Folstein, Folstein, & McHugh, 1975) with a score of 26 or better, and there were no significant differences in MMSE scores between the hearing-impaired and control groups (t38=−.72, p=.475). Approximately half of the data were collected at Northwestern University and half at University of Colorado, using identical equipment and procedures. The test procedures were reviewed and approved by the local Institutional Review Boards and listeners were reimbursed for their time.
Materials
Speech intelligibility test materials consisted of a set of 660 low-context sentences spoken by a female talker, drawn from the IEEE corpus. Speech quality test materials consisted of two sentences (“Two cats played with yarn. She needs an umbrella.”) spoken by a female talker (Nilsson, Ghent, Bray, & Harris, 2005). All of the stimuli were digitized at a 44.1 kHz sampling rate and downsampled to 22.05 kHz. Auditory information was therefore transmitted to a maximum bandwidth of 11.025 kHz, representative of a high-quality, wide-bandwidth hearing aid (Kates, 2008). However, even when frequency-gain shaping (described below) was applied, access to high-frequency speech information was limited by the rolloff of the speech spectrum at high frequencies in combination with the listener’s hearing thresholds. Spectral analysis of the speech materials received by the listeners showed that audible signal bandwidth across all subjects ranged from 4 to 6 kHz depending on the specific frequency-gain shaping and high-frequency thresholds. Sentence level at the input to the hearing-aid simulation was set at 65 dB SPL, representing conversational speech. The sentences were digitally mixed with six-talker babble drawn from a recorded version of the Connected Speech Test (Cox, Alexander, & Gilmore, 1987). Six different noise conditions were created, representing a range of noise levels that might be encountered in everyday listening (Hodgson, Steininger, & Razavi, 2007; Olsen, 1998). These included five signal-to-noise ratios (SNRs) of −10, −5, 0, 5 and 10 dB, plus a quiet (no noise) condition. Extreme (very easy or very difficult) SNRs were deliberately included because we wished to describe the effects of frequency lowering in noise across the entire range of performance (i.e., from low to high intelligibility, as well as to allow for a full range of quality ratings). In each case, the speech level was fixed at 65 dB SPL and the noise added to create the desired SNR. The speech-plus-noise signal was submitted to the frequency lowering and shaping described below.
Frequency Lowering
Frequency lowering was implemented using a form of frequency compression. Specifically, the signal processing used a two-band system in which the low-frequency band was used without processing to minimize potential signal distortion, while frequency compression was applied to the high-frequency band. The frequency compression used sinusoidal modeling (McAulay & Quatieri, 1986), in which the signal is represented as a set of sinusoids of varying amplitude, phase, and frequency. Reproducing the sinusoids at frequencies lower than found in the input signal provides the frequency compression (Aguilera Munoz, Nelson, Rutledge, & Gago, 1999; Quatieri & McAulay, 1986).
The band separation used in the present implementation comprised a complementary pair of filters which provided a flat total power response across frequency. The filters were five-pole Butterworth high-pass and low-pass with the same cutoff frequency, transformed into digital infinite impulse response (IIR) filters. Sinusoidal modeling was then applied to the high-frequency signal, as follows:
The high-frequency signal was windowed in 6 msec segments (von Hann raised-cosine window). A new segment was acquired every 3 msec, giving a 50-percent overlap. A 24-ms FFT (i.e., 41.6 Hz resolution) was computed for each segment.
The ten highest signal peaks were selected and the amplitude and phase of each peak was preserved while the frequencies were reassigned to lower values. Sinusoids were generated for each of the shifted frequency components. If the sinusoid was close in frequency to one generated for the previous segment, the amplitude, phase, and instantaneous frequency were interpolated across the output segment duration to produce an amplitude- and frequency-modulated sinusoid. A frequency component that did not have a match from the previous segment was weighted with a rising ramp to provide a smooth onset transition, and a frequency component that was present in the previous segment but not in the current one was weighted with a falling ramp to provide a smooth transition to zero amplitude.
The synthesized high-frequency and original low-frequency signals were recombined.
The frequency lowering parameters included three compression ratios (CRs) (1.5:1, 2:1, and 3:1) and three cutoff frequencies (CFs) (1, 1.5, and 2 kHz). This range of parameters was selected to explore the limits of acceptable signal manipulation. A set of control (i.e., no frequency lowering) sentences were also included. The control condition included the lowpass and highpass filter signal band separation, after which the two bands were recombined without the high-frequency sinusoidal modeling. The filtering ensured that all stimuli had the same group delay as a function of frequency. The processing and noise conditions, when combined, resulted in 60 different test conditions (Table 1).
Table 1.
Summary of test conditions.
| No frequency lowering |
CR=1.5 | CR=2.0 | CR = 3.0 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1.0 kHz |
1.5 kHz |
2.0 kHz |
1.0 kHz |
1.5 kHz |
2.0 kHz |
1.0 kHz |
1.5 kHz |
2.0 kHz |
|
| −10 dB SNR | −10 dB SNR | −10 dB SNR | −10 dB SNR | ||||||
| −5 dB SNR | −5 dB SNR | −5 dB SNR | −5 dB SNR | ||||||
| 0 dB SNR | 0 dB SNR | 0 dB SNR | 0 dB SNR | ||||||
| +5 dB SNR | +5 dB SNR | +5 dB SNR | +5 dB SNR | ||||||
| +10 dB SNR | +10 dB SNR | +10 dB SNR | +10 dB SNR | ||||||
| Quiet | Quiet | Quiet | Quiet | ||||||
Following frequency lowering, the signals were amplified using the National Acoustics Laboratories-Revised (NAL-R) linear prescriptive formula (Byrne & Dillon, 1986) based on individual thresholds. In this study of frequency lowering absent the confounding effects of other signal processing, NAL-R shaping was used to control audibility. Our processing did not include the wide-dynamic range compression often used in wearable hearing aids. The NAL-R shaping was implemented through 128-point linear-phase FIR digital filtering. Stimuli were customized for each listener in advance of the testing and stored on a personal computer. For the listeners in the hearing-impaired group, this customization resulted in a frequency-gain response similar to that which might be applied to conversational-level speech in a wearable aid. Stimuli for the listeners with normal hearing also received customized frequency-gain shaping, with the constraint that gain was always zero or positive. The purpose of the NAL-R shaping for the listeners with normal hearing was to compensate for loss of high-frequency audibility in cases where high-frequency thresholds were poorer than normal.
Procedures
Each listener was seated in a double-walled sound booth. The digitally stored stimuli were routed through a digital-to-analog converter (TDT RX6 or RX8), an attenuator (TDT PA5), and a headphone buffer (TDT HB7) and were presented monaurally to each listener through a Sennheiser HD 25-1 earphone. Responses were collected using a monitor and computer mouse.
Speech Intelligibility
On each trial, listeners heard a sentence randomly drawn from one of the test conditions shown in Table 1. The timing of presentation was controlled by the subject. No feedback was provided. No sentence was repeated and the sentence order was different for each listener. The listener repeated the sentence heard. Scoring was based on key words (5 per sentence for 50 words per condition, per listener). Scoring was completed by the experimenter seated outside the sound booth and the listener’s verbal response was recorded for later access in case of any ambiguities. Sixty practice sentences were presented first to familiarize the listener with the processing. Responses to those sentences were scored, but the scores were not included in final data. The practice set was followed by 600 test sentences.
Speech Quality
Speech quality measures always followed speech intelligibility. This meant that each listener had listened to frequency-lowered speech for about two hours prior to providing quality ratings. On each trial, listeners heard one presentation of the same two sentences processed with one (randomly-selected) condition. The same sentences were used each time to avoid confounding effects of intelligibility, and allow for the desired focus on quality. Sound quality is multidimensional in nature (Arehart, Kates, Anderson, & Harvey, 2007; Gabrielsson, Schenkman, & Hagerman, 1988). However, specific quality aspects of speech processed by hearing aid signal processing algorithms are well predicted by metrics using a single “overall quality” rating scale (Arehart et al., 2010; Arehart, Kates, Anderson, & Moats, 2011; Kates & Arehart, 2010). Accordingly, we asked listeners to rate the overall sound quality using a rating scale which ranged from 0 (poor sound quality) to 10 (excellent sound quality) (ITU, 2003). The rating scale was implemented with a slider bar that registered responses in 0.05 increments. Listeners made their selections from the slider bar displayed on the computer screen using a customized interface that included a point-and-click method for recording and verifying rating scores. The timing of presentation was controlled by the subject. Listeners rated one practice block followed by two test blocks. Each practice and test block contained 60 two-sentence presentations. No feedback was provided.
Results
Speech Intelligibility (Group Data)
Figure 2 shows performance on the sentence intelligibility task for the two listener groups. Results for the listeners with hearing loss are shown in the upper panels and for the control group in the lower panels. Each column shows results for a different CF, and within each panel results are plotted as a function of CR. The condition without frequency lowering (CR=1) is repeated within each panel. Some general patterns were seen, as follows:
Intelligibility was strongly influenced by SNR, ranging from near-0% to near-100%.
Listeners with hearing loss performed more poorly than listeners with normal hearing.
The effect of frequency lowering depended strongly on the specific parameters used.
Figure 2.
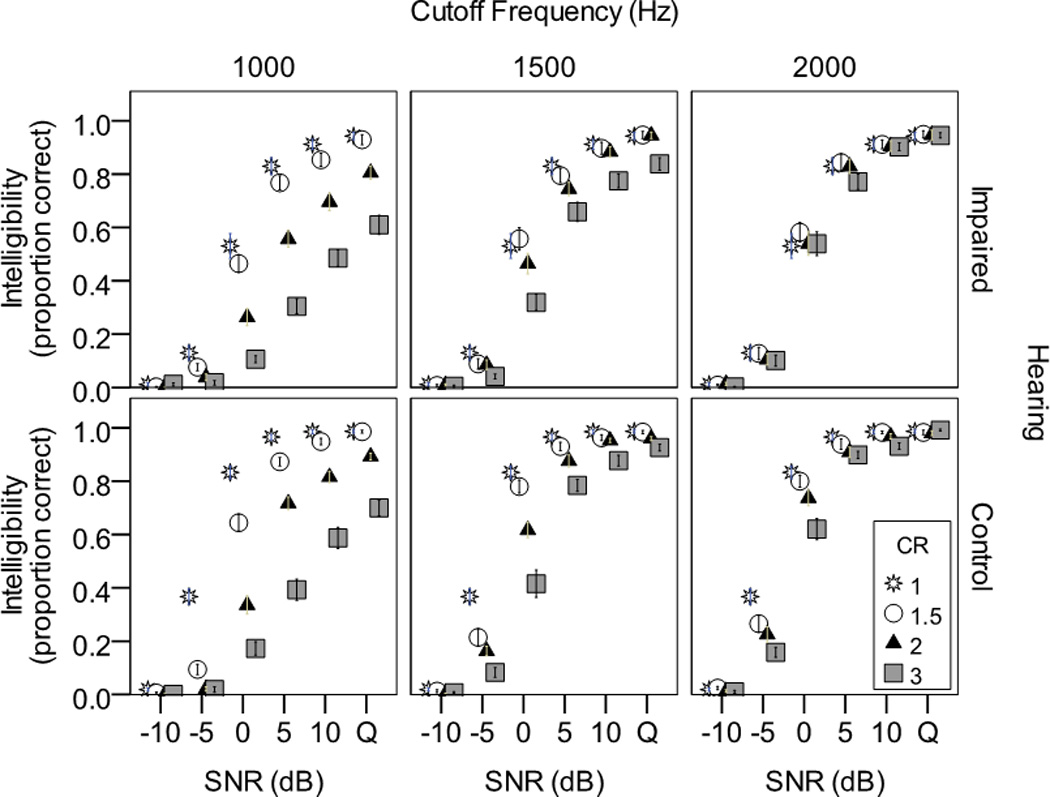
Effect of frequency lowering on speech intelligibility. Each panel shows intelligibility for a different cutoff frequency, as a function of signal-to-noise ratio (SNR; Q=quiet) and compression ratio. The control condition (no frequency lowering) is plotted in each panel as asterisks. Results for listeners with hearing loss are shown in the top panels and for the control group in the lower panels. Error bars show +/− one standard error about the mean.
At the 2000 Hz CF, frequency lowering had little effect (either positive or negative), regardless of the CR. The effects of frequency lowering were also minimal when a lower CF (1000 or 1500 Hz) was combined with a low CR. As the magnitude of frequency lowering increased beyond that point, intelligibility decreased.
For statistical analysis, the percent correct scores were transformed to rationalized arcsine units (Studebaker, 1985) to normalize variance across the range of scores. Data for the −10 and −5 dB SNRs were excluded from analysis because scores for those conditions were very low (<10%) for most listeners. For the remaining data, a four-way repeated-measures ANOVA was conducted. The factors examined were hearing group (impaired or control); CR; CF; and SNR, as well as the interactions among those factors. To maintain balanced levels among the factors, the “no frequency lowering” condition was not included; those data will be discussed separately. Group was entered into the model as a between-subject factor; the remaining factors were entered as within-subjects (repeated measures) factors. Results are shown in Table 2 and were considered in order of the highest-order interactions, starting with the four-way interaction which was nonsignificant.
Table 2.
Results of 4-way ANOVA on intelligibility
| Factor | Df | Df (error) | F* | P* |
|---|---|---|---|---|
| SNR × CR × CF × Group | 12 | 456 | 1.14 | .323 |
| SNR × CR × CF | 12 | 456 | 1.93 | .029 |
| SNR × CR × Group | 6 | 228 | 2.77 | .013 |
| SNR × CF × Group | 6 | 228 | 1.13 | .346 |
| CR × CF × Group | 4 | 152 | 0.24 | .914 |
| SNR × Group | 3 | 114 | 3.03 | .032 |
| CR × Group | 2 | 76 | 3.24 | .045 |
| CF × Group | 2 | 76 | .12 | .891 |
| SNR × CR | 6 | 228 | 6.35 | <.005 |
| SNR × CF | 6 | 228 | 5.93 | <.005 |
| CR × CF | 4 | 152 | 127.05 | <.005 |
| SNR | 3 | 114 | 743.83 | <.005 |
| CR | 2 | 76 | 408.01 | <.005 |
| CF | 2 | 76 | 544.60 | <.005 |
If Mauchley’s test was significant, Greenhouse-Geisser adjusted values are reported.
SNR interacted with CR and CF; and also with CR and group. To explore the significant three-way interactions, separate two-way repeated measures ANOVAs were completed at each SNR. Results of the analysis are shown in Table 3. For situations with moderate to no noise (i.e., SNRs of +5, +10 and in quiet), the effect of hearing group was significant, with poorer performance for the listeners with hearing loss. The compression parameters affected both groups in similar ways. There was a significant effect of increasing CR and decreasing CF, and those parameters interacted with each other. At the poorest SNR (0 dB), we continued to see poorer performance by listeners with hearing loss but now group interacted with CR. To illustrate this, consider the 2000 Hz CF: as CR was increased, performance dropped for the control group but remained stable for the hearing-impaired group. The same effect could be seen, although to a lesser extent, for CFs of 1500 and 1000 Hz. This interaction is broadly consistent with the idea that there is a tradeoff between improved audibility and increased distortion, since listeners with high-frequency loss would be expected to receive some benefit from improved high-frequency audibility, whereas listeners with normal hearing would not. CF did not interact with group at any CR.
Table 3.
Results of 3-way ANOVAs on intelligibility
| SNR (dB) |
Quiet | +10 | +5 | 0 | df | df (error) |
||||
|---|---|---|---|---|---|---|---|---|---|---|
| F* | p | F | p | F | p | F | p | |||
| CR × CF × Group | 1.08 | .369 | .77 | .544 | 1.28 | .282 | 6638 | .636 | 4 | 152 |
| CR × CF | 54.52 | <.005 | 28.02 | <.005 | 43.89 | <.005 | 21.88 | <.005 | 4 | 152 |
| CR × Group | 1.79 | .174 | 1.13 | .329 | .50 | .610 | 6.49 | .002 | 2 | 76 |
| CF × Group | .45 | .642 | .71 | .497 | .71 | .497 | 1.06 | .351 | 2 | 76 |
| CR | 135.78 | <.005 | 143.21 | <.005 | 171.72 | <.005 | 161.34 | <.005 | 2 | 76 |
| CF | 126.85 | <.005 | 279.80 | <.005 | 246.42 | <.005 | 161.99 | <.005 | 2 | 76 |
| Group | 7.99 | .007 | 9.97 | .003 | 11.73 | .001 | 10.62 | .002 | 1 | 38 |
If Mauchley’s test was significant, Greenhouse-Geisser adjusted values are reported.
At each SNR, the control condition (no compression; plotted as CR=1 in Figure 2) was compared to the condition with least compression (CR = 1.5, CF = 2000 Hz) using a paired t-test. In each case, the difference was non-significant. That is, minimal amounts of frequency lowering (high CF combined with low CR) were indistinguishable from no frequency lowering.
Speech Intelligibility (Individual Data)
The group analysis indicated that many combinations of frequency lowering parameters are “neutral” in their effect on sentence recognition; that is, they produce equivalent sentence intelligibility compared to a control condition. Other parameter combinations, particularly those that combined a low cutoff frequency and high compression ratio, were generally deleterious. However, it is also of interest to examine effects for individual listeners. We have suggested that frequency lowering (as well as other processing strategies) should not be viewed as wholly positive or negative, but rather in terms of an audibility-by-distortion tradeoff which will depend on individual listener characteristics, selected parameters, and processing implementation. In the context of the expected effects of frequency lowering, one factor of interest within this dataset is the degree of high-frequency loss. Listeners with poorer high-frequency thresholds might be expected to receive the greatest audibility benefits, and, to the extent that improved audibility outweighs any distortive effects of signal alteration, those listeners would be expected to show a net positive effect of frequency lowering.
Figure 3 shows an example of such data for the +5 dB SNR condition. Each panel shows intelligibility benefit (calculated as intelligibility score with frequency lowering minus intelligibility score for the control condition) as a function of high-frequency thresholds (average of 4, 6 and 8 kHz). Values above the zero (dashed) line represent participants for whom frequency lowering improved sentence recognition over the control condition. Open circles show data for the listeners with hearing loss and asterisks for the control group. Note that even for conditions where frequency lowering had no significant effect on group scores, some individuals with hearing loss do receive benefit. Consider for example a compression ratio of 2:1 combined with a 2000 Hz cutoff frequency, where frequency lowering improved intelligibility for approximately half the listeners with hearing loss, in some cases by as much as 20%.
Figure 3.
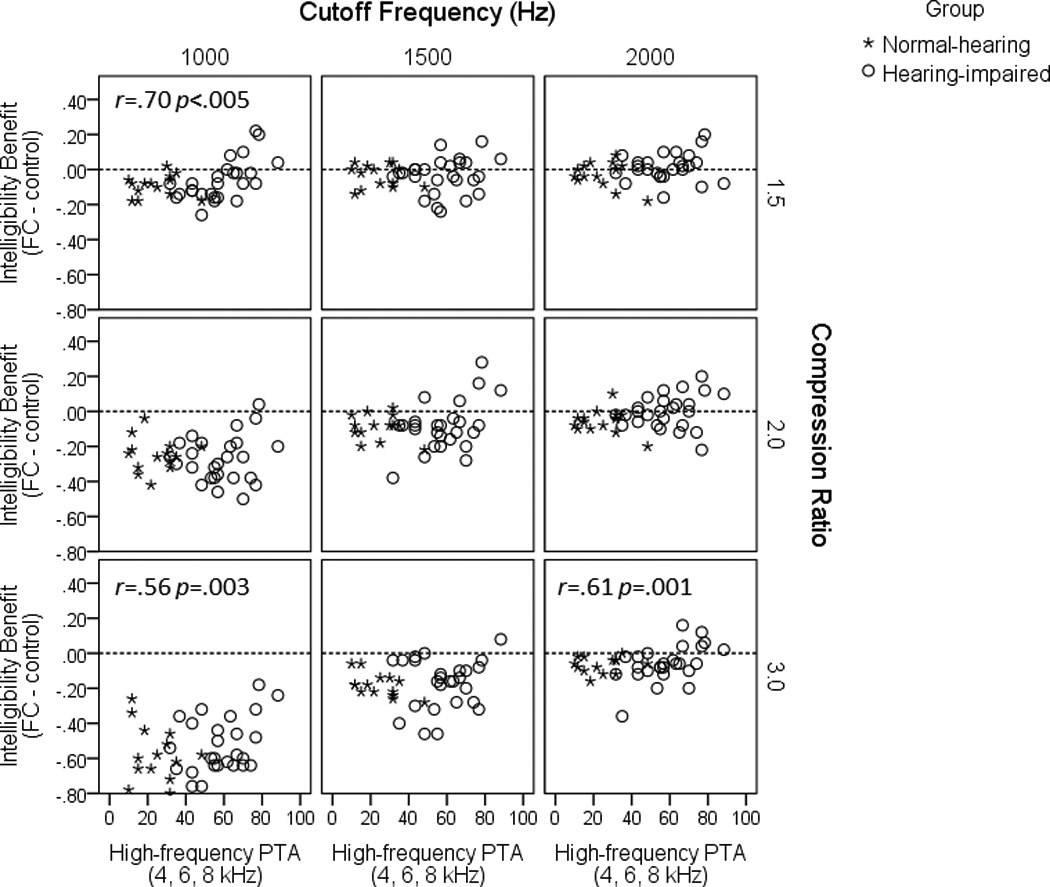
Intelligibility benefit (calculated as intelligibility score with frequency lowering minus intelligibility score for the control condition) as a function of high-frequency thresholds (average of 4, 6 and 8 kHz) for each listener. Filled circles represent listeners in the hearing-impaired group and asterisks represent listeners in the control group. Values above the zero (dashed) line represent participants for whom frequency lowering improved sentence recognition over the control condition. Data shown are for +5 dB SNR.
The data shown in Figure 3 also suggest that intelligibility benefit was greatest for listeners with the poorest high-frequency thresholds, at least for some frequency-lowering conditions. Bivariate Pearson correlation coefficients indicated a significant relationship between high-frequency hearing threshold and intelligibility benefit for several conditions (indicated by r and p values within panels in Figure 3), even after correction for multiple comparisons (Holm, 1979). Even for frequency-lowering conditions that were generally undesirable, such as the 1000 Hz cutoff frequency × high CRs (i.e., all data points fall below the zero benefit line), the listeners with the poorest hearing received the smallest negative effects. In general, these trends support the idea that benefits of improved audibility from frequency lowering outweigh negative effects of signal alteration (distortion) for some listeners.
Speech Quality (Group data)
Quality ratings for each listener were normalized by dividing each rating by the mean rating score for that listener. The normalized ratings are plotted in Figure 4. Recall that for the intelligibility results, some combinations of parameters had no effect on intelligibility scores. When frequency lowering affected intelligibility, the degree of change was sensitive to the specific parameters. For quality, the pattern was different. For speech in quiet, any amount of frequency lowering degraded speech quality, but changing parameters had little additional effect. Any amount of background noise resulted in lower quality ratings. The greater the level of background noise, the more noise (as opposed to frequency lowering) dominated the quality ratings (i.e., there was little difference for speech with and without frequency lowering).
Figure 4.
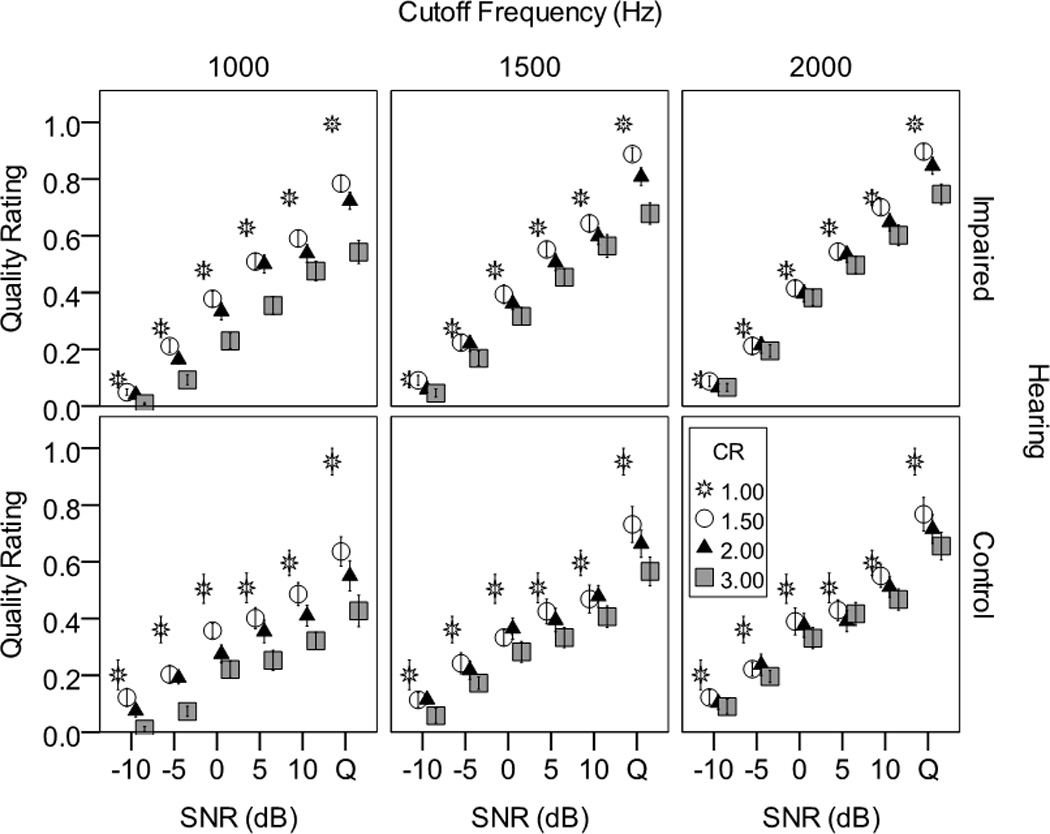
Effect of frequency lowering on speech quality. Each panel shows normalized quality for a different cutoff frequency, as a function of signal-to-noise ratio (SNR; Q=quiet) and compression ratio. The control condition (no frequency lowering) is plotted in each panel as asterisks. Results for listeners with hearing loss are shown in the top panels and for the control group in the lower panels. Error bars show +/− one standard error about the mean.
The quality data were analyzed using a similar approach to the intelligibility data. Again, data for the −10 and −5 dB SNRs were excluded from analysis because group ratings for those conditions were very low. For the remaining data, a four-way repeated-measures ANOVA was conducted. The factors examined were hearing group (hearing-impaired or control); CR; CF; and SNR, as well as the interactions among those factors. Results are shown in Table 4.
Table 4.
Results of 4-way ANOVA on quality
| Factor | Df | Df (error) | F* | P* |
|---|---|---|---|---|
| SNR × CR × CF × Group | 12 | 456 | .34 | .982 |
| SNR × CR × CF | 12 | 456 | .98 | .463 |
| SNR × CR × Group | 6 | 228 | .892 | .501 |
| SNR × CF × Group | 6 | 228 | .303 | .935 |
| CR × CF × Group | 4 | 152 | 1.09 | .361 |
| SNR × Group | 3 | 114 | 2.67 | .051 |
| CR × Group | 2 | 76 | .45 | .643 |
| CF × Group | 2 | 76 | .18 | .834 |
| SNR × CR | 6 | 228 | 7.54 | <.005 |
| SNR × CF | 6 | 228 | 6.01 | <.005 |
| CR × CF | 4 | 152 | 8.45 | <.005 |
| SNR | 3 | 114 | 97.79 | <.005 |
| CR | 2 | 76 | 111.19 | <.005 |
| CF | 2 | 76 | 101.76 | <.005 |
| Group | 1 | 38 | 9.70 | .003 |
If Mauchley’s test was significant, Greenhouse-Geisser adjusted values are reported.
There were three interactions of note. First, CR interacted with CF. As illustrated in Figure 4, the effect of CR was somewhat larger at low CFs. Second, SNR interacted with CR (most noticeable in the comparison of quiet to noise within each panel). Third, SNR interacted with CF (most noticeable as a shallower slope as a function of SNR at the lower CFs). Note also that the range of intelligibility ratings as the parameters were varied was largest for quiet speech. For example, for the listeners with hearing loss, mean (normalized) ratings across all frequency lowering conditions in quiet ranged from about 0.9 to 0.5, while mean ratings across all conditions at 0 dB SNR ranged from about 0.2 to 0.4. Thus, the SNR interactions are due, at least in part, to compression of the rating scale with noise.
At each SNR, the control condition (no frequency lowering; plotted as CR=1 in Figure 4) was compared to the condition with least compression (CR of 1.5, CF of 2000 Hz) using a paired t-test. The effect of using any frequency lowering was significant in quiet and at 0 dB SNR (p=.002 in each case) and nonsignificant at +5 and +10 SNR (p=.283 and p=.113, respectively).
The main effect of hearing was significant. As can be seen in Figure 4, listeners with hearing loss tended to give higher (normalized) quality ratings than listeners in the control group. Hearing did not interact with any other factor.
Speech Quality (Individual Data)
Figure 5 shows individual quality ratings for speech in quiet, expressed as quality benefit (defined as frequency lowering rating minus control rating). Individual ratings support the group data, in that frequency-lowered speech is usually rated as having lower quality than speech without frequency lowering. However, the data also show a relationship with amount of hearing loss. Listeners with poorer high-frequency thresholds (defined here as the average of thresholds at 4, 6 and 8 kHz) rated quality higher, in some cases as equivalent to that of speech without frequency lowering (i.e., at the “zero benefit” line). The bivariate Pearson correlation coefficient (after correction for multiple comparisons [Holm, 1979]) was only significant for the 1500 Hz cutoff frequency × 1.5:1 compression ratio. However, the trend was similar to that described for individual intelligibility data (Figure 3): frequency lowering has a less negative effect on speech quality when the listener has poorer high-frequency thresholds.
Figure 5.
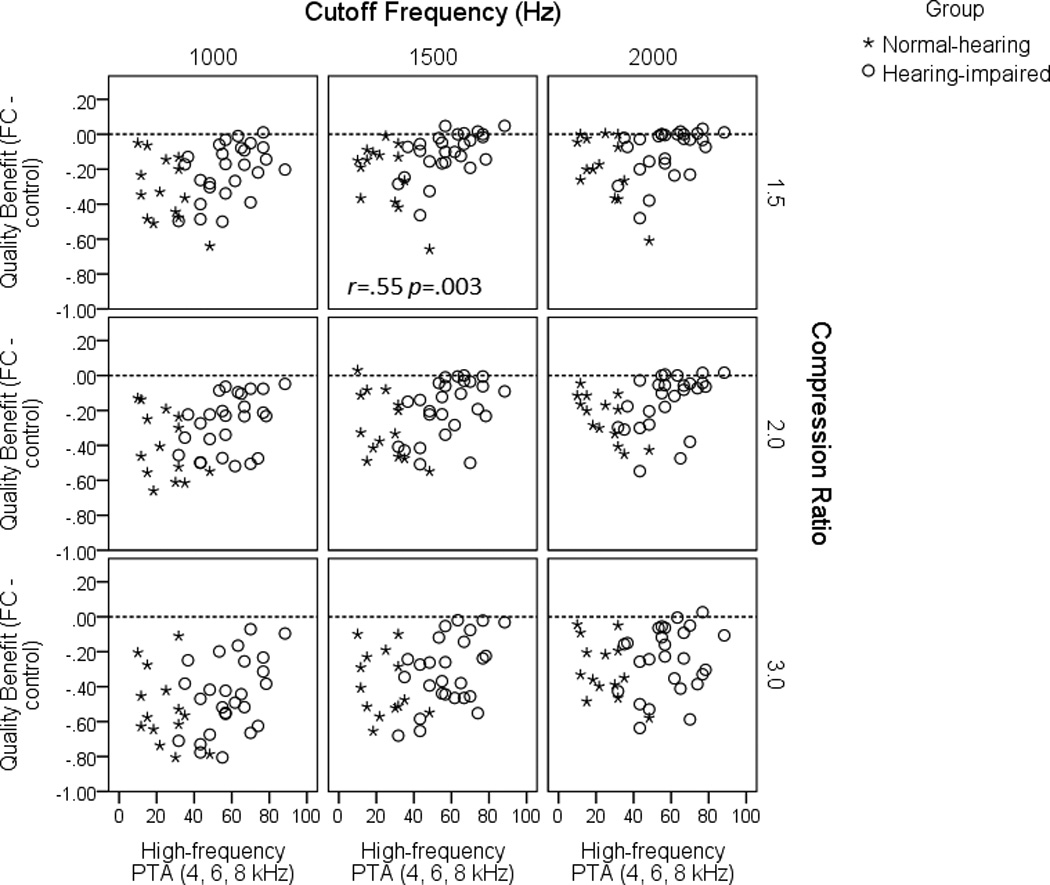
Quality benefit (calculated as quality rating with frequency lowering minus quality rating for the control condition) as a function of high-frequency thresholds (average of 4, 6 and 8 kHz) for each listener. Values above the zero (dashed) line represent participants for whom frequency lowering improved sentence recognition over the control condition. Data shown are for quiet.
The Relationship between Intelligibility and Quality
Figure 6 shows the relationship between intelligibility and quality. For all conditions, including those without frequency lowering, intelligibility and quality were related. For both groups of listeners, signals with poor intelligibility were generally perceived as having poor quality. However, quality ratings for signals with high intelligibility were more variable. For example, consider the data shown in the top right panel, which shows quality ratings when frequency lowering is applied above CF=2000 Hz for listeners with hearing loss. For low-intelligibility speech, normalized quality ratings ranged from 0 to 0.4. When speech intelligibility was at a maximum, normalized quality ratings ranged from 0.2 to 1.0. This suggests that quality is strongly influenced by intelligibility only in cases when intelligibility is poor. Across all conditions and groups, intelligibility and quality were highly correlated (Pearson r=.76, p<.005). The relationship was similar within each group and regardless of frequency-lowering parameters (Table 5).
Figure 6.
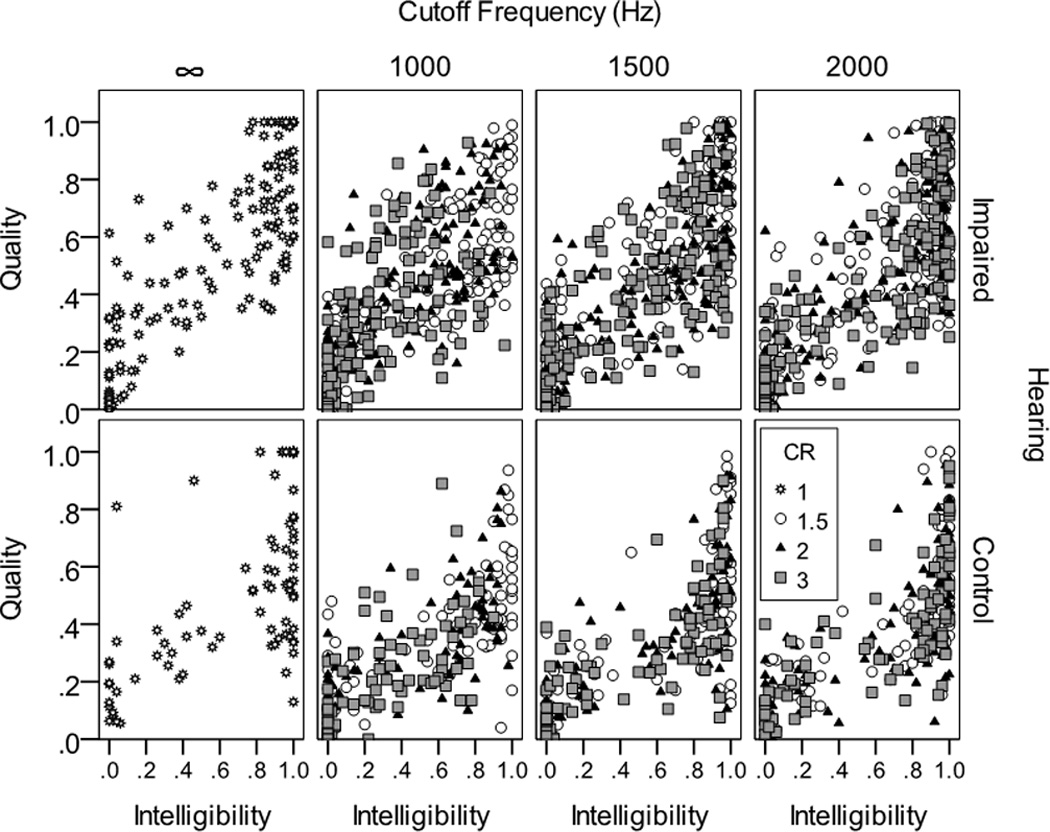
Relationship between intelligibility and quality. The left panels, indicated by the infinity symbol, show results for the control condition (no frequency lowering). The remaining panels show results with frequency lowering, ordered by cutoff frequency. Compression ratios are indicated by different symbols. Data are collapsed across SNR.
Table 5.
Correlations (Pearson’s r) for the within-group, within-condition relationships shown in Figure 5. All correlations were calculated across four SNRs (0, 5, 10, and quiet). All conditions except for unprocessed were calculated across three frequency compression ratios (1.5, 2, 3). All were significant at p<.005.
| Unprocessed | CF=1000 | CF=1500 | CF=2000 | |
|---|---|---|---|---|
| Normal | 0.63 | 0.74 | 0.72 | 0.74 |
| Impaired | 0.85 | 0.80 | 0.80 | 0.81 |
Figure 7 shows the relationship between quality and intelligibility, plotted as a function of benefit (defined as frequency-lowered rating minus control rating) for each measure. This view of the data supplements Figure 6 by showing the change in quality relative to the change in intelligibility for each listener. For many conditions, intelligibility was maintained, such that the data points are all close to zero (vertical dashed line). However, in these same conditions, quality benefit varied substantially. For example, in the center panel (CF=1500 Hz, CR =2), almost all listeners show zero intelligibility benefit but quality benefit varies from 0 to −0.6.
Figure 7.
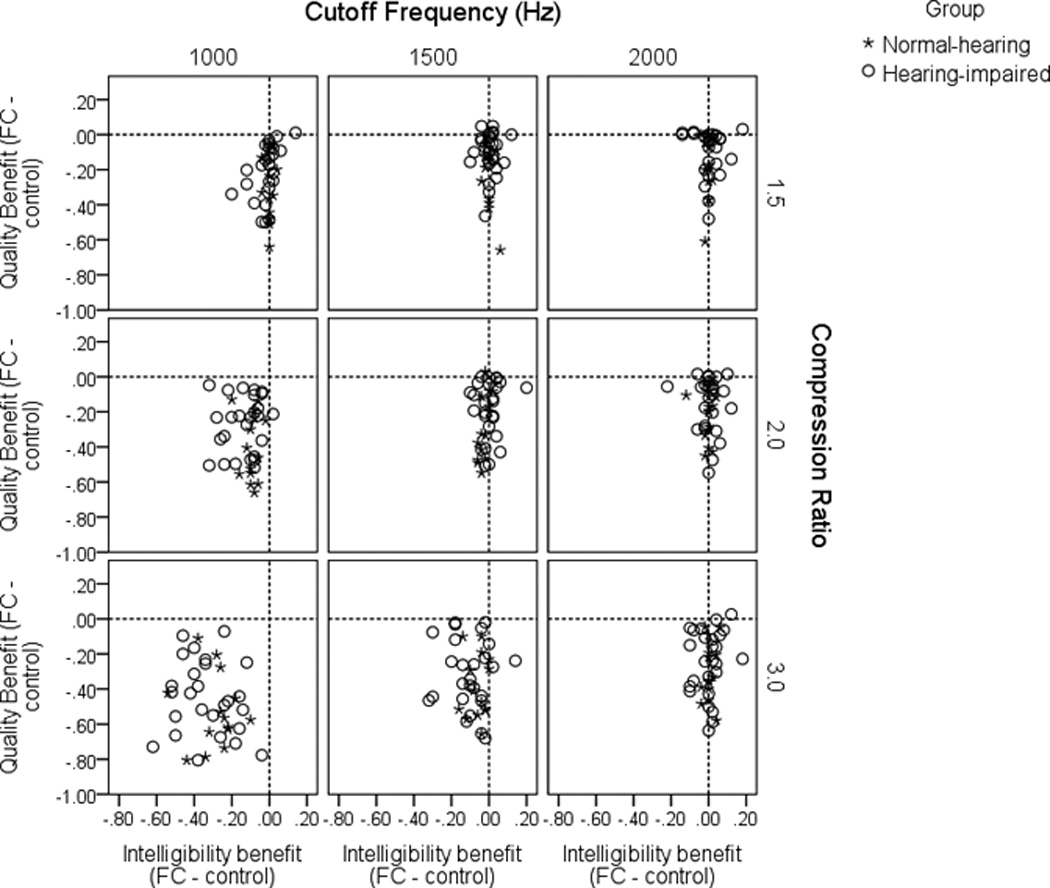
Quality benefit (as in Figure 5) as a function of intelligibility benefit (as in Figure 3). Filled circles represent listeners in the hearing-impaired group and asterisks represent listeners in the control group. Symbols falling above or to right of dashed lines indicate positive benefit. Symbols falling below or to the left of the dashed lines indicate negative benefit.
Discussion
Effects of Frequency Lowering for Speech Intelligibility
In the present study, there was no benefit of frequency lowering for listeners with mild-to-moderate high-frequency loss when those listeners were considered as a group. Some conditions, particularly those with low CRs and/or high CFs were “neutral”, in that sentence intelligibility was equivalent to that without frequency lowering. Other conditions which combined a high CR with a low CF reduced sentence intelligibility.
Despite the lack of group benefit, we should not dismiss use of frequency lowering. Individual data indicated that those listeners who had poorer high-frequency thresholds and might be expected to benefit from improved speech sound audibility did show improved sentence recognition with frequency lowering. A very coarse characterization of the data in Figure 3 suggests that the benefits for the frequency lowering implemented in this study begin to occur for individuals with high-frequency thresholds above 60 dB HL. Those benefits also depend on the choice of specific parameters; in general, fewer listeners benefited when more aggressive parameters were applied.
These data complement and extend the work of Glista et al. (2009) who showed clear benefits of frequency compression in terms of speech-sound detection and consonant recognition. The present study takes our knowledge one step further by assessing the extent to which expected improvements in audibility might translate to improved sentence recognition. The finding that frequency lowering improved sentence recognition for adults with the poorest high-frequency thresholds is consistent with Glista and colleagues’ observation that high-frequency threshold severity predicts /s/ and /∫/ detection. One likely explanation is that for those listeners who already had adequate audibility of high-frequency speech cues, the acoustic distortion created by some combinations of parameters outweighed the benefits of improved audibility. This idea is consistent with the finding that no listener in the control group received any benefit of frequency lowering (i.e., all of the asterisks in Figure 3 fall at or below the zero benefit line). Presumably, those listeners received no audibility advantage from the frequency lowering, leaving them susceptible to any distortions. This idea is also consistent with the arguments put forth by McDermott (2011) and with the finding that intelligibility decreased at high CRs and/or low CFs, conditions that might be expected to produce more dramatic acoustic alterations. Indeed, if acoustic distortion is a determining factor, our data suggest that it would be possible to minimize distortion by careful selection of parameters. In addition, different implementations of frequency lowering would also be expected to differ in the amount of distortion produced by the processing and hence in the exact nature of the trade-off between distortion and audibility. Further acoustic analysis of frequency-lowered signals may be useful in understanding these issues.
An accompanying issue for the present data is that our participants were older adults with hearing loss acquired late in life, who had long experience of language. When considering amplification benefits, adults operate under different conditions than do children. For example, a child with hearing loss may not be aware of the plural /s/ until it is audible, whereas an adult with post-lingual hearing loss can use linguistic knowledge to infer the plural /s/ from verb agreement or from the sentence context. The (potential) advantage of improved audibility should be considered in view of a listener’s ability to extract additional useful information from newly audible cues for the speech materials of interest. While Glista et al.’s data indicate that frequency compression can improve access to some phonemes such as high-frequency fricatives, our data suggest that those segmental benefits did not always generalize to improvements in sentence recognition. Perhaps our listeners were already using syntactic and prosodic information in the sentence to infer the presence of high-frequency consonants. For the age group studied here, this may reflect use of top-down contributions to sentence recognition in older listeners (Rogers, Jacoby, & Sommers, 2012) and explain why the amount of benefit for these sentence materials was relatively small. This idea is also supported by previous work showing equivocal benefits of frequency compression even for patients with severe high-frequency loss who should benefit from improved high-frequency audibility (Bohnert, Nyffeler, & Keilmann, 2010; Simpson et al., 2006).
In view of the lack of group benefit, it is also possible that frequency lowering—and concomitant improvements in phoneme audibility—improved listening ease, but without measurable differences in speech recognition. That is, listeners might have expended fewer cognitive resources to understand the frequency-lowered speech. Such effects can be assessed with other methods, such as dual-task performance, and have been of increasing interest as they relate to other signal-processing technologies (Sarampalis, Kalluri, Edwards, & Hafter, 2009; Zakis, Hau, & Blamey, 2009). Those measures represent an interesting avenue for future exploration of frequency lowering as well as other technologies.
Finally, we noted that some amounts of frequency lowering were more problematic for intelligibility in noise than in quiet. Considering that many everyday listening situations occur in noise, it would be desirable to choose parameters that do not prevent use of spectral information under such listening conditions. The finding that the effects of frequency lowering depend on the level of the background noise suggests that the activation of frequency lowering might also be based on the listening environment, and incorporated into auditory scene selection.
Speech Quality
The factor of greatest interest to us was the relationship between intelligibility and quality. In previous work, Preminger and Van Tasell (1995) found that for listeners with normal hearing, low perceived intelligibility was always associated with low quality ratings. When rated intelligibility was high, listeners indicated a wider range of quality perceptions. Preminger and Van Tasell suggested the speech quality should only be evaluated once the perception of relative intelligibility was acceptable; otherwise, low intelligibility would dominate other attributes of quality. However, Preminger and Van Tasell relied on rated intelligibility rather than objective intelligibility measures. More recent work has demonstrated that there may be a mismatch between a listener’s hearing ability and their own estimate of that ability (Saunders & Forsline, 2006; Saunders, Forsline, & Fausti, 2004; Smits, Kramer, & Houtgast, 2006). In one study (Saunders & Forsline, 2006), 44 out of 94 listeners with hearing loss gave inaccurate estimates of their own speech recognition. To understand the quality-intelligibility relationship, then, we should also examine the relationship between quality and measured intelligibility scores.
Our data add to the work of Preminger and Van Tasell in two ways. First, we confirm that quality is strongly related to measured intelligibility. Second, we demonstrate that the same relationship holds true for listeners with hearing loss. Individual data (Figure 5) demonstrate that listeners with greater amounts of hearing loss show either none or a smaller decrease in sound quality with the application of frequency lowering.
In the present study, even small amounts of frequency lowering had a negative effect for many listeners, particularly for speech in quiet. Listeners with hearing loss tended to give higher (normalized) quality ratings than listeners in the control group; and in some conditions, those listeners with the poorest hearing gave the highest quality ratings. One possible explanation is that improved audibility of speech outweighed distortion, including distortion that may have remained below threshold for listeners with hearing loss (even with the frequency-gain shaping provided).
These findings are related to a larger issue as to how strongly quality ratings should be considered in the context of a hearing-aid fitting. Data from wearer surveys (Kochkin, 2010) showed that factors related to sound quality (clarity, naturalness, richness, and fidelity) were strongly correlated with device satisfaction. The American Academy of Audiology and American Speech-Language-Hearing Association guidelines for hearing-aid fitting (ASHA, 1998; Valente et al., 2006) provide some direction regarding loudness comfort but, somewhat surprisingly, do not directly consider fitting adjustments for listener-perceived sound quality. However, one would be hard pressed to find a clinical audiologist who does not make at least some effort to address sound quality concerns during the initial fitting. In general, priority is given to improved intelligibility, at least for new users (indeed, many listeners continue to prefer the quality of unaided speech!). In this case, ratings represented the listener’s initial reaction to the speech, absent any future effects of acclimatization. Nonetheless, the data presented here confirm that sound quality can vary even when intelligibility has been addressed.
Implications for Clinical Practice
Before these data can inform clinical use of frequency lowering, one important question is the extent to which our signal processing and choice of frequency lowering parameters mimicked those that might be used with hearing-aid wearers. First, to what extent can our processing be directly compared to commercial systems? Our approach to frequency lowering, in which the high-frequency portion of the signal was reproduced using sinusoidal oscillators at shifted frequencies, had some similarities to the hearing-aid algorithm described by Simpson et al. (2005) as well as to the frequency-compression procedures implemented in commercial hearing aids (McDermott, 2011), but there were also important differences. One difference is that our system applied ten sinusoidal peaks, where other systems have used greater peak density. That this application had no deleterious effects on intelligibility for many combinations of parameters suggests that the implementation per se did not introduce unintended distortion. Nonetheless, these data are best interpreted as relative comparisons between different frequency compression parameters and not taken as the absolute intelligibility scores and quality ratings that would occur in other frequency-lowering implementations.
A second issue concerns the implementation of frequency lowering in combination with other signal processing. Nearly all wearable aids include multichannel wide-dynamic range processing, and most also control noise through a combination of microphone directionality and digital noise suppression. Combinations of those features with frequency lowering could modify the results obtained here. The extension of these data to real-life use is an area of continued investigation in our laboratory.
A third issue is that the adults under study listened to frequency-lowered speech in a familiarization task, but were not exposed to frequency lowering on a daily basis over weeks or months. Because our study participants did not wear the processing over time, the intelligibility scores and quality ratings presented here can only represent the listener’s initial response to frequency-compressed speech. Could listening experience have improved intelligibility and/or quality of the frequency-lowered speech?
Regarding intelligibility, we know that consistent use of frequency compression over several months benefits children (Glista et al., 2012; Wolfe et al., 2011) but there is no compelling evidence so far that acclimatization is important for adults. Early studies showed apparent effects of experience with frequency compression, but these effects were later thought to be task-specific, as they did not generalize to novel signals (Simpson, 2009). Indeed, McDermott (2011) suggested there might be less adaptation to frequency compression than to other frequency lowering strategies, because it has a less dramatic effect on the acoustic signal. In the clinic, it may be assumed that the benefits of frequency compression are subtle and that adjustment to the new sound is no greater than to any newly-amplified speech signal. However, it is possible that long-term training might influence speech intelligibility.
Regarding quality, we know that dislike of amplified sound quality affects satisfaction and retention of hearing aids (Franks & Beckmann, 1985; Kochkin, 2010). There is some evidence that initial reactions to hearing-aid sound quality from other signal processing implementations may not change over time for older adults with losses similar to our cohort (Munro & Lutman, 2005). The present data do not address the question as to whether quality ratings might improve with continued use of frequency lowering. At the least, if frequency lowering is desired for a particular individual, a reduced-quality reaction might be anticipated and appropriate counseling provided.
Conclusions
The present data indicate that there is considerable variability in how frequency lowering using one form of frequency compression affects sentence intelligibility and quality. Even when intelligibility is optimized, quality may still be negatively affected with some combinations of parameters. Although these data should be interpreted with caution because they do not mimic all aspects of commercial frequency-lowering hearing aids, they suggest that frequency compression should not be universally prescribed for all listeners with mild-to-moderate sloping loss. However, trends in the data indicate that some listeners do benefit, with the greatest benefit for individuals with the poorest high-frequency thresholds. Listeners with less high-frequency hearing loss (as well as those in the control group, with normal or near-normal high-frequency hearing) demonstrated reduced intelligibility with frequency lowering and also reacted more negatively in terms of sound quality. The pattern of benefit is consistent with the idea that frequency lowering can be viewed in terms of an improved audibility vs increased distortion tradeoff that varies by individual.
Acknowledgments
The authors thank Peggy Nelson for sharing speech materials and Eric Hoover and Ramesh Muralimanohar for assistance with calibration. This work was supported by the National Institutes of Health (R01 DC60014 (P. Souza); R01 DC012289 (P. Souza/K. Arehart) and by a grant to the University of Colorado by GN ReSound (K. Arehart).
Abbreviations
- HI
hearing impaired
- NH
normal hearing
- CF
cutoff frequency
- CR
compression ratio
- dB HL
decibels hearing level
- FFT
fast Fourier transform
- SNR
signal-to-noise ratio
- MMSE
Mini-Mental Status Exam
Footnotes
Declaration of Interest
James M. Kates was an employee of GN ReSound during the period when these experiments were conducted.
References
- Aguilera Munoz CM, Nelson PB, Rutledge JC, Gago A. Electronics, Circuits and Systems: Proc. ICECS. Pafos, Cypress; 1999. Sept. Frequency lowering processing for listeners with significant hearing loss. 1999, 1999. [Google Scholar]
- Arehart KH, Kates JM, Anderson MC. Effects of noise, nonlinear processing, and linear filtering on perceived speech quality. Ear and Hearing. 2010;31(3):420–436. doi: 10.1097/AUD.0b013e3181d3d4f3. [DOI] [PubMed] [Google Scholar]
- Arehart KH, Kates JM, Anderson MC, Harvey LO., Jr Effects of noise and distortion on speech quality judgments in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America. 2007;122(2):1150–1164. doi: 10.1121/1.2754061. [DOI] [PubMed] [Google Scholar]
- Arehart KH, Kates JM, Anderson MC, Moats P. Determining perceived sound quality in a simulated hearing aid using the international speech test signal. Ear and Hearing. 2011;32(4):533–535. doi: 10.1097/AUD.0b013e31820c81cb. [DOI] [PubMed] [Google Scholar]
- ASHA. Guidelines for Hearing Aid Fitting for Adults. American Journal of Audiology. 1998;7:5–13. [Google Scholar]
- Bohnert A, Nyffeler M, Keilmann A. Advantages of a non-linear frequency compression algorithm in noise. European Archives of Otolaryngology. 2010;267:1045–1053. doi: 10.1007/s00405-009-1170-x. [DOI] [PubMed] [Google Scholar]
- Byrne D, Dillon H. The National Acoustic Laboratories' (NAL) new procedure for selecting gain and frequency response of a hearing aid. Ear and Hearing. 1986;7:257–265. doi: 10.1097/00003446-198608000-00007. [DOI] [PubMed] [Google Scholar]
- Cox RM, Alexander GC, Gilmore C. Development of the Connected Speech Test (CST) Ear and Hearing. 1987;8(5 Suppl):119S–126S. doi: 10.1097/00003446-198710001-00010. [DOI] [PubMed] [Google Scholar]
- Folstein MF, Folstein SE, McHugh PR. "Mini-mental state". A practical method for grading the cognitive state of patients for the clinician. Journal of Psychiatric Research. 1975;12(3):189–198. doi: 10.1016/0022-3956(75)90026-6. [DOI] [PubMed] [Google Scholar]
- Franks JR, Beckmann NJ. Rejection of hearing aids: Attitudes of a geriatric sample. Ear and Hearing. 1985;6(3):161–166. doi: 10.1097/00003446-198505000-00007. [DOI] [PubMed] [Google Scholar]
- Gabrielsson A, Schenkman BN, Hagerman B. The effects of different frequency responses on sound quality judgments and speech intelligibility. Journal of Speech and Hearing Research. 1988;31(2):166–177. doi: 10.1044/jshr.3102.166. [DOI] [PubMed] [Google Scholar]
- Glista D, Scollie S, Bagatto M, Seewald R, Parsa V, Johnson A. Evaluation of nonlinear frequency compression: Clinical outcomes. International Journal of Audiology. 2009;48:632–644. doi: 10.1080/14992020902971349. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glista D, Scollie S, Sulkers J. Perceptual acclimitization post nonlinear frequency compression hearing aid fitting in older children. Journal of Speech, Language and Hearing Research. 2012 doi: 10.1044/1092-4388(2012/11-0163). [epub]. [DOI] [PubMed] [Google Scholar]
- Hodgson M, Steininger G, Razavi Z. Measurement and prediction of speech and noise levels and the Lombard effect in eating establishments. Journal of the Acoustical Society of America. 2007;121(4):2023–2033. doi: 10.1121/1.2535571. [DOI] [PubMed] [Google Scholar]
- Holm S. A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics. 1979;6:65–70. [Google Scholar]
- ITU. General methods for the subjective assessment of sound quality. Geneva: ITU; 2003. International Telecommunication Union-R: BS. 1284-1. [Google Scholar]
- Jenstad LM, Souza PE. Quantifying the effect of compression hearing aid release time on speech acoustics and intelligibility. Journal of Speech, Language and Hearing Research. 2005;48(3):651–667. doi: 10.1044/1092-4388(2005/045). [DOI] [PubMed] [Google Scholar]
- Jenstad LM, Souza PE. Temporal envelope changes of compression and speech rate: combined effects on recognition for older adults. Journal of Speech, Language and Hearing Research. 2007;50(5):1123–1138. doi: 10.1044/1092-4388(2007/078). [DOI] [PubMed] [Google Scholar]
- Kates JM. Digital Hearing Aids. San Diego, CA: Plural Publishing; 2008. [Google Scholar]
- Kates JM, Arehart KH. Hearing Aid Sound Quality Index. Journal of the Audio Engineering Society. 2010;58(5):363–381. [Google Scholar]
- Killion MC, Niquette PA, Gudmundsen GI, Revit LJ, Banerjee S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America. 2004;116(4 Pt 1):2395–2405. doi: 10.1121/1.1784440. [DOI] [PubMed] [Google Scholar]
- Kochkin S. MarkeTrak VIII: Consumer satisfaction with hearing aids is slowly increasing. Hearing Journal. 2010;63:19–32. [Google Scholar]
- McAulay RJ, Quatieri TF. Speech analysis/synthesis based on a sinusoidal representation. IEEE Transactions on Acoustics, Speech and Signal Processing, ASSP-34. 1986:744–754. [Google Scholar]
- McCreery RW, Stelmachowicz PG. Audibility-based predictions of speech recognition for children and adults with normal hearing. Journal of the Acoustical Society of America. 2011;130(6):4070–4081. doi: 10.1121/1.3658476. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McDermott HJ. A technical comparison of digital frequency-lowering algorithms available in two current hearing aids. PLOS ONE. 2011;6:1–6. doi: 10.1371/journal.pone.0022358. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meister H, Lausberg I, Walger M, von Wedel H. Using conjoint analysis to examine the importance of hearing aid attributes. Ear and Hearing. 2001;22(2):142–150. doi: 10.1097/00003446-200104000-00007. [DOI] [PubMed] [Google Scholar]
- Moeller MP, Hoover B, Putman C, Arbataitis K, Bohnenkamp G, Peterson B, Stelmachowicz P. Vocalizations of infants with hearing loss compared with infants with normal hearing: Part I--phonetic development. Ear and Hearing. 2007;28(5):605–627. doi: 10.1097/AUD.0b013e31812564ab. [DOI] [PubMed] [Google Scholar]
- Moeller MP, McCleary E, Putman C, Tyler-Krings A, Hoover B, Stelmachowicz P. Longitudinal development of phonology and morphology in children with late-identified mild-moderate sensorineural hearing loss. Ear and Hearing. 2010;31(5):625–635. doi: 10.1097/AUD.0b013e3181df5cc2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Munro KJ, Lutman ME. Sound quality judgements of new hearing instrument users over a 24-week post-fitting period. International Journal of Audiology. 2005;44(2):92–101. doi: 10.1080/14992020500031090. [DOI] [PubMed] [Google Scholar]
- Nilsson M, Ghent RM, Bray V, Harris R. Development of a test environment to evaluate performance of modern hearing aid features. Journal of the American Academy of Audiology. 2005;16(1):27–41. doi: 10.3766/jaaa.16.1.4. [DOI] [PubMed] [Google Scholar]
- Olsen W. Average speech levels and spectra in various speaking/listening conditions: A summary of the Pearson, Bennett & Fidell (1977) report. American Journal of Audiology. 1998;7:21–25. doi: 10.1044/1059-0889(1998/012). [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK. Use of supportive context by younger and older adult listeners: Balancing bottom-up and top-down information processing. International Journal of Audiology. 2008;47(Supplement 2):S72–S82. doi: 10.1080/14992020802307404. [DOI] [PubMed] [Google Scholar]
- Pichora-Fuller MK, Souza PE. Effects of aging on auditory processing of speech. International Journal of Audiology. 2003;42(Suppl 2):2S11–2S16. [PubMed] [Google Scholar]
- Pittman AL, Stelmachowicz PG, Lewis DE, Hoover BM. Spectral characteristics of speech at the ear: implications for amplification in children. Journal of Speech, Language and Hearing Research. 2003;46(3):649–657. doi: 10.1044/1092-4388(2003/051). [DOI] [PubMed] [Google Scholar]
- Preminger JE, Van Tasell DJ. Quantifying the relation between speech quality and speech intelligibility. Journal of Speech and Hearing Research. 1995;38:714–725. doi: 10.1044/jshr.3803.714. [DOI] [PubMed] [Google Scholar]
- Quatieri TF, McAulay RJ. Speech transformations based on a sinusoidal representation. IEEE Transactions on Acoustics, Speech and Signal Processing, ASSP-34. 1986:1446–1464. [Google Scholar]
- Ricketts T, Mueller G. Today's hearing aid features: Fluff or true patient benefit?; Paper presented at the Joint Defense Veterans Audiology Conference; Dallas, TX. 2012. [Google Scholar]
- Rogers CS, Jacoby LL, Sommers MS. Frequent false hearing by older adults: the role of age differences in metacognition. Psychology and Aging. 2012;27(1):33–45. doi: 10.1037/a0026231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ross M. Hearing loss features: A closer look. Hearing Loss Magazine: The Journal of the Hearing Loss Association of America. 2010;31(5):30–33. [Google Scholar]
- Sarampalis A, Kalluri S, Edwards B, Hafter E. Objective measures of listening effort: effects of background noise and noise reduction. Journal of Speech, Language and Hearing Research. 2009;52(5):1230–1240. doi: 10.1044/1092-4388(2009/08-0111). [DOI] [PubMed] [Google Scholar]
- Saunders GH, Forsline A. The Performance-Perceptual Test (PPT) and its relationship to aided reported handicap and hearing aid satisfaction. Ear and Hearing. 2006;27(3):229–242. doi: 10.1097/01.aud.0000215976.64444.e6. [DOI] [PubMed] [Google Scholar]
- Saunders GH, Forsline A, Fausti SA. The performance-perceptual test and its relationship to unaided reported handicap. Ear and Hearing. 2004;25(2):117–126. doi: 10.1097/01.aud.0000120360.05510.e5. [DOI] [PubMed] [Google Scholar]
- Simpson A. Frequency-lowering devices for managing high-frequency hearing loss: A review. Trends in Amplification. 2009;13:87–106. doi: 10.1177/1084713809336421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simpson A, Hersbach AA, McDermott HJ. Improvements in speech perception with an experimental nonlinear frequency compression hearing device. International Journal of Audiology. 2005;44:281–292. doi: 10.1080/14992020500060636. [DOI] [PubMed] [Google Scholar]
- Simpson A, Hersbach AA, McDermott HJ. Frequency-compression outcomes in listeners with steeply sloping audiograms. International Journal of Audiology. 2006;45:619–629. doi: 10.1080/14992020600825508. [DOI] [PubMed] [Google Scholar]
- Smits C, Kramer SE, Houtgast T. Speech reception thresholds in noise and self-reported hearing disability in a general adult population. Ear and Hearing. 2006;27(5):538–549. doi: 10.1097/01.aud.0000233917.72551.cf. [DOI] [PubMed] [Google Scholar]
- Souza P, Wright R, Bor S. Consequences of broad auditory filters for identification of multichannel-compressed vowels. Journal of Speech, Language and Hearing Research. 2012;55(2):474–486. doi: 10.1044/1092-4388(2011/10-0238). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stelmachowicz PG, Pittman AL, Hoover BM, Lewis DE. Effect of stimulus bandwidth on the perception of /s/ in normal- and hearing-impaired children and adults. Journal of the Acoustical Society of America. 2001;110(4):2183–2190. doi: 10.1121/1.1400757. [DOI] [PubMed] [Google Scholar]
- Stelmachowicz PG, Pittman AL, Hoover BM, Lewis DE. Aided perception of /s/ and /z/ by hearing-impaired children. Ear and Hearing. 2002;23(4):316–324. doi: 10.1097/00003446-200208000-00007. [DOI] [PubMed] [Google Scholar]
- Studebaker GA. A "rationalized" arcsine transform. Journal of Speech and Hearing Research. 1985;28(3):455–462. doi: 10.1044/jshr.2803.455. [DOI] [PubMed] [Google Scholar]
- Teie P. Clinical experience with and real-world effectiveness of frequency-lowering technology for adults in select US clinics. Hearing Review. 2012;19(02):34–39. [Google Scholar]
- Valente M, Abrams H, Benson D, Chisolm T, Citron D, Hampton D, Sweetow R. Guidelines for audiologic management of adult hearing impairment: American Academy of Audiology. 2006 [Google Scholar]
- Versfeld NJ, Festen JM, Houtgast T. Preference judgments of artificial processed and hearing-aid transduced speech. Journal of the Acoustical Society of America. 1999;106(3 Pt 1):1566–1578. doi: 10.1121/1.428035. [DOI] [PubMed] [Google Scholar]
- Wiley TL, Cruickshanks KJ, Nondahl DM, Tweed TS, Klein R, Klein BE. Tympanometric measures in older adults. Journal of the American Academy of Audiology. 1996;7:260–268. [PubMed] [Google Scholar]
- Wolfe J, John A, Schafer E, Nyffeler M, Boretzki M, Caraway T, Hudson M. Long-term effects of non-linear frequency compression for children with moderate hearing loss. International Journal of Audiology. 2011;50:396–404. doi: 10.3109/14992027.2010.551788. [DOI] [PubMed] [Google Scholar]
- Zakis JA, Hau J, Blamey PJ. Environmental noise reduction configuration: Effects on preferences, satisfaction, and speech understanding. International Journal of Audiology. 2009;48(12):853–867. doi: 10.3109/14992020903131117. [DOI] [PubMed] [Google Scholar]