

Abstract
Background
Many audiologists have observed a situation where a patient appears to understand something spoken by his/her spouse or a close friend but not the same information spoken by a stranger. However, it is not clear whether this observation reflects choice of communication strategy or a true benefit derived from the talker’s voice.
Purpose
The current study measured the benefits of long-term talker familiarity for older individuals with hearing impairment in a variety of listening situations.
Research Design
In Experiment 1, we measured speech recognition with familiar and unfamiliar voices when the difficulty level was manipulated by varying levels of a speech-shaped background noise. In Experiment 2, we measured the benefit of a familiar voice when the background noise was other speech (informational masking).
Study Sample
A group of 31 older listeners with high-frequency sensorineural hearing loss participated in the study. Fifteen of the participants served as talkers, and sixteen as listeners. In each case, the talker-listener pair for the familiar condition represented a close, long-term relationship (spouse or close friend).
Data Collection and Analysis
Speech-recognition scores were compared using controlled stimuli (low-context sentences) recorded by the study talkers. The sentences were presented in quiet and in two levels of speech-spectrum noise (Experiment 1) as well as in multitalker babble (Experiment 2). Repeated-measures analysis of variance was used to compare performance between the familiar and unfamiliar talkers, within and across conditions.
Results
Listeners performed better when speech was produced by a talker familiar to them, whether that talker was in a quiet or noisy environment. The advantage of the familiar talker was greater in a more adverse listening situation (i.e., in the highest level of background noise), but was similar for speech-spectrum noise and multi-talker babble.
Conclusions
The present data support a frequent clinical observation: listeners can understand their spouse better than a stranger. This effect was present for all our participants and occurred under strictly controlled conditions in which the only possible cue was the voice itself, rather than under normal communicative conditions where listener accommodation strategies on the part of the talker may confound the measurable benefit. The magnitude of the effect was larger than shown for short-term familiarity in previous work. This suggests that older listeners with hearing loss who inherently operate under deficient auditory conditions can benefit from experience with the voice characteristics of a long-term communication partner over many years of a relationship.
Keywords: aging, hearing loss, familiarity, speech recognition, benefit
Many audiologists have observed a situation where a patient seems to understand something spoken by his/her spouse but not the same information spoken by a stranger. We know from both anecdotal observations and research (Scarinci et al., 2008) that spouses or family members make accommodations for the hearing-impaired conversation partner. In long-term relationships in which one partner has hearing impairment, the talker may raise her voice, speak more clearly, or choose vocabulary or syntax that are familiar to the listener. We also know that such strategies have been shown to improve communication within the couple (Preminger, 2008). In other words, audiologists may be observing the benefits of communication strategies rather than voice familiarity per se.
However, there is also evidence that familiarity with a talker’s voice can improve speech recognition under some circumstances. Research in this area has focused on deliberately-trained recognition of previously unknown speakers, usually by young listeners with normal hearing. In general, those data indicate that speech recognition is improved when stimuli are produced by a previously-heard talker compared to a novel talker (Palmeri et al., 1993; Nygaard, Sommers and Pisoni, 1992; Nygaard and Pisoni, 1998; Yonan and Sommers, 2000; Sheffert et al., 2002; Newman and Evers, 2007). To understand why this happens, consider the wide variability in speech production. Listeners are able to identify speech sounds despite intra-talker differences in fundamental frequency, speech rate, frequency location of vocal tract resonances, and overriding voice qualities such as tremor or hoarseness. Originally, this information was viewed as a type of noise that listeners had to discard in order to abstract the identifiable components of speech for comparison to stored lexical representations (Pisoni, 1981). More recent work has argued that information about the talker is stored and may be used in combination with lexical information (Palmieri et al., 1993; Nygaard et al., 1994, 1995; Goldinger, 1996; Remez et al, 2007). This second view is consistent with the idea that a familiar voice might aid in speech recognition.
If learning to understand a particular talker is anything like language learning in general, we would expect talker familiarity to be a gradient phenomenon that improves with increased exposure. However, because of practical constraints, most published studies evaluated deliberate short-term exposure (hours to days), usually with strictly controlled test material. In those cases, the listener did not know the talker or interact with them in person, but simply heard their recorded voice. In such studies it has been found that mere exposure to a voice does not necessarily confer an advantage across varying task conditions. As one example of this, exposure to sentences by a target talker improved recognition of single words by that talker, but exposure to single words did not improve recognition of sentences (Nygaard and Pisoni, 1998; Yonan and Sommers, 2000). A plausible explanation for such findings is the idea that familiarity might be aided by exposure to a richer variety of utterances which cover a range of topics, prosody and context, as would occur in a long-term relationship. Indeed, one study which failed to show an advantage of implicit familiarity exploited a short-term relationship (professor/student) which existed under constrained communication conditions (classroom teaching) (Newman and Evers, 2007).
An additional group of studies focused on deliberate auditory training of listeners with hearing loss, often via a computer-based program that the listener completed on an individual basis over weeks or months. Such programs may be completed either with or without hearing aids; may employ syllables, words or sentences; and typically increase in difficulty (such as increasing level of background noise) throughout the course of the training. Like the short-term training studies with normal-hearing listeners, these studies also show that learning does not generalize to improved recognition of novel speech materials that are dissimilar to those used in the training programs (see Boothroyd, 2010 and Sweetow and Palmer, 2005 for recent reviews). For example, in one study training words for a single talker produced improvement in words by novel talkers, but not on connected speech using the same words (Burk & Humes, 2008). Thus, a real-life paradigm of interest to clinicians is the benefit of long-term, implicit learning over many years of interaction within a relationship.
The case of long-term relationships in which one individual has a hearing loss presents an interesting scenario. First, we focus here on older talker-listener pairs. There has been less attention to the advantage conferred by a familiar (or trained) voice for older listeners, although the available data hint that older listeners may respond differently. Several studies have identified age deficits for speaker identification (Yonan and Sommers, 2000; Helfer and Freyman, 2008; Rossi-Katz and Arehart, 2009) or auditory priming tasks (Schacter et al., 1994; Huang et al., 2010). However, Yonan and Sommers (2000) found that older listeners trained over a two-day period derived as much or more benefit from talker familiarity than younger listeners. Taken together, these data suggest that older listeners may process and/or store voice information differently than younger listeners, but that does not preclude using voice information to improve perception. A final point with regard to age is that all of the training studies conducted thus far have used test materials created within the laboratory. Although talker age was usually not specified, we can assume that the materials were produced by “ideal” (and probably younger) talkers. In the real-life situation we consider, the talker’s voice may also be subject to age-related changes, such as vocal tremor or hoarseness (Kendall, 2007) which could make the voice more immediately identifiable, but perhaps alsoless intelligible.
Second, we consider a situation in which the listener has hearing loss. There is some evidence that the advantage of talker familiarity may be more beneficial under degraded listening conditions. McLennan and Luce (2005) have argued that familiarity effects are more likely to be observed when processing of the input signal is slowed, as might be the case when the signal is impoverished. Available data for normal-hearing younger listeners presented with low-pass filtered speech (Church and Schacter, 1994) or speech in noise (Nygaard and Pisoni, 1998; Yonan and Sommers, 2000) support this idea. Previous work on talker familiarity, including those studies focused on older listeners (Yonan & Sommers, 2000; Huang et al., 2010), tested adults with normal- to near-normal auditory thresholds. Thus, available data may not reflect the effects of familiarity that occur in the older hearing-impaired population.
A further consideration is the fact that most older, hearing-impaired listeners show considerable difficulty understanding speech in noise. This is most apparent in situations where there is both energetic and informational masking (as when the background consists of other speech). Under such circumstances, Newman and Evers (2007) proposed that familiarity with the target voice could aid auditory stream segregation. It is not known what specific aspects of the familiar voice might contribute to this, but we know that listeners can use a wide variety of acoustic cues to familiarity, including fundamental frequency (Church and Schacter, 1994) and formant trajectories (Sheffert et al., 2002). Familiarity aside, we know that ability to track such frequency variations aids source segregation (Binns and Culling, 2007; Miller et al., 2010). Finally, the ability to follow frequency variations is impaired in some older listeners (Souza et al., 2011). Taken together, these data suggest that even if familiarity enhances those cues for younger listeners, that enhancement may not be the same in older listeners. Because previous work used broad-band noise maskers rather than speech (Yonan and Sommers, 2000), this issue has not been investigated.
The current study addressed the issue of long-term talker familiarity for older individuals with hearing impairment in a variety of listening situations. In each case, the talker-listener pair for the familiar condition represented a close, long-term relationship (spouse or close friend). In Experiment 1, we measured the benefit of a familiar voice when the difficulty level was manipulated by controlling the level of a speech-shaped background noise. In Experiment 2, we measured the benefit of a familiar voice when the background noise was other speech (introducing aspects of informational masking).
Experiment 1
Participants
Sixteen adult participants with hearing loss (9 female, 7 male; mean age 71.9 years) were designated as study listeners. All listeners had bilateral sensorineural loss defined as no air-bone gaps greater than 10 dB and normal tympanograms (Wiley et al., 1987; 1996). Listeners had sloping losses, with high-frequency thresholds in the moderate-to-severe range. In all cases, hearing loss was symmetrical and one ear was randomly selected for testing. Individual test-ear audiograms are shown in Table 1. The majority (14 listeners) did not wear hearing aids. The remaining two listeners were bilateral hearing-aid wearers, one having worn aids for 3 months and the other for 1 year. Those listeners did not wear their hearing aids during the study testing. All listeners had normal short-term memory capacity and orientation to time and place as indicated by a score of 28 or better on the Mini-Mental State Exam (Folstein et al., 1975). As part of our baseline audiometric protocol, each listener also completed speech-in-noise testing using two lists of the QuickSIN administered via earphones with presentation levels and scoring according to published guidelines (Killion et al., 2004).
Table 1.
Participant characteristics
| Listener Study ID | Age (years) | Listener hearing thresholds (dB HL) for test ear | Talker Relationship | Duration (years) | Age (years) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| .25 | .5 | 1 | 2 | 4 | 8 | |||||
| 001 | 65 | 30 | 20 | 15 | 40 | 55 | 75 | Spouse | 42 | 68 |
| 002 | 82 | 15 | 20 | 15 | 30 | 35 | 75 | Spouse | 58 | 80 |
| 003 | 78 | 35 | 20 | 20 | 30 | 45 | 65 | Friend | 30 | 61 |
| 004 | 72 | 25 | 25 | 35 | 45 | 50 | 90 | Friend | 35 | 70 |
| 005 | 79 | 45 | 45 | 50 | 55 | 70 | 75 | Friend | 8 | 82 |
| 006 | 70 | 20 | 20 | 30 | 40 | 60 | 60 | Spouse | 47 | 67 |
| 007 | 78 | 20 | 30 | 45 | 50 | 55 | 65 | Friend | 8 | 82 |
| 008 | 83 | 35 | 45 | 50 | 55 | 50 | 65 | Friend | 8 | 84 |
| 009 | 60 | 15 | 20 | 15 | 40 | 55 | 50 | Friend | 11 | 73 |
| 010 | 63 | 10 | 15 | 15 | 50 | 70 | 60 | Spouse | 44 | 62 |
| 011 | 53 | 20 | 25 | 25 | 55 | 45 | 55 | Spouse | 23 | 55 |
| 012 | 80 | 25 | 40 | 45 | 60 | 65 | 85 | Friend | 30 | 68 |
| 013 | 66 | 15 | 25 | 20 | 25 | 55 | 60 | Friend | 40 | 66 |
| 015 | 74 | 30 | 25 | 20 | 25 | 45 | 75 | Spouse | 48 | 71 |
| 016 | 76 | 35 | 40 | 40 | 35 | 50 | 65 | Friend | 7 | 64 |
| 204 | 72 | 10 | 15 | 10 | 30 | 60 | 80 | Spouse | 52 | 70 |
The criterion for the familiar talker for each listener was to be a frequent communication partner (see Table 1 for details). Seven of the talker-listener pairs were spouses. The remaining talker-listener pairs were long-term friends, where the pair reported communicating at least three hours each week. Because a primary goal of this study was to investigate communication in older listeners and also to maintain consistency across the talker set, the talkers were all older females (mean age 70.2 years). No talker reported any history of voice, speech or language disorders. Nine of the talkers had normal hearing; the remaining six talkers had acquired mild or moderate hearing loss, with presbycusis as the likely etiology based on patient history. None had hearing loss of a severity or duration which would have impacted articulation.
All of the talkers and listeners were native speakers of American English. To control for effects of regional dialect (Wright et al., 2006), all of the talkers and listeners had lived in the greater Chicago area for at least 30 years. All individuals participating in the study completed an informed consent process approved by the Northwestern Institutional Review Board, and were compensated at an hourly rate for their time.
Material
Sentences were low-context sentences drawn from the IEEE corpus. A set of 200 sentences were chosen for recording based on avoidance of alliteration or rhyming patterns (e.g., “it’s easy to tell the depth of a well”); avoidance of highly marked locutions (e.g., “the juice of lemons makes fine punch”); and a general preference against sentences that had a natural focus or contrast reading, so that all sentences would be read with similar declarative prosody. The recording apparatus consisted of a head-worn close-talking directional microphone (Shure SM10A) coupled via a microphone amplifier (Rane MS 1S) to an analog-to-digital processor (TDT RX6). Sentences were recorded at a 44.1 kHz sampling rate and quantized at 16 bits. The sentences were read in three randomizations to control for list effects. Each talker was instructed to read the sentences at a natural pace and vocal intensity, without any extra effort to speak clearly or loudly and without giving extra emphasis to any specific words (i.e., to use normal declarative prosody). Vocal level was monitored via a VU meter to ensure sufficient output levels without clipping.
Within each talker, the “best” token of each sentence was chosen as the one absent of any digital clipping or microphone overloading, with a secondary preference for fluent reading (e.g., no unnatural pauses, prosodic consistency) and general clarity, as judged by two trained phoneticians. Each sentence was placed into a separate file, taking care to include the onsets of phonemes with gradual increases in amplitude (such as fricatives) and with low amplitude (such as /h/ and /f/). Each file was padded with 50 ms of silence at the beginning and end of each sentence. Root-mean square levels were normalized across the entire sentence set (200 sentences × 16 talkers), using locally-developed Matlab code.
Procedure
For Experiment 1, 120 sentences were selected for testing. Listeners were seated in a double-walled sound-treated booth. For each listener, the sentences were randomly assigned on a trial-by-trial basis (without replacement) across five talkers and three conditions. The five talkers included the talker familiar to that listener plus four unfamiliar talkers, with the additional four talkers randomly selected from the set of unfamiliar talkers. Listeners were not explicitly told that their familiar talker would be part of the set. The conditions included sentences in quiet and in two levels of speech-shaped noise (+2 and +6 dB signal-to-noise ratio [SNR]). Each listener therefore heard a total of eight test sentences (40 key words) per talker × noise type. The noise was a broad-band noise shaped to match the long-term spectrum of all sentences × all talkers, generated using locally-developed Matlab code. In each trial, the sentence was presented at the specified presentation level in dB SPL (dB RMS in a 2cc coupler) and the noise level (for noise trials) was digitally adjusted to the desired SNR. The speech-plus-noise (or speech in quiet) stimulus was then converted to analog (TDT RX6 processor), passed through an attenuator (TDT PA5) and headphone buffer (TDT HB6) and presented over an Etymotic Research ER-2 insert headphone in the test ear.
Sentences were nominally presented at 35 dB above the listener’s pure-tone average at .5, 1 and 2 kHz. First, the listener was familiarized with the task by listening to and repeating 20 different IEEE sentences presented in the same conditions but spoken by a different set of talkers. If during the familiarization procedure a listener indicated that 35 dB SL was uncomfortable, the level was reduced. Across all listeners, the minimum presentation level was 30 dB SL re: pure-tone average. No frequency shaping was used. Listeners were instructed to repeat the sentences, stating individual words recognized. No feedback was provided. The experimenter was seated outside the sound booth and controlled presentation timing and scoring of the five key words using locally-developed Matlab code. Words were counted as correct if spoken in any order, and appended grammatical morphemes were disregarded.
Results
Figure 1 illustrates the effect of familiarity and noise level on recognition accuracy (percent correct). Listeners performed better when speech was produced by a talker familiar to them, even for speech in quiet (although the quiet speech comparison may have been constrained by a ceiling effect). The advantage of familiarity was substantial as much as 15%, on average, depending on the test condition.
Figure 1.
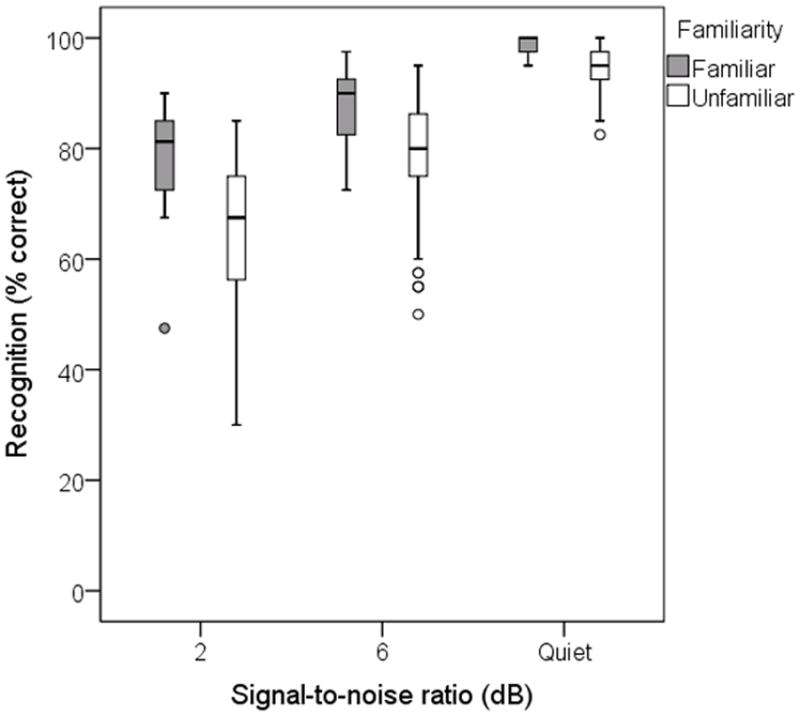
Speech recognition as a function of signal-to-noise ratio. In each case, the background noise was a broad-band noise shaped to the spectrum of the test sentences. Scores for the familiar talkers are shown by the filled boxes and scores for the unfamiliar talkers by the unfilled boxes. The ends of the box indicate the quartile values and the bar indicates the sample median. The whiskers extend to 1.5 times the height of the box or, if no case/row has a value in that range, to the minimum or maximum values. Outliers greater than 1.5 times the box height are plotted as open circles.
Data were analyzed using a two-way (familiarity × SNR) repeated measures analysis of variance (ANOVA)1. As expected, overall performance decreased with increasing noise level (F2,156=341.16, p<.005). Post-hoc analysis using paired t-tests indicated significantly different scores between quiet and +6 dB SNR, and between +6 dB and +2 dB SNR (p<.005 in each case). Across all conditions, listeners had more difficulty recognizing sentences spoken by unfamiliar talkers (F1,78)=22.20, p<.005. The interaction was not significant (F2,156=.83, p=.411), suggesting that when considered in terms of absolute performance, the benefit of familiarity was similar across noise conditions.
One weakness of the above analysis is that the variability in absolute intelligibility across listeners exceeded the within-listener effect of familiarity. To understand this issue, consider Figure 2, which shows individual scores for each listener. Each data “column” across the abscissa represents scores for a single listener, where each symbol shows average score by that listener for a different talker. Across all noise conditions, every listener obtained the best performance with their familiar talker, magnitude of the difference varied from listener to listener. It is also evident from Figure 2 that some listeners are simply better speech recognizers than others. This variability among older listeners, even those with similar audiograms, is well-established in the literature (e.g., Humes, 2007). Reporting an absolute-score analysis as in the ANOVA results described above (i.e., comparing the vertical distribution of all filled triangles to the vertical distribution of all open circles) introduces considerable listener-to-listener variability which may underrepresent the familiar-to-unfamiliar differences. Accordingly, we calculated the familiarity benefit for each listener by calculating the difference in performance between their familiar talker and each unfamiliar talker they heard. The effect of familiarity benefit in the three noise conditions is shown in Figure 3. A one-way ANOVA indicated a significant effect of SNR (F2,126=6.53, p=.002). Post-hoc t-tests showed that the benefit of familiarity was greater at +2 dB SNR than at +6 SNR (t63=3.71, p<.005). The benefit of the familiar talker was statistically equivalent in quiet and at +6 dB SNR (t63=−.07, p=.943). Note, however, that this pattern may have been influenced by a ceiling effect for the quiet condition, and perhaps to a lesser extent for the +6 dB SNR condition.
Figure 2.
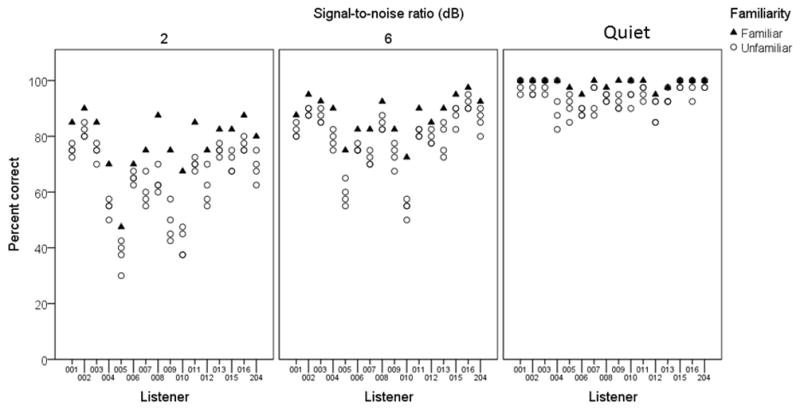
Speech-recognition scores for individual listeners. Each data point represents a score for a different talker, with the familiar talkers plotted as filled triangles and the unfamiliar talkers plotted as open circles. Each listener heard one familiar and four unfamiliar talkers. For some listeners identical unfamiliar-talker scores are overlaid on the plot. Panels show the three SNR conditions from Experiment 1.
Figure 3.
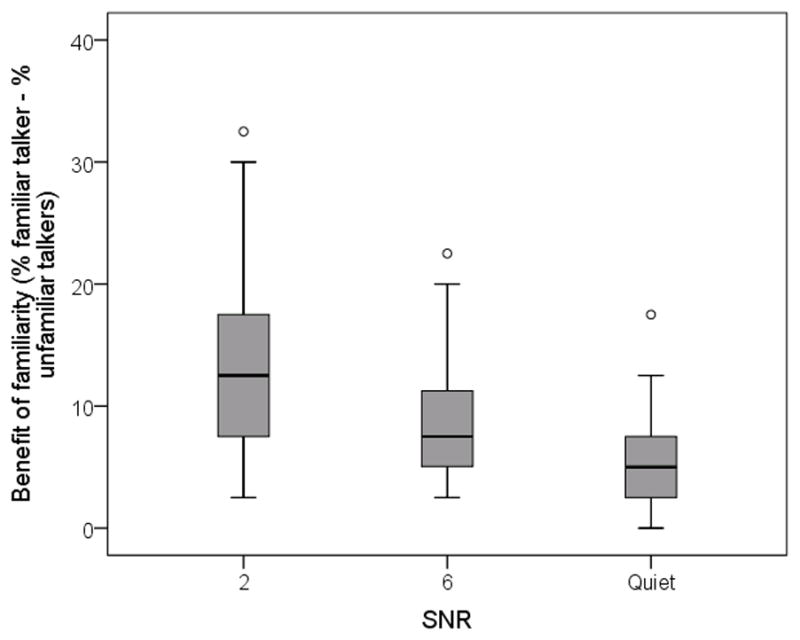
Familiarity benefit, calculated as the difference between the familiar and unfamiliar talker for each listener, as a function of signal-to-noise ratio. Outliers who fall more than 1.5 box lengths from the median are plotted as open circles.
Discussion
The perceptual advantage gained from familiarity with the talker was substantial. One marker of this advantage was that scores for sentences spoken by a familiar talker in a +2 dB SNR were nearly identical to scores for an unfamiliar talker in a +6 dB SNR—a 4 dB improvement in performance (see Figure 1). Although we expected to see some benefit of familiarity, the magnitude was substantial considering the strict controls to test materials. Indeed, every listener obtained this benefit to some extent: for every listener, scores for their familiar talker (filled triangles in Figure 2) were higher than scores for each of the unfamiliar talkers they heard (open circles in Figure 2). Moreover, since the talkers were reading sentences in a recording booth, rather than talking directly to their spouses or friends, the benefit seen cannot be due to partner-specific conversational or communicative strategies. In other words, the familiarity benefit—and its enhancement in more challenging conditions—is due to abilities or strategies on the part of the listener, not the talker. The fact that this familiarity benefit was stronger in the most adverse noise condition suggests that talker familiarity benefits are robust in noise. or equivalently, the advantage conferred by familiarity can be triggered and exploited even by very brief glimpses of the target signal that “pop out” above the masker noise. To explore this further, Experiment 2 used a multitalker babble noise that represented an everyday listening environment. Babble introduces an informational masking component whereby the background (although not intelligible) is more similar to the target in percept than speech-spectrum noise. Such similarity may create a more adverse listening situation (e.g., Freyman, Balakrishnan & Helfer, 2004; Pichora-Fuller and Souza, 2003; Rosen, Souza, Ekelund and Majeed, submitted; Simpson & Cooke, 2005). Based on the finding that the benefit of familiarity was smaller in less adverse listening conditions (quiet and +6 dB SNR), we expected that increased task difficulty in babble might alter the extent of familiarity benefit.
Experiment 2
Participants
Thirteen of the 16 listeners from Experiment 1 (excluding listeners 2, 11 and 13, who were not available) participated in Experiment 2. As in Experiment 1, the majority (10 listeners) were not hearing aid users. One listener had 6 months of hearing aid experience; the remaining two listeners were unaided prior to Experiment 1 but purchased new hearing aids prior to Experiment 2. Those individuals had approximately 2 months of hearing aid experience prior to testing. None of the listeners wore hearing aids during the experiment.
Materials
Test materials were the 80 recorded sentences not previously used in Experiment 1. Each sentence was presented in either speech-shaped noise or multitalker babble, both at a +2 dB SNR. Sentences were grouped such that all sentences with a particular noise type were presented contiguously, and the order of the two noise types was counterbalanced across participants. The speech-shaped noise was the same noise as used in Experiment 1. Note that the speech-shaped noise condition for Experiment 2 replicated one of the test conditions in Experiment 1, albeit with a different set of unfamiliar talkers for each listener. The multi-talker babble was a six-talker babble taken from the recording of the Connected Speech Test (Cox et al., 1987), spectrally shaped to be identical to the long-term average spectrum of the sentence set and of the speech-shaped noise. As in Experiment 1, each listener heard sentences spoken by a total of five talkers (the talker familiar to them, plus four unfamiliar talkers). As in Experiment 1, listeners were not explicitly told that their familiar talker would be part of the set. The unfamiliar talkers were chosen randomly and did not repeat any of the unfamiliar talkers heard by that listener in Experiment 1. Each listener therefore heard a total of eight test sentences (40 key words) per talker × noise type. As in Experiment 1, a set of 20 practice sentences from a different set of talkers was presented to familiarize the listener with the task; half of the practice sentences were presented with speech-shaped noise and half with multitalker babble. Sentence presentation and scoring were otherwise identical to Experiment 1.
Results
Figure 4 shows results, grouped by noise type. Overall performance was higher in speech-spectrum noise than in multitalker babble. For both noises, scores were approximately 15% better for sentences spoken by a familiar talker. The pattern of performance was confirmed with a two-way repeated-measures ANOVA (noise type × familiarity): there was a significant effect of noise type (F1,63=216.54, p<.005) and of familiarity (F1,63=14.76, p<.005). Noise type and familiarity did not interact (F1,63=.38, p=.537).
Figure 4.
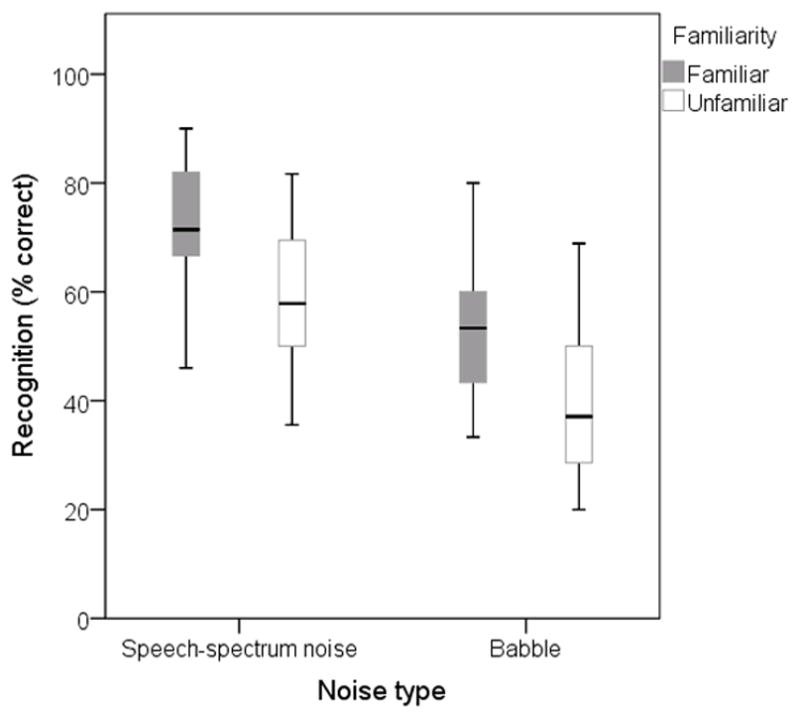
Speech recognition as a function of noise type. In each case, the background noise was presented at +2 dB signal-to-noise ratio. Scores for the familiar talkers are shown by the filled boxes and scores for the unfamiliar talkers by the unfilled boxes.
Figure 5 shows individual scores for each talker, plotted as in Figure 2. Similar to Experiment 1, performance was always best with the listener’s familiar talker. In general, the pattern of performance is quite similar across noise types, except that performance is lower for the multitalker babble. However, we can also see that some listeners are more susceptible to the babble vs. speech spectrum noise difference than other listeners. For example, compare the effect of babble on listeners 10 and 204; the latter shows similar performance in speech-shaped noise and babble, whereas the former shows a marked decrease in performance in the babble condition. The fact that listeners are differentially susceptible to babble may reflect differences in susceptibility to informational masking, top-down processing; or other mechanisms.
Figure 5.
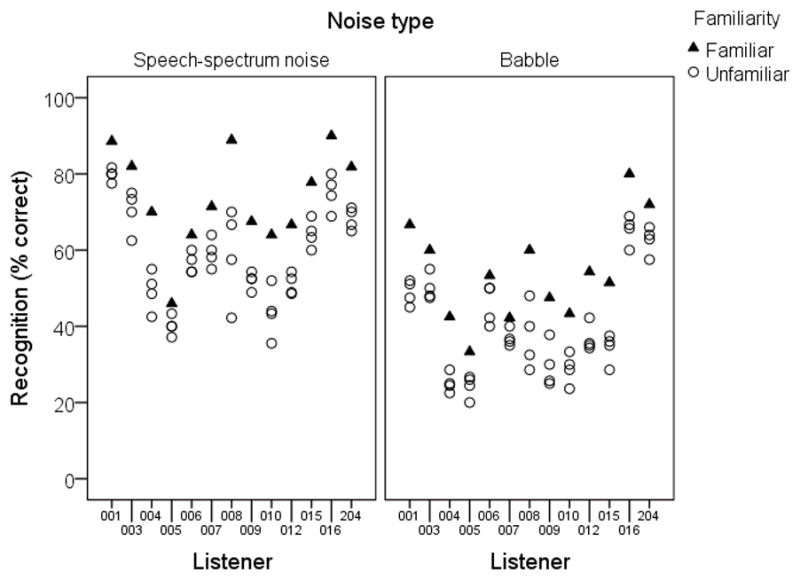
Speech-recognition scores for individual listeners. Each data point represents a score for a different talker, with the familiar talkers plotted as filled triangles and the unfamiliar talkers plotted as open circles. Each listener heard one familiar and four unfamiliar talkers, but for some listeners cases identical unfamiliar-talker scores are overlaid on the plot. Panels show the two noise types from Experiment 2.
Because Experiment 2 repeated one of the conditions from Experiment 1 (speech-spectrum noise at +2 dB SNR), we also compared data for that condition across experiments (Figure 6). In essence, this comparison serves as a reliability check for repeat testing with the same participants under the same test conditions. Only those individuals who participated in both experiments were included in the analysis. There was no difference in performance for the listeners’ familiar talker (t12=1.76, p=.104) or the benefit of familiarity (t51=−.88, p=.381). Although there was a statistically significant difference for the unfamiliar talkers (t51=2.22, p=.031), the difference is small (2% on average) and may reflect the comparison across different sets of unfamiliar talkers.
Figure 6.
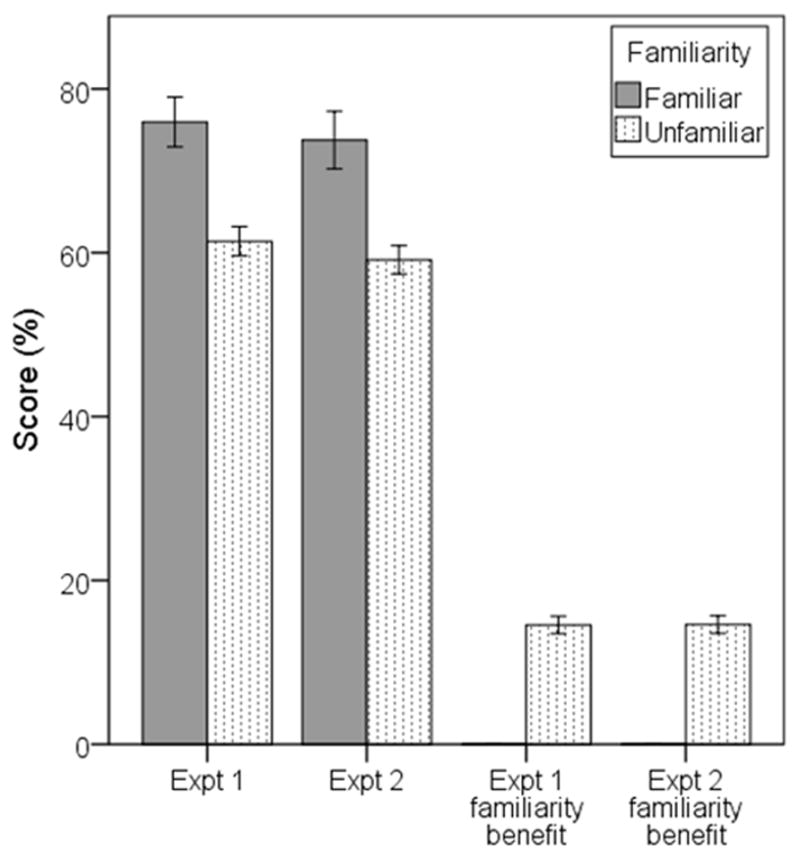
Comparison of speech-recognition scores with +2 dB of speech-spectrum noise across Experiments 1 and 2. The two left bars show absolute scores. The two right bars show familiarity benefit calculated as the difference between the familiar and each unfamiliar talker. Error bars show +/− one standard error about the mean.
Discussion
Contrary to our hypothesis, we did not find that the group benefit of familiarity was greater when task difficulty was manipulated by changing to a multitalker babble. We expected multitalker babble to be a more difficult masker than speech-spectrum noise (e.g. Rosen et al., submitted; Simpson & Cooke, 2005). That was certainly the case here, with all listeners showing poorer performance in the babble masker. However, the benefit of familiarity did not increase, as it did in Experiment 1 when the situation was made more difficult by increasing the speech-spectrum noise level. It is possible that the benefit of familiarity depends on some acoustic cue that was less available in the presence of multitalker babble than in speech-spectrum noise. For example, if listeners were taking advantage of the fundamental frequency of the familiar talker, it might have been more difficult to extract that information in the presence of multiple pitch tracks. It’s also possible that the participants, all of whom had hearing loss which would prevent full use of acoustic cues, had simply reached the maximum advantage that could be gained from familiarity.
General discussion
The present data support a frequent clinical observation: listeners can understand their spouse or a close friend better than a stranger. This effect was noted in all our participants, regardless of their degree of hearing loss and whether the relationship was with a spouse or close friend. The effect persisted even when measured under strictly controlled conditions in which the only possible cue was the voice itself, rather than under normal communicative conditions where listener accommodation strategies on the part of the talker may confound the measurable benefit. Additionally, the effect was implicit: although participants were aware that a close friend or family member had been involved in a previous study visit, they were told only that they would hear sentences spoken by a variety of different speakers, and were not told that they would hear a recognizable voice. Indeed, when asked at the conclusion of the experiment, approximately half the listeners indicated that they had not recognized any of the voices they heard.
Our paradigm probably underrepresented the benefit that might occur under normal communications. For one thing, in everyday listening the listener can often or usually see the talker. This both activates explicit familiarity (shown to provide an even greater advantage; Newman and Evers, 2007) and offers multimodal input, with visual cues to familiarity as well as auditory cues. Moreover, in real-world situations where one person talks for a period of time, rather than interspersing talkers as was done here, the situation is akin to “blocked” experimental designs, which should enhance the ability to recognize a familiar voice (Magnuson et al., 1995) and therefore further aid in the perceptual task. We also controlled to a degree for linguistic-prosodic variables in that we used RMS-normalized, read, declarative sentences; in real-world situations. Finally, when materials are not as controlled as they were here, talkers are likely to adapt to the listener by deliberately producing louder or clearer speech. Two individuals in a long-term relationship will also have the advantage of shared experience in their choice of conversation topics, which may function as a type of contextual benefit. Thus our experiments were more difficult than everyday communication on a variety of dimensions, and the true magnitude of familiarity benefit may well exceed the findings reported here.
An interesting comparison can be made to work by Newman and Evers (2007), a study with some similarities to the present study. In their “implicit familiarity” condition, listeners were presented with material produced by unfamiliar talkers or by a talker with whom they had a previous relationship, but were not told who the speaker would be. In that case, the listeners were university students who had attended a course taught by the familiar speaker. In contrast to the present data, Newman and Evers found no benefit of implicit familiarity. Several differences are of interest here. First, Newman and Evers tested younger listeners with normal hearing using a high-context task (narrative shadowing) at a +5 dB SNR. Considering that normal-hearing young adults can recognize even low-context speech at less favorable SNRs, Newman and Evers’s paradigm would be construed as relatively easy (i.e., high redundancy). McLennan and Luce (2005) have posed that the benefits of familiarity will be greatest in conditions in which processing is slowed; i.e., low redundancy conditions. That idea is generally supported by the present data, which showed a high degree of benefit from listening to a familiar voice in a situation which combined high-frequency hearing loss and speech in background noise.
Second, many college lectures are presented in a large reverberant space, sometimes combined with projection of the speaker’s voice through a low-fidelity sound system. This raises the possibility that the voice source characteristics could have been slightly different when presented through the high-fidelity recording system used for study materials compared to the listener’s previous experience with that voice. Because we know that voice source characteristics are a determinant of familiarity (Sheffert et al., 2002), this design represents another possible difference between previous data and the present study. Third, we believe that the relationship exploited by Newman and Evers would have involved minimal familiarity. Good experimental controls were used, in that students who reported they seldom attended class were excluded. However, students would have been exposed to the speaker’s voice for several hours each week, over a few months. In those communications, the instructor’s topic focus, vocabulary and emotion were likely to have been constrained. Moreover, in our experience as college instructors, attending class—particularly the type of introductory psychology class sampled—here does not guarantee a close focus on the speaker’s voice. In that respect, Newman and Evers’ design represents a very different relationship than tested in the present study, where the listener actively communicated with the talker in a rich and varied conversational environment over a long period of time. A similar criticism can be made of the generalization from a trained voice to novel voices used in formal auditory training paradigms. The fact that such improvements do not seem to generalize to more varied materials and situations suggests that limited exposure to a voice represents a different type of learning than listeners who communicate with a conversation partner over a range of topics, situations and backgrounds.
The source of familiarity
An interesting experimental question is, “What conveys familiarity?” Source characteristics of the talker’s voice (such as fundamental frequency and glottal harmonics) have been shown to be important in learning to identify a new talker (Sheffert et al., 2002). Therefore, we think that source characteristics are important to the familiar-talker benefit that we have observed. However, listeners can also identify individual voices on the basis of fine-structure or phonetic properties when voices are processed to remove source characteristics such as fundamental frequency (Remez et al., 1997; Fellowes et al., 1997). Dynamic aspects of the voice such as intonation (Church and Schacter, 1994) and perhaps speech rate (Bradlow and Nygaard, 1996; Bradlow et al., 1999) may also play a role in talker recognition. Indeed, listeners are able to judge similarity of “voices” after sinewave resynthesis, suggesting that global properties such as prosodic rhythm may play a role in talker identification (Remez et al., 2007) and the concomitant familiar-talker benefit.
This question can also be informed by research on signal familiarity that is not limited to a specific talker. For example, listeners perform better at recognizing speech produced in their own regional dialect (Adank, Evans, Stuart-Smith and Scott, 2009; Wright et al., 2006). In that case, aspects of familiarity may include phonemic or allophonic segmental differences known to vary across dialects (e.g., pre-velar /æ/ raising [Dahan et al., 2008]). Regional/dialect differences may also include prosodic differences such as speech rate or pitch accent placement or direction (Clopper and Smiljanic, 2011).
Similarly, it is known that talker identification training and familiar talker advantage is more successful when framed in a language the listener understands (Winters et al., 2008; Perrachione et al., 2009; 2011; Levi et al., 2011). One explanation for this effect is that word recognition gives listeners a “toehold” on which to base judgments of talker variation (Perrachione et al., 2009; 2011). Our findings relative to talker familiarity might reflect the same process, although in the reverse direction (leveraging talker identification to help with lexical identification, instead of the other way around).
Within-listener variation and the familiarity benefit
There was a clear group benefit of hearing a familiar rather than an unfamiliar talker, whether that talker was in a quiet or noisy environment. The advantage of the familiar talker was greater in a more adverse listening situation (i.e., in the highest level of background noise). As Figures 2 and 5 illustrate, the benefit of familiarity varied across individuals. Nevertheless, there was no systematic patterning of the magnitude of the familiarity benefit with the “best” or “worst” speech recognizers. For example, compare listeners 3 and 5 in the left panel of Figure 2, who had very different overall performance but whose familiar talkers provided about the same improvement relative to the unfamiliar talkers. Similarly, compare listeners 8 and 12, whose performance on unfamiliar talkers was equivalent, but who derived different familiarity benefits. Moreover, the familiarity benefit did not depend on the familiar talker being highly intelligible per se, because each talker was more intelligible to the listener for whom they were familiar regardless of their intelligibility as an unfamiliar talker to the remaining listeners. This makes the consistency of the familiarity advantage across listeners all the more striking.
Audibility is another source of listener variability: although our listeners had generally similar audiograms and listened at similar sensation levels relative to their pure-tone average, differences in high-frequency severity and audiometric slope meant that they did not listen under identical audibility levels. Such differences would have been most apparent for speech in quiet, but might have occurred even when speech audibility was largely determined by the signal-to-noise ratio. Knowing that audibility is perhaps the primary challenge for listeners with hearing loss (e.g., Humes, 2007), and considering that the benefit of familiarity is greatest under adverse conditions (i.e., +2 dB SNR), it is possible that the magnitude of the familiarity benefit might have been smaller if customized hearing-aid responses were taken into account. Accordingly, an unanswered question is the extent to which the familiarity benefit varies under different amplification conditions.
In this study, familiar talkers imparted an average of 10% improvement across all listeners and test conditions. As discussed above, it is possible that the familiarity benefit varied over a constrained range which was dictated by the properties of the listener’s hearing, the talker’s voice, and the conversational situation. From a clinical perspective, then, perhaps the most salient point is how much benefit can be gained by familiarity with the talker under adverse listening conditions. The benefit of familiarity was largest for this population under the most adverse SNRs. Individuals do vary in their ability to hear in noisy environments. As a first step toward relating our results to real-world situations, we compared each listener’s familiarity benefit to their QuickSIN scores (obtained as part of their initial screening). Figure 7 shows familiarity benefit, grouped by QuickSIN performance and collapsed across SNR. Despite apparently larger benefits for listeners with poorer QuickSIN scores, the difference was not statistically significant (F2,61=1.12, p=.334). The limited statistical power for this comparison (only a few listeners fell into the “moderate” QuickSIN category) prevents drawing definitive conclusions. With regard to the listening environment, babble clearly made listening more difficult but did not increase the familiarity benefit. Clinically, it would be useful to understand the factors underlying familiarity benefit so they could be exploited to improve communication.
Figure 7.
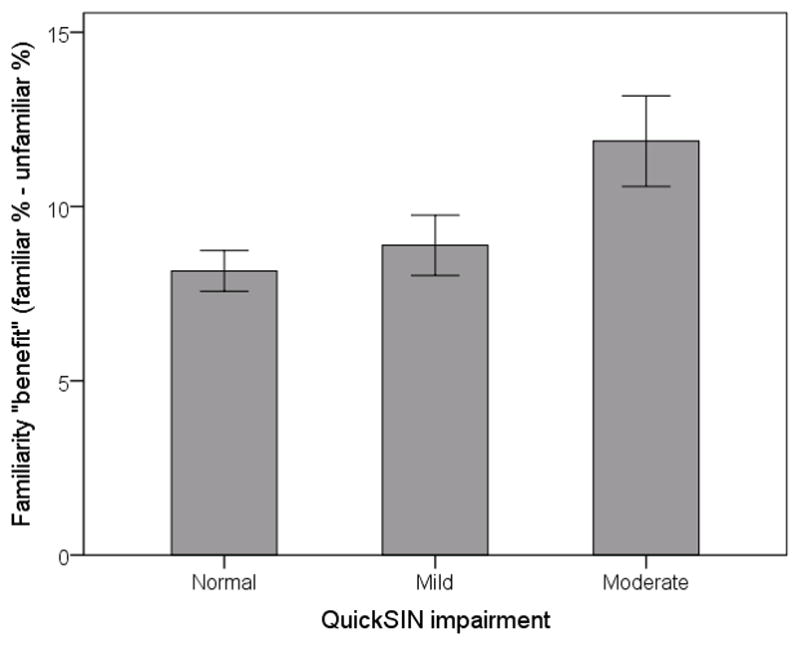
Mean familiarity benefit (error bars indicate +/− one standard error) from Experiment 1, as a function on listener speech-in-noise ability (measured with QuickSIN).
Conclusion
The present data support a frequent clinical observation: listeners can understand their spouse or a close friend better than a stranger. This effect was present for all our participants and occurred under strictly controlled conditions in which the only possible cue was listener familiarity with the voice itself, rather than under normal communicative conditions where listener accommodation strategies on the part of the talker may confound the measurable benefit. The magnitude of the familiarity benefit was larger than shown in similar studies with young, normal hearing listeners, suggesting that older listeners with hearing loss may partially compensate for their hearing deficit by relying on their experience in a rich communication environment over many years of a relationship. Understanding the sources of familiarity for this population, and the extent to which familiarity benefits vary across listening situations, presents an interesting area for future work.
Acknowledgments
Work was supported by the National Institutes of Health (R01DC60014 and R01DC012289). The authors thank Frederick Gallun for sharing Matlab code for some portions of this study, and August McGrath for her assistance with materials preparation.
Abbreviations
- dB SNR
decibel signal-to-noise ratio
- dB HL
decibels hearing level
- ANOVA
analysis of variance
Footnotes
For all statistical analyses, raw data were transformed to rationalized arcsine units (RAUs; Studebaker, 1985) to normalize variance across the score range. In cases where the assumption of homogeneity was violated, the values reported follow the Greenhouse-Geisser correction.
Work presented in this paper was supported by NIH grants R01DC60014 and R01DC012289. This data has been submitted for presentation at the Illinois Academy of Audiology conference in January 2013.
Contributor Information
Pamela Souza, Roxelyn and Richard Pepper Department of Communication Sciences and Disorders, Northwestern University, Evanston, IL.
Namita Gehani, Roxelyn and Richard Pepper Department of Communication Sciences and Disorders, Northwestern University, Evanston, IL.
Richard Wright, Department of Linguistics, University of Washington, Seattle, WA.
Daniel McCloy, Department of Linguistics, University of Washington, Seattle, WA.
References
- Adank P, Evans BG, Stuart-Smith J, Scott SK. Comprehension of familiar and unfamiliar native accents under adverse listening conditions. J Exp Psychol Hum Percept Perform. 2009;35:520–9. doi: 10.1037/a0013552. [DOI] [PubMed] [Google Scholar]
- Binns C, Culling J. The role of fundamental frequency contours in the perception of speech against interfering speech. J Acoust Soc Am. 2007;122:1765–1776. doi: 10.1121/1.2751394. [DOI] [PubMed] [Google Scholar]
- Boothroyd A. Adapting to changed hearing: the potential role of formal training. J Am Acad Audiol. 2010;21:601–11. doi: 10.3766/jaaa.21.9.6. [DOI] [PubMed] [Google Scholar]
- Bradlow A, Nygaard L, Pisoni D. Effects of talker, rate, and amplitude variation on recognition memory for spoken words. Percept Psychophys. 1999;61:206–219. doi: 10.3758/bf03206883. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bradlow A, Nygaard L. The effect of talker rate and amplitude variation on memory representation of spoken words. J Acoust Soc Am. 1996;99:2588. [Google Scholar]
- Burk MH, Humes LE. Effects of long-term training on aided speech-recognition performance in noise in older adults. J Speech Lang Hear Res. 2008;51:759–71. doi: 10.1044/1092-4388(2008/054). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Church B, Schacter D. Perceptual specificity of auditory priming: Implicit memory for voice intonation and fundamental frequency. J Exp Psychol: Learning, Memory and Cognition. 1994;20:521–533. doi: 10.1037//0278-7393.20.3.521. [DOI] [PubMed] [Google Scholar]
- Clopper C, Smiljanic R. Effects of gender and regional dialect on prosodic patterns in American English. Journal of Phonetics. 2011;39:237–245. doi: 10.1016/j.wocn.2011.02.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox R, Alexander G, Gilmore C. Development of the Connected Speech Test. Ear Hear. 1987;8:119S–126S. doi: 10.1097/00003446-198710001-00010. [DOI] [PubMed] [Google Scholar]
- Dahan D, Drucker S, Scarborough R. Talker adaptation in speech perception: Adjusting the signal or the representation? Cognition. 2008;108:710–718. doi: 10.1016/j.cognition.2008.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fellowes J, Remez R, Rubin P. Perceiving the sex and identity of a talker without natural vocal timbre. Percept Psychophys. 1997;59:839–849. doi: 10.3758/bf03205502. [DOI] [PubMed] [Google Scholar]
- Folstein M, Folstein S, McHugh P. “Mini-mental state”: A practical method forgraidng the cognitive state of patients for the clinician. J Psychiatr Res. 1975;12:189–198. doi: 10.1016/0022-3956(75)90026-6. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Effect of number of masking talkers and auditory priming on informational masking in speech recognition. J Acoust Soc Am. 2004;115(5 Pt 1):2246–56. doi: 10.1121/1.1689343. [DOI] [PubMed] [Google Scholar]
- Goldinger S. Words and voices: episodic traces in spoken word identification and recognition memory. J Exp Psychol: Learning, Memory and Cognition. 1996;22:1166–1183. doi: 10.1037//0278-7393.22.5.1166. [DOI] [PubMed] [Google Scholar]
- Helfer K, Freyman R. Aging and speech-on-speech masking. Ear Hear. 2008;29:87–98. doi: 10.1097/AUD.0b013e31815d638b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang Y, Xu L, Wu X, Li L. The effect of voice cueing on releasing speech from informational masking disappears in older adults. Ear Hear. 2010;31:579–583. doi: 10.1097/AUD.0b013e3181db6dc2. [DOI] [PubMed] [Google Scholar]
- Humes LE. The contributions of audibility and cognitive factors to the benefit provided by amplified speech to older adults. J Am Acad Audiol. 2007;18:590–603. doi: 10.3766/jaaa.18.7.6. [DOI] [PubMed] [Google Scholar]
- Kendall K. Presbyphonia: a review. Curr Opin Otolaryngol Head Neck Surg. 2007;15:137–140. doi: 10.1097/MOO.0b013e328166794f. [DOI] [PubMed] [Google Scholar]
- Killion M, Niquette P, Gudmundsen G, Revit L, Banerjee S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio in normal-hearing and hearing-impaired listeners. J Acoust Soc Am. 2004;116:2395–2405. doi: 10.1121/1.1784440. [DOI] [PubMed] [Google Scholar]
- Levi S, Winters S, Pisoni D. Effects of cross-language voice training on speech perception: Whose familiar voices are more intelligible? J Acoust Soc Am. 2011;130:4053–4062. doi: 10.1121/1.3651816. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Magnuson J, Yamada R, Nusbaum H. The effects of familiarity with a coive on speech perception. Proceedings of the Meeting of the Acoustical Society of Japan; 1995. pp. 391–392. [Google Scholar]
- McLennan C, Luce P. Examining the time course of indexical specificity effects in spoken word recognition. J Exp Psychol: Learning, Memory and Cognition. 2005;31:306–321. doi: 10.1037/0278-7393.31.2.306. [DOI] [PubMed] [Google Scholar]
- Miller S, Schlauch R, Watson P. The effects of fundamental frequency contour manipulations on speech intelligibility in background noise. J Acoust Soc Am. 2010;128:435–443. doi: 10.1121/1.3397384. [DOI] [PubMed] [Google Scholar]
- Newman R, Evers S. The effect of talker familiarity on stream segregation. Journal of Phonetics. 2007;35:85–103. [Google Scholar]
- Nygaard L, Pisoni D. Talker specific learning in speech perception. Percept Psychophys. 1998;60:355–376. doi: 10.3758/bf03206860. [DOI] [PubMed] [Google Scholar]
- Nygaard LC, Sommers MS, Pisoni DB. Effects of speaking rate and talker variability on the recall of spoken words. Journal of the Acoustical Society of America. 1992;91:2340. doi: 10.1121/1.411453. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nygaard L, Sommers M, Pisoni D. Speech perception as a talker-contingent process. Psychological Sciences. 1994;5:42–46. doi: 10.1111/j.1467-9280.1994.tb00612.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nygaard L, Sommers M, Pisoni D. Effects of stimulus variability on perception and representation of spoken words in memory. Percept Psychophys. 1995;57:989–1001. doi: 10.3758/bf03205458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Palmeri T, Goldinger S, Pisoni D. Episodic encoding of voice attributes and recognition memory for spoken words. J Exp Psychol. 1993;19:309–328. doi: 10.1037//0278-7393.19.2.309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perrachione T, del Tufo S, Gabrieli J. Human voice recognition depends on language ability. Science. 2011;333:595. doi: 10.1126/science.1207327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Perrachione T, Pierrehumbert J, Wong P. Differential neural contributions to native- and foreign-language talker identification. J Exp Psychol: Hum Percept Perform. 2009;35:1950–1960. doi: 10.1037/a0015869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pichora-Fuller M, Souza P. Effects of aging on auditory processing of speech. Int J Audiol. 2003;42(suppl 2):2S11–2S16. [PubMed] [Google Scholar]
- Pisoni DB. Some current theoretical issues in speech perception. Cognition. 1981;10:249–59. doi: 10.1016/0010-0277(81)90054-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Preminger J. Should significant others be encouraged to join adult group audiologic rehabilitation classes? J Am Acad Audiol. 2008;14:545–555. doi: 10.3766/jaaa.14.10.3. [DOI] [PubMed] [Google Scholar]
- Remez R, Fellowes J, Nagel D. On the perception of similarity among talkers. J Acoust Soc Am. 2007;122:3688–3697. doi: 10.1121/1.2799903. [DOI] [PubMed] [Google Scholar]
- Remez R, Fellowes J, Rubin P. Talker identification based on phoneticinformation. J Exp Psychol Hum Percept Perform. 1997;23:651–666. doi: 10.1037//0096-1523.23.3.651. [DOI] [PubMed] [Google Scholar]
- Rosen S, Souza P, Ekelund C, Majeed A. Listening to speech in a background of other talkers: effects of talker number and noise vocoding. (submitted) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rossi-Katz J, Arehart K. Message and talker identification in older adults: Effects of task, distinctiveness of the talkers’ voices, and meaningfulness of the competing message. J Speech Lang Hear Res. 2009;52:435–453. doi: 10.1044/1092-4388(2008/07-0243). [DOI] [PubMed] [Google Scholar]
- Scarinci N, Worrall L, Hickson L. The effect of hearing impairment in older people on the spouse. Int J Audiol. 2008;47:141–151. doi: 10.1080/14992020701689696. [DOI] [PubMed] [Google Scholar]
- Schacter D, Church B, Osowiecki D. Auditory priming in elderly adults: impairment of voice-specific implicit memory. Memory. 1994;2:295–323. doi: 10.1080/09658219408258950. [DOI] [PubMed] [Google Scholar]
- Sheffert S, Pisoni D, Fellowes J, Remez R. Learning to recognize talkers from natural, sinewave, and reversed speech samples. J Exp Psychol. 2002;28:1447–1469. [PMC free article] [PubMed] [Google Scholar]
- Souza P, Arehart K, Miller C, Muralimanohar R. Effects of age on F0 discrimination and intonation perception in simulated electric and electroacoustic hearing. Ear Hear. 2011;32:75–83. doi: 10.1097/AUD.0b013e3181eccfe9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sweetow R, Palmer CV. Efficacy of individual auditory training in adults: a systematic review of the evidence. J Am Acad Audiol. 2005;16:494–504. doi: 10.3766/jaaa.16.7.9. [DOI] [PubMed] [Google Scholar]
- Rosen S, Souza P, Ekelund C, Majeed A. Listening to speech in a background of other talkers: effects of talker number and noise vocoding. (submitted) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiley T, Cruickshanks K, Nondahl D, Tweed T, Klein R, Klein B. Tympanometric measures in older adults. J Am Acad Audiol. 1996;7:260–268. [PubMed] [Google Scholar]
- Wiley T, Oviatt D, Block M. Acoustic-immittance measures in normal ears. J Speech Hear Res. 1987;30:161–170. doi: 10.1044/jshr.3002.161. [DOI] [PubMed] [Google Scholar]
- Winters S, Levi S, Pisoni D. Identification and discrimination of bilingual talkers across languages. J Acoust Soc Am. 2008;123:4524–4538. doi: 10.1121/1.2913046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wright R, Bor S, Souza P. Region, gender and vowel quality: a word to the wisehearing scientist. Paper presented at the Acoustical Society of America; Honolulu, HI. 2006. [Google Scholar]
- Yonan C, Sommers M. The effects of talker familiarity on spoken word identification in younger and older listeners. Psychology and Aging. 2000;15:88–99. doi: 10.1037//0882-7974.15.1.88. [DOI] [PubMed] [Google Scholar]