

In the natural course of a day, toddlers hear a great deal of conversation about objects and events that are nowhere to be seen (e.g., “Daddy’s outside painting the fence”). This is particularly true for verbs: More than 60% of the verbs that mothers produce in conversations with their children refer to absent events, that is, to events that are not currently observable (Tomasello & Kruger, 1992). Can toddlers learn verbs from such encounters? To do so, toddlers must establish an initial representation for the verb based on its linguistic context alone. But a single encounter with a new word can offer only a rough index of its meaning (Carey & Bartlett, 1978). If toddlers are to fill in more precise aspects of meaning, they must also be able to access their initial representation, however sparse it may be, and add to or refine it when they encounter that word later, an ability known as ‘cross-situational learning’ (e.g., Blythe, Smith, & Smith, 2010; Gillette, Gleitman, Gleitman, & Lederer, 1999; Gleitman, 1990; Pinker, 1989; Siskind, 1996; Smith & Yu, 2008; Yu & Smith, 2007).
Are young word learners up to these challenges? Can they establish an initial representation of a novel verb’s meaning from its linguistic context – even absent a corresponding event – and then retrieve that representation on later encounters? The literature on verb learning suggests that they can. Two-year-olds are sensitive to correlations between a verb’s meaning and its syntactic properties (e.g., that in English, verbs occurring in transitive syntax often refer to causative events), and capitalize on these correlations to acquire meaning: If a novel verb occurs in transitive syntax, they expect it to refer to a causative event, but if it occurs in intransitive syntax, they do not (Arunachalam & Waxman, 2010; Hirsh-Pasek & Golinkoff, 1996; Naigles, 1990; Naigles & Kako, 1993; Noble, Pine, & Rowland, 2011; Yuan & Fisher, 2009).
Recent evidence reveals that even in the absence of any accompanying event, 2-year-olds hearing a novel verb in transitive syntax are able to (a) establish an initial representation for the verb based on its syntactic properties alone, and (b) retrieve this representation later when a candidate causative referent comes into view (Arunachalam & Waxman, 2010; Yuan & Fisher, 2009). In Arunachalam & Waxman, 27-month-olds first viewed scenes in which two actors were engaged in conversation, incorporating a novel verb (e.g., fezzing). The novel verb appeared in either transitive syntax (e.g., “The boy wants to fez the girl”) or intransitive syntax (e.g., “The boy and the girl want to fez”). Toddlers then viewed two dynamic scenes. In one, two actors were engaged in a causative action (e.g., boy spins girl in circles); in the other, the same two actors performed synchronous actions (e.g., boy and girl each wave one hand). Toddlers were asked to “find fezzing.” The results were clear: Toddlers who had heard conversations with transitive sentences chose the causative scene at test; those who had heard intransitive sentences did not. Strikingly, although most 27-month-olds have only recently begun to express familiar verbs consistently in syntactic constructions (e.g., Tomasello & Merriman, 1995; Tomasello, 2003), they were nonetheless able to use such constructions to establish an initial representation for a novel verb, even in the absence of a relevant visual scene, and then retrieve this representation later.
What remains to be seen, however, is whether these capacities are available to language learners even earlier. To address this issue, we focused on 21-month-olds: At this developmental juncture, although most toddlers produce some verbs, they do not yet embed them consistently in transitive or intransitive constructions (e.g., Tomasello & Merriman, 1995; Tomasello, 2003). At issue, then, is whether these toddlers can use syntactic information (e.g., transitivity) to establish initial representations of verb meaning, and whether these representations are sufficiently robust to be accessed later, when toddlers encounter the verbs again.
Some evidence exists on 21-month-olds’ abilities to use linguistic information to interpret novel verbs. First, Yuan, Messenger, and Fisher (2011) report that 21-month-olds hearing a novel verb in a sentence can count the number of participants mentioned in the sentence and match this to the number of actors they expect to see in the event (see also Brandone, Addy, Pulverman, Golinkoff, and Hirsh-Pasek, 2006). In addition, Gertner, Fisher and Eisengart (2006) document that 21-month-olds can use the word order of the sentence in which a novel verb appears as a cue to its meaning. For example, toddlers who heard “The girl is gorping the boy” preferred a scene in which a girl acted on a boy to a scene in which a boy acted on a girl.
But whether toddlers can take advantage of syntactic information alone to establish a novel verb’s meaning remains an open question. For example, if the number of participants mentioned in the sentence and their relative order are held constant, can toddlers use the syntactic positions of the named participants (in a transitive or intransitive construction) to determine a novel verb’s meaning, absent a relevant referential scene?
To address this question, we adapted Arunachalam and Waxman’s (2010) task, designed for 27-month-olds, modifying it slightly to accommodate younger toddlers. Specifically, we measured toddlers’ looking behavior rather than their pointing responses to the test query.
Looking time measures offer several distinct advantages over pointing in participants younger than 2 years of age. Not only is looking time more robust at this age (see Arunachalam and Waxman, 2011), it also allows us to determine how quickly toddlers fixate a particular scene once they hear the novel verb in the test query. Note that for cross-situational learning to be effective, it is essential that toddlers retrieve their representation of a novel word’s meaning rapidly and update it with new information as it becomes available. Interestingly, most research on how quickly children retrieve lexical representations and identify their referents has focused on familiar words (e.g., Fernald & Hurtado, 2006; Fernald, Pinto, Swingley, Weinberg, & McRoberts, 1998; Lew-Williams & Fernald, 2007; Swingley, Pinto, & Fernald, 1999). Considerably less is known about novel word processing. Moreover, most of the research that has focused on novel words has primarily studied novel nouns and not novel verbs (Booth & Waxman, 2009; Halberda, 2006; Schafer, 2006; Thorpe & Fernald, 2006; Vouloumanos & Werker, 2009). This research on novel nouns suggests that toddlers may require significantly more time to retrieve representations for novel words than familiar ones (e.g., Booth & Waxman, 2009).
Methods
Participants
Forty typically-developing toddlers (mean: 21.2 months; range: 19.0 to 23.9) were included in the final sample. All were recruited from Evanston, IL and surrounding communities, and were acquiring English as their native language, hearing other languages less than 25% of the time. Caretakers completed the MacArthur Long Form Vocabulary Checklist: Words and Sentences (Fenson et al., 1993). Toddlers’ production vocabulary ranged from 6 to 566 words; there were no significant differences in vocabulary between conditions. An additional 9 toddlers were excluded from analysis due to fussiness, and 9 due to failure to look at the screen for 50% or more of the time during the test phase on 3 or more test trials.
Materials
Our materials were identical to Arunachalam and Waxman (2010). See Table 1. Toddlers in both conditions viewed precisely the same visual scenes throughout. What varied was the syntactic context in which novel verbs were presented within the Dialogue Phase only. To begin each trial, toddlers viewed digitized video recordings of two women engaged in a dialogue which incorporated a novel verb (e.g., fezzing). Toddlers in the Transitive condition heard the novel verb in a transitive sentence; those in the Intransitive condition heard the same content words, but in intransitive sentences. Because no candidate referents of the verb were available for inspection, if toddlers were to glean information about the verb’s meaning from these dialogues, they had to do so from the syntactic information alone. Next, two test scenes were presented simultaneously. Toddlers in both conditions heard, e.g., “Where’s fezzing?” Because no syntactic information was available at test, if toddlers were to identify the verb’s referent, they had to call upon their initial representation, established earlier in the Dialogue Phase.
TABLE 1.
Stimuli from one representative trial.
| Dialogue Phase | Test Phase | ||||
|---|---|---|---|---|---|
| Observational Stream |
 |
Baseline (24 sec) | Response (24 sec) | ||
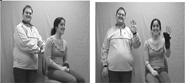 |
 |
 |
|||
| Linguistic Stream |
Transitive Condition A: Guess what? B: What? A: The lady fezzed my brother. B: Really? The lady fezzed your brother? A: And the boy is going to fez the girl. B: Oh yes. He is going to fez her. |
Intransitive Condition A: Guess what? B: What? A: The lady and my brother fezzed. B: Really? The lady and your brother fezzed? A: And the boy and the girl are going to fez. B: Oh yes. They are going to fez. |
Look! Wow! | Where’s fezzing? | Do you see fezzing? |
Apparatus and Procedure
Toddlers played freely with toys while the caregiver signed a consent form and completed the MacArthur Vocabulary Inventory. The toddler and caregiver were then invited into an adjoining room where the toddler was seated in an infant seat, 18 in from a 16 × 12 in television monitor. The caregiver sat behind the toddler and was requested not to talk or otherwise interact with the child during the session. The experimenter controlled the experimental procedure from behind a curtain. Toddlers’ looking behavior was recorded with a video camera centered above the screen.
Toddlers participated in six trials, each featuring a different verb. Two training trials involving familiar verbs (sleep and hug) were followed by six experimental trials involving novel verbs (e.g., fez). Each trial incorporated two phases: Dialogue and Test. For experimental trials, toddlers were randomly assigned to either the Transitive or Intransitive condition. Toddlers in both conditions saw the same video scenes on all trials, but heard different auditory stimuli. See Table 1. The four experimental trials were presented in one of two random orders, balanced across conditions. The left-right positions of the two types of test scene were counterbalanced across trials.
Dialogue phase
Each trial began with a scene of two women conversing, using either a known verb (on the two training trials) or a novel verb (on the four experimental trials). One training trial involved the verb “sleep,” used intransitively, and the other involved the verb “hug,” used transitively. The experimental trials varied by condition. They involved either transitive sentences, e.g., “Guess what? The boy fezzed his brother” (Transitive condition), or conjoined-subject intransitive sentences, e.g., “Guess what? The boy and his brother fezzed” (Intransitive condition). Each dialogue consisted of two six-sentence video clips, averaging 34 s, including eight mentions of the verb in different tenses and with different noun phrase arguments. Dialogue videos appeared in the center of the screen.
Test phase
Toddlers then saw the two test scenes presented simultaneously, side-by-side. On training trials, the event type was held constant across test scenes: On the sleep trial, both test scenes depicted one participant (a woman sleeping, and the same woman crying). On the hug trial, both scenes depicted two participants (a woman hugging a toy, and the same woman lifting a box). On experimental trials, both test scenes depicted the same two participants (e.g., a man and a woman), with the event type differing in each test scene: (1) a synchronous event (e.g., man and woman each wave one hand in circles), and (2) a causative event (e.g., the man spins the woman). On all four experimental trials, each test scene depicted two moving participants. Each test scene was 5 × 4.5 in. They appeared on a black background with 3 in horizontal space between them.
For both training and experimental trials, the test phase began with a 24 s inspection period, during which toddlers heard “Look! Wow!” and had an opportunity to inspect the test scenes, both of which were novel to them. The screen then went black for 1.5 s, during which time toddlers heard the test query involving the novel verb, e.g., “Where’s fezzing?” The test scenes then reappeared for 24 s, and toddlers heard: “Do you see fezzing? Find fezzing!” Toddlers’ eye gaze was recorded as they viewed the scenes. Because the novel verb appeared only in a neutral syntactic context during this test phase, any difference in eye gaze behavior in the two conditions must be due to the syntactic information presented in the dialogues, before the candidate visual scenes appeared.
Coding
A trained coder, blind to condition assignment, coded the video recordings of toddlers’ eye gaze with the sound removed. The coder identified for each frame (30 frames per second) whether the eyes were oriented to the left scene, the right scene, or neither scene (including track loss). Trials on which “neither” looks comprised over 50% of the Test Phase were excluded from the analysis (8% of all trials). A second trained coder independently coded 20% of trials; agreement was 96% (Cohen’s kappa = .95).
Predictions
If 21-month-olds are able to use the syntactic information presented in the dialogues to determine the event type described by the novel verb, then toddlers in the Transitive condition should devote more visual attention to the causative test scene than toddlers in the Intransitive condition. Recent evidence on novel noun processing in a similar paradigm suggests that toddlers’ responses will not become evident until at least 2.5 s after the novel verb’s onset (Booth & Waxman, 2009).
Results
We examined toddlers’ looks to the causative scene upon hearing the novel verb in the test query (e.g., “Where’s mooping?”). Proportions were calculated by dividing looks to causative scene by total coded looks (that is, including “neither” looks). Because we expected that toddlers would require at least 2.5 seconds to look to the verb’s referent (Booth & Waxman, 2009), we analyzed looking behavior in the first five seconds of the test period, dividing this window into two periods of 2.5 seconds each. See Figure 1. In the first 2.5 seconds after the novel verb’s onset, performance in the two conditions did not differ (mean proportion of frames on which toddlers looked to the causative scene: Transitive condition .41, Intransitive condition .40). But after about 2.5 sec, performance in the two conditions begin to diverge; from 2.5 – 5 sec from verb onset, toddlers in the Transitive condition prefer the causative scene (.57) compared to those in the Intransitive condition (.41).
FIGURE 1.

Depiction of time-course of toddlers’ looking time to the causative scene in response to the test question (e.g., “Where’s fezzing?”), depicted here from the onset of the novel verb.
To assess these patterns statistically, we first aggregated the proportion data from each time window (0 – 2.5 sec, and 2.5 – 5 sec from novel verb onset in the test query1) into 50 ms bins (Barr, 2008). Following Barr, we then transformed the proportion data using an empirical-logit function, and fit the transformed data within each time window using a multi-level linear model treating Syntactic Condition (Transitive vs. Intransitive) as a fixed effect. The beta coefficients for the models are reported in Table 2.
TABLE 2.
Fixed effects from best-fitting multi-level linear model of proportion of time spent looking at causative scene (empirical logit transformed)
| Analysis with Subject as Random Intercept | ||||
|---|---|---|---|---|
| Window | Effect | Estimate | S.E. | t-value |
| 0 – 2.5 sec | Intercept | −0.51 | 0.22 | −2.34* |
| Syntactic Condition (Trans vs. Intrans) | 0.02 | 0.31 | 0.06 | |
| 2.5 – 5 sec | Intercept | −0.48 | 0.19 | −2.56* |
| Syntactic Condition (Trans vs. Intrans) | 0.80 | 0.27 | 3.01* | |
| Analysis with Item as Random Intercept | ||||
| Window | Effect | Estimate | S.E. | t-value |
| 0 – 2.5 sec | Intercept | −0.44 | 0.20 | −2.17* |
| Syntactic Condition (Trans vs. Intrans) | 0.08 | 0.06 | 1.36 | |
| 2.5 – 5 sec | Intercept | −0.39 | 0.38 | −1.02 |
| Syntactic Condition (Trans vs. Intrans) | 0.70 | 0.07 | 10.18* | |
p < 0.05 (on normal distribution)
Note: Models reported, with Syntactic Condition as fixed effect, are significantly better fitting than models with no fixed effects, based on a chi-square test of the change in log likelihood.
The results of these analyses were straightforward. Syntactic Condition is a reliable predictor of looks to the causative scene in Window 2 but not Window 1. This effect of syntactic condition held up in analyses with either Subjects or Items as a random intercept. The effect size in Window 2 is large, Cohen’s d = 0.8.
Discussion
Even before they have mastered transitive and intransitive syntactic constructions in their own productive speech, 21-month-olds successfully and spontaneously (a) establish an initial representation of a novel transitive verb based on syntactic information alone, and (b) retrieve this initial representation, however sparse it may be, at a later point when a candidate referent event is visible. Clearly, then, 21-month-olds ‘have what it takes’ to benefit from cross-situational learning. They can glean whatever information is available about a novel verb in one encounter, and access that information in a subsequent encounter. Their initial representations for these novel verbs—formed on the basis of syntactic information alone—are clearly robust enough for later retrieval. This is a prerequisite for being able to add to these representations over multiple situations.
The results of the current experiment also contribute to our understanding of how quickly newly-learned lexical representations are retrieved from the mental lexicon. In previous work on speed of lexical retrieval of familiar words (e.g., shoe),Fernald et al. (1998) found that 2-year-olds require approximately 0.7 seconds from the onset of a familiar word to fixate the correct referent. In comparison, in the current study, toddlers required approximately 2.5 seconds.
There are several possible explanations for this relative delay in retrieval. First, an important factor in the speed of fixating a word’s referent is lexical frequency (Dahan, Magnuson, & Tanenhaus, 2001). Because the current study introduces novel words (whose lexical frequency is a total of 8 exposures), toddlers’ representations for these novel words are likely to be fragile. This leads a clear prediction: If we presented toddlers with additional exposures to the novel words, for example by doubling the number of dialogue scenes, their speed of retrieval should be faster. Second, in the current study, toddlers mapped the novel verbs to its referent for the very first time during the test phase. Again, a clear prediction arises: If some of the time toddlers required to fixate the causative scene was spent mapping the novel verb to meaning, then if we presented the novel verb again in a subsequent encounter, toddlers should require less time to fixate the referent.
Interestingly, despite the developmental decalage between noun acquisition and verb acquisition (e.g., Gentner, 1982; Gleitman, Cassidy, Papafragou, Nappa, & Trueswell, 2005; Waxman & Lidz, 2006), our results demonstrate that the time-course underlying 21-month-olds’ response to novel verbs is comparable to their responses to novel nouns (Booth & Waxman, 2009). This similarity in response time is especially compelling in the current paradigm, where the test scenes provided the first opportunity for toddlers to identify a specific referent for the verb. This suggests that even if mapping a novel verb to meaning is more difficult than mapping a novel noun, once toddlers do succeed in mapping to meaning, they form similarly robust representations that the parser can access within a few seconds, and can use these to quickly identify a referent in the observable world. Toddlers’ ability to access initial representations rapidly should serve them in good stead, especially when it comes to learning verbs. After all, the events described by most verbs, if present at all in the context of a conversation, are typically more fleeting than the concrete objects described by most nouns (Gentner, 1982; Gleitman, 1990).
Acknowledgements
We are grateful to Paul Bloom and an anonymous reviewer for helpful comments, and to Mihwa Kim for help with data collection and coding. A subset of these data was reported in the Proceedings of the 35th Annual Boston University Conference on Language Development. This research was supported by NIH-HD30410 (SRW).
Footnotes
Note that for approximately the first 1 sec of Window 1, the screen was black; the test scenes were not visible. We nevertheless included this time period in our analysis to allow for the possibility that toddlers would launch anticipatory eye movements to the location in which the relevant test scene had been during the immediately preceding inspection period (Altmann, 2004).
Contributor Information
Sudha Arunachalam, Boston University.
Emily Escovar, Northwestern University.
Melissa A. Hansen, Northwestern University
Sandra R. Waxman, Northwestern University
References
- Altmann G. Language-mediated eye movements in the absence of a visual world: The ‘blank screen’ paradigm. Cognition. 2004;93:B79–B87. doi: 10.1016/j.cognition.2004.02.005. [DOI] [PubMed] [Google Scholar]
- Arunachalam S, Waxman SR. Grammatical form and semantic context in verb learning. Language Learning and Development. 2011;7:169–184. doi: 10.1080/15475441.2011.573760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arunachalam S, Waxman SR. Meaning from syntax: Evidence from 2-year-olds. Cognition. 2010;110:442–446. doi: 10.1016/j.cognition.2009.10.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barr DJ. Analyzing ‘visual world’ eye-tracking data using multilevel logistic regression. Journal of Memory and Language. 2008;59:457–474. [Google Scholar]
- Blythe RA, Smith K, Smith AD. Learning times for large lexicons through cross-situational learning. Cognitive Science. 2010;34:620–642. doi: 10.1111/j.1551-6709.2009.01089.x. [DOI] [PubMed] [Google Scholar]
- Booth AE, Waxman SR. A horse of a different color: Specifying with precision infants� mappings of novel nouns and adjectives. Child Development. 2009;80:15–22. doi: 10.1111/j.1467-8624.2008.01242.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brandone A, Addy DA, Pulverman R, Golinkoff RM, Hirsh-Pasek K. One-for-one and two-for-two: Anticipating parallel structure between events and language. In: Bamman D, Magnitskaia T, Zaller C, editors. Proceedings of the 30th Annual Boston University Conference on Language Development; 2006. pp. 36–47. [Google Scholar]
- Carey S, Bartlett E. Acquiring a single new word. Papers and Reports on Child Language Development. 1978;15:17–29. [Google Scholar]
- Dahan D, Magnuson JS, Tanenhaus MK. Time course of frequency effects in spoken word recognition: evidence from eye movements. Cognitive Psychology. 2001;42:317–367. doi: 10.1006/cogp.2001.0750. [DOI] [PubMed] [Google Scholar]
- Fenson L, Dale PS, Reznick JS, Thal D, Bates E, Hartung J, Pethick S, Reilly JS. User’s guide and technical manual for the MacArthur Communicative Development Inventories. San Diego, CA: Singular Press; 1993. [Google Scholar]
- Fernald A, Hurtado N. Names in frames: infants interpret words in sentence frames faster than words in isolation. Developmental Science. 2006;9:F33–F40. doi: 10.1111/j.1467-7687.2006.00482.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernald A, Pinto JP, Swingley D, Weinberg A, McRoberts GW. Rapid gains in speed of verbal processing by infants in the second year. Psychological Science. 1998;9(3):228–231. [Google Scholar]
- Gentner D. Why nouns are learned before verbs: Linguistic relativity versus natural partitioning. In: Kuczaj SA II, editor. Language Development, Vol. 2: Language, Thought, and Culture. Hillsdale, NJ: Lawrence Erlbaum; 1982. pp. 301–334. [Google Scholar]
- Gertner Y, Fisher C, Eisengart J. Learning words and rules: Abstract knowledge of word order in early sentence comprehension. Cognition. 2006;17:684–691. doi: 10.1111/j.1467-9280.2006.01767.x. [DOI] [PubMed] [Google Scholar]
- Gillette J, Gleitman H, Gleitman L, Lederer A. Human simulations of vocabulary learning. Cognition. 1999;73:135–176. doi: 10.1016/s0010-0277(99)00036-0. [DOI] [PubMed] [Google Scholar]
- Gleitman LR. The structural sources of verb meanings. Language Acquisition. 1990;1:3–55. [Google Scholar]
- Gleitman LR, Cassidy K, Papafragou A, Nappa R, Trueswell JT. Hard words. Language Learning and Development. 2005;1:23–64. [Google Scholar]
- Halberda J. Is this a dax which I see before me? Use of the logical argument disjunctive syllogism supports word-learning in children and adults. Cognitive Psychology. 2006;53:310–344. doi: 10.1016/j.cogpsych.2006.04.003. [DOI] [PubMed] [Google Scholar]
- Hirsh-Pasek K, Golinkoff R. The Origins of Grammar: Evidence from Early Language Comprehension. Cambridge, MA: MIT Press; 1996. [Google Scholar]
- Lew-Williams C, Fernald A. Young children learning Spanish make rapid use of grammatical gender in spoken word recognition. Psychological Science. 2007;18:193–198. doi: 10.1111/j.1467-9280.2007.01871.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Naigles L. Children use syntax to learn verb meanings. Journal of Child Language. 1990;17:357–374. doi: 10.1017/s0305000900013817. [DOI] [PubMed] [Google Scholar]
- Naigles L, Kako ET. First contact in verb acquisition: Defining a role for syntax. Child Development. 1993;64:1665–1687. [PubMed] [Google Scholar]
- Noble CH, Rowland CF, Pine JM. Comprehension of argument structure and semantic roles: Evidence from English-learning children and the forced-choice pointing paradigm. Cognitive Science. 2011;35:963–982. doi: 10.1111/j.1551-6709.2011.01175.x. [DOI] [PubMed] [Google Scholar]
- Pinker S. Learnability and Cognition: The Acquisition of Argument Structure. Cambridge, MA: MIT Press; 1989. [Google Scholar]
- Schafer G. Infants can learn decontextualized words before their first birthday. Child Development. 2005;76:87–96. doi: 10.1111/j.1467-8624.2005.00831.x. [DOI] [PubMed] [Google Scholar]
- Siskind JM. A computational study of cross-situational techniques for learning word-to-meaning mappings. Cognition. 1996;61:1–38. doi: 10.1016/s0010-0277(96)00728-7. [DOI] [PubMed] [Google Scholar]
- Smith LB, Yu C. Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition. 2008;106:333–338. doi: 10.1016/j.cognition.2007.06.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Swingley D, Pinto JP, Fernald A. Continuous processing in word recognition at 24 months. Cognition. 1999;71:73–108. doi: 10.1016/s0010-0277(99)00021-9. [DOI] [PubMed] [Google Scholar]
- Thorpe K, Fernald A. Knowing what a novel word is not: Two-year-olds “listen through” ambiguous adjectives in fluent speech. Cognition. 2006;100:389–433. doi: 10.1016/j.cognition.2005.04.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tomasello M, Merriman WE, editors. Beyond names for things: Young children's acquisition of verbs. Hillsdale, NJ: Erlbaum; 1995. [Google Scholar]
- Tomasello M. Constructing a Language. Cambridge, MA: Harvard University Press; 2003. [Google Scholar]
- Tomasello M, Kruger AC. Joint attention on actions: Acquiring verbs in ostensive and non-ostensive contexts. Journal of Child Language. 1992;19:311–333. doi: 10.1017/s0305000900011430. [DOI] [PubMed] [Google Scholar]
- Vouloumanos A, Werker J. Infants’ learning of novel words in a stochastic environment. Developmental Psychology. 2009;45:1611–1617. doi: 10.1037/a0016134. [DOI] [PubMed] [Google Scholar]
- Waxman SR, Lidz JL. Kuhn D, Siegler R. Handbook of Child Psychology: Cognition, Perception and Language. New York, NY: Wiley; 2006. Early word learning; pp. 299–335. [Google Scholar]
- Yu C, Smith LB. Rapid word learning under uncertainty via cross-situational statistics. Psychological Science. 2007;18:414–420. doi: 10.1111/j.1467-9280.2007.01915.x. [DOI] [PubMed] [Google Scholar]
- Yuan S, Fisher C. “Really? She blicked the baby”: Two-year-olds learn combinatorial facts about verbs by listening. Psychological Science. 2009;20:619–626. doi: 10.1111/j.1467-9280.2009.02341.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan S, Messenger K, Fisher C. Syntax and selection: Learning combinatorial properties of verbs from listening; Paper presented at the Biennial Meeting of the Society for Research in Child Development; Montreal, QC: Canada; 2011. Mar, [Google Scholar]