

Abstract
Higher visual areas in the occipitotemporal cortex contain discrete regions for face processing, but it remains unclear if V1 is modulated by top-down influences during face discrimination, and if this is widespread throughout V1 or localized to retinotopic regions processing task-relevant facial features. Employing functional magnetic resonance imaging (fMRI), we mapped the cortical representation of two feature locations that modulate higher visual areas during categorical judgements – the eyes and mouth. Subjects were presented with happy and fearful faces, and we measured the fMRI signal of V1 regions processing the eyes and mouth whilst subjects engaged in gender and expression categorization tasks. In a univariate analysis, we used a region-of-interest-based general linear model approach to reveal changes in activation within these regions as a function of task. We then trained a linear pattern classifier to classify facial expression or gender on the basis of V1 data from ‘eye’ and ‘mouth’ regions, and from the remaining non-diagnostic V1 region. Using multivariate techniques, we show that V1 activity discriminates face categories both in local ‘diagnostic’ and widespread ‘non-diagnostic’ cortical subregions. This indicates that V1 might receive the processed outcome of complex facial feature analysis from other cortical (i.e. fusiform face area, occipital face area) or subcortical areas (amygdala).
Keywords: diagnostic information, fMRI, multivariate pattern classification, V1
Introduction
Previous studies have found evidence supporting the theory that substantial information is transferred from higher visual areas to V1, even outside the classical receptive field. Electrophysiological recordings in primates reveal that V1 is exposed to considerable feedback modulation (Bullier, 2001; Thiele et al., 2009; Self et al., 2012), and functional brain imaging experiments show that V1 is involved in cognitive tasks including visual spatial attention (Kanwisher & Wojciulik, 2000; Ress & Heeger, 2003; Watanabe et al., 2011), mental tracking (Kaas et al., 2010), mental imagery (Slotnick et al., 2005), visual expectation (Kastner et al., 1999) and visual working memory (Harrison & Tong, 2009). V1 neurons display responses outside the classical receptive field (Angelucci et al., 2002; Harrison et al., 2007; Muckli & Petro, 2013; Shushruth et al., 2013), and modulation in non-stimulated areas by apparent motion along the illusory path (Muckli et al., 2005) and by surrounding scene context (Smith & Muckli, 2010).
Top-down influences on early visual cortex during face processing are still relatively unexplored, although a recent study in behaving monkeys revealed that evoked neural population responses in V1 correlate with the perceptual processing of faces (Ayzenshtat et al., 2012), reported to be feedback related. This result is supported by anatomical studies showing direct feedback projections from temporal cortices, including the superior temporal sulcus (Rockland & Van Hoesen, 1994), which is involved in processing facial expressions in humans (Haxby et al., 2000). The application of multivariate statistics to activation patterns in early visual cortex uncovers rich visual information content, beyond that expected of neurons yielding small receptive fields (Kamitani & Tong, 2005, 2006; Kay et al., 2008; Miyawaki et al., 2008; Walther et al., 2009; Smith & Muckli, 2010; Meyer, 2012). Cortical feedback to early visual areas is implicated in several of these findings, and there is no reason to preclude a contribution during face processing (Ayzenshtat et al., 2012). Additional input to early visual areas may arise from amygdala neurons (Vuilleumier et al., 2004; Gschwind et al., 2012), reported to coordinate responses to biologically salient stimuli such as faces, which are thought to be primarily cortical in nature (Pessoa & Adolphs, 2011).
Using functional magnetic resonance imaging (fMRI), we investigated whether V1 is modulated by task during face processing in subregions responding to two facial features (eyes and mouth). These features task-dependently activate higher visual regions (Gosselin & Schyns, 2001; Schyns et al., 2003, 2007, 2009; Smith et al., 2004, 2005, 2008, 2009, 2012). In a univariate analysis we explored changes within these ‘eye’ and ‘mouth’ regions-of-interest (ROIs) as a function of task. We used multivariate pattern analysis (MVPA; e.g. Haynes & Rees, 2005; Kamitani & Tong, 2005, 2006; Walther et al., 2009; Smith & Muckli, 2010; Chiu et al., 2011) to determine if the remaining (‘non-diagnostic’) regions of V1 can decode expression and gender, and we compared this with the decoding performance in each of the target subregions of V1. We show that feature-specific regions of V1 engage in face discriminations in a task-specific manner, and further that the remainder of V1 also contains task-relevant information.
Materials and methods
Participants
Nine subjects (21–29 years, five males) with normal vision were screened for potential health risks. All subjects gave written, informed consent, and the experiment was approved by the local ethics committee of the College of Science and Engineering (University of Glasgow) under the project number FIMS00579. The experiment conforms to the Code of Ethics of the World Medical Association (Declaration of Helsinki).
Stimuli
The same images were used for gender and expression categorization tasks. Face stimuli were grey-scale images of five males and five females taken under standardized illumination, all displaying happy, fearful and neutral expressions. (Neutral was included to maintain a reasonable level of task difficulty, i.e. to minimize subjects performing the task using only one feature, e.g. ‘happy’ or ‘not happy’ using the wide open mouth; see also Smith et al., 2008). Stimuli were normalized for location of mouth and eyes, and comply with the Facial Action Coding System (CAFE database; Ekman & Friesen, 1978; unpublished data). Face stimuli spanned 19° × 13° of visual angle; the large size of the images was required in order to obtain clear separation in early visual cortex of the two features of interest. For retinotopic mapping of the eyes and mouth, contrast-reversing checkerboards (4 Hz) were presented in the location at which these features appeared in the face stimuli. The mouth checkerboard spanned 2.8° × 7.2°, and the eye checkerboards 2.8° × 3.6° of visual angle. The vertical distance from the bottom of the eye checkerboard to the top of the mouth checkerboard was 4.9°. The total pixel area of the mouth checkerboard was equal to the summed area of the two eye checkerboards.
We chose to map the eyes and the mouth for two reasons, one methodological and one conceptual. Firstly, we required a clear separation of features in the cortex, achievable by selecting the features with sufficient spatial distance between them. Secondly, behavioural and brain-imaging evidence have shown that eye or mouth information can be selectively extracted from the same image depending on the task. For example, gender is judged using eye information and expressive-or-not by the mouth (Gosselin & Schyns, 2001; Smith et al., 2004). Further, we used happy and fearful faces, which typically require mouth and eye information, respectively (Smith et al., 2005; Schyns et al., 2007). Thus, we had an a priori expectation that regions of the cortex representing these features may respond task dependently.
Design and procedure
Face categorization and retinotopic mapping of features
Prior to scanning, subjects briefly viewed the images to confirm that correct gender and expression classification could be performed. During the rapid event-related fMRI experiment, stimuli were generated using Presentation software (version 10.3; Neurobehavioral Systems) and presented using an MR-compatible binocular goggle system [NordicNeuroLab (NNL), Bergen, Norway; Engström et al., 2005]. Eye movements of the right eye were monitored using the NNL Eyetracking Camera, and data collected using a ViewPoint EyeTracker® by Arrington Research. The experiment consisted of presenting one of six different experimental conditions in each run – happy, neutral or fearful face, mapping of eyes or mouth, or fixation baseline. Subjects were instructed to keep fixation on the small central fixation checkerboard (subtending 0.44° × 0.46°) throughout the whole experiment. Faces were centred and normalized for location of features and illumination, and presented at a constant size and view. Face and mapping conditions were presented (randomly ordered) for 1 s, and were followed by 3 s of fixation (Fig. 1). Subjects performed 720 trials (120 per condition) split into six functional runs (each lasting approximately 8.5 min). Runs alternated between expression (three alternative forced choices) and gender categorization (two alternative forced choices) tasks. A button pad was used for response, with the same buttons being used in each task in order that differential patterns of neural activity in V1 are not attributed to motor responses. We expected happy and fearful face images to induce slightly different activation patterns in V1 due to different low-level properties (e.g. higher contrast of the eyes in ‘fear’ or the teeth in ‘happy’). To ensure that activation was not solely driven by these properties, subjects performed both expression and gender tasks on the identical images.
Fig. 1.
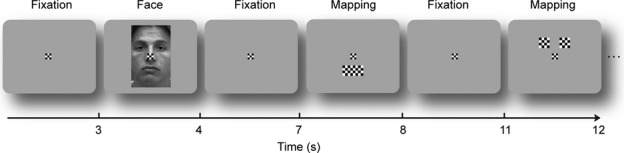
Time line of stimulus sequence.
Retinotopic mapping of early visual areas
Early visual areas were mapped using a standard phase-encoded polar angle protocol (Sereno et al., 1995) using standard parameters employed in our lab (Muckli et al., 2005, 2009; Fig. 2).
Fig. 2.
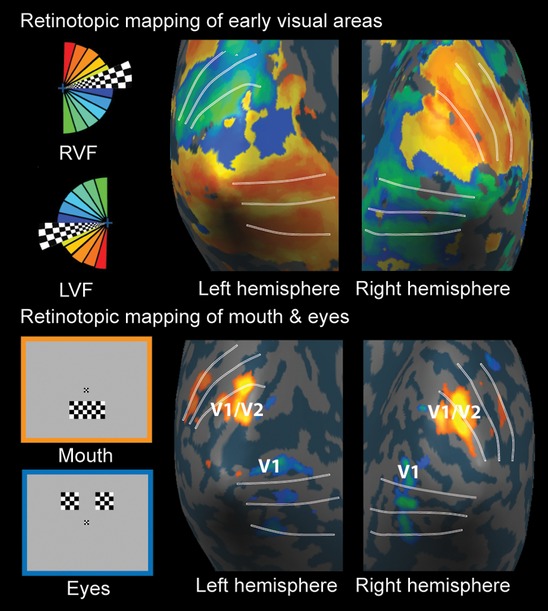
(Upper) Retinotopic mapping of early visual areas using a standard phase-encoded rotating checkerboard, shown for one subject in both hemispheres. The borders between early visual areas are indicated by white lines. (Lower) Feature mapping conditions (left) to identify regions of V1 (right) responding to the eyes (blue/green) and mouth (yellow/orange) of the same subject.
MRI procedures
Imaging
Imaging was performed at the Centre for Cognitive Neuroimaging, Glasgow, using a 3T Siemens Tim Trio MRI scanner (Siemens, Erlangen, Germany) with a 12-channel head coil. An echo planar imaging sequence was used for parallel imaging [17 slices in an oblique orientation roughly in line with the AC-PC plane (angled around the x-axis at −5° on average) to cover visual cortex; repetition time (TR), 1 s; echo time (TE), 30 ms; flip angle (FA), 62°; field of view (FOV), 210 mm; resolution isotropic voxel size 2.5 mm; and gap thickness, 10% (0.25 mm), PACE motion correction; iPAT factor 2]. In addition, T1-weighted anatomical scans were acquired for all subjects (TR, 2 s; TE, 4.38 ms; FA, 15°; FOV, 240 mm, isotropic voxel size, 1 mm3).
Data analysis
Analysis was performed using BrainVoyager software 1.10.4 (BrainInnovation, http://www.brainvoyager.com) and Matlab 2007b (Mathsworks). The first two volumes of each run were discarded due to T1 saturation effects. Standard pre-processing was as follows – slice scan time correction was performed using sync interpolation based on the TR of 1000 ms and on the ascending, interleaved order of slice scanning. Standard three-dimensional motion correction to adjust for head movements was performed as well as linear-trend removal and temporal high-pass filtering at 0.006 Hz. After alignment with the anatomical scan, all individual datasets were transformed into Talairach space (Talairach & Tournoux, 1988).
Retinotopic mapping
A cross-correlation analysis was used for the retinotopic mapping experiment. We used the predicted haemodynamic signal time course for the first 1/8th of a stimulation cycle (32 volumes/4 volumes per predictor) and shifted this reference function slowly clockwise in time (four volumes corresponding to 45° visual angle).
Cortical surface reconstruction and patch-of-interest (POI) definition
High-resolution anatomical scans were used to reconstruct surfaces of both cortical hemispheres for all nine subjects (Kriegeskorte & Goebel, 2001). Inhomogeneity correction of signal intensity was followed by segmentation of the white and grey matter border. Functional data were projected onto the inflated hemispheres allowing the borders between early visual areas to be identified (Fig. 2). Checkerboard mapping of mouth and eye regions were used to identify three POIs: (i) ‘mouth’ in V1/V2; (ii) ‘eyes’ in V1; (iii) rest-of-V1 region (V1 without mouth and eye regions). In order to create a rest-of-V1 POI that was not immediately adjacent to the eye and mouth POIs, we increased the size of the patches by lowering the threshold of eye and mouth maps, and subtracted these patches from the entire V1 patch. We ensured that the rest-of-V1 region and entire V1 regions included only vertices sampled in the main experimental runs by intersecting these functionally constrained regions with a map defined from the set of functionally responsive voxels – all faces minus baseline, threshold (P < 0.0001, corrected).
Eye movements
Data were linearly detrended per run and transformed into units of degrees of visual angle before being classified as a saccade if a succession of samples had a radius > 1.5° of visual angle for a duration of 150 ms (Weigelt et al., 2007). Mean vertical and horizontal fixation locations were compared across tasks to reveal no significant differences.
General linear model (GLM) deconvolution – univariate analysis
We used a GLM deconvolution approach (20 predictors per condition excluding baseline) to estimate blood oxygen level-dependent (BOLD) response amplitudes to faces in ‘mouth’ and ‘eye’ POIs, independently for gender and expression tasks. Differences in the beta values (parameter estimates in the GLM analysis) were tested for significance using anovas. Contrasts of mouth and eye checkerboard mapping conditions were used to define two non-overlapping ROIs in each hemisphere, in individual subjects – a ‘mouth’ region in dorsal V1/V2 and an ‘eye’ region in ventral V1. Thresholds were kept above 3.2, but were slightly adjusted individually in order to get the most optimal separation of feature regions for subjects 1–9 (S1–9) as follows: S1, t3002 > ± 3.70; S2, t3002 > ± 3.82; S3, t3002 > ± 3.61; S4, t3002 > ± 3.62; S5, t3002 > ± 3.78; S6, t3002 > ± 3.78; S7, t3002 > ± 3.29; all P < 0.0003 correcting for multiple comparisons using a false discovery rate correction of 0.01. However, for two subjects thresholds had to be lowered to t3002 > ± 2.27 (S8) and t3002 > ± 2.07 (S9) in order to obtain comparable ROIs.
MVPA
For each participant we applied a GLM to estimate single trial response amplitudes (Kay et al., 2008; Kriegeskorte et al., 2008; Smith & Muckli, 2010) for each vertex time course, independently per run and POI. The design matrix pertaining to single trial response estimation consisted of as many columns (predictors) as trials (plus one for mean confound), coding stimulus presentation. This was then convolved with a standard 2 gamma model of the haemodynamic response function. These single trial response estimates (beta weights), taken according to the corresponding subregion of V1 (see POIs i–iii above), were the input to the pattern classifier. We trained a linear pattern classifier [Support Vector Machine (SVM)], independently per participant per region of V1, to learn the mapping between a set of multivariate brain observations and the corresponding expression label (happy or fear). We then tested the ability of the classifier to generalize to an independent set of test data. Thus, we trained the classifiers with a set of single trial brain activity patterns and tested the classifiers either on independent ‘single trials’ or on the ‘average’ brain activity pattern for each expression in the independent set of test data. In order to control for the different number of vertices present within each POI, a factor that could influence classifier performance, we used a sub-sampling approach comparable to Smith & Muckli (2010). This involved randomly selecting a subset of vertices – i.e. sampling 30 times for each of several different vertex set sizes (1 : 10 : 160, giving 15 different set sizes), and building independent classifiers for each random selection of vertices at each vertex set size. To estimate the performance of our classifiers we used a leave one run out cross-validation procedure (see Kamitani & Tong, 2005; Walther et al., 2009; Smith & Muckli, 2010) – that is, the classifier was trained on n−1 runs and tested on the independent nth run (repeated for the n different possible partitions of the runs in this scheme).
To estimate the amount of task-related top-down influence, independent classifiers were constructed for trials in which the subjects were engaged in an expression classification task (explicitly doing the same classification happy/fear) or in a gender classification task (where the happy/fear classification might only be made implicitly). We report across subject average performance and use one-sample t-tests (one-tailed) to test whether average performance, for the maximal number of vertices, was significantly greater than chance (50%). The linear SVM was implemented using the LIBSVM toolbox (Chang & Lin, 2001), with default parameters (notably C = 1). Note that the beta weights of each vertex were normalized in the training data within a range of −1 to 1 prior to input to the SVM. Test data were independently normalized using the same parameters (max, min, range) as the training data.
Results
Behaviour
In alternating runs of fMRI recordings, subjects discriminated either emotional content or gender of the same 30 images (three emotions, ten identities, two genders).
Reaction time
Data contributing to behavioural analysis included eight of the nine subjects due to technical reasons. Subjects were faster to respond during the gender task than during the expression task (anova of correct trials: F1,7 = 23.6, P = 0.001). Within tasks, subjects were significantly faster to respond to happy faces than to fearful and neutral faces (F2,14 = 14.8, P = 0.0004), and equally fast to categorize female and male faces (F1,7 = 2.9, P = 0.12; Fig. 3A–C).
Fig. 3.
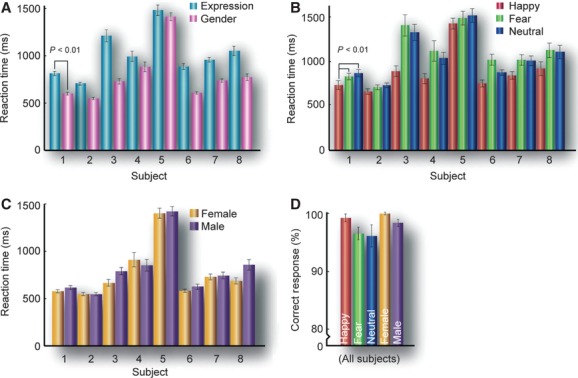
(A) Per subject average reaction times during expression (3AFC) and gender (2AFC) tasks (asterisks show significance to P < 0.01 across subjects). (B) Average reaction times to happy, fearful and neutral faces during the expression task. (C) Average reaction times to female and male faces during the gender task. (D) Categorization accuracy for happy, fearful, neutral, male and female judgements (error bars state 1 SE).
Accuracy
During fMRI scans, accuracy across subjects was 98.7, 96.0 and 95.8% for ‘happy’, ‘fear’ and ‘neutral’, respectively, in the expression task (anova: F2,14 = 1.77, P = 0.21), and 99.5% and 97.9% for females and males, respectively, in the gender task (F1,7 = 1.88, P = 0.22; Fig. 3D).
‘Mouth’ and ‘eye’ POIs – univariate analysis
We localized the cortical representation of the eyes and mouth using checkerboards covering each respective area. The contrast of checkerboard mapping conditions was used to define non-overlapping POIs in each hemisphere in individual subjects – a ‘mouth’ region in dorsal V1/V2 and an ‘eye’ region in ventral V1. From within ‘mouth’ and ‘eye’ regions we extracted the average deconvolved BOLD responses to face stimuli during both tasks. Tasks alternated between runs but the face stimuli remained identical. We subjected the beta values to three-way anovas in two different ways – firstly taking the individually adjusted peak value (between 5 and 7 s); and secondly averaging across time points 3–9 s.
Expression classification – peak time point
A three-way anova of the peak BOLD response of classification (happy/fear), task (expression/gender) and region (eyes/mouth) revealed no main effects, but a significant interaction of classification and region (F1,8 = 38.3, P = 0.0003).
Gender classification – peak time point
A three-way anova of classification (male/female), task (expression/gender) and region (eyes/mouth) revealed no main effects, but a significant interaction of classification and task (F1,8 = 8.260, P = 0.0207).
Expression classification 3–9 s
Averaging beta across time points 3–9 s, a three-way anova of classification (happy/fear), task (expression/gender) and region (eyes/mouth) revealed no main effects, but significant interactions between classification and region (F1,8 = 10.2, P = 0.01) and between task and region (F1,8 = 11.4, P = 0.009).
Gender classification 3–9 s
A three-way anova of classification (male/female), task (expression/gender) and region (eyes/mouth) revealed a significant main effect of task (F1,8 = 5.624, P = 0.04), and a significant interaction between classification and task (F1,8 = 12.1, P = 0.008).
Fixed effects
For a more detailed examination of time points, we also performed a fixed effect analysis, testing individual time points from 3 to 9 s. For this, we ran a GLM with only one predictor per stimulus condition and many confounds (one per participant per run). This revealed differential effects (over the peak of the BOLD signal) of expression (happy > fear) in the ‘mouth’ ROI when judging gender, and in the ‘eyes’ ROI when judging expression (fear > happy, over later time points; Fig. 4A). We also observed an increased response to female over male faces, only at later time points (for these effects, see asterisks in Fig. 4A; all passing a Holm–Bonferroni correction that controls for the family-wise error rate). The differences in peak beta values between happy and fearful faces, and female and male faces, in all ROIs during both tasks can be seen in Fig. 4B for individual subjects.
Fig. 4.
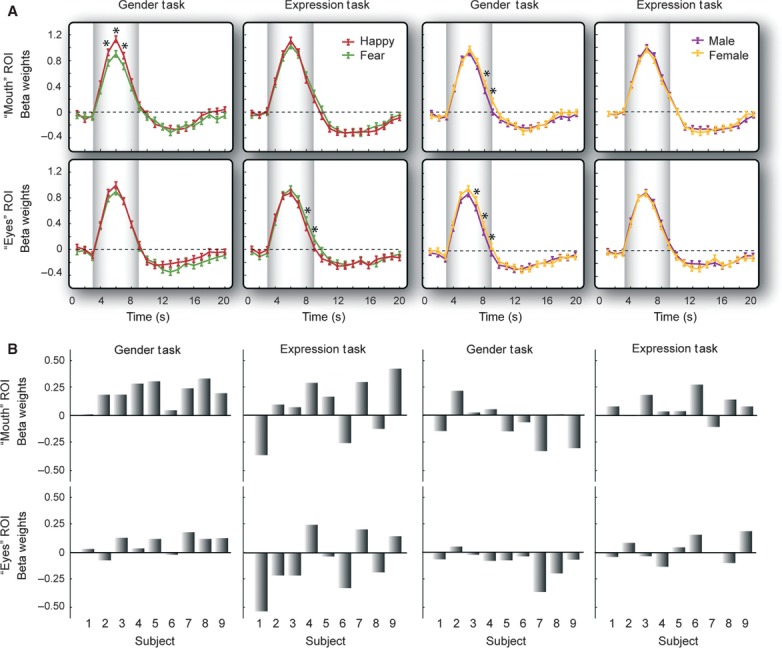
(A) Deconvolved blood oxygen level-dependent (BOLD) signal time courses to happy and fearful faces in eye and mouth patches-of-interest (POIs) during expression and gender tasks across subjects, and deconvolved BOLD signal time courses to male and female faces in eye and mouth POIs during expression and gender tasks, across subjects. Contrasts between happy and fearful faces, and between male and female faces, were tested for significance: (i) for the peak (see text); (ii) collapsed across 3–9 s (see text); and (iii) at individual time points in a general linear model (GLM) with only one predictor per stimulus condition and many confounds (one per participant per run, see asterisks, all passing a Holm–Bonferroni correction). Error bars report standard errors between subjects. (B) Individual subject data of the difference in peak beta values (happy minus fear) and (male minus female).
The deconvolution analysis allows an independent interpretation of time points, as they are estimated individually, but we did not have any a priori hypothesis about different time points and cannot draw firm conclusions from this result. Although speculative, the variance we observed in the time at which differences occurred could be indicative of additional cognitive modules, for example integrating information from a different facial location, itself related to the unfolding of top-down inputs over time. This remains to be tested.
POI-based MVPA in V1
We next addressed, with MVPA, the contribution that the remainder of V1 has in discriminating expression and gender during the two tasks, in comparison to ‘eye’ and ‘mouth’ regions. To this end, we defined a third POI, from the remainder of V1, i.e. not processing the eyes or mouth. Figure 5 and Table 1 show classifier performance as a function of the number of vertices (maximum 160) entering the analysis, when trained to discriminate either expression or gender, for each V1 subregion and task (sub-sampling was used to equate the number of vertices across different V1 subregions). By way of summary, Fig. 6 displays the classifier performance for the maximum number of vertices (arrows in Fig. 5). The classification of happy and fear was significantly above chance in the mouth (performance = 57.96%, t8 = 2.01, P = 0.04) and rest-of-V1 (performance = 67.47%, t8 = 4.25, P = 0.001) POIs during the expression task, and interestingly even when the explicit judgement was gender (performance = 64.94%, t8 = 2.86, P = 0.01 and 62.1%, t8 = 3.11, P = 0.007, in the ‘mouth’ and ‘rest-of-V1’, respectively). In contrast, the classification of gender was significantly above chance in the ‘eyes’ when the task was expression discrimination (performance = 61.79%, t8 = 2.17, P = 0.03), and in the ‘mouth’ when the task was gender discrimination (performance = 59.20%, t8 = 2.05, P = 0.04). Comparable to expression classification, gender classification was highly significant in the rest-of-V1, during both tasks (performance = 61.3%, t8 = 2.68, P = 0.01 and 65.12%, t8 = 3.68, P = 0.003, in expression and gender tasks, respectively). The classifier performance values were submitted to a three-way anova of task (expression or gender), region (eyes, mouth or rest-of-V1) and classification (expression or gender), and revealed a significant effect of region (F1,8 = 4.89, P = 0.02); overall decoding performance was higher in the rest of V1 than either of the diagnostic patches.
Fig. 5.
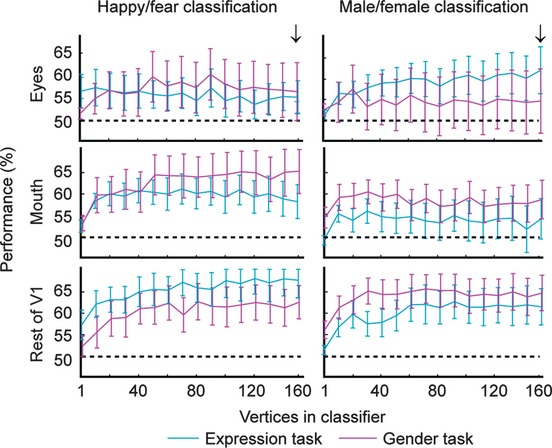
Multivariate pattern classification analysis (MVPA). Percentage performance for classifying facial expression (happy or fear, left) or gender (male, female, right) from activity patterns extracted from mouth, eye and rest of V1 patches-of-interest (POIs), during expression (blue) and gender (pink) tasks. Performance is predicted on averaged data. The arrows show performance for maximum number of voxels sampled (160). Error bars represent 1 SEM.
Table 1.
Average (upper) and single-trial (lower) classifier performance (%) in decoding either expression or gender during both tasks, within the cortical representation of the eyes, mouth and remaining V1
| Eyes (%) | Mouth (%) | Rest of V1 (%) | |
|---|---|---|---|
| Expression task | |||
| Happy/fear | 54.20, t8 = 1.410, P = 0.098 | 57.96, t8 = 2.005, P = 0.040 | 67.47, t8 = 4.253, P = 0.001 |
| 54.26, t8 = 2.050, P = 0.037 | 54.47, t8 = 2.811, P = 0.011 | 55.39, t8 = 3.998, P = 0.002 | |
| Male/female | 61.79, t8 = 2.174, P = 0.031 | 54.69, t8 = 0.999, P = 0.174 | 61.30, t8 = 2.681, P = 0.014 |
| 52.94, t8 = 2.380, P = 0.022 | 52.18, t8 = 1.451, P = 0.092 | 53.50, t8 = 2.571, P = 0.017 | |
| Happy/fear/neutral | 37.00, t8 = 0.822, P = 0.217 | 37.90, t8 = 1.286, P = 0.117 | 42.84, t8 = 3.850, P = 0.024 |
| 35.26, t8 = 1.323, P = 0.112 | 36.52, t8 = 2.297, P = 0.025 | 36.93, t8 = 6.527, P = 0.0001 | |
| Gender task | |||
| Happy/fear | 56.42, t8 = 0.950, P = 0.185 | 64.94, t8 = 2.856, P = 0.011 | 62.10, t8 = 3.106, P = 0.007 |
| 52.65, t8 = 1.848, P = 0.051 | 54.88, t8 = 2.457, P = 0.020 | 53.97, t8 = 3.355, P = 0.005 | |
| Male/female | 54.69, t8 = 0.632, P = 0.273 | 59.20, t8 = 2.046, P = 0.038 | 65.12, t8 = 3.678, P = 0.003 |
| 51.28, t8 = 0.933, P = 0.189 | 52.29, t8 = 1.804, P = 0.054 | 54.08, t8 = 4.233, P = 0.001 | |
| Happy/fear/neutral | 36.30, t8 = 0.817, P = 0.219 | 45.56, t8 = 3.462, P = 0.004 | 39.01, t8 = 2.038, P = 0.038 |
| 34.91, t8 = 1.453, P = 0.092 | 37.02, t8 = 2.947, P = 0.009 | 35.06, t8 = 2.506, P = 0.018 | |
Fig. 6.
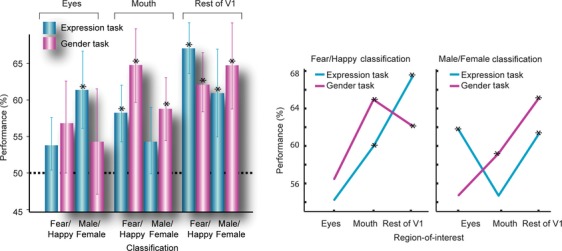
Multivariate pattern classification analysis (MVPA) shown both as a bar graph and line plot (to visualize the interaction, SEM same as bar plot, not shown). Percentage performance of MVPA classification computed on averaged data for classifying expression and gender of faces during expression and gender tasks, for the maximal number of vertices (160, see arrow in Fig. 5; asterisks reveal significance above chance of 50%, P < 0.05).
One initial motivation for the study was to investigate whether cortical regions processing the features that are most important for a specific categorization task also exhibit the greatest classification information in their activation profile. From previous behavioural research it is known that gender discrimination relies on the processing of the eyes and the detection of a happy expression on processing the smiling mouth. One could therefore expect that there is differential activation in the eye region for male/female classification especially during the gender task, and in the mouth region for happy/fear classification during the expression task. However, there is no indication in our data that supports this hypothesis (see Discussion). The pattern classifier analysis demonstrates that the rest of V1 has a significant contribution to facial expression and gender discrimination (in line with the hypothesis of distributed feedback to V1). In summary, the data show that each subregion of V1 contains important information for discriminating face categories.
Discussion
Behavioural studies have shown that facial features are extracted task-dependently, for example, eye information is typically used to diagnose gender (Gosselin & Schyns, 2001). Moreover, signals in distributed visual areas are modulated by task-dependent facial feature use, as shown using electroencephalography, magnetoencephalography and fMRI (Smith et al., 2004, 2008, 2009; Schyns et al., 2007, 2009). In light of findings showing that V1 is susceptible to higher cognitive functions and that rich stimulus information can be decoded from V1 activation profiles (Kamitani & Tong, 2005, 2006; Kay et al., 2008; Miyawaki et al., 2008; Walther et al., 2009; Smith & Muckli, 2010; Meyer, 2012; Muckli & Petro, 2013), we investigated if V1 also contains complex information about facial features, i.e. does V1 contain facial features in a task-dependent manner as higher visual areas do? Specifically, we took advantage of the retinotopic organization of V1 by spatially mapping the visual field coordinates of individual facial features into cortical coordinates. Statistically significant multivariate pattern classification was observed both within these ‘feature’ regions and also in the remaining V1 (responding to the rest of the face). To our knowledge, this is the first study to observe task effects in retinotopically discrete regions of primary visual cortex responding to facial features; however, our data do not offer a straightforward interpretation. To illustrate, we observed the following task effects – in the ‘eye’ region, gender was only decoded during the expression task and not during the gender task; and vice versa in the ‘mouth’ region. Expression, on the other hand, was only ever decoded in the ‘mouth’ region, but not in the ‘eye’ region. Lastly, to our surprise, we observed higher classification of expression and gender in the remaining V1, during both tasks.
Gender decoding in early visual areas has been hinted at in previous studies (trend toward significance; Kaul et al., 2011), and anatomical connectivity studies using diffusion tensor imaging support the notion of top-down or recurrent feedback effects via long-range fibre tracts from face areas and the amygdala to early visual cortex (directly or via the occipital face area; Gschwind et al., 2012). Given the findings of this latter study, and the task effects that we observed, we are inclined to consider our data in the context of top-down modulation by higher visual areas. Functionally, this modulation could transfer task effects in higher visual areas (Chiu et al., 2011) to V1, where the high-resolution spatial map acts as a foundation upon which top-down influences improve stimulus discriminations by targeting early stages of processing (Ahissar & Hochstein, 2002).
Our findings raise at least five questions: (i) How are task-relevant facial features available at the level of V1? (ii) How do task requirements influence V1 processing? (iii) What is the involvement of cortical or subcortical top-down effects and recurrent feedback? (iv) How do our findings relate to studies investigating top-down processing using different techniques? (v) What do our findings suggest about the spatial precision of top-down processing?
How are task-relevant facial features available at the level of V1?
Task instructions were processed at the beginning of each experimental run after verbal directions, and task effects cannot be explained by feedforward visual processing as identical images were used in both tasks. We suggest that task effects are processed in auditory, multi-modal and central executive areas, likely engaging face-sensitive areas, which may then exert top-down influences to early visual areas. To be explicit, by top-down influence we refer to how high-level categorizations task-dependently modulate internal representations (Chiu et al., 2011). In the context of our V1 data, this cognitive process could be reflected in differential baseline levels prior to stimulation, or differential activation subsequent to stimulation. We differentiate here between the cognitive term ‘top-down’ and the anatomical term ‘feedback’. By feedback we refer to recurrent neuronal input to V1 that is not projected from the lateral geniculate nucleus (i.e. extrastriate cortex, pulvinar, amygdala). We discuss below how feedback might be contributing to our data, without differentiating between task-related and non task-related feedback. Task-related (top-down) modulation may or may not be carried by recurrent feedback (i.e. be reflected in baseline activity).
How do task requirements influence V1 processing?
To our surprise, the gender task did not lead to higher classifier information in the eye region and the expression task did not enhance information in the mouth region, which could be hypothesized based on the idea of diagnostic information (Gosselin & Schyns, 2001). One possible explanation in line with the idea of diagnosticity is that features most relevant for the task are channelled through to higher areas for processing so, for the gender discrimination, the relevant eye region (Gosselin & Schyns, 2001) might be activated in recurrent loops leading to sustained activity that is not differential to male and female images (i.e. ceiling effects). The non-relevant task dimension (emotion information) might still trigger differential feedforward effects (i.e. happy faces vs. fearful faces) that can lead to differential activation patterns in the mouth region. In a predictive coding framework, it could be conceptualized that internal models for gender prototypes are recurrently processed during the gender task leading to maximal activation but no differential activation for this dimension. The non-task-relevant dimension (expression) may lead to surprise (prediction error) responses. Likewise, during an expression task, which may require more mouth information (Gosselin & Schyns, 2001), enhanced activation could reflect ceiling effects and therefore no difference in BOLD signal. This post hoc explanation may justify why the classifier performance can be better for differences in the other task than the one that is currently dominant. Our explanation of the direction of task effects is speculative and requires more specific testing.
At this point we would like to acknowledge the possible contribution of low-level features. In a recent study of face viewpoint invariance, V1 was shown to respond sensitively to low-level similarities in a study about view-invariance (Kietzmann et al., 2012), and at present we cannot entirely rule out this explanation. Low-level stimulus features, however, cannot account for the task effects as 30 identical stimuli were used in both tasks. Moreover, we and others (Williams et al., 2008) have shown in non-stimulated regions of V1, complex contextual effects independently of certain low-level features (even in non-stimulated regions of V1; Smith & Muckli, 2010).
What is the involvement of cortical or subcortical top-down effects and recurrent feedback?
Task-dependent top-down modulation to V1 can arise from cortical and subcortical areas directly or indirectly connected to V1. This could occur prior to stimulus processing (baseline activity) or in response to stimulus processing (including recurrent feedback). Candidate regions are likely to be recurrently connected to V1 (Felleman & Van Essen, 1991; Clavagnier et al., 2005), but we cannot differentiate between top-down modulation and recurrent feedback.
In the case of expression categorization, input to V1 might be relayed through the subcortical superior colliculus–pulvinar–amaygdala pathway (Vuilleumier et al., 2004; see Pessoa & Adolphs, 2011 for review). Electrophysiology has shown that the monkey pulvinar responds to facial expression (Maior et al., 2010). The pulvinar is known to gate activity to V1 (Purushothaman et al., 2012). The human amygdala has been shown to respond to faces and face parts (Rutishauser et al., 2011). In the macaque, input to V1 from the amygdala has been shown to originate from the basal nucleus (Freese & Amaral, 2005).
Studies of prosopagnosia (Rossion, 2008) suggest a direct pathway from early visual areas to the right fusiform face area. As mentioned, diffusion tensor imaging studies suggest connectivity between the early visual areas and the occipital face area (Gschwind et al., 2012). Whether or not these connections are recurrent and extend to V1, and what functional role they may play remains an interesting question. Recurrent feedback connections from temporal areas may guide face-selective occipital areas to extract fine-grained features (Gauthier et al., 2000; Rossion et al., 2003), which could logically include V1 given that it contains high spatial resolution information. Although it remains to be tested, it is conceivable that features are extracted in higher cortical or subcortical areas (which are specialized for face processing) and sent back to V1 where they contribute to the V1 BOLD signal, which is especially susceptible to feedback (Muckli, 2010; Schmidt et al., 2011; Watanabe et al., 2011; Cardoso et al., 2012).
How do our findings relate to studies investigating top-down processing using different techniques?
Inactivation studies using transcranial magnetic stimulation (TMS) in humans (de Graaf et al., 2012) or cortical cooling in animal experiments (Schmidt et al., 2011) might be able to provide further details about the nature of top-down influences to the processing of complex information in V1. Face information and grating information are similarly affected by TMS pulses between 50 and 100 ms after stimulus onset, indicating recurrent processing in the visual cortex during the first 100 ms. For face images, this TMS interference remains noticeable for longer integrating windows (110–130 ms), indicating longer recurrent processing of face information relative to grating information.
A recent study in behaving monkeys using voltage-sensitive dye imaging demonstrated a biphasic response profile in V1, the second phase corresponding to high-level perceptual processing of the face stimulus, achieved via feedback activation of the primary visual cortex (Ayzenshtat et al., 2012). The temporal resolution granted by fMRI does not allow us to draw the same conclusions as this study. However, it is feasible that we are observing task effects due to a secondary temporal response profile in V1 carried by feedback (subsequent to activation in higher face-selective cortex).
What do our findings suggest about the spatial precision of top-down processing?
Activation profiles of localized subregions of V1 can provide valuable information about the nature of top-down influences, as this activation might either enhance the processing of local (e.g. eyes or mouth), global (head shape) or distributed diagnostic features (Miellet et al., 2011). We found evidence supporting globally distributed information across V1, and in a task-dependent manner. Distributed feedback might enhance categorization mechanisms (i.e. by sharpening cortical representations; Hohwy, 2012; Kok et al., 2012), change global filter properties (i.e. spatial frequency) or provide contextual information (i.e. relevant for predictive coding; Bar, 2007; Peelen et al., 2009; Clark, 2012; Muckli et al., 2013). In line with our data, neuroanatomically, feedback is believed to be spatially spread; in higher cortical regions neurons have larger receptive fields and feedback from higher cortical areas is believed to have the same divergent spread as the feedforward connections are convergent (Salin & Bullier, 1995; Cavanaugh et al., 2002; Wandell & Smirnakis, 2009). Some of our own previous results support the idea that top-down influences can spread and fan-out to various non-stimulated regions of V1 (Muckli et al., 2005; Smith & Muckli, 2010; see also Williams et al., 2008; Muckli & Petro, 2013). Classifier performance is highest in the rest of V1, whereas behavioural studies have shown that it is harder to judge expression or gender without eye or mouth information (Gosselin & Schyns, 2001). We believe that the pattern of decoding observed in the rest of V1, which is highly suggestive of a task interaction, is indicative of top-down or recurrent feedback effects that may spread over a greater surface area of the cortex. However, future studies will be necessary to fully understand the complex interplay of top-down and recurrent feedback effects together with bottom-up stimulus processing in the rest of the V1 region.
In conclusion, V1 processes complex face-related information both within and outside the feedforward regions that process diagnostic information. Although the precise function of this top-down modulation remains unknown, we take this as evidence that information is back-projected in a task-related and spatially distributed manner to a larger region of V1 during face processing than the small diagnostic regions that may be driving higher visual areas. We hypothesize that the task-related activation profiles detected in V1 arise from higher visual face-selective cortical areas, with likely subcortical contributions arising from reciprocal connections to the amygdala. Investigating activation with high temporal resolution in functionally defined higher visual areas and subcortical structures concurrently with early visual areas would be a compelling future extension to this work (demanding high temporal resolution fMRI in humans or non-human primate electrophysiological recordings), and central to increasing our understanding of visual information processing in general.
Acknowledgments
The authors thank Frances Crabbe for her help in acquiring the MRI data, and Andrew Morgan for comments. This work was supported by an Economic and Social Research Council grant to L.S.P. (grant number PTA-031-2006-00386), an Economic and Social Research Council grant to P.G.S. (grant number R000237901), a Biotechnology and Biological Sciences Research Council grant to L.M. (grant number BB/005044/1), and a European Research Council Starting Grant to L.M. (ERC StG 2012_311751).
Glossary
- BOLD
blood oxygen level-dependent
- FA
flip angle
- fMRI
functional magnetic resonance imaging
- FOV
field of view
- GLM
general linear model
- MVPA
multivariate pattern analysis
- POI
patch-of-interest
- ROI
region-of-interest
- SVM
Support Vector Machine
- TE
echo time
- TMS
transcranial magnetic stimulation
- TR
repetition time
References
- Ahissar M, Hochstein S. View from the top: hierarchies and reverse hierarchies in the visual system. Neuron. 2002;36:791–804. doi: 10.1016/s0896-6273(02)01091-7. [DOI] [PubMed] [Google Scholar]
- Angelucci A, Levitt JB, Walton EJ, Hupe JM, Bullier J, Lund JS. Circuits for local and global signal integration in primary visual cortex. J. Neurosci. 2002;22:8633–8646. doi: 10.1523/JNEUROSCI.22-19-08633.2002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ayzenshtat I, Gilad A, Zweig S, Slovin H. Populations' response to natural images in the primary visual cortex encodes basic attributes and perceptual processing. J. Neurosci. 2012;3:13971–13986. doi: 10.1523/JNEUROSCI.1596-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bar M. The proactive brain: using analogies and associations to generate predictions. Trends. Cogn. Sci. 2007;11:280–289. doi: 10.1016/j.tics.2007.05.005. [DOI] [PubMed] [Google Scholar]
- Bullier J. Integrated model of visual processing. Brain Res. Rev. 2001;36:96–107. doi: 10.1016/s0165-0173(01)00085-6. [DOI] [PubMed] [Google Scholar]
- Cardoso MM, Sirotin YB, Lima B, Glushenkova E, Das A. The neuroimaging signal is a linear sum of neurally distinct stimulus- and task-related components. Nat. Neurosci. 2012;15:1298–1306. doi: 10.1038/nn.3170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanaugh JR, Bair W, Movshon JA. Selectivity and spatial distribution of signals from the receptive field surround in macaque V1 neurons. J. Neurophysiol. 2002;88:2547–2556. doi: 10.1152/jn.00693.2001. [DOI] [PubMed] [Google Scholar]
- Chang CC, Lin CJ. 2001. LIBSVM: a library for support vector machines. Available http://www.csie.ntu.edu.tw/
- Chiu Y-C, Esterman M, Han Y, Rosen H, Yantis S. Decoding task-based attentional modulation during face categorization. J. Cognitive Neurosci. 2011;23:1198–1204. doi: 10.1162/jocn.2010.21503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clark A. Whatever next? Predictive brains, situated agents and the future. Behav. Brain Sci. 2012 doi: 10.1017/S0140525X12000477. in press. [DOI] [PubMed] [Google Scholar]
- Clavagnier S, Falschier A, Kennedy H. Long-distance feedback projections to area V1: Implications for multisensory integration, spatial awareness, and visual consciousness. Cogn. Affect. Behav. Neurosci. 2004;4:117–126. doi: 10.3758/cabn.4.2.117. [DOI] [PubMed] [Google Scholar]
- Ekman P, Friesen WV. Facial Action Coding System: A Technique for the Measurement of Facial Movement. Palo Alto, CA: Consulting Psychologists Press; 1978. [Google Scholar]
- Engström M, Ragnehed M, Lundberg P. Projection screen or video goggles as stimulus modality in functional magnetic resonance imaging. Magn. Reson. Imaging. 2005;23:695–699. doi: 10.1016/j.mri.2005.04.006. [DOI] [PubMed] [Google Scholar]
- Felleman DJ, Van Essen DC. Distributed hierarchical processing in the primate cerebral cortex. Cereb. Cortex. 1991;1:1–47. doi: 10.1093/cercor/1.1.1-a. [DOI] [PubMed] [Google Scholar]
- Freese JL, Amaral DG. The organization of projections from the amygdala to visual cortical areas TE and V1 in the macaque monkey. J. Comp. Neurol. 2005;13:295–317. doi: 10.1002/cne.20520. [DOI] [PubMed] [Google Scholar]
- Gauthier I, Tarr MJ, Moylan J, Skudlarski P, Gore JC, Anderson AW. The fusiform ‘face area’ is part of a network that processes faces at the individual level. J. Cognitive Neurosci. 2000;12:495–504. doi: 10.1162/089892900562165. [DOI] [PubMed] [Google Scholar]
- Gosselin F, Schyns PG. Bubbles: a technique to reveal the use of information in recognition tasks. Vision Res. 2001;41:2261–2271. doi: 10.1016/s0042-6989(01)00097-9. [DOI] [PubMed] [Google Scholar]
- de Graaf TA, Goebel R, Sack AT. Feedforward and quick recurrent processes in early visual cortex revealed by TMS? Neuroimage. 2012;61:651–659. doi: 10.1016/j.neuroimage.2011.10.020. [DOI] [PubMed] [Google Scholar]
- Gschwind M, Pourtois G, Schwartz S, Van De Ville D, Vuilleumier P. White-matter connectivity between face-responsive regions in the human brain. Cereb. Cortex. 2012;22:1564–1576. doi: 10.1093/cercor/bhr226. [DOI] [PubMed] [Google Scholar]
- Harrison SA, Tong F. Decoding reveals the contents of visual working memory in early visual areas. Nature. 2009;458:632–635. doi: 10.1038/nature07832. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harrison LM, Stephan KE, Rees G, Friston KJ. Extra-classical receptive field effects measured in striate cortex with fMRI. Neuroimage. 2007;34:1199–1208. doi: 10.1016/j.neuroimage.2006.10.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haxby JV, Hoffman EA, Gobbini MI. The distributed human neural system for face perception. Trends. Cogn. Sci. 2000;4:223–233. doi: 10.1016/s1364-6613(00)01482-0. [DOI] [PubMed] [Google Scholar]
- Haynes JD, Rees G. Predicting the orientation of invisible stimuli from activity in human primary visual cortex. Nat. Neurosci. 2005;8:686–691. doi: 10.1038/nn1445. [DOI] [PubMed] [Google Scholar]
- Hohwy J. Attention and conscious perception in the hypothesis testing brain. Front. Psychol. 2012;3:96. doi: 10.3389/fpsyg.2012.00096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaas A, Weigelt S, Roebroeck A, Kohler A, Muckli L. Imagery of a moving object: the role of the occipital cortex and human MT/V5+ Neuroimage. 2010;49:794–804. doi: 10.1016/j.neuroimage.2009.07.055. [DOI] [PubMed] [Google Scholar]
- Kamitani Y, Tong F. Decoding the visual and subjective contents of the human brain. Nat. Neurosci. 2005;8:679–685. doi: 10.1038/nn1444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kamitani Y, Tong F. Decoding seen and attended motion directions from activity in the human visual cortex. Curr. Biol. 2006;16:1096–1102. doi: 10.1016/j.cub.2006.04.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kanwisher N, Wojciulik E. Visual attention: insights from brain imaging. Nat. Rev. Neurosci. 2000;1:91–100. doi: 10.1038/35039043. [DOI] [PubMed] [Google Scholar]
- Kastner S, Pinsk MA, De Weerd P, Desimone R, Ungerleider LG. Increased activity in human visual cortex during directed attention in the absence of visual stimulation. Neuron. 1999;22:751–761. doi: 10.1016/s0896-6273(00)80734-5. [DOI] [PubMed] [Google Scholar]
- Kaul C, Rees G, Ishai A. The gender of face stimuli is represented in multiple regions in the human brain. Front. Hum. Neurosci. 2011;4:1–12. doi: 10.3389/fnhum.2010.00238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kay KN, Naselaris T, Prenger RJ, Gallant JL. Identifying natural images from human brain activity. Nature. 2008;452:352–355. doi: 10.1038/nature06713. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kietzmann TC, Swisher J, König P, Tong F. Prevalence of selectivity for mirror-symmetric views of faces in the ventral and dorsal visual pathways. J. Neurosci. 2012;32:11763–11772. doi: 10.1523/JNEUROSCI.0126-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kok P, Jehee JF, de Lange FP. Less is more: expectation sharpens representations in the primary visual cortex. Neuron. 2012;75:265–270. doi: 10.1016/j.neuron.2012.04.034. [DOI] [PubMed] [Google Scholar]
- Kriegeskorte N, Goebel R. An efficient algorithm for topographically correct segmentation of the cortical sheet in anatomical mr volumes. Neuroimage. 2001;14:329–346. doi: 10.1006/nimg.2001.0831. [DOI] [PubMed] [Google Scholar]
- Kriegeskorte N, Mur M, Ruff DA, Kiani R, Bodurka J, Esteky H, Tanaka K, Bandettini PA. Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron. 2008;60:1126–1141. doi: 10.1016/j.neuron.2008.10.043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maior RS, Hori E, Tomaz C, Ono T, Nishijo H. The monkey pulvinar neurons differentially respond to emotional expressions of human faces. Behav. Brain Res. 2010;215:129–135. doi: 10.1016/j.bbr.2010.07.009. [DOI] [PubMed] [Google Scholar]
- Meyer K. Another remembered present. Science. 2012;335:415–416. doi: 10.1126/science.1214652. [DOI] [PubMed] [Google Scholar]
- Miellet S, Caldara R, Schyns PG. Local Jekyll and global Hyde: the dual identity of face identification. Psych. Sci. 2011;22:1518–1526. doi: 10.1177/0956797611424290. [DOI] [PubMed] [Google Scholar]
- Miyawaki Y, Uchida H, Yamashita O, Sato M, Morito Y, Tanabe HC, Sadato N, Kamitani Y. Visual image reconstruction from human brain activity using a combination of multiscale local image decoders. Neuron. 2008;60:915–929. doi: 10.1016/j.neuron.2008.11.004. [DOI] [PubMed] [Google Scholar]
- Muckli L. What are we missing here? Brain imaging evidence for higher cognitive functions in primary visual cortex V1. Int. J. Imag. Syst. Tech. 2010;20:131–139. [Google Scholar]
- Muckli L, Petro LS. Network interactions: non-geniculate input to V1. Curr. Opin. Neurobiol. 2013 doi: 10.1016/j.conb.2013.01.020. in press. [DOI] [PubMed] [Google Scholar]
- Muckli L, Kohler A, Kriegeskorte N, Singer W. Primary visual cortex activity along the apparent-motion trace reflects illusory perception. PLoS Biol. 2005;3:1501–1510. doi: 10.1371/journal.pbio.0030265. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muckli L, Naumer MJ, Singer W. Bilateral visual field maps in a patient with only one hemisphere. Proc. Natl. Acad. Sci. USA. 2009;106:13034–13039. doi: 10.1073/pnas.0809688106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muckli L, Petro LS, Smith FW. Backwards is the way forward. Behav. Brain Sci. 2013 doi: 10.1017/S0140525X12002361. in press. [DOI] [PubMed] [Google Scholar]
- Peelen MV, Fei-Fei L, Kastner S. Neural mechanisms of rapid natural scene categorization in human visual cortex. Nature. 2009;460:9497. doi: 10.1038/nature08103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pessoa L, Adolphs R. Emotion and the brain: multiple roads are better than one. Nat. Rev. Neurosci. 2011;12:425. [Google Scholar]
- Purushothaman G, Marion R, Li K, Casagrande VA. Gating and control of primary visual cortex by pulvinar. Nat. Neurosci. 2012;15:905–912. doi: 10.1038/nn.3106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ress D, Heeger DJ. Neuronal correlates of perception in early visual cortex. Nat. Neurosci. 2003;6:414–420. doi: 10.1038/nn1024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rockland KS, Van Hoesen GW. Direct temporal-occipital feedback connections to striate cortex (V1) in the macaque monkey. Cereb. Cortex. 1994;4:300–313. doi: 10.1093/cercor/4.3.300. [DOI] [PubMed] [Google Scholar]
- Rossion B. Constraining the cortical face network by neuroimaging studies of acquired prosopagnosia. Neuroimage. 2008;40:423–426. doi: 10.1016/j.neuroimage.2007.10.047. [DOI] [PubMed] [Google Scholar]
- Rossion B, Caldara R, Seighier M, Schuller AM, Lazeyras F, Mayer E. A network of occipito-temporal face sensitive areas besides the right middle fusiform gyrus is necessary for normal face processing. Brain. 2003;116:2381–2395. doi: 10.1093/brain/awg241. [DOI] [PubMed] [Google Scholar]
- Rutishauser U, Tudusciuc O, Neumann D, Mamelak A, Heller C, Ross I, Philpott L, Sutherling W, Adolphs R. Single-unit responses selective for whole faces in the human amygdala. Curr. Biol. 2011;21:1654–1660. doi: 10.1016/j.cub.2011.08.035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Salin PA, Bullier J. Corticocortical connections in the visual system: structure and function. Physiol. Rev. 1995;75:107–154. doi: 10.1152/physrev.1995.75.1.107. [DOI] [PubMed] [Google Scholar]
- Schmidt KE, Lomber SG, Payne BR, Galuske RA. Pattern motion representation in primary visual cortex is mediated by transcortical feedback. Neuroimage. 2011;54:474–484. doi: 10.1016/j.neuroimage.2010.08.017. [DOI] [PubMed] [Google Scholar]
- Schyns PG, Jentzsch I, Johnson M, Schweinberger SR, Gosselin F. A principled method for determining the functionality of ERP components. NeuroReport. 2003;14:1665–1669. doi: 10.1097/00001756-200309150-00002. [DOI] [PubMed] [Google Scholar]
- Schyns PG, Petro LS, Smith ML. Dynamics of visual information integration in the brain for categorizing facial expressions. Curr. Biol. 2007;17:1580–1585. doi: 10.1016/j.cub.2007.08.048. [DOI] [PubMed] [Google Scholar]
- Schyns PG, Petro LS, Smith ML. Transmission of facial expressions of emotion co-evolved with their efficient decoding in the brain: behavioural and brain evidence. PLoS ONE. 2009;4:e5625. doi: 10.1371/journal.pone.0005625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Self MW, Kooijmans RN, Supèr H, Lamme VA, Roelfsema PR. Different glutamate receptors convey feedforward and recurrent processing in macaque V1. Proc. Natl. Acad. Sci. USA. 2012;109:11031–11036. doi: 10.1073/pnas.1119527109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sereno MI, Dale AM, Reppas JB, Kwong KK, Belliveau JW, Brady TJ, Rosen BR, Tootell RBH. Borders of multiple visual areas in humans revealed by functional magnetic resonance imaging. Science. 1995;268:889–893. doi: 10.1126/science.7754376. [DOI] [PubMed] [Google Scholar]
- Shushruth S, Nurminen L, Bijanzadeh M, Ichida JM, Vanni S, Angelucci A. Different orientation tuning of near- and far-surround suppression in macaque primary visual cortex mirrors their tuning in human perception. J. Neurosci. 2013;33:106–119. doi: 10.1523/JNEUROSCI.2518-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Slotnick SD, Thompson WL, Kosslyn SM. Visual mental imagery induces retinotopically organized activation of early visual areas. Cereb. Cortex. 2005;15:1570–1583. doi: 10.1093/cercor/bhi035. [DOI] [PubMed] [Google Scholar]
- Smith FW, Muckli L. Nonstimulated early visual areas carry information about surrounding context. Proc. Natl. Acad. Sci. USA. 2010;16:20099–20103. doi: 10.1073/pnas.1000233107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith FW, Muckli L, Brennan D, Pernet C, Smith ML, Belin P, Gosselin F, Hadley DM, Cavanagh J, Schyns PG. Classification images reveal the information sensitivity of brain voxels in fMRI. Neuroimage. 2008;40:1643–1654. doi: 10.1016/j.neuroimage.2008.01.029. [DOI] [PubMed] [Google Scholar]
- Smith ML, Gosselin F, Schyns PG. Receptive fields for flexible face categorizations. Psychol. Sci. 2004;15:753–761. doi: 10.1111/j.0956-7976.2004.00752.x. [DOI] [PubMed] [Google Scholar]
- Smith ML, Cottrell GW, Gosselin F, Schyns PG. Transmitting and decoding facial expressions. Psychol. Sci. 2005;16:184–189. doi: 10.1111/j.0956-7976.2005.00801.x. [DOI] [PubMed] [Google Scholar]
- Smith ML, Fries P, Gosselin F, Goebel R, Schyns PG. Inverse mapping the neuronal substrates of face categorizations. Cereb. Cortex. 2009;19:2428–2438. doi: 10.1093/cercor/bhn257. [DOI] [PubMed] [Google Scholar]
- Smith ML, Gosselin F, Schyns PG. Measuring internal representations from behavioral and brain data. Curr. Biol. 2012;22:191–196. doi: 10.1016/j.cub.2011.11.061. [DOI] [PubMed] [Google Scholar]
- Talairach J, Tournoux P. Co-Planar Stereotaxic Atlas of the Human Brain. Stuttgart: Thieme; 1988. [Google Scholar]
- Thiele A, Pooresmaeili A, Delicato LS, Herrero JL, Roelfsema PR. Additive effects of attention and stimulus contrast in primary visual cortex. Cereb. Cortex. 2009;19:2970–2981. doi: 10.1093/cercor/bhp070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vuilleumier P, Richardson MP, Armony JL, Driver J, Dolan RJ. Distant influences of amygdala lesion on visual cortical activation during emotional face processing. Nat. Neurosci. 2004;7:1271–1278. doi: 10.1038/nn1341. [DOI] [PubMed] [Google Scholar]
- Walther DB, Caddigan E, Fei-Fei L, Beck DM. Natural scene categories revealed in distributed patterns of activity in the human brain. J. Neurosci. 2009;29:10573–11058. doi: 10.1523/JNEUROSCI.0559-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wandell BA, Smirnakis SM. Plasticity and stability of visual field maps in adult primary visual cortex. Nat. Rev. Neurosci. 2009;10:873–884. doi: 10.1038/nrn2741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watanabe M, Cheng K, Murayama Y, Ueno K, Asamizuya T, Tanaka K, Logothetis N. Attention but not awareness modulates the BOLD signal in the human V1 during binocular suppression. Science. 2011;334:829–831. doi: 10.1126/science.1203161. [DOI] [PubMed] [Google Scholar]
- Weigelt S, Kourtzi Z, Kohler A, Singer W, Muckli L. The cortical representation of objects rotating in depth. J. Neurosci. 2007;27:3864–3874. doi: 10.1523/JNEUROSCI.0340-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams MA, Baker CI, Op de Beeck HP, Shim WM, Dang S, Triantafyllou C, Kanwisher N. Feedback of visual object information to foveal retinotopic cortex. Nat. Neurosci. 2008;11:1439–1445. doi: 10.1038/nn.2218. [DOI] [PMC free article] [PubMed] [Google Scholar]