

Abstract
Reference frames are important for understanding sensory processing in the cortex. Previous work showed that vestibular heading signals in the ventral intraparietal area (VIP) are represented in body-centered coordinates. In contrast, vestibular heading tuning in the medial superior temporal area (MSTd) is approximately head centered. We considered the hypothesis that visual heading signals (from optic flow) in VIP might also be transformed into a body-centered representation, unlike visual heading tuning in MSTd, which is approximately eye centered. We distinguished among eye-centered, head-centered, and body-centered spatial reference frames by systematically varying both eye and head positions while rhesus monkeys viewed optic flow stimuli depicting various headings. We found that heading tuning of VIP neurons based on optic flow generally shifted with eye position, indicating an eye-centered spatial reference frame. This is similar to the representation of visual heading signals in MSTd, but contrasts sharply with the body-centered representation of vestibular heading signals in VIP. These findings demonstrate a clear dissociation between the spatial reference frames of visual and vestibular signals in VIP, and emphasize that frames of reference for neurons in parietal cortex can depend on the type of sensory stimulation.
Introduction
Visual and vestibular signals provide critical spatial information about the environment and our self-motion as we navigate through the world. Extensive convergence of visual signals related to optic flow and vestibular signals related to self-translation occurs in both the dorsal medial superior temporal area (MSTd; Gu et al., 2006, 2008, 2012; Fetsch et al., 2007, 2009, 2010, 2012; Chen et al., 2008; Yang et al., 2011) and the ventral intraparietal area (VIP; Bremmer et al., 2002a,b, 2005, 2011; Schlack et al., 2002; Chen et al., 2011b, 2013a). One key step in understanding this integration is to investigate the spatial reference frames (i.e., eye, head, body, or even world centered) in which these signals are represented in the cortex (Deneve et al., 2001; Maier and Groh, 2009; Crawford et al., 2011). Visual signals originate from the retina and are thus initially coded in an eye-centered reference frame, whereas translational vestibular signals originate from the otolith organs and are initially coded in a head-centered frame. Heading signals carried by multisensory neurons in area MSTd are only modestly shifted from these native reference frames: MSTd neurons signal heading from optic flow in a nearly eye-centered reference frame, whereas they convey vestibular heading signals in a reference frame that is intermediate between eye and head centered (Fetsch et al., 2007).
In contrast to the eye-centered visual receptive fields (RFs; Lee et al., 2011) and optic flow tuning (Fetsch et al., 2007) observed in MSTd, Duhamel et al. (1997) and Avillac et al. (2005) reported that the visual RFs of VIP neurons are organized along a continuum from eye- to head-centered reference frames. By varying both the position of the eyes relative to the head and the position of the head relative to the body, Chen et al. (2013b) found that vestibular heading tuning of VIP neurons remains invariant in a body-centered reference frame. Because head position relative to the body was not manipulated in the experiments by Duhamel et al. (1997) and Avillac et al. (2005), head- and body-centered reference frames could not be dissociated. Thus, it is possible that visual heading signals in VIP are also represented in a body-centered (or world-centered) reference frame, as hypothesized in a number of recent human studies (Bolognini and Maravita, 2007; Azañón et al., 2010; Klemen and Chambers, 2012; McCollum et al., 2012; Renzi et al., 2013). Under this hypothesis, visual and vestibular heading signals would be expressed in similar reference frames in VIP, at least for a portion of the neurons.
We tested this hypothesis by measuring heading tuning from optic flow in VIP, while systematically manipulating both eye position relative to the head and head position relative to the body. Inconsistent with the above hypothesis, we found that visual heading tuning in VIP is expressed in an eye-centered, rather than a head- or body-centered, reference frame. Thus, our results demonstrate that visual and vestibular heading signals are expressed in widely disparate spatial reference frames in VIP.
Materials and Methods
Subjects and experimental protocols
Extracellular recordings were made from four hemispheres in two male rhesus monkeys (Macaca mulatta), weighing 7–10 kg. The methods for surgical preparation, training, and electrophysiological recordings have been described in detail in previous publications (Gu et al., 2006; Fetsch et al., 2007; Takahashi et al., 2007; Chen et al., 2013a). Briefly, the monkeys were chronically implanted, under sterile conditions, with a circular Delrin ring for head stabilization, as well as two scleral search coils for measuring binocular eye position. Behavioral training was accomplished using standard operant conditioning procedures. All procedures were approved by the Institutional Animal Care and Use Committee at Washington University in St. Louis (St. Louis, MO) and were in accordance with National Institutes of Health guidelines.
During experiments, the monkey was seated comfortably in a primate chair, which was secured to a 6 df motion platform (6DOF2000E, MOOG). Computer-generated visual stimuli were rear projected (Mirage 2000, Christie Digital) onto a tangent screen placed 30 cm in front of the monkey (subtending 90° of visual angle). Visual stimuli simulated self-motion through a 3D random dot field that was 100 cm wide, 100 cm tall, and 40 cm deep. The sides and top of the coil frame were covered with black enclosures such that the monkey's field of view was restricted to the tangent screen mounted on the front of the field coil frame. Visual stimuli were programmed using the OpenGL graphics library and generated using an OpenGL accelerator board (Quadro FX 3000G, PNY Technologies; for details, see Gu et al. (2006)). The projector, screen, and magnetic field coil frame were mounted on the platform and moved together with the monkey. Image resolution was 1280 × 1024 pixels, and the refresh rate was 60 Hz. Dot density was 0.01/cm3, with each dot rendered as a 0.15 × 0.15 cm triangle. Visual stimuli were viewed binocularly at zero disparity (i.e., no stereo depth cues).
Ten headings within the horizontal plane were simulated (0°, 45°, 70°, 90°, 110°, 135°, 180°, 225°, 270°, and 315°, where 90° indicates straight forward), which included the four cardinal and four oblique directions, plus two additional headings (20° to the left and right of straight ahead). Simulated translation of the monkey followed a Gaussian velocity profile with the following parameters: duration, 1 s; displacement, 13 cm; peak acceleration, 0.1 G (0.98 m/s2); peak velocity, 0.30 m/s.
The head-restraint ring was attached, at three points, to a collar that was embedded within a thick plastic plate (for details, see Chen et al., 2013b). When a stop pin was removed, the collar could rotate, on ball bearings, within the plane of the plate on top of the chair. This allowed the head to rotate freely in the horizontal plane (yaw rotation about the center of the head), but head movements were otherwise restrained. When the stop pin was in place, the head was fixed to the chair in primary position. A head coil was used to track the angular position of the head (Chen et al., 2013b). A laser mounted on top of the collar, which rotated together with the monkey's head, projected a green spot of light onto the display screen and was used to provide feedback to the monkey about the current head position.
Experiments were performed with the head free to rotate in the horizontal plane, and we manipulated the relative positions of both eye and head targets on the screen. At the start of each trial, a head target was presented on the screen and the head-fixed laser was turned on simultaneously. The monkey was required to make the head-fixed laser align with the head target by rotating its head. After the head fixation target was acquired and maintained within a 2° × 2° window for 300 ms, an eye target was presented. The monkey was required to fixate this target and to simultaneously maintain both head and eye fixation for another 300 ms. Subsequently, the visual stimulus began, and the monkey had to maintain both eye and head fixation throughout the 1 s stimulus duration and for an additional 0.5 s after the stimulus ended. A juice reward was given after each successful trial.
To distinguish eye-centered from head-centered reference frames, eye position was varied relative to the head. This was implemented by the Eye-versus-Head condition, in which the head target was always presented at the 0° position (directly in front of the monkey), while the eye target was presented at one of the following three locations: left (−20°), straight ahead (0°), or right (20°). Thus, this condition included three combinations of eye and head positions, which we denote in the format of [eye relative to head, head relative to body]: [−20°, 0°], [0°, 0°], and [20°, 0°]. Similarly, head-centered versus body-centered spatial reference frames were distinguished by varying head position relative to the body, while keeping eye-in-head position constant. This was implemented by the Head-versus-Body condition, in which both the eye and head targets were presented together at the following three locations: left (−20°), straight ahead (0°), and right (20°). This resulted in three combinations of eye and head positions: [0°, −20°], [0°, 0°], and [0°, 20°]. Since the [0°, 0°] combination appears in both Eye-versus-Head and Head-versus-Body conditions, there were a total of five distinct combinations of eye and head target positions, as follows: [0°, −20°], [−20°, 0°], [0°, 0°], [20°, 0°], and [0°, 20°]. These five combinations were randomly interleaved in a single block of trials.
Note that head movements were restricted to rotations in the horizontal plane, such that complications due to torsion could be avoided. Specifically, during natural head-free movements, head (and eye in space) torsion varies by up to 10° for each head/gaze direction (Klier et al., 2003). Such an increase in torsional variability when the head is free to move in three dimensions would potentially add noise to our reference frame analysis. Thus, by restricting head rotations to the horizontal plane, problems associated with increased torsional eye/head movement variability were avoided.
Neural recordings
A plastic grid made from Delrin (3.5 × 5.5 × 0.5 cm), containing staggered rows of holes (0.8 mm spacing), was stereotaxically attached to the inside of the head-restraint ring using dental acrylic and was positioned to overlay VIP in both hemispheres. The patterns of white and gray matter, as well as neuronal response properties, were used to identify VIP as described previously (Chen et al., 2011a,b, 2013a). VIP neurons typically respond strongly to large random-dot patches (>10° × 10°), with RFs in the contralateral visual field that often extend into the ipsilateral field and include the fovea. To locate VIP, we first identified the medial tip of the intraparietal sulcus (IPS) and then moved laterally from the tip until directionally selective visual responses could no longer be found in multiunit activity. At the anterior end of VIP, visually responsive neurons gave way to purely somatosensory neurons in the fundus of the sulcus. At the posterior end, directionally selective visual neurons gave way to responses that were not selective for visual motion (Chen et al., 2011b). Recording sites were mapped on the cortical surface using Caret software (Lewis and Van Essen, 2000; Chen et al., 2011b).
Recordings were made using tungsten microelectrodes (FHC) that were inserted into the brain via transdural guide tubes. For each neuron encountered in an electrode penetration, we first explored the receptive field and tuning properties by manually controlling the parameters of a flickering or moving random-dot stimulus and observing the instantaneous firing rate of the neuron in a graphical display. The visual heading tuning protocol was delivered after the preliminary mapping of visual response properties. Overall, data were collected from 110 neurons in monkey E and 51 neurons in monkey Q. Most neurons were tested in both Eye-versus-Head and Head-versus-Body conditions (n = 110 from monkey E; n = 21 from monkey Q), but some neurons were only tested in the Eye-versus-Head condition (n = 30 from monkey Q). For the latter, we used the stop pin to fix head orientation to be straight ahead relative to the body. Additionally, some VIP neurons (n = 96 from monkey E; n = 5 from monkey Q) were tested with both visual and vestibular heading protocols, randomly interleaved within the same block of trials, whereas the remaining neurons were tested only with visual heading stimuli. Data for vestibular heading tuning have been presented elsewhere (Chen et al., 2013b; see also Fig. 3), so we focus on the visual responses in this report. Results were similar in the two monkeys, thus data were pooled across monkeys for all population analyses.
Figure 3.

Reference frame classification. For each neuron, the abscissa shows the DI value for the Head-vs-Body condition and the ordinate shows the DI value for the Eye-vs-Head condition. Eye-centered (blue cross), head-centered (green cross), and body-centered (red cross) reference frames are indicated by the coordinates (1, 1), (1, 0), and (0, 0), respectively. Open circles and triangles denote visual heading tuning data (monkey E, n = 42; monkey Q, n = 7). Small filled gray symbols denote vestibular heading tuning data from the study of Chen et al. (2013b) (n = 76). Blue open symbols represent neurons that were significantly classified as eye centered, whereas gray open symbols represent neurons that were unclassified (for details, see Materials and Methods). Black open symbols denote neurons with intermediate reference frames on both axes. Note that no neurons with head-centered (green) or body-centered (red) visual heading tuning were found in VIP. The star represents the example neuron shown in Figure 1.
Analyses for heading tuning measurements
All data analyses were done in Matlab (MathWorks), and population analyses included neurons that were tested with at least three stimulus repetitions of the heading tuning protocol (n = 97 from monkey E; n = 45 from monkey Q). For the majority of neurons (88.1%), 5 or more repetitions of each of the 50 stimulus combinations (10 heading directions by 5 eye/head position combinations) were obtained. Peristimulus time histograms (PSTHs) were constructed for each heading and each combination of eye and head positions. For each neuron, heading tuning curves for each condition (Eye-versus-Head and Head-versus-Body) were constructed by plotting firing rate, computed in a 400 ms window centered on the “peak time” of the neuron (Chen et al., 2010), as a function of heading. The peak time was defined as the center of the 400 ms window for which the neuronal response reached its maximum across all stimulus conditions. To identify the peak time, firing rates were computed in many different 400 ms time windows spanning the range of the data in 25 ms steps. For each 400 ms window, a one-way ANOVA (response by heading direction) was performed for each combination of eye and head positions. Heading tuning was considered statistically significant if the one-way ANOVA passed the significance test (p < 0.05) for five contiguous time points centered on the peak time. Only neurons with significant tuning for at least two of the three eye/head position combinations in either the Eye-versus-Head and/or Head-versus-Body condition were included in the reference frame analyses described next.
The heading tuning displacement index.
To assess the shift of heading tuning curves relative to the change in eye and/or head position, a heading tuning displacement index (DI), was computed by the following equation (Avillac et al., 2005; Fetsch et al., 2007):
 |
where k (in degrees) is the shift between a pair of tuning curves (denoted Ri and Rj), and the superscript above k refers to the maximum covariance between the tuning curves as a function of k (ranging from −180° to +180°). The denominator represents the difference between the eye or head positions (Pi and Pj) at which the tuning functions were measured. DI ranges between 1 (when the tuning curve shifts by an amount equal to the change in eye or head position) and 0 (when there is no shift with eye/head position). A single average DI was computed for each condition (Eye-versus-Head or Head-versus-Body), as long as at least two of the three tuning curves passed the significance test (as defined above); otherwise, this condition was not included in the DI analysis. The numbers of neurons that met these criteria and were included in the analysis were as follows: Eye-versus-Head condition, n = 66 (42 from monkey E, 24 from monkey Q); Head-versus-Body condition, n = 50 (43 from monkey E, 7 from monkey Q).
A confidence interval (CI) was computed for the DI in each condition using a bootstrap method. Bootstrapped tuning curves were generated by resampling (with replacement) the data for each heading, and then a DI value was computed for each bootstrapped tuning curve. This was repeated 1000 times to produce a distribution of bootstrap DI values from which a 95% CI was derived (percentile method). A DI value was considered significantly different from a particular value (0 and/or 1) if its 95% CI did not include that value. A neuron was classified as eye centered in the Eye-versus-Head condition or eye/head centered in the Head-versus-Body condition if the CI did not include 0 but included 1. A neuron was classified as head/body centered in the Eye-versus-Head condition or body centered in the Head-versus-Body condition if the CI did not include 1 but included 0. Finally, neurons were classified as having “intermediate” reference frames if the CI was contained within the interval between 0 and 1, without including 0 or 1. All other cases were designated as unclassified.
Combining data across stimulus conditions, a neuron was classified as eye centered if the CIs in both the Eye-versus-Head and Head-versus-Body conditions did not include 0 but included 1. A neuron was classified as head centered if the CI in the Eye-versus-Head condition included 0 but did not include 1, and if the CI in the Head-versus-Body condition did not include 0 but included 1. Alternatively, a neuron was classified as having body-centered heading tuning if the CIs in both the Eye-versus-Head and Head-versus-Body conditions included 0 but did not include 1. Finally, a neuron was classified as having jointly intermediate reference frames if the CIs in both the Eye-versus-Head and Head-versus-Body conditions were contained within the interval between 0 and 1, without including 0 or 1. If a neuron did not satisfy any of these conditions, it was labeled as “unclassified.”
Fitting tuning curves with eye-, head-, and body-centered models.
To determine whether the whole set of tuning curves for each neuron in each condition (Eye-versus-Head and Head-versus-Body) was most consistent with an eye-centered, head-centered, or body-centered representation, the three tuning curves in each condition were fitted simultaneously with a set of von Mises functions (Fetsch et al., 2007):
 |
where A is the response amplitude, θp is the preferred heading, σ is the tuning width, and rb is the baseline response level. von Mises functions provide excellent fits to the heading data when all parameters are free, as quantified by computing R2 values. Median values of R2 were 0.92, 0.91, 0.91, 0.90, and 0.91 for each of the five combinations of eye/head positions. To assess reference frames using model fits, we fit different models in which A, σ, and rb were all free parameters for each eye/head position, and only θp was constrained. Data from the Eye-versus-Head condition were fit with both an eye-centered model and a head/body-centered model. Specifically, θp was constrained to shift by exactly the amount of the eye position change (i.e., θp for straight ahead, θp + 20° for left fixation, and θp − 20° for right fixation) in the eye-centered model, but was constrained to be constant (θp) for all the three tuning curves (no shift) in the head/body-centered model. Similarly, data from the Head-versus-Body condition were fitted with both an eye/head-centered model and a body-centered model, in which θp was constrained to shift by exactly the amount of head position change (i.e., θp for straight ahead, θp + 20° for the left head position, and θp − 20° for the right head position) in the eye/head-centered model and to be constant (θp) for all the three tuning curves (no shift) in the body-centered model. Thus, the total number of free parameters for each model was 10 (3 free parameters by 3 tuning curves plus θp).
Neurons included in these model fitting analyses needed to meet the following two requirements: (1) all three tuning curves passed the significance criteria described above; and (2) all three tuning curves were well fit separately (i.e., when all four parameters were free) by the function of Equation 2, as indicated by individual R2 values >0.6. The numbers of neurons that passed both of these criteria were as follows: Eye-versus-Head condition, n = 52 (33 from monkey E, 19 from monkey Q); and Head-versus-Body condition, n = 42 (36 from monkey E, 6 from monkey Q).
For each fit, the correlation between the best-fitting function and the data was computed to measure the goodness-of-fit. To remove the influence of correlations between the models themselves, partial correlation coefficients were computed by the Matlab function “partialcorr” and subsequently normalized using Fisher's r-to-Z transform (Angelaki et al., 2004; Smith et al., 2005; Fetsch et al., 2007), such that Z-scores from two models could be compared in a scatter plot. If the Z-score for one model was >2.326 and exceeded the Z-score for the other model by at least 2.326 (equivalent to a p value of 0.01), that model was considered a significantly better to fit to the data than the alternative model (Fetsch et al., 2007).
Results
Quantification of visual heading tuning shift by displacement index
We explored whether visual heading tuning in VIP is eye, head, or body centered by performing two interleaved experimental manipulations of eye and head positions. In the Eye-versus-Head condition, the head remained fixed straight ahead while the eyes fixated on one of three target locations (left, center, or right). In the Head-versus-Body condition, the monkeys rotated their heads to fixate on one of the same three target locations while the eyes remained fixed in the head. We measured the visual heading tuning of VIP neurons in the horizontal plane for each of five distinct [eye, head] position combinations, as illustrated in Figure 1A.
Figure 1.

Heading tuning of an example VIP neuron at different eye/head positions. A, PSTHs of the responses of the neuron to optic flow stimuli are shown for all 50 stimulus conditions tested, all permutations of 10 directions of translation (x-axis) and 5 combinations of [eye, head] positions: [0°, −20°], [−20°, 0°], [0°, 0°], [20°, 0°], [0°, 20°] (rows). The red and green dashed lines represent the start and end of the motion stimulus. B, Tuning curves from the Eye-vs-Head condition. The three tuning curves show mean firing rate (±SEM) as a function of heading for the three combinations of [eye, head] position ([−20°, 0°], [0°, 0°], [20°, 0°]), as indicated by the red, black, and blue curves, respectively. C, Tuning curves from the Head-vs-Body condition for the three combinations of [eye, head] position ([0°, −20°], [0°, 0°], [0°, 20°]). The format is the same as in B.
The Eye-versus-Head condition (Fig. 1B) allows us to distinguish an eye-centered reference frame from a head/body-centered frame. If the three tuning curves are systematically displaced from one another by an amount equal to the change in eye position, this would indicate an eye-centered reference frame. In contrast, no shift would illustrate a head- or body-centered reference frame. The Head-versus-Body condition (Fig. 1C) allows us to separate an eye/head-centered reference frame from a body-centered reference frame (Chen et al., 2013b). If the tuning curves are systematically displaced from one another by an amount equal to the change in head position, this would indicate an eye- or head-centered frame, whereas no shift would reveal a body-centered reference frame. The typical VIP neuron shown in Figure 1 exhibited systematic tuning curve shifts in both the Eye-versus-Head and Head-versus-Body conditions, as illustrated in Figure 1, B and C. This pattern of results suggests an eye-centered representation of visual heading cues.
A heading tuning DI was computed to quantify the shift of each pair of tuning curves relative to the change in eye or head position, using a cross-covariance method (Avillac et al., 2005; Fetsch et al., 2007). Importantly, this technique takes into account the entire tuning function rather than just one parameter such as the peak or the vector sum direction. As a result, the DI is robust to changes in the gain or width of the tuning curves and can tolerate a wide variety of tuning shapes. For the example VIP neuron in Figure 1, the mean DI (across all pairs of eye or head positions) values for both the Eye-versus-Head and Head-versus-Body conditions were close to 1 (0.83 and 0.91, respectively), consistent with an eye-centered representation of heading.
Distributions of DI values are summarized in Figure 2. These distributions were not found to differ significantly from normality (p > 0.1, Lilliefors test); hence, the central tendencies were summarized by mean values. DI values generally clustered around 1 in the Eye-versus-Head condition (Fig. 2A), with a mean value of 0.89 ± 0.06 (mean ± SE), which was significantly different from both 0 and 1 (p < 0.001, t test). Thus, at the population level, the mean DI was much closer to an eye-centered than a head/body-centered reference frame, but was significantly shifted away from eye centered. The DI distribution for the Eye-versus-Head condition in VIP was not significantly different (p = 0.66, Wilcoxon rank sum test) from that measured previously in MSTd (Fetsch et al., 2007). Based on confidence intervals computed by bootstrap for each neuron, we further classified each VIP neuron as eye centered, head/body centered, or intermediate (for details, see Materials and Methods). As shown by different colors in Figure 2A, 40 of 66 neurons were classified as eye centered (blue), 0 of 66 were classified as head/body centered, 8 of 66 were classified as intermediate (black), and the remainder were unclassified (gray).
Figure 2.

Summary of spatial reference frames for visual heading tuning, as quantified by the DI. A, In the Eye-vs-Head condition, DI values of 0 and 1 indicate head/body-centered and eye-centered representations, respectively (n = 66). B, In the Head-vs-Body condition, DI values of 0 and 1 indicate body-centered and eye/head-centered reference frames, respectively (n = 50). Blue bars in A represent neurons that were significantly classified as eye centered (n = 40; for details, see Materials and Methods). Cyan and red bars in B represent neurons that were significantly classified as eye/head centered (n = 37) and body centered (n = 1), respectively. Black bars in A and B represent neurons that were classified as intermediate (A, n = 8; B, n = 4), whereas gray bars represent neurons that were unclassified (A, n = 18; B, n = 8). Arrowheads indicate mean DI values for each distribution.
DI values from VIP also clustered around 1 in the Head-versus-Body condition, with a mean value of 0.97 ± 0.07 (mean ± SE), which was not significantly different from 1 (p = 0.37, t test). Thus, at the population level, the mean DI was not significantly shifted away from a purely eye/head-centered reference frame. As shown by different colors in Figure 2B, 37 of 50 neurons were classified as eye/head centered (cyan), 1 of 50 was classified as body-centered (red), 4 of 50 were classified as intermediate (black), and the remainder were unclassified (gray). Together, the DI analyses shown in Figure 2, A and B, show that VIP neurons code visual heading signals in a reference frame that is close to eye centered, but with a small but significant shift toward a head-centered reference frame, as observed previously for area MSTd (Fetsch et al., 2007).
To better visualize the distribution of reference frames across neurons, DI values from the Eye-versus-Head condition were plotted against DI values from the Head-versus-Body condition (Fig. 3). In this joint representation, eye-, head-, and body-centered spatial reference frames are indicated by coordinates (1, 1), (1, 0), and (0, 0), respectively (blue, green, and red crosses). The 95% CIs were computed, using a bootstrap method (for details, see Materials and Methods), to classify each neuron as eye centered, head centered, body centered, or intermediate. Most of the visual heading tuning data clustered around an eye-centered representation, with 52% (26 of 50) of the neurons classified as significantly eye centered (blue open symbols) and none classified as significantly head centered (green) or body centered (red). In addition, 4% (2 of 50) of neurons had CIs contained within the interval between 0 and 1, without including 0 or 1, for both the Eye-versus-Head and Head-versus-Body conditions, and were classified as intermediate (black open symbols).
For comparison, Figure 3 also illustrates the corresponding DI values for vestibular heading tuning (gray filled symbols), from an experiment in which the monkey was translated along a similar set of heading trajectories by a motion platform (Chen et al., 2013b). Note that these vestibular heading data cluster around a body-centered representation, with nearly half of the neurons classified as body centered and none classified as eye centered (Chen et al., 2013b). Thus, visual and vestibular heading signals are clearly represented in very different reference frames in VIP. Note that this distinction was also clear for a subset of neurons from monkey E (n = 14) that were tested with both the visual and vestibular heading tuning protocols.
Model-based analysis of reference frames of visual heading tuning
The fact that von Mises functions provide excellent fits to the heading data allows an additional analysis, in which tuning curves in the Eye-versus-Head condition were fitted simultaneously with an eye-centered or a head/body-centered model, whereas tuning curves in the Head-versus-Body condition were fitted simultaneously with an eye/head-centered or a body-centered model (Fig. 4A; for details, see Materials and Methods). The goodness-of-fit of each model was measured by computing correlation coefficients between the fitted function and the data (Fig. 4B), which were then converted into partial correlation coefficients and normalized using Fisher's r-to-Z transform to enable meaningful comparisons between models independent of the number of data points (Angelaki et al., 2004; Smith et al., 2005).
Figure 4.

von Mises fits to visual heading tuning curves. A, Heading tuning curves for an example VIP neuron (mean firing rate ± SEM) are shown for both conditions. In the Eye-vs-Head condition, the three tuning curves were fit simultaneously with eye (solid curves) and head/body (dashed curves) models. In the Head-vs-Body condition, the three tuning curves were fit simultaneously with eye/head (solid curves) and body (dashed curves) models. B, Distributions of R2 values, which measure goodness of fit with the von Mises functions. In the Eye-vs-Head condition, black bars represent fits with the eye model, whereas gray bars denote fits with the head/body model (n = 156). In the Head-vs-Body condition, black bars represent fits with the eye/head model, whereas gray bars denote fits with the body model (n = 126).
Z-scores for each pair of model comparisons are shown in the scatter plots of Figure 5. The gray region in each scatter plot marks the boundaries of confidence intervals that distinguish between models. Data points lying in the white area above the gray region were significantly better fit by the model indicated along the ordinate than by the model indicated along the abscissa (p < 0.01). Data points lying in the white area below the gray region were significantly better fit by the model indicated along the abscissa (p < 0.01). In the Eye-versus-Head condition, 28.9% of the neurons (15 of 52) were classified as eye centered, 1.9% of neurons (1 of 52) were classified as head/body centered, and 69.2% of neurons (36 of 52) were unclassified (Fig. 5A). The large percentage of neurons in the gray zone may partially reflect tuning in a reference frame that is intermediate between eye centered and head/body centered, but likely also reflects a lack of statistical power when data are noisy. The mean Z-score difference was 1.70 for the Eye-versus-Head condition, which is significantly greater than 0 (p ≪ 0.001, t test). In the Head-versus-Body condition, 52.4% of the neurons (22 of 42) were classified as eye/head centered, 0% were classified as body centered, and 47.6% (20 of 42) were unclassified (Fig. 5B). The mean Z-score difference was 2.79, also significantly greater than 0 (p ≪ 0.001, t test). Thus, in line with the DI results, the model-fitting analysis indicates that visual heading tuning in VIP is coded in a reference frame that is often eye centered and rarely head centered.
Figure 5.

Model-based classification of spatial reference frames for visual heading tuning in VIP. A, B, Data are shown separately for the Eye-vs-Head condition (n = 52; A) and the Head-vs-Body condition (n = 42; B). Each scatter plot represents Z-scored partial correlation coefficients between the data and the two models. Data points falling within the gray region in each panel cannot be classified, but data points falling into the areas above or below the gray region are classified as being best fit by the model represented on the ordinate or abscissa, respectively. The star represents the example neuron of Figure 1. Diagonal histograms represent distributions of differences between Z-scores for each pair of models. Arrowheads indicate the mean values for each distribution.
Recording locations
Superposition of recording locations onto two coronal sections (2.5 mm apart) from the left hemisphere of monkey Q and the right hemisphere of monkey E (where the majority of the neurons were recorded) are illustrated in Figure 6A–E [the parcellation scheme is after Lewis and Van Essen (2000)]. Recording locations are also shown on a flat map of cortex in Figure 6, F and G. The vast majority of recordings was reconstructed to lie within the anatomical boundaries of macaque VIP, except for a few neurons that were located very close to the VIP/lateral intraparietal (LIP) area border. These reconstructions also demonstrate that our recordings covered a substantial portion of the anterior/posterior span of VIP (∼5 mm).
Figure 6.
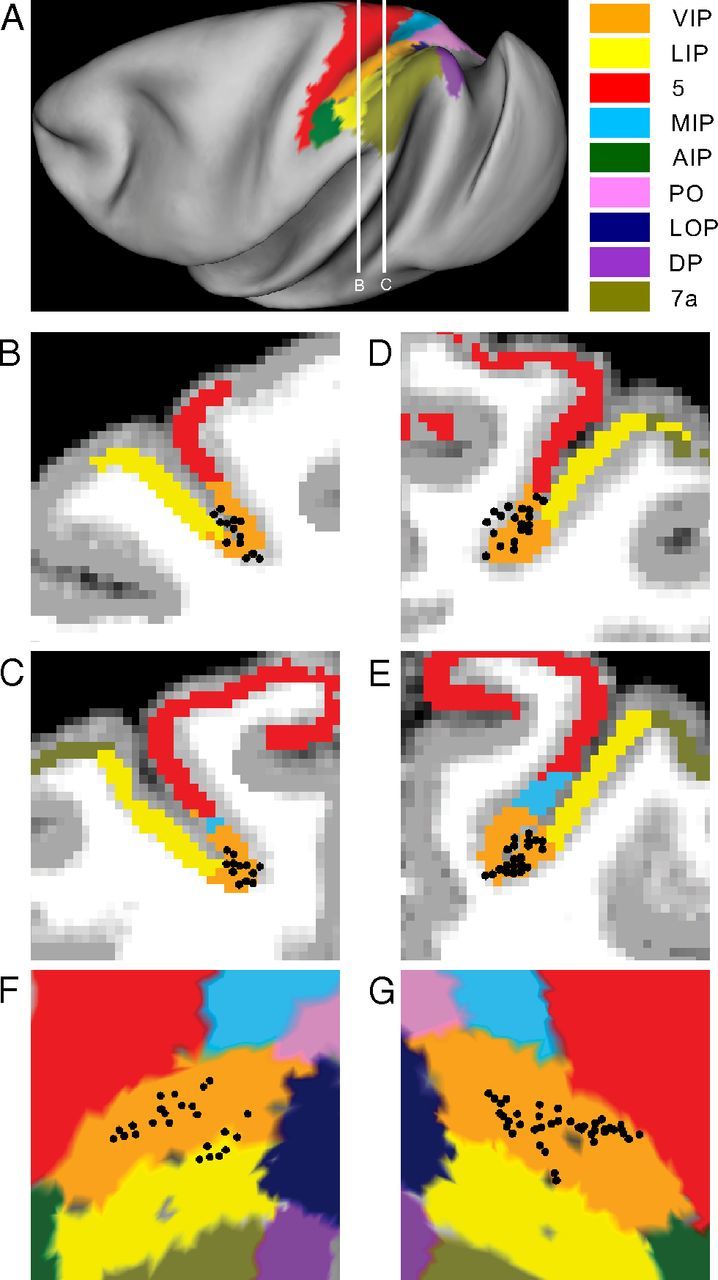
Anatomical localization of recording sites. A, Inflated cortical surface illustrating the major subareas of the parietal cortex (color coded) in the left hemisphere of monkey Q, as well as the locations (white lines) of the coronal sections drawn in B and C. B, C, Coronal sections from the left hemisphere of monkey Q, spaced 2.5 mm apart. D, E, Corresponding coronal sections from the right hemisphere of monkey E. Recording locations (black circular symbols) of neurons that were located within ±1.25 mm of each section were projected onto that section. Only neurons that met the criteria to be included in our DI analyses of heading tuning are shown here (animal Q, n = 24 neurons; animal E, n = 42 neurons). Because only one neuron was recorded from each of the other two hemispheres, they are not illustrated here. F, G, Anatomical localization of recorded neurons on flat maps of the left hemisphere of monkey Q and the right hemisphere of monkey E, respectively. Different functional brain areas are color coded, as indicated in the legend. The four corners of each panel (top left, bottom left, bottom right, top right) indicate the approximate orientation of the flat map relative to the surface of a hemisphere, which is medial, anterior, lateral, posterior in F and posterior, lateral, anterior, medial in G.
Discussion
We systematically explored the spatial reference frames of visual heading tuning in VIP. Results from both empirical and model-based analyses show that, as found previously in MSTd (Fetsch et al., 2007; Lee et al., 2011), optic flow tuning is approximately eye centered. We found no neurons with head-centered or body-centered visual heading tuning (Fig. 3), although a small proportion of neurons had reference frames that were significantly intermediate between eye and head centered. Although the optic flow stimuli used here did not contain stereoscopic depth cues, this property has not been reported to influence reference frame measurements. Thus, we consider it unlikely that different results would have been obtained were stereoscopic stimuli used. Importantly, most MSTd and VIP neurons respond best to lateral motion (Gu et al., 2006, 2010; Chen et al., 2011b); thus, many neurons have monotonic tuning around straightforward (Gu et al., 2008). This makes it difficult to distinguish shifts of the heading tuning curve from changes in response gain, unless the complete tuning function is measured, as we have done here.
Duhamel et al. (1997) and Avillac et al. (2005) reported that visual receptive fields in VIP are organized along a continuum from eye to head centered, with a substantial minority of neurons representing spatial locations in a head-centered reference frame. There is no particular reason to believe that shifts in heading tuning and receptive field location should necessarily be linked. Additional experiments testing both properties (optic flow tuning and receptive field shifts) in the same neurons would be needed to investigate this relationship.
VIP is a multimodal area receiving sensory inputs from visual, vestibular, auditory, and somatosensory systems (Colby et al., 1993; Duhamel et al., 1998; Lewis and Van Essen, 2000; Bremmer et al., 2002a,b; Schlack et al., 2002, 2005; Avillac et al., 2005; Maciokas and Britten, 2010; Zhang and Britten, 2010; Chen et al., 2011a,b). Several recent human studies have suggested that VIP remaps modality-specific spatial coordinates into body- and/or world-centered representations (Bolognini and Maravita, 2007; Azañón et al., 2010; Klemen and Chambers, 2012; McCollum et al., 2012; Renzi et al., 2013). Quantitative characterization of the spatial reference frames employed by individual VIP neurons is, however, generally inconsistent with this notion. Specifically, facial tactile receptive fields are represented in a head-centered reference frame in VIP (Avillac et al., 2005), while auditory RFs are organized in a continuum between eye-centered and head-centered coordinates (Schlack et al., 2005). Only vestibular heading signals are known to be represented in a body-centered reference frame in VIP (Chen et al., 2013b).
Like MSTd, VIP has been suggested to play an important role in multisensory heading perception (Zhang et al., 2004; Maciokas and Britten, 2010; Zhang and Britten, 2010; Chen et al., 2013a). Most notably, strong choice probabilities, greater than those found in MSTd, were exhibited by VIP neurons for both the visual and vestibular conditions of a heading discrimination task (Chen et al., 2013a). The present findings regarding visual reference frames, along with those of Chen et al. (2013b) regarding vestibular reference frames, clearly indicate that visual and vestibular heading cues are represented in highly disparate coordinate systems in VIP: eye centered and body centered, respectively. Because a subset of VIP neurons was tested with both sets of stimuli, these findings clearly show that even multisensory VIP neurons represent visual and vestibular heading signals in different spatial reference frames. In fact, this reference frame disparity is even larger than in MSTd, where vestibular tuning follows a head-centered representation that is slightly but significantly shifted toward an eye-centered representation.
Our findings are in general agreement with previous observations that VIP contains multiple sensory representations with diverse and mismatched reference frames, including tactile and visual receptive fields (Avillac et al., 2005), as well as auditory and visual receptive fields (Mullette-Gillman et al., 2005; Schlack et al., 2005). Moreover, these and other representations in the parietal cortex are often “hybrid” (Maier and Groh, 2009) or intermediate (Mullette-Gillman et al., 2005; Batista et al., 2007; Chang and Snyder, 2010), characterized by partially shifting tuning curves or receptive fields, and there has been debate about whether this diversity represents meaningless noise or has important meaning. Computational models have proposed that a mixed representation is advantageous when considering the posterior parietal cortex as an intermediate layer that uses basis functions to perform multidirectional coordinate transformations (Pouget and Snyder, 2000). Such distributed multisensory representations employing disparate spatial reference frames, although perhaps unintuitive, may be consistent with optimal population coding (Deneve et al., 2001; Deneve and Pouget, 2004).
Flexibility in reference frames according to both sensory and attentional contexts has been highlighted in recent neuroimaging studies. For example, human MT+ was described to be retinotopic when attention was focused on the fixation point, and spatiotopic when attention was allowed to be directed to the motion stimuli themselves (Burr and Morrone, 2011). Furthermore, fMRI activation in reach-coding areas has shown different reference frames when tested with visual versus somatosensory stimuli. When targets were defined visually, the motor goal was encoded in gaze-centered coordinates; in contrast, when targets were defined by unseen proprioceptive cues, activity reflecting the motor goal was represented in body-centered coordinates (Bernier and Grafton, 2010).
Reference frames of neural representations of space may also change dynamically over time in some parts of the brain. Recent work shows that, in a saccade task, the reference frame of auditory signals in primate superior colliculus neurons changes dynamically from a hybrid eye- and head-centered frame to a predominantly eye-centered frame around the time of the eye movement (Lee and Groh, 2012). This finding contrasts with the response properties of neurons in the intraparietal cortex, for which the sensory- and motor-related activity was found to be expressed in a predominantly hybrid reference frame for both vision and audition (Mullette-Gillman et al., 2005, 2009). Thus, the timing of neural signals relative to behavioral events also needs to be considered in evaluating the reference frames of signals in different brain areas.
Theoretical models have suggested that the sensory receptive field of sensorimotor neurons may be dominated by the reference frame of the sensory apparatus that provides its input, and moreover, that the same neurons may use different frames of reference according to sensory context (Sober and Sabes, 2005; Blohm et al., 2009; McGuire and Sabes, 2009). Each of these native sensory signals would be converted to the appropriate representation according to the motor goal simultaneously in multiple reference frames (Buneo et al., 2002; Battaglia-Mayer et al., 2003; Medendorp et al., 2005, 2008; Pesaran et al., 2006; Chang and Snyder, 2010). These neural network models even predict that some neurons will have tuning curves that shift more than expected (i.e., DI values >1). This emphasizes that, while it is the overall population effect that matters, variability in reference frame distributions might simply reflect the way things balance out within a network (Blohm et al., 2009).
In closing, our findings, combined with those of Chen et al. (2013b), demonstrate a clear dissociation between the spatial reference frames of visual and vestibular heading tuning in VIP, and emphasize that frames of reference for neurons in parietal cortex can depend on the type of sensory stimulation, consistent with some previous findings (Avillac et al., 2005; Mullette-Gillman et al., 2005, 2009; Schlack et al., 2005). These findings suggest that flexibility and diversity in spatial reference frames represent a general feature of spatial representations in cerebral cortex.
Footnotes
The study was supported by National Institutes of Health Grant R01- EY017866 to D.E.A. We thank Dr. E. Klier for helping with the writing; and Amanda Turner and Jing Lin for excellent technical assistance.
References
- Angelaki DE, Shaikh AG, Green AM, Dickman JD. Neurons compute internal models of the physical laws of motion. Nature. 2004;430:560–564. doi: 10.1038/nature02754. [DOI] [PubMed] [Google Scholar]
- Avillac M, Denève S, Olivier E, Pouget A, Duhamel JR. Reference frames for representing visual and tactile locations in parietal cortex. Nat Neurosci. 2005;8:941–949. doi: 10.1038/nn1480. [DOI] [PubMed] [Google Scholar]
- Azañón E, Longo MR, Soto-Faraco S, Haggard P. The posterior parietal cortex remaps touch into external space. Curr Biol. 2010;20:1304–1309. doi: 10.1016/j.cub.2010.05.063. [DOI] [PubMed] [Google Scholar]
- Batista AP, Santhanam G, Yu BM, Ryu SI, Afshar A, Shenoy KV. Reference frames for reach planning in macaque dorsal premotor cortex. J Neurophysiol. 2007;98:966–983. doi: 10.1152/jn.00421.2006. [DOI] [PubMed] [Google Scholar]
- Battaglia-Mayer A, Caminiti R, Lacquaniti F, Zago M. Multiple levels of representation of reaching in the parieto-frontal network. Cereb Cortex. 2003;13:1009–1022. doi: 10.1093/cercor/13.10.1009. [DOI] [PubMed] [Google Scholar]
- Bernier PM, Grafton ST. Human posterior parietal cortex flexibly determines reference frames for reaching based on sensory context. Neuron. 2010;68:776–788. doi: 10.1016/j.neuron.2010.11.002. [DOI] [PubMed] [Google Scholar]
- Blohm G, Keith GP, Crawford JD. Decoding the cortical transformations for visually guided reaching in 3D space. Cereb Cortex. 2009;19:1372–1393. doi: 10.1093/cercor/bhn177. [DOI] [PubMed] [Google Scholar]
- Bolognini N, Maravita A. Proprioceptive alignment of visual and somatosensory maps in the posterior parietal cortex. Curr Biol. 2007;17:1890–1895. doi: 10.1016/j.cub.2007.09.057. [DOI] [PubMed] [Google Scholar]
- Bremmer F. Navigation in space—the role of the macaque ventral intraparietal area. J Physiol. 2005;566:29–35. doi: 10.1113/jphysiol.2005.082552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bremmer F. Multisensory space: from eye-movements to self-motion. J Physiol. 2011;589:815–823. doi: 10.1113/jphysiol.2010.195537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bremmer F, Duhamel JR, Ben Hamed S, Graf W. Heading encoding in the macaque ventral intraparietal area (VIP) Eur J Neurosci. 2002a;16:1554–1568. doi: 10.1046/j.1460-9568.2002.02207.x. [DOI] [PubMed] [Google Scholar]
- Bremmer F, Klam F, Duhamel JR, Ben Hamed S, Graf W. Visual-vestibular interactive responses in the macaque ventral intraparietal area (VIP) Eur J Neurosci. 2002b;16:1569–1586. doi: 10.1046/j.1460-9568.2002.02206.x. [DOI] [PubMed] [Google Scholar]
- Buneo CA, Jarvis MR, Batista AP, Andersen RA. Direct visuomotor transformations for reaching. Nature. 2002;416:632–636. doi: 10.1038/416632a. [DOI] [PubMed] [Google Scholar]
- Burr DC, Morrone MC. Spatiotopic coding and remapping in humans. Philos Trans R Soc Lond B Biol Sci. 2011;366:504–515. doi: 10.1098/rstb.2010.0244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang SW, Snyder LH. Idiosyncratic and systematic aspects of spatial representations in the macaque parietal cortex. Proc Natl Acad Sci U S A. 2010;107:7951–7956. doi: 10.1073/pnas.0913209107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen A, Gu Y, Takahashi K, Angelaki DE, DeAngelis GC. Clustering of self-motion selectivity and visual response properties in macaque area MSTd. J Neurophysiol. 2008;100:2669–2683. doi: 10.1152/jn.90705.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen A, DeAngelis GC, Angelaki DE. Macaque parieto-insular vestibular cortex: responses to self-motion and optic flow. J Neurosci. 2010;30:3022–3042. doi: 10.1523/JNEUROSCI.4029-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen A, DeAngelis GC, Angelaki DE. A comparison of vestibular spatiotemporal tuning in macaque parietoinsular vestibular cortex, ventral intraparietal area, and medial superior temporal area. J Neurosci. 2011a;31:3082–3094. doi: 10.1523/JNEUROSCI.4476-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen A, DeAngelis GC, Angelaki DE. Representation of vestibular and visual cues to self-motion in ventral intraparietal cortex. J Neurosci. 2011b;31:12036–12052. doi: 10.1523/JNEUROSCI.0395-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen A, DeAngelis GC, Angelaki DE. Functional specializations of the ventral intraparietal area for multisensory heading discrimination. J Neurosci. 2013a;33:3567–3581. doi: 10.1523/JNEUROSCI.4522-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X, DeAngelis GC, Angelaki DE. Diverse spatial reference frames of vestibular signals in parietal cortex. Neuron. 2013b;80:1–12. doi: 10.1016/j.neuron.2013.09.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Colby CL, Duhamel JR, Goldberg ME. Ventral intraparietal area of the macaque: anatomic location and visual response properties. J Neurophysiol. 1993;69:902–914. doi: 10.1152/jn.1993.69.3.902. [DOI] [PubMed] [Google Scholar]
- Crawford JD, Henriques DY, Medendorp WP. Three-dimensional transformations for goal-directed action. Annu Rev Neurosci. 2011;34:309–331. doi: 10.1146/annurev-neuro-061010-113749. [DOI] [PubMed] [Google Scholar]
- Deneve S, Pouget A. Bayesian multisensory integration and cross-modal spatial links. J Physiol Paris. 2004;98:249–258. doi: 10.1016/j.jphysparis.2004.03.011. [DOI] [PubMed] [Google Scholar]
- Deneve S, Latham PE, Pouget A. Efficient computation and cue integration with noisy population codes. Nat Neurosci. 2001;4:826–831. doi: 10.1038/90541. [DOI] [PubMed] [Google Scholar]
- Duhamel JR, Bremmer F, Ben Hamed S, Graf W. Spatial invariance of visual receptive fields in parietal cortex neurons. Nature. 1997;389:845–848. doi: 10.1038/39865. [DOI] [PubMed] [Google Scholar]
- Duhamel JR, Colby CL, Goldberg ME. Ventral intraparietal area of the macaque: congruent visual and somatic response properties. J Neurophysiol. 1998;79:126–136. doi: 10.1152/jn.1998.79.1.126. [DOI] [PubMed] [Google Scholar]
- Fetsch CR, Wang S, Gu Y, DeAngelis GC, Angelaki DE. Spatial reference frames of visual, vestibular, and multimodal heading signals in the dorsal subdivision of the medial superior temporal area. J Neurosci. 2007;27:700–712. doi: 10.1523/JNEUROSCI.3553-06.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fetsch CR, Turner AH, DeAngelis GC, Angelaki DE. Dynamic reweighting of visual and vestibular cues during self-motion perception. J Neurosci. 2009;29:15601–15612. doi: 10.1523/JNEUROSCI.2574-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fetsch CR, DeAngelis GC, Angelaki DE. Visual-vestibular cue integration for heading perception: applications of optimal cue integration theory. Eur J Neurosci. 2010;31:1721–1729. doi: 10.1111/j.1460-9568.2010.07207.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fetsch CR, Pouget A, DeAngelis GC, Angelaki DE. Neural correlates of reliability-based cue weighting during multisensory integration. Nat Neurosci. 2012;15:146–154. doi: 10.1038/nn.2983. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu Y, Watkins PV, Angelaki DE, DeAngelis GC. Visual and nonvisual contributions to three-dimensional heading selectivity in the medial superior temporal area. J Neurosci. 2006;26:73–85. doi: 10.1523/JNEUROSCI.2356-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu Y, Angelaki DE, DeAngelis GC. Neural correlates of multisensory cue integration in macaque MSTd. Nat Neurosci. 2008;11:1201–1210. doi: 10.1038/nn.2191. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu Y, Fetsch CR, Adeyemo B, DeAngelis GC, Angelaki DE. Decoding of MSTd population activity accounts for variations in the precision of heading perception. Neuron. 2010;66:596–609. doi: 10.1016/j.neuron.2010.04.026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gu Y, DeAngelis GC, Angelaki DE. Causal links between dorsal medial superior temporal area neurons and multisensory heading perception. J Neurosci. 2012;32:2299–2313. doi: 10.1523/JNEUROSCI.5154-11.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klemen J, Chambers CD. Current perspectives and methods in studying neural mechanisms of multisensory interactions. Neurosci Biobehav Rev. 2012;36:111–133. doi: 10.1016/j.neubiorev.2011.04.015. [DOI] [PubMed] [Google Scholar]
- Klier EM, Wang H, Crawford JD. Three-dimensional eye-head coordination is implemented downstream from the superior colliculus. J Neurophysiol. 2003;89:2839–2853. doi: 10.1152/jn.00763.2002. [DOI] [PubMed] [Google Scholar]
- Lee B, Pesaran B, Andersen RA. Area MSTd neurons encode visual stimuli in eye coordinates during fixation and pursuit. J Neurophysiol. 2011;105:60–68. doi: 10.1152/jn.00495.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee J, Groh JM. Auditory signals evolve from hybrid- to eye-centered coordinates in the primate superior colliculus. J Neurophysiol. 2012;108:227–242. doi: 10.1152/jn.00706.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lewis JW, Van Essen DC. Corticocortical connections of visual, sensorimotor, and multimodal processing areas in the parietal lobe of the macaque monkey. J Comp Neurol. 2000;428:112–137. doi: 10.1002/1096-9861(20001204)428:1<112::AID-CNE8>3.0.CO%3B2-9. [DOI] [PubMed] [Google Scholar]
- Maciokas JB, Britten KH. Extrastriate area MST and parietal area VIP similarly represent forward headings. J Neurophysiol. 2010;104:239–247. doi: 10.1152/jn.01083.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maier JX, Groh JM. Multisensory guidance of orienting behavior. Hear Res. 2009;258:106–112. doi: 10.1016/j.heares.2009.05.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCollum G, Klam F, Graf W. Face-infringement space: the frame of reference of the ventral intraparietal area. Biol Cybern. 2012;106:219–239. doi: 10.1007/s00422-012-0491-9. [DOI] [PubMed] [Google Scholar]
- McGuire LM, Sabes PN. Sensory transformations and the use of multiple reference frames for reach planning. Nat Neurosci. 2009;12:1056–1061. doi: 10.1038/nn.2357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Medendorp WP, Goltz HC, Crawford JD, Vilis T. Integration of target and effector information in human posterior parietal cortex for the planning of action. J Neurophysiol. 2005;93:954–962. doi: 10.1152/jn.00725.2004. [DOI] [PubMed] [Google Scholar]
- Medendorp WP, Beurze SM, Van Pelt S, Van Der Werf J. Behavioral and cortical mechanisms for spatial coding and action planning. Cortex. 2008;44:587–597. doi: 10.1016/j.cortex.2007.06.001. [DOI] [PubMed] [Google Scholar]
- Mullette-Gillman OA, Cohen YE, Groh JM. Eye-centered, head-centered, and complex coding of visual and auditory targets in the intraparietal sulcus. J Neurophysiol. 2005;94:2331–2352. doi: 10.1152/jn.00021.2005. [DOI] [PubMed] [Google Scholar]
- Mullette-Gillman OA, Cohen YE, Groh JM. Motor-related signals in the intraparietal cortex encode locations in a hybrid, rather than eye-centered reference frame. Cereb Cortex. 2009;19:1761–1775. doi: 10.1093/cercor/bhn207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pesaran B, Nelson MJ, Andersen RA. Dorsal premotor neurons encode the relative position of the hand, eye, and goal during reach planning. Neuron. 2006;51:125–134. doi: 10.1016/j.neuron.2006.05.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pouget A, Snyder LH. Computational approaches to sensorimotor transformations. Nat Neurosci. 2000;(3 Suppl):1192–1198. doi: 10.1038/81469. [DOI] [PubMed] [Google Scholar]
- Renzi C, Bruns P, Heise KF, Zimerman M, Feldheim JF, Hummel FC, Röder B. Spatial remapping in the audio-tactile ventriloquism effect: a TMS investigation on the role of the ventral intraparietal area. J Cogn Neurosci. 2013;25:790–801. doi: 10.1162/jocn_a_00362. [DOI] [PubMed] [Google Scholar]
- Schlack A, Hoffmann KP, Bremmer F. Interaction of linear vestibular and visual stimulation in the macaque ventral intraparietal area (VIP) Eur J Neurosci. 2002;16:1877–1886. doi: 10.1046/j.1460-9568.2002.02251.x. [DOI] [PubMed] [Google Scholar]
- Schlack A, Sterbing-D'Angelo SJ, Hartung K, Hoffmann KP, Bremmer F. Multisensory space representations in the Macaque ventral intraparietal area. J Neurosci. 2005;25:4616–4625. doi: 10.1523/JNEUROSCI.0455-05.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith MA, Majaj NJ, Movshon JA. Dynamics of motion signaling by neurons in macaque area MT. Nat Neurosci. 2005;8:220–228. doi: 10.1038/nn1382. [DOI] [PubMed] [Google Scholar]
- Sober SJ, Sabes PN. Flexible strategies for sensory integration during motor planning. Nat Neurosci. 2005;8:490–497. doi: 10.1038/nn1427. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Takahashi K, Gu Y, May PJ, Newlands SD, DeAngelis GC, Angelaki DE. Multimodal coding of three-dimensional rotation and translation in area MSTd: comparison of visual and vestibular selectivity. J Neurosci. 2007;27:9742–9756. doi: 10.1523/JNEUROSCI.0817-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Y, Liu S, Chowdhury SA, DeAngelis GC, Angelaki DE. Binocular disparity tuning and visual-vestibular congruency of multisensory neurons in macaque parietal cortex. J Neurosci. 2011;31:17905–17916. doi: 10.1523/JNEUROSCI.4032-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang T, Britten KH. The responses of VIP neurons are sufficiently sensitive to support heading judgments. J Neurophysiol. 2010;103:1865–1873. doi: 10.1152/jn.00401.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang T, Heuer HW, Britten KH. Parietal area VIP neuronal responses to heading stimuli are encoded in head-centered coordinates. Neuron. 2004;42:993–1001. doi: 10.1016/j.neuron.2004.06.008. [DOI] [PubMed] [Google Scholar]