

Abstract
Temporal information in clinical narratives plays an important role in patients’ diagnosis, treatment and prognosis. In order to represent narrative information accurately, medical natural language processing (MLP) systems need to correctly identify and interpret temporal information. To promote research in this area, the Informatics for Integrating Biology and the Bedside (i2b2) project developed a temporally annotated corpus of clinical narratives. This corpus contains 310 de-identified discharge summaries, with annotations of clinical events, temporal expressions and temporal relations. This paper describes the process followed for the development of this corpus and discusses annotation guideline development, annotation methodology, and corpus quality.
Keywords: Natural Language Processing, Temporal Reasoning, Medical Informatics, Corpus Building, Annotation
1. Introduction
Electronic Medical Records (EMRs) contain significant amounts of unstructured narrative text, which can be turned into structured data with help from automated medical language processing (MLP) systems. Some sub-areas of MLP, such as de-identification and clinical concept (e.g. disorder, medication) extraction are well-studied. Other areas, such as analysis of the temporal structures embedded in clinical texts, are less so [1]. Besides being a more complicated task, we believe that the lack of availability of manually annotated clinical corpora with temporal information also hindered the progress of MLP in this area [2].
Temporal information in clinical narratives plays an important role in medical decision-making and care assessment [3]. Some examples of clinical applications that utilize temporal information include: diagnosis, prognosis and treatment decision support [3, 4], time specific clinical information extraction [5, 6, 7], and time-related question answering [8, 9, 10]. These applications rely on temporal reasoning systems which extract temporal information from natural language, and perform temporal inference over the extracted information. Temporal information in narrative texts includes the events and the temporal expressions that appear in the text, as well as the temporal relations among them.
In order to develop and evaluate temporal reasoning systems, we need clinical corpora annotated with temporal information. Given this need, the 2012 Informatics for Integrating Biology and the Bedside (i2b2) project provided the community with a corpus of temporally annotated clinical narratives [11]. This corpus contains the clinical history and the hospital course sections of 310 de-identified discharge summaries from Partners Healthcare and the Beth Israel Deaconess Medical Center, for a total of approximately 178,000 tokens. The corpus was annotated for three layers of information: events, temporal expressions and their normalization, and temporal relations. Our annotation scheme was adapted from TimeML [12]. More specifically, we annotate three types of temporal information: 1) EVENTs which represent the semantic events mentioned in the text that affect the patient’s clinical timeline; 2) TIMEX3s that represent temporal expressions of date, times, durations, and frequencies; and 3) TLINKs which represent the temporal relations between EVENTs and TIMEX3s. We refer to this corpus as the i2b2 temporal relations corpus.
In this paper, we present the process followed for the development of the i2b2 temporal relations corpus, including the creation of a temporal annotation scheme tailored to clinical narratives, the methodology for applying the scheme to the i2b2 temporal relations corpus, the evaluation of the resulting annotation quality, and a description of the resulting annotated corpus. We hope that this paper will: 1) inform the MLP researchers about the temporal data preparation process, 2) guide the development of future clinical temporal annotation guidelines, 3) caution against pitfalls and the issues often raised in the representation of temporal information, and 4) share our solutions to these problems with the community.
The remainder of this paper is organized as follows: Section 2 summarizes the related work in temporal representation and existing temporally annotated corpora in the general as well as the MLP domains. Section 3 summarizes our annotation guidelines. Section 4 presents our annotation methodology and procedures. The annotation quality evaluation and corpus statistics are presented in Section 5 and 6, respectively.
2. Related Work
2.1 Temporal annotation
A temporal representation scheme translates time-related information into a computer readable form to support temporal reasoning. Temporal annotation is a type of temporal representation that focuses on interpreting time-related natural language information. Defining a temporal representation scheme is non-trivial in that it requires the specification of many fundamental assumptions about time [13]. This task becomes even more challenging when the targeted temporal information is embedded in natural language because time-related concepts are usually vaguely and implicitly conveyed in free text [14, 15]. For instance the verbal event ‘know’ describes a continuous state, and the event ‘catch’ is instantaneous [2].
The most prominent challenges in temporal annotation include: 1) large search space in the assignment of TLINKs. Given the EVENTs and TIMEX3s in one document, the theoretical search space for TLINKs is (N-1)N/2 (N: total number of entities). 2) Multiple ways to represent the same set of TLINKs. TLINKs can be transitive (e.g. before or after) or equivalent (e.g. concurrence). For example, let ‘<’ represent the before relation, ‘>’ for the after relation, and ‘=’ for the concurrence relation, and for entities A, B, and C, we have ‘A<B, B=C’. We can equivalently represent this relation with ‘B>A, A<C, B=C’ among many other sets of TLINKs, which give the annotators flexibility during annotation but whose equivalence is difficult to manually confirm. For this reason, we usually need to compute temporal closure when handling TLINKs. The temporal closure of a set of TLINKs is the set of minimal transitive relations that contains the original TLINKs. In the previous example, the temporal closure of ‘A<B, B=C’ contains the following relations: ‘A<B, A<C, B>A, C>A, B=C, C=B’. 3) Conflict in TLINKs. The transitive and equivalent relations can give rise to conflicts in the annotations. For example, if ‘A<C’ is already established, then annotating ‘A>C’ would create a conflict. Such a conflict can be inferred from ‘non-conflicting’ relations (e.g. A=B, B>C) during temporal closure and can be difficult for even human annotators to spot. We will discuss our approaches to addressing these issues in Section 4.
2.2 Existing temporal annotation guidelines and corpora
With temporal reasoning attracting increasingly more research attention [16], the creation of temporally annotated datasets becomes a pressing task. As a result, several temporal annotation schemes and annotated datasets have become available [17, 18, 19, 20, 21, 22]. In the general domain, these datasets include:
TimeBank [17] and the AQUAINT corpora1 contain newswire articles annotated under the TimeML guidelines [12]. The TimeBank corpus contains 183 news reports and the AQUAINT corpus contains 73 news reports. The TimeML guidelines specify three types of entities (EVENTs, TIMEX3s, and Signals) as well as three types of relations (TLINKs, ALINKs, and SLINKs). In addition to the EVENT, TIMEX3 and TLINK tags that we introduced in Section 1, signals are functional words or phrases that indicate the temporal relation between two entities; ALINKs describe the aspectual relation between entities, such as initiating, terminating and continuing; SLINKs indicate the subordinate relations between EVENTs (e.g. the conditional or evidential relations between two EVENTs ) [23].
The TempEval [18, 19, 20] 2007 corpus applied a simplified TimeML annotation, and restricted the TLINK assignment to those 1) between EVENTs and document creation times, that is, the time stamp of the document creation; 2) between EVENTs/TIMEX3s in the same sentence and 3) between main EVENTs (syntactically dominating verbs) in adjacent sentences. The TempEval 2010 extended the 2007 annotations to multiple languages. TempEval 2012 used subsets of the TimeBank and AQUAINT corpora, as well as an automatically annotated English Gigaword corpus [24, 25, 26].
In the clinical domain, Galescu et al. [22] applied an adaptation of TimeML guidelines to 40 discharge summaries [27]. Savova et al. [28] also described an adaptation of TimeML to clinical narratives. The Clinical E-Science Framework (CLEF) project annotated a corpus of 167 clinical records for temporal relations [21]; however, they limited their annotations to intra-sentence temporal relations and to the temporal relations between events and document creation times. In addition to these full temporal relation annotation schema, there are also annotations that focus on some more specific temporal elements in the clinical narratives, such as conditions, temporal expressions [29, 7, 30]. These resources served as a good start at addressing the need for a temporally annotated MLP corpus, and highlighted the need for comprehensive temporal annotations that can support the extraction of the complete patient clinical timeline from narrative patient records. We aimed to fill this gap.
3. Design of i2b2 annotation guidelines
We built our annotation guidelines on the following principles:
Ease of Use: the annotators should become proficient in the task after a few short training sessions, and the human annotation burden should be light.
Completeness: the annotation should capture a broad range of key clinical concepts and it should support complete timeline extraction from medical records.
Definitiveness: the guidelines should be unambiguous so as to ensure inter-annotator agreement.
Maximum utilization of existing annotations: The guidelines should reuse and add value to existing corpora and annotations.
With these design principles in mind, we separated the annotation task into: clinical event annotation (EVENT), temporal expression annotation (TIMEX3), and temporal relation annotation (TLINK). Two annotators with clinical background assisted in the development of the annotation guidelines. After each round of pilot training (see Figure 1), the annotators were asked to independently annotate 5 clinical records (pilot annotations). We analyzed the errors and the disagreements in the pilot annotations after each round, and modified the guidelines accordingly. We repeated this process until the annotations stabilized. The guideline development process lasted two months. The finalized annotation guidelines can be found in the appendix.
Figure 1.
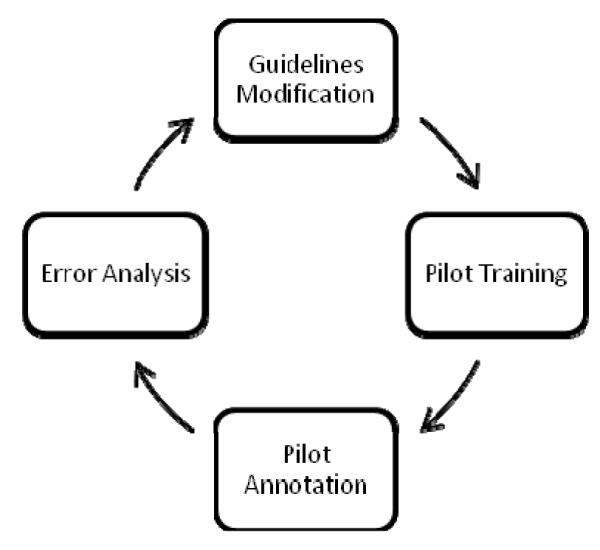
Annotation guidelines development process
3.1 Annotation scope
We annotated a corpus consisting of de-identified discharge summaries from Partners Healthcare and the Beth Israel Deaconess Medical Center [27, 31, 32]. After analyzing a set of stratified samples from these sources, we found that the clinical history and the hospital course sections of discharge summaries contained abundant temporal information expressed in narrative text. We therefore focused our efforts on these sections.
Our temporal annotation guidelines are adapted from TimeML. In addition to TimeML, we consulted the annotation guidelines of the THYME project [33]. As an effort to simplify the annotation task, we removed TimeML’s SIGNALs, as well as the ALINKs and the SLINKs. Our guidelines included EVENTs, TIMEX3s and TLINKs, with modified attributes (see section 3.2, 3.3 and 3.4). We also introduced a SECTIME (section time) tag, which keeps track of the ‘section creation date’ of each section in the discharge summary. The SECTIME for the clinical history section is defined as the date of admission, and the SECTIME for the hospital course section is the date of discharge.
Our i2b2 temporal relations corpus included previously generated layers of gold standard annotations, in the form of clinical concepts (problems, tests, treatments) [31] and coreference relations [32] which can support temporal reasoning. Locating a patient’s disease, treatment and test results on a timeline is important for care providers. Coreference, linking two mentions that refer to the same incidence of the same event, is a prerequisite for temporal reasoning. We used clinical concepts as pre-annotated EVENTs (see section 3.2), and the coreference relations as SIMULTANEOUS type TLINKs (see section 3.4).
3.2 EVENT Annotation
EVENTs include: clinical concepts (i.e. PROBLEMs, TESTs and TREATMENTs [31]), clinical departments (the mentions of the clinical departments or services where the patient was, is or will be admitted to), EVIDENTIALs (words or phrases that indicate the source of information such as the word ‘complained’ in ‘The patient complained about a week-long headache’) and OCCURRENCEs (other events such as ‘admit’, ‘transfer’ or ‘discharge’, …. that affect the patient’s clinical timeline).
EVENTs have three attributes, TYPE, MODALITY and POLARITY. The TYPE attribute specifies the EVENT as a PROBLEM, TEST, TREATMENT, CLINICAL_DEPT, EVIDENTIAL or OCCURRENCE. MODALITY specifies if an EVENT is factual, hypothetical, hedged or conditional. POLARITY specifies whether an EVENT has positive (POS) or negative (NEG) polarity. Figure 2 shows a snippet of a sample discharge summary; the EVENTs in this record are shown in Table 1.
Figure 2.

Sample clinical record snippet (Underscore: EVENTs, Italics: TIMEX3s)
Table 1.
EVENT annotation examples
| EVENT | TYPE | MODALITY | POLARITY |
|---|---|---|---|
| [Admission] | OCCURRENCE | FACTUAL | POS |
| [Discharge] | OCCURRENCE | FACTUAL | POS |
| [complained] | EVIDENTIAL | FACTUAL | POS |
| [increasing chest pains] | PROBLEM | FACTUAL | POS |
| [his admission] | OCCURRENCE | FACTUAL | POS |
| [the pain] | PROBLEM | FACTUAL | POS |
| [Diltiazen] | TREATMENT | FACTUAL | POS |
| [calling] | OCCURRENCE | FACTUAL | POS |
3.3 Temporal expression annotation
Temporal expressions in the clinical records are marked as TIMEX3s. Our guidelines include four types of TIMEX3s: dates, times, durations and frequencies. Each TIMEX3 needs to be normalized to the ISO8601 standard in its value (VAL). ISO8601 requires date/time TIMEX3s to be normalized to [YYYY-MMDD]T[HH:MM] format, and duration/frequency TIMEX3s to be normalized to R[#1 times]P[#2][Units] (repeat for #1 times during #2 units of time). For example, ‘twice every three weeks’ is normalized as R2P3W. Like the TimeML TIMEX3s, the i2b2 TIMEX3s also have a modifier attribute (MOD), which represents a subset of the TimeML TIMEX3 modifier values: MORE, LESS, APPROX, START, END MIDDLE and the default NA. Table 2 shows the sample annotations of TIMEX3s in the snippet displayed in Figure 2. TimeML uses temporal function, a mechanism that allows TIMEX3s to anchor to each other, to handle durations and relative time annotations. To simplify the annotation procedure, we omitted temporal functions, and used TLINKs between two TIMEX3s to handle the anchoring of durations and relative times (see guidelines for details).
Table 2.
TIMEX3 annotation examples
| TIMEX3 | TYPE | VAL | MOD |
|---|---|---|---|
| [09/14/2001] | DATE | 2001-09-14 | NA |
| [09/21/2001] | DATE | 2001-09-21 | NA |
| [the last three to four weeks] | DURATION | P3.5W | APPROX |
| [every few days] | FREQUENCY | RP2D | APPROX |
| [noon 09/17/01] | TIME | 2001-08-17T12:00 | NA |
| [q.d.] | FREQUENCY | RP1D | NA |
3.4 Temporal relation annotation
TLINKs mark the temporal relation between EVENTs and TIMEX3s. Our TLINK TYPEs include a subset of the TimeML TLINK TYPEs. These TYPEs are: BEFORE, AFTER, BEGUN_BY, ENDED_BY, DURING, SIMULTANEOUS, OVERLAP and BEFORE_OVERLAP. Table 3 shows the TLINKs of the snippet in Figure 2.
Table 3.
TLINK annotation examples
| FROM EXTENT | TYPE | TO EXTENT |
|---|---|---|
| [Admission] | SIMULTANEOUS | [09/14/2001] |
| [Discharge] | SIMULTANEOUS | [09/21/2001] |
| [complained] | BEFORE | SECTIME: 09/21/2001 |
| [increasing chest pains] | BEFORE | SECTIME: 09/21/2001 |
| [increasing chest pains] | OVERLAP | [the last three to four weeks] |
| [increasing chest pains] | BEFORE_OVERLAP | [complained] |
| [his admission] | BEFORE | SECTIME: 09/21/2001 |
| [the last three to four weeks] | ENDED_BY | [his admission] |
| [the pain] | BEFORE | SECTIME: 09/21/2001 |
| [the pain] | SIMULTANEOUS | [increasing chest pain] |
| [the pain] | OVERLAP | [every few days] |
| [Diltiazen] | BEFORE_OVERLAP | SECTIME: 09/21/2001 |
| [Diltiazen] | OVERLAP | [q.d.] |
| [Diltiazen] | BEGUN_BY | [noon 09/17/01] |
| [Diltiazen] | AFTER | [calling] |
| [calling] | BEFORE | SECTIME: 09/21/2001 |
In order to support the extraction of a complete timeline from discharge summaries, our guidelines allow the annotators to assign TLINKs to any pair of EVENTs/TIMEX3s in a record. Nonetheless, as pointed out in Section 2.1, there are multiple ways to represent the same set of TLINKs (e.g. any relations in the set ‘A<B, A<C, B>A, C>A, B=C, C=B’ are correct for representing ‘A<B, B=C’). Requiring the annotator to mark every relation in the temporal closure is time-consuming and unnecessary. Instead, we informed our annotators that we would compute temporal closure on the TLINKs that they marked, and hence they only needed to mark a minimal set of TLINKs. We provided them the following instructions to help them select candidate entity pairs when facing multiple possibilities to assign TLINKs:
- A TLINK can only be assigned to a pair of TIMEX3s, if:
- ○ it anchors a relative TIMEX3 (e.g. last Friday, three days before discharge) to an absolute TIMEX3 (e.g. a calendar date),
- ○ it marks the start point or the end point of a duration.
- A TLINK involving at least one EVENT can be marked, if:
- ○ there is a TIMEX3 in the same sentence or in adjacent sentences,
- ○ an explicit relation between EVENTs is signaled by words such as ‘before’ or ‘after’,
- ○ there is an implicit relation, such as a causal or concurrent relation, between EVENTs, and if such a relation cannot be inferred from existing TLINKs.
A TLINK must be assigned to every EVENT and its SECTIME.
4. Annotation procedure
The i2b2 temporal relations corpus was annotated in a single-pass, dual annotation with adjudication. As Figure 2 illustrates, the annotation process started with data selection and pre-annotation on EVENTs and coreference relations (i.e., SIMULTANEOUS TLINKs). Each record, with its pre-annotations, was assigned to two independent annotators. These annotators made a single pass over each record, completing all three layers of annotation in a single pass. Our pilot showed that single pass annotation was more efficient for our project. As opposed to a multi-pass annotation which requires the annotators to complete one of the layers, submit for adjudication, and continue to annotate the next layer on adjudicated records, single pass annotation had each annotator complete all three layers of annotation in a clinical record and then submit for adjudication, reducing total reading time as well as the overhead in submitting and receiving assignments.
Annotator Expertise
The team consists of eight annotators, four of whom have medical background. Roberts et al. [21] showed that annotators with medical background are more likely to find relations between clinical events. Our pilot study also showed that annotators with medical background were more successful in interpreting ambiguous or uncommon abbreviations, as well as finding TLINKs that were based on causal relations between clinical concepts. Therefore, in the dual annotation, the annotators with medical background were each paired with an annotator without medical background.
Annotation Tool
We chose to use the Multi-purpose Annotation Environment (MAE) toolkit for annotation and the Multi-document Adjudication Interface (MAI) toolkit for adjudication [34]. Due to the fact that we allow TLINKs to span sentences, and even sections, the annotation tool needs to display each clinical record in its entirety during annotation. The MAE/MAI tools also enable fast look-up of all relations of an entity as well as the look-up of all entities involved in a relation, which makes the tool an ideal choice for our task.
Training
The annotator training process is shown in Figure 4. We started with a 2-hour group tutorial meeting. Afterwards, each annotator received 5 training discharge summaries for practice. The trainer then reviewed and conducted error analysis on these practice annotations. Afterwards, the trainer held individual meetings with the annotators, as necessary, to better understand the sources of errors. The entire training process was repeated twice before annotations stabilized. The average time that an annotator spent in training (including full annotation of 10 training records) was 15.25 hours. During the practice annotation, the annotators were encouraged to utilize an online discussion board to raise questions and help each other understand the guidelines. A total of 37 threads, containing 128 messages, were posted in the discussion board. We found that the discussion board was helpful for annotators to quickly find answers to their questions when the trainer was not available; it also helped the trainer clarify the guidelines and prepare more targeted training sessions.
Figure 4.
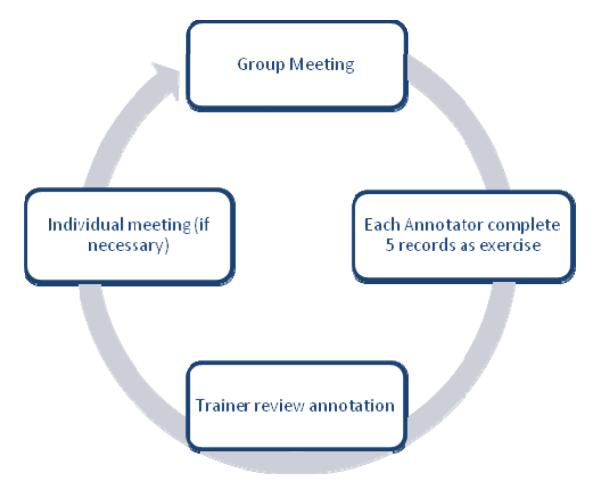
Annotator training process
Dual Annotation
The dual annotation ensured that each record was annotated by at least one medical background annotator. The average time for one annotator to complete a full annotation of one clinical record was about 55 minutes. The overall annotator-hours spent in annotation are 568 hours.
Adjudication
The disagreements between the annotators were presented to an adjudicator, different from the original annotators for tie-breaking. The adjudicators could edit or remove disputed annotations, or add new annotations, but could not edit or remove agreed annotations. The adjudicators participated in adjudication training before starting the task. Their training resembled annotation training. Average training time for one adjudicator was about 8 hours. The average time for an adjudicator to complete the adjudication of one clinical record was about 50 minutes – not much less than the annotation time.
The long adjudication time is caused by the fact that in order to address the disagreements between the two annotations, the adjudicators have to do the temporal relation inference manually. The TLINK disagreements usually correspond to the more difficult and vague temporal relations in clinical narratives. Moreover, each addition, removal or modification of the problematic TLINK may cause a potential conflict with TLINKs that are already adjudicated. Hence, the adjudicator not only needs to more carefully examine the context of the temporal relation, but also needs to understand the thought processes in the two annotations to be able to address the differences.
As an effort to reduce the manual inference work required in the adjudication process, we experimented with presenting to the adjudicator differences between the complete TLINKs transitive closures in the two annotations instead of the differences between the raw TLINKs. However, the transitive closure process drastically increased the number of disagreed TLINKs and made the adjudication process even more difficult. Another effort to improve the adjudication efficiency was to add the adjudicator-requested highlighting and indexing features in the relation adjudication tool, MAI2 [34]. The highlighting helps the adjudicators to easily locate related entities for a given TLINK, while the indexing feature helps them to browse other relations that involve a given entity. The adjudicators reported that these features were very helpful. Looking forward, we believe that an adjudication interface with embedded temporal closure and TLINK conflict detection components will benefit future temporal annotation efforts.
Post-processing
As mentioned in Section 2.1, some TLINKs may conflict others. Although the adjudicators did a good job of removing most of the conflicting TLINKs (e.g. ‘A>B’ against ‘A=B’), we found that adjudicated annotations contained an average of 5.24 conflicting TLINKs per record, amounting to 2.98% of all TLINKs. We manually corrected these conflicting TLINKs in post processing.
5. Annotation quality
EVENT/TIMEX3
To assess the quality of the EVENT/TIMEX3 annotations, we computed the average precision and recall between two annotators by holding one annotation as key and the other as response. Since precision and recall are symmetric, it does not matter which annotation is held as key. We reported both ‘exact span match’ and ‘partial span match’ results. In ‘exact span match’, two annotations are considered a match only if the text spans agree exactly. In ‘partial span match’, two annotations are considered a match if their text spans overlap; this includes exact span match. We choose to report average precision and recall as IAA for entity spans instead of kappa score [35] in order to make our result comparable to TimeBank’s IAA. As shown by Hripcsak et al. [36], in cases where the null labels are ubiquitous, the kappa score is comparable to average precision and recall. For attributes, we report the percentage of agreed attributes in partially matched EVENTs/TIMEX3s, and the kappa scores. We notice that the kappa scores for EVENT Modality, EVENT Polarity, TIMEX3 Type and TIMEX3 Modifier attributes are low. The reason for this is that each of these attributes has a dominant attribute value, for example, the majority of EVENTs have the Modality ‘Factual’, which increases the by-chance agreement score and thus lowers the kappa scores. The TimeBank 1.2 documentation3 reports similar inter-annotator agreement (IAA) measures. But the reported TimeBank agreement was computed over 10 documents annotated by two expert annotators, while our agreement is reported over the entire corpus. As shown in Table 4 and 5 below, the IAA of our entire corpus by all eight annotators is comparable to TimeBank’s IAA on ten documents between two expert annotators.
Table 4.
Average precision and recall on EVENT/TIMEX3 span compared against TimeBank
| Exact Match | Partial Match | |||
|---|---|---|---|---|
| i2b2 | TimeBank | i2b2 | TimeBank | |
| EVENT | .83 | .78 | .87 | .81 |
| TIMEX3 | .73 | .83 | .89 | .96 |
Table 5.
Accuracy of EVENT/TIMEX3 attribute agreement, compared against TimeBank
| EVENT | i2b2 | TimeBank | TIMEX3 | i2b2 | TimeBank | ||
|---|---|---|---|---|---|---|---|
| Accuracy | Kappa | Accuracy | Accuracy | Kappa | Accuracy | ||
| TYPE | 0.93 | 0.9 | 0.77 | TYPE | 0.9 | 0.37 | 1 |
| MODALITY | 0.96 | 0.37 | 1 | VAL | 0.75 | - | 0.9 |
| POLARITY | 0.97 | 0.74 | 1 | MOD | 0.83 | 0.21 | 0.95 |
TLINKs
Each TLINK connects two extents and specifies the TYPE of the TLINK. An extent can be an EVENT or a TIMEX3. We evaluate TLINK extent agreement and TYPE agreement separately using the three methods that have been reported in previous literature [17, 37, 38]:
comparing the raw TLINKs : The ‘raw against raw’ evaluation does not require the computation of temporal closure. However, since the annotators can assign TLINKs to any two extents, there are many different ways to annotate the exact same timeline. For example, if we have three extents A, B and C happening at the exact same time, we may choose any two and assign a ‘SIMULTANEOUS’ relation. This explains the low agreement score on raw against raw TLINK extent match (see column ‘Raw-Raw’ in Table 6). TimeBank uses this IAA method and reports a 0.55 extent agreement and 0.77 in TYPE agreement.
comparing the temporal closures generated from two TLINK annotations [37]. To account for the non-uniqueness of raw TLINK annotations, we also experimented with comparing the temporal closures of the two sets of TLINK annotations. The drawback of this method is its sensitivity to small changes in the annotation. In certain cases, this method heavily penalizes the agreement score because of a difference in just one TLINK between the annotations. Consider the following case: one of the raw TLINK annotations contains two sets of EVENTs such that the EVENTs within the same set are temporally related to each other, but there is no TLINKs between EVENTs from different sets. The other annotation is exact the same except that it contains an additional TLINK that links an EVENT of one set to an EVENT in the other set. The agreement score between the two annotations will be very low because the additional link in the second annotation may create transitive TLINKs between every pair of EVENTS between the two sets. The ‘Closure - Closure’ column in Table 6 exhibits the evaluation score using this method.
comparing the raw TLINK annotations against the temporal closure of the other annotation [38]: The ‘raw against closure’ evaluation computes the percentage of raw TLINKs in one annotation against the temporal closure of the other. It overcomes the drawbacks of the previous methods. The result of ‘raw - closure’ method is shown in the last column in Table 6.
Table 6.
TLINK inter-annotator agreement
| TLINK | Raw - Raw | Closure - Closure | Raw – Closure |
|---|---|---|---|
|
Extents
(Average precision and recall) |
0.39 | 0.37 | 0.86 |
|
TYPE
(Accuracy) |
0.79 | 0.72 | 0.73 |
Even though the overall TYPE accuracy looks acceptable, we noticed that the score is heavily influenced the dominating TLINK TYPEs. BEFORE_OVERLAP, DURING, BEGUN_BY and ENDED_BY TLINKs account for about 20% of the raw TLINKs, and only about 4% of the temporal closure. The accuracy for these TLINK TYPEs is much worse than those for the dominating TLINK TYPEs (BEFORE/AFTER and OVERLAP/SIMULTANEOUS). Table 7 shows the raw against closure score breakdowns for each TLINK TYPE. Table 8 shows the TLINK confusion matrix and indicates that the minority TLINK TYPEs caused much confusion between annotators. Thus, in the i2b2 temporal relations corpus, we collapsed the 8 TLINK TYPEs into 3 major TLINK TYPEs:
BEFORE: The original BEFORE, BEFORE_OVERLAP and ENDED_BY relations were merged as BEFORE relations
AFTER: The original AFTER and BEGUN_BY relations were merged as AFTER relations
OVERLAP: The original OVERLAP, SIMULTANEOUS and DURING relations were merged as OVERLAP relations
Table 7.
TLINK accuracy score TYPE breakdown (before merging)
| BEFORE /AFTER |
OVERLAP/ SIMULTANEOUS |
DURING | BEGUN_BY | BEFORE_ OVERLAP |
ENDED_BY | Overall | |
|---|---|---|---|---|---|---|---|
| Accuracy | 0.85 | 0.78 | 0.3 | 0.23 | 0.1 | 0.34 | 0.73 |
Table 8.
TLINK confusion matrix
| BEFORE | AFTER | OVERLAP/SIMULTANEOUS | BEFORE_OVERLAP | DURING | BEGUN | ENDED | |
|---|---|---|---|---|---|---|---|
| BEFORE | 7744 | 91 | 91 | 350 | 1 | 1 | 10 |
| AFTER | 130 | 261 | 51 | 11 | 4 | 15 | 2 |
|
OVERLAP/
SIMULTANEOUS |
963 | 205 | 6159 | 277 | 56 | 108 | 60 |
|
BEFORE_
OVERLAP |
918 | 39 | 312 | 398 | 33 | 3 | 2 |
| DURING | 1 | 21 | 244 | 6 | 103 | 5 | 3 |
| BEGUN_BY | 3 | 52 | 158 | 8 | 5 | 74 | 0 |
| ENDED_BY | 27 | 5 | 38 | 10 | 1 | 2 | 75 |
The TLINK TYPE agreement (raw against closure) by merged TYPEs is shown in Table 9. The overall TLINK agreement increased from 0.73 before the merge to 0.84 after the merge. However, the merging process inevitably created conflicting TLINKs in the gold standard. For example, given EVENTs A, B and C with the original TLINKs ‘A DURING B’, ‘C DURING B’ and ‘A BEFORE C’, after merging, the DURING relations become SIMULTANEOUS, and thus creating conflicting TLINKs. Fortunately, such conflicts are infrequent. There are on average 6.5 such TLINKs in each document (amounting to 3.6% of the total number of raw TLINKs, or 0.55% of the TLINK closure). Since most of the machine learning systems train on the TLINK closure, the number of conflicting TLINKs can be considered negligible. These conflicts are an inevitable result of merging different TLINK types. One of the ways to obtain a non-conflicting TLINK corpus using the present annotation would be to use the un-merged raw annotation, and address each conflicting TLINK case by case as during the merging process.
Table 9.
TLINK accuracy score TYPE breakdown (after merging)
| BEFORE /AFTER |
OVERLAP/ SIMULTANEOUS |
Overall | |
|---|---|---|---|
| Accuracy | 0.86 | 0.81 | 0.84 |
6. i2b2 Temporal Relations Corpus
The i2b2 temporal relations corpus consists of 310 discharge summaries of more than 178,000 tokens. The annotated corpus includes both merged and unmerged TLINK annotations and can be obtained from https://www.i2b2.org/NLP. On average, each discharge summary in the corpus contains 86.6 EVENTs, 12.4 TIMEX3s and 176 raw TLINKs (1145.8 TLINKs in the temporal closure). The EVENT, TIMEX3, TLINK (before temporal closure) TYPE distributions are shown in Table 10. The TLINK TYPE distribution in temporal closures is shown in Table 11.
Table 10.
Annotation TYPE distribution
| EVENTS | TIMEX3 | TLINK (before TC) | |||
|---|---|---|---|---|---|
| OCCURRENCE | 17.9 % | DATE | 70.5 % | BEFORE/AFTER | 13.0 % |
| EVIDENTIAL | 4.1 % | TIME | 2.7 % | OVERLAP/SIMULTANEO | 66.6 % |
| TEST | 16.4 % | DURATION | 16.7 % | DURING | 4.5 % |
| PROBLEM | 32.4 % | FREQUENCY | 10.1 % | BEFORE_OVERLAP | 9.0 % |
| TREATMENT | 24.4 % | BEGUN_BY | 3.7 % | ||
| CLINICAL DEPT | 4.9 % | ENDED_BY | 2.7 % | ||
Table 11.
TLINK TYPE distribution in temporal closures
| BEFORE/AFTER | OVERLAP/ SIMULTANEOUS |
DURING | BEFORE_OVERLAP | BEGUN_BY | ENDED_BY |
|---|---|---|---|---|---|
| 80.9% | 14.7% | 0.7% | 0.4% | 1.6% | 1.7% |
7. Conclusions
i2b2 created a temporally annotated discharge summary corpus that is accessible by the research community. The i2b2 temporal relations corpus provides a rich resource for temporal reasoning study in the clinical domain. The annotation quality of this corpus is on par with stable and proven temporal annotation corpora in the general domain. The temporal reasoning systems that perform well on this corpus can potentially support time-related downstream clinical applications on narrative discharge summaries, such as time-specific question answering, medication reconciliation, and computer assisted coding.
We identified several challenges in temporal annotation, including: the handling of TLINK conflicts in annotation time; the TLINK closure representation in adjudication and the trade-off between the administrative overhead in multi-pass annotation and the quality of the single-pass annotation. We believe that addressing these issues will help increase annotation efficiency and accuracy in future temporal annotation tasks.
Supplementary Material
Research Highlights.
This paper describes the creation of a temporally annotated clinical corpus
It is the largest publically available clinical corpus with full temporal information
- This paper
- ○ informs the MLP researchers about the temporal data preparation process
- ○ guides the development of future clinical temporal annotation guidelines
- ○ cautions against pitfalls and the issues often raised in the representation of temporal information
* This paper describes the creation of a temporally annotated clinical corpus
* It is the largest publically available clinical corpus with full temporal information
* This paper informs the MLP researchers about the temporal data preparation process
* This paper guides the development of future clinical temporal annotation guidelines
* It cautions against pitfalls and the issues often raised in the temporal representation
Figure 3.

Annotation process
Acknowledgments
Funding: This project was supported by Informatics for Integrating Biology and the Bedside (i2b2) award No. 2U54LM008748 from the National Institutes of Health (NIH)/National Q5 Library of Medicine (NLM), by the National Heart, Lung, and Blood Institute (NHLBI), and by award No. 1R13LM01141101 from the NIH NLM. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NLM, NHLBI, or NIH.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
The author of the MAE/MAI toolkit [34], Amber Stubbs, kindly provided these requested features for this project.
8. Reference
- [1].Meystre S, Savova G, Kipper-Schuler K, Hurdle J, et al. Extracting information from textual documents in the electronic health record: a review of recent research. Yearb Med Inform. 2008;35:128–44. [PubMed] [Google Scholar]
- [2].Sun W, Rumshisky A, Uzuner O. Temperal reasoning on clinical text: the state of the art. Journal of the American Medical Informatics Association. 2013 doi: 10.1136/amiajnl-2013-001760. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Augusto JC. Temporal reasoning for decision support in medicine. Artificial Intelligence in Medicine. 2005;33(1):1–24. doi: 10.1016/j.artmed.2004.07.006. [DOI] [PubMed] [Google Scholar]
- [4].Michael Stacey and Carolyn McGregor. Temporal abstraction in intelligent clinical data analysis: A survey. Artificial Intelligence in Medicine. 2007;39(1):1–24. doi: 10.1016/j.artmed.2006.08.002. [DOI] [PubMed] [Google Scholar]
- [5].Denny Joshua C, Peterson Josh F, Choma Neesha N, Xu Hua, Miller Randolph A, Bastarache Lisa, Peterson Neeraja B. Extracting timing and status descriptors for colonoscopy testing from electronic medical records. Journal of the American Medical Informatics Association. 2010;17(4):383–388. doi: 10.1136/jamia.2010.004804. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Liu Mei, Jiang Min, Kawai Vivian K, Stein Charles M, Roden Dan M, Denny Joshua C, Xu Hua. Modeling drug exposure data in electronic medical records: an application to warfarin. AMIA Annual Symposium Proceedings; American Medical Informatics Association; 2011. p. 815. [PMC free article] [PubMed] [Google Scholar]
- [7].Irvine Ann K, Haas Stephanie W, Sullivan Tessa. Tn-ties: A system for extracting temporal information from emergency department triage notes. AMIA Annual Symposium proceedings; American Medical Informatics Association; 2008. p. 328. [PMC free article] [PubMed] [Google Scholar]
- [8].Zhou Li, Parsons Simon, Hripcsak George. The evaluation of a temporal reasoning system in processing clinical discharge summaries. Journal of the American Medical Informatics Association. 2008;15(1):99–106. doi: 10.1197/jamia.M2467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Clark Kimberly K, Sharma Deepak K, Chute Christopher G, Tao Cui. Application of a temporal reasoning framework tool in analysis of medical device adverse events. AMIA Annual Symposium Proceedings; American Medical Informatics Association; 2011. p. 1366. [PMC free article] [PubMed] [Google Scholar]
- [10].Li M, Patrick J. Extracting temporal information from electronic patient records. AMIA Annual Symposium Proceedings; 2012. p. 542. [PMC free article] [PubMed] [Google Scholar]
- [11].Sun W, Rumshisky A, Uzuner O. Evaluating temporal relations in clinical text: 2012 i2b2 challenge. Journal of the American Medical Informatics Association. 2013 doi: 10.1136/amiajnl-2013-001628. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Pustejovsky J, Castano J, Ingria R, Sauri R, Gaizauskas R, Setzer A, Katz G, Radev D. Timeml: Robust specification of event and temporal expressions in text. New Directions in Question Answering. 2003;3:28–34. [Google Scholar]
- [13].Augusto JC. The logical approach to temporal reasoning. Artificial Intelligence Review. 2001;16(4):301–333. [Google Scholar]
- [14].Mani I, Pustejovsky J, Gaizauskas R. The language of time: a reader. Oxford University Press; 2005. [Google Scholar]
- [15].Allen JF. An interval-based representation of temporal knowledge. Proc. 7th International Joint Conference on Artificial Intelligence; Vancouver, Canada. 1981. pp. 221–226. [Google Scholar]
- [16].Mani I, Pustejovsky J, Sundheim B. Introduction to the special issue on temporal information processing. ACM Transactions on Asian Language Information Processing (TALIP) 2004;3(1):1–10. [Google Scholar]
- [17].Pustejovsky J, Hanks P, Sauri R, See A, Gaizauskas R, Setzer A, Radev D, Sundheim B, Day D, Ferro L, et al. The timebank corpus. Corpus Linguistics. 2003;volume 2003:40. [Google Scholar]
- [18].Verhagen M, Gaizauskas R, Schilder F, Hepple M, Katz G, Pustejovsky J. Semeval-2007 task 15: Tempeval temporal relation identification. Proceedings of the 4th International Workshop on Semantic Evaluations.2007. pp. 75–80. [Google Scholar]
- [19].Verhagen M, Sauri R, Caselli T, Pustejovsky J. Semeval-2010 task 13: Tempeval-2. Proceedings of the 5th International Workshop on Semantic Evaluation; Association for Computational Linguistics; 2010. pp. 57–62. [Google Scholar]
- [20].UzZaman N, Llorens H, Allen J, Derczynski L, Verhagen M, Pustejovsky J. Tempeval-3: Evaluating events, time expressions, and temporal relations. arXiv preprint arXiv. 2012:1206.5333. [Google Scholar]
- [21].Roberts A, Gaizauskas R, Hepple M, Demetriou G, Guo Y, Setzer A, Roberts I. Semantic annotation of clinical text: The clef corpus. Proceedings of Building and evaluating resources for biomedical text mining: workshop at LREC.2008. [Google Scholar]
- [22].Galescu L, Blaylock N. A corpus of clinical narratives annotated with temporal information. Proceedings of the 2nd ACM SIGHIT symposium on International health informatics; ACM; 2012. pp. 715–720. [Google Scholar]
- [23].Gaizauskas Castaño J., Ingria R, Katz B, Knippen G, Littman B, Mani J, Pustejovskym I, Sanfilippo J, See A, Setzer A, Saurí A, Stubbs R, Sundheim A, Symonenko B, Verhagen S, Boguraev M, Timeml B. 1.2.1 a formal specification language for events and temporal expressions. 2005;10 [Google Scholar]
- [24].UzZaman N, Allen JF. Trips and trios system for tempeval-2: Extracting temporal information from text. Proceedings of the 5th International Workshop on Semantic Evaluation; Association for Computational Linguistics; 2010. pp. 276–283. [Google Scholar]
- [25].Llorens H, Saquete E, Navarro B. Tipsem (english and spanish): Evaluating crfs and semantic roles in tempeval-2. Proceedings of the 5th International Workshop on Semantic Evaluation.2010. pp. 284–291. [Google Scholar]
- [26].Graff D, Cieri C. English Gigaword. Linguistic Data Consortium; Philadelphia: 2003. [Google Scholar]
- [27].Uzuner O, Solti I, Cadag E. Extracting medication information from clinical text. Journal of the American Medical Informatics Association. 2010;17(5):514–518. doi: 10.1136/jamia.2010.003947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Savova G, Bethard S, Styler W, Martin J, Palmer M, Masanz J, Ward W. Towards temporal relation discovery from the clinical narrative. AMIA Annual Symposium Proceedings; American Medical Informatics Association; 2009. p. 568. [PMC free article] [PubMed] [Google Scholar]
- [29].Jordan PW, Mowery DL, Wiebe J, Chapman WW. Annotating conditions in clinical narratives to support temporal classification. Proc American Medical Informatics Association Symposium.2010. p. 1005. [Google Scholar]
- [30].Bramsen P, Deshpande P, Lee YK, Barzilay R. Finding temporal order in discharge summaries. AMIA Annual Symposium Proceedings; American Medical Informatics Association; 2006. p. 81. [PMC free article] [PubMed] [Google Scholar]
- [31].Uzuner O, South B, Shen S, DuVall S. i2b2/va challenge on concepts, assertions, and relations in clinical text. Journal of the American Medical Informatics Association. 2011;18(5):552–556. doi: 10.1136/amiajnl-2011-000203. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Uzuner O, Bodnari A, Shen S, Forbush T, Pestian J, South B. Evaluating the state of the art in coreference resolution for electronic medical records. Journal of the American Medical Informatics Association. 2012;19(5):786–791. doi: 10.1136/amiajnl-2011-000784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [33].Temporal histories of your medical events, thyme.
- [34].Stubbs A. Mae and mai: lightweight annotation and adjudication tools. Proceedings of the 5th Linguistic Annotation Workshop; Association for Computational Linguistics; 2011. pp. 129–133. [Google Scholar]
- [35].Fleiss Joseph L, Levin Bruce, Paik Myunghee Cho. Statistical methods for rates and proportions. John Wiley & Sons; 2013. [Google Scholar]
- [36].Hripcsak George, Rothschild Adam S. Agreement, the f-measure, and reliability in information retrieval. Journal of the American Medical Informatics Association. 2005;12(3):296–298. doi: 10.1197/jamia.M1733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Setzer A, Gaizauskas R, Hepple M. Using semantic inferences for temporal annotation comparison. Proceedings of the Fourth International Workshop on Inference in Computational Semantics (ICOS-4).2003. pp. 25–26. [Google Scholar]
- [38].UzZaman N, Allen J. Temporal evaluation. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies.2011. pp. 351–356. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.