

Abstract
The Arabic language is acquired by its native speakers both as a regional spoken Arabic dialect, acquired in early childhood as a first language, and as the more formal variety known as Modern Standard Arabic (MSA), typically acquired later in childhood. These varieties of Arabic show a range of linguistic similarities and differences. Since previous psycholinguistic research in Arabic has primarily used MSA, it remains to be established whether the same cognitive properties hold for the dialects. Here we focus on the morphological level, and ask whether roots and word patterns play similar or different roles in MSA and in the regional dialect known as Southern Tunisian Arabic (STA). In two intra-modal auditory-auditory priming experiments, we found similar results with strong priming effects for roots and patterns in both varieties. Despite differences in the timing and nature of the acquisition of MSA and STA, root and word pattern priming was clearly distinguishable from form-based and semantic-based priming in both varieties. The implication of these results for theories of Arabic diglossia and theories of morphological processing are discussed.
Keywords: Morphology, Diglossia, Language comprehension, Modern Standard Arabic, Dialectal Arabic
Native speakers of Arabic acquire their language in the special linguistic context of diglossia, where a regional spoken Arabic dialect (acquired as a first language) coexists with the more formal variety known as Modern Standard Arabic (MSA), typically acquired later in childhood (Badawi, 1973; Ferguson, 1959; Kirchhoff & Vergyri, 2005). The two varieties show both similarities and divergences at all levels of linguistic description. Since most psychological research on Arabic so far has been conducted on MSA, it is not clear whether the claims made about the cognitive processing and representation of Arabic are also true of the dialects. Here we focus on the role of morphology in the Arabic mental lexicon, and ask whether root and word pattern morphemes play similar or different roles in MSA and in the regional dialect known as Southern Tunisian Arabic (STA). We begin by summarising (1) the principal contrasts between the modes of acquisition of MSA and STA, (2) current views of the Arabic mental lexicon based on work with MSA—which are largely consistent with research in Hebrew, and (3) the main linguistic similarities and differences between MSA and STA. This background provides the motivation for the psycholinguistic tests we construct to probe the mental representations of root and word pattern morphemes in these two varieties of Arabic.
The acquisition of MSA and STA in modern Tunisia
MSA is the variety of Arabic shared by educated speakers throughout the Arabic world. It is the language used for written and formal oral communication such as broadcast news, courtroom language, and university lectures, and is generally the language of the mass media (radio, television, newspapers). Everyday communication, however, is more likely to be carried out in one of the various regional dialects (which typically do not exist in a written form).
Despite their common origins, MSA and regional dialects like STA differ in many details of their phonological, lexical, and morpho-syntactic properties, but the psycholinguistically most important differences are likely to be in their mode of acquisition. There are two aspects to this. The first is that the regional dialects are acquired as a mother tongue, and are spoken to the child from birth, with the child going through the usual stages of untaught early language acquisition. MSA, in contrast, is typically not acquired as a first language, although children are exposed to it as soon as they start to watch TV cartoons, hear the radio, or begin attending nursery school. Modern-day Arab children, as a result, are acquiring familiarity with MSA well before they start formal schooling (Badry, 2001; Omar, 1973). Nonetheless, full exposure to and immersion in MSA would normally not start until the child is 6 or 7 years old, with the onset of formal primary education, where the language of teaching is exclusively MSA.
This leads to the second main difference in the acquisition of MSA, which is that the properties of the language are taught as part of the school syllabus (e.g., comparable to the teaching of English grammar in British schools). Of particular relevance in the present context is that children are taught how the morphological system works, so that they develop an overt metalinguistic knowledge of roots and word patterns as the building blocks of MSA words. This kind of metalinguistic knowledge is not available for the regional dialect since its structure is never taught in an explicit way.
These contrasts between MSA and (in this case) STA raise several issues about how linguistic distinctions are acquired by language learners and how manner of acquisition interacts with the role of these distinctions in dynamic aspects of language production and comprehension. We will investigate a subset of these issues, using the auditory-auditory priming paradigm (Marslen-Wilson, Moss, & van Halen, 1996), to ask whether morphological structure, in the form of roots and word patterns, plays the same role in the processing of STA as we have previously observed for MSA. In doing so, we will be able to address the critical question of whether research using MSA, conducted under the appropriate sociolinguistic circumstances, should be considered equivalent to research into native language psycholinguistic systems in nondiglossic languages such as Hebrew, French, and English. This question is especially salient in the context of claims by some linguists that dialectal and standard Arabic are different languages (Heath, 1997; Versteegh, 1997), and by some psychologists, chiefly working on reading acquisition in Palestinian Arabic, that MSA constitutes a second language for the native Arabic speaker (Abu-Rabia, 2000; Ibrahim & Aharon-Peretz, 2005).
Morphological structure in the Semitic mental lexicon—evidence from MSA and Hebrew
The question of whether morphology, the language component concerned with the internal structure of words, provides an independent principle for lexical organisation and processing is a major empirical and theoretical issue in the study of language. Are morphemes, the smallest units of form and meaning, represented as independent units in the mental lexicon (Marslen-Wilson, Tyler, Waksler, & Older, 1994; Schreuder & Baayen, 1995; Taft, 1994), or is the mental lexicon mainly a repository of full forms (Butterworth, 1983), with morphological effects arising as a consequence of the learned mapping between form and meaning (Plaut & Gonnerman, 2000; Seidenberg, 1987; Seidenberg & Gonnerman, 2000)? In the context of a Semitic language such as Arabic or Hebrew these questions are equivalent to asking whether the mental lexicon is organised in terms of roots and word patterns (Boudelaa & Marslen-Wilson, 2004, 2005; Holes, 1995; Prunet, Béland, & Idrissi, 2000; Versteegh, 1997; Wright, 1995), or in terms of full forms or CCVC-stems as some linguists have recently argued (Benmamoun, 1998; Gafos, 2003).
Experimental research, mainly using priming techniques, has established both in Arabic and in Hebrew that primes and targets sharing a root (e.g., [madxalun]-[duxuulun] inlet-entering) prime each other (Boudelaa & Marslen-Wilson, 2003, 2004, 2005; Deutsch, Frost, Pollatsek, & Rayner, 2000; Frost, Forster, & Deutsch, 1997; Frost, Kugler, Deutsch, & Forster, 2001, 2005). More importantly, root priming in Semitic languages, unlike stem priming in Indo-European languages, is not significantly modulated by semantic variables. Words sharing a root morpheme facilitate each other even if the semantic interpretation of the root is different across prime and target, as in pairs like [katiibatun]-[maktabun] squadron-office, where the root {ktb} in the prime word is unrelated to the meaning of writing inherent in the target. Similarly strong priming effects are obtained for the word pattern morpheme in Arabic verbs and nouns (though only for verbs in Hebrew). Prime-target pairs like [tiӡaaratun]-[tʕibaaʕatun] trade-art of typography facilitate each other significantly by virtue of sharing the nominal word pattern {fiʕaalatun}, as do pairs like [ʔaskata]-[ʔaxraӡa] cause to keep quiet-cause to come out, which share the causative verbal word pattern [ʔafʕala]. These morphological effects are obtained even when semantically and orthographically related pairs either fail to prime, or prime at a later point during online processing (Boudelaa & Marslen-Wilson, 2005). In general, morphemic effects in Arabic can be convincingly dissociated from form- and meaning-based effects, making an account of Arabic morphemic effects simply in terms of an interaction between form and meaning hard to sustain (Plaut & Gonnerman, 2000; Seidenberg & Gonnerman, 2000).
These behavioral results mesh well with recent neuro-imaging and neuropsychological research into Arabic. In a study using electroencephalography to record brain responses to Arabic words differing either by a root consonant (e.g., [ʕariis]-[ʕariif] bridegroom-corporal), or a word pattern vowel (e.g., [ʕariis]-[ʕaruus] bridegroom-bride), we found that roots are supported by a bi-hemispheric fronto-central network, while word patterns engage a smaller network limited to classical language areas on the left (Boudelaa, Pulvermüller, Hauk, Shtyrov, & Marslen-Wilson, 2010). This dissociation is corroborated by neuropsychological evidence showing that speakers of Semitic languages may show selective impairment of the root (Prunet et al., 2000), or the word pattern (Barkai, 1980). Taken together the behavioral, imaging and neuropsychological evidence strongly suggest that morphology is a significant principle of lexical organisation, and that Arabic surface forms are automatically decomposed into roots and word patterns during lexical access.
Linguistic similarities and differences between MSA and STA
To construct an informed test of the cognitive consequences of the differences in modes of acquisition between MSA and STA, we need to take into account a range of linguistic differences between MSA and the regional dialects, while also bearing in mind the fundamental underlying similarities between these two varieties. For MSA and STA, although the contrast between them has not itself been systematically studied, the results of studies comparing MSA and other dialects (Badawi, 1973; Holes, 1995; Kirchhoff & Vergyri, 2005; Maamouri, 1998; Saiegh-Haddad, 2003, 2005), as well as our own observations,1 suggest that the dialects are different in similar ways from MSA, and that this difference affects several linguistic components. STA and MSA do not have identical phonological inventories, with a small number of phonemes being realised differently—for example, the MSA voiceless uvular plosive /q/ is realised as a voiced velar plosive /g/ in STA. Syntactically, and in common with other dialects, the dominant VSO word order in MSA is superseded by an SVO order in STA (Holes, 1995; Kirchhoff & Vergyri, 2005; Maamouri, 1998; Saiegh-Haddad, 2003). At the level of the lexeme, the two varieties have several items which belong exclusively to one or the other—the word for car, for example, is [sajjaaratun] in MSA, but [kәrhbә] in STA.
Noteworthy differences between MSA and STA are also found in the morphological domain, although the basic interplay between root and word pattern morpheme seems intact. STA, for example, exhibits some restructuring of the word pattern morpheme both at the level of form and function. At the form level, MSA word patterns often appear in STA with reduced or deleted vowels and/or consonants. For example, the MSA word patterns {fuʕuulun} and {ʔinfaʕala} correspond, respectively, to the STA {fʕuul} and {nfәʕal} patterns. Functionally some STA word patterns differ significantly from their MSA counterparts. The active-passive opposition, for example, which is coded word pattern internally in MSA by changing the vowels of the word pattern {faʕal} into {fuʕil} (e.g., [kasar]-[kusir] break-be broken), is expressed by using a different word pattern in STA (e.g., [kәsar]-[ʔłnkәsar] break-be broken). There are also some cases where word patterns in STA diverge substantially in form from their counterparts in MSA—for example the STA word pattern [faʕlaaӡi], with the meaning of profession noun (as in [marmaaӡi] building worker, [taksaaӡi] taxi driver or owner), has the form {faʕʕaal} in MSA.
There are also distributional differences between root morphemes in STA and MSA, with the dialectal variety being less quantitatively productive, in the sense that roots and word patterns participate in the creation of fewer forms. The root {ktb} writing, for example, is encountered in 31 surface forms in MSA (Wehr, 1994), whilst in STA it appears in only 8 forms. This difference in morphological family size also holds for word patterns. More generally, the average number of forms featuring the same root is 13 in MSA but 4 in STA.2 This means that STA roots and word patterns occur in a less densely populated morphological environment than their MSA counterparts. However, if we look at word pattern and root productivity from the qualitative perspective, defining it as the potential for a morphemic unit to be involved in the creation of new forms (Baayen & Lieber, 1991; Boudelaa & Gaskell, 2002; Marslen-Wilson, Ford, Older, & Zhou, 1996), then roots and word patterns, especially verbal word patterns, seem equally productive in the two varieties.
Morphological representation and processing in STA and MSA: Experimental issues
In the context of the differences in mode of acquisition of MTA and STA highlighted earlier, we use two parallel auditory-auditory priming experiments to ask whether the same cognitive processing mechanisms are at play in the two varieties during the comprehension of morphologically complex words. In particular, does STA reveal similar evidence to MSA of morphological structure being extracted from speech and represented as an independent aspect of lexical representation? Do STA roots and word patterns prime each other, and are such effects distinguishable from purely semantic and purely phonological effects as they are for MSA?
Previous research in MSA (and in Hebrew) has mainly used visually based priming tasks—either masked priming (where both prime and target are written forms) or cross-modal priming, where an auditory prime is followed by a visual target. These are not suitable for research in STA, which like other regional dialects does not exist in a stable written form. Instead we use auditory-auditory priming, where an auditory prime word is closely followed (at lags of 250 msc or less) by an auditory target, to which the participant makes a lexical decision response. Previous research, both in MSA (Boudelaa & Marslen-Wilson, 2003) andin English (e.g., Marslen-Wilson &Zhou, 1999; Monsell & Hirsh, 1998), shows that this task is strongly sensitive to the morphological links between prime and target. In the earlier Arabic research, furthermore, focusing on different morphemic constituents of the word pattern morpheme (Boudelaa & Marslen-Wilson, 2003), we saw exactly parallel effects in auditory-auditory priming as in masked priming and in cross-modal auditory-visual priming.
In Tables 1 and 2, we lay out the design of the matched sets of conditions, in STA and MSA, designed to determine (1) whether priming by STA roots and patterns can be observed, (2) whether the pattern of priming across conditions is comparable for STA and MSA roots and patterns, and (c) whether root and word pattern priming in each variety can be clearly distinguished from semantic priming and phonological priming. Teasing apart morphological effects from semantic and phonological effects has been a long-standing concern in psychological research aimed at distinguishing theories which view morphology as an independent level of representation (Marslen-Wilson et al., 1994; Schreuder & Baayen, 1995; Taft, 1994) from those which view it as a correlation between form and meaning (Plaut & Gonnerman, 2000; Rueckl & Raveh, 1999; Seidenberg, 1987; Seidenberg & Gonnerman, 2000).
TABLE 1.
STA experimental conditions and sample stimuli
|
Prime |
|||
|---|---|---|---|
| Conditions | Baseline | Test | Target |
| 1. + WP | [ħәsaan] | [sʕarrif] | [kallim] |
| Horse | exchange | talk to | |
| 2. + Phon 1 | [ӡaldah] | [ħӡær] | [bәlæɤ] |
| Whipping | stone | Reach | |
| 3. + R + S | [kәtif] | [buxәl] | [bәxiil] |
| Shoulder | stinginess | stingy | |
| 4. + R − S | [mlææxәh] | [frææħәh] | [færħææn] |
| shoe repairing trade | litter | happy | |
| 5. + Phon 2 | [dabbuus] | [mæzruub] | [mæzәrʕәh] |
| Stick | in a hurry | farm | |
TABLE 2.
MSA experimental conditions and sample stimuli
|
Prime |
|||
|---|---|---|---|
| Conditions | Baseline | Test | Target |
| 1.+ WP | [buʔsun] | [ʔakala] | [xaraӡa] |
| Misery | eat | go out | |
| 2. + Phon 1 | [buruuzun] | [ɤaajatun] | [ʕaalaӡa] |
| Prominence | goal | treat | |
| 3. + R + S | [kaamilun] | [ʃaahidun] | [ʃahaadatun] |
| Perfect | witness | testimony | |
| 4. + R–S | [mukuuθun] | [ɤuruuθun] | [ɤariibun] |
| Dwelling | sunset | foreign | |
| 5. + Phon 2 | [mindiilun] | [taʔӡiilun] | [taaӡun] |
| Handkerchief | deferment | crown | |
The first two conditions test for the presence of word pattern priming (we focus here on the examples in Table 1 for the STA stimuli; the same logic applies to the MSA stimuli in Table 2). In condition 1, labeled + WP, the target word (e.g., [kallim] talk to) and the related prime (e.g., [sʕarrif] exchange) share a verbal word pattern {fæʕʕil} (this conveys the meaning of active perfective in both prime and target). We used verbal rather than nominal word patterns because of the sensitivity of word pattern priming in Arabic to the productivity of the root with which it is combined (Boudelaa & Marslen-Wilson, 2011). STA lacks the necessary linguistic databases to provide adequate distributional information about root productivity in relation to nominal word patterns. For verbal word patterns, this problem is less severe since there are only 11 word patterns, and it is more straightforward to select stimulus materials with productive roots.
Response-times to the related prime-target pairs are compared both with an unrelated baseline condition ([ħәsʕaan] horse in Table 1) and with a separate phonological control set (Condition 2, labeled + Phon1 in Table 1).3 Since the overlap among primes and targets sharing a word pattern in condition 1 is mainly in terms of vowels, this control set of word pairs, matched on length in letters, syllables and familiarity, shares the same overlap in vowels but where these vowels belong to morphemically different word patterns. Thus, in the example pair [ħәӡær]-[bәlæɤ] stone-reach, the related prime and the target share two vowels (and the same CV-structure). This corresponds to the nominal word pattern {fәʕæl}, with the meaning masculine noun, in the prime word [ħәӡær], but to the verbal word pattern {fәʕæl}, meaning active perfective, in the target word [bәlæɤ]. This is a strong test for whether priming between pairs sharing a word-pattern is driven by surface phonological similarity or by sharing the same underlying morpheme. In previous research we have seen no priming in cases similar to Condition 2 here (e.g., Boudelaa & Marslen-Wilson, 2003, Experiment 3; Boudelaa & Marslen-Wilson, 2012). If these highly abstract grammatical morphemes are extracted on-line, as part of the process of comprehending STA, then we expect to see a similar pattern of results (priming in Condition 1 but not in Condition 2), across both the STA and MSA sets of word pattern-related contrasts. In each case priming is assessed relative to an unrelated baseline prime, averaging less than one segment in common with the target (see Table 5).
TABLE 5.
Mean phonological overlap and (standard deviation) between primes and targets across conditions in STA and MSA
|
Phonological
overlap |
||
|---|---|---|
| Conditions | STA | MSA |
| 1.+ WP | ||
| Test prime-target | 2.33 (0.48) | 3.29 (0.46) |
| Baseline prime-target | 0.67 (0.64) | 0.0 (0.0) |
| 2. + Phon1 | ||
| Test prime-target | 2.00 (0.00) | 2.08 (0.41) |
| Baseline prime-target | 0.13 (0.34) | 0.0 (0.0) |
| 3. + R + S | ||
| Test prime-target | 3.08 (0.28) | 3.21 (0.59) |
| Baseline prime-target | 0.04 (0.20) | 0.21 (0.41) |
| 4. + R − S | ||
| Test prime-target | 3.13 (0.34) | 3.46 (0.41) |
| Baseline prime-target | 0.08 (0.28) | 0.04 (0.20) |
| 5. + Phon 2 | ||
| Test prime-target | 2.33 (0.48) | 2.50 (0.66) |
| Baseline prime-target | 0.13 (0.34) | 0.08 (0.28) |
The remaining three conditions relate to the root morpheme in regional and standard Arabic, and are designed to separate out morphological effects from potentially confounding semantic effects, as well as controlling, as before, for possible phonological overlap effects. Condition 3, labeled + R + S, consists of primes like [buxәl] laziness, and targets like [bәxiil] lazy which share the same root {bxl} with the general meaning laziness, and where there is a transparent semantic relationship between them (as determined in a semantic judgment test). In contrast, Condition 4, + R-S, consists of prime-target pairs like [frææħә] litter and [farħaan] happy, which also share a root {frħ}, but whose semantic relationship is opaque. The phonological control condition for word-pattern priming (Condition 2 + Phon1) is not adequate here because root information is carried by consonants and not by vowels. Accordingly we contrast the two root priming conditions with a further control condition (Condition 5, labeled + Phon2), where the primes and targets share two to three consonants but do not share the same root. In the pair [mæzruub]-[mazirʕah] in a hurry-farm, for example, the related prime and the target share three consonants (mzr), while the actual root in the prime is {zrb} and the root in the target is {zrʕ}.
Again, the key finding in previous research in MSA, as well as in Hebrew (e.g., Frost et al, 1997), is that priming between pairs sharing a root is equally strong irrespective of the degree of semantic transparency, while no priming (and often some interference) is seen in phonological (or orthographic) overlap conditions. If the representation of root morphemes in STA is similarly independent of semantic support, and this is reflected in the same way in the mechanisms of online access and decomposition, then we expect to see the same pattern of priming results across both language varieties.
More generally, the quantitative and qualitative similarities and differences between STA and MSA in response to these sets of linguistic contrasts will allow us to evaluate the potential effects of the differences in the manner and the timing with which these varieties of Arabic are acquired. We have argued in previous research that the pervasive root and word pattern priming effects that we see for MSA reflect the obligatory nature of morphological composition and decomposition for almost all Arabic surface forms (Boudelaa & Marslen-Wilson, 2005; Marslen-Wilson, 2001), operating independently of the semantic properties of the forms involved. If obligatory morphological analysis underpins STA in the same way, then we should expect to see comparable root and word pattern priming effects.
There are various reasons, however, why MSA and STA might diverge. The most salient, of course, is the possibility that the ubiquity of the morphological priming effects in MSA—and especially their apparent independence from semantic links between prime and target—is in some way a consequence of the later acquisition of MSA, and the explicit teaching of its morphological structure in the classroom. Bentin and Frost (2001), for example, have suggested that MSA priming effects may be strongly influenced by metalinguistic knowledge of the relevant linguistic unit, where this knowledge is contingent on explicit learning. If so, then we may see less sensitivity in STA to the more specifically grammatical aspects of Arabic morphology, with weaker effects in the word pattern priming conditions, and more dependence on semantic support in the root priming conditions.
The nature of the morphological effects across the two varieties may also reflect the distributional differences between them. Since quantitative productivity (or family size) affects the root and word pattern priming effects observed for MSA (Boudelaa & Marslen-Wilson, 2011; for family size studies in Hebrew see Moscoso del Prado Martín et al., 2005), the two units may show weaker priming in STA given the smaller morphological family sizes in the dialect. Boudelaa and Marslen-Wilson (2011), using masked and cross-modal priming tasks in spoken and written MSA, show that word pattern priming in particular is sensitive to the family size of the root in the prime and target words. Although we are not using these specific priming tasks in this study, it is still possible that the smaller root family sizes in STA may reduce word pattern priming effects, as they seem to in MSA.
Two further sources of representational and processing differences between the two varieties would follow from the relatively later acquisition of MSA, and from its potential status as a “second language” (as discussed above). Both of these would point to slower and less efficient processing of MSA compared to STA. The “age of acquisition” (AoA) effect refers to the finding that words acquired earlier in life tend to be processed faster and more accurately than those acquired later. Accounts of AoA within a connectionist framework, for example, argue that items learned first produce the most important changes in the network's connection weights, so that later acquired items are forced to adapt to the already generated structure (Ellis & Lambon Ralph, 2000; Monaghan & Ellis, 2002). Since STA is acquired prior to MSA, this should lead to better overall performance in timed response tasks. This should hold in the current experiment, even though we do not have specific AoA data for the stimuli used here, either for STA or MSA. Statistically, however, if it were assumed that STA is acquired substantially earlier, as a complete and different language to the later acquired and differently taught MSA, then it follows that the overall AoA profile for the STA words and the MSA words in the experiment—which are matched in their other lexical properties—will also be substantially different. To the extent that MSA is considered to be a genuine second language—analogous, perhaps, to a German speaker learning Dutch—then these order of acquisition effects should be even stronger. If MSA does have a subsidiary neurocognitive status as a second language, this could anyway lead to generally poorer performance in terms of speed and accuracy, as reported in other studies of second languages (Isel, Baumgaertner, Thrän, Meisel, & Büchel, 2009).
METHOD
Participants
Sixty-eight volunteers, aged 16–20 years, from the High School of Tataouine, Southern Tunisia, took part in the experiment. Thirty-six of them were randomly assigned to the STA experiment and the remaining 32 to the MSA experiment. They were all native speakers and users of STA and MSA, and had no history of hearing loss or speech disorder.
Materials and design
Each of the five conditions described above and shown in Tables 1 and 2 consisted of 24 triplets: a target, a related test prime, and a baseline prime. In both experiments the baseline prime was matched as closely as possible to the test prime in terms of number of syllables, number of phonemes, and familiarity. In the absence of established frequency counts for STA, familiarity was estimated by 30 further subjects, recruited from the same population, who did not take part in either of the priming experiments. Their task was to rate an auditorily presented list of potential experimental items for familiarity on a 1–5 scale, with 1 representing not familiar at all and 5 standing for highly familiar. Only words rated at least 3 by 90% or more of the subjects were included in the experiments.
Since we are using auditory-auditory priming, it was also necessary to match the test and the baseline primes in both experiments on their Recognition Point (RP)—the point in a word at which it becomes unique (Marslen-Wilson, 1987; Marslen-Wilson & Welsh, 1978). Priming effects may be modulated by RP, since late RPs may potentially generate smaller priming effects. To compute the RP for the MSA words we used Al-Mawrid (Baalbaki, 2001), a dictionary based on the surface form itself and providing the competitor environment for every word. For STA, we presented all the experimental words (360 of them) in a reduced form of the gating task in which 5 native speakers heard each word at two points: (1) where the experimenter subjectively judged the RP to fall and (2) 50 milliseconds after this estimated RP. After each presentation participants wrote down what they thought the complete word was, and rated the confidence of their decision on a scale of 1 (“complete guess”) to 7 (“certainty”). The potential RP was defined as the point where 90% of the subjects isolated the correct word and had an average confidence rating of 5 or higher (Grosjean, 1980).
Tables 3 and 4 summarise the distributional properties of the stimuli in STA and MSA, respectively. The small differences in RP across conditions are not statistically significant. The average overlap in phonemes between primes and targets was also computed for each condition in both experiments and is given in Table 5. The match between conditions and between language varieties in terms of phonological overlap was as good as we could achieve given the between-word design and linguistic constraints. In the data analyses reported below, we will use regression techniques to evaluate the possible contribution of this factor to priming.
TABLE 3.
Characteristics of STA materials across conditions
| Conditions | Number of syllables | Number of phonemes | Recognition point | Familiarity |
|---|---|---|---|---|
| 1.+ WP | ||||
| Baseline prime | 2.25 (0.61) | 5.54 (0.98) | 4.17 (1.01) | 4.25 (0.79) |
| Test prime | 2.33 (0.48) | 6.33 (1.09) | 5.25 (0.99) | 4.21 (0.83) |
| Target | 2.33 (0.48) | 6.29 (0.18) | 5.75 (1.03) | 4.25 (0.79) |
| 2. + Phon1 | ||||
| Baseline prime | 2.04 (0.36) | 5.13 (0.61) | 4.08 (0.83) | 3.96 (0.81) |
| Test prime | 2.04 (0.20) | 5.00 (0.0) | 4.63 (0.49) | 4.13 (0.95) |
| Target | 2.04 (0.20) | 5.00 (0.0) | 4.79 (0.51) | 3.92 (0.83) |
| 3. + R + S | ||||
| Baseline prime | 2.33 (0.56) | 5.83 (1.09) | 4.83 (1.43) | 4.08 (0.83) |
| Test prime | 2.17 (0.48) | 5.92 (1.14) | 4.63 (0.92) | 4.17 (0.82) |
| Target | 2.13 (0.45) | 5.54 (0.72) | 4.42 (1.01) | 4.21 (0.83) |
| 4. + R − S | ||||
| Baseline prime | 2.21 (0.51) | 5.54 (1.02) | 4.29 (1.33) | 3.96 (0.69) |
| Test prime | 2.17 (0.56) | 5.79 (1.32) | 4.58 (1.25) | 3.96 (0.75) |
| Target | 2.08 (0.28) | 5.54 (0.83) | 4.63 (0.92) | 4.08 (0.78) |
| 5. + Phon2 | ||||
| Baseline prime | 2.13 (0.45) | 5.25 (0.74) | 4.00 (0.59) | 4.17 (0.70) |
| Test prime | 2.08 (0.28) | 5.42 (0.83) | 4.46 (0.93) | 4.21 (0.72) |
| Target | 2.08 (0.28) | 5.75 (1.11) | 4.38 (1.06) | 4.13 (0.74) |
TABLE 4.
Characteristics of MSA materials across conditions
| Conditions | Number of syllables | Number of phonemes | Recognition point | Familiarity |
|---|---|---|---|---|
| 1.+ WP | ||||
| Baseline prime | 2.71 (0.46) | 6.92 (0.93) | 4.33 (0.70) | 3.83 (0.82) |
| Test prime | 3.29 (0.46) | 7.33 (1.17) | 5.83 (1.40) | 4.00 (0.88) |
| Target | 3.29 (0.46) | 7.33 (1.17) | 5.96 (1.04) | 4.08 (0.88) |
| 2. + Phon1 | ||||
| Baseline prime | 2.63 (0.58) | 6.17 (1.05) | 4.33 (1.05) | 3.71 (0.75) |
| Test prime | 3.08 (0.28) | 7.58 (0.72) | 5.38 (0.88) | 3.75 (0.61) |
| Target | 3.17 (0.38) | 6.88 (1.12) | 5.79 (1.14) | 4.17 (0.87) |
| 3. + R + S | ||||
| Baseline prime | 3.33 (0.48) | 8.17 (1.01) | 5.17 (1.05) | 3.92 (0.78) |
| Test prime | 3.38 (0.49) | 8.29 (1.08) | 5.67 (1.24) | 4.08 (0.58) |
| Target | 3.50 (0.59) | 8.46 (1.22) | 5.79 (0.98) | 4.08 (0.78) |
| 4. + R − S | ||||
| Baseline prime | 3.42 (0.58) | 8.13 (1.36) | 5.71 (0.86) | 3.83 (0.92) |
| Test prime | 3.33 (0.64) | 8.17 (1.40) | 5.63 (1.10) | 4.17 (0.64) |
| Target | 3.50 (0.72) | 8.42 (1.47) | 5.42 (1.32) | 3.96 (0.69) |
| 5. + Phon2 | ||||
| Baseline prime | 3.13 (0.34) | 7.75 (0.79) | 5.21 (1.10) | 3.92 (0.88) |
| Test prime | 3.08 (0.50) | 7.92 (1.10) | 5.63 (1.10) | 3.46 (0.59) |
| Target | 3.00 (0.72) | 7.25 (1.26) | 5.00 (1.10) | 4.17 (0.87) |
The degree of semantic relationship between primes and targets in each condition was determined in another pretest in which a further 30 participants (who did not take part either in the priming experiments or the familiarity pre-test) rated possible prime-target pairs and unrelated filler pairs on a 9-point scale of semantic relatedness, with 9 representing highly related in meaning and 1 representing not related at all. Fifteen of the subjects rated STA pairs and 15 MSA pairs. The word pairs were presented to them auditorily. To encourage the participants not to use form overlap to bias their responses, the list included filler pairs that were related in form but not in meaning. We accepted prime-target pairs for the semantically related conditions, + R + S, if they were given average ratings of over 7.00; and for the semantically unrelated conditions, + R − S if they were given average ratings of 3.00 or below. The overall average rating for the + WP pairs used in the experiments was 1.7.
The STA and MSA roots and patterns were further matched on their qualitative productivity, in the sense that they were all potentially usable to create novel forms. The MSA items were quantitatively productive, with roots and verbal word patterns having morphological family sizes averaging 14.4 and 553 surface forms respectively.4 For the STA items, the roots and patterns were generally less productive, reflecting the overall characteristics of this variety, with roots appearing on average in 7.66 forms and verbal patterns featuring in less than a hundred forms. We will use regression analyses to evaluate the contributions of quantitative productivity to priming in the two varieties.
Another 120 words were selected in each variety and paired with pseudoword targets in order to provide 50% NO responses for the lexical decision task. The pseudowords were formed by changing one or two root phonemes in existing STA and MSA words. For example the STA word [wæhәræ] charisma, was converted into the pseudoword ∗[wæhәtʕæ] by changing the last phoneme /r/ of the root {whr} into a/tʕ/. To mimic the relationship between word-word pairs, half of the pseudoword targets shared a vocalic or a consonantal phonological overlap with their word primes. Because auditory-auditory priming is an overt task it was necessary to reduce the proportion of relatedness in the experiment to discourage participants from developing response strategies. A further 60 unrelated word-word pairs and 60 unrelated word-pseudoword pairs were constructed for each language variety, bringing the relatedness proportion down to 33% in both experiments. To familiarise the subjects with the task, a set of 20 practice trials, consisting of 10 word responses and 10 pseudoword responses, was constructed for each variety. The practice trials were representative of the overall experimental trials.
Two experimental lists were constructed each consisting of 190 word-word responses and 190 word-pseudoword responses. The stimuli were rotated in each list such that the same prime or target was never heard by any subject more than once.5 Overall 86% of the materials used cognate roots—that is, roots which were common to both varieties. In 10% of these the identical root was used in both experiments. The remaining 14% of roots belonged exclusively either to the dialect or to MSA. This reflects the general lexical distributions for the two varieties, where most of their lexical stock is shared.
Materials and apparatus
The words were recorded by a native speaker of STA and MSA and digitised at a sampling rate of 44 kHz. They were then downsampled to 22 kHz using the coolEdit program and stored on a portable PC. The items were recorded in different sessions in random sequence but with members of prime-probe pairs in each variety well separated to avoid any similarities in voice quality. Three portable PCs were used to allow testing three subjects simultaneously in a quiet room. They heard the stimuli at a comfortable level through HD 250 Sennheiser headphones. Each trial consisted of an auditory prime followed by a 50 ms SOA and a target word or pseudoword. This SOA was chosen because it was sufficient to prevent the two words from being heard as one unit, but minimised the possibilities for strategic factors to intervene. The time out was 2,000 ms, and the inter-trial interval was 1,000 ms. Timing and response collection were controlled by laptop PCs running the DMDX package (Forster & Forster, 2003). Latencies were measured from the target words’ acoustic onset. Participants were instructed to make a lexical decision as quickly and as accurately as possible by pressing a YES or NO key. They were asked to press the YES button with the forefinger of their preferred hand. In both varieties, an experimental session lasted about 35 minutes, and started with the practice trials followed by the rest of the stimuli. Participants were allowed to rest at different intervals during the experiment, and prompted to press the space bar to carry on when they were ready.
RESULTS
Data from two participants in the STA experiment and one participant in the MSA experiment were removed because they had overall error rates exceeding 30%. Remaining errors (6.6% and 2.4% in the STA and the MSA experiments, respectively) were removed from the analyses. Timeouts, defined as responses longer than 2,000 ms, were also removed (0.1% in STA and 0.2% in MSA). No items were rejected as a result of excessive error rates. The raw RTs for all correct responses data were inverse-transformed to reduce the influence of outliers (Ratcliff, 1993), and entered into a series of analyses of variance (ANOVAs) for each experiment separately. The factors used were Condition (with five levels corresponding to the conditions shown in Tables 1 and 2), Prime Type (with the two levels of baseline and test prime) and List (also with two levels). Note that List was introduced only to extract any variance introduced by counterbalancing the items. The main factors Condition and Priming were treated as repeated measures in the subjects analysis (F1) and as unrepeated and repeated measures, respectively, in the items analysis.
STA experiment
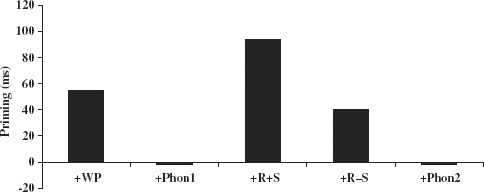
Mean RTs and error rates are displayed in Table 6. Priming effects, where response time in the test condition is subtracted from response time to the baseline prime, are shown in Figure 1.
TABLE 6.
STA experiment∗ Harmonic mean RTs (ms), error rates (%), and net priming by condition
|
Prime type |
|||
|---|---|---|---|
| Conditions | Baseline (%) | Test (%) | Priming (ms) |
| 1.+WP | 911(7.6) | 856(6.3) | 55 |
| 2.+Phon 1 | 944(7.3) | 946(7.6) | −2 |
| 3.+R+S | 894(6.1) | 799(4.4) | 94 |
| 4.+R−S | 864(7.6) | 824(4.4) | 40 |
| 5.+Phon 2 | 955(6.8) | 957(7.6%) | −2 |
Figure 1.
Net priming in the 5 conditions in STA.
There was a strong main effect of Condition [F1(4, 80) = 45.44, p <.000; F2(4, 110) = 20.49, p <.000], and Prime Type, with faster RTs to targets with related (877 ms) as opposed to baseline (919 ms) primes [F1(1, 128) = 59.16, p <.000; F2(1, 110) = 19.46, p <.000]. These two factors interacted significantly [F1(3, 80) = 6.87, p <.001; F2(4, 110) =4.65, p <.002]. In further Bonferroni corrected planned comparisons we evaluated the significance of priming in each of the five conditions and assessed the difference in the magnitude of priming between them (Keppel, 1982). These analyses revealed significant priming for condition 1, + WP, [F1(1, 32) = 5.79, p <.002; F2(1, 22) = 5.18, p <.03], condition 3, + R+S [F1(1, 32) = 66.39, p <.000; F2(1, 22) = 20.89, p <.000], and condition 4, +R −S, [F1(1, 32) = 6.17, p <.018; F2(1, 22) = 3.51, p <.04]. Pairwise comparisons on the test-baseline difference scores (i.e., magnitude of priming) showed that priming in the + WP condition was significantly different from that in the + Phon1 condition [F1(1, 32) = 4.15, p <.05; F2(1, 44) = 4.61, p <.03]. Similarly the magnitude of priming in the +R + S condition was significantly different from the + Phon2 condition [F1(1, 32) = 22.82, p <.000; F2(1, 44) = 11.61, p <.001], as was the difference in priming between the+R − S and the + Phon2 conditions [F1(1, 32) = 4.10, p <.05; F2(1, 44) = 5.48, p <.05]. Unlike the pattern of results reported in earlier studies of MSA using masked and cross-modal priming (Boudelaa & Marslen-Wilson, 2000, 2005), the 94 ms priming effect in the +R+S condition was reliably different from the 40 ms priming seen in the + R − S condition in the subjects analysis [F1(1,32) = 5.07, p <.03] though marginal in the items analysis [F2(1, 44) = 3.62, p <.06].
The error data were analysed in the same way as the latency data, but none of the main effects or the interaction between them reached significance. Finally we ran a series of regression analyses to determine whether or not differences in phonological overlap and productivity (i.e., number of root and pattern derivatives) between primes and targets modulated priming significantly. The results show that neither of these factors was a good predictor of priming (all F < 1). Together with the lack of priming in the two phonological conditions (i.e., + Phon1, + Phon2), this suggests that STA word pattern and root priming are genuine morphological effects triggered by access to a common underlying morpheme.
MSA experiment
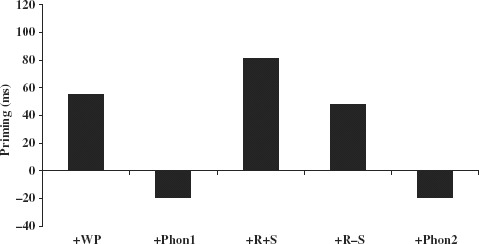
Mean RTs and error rates are displayed in Table 7, and priming effects as a function of condition are plotted in Figure 2.
TABLE 7.
MSA experiment—Harmonic mean RTs (ms), error rates (%), and net priming by condition
|
Prime type |
|||
|---|---|---|---|
| Conditions | Baseline (%) | Test (%) | Priming (ms) |
| 1.+ WP | 873 (1.9) | 819 (2.7) | 54 |
| 2. + Phon 1 | 900 (3.4) | 919 (2.4) | −19 |
| 3. + R+S | 844 (2.0) | 764 (1.5) | 81 |
| 4. + R − S | 872 (2.3) | 823 (2.3) | 48 |
| 5. + Phon 2 | 838 (2.2) | 857 (3.2) | −19 |
Figure 2.
Net priming in the 5 conditions in MSA.
As in the STA experiment, the main effect of Condition [F1(4, 116) = 13.83, p <.000; F2(4, 110) = 22.29, p <.000] and Prime Type [F1(1, 29) = 39.47, p <.000; F2(1, 110) = 4.74, p <.03] were significant with an advantage for targets with related (836 ms) as opposed to baseline (865 ms) primes. The interaction between these two factors was also significant [F1(3, 80) = 5.49, p <.002; F2(4, 110) = 4.99, p <.001]. Planned comparisons using Bonferroni corrected significance levels revealed reliable priming in the + WP condition [F1(1, 29) = 16.29, p <.000; F2(1, 22) = 4.91, p <.03], the+R + S condition [F1(1, 29) = 20.28, p <.000; F2(1, 22) = 11.40, p <.003], and the +R − S condition [F1(1, 29) = 10.98, p <.002; F2(1, 22) = 7.79, p <.01]. Priming in the + Phon1 and the + Phon2 conditions was not significant (all F's < 1). Turning to the differences in priming between the morphological conditions and their respective phonological control conditions, the amount of facilitation in the + WP and the + Phon1 conditions was significantly different [F1(1, 29) = 5.23, p <.03; F2(1, 46) = 6.95, p <.01], as was the difference between + R + S and + Phon2 [F1(1, 29) = 16.62, p <.000; F2(1, 46) = 8.52, p <.005], and +R − S and + Phon2 [F1(1, 29) = 6.65, p <.015; F2(1, 46) = 6.97, p <.01]. The 33 ms priming gain in the + R + S condition (81 ms) over the +R − S condition (48 ms) did not reach significance (all Fs < 1).
Similar analyses on the error data revealed no significant effects. In a final regression analysis, the factors of overlap in phonemes between primes and targets, and of root and pattern quantitative productivity (i.e., number of surface forms featuring a given root or a given word pattern) were entered as a possible predictor of amount of priming. As in the STA experiments, neither factor proved to be a significant predictor of priming in any of the five conditions (all Fs < 1).
Combined analysis
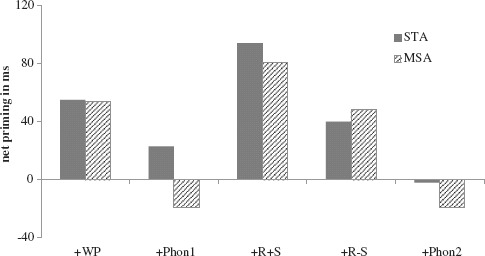
In order to determine whether there were significant differences in the pattern of priming across the five probe positions tested in STA and MSA, we combined the data from the two experiments into single analysis (Tyler, Moss, Galpin, & Voice, 2002). The inverse transformed latency scores following test prime and baseline prime were normalized and entered into a three-way ANOVA with the factors Condition (5 levels), Prime Type (2 levels: Related and Unrelated), and Language Variety (2 levels: STA and MSA), with List (2 levels), again used to correct for variance due to counterbalancing. The factor Language Variety was coded as a between-group factor both in the analysis by subjects and by items. This combined analysis did not show any main effect of Language Variety, F1 and F2 < 1, nor any interaction between Language Variety and other factors (Language Variety × Condition, and Language Variety × Prime Type and Language Variety × Condition × Prime Type; all Fs < 1). However, the effects of Condition [F1(4, 61) = 4.33, p <.003; F2(4, 220) = 43.50, p <.000], Prime Type [F1(1, 61) = 18.00, p <.000; F2(1, 220) = 13.91, p <.000], and their two-way interaction [F1(4, 61) = 4.91, p <.001; F2(4, 220) = 12.20, p <.000] were highly significant both by subjects and items. A similar analysis run on the accuracy data did not reveal any significant main effects or interactions. This combined analysis reinforces the conclusion that the two language varieties are processed in a similar manner, with similarly reliable priming effects for word patterns and roots, as summarised in Figure 3.
Figure 3.
Net priming in STA and MSA.
GENERAL DISCUSSION
The aim of the present study was to advance our understanding of how linguistic structure, as instantiated in the morphological domain, is extracted in dialectal Arabic and Standard Arabic, and whether this varied as a function of the different timing and modes of acquisition of these two varieties. To do this, we addressed several issues: Whether word patterns and root priming can be observed in a dialectal variety of Arabic (here STA), whether such priming is as strong in the dialect as it is in MSA, and whether root and word pattern priming in STA can be distinguished from semantically-based and phonologically based priming in the same way as has been documented for MSA. In addition we asked whether MSA, reflecting its putative status as a later learned second language, showed signs of less effective on-line processing, in terms of response speed and accuracy, than STA.
In answer to the first set of questions, it is clear that the quantitative and qualitative pattern of priming effects is almost identical in the two varieties (see Figure 3). STA and MSA each show significant priming for word patterns, both relative to baseline and relative to a vowel-based phonological control [+ Phon1]. They also show strong priming for roots—weaker but still significant for the semantically opaque condition [+ R − S]—and no priming in the consonantal phonological control condition [+ Phon2]. For both varieties, the significant effects for the word pattern and the opaque root conditions—numerically of equivalent size across varieties—demonstrates the separability of primarily morphological effects from semantic effects. In neither case are prime and target semantically related. The only tendency to a divergence between STA and MSA is the somewhat elevated (though not significant) priming effect in the [+ Phon1] control condition for STA. However, the critical comparison still holds with the word pattern condition [+ WP], and there are no significant relevant interactions in the combined analysis of the two experiments.
Both the STA and the MSA results diverge from the previous literature for Arabic in one respect. This is the relatively larger difference in the size of the priming effect in the semantically transparent root condition [+ R + S] relative to the opaque condition [+ R − S], reaching 33 ms in MSA and an almost significant 54 ms in STA. In previous studies of MSA using either masked priming or cross-modal priming (e.g., Boudelaa & Marslen-Wilson, 2004, 2005), there has been little systematic evidence for a processing advantage due to a semantically transparent relationship between primes and targets sharing a root. The tendency in this direction here may reflect the generally larger priming effects in this task, providing more headroom for a semantic boost to emerge. Similar considerations may apply in Hebrew, where a significant advantage for semantically related prime-target pairs only emerged when a cross-modal paradigm was used, as in Frost, Deutsch, Gilboa, Tannenbaum, and Marslen-Wilson (2000).
Turning to the second set of questions, asking whether MSA was processed less effectively than STA, in terms of speed and accuracy, we see no evidence to support this. Not only there is no statistically significant difference overall between MSA and STA, but also the numerical trend is in fact, for MSA words to be processed more quickly and with fewer errors than STA words (see Table 8). We now turn to the implications of these results for different theoretical views about lexical processing in diglossic Arabic.
TABLE 8.
Overall RTs in ms (standard deviations), and percent error rates in the two experiments
| Baseline | Test | |
|---|---|---|
| STA | ||
| Overall RT | 918 (43) | 876 (71) |
| Overall error rate | 7.1 (0.64) | 6.1 (1.61) |
| MSA | ||
| Overall RT | 865 (25) | 836 (57) |
| Overall error rate | 2.36 (0.60) | 2.42 (0.62) |
Implications for Arabic diglossia
One motivation for these experiments was the claim advanced by some theorists that dialectal and Standard Arabic are distinct languages (Heath, 1997; Kirchhoff & Vergyri, 2005; Saiegh-Haddad, 2003). This raises the possibility that the word pattern and root effects that have been documented for MSA so far (Boudelaa & Marslen-Wilson, 2000, 2004, 2005; Prunet et al., 2000), might not hold in a dialectal variety, so that the importance of morphology in MSA processing would be diagnostic of the importance of metalinguistic knowledge rather than indicative of natural processing mechanisms applying to Semitic languages. The results reported here show that MSA and STA are treated in similar ways with word patterns and roots acting as linguistic units whose effects are distinct from the effects of form and meaning in both varieties. This is the case despite the differences underlying the two varieties in terms of the productivity of their morphological systems, the age at which they are acquired and the sociolinguistic context in which they are experienced.
These results also bear on the related claim that MSA is a “second language” for native speakers of Arabic. The phrase “second language” is essentially a chronological label referring to a linguistic system learned after another has already been established. However, there is an important distinction to make between a second language learned early, as a child, and one learned later in life. This distinction between early and late second languages is central to “critical period” hypotheses, according to which learning a second language after puberty necessarily leads to a nonnative-like end state due to developmental factors that affect all members of the species, while learning one's second language before the onset of puberty can lead to native-like performance (Birdsong, 1999; Isel et al., 2009). Evidence in support of this view includes functional Magnetic Resonance Imaging (fMRI) research which shows that, within the anterior language areas, the cortical locations for some aspects of first and second language function overlap in early learners but not in late learners (e.g., Kim, Relkin, Lee, & Hirsch, 1997).
If, therefore, a second language learned in early childhood can be neuro-biologically instantiated as a first language and supported by the same cortical network, then MSA need not qualify as a second language because it is learned within this window of opportunity—especially if, as suggested above, cognate roots, word patterns, and lexical forms in the two varieties in fact share common underlying representations. Arab children are exposed to MSA at home through the media at a very early age and start learning it even before they attend primary school. The absence of AoA effects, as well as any sign generally that MSA was processed less rapidly or less accurately than STA, is also consistent with the absence of a clear first language/second language distinction between MSA and STA for these groups of native speakers.
Other cognitive and linguistic factors which may affect the status of a given language as a separately represented second language seem to be operating in the Arabic situation to militate against the treatment of MSA as a true second language relative to STA (or other comparable dialects). Salient among these are the close linguistic parallels, at all levels of the language system, between MSA and the dialect. For example, the consonantal repertoires of MSA and any local dialect overlap substantially, meaning that the child needs to acquire very few, typically two or three, new phonetic categories when learning MSA. Learning the phonological system of MSA is a relatively trivial task for the child who ends up mastering both MSA and dialect systems early in life (Amayreh & Dyson, 1998; Amayreh, 2003). Finally, because MSA and dialectal Arabic fulfill distinct sociolinguistic and communicative functions, it is inappropriate to describe one as a first and the other as a second language. They are two varieties in overlapping but partially complementary distribution.
It is important to stress, however, that the sociolinguistic context in which MSA and the dialect are learnt and used will have a substantial effect on the extent to which MSA and the local dialect are psycholinguistically parallel for a given language community. It is likely that factors of this sort underlie recent research with speakers of Palestinian Arabic in Israel, where Hebrew takes over many of the roles in education and in public communication that are occupied by MSA elsewhere in the Arab-speaking world. Ibrahim and Aharon-Peretz (2005), for example, used an auditory-auditory priming task to compare semantic facilitation between Palestinian Arabic words with facilitation between a Standard Arabic word or a Hebrew word and a Palestinian Arabic word used as a prime or a target. The results showed that within dialect-priming was stronger than priming by a Standard Arabic word or a Hebrew word. On the basis of these Ibrahim and Aharon-Peretz (2005) concluded that Standard Arabic constitutes “a second language for the native Arabic speaker” (p. 65).
However, this generalisation seems unwarranted. Leaving aside concerns about the logic of the experimental test here,6 it is doubtful whether Palestinian Arabic speakers (tested, as were our participants, in their final years of secondary education) have levels of MSA competence, or indeed MSA exposure, comparable to Arabic speakers living in the rest of the Arabic-speaking world. In the difficult sociolinguistic situation of the Israeli Palestinian Arabs, any relative lack of facility in accessing lexical representations in MSA (compared to the Palestinian Arabic dialect) may reflect the relative disuse of MSA in this population, compared to dialectal Arabic which retains its status as a first language by virtue of being used daily at home, and compared to Hebrew which has a dominant cultural presence—not least by being the main language of education. In the diglossic situation holding almost everywhere else in the modern Arab world, exemplified by the Southern Tunisian environment of the STA speakers tested here, it is much more likely that STA and MSA have a parallel psycholinguistic and neurocognitive status, as reflected in the priming results we reported in this paper, and that MSA is not a “second language” in the sense of being less well-learnt and less effectively processed.
CONCLUSIONS
The present results have implications for theories of morphological processing and representation in general, and theories of Arabic diglossia in particular.
With regard to a general theory of morphological processing and representation, these results suggest that root and pattern effects are genuine morphological effects that cannot be reduced to pure form-based or pure meaning based effects, and that are not in some way artefacts of the explicit teaching of morphological structure to speakers of MSA. The present data and previous behavioral data from Arabic and Hebrew (Boudelaa & Marslen-Wilson, 2005; Deutsch, Frost, Pollatsek, & Rayner, 2005; Feldman, Frost, & Pnini, 1995; Frost et al., 1997) as well as from patients (Barkai, 1980) converge to show that morphological effects in Semitic languages evolve into an independent domain of knowledge with cognitively and neurophysio-logically distinct representational structures (Boudelaa et al., 2010).
Turning to the issue of Arabic diglossia and the differences between the dialects and MSA, this study is the first to offer experimental evidence that despite the apparent structural, functional, and distributional differences between the Arabic varieties (Kirchhoff & Vergyri, 2005; Maamouri, 1998; Saiegh-Haddad, 2003; Versteegh, 1997), they are cognitively processed and represented in fundamentally similar ways. The same obligatory morpho-phonological composition and decomposition processes are at play in Standard and dialectal Arabic. Roots and word-patterns are the relevant domains to which language learning is tuned in both varieties and around which adult language processing is organised. We predict on this basis that even illiterate speakers of dialectal Arabic, who do not know MSA at all, should also show root and pattern effects despite never having been told what a root or a word pattern is.
Footnotes
Author SB is a native speaker of STA.
These figures are based on a compilation, put together by ourselves, of the 1,043 most frequent roots in MSA and the 343 most familiar roots in STA. The MSA roots are a subset of those listed in (Khouloughli, 1992), and the STA roots are mostly a subset of these with few roots that are specific to STA. For each root in the two varieties we counted the number of derived forms in which they took part. The average number of derivatives per morpheme in both varieties might change if we could average over the entire set of roots in the two varieties. However it is unlikely that this would bring root and pattern productivity in the dialectal variety up to the levels of MSA.
Note that the baseline condition in the two experiments consists of nouns. This was necessary to avoid unwanted vocalic overlap between baseline primes and their respective targets, given the restrictions imposed by the small inventory of vowels in Arabic (6 in total).
The difference in family size between roots and word patterns reflects the much greater productivity of grammatical morphemes, observed also in Indo-European languages.
The full stimulus set can be provided by author SB upon request.
It is not clear, for example, that it is seriously claimed by anyone that MSA and the relevant local dialect are in fact the same language, and there is little doubt that Arabic diglossic speakers keep some cognitive separation between the two varieties. Testing for between-variety priming does not tell us what we want to know – namely, how well is MSA itself learned and processed, and whether it shares the same underlying organizational linguistic principles as a sister variety such as STA.
REFERENCES
- Abu-Rabia S. Effects of exposure to literary Arabic on reading comprehension in a diglossic situation. Reading and Writing: An Interdisciplinary Journal. 2000;13:147–157. [Google Scholar]
- Amayreh M. M. Completion of the consonant inventory of Arabic. Journal of Speech, Language and Hearing Research. 2003;46:517–529. doi: 10.1044/1092-4388(2003/042). [DOI] [PubMed] [Google Scholar]
- Amayreh M. M., Dyson A. T. The acquisition of Arabic consonants. Journal of Speech, Language and Hearing Research. 1998;41:642–653. doi: 10.1044/jslhr.4103.642. [DOI] [PubMed] [Google Scholar]
- Baalbaki R. Al-Mawrid: A modern Arabic-English dictionary. 14 ed. Beirut, Lebanon: Dar El Ilm Lilmalayin; 2001. [Google Scholar]
- Baayen H., Lieber R. Productivity and English derivation: A corpus based study. Linguistics. 1991;29:801–843. [Google Scholar]
- Badawi M. S. Mustawayaat al-‘arabiya al-mu'asirafi Misr [Levels of contemporary Arabic in Egypt] Cairo: Dar Al-ma'aArif; 1973. [Google Scholar]
- Badry F. Acquiring the Arabic lexicon: Evidence of productive strategies and pedagogical implications. Palo Alto, CA: Academic Press, LLC; 2001. [Google Scholar]
- Barkai M. Aphasic evidence for lexical and phonological representations. Afroasiatic Linguistics. 1980;7/6:163–187. [Google Scholar]
- Benmamoun E. Arabic morphology: The central role of the imperfective. Lingua. 1998;108:175–201. [Google Scholar]
- Bentin S., Frost R. Linguistic theory and psychological reality: A reply to Boudelaa & Marslen-Wilson. Cognition. 2001;81:113–118. doi: 10.1016/s0010-0277(01)00120-2. [DOI] [PubMed] [Google Scholar]
- Birdsong D. Introduction: Whys and why nots of the critical period hypothesis for second language acquisition. In: Birdsong D., editor. Second language acquisition and the critical period hypothesis. Mahwah, NJ: Lawrence Erlbaum; 1999. pp. 1–21. [Google Scholar]
- Boudelaa S., Bozic M., Marslen-Wilson W D. Engaging the fronto-temporal brain systems with derivational morphemes: An fMRI study of Arabic. 2010. In 17th annual meeting of the cognitive neuroscience society, Montreal, Canada.
- Boudelaa S., Gaskell G. A re-examination of the default system for Arabic plurals. Language and Cognitive Processes. 2002;17:321–343. [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Non-concatenative morphemes in language processing: Evidence from modern standard Arabic. In: McQueen J., Cutler A., editors. Proceedings of the workshop on spoken word access processes. Vol. 1. Nijmegen, the Netherlands: Max Planck Institute for Psycholinguistics; 2000. pp. 23–26. [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Abstract morphemes and lexical representation: The CV-Skeleton in Arabic. Cognition. 2003;92:271–303. doi: 10.1016/j.cognition.2003.08.003. [DOI] [PubMed] [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Allomorphic variation in Arabic: Implications for lexical processing and representation. Brain and Language. 2004;90:106–116. doi: 10.1016/S0093-934X(03)00424-3. [DOI] [PubMed] [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Discontinuous morphology in time: Incremental masked priming in Arabic. Language and Cognitive Processes. 2005;20:207–260. [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Productivity and priming. Language and Cognitive Processes. 2011;26:624–652. doi: 10.1080/01690965.2012.719629. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boudelaa S., Marslen-Wilson W D. Structure, form, and meaning in the mental lexicon: Evidence from Arabic. Journal of Memory and Language. 2012. submitted. [DOI] [PMC free article] [PubMed]
- Boudelaa S., Pulvermüller F., Hauk O., Shtyrov Y, Marslen-Wilson W D. Arabic morphology in the neural language system. Journal of Cognitive Neuroscience. 2010;22:998–1010. doi: 10.1162/jocn.2009.21273. [DOI] [PubMed] [Google Scholar]
- Butterworth B. Lexical representation. In: Butterworth B., editor. Language production. London: Academic Press; 1983. pp. 257–294. [Google Scholar]
- Deutsch A., Frost R., Pollatsek A., Rayner K. Early morphological effects in word recognition in Hebrew: Evidence from parafoveal preview benefit. Language and Cognitive Processes. 2000;15:487–506. [Google Scholar]
- Deutsch A., Frost R., Pollatsek A., Rayner K. Morphological parafoveal preview benefit effects in reading: Evidence from Hebrew. Language and Cognitive Processes. 2005;20:341–371. [Google Scholar]
- Ellis A. W., Lambon Ralph M. A. Age of acquisition effects in adult lexical processing reflect loss of plasticity in maturing systems: Insights from connectionist networks. Journal of Experimental Psychology: Learning Memory & Cognition. 2000;26:1103–1123. doi: 10.1037//0278-7393.26.5.1103. [DOI] [PubMed] [Google Scholar]
- Feldman L., Frost R., Pnini T. Decomposing words into their constituent morphemes: Evidence from English and Hebrew. Journal of Experimental Psychology: Learning, Memory & Cognition. 1995;21:947–960. doi: 10.1037//0278-7393.21.4.947. [DOI] [PubMed] [Google Scholar]
- Ferguson C. A. Diglossia: Language in culture and society. Word. 1959;15:325–340. [Google Scholar]
- Forster K., Forster J. C. DMDX: A windows display program with millisecond accuracy. Behavior Research Methods, Instruments, and Computers. 2003;35:116–124. doi: 10.3758/bf03195503. [DOI] [PubMed] [Google Scholar]
- Frost R., Deutsch A., Gilboa O., Tannenbaum M., Marslen-Wilson W D. Morphological priming: Dissociation of phonological, semantic, and morphological factors. Memory & Cognition. 2000;28:1277–1288. doi: 10.3758/bf03211828. [DOI] [PubMed] [Google Scholar]
- Frost R., Forster K. I., Deutsch A. What can we learn from the morphology of Hebrew: A masked priming investigation of morphological representation. Journal of Experimental Psychology: Learning, Memory & Cognition. 1997;23:829–856. doi: 10.1037//0278-7393.23.4.829. [DOI] [PubMed] [Google Scholar]
- Frost R., Kugler T., Deutsch A., Forster K. I. Orthographic structure versus morphological structure: Principles of lexical organization in a given language. 2001. Paper presented at the Perspectives on morphological processing, Nijmegen, The Netherlands. [DOI] [PubMed]
- Frost R., Kugler T, Deutsch A., Forster K. I. Orthographic structure versus morphological structure: Principles of lexical organization in a given language. Journal of Experimental Psychology: Learning, Memory & Cognition. 2005;31:1293–1326. doi: 10.1037/0278-7393.31.6.1293. [DOI] [PubMed] [Google Scholar]
- Gafos I. A. Greenberg's asymmetry in Arabic: A consequence of stems in paradigms. Language. 2003;79:317–355. [Google Scholar]
- Grosjean F. Spoken word recognition processes and the gating paradigm. Perception & Psychophysics. 1980;82:267–283. doi: 10.3758/bf03204386. [DOI] [PubMed] [Google Scholar]
- Heath J. Moroccan Arabic phonology. In: Kaye A. S., Deniels P. T., editors. Phonologies of Asia and Africa: Including the Caucasus. I. Winona Lake, IN: Eisenbrauns; 1997. pp. 205–217. [Google Scholar]
- Holes C. Modern Arabic. London and NY: Longman; 1995. [Google Scholar]
- Ibrahim R., Aharon-Perets J. Is literary Arabic a second language for native Arab speakers? Journal of Psycholinguistic Research. 2005;34:51–70. doi: 10.1007/s10936-005-3631-8. [DOI] [PubMed] [Google Scholar]
- Isel F., Baumgaertner A., Thrän J., Meisel M., Büchel C. Neural circuitry of the bilingual mental lexicon: Effect of age of second language acquisition. Brain and Cognition. 2009;72:169–180. doi: 10.1016/j.bandc.2009.07.008. [DOI] [PubMed] [Google Scholar]
- Keppel G. Design and analysis: A researcher's handbook. Englewood Cliffs, NJ: Prentice-Hall; 1982. [Google Scholar]
- Kim K. H., Relkin N. R., Lee K. M., Hirsch J. Distinct cortical areas associated with native and second languages. Nature. 1997;388:171–174. doi: 10.1038/40623. [DOI] [PubMed] [Google Scholar]
- Kirchhoff K., Vergyri D. Cross-dialectal data sharing for acoustic modeling in Arabic speech recognition. Speech Communication. 2005;46:37–51. [Google Scholar]
- Maamouri M. Language education and human development: Arabic diglossia and its impact on the quality of education in the Arab region. Marrakech, Morocco: The Mediterranean Development Forum; 1998. [Google Scholar]
- Marslen-Wilson W. D. Functional parallelism in spoken word recognition. Cognition. 1987;25:71–102. doi: 10.1016/0010-0277(87)90005-9. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W D. Access to lexical representations: Cross linguistic issues. Language and Cognitive Processes. 2001;16:699–708. [Google Scholar]
- Marslen-Wilson W D., Ford M., Older L., Zhou X. The combinatorial lexicon: Priming derivational affixes. In: Cottrell G., editor. Proceedings of the 18th Annual Conference of the Cognitive Science Society. Mahwah, NJ: Lawrence Erlbaum Associates; 1996. pp. 223–227. [Google Scholar]
- Marslen-Wilson W D., Moss H. E., van Halen S. Perceptual distance and competition in lexical access. Journal of Experimental Psychology: Human Perception & Performance. 1996;22:1376–1392. doi: 10.1037//0096-1523.22.6.1376. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W D., Tyler L. K., Waksler R., Older L. Morphology and meaning in the English mental lexicon. Psychological Review. 1994;101:3–33. [Google Scholar]
- Marslen-Wilson W D., Welsh A. Processing interactions during word recognition in continuous speech. Cognitive Psychology. 1978;10:29–63. [Google Scholar]
- Marslen-Wilson W D., Zhou X.-L. Abstractness, allomorphy, and lexical architecture. Language and Cognitive Processes. 1999;14:321–352. [Google Scholar]
- Monaghan J., Ellis A. W. What exactly interacts with spelling-sound consistency in word naming? Journal of Experimental Psychology: Learning Memory & Cognition. 2002;28:183–206. doi: 10.1037/0278-7393.28.1.183. [DOI] [PubMed] [Google Scholar]
- Monsell S., Hirsh K. W. Competitor priming in spoken word recognition. Journal of Experimental Psychology: Human Perception & Performance. 1998;24:1495–1520. doi: 10.1037//0278-7393.24.6.1495. [DOI] [PubMed] [Google Scholar]
- Moscoso del Prado Martín F, Deutsch A., Frost R., Schreuder R., De Jong N, Baayen H. Changing places: A cross-language perspective on frequency and family size in Dutch and Hebrew. Journal of Memory and Language. 2005;53:496–512. [Google Scholar]
- Omar M. The acquisition of Egyptian Arabic as a native language. The Hague: Mouton; 1973. [Google Scholar]
- Plaut D., Gonnerman L. M. Are non-semantic morphological effects incompatible with a distributed connectionist approach to lexical processing? Language and Cognitive Processes. 2000;15:445–485. [Google Scholar]
- Prunet J. F., Béland R., Idrissi A. The mental representation of Semitic words. Linguistic Inquiry. 2000;31:609–648. [Google Scholar]
- Ratcliff R. Methods for dealing with reaction time outliers. Psychological Bulletin. 1993;114:510–532. doi: 10.1037/0033-2909.114.3.510. [DOI] [PubMed] [Google Scholar]
- Rueckl J. G., Raveh M. The influence of morphological regularities on the dynamics of a connectionist network. Brain and Language. 1999;68:110–117. doi: 10.1006/brln.1999.2106. [DOI] [PubMed] [Google Scholar]
- Saiegh-Haddad E. Linguistic distance and initial reading acquisition: The case of Arabic diglossia. Applied Psycholinguistics. 2003;24:115–135. [Google Scholar]
- Saiegh-Haddad E. Correlates of reading fluency in Arabic: Diglossic and orthographic factors. Reading and Writing. 2005;18:559–582. [Google Scholar]
- Schreuder R., Baayen R. H. Modelling morphological processing. In: Feldman L. B., editor. Morphological aspects of language processing. Hillsdale, NJ: Erlbaum; 1995. pp. 131–154. [Google Scholar]
- Seidenberg M. Sublexical structure in visual word recognition: Access units or orthographic redundancy? In: Coltheart M., editor. Attention and performance XII. Hillsdale, NJ: Lawrence Erlbaum Associates; 1987. pp. 244–263. [Google Scholar]
- Seidenberg M., Gonnerman L. M. Explaining derivational morphology as the convergence of code. Trends in Cognitive Sciences. 2000;4:353–361. doi: 10.1016/s1364-6613(00)01515-1. [DOI] [PubMed] [Google Scholar]
- Taft M. Interactive-activation as a framework for understanding morphological processing. Language and Cognitive Processes. 1994;9:271–294. [Google Scholar]
- Tyler L. K., Moss H. E., Galpin A., Voice J. K. Activating meaning in time: The role of imageability and form-class. Language and Cognitive Processes. 2002;17:471–502. [Google Scholar]
- Versteegh K. The Arabic language. Edinburgh: Edinburgh University Press; 1997. [Google Scholar]
- Wehr H. A dictionary of modern written Arabic. Ithaca, NY: Otto Harrassowitz; 1994. [Google Scholar]
- Wright W. A grammar of the Arabic language. Cambridge: Cambridge University Press; 1995. [Google Scholar]