

Abstract
The ℓ1-penalized method, or the Lasso, has emerged as an important tool for the analysis of large data sets. Many important results have been obtained for the Lasso in linear regression which have led to a deeper understanding of high-dimensional statistical problems. In this article, we consider a class of weighted ℓ1-penalized estimators for convex loss functions of a general form, including the generalized linear models. We study the estimation, prediction, selection and sparsity properties of the weighted ℓ1-penalized estimator in sparse, high-dimensional settings where the number of predictors p can be much larger than the sample size n. Adaptive Lasso is considered as a special case. A multistage method is developed to approximate concave regularized estimation by applying an adaptive Lasso recursively. We provide prediction and estimation oracle inequalities for single- and multi-stage estimators, a general selection consistency theorem, and an upper bound for the dimension of the Lasso estimator. Important models including the linear regression, logistic regression and log-linear models are used throughout to illustrate the applications of the general results.
Keywords: variable selection, penalized estimation, oracle inequality, generalized linear models, selection consistency, sparsity
1. Introduction
High-dimensional data arise in many diverse fields of scientific research. For example, in genetic and genomic studies, more and more large data sets are being generated with rapid advances in biotechnology, where the total number of variables p is larger than the sample size n. Fortunately, statistical analysis is still possible for a substantial subset of such problems with a sparse underlying model where the number of important variables is much smaller than the sample size. A fundamental problem in the analysis of such data is to find reasonably accurate sparse solutions that are easy to interpret and can be used for the prediction and estimation of covariable effects. The ℓ1-penalized method, or the Lasso (Tibshirani, 1996; Chen et al., 1998), has emerged as an important approach to finding such solutions in sparse, high-dimensional statistical problems.
In the last few years, considerable progress has been made in understanding the theoretical properties of the Lasso in p ≫ n settings. Most results have been obtained for linear regression models with a quadratic loss. Greenshtein and Ritov (2004) studied the prediction performance of the Lasso in high-dimensional least squares regression. Meinshausen and Bühlmann (2006) showed that, for neighborhood selection in the Gaussian graphical models, under a neighborhood stability condition on the design matrix and certain additional regularity conditions, the Lasso is selection consistent even when p → ∞ at a rate faster than n. Zhao and Yu (2006) formalized the neighborhood stability condition in the context of linear regression as a strong irrepresentable condition. Candes and Tao (2007) derived an upper bound for the ℓ2 loss of a closely related Dantzig selector in the estimation of regression coefficients under a condition on the number of nonzero coefficients and a uniform uncertainty principle on the design matrix. Similar results have been obtained for the Lasso. For example, upper bounds for the ℓq loss of the Lasso estimator has being established by Bunea et al. (2007) for q = 1, Zhang and Huang (2008) for q ∈ [1;2], Meinshausen and Yu (2009) for q = 2, Bickel et al. (2009) for q ∈ [1;2], and Zhang (2009) and Ye and Zhang (2010) for general q ≥ 1. For convex minimization methods beyond linear regression, van de Geer (2008) studied the Lasso in high-dimensional generalized linear models (GLM) and obtained prediction and ℓ1 estimation error bounds. Negahban et al. (2010) studied penalized M-estimators with a general class of regularizers, including an ℓ2 error bound for the Lasso in GLM under a restricted strong convexity and other regularity conditions.
Theoretical studies of the Lasso have revealed that it may not perform well for the purpose of variable selection, since its required irrepresentable condition is not properly scaled in the number of relevant variables. In a number of simulation studies, the Lasso has shown weakness in variable selection when the number of nonzero regression coefficients increases. As a remedy, a number of proposals have been introduced in the literature and proven to be variable selection consistent under regularity conditions of milder forms, including concave penalized LSE (Fan and Li, 2001; Zhang, 2010a), adaptive Lasso (Zou, 2006; Meier and Bühlmann, 2007; Huang et al., 2008), stepwise regression (Zhang, 2011a), and multi-stage methods (Hunter and Li, 2005; Zou and Li, 2008; Zhang, 2010b, 2011b).
In this article, we study a class of weighted ℓ1-penalized estimators with a convex loss function. This class includes the Lasso, adaptive Lasso and multistage recursive application of adaptive Lasso in generalized linear models as special cases. We study prediction, estimation, selection and sparsity properties of the weighted ℓ1-penalized estimator based on a convex loss in sparse, high-dimensional settings where the number of predictors p can be much larger than the sample size n. The main contributions of this work are as follows.
We extend the existing theory for the unweighted Lasso from linear regression to more general convex loss function.
We develop a multistage method to approximate concave regularized convex minimization with recursive application of adaptive Lasso, and provide sharper risk bounds for this concave regularization approach in the general setting.
We apply our results to a number of important special cases, including the linear, logistic and log-linear regression models.
This article is organized as follows. In Section 2 we describe a general formulation of the absolute penalized minimization problem with a convex loss, along with two basic inequalities and a number of examples. In Section 3 we develop oracle inequalities for the weighted Lasso estimator for general quasi star-shaped loss functions and an ℓ2 bound on the prediction error. In Section 4 we develop multistage recursive applications of adaptive Lasso as an approximate concave regularization method and provide sharper oracle inequalities for this approach. In Section 5 we derive sufficient conditions for selection consistency. In Section 6 we provide an upper bound on the dimension of the Lasso estimator. Concluding remarks are given in Section 7. All proofs are provided in an appendix.
2. Absolute Penalized Convex Minimization
In this section, we define the weighted Lasso for a convex loss function and characterize its solutions via the KKT conditions. We then derive some basic inequalities for the weighted Lasso solutions in terms of the symmetrized Bregman divergence (Bregman, 1967; Nielsen and Nock, 2007). We also illustrate the applications of the basic inequalities in several important examples.
2.1 Definition and the KKT Conditions
We consider a general convex loss function of the form
| (1) |
where ψ(β) is a known convex function, z is observed, and β is unknown. Unless otherwise stated, the inner product space is ℝp, so that {z,β} ⊂ ℝp and 〈β,z〉 = β′z. Our analysis of (1) requires certain smoothness of the function ψ(β) in terms of its differentiability. In what follows, such smoothness assumptions are always explicitly described by invoking the derivative of ψ. For any v = (v1,…, vp)′, we use ||v|| to denote a general norm of v and |v|q the ℓq norm (Σj |vj|q)1/q, with |v|∞ = maxj |vj|. Let ŵ ∈ ℝp be a (possibly estimated) weight vector with nonnegative elements ŵj, 1 ≤ j ≤ p, and Ŵ = diag(ŵ). The weighted absolute penalized estimator, or weighted Lasso, is defined as
| (2) |
Here we focus on the case where Ŵ is diagonal. In linear regression, Tibshirani and Taylor (2011) considered non-diagonal, predetermined Ŵ and derived an algorithm for computing the solution paths.
A vector β̂ is a global minimizer in (2) if and only if the negative gradient at β̂ satisfies the Karush-Kuhn-Tucker (KKT) conditions,
| (3) |
where ℓ̇(β) = (∂/∂β)ℓ(β) and ψ̇(β) = (∂/∂β)ψ (β). Since the KKT conditions are necessary and sufficient for (2), results on the performance of β̂ can be viewed as analytical consequences of (3).
The estimator (2) includes the ℓ1-penalized estimator, or the Lasso, with the choice ŵj = 1, 1 ≤ j ≤ p. A careful study of the (unweighted) Lasso in general convex minimization (1) is by itself an interesting and important problem. Our work includes the Lasso as a special case since ŵj = 1 is allowed in our theorems.
In practice, unequal ŵj arise in many ways. In adaptive Lasso (Zou, 2006), a decreasing function of a certain initial estimator of βj is used as the weight ŵj to remove the bias of the Lasso. In Zou and Li (2008) and Zhang (2010b), the weights ŵj are computed iteratively with ŵj = ρ̇λ(β̂j), where ρ̇λ(t) = (d/dt)ρλ(t) with a suitable concave penalty function ρλ(t). This is also designed to remove the bias of the Lasso, since the concavity of ρλ(t) guarantees smaller weight for larger β̂j. In Section 4, we provide results on the improvements of this weighted Lasso over the standard Lasso. In linear regression, Zhang (2010b) gave sufficient conditions under which this iterative algorithm provides smaller weights ŵj for most large βj. Such nearly unbiased methods are expected to produce better results than the Lasso when a significant fraction of nonzero |βj| are of the order λ or larger. Regardless of the computational methods, the results in this paper demonstrate the benefits of using data dependent weights in a general class of problems with convex losses.
Unequal weights may also arise for computational reasons. The Lasso with ŵj = 1 is expected to perform similarly to weighted Lasso with data dependent 1 ≤ ŵj ≤ C0, with a fixed C0. However, the weighted Lasso is easier to compute since ŵj can be determined as a part of an iterative algorithm. For example, in a gradient descent algorithm, one may take larger steps and stop the computation as soon as the KKT conditions (3) are attained for any weights satisfying 1 ≤ ŵj ≤ C0.
The weight function ŵj can be also used to standardize the penalty level, for example with ŵj = {ψ̈j j(β̂)}1/2, where ψ̈j j(β) is the j-th diagonal element of the Hessian matrix of ψ(β). When ψ(β) is quadratic, for example in linear regression, ŵj = {ψ̈jj(β̂)}1/2 does not depend on β̂. However, in other convex minimization problems, such weights need to be computed iteratively.
Finally, in certain applications, the effects of a certain set S* of variables are of primary interest, so that penalization of β̂S*, and thus the resulting bias, should be avoided. This leads to “semi-penalized” estimators with ŵj = 0 for j ∈ S*, for example, with weights ŵi = I{j ∉ S*}.
2.2 Basic Inequalities, Prediction, and Bregman Divergence
Let β* denote a target vector for β. In high-dimensional models, the performance of an estimator β̂ is typically measured by its proximity to a target under conditions on the sparsity of β* and the size of the negative gradient −ℓ̇(β*) = z − ψ̇(β*). For ℓ1-penalized estimators, such results are often derived from the KKT conditions (3) via certain basic inequalities, which are direct consequences of the KKT conditions and have appeared in different forms in the literature, for example, in the papers cited in Section 1. Let D(β,β*) = ℓ(β) − ℓ(β*) − 〈ℓ̇(β*), β − β*〉 be the Bregman divergence (Bregman, 1967) and consider its symmetrized version (Nielsen and Nock, 2007)
| (4) |
Since ψ is convex, Δ(β, β*) ≥ 0. Two basic inequalities below provide upper bounds for the symmetrized Bregman divergence Δ(β̂, β*). The sparsity of β* is measured by a weighted ℓ1 norm of β* in the first one and by a sparse set in the second one.
Let S be any set of indices satisfying and let Sc be the complement of S in {1, …, p}. We shall refer to S as the sparse set. Let W = diag(w) for a possibly unknown vector w ∈ ℝp with elements wj ≥ 0. Define
| (5) |
| (6) |
where for any p-vector v and set A, vA = (vj : j ∈ A)′. Here and in the sequel MAB denotes the A × B subblock of a matrix M and MA = MAA.
Lemma 1
- Let β* be a target vector. In the event Ω0 ∩ {|(z − ψ̇(β*))j| ≤ ŵjλ ∀j},
(7) -
For any target vector β* and , the error h = β̂ − β* satisfies
(8) in Ω0 for a certain negative gradient vector g satisfying |gj| ≤ ŵjλ. Consequently, in , h ≠ 0 belongs to the sign-restricted cone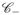 (ξ, S) = {b ∈
(ξ, S) = {b ∈
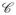 (ξ, S) : bj(ψ̇(β+ b) − ψ̇(β))j ≤ 0 ∀ j ∈ Sc}, where
(ξ, S) : bj(ψ̇(β+ b) − ψ̇(β))j ≤ 0 ∀ j ∈ Sc}, where
(9)
Remark 2
Sufficient conditions are given in Subsection 3.2 for {|(z − ψ̇(β*))j| ≤ ŵj λ ∀j} to hold with high probability in generalized linear models. See Lemma 8, Remarks 10 and 11 and Examples 7, 8, and 9.
A useful feature of Lemma 1 is the explicit statements of the monotonicity of the basic inequality in the weights. By Lemma 1 (ii), it suffices to study the analytical properties of the penalized criterion with the error h = β̂ − β* in the sign-restricted cone, provided that the event
has large probability. However, unless
(ξ, S) is specified, we will consider the larger cone in (9) in order to simplify the analysis. The choices of the target vector β*, the sparse set
, weight vector ŵ and its bound w are quite flexible. The main requirement is that {|S|,
} should be small. In linear regression or generalized linear models, we may conveniently consider β* as the vector of true regression coefficients under a probability measure Pβ*. However, β* can also be a sparse version of a true β, for example,
for a threshold value τ under Pβ.
The upper bound in Lemma 1 (i) gives the so called “slow rate” of convergence for the Bregman divergence. In Section 3, we provide “fast rate” of convergence for the Bregman divergence via oracle inequalities for |hS|1 in (8).
The symmetrized Bregman divergence Δ(β̂, β*) has the interpretations as the regret in prediction error in linear regression, the symmetrized Kullback-Leibler (KL) divergence in generalized linear models (GLM) and density estimation, and a spectrum loss for the graphical Lasso, as shown in examples below. These quantities can be all viewed as the size of the prediction error since they measure distances between a target density of the observations and an estimated density.
Example 1 (Linear regression)
Consider the linear regression model
| (10) |
where yi is the response variable, xi j are predictors or design variables, and εi is the error term. Let y = (y1, …, yn)′ and let X be the design matrix whose ith row is xi = (xi1,…, xip). The estimator (2) can be written as a weighted Lasso with and z = X′y/n in (1). For predicting a vector ỹ with Eβ*[ỹ|X, y] = Xβ*,
is the regret of using the linear predictor Xβ̂ compared with the optimal predictor. See Greenshtein and Ritov (2004) for several implications of (7).
Example 2 (Logistic regression)
We observe (X, y) ∈ ℝn×(p+1) with independent rows (xi,yi), where yi ∈ {0,1} are binary response variables with
| (11) |
The loss function (1) is the average negative log-likelihood:
| (12) |
Thus, (2) is a weighted ℓ1 penalized MLE. For probabilities {π′, π″} ⊂ (0,1), the KL information is K(π′, π″) = π′log(π′/π″) + (1 − π′)log{(1 − π′)/(1 − π″)}. Since and logit(πi(β*)) − logit(πi(β)) = xi(β* − β), (4) gives
Thus, the symmetrized Bregman divergence Δ(β*,β) is the symmetrised KL-divergence.
Example 3 (GLM)
The GLM contains the linear and logistic regression models as special cases. We observe (X,y) ∈ ℝn×(p+1) with rows (xi, yi). Suppose that conditionally on X, yi are independent under Pβ with
| (13) |
Let . The loss function can be written as a normalized negative likelihood ℓ(β) = (σ2/n)log f(n)(y|X,β) with and z = X′y/n. The KL divergence is
The symmetrized Bregman divergence can be written as
Example 4 (Nonparametric density estimation)
Although the focus of this paper is on regression models, here we illustrate that Δ (β̂, β*) is the symmetrised KL divergence in the context of non-parametric density estimation. Suppose the observations y = (y1, …, yn)′ are iid from f(·|β) = exp{〈β, T(·)〉 − ψ(β)} under Pβ, where T(·) = (uj(·), j ≤ p)′ with certain basis functions uj(·). Let the loss function ℓ(β) in (1) be the average negative log-likelihood with . Since EβT (yi) = ψ̇(β), the KL divergence is
Again, the symmetrized Bregman divergence is the symmetrised KL divergence between the target density f(·|β*) and the estimated density f(·|β̂):
van de Geer (2008) pointed out that for this example, the natural choices of the basis functions uj and weights wj satisfy ∫ujdν = 0 and .
Example 5 (Graphical Lasso)
Suppose we observe X ∈ ℝn×p and would like to estimate the precision matrix β = (EX′X/n)−1 ∈ ℝp×p. In the graphical Lasso, (1) is the length normalized negative likelihood with ψ(β) = −logdetβ, z = −X′X/n, and 〈β, z〉 = −trace(βz). Since the gradient of ψ is ψ̇(β) = Eβz = −β−1, we find
where (λ1, …, λp) are the eigenvalues of (β*)−1/2β̂(β*)−1/2. In graphical Lasso, the diagonal elements are typically not penalized. Consider ŵjk = I{j ≠ k}, so that the penalty for the off-diagonal elements are uniformly weighted. Since Lemma 1 requires |(z − ψ̇(β*))jk| ≤ ŵjkλ, β* is taken to match X′X/n on the diagonal and the true β in correlations. Let S = {(j,k) : βjk ≠ 0, j ≠ k}. In the event , Lemma 1 (i) gives
where ||·||2 is the spectrum norm. Rothman et al. (2008) proved the consistency of the graphical Lasso under similar conditions with a different analysis.
3. Oracle Inequalities
In this section, we extract upper bounds for the estimation error β̂ − β* from the basic inequality (8). Since (8) is monotone in the weights, the oracle inequalities are sharper when the weights ŵj are smaller in and larger in Sc.
We say that a function φ(b) defined in ℝp is quasi star-shaped if φ(tb) is continuous and non-decreasing in t ∈ [0,∞) for all b ∈ ℝp and limb→0 φ(b) = 0. All seminorms are quasi star-shaped. The sublevel sets {b : φ(b) ≤ t} of a quasi star-shaped function are all star-shaped. Constant factors of the following form play a crucial role in our analysis.
Definition 3
For 0 ≤ η* ≤ 1 and any pair of quasi star-shaped functions φ0(b) and φ(b), define a general invertibility factor (GIF) over the cone (9) as follows:
| (14) |
where Δ(β, β*) is as in (4).
The GIF extends the squared compatibility constant (van de Geer and Bühlmann, 2009) and the weak and sign-restricted cone invertibility factors (Ye and Zhang, 2010) from the linear regression model with φ0(·) = 0 to the general model (1) and from ℓq norms to general φ(·). They are all closely related to the restricted eigenvalues (Bickel et al., 2009; Koltchinskii, 2009) as we will discuss in Subsection 3.1.
The basic inequality (8) implies that the symmetrized Bregman divergence Δ(β̂, β*) is no greater than a linear function of |hS|1, where h = β̂ − β*. If Δ(β̂, β*) is no smaller than a linear function of the product |hS|1φ(h), then an upper bound for φ(h) exists. Since the symmetrized Bregman divergence (4) is approximately quadratic, Δ(β̂, β*) ≈ 〈h, ψ̈(β*)h〉, in a neighborhood of β*, this is reasonable when h = β̂ − β* is not too large and ψ̈ (β*) is invertible in the cone. A suitable factor eφ0(b) in (14) forces the computation of this lower bound in a proper neighborhood of β*.
We first provide a set of general oracle inequalities.
Theorem 4
Let { } be as in (5) with , Ω0 in (6), 0 ≤ η ≤ η* ≤ 1, and {φ0(b), φ(b)} be a pair of quasi star-shaped functions. Then, in the event
| (15) |
the following oracle inequalities hold:
| (16) |
and with φ1,S(b) = |bS|1/|S|
| (17) |
Remark 5
Sufficient conditions are given in Subsection 3.2 for (15) to hold with high probability. See Lemma 8, Remarks 10 and 11 and Examples 7, 8, and 9.
The oracle inequalities in Theorem 4 control both the estimation error in terms of φ(β̂ − β*) and the prediction error in terms of the symmetrized Bregman divergence Δ(β̂,β*) discussed in Section 2. Since they are based on the GIF (14) in the intersection of the cone and the unit ball {b : φ0(b) ≤ 1/e}, they are different from typical results in a small-ball analysis based on the Taylor expansion of ψ(β) at β = β*. An important feature of Theorem 4 is that its regularity condition is imposed only on the GIF (14) evaluated at the target β*; The uniformity of the order of Δ(β + b, β) in β is not required. Theorem 4 does allow φ0(·) = 0 with F(ξ, S;φ0, φ0) = ∞ and η = 0 in linear regression.
3.1 The Hessian and Related Quantities
In this subsection we describe the relationship between the GIF (14) and the Hessian of the convex function ψ(·) in (1) and examine cases where the quasi star-shaped functions φ0(·) and φ(·) are familiar seminorms. Throughout, we assume that ψ(β) is twice differentiable. Let ψ̈(β) be the Hessian of ψ(β) and Σ* = ψ̈(β*).
The GIF (14) can be simplified under the following condition.
Definition 6
Given a nonnegative-definite matrix Σ and constant η* > 0, the symmetriized Bregman divergence Δ(β, β*) satisfies the φ0-relaxed convexity (φ0-RC) condition if
| (18) |
The φ0-RC condition is related to the restricted strong convexity condition for the Bregman divergence (Negahban et al., 2010): ℓ(β* + b) − ℓ(β*) − 〈ℓ̇ (β*), b〉 ≥ κ̃||b||2 with a certain restriction b ∈
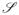 and a loss function ||b||. It actually implies the restricted strong convexity of the symmetrized Bregman divergence with κ̃ = e−η* and loss ||b||* = 〈b,Σb〉1/2. However, (18) is used in our analysis mainly to find a quadratic form as a media for the eventual comparison of Δ(β* + b, β*) with |bS|1φ(b) in (14), where φ(b) is the loss function. In fact, in our examples, we find quasi star-shaped functions φ0 for which (18) holds for unrestricted b(η* = ξ = ∞). In such cases, the φ0-RC condition is a smoothness condition on the Hessian operator ψ̈(β) = ℓ̈(β), since
by (4).
and a loss function ||b||. It actually implies the restricted strong convexity of the symmetrized Bregman divergence with κ̃ = e−η* and loss ||b||* = 〈b,Σb〉1/2. However, (18) is used in our analysis mainly to find a quadratic form as a media for the eventual comparison of Δ(β* + b, β*) with |bS|1φ(b) in (14), where φ(b) is the loss function. In fact, in our examples, we find quasi star-shaped functions φ0 for which (18) holds for unrestricted b(η* = ξ = ∞). In such cases, the φ0-RC condition is a smoothness condition on the Hessian operator ψ̈(β) = ℓ̈(β), since
by (4).
In what follows, Σ = Σ* = ψ̈ (β*) is allowed in all statements unless otherwise stated. Under the φ0-RC (18), the GIF (14) is bounded from below by the following simple GIF:
| (19) |
In linear regression, F0(ξ, S;φ) is the square of the compatibility factor for φ(b) = φ1,S(b) = |bS|1/|S| (van de Geer, 2007) and the weak cone invertibility factor for φ(b) = φq(b) = |b|q/|S|1/q (Ye and Zhang, 2010). They are both closely related to the restricted isometry property (RIP) (Candes and Tao, 2005), the sparse Rieze condition (SRC) (Zhang and Huang, 2008), and the restricted eigenvalue (Bickel et al., 2009). Extensive discussion of these quantities can be found in Bickel et al. (2009), van de Geer and Bühlmann (2009) and Ye and Zhang (2010). The following corollary is an extension of an oracle inequality of Ye and Zhang (2010) from linear regression to the general convex minimization problem (1).
Corollary 7
Let η ≤ η* ≤ 1. Suppose the φ0-RC condition (18). Then, in the event
the oracle inequalities (16) and (17) in Theorem 4 hold with the GIF F(ξ, S;φ0, φ) replaced by the simple GIF F0(ξ, S; φ) in (19). In particular, in the same event,
with φq(b) = |b|q/| S|1/q and h = β̂ − β*, and with φ1,S(b) = |bS|1/|S|,
Here the only differences between the general model (1) and linear regression (φ0(b) = 0) are the extra factor eη with η≤ 1, the extra constraint , and the extra φ0-RC condition (18). Moreover, the simple GIF (19) explicitly expresses all conditions on F0(ξ, S;φ) as properties of a fixed matrix Σ.
Example 6 (Linear regression: oracle inequalities)
For and Σ = X′X/n, F0(ξ, S;φq) is the weak cone invertibility factor for q ∈ [1,∞] (Ye and Zhang, 2010), where a sharper version is defined as the sign restricted invertibility factor (SCIF):
For q = 1, is the compatibility constant (van de Geer, 2007)
| (20) |
They are all closely related to the ℓ2 restricted eigenvalues
(Bickel et al., 2009; Koltchinskii, 2009). Since , κ*(ξ,S) ≥ RE2(ξ, S) (van de Geer and Bühlmann, 2009). For the Lasso with ŵj = 1,
| (21) |
in the event (Ye and Zhang, 2010). Thus, cone and general invertibility factors yield sharper ℓ2 oracle inequalities.
The factors in the oracle inequalities in (21) do not always have the same order for large |S|. Although the oracle inequality based on SCIF2(ξ, S) is the sharpest among them, it seems not to lead to a simple extension to the general convex minimization in (1). Thus, we settle with extensions of the second sharpest oracle inequality in (21) with F0(ξ, S;·).
3.2 Oracle Inequalities for the Lasso in GLM
An important special case of the general formulation is the ℓ1-penalized estimator in a generalized linear model (GLM) (McCullagh and Nelder, 1989). This is Example 3 in Subsection 2.2, where we set up the notation in (13) and gave the KL divergence interpretation to (4). The ℓ1 penalized, normalized negative likelihood is
| (22) |
Assume that ψ0 is twice differentiable. Denote the first and second derivatives of ψ0 by ψ̇0 and ψ̈0, respectively. The gradient and Hessian are
| (23) |
where θ = Xβ and ψ̇0 and ψ̈0 are applied to the individual components of θ.
A crucial condition in our analysis of the Lasso in GLM is the Lipschitz condition
| (24) |
where M1 and η* are constants determined by ψ0. This condition gives
which implies the following lower bound for the GIF in (14):
For seminorms φ0 and φ, the infimum above can be taken over φ0(b) = M2 due to scale invariance. Thus, for φ0(b) = M2|b|2 and seminorms φ, this lower bound is
| (25) |
due to .
If (24) holds with η* = ∞, , so that by the Jensen inequality (18) holds with Σ = Σ* = ψ̈(β*) and
| (26) |
This gives a special F0(ξ, S;φ0) as
| (27) |
Since
in the cone
(ξ,S) in (9), for φ0(b) = M3|bS|1 with
, the φ0-RC condition (18) automatically implies the stronger
| (28) |
Under the Lipschitz condition (24), we may also use the following large deviation inequalities to find explicit penalty levels to guarantee the noise bound (15).
Lemma 8
-
Suppose the model conditions (13) and (24) with certain {M1, η*}. Let xj be the columns of X, be the elements of Σ* = ψ̈(β*). For penalty levels {λ0, λ1} define tj = λ0I{j ∈ S} + wjλ1I{j ∉ S}. Suppose the bounds wj in (6) are deterministic and
(29) for certain constants η0 ≤ η* and ε0 > 0. Then, .
-
In particular, if , 1 ≤ j ≤ p, wj = 1, j ∉ S and λ0 = λ1 = λ (so tj = λ), then part (i) still holds if .
The following theorem is a consequence of Theorem 4, Corollary 7 and Lemma 8.
Theorem 9
-
Let β̂ be the weighted Lasso estimator in (2) with GLM loss function in (22). Let β* be a target vector and h = β̂−β*. Suppose that the data follows the GML model (13) satisfying the Lipschitz condition (24) with certain {M1, η*}. Let F*(ξ,S;φ) be as in (25) with and a constant M2. Let η ≤ 1 ∧ η* and {λ, λ0, λ1} satisfy
(31) Suppose η* = ∞ and (31) holds with F*(ξ,S;M2|·|2) replaced by the special simple GIF F*(ξ,S) in (27) for the φ0 in (26). Then, the conclusions of part (i) hold with F*(ξ,S;·) replaced by the simple GIF F0(ξ, S;·) in (19). Moreover, φ0(h) ≤ η and (32) can be strengthened with the lower bound Δ(β* + h,β*) ≥ e−η〈h,Σ*h〉.
For any η* > 0, the conclusions of part (ii) hold for the φ0(b) = M3|bS|1 in (28), if F*(ξ,S) is replaced by in (31), where κ*(ξ,S) is the compatibility constant in (20).
Remark 10
If either (29) or (30) holds for the penalty levels {λ0, λ1} and the bounds wj in (6) are deterministic, then (32) implies Pβ*{the noise bound (15) holds} ≥ Pβ*(Ω0) − ε0.
Remark 11
Suppose that maxj ∉ S 1/wj, , maxj∈S wj, , and M1 are all bounded, and that . Then, (29) holds with the penalty level for certain , due to max{λ0, η, η0} → 0+. Again, the conditions and conclusions of Theorem 9 “converge” to those for the linear regression as if the Gram matrix is Σ*.
Remark 12
In Theorem 9, the key condition (31) is weaker in parts (i) and (ii) than part (iii), although part (ii) requires η* = ∞. For Σ = Σ* and M1 = M2 ≤ M3/(1 + ξ),
since as in the derivation of (28) and |b|2 ≤ |b|1 ≤ (1 + ξ)|bS|1 in the cone (9). For the more familiar with the compatibility constant, (31) essentially requires a small . The sharper Theorem 9 (i) and (ii) provides conditions to relax the requirement to a small |S|(log p)/n.
Remark 13
For ŵj = 1, Negahban et al. (2010) considered M-estimators under the restricted strong convexity condition discussed below Definition 6. For the GLM, they considered iid sub-Gaussian xi and used empirical process theory to bound the ratio Δ(β* + b,β*)/{|b|2(|b|2 − c0|b|1} from below over the cone (9) with a small c0. Their result extends the ℓ2 error bound of Bickel et al. (2009), while Theorem 9 extends the sharper (21) with the factor F0(ξ, S;φ2). Theorem 9 applies to both deterministic and random designs. Similar to Negahban et al. (2010), for iid sub-Gaussian xi, empirical process theory can be applied to the lower bound (25) for the GIF to verify the key condition (31) with F*(ξ,S;M2|·|2) ≳ |S|−1/2, provided that |S|(log p)/n is small.
Example 7 (Linear regression: oracle inequalities, continuation)
For the linear regression model (10) with quadratic loss, ψ0(θ) = θ2/2, so that (24) holds with M1 = 0 and η* = ∞. It follows that F*(ξ,S;M2|·|2) = ∞ and (31) has the interpretation with η = 0+ and ηe−ηF*(ξ,S;M2| · |2) = ∞. Moreover, since M1 = 0, η0 = 0+ in (29). Thus, the conditions and conclusions of Theorem 9 “converge” to the case of linear regression as M1 → 0+. Suppose iid εi ~ N(0,σ2) as in (13). For ŵj = w j = 1 and , (29) holds with and (31) holds with λ = λ0(1 + ξ)/(1 − ξ). The value of σ can be estimated iteratively using the mean residual squares (Städler et al., 2010; Sun and Zhang, 2011). Alternatively, cross-validation can be used to pick λ. For φ(b) = φ2(b) = | b |2/|S|1/2, (32) matches the risk bound in (21) with the factor F0(ξ, S;φ2).
Example 8 (Logistic regression: oracle inequalities)
The model and loss function are given in (11) and (12) respectively. Here we verify the conditions of Theorem 9. The Lipschitz condition (24) holds with M1 = 1 and η* = ∞ since ψ0(t) = log(1 + et) provides
Since maxt ψ̈(t) = c0 = 1/4 we can apply (30). In particular, if and λ{2ξ/(ξ + 1)}/F*(ξ,S) ≤ ηe−η, then (32) holds with at least probability 1 − ε0 under Pβ*. For such deterministic Ŵ and X, an adaptive choice of the penalty level is with , where πi(β) is as in Example 2.
Example 9 (Log-linear models: oracle inequalities)
Consider counting data with yi ∈ {0,1,2,…}. In log-linear models, it is assume that
This becomes a GLM with the average negative Poisson log-likelihood function
In this model, ψ0(t) = et, so that the Lipschitz condition (24) holds with M1 = 1 and η* = ∞. Although (30) is not useful with c0 = ∞, (29) can be used in Theorem 9.
4. Adaptive and Multistage Methods
We consider in this section an adaptive Lasso and its repeated applications, with weights recursively generated from a concave penalty function. This approach appears to provide the most appealing choice of weights both from heuristic and theoretical standpoints. The analysis here uses the results in Section 3 and an idea in Zhang (2010b).
We first consider adaptive Lasso and provide conditions under which it improves upon its initial estimator. Let ρλ(t) be a concave penalty function with ρ̇λ(0+) = λ, where ρ̇λ(t) = (∂/∂t)ρλ(t). The maximum concavity of the penalty is
| (33) |
Let
(ξ,S) be the cone in (9). Let φ0(b) be a quasi star-shaped function and define
| (34) |
This quantity is an ℓ2 version of the GIF in (14). The analysis in Section 3 can be used to find lower bounds for (34) in the same way simply by taking φ(b) = |b|2 and replacing |bS|1 with |bS|2. For example, in generalized linear models (13) satisfying the Lipschitz condition (24), the derivation of (25) yields
Given 0 < ε0 < 1, the components of the error vector z − ψ̇(β*) are sub-Gaussian if for all ,
| (35) |
This condition holds for all GLM when the components of Xβ* are uniformly in the interior of the natural parameter space for the exponential family.
Theorem 14
Let κ be as in (33), , λ0 > 0, 0 < η < 1, 0 < γ0 < 1/κ, A > 1, and ξ ≥ (A+1 − κγ0)/(A−1). Let φ0 be a quasi star-shaped function, F(ξ, S;φ0, φ0) be the GIF in (14), and F2(ξ, S;φ0) its ℓ2-version in (34). Suppose
| (36) |
for all S ⊇ S0 with |S\S0| ≤ ℓ*. Let β̃ be an initial estimator of β and β̂ be the weighted Lasso in (2) with weights ŵj = ρ̇λ(|β̃j|)/λ and penalty level λ = Aλ0/(1 − κγ0). Then,
in the event . Moreover, if (35) holds and with 0 < ε0 < 1, then Pβ* {|z − ψ̈(β*)| ≥ λ0} ≤ ε0.
Theorem 14 raises the possibility that β̂ improves β̃ under proper conditions. Thus it is desirable to repeatedly apply this adaptive Lasso in the following way,
| (37) |
Such multistage algorithms have been considered in the literature (Fan and Li, 2001; Zou and Li, 2008; Zhang, 2010b). As discussed in Remark 16 below, it is beneficial to use a concave penalty ρλ in (37). Natural choices of ρλ include the smoothly clipped absolute deviation and minimax concave penalties (Fan and Li, 2001; Zhang, 2010a).
Theorem 15
Let {κ,S0, λ0, η, γ0, A, ξ, ℓ*, λ} be the same as Theorem 14. Let β̂(0) be the unweighted Lasso with ŵj = 1 in (2) and β̂(ℓ) be the ℓ-th iteration of the recursion (37) initialized with β̂(0). Let ξ0 = (λ + λ0)/(λ − λ0). Suppose (36) holds and
| (38) |
Define r0 = (eη/F*){κ + 1/(γ0A) − κ/A}. Suppose r0 < 1. Then,
| (39) |
in the event
| (40) |
Moreover, if (35) holds and with 0 < ε0 < 1, then the intersection of the events (40) and happens with at least Pβ*probability 1 − ε0, provided that
Remark 16
Define R(0) = λeη{1 + (1 − κγ0)/A}/F(ξ0, S0; φ0, |·|2) and
It follows from (39) that R(ℓ) is an upper bound of |β̂(ℓ) − β*|2 under proper conditions. This implies |β̂(ℓ) − β*| ≤ 2R(∞) after ℓ = |logr0|−1 log(R(∞)/R(0)) iterations of the recursion (37). Under condition (35),
Since ρλ(t) is concave in t, . This component of Eβ*R(∞)matches the noise inflation due to model selection uncertainty since . This noise inflation diminishes when and ρ̇λ(t) = 0 for |t| ≥ γλ, yielding the super-efficient without the log p factor. The risk bound R(∞) is comparable with those for concave penalized least squares in linear regression (Zhang, 2010a).
Remark 17
For log(p/n) ≍ log p, the penalty level λ in Theorems 14 and 15 are comparable with the best proven results and of the smallest possible order in linear regression. For log(p/n) ≪ log p, the proper penalty level is expected to be of the order under a vectorized sub-Gaussian condition which is slightly stronger than (35). This refinement for log(p/n) ≪ log p is beyond the scope of this paper.
5. Selection Consistency
In this section, we provide a selection consistency theorem for the ℓ1 penalized convex minimization estimator, including both the weighted and unweighted cases. Let ||M||∞ = max|u|∞≤1 |Mu|∞ be the ℓ∞-to-ℓ∞ operator norm of a matrix M.
Theorem 18
Let ψ̈(β) = ℓ̈(β) be the Hessain of the loss in (1), β̂ be as in (2), β* be a target vector, be as in (5), Ω0 in (6), and F(ξ,S;φ0, φ) as in (14).
-
Let 0 < η ≤ η* ≤ 1, and Sβ = { j: βj ≠ 0}. Suppose
(41) (42) Then, {j: β̂j ≠ 0} ⊆ S in the event(43) Suppose conditions of Theorem 9 hold for the GLM. Then, the conclusions of (i) and (ii) hold under the respective conditions if F(0,S;φ0, φ0) is replaced by F*(ξ,S;M2|·|2) or F*(ξ,S) or with the respective φ0 in Theorem 9.
For ŵj = 1, this result is somewhat more specific in the radius η for the uniform irrepresentable condition (41), compared with a similar extension of the selection consistency theory to the graphical Lasso by Ravikumar et al. (2008). In linear regression (10), ψ̈β) = Σ = X′X/n does not depend on β, so that Theorem 18 with the special wj = 1 matches the existing selection consistency theory for the unweighted Lasso (Meinshausen and Bühlmann, 2006; Tropp, 2006; Zhao and Yu, 2006; Wainwright, 2009). We discuss below the ℓ1 penalized logistic regression as a specific example.
Example 10 (Logistic regression: selection consistency)
Suppose where xj are the columns of X. If (43) and (44) hold with and replaced by , then the respective conclusions of Theorem 18 hold with at least probability 1 − ε0 in Pβ*.
6. The Sparsity of the Lasso and SRC
The results in Sections 2, 3, and 4 are concerned with prediction and estimation properties of β̂, but not dimension reduction. Theorem 18 (i) and (iii) provide dimension reduction under ℓ∞-type conditions (41) and (42). In this section, we provide upper bounds for the dimension of β̂ under conditions of a weaker ℓ2 type. For this purpose, we introduce
| (45) |
as a restricted upper eigenvalue, where λmax(M) is the largest eigenvalue of matrix M, B ⊆ {1,…, p}, and ψ̈B(β) and WB are the restrictions of the Hessian of (1) and the weight operator W = diag(w1,…, wp) to ℝB.
Theorem 19
Let β* be a target vector, , β̂ be the weighted Lasso estimator (2), and be the ℓ∞-noise level as in (5). Let 0 ≤ η* ≤ 1, φ1,S(b) = |bS|1/|S|, φ0 be a quasi star-shaped function, and F(ξ,S;φ0, φ) be the GIF in (14). Then, in the event (15),
It follows from the Cauchy-Schwarz inequality that κ+(m) is sub-additive, κ+(m1 + m2) ≤ κ+(m1) + κ+(m2), so that m/κ+(m) is non-decreasing in m. For GLM, lower bounds for the GIF and probability upper bounds for can be found in Subsection 3.2. For . Theorem 19 gives an upper bound for the false negative.
In linear regression, upper bounds for the false negative of the Lasso or concave penalized LSE can be found in Zhang and Huang (2008) and Zhang (2010a) under a sparse Riesz condition (SRC). We now extend their results to the Lasso for the more general convex minimization problem (1). For this purpose, we strengthen (18) to
| (46) |
and assume the following SRC: for certain constants {c*, c*}, integer d*, 0 < α < 1, 0 < η ≤ η* ≤ 1, all A ⊃ S with |A| = d*, and all u ∈ ℝA with |u| = 1,
| (47) |
Theorem 20
Let β̂ be the Lasso estimator (2) with wj = 1 for all j, β* be a target vector, , and be the ℓ∞-noise level as in (5). Let φ0 be a quasi star-shaped function, and F(ξ,S;φ0,φ) be the GIF in (14). Suppose (46) and (47) hold. Let d1 be the integer satisfying d1 − 1 ≤ |S|(e2ηc*/c* − 1)/(2 − 2α) < d1. Then,
when , and
Theorems 19 and 20 use different sets of conditions to derive dimension bounds since different analytical approaches are used. These sets of conditions do not imply each other. In the most optimistic case, the SRC (47) allows d* = d1 +|S| to be arbitrary close to |S| when e2ηc*/c* ≈ 1, while Theorem 19 requires d1 ≥ |S| when κ+(m) ≥ 1 and F(ξ,S;φ0,φ1,S) ≤ 1 (always true for Σ* with 1 in the diagonal).
7. Discussion
In this paper, we studied the estimation, prediction, selection and sparsity properties of the weighted and adaptive ℓ1-penalized estimators in a general convex loss formulation. We also studied concave regularization in the form of recursive application of adaptive ℓ1-penalized estimators.
We applied our general results to several important statistical models, including linear regression and generalized linear models. For linear regression, we extend the existing results to weighted and adaptive Lasso. For the GLMs, the ℓq,q ≥ 1 error bounds for a general q ≥ 1 for the GLMs are not available in the literature, although ℓ1 and ℓ2 bounds have been obtained under different sets of conditions respectively in van de Geer (2008) and ]citeNegahbanRWY10. Our fixed-sample analysis provides explicit definition of constant factors in an explicit neighborhood of a target. Our oracle inequalities yields even sharper results for multistage recursive application of adaptive Lasso based on a suitable concave penalty. The results on the sparsity of the solution to the ℓ1-penalized convex minimization problem is based on a new approach.
An interesting aspect of the approach taken in this paper in dealing with general convex losses such as those for the GLM is that the conditions imposed on the Hessian naturally “converge” to those for the linear regression as the convex loss “converges” to a quadratic form.
A key quantity used in the derivation of the results is the generalized invertibility factor (14), which grow out of the idea of the ℓ2 restricted eigenvalue but improves upon it. The use of GIF yields sharper bounds on the estimation and prediction errors. This was discussed in detail in the context of linear regression in Ye and Zhang (2010).
We assume that the convex function ψ(·) is twice differentiable. Although this assumption is satisfied in many important and widely used statistical models, it would be interesting to extend the results obtained in this paper to models with less smooth loss functions, such as those in quantile regression and support vector machine.
Acknowledgments
The work of Jian Huang is supported in part by the National Institutes of Health (NIH Grants R01CA120988 and R01CA142774) and the National Science Foundation (NSF Grant DMS-08-05670). The work of Cun-Hui Zhang is supported in part by the National Science Foundation (NSF Grants DMS-0906420 and DMS-1106753) and the National Security Agency (NSA Grant H98230-11-1-0205).
Appendix A
Proof of Lemma 1
Since ψ̇(β̂) − ψ̇(β*) = z − ψ̇(β*) − g, (3) implies
and |gj| ≤ ŵjλ. Thus, (7) follows from |(z − ψ̇(β*)j| ≤ ŵjλ and ŵj ≤ wj in S in Ω0.
For (8), we have hSc = β̂Sc and , so that in Ω0 (3) gives
This gives (8). Since Δ(β̂,β*)>0, h ∈
(ξ,S) when
. For j ∉ S, hj(ψ̇(β + h) − ψ̇(β))j = β̂j(z − ψ̇(β*) − g)j ≤ |β̂j|(wjλ − gj) ≤ 0.
Proof of Theorem 4
Let h = β̂ − β*. Since ψ(β) is a convex function,
is an increasing function of t. For 0 ≤ t ≤ 1 and in the event Ω1, (8) implies
By (9) and (14), F(ξ,S;φ0,φ0) ≤ Δ(β* + th,β*)eφ0(th)/{t|hS|1φ0(th)} for φ0(th) ≤ η*. Thus, for φ0(th) ≤ min{η*,φ0(h)} and in the event Ω1,
If η* < φ0(h), the above inequality at φ0(th) = η* would give η*e−η*< ηe−η, which contradicts to η ≤ η* ≤ 1. Thus, η* ≥ φ0(h) and φ0(th)e−φ0(th) ≤ ηe−η for all 0 ≤ t ≤ 1. This implies φ0(h) ≤ η ≤ η*. Another application of (8) yields
We obtain (17) by applying (16) with φ = φ1,S to the right-hand side of (8).
Proof of Lemma 8
-
Since by (23),
(48) This and (24) imply that for M1|Xb|∞ ≤ η0,(49) Since by (5),with . Since M1 maxij|xij|bj ≤ η0, (49) gives If (30) holds, we simply replace ¨0(xi(β + tb)) by c0 in (48). The rest is simpler and omitted.
Proof of Theorem 9
(i) Since F*(ξ,S;φ) in (25) is a lower bound of F(ξ,S;φ0,φ) in (14), (32) follows from Theorem 4 with φ0(b) = M2|b|2. The probability statement follows from Lemma 8. (ii) Since (18) holds for the φ0(b) in (26), we are allowed to use F*(ξ,S) = F0(ξ,S;φ0) in Corollary 7. The condition η* = ∞ is used since φ0(b) does not control M1|Xb|∞. (iii) We are also allowed to use φ0(b) = M3|bS|1 in (28) due to M1|Xb|∞ ≤ φ0(b).
Proof of Theorem 14
Let h = β̂ − β*, wj = ŵj and S = {j : |β̂j| > γ0λ}∪ S0. For j ∉ S, wj = ρ̇λ(|β̃j|)/λ ≥ {ρ̇λ(0+) − κγ0λ}/λ = 1 − κγ0, so that . We also have . Since |ŵ|∞ ≤ 1, these bounds for and yield
Thus, since |gj| ≤ ŵjλ in (8), Lemma 1 provides
Since , we have by (36)
Thus, φ0(h) ≤ η by (16), so that by (34) and (36),
Since |hS| = 0 implies h = 0 for h ∈
(ξ,S), we find
| (50) |
Since , we have
Since |z − ψ̇(β*)|∞ ≤ λ0 = (1 − κγ0)λ/A and for j ∈ S\S0,
Inserting the above inequalities into (50), we find that
The probability statement follows directly from (35) with the union bound.
Proof of Theorem 15
Let R(ℓ) be as in Remark 16. For |z − ψ̇(β*)|∞ ≤ λ0, (16) of Theorem 4 gives |β̂(0) − β*|2 ≤ eη(λ + λ0)/F(ξ0,S0;φ0, |·|2) = R(0). Under conditions (38) and (40), we have for all ℓ ≥ 0. We prove (39) by induction. We have already proved (39) for ℓ = 0. For ℓ ≥ 1, we let β̃ = β̂(ℓ−1) and apply Theorem 14: |β̂(ℓ) − β*|2 ≤ (1 − r0)R(∞) + r0R(ℓ−1) = R(ℓ). The probability statement follows directly from (35) with the union bound.
Proof of Theorem 18
Let z̃ = z − ψ̇(β*) and λ be fixed. Consider
| (51) |
as an artificial path for 0 ≤ t ≤ 1. For each t, the KKT conditions for β̂(λ, t) are
where g(λ, t) = −ψ̇(β̂(λ, t)) + ψ̇(β*) + tz̃. Since (51) is constrained to βSc= 0 and both the error z̃ and the penalty level λ are scaled with t, Theorem 4 with ξ = 0 yields
| (52) |
Let St = {j : β̂j(λ, t) ≠ 0}. Applying the differentiation operator D = (∂/∂t) to the KKT conditions, we find that almost everywhere in t,
It follows that
| (53) |
and with an application of the chain rule,
Since g(λ, t) is almost differentiabe and β̂(λ, 0+) = β*, we have g(λ, 0+) = 0 and
Thus, (52), (41), and (42) imply
which is smaller than λ in the event in (43). Thus, since ¨S(β̂(λ, 1−)) is of full rank, β̂(λ, 1−) is the unique solution of the KKT conditions (3) for β̂. This completes the proof of part (i).
For part (ii), we observe that (44) implies
. Since β̂(λ, 0+) = β*, there exists t1 > 0 such that
for all 0 <t <t1. By (52), β̂(λ, t) ∈
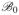 for 0 <t <t1. It follows from (53) and (44) that
for 0 <t <t1. It follows from (53) and (44) that
for 0 <t <t1 and some ε1 > 0. Since β̂(λ, 0+) = β*, this implies
for all 0 <t <t1 ∧ 1. It follows that sgn(β̂(λ, t)) = sgn(β*) for 0 < t ≤ 1 by the continuity of β̂(λ, t) in t, that is, t1 = 1. Consequently, conditions (41), and (42) are only needed for the smaller class
in the proof of part (i). This gives β̂(λ, 1) = β̂ and completes the proof of part (ii).
Finally, in part (iii), F0(ξ,S;φ0,φ0) is simply replaced by its lower bounds with the respective φ0.
Proof of Theorem 19
Suppose the event Ω1 in (15) happens, so that ŵj ≥ wj for j ∉ S and the conclusion of Theorem 4 hold. Let h = β̂ − β* and . It follows from (1) that Σ̂h = ψ̇(β* + h) − ψ̇(β*) = ℓ̇(β̂) − ℓ̇(β*). By the KKT conditions (3),
Let B ⊆ {j ∉ S : β̂j ≠ 0} with |B| ≤ d1. It follows from Theorem 4 that φ0(h) ≤ η ≤ η*, so that (45) implies . Thus, by the definition of Δ(β, β*) in (4),
This and the prediction bound in Theorem 4 yield
Since all subsets B ⊆ {j ∉ S : β̂j ≠ 0} with |B| ≤ d1 satisfies |B| < d1, it must hold that #{j ∉ S : β̂j ≠ 0} < d1.
Proof of Theorem 20
Let z̃ = z − ψ̇(β*) = −ℓ̇(β*) and β̂(λ, t) be the artificial estimator in (51) with ŵj = 1, and h(λ, t) = β̂(λ, t) − β*. Let λ* ≤ λ* be penalty levels satisfying
| (54) |
We pick such an interval [λ*,λ*] containing the penalty level λ of concern in the theorem. This is allowed by Lemma 1 and Theorem 4. We first prove the stronger conclusion
| (55) |
under the additional assumption
| (56) |
Let g(λ, t) = tz̃ + ψ̇(β*) − ψ̇(β̂(λ, t)) be the negative gradient at β̂(λ, t) in (51). By the KKT conditions for (51), sgn(β̂j(λ, t±)) ≠ 0 implies |g(λ, t)| = tλ. Thus, (56) implies the existence of λ ∈ [λ*,λ*], t1 ∈ (0, 1], and A1 ⊂ {1, …, p} satisfying
| (57) |
Moreover, if maxλ*≤λ≤λ* max0<t≤1 #{j : β̂j(λ, t) ≠ 0, j ∉ S} ≥ d1, then by the continuity of β̂(λ, t), it would be possible to restrict (57) to |A1| = d1 + |S| with some different λ ∈ [λ*,λ*] and t1 ∈ (0, 1]. Therefore, it suffices to deny this possibility by proving |A1| < d1 + |S| based on (57) and (54). Let A0 = A1\S. We prove |A0| < d1, which is equivalent to |A1| < d1 + |S|.
Let v(A) =(vjI{j ∈ A}, j ∈ A1)′ ∈ ℝA1 and vA = (vj, j ∈ A)′ ∈ ℝA for all vectors v = (v1, …, vp)′. Let h = h(λ, t1), , and g = g(λ, t1) =t1z̃ + ψ̇(β*) − ψ̇(β* + h) =t1z̃ − Σ̂h. Since . Thus, since gj =t1λsgn(hj) for j ∈ A0 by the KKT conditions,
Since , we have
Moreover, since |A1| ≤ d1 + |S| ≤ d*, it follows from (54), (46), and (47) that the eigenvalues of Σ̂A1all lie in the interval c*e−η and c*eη. Thus, since gA0= t1λsgn(β̂A0),
Since |g|∞ ≤ t1λ, the above inequality gives by algebra the dimension bound
This proves (55) under the additional assumption (56).
Now we prove (56). In the special case of φ0(b) = 0, the condition on λ in (54) is monotone so that we are allowed to pick λ* = ∞. Since β̂(λ, 1) = 0 for very large λ, (56) holds automatically for φ0(b) = 0. By (46), this special case is equivalent to linear regression since the Hessian does not depend on β. The difference of the general model (1) from linear regression is that the condition , which excludes large λ, is needed to prove φ0(h(λ, t)) ≤ η by Theorem 4. To overcome this difficulty, we consider very small t > 0. Let b = (β − β*)/t. By (51),
Let . Since as t → 0+, t−1{β̂(λ, t) − β*} converges (along a subsequence if necessary) to
Moreover, since z̃ − ¨(β*)b̂(λ) is the negative gradient at b̂(λ), we have
| (58) |
Since this limit does not depend on φ0(·), the dimension bound (55) in the special case of linear regression implies that the right-hand side of (58) contains a smaller number of elements than d1. This gives (56) in the general case by (58) and completes the proof.
Contributor Information
Jian Huang, Email: JIAN-HUANG@UIOWA.EDU, Department of Statistics and Actuarial Science, University of Iowa, Iowa City, IA 52242, USA.
Cun-Hui Zhang, Email: CZHANG@STAT.RUTGERS.EDU, Department of Statistics and Biostatistics, Rutgers University, Piscataway, New Jersey 08854, USA.
References
- Bickel PJ, Ritov Y, Tsybakov A. Simultaneous analysis of Lasso and Dantzig selector. Annals of Statistics. 2009;37(4):1705–1732. [Google Scholar]
- Bregman LM. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR Computational Mathematics and Mathematical Physics. 1967;7:200–217. [Google Scholar]
- Bunea F, Tsybakov A, Wegkamp MH. Sparsity oracle inequalities for the Lasso. Electronic Journal of Statistics. 2007;1:169–194. [Google Scholar]
- Candes EJ, Tao T. Decoding by linear programming. IEEE Trans on Information Theory. 2005;51:4203–4215. [Google Scholar]
- Candes EJ, Tao T. The dantzig selector: statistical estimation when. p is much larger than n (with discussion) Annals of Statistics. 2007;35:2313–2404. [Google Scholar]
- Chen S, Donoho DL, Saunders MA. Atomic decomposition by basis pursuit. SIAM J Sci Comput. 1998;20:33–61. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Greenshtein E, Ritov Y. Persistence in high–dimensional linear predictor selection and the virtue of overparametrization. Bernoulli. 2004;10:971–988. [Google Scholar]
- Huang J, Ma S, Zhang CH. Adaptive lasso for sparse high-dimensional regression models. Statistica Sinica. 2008;18:1603–1618. [Google Scholar]
- Hunter DR, Li R. Variable selection using mm algorithms. Annals of Statistics. 2005;33:1617–1642. doi: 10.1214/009053605000000200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Koltchinskii V. The dantzig selector and sparsity oracle inequalities. Bernoulli. 2009;15:799–828. [Google Scholar]
- McCullagh P, Nelder JA. Generalized Linear Models. Chapmann & Hall; 1989. [Google Scholar]
- Meier L, Bühlmann P. Smoothing ℓ1-penalized estimators for high-dimensional time-course data. Electronic Journal of Statistics. 2007;1:597–615. [Google Scholar]
- Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the lasso. Annals of Statistics. 2006;34:1436–1462. [Google Scholar]
- Meinshausen N, Yu B. Lasso-type recovery of sparse representations for high-dimensional data. Annals of Statistics. 2009;37:246–270. [Google Scholar]
- Negahban S, Ravikumar P, Wainwright MJ, Yu B. Technical Report arXiv:1010.2731, arXiv. 2010. A unified framework for high-dimensional analysis of m-estimators with decomposable regularizer. [Google Scholar]
- Nielsen F, Nock R. On the centroids of symmetrized bregman divergences. CoRR. 2007 abs/0711.3242. [Google Scholar]
- Ravikumar P, Wainwright MJ, Raskutti G, Yu B. Model selection in gaussian graphical models: High-dimensional consistency of ℓ1-regularized mle. Advances in Neural Information Processing Systems (NIPS) 2008;21 [Google Scholar]
- Rothman AJ, Bickel PJ, Levina E, Zhu J. Sparse permutation invariant covariance estimation. Electronic Journal of Statistics. 2008;2:494–515. [Google Scholar]
- Städler N, Bühlmann P, van de Geer S. ℓ1-penalization for mixture regression models (with discussion) Test. 2010;19(2):209–285. [Google Scholar]
- Sun T, Zhang C-H. Technical Report arXiv:1104.4595, arXiv. 2011. Scaled sparse linear regression. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 1996;58:267–288. [Google Scholar]
- Tibshirani R, Taylor J. The solution path of the generalized lasso. The Annals of Statistics. 2011;39:1335–1371. [Google Scholar]
- Tropp JA. Just relax: convex programming methods for identifying sparse signals in noise. IEEE Transactions on Information Theory. 2006;52:1030–1051. [Google Scholar]
- van de Geer S. Technical Report 140. ETH Zurich; Switzerland: 2007. The deterministic lasso. [Google Scholar]
- van de Geer S. High–dimensional generalized linear models and the lasso. Annals of Statistics. 2008;36:614–645. [Google Scholar]
- van de Geer S, Bühlmann P. On the conditions used to prove oracle results for the lasso. Electronic Journal of Statistics. 2009;3:1360–1392. [Google Scholar]
- Wainwright MJ. Sharp thresholds for noisy and high–dimensional recovery of sparsity using ℓ1–constrained quadratic programming (lasso) IEEE Transactions on Information Theory. 2009;55:2183–2202. [Google Scholar]
- Ye F, Zhang CH. Rate minimaxity of the lasso and dantzig selector for the ℓ q loss in ℓr balls. Journal of Machine Learning Research. 2010;11:3481–3502. [Google Scholar]
- Zhang C-H. Least squares estimation and variable selection under minimax concave penalty. Mathematisches Forschungsintitut Oberwolfach: Sparse Recovery Problems in High Dimensions. 2009;3 [Google Scholar]
- Zhang CH. Nearly unbiased variable selection under minimax concave penalty. The Annals of Statistics. 2010a;38:894–942. [Google Scholar]
- Zhang CH, Huang J. The sparsity and bias of the Lasso selection in high-dimensional linear regression. Annals of Statistics. 2008;36(4):1567–1594. [Google Scholar]
- Zhang T. Analysis of multi-stage convex relaxation for sparse regularization. Journal of Machine Learning Research. 2010b;11:1087–1107. [Google Scholar]
- Zhang T. Adaptive forward-backward greedy algorithm for learning sparse representations. IEEE Transactions on Information Theory. 2011a;57:4689–4708. [Google Scholar]
- Zhang T. Technical Report arXiv:1106.0565, arXiv. 2011b. Multi-stage convex relaxation for feature selection. [Google Scholar]
- Zhao P, Yu B. On model selection consistency of Lasso. Journal of Machine Learning Research. 2006;7:2541–2567. [Google Scholar]
- Zou H. The adaptive lasso and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models. Annals of Statistics. 2008;36(4):1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]