

Abstract
Objective
To develop methods for visual analysis of temporal phenotype data available through electronic health records (EHR).
Materials and methods
24 580 adults from the multiparameter intelligent monitoring in intensive care V.6 (MIMIC II) EHR database of critically ill patients were analyzed, with significant temporal associations visualized as a map of associations between hospital length of stay (LOS) and ICD-9-CM codes. An expanded phenotype, using ICD-9-CM, microbiology, and computerized physician order entry data, was defined for hospital-acquired Clostridium difficile (HA-CDI). LOS, estimated costs, 30-day post-discharge mortality, and antecedent medication provider order entry were evaluated for HA-CDI cases compared to randomly selected controls.
Results
Temporal phenome analysis revealed 191 significant codes (p value, adjusted for false discovery rate, ≤0.05). HA-CDI was identified in 414 cases, and was associated with longer median LOS, 20 versus 9 days, and adjusted HR 0.33 (95% CI 0.28 to 0.39). This prolongation carries an estimated annual incremental cost increase of US$1.2–2.0 billion in the USA alone.
Discussion
Comprehensive EHR data have made large-scale phenome-based analysis feasible. Time-dependent pathological disease states have dynamic phenomic evolution, which may be captured through visual analytical approaches. Although MIMIC II is a single institutional retrospective database, our approach should be portable to other EHR data sources, including prospective ‘learning healthcare systems’. For example, interventions to prevent HA-CDI could be dynamically evaluated using the same techniques.
Conclusions
The new visual analytical method described in this paper led directly to the identification of numerous hospital-acquired conditions, which could be further explored through an expanded phenotype definition.
Keywords: Electronic Health Records, Phenotype, Data Mining, Computing Methodologies, Computer Graphics
Background and significance
Clinical phenomics, the measurement of the diversity of disease states across human subjects, is of increasing importance in the analysis of large clinical datasets.1 Electronic health records (EHR) now make it possible to evaluate disease prevalence, distribution, and correlation across a predefined comprehensive collection of phenotypes (a ‘phenome’) to a degree that was previously not achievable.2–4 Due to the complexity of EHR and related medical data, visual analytics has become of increasing prominence.5 6
Earlier work has demonstrated that a clinical phenome, for example, as defined by the prevalence of International Classification of Disease, Ninth Revision, Clinical Modification (ICD-9-CM) codes or aggregations of such codes, can be used to calculate a phenome-wide association of disease codes with single-nucleotide polymorphisms (SNP).7–9 However, most work in this area has focused on dichotomous variables, such as SNP, which are amenable to display by conventional probability plotting (eg, Manhattan and Q-Q plots). In previous work, we demonstrated that complex phenomic information can be visualized as a function of a continuous laboratory value, such as the white blood cell count.10 As disease conditions are expected to change over time, capturing the continuous temporal evolution of a phenome could lead to new and valuable discoveries. For example, hospital-acquired complications are well known to prolong the length of hospitalizations, but may do so to varying degrees. Information about the temporal associations of specific hospital-acquired conditions, optimized for data visualization, may be evaluable through comprehensive EHR resources. Previous work on temporal phenotype extraction from EHR has focused primarily on individual patient trajectories or specific case scenarios (eg, LifeLines,11 LifeLines2,12 VISITORS);13 we propose to examine a large cohort for undiscovered temporal associations.
Objective
In this paper, we describe a new method for: visual analysis of phenomic associations as a function of time; and hypothesis generation based on the resultant temporal phenome map. These two steps comprise a substantial portion of the ‘learning healthcare system,’ as shown in figure 1. For a clinical use case, we demonstrate how the application of these visual analytical methods can lead to recognition of specific hospital-acquired complications, as a function of the length of inpatient hospitalization, in a diverse EHR database of critically ill patients.
Figure 1.
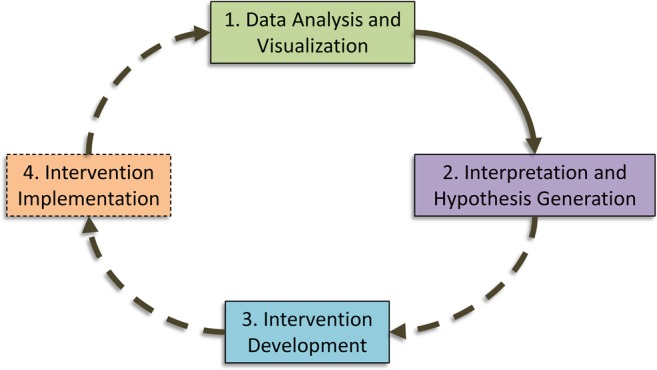
Example schema of a ‘learning healthcare system’. This example demonstrates the ideal flow of a learning healthcare system environment, which begins with data analysis and visualization. Based on interpretation of these data, potential problems are recognized and hypotheses are generated. These lead to the development of interventions to mitigate or improve the identified problems, which are then implemented and evaluated in an iterative fashion. The first two steps of this process, represented by solid lines, are described within the paper.
Materials and methods
Data source
Multiparameter intelligent monitoring in intensive care V.6 (MIMIC II), an EHR-based database of critically ill patients admitted to Beth Israel Deaconess Medical Center between 2001 and 2007, was the primary data source.14 MIMIC II contains detailed information about vital sign parameters, laboratory data, and provider order entry (POE), including time stamps of ordering, start, and stop times for medications. Our analysis was restricted to adult patients (≥16 years old). All investigators completed appropriate human subjects training before accessing the data, which is classified as institutional review board exempt. This study complies with the guidelines of the Declaration of Helsinki.
Duration of healthcare exposure definition
We defined healthcare exposure duration as the interval from initial contact with the healthcare system to hospital discharge. In MIMIC II, hospital admissions and discharges are recorded as midnight-timed date stamps; intensive care unit (ICU) admission and discharge, POE orders, and laboratory tests are recorded with time stamps. We used the first time stamp for a laboratory test or POE obtained within ±48 h of the admission date stamp as a proxy for initial contact. For same-day hospital/ICU discharges, we used the ICU discharge time as the last contact. Otherwise, we used the last time stamp of a laboratory test or POE stop order occurring within 24 h of the hospital discharge date stamp as a proxy for last contact. If there were no stop orders or labs within 24 h of the discharge date stamp, the date stamp itself was used as the last contact time.
Phenome definition and temporal phenome mapping
The ICD-9-CM codes recorded for each hospitalization were used to define patient phenotypes. We aggregated individual hospitalizations into subgroups defined by healthcare exposure duration intervals. The intervals were defined such that approximately 200 patients would be included in each subgroup. All ICD-9-CM codes in each subgroup were tabulated, and 2×2 contingency tables were formulated comparing the number of instances of each ICD-9-CM code in the subgroup to those in the remainder of the population. Fisher's exact test with two-sided hypothesis testing was used to determine significance for each contingency table. Adjusted p values of 0.05 or less, controlling for the false discovery rate using the method of Benjamini and Hochberg,15 were considered to report statistically significant associations of ICD-9-CM codes to subgroups. In order to study the robustness of our results to the number of patients in each subgroup, we explored how varying the healthcare exposure duration intervals affected the results.
A two-dimensional ‘temporal phenome map’ was rendered by plotting time as a function of ICD-9-CM codes, displaying line segments for significant adjusted p values, with segment length corresponding to the time interval containing the subgroup, and width proportionate to the negative logarithm of the adjusted p value. In the baseline analysis, an additional temporal phenome map with all adjusted p values less than 0.99 was rendered.
Visual analysis of the temporal phenome map
For the purposes of this pilot project, we limited the scope of extended evaluation to those ICD-9-CM codes in chapter one: Infectious and parasitic disease. These codes were systematically examined, and those that appeared to be consistent with hospital-acquired complications were selected for further study, with a final selection of one condition for further evaluation: hospital-acquired Clostridium difficile infection (HA-CDI).
Expanded case definitions
We then developed an expanded phenotypic definition for HA-CDI, using medication and microbiology information available in MIMIC II. Cases of HA-CDI were defined by one or more of the following occurring at least 48 h after initial contact: (1) a positive assay for C difficile toxin; (2) POE for oral or rectal vancomycin; (3) POE for oral or intravenous metronidazole and ICD-9-CM code 008.45: C difficile. For the second criterion, treatment of C difficile is the only common use for oral or rectal vancomycin so the ICD-9-CM code was not required; conversely, oral or intravenous metronidazole is used to treat other conditions, so the ICD-9-CM code was required for the third criterion. Non-HA-CDI was defined using the same criteria but with cutoffs before 48 h for case definition.
Matching controls to cases
For the set of HA-CDI cases, the outlying 1st percentile and 99th percentile of healthcare exposure duration were excluded before selection of a matching control group. Candidate controls were randomly selected from the remaining MIMIC II cohort, excluding cases of non-HA-CDI. Candidates were excluded if their healthcare exposure duration was less than the 1st percentile or greater than the 99th percentile of the case hospitalizations. If candidates had at least one laboratory value measurement during the first 48 h of hospitalization, they were included as a control. This criterion was set to exclude any test patients present in MIMIC II who appear identical to real patients but do not have laboratory information recorded. Candidate evaluation continued until a 1:1 match was achieved. Demographics (age, gender, ethnicity, and Elixhauser comorbidity scores) were recorded for all cases and controls; Elixhauser comorbidity is pre-calculated for the MIMIC II cohort.16 In order to explore patterns of antecedent medication use, which can be associated with propensity to HA-CDI, medication POE data were used to develop three aggregate groupings: (1) antibacterial agents not known to be associated with C difficile (low-risk antibacterial agents); (2) antibacterial agents known to be associated with C difficile (high-risk antibacterial agents); and (3) proton pump inhibitors and H2 receptor antagonists (H2-blocker).
Statistical and general methods
Multiple hospitalizations of the same patient were treated as independent events, and the adjusted p values for each subgroup were calculated independently. Differences between cases and controls were compared as follows: (1) categorical data (gender, ethnicity, and antecedent medication POE) with Fisher's exact test; (2) nominal data (age and Elixhauser comorbidity indices) with the Wilcoxon rank-sum test; and (3) outcome data (length of hospitalization and death within 30 days of discharge) with unadjusted and adjusted (for age, gender, ethnicity, and Elixhauser comorbidity) Cox proportional hazards models. For all of these comparisons, statistical tests were two-sided and a p value less than 0.05 was considered to be statistically significant. The incremental cost of prolonged hospitalization was estimated from a retrospective analysis of the Medicare inpatient prospective payment system, using a range of US$1500 adjusted floor cost per day to US$2500 adjusted ICU cost per day, in 2004 dollars.17 18 The overall potential yearly incremental cost to the USA healthcare system was extrapolated using a retrospective analysis of the hospital cost report information system.19
MIMIC II is stored in a standard PostgreSQL database format (The PostgreSQL Global Development Group, http://www.postgresql.org). Queries to the database and the visual analysis were conducted with R (The R Project for Statistical Computing http://cran.r-project.org/). The R scripts, which include routines for generating and zooming into the temporal phenome maps, are freely available at http://www.dryang.org/temporalphenome/temporalphenome.html.
Results
Temporal phenome analysis of the adult MIMIC II population
There were 24 580 adult patients, with 28 061 unique admissions, identified in MIMIC II. These admissions were associated with 267 984 ICD-9-CM codes. The baseline characteristics of this population are shown in table 1. For the baseline visual analysis, temporal phenome maps are shown in figure 2. Figure 2A shows that 191 of 5675 distinct ICD-9-CM codes (3.4%) present in MIMIC II were significant for at least one subgroup time interval; all significant ICD-9-CM codes along with their descriptions are shown in supplementary table S1 (available online only).
Table 1.
Baseline demographics of the MIMIC II V.6 dataset
| Characteristics | Total adult hospitalizations (n=28 061) | HA-CDI cases (n=362) | HA-CDI controls (n=362) | p Value, HA-CDI cases compared to controls |
|---|---|---|---|---|
| Age, median (IQR), year | 65 (51–77) | 68 (22–99) | 65 (21–95) | 0.079 |
| Men, no. (%) | 15 781 (56) | 199 (55) | 201 (56) | 0.940 |
| Race/ethnicity, no. (%) | 0.121 | |||
| Asian | 586 (2) | 5 (1) | 13 (4) | |
| Black | 2362 (8) | 27 (7) | 27 (7) | |
| Hispanic | 825 (3) | 7 (2) | 10 (3) | |
| White | 19 704 (70) | 282 (78) | 257 (71) | |
| Other/unknown | 4584 (16) | 41 (11) | 55 (15) | |
| Elixhauser comorbidity index, median (IQR) | 2 (1–4) | 2 (1–3) | 2 (1–3) | 0.480 |
Total adult hospitalizations include all patients 16 years of age and older at the time of hospital admission. HA-CDI cases and randomly selected controls are well-matched by age, gender, ethnicity, and comorbidity.
HA-CDI, hospital-acquired C difficile; MIMIC II, multiparameter intelligent monitoring in intensive care V.6.
Figure 2.

Temporal phenome maps. Temporal phenome-wide association of International Classification of Disease, Ninth Revision, Clinical Modification (ICD-9-CM) codes: (A) Only associations with adjusted p values of 0.05 or less are shown. (B) All associations with adjusted p value less than 0.99 are shown. For both visualizations, the width of the rendered line segments is proportionate to the negative logarithm of the adjusted p value. Each chapter of the ICD-9-CM coding schema is shown in a separate color, with vertical bars separating the chapters, and V and E codes on the right. Times are shown in days, using deciles, ranging from the 0th to 100th percentile. Median duration of hospitalization and IQR for the entire multiparameter intelligent monitoring in intensive care V.6 (MIMIC II) adult population are shown as horizontal lines.
ICD-9-CM chapter one appeared to contain multiple events occurring with long hospitalizations. On closer examination of ICD-9-CM chapter one, we found that codes for pathogens often considered to be hospital acquired were significantly associated with lengthier hospitalizations, for example: intestinal infection due to C difficile (ICD-9-CM 008.45, temporal range 28.7–294.5 days, OR range 3.15–5.16); Pseudomonas aeruginosa infection (ICD-9-CM 041.7, temporal range 42.4–49.6 days and 61.5–294.5 days, OR 10.6); and aspergillosis (ICD-9-CM 117.3, temporal range 61.5–294.5 days, OR 35.4). In a sensitivity analysis, the calculations were repeated using subgroup sizes of 25, 50, 100, and 400 patients; these results are shown in figure 3. The smaller subgroups (25, 50 patients) had very few significant findings—40 (0.7%) and 73 (1.3%) of the possible ICD-9-CM codes, respectively. Conversely, the larger subgroup (400 patients) had more findings than the baseline case (285, 5%), but the graphic was distorted by the large time intervals.
Figure 3.

Temporal phenome map sensitivity analysis. Calculations were repeated using a subgroup size of (A) 25, (B) 50, (C) 100, and (D) 400 patients. Only associations with adjusted p values of 0.05 or less are shown. ICD-9-CM, International Classification of Disease, Ninth Revision, Clinical Modification.
HA-CDI associated with longer hospital stays, increased mortality, and greater antecedent medication POE
In the MIMIC II database, we identified 414 cases (1.5% of hospitalizations) that met our expanded phenotypic definition of HA-CDI. For HA-CDI cases, first identification was as follows: 56% by a positive C difficile toxin, 41% by POE for metronidazole plus C difficile ICD-9 code, and 3% by POE for oral or rectal vancomycin.
For the matching analysis, 362 HA-CDI cases (87%) met inclusion criteria, after exclusion for outlying length of stay (LOS) and/or lack of POE information. Randomly selected candidate controls met the eligibility criteria 63.5% of the time. Compared to cases, controls were well matched for age, gender, ethnicity, and Elixhauser comorbidity index (p value non-significant for all comparisons, table 1). Length of hospitalization was significantly longer for cases, median 20 days versus 9 days (HA-CDI vs controls—table 2 and figure 4); this 11-day prolongation in length of hospitalization would be expected to add US$13 500–27 500 (2004 dollars) to the cost of care for a patient with HA-CDI, dependent on how much time was spent in the ICU versus the standard hospital floor. Cases were also more likely to die within 30 days of hospital discharge: 22% vs 12% (HA-CDI vs controls), although this comparison was no longer significant after adjustments for demographic factors—table 2 and figure 4.
Table 2.
Exposures and outcomes of HA-CDI cases as compared to matched controls
| Exposure or outcome | HA-CDI cases (n=362) | HA-CDI controls (n=362) | p Value | HR or OR (95% CI) |
|---|---|---|---|---|
| Length of stay, median (IQR), days | 20 (13–33) | 9 (6–14) | <0.001 | 0.34 (0.30 to 0.41)* |
| <0.001 | 0.33 (0.28 to 0.39)† | |||
| 30-Day post-discharge mortality, no. (%) | 80 (22) | 42 (12) | 0.05 | 1.48 (1.00 to 2.17)* |
| 0.10 | 1.38 (0.94 to 2.04)† | |||
| High-risk antibacterial exposure, no. (%)‡,§ | 240 (66) | 124 (34) | <0.001 | 3.77 (2.74 to 5.20)¶ |
| Low-risk antibacterial exposure, no. (%)‡,§ | 249 (69) | 168 (46) | <0.001 | 2.54 (1.86 to 3.49)¶ |
| PPI or H2-blocker exposure, no. (%)‡,§ | 297 (82) | 265 (73) | 0.006 | 1.67 (1.16 to 2.43)¶ |
*Unadjusted HR.
†Adjusted HR.
‡Medication POE data collected up to 24 h before diagnosis for cases, and for the first 48 h of healthcare exposure, for controls.
§Aggregate medication categories are defined in supplementary Table S2 (available online only).
¶OR.
HA-CDI, hospital-acquired C difficile; POE, provider order entry.
Figure 4.
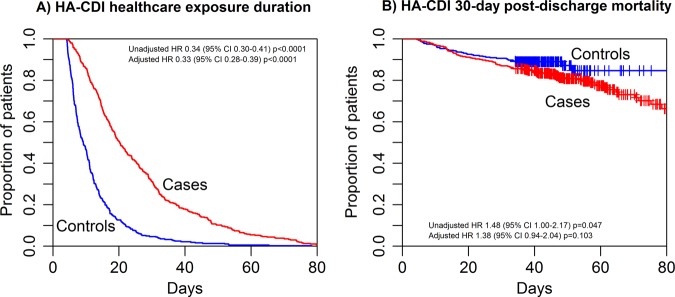
Outcomes for hospital-acquired Clostridium difficile (HA-CDI) cases compared to randomly selected controls. (A) Hospitalization duration is significantly longer for HA-CDI cases; (B) 30-day post-discharge mortality is slightly worse for HA-CDI cases compared to controls. HR, 95% CI, and p values are shown within figure panels.
The aggregated medication categories, as described above, are detailed in supplementary Table S2 (available online only). HA-CDI cases were almost twice as likely to have antecedent POE for high-risk antibacterial agents up to 24 h before HA-CDI case definition, compared to control POE during the first 48 h of hospitalization (66% vs 34%, table 2). They were also more likely to have POE for low-risk antibacterial agents and for H2-blockers or proton pump inhibitors.
Discussion
We have demonstrated a new method for the quantification and visualization of temporal patterns of risk of disease, as defined by ICD-9-CM codes available from EHR data. Given the high dimensionality of the EHR data under consideration, the human visual system is well suited to high-level interpretation of the data. Although tabular views may provide the same information, the pattern recognition abilities of the visual system are not engaged under this circumstance. We were immediately able to recognize temporal patterns, as well as regions of interest, such as ICD-9-CM chapter one, which were selected for more intensive analysis. Given that the visual appearance of displayed temporal phenome maps was notable for many significant associations with prolonged hospitalizations, our suspicion immediately turned to the possibility of severe hospital-acquired complications. As a proof of concept, the definition of a HA-CDI cohort, the recruitment of a well-matched control cohort from the remaining MIMIC II patients, and the finding of increased LOS and a trend towards increased mortality in the HA-CDI cohort affirms the legitimacy of this approach. The method described for control selection is expected to be robust to biases and confounding, although inherently the context of the eligible pool will affect control characteristics (critically ill adult and neonatal patients, in the case of MIMIC II). Date of death information is available through MIMIC II data; however, cause of death information is not. Therefore, the trend towards increased mortality observed in the HA-CDI group may have been directly from HA-CDI or from unrelated causes.
Preventable hospital-acquired complications with modifiable risk factors, such as HA-CDI, are a major cause of morbidity and mortality, and add significantly to hospitalization costs.20–22 This increased cost is supported by our study, which suggests average incremental costs of US$13 500–27 500 for an individual diagnosed with HA-CDI, as defined by our phenotyping algorithm. With extrapolation to the total USA population of critically ill patients, the estimated average annual incremental cost is US$1.2–2.0 billion for cases of HA-CDI, or approximately 1.4–2.3% of USA critical care expenditures.19 While the association of HA-CDI with increased LOS and increased costs is not novel, the finding increases confidence in our approach. Less well-studied conditions, such as multidrug-resistant Gram negative bacteria (particularly carbapenem-resistant Enterobacteriaceae), may also be identifiable through the described method. A brief review of other ICD-9-CM chapters revealed additional possible hospital-acquired conditions, for example: iatrogenic pulmonary embolism and infarction (ICD-9-CM 415.11); iatrogenic pneumothorax (ICD-9-CM 512.1); decubitus ulcer (ICD-9-CM 707.0); and infection due to other vascular device, implant, and graft (ICD-9-CM 996.62). Identifying hospital-acquired complication phenotypes through large-scale analysis of EHR data, as we have demonstrated in this pilot study, could be a precursor to targeted proactive measures, such as clinical decision support, which could yield significant cost savings while also reducing morbidity and mortality rates. In addition, this tool can be implemented to identify characteristics of conditions at the local level, and then change factors at the local level. For example, if C difficile infection is not associated with preceding antibiotic use in the reviewer’s hospital, then antimicrobial stewardship might not be the first intervention made to improve infection rates. Such evidence-driven clinical decision support, based on global as well as local factors, is essential to successful learning healthcare systems.
There are several notable limitations to this study. Primarily, tests of association as used in the temporal phenome analysis cannot distinguish between cause and effect. Currently, therefore, it is necessary to apply external medical domain knowledge to determine whether an identified code is or is not a potential hospital-acquired complication. Second, we chose to use ICD-9-CM codes due to their ready availability, despite the caveat that they are known to be recorded with variable accuracy.23–25 Furthermore, ICD-9-CM codes are generated at the end of a (potentially lengthy) hospitalization and are thus subject to the recency effect, suggesting that important diagnostic events occurring early in a prolonged admission may not be captured. It is likely that the accuracy of the phenome maps would be improved through expanded phenotype definitions based on structured clinical information (eg, encoded problem lists/summaries) as well as narrative clinical elements.26–29 While definitions such as those provided by the phenome knowledge base (http://www.phekb.org/) hold promise as more specific and sensitive phenotype definitions, they are not yet extensive enough to be practicable across the entire human phenome.28 30 Replication of this study in less well-structured environments than MIMIC II would be difficult; fortunately, the use of robust clinical data warehouses as well as secondary solutions such as Informatics for Integrating Biology and the Bedside31 is becoming more widespread.
We chose to aggregate by fixed patient numbers due to the marked non-linearity of time epochs. In addition, it was unclear a priori what time intervals could or should be considered clinically significant. Future enhancements to this tool will include the ability to toggle between patient and temporal groupings. Our sensitivity analysis demonstrates that the choice of subgroup size can have a strong influence on the results. Clearly, a fixed subgroup size of 25 was too underpowered to generate meaningful results. In addition to the choice of interval size for fixed subgroups, several other questions and complications arise: (1) Should subgroup size be non-linear, for example, dependent on the degree to which a time value is ‘out of range’? It is clear that patients with extreme out of range values are markedly different both from the general population and perhaps from each other, which is why they are conventionally excluded from analyses, including our case–control analysis. (2) Should subgroups have ‘soft’ boundaries such that patients are potentially included in more than one subgroup? (3) Computational complexity increases substantially with smaller subgroups. Future work will also focus on developing new methods to define optimally sized subgroups.
Our time definitions may lead to several systemic errors, which are likely to be widely present in EHR databases. For example, if a patient was transferred from another institution, the exposure at the previous institution would not be captured by MIMIC II. Conversely, the day of discharge should be fairly accurate but the hour of discharge is subject to unmeasured variability, leading to systemic underestimation of hospitalization time. Case definition was timed using the surrogate of a treatment decision, recorded as POE. It is assumed that the time lapse between a treatment decision and the entering of POE for that treatment is minimal, although this may not always be the case. Ultimately, we chose to use POE information because it is readily available in structured format, whereas the diagnostic information that prompts treatment decisions is typically in narrative format and difficult to access.32 As such, patients who were diagnosed with HA-CDI by means other than a positive toxin but not treated (for whatever reason) would not be captured by our phenotype definition. Whether this presumably small unmeasured cohort may have influenced our findings is unknown; future work will focus on whether such cohorts can be identified by other means.
Conclusion
There is a general need for ‘learning healthcare systems’, which will enable effective translation of EHR-driven discoveries into clinical interventions at the institutional, regional, and national levels.33 34 This work presents a new methodology for visual analytics and testable hypothesis generation from EHR data, which reveals patterns of context-specific complications with clinical implications. This analysis and interpretation begins to create a prototypical learning healthcare system, as shown in figure 1. In order to ‘complete the loop’ these findings would have to be implemented as an intervention, the effects of which could then be measured and re-evaluated. This process could continue until an identified problem has been resolved, and could also be used to provide objective evidence of quality improvement efforts.
Acknowledgments
The authors would like to extend special thanks to Peter Szolovits, Leo Celi, Federico Cismondi, Daniel Scott, Tom Lasko, and Josh Denny, for their support and advice in regards to MIMIC II and general considerations. The authors would also like to thank Peter Yang for hosting files.
Footnotes
Contributors: JLW had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. JLW and GA conceived the study design. JLW and PZ performed the experiments. JLW, AZ, PZ, and GMS analyzed the data. JLW, QD, AZ, PZ, and GMS contributed to the manuscript writing; all authors approved the final manuscript.
Funding: This work was supported in part by grants 5R21DA025168-02 (GA), 1R01HG004836-01 (GA), and 4R00LM009826-03 (GA). The funders had no role in the study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing interests: None.
Provenance and peer review: Not commissioned; externally peer reviewed.
Data sharing statement: The R code developed for the study is freely available through a website described in the paper.
References
- 1.Houle D, Govindaraju DR, Omholt S. Phenomics: the next challenge. Nat Rev Genet 2010;11:855–66 [DOI] [PubMed] [Google Scholar]
- 2.Butte AJ, Kohane IS. Creation and implications of a phenome-genome network. Nat Biotechnol 2006;24:55–62 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Kohane IS. Using electronic health records to drive discovery in disease genomics. Nat Rev Genet 2011;12:417–28 [DOI] [PubMed] [Google Scholar]
- 4.Murphy S, Churchill S, Bry L, et al. Instrumenting the health care enterprise for discovery research in the genomic era. Genome Res 2009;19:1675–81 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Boyle J, Kreisberg R, Bressler R, et al. Methods for visual mining of genomic and proteomic data atlases. BMC Bioinformatics 2012;13:58. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Chui KK, Wenger JB, Cohen SA, et al. Visual analytics for epidemiologists: understanding the interactions between age, time, and disease with multi-panel graphs. PLoS ONE 2011;6:e14683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Denny JC, Ritchie MD, Basford MA, et al. PheWAS: demonstrating the feasibility of a phenome-wide scan to discover gene–disease associations. Bioinformatics 2010;26:1205–10 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Pendergrass SA, Brown-Gentry K, Dudek SM, et al. The use of phenome-wide association studies (PheWAS) for exploration of novel genotype-phenotype relationships and pleiotropy discovery. Genet Epidemiol 2011;35:410–22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Denny JC, Crawford DC, Ritchie MD, et al. Variants near FOXE1 are associated with hypothyroidism and other thyroid conditions: using electronic medical records for genome- and phenome-wide studies. Am J Hum Genet 2011;89:529–42 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Warner JL, Alterovitz G. Phenome-based analysis as a means for discovering context-dependent clinical reference ranges. AMIA Annual Symposium Proceedings; 2012:1441–9 [PMC free article] [PubMed] [Google Scholar]
- 11.Plaisant C, Mushlin R, Snyder A, et al. LifeLines: using visualization to enhance navigation and analysis of patient records. Proceedings of AMIA Symposium 1998:76–80 [PMC free article] [PubMed] [Google Scholar]
- 12.Wang TD, Wongsuphasawat K, Plaisant C, et al. Extracting insights from electronic health records: case studies, a visual analytics process model, and design recommendations. J Med Syst 2011;35:1135–52 [DOI] [PubMed] [Google Scholar]
- 13.Klimov D, Shahar Y, Taieb-Maimon M. Intelligent visualization and exploration of time-oriented data of multiple patients. Artif Intell Med 2010;49:11–31 [DOI] [PubMed] [Google Scholar]
- 14.Saeed M, Villarroel M, Reisner AT, et al. Multiparameter intelligent monitoring in intensive care II: a public-access intensive care unit database. Crit Care Med 2011;39:952–60 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc B (Methodological) 1995;57:289–300 [Google Scholar]
- 16.Elixhauser A, Steiner C, Harris DR, et al. Comorbidity measures for use with administrative data. Med Care 1998;36:8–27 [DOI] [PubMed] [Google Scholar]
- 17.Milbrandt EB, Kersten A, Rahim MT, et al. Growth of intensive care unit resource use and its estimated cost in Medicare. Crit Care Med 2008;36:2504–10 [DOI] [PubMed] [Google Scholar]
- 18.Cooper LM, Linde-Zwirble WT. Medicare intensive care unit use: analysis of incidence, cost, and payment. Crit Care Med 2004;32:2247–53 [DOI] [PubMed] [Google Scholar]
- 19.Halpern NA, Pastores SM. Critical care medicine in the United States 2000–2005: an analysis of bed numbers, occupancy rates, payer mix, and costs. Crit Care Med 2010;38:65–71 [DOI] [PubMed] [Google Scholar]
- 20.Fuller RL, McCullough EC, Bao MZ, et al. Estimating the costs of potentially preventable hospital acquired complications. Health Care Financ Rev 2009;30:17–32 [PMC free article] [PubMed] [Google Scholar]
- 21.Ghantoji SS, Sail K, Lairson DR, et al. Economic healthcare costs of Clostridium difficile infection: a systematic review. J Hosp Infect 2010;74:309–18 [DOI] [PubMed] [Google Scholar]
- 22.Wiegand PN, Nathwani D, Wilcox MH, et al. Clinical and economic burden of Clostridium difficile infection in Europe: a systematic review of healthcare-facility-acquired infection. J Hosp Infect 2012;81:1–14 [DOI] [PubMed] [Google Scholar]
- 23.Dubberke ER, Reske KA, McDonald LC, et al. ICD-9 codes and surveillance for Clostridium difficile-associated disease. Emerg Infect Dis 2006;12:1576–9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Dubberke ER, Butler AM, Yokoe DS, et al. Multicenter study of surveillance for hospital-onset Clostridium difficile infection by the use of ICD-9-CM diagnosis codes. Infect Control Hosp Epidemiol 2010;31:262–8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Chan M, Lim PL, Chow A, et al. Surveillance for Clostridium difficile infection: ICD-9 coding has poor sensitivity compared to laboratory diagnosis in hospital patients, Singapore. PLoS One 2011;6:e15603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ohno-Machado L. Realizing the full potential of electronic health records: the role of natural language processing. J Am Med Inform Assoc 2011;18:539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Carroll RJ, Thompson WK, Eyler AE, et al. Portability of an algorithm to identify rheumatoid arthritis in electronic health records. J Am Med Inform Assoc 2012;19:e162–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Kho AN, Pacheco JA, Peissig PL, et al. Electronic medical records for genetic research: results of the eMERGE consortium. Sci Transl Med 2011;3:79re1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Murff HJ, FitzHenry F, Matheny ME, et al. Automated identification of postoperative complications within an electronic medical record using natural language processing. JAMA 2011;306:848–55 [DOI] [PubMed] [Google Scholar]
- 30.Newton KM, Peissig PL, Kho AN, et al. Validation of electronic medical record-based phenotyping algorithms: results and lessons learned from the eMERGE network. J Am Med Inform Assoc 2013;20:e147–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Murphy SN, Weber G, Mendis M, et al. Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2). J Am Med Inform Assoc 2010;17:124–30 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Rosenbloom ST, Denny JC, Xu H, et al. Data from clinical notes: a perspective on the tension between structure and flexible documentation. J Am Med Inform Assoc 2011;18:181–6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Institute_of_Medicine The learning healthcare system: workshop summary (IOM Roundtable on Evidence-Based Medicine). Washington, DC: National Academies Press, 2007 [PubMed] [Google Scholar]
- 34.Friedman CP, Wong AK, Blumenthal D. Achieving a nationwide learning health system. Sci Transl Med 2010;2:57cm29. [DOI] [PubMed] [Google Scholar]