

Abstract
Functional principal component analysis (FPCA) has become the most widely used dimension reduction tool for functional data analysis. We consider functional data measured at random, subject-specific time points, contaminated with measurement error, allowing for both sparse and dense functional data, and propose novel information criteria to select the number of principal component in such data. We propose a Bayesian information criterion based on marginal modeling that can consistently select the number of principal components for both sparse and dense functional data. For dense functional data, we also developed an Akaike information criterion (AIC) based on the expected Kullback-Leibler information under a Gaussian assumption. In connecting with factor analysis in multivariate time series data, we also consider the information criteria by Bai & Ng (2002) and show that they are still consistent for dense functional data, if a prescribed undersmoothing scheme is undertaken in the FPCA algorithm. We perform intensive simulation studies and show that the proposed information criteria vastly outperform existing methods for this type of data. Surprisingly, our empirical evidence shows that our information criteria proposed for dense functional data also perform well for sparse functional data. An empirical example using colon carcinogenesis data is also provided to illustrate the results.
Keywords: Akaike information criterion, Bayesian information criterion, Functional data analysis, Kernel smoothing, Principal components
1 Introduction
Advances in technology has made functional data (Ramsay and Silverman, 2005) increasingly available in many scientific fields, such as many longitudinal data in medical, biological research, electroencephalography (EEG) and functional magnetic resonance imaging (fMRI) data. There is tremendous research interest in functional data analysis (FDA) for the past decade. Among the newly developed methodology, functional principal component analysis (FPCA) has become the most widely used dimension reduction tool for functional data analysis. There is some existing work on selecting the number of functional principal components, but to the best of our knowledge, none of them were rigorously studied either theoretically or empirically. In this paper, we consider functional data that are observed at random, subject-specific observation times, allowing for both sparse and dense functional data. We propose novel information criteria to select the number of principal components, and investigate their theoretical and empirical performance.
There are two main streams of methods for FPCA, kernel based FPCA methods including Yao, Müller and Wang (2005a), Hall, Müller and Wang (2006), and spline based methods including Rice and Silverman (1991), James and Hastie (2001), and Zhou, Huang and Carroll (2008). Some applications of FPCA include Functional Generalized Linear Models, (Müller and Studtmüller, 2005; Yao, Müller and Wang, 2005b; Cai and Hall, 2005; Li, Wang and Carroll, 2010) and Functional Sliced Inverse Regression (Li and Hsing, 2010a).
At this point, the kernel based FPCA methods are better understood in terms of theoretical properties. This is due to the work of Hall and Hosseini-Nasab (2006), who proved various asymptotic expansions of the estimated eigenvalues and eigenfunction for dense functional data, and by Hall et al. (2006) who provided the optimal convergence rate of FPCA in sparse functional data. An important result of Hall et al. (2006) was that, although FPCA is applied to the covariance function estimated by a two dimensional smoother, when the bandwidths were properly tuned, estimating the eigenvalues is a semiparametric problem and enjoys a root n convergence rate, and estimating the eigenfunctions is a nonparametric problem with the convergence rate of a one dimensional smoother.
In the work on FDA mentioned above, functional data were classified as (a) dense functional data where the curves are densely sampled so that passing a smoother on each curve can effectively recover the true sample curves (Hall et al., 2006); and (b) sparse functional data where the number of observations per curve is bounded by a finite number and pooling all subjects together is required to obtain consistent estimates of the principal components (Yao et al., 2005a; Hall et al., 2006). There has been a gap in methodologies for dealing with these two types of data. Hall et al. (2006) showed that when the number of observations per curve diverges to ∞ with a rate of at least n1/4, the pre-smoothing approach is justifiable and the errors in smoothing each individual curve are asymptotically negligible. However, in reality it is hard to decide when the observations are dense enough. In some longitudinal studies it is possible that we have dense observations on some subjects and sparse observations on the others. In view of these difficulties, Li and Hsing (2010b) studied all types of functional data in a unified framework, and derived a strong uniform convergence rate for FPCA, where the number of observations per curve can be of any rate relative to the sample size.
A common finding in the aforementioned work is that higher order principal components are much harder to estimate and harder to interpret. Because seeking sparse representation of the data is at the core of modern statistics, it is reasonable in many situations to model the high order principal components as noise. Therefore, selecting the number of principal components is an important model selection problem in almost all practical contexts of FDA. Yao et al. (2005a) proposed an AIC criterion for selecting the number of principal components in sparse functional data. However, so far there is no theoretical justification for this approach, and whether this criterion also works for dense functional data or the types of data in the grey zone between sparse and dense functional data remains unknown. Hall and Vial (2006) included theoretical discussion about the difficulty of selecting the number of principal components using a hypothesis testing approach. The bootstrap approach proposed by Hall and Vial provides a confidence lower bound υ̂q for the “unconfounded noise variance”, and can provide some guidance in selecting the number of principal components. However, their approach is not a real model selection criterion, and one needs to watch the decreasing trend of υ̂q and decide the cut point subjectively. The minimum description length (MDL) method by Poskitt and Sengarapillai (2011) is similar to Yao’s AIC in that each principal component is counted as one parameter, although of course the criteria are numerically different. We emphasize that, in reality, each principal component consists of one variance parameter and one nonparametric function. A main point of our paper is to justify how much penalty is needed in a model selection criterion, when selecting the number of nonparametric components in the data.
We approach this problem from three directions, with all approaches built upon the foundation of information criteria. In the marginal modeling approach, we focus on the decay rate of the estimated eigenvalues and develop a Bayesian Information Criterion (BIC) based selection method. The advantages of this approach include that it only uses existing outcomes from FPCA, namely the estimated eigenvalues and the residual variance, and that it is consistent for all types of functional data. As an alternative, we find that, with some additional assumptions, a modified Akaike Information Criterion (AIC) based on conditional likelihood could produce superior numerical outcomes. A referee pointed out to us that when the data are observed densely on a regular grid, where no kernel smoothing is necessary, there is some existing work in the econometrics literature based on a factor analysis model (Bai and Ng, 2002) to select the number of principal components. We study this class of information criteria in our setting and find out that they are still consistent if a specific undersmoothing scheme is carried out in the FPCA method. In addition, we also provide some discussion for the case that the true number of principal components diverges to infinity.
The remainder of the paper is organized as follows. In Section 2, we describe the data structure and the FPCA algorithm. In Sections 3.1 and 3.2, we propose and study the new marginal BIC and conditional AIC criteria, and we investigate the information criteria by Bai and Ng in Section 3.3. The proposed information criteria are tested by simulation studies in Section 4, and applied to an empirical example in Section 5. Some concluding remarks are given in Section 6, where we also provide discussion for the case that the true number of principal components diverges. All proofs are provided in the Supplementary Material.
2 Functional principal component analysis
2.1 Data structure and model assumptions
Let X(t) be functional data defined on a fixed interval T = [a, b], with mean function μ(t) and covariance function R(s, t) = cov{X(s), X(t)}. Suppose the covariance function has the eigen-decomposition , where the ωj are the nonnegative eigenvalues of R(·,·), which, without loss of generality, satisfy ω1 ≥ ω2 ≥ ⋯ > 0, and the ψj are the corresponding eigenfunctions.
Although, in theory, the spectral decomposition of the covariance function consists of infinite number of terms, to motivate practically useful information criteria, it is sensible to assume that there is a finite dimensional true model. Due to the nature of spectral decomposition, the higher order terms are less reliably assessed and their estimates tend to have high variation. Consequently, even though one could assume that there are an infinite number of components, unless the data size is very large, sensible variable selection criteria will still select a relatively small number of components – the first several that can be reasonably assessed. This phenomenon is reflected by the numerical outcomes reported in Table S.7 of the Supplementary Material, in which a much-improved performance of BIC is observed when the sample size increases to 2000. The performance of BIC is mostly determined by the accuracy of detecting non-zero eigenvalues and that this detection can be difficult for higher order terms. For the rest of the paper, except for Section 6.2, we assume that the spectral decomposition of R ends at a finite p terms, i.e. ωj = 0 for j > p. Then the Karhunen-Loève expansion of X(t) is
| (1) |
where ξj = ∫ψj(t) {X(t) − μ(t)}dt has mean zero, with cov(ξj, ξj′) = I(j = j′)ωj. Let p0 be the true value of p.
Suppose we sample from n independent sample trajectories, Xi(·), i = 1, ⋯, n. It often happens that the observations contain additional random errors and instead we observe
| (2) |
where Uij are independent zero-mean errors, with and the Uij are also independent of Xi(·). Here the (tij) are random, subject-specific observation times. Suppose tij has a continuous density f1(t) with support T. We adopt the framework in Li and Hsing (2010b) so that mi can be of any rate relative to n. The only assumption on mi is that all mi ≥ 2, so that we can estimate the within-curve covariance matrix. In other words, we allow mi to be bounded by a finite number as in sparse functional data, or diverging to ∞ as in dense functional data.
2.2 Functional principal component analysis
The functions μ(·) and R(·,·) can be estimated by local polynomial regression, and then ψk(·), ωk and can be estimated using the functional principal component analysis method proposed in Yao, et al. (2005a) and Hall, et al. (2006). We now briefly describe the method. We first estimate μ(·) by a local linear regression, μ̂(t) = â0 where , K(·) is a symmetric density function and hμ is the bandwidth for estimating μ. Define CXX (s, t) = E{X(s)X(t)} and Mi = (mi − 1)mi. We denote the bandwidth for estimating CXX(·,·) by hC and let ĈXX (s, t) = b̂0, where (b̂0, b̂1, b̂2) minimizes
Then R̂(s, t) = ĈXX (s, t) − μ̂(s)μ̂(t). In addition, (ωk) and {ψk(·)} can be estimated from an eigenvalue decomposition of R̂(·,·) by discretization of the smoothed covariance function, see Rice and Silverman (1991) and Capra and Müller (1997). Let , and , where, with a given bandwidth, hσ, (ĉ0, ĉ1) minimizes . One possible estimator if is
| (3) |
Define ω̂k and ψ̂k(·) to be the kth eigenvalue and eigenfunction of R̂(s, t), respectively. Rates of convergence results for μ̂(·), R̂(·), , and ψ̂k(·) are described in the Supplementary Material, Section S.1.
3 Methodology
3.1 Marginal Bayesian Information Criterion
In a traditional regression setting with sample size n, parameter size p, and normally distributed errors of mean zero and variance , BIC is commonly defined as
Considering the model equations (1) and (2), linking the current setup for each subject and then marginalizing over all subjects, we consider a generalized BIC criterion of the structure of
| (4) |
where is an estimate of by marginally pooling error information from all subjects and Pn(p) is a penalty term. Even though the concept behind our criterion has been motivated by the traditional BIC in regression setting, there are some marked differences. For example, the ξj in model (1) are random. As a result, marginally, there are not np parameters. Further, unlike the traditional regression problems, we do not need to estimate/predict ξj. Consequently, the number of parameters in a marginal analysis is not determined by the degrees of freedom of these unknown ξj. Inspired by standard BIC, we let the penalty be of the form Pn(p) = Cn,pp and then determine the rate of Cn,p.
Let be the estimator of based on the residuals after taking into account of the first p principal components. Define
If p is the true number of principal components, then R[p](s,t) = R(s,t). Since for all k, we can estimate by
| (5) |
Replacing by in (4), the new BIC criterion is given by
| (6) |
That is, instead of estimating from the estimated residuals, we will estimate it from a ‘marginal’ approach by pooling all subjects together. This way, we avoid estimating the principal component scores and dealing with the estimation errors in them.
Denote ∥·∥ as the L2 functional norm, and define , which is the kth harmonic mean of the mi’s. When mi = m for all i, we have that γn1 = m and γn2 = m2. For any bandwidth h, define
We make the following assumptions.
-
(C.1)
The observations time tij ~ f1(t), (tij, tij′) ~ f2(t1, t2), where f1 and f2 are continuous density functions with bounds 0 < mT ≤ f1(t1), f2(t1, t2) ≤ MT < ∞ for all t1, t2 ∈ T. Both f1 and f2 are differentiable with bounded (partial) derivatives.
-
(C.2)
The kernel function K(·) is a symmetric probability density function on [−1, 1], and is of bounded variation on [−1, 1]. Denote .
-
(C.3)
μ(·) is twice differentiable and its second derivative is bounded on [a, b].
-
(C.4)
All second-order partial derivatives of R(s, t) exist and are bounded on [a, b]2.
-
(C.5)
There exists C > 4 such that E(|Uij|C) + E{supt∈[a,b] |X(t)|C} < ∞.
-
(C.6)
hμ, hC, hσ, δn1(hμ), δn2(hC), δn1(hσ) → 0 as n → ∞.
-
(C.7)
We have ω1 > ω2 > ⋯ > ωp0 > 0 and ωk = 0 for all k > p0.
Let p̂ be the minimizer of BIC(p). The following theorem gives a sufficient condition for p̂ to be consistent to p0.
Theorem 1
Make assumptions (C.1)-(C.7). Recall that Pn(p) is the penalty defined in (6), and define . Suppose the following conditions hold
for any p < p0, pr[limsupn→∞ {Pn(p0) − Pn(p)} ≤ 0] = 1;
for any p > p0, .
Then limn→∞pr(p̂ = p0) = 1.
By Theorem 1, there is a large range of penalties that can result in a consistent BIC criterion. For example, let N = Σi mi and recall that the penalty term Pn(p) = Cn,pp. If we let , it is easy to verify that the conditions in Theorem 1 are satisfied.
We now derive a data-based version of Pn(p) that satisfies condition (i) and (ii). By Lemma S.1.1 in the Supplementary Material, is actually the L2 convergence rate of R̂(·,·), which by Lemma S.1.3 in the Supplementary Material is also the bound for the null eigenvalues, {ω̂k; k > p0}. In reality, ∥R̂ − R∥ not only depends on but also on unknown constants depending on the true function R(·,·) and the distribution of W. To make the information criterion data-adaptive, we propose the following penalty
| (7) |
Justification for (7) is given in the Supplementary Material, Section S.2.
3.2 Akaike Information Criterion based on conditional likelihood
The marginal BIC criterion can be computed by using outcomes from FPCA directly and it is consistent. However, its performances heavily rely on the precision in estimating ωj, particularly when j is near the true number of principle components, p0. It is known that the estimation of ωj can deteriorate when j increases. In this subsection, we propose an alternative approach that, by having some additional conditions, allows us to take advantage of the use of likelihood. We consider the principal component scores as random effects, and proposed a new AIC criterion based on the conditional likelihood and estimated principal component scores. Such an approach is referred as conditional AIC in linear mixed models, see Claeskens and Hjort (2008). In an alternative context, Hurvich et al. (1998) proposed an AIC criterion for choosing the smoothing parameters in nonparametric smoothing. The FPCA method is to project the discrete longitudinal trajectories on some nonparametric functions (i.e. the eigenfunctions), and can thus be considered as simultaneously smoothing n curves. The AIC in the FPCA context is connected to that for the nonparametric smoothing problem, but the way of counting the effective number of parameters in the model will be different. Therefore, the penalty in our AIC will also be very different from that of the nonparametric smoothing problem.
Define Wi = (Wi1, …, Wi,mi)T, μi = {μ(ti1), ⋯, μ(ti,mi)}T and ψik = {ψk(ti1), ⋯, ψk(ti,mi)}T. Under the assumption that there are p non-zero eigenvalues, denote , and Xi,[p] = {Xi,[p](ti1), …, Xi,[p](ti,mi)}T = μi + Ψi,[p]ξi,[p], where Ψi,[p] = (ψi1, …, ψip) and ξi,[p] = (ξi1, …, ξip)T. Under a Gaussian assumption, the conditional log likelihood of the observed data {Wi} given the principal component scores is
| (8) |
where N = Σi mi and .
Following the method proposed by Yao et al. (2005a), we estimate the trajectories by
| (9) |
where μ̂(·) and ψ̂j(·) are the estimators described in Section 2. The estimated principal component scores, ξ̂ij, are given by the principal component analysis through the conditional expectation (PACE) estimator by Yao et al. (2005a). Under the Gaussian model, the best linear unbiased predictor (BLUP) for ξi,[p] is , where Λ[p] = diag(ω1, …, ωp), and . To estimate ξ̂i,[p], the PACE estimator requires a pilot estimator of , for which we can use the integral estimator defined in (3). The PACE estimator is given by
| (10) |
where μ̂i, Λ̂[p] and Ψ̂i,[p] are the estimates using the FPCA method described in Section 2, and .
To choose p, Yao et al. (2005a) proposed the pseudo AIC
| (11) |
where X̂[p] is the estimated value of X[p] by interpolating the estimated trajectories defined in (9) on the subject-specific times. By adding a penalty p to the estimated conditional likelihood, Yao et al. essentially counted each principal component as one parameter.
To motivate our own AIC criterion, we consider dense functional data satisfying
| (12) |
We follow the spirit of the derivation of Hurvich and Tsai (1989), and define the Kullback-Leibler information to be
| (13) |
for any fixed X̂[p] and σ̂2, where F is the true normal distribution given the true curves {Xi(·), i = 1, …, n}. Using similar derivations as in Hurvich and Tsai (1989), for any fixed parameters and σ̂2, we have
| (14) |
By substituting in the FPCA and PACE estimators, the estimated variance under the model with p principal components is given by
Then the Kullback-Leibler information for these estimators is
| (15) |
where .
To derive the new AIC criterion, we need the following theoretical results to evaluate the expected Kullback-Leibler information. As discussed in Hurvich et al. (1998, page 275), in derivation of AIC, one needs to assume that the true model is included in the family of candidate models, and any model bias is ignored. For example, Hurvich et al. (1998) ignored the smoothing bias when developing AIC for nonparametric regressions. Following the same argument, we will ignore all the biases in μ̂(·) and ψ̂k(·), and only take into account the variation in the estimators.
Proposition 1
Under assumptions (C.1)-(C.7), condition (12) and the additional assumption that n (hμ + hC) → ∞, , where the χij are independent random variables and . As a result, in probability as n → ∞
The next proposition gives the asymptotic expansion for E{An(p0)}.
Proposition 2
Under the same conditions as in Proposition 1, E{An(p0)} = N + 2np0 + o(n).
Thus, the expected Kullback-Leibler information is . This justifies defining AIC as
| (16) |
When mi → ∞ and p is fixed, an intuitive interpretation for the proposed AIC in (16) is to consider FPCA as a linear regression on the observed data Wi − μi against covariates (ψi1,…, ψip) for subject i, and consider the principal component scores as the subject-specific coefficients. By pooling n independent curves together and by adding up the individual AIC, we have a total of np regression parameters and the AIC in (16) coincides with that of a simple linear regression. The biggest difference between our AIC and that of Yao et al. in (11) is the way we count the number of parameters in the model.
3.3 Consistent information criteria
As pointed out by a referee, functional principal component analysis is closely related to factor models in econometrics, where there are some existing information criteria to choose the number of factors consistently (Bai and Ng, 2002). We stress that the data considered in the econometrics literature are multivariate time series data observed on regular time points, while we consider irregularly spaced functional data. The estimator and criteria proposed by Bai and Ng were based on matrix projections, while our FPCA method relies heavily on kernel smoothing and operator theory. As a result, deriving consistent model selection criteria for our problem is technically much more involved.
Inspired by Bai and Ng (2002), we consider two classes of information criteria:
| (17) |
| (18) |
where is the error variance estimator used in our AIC (15) and gn is a penalty. The estimator in Bai and Ng (2002) was a mean squared error based on a simple regression, while our estimator is based on the PACE method involving kernel smoothing and BLUP.
For any p ≤ p0, denote ψ[p](t) = (ψ1, …, ψp)T (t), ψ[p+1:p0] = (ψp+1, …, ψp0)T (t), and define the inner product matrices and . Put Λ[p+1:p0] = diag(ωp+1, …, ωp0), and
| (19) |
Theorem 2
Suppose τp defined at (19) exists and is positive for all 0 ≤ p < p0. Let p̂ be the minimizer of the information criteria defined in (17) or (18) among 0 ≤ p ≤ pmax with pmax > p0 being a fixed search limit, and define . Under the assumptions (C.1) - (C.7) and condition (12), limn→∞ pr(p̂ = p0) = 1 if the penalty function gn satisfies (i) and (ii) .
In the factor analysis context, the penalty term in the information criteria proposed by Bai and Ng (2002) converges to 0 with a rate slower than , where Cn = min(m1/2, n1/2) translating to our notation. Their rate shows a sense of symmetry in the roles of m and n. Indeed, when the curves are observed on a regular grid, the data can be arranged into a n × m matrix W, the factor analysis can be carried out by a singular value decomposition of W, and hence the roles of m and n are symmetric. For the random design that we consider, we apply nonparametric smoothing along t, not among the subjects. Therefore, m and n play different roles in our rate. Not only does the smoothing make our derivation much more involved, but the fact the within-subject covariance matrices are defined on subject specific time points poses many theoretical challenges. Our proof uses many techniques from perturbation theory of random operators and matrices.
The following corollary shows that when the bandwidths are chosen properly, penalties similar to those in Bai and Ng (2002) can still lead to consistent information criteria.
Corollary 1
Suppose all conditions in Theorem 2 hold, and hμ ≍ max(n,m)−c1, hC ≍ max(n,m)−c2, hσ ≍ max(n,m)−c3, where 1/4 ≤ c1, c2 ≤ 1, 1/4 ≤ c3 ≤ 3/2. Then p̂ that minimizes PC(p) or IC(p) is consistent if (i) and (ii) , where Cn = min(n1/2, m1/2) as defined in Bai and Ng (2002).
Bai and Ng (2002) proposed the following information criteria that satisfy the conditions in Corollary 1,
| (20) |
where is a pilot estimator for . In our setting, we can use defined at (3) in place of , and replace m by either the arithmetic or the harmonic mean of mi’s. Under the undersmoothing choices of bandwidths described in Corollary 1, all information criteria in (20) are consistent. One can easily see the similarity between the ICp criteria and the AIC proposed in (16). In general, the ICp criteria impose greater penalties to over-fitting than AIC. By comparing AIC with the conditions in Theorem 2 and other consistent criteria we developed, we can see the penalty term in AIC is a little bit small and that explains the non-vanishing chance of overfitting witnessed in our simulation studies, see Section 4.
4 Simulation Studies
4.1 Empirical performance of the proposed criteria
To illustrate the finite sample performance of the proposed methods, we performed various simulation studies. Let T = [0, 1], and suppose that the data are generated from the model (1) and (2). Let the observation time points Tij ~ Uniform [0, 1], mi = m for all i and .
We consider the following five scenarios.
Scenario I: Here the true mean function is μ(t) = 5(t − 0.6)2, the number of principal components is p0 = 3, the true eigenvalues are (ω1, ω2, ω3) = (0.6, 0.3, 0.1), the variance of the error is and the eigenfunctions are ψ1(t) = 1, , . The principal component scores are generated from independent normal distributions, i.e. ξij ~ Normal(0, ωj). Here .
Scenario II: The data are generated in the same way as in Scenario I, except that we replace the third eigenfunction by a rougher function so that the covariance function is less smooth, and we let the principal component scores follow a skewed Gaussian mixture model. Specifically, ξij has 1/3 probability of following a distribution, and 2/3 probability of following , for j = 1, 2, 3.
Scenario III: Set μ(t) = 12.5(t − 0.5)2 − 1.25, ϕ1(t) = 1, , , and (ω1, ω2, ω3, σ2) = (4.0, 2.0, 1.0, 0.5). The principal component scores are generated from a Gaussian distribution. Here .
Scenario IV: The mean function, eigenvalues, eigenfunction and noise level are set to be the same as in Scenario III, but the ξij’s are generated from a Gaussian mixture model similar to that in Scenario II.
- Scenario V: In this simulation, we set p0 = 6, the true eigenvalues are (4.0, 3.5, 3.0, 2.5, 2.0, 1.5) and . We assume that the principal component scores are normal random variables and let the eigenfunctions be
In each simulation, we generated n = 200 trajectories from the models above, and compared the cases with m = 5, 10 and 50. The cases m = 5 and m = 50 may be viewed as representing sparse and dense functional data, respectively, whereas m = 10 represents scenarios between the two extremes. For each m, we apply the FPCA procedure to estimate , then use the proposed information criteria to choose p. The simulation was then repeated 200 times for each scenario.
The performance of the estimators depends on the choice of bandwidths for μ(t), C(s, t) and , and the optimal bandwidths vary with n and m. We picked the bandwidths that are slightly smaller than those minimizing the integrated mean squared error (IMSE) of the corresponding functions, since undersmoothing in functional principal component analysis was also advocated by Hall et al. (2006) and Li and Hsing (2010b).
We consider Yao’s AIC, MDL by Poskitt and Sengarapillai (2011), the proposed BIC and AIC in (6) and(16), and the criteria by Bai and Ng in (20). Yao’s AIC is calculated using the publicly available PACE package (http://anson.ucdavis.edu/mueller/data/pace.html), where all bandwidths are data-driven and selected by generalized cross-validation (GCV). The empirical distribution of p̂ under Scenarios I to IV are summarized in Tables 1-3. Since the true number of principal components p0 is different in Scenario V, the distribution of p̂ is summarized in a separate Table 4.
Table 1.
When m = 5, displayed are the distributions of the number of selected principal components p̂ for all methods and across Scenarios I-IV. The true number of principal components is 3.
| Scenario | Method | p̂ ≤ 1 | p̂ = 2 | p̂ = 3 | p̂ = 4 | p̂ ≥ 5 |
|---|---|---|---|---|---|---|
| I | AICPACE | 0.000 | 0.008 | 0.000 | 0.121 | 0.870 |
| AIC | 0.000 | 0.405 | 0.580 | 0.010 | 0.005 | |
| BIC | 0.155 | 0.335 | 0.380 | 0.115 | 0.015 | |
| PCp1 | 0.005 | 0.565 | 0.410 | 0.010 | 0.010 | |
| ICp1 | 0.000 | 0.215 | 0.735 | 0.045 | 0.005 | |
| II | AICPACE | 0.000 | 0.000 | 0.005 | 0.125 | 0.870 |
| AIC | 0.000 | 0.205 | 0.630 | 0.155 | 0.010 | |
| BIC | 0.230 | 0.395 | 0.245 | 0.110 | 0.020 | |
| PCp1 | 0.000 | 0.000 | 0.375 | 0.440 | 0.185 | |
| ICp1 | 0.000 | 0.140 | 0.605 | 0.210 | 0.045 | |
| III | AICPACE | 0.000 | 0.025 | 0.005 | 0.130 | 0.840 |
| AIC | 0.000 | 0.035 | 0.720 | 0.170 | 0.075 | |
| BIC | 0.335 | 0.260 | 0.325 | 0.080 | 0.000 | |
| PCp1 | 0.000 | 0.220 | 0.640 | 0.075 | 0.065 | |
| ICp1 | 0.000 | 0.005 | 0.590 | 0.280 | 0.125 | |
| IV | AICPACE | 0.000 | 0.015 | 0.015 | 0.145 | 0.825 |
| AIC | 0.000 | 0.020 | 0.710 | 0.185 | 0.085 | |
| BIC | 0.315 | 0.180 | 0.410 | 0.070 | 0.025 | |
| PCp1 | 0.000 | 0.160 | 0.640 | 0.095 | 0.105 | |
| ICp1 | 0.000 | 0.015 | 0.560 | 0.260 | 0.165 |
Table 3.
For m = 50, displayed are the distributions of the number of selected principal components p̂ for all methods and across Scenarios I-IV. The true number of principal components is 3.
| Scenario | Method | p̂ = 1 | p̂ = 2 | p̂ = 3 | p̂ = 4 | p̂ ≥ 5 |
|---|---|---|---|---|---|---|
| I | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| BIC | 0.000 | 0.000 | 0.830 | 0.150 | 0.020 | |
| PCp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| ICp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| II | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.000 | 0.630 | 0.320 | 0.050 | |
| BIC | 0.000 | 0.000 | 0.795 | 0.185 | 0.020 | |
| PCp1 | 0.000 | 0.000 | 0.955 | 0.045 | 0.000 | |
| ICp1 | 0.000 | 0.000 | 0.945 | 0.055 | 0.000 | |
| III | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| BIC | 0.000 | 0.000 | 0.775 | 0.200 | 0.025 | |
| PCp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| ICp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| IV | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.000 | 0.945 | 0.055 | 0.000 | |
| BIC | 0.000 | 0.000 | 0.835 | 0.140 | 0.025 | |
| PCp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | |
| ICp1 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 |
Table 4.
Distributions of the number of selected principal components p̂ for Scenario V. The true number of principal components is 6.
| Scenario | Method | p̂ ≤ 4 | p̂ = 5 | p̂ = 6 | p̂ = 7 | p̂ ≥ 8 |
|---|---|---|---|---|---|---|
| m=5 | AICPACE | 0.005 | 0.005 | 0.705 | 0.245 | 0.040 |
| AIC | 0.165 | 0.330 | 0.470 | 0.035 | 0.000 | |
| BIC | 0.835 | 0.020 | 0.090 | 0.050 | 0.005 | |
| PCp1 | 0.580 | 0.345 | 0.070 | 0.005 | 0.000 | |
| ICp1 | 0.060 | 0.335 | 0.545 | 0.060 | 0.000 | |
| m=10 | AICPACE | 0.005 | 0.000 | 0.065 | 0.475 | 0.455 |
| AIC | 0.000 | 0.000 | 0.570 | 0.280 | 0.15 | |
| BIC | 0.250 | 0.030 | 0.525 | 0.165 | 0.030 | |
| PCp1 | 0.000 | 0.145 | 0.775 | 0.020 | 0.060 | |
| ICp1 | 0.000 | 0.000 | 0.705 | 0.185 | 0.110 | |
| m=50 | AICPACE | 0.000 | 0.065 | 0.000 | 0.000 | 0.935 |
| AIC | 0.000 | 0.000 | 0.260 | 0.405 | 0.335 | |
| BIC | 0.005 | 0.000 | 0.590 | 0.325 | 0.080 | |
| PCp1 | 0.000 | 0.000 | 0.980 | 0.010 | 0.010 | |
| ICp1 | 0.000 | 0.000 | 0.965 | 0.035 | 0.000 |
The proposed BIC method is based on the convergence rate results on the eigenvalues, and does not rely much on the distributional assumptions for X and U. From Tables 1-3, we see that BIC picks the correct number of principal components with high percentage in almost all scenarios, except for the cases where the data are sparse, i.e. m = 5. This phenomena is as expected, because it is harder to pick up the correct number of signals from sparse and noisy data.
Compared to BIC, the performance of the proposed AIC method is even more impressive. Although BIC is designed to be a consistent model selector, the AIC method selects the right number of principal component with a higher percentage in most of the cases we considered. This is partially due to the fact that AIC makes more use of the information from the likelihood. Even though the data are non-Gaussian in Scenario II and IV, the AIC still performs better than the BIC, and it shows that both the PACE method and the AIC method are quite robust against mild violation of the Gaussian Assumption. Even though the motivation and theoretical development for the AIC method described in Section 3.2 are for dense functional data, it performs surprisingly well for sparse data, such as the case m = 5.
There are six criteria in (20), and we find that the PCp’s and the ICp’s tend to perform similarly. To save journal space, we only provide the results for PCp1 and ICp1, and the results for the remaining criteria in (20) can be find in the expanded versions of Tables 1-4 in the Supplementary Material. As we can see, these criteria behave similar to the AIC, and they tend to do better only in a few occasions when AIC overestimates p.
For almost all scenarios considered, Yao’s AIC hardly ever picks the correct model, with the exception of Scenario V, m = 5, which will be discussed in more detail below. When the true number of principal components is 3, Yao’s AIC will normally chose a number greater than 5. This phenomenon becomes more severe when the data are dense. For example, when m = 50, Yao’s AIC almost always pick the maximum order considered, which is 15 in our simulations. The behavior of the MDL by Poskitt and Sengarapillai (2011) is similar to Yao’s AIC, and hence these results are only provided in Tables S.2 - S.5 in the Supplementary Material.
Scenario V, Table 4 is specially designed to check the performance of the proposed information criteria under the situations where we have a relatively large number of principal components. The proposed criteria worked reasonably well for m = 10 and 50, and performed much better than Yao’s AIC. The case of m = 5 under Scenario V is the only case in all of our simulations that Yao’s AIC picks the correct model more often than our criteria. With a closer look at the results, we find an explanation. The true covariance function under Scenario V is quite rough, and the GCV criterion in the PACE package chose a large bandwidth so that the local fluctuations on the true covariance surface are smoothed out. In other words, high frequency signals are smoothed out and treated as noise. In a typical run, the PACE estimates for the eigenvalues are (4.1736, 2.1350, 1.6697, 1.0009, 0.3978, 0.0476) which are far from the truth, (4.0, 3.5, 3.0, 2.5, 2.0, 1.5), and the estimated error variance is 6.519 in contrast to the truth . It is the combination of seriously underestimating the high order eigenvalues and small penalty in AIC that makes Yao’s criterion pick the correct number of principal components. Switching to our undersmoothing bandwidths, these estimates are improved but then Yao’s AIC will choose much larger values for p. This case also highlights the difficulty of FPCA when p is large but the data are sparse. Unless we have a very large sample size, estimation of these principal components is very difficult, and comparing the model selection procedures in such a case would not be meaningful.
4.2 Further Simulations
The Supplementary Material, Section S.4 contains further simulations, including (a) Expanded results with other model selectors in Tables S.2-S.5; (a) an examination of the sensitivity of the results to the bandwidth (Supplementary Table S.6); (c) the behavior of BIC with much larger sample size (Supplementary Table S.7); and (c) results when the value of m is not constant, i.e., mi ≠ m for all i (Supplementary Table S.8).
5 Data analysis
The colon carcinogenesis data in our study have been analyzed in Li, Wang et al. (2007, 2010) and Baladandayuthapani et al. (2008). The biomarker of interest in this experiment is p27, which is a protein that inhibits cell cycle. We have 12 rats injected with carcinogen and sacrificed 24 hours after the injection. Beneath the colon tissue of the rats, there are pore structures called ‘colonic crypts’. A crypt typically contains 25 to 30 cells, lined up from the bottom to the top. The stem cells are at the bottom of the crypt, where daughter cells are generated. These daughter cells move towards the top as they mature. We sampled about 20 crypts from each of the 12 rats. The p27 expression level was measured for each cell within the sampled crypts. As previously noted in the literature (Morris et al. 2001, 2003), the p27 measurements, indexed by the relative cell location within the crypt, are natural functional data. We have m = 25-30 observations (cells) on each function. As in the previous analyses, we consider p27 in the logarithmic scale. By pooling data from the 12 rats, we have a total of n = 249 crypts (functions). In the literature, it has been noted that there is spatial correlation among the crypts within the same rat (Li et al., 2007, Baladandayuthapani et al., 2008). In this experiment, we sampled crypts sufficiently far apart so that the spatial correlations are negligible, and thus we can assume that the crypts are independent.
We perform the FPCA procedure as described in Section 2, with the bandwidths chosen by leave one curve out cross-validation. The estimated covariance function is given in the top panel of Figure 1. The estimated variance of measurement error by integration is σ̃u,I = 0.103. In contrast, the top 3 eigenvalues are 0.8711, 0.0197 and 0.0053. Let kn = max{k; ω̂k > 0}, then the percentage of variation explained by the kth principal component is estimated by . The percentage of variation explained by the first 7 principal components are (0.966, 0.022, 0.006, 0.003, 0.002, 0.001, 0.000).
Figure 1.
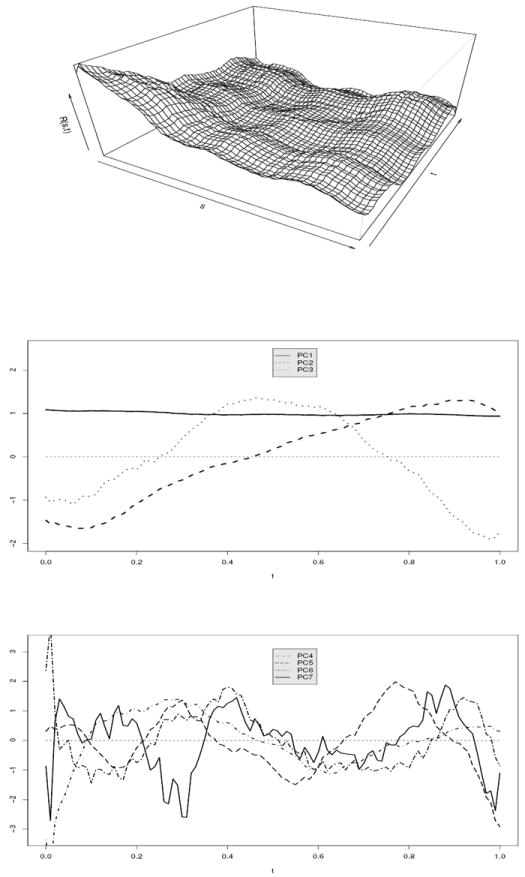
Functional principal component analysis for the colon carcinogenesis p27 data. Top panel: estimated covariance function; middle panel: the first 3 eigenfunctions; lower panel: eigenfunctions 4-7.
We apply the proposed AIC, adaptive BIC, the Bai and Ng criteria (20) and Yao’s AIC to the data. All of the proposed methods lead to p = 3 principal components, for which the corresponding eigenfunctions are shown in the middle panel Figure 1. As we can see, the first principal component is a constant over time, and the second and third eigenfunctions are essentially linear and quadratic functions. Eigenfunction 4 to 7 are shown in the bottom panel of Figure 1, and they are basically noises and are hard to interpret. We therefore can see that the variation among different crypts can be explained by random quadratic polynomials. Yao’s AIC, on the other hand, picked a much large number of principal components, with p = 9. This is due to the fact that a much smaller penalty is used in Yao’s AIC criterion. We have repeated the data analysis using other choices of bandwidths, and the results are the same.
6 Summary
6.1 Basic Summary
Choosing the number of principal components is a crucial step in functional data analysis. There have been some data-driven procedures proposed in the literature that can be used to choose the number of principal components, but these procedures have not been studied theoretically, nor were they tested numerically as extensively as in this paper.
To promote practically useful model selection criteria, we have assumed that there exists a finite dimensional true model. We found that the consistency of the model selection criteria depends on both the sample size n and the number of repeated measurements m on each curve. We proposed a marginal BIC criterion that is consistent for both dense and sparse functional data, which means m can be of any rate relative to n. In the framework of dense functional data, where both n and m diverge to infinity, we proposed a conditional Akaike information criterion, which is motivated by an asymptotic study of the expected Kullback-Leibler distance under Gaussian assumption.
Following the standard approach of Hurvich et al. (1998), we ignored smoothing biases in developing AIC. Our intensive simulation studies also confirm that bias plays a very small role in model selection. In our simulations in Section 4.2, we tried a wide range of bandwidths and thus increase or decrease the biases in the estimators, but the performance of AIC is almost the same. Intuitively, the models under different numbers of principal components are nested, for a fixed bandwidth the smoothing bias exists in all models that we compare, and therefore variation is a more decisive factor in model selection.
In view of the connection of FPCA with factor analysis in multivariate time series data, we revisited the information criteria proposed by Bai and Ng (2002). Even though our setting is fundamentally different, since we assumed that the observational times are random, and the FPCA estimators depend heavily on nonparametric smoothing and are much more complex than those in Bai and Ng, we show essentially similar information criteria can be constructed. Using perturbation theory of random operators and matrices, and under an under-smoothing scheme prescribed in Section 3.3, we showed that these information criteria are consistent when both n and m go to infinity.
6.2 Discussion of the case p0 → ∞
Some processes considered as functional data are intrinsically infinite dimensional. In those cases, the assumption of p0 being finite is a finite sample approximation. As the sample size n increases, we can afford to include more principal components in the model and data analysis. It is helpful to consider that the true dimension p0n increases to infinity as a function of n. This setting was considered in the estimation of a functional linear model (Cai and Hall, 2006). To the best of our knowledge, no information criteria have been previously studied under this setting.
While allowing p0n → ∞, the convergence rates for μ̂(t) and R̂(s, t) remain the same as those given in Lemma S.1.1 in the Supplementary Material, but the convergence rates for ψ̂j(t) are affected by the spacing of the true eigenvalues. Following condition (4.2) in Cai and Hall (2006), we assume that for some positive constants C and α,
| (21) |
To ensure that , we assume that α > 1. Define the distances between the eigenvalues, δj = mink≤j(ωk − ωk+1), which is no less than C−1j−1−α under condition (21). By the asymptotic expansion of ψ̂j(t), see (2.8) in Hall and Hosseini-Nasab, 2006, one can show that the convergence rate of ψ̂j is times those in Lemma S.1.2 in the Supplementary Material, i.e.
Assume that n, m, p0n → ∞, , and . Following the proof of Theorem 2, while taking into account the increasing estimation error in ψ̂j(t) as j increases and the increasing dimensionality of the design matrix Ψi, we can show that
| (22) |
where τp ≍ tr(Λ[p+1:p0n]) is analogous to (19) and ϱn is as defined in Theorem 2. Since the eigenvalues are decaying to 0, the size of the signal τp ≍ p−α as p increases to p0n. In order to have some hope of choosing p0n correctly, we need τp to be greater than the size of the estimation error, which implies that .
Now, consider the class of information criteria in Section 3.3. Suppose that p0n increases slowly enough so that , and that the penalty term satisfies τp/(pgn) → ∞ for p < p0n and for p > p0n. Then we can show that the p̂ which minimizes PC(p) or IC(p) is consistent. These conditions translate to
| (23) |
If p0n = {min(m, n)}β where 0 < β < 1/(2α+3), one can see that the criteria in (20) do not satisfy the conditions in (23) automatically and hence are not guaranteed to be consistent. An information criterion satisfying condition (23) requires a priori knowledge of the decay rate of the eigenvalues. Developing a data-adaptive information criterion that does not require such a priori knowledge is a challenging topic for future research.
Supplementary Material
Table 2.
When m = 10, displayed are the distributions of the number of selected principal components p̂ for all methods and across Scenarios I-IV. The true number of principal components is 3.
| Scenario | Method | p̂ ≤ 1 | p̂ = 2 | p̂ = 3 | p̂ = 4 | p̂ ≥ 5 |
|---|---|---|---|---|---|---|
| I | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.005 | 0.980 | 0.015 | 0.000 | |
| BIC | 0.000 | 0.040 | 0.670 | 0.255 | 0.035 | |
| PCp1 | 0.000 | 0.040 | 0.955 | 0.000 | 0.005 | |
| ICp1 | 0.000 | 0.005 | 0.985 | 0.010 | 0.000 | |
| II | AICPACE | 0.000 | 0.000 | 0.000 | 0.005 | 0.995 |
| AIC | 0.000 | 0.000 | 0.710 | 0.260 | 0.030 | |
| BIC | 0.000 | 0.170 | 0.665 | 0.135 | 0.030 | |
| PCp1 | 0.000 | 0.000 | 0.570 | 0.355 | 0.075 | |
| ICp1 | 0.000 | 0.000 | 0.805 | 0.185 | 0.010 | |
| III | AICPACE | 0.000 | 0.015 | 0.000 | 0.000 | 0.985 |
| AIC | 0.000 | 0.000 | 0.580 | 0.400 | 0.020 | |
| BIC | 0.005 | 0.035 | 0.770 | 0.145 | 0.045 | |
| PCp1 | 0.000 | 0.000 | 0.965 | 0.030 | 0.005 | |
| ICp1 | 0.000 | 0.000 | 0.665 | 0.320 | 0.015 | |
| IV | AICPACE | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 |
| AIC | 0.000 | 0.000 | 0.830 | 0.150 | 0.020 | |
| BIC | 0.010 | 0.005 | 0.775 | 0.190 | 0.020 | |
| PCp1 | 0.000 | 0.000 | 0.920 | 0.045 | 0.035 | |
| ICp1 | 0.000 | 0.000 | 0.900 | 0.085 | 0.015 |
Acknowledgments
Li’s research was supported by the National Science Foundation (DMS-1105634, DMS-1317118). Wang’s research was supported by a grant from the National Cancer Institute (CA74552). Carroll’s research was supported by a grant from the National Cancer Institute (R37-CA057030) and by Award Number KUS-CI-016-04, made by King Abdullah University of Science and Technology (KAUST). The authors thank the associate editor and two anonymous referees for their constructive comments that led to significant improvements in the paper.
Contributor Information
Yehua Li, Email: yehuali@iastate.edu, Department of Statistics & Statistical Laboratory, Iowa State University, Ames, IA 50011.
Naisyin Wang, Email: nwangaa@umich.edu, Department of Statistics, University of Michigan, Ann Arbor, MI 48109-1107.
Raymond J. Carroll, Email: carroll@stat.tamu.edu, Department of Statistics, Texas A&M University, TAMU 3143, College Station, TX 77843-3143.
References
- Bai J, Ng S. Determining the number of factors in approximate factor models. Econometrika. 2002;70:191–221. [Google Scholar]
- Baladandayuthapani V, Mallick B, Hong M, Lupton J, Turner N, Carroll RJ. Bayesian hierarchical spatially correlated functional data analysis with application to colon carcinogenesis. Biometrics. 2008;64:64–73. doi: 10.1111/j.1541-0420.2007.00846.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cai T, Hall P. Prediction in functional linear regression. Annals of Statistics. 2006;34:2159–2179. [Google Scholar]
- Capra WB, Müller HG. An accelerated-time model for response curves. Journal of the American Statistical Association. 1997;92:72–83. [Google Scholar]
- Claeskens G, Hjort NL. Model Selection and Model Averaging. Cambridge University Press; New York: 2008. [Google Scholar]
- Hall P, Hosseini-Nasab M. On properties of functional principal components analysis. Journal of the Royal Statistical Society, Series B. 2006;68:109–126. [Google Scholar]
- Hall P, Müller H-G, Wang J-L. Properties of principal component methods for functional and longitudinal data analysis. Annals of Statistics. 2006;34:1493–1517. [Google Scholar]
- Hall P, Vial C. Assessing the finite dimensionality of functional data. Journal of the Royal Statistical Society, Series B. 2006;68:689–705. [Google Scholar]
- Hurvich CM, Simonoff JS, Tsai CL. Smoothing parameter selection in nonparametric regression using an improved Akaike information criterion. Journal of the Royal Statistical Society, Series B. 1998;60:271–293. [Google Scholar]
- Hurvich CM, Tsai CL. Regression of time series model selection in small samples. Biometrika. 1989;76(2):297–307. [Google Scholar]
- Horn RA, Johnson CR. Matrix Analysis. Cambridge University Press; New York: 1985. [Google Scholar]
- Kato T. Variation of discrete spectra. Communications in Mathematical Physics. 1987;111:501–504. [Google Scholar]
- Li Y, Hsing T. Deciding the dimension of effective dimension reduction space for functional and high-dimensional data. Annals of Statistics. 2010a;38:3028–3062. [Google Scholar]
- Li Y, Hsing T. Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data. Annals of Statistics. 2010b;38:3321–3351. [Google Scholar]
- Li Y, Wang N, Hong M, Turner N, Lupton J, Carroll RJ. Nonparametric estimation of correlation functions in spatial and longitudinal data, with application to colon carcinogenesis experiments. Annals of Statistics. 2007;35:1608–1643. [Google Scholar]
- Li Y, Wang N, Carroll RJ. Generalized functional linear models with semiparametric single-index interactions. Journal of the American Statistical Association. 2010;105:621–633. doi: 10.1198/jasa.2010.tm09313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morris JS, Wang N, Lupton JR, Chapkin RS, Turner ND, Hong MY, Carroll RJ. Parametric and nonparametric methods for understanding the relationship between carcinogen-induced DNA adduct levels in distal and proximal regions of the colon. Journal of the American Statistical Association. 2001;96(455):816–826. [Google Scholar]
- Morris JS, Vannucci M, Brown PJ, Carroll RJ. Wavelet-based nonparametric modeling of hierarchical functions in colon carcinogenesis. Journal of the American Statistical Association. 2003;98(463):573–583. [Google Scholar]
- Müller H-G, Stadtmüller U. Generalized functional linear models. Annals of Statistics. 2005;33:774–805. [Google Scholar]
- Poskitt DS, Sengarapillai A. Description length and dimensionality reduction in functional data analysis. Computational Statistics & Data Analysis. 2011 in press. [Google Scholar]
- Ramsay JO, Silverman BW. Functional Data Analysis. 2. Springer-Verlag; New York: 2005. [Google Scholar]
- Rice J, Silverman B. Estimating the mean and covariance structure nonparametrically when the data are curves. Journal of the Royal Statistical Society, Series B. 1991;53:233–243. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005a;100:577–590. [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional linear regression analysis for longitudinal data. Annals of Statistics. 2005b;33:2873–2903. [Google Scholar]
- Zhou L, Huang JZ, Carroll RJ. Joint modelling of paired sparse functional data using principal components. Biometrika. 2008;95(3):601–619. doi: 10.1093/biomet/asn035. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.