

Abstract
The goal of ecology is to understand interactions that determine the distribution and abundance of organisms. In principle, ecologists should be able to identify a small number of limiting resources for a species of interest, estimate densities of these resources at different locations across the landscape, and then use these estimates to predict the density of the focal species at these locations. In practice, however, development of functional relationships between abundances of species and their resources has proven extremely difficult, and examples of such predictive ability are very rare. Ecological studies of prey requirements of tigers Panthera tigris led us to develop a simple mechanistic model for predicting tiger density as a function of prey density. We tested our model using data from a landscape-scale long-term (1995–2003) field study that estimated tiger and prey densities in 11 ecologically diverse sites across India. We used field techniques and analytical methods that specifically addressed sampling and detectability, two issues that frequently present problems in macroecological studies of animal populations. Estimated densities of ungulate prey ranged between 5.3 and 63.8 animals per km2. Estimated tiger densities (3.2–16.8 tigers per 100 km2) were reasonably consistent with model predictions. The results provide evidence of a functional relationship between abundances of large carnivores and their prey under a wide range of ecological conditions. In addition to generating important insights into carnivore ecology and conservation, the study provides a potentially useful model for the rigorous conduct of macroecological science.
Ecological investigations basically involve efforts to understand interactions that determine the spatial distribution and abundance of organisms (1–3). Ecologists strive for a predictive science in which they can identify key attributes as potential limiting factors for a focal species, measure these attributes at different locations, and make predictions about the abundance of the focal species based on these measured attributes. An alternative popular approach to the study of spatial distribution and abundance is to search for patterns in existing data and then to treat perceived patterns as phenomenological models to be used for making predictions. Regardless of research approach, the study of the distribution and abundance of organisms at large spatial scales (i.e., macroecological patterns) has received substantial emphasis recently (3–8).
Analyses directed at macroecological questions require data collected at a scale far beyond the typical study areas of most field ecologists. As a result, such analyses are usually based on either large-scale count surveys of animal populations (6) or on metaanalyses of results from numerous individual studies (8). However, most large-scale count surveys of animal populations fail to yield strong inferences for two reasons: they are based on raw count data (indices) bearing an unknown relationship to true animal abundance, and spatial sampling units are not selected in a manner that permits inference about the entire area of interest (9–11). Individual studies used in metaanalyses also frequently suffer from these two problems, besides being constrained by their individual sets of objectives, field techniques, and analytic methods. As a result, the inferences about existence and nonexistence of potential patterns derived from macroecological analyses are often weak and unreliable. The detection and nondetection of patterns may have more to do with spatial variation in detectability of animals and selection of sample locations than with true ecological variations.
The study reported here represents an effort to avoid the above weaknesses associated with many macroecological investigations. This effort focuses on two key aspects (11) of such investigations: (i) modeling and prediction and (ii) sampling and estimation. With respect to modeling and prediction, instead of looking for macroecological patterns and then treating such patterns as phenomenological models to be tested, we emphasize a more mechanistic approach based on the ecological concept of “limiting factors,” factors that are determinants of equilibrium population size or, more generally, of the stationary probability distribution of population densities (12–14). Changes in limiting factors are expected to cause corresponding changes in equilibrium population densities (12–15), thus providing a logical basis for prediction. This approach is more direct and mechanistic than the use of phenomenological models.
With respect to sampling and estimation, we selected 11 study sites located within protected areas throughout India. Each site was sampled by teams of trained investigators, using methods developed specifically to estimate densities of the focal species (the tiger) and their primary resource (prey species). This field study required 8 years and substantial effort to complete but resulted in data that were adequate to test our model-based predictions at a landscape-level spatial scale.
Materials and Methods
Model Development. Generally, carnivores (order Carnivora) appear to be limited by food resources (8, 16), with species in the family Felidae being obligate meat eaters. Tigers are the largest of the felids and prey almost exclusively on large ungulates (17, 18). They are socially dominant over other sympatric carnivores (18, 19). Consequently, tiger densities in protected habitats are likely to be mediated chiefly by prey abundance rather than interspecific social dominance and competitive exclusion. Therefore, we proposed a mechanistic model that predicts tiger density as a function of prey density.
Based on earlier field studies of large carnivore guilds (17, 18, 20), we hypothesized that predators annually removed ≈15% of all available prey, with tigers cropping ≈10% and other sympatric predators such as leopards Panthera pardus and/or dholes Cuon alpinus exploiting the remaining 5%. The body masses of individual ungulates killed by tigers (20–1,000 kg) and the proportion of the kill actually consumed are both highly variable factors (18). Therefore, we represented prey availability in terms of ungulate numbers rather than biomass (21) in our model. We applied the average kill rate of 50 ungulates/tigers per year consistently observed in field studies of tigers (18, 21). Thus, we predicted tiger density, Tj at location j, based on prey density, Uj, according to the following expression:
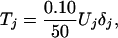 |
where δj is a mean one random variable.
The above model of the functional relationship between prey density and tiger density could potentially be tested by manipulating prey density at multiple locations to look for the predicted response in tiger density. However, because manipulative experimentation on populations of these rare endangered animals was neither possible nor desirable, we tested our model by estimating population densities of both tigers and prey in a field study that covered a total area of 3,024 km2 in 11 ecologically diverse landscapes across India. Our study sites represented a wide range of ecological variations in terms of both abundance and composition of the prey assemblages.
Estimation of Prey Abundance. Ungulate prey species were visible during the day and could be directly counted by investigators. However, investigators could not detect all animals present in the surveyed areas during field counts because of dense cover and other factors. Thus the estimation of prey density required the estimation of detection probability (9–11). Therefore, prey densities were estimated by using line transect surveys in conjunction with distance sampling methods (22). Investigators walked along forest trails established to representatively sample the surveyed areas. Visual detections of ungulates were followed by counts of group (cluster) size and measurements of sighting distances and sighting angles (22, 23) to obtain perpendicular distances of sighted animals from the transect line. The animal counts and associated distance data were later used to model visual detection probabilities as a decreasing function of distance from the transect line. This modeling and the subsequent estimation of prey densities and their variances were accomplished by using the estimation algorithms implemented in computer software distance (24). Generally, models of detectability based on the half-normal key function with one or no adjustment terms adequately fitted data from most prey species–habitat combinations, with the hazard rate or uniform–cosine key function fitting data adequately in the remaining cases (22–24).
Estimation of Tiger Densities. Tigers were photographed by using surveys deploying automatic camera traps activated by animal movement (25, 26). Because tigers can be individually identified from their stripe patterns, it is possible to photographically “capture” and “recapture” them on one or more sampling occasions. Resulting data can be summarized as capture histories, vectors of 1s and 0s reflecting whether each individual tiger was captured (1) or not (0) on each sampling occasion. These data are then used in conjunction with capture–recapture models developed for closed animal populations (11, 27) to estimate tiger abundance (25, 26, 28). Specifically, we used program capture (29) to compute test statistics for the hypothesis of a closed population and model selection statistics based on a discriminant function developed from extensive simulations and to derive estimates of capture probability (p) and tiger abundance (N) at each site using various possible models and associated estimators. Because of our interest in comparing tiger density estimates across sites, we preferred a single model and estimator for use on data from all sites.
Tiger density was then estimated by dividing the estimated population size (N̂) by the estimated area sampled by the camera traps. This area was estimated by first computing the area (A) of the polygon connecting the outermost traps. Then, half the mean maximum distances moved by individual tigers between photo-captures at each site was used to estimate the width of a buffer strip (ŵ) that was added to the polygon area to estimate Â(ŵ), the area effectively sampled by camera traps (25, 28, 30). Density was then estimated as: D̂ = N̂/Â(ŵ).
Modeling the Relation Between Tiger and Prey Numbers. We supposed that the natural logarithms of prey density and tiger density have a bivariate normal distribution. This model induces a regression relation
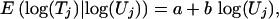 |
with the regression coefficients determined by the parameters of the bivariate normal distribution, as follows:
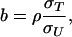 |
where σT and σU are the standard deviations corresponding to tiger and prey densities, respectively; ρ is the correlation coefficient; and
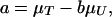 |
where μT and μU are the means corresponding to tiger and prey, respectively. It follows that, conditional on Uj,
 |
where δj is a mean one random variable and
 |
Thus the model corresponds to our a priori prediction of the relation between tiger and prey density, with A = 0.002 and b = 1. Because we express tiger density as animals per 100 km2 and prey density as animals per km2, we actually predict A = 0.2.
We fitted this model by means of a hierarchical Bayesian analysis (31–33) based on estimates T̂j and Ûj and their estimated standard errors ŜTj and ŜUj. We treated the density estimates as normally distributed and unbiased. In a preliminary analysis, we treated the estimated standard errors as though they were true values, known without error. Subsequently, we investigated the effect of uncertainty in the estimated standard errors by supposing that the sampling distributions of the ratios
 |
could be approximated by the distribution of a χ2 random variable divided by its degrees of freedom (df). Jackknife analyses of the raw data suggested the use of df = 20 as a reasonable representation of the uncertainty in these estimates, specifying that there is an 80% chance that the estimated standard error is within 20% of the true value and a 95% chance that it is within 30% of the true value.
We used flat normal priors for the means μT and μU and a uniform prior on [–1, 1] for ρ. Posterior distributions of parameters of interest were sampled by Markov chain Monte Carlo, implemented by using the program winbugs (34). Code and output are available at www.mbr-pwrc.usgs.gov/pubanalysis.
These analyses were based on data from 9 of the 11 surveyed sites, because there were a priori reasons (25) for our expectation that the other two sites would not conform to the model relationship. At Pench-MP, intensive poaching just before our survey was suspected to have depressed tiger densities below levels that could have been supported by the prey base. At Kaziranga, large predators other than tigers were virtually absent, leading to the expectation that tigers take a larger proportion of prey at that location and likely achieve higher densities relative to prey density there than at the other study sites.
Results
Prey Abundance. The composition of the ungulate prey assemblage varied among our study sites. The principal ungulate prey of tigers were: wild pig, Sus scrofa (11 sites); sambar, Cervus unicolor (10 sites); axis deer, Axis axis (nine sites); gaur, Bos gaurus (seven sites); muntjac, Muntiacus muntjak; and four-horned antelope, Tetracerus quadricornis (six sites each); nilgai, Boselaphus tragocamelus (five sites); barasingha, Cervus duvaceli; and chinkara, Gazella bennetti (two sites each); wild buffalo, Bubalus bubalis; and hog deer, Axis porcinus (one site each).
The sampling effort involved walking a total distance of 6,820 km at 11 sites, resulting in detections of a total of 8,061 clusters of prey species. The estimated average probabilities for visual detection of prey in the sampled strip varied greatly among species and sites, ranging between 0.2 and 0.8, clearly showing the need for an estimation method such as distance sampling that could model and estimate these variations.
The estimates of combined wild ungulate densities at different sites ranged between 5.3 and 63.8 animals per km2 (Table 1). The study areas in Kanha, Nagarahole, Pench-MP, Ranthambore, and Kaziranga had prior histories of effective protection from adverse human impacts such as livestock grazing and hunting. Although these sites varied ecologically, they supported comparable ungulate densities, which were substantially higher (56.1–63.8 ungulates per km2) than at other sites. The prey densities at Panna (30.9 ungulates per km2) and Bandipur (35.2 ungulates per km2) appeared to be lower because of less effective protection mechanisms. Ungulate densities at comparably productive sites at Bhadra (16.8 ungulates per km2), Tadoba (13.1 ungulates per km2), Pench-MR (16.2 ungulates per km2), and Melghat (5.3 ungulates per km2) appeared to be well below their potential capacity, because of adverse anthropogenic impacts from several villages located within these reserves. Thus, a combination of both natural and anthropogenic factors produced a >10-fold difference in densities of wild ungulates across the 11 sites, providing a range of ecological conditions under which our model could be tested.
Table 1. Combined density estimates for principal ungulate prey species of tigers [Û(SÊ[Û])] derived from line transect sampling at 11 ecologically diverse study locations in India and the corresponding tiger densities (T) predicted by the model.
| Location | Annual rainfall, mm | Forest type | Sampling effort, km | Û(SÊ[Û]), nos. per km2 | (T), nos. per 100 km2 |
|---|---|---|---|---|---|
| Melghat | 1,100 | Dry forest | 771 | 5.3 (0.76) | 1.04 |
| Tadoba | 1,175 | Moist and dry forest | 1,088 | 13.1 (1.41) | 2.61 |
| Pench-MR | 1,400 | Moist forest | 894 | 16.2 (2.72) | 3.24 |
| Bhadra | 2,200 | Moist forest | 728 | 16.8 (1.75) | 3.36 |
| Panna | 1,100 | Dry forest | 532 | 30.9 (1.49) | 6.18 |
| Bandipur | 1,200 | Moist and dry forest | 476 | 35.2 (7.55) | 7.04 |
| Nagarahole | 1,500 | Moist forest | 732 | 56.1 (3.95) | 11.22 |
| Kanha | 1,500 | Moist forest | 476 | 57.3 (4.07) | 11.46 |
| Kaziranga | 3,000 | Alluvial grassland | 158 | 58.1 (6.51) | 11.62 |
| Ranthambore | 800 | Dry forest | 448 | 60.6 (3.44) | 12.12 |
| Pench-MP | 1,400 | Moist forest | 517 | 63.8 (3.14) | 12.76 |
Tiger Population Size and Density. We invested a total effort of 8,677 camera trap-days at 11 sites, photo-capturing 167 individual tigers. We could clearly identify individual tigers from their photographs based on differences in the shape and arrangement of stripes on their flanks, limbs, and faces (Fig. 1). The number of individual tigers photo-captured (denoted as Mt+1) varied from a minimum of five tigers in Pench-MP to a maximum of 26 in Kanha. The effectively sampled areas at each site were estimated based on distances between multiple captures of the same individuals, as described in Materials and Methods. The camera trapping data are reported in Table 2.
Fig. 1.

Individual identification of tigers from differences in stripe patterns, exemplified by photographs of two different animals in A and B.
Table 2. Estimates of tiger densities derived from photographic capture–recapture sampling at 11 study locations in India.
| Location | C (trap-days) | Â(Ŵ), km2 | Mt+1 | p̂ | N̂(SÊ[N̂]) | D̂(SÊ[D̂]), tigers per 100 km2 |
|---|---|---|---|---|---|---|
| Tadoba | 706 | 367 | 10 | 0.174 | 12 (1.97) | 3.27 (0.59) |
| Bhadra | 587 | 263 | 7 | 0.220 | 9 (1.93) | 3.42 (0.84) |
| Pench-MP | 788 | 122 | 5 | 0.220 | 6 (1.41) | 4.94 (1.37) |
| Melghat | 896 | 360 | 15 | 0.058 | 24 (6.09) | 6.67 (1.85) |
| Panna | 914 | 418 | 11 | 0.039 | 29 (9.65) | 6.94 (3.23) |
| Pench-MR | 715 | 274 | 14 | 0.108 | 20 (4.41) | 7.29 (2.54) |
| Ranthambore | 840 | 244 | 16 | 0.115 | 28 (7.29) | 11.46 (4.20) |
| Kanha | 803 | 282 | 26 | 0.180 | 33 (4.69) | 11.70 (1.93) |
| Nagarahole | 938 | 243 | 25 | 0.120 | 29 (3.77) | 11.92 (1.71) |
| Bandipur | 946 | 284 | 16 | 0.055 | 34 (9.9) | 11.97 (3.71) |
| Kaziranga | 544 | 167 | 22 | 0.190 | 28 (4.51) | 16.76 (2.96) |
The count statistics and parameter estimates reported are as follows: sampling effort (C), estimated area sampled [Â(Ŵ)], number of photo-captured tigers (Mt+1), average estimated capture probability per sample (p̂), estimated tiger population size N̂(SÊ[N̂]), and density D̂(SÊ[D̂]).
We constructed capture histories for individual tigers photographed at each site and analyzed these histories using the program capture (25–29). Closure test statistics provided little evidence that these tiger populations violated the assumption of closure during our surveys. Among the eight possible models of the underlying capture–recapture process likely to have generated the capture histories we observed, model Mh seemed most appropriate for our data based on results of the various between-model tests and the overall discriminant function for model selection (27–29). The jackknife estimator under model Mh is known to be statistically robust relative to other available estimators (26, 27). Therefore, we used the jackknife estimator for model Mh (27), which permits each individual to have a different capture probability.
The capture–recapture analysis showed that average capture probability per sampling occasion estimated under model Mh varied widely among study sites (p̂ = 0.039–0.220, Table 2). The overall probabilities of photo-capturing tigers present at the study sites were computed as Mt+1/N̂. These estimates were not only <1 at each site but also varied substantially among sites (0.38–0.86), once again highlighting the need for models that incorporate variable detection probabilities. Estimated tiger densities differed across the study sites, ranging from a low of 3.27 animals per 100 km2 at Tadoba to a high of 16.76 tigers per 100 km2 at Kaziranga (Table 2).
Relationship Between Prey Density and Tiger Density. The model we fitted implies that, conditional on Uj,
 |
where δj is a mean one random variable. Our a priori prediction was that A = 0.2 and b = 1. In a preliminary analysis in which standard errors were treated as known values, we obtained a Bayesian estimate (posterior mean) of b̂ = 0.503, with 95% credible interval (0.006, 0.982), providing some evidence against our prediction. Subsequent analyses accounting for sampling variation in the estimated standard errors led to a point estimate of b̂ = 0.514, with 95% credible interval (0.001, 1.009). Fig. 2A displays the mean prediction and 95% prediction intervals for tiger density and prey density based this on latter analysis. Point estimates (Ûj, T̂j) are plotted with 75% confidence ellipses and connected to posterior mean values of the pairs (Uj, Tj).
Fig. 2.

Mean prediction and 95% prediction intervals for tiger density (animals per 100 km2), given prey density (animals per km2), based on the Bayesian analysis of the unrestricted model with no constraints on b (A) and the restricted model with b ≡ 1(B). The point estimates of densities (Ûj, T̂j) are plotted (solid dots) with 75% confidence ellipses, and connected to posterior mean values of the pairs ((Ûj, T̂j; open dots). Two data points omitted from analysis are indicated by confidence ellipses using dashed lines.
The evidence, although suggestive that b < 1, is not conclusive against our prediction. We thus fitted a reduced model with b ≡ 1; this was accomplished by retaining the uniform prior on ρ and flat inverse γ prior on 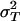 and calculating σU = ρσT. Under this reduced model, the posterior mean for A was 0.247, with 95% credible interval (0.181, 0.336), a result entirely consistent with our prediction. Fig. 2B reproduces Fig. 2 A but with results for the reduced model.
and calculating σU = ρσT. Under this reduced model, the posterior mean for A was 0.247, with 95% credible interval (0.181, 0.336), a result entirely consistent with our prediction. Fig. 2B reproduces Fig. 2 A but with results for the reduced model.
As noted in Materials and Methods, the density estimates for two sites, Pench-MP and Kaziranga, were not included in the analyses displayed in Fig. 2 for reasons identified a priori. Indeed, the density estimates for one of these sites, Pench-MP, fall outside the 95% prediction intervals of Fig. 2B. Estimates from one other site, Melghat, also fall outside the prediction interval of Fig. 2B. Although we made no a priori prediction of unusually high tiger density at Melghat, we speculate that this may be partially explained by the presence of large numbers of alternate prey in the form of livestock at this site.
Discussion
In general, the ability of our model to predict tiger densities from prey abundance was good. We consider our simple macroecological hypothesis to have been generally corroborated by these data, although there is some uncertainty associated with the exact form of the relationship (Fig. 2), as well as some additional variation in tiger densities beyond that explained by our model. As noted in the Introduction, we believe that two aspects of our study distinguish it from other types of macroecological analyses, and that these aspects merit brief discussion. First, we developed our predictions a priori based on simple mechanistic modeling (35) combined with empirical work on the focal species of interest. Despite the straightforward simplicity of identifying potential limiting factors and using these to predict abundance of a focal species, successful applications of this approach are rare in macroecological studies. Much of current macroecological work is not focused on potential limiting factors but instead attempts to take advantage of various landscape-level covariates available to the analyst.
The second characteristic distinguishing this work from many other macroecological studies involves the estimation of animal density. Such estimation is a nontrivial task on which statisticians and population biologists have expended substantial effort developing appropriate methods (9–11, 22, 24, 27, 29, 30, 36). As noted, many macroecological studies are based on indices, count statistics thought to be related to abundance or density through a proportionality constant that holds over space, time, and species (9–11, 36). Whenever the assumed relationship does not hold, that is, whenever the average fraction of animals counted is not a constant over time, space, and species, inferences about variation in abundance are confounded by potential variation in sampling and detection probabilities. We estimated the animal population parameters of interest using methods that are specifically tailored to deal with variation in detection probabilities associated with our count statistics (9–11, 22, 27).
A recent discussion (3) of important unanswered questions in ecology emphasized the small spatial scale at which much serious ecological research is conducted. Although our large spatial scale approach required substantial field effort, it resulted in robust density estimates of multiple species of mammals at 11 locations throughout India. This study demonstrates the potential for carrying out ecological studies at landscape scales with a degree of rigor that usually characterizes only studies of small organisms conducted at small spatial scales. We hope that greater attention directed at developing models and associated predictions and at estimating relevant quantities with which to confront these predictions will permit more rapid advances in ecology.
From a conservation perspective, our study supports the hypothesis that prey density is a key determinant of large felid abundance (20, 25, 26). Although Bhadra, Tadoba, Melghat, and Pench-MR are ecologically similar to some of the high-tiger-density sites, during historical times, tiger densities at these sites appear to have readjusted downwards in response to human-induced depression of prey densities. Our results are consistent with the hypothesis that declines of wild tiger populations are primarily a consequence of prey depletion driven by adverse human impacts (21). Therefore, reducing these impacts through appropriate management interventions should be a central concern of conservationists.
Acknowledgments
We thank R. S. Chundawat for helpful discussions and logistical assistance during data collection at Panna. We are grateful to the editor and three anonymous reviewers for valuable comments. We acknowledge support for this study from the Wildlife Conservation Society, the U.S. Geological Survey (Patuxent Wildlife Research Center), the U.S. Fish and Wildlife Service (Division of International Conservation), the Save the Tiger Fund of the National Fish and Wildlife Foundation, and the Central and State Governments of India.
This paper was submitted directly (Track II) to the PNAS office.
References
- 1.Andrewartha, H. G. & Birch, L. C. (1972) in The Distribution and Abundance of Animals (Univ. Chicago Press, Chicago), p. 782.
- 2.Krebs, C. J. (2002) in Ecology: The Experimental Analysis of Distribution and Abundance (Prentice–Hall, Upper Saddle River, NY), p. 608.
- 3.May, R. (1999) Philos. Trans. R. Soc. London B 354, 1951–1959. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Brown, J. H. (1995) in Macroecology (Univ. Chicago Press, Chicago), p. 269.
- 5.Rosenweig, M. L. (1995) in Species Diversity in Space and Time (Cambridge Univ. Press, Cambridge, U.K.), p. 436.
- 6.Keitt, T. H. & Stanley, H. E. (1998) Nature 393, 257–260. [Google Scholar]
- 7.Hubbell, S. P. (2001) in The Unified Neutral Theory of Biodiversity and Biogeography (Princeton Univ. Press, Princeton), p. 375.
- 8.Carbone, C. & Gittleman, J. L. (2002) Science 295, 2273–2276. [DOI] [PubMed] [Google Scholar]
- 9.Yoccoz, N. G., Nichols, J. D. & Boulinier, T. (2001) Trends Ecol. Evol. 16, 446–453. [Google Scholar]
- 10.Pollock, K. H., Nichols, J. D., Simons, T. R., Farnsworth, G. L., Bailey, L. L. & Saur, J. R. (2002) Environmetrics 13, 105–119. [Google Scholar]
- 11.Williams, B. K., Nichols, J. D. & Conroy, M. J. (2002) in Analysis and Management of Animal Populations (Academic, San Diego), p. 817.
- 12.Sinclair, A. R. E. (1989) in Ecological Concepts, ed. Cherrett, M. (Blackwell Scientific, Oxford), pp. 197–241.
- 13.Murdoch, W. W. (1995) Ecology 75, 71–87. [Google Scholar]
- 14.Turchin, P. (1995) in Population Dynamics: New Approaches and Synthesis, eds. Cappuccino, N. & Price, P. W. (Academic, San Diego), pp. 19–40.
- 15.Fretwell, S. D. (1972) in Populations in a Seasonal Environment (Princeton Univ. Press, Princeton), p. 217.
- 16.Hairston, N. G., Smith, F. E. & Slobodkin, L. B. (1960) Am. Nat. 94, 421–425. [Google Scholar]
- 17.Karanth, K. U. & Sunquist, M. E. (1995) J. Anim. Ecol. 64, 439–450. [Google Scholar]
- 18.Karanth, K. U. & Sunquist, M. E. (2000) J. Zool. London 250, 255–265. [Google Scholar]
- 19.Seidensticker, J. (1976) Biotropica 8, 225–234. [Google Scholar]
- 20.Schaller, G. B. (1972) in The Serengeti Lion: A Study of Predator–Prey Relations (Univ. Chicago Press, Chicago), p. 480.
- 21.Karanth, K. U. & Stith, B. M. (1999) in Riding the Tiger: Tiger Conservation in Human Dominated Landscapes, eds. Seidensticker, J., Christie, S. & Jackson, P. (Cambridge Univ. Press, Cambridge, U.K.), pp. 100–113.
- 22.Buckland, S. T., Anderson, D. R., Burnham, K. P., Laake, J. L., Borchers, D. L. & Thomas, L. (2001) in Introduction to Distance Sampling: Estimating Abundance of Biological Populations (Oxford Univ. Press, Oxford), p. 432.
- 23.Thomas, L. & Karanth, K. U. (2002) in Monitoring Tigers and Their Prey: A Manual for Researchers, Managers and Conservationists in Tropical Asia, eds. Karanth, K. U. & Nichols, J. D. (Centre for Wildlife Studies, Bangalore, India), pp 121–138.
- 24.Thomas, L., Laake, J. L., Strindberg, S., Marques, F. F. C., Borchers, D. L., Buckland, S. T., Anderson, D. R., Burnham, K. P., Hedley, S. L. & Pollard, J. H. (2001) distanceUser's Guide (Research Unit for Wildlife Population Assessment, Univ. of St. Andrews, St. Andrews, U.K.), Ver. 4.0, p. 185.
- 25.Karanth, K. U. &. Nichols, J. D. (1998) Ecology 79, 2852–2862. [Google Scholar]
- 26.Nichols, J. D. & Karanth, K. U. (2002) in Monitoring Tigers and Their Prey: A Manual for Researchers, Managers and Conservationists in Tropical Asia, eds. Karanth, K. U. & Nichols, J. D. (Centre for Wildlife Studies, Bangalore, India), pp 121–138.
- 27.Otis, D. L., Burnham, K. P., White, G. C. & Anderson, D. R. (1978) Wildl. Monogr. 62, 1–135. [Google Scholar]
- 28.Karanth K. U., Kumar, N. S. & Nichols, J. D. (2002) in Monitoring Tigers and Their Prey: A Manual for Researchers, Managers and Conservationists in Tropical Asia, eds. Karanth, K. U. & Nichols, J. D. (Centre for Wildlife Studies, Bangalore, India), pp. 139–152.
- 29.Rexstad, E. & Burnham, K. P. (1991) in User's Guide for Interactive Program capture (Colorado State University, Fort Collins), p. 29.
- 30.Wilson, K. R. & Anderson, D. R. (1985) J. Mammal. 66, 13–21. [Google Scholar]
- 31.Link, W. A., Cam, E., Nichols, J. D. & Cooch, E. G. (2002) J. Wildl. Manage. 66, 277–291. [Google Scholar]
- 32.Clark, J. S. (2003) Ecology 84, 1370–1381. [Google Scholar]
- 33.Wikle, C. K. (2003) Ecology 84, 1382–1394. [Google Scholar]
- 34.Spiegelhalter, D., Best, N. & Lunn, D. (2003) winbugsUser Manual (MRC Biostatistics Unit, Cambridge, U.K.), Ver. 1.4, p. 60.
- 35.Schoener, T. W. (1986) Am. Zool. 26, 81–106. [Google Scholar]
- 36.Seber, G. A. F. (1982) in The Estimation of Animal Abundance and Related Parameters (MacMillan, New York), p. 654.