

Abstract
The purpose of this study was to evaluate a global deficit in sequential processing as candidate endophenotypein a family with familial childhood apraxia of speech (CAS). Of 10 adults and 13 children in a three-generational family with speech sound disorder (SSD) consistent with CAS, 3 adults and 6 children had past or present SSD diagnoses. Two preschoolers with unremediated CAS showed a high number of sequencing errors during single-word production. Performance on tasks with high sequential processing loads differentiated between the affected and unaffected family members, whereas there were no group differences in tasks with low processing loads. Adults with a history of SSD produced more sequencing errors during nonword and multisyllabic real word imitation, compared to those without such a history. Results are consistent with a global deficit in sequential processing that influences speech development as well as cognitive and linguistic processing.
Keywords: speech sound disorder, motor programming, memory encoding, reading, spelling
Childhood apraxia of speech (CAS) is a proposed subtype of speech sound disorder (SSD). According to a 2007 position statement by the American Speech–Language–Hearing Association (ASHA; http://www.asha.org/docs/html/PS2007-00277.html), CAS is a “distinct diagnostic subtype of childhood (pediatric) speech sound disorder,” further defined as follows:
[CAS] is a neurological childhood (pediatric) speech sound disorder in which the precision and consistency of movements underlying speech are impaired in the absence of neuromuscular deficits (e.g., abnormal reflexes, abnormal tone). CAS may occur as a result of known neurological impairment, in association with complex neurobehavioral disorders of known or unknown origin, or as an idiopathic neurogenic speech sound disorder. The core impairment in planning and/or programming spatiotemporal parameters of movement sequences results in errors in speech sound production and prosody.
The speech of children with CAS is frequently described with the following characteristics: vowel distortions, difficulty initiating or transitioning between articulatory gestures, lack of differentiation between stressed and unstressed syllables or mis-stressing syllables, distorted substitutions, syllable segregation, schwa insertions, voicing errors, slow rate, slow diadochokinetic (DDK) rates and increased difficulty with multisyllabic words (Shriberg, Potter, & Strand, 2011). A 2007 technical report published by ASHA (www.asha.org/docs/pdf/TR2007-00278.pdf) includes the following accompanying signs and symptoms: Prespeech development: absence or paucity of babbling or immature babble patterns; Nonspeech motor behaviors: clumsiness, impaired volitional movements, mild delays in motor development, mildly low muscle tone, abnormal orosensory perception (hyper- or hyposensitivity in the oral area) and oral apraxia, with tentative evidence of feeding and swallowing difficulties; Speech and motor speech behaviors: slowed rates during rapid repetition of mono- and multisyllables, delays in speech development, reduced phonetic or phonemic inventories, multiple speech sound errors, predominant use of simple syllable shapes, speech difficult to understand, vowel errors, inconsistent errors, increased errors in longer or more complex syllable and word, groping, unusual errors that are not readily explained with phonological process analysis, errors in words or sounds that were previously mastered, fewer errors in overlearned utterances compared to spontaneous ones and errors in the order of speech sounds (migration and metathesis), syllables, morphemes or even words; Prosodic characteristics: staccato-like rhythm, excessive/equal lexical stress, monotone- or monoloud-sounding speech; Speech perception characteristics: impaired auditory perception, auditory discrimination or auditory memory; Language characteristics: syntactic and morphological errors that cannot be explained by phonological constraints; Metalinguistic/literacy characteristics: delays in learning to read and spell, but it is unclear how these differ between children with CAS and children with other types of SSD. The technical report further states that, in general, there are no definitive diagnostic markers for CAS that reliably distinguish between CAS and non-CAS speech disorders.
There has been debate regarding deficits beyond the programming of speech movements in CAS. Whereas some propose that linguistic elements and processes such as phonemic representations of sounds, syllables and words are core characteristics of CAS (Marquardt, Jacks, & Davis, 2004), others have argued that linguistic units are not part of the core CAS symptomatology but, rather, can be affected secondarily by the primary motor programming deficit in CAS (McNeil, 1997, 2009). The present study addresses the hypothesis that the speech and associated characteristics in CAS are fundamentally influenced by the same endophenotype, namely a deficit in sequential processing.
There is evidence from genetic studies that CAS has a biological basis in some cases. Syndromic speech difficulties consistent with CAS have been observed in diseases such as galactosemia (Shriberg, Potter, & Strand, 2010), where they are frequently caused by mutations in the GALT gene on chromosome 9 (Elsas, Langley, Paulk, Hjelm, & Dembure, 1995), as well as in rare cases of disordered speech in the presence of disordered language and structural brain abnormalities, caused by mutations in the FOXP2 gene on chromosome 7 (Fisher, Vargha-Khadem, Watkins, Monaco, & Pembrey, 1998; Lai, Fisher, Hurst, Vargha-Khadem, & Monaco, 2001). Among those with nonsyndromic CAS, however, FOXP2 mutations are rare (Laffin et al., 2012; MacDermot et al., 2005). Nonetheless, there is evidence that CAS has a genetic component, although the relative magnitudes of genetic and environmental influences are not yet known. For instance, of 22 children with a CAS diagnosis, 13 had at least one biological relative with speech difficulties, although only two of these were also diagnosed with CAS (Lewis et al., 2004). In a chromosomal analysis in 24 unrelated children with CAS, 12 had copy number variations in diverse locations on ten different chromosomes (Laffin et al., 2012). Except for one confirmed FOXP2 mutation, causal genes in the duplicated or deleted regions were not identified. In three individuals with CAS, evidence from duplicated or deleted DNA regions pointed to a region on chromosome 16 as a candidate region (Newbury et al., 2012; Raca et al., 2012). Generally, these findings are consistent with a genetic CAS etiology where the specific causal genes may vary from case to case, indicating a heterogeneous etiology.
Additional evidence for a genetic CAS etiology was found in a set of genetics studies in samples of multigenerational families with familial SSD, where two of five participating families had children with a CAS diagnosis (Peter & Raskind, 2011). In these two families, children and adults with a history of SSD exhibited slowed speeds during alternating motor tasks, relative to repetitive motor tasks. This deficit was observed not only during syllable repetitions (e.g. /papa/, /pata/) but also during keyboard tapping. A genome-wide linkage analysis in one of these two families (Peter, Matsushita, & Raskind, 2012) showed four novel regions of interest including one on chromosome 6p that overlapped with a novel candidate region for dyslexia (Konig et al., 2011). The results of these phenotypic and genetic studies in families with familial SSD where CAS can be suspected as the segregating subtype are consistent with the hypothesis that CAS has a genetic etiology and that a deficit in sequential motor processing is an endophenotype affecting motor systems besides the speech production system.
The presence of alternating motor deficits in individuals with current or past SSD where CAS is suspected led to our hypothesis that sequential processing deficits are not only expressed in motor tasks but across a variety of linguistic and cognitive tasks, constituting a endophenotype of genetic origin. Regarding the notion that functions in addition to motor programming are involved in CAS, Shriberg and colleagues (Shriberg, Lohmeier, Strand, & Jakielski, 2012) recently evaluated errors during a nonword imitation task in children with CAS based on a framework of cognitive processing tiers. An encoding tier encompasses perceptual and representational processes, a memory tier contains storage and withdrawal processes of encoded information and a transcoding tier is the locus of motor planning and/or programming processes (i.e. the translation of retrieved sound sequences into a sequence of finely tuned articulatory movement commands); the execution of these motor commands is not addressed in this framework. Based on the definition of CAS as a motor speech disorder and Shriberg et al.’s (2012) framework, transcoding errors such as phoneme insertions are expected in a sample of children with CAS. Shriberg and colleagues indeed observed a high proportion of transcoding errors in these children, but in addition, they found evidence of encoding (within-class sound substitutions) and memory (increased error rates with increased nonword length) error types. The authors concluded that children with CAS exhibit processing errors not limited to those attributed to faulty motor planning and/or programming.
Another framework addressing the motor deficits associated with apraxia in general is that proposed by Klapp (1995, 2003), a two-stage model of motor programming that is predicated on the notion of complex responses planned as a sequence of units or “chunks.” In this model, there are two forms of parallel response processing: INT, which programs the internal structure of each chunk, and SEQ, which programs the overall sequence of chunks. Klapp supported this model with findings from studies of reaction time in a Morse code task (1995) and a nonword repetition task (2003), showing that simple reaction time increased with number of chunks but not with the complexity of one chunk, while choice reaction time increased with the complexity of one chunk but did not increase with the number of chunks. Simple reaction time, in which the participant is instructed about the required response in advance of the measured reaction time interval, is linked by Klapp to SEQ processing, while choice reaction time, in which the participant is instructed about the nature of the required response as part of the start signal that marks the beginning of the measured reaction time interval, is linked to INT processing. In a motor speech experiment, motor programming as measured with INT was sensitive not only to syllable complexity but also to the composition of a syllable string, where multisyllables required longer motor programming times, compared to monosyllables (Wright et al., 2009). Evidence for the hypothesis that apraxia affects the processes captured by INT but not SEQ was found in individuals with acquired apraxia of speech (Maas, Robin, Wright, & Ballard, 2008). Interestingly, these results were seen in a hand motor task as well as in a speech production tasks, suggesting a central motor programming deficit in the participants with acquired apraxia with multimodal effects.
The sequential processing hypothesis proposed here partially overlaps with that introduced by Shriberg et al. (2012). Similar to Shriberg et al.’s hypothesis that children with CAS experience difficulties with processes upstream from motor programming, we hypothesize that their speech disorder is the result of underlying deficits not limited to the programming of articulatory movements. As shown in our prior studies (Peter et al., 2012; Peter & Raskind, 2011), children and adults with a history of speech difficulties consistent with CAS showed relatively slower speeds during sequentially alternating movements, compared to performance during repetitive movements, and these deficits were observed during syllable repetition as well as during key presses. Slower motor speeds during these alternating tasks can be interpreted as multimodal motor programming (“transcoding”) deficits in tasks with low encoding and memory loads; however, an alternate interpretation under the sequential processing deficit hypothesis is that slow alternating motor speeds result from a sequencing deficit at the motor output level. Alternating movements require the integration of multiple and separate motor commands for distinct muscle groups (e.g. lips and tongue for sequences like /pata/ and two different fingers for an alternating key press task) into a temporally ordered sequence. Temporal-sequential integration of complex information and errors due to deficits in sequential processing can be modeled on all levels of the Shriberg et al. (2012) framework. For instance, speech sounds in nonwords can be encoded and stored in an incorrect sequence, and they can be produced in an incorrect sequence due to a faulty translation of a stored phoneme sequence into a motor plan. Insofar, as Shriberg et al.’s (2012) model links the length of a target nonword to the memory processing load, their model addresses sequential processing during that preparatory stage, but sequential processing is not specifically addressed in the encoding and transcoding stages. The model proposed here specifies sequential processing at the levels of encoding, memory and translation into motor programs.
The sequential processing hypothesis also partially overlaps with the Klapp model (1995, 2003) in that it addresses the differences in processing loads for simple and complex sequences at the level of motor programming. It differs from the Klapp model in that it addresses sequential processing loads not only with respect to preparatory steps for motor output but also for functions further upstream, such as encoding and memory. It also differs from the Klapp model in that sequential processing is not only addressed with respect to motor tasks but other domains as well, for instance verbal reasoning, phonemic memory and written word forms.
The sequential processing hypothesis states that sequencing errors in CAS are not only limited to the temporal integration of complex motor activities during speech, motor speech and handactivities but also can be observed at the level of linguistic units (i.e. sequences of phonemes, words and graphemes) and that sequencing errors can occur during encoding, storage in working or short-term memory and transduction into a motor program. It postulates that the deficits in spoken and written language as described in the ASHA technical report (www.asha.org/docs/pdf/TR2007-00278.pdf) are fundamentally caused by difficulty with sequential processing. Here, we investigate a global deficit in sequential processing in motor and linguistic tasks as a candidate endophenotype in an extended multigenerational family with familial SSD consistent with CAS. This family was ideally suited for this study because, in addition to several children who had an extremely late onset of first words, it included two 3-year-old cousins who expressed the familial disorder to a milder extent and had not yet received intervention services, providing an opportunity to study the disorder in its unaltered form. In addition, this family provided opportunities to study sequential processing in six affected children and three affected adults at a variety of ages and to compare these findings to those in unaffected adults and children in the same family. Performance on tasks requiring sequential processing during encoding, storage in memory and/or motor programming was evaluated for association with CAS, and the familial phenotype was characterized according to the locus of impairment with respect to sequential processing.
To test the sequential processing deficit hypothesis in CAS further, a companion study in this volume addresses associations among measures incorporating sequential processing in multiple modalities (Button, Peter, Stoel-Gammon, & Raskind, submitted). The companion study is based on data from 21 adults representing five families not including the one described here. Imitations of words and nonwords and performance on reading tasks were evaluated with a qualitative error analysis. Global sequential processing deficits are described as residual signs of CAS in adults with a family history of SSD consistent with CAS.
Methods
Participants
This study is part of a larger research project investigating the genetic causes of SSD in multigenerational families. It was conducted with the approval of the University of Washington’s Human Subject Division. All adults gave consent, children age 6 years or older gave assent and parents gave consent for their minor children. Conventional inclusionary and exclusionary criteria were applied. All participants were monolingual or native speakers of English, had no neurological or psychiatric disorders that could have affected speech production and had no hearing impairments.
Participants were 23 members of an extended family spanning three generations (2 founders, 4 adult offspring, 4 married-ins, 4 sets of generation, 3 offspring). All provided a DNA sample and all but the youngest, age 15 months, completed all or part of a study protocol. Five-digit participant codes were assigned, reflecting the two-digit family identifier, generation number and individual two-digit code. The following background information was obtained through pre-study interviews and questionnaires: the grandfather, code 11101, had a childhood history of speech difficulties, as did two of his four participating adult children, codes 11206 and 11207, respectively. All three had received intervention beginning in early grade school and conversational speech had normalized. One of these adults, code 11206, reported saying words “backwards” (e.g. “sorsie” for “horsie”) as a child and had received school-based speech intervention services, continuing to qualify for these services as late as high school. One of the unaffected adults, code 11202, and her unaffected husband, code 11201, had five children. Two of these, aged 19 and 15, codes 11301 and 11302, respectively, had a history of mild SSD and had received intervention to remediate a frontal lisp, and their affectation status regarding the familial CAS-like SSD was deemed as uncertain. Behavioral data and DNA were not available for 11301. One child, aged 11, code 11303, had typical development in all areas including speech. Two children, aged 10 and 7, codes 11304 and 11305, respectively, had a history of extremely late onset of first words around age 3 years and severely unintelligible speech until entering school; both began receiving speech services at age 3 for multiple speech sounds with slow rates of progress and both had a diagnosis of CAS. Both had a history of feeding difficulties up until age 5, resulting in the use of a feeding tube for 11305 when they were infants, and delayed gross and fine motor development, the latter being addressed with a course occupational therapy for both children. Both also had a history of frequent ear infections. The 10-year-old additionally had a history of oversensitivity to loud sounds. The 10-year-old was receiving special services for reading and writing and the 7-year-old, for reading, writing and math. The other unaffected adult, code 11204, and her husband, code 11203, had three unaffected children, codes 11306, 11307 and 11308, respectively, aged 15, 10 and 5, respectively. Participant 11204 reported that she had great difficulty with number sequences, for instance, when balancing checkbooks. One of the affected adults and her unaffected husband had five children, the oldest of whom, aged 12, code 11309, had typical or even advanced development in all areas including speech, starting to walk at 7 months and starting to read at 3 years. Two children, aged 9 and 6, codes 11310 and 11311, respectively, had extremely late onset of babbling around age 2 years and first words at age 2;9 and 3;3 (years; months), respectively, with highly unintelligible speech until approximately age 5. Both had received intensive therapy for multiple speech sounds. The 9-year-old had a history of struggling with mathematics, especially with interpreting number sequences (e.g. 21 vs. 12) correctly, and with learning to read and spell, receiving special services in these areas; he also had a history of oversensitivity to loud sounds and bright lights and with fine motor delays that were addressed with occupational therapy. Further, it was noted that he was easily distracted and had difficulty staying on task, although he did not have a medical diagnosis of attention deficit disorder. Another child, aged 3, code 11312, had not previously been evaluated for SSD but according to parent report, she said many words “backwards,” for instance [los] for “slow” and [mɔs] for “small.” The youngest child in this family, aged 15 months, code 11313, had begun babbling at age 13 months and had not yet produced any words. The other affected adult, code 11207, and his wife, code 11208, who reported a childhood history of late onset of speech but no intervention, had a child, aged 3, code 11314, who had not been evaluated by a speech–language pathologist prior to participating in this study but whose speech was difficult to understand. Because of her late onset of speech, participant 11208 was entered into the data with an uncertain affectation status regarding the familial form of SSD. The five households represented in the extended family were located in different geographical regions of the same state and the children spent time with their cousins on an infrequent basis. Figure 1 is a family diagram. Note that the labels show abbreviated codes in that the family code 11 was removed.
Figure 1.
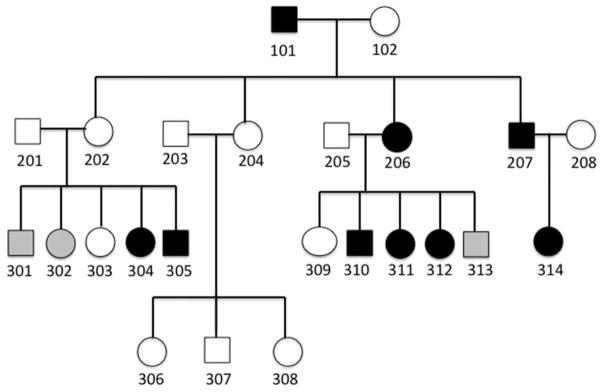
Family pedigree. Square, male; circle, female; open shape, unaffected; black fill, affected; gray fill, affectation status uncertain.
The affectation pattern in the family is consistent with autosomal dominant inheritance, with one case of nonpenetrance (code 11202). The familial phenotype in the six children with a history of severe speech difficulties (this excludes 11301 and 11302 with mild speech delays and no accompanying signs or symptoms), as described in parent interviews and questionnaires, includes the following aggregated traits (number of observations) that are consistent with CAS: feeding difficulties (2), extremely late onset of babble and/or first words (6), multiple speech sounds in error (5), mis-sequenced speech sounds (1); the parent in this case was reported to mis-sequence sounds in words as well, highly unintelligible speech until age 5 (6), gross motor and fine motor delays (3), delays in reading, writing, spelling and/or mathematics (3). Two children had a history of oversensitivity to sounds and lights, and one child had difficulty maintaining attention; abnormal auditory and visual sensitivity as well as inattention and distractibility have recently been observed in a sample of children with CAS (Newmeyer et al., 2009). Three children had a history of ear infections, which can cause speech delays not related to CAS.
Measures and data analysis
Articulation and phonology in children
To describe the speech disorder phenotype at different ages and stages of intervention, children 3 years and older were asked to produce single words in response to the stimulus pictures in the Goldman–Fristoe Test of Articulation 2 (GFTA-2; Goldman, 2000). The Khan–Lewis Phonological Analysis 2 (KLPA-2; Khan & Lewis, 2002) evaluates the presence of phonological error patterns based on the GFTA-2 word productions. The words elicited with the GFTA-2 sum to a phoneme count of 231.
Quantitative analyses of standardized measures with low and high processing demands
To observe differences in sequential processing ability across modalities between affected and unaffected family members of various ages, standardized tasks with low and high sequential processing demands were selected; see the detailed descriptions of these measures in the text below and the summary in Table 1. Age-adjusted normed scores allowed comparisons between affected and unaffected family members across a large age range. Sampled modalities included motor, linguistic and cognitive processing. Within each modality, sequential processing is modeled on the levels of encoding, storage in working or long-term memory and motor programming, following Shriberg et al.’s (2012) taxonomy. Tasks with generally low sequential processing demands included repetitive syllable repetition, repetitive keyboard tapping, nonverbal processing and sight word reading. Tasks with generally high sequential processing demands included alternating syllable repetition, nonword imitation, verbal processing, nonword reading and spelling.
Table 1.
Selected measures by domain and sequential processing loads in encoding, storing and motor programming.
| Task domain | Measure | Encode | Store | Motor program |
|---|---|---|---|---|
| Motor | DDK: monosyllables | L | L | L |
| DDK: multisyllables | L | H | H | |
| Key press: repetitive | L | L | L | |
| Simultaneous perceptual, linguistic and motor processing | RAN | H | H | L to H |
| RAS | H | H | L to H | |
| Phonological processing | NWR | H | H | H |
| NRT | H | H | H | |
| SRT | H | H | L | |
| Reading | WID | L | L | L to H |
| PDE | H | H | L to H | |
| Spelling | WIAT spelling subtest | H | H | H |
| Verbal processing | Guess What | L | L | N/A |
| Verbal Reasoning | H | H | N/A | |
| Nonverbal processing | Odd Item Out | L | L | N/A |
| What’s Missing? | L | L | N/A |
Notes: L, low sequential processing loads; H, high sequential processing loads. N/A, not applicable.
As in our previous studies (Peter et al., 2012; Peter & Raskind, 2011), participants completed DDK testing, rapidly repeating monosyllables (/pa/, /ta/, /ka/) and multisyllables (/pata/, /taka/, /pataka/), following published procedures (Fletcher, 1972). For each syllable type, the average syllable duration was calculated using the freely available software Praat (Boersma, 2001), version 5.1.25. First and last syllables in each breath group were excluded from the analysis to avoid nonlinear rate effects. For each participant, the syllable durations were averaged and converted into z scores using published norms for ages 2;6 through 6;11 (Robbins & Klee, 1987) and 6 through 13 years (Fletcher, 1972). For the purposes of this study, we averaged the z scores from the monosyllable tasks and, separately, the z scores from the multisyllable tasks. Multisyllable repetition requires more sequential motor processing, compared to monosyllable repetition, and storing a multisyllabic sequence in short-term memory is more challenging, compared to monosyllabic sequences, particularly during rapid performance when motor execution and motor programming processes are active simultaneously.
As in our previous studies (Peter et al., 2012; Peter & Raskind, 2011), participants tapped the spacebar of a computer keyboard repetitively in trials of 10 s, following published protocols of this activity (Gualtieri & Johnson, 2006). Ten trials were administered, five for the right hand and five for the left, switching hands after each trial to minimize fatigue. Tapping intervals were recorded using a computer program custom-designed with LabView (National Instruments, Austin, TX, USA). According to questionnaire responses using the Edinburgh Handedness Inventory (Old-field, 1971), all participants had moderate-to-strong hand preference for the right hand. Raw durations showed that all participants tapped more rapidly with their right hand, compared to their left hand, and that the difference of this magnitude varied with age. In the participants age 3–15, relative differences in average tapping intervals ranged from 3% to 32% (percent difference of interval in the right hand); in all others, the differences ranged from 1% to 21%. Raw durations were converted to z scores using norms for ages 5 years through 7 years (Gray, Livingston, Marshall, & Haak, 2000) and 8 years to 83 years (Gualtieri & Johnson, 2006). The norms for the younger children were available for the dominant and nondominant hand, whereas those for older children and adults, the norms were based on right and left hands. Therefore, the z scores averaged for both hands were selected for normalizing the present data. In analogy to repetitive syllable repetition, repetitive keyboard tapping carries a low sequential processing load. Participants also completed an alternating keyboard tapping task, tapping two keys with two fingers, but normative information was not available to calculate age-adjusted standard scores and these results are not reported here.
To obtain measures of performance on tasks that require substantial cognitive effort with varying demands on sequential processing, two verbal and two nonverbal tasks from the Reynolds Intellectual Assessment Scales (RIAS; Reynolds & Kamphaus, 2003) were administered. During the verbal tasks, participants were asked to name terms that fit a given definition (Guess What, GW) and to complete verbal analogies (Verbal Reasoning, VRZ). The GW subtest is designed to measure verbal reasoning in conjunction with vocabulary knowledge and overall world knowledge. For the purposes of the present study, the tasks were classified according to sequential processing loads. Sequential processing is moderately involved during the encoding stage when the participant analyzes the verbally presented information; sequential processing is not relevant during the storage stage because the sequence of the presented information is not relevant for arriving at the answer. Performance on this task as well as the other selected RIAS subtests does not depend on the quality of the motor output of the response and is therefore not tracked here. The VRZ subtest is designed to measure deduction of semantic relationships between two given terms, then generating an analogous relationship by supplying the corresponding term to one given term. Sequential processing is crucial during the encoding and storage stages. The Verbal Intelligence Index (VIX) is constructed from the sum of the raw scores of these two subtests adjusted for age. During the non-verbal tasks, participants identify one pictured item in an array of several that differs from the rest (Odd Item Out, OIO) and identify a missing object in a pictured scene (What’s Missing, WHM). The OIO subtest is designed to measure nonverbal reasoning skills, spatial ability and visual imagery, and sequential processing loads are low during encoding and storage in memory. The WHM subtest is designed to measure conceptualization of visually presented scenes, analysis of its gestalt and deduction of the missing element. As in the OIO, the sequential processing load is low during the encoding and storage stages. The Nonverbal Intelligence Index (NIX) is constructed from the sum of the raw scores of these two subtests, adjusted for age.
Rapid automatic naming of arrays of stimuli involves the temporal integration of multiple perceptual, cognitive, linguistic and motor processes under time pressure. While the participant is speaking the label for one item, she or he is simultaneously scanning ahead, analyzing the next items, and retrieving labels, phoneme sequences and motor programs for the production of these upcoming items (Wolf & Denckla, 2005). The simultaneous processing of multiple stimulus items taxes sequential processing during the encoding and storage stages. When the stimuli are a mixture of items from different categories, rapid naming additionally involves category switching during the process of retrieving the linguistic label from long-term memory (Wolf, 1986). Participants were asked to rapidly name items on within-category arrays of objects, colors, letters and numbers and mixed-category arrays of letters and numbers, and letters, numbers and colors in response to array cards from the Rapid Automatized Naming and Rapid Alternating Stimulus Tests (RAN/ RAS; Wolf & Denckla, 2005). Age-adjusted standard scores were averaged separately for the within-category (RAN) and mixed-category (RAS) naming tasks.
Imitating nonwords requires isolating units of speech (syllables, phonemes) and their prosodic features from a stream of speech, storing them in their correct sequence in working memory, and retrieving them from there to translate them sequentially into motor programs and motor activation. Participants 5 years and older completed three nonword imitation tasks with different phoneme inventories and prosodic patterns, the Nonword Repetition (NWR) subtest from the Comprehensive Test of Phonological Processing (CTOPP; Wagner, Torgesen, & Rashotte, 1999), the Nonword Repetition Task (NRT; Dollaghan & Campbell, 1998) and the Syllable Repetition Test (SRT) (Shriberg et al., 2009). The NWR includes items with low and high articulatory complexity and is standardized on a large norming sample of 1656 individuals. Of the three measures of nonword imitation, the NWR is the most complex in terms of phonology. The phoneme inventory in the 18 target nonwords consists of 20 consonants (Cs) including mid- to late-developing Cs such as /ɹ, l, ʃ, ʧ, ʤ/, either as singletons or in CC sequences, 9 monophthong vowels (Vs), and 4 diphthong Vs. The sum of target phonemes in the NRW is 147, with an average nonword length of 8.2 phonemes. The NRT is slightly less complex than the NWR in terms of phonology. It consists of 16 nonwords without unstressed syllables where only 11 consonants, 4 monophthongs and 5 diphthongs are arranged into CV (nonfinal syllables) and CVC (single and final) syllables. Some of the Cs such as /ʃ, ʧ, ʤ/ are late-developing. The total number of target phonemes in the NRT is 96, with an average nonword length of 6 phonemes. The SRT was selected because it controls for articulatory complexity by limiting the phoneme set to the vowel /ɑ/, the stops /b, d/ and the nasals /m, n/, which are all early-developing phonemes and seldom produced in error by children with SSD. In sum, 50 target consonants arranged in C + /ɑ/ sequences are sampled, with an average nonword length of 5.6 phonemes. For the NRT and SRT, z scores were calculated using the normative information in technical reports published online (http://www.waisman.wisc.edu/phonology/BIB/tech.htm). In all three nonword imitation tasks, sequential processing loads are high during encoding and storage. During the SRT, sequential programming loads when converting the phoneme strings to strings of speech sounds are substantially lower, compared to the NWR and NRT, due to the small phoneme inventory, the same monophthong vowel in all syllables and the use of early-developing, unmarked phonemes.
To observe the performance on a reading task with low sequential processing load, participants were asked to read sight words under untimed conditions, using the Word Identification (WID) subtest of the Woodcock Reading Mastery Tests – Revised (Woodcock, 1998). Reading sight words requires whole-word recognition and retrieval of the phonological form from long-term memory, as the orthography of sight words does not reliably predict pronunciation and lexical stress. Unlike the RAN/RAS task, which also requires item recognition and retrieval of phonological forms, the WID is untimed and, hence, does not require simultaneous processing of multiple items. To observe performance on a reading task requiring substantial amounts of sequential processing, participants were asked to read nonwords, using the Word Attack (WATT) subtest of the Woodcock Reading Mastery Tests – Revised (Woodcock, 1998). Nonwords cannot be recognized as whole chunks and retrieved from memory; rather, decoding them requires sequential grapheme-to-phoneme conversion from left to right, by applying the basic spelling rules of English to individual graphemes as well as digraphs such as “ph” or trigraphs such as “V + C + e.”
Spelling words in response to a verbally presented target requires retrieving the word from long-term memory and writing the letters in their correct sequence from left to right. To observe the performance on this task, participants were asked to complete the Spelling subtest from the Wechsler Individual Achievement Test – II (WIAT-II; Wechsler, 2002). Recognizing single familiar words from dictation does not impose high sequential processing loads, but the letter sequences, which contain silent letters (“eight”, “knight” and ambiguous letter-sound associations (“weak” vs. “week,” “some” vs. “sum,” “assistants” vs. “assistance”) must be stored in their correct sequence in long-term memory and motorically converted to written letter sequences upon dictation.
Care was taken to avoid confounding of the results due to speech errors manifest in the children. Two 3-year-old children, codes 11312 and 11314, with low articulation test scores and multiple speech sounds in error did not complete the NWR and NRT and only 11312 completed the SRT. Two older children, codes 11311 and 11305, aged 6 and 7, showed evidence of speech sound substitution errors during articulation testing, and these errors were factored out of the imitation and reading tasks. The 6-year-old child had only /ɹ/ in error and these errors were not tabulated as substitution errors. The 7-year-old had /ɹ, l, θ, ð/ in error. Because the NWR contains /l, ɹ/, the child did not complete it. Substitution errors of the sounds missing in his inventory were not tabulated during the other tasks.
Table 1 summarizes the tasks selected for this study in terms of task domain, task description and sequential processing loads in the stages of encoding, storing and motor programming as described in Shriberg et al. (2012). Note that here, these stages are specifically modeled with respect to sequential processing. Note also that accurate responses during the verbal and nonverbal processing tasks do not depend on motor programming skills.
Qualitative measures of sequential processing
To observe sequencing errors on the level of phoneme strings, a qualitative error analysis was performed on children’s word productions from the articulation testing, multisyllabic word imitations in adults and nonword imitations in children and adults. Note that, while the NWR scoring guidelines with respect to ceiling scores were followed to arrive at the correct standard score, all words were elicited regardless of ceilings to tabulate segmental errors. Individual error types are shown in Table 2. Assimilations, migrations, metatheses, omissions, insertions of sounds that occurred elsewhere in the word and insertions of sounds that did not occur in the word closely were deemed most closely related to changes of phoneme sequences. Substitution errors were considered potentially related to faulty auditory processing. False starts, hesitations and syllable repetitions were interpreted as disruptions of fluency that indicated awareness of an error, leading to an attempt to correct it. Table 2 summarizes these error types and provides examples.
Table 2.
Error codes for multisyllabic word and nonword imitations.
| Code | Term | Explanation | Example |
|---|---|---|---|
| A | Assimilation | An incorrect sound is the same as another sound in the word (“copy and paste”) | [lmiʔi] monkey [stæɾɪlʃtiʃən] statistician |
| Mig | Migration | A sound is moved to an incorrect position in the word (“cut and paste”) | [bus] spoon [lʃɪlvəɹi] chivalry |
| Met | Metathesis | Two sounds switch places | [ltθεa] shovel [lspεktɪkəl] skeptical |
| O | Omission | A sound is missing | [haʊ] house [səlsεpəbəl] susceptible |
| IW | Insertion (within) | A sound occurring in the target word is inserted | [llæʔæmp] lamp [lfʌʤəsɪkəl] fudgesicle |
| IO | Insertion (outside) | A sound outside the target word is inserted | [ljafʃo] shovel [əklspεʃəli] especially |
| S | Substitution | A sound not in the word is substituted for a sound in the word | [tʌp] cup [lsɪnfəsɪs] synthesis |
| FS | False Start | A word is stopped and restarted | [lʃɪvɚ … lʃɪvəlɹi] chivalry |
| H | Hesitation | A word is interrupted by a pause or prolongation | [lɹεgjəlɚ:::li] regularly |
| SR | Syllable repetition | A syllable is revised by saying it again | [səlsεk … lsεptɪbəl] susceptible |
The error codes listed in Table 2 were applied to the word productions elicited from children with the GFTA-2, but only if the target sound was in the child’s phoneme inventory. Errors of assimilation, migration, metathesis, omission and insertion were interpreted as altering the phoneme sequence in the target word. Vowel errors were tracked because of their role in characterizations of CAS. Substitution errors and fluency errors (false starts, hesitations and syllable repetitions) were not tracked in the qualitative analysis of GFTA-2 word productions, although substitution errors were included in the standardized error analysis of that test.
The error codes were also applied to the nonword imitations elicited with the NWR and the NRT. To observe phoneme sequences during real word imitations, participants aged 18 and older were asked to imitate 29 multisyllabic words following the guidelines in the Multisyllabic Word (MSW) imitation task (Catts, 1986). Imitating multisyllabic real words differs from imitating nonwords with respect to sequential processing load. Real words are represented in long-term memory and the encoding, word retrieval and motor programming stages can be assumed to be more automatic than in the case of non-words, as they are not represented in long-term memory and there is no established motor program for converting the phoneme sequence into speech sounds. Multisyllabic real words produced by children and adolescents were not analyzed because some of the stimuli may be unfamiliar to them, and imitating novel words would have the characteristics of a nonword imitation task.
Reliability
The first author collected all data and completed the initial data reduction and analysis. Approximately 15% of the data were checked for reliability by the fourth author and a team of undergraduate and graduate students in the Department of Speech and Hearing Sciences at the University of Washington. The mean syllable durations from the mono- and disyllabic production task differed by less than 1 ms. For the measures of articulation, phonology, rapid naming, reading, spelling, verbal processing and nonverbal processing, any discrepancies greater than three raw score points were resolved by consensus.
Statistical analyses
For all standardized tests, z scores were computed directly from published norms or by conversion from standard scores in other formats, i.e. population mean of 100 (SD = 15) or 10 (SD = 3). Per-group z score averages for affected and unaffected family members were calculated. Group differences were computed using two statistics, t tests with unequal variances and effect size (Cohen’s d). Testing for effect sizes was added to the t tests because of the small sample size, which results in reduced power to detect group differences with t tests. For the t tests, nominal p values are reported, as the small sample size did not support adjustments for multiple testing. Cohen’s d is the difference between the mean group scores in units of the pooled and weighted SD. For instance, the average group z score for the multisyllabic DDK task was −0.94 (SD = 1.43) in the affected group consisting of 7 participants and 0.39 (SD = 0.42) in the unaffected group consisting of 11 participants. The difference between these two z scores, −1.33, is divided into the combined and weighted standard deviation, ([7 × 1.43] + [11 × 0.42])/18; Cohen’s d = −1.64. Usually, Cohen’s d is reported as an absolute value; here, we show negative signs where the score in the affected group was lower than that in the unaffected group. For context, a Cohen’s d of 0.2 indicates a small group difference; at 0.5, the group difference is considered of medium magnitude and, at or above 0.8, large (Cohen, 1992).
To allow comparison of the qualitative error codes across tasks, they were summed and converted to a percent occurrence, relative to the sum of phonemes in the targets. For instance, the MSW task represents 181 phonemes. A participant who produced four sequencing errors would obtain a percent sequencing error rate of (4/181) × 100 = 2.21%; in other words, 2.21% of the target phonemes in the MSW task were altered by sequencing errors. Percent error scores were averaged for the participant groups.
Results
Articulation and phonology testing
Of the participating children with severe speech difficulties, four, aged 10, 9, 7 and 6, had received intense treatment beginning approximately at the age of 3. Of these, only the 7- and 6-year-old produced speech sound errors during single-word productions as tested with the GFTA-2. The 7-year-old obtained a raw score of 21, a standard score of 57 and a percentile ranking of 3. His KLPA-2 raw score was 28, with a standard score of 54 and a percentile ranking of 3. Of his 28 errors, 21 were listed under Liquid Simplification. He replaced liquids with glides and interdental fricatives with labiodental fricatives. Regarding the phoneme sequences in the target words, he omitted phonemes on six occasions ([gɜ]/gɝl, [bɔ]/bɔl, [bɪæna]/bənænə, [ɔɪnʤ]/ɔɹɪnʤ, [fɔg]/fɹɔg,[bwunz]/bəlunz) but did not produce any other sequencing errors. The 6-year-old obtained a GFTA-2 raw score of 7, a standard score of 96 and a percentile ranking of 18. She obtained a KLPA-2 raw score of 17, a standard score of 82 and a percentile ranking of 9. All 17 phonological process errors were listed under Liquid Simplification. She distorted, glided or vowelized /ɹ/ and she omitted it on one occasion ([fɔg]/fɹɔg), which was her only sequencing error.
Two cousins, codes 11312 and 11314 and aged 3;5 and 3;10, respectively, had not been evaluated by a speech–language pathologist prior to participating in the study and their speech productions thus provided an opportunity to observe an unaltered phenotypic expression of their speech disorder. In both cases, parents believed that their child was unaffected because, unlike the older affected children in the extended family at age 3, the child was able to say many different words, even though conversational speech was difficult to understand by others.
The child age 3;5 obtained a GFTA-2 raw score of 44, a standard score of 76 and a percentile ranking of 13.When her word productions were analyzed with the KLPA-2 to quantify the presence of phonological processes, she obtained a raw score of 56, a standard score of 82 and a percentile ranking of 12. Of her phonological errors, 17 were listed under Cluster Simplification, 12 under Initial Voicing, 11 under Liquid Simplification, 7 under Velar Fronting and 3 each under Deletion of Final Consonants, Syllable Reduction and Final Devoicing.
In terms of common vs. rare errors, the child age 3;5 produced a number of common speech sound errors and patterns such as [f]/ for /θ/, [w] for /r/, velar fronting ([tʌp] for /kʌp/), prevocalic voicing ([ʤεɔ] for /ʧεɹ/), final devoicing ([ɔɪʧ] for /lɔɹɪnʤ/) and stopping ([lwεda] for /lfεðɚ/). She further produced some sound errors less commonly seen, such as [w] for /f, v, θ/, and five vowel errors.
The child produced several unusual errors affecting the sequence of the segments. Examples include [bus] for /spun/, [ljafʃo] for /lʃʌvəl/, [lwεbzɪbæg] for /lzɪpɚ/, [lwɪpsin] for /lswɪmɪŋ/ and [laɪs] for /slaɪd/. Analysis with the error codes listed in Table 1 showed that she produced 43 common and unusual sequencing errors during the GFTA-2 words: 28 omissions (12.1% of target phonemes in the GFTA-2), 4 of which occurred as part of 2 weak syllable deletions, 3 assimilations (1.3%), 4 migrations (1.7%), 7 insertions of sounds not in the target word (3.0%) and 1 insertion of a sound in the target word (0.4%). During other research tasks and conversational speech, similar mis-sequenced productions were observed, for instance, [mas] for /smal/, [los] for /slo/, [lhɔpsɔ] for /lhɔspɪɾəl/, [jɪps] for /zɪp/ and [ldeʃin] for /lʧesɪŋ/. The child’s mother reported that she, as a child, said her words “backwards” as well, e.g. “sorsie” for “horsie.”
The child aged 3;10 obtained a GFTA-2 raw score of 53, a standard score of 59 and a percentile ranking of 3. Her KLPA-2 raw score was 63, which was equivalent to a standard score of 48 and a percentile ranking of 1. Of her phonological process errors, 28 fell under Deletion of Final Consonants, 19 under Cluster Simplification, 9 under Liquid Simplification, 4 under Velar Fronting, 2 under Syllable Reduction and 1 under Stopping.
Like her cousin, this child exhibited some commonly seen speech sound errors and patterns including [w]/ɹ or vowel/ɹ substitutions and velar fronting ([tʌp] for /kʌp/). She also produced several uncommon speech sound errors such as [θ] for /kl/,[f] for /gr/, [w] for /dɹ/ and glottal stop replacements with inconsistency. Further, she produced six vowel errors, for instance, [lfεʔε] for /lfɪʃɪŋ/, [dɔɪ] for /kaɹ/ and [ʧi] for /ʧεɹ/.
Like her 3-year-old cousin, this child produced several words with unusual sequencing errors, for instance, [lwænə] for /lwægən/, [tθεa] for /lʃʌvəl/ and [halbu] for /bəllunz/. In sum, she produced 77 common and unusual errors affecting the sequence of segments in the target words: 62 omissions (26.8% of target phonemes), 4 of which could be grouped into 2 weak syllable deletions, 8 assimilations (3.5%), 3 migrations (1.3%), 1 metathesis (0.4%) and 3 insertions of sounds not occurring in the target word (1.3%). In other tasks and conversation, she produced additional sequencing errors, e.g. [lsεnə] for /lsεvən/. The transcriptions and qualitative error analyses based on the GFTA-2 productions of the two 3-year-old cousins are listed in Table 3.
Table 3.
Incorrect word productions by two 3-year-old cousins during articulation testing.
| Item | Code 11312 (age 3;5)
|
Code 11314 (age 3;10)
|
||
|---|---|---|---|---|
| Production | Sequencing and vowel errors | Production | Sequencing and vowel errors | |
| House | haʊ | O | ||
| Tree | ʧi | hwi | ||
| Window | lwɪno | O | lwɪno | O |
| Telephone | ltεwəwon(Im) | A | fo(Im) | O (AF) |
| Cup | tʌp | tʌp | ||
| Knife | naɪ | O | ||
| Spoon | Bus | Mig, O | bu(Im) | O, O |
| Girl | gɜl | dɔʊ | ||
| Ball | ba | O | ||
| Wagon | (Im) | lwænɛ(Im) | Mig, O | |
| Shovel | ljafʃo | Mig, IO, O | ltθεa | IO, Met, O |
| Monkey | lmiʔi | O, A | ||
| Banana | lnæna | O, O (WSO) | lnæna | O, O (WSO) |
| Zipper | lwεbzɪbæg | IO, IO, IO, V, IO | ðɪpɔ | |
| Scissors | aljɪzɔs | IO | lθanɔ | V, O |
| Duck | ldʌki | (AF) | dʌ | O |
| Quack | ldʌkədʌk | (AF) | (N/E) | |
| Yellow | llεlo | A | ljojo | A, A |
| Vacuum | lwækəm | O | (Im) | |
| Watch | wɔ | O | ||
| Plane | lεəbeɪn(airplane) | O | leɪbeɪ(airplane) | O, O, A, O |
| Swimming | lwɪpsin(Im) | Mig | lwɪmɪn(Im) | O |
| Watches | lwɔʃəs | lwaʔε(Im) | O | |
| Lamp | llæʔæmp | IO, IW | læp(Im) | O |
| Car | daɔ | dɔɪ | V | |
| Blue | bεo | O, V | bu | O |
| Rabbit | lwæbɪʔ(Im) | wæbʔæ | A, Mig | |
| Carrot | ldεwə | O | ldænə | O |
| Orange | ɔɪʧ | O, O | lɔɪ | O, O, O |
| Fishing | lwεʃɪn | V | lfεʔε | V, A. O |
| Chair | ʤεɔ | ʃi | V, O | |
| Feather | lwεda | ljεa | O | |
| Pencils | lbεsəs | O, O | lpεtso(Im) | O |
| This | dɪs(Im) | dɪ(Im) | O | |
| Bathtub | lbæftʌb | lbæta(Im) | O, A, O | |
| Bath | Bæf | bæ | V, O | |
| Ring | wɪŋk(Dialect) | wε | V, O | |
| Finger | lwɪgɔ | O | lfɪjɔ(Im) | O |
| Thumb | wʌm | fʌm(Im) | ||
| Jumping | lʤapɪn | O | lðapi | O, O |
| Pajamas | lʧæməs | O, O (WSO) | lðama | O, O (WSO), O |
| Flowers | lwæwɔs | O, V | lfaʊwɔ | O, IO, O |
| Brush | hæəbʌʃ(hairbrush) | V, O | hεbε(hairbrush) | O, O, A, O |
| Drum | ʤʌm | O | wʌm | O |
| Frog | lwagi | O (AF) | fwa(Im) | O |
| Green | Din | O | fi | O, O |
| Clown | daʊd(Im) | O, A | tθaʊ(Im) | O |
| Balloons | Bluns | O | halbu | Mig, O, O |
| Crying | ldaɪɪn | O | lfaɪwi | O, IO, O |
| Glasses | ldæsəs | O | lθaʔε | O, O |
| Slide | laɪs | Mig, O | θaɪ | O, O |
| Stars | daʊs | O | dɔɪ | O, V, O |
| Five | faɪ(Im) | O | ||
Notes: Correct productions were not transcribed. (Im), imitation (AF, alternate form); A, assimilation; IO, insertion of a sound outside the target word; Met, metathesis; Mig, migration; O, omission; WSO, weak syllable omission; V, vowel; N/E, not elicited.
Differences in standardized measures of sequential processing between affected and unaffected family members
Results from standardized testing are shown in Appendix 1. Data for the variables of interest were available from 7 to 8 family members with a history or presence of CAS and 10 to 12 family members without CAS, 4 of whom were married-ins. In the four tasks with low sequential processing loads, the average t statistic was −0.83 (average p = 0.2764), and the average effect size between the affected and unaffected groups was −0.41, indicating slightly lower scores in the affected group, compared to the unaffected group. The affected members had lower scores in the monosyllable DDK task (d = −0.85), NIX (d = −0.76) and the repetitive keyboard tapping task (d = 0.10). Their performance on the sight word reading task was slightly higher than that in the unaffected group (d = 0.10).
Appendix 1.
Results from standardized testing.
| Code | Sex | Age (years) | Aff. | VIX | NIX | NWR | NRT | SRT | Rep. keyboard taps | DDK monosyll. | DDK multisyll. | RAN Avg. | RAS Avg. | WID | WATT | WIAT SP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11101 | 1 | 66 | A | 0.07 | 1.20 | −2.00 | −7.21 | −7.79 | 0.11 | −0.96 | −1.06 | 0.45 | 0.80 | −0.67 | −1.07 | −1.27 |
| 11206 | 2 | 36 | A | 0.47 | 1.47 | −1.00 | −1.09 | −0.10 | −0.15 | 0.67 | −0.88 | 1.20 | 0.93 | −0.07 | −0.33 | −0.07 |
| 11207 | 1 | 34 | A | 0.27 | 0.73 | −1.67 | −2.41 | −3.18 | 0.96 | 0.24 | −1.80 | 0.45 | 0.93 | −0.87 | 0.47 | −1.07 |
| 11304 | 2 | 10 | A | 1.00 | NA | −1.33 | 1.22 | 0.15 | −0.96 | −1.07 | −1.56 | −0.47 | −0.40 | −0.20 | 0.27 | 0.13 |
| 11305 | 1 | 7 | A | −1.67 | −0.87 | NA | −4.06 | −3.21 | 0.62 | −1.03 | −3.04 | −1.45 | −1.40 | −0.73 | −1.00 | −0.80 |
| 11310 | 1 | 9 | A | 1.40 | 1.20 | 0.33 | 1.12 | 0.76 | 0.08 | 0.83 | 0.77 | 0.37 | 0.67 | 0.53 | 0.33 | −0.47 |
| 11311 | 2 | 6 | A | 1.27 | 1.13 | 0.33 | 3.01 | 0.26 | 1.73 | 1.34 | 0.99 | 1.28 | 0.60 | 2.13 | 1.40 | 1.07 |
| 11312 | 2 | 3 | A | 0.00 | 1.47 | NA | NA | 0.52 | NA | NA | NA | NA | NA | NA | NA | NA |
| 11314 | 2 | 3 | A | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| 11102 | 2 | 65 | U | 0.07 | 1.73 | −1.33 | −0.01 | −0.62 | 0.40 | −0.45 | 0.09 | 0.43 | 0.77 | −0.93 | −0.27 | −0.47 |
| 11201 | 1 | 42 | U | 1.40 | 1.07 | 0.00 | −0.40 | −0.10 | 1.07 | 0.88 | 0.29 | 0.43 | 0.80 | 0.40 | 0.73 | 1.53 |
| 11202 | 2 | 41 | U | 1.13 | 1.60 | −0.67 | 1.07 | −0.10 | −0.22 | −0.11 | −0.25 | 1.27 | 1.37 | 0.13 | 0.13 | 0.93 |
| 11203 | 1 | 41 | U | −0.20 | 0.67 | −0.67 | −0.80 | −1.13 | 1.04 | 1.05 | 0.85 | 1.22 | 1.27 | −0.07 | 0.53 | 0.93 |
| 11204 | 2 | 40 | U | 1.33 | 1.87 | −0.67 | 2.14 | 0.92 | 0.01 | 0.42 | 0.05 | 1.15 | 0.43 | −0.07 | 0.73 | 0.93 |
| 11205 | 1 | 38 | U | 0.93 | NA | 1.00 | 1.60 | 0.92 | 1.13 | 1.06 | 0.67 | 1.77 | 1.30 | 0.53 | 0.53 | 0.73 |
| 11303 | 2 | 11 | U | 0.27 | 0.47 | −0.67 | 1.55 | −0.52 | −0.76 | 0.28 | 0.38 | 0.72 | 0.17 | −0.20 | 0.67 | 0.80 |
| 11306 | 2 | 15 | U | 0.47 | 1.07 | −1.00 | 0.87 | −2.38 | −0.25 | 0.40 | 0.20 | 1.15 | 0.63 | −0.40 | 0.00 | −1.13 |
| 11307 | 1 | 10 | U | 1.93 | 2.80 | −0.67 | 0.80 | 0.06 | 0.14 | 1.50 | 1.04 | 0.97 | 1.30 | 0.40 | 1.07 | 0.00 |
| 11308 | 2 | 5 | U | 1.40 | 3.20 | 1.33 | 0.39 | 0.45 | 1.88 | 0.74 | 0.03 | NA | NA | NA | NA | NA |
| 11309 | 2 | 12 | U | 0.07 | 1.07 | 0.00 | 2.03 | −1.11 | 0.31 | 1.55 | 0.88 | 1.48 | 1.43 | −0.27 | 0.47 | 0.07 |
| 11208 | 2 | 27 | ? | 0.20 | NA | −1.33 | −2.53 | 0.92 | −0.51 | 1.21 | 0.14 | 0.87 | 0.47 | 0.13 | 0.67 | 0.93 |
| 11302 | 0 | 15 | ? | −0.20 | −0.13 | −2.00 | 0.87 | 1.07 | 0.12 | −0.71 | −1.58 | 0.58 | 0.50 | −0.07 | 0.67 | 1.47 |
| 11313 | 1 | 1 | ? | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
Notes: All scores are in units of z scores. NA, score not available.
The nine tasks with high sequential processing loads showed consistently lower performance in the affected group, compared to the unaffected group, with an average t statistic of −1.83 (p = 0.0605) and Cohen’s d of −0.96. The greatest group difference was seen in the multisyllabic DDK task (d = −1.64), followed by RAN (d = −1.23) and NRT (d = −1.11). Table 4 summarizes the per-group mean scores and standard deviations in units of z scores and the group differences in terms of t scores and units of effect sizes (Cohen’s d) for the four tasks with overall low sequential processing loads and the nine tasks with overall high sequential processing loads.
Table 4.
Mean z scores (number of participants) and standard deviations for the affected and unaffected group and group differences (t test results, effect sizes) for the variables of interest, by sequential processing load (mostly low vs. mostly high).
| Sequencing loads (encode, store, plan/program) | Variable | Affected z score | Affected SD | Unaffected z score | Unaffected SD | t Test t | t Test p | Effect size |
|---|---|---|---|---|---|---|---|---|
| L, L, L | DDK Monosyllables | 0.00 (7) | 1.01 | 0.66 (11) | 0.63 | −1.73 | 0.0518 | −0.85 |
| L, L, L | Keyboard Repetitive Tapping | 0.34 (7) | 0.86 | 0.43 (11) | 0.77 | −0.22 | 0.4126 | −0.11 |
| L, L, N/A | Nonverbal Processing Index: OIO, WHM | 0.90 (7) | 0.82 | 1.55 (10) | 0.89 | −1.55 | 0.0716 | −0.76 |
| L, L, L-H | Reading: Word Identification | 0.02 (7) | 1.05 | −0.05 (10) | 0.44 | 0.18 | 0.5697 | 0.10 |
| Average | 0.32 | 0.93 | 0.65 | 0.68 | −0.83 | 0.2764 | −0.41 | |
| L, H, H | DDK Multisyllables | −0.94 (7) | 1.43 | 0.39 (11) | 0.42 | −2.94 | 0.0048 | −1.64 |
| H, H, L-H | RAN | 0.26 (7) | 0.95 | 1.06 (10) | 0.43 | −2.34 | 0.0167 | −1.23 |
| H, H, L-H | RAS | 0.30 (7) | 0.88 | 0.95 (10) | 0.45 | −1.99 | 0.0327 | −1.03 |
| H, H, H | Nonword Imitation: NWR | −0.89 (6) | 1.00 | −0.30 (11) | 0.82 | −1.30 | 0.1064 | −0.66 |
| H, H, H | Nonword Imitation: NRT | −1.35 (7) | 3.53 | 0.84 (11) | 0.97 | −1.97 | 0.0332 | −1.11 |
| H, H, L | Nonword Imitation: SRT | −1.57 (8) | 2.98 | −0.33 (11) | 0.98 | −1.31 | 0.1046 | −0.68 |
| GW: L, L, N/A VRZ: H, H, N/A | Verbal Processing Index: GW, VRZ | 0.35 (8) | 0.98 | 0.80 (11) | 0.70 | −1.18 | 0.1281 | −0.55 |
| Reading: Word Attack | 0.01 (7) | 0.88 | 0.46 (10) | 0.40 | −1.44 | 0.0849 | −0.76 | |
| Spelling | −0.35 (7) | 0.81 | 0.43 (10) | 0.80 | −1.99 | 0.0328 | −0.98 | |
| Average | −0.46 | 1.49 | 0.48 | 0.66 | −1.83 | 0.0605 | −0.96 |
Notes: L, low sequential processing load; H, high sequential processing load; N/A, does not apply; OIO, odd item out, WHM, What’s Missing; GW, guess what; VRZ, verbal reasoning.
Qualitative error analysis of multisyllabic real word and nonword imitations
Only data from adults were considered for the MSW task to avoid confounding from nonword effects for words unfamiliar to children. Among the adults, age in months was not correlated significantly or to a concerning extent with the percent occurrences of sequencing (r = 0.31, p = 0.3772), substitution (r = v – 0.12, p = 0.7508) and fluency (r = 0, p = 0.9882) errors.
During the MSW task, the three affected adults produced an average sequencing error percentage of 3.31 (SD = 1.46), an average substitution error percentage of 1.10 (SD = 1.46) and an average fluency error percentage of 1.10 (SD = 1.10). The equivalent error percentages in the six unaffected adults were 1.01 (SD = 1.42), 0.00 and 0.18 (SD = 0.45), respectively. Overall, omissions and assimilations contributed the most errors to the sequencing error class. Only two participants, both in the affected group, produced substitution errors. Fluency errors were also rare. Two of the three affected adults but only one of the unaffected participants produced fluency errors in the form of false starts, and one hesitation was observed in an affected participant. Table 5 summarizes the raw error counts for each error type and the occurrence percentages by error class for each participant.
Table 5.
Error counts by types and % occurrences of target phonemes by error class in adults during the MSW task.
| Code | Aff. | A | Mig | Met | O | IW | IO | S | FS | H | SR | % Sequ. errors | % Subst. errors | % Fluency errors |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11101 | A | 4 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 2.76 | 0.55 | 0.00 |
| 11206 | A | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 4 | 0 | 0 | 2.21 | 0.00 | 2.21 |
| 11207 | A | 2 | 0 | 0 | 5 | 0 | 2 | 5 | 1 | 1 | 0 | 4.97 | 2.76 | 1.10 |
| 11102 | U | 0 | 0 | 1 | 6 | 0 | 0 | 0 | 2 | 0 | 0 | 3.87 | 0.00 | 1.10 |
| 11201 | U | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.55 | 0.00 | 0.00 |
| 11202 | U | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.55 | 0.00 | 0.00 |
| 11203 | U | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0.55 | 0.00 | 0.00 |
| 11204 | U | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.55 | 0.00 | 0.00 |
| 11205 | U | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.00 | 0.00 | 0.00 |
| 11208 | ? | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1.66 | 0.00 | 0.00 |
| Average | 0.8 | 0 | 0.6 | 1.5 | 0 | 0.3 | 0.6 | 0.7 | 0.1 | 0 | 1.77 | 0.33 | 0.44 | |
| SD | 1.3 | 0.0 | 0.5 | 2.2 | 0.0 | 0.7 | 1.6 | 1.3 | 0.3 | 0.0 | 1.66 | 0.87 | 0.77 |
Notes: Aff., affected (A, affected; U, unaffected; ?, affectation status uncertain); A, assimilation; Mig, migration; Met, metathesis; O, omission; IW, insertion of a sound within the word; IO, insertion of a sound outside the target word; S, substitution; FS, false start; H, hesitation; SR, syllable repetition.
For the NWR measures, responses from 10 adults and 9 children were analyzed. Age in months was correlated with the percent occurrences of sequencing errors at r = −0.36, p = 0.1250), substitution errors at r = 0.42 (p = 0.0753) and fluency errors at r = −0.32 (r = 0.1828). None of these correlations reached statistical significance, although the age correlation with substitution measures approached significance. In the affected group, consisting of three adults and three children, the average age was 26.8 years (SD = 23.3) and in the unaffected group, consisting of six adults and five children, the average age was 29.1 years (SD = 19.2), indicating that the age distribution was roughly equivalent in the two groups and that they could be compared to each other despite the slight age effect regarding substitution errors. Figure 2 shows the age distribution of the error classes by age and affectation status.
Figure 2.

Percent sequencing errors during the NWR task by age and affectation status. Note: A, affected; U, unaffected; ?, affectation status uncertain.
In the affected group, the percent occurrences for sequencing, substitution and fluency errors were 9.52 (SD = 3.92), 7.14 (SD = 3.70) and 0.91 (SD = 0.71), respectively. The analogous occurrence rates in the unaffected group were 6.56 (SD = 5.39), 3.65 (SD = 2.05) and 0.19 (SD = 0.32), respectively.
Assimilations and omissions contributed the most errors to the overall sequencing error percentages, followed by insertions if the two types, inserting sounds from outside (IO) and within (IW) the target word, were collapsed into one error type. Table 6 summarizes the raw error counts by type and participant and the percentages for sequencing, substitution and fluency errors.
Table 6.
Error counts by types and % occurrences of target phonemes by error class during the NWR task.
| Code | Aff. | Age | A | Mig. | Met | O | IW | IO | S | FS | H | SR | % Sequ. errors | % Subst. errors | % Fluency errors |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11101 | A | 66 | 2 | 4 | 0 | 7 | 0 | 1 | 20 | 0 | 0 | 0 | 9.52 | 13.61 | 0.00 |
| 11206 | A | 36 | 4 | 1 | 2 | 1 | 1 | 1 | 10 | 2 | 0 | 0 | 6.80 | 6.80 | 1.36 |
| 11207 | A | 34 | 8 | 0 | 1 | 3 | 3 | 2 | 8 | 0 | 1 | 0 | 11.56 | 5.44 | 0.68 |
| 11304 | A | 10 | 12 | 1 | 0 | 6 | 1 | 4 | 10 | 1 | 0 | 0 | 16.33 | 6.80 | 0.68 |
| 11310 | A | 9 | 1 | 1 | 1 | 1 | 5 | 1 | 7 | 1 | 0 | 2 | 6.80 | 4.76 | 2.04 |
| 11311 | A | 6 | 2 | 2 | 1 | 3 | 0 | 1 | 8 | 1 | 0 | 0 | 6.12 | 5.44 | 0.68 |
| 11102 | U | 65 | 4 | 2 | 0 | 3 | 0 | 0 | 10 | 0 | 0 | 0 | 6.12 | 6.80 | 0.00 |
| 11201 | U | 42 | 1 | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 1.36 | 1.36 | 0.00 |
| 11202 | U | 41 | 4 | 0 | 0 | 1 | 0 | 0 | 5 | 0 | 0 | 0 | 3.40 | 3.40 | 0.00 |
| 11203 | U | 41 | 7 | 1 | 0 | 4 | 0 | 1 | 8 | 0 | 0 | 0 | 8.84 | 5.44 | 0.00 |
| 11204 | U | 40 | 2 | 1 | 1 | 1 | 1 | 0 | 8 | 1 | 0 | 0 | 4.08 | 5.44 | 0.68 |
| 11205 | U | 38 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0.68 | 0.68 | 0.00 |
| 11303 | U | 11 | 4 | 1 | 0 | 1 | 3 | 1 | 7 | 0 | 0 | 1 | 6.80 | 4.76 | 0.68 |
| 11306 | U | 15 | 3 | 0 | 2 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 3.40 | 4.76 | 0.00 |
| 11307 | U | 10 | 4 | 5 | 0 | 2 | 3 | 5 | 5 | 0 | 1 | 0 | 12.93 | 3.40 | 0.68 |
| 11308 | U | 5 | 5 | 2 | 0 | 19 | 1 | 1 | 1 | 0 | 0 | 0 | 19.05 | 0.68 | 0.00 |
| 11309 | U | 12 | 3 | 3 | 0 | 2 | 0 | 0 | 5 | 0 | 0 | 0 | 5.44 | 3.40 | 0.00 |
| 11208 | ? | 27 | 4 | 3 | 0 | 2 | 2 | 0 | 12 | 0 | 0 | 0 | 7.48 | 8.16 | 0.00 |
| 11302 | ? | 15 | 8 | 1 | 1 | 2 | 2 | 0 | 8 | 0 | 0 | 0 | 9.52 | 5.44 | 0.00 |
| Average | 4.1 | 1.5 | 0.5 | 3.1 | 1.2 | 0.9 | 7.5 | 0.3 | 0.1 | 0.2 | 7.70 | 5.08 | 0.39 | ||
| SD | 2.9 | 1.4 | 0.7 | 4.3 | 1.5 | 1.4 | 4.3 | 0.6 | 0.3 | 0.5 | 4.75 | 2.92 | 0.57 |
Notes: Aff., affected (A, affected; U, unaffected; ?, affectation status uncertain); A, assimilation; Mig, migration; Met, metathesis; O, omission; IW, insertion of a sound within the word; IO, insertion of a sound outside the target word; S, substitution; FS, false start; H, hesitation; SR, syllable repetition.
For the NRT measures, responses from 10 adults and 10 children were available, with one child and one adult coded as uncertain affectation status. Age in months was correlated with percent occurrence of sequencing errors at r = −0.20 (p = 0.3904), substitution errors at r = −0.19 (p = 0.4154), and fluency errors at r = −0.18 (p = 0.4387). None of these correlations were statistically significant or concerning. Similar to the NWR analysis, the age distribution in the two groups were roughly comparable. In the affected group, consisting of three adults and four children, the average age was 24.0 years (SD = 22.5) and in the unaffected group, consisting of six adults and five children, 29.1 years (SD = 19.2). Figure 3 shows the age distribution of the sequencing error percentages.
Figure 3.

Percent sequencing errors during the NRT task by age and affectation status. Note: A, affected; U, unaffected; ?, affectation status uncertain.
In the affected group, percentages of occurrence in target phonemes for sequencing, substitution and fluency errors were 7.99 (SD = 8.86), 9.03 (SD = 6.99) and 0.87 (SD = 1.11), respectively. The analogous occurrences in the unaffected group were 3.82 (SD = 4.69), 2.52 (SD = 1.80) and 0.17 (SD = 0.41), respectively.
Assimilations and omissions were the greatest contributors to sequencing errors, followed by insertions if the two types, IO and IW, were collapsed into one type. Table 7 summarizes the raw error counts by type and participant and the percentages for sequencing, substitution and fluency errors.
Table 7.
Error counts by types and % occurrences of target phonemes by error class during the NRT task.
| Code | Aff. | Age | A | Mig | Met | O | IW | IO | S | FS | H | SR | % Sequ. errors | % Subst. errors | % Fluency errors |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11101 | A | 66 | 6 | 1 | 0 | 2 | 0 | 0 | 7 | 0 | 0 | 0 | 9.38 | 7.29 | 0.00 |
| 11206 | A | 36 | 5 | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 6.25 | 2.08 | 0.00 |
| 11207 | A | 34 | 1 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 1 | 0 | 1.04 | 10.42 | 1.04 |
| 11304 | A | 10 | 2 | 0 | 0 | 0 | 0 | 2 | 4 | 0 | 0 | 0 | 4.17 | 4.17 | 0.00 |
| 11305 | A | 7 | 3 | 2 | 3 | 6 | 4 | 7 | 22 | 1 | 2 | 0 | 26.04 | 22.92 | 3.13 |
| 11310 | A | 9 | 1 | 0 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 1 | 1.04 | 7.29 | 1.04 |
| 11311 | A | 6 | 1 | 0 | 1 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 2.08 | 5.21 | 0.00 |
| 11102 | U | 65 | 3 | 0 | 1 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 5.21 | 2.08 | 0.00 |
| 11201 | U | 42 | 1 | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2.08 | 2.08 | 0.00 |
| 11202 | U | 41 | 2 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 1 | 2.08 | 3.13 | 1.04 |
| 11203 | U | 41 | 1 | 0 | 2 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 3.13 | 2.08 | 1.04 |
| 11204 | U | 40 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0.00 | 2.08 | 0.00 |
| 11205 | U | 38 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.04 | 0.00 | 0.00 |
| 11303 | U | 11 | 1 | 1 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 2.08 | 6.25 | 0.00 |
| 11306 | U | 15 | 1 | 1 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 2.08 | 3.13 | 0.00 |
| 11307 | U | 10 | 1 | 3 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6.25 | 0.00 | 0.00 |
| 11308 | U | 5 | 3 | 3 | 1 | 9 | 0 | 1 | 2 | 0 | 0 | 0 | 17.71 | 2.08 | 0.00 |
| 11309 | U | 12 | 2 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 2.08 | 2.08 | 0.00 |
| 11208 | ? | 27 | 0 | 1 | 0 | 1 | 0 | 0 | 14 | 0 | 0 | 0 | 2.08 | 14.58 | 0.00 |
| 11302 | ? | 15 | 2 | 0 | 0 | 0 | 0 | 0 | 4 | 1 | 0 | 0 | 2.08 | 4.17 | 1.04 |
| Average | 1.8 | 0.6 | 0.7 | 0.9 | 0.2 | 0.6 | 5.0 | 0.2 | 0.2 | 0.1 | 4.90 | 5.16 | 0.42 | ||
| SD | 1.6 | 1.0 | 0.9 | 2.4 | 0.9 | 1.6 | 5.3 | 0.4 | 0.5 | 0.3 | 6.37 | 5.49 | 0.79 |
Notes: Aff., affected (A, affected; U, unaffected;?, affectation status uncertain); A, assimilation; Mig, migration; Met, metathesis; O, omission; IW, insertion of a sound within the word; IO, insertion of a sound outside the target word; S, substitution; FS, false start; H hesitation; SR, syllable repetition.
To compare the results from the three imitation tasks, MSW, NWR and NRT, only data from the adults were considered because MSW productions from children were not analyzed for this study. The comparison shows that in all tasks and all error classes, the affected adults had higher error occurrence rates, compared to the unaffected adults. The only exception to this pattern was fluency errors in the NRT task, where the percentages were equivalent in the two groups. In both groups, the highest percent occurrence of sequencing errors was observed for the NWR task, followed by the NRT task and the MSW task. In both groups, sequencing and substitution errors occurred with roughly similar frequencies during the two nonword imitation tasks but in the MSW task, substitution errors were less frequent in the affected group and no substitution errors were observed in the unaffected group. Within each group and task, by far the lowest percent occurrence was seen for the category of fluency errors. Most fluency errors were observed in the affected group during the MSW task. Figure 4 summarizes the percent occurrences for the three tasks, the three error categories and the two participant groups.
Figure 4.
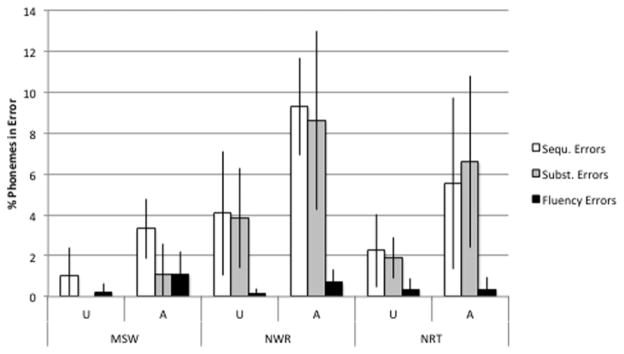
Average error percentages in adult participants by task; participant group and error class. Note: U, unaffected; A, affected. Error bars indicate ±1 SD.
Discussion
The purpose of this study was to evaluate the hypothesis that, in a multigenerational family with familial SSD consistent with CAS, deficits in sequential processing underlie not only the disordered speech development but can also be observed across a variety of other domains in those family members with present or past disordered speech. Results are generally consistent with the sequential processing hypothesis. Further, they are consistent with a genetic CAS etiology and show that residual effects of sequencing deficits can be observed in adults with a CAS history whose conversational speech has normalized.
Disorder phenotype
In two 3-year-old cousins who had not been previously evaluated for SSD and had not yet received treatment, incorrect speech sound production could be observed in unremediated form. Their conversational speech was judged difficult to understand. During articulation testing based on single-word productions, both children obtained low or very low articulation and phonological process test scores. They exhibited several common as well as uncommon speech sound errors and patterns; in addition, they produced vowel errors. Severely unintelligible speech, uncommon errors and vowel errors are all consistent with CAS. This finding, in the context of other CAS diagnoses and developmental traits consistent with CAS in the same extended family, is consistent with a familial and potentially also genetic etiology of CAS.
Both children produced many errors that altered the phoneme sequence in the target word. The most frequently observed error type for both was omission in the context of C sequence reduction for participant 11312 and, additionally, final C deletion for participant 11314. These types of errors result in the predominant use of simplified syllable shape, a frequently cited trait of CAS. Altered target phonemes due to assimilation even when the target phoneme is within the child’s inventory, phoneme migrations, metatheses and insertions are not related to articulatory ability to produce certain speech sounds; rather, they can result from faulty perceptual processes, incorrect storage in long-term memory and/or faulty construction of the phoneme sequence prior to motor execution. As mentioned, there is a debate whether or not mis-sequenced linguistic units are a primary or secondary feature of CAS (Shriberg et al., 2012), as some view CAS as a motor speech disorder, not a disorder at the level of linguistic units (McNeil, 1997, 2009). Mis-sequenced segments were observed in both of these children, and one of the parents reported a similar error pattern during her childhood. This suggests that deficits in sequential processing were not limited to motor programming but also affected other components upstream from motor programming such as mis-sequenced perceptual encoding of the segment sequences at the word level, mis-sequenced representation in memory, and/or errors during the assembly of the motor programs.
Performance on standardized tasks with varying levels of sequential processing loads in family members with, and without, a CAS history
Analyses of four standardized tasks with generally low sequential processing loads and nine standardized tasks with generally high sequential processing loads showed substantial group differences between affected and unaffected family members in the high-load tasks but smaller group differences in the low-load tasks.
Several of these tasks were set up such that high-load and low-load tasks could be compared within the same task domain. For instance, monosyllabic DDK and multisyllabic DDK both are designed to measure motor programming, but multisyllable repetition invokes much greater sequential processing loads. Similarly, two reading tasks, WID and WATT, provided an opportunity to observe word reading performance when sequential processing loads were low and high, respectively. In both of these paired measures, the group differences between affected and unaffected family members supported the sequential processing hypothesis, as the group differences were large for the high-load task and small for the low-load task. The nonverbal and verbal processing indices, by contrast, only partially supported this hypothesis, as group differences were larger in the nonverbal measures than in the verbal measure. In both of these measures, both groups obtained scores that were, on average, above the population means.
The measures that were not set up as corresponding pairs with low and high sequential processing loads supported the sequential processing hypothesis. As predicted, the repetitive keyboard tapping task showed no difference between the affected and unaffected groups, whereas large group differences were seen for the measures of rapid naming, nonword imitation and spelling, which was also predicted under the sequential processing deficit hypothesis.
Regarding the locus of impairment in CAS with respect to cognitive processes operating on sequences of items, results from this study are consistent with the view that sequential processing deficits can be observed at levels at, as well as upstream from, the motor programming stage. Regarding motor programming, the group differences were much greater in the multisyllabic repetition task, compared to the monosyllabic repetition task, although it should be noted that even in the monosyllabic repetition task, the affected family members had slower rates than the unaffected family members. The fact that the affected and unaffected groups did not differ in repetitive keyboard tapping speeds but did differ in repetitive DDK speeds suggests that the motor speech system is especially susceptible to CAS even when sequential processing loads are low. The relative group differences for mono- and multisyllabic DDK speeds suggest that individuals with CAS may struggle with motor programming when multiple muscle groups are simultaneously active and movements must be integrated into a temporal sequence. It is possible that maintaining the motor program for multisyllable repetitions such as /pataka/ in working memory while executing the movements is an additional stress.
Additional evidence for involvement of processes upstream of the motor system comes from various measures with high sequential processing loads for encoding and/or memory storage. Of the three nonword imitation tasks, the SRT is designed with minimal motor programming loads due to the use of unmarked phonemes, short phoneme sequences and simple syllable shapes, yet the affected family members obtained substantially lower z scores, compared to the unaffected family members. High sequential processing loads are required for encoding nonwords and storing them in working memory, regardless of motor demands for speech output. Similarly, in the two word reading tasks, the group differences between the affected and unaffected family members were larger for WATT, compared to WID. Nonword decoding involves highly sequential processes of encoding and storing a string of graphemes in working memory, then converting them sequentially into strings of phonemes, whereas word recognition involves whole-chunk word recognition. In both tasks, the sequencing load for the motor output ranges from low to high. A large group difference for WATT but not for WID is consistent with CAS-related sequencing deficits during encoding and/or storing the graphemes in working memory. Also regarding written language, the spelling measure differentiated between the affected and unaffected family members. Spelling English words correctly requires storing grapheme sequences correctly in long-term memory, retrieving the sequences from there, and converting them into written sequences of gra-phemes. The words tested with the WIAT-II include many sight words that cannot be spelled by applying orthographic rules to a string of phonemes, but rather, require that the letter sequence be memorized due to the presence of silent letters and ambiguous letter–sound associations. Reading sight words, as tested with WID, on the other hand, requires much less sequential processing and more whole-chunk processing.
Consistent with the expectation that the rapid naming task taxes sequential processing due to the simultaneous action upon two or more items, the two measures of rapid naming, RAN and RAS, showed large group differences between the affected and unaffected family members. The effect sizes for these two measures were similar, which is consistent with a relative sequential processing deficit in the affected family members where the added aspect of switching categories during RAS had no effect on performance. Rapid automatized naming requires rapid performance of multiple processes including speech production, and it is possible, although not ascertainable, that slowed speech production in the affected group may have contributed to the group difference in this type of task.
The unaffected members as a group obtained scores substantially above the population mean, for instance for NIX and RAN, which drove the group differences between the unaffected and affected groups, whereas the affected members obtained scores below the population mean in all three measures of nonword imitation, multisyllabic syllable repetition, and spelling. It is possible that the general background in this family is characterized by overall high verbal and nonverbal functioning but a particularly strong effect of sequencing deficits may be evident in affected members for those measures requiring sequential processing of phoneme and letter units.
Two children with extremely delayed speech development, codes 11310 and 11311 and ages 9 and 6 years, respectively, did not fit the general trends evident in the other affected family members. These two siblings had average to above-average scores in the measures of nonword imitation, multisyllabic DDK, automatized naming, reading, and spelling. It is unclear what caused this difference in phenotypic expression. Potential explanations include the effects of intense intervention and the possibility that their speech difficulties had a different cause than those in the rest of the family.
Qualitative error analysis in words and nonwords
Based on the data from the adults, the unaffected family members showed lower error rates, compared to the affected family members, in all three imitation tasks (MSW, NWR, NRT) and error classes (sequencing, substitution, fluency). This finding is remarkable in that the affected adults had long compensated their speech difficulties in childhood, and it points to residual effects of CAS during tasks that require high loads of sequential processing.
The lowest occurrence rates for sequencing and substitution errors were noted during the MSW task, followed by the NRT and NWR task. Imitating real words involves much lower demands for sequential processing during the encoding and storage stages, compared to imitating nonwords, because the word form and associated motor programs are stored in long-term memory and merely need to be retrieved for the speech production stage, whereas the phoneme sequences in non-words must be perceptually analyzed and stored in working memory prior to the assembly and execution of the motor programs. The observation that the affected family members produced more sequencing errors than the unaffected family members when imitating real words may be explained by the fact that these words were chosen because of their phonological complexity. For instance, the word “statistician” (/stæɾɪlstiʃən/) contains two C sequences and three C singletons in alternation, and of the three fricative Cs, two are voiceless alveolars and one, a voiceless palatal, frequently triggering an anticipatory assimilation between these phonologically similar sounds differing only in place of articulation (/stæɾɪlʃtiʃən/). Higher rates of substitution errors during nonword imitation, compared to real word imitation, were observed in both participant groups and they are consistent with perceptual and/or storage difficulties when presented with nonwords. During both nonword imitation tasks, the affected group produced substantially more substitution errors, compared to the unaffected group, which is consistent with additional deficits in perceiving and storing the sounds in the nonwords in that group.
Of the two nonword imitation tasks, the NWR task is more challenging than the NRT task in terms of phonological structures. It contains a greater number of different phonemes, longer phoneme sequences per nonword, and more complex word shapes due to the presence of clusters and closed syllables, whereas the NRT consists only of CV and CVC syllables. In both cases, the task involves high loads of sequential processing during the encoding, storage, and motor programming stages but the smaller phoneme inventory and the simplicity and predictability of the syllable shapes during the NRT result in slightly less sequential processing effort during all three preparatory stages. Both participant groups showed higher error rates during the NWR task, compared to the NRT task, but in both tasks, the affected group had higher sequencing and substitution error rates, which suggests a deficit in sequential processing at one or more of the preparatory stages and/or a general deficit in perceptual processing regarding the substitution errors.
Regarding error classes in the real word and nonword imitation tasks, the most frequently observed error class was sequencing errors, followed by substitution errors and fluency errors. The only exception to this pattern was a higher substitution error percentage, compared to the sequencing error percentage, in the affected group during the NRT. Fluency errors were interpreted as a sign of error awareness. Their occurrence was rare and the affected group showed slightly more fluency errors during MSW and NWR than the unaffected group. Due to the low occurrence rates, however, a meaningful group difference could not be described.
Integration of results with prior models of CAS
The results presented here fit with Shriberg et al.’s (2012) model in that they support a locus of impairment not only at, but also upstream from, the motor programming preparatory stage prior to motor execution. Results from the three nonword imitation tasks showed that participants with current or past CAS produced sequencing errors not only when the motor output was complex but also when encoding and memory storage demands were high but motor output demands were low. The results from this study extend the framework in Shriberg et al. (2012) in that they specifically highlight the role of processing sequentially arranged items, e.g. phonemes in nonwords, and in that they address aspects of sequential processing not restricted to speech tasks, e.g. reading and writing graphemes in nonwords. They also extend the framework of Shriberg and colleagues in that residual sequencing errors were found in adults with a childhood history of speech difficulty.
Similarly, the results from this study fit with Klapp’s (1995, 2003) two-stage model of motor programming as investigated in repetitive and alternating strings of simple and complex syllables (Wright et al., 2009) and as applied to adults with acquired apraxia of speech (AOS; Maas et al., 2008). Although the present study did not measure motor programming times directly, slowed repetitions of multisyllables, compared to monosyllables, were evident in the family members present or past CAS, consistent with a motor programming deficit. The present study exceeds the framework of Klapp’s model in that sequential processing was addressed in cognitive operations upstream from motor programming (encoding and storage) and in modalities hand and oral motor tasks (e.g. reading and spelling).
As mentioned earlier, there is debate whether deficits in domains other than motor programming for speech are core or secondary traits of CAS. The present study of a family with familial CAS provides evidence for the view that deficits in sequential processing underlie not only motor programming for speech but also aspects of cognitive and linguistic activities. In this view, deficits not related to speech are not secondary to CAS but, rather, due a shared common substrate. The following evidence is consistent with the shared origin model: The affected family members showed difficulties with all three measures of nonword imitation, even though one of them was less complex in terms of articulation than the other two. Deficits in the sequential order of phonemes during nonword and multisyllabic word imitations were seen in adults with a childhood history of CAS, even though their speech had long normalized. Both types of word reading task, sight-word identification and nonword decoding, require speech output with comparable levels of articulatory complexity, yet the group differences between those family members with, and without, a history of SSD were minimal during the word identification task and larger during the nonword decoding task. It is theoretically possible, however, that the acquisition of motor-related aspects of speech during childhood has a priming effect on the acquisition of linguistic and cognitive functions. If so, the observed sequencing deficits would be secondary to the speech deficit, not an equally primary consequence of an underlying deficit in sequential processing.
Limitations and future studies
Evidence that the family under study had familial CAS was supported not only by information obtained through questionnaires and interviews but also through quantified deficits in tasks requiring high loads of sequential processing. This phenotypic analysis provides the necessary background information for a genetic analysis, which is currently underway, using a combination of traditional linkage analysis and next-generation sequencing.
This family study provided important insights into the role of sequential processing beyond articulatory phonetics in CAS. Because of the wide age ranges and the relatively small sample size when considering adults and children separately, it was not possible to evaluate broader associations among continuous measures of sequencing. A companion paper (Button et al., submitted) reports on this type of association in a sample of 21 adults with a wide range of motor and linguistic abilities.
One limitation inherent in the present study is the fact that adults of all ages participated in some tasks for which norming information throughout the lifespan was not available. For instance, norms for the verbal and nonverbal processing tasks (GWH, VRZ, OIO, WHM) are available for ages 3 to 94 years and for WID for ages 5 to 75 years. For other measures, the highest available norming age is in early adulthood, for instance, 24;11 for NWR. It is unknown how accurately these norms reflect score distributions in adults beyond the highest normed age.
Future studies should evaluate the sequential processing hypothesis in CAS with additional measures. For instance, according to anecdotal evidence in the family under study, some members had difficulty interpreting number sequences correctly. Interpreting number sequences, distinguishing between spatially confusable letters and numbers (e.g. b/d, p/q, 6/9/e), and tracking objects in a spatial array are all tasks that may be challenging to individuals with current or past CAS if a central deficit in sequential processing is indeed the underlying endophenotype.
The present study provides motivation to investigate the role of the cerebellum in CAS. The cerebellum is known to coordinate not only motor processes but also diverse cognitive and linguistic functions such as visual-spatial processing (Neau, Arroyo-Anllo, Bonnaud, Ingrand, & Gil, 2000), working memory (Desmond, Gabrieli, Wagner, Ginier, & Glover, 1997), verbal memory (Grasby et al., 1993), processing words (Petersen & Fiez, 1993) and cognitive sequencing of logically and temporally related sentences and images (Leggio et al., 2008). Cerebellar dysfunction could explain sequencing deficits across multiple modalities in CAS, although brain imaging is beyond the scope of the present study. Targeted functional and structural imaging studies can shed light on a potential association between cerebellar deficits and a wide range of manifestations of sequencing deficits in individuals with CAS.
The importance of sequential processing in reading and spelling provides motivation to investigate the sequential processing deficit hypothesis in participant samples with dyslexia. It is possible that, at least in a subset of individuals with dyslexia, deficits in sequential processing underlie errors in reading and spelling.
Acknowledgments
The authors thank the families whose participation made this study possible. Many thanks to the following undergraduate and graduate students for their assistance with the data collection and analyses: Alice Cho, Erica Gonzales, Mariya Legesse, Jonathan Mahaffie, Kyle Middleton, Elaine Nguyen, David Ramm, Kate Sailor and Nancy Yuan. Many thanks to Elias Peter for technical assistance.
Footnotes
Declaration of Interest: The authors gratefully acknowledge the following funding sources: American Speech–Language–Hearing Foundation New Century Scholars Research Grant (B. Peter), NIDCD T32DC00033 (B. Peter), NIDCD 1R03DC010886 (B. Peter), and R01HD054562 (W. H. Raskind). The authors report no conflict of interest.
References
- Boersma P. Praat, a system for doing phonetics by computer. Glot International. 2001;5(9/10):341–345. [Google Scholar]
- Button LA, Peter B, Stoel-Gammon C, Raskind WH. Associations among measures of sequential processing in motor and linguistics tasks in adults with and without a history of childhood apraxia of speech. doi: 10.3109/02699206.2012.744097. submitted. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Catts HW. Speech production/phonological deficits in reading-disordered children. [Research Support, Non-U.S. Gov’t] Journal of Learning Disabilities. 1986;19(8):504–508. doi: 10.1177/002221948601900813. [DOI] [PubMed] [Google Scholar]
- Cohen J. A power primer. Psychological Bulletin. 1992;112(1):155–159. doi: 10.1037//0033-2909.112.1.155. [DOI] [PubMed] [Google Scholar]
- Desmond JE, Gabrieli JD, Wagner AD, Ginier BL, Glover GH. Lobular patterns of cerebellar activation in verbal working-memory and finger-tapping tasks as revealed by functional MRI. [Research Support, Non-U.S. Gov’t-Research Support, U.S. Gov’t, P.H.S.] Journal of Neuroscience. 1997;17(24):9675–9685. doi: 10.1523/JNEUROSCI.17-24-09675.1997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dollaghan C, Campbell TF. Nonword repetition and child language impairment. [Research Support, U.S. Gov’t, P.H.S.] Journal of Speech Language and Hearing Research. 1998;41(5):1136–1146. doi: 10.1044/jslhr.4105.1136. [DOI] [PubMed] [Google Scholar]
- Elsas LJ, 2nd, Langley S, Paulk EM, Hjelm LN, Dembure PP. A molecular approach to galactosemia. [Research Support, U.S. Gov’t, P.H.S.] European Journal of Pediatrics. 1995;154(7 Suppl 2):S21–S27. doi: 10.1007/BF02143798. [DOI] [PubMed] [Google Scholar]
- Fisher SE, Vargha-Khadem F, Watkins KE, Monaco AP, Pembrey ME. Localisation of a gene implicated in a severe speech and language disorder. Nature Genetics. 1998;18(2):168–170. doi: 10.1038/ng0298-168. [DOI] [PubMed] [Google Scholar]
- Fletcher SG. Time-by-count measurement of diadochokinetic syllable rate. Journal of Speech and Hearing Research. 1972;15(4):763–770. doi: 10.1044/jshr.1504.763. [DOI] [PubMed] [Google Scholar]
- Goldman RFM. Goldman-Fristoe Test of Articulation 2. Circle Pines: American Guidance Service; 2000. [Google Scholar]
- Grasby PM, Frith CD, Friston KJ, Bench C, Frackowiak RS, Dolan RJ. Functional mapping of brain areas implicated in auditory-verbal memory function. Brain. 1993;116(Pt 1):1–20. doi: 10.1093/brain/116.1.1. [DOI] [PubMed] [Google Scholar]
- Gray RM, Livingston RB, Marshall RM, Haak RA. Reference group data for the Reitan-Indiana Neuropsychological Test Battery for Young Children. Perceptual and Motor Skills. 2000;91(2):675–682. doi: 10.2466/pms.2000.91.2.675. [DOI] [PubMed] [Google Scholar]
- Gualtieri CT, Johnson LG. Reliability and validity of a computerized neurocognitive test battery, CNS Vital Signs. Archives of Clinical Neuropsychology. 2006;21(7):623–643. doi: 10.1016/j.acn.2006.05.007. S0887-6177(06)00083-7[pii] doi:10.1016/j. acn.2006.05.007. [DOI] [PubMed] [Google Scholar]
- Khan L, Lewis N. Khan-Lewis Phonological Analysis, Second Edition. Circle Pines: American Guidance Service; 2002. [Google Scholar]
- Klapp ST. Motor response programming during simple and choice-reaction time – The role of practice. Journal of Experimental Psychology-Human Perception and Performance. 1995;21(5):1015–1027. [Google Scholar]
- Klapp ST. Reaction time analysis of two types of motor preparation for speech articulation: action as a sequence of chunks [Research Support, Non-U.S. Gov’t] Journal of Motor Behavior. 2003;35(2):135–150. doi: 10.1080/00222890309602129. [DOI] [PubMed] [Google Scholar]
- Konig IR, Schumacher J, Hoffmann P, Kleensang A, Ludwig KU, Grimm T, Schulte-Korne G. Mapping for dyslexia and related cognitive trait loci provides strong evidence for further risk genes on chromosome 6p21. American Journal of Medical Genetics. Part B, Neuropsychiatric Genetics. 2011;156B(1):36–43. doi: 10.1002/ajmg.b.31135. [DOI] [PubMed] [Google Scholar]
- Laffin JJ, Raca G, Jackson CA, Strand EA, Jakielski KJ, Shriberg LD. Novel candidate genes and regions for childhood apraxia of speech identified by array comparative genomic hybridization. Genetics in Medicine. 2012 doi: 10.1038/gim.2012.72. [Epubs ahead of print] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lai CS, Fisher SE, Hurst JA, Vargha-Khadem F, Monaco AP. A forkhead-domain gene is mutated in a severe speech and language disorder. Nature. 2001;413(6855):519–523. doi: 10.1038/350970735097076. [pii] [DOI] [PubMed] [Google Scholar]
- Leggio MG, Tedesco AM, Chiricozzi FR, Clausi S, Orsini A, Molinari M. Cognitive sequencing impairment in patients with focal or atrophic cerebellar damage [Research Support, Non-U.S. Gov’t] Brain. 2008;131(Pt 5):1332–1343. doi: 10.1093/brain/awn040. [DOI] [PubMed] [Google Scholar]
- Lewis BA, Freebairn LA, Hansen A, Gerry Taylor H, Iyengar S, Shriberg LD. Family pedigrees of children with suspected childhood apraxia of speech. Journal of Communication Disorders. 2004;37(2):157–175. doi: 10.1016/j.jcomdis.2003.08.003S0021992403000765. [pii] [DOI] [PubMed] [Google Scholar]
- Maas E, Robin DA, Wright DL, Ballard KJ. Motor programming in apraxia of speech. Brain and Language. 2008;106(2):107–118. doi: 10.1016/J.Bandl.2008.03.004. [DOI] [PubMed] [Google Scholar]
- MacDermot KD, Bonora E, Sykes N, Coupe AM, Lai CS, Vernes SC, Fisher SE. Identification of FOXP2 truncation as a novel cause of developmental speech and language deficits. American Journal of Human Genetics. 2005;76(6):1074–1080. doi: 10.1086/430841]. S0002-9297(07)62902-4 [pii. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marquardt TP, Jacks A, Davis BL. Token-to-token variability in developmental apraxia of speech: three longitudinal case studies [Case Reports] Clinical Linguistics and Phonetics. 2004;18(2):127–144. doi: 10.1080/02699200310001615050. [DOI] [PubMed] [Google Scholar]
- McNeil MR. Clinical management of sensorimotor speech disorders. New York: Thieme; 1997. [Google Scholar]
- McNeil MR. Clinical management of sensorimotor speech disorders. 2. New York: Thieme; 2009. [Google Scholar]
- Neau JP, Arroyo-Anllo E, Bonnaud V, Ingrand P, Gil R. Neuropsychological disturbances in cerebellar infarcts. Acta Neurologica Scandinavica. 2000;102(6):363–370. doi: 10.1034/j.1600-0404.2000.102006363.x. [DOI] [PubMed] [Google Scholar]
- Newbury DF, Mari F, Akha ES, Macdermot KD, Canitano R, Monaco AP, Knight SJ. Dual copy number variants involving 16p11 and 6q22 in a case of childhood apraxia of speech and pervasive developmental disorder. European Journal of Human Genetics. 2012 doi: 10.1038/ejhg.2012.166. Epubs ahead of print. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Newmeyer AJ, Aylward C, Akers R, Ishikawa K, Grether S, deGrauw T, White J. Results of the Sensory Profile in children with suspected childhood apraxia of speech [Comparative Study Research Support, Non-U.S. Gov’t] Physical & Occupational Therapy in Pediatrics. 2009;29(2):203–218. doi: 10.1080/01942630902805202. [DOI] [PubMed] [Google Scholar]
- Oldfield RC. The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia. 1971;9(1):97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- Peter B, Matsushita M, Raskind WH. Motor sequencing deficit as an endophenotype of speech sound disorder: A genome-wide linkage analysis in a multigenerational family. Psychiatric Genetics. 2012;22(5):226–234. doi: 10.1097/YPG.0b013e328353ae92. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peter B, Raskind WH. A multigenerational family study of oral and hand motor sequencing ability provides evidence for a familial speech sound disorder subtype. Top Lang Disord. 2011;31(2):145–167. doi: 10.1097/TLD.0b013e318217b855. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petersen SE, Fiez JA. The processing of single words studied with positron emission tomography [Research Support, Non-U.S. Gov’Research Support, U.S. Gov’t, Non-P.H.S.Research Support, U.S. Gov’t, P.H.S.Review] Annual Review of Neuroscience. 1993;16:509–530. doi: 10.1146/annurev.ne.16.030193.002453. [DOI] [PubMed] [Google Scholar]
- Raca G, Baas BS, Kirmani S, Laffin JJ, Jackson CA, Strand EA, Shriberg LD. Childhood apraxia of speech (CAS) in two patients with 16p11.2 microdeletion syndrome. European Journal of Human Genetics. 2012 doi: 10.1038/ejhg.2012.165. Epubs ahead of print. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reynolds CR, Kamphaus RW. RIAS, Reynolds Intellectual Assessment Scales. Lutz, FL: Psychological Assessment Resources; 2003. [Google Scholar]
- Robbins J, Klee T. Clinical assessment of oropharyngeal motor development in young children. Journal of Speech and Hearing Disorders. 1987;52(3):271–277. doi: 10.1044/jshd.5203.271. [DOI] [PubMed] [Google Scholar]
- Shriberg LD, Lohmeier HL, Campbell TF, Dollaghan CA, Green JR, Moore CA. A nonword repetition task for speakers with misarticulations: the Syllable Repetition Task (SRT) [Research Support, N.I.H., Extramural Validation Studies] Journal of Speech Language and Hearing Research. 2009;52(5):1189–1212. doi: 10.1044/1092-4388(2009/08-0047). doi:10.1044/1092-4388 (2009/08-0047) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shriberg LD, Lohmeier HL, Strand EA, Jakielski KJ. Encoding, memory, and transcoding deficits in Childhood Apraxia of Speech [Research Support, N.I.H., Extramural] Clinical Linguistics and Phonetics. 2012;26(5):445–482. doi: 10.3109/02699206.2012.655841. Epubs ahead of print. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shriberg LD, Potter NL, Strand EA. Prevalence and phenotype of childhood apraxia of speech in youth with galactosemia. Journal of Speech Language and Hearing Research. 2010 doi: 10.1044/1092-4388(2010/10-0068). 1092-4388_2010_10-0068 [pii] [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shriberg LD, Potter NL, Strand EA. Prevalence and phenotype of childhood apraxia of speech in youth with galactosemia [Research Support, N.I.H., Extramural] Journal of Speech Language and Hearing Research. 2011;54(2):487–519. doi: 10.1044/1092-4388(2010/10-0068). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wagner RK, Torgesen JK, Rashotte CA. CTOPP, Comprehensive Test of Phonological Processing. Austin, TX: PRO-ED; 1999. [Google Scholar]
- Wechsler D. Wechsler Individual Achievement Test. 2. New York: Psychological Corporation; 2002. [Google Scholar]
- Wolf M. Rapid alternating stimulus naming in the developmental dyslexias [Research Support, Non-U.S. Gov’t Review] Brain and Language. 1986;27(2):360–379. doi: 10.1016/0093-934x(86)90025-8. [DOI] [PubMed] [Google Scholar]
- Wolf M, Denckla M. Rapid automatized naming and rapid alternating stimulus tests. Austin: Pro-Ed; 2005. [Google Scholar]
- Woodcock RW. Woodcock Reading Mastery Tests – Revised. Minneapolis: Pearson; 1998. [Google Scholar]
- Wright DL, Robin DA, Rhee J, Vaculin A, Jacks A, Guenther FH, Fox PT. Using the self-select paradigm to delineate the nature of speech motor programming [Research Support, N.I.H., Extramural] Journal of Speech Language and Hearing Research. 2009;52(3):755–765. doi: 10.1044/1092-4388(2009/07-0256). [DOI] [PMC free article] [PubMed] [Google Scholar]