

Abstract
Two-way selection is a common phenomenon in nature and society. It appears in the processes like choosing a mate between men and women, making contracts between job hunters and recruiters, and trading between buyers and sellers. In this paper, we propose a model of two-way selection system, and present its analytical solution for the expectation of successful matching total and the regular pattern that the matching rate trends toward an inverse proportion to either the ratio between the two sides or the ratio of the state total to the smaller group's people number. The proposed model is verified by empirical data of the matchmaking fairs. Results indicate that the model well predicts this typical real-world two-way selection behavior to the bounded error extent, thus it is helpful for understanding the dynamics mechanism of the real-world two-way selection system.
Introduction
Human-initiated systems always run in a complex way. In the past ten years, related work mainly focused on the temporal and spatial distribution characteristics of human activity patterns. Because of the complexity of human behavior, many underlying mechanisms have not been discovered yet. The two-way selection scenario among humans is one of the complicated but common phenomena in daily life. It happens in the processes like choosing a mate between men and women, making contracts between job hunters and recruiters, and trading between buyers and sellers. In a sense, two-way selections can be regarded as the base of building many social relationships. Generally, the participants in a two-way selection process are first classified into two groups by their natural status. Then they observe, study the factors of the people on the other side, and finally make their choices. For instance, in the case of marriages, one's appearance, personality, wealth, and sense of humor, are prevalently taken into consideration. Besides the individual characters, impersonal factors also exert an influence, e.g. the member totals on each side and their ratio. How many characters will be inspected and chosen deeply affects the result of a selection process. However, usually it is difficult to compare and to distinguish these characteristics quantitatively even qualitatively through traditional methods, such as psychological tests and social surveys.
The well-known marriage game in statistical physics has been researched in these papers [1]–[6], whose main novel concept is the stability of marriages. This view point aims to find a stable matching between the two sets of men and women. Such a model results in the destiny that every one in the sets gets married and the final marriage relationships are “stable”. However, the internal mechanism of a two-way selection system can be modeled in another way: not all of the participants have to get married in one trial of the processes, i.e. some of them would be successful in matching but the others not. This mechanism would render assistance to some social problems, such as the prediction of the total of friendships or other gregarious relations [7]–[15]. In this paper, we present a model for two-way selections to investigate the factors influencing the matching rate. The data of matchmaking fairs are analyzed to support our model. Based on this model, the method of estimating the number of factors impacting people's decisions is also proposed.
The Model and Analytical Results
Our model of the two-way selection is stated as follows:
The system has two sets of agents, A and B, respectively amounting to
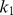 and
and 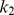 .
.The ith agent in set A (or set B) has its own character denoted by
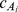 (or
(or 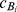 ). Correspondingly, the character the ith agent attempts to select is denoted by
). Correspondingly, the character the ith agent attempts to select is denoted by 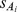 (or
(or 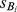 ).
).The agents' characters are denoted by integers without loss of generality. Assume the characters has n types, i.e.
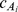 ,
, 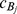 ,
, 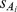 ,
, 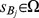 ,
, 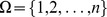 ,
, 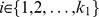 ,
, 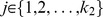 . In one trial of the model,
. In one trial of the model,  ,
,  ,
,  ,
, 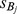 pick an element in S following the uniform distribution.
pick an element in S following the uniform distribution.The condition of successful matching of two agents
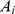 and
and 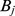 is
is 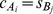 and
and 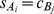 . That is, when agent
. That is, when agent 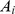 's character meets agent
's character meets agent 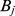 's requirement and vice versa, agent
's requirement and vice versa, agent 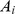 and agent
and agent 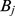 have a successful matching.
have a successful matching.
For given 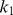 ,
, 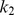 and n, the expectation E of the total number of matching pairs in the model is
and n, the expectation E of the total number of matching pairs in the model is
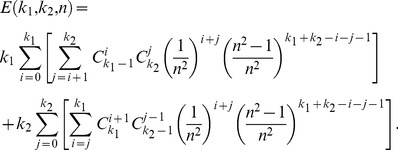 |
(1) |
According to
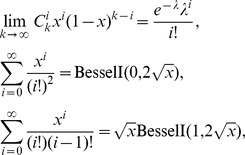 |
where 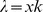 ,
, 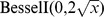 and
and 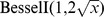 are the modified Bessel functions of the first kind, the expectation in (1) can approximate to
are the modified Bessel functions of the first kind, the expectation in (1) can approximate to
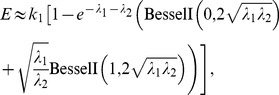 |
(2) |
where 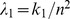 ,
, 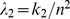 .
.
Due to the symmetry of 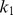 and
and 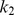 in (1), without loss of generality, we just study the
in (1), without loss of generality, we just study the 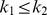 case under three conditions:
case under three conditions: 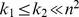 ,
, 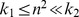 , and
, and 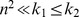 . When
. When 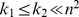 , resulting in
, resulting in  , calculating the zeroth power term and the first power term of (2) obtains
, calculating the zeroth power term and the first power term of (2) obtains
| (3) |
When 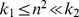 or
or 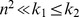 , according to
, according to
| (4) |
Equation (2) can be simplified as
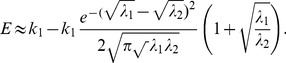 |
(5) |
Because in this case 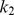 is very large, Equation (5) can be further simplified as
is very large, Equation (5) can be further simplified as
| (6) |
Define
| (7) |
where η denotes the ratio of 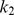 to
to 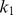 ;
;  denotes the ratio of
denotes the ratio of 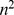 to
to 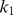 ; P denotes the estimated ratio of successful matching pairs to the average number of two type agents. Then Equation (2) can be transformed into
; P denotes the estimated ratio of successful matching pairs to the average number of two type agents. Then Equation (2) can be transformed into
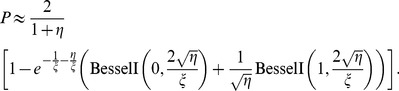 |
(8) |
Equation (3) can be written as:
| (9) |
Equation (6) can be written as:
| (10) |
Figure 1 shows the comparison between the analytical predictions of (1) and the simulation results. Figure 2(a) shows the comparison between the analytical predictions of (9) and the simulation results under the condition 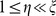 and displays a power-law relation with the exponent −1 between P and
and displays a power-law relation with the exponent −1 between P and  . Figure 2(b) shows the comparison between the analytical predictions of (10) and the simulation results under the condition
. Figure 2(b) shows the comparison between the analytical predictions of (10) and the simulation results under the condition 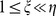 and displays a power-law relation with the exponent −1 between P and η; Figure 2(d) shows the comparison between the analytical predictions of (10) and the simulation results under the condition
and displays a power-law relation with the exponent −1 between P and η; Figure 2(d) shows the comparison between the analytical predictions of (10) and the simulation results under the condition 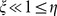 and displays the same power-law relation to the result in Figure 2(b). The above analytical predictions and simulation results are consistent with each other. That is to say all analytical results are reliable.
and displays the same power-law relation to the result in Figure 2(b). The above analytical predictions and simulation results are consistent with each other. That is to say all analytical results are reliable.
Figure 1. The comparison between the analytical predictions and the simulation results.
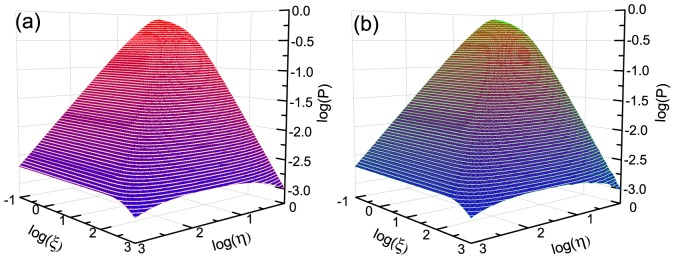
In the two sub-figures, the parameter 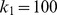 ; η is assigned to values from 1 to 1000;
; η is assigned to values from 1 to 1000;  is assigned to values from 0.1 to 1000. (a) shows analytical predictions of (1); (b) shows the simulation results.
is assigned to values from 0.1 to 1000. (a) shows analytical predictions of (1); (b) shows the simulation results.
Figure 2. The comparison between analytical predictions and the simulation results in the log-log plots.

In the four sub-figures, the parameter 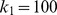 ; the squares are the simulation data; the solid lines are analytical predictions. In (a),
; the squares are the simulation data; the solid lines are analytical predictions. In (a), 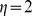 ;
;  is assigned to values from 100 to 1000; the solid line is obtained from (9). In (b),
is assigned to values from 100 to 1000; the solid line is obtained from (9). In (b), 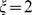 ;
; 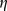 is assigned to values from 10 to 1000; the solid line is obtained from (10). In (c),
is assigned to values from 10 to 1000; the solid line is obtained from (10). In (c), 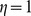 ;
;  is assigned to values from 10 to 100; the solid line is obtained from (11). In (d),
is assigned to values from 10 to 100; the solid line is obtained from (11). In (d), 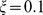 ; η is assigned to values from 10 to 1000; the solid line is obtained from (10).
; η is assigned to values from 10 to 1000; the solid line is obtained from (10).
Consider a special case 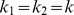 , resulting in
, resulting in 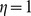 . On the one hand, Equation (9) can be simplified as
. On the one hand, Equation (9) can be simplified as
| (11) |
The relation between P and  approximates a power law with the exponent −1, and this case is shown in Figure 2(c). Equation (10) can be simplified as
approximates a power law with the exponent −1, and this case is shown in Figure 2(c). Equation (10) can be simplified as 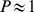 , suggesting that almost all of the agents can match successfully under the condition
, suggesting that almost all of the agents can match successfully under the condition 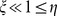 . On the other hand, because the condition
. On the other hand, because the condition 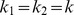 results in
results in 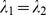 , from (5) we can obtain
, from (5) we can obtain
| (12) |
The second term of (12) is the number of the agents that can not successfully match in type A or type B. The larger k is, the smaller 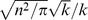 is. In reality, this is a result of fluctuation. The total combinations of the “own” state and the “expecting” state for an agent have
is. In reality, this is a result of fluctuation. The total combinations of the “own” state and the “expecting” state for an agent have 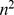 possibilities in the model. In theory, the expected times of each state appearance is
possibilities in the model. In theory, the expected times of each state appearance is 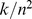 . However, due to the fluctuations, almost all frequencies of every state appearance deviate around
. However, due to the fluctuations, almost all frequencies of every state appearance deviate around 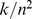 . As a result, some agents can not successfully match. The number of times that each state may appear obeys the binomial distribution. The fluctuation is closely related to the standard deviation, according to the binomial theorem and standard deviation formula, we can obtain that the standard deviation equals
. As a result, some agents can not successfully match. The number of times that each state may appear obeys the binomial distribution. The fluctuation is closely related to the standard deviation, according to the binomial theorem and standard deviation formula, we can obtain that the standard deviation equals 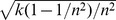 , which is directly proportional to
, which is directly proportional to 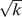 . Thus, the number of the agents that can not successfully match is also proportional to
. Thus, the number of the agents that can not successfully match is also proportional to 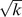 . It explains the relationship between the second item of (12) and
. It explains the relationship between the second item of (12) and 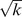 . From (12), we know that the proportionality coefficient is
. From (12), we know that the proportionality coefficient is 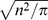 .
.
The Verification Between the Model and Experimental Data
As the mate choosing between men and women is a typical real-world two-way selection system, eighty-two reported records of matchmaking fairs are analyzed to verify our model. Due to the uncertainty of approximation in these reports, we classify the data into three categories with specified possible ranges according to their descriptions: i) “nearly x” (possible range 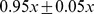 ); ii) “about x” (possible range
); ii) “about x” (possible range 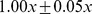 ); iii) “over x” (possible range
); iii) “over x” (possible range 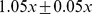 ). The full list of the data records is shown in Table 1. All data of matchmaking fairs are collected from the websites shown in Table 2.
). The full list of the data records is shown in Table 1. All data of matchmaking fairs are collected from the websites shown in Table 2.
Table 1. The data of matchmaking fairs.
| Website no. | Original descriptions | Total participants K | Matched pairs E | Matching ratio P | |
| joined | matched | ||||
| 01 | 13 | 3 | 13 | 3 |
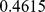
|
| 02 | 18 | 6 | 18 | 6 |
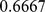
|
| 03 | 20 | 1 | 20 | 1 |
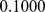
|
| 04 | 21 | 6 | 21 | 6 |
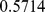
|
| 05 | 25 | 5 | 25 | 5 |
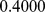
|
| 06 | 26 | 3 | 26 | 3 |
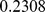
|
| 07 | 26 | 4 | 26 | 4 |
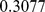
|
| 08 | 30 | 2 | 30 | 2 |
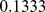
|
| 09 | 32 | 4 | 32 | 4 |
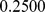
|
| 10 | 36 | 6 | 36 | 6 |
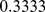
|
| 11 | 36 | 6 | 36 | 6 |
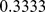
|
| 12 | 38 | 6 | 38 | 6 |
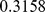
|
| 13 | 40 | 8 | 40 | 8 |
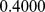
|
| 14 | >40 | 3 |
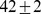
|
3 |
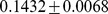
|
| 15 | >50 | 3 |
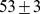
|
3 |
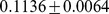
|
| 16 | ≈60 | 5 |
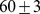
|
5 |
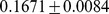
|
| 17 | >60 | 4 |
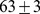
|
4 |
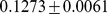
|
| 18 | >60 | 5 |
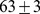
|
5 |
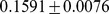
|
| 19 | >60 | ≈10 |
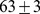
|
10±1 |
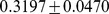
|
| 20 | 72 | 11 | 72 | 11 |
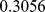
|
| 21 | 80 | 5 | 80 | 5 |
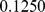
|
| 22 | 80 | 10 | 80 | 10 |
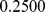
|
| 23 | 80 | 13 | 80 | 13 |
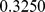
|
| 24 | 80 | 18 | 80 | 18 |
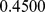
|
| 25 | ∼100 | 5 | 95±5 | 5 |
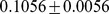
|
| 26 | 99 | 8 | 99 | 8 |
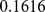
|
| 27 | 100 | 5 | 100 | 5 |
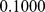
|
| 28 | ≈100 | 7 | 100±5 | 7 |
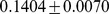
|
| 29 | >100 | 16 | 110±10 | 16 |
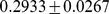
|
| 30 | 150 | 7 | 150 | 7 |
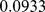
|
| 31 | ∼200 | 8 |
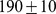
|
8 |
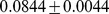
|
| 32 | ∼200 | 22 |
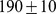
|
22 |
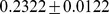
|
| 33 | ≈200 | 4 |
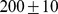
|
4 |
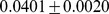
|
| 34 | 206 | 10 | 206 | 10 |
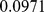
|
| 35 | >200 | 7 |
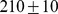
|
7 |
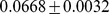
|
| 36 | >200 | 8 |
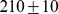
|
8 |
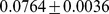
|
| 37 | >200 | 38 |
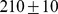
|
38 |
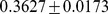
|
| 38 | 216 | 19 |
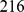
|
19 |
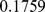
|
| 39 | >240 | 22 |
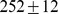
|
22 |
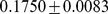
|
| 40 | ≈258 | >10 |
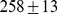
|
11±1 |
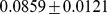
|
| 41 | ∼300 | 4 |
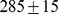
|
4 |
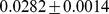
|
| 42 | ≈300 | 8 |
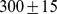
|
8 |
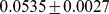
|
| 43 | >300 | >10 |
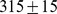
|
11±1 |
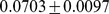
|
| 44 | >300 | 32 |
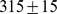
|
32 |
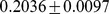
|
| 45 | 400 | ∼20 |
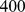
|
19±1 |
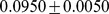
|
| 46 | >500 | 3 |
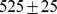
|
3 |
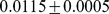
|
| 47 | >500 | 8 |
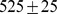
|
8 |
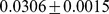
|
| 48 | >500 | >10 |
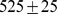
|
11±1 |
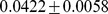
|
| 49 | ∼600 | ∼40 |
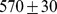
|
38±2 |
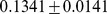
|
| 50 | >600 | >78 |
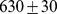
|
78 |
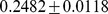
|
| 51 | ∼800 | 58 |
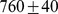
|
58 |
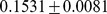
|
| 52 | >800 | >20 |
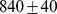
|
21±1 |
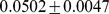
|
| 53 | ∼1000 | ≈20 |
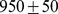
|
20±1 |
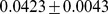
|
| 54 | ∼1000 | 58 |
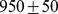
|
58 |
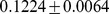
|
| 55 | ∼1000 | 64 |
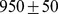
|
64 |
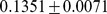
|
| 56 | ≈1000 | 12 |
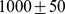
|
12 |
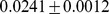
|
| 57 | ≈1000 | 15 |
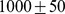
|
15 |
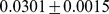
|
| 58 | ≈1000 | ∼100 |
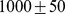
|
95±5 |
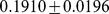
|
| 59 | >1000 | 3 |
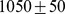
|
3 |
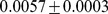
|
| 60 | >1000 | 4 |
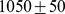
|
4 |
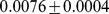
|
| 61 | >1500 | 48 |
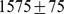
|
48 |
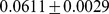
|
| 62 | >1500 | >100 |
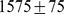
|
105±5 |
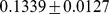
|
| 63 | >1600 | 31 |
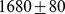
|
31 |
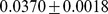
|
| 64 | >2000 | ∼100 |
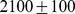
|
95±5 |
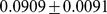
|
| 65 | >2000 | >113 |
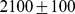
|
119±6 |
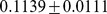
|
| 66 | ∼3000 | ∼100 |
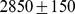
|
95±5 |
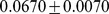
|
| 67 | ≈3000 | 186 |
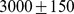
|
186 |
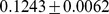
|
| 68 | >3000 | >200 |
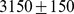
|
210±10 |
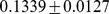
|
| 69 | >4000 | >500 |
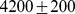
|
525±25 |
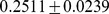
|
| 70 | ∼5000 | 108 |
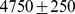
|
108 |
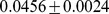
|
| 71 | >5000 | 218 |
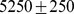
|
218 |
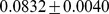
|
| 72 | >5000 | 231 |
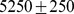
|
231 |
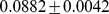
|
| 73 | >5000 | 237 |
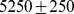
|
237 |
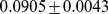
|
| 74 | >6000 | >270 |
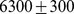
|
284±14 |
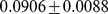
|
| 75 | ∼10000 | 28 |
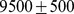
|
28 |
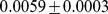
|
| 76 | ∼10000 | ≈100 |
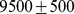
|
100±5 |
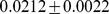
|
| 77 | ∼10000 | ∼2000 |
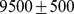
|
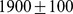
|
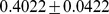
|
| 78 | >10000 | ≈400 |
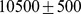
|
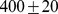
|
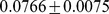
|
| 79 | >10000 | >1000 |
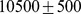
|
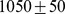
|
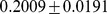
|
| 80 | ≈16000 | >700 |
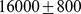
|
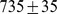
|
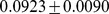
|
| 81 | >16000 | >600 |
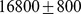
|
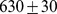
|
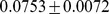
|
| 82 | >50000 | >3000 |
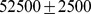
|
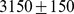
|
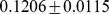
|
Note: ≈ denotes “about”, ∼ denotes “nearly”, and > denotes “above”.
Table 2. Data sources of matchmaking fairs.
In our model, n is an internal parameter needed to be measured. Because a news report (descried as an experiment below) generally includes only the total of participants and the number of successful matching pairs, the male–female or female–male ratio η defined in (7) should be estimated first. Under the assumption 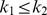 , the lower bound of η is
, the lower bound of η is 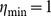 , and once the total of participants
, and once the total of participants 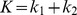 and the number of matching couples E is determined, the upper bound of η in that experiment is known:
and the number of matching couples E is determined, the upper bound of η in that experiment is known: 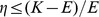 . Let N be the number of experiments,
. Let N be the number of experiments, 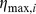 be the upper bound of η in the ith experiment, and
be the upper bound of η in the ith experiment, and 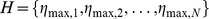 be the set of all upper bounds. By processing
be the set of all upper bounds. By processing 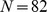 experiments in Table 1, we obtain
experiments in Table 1, we obtain 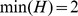 and
and 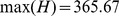 . Consider the least square criterion for fitting the model and the experimental data
. Consider the least square criterion for fitting the model and the experimental data
| (13) |
where 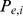 denotes the experimental data in the ith experiment and
denotes the experimental data in the ith experiment and 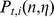 denotes the corresponding theoretical value calculated by (8), and the reality that in a matchmaking fair the numbers of males and females would not differ over some extent. We narrow the range of η to [1], [2] and solve this optimization problem
denotes the corresponding theoretical value calculated by (8), and the reality that in a matchmaking fair the numbers of males and females would not differ over some extent. We narrow the range of η to [1], [2] and solve this optimization problem
| (14) |
Finally we obtain the estimation 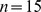 .
.
Figure 3 shows the relationship between the experimental data and the analytical predictions of our model. The red curve and olive curve are obtained from (8). The parameters of red curve are 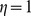 ,
, 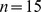 ; the parameters of olive curve are
; the parameters of olive curve are 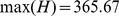 ,
, 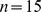 . According to (7), when
. According to (7), when 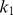 is equal to the minimum 1,
is equal to the minimum 1,  takes the maximum value 225. The error bars of ordinate P of round dots represent the ranges of empirical data P in Table 1. Because
takes the maximum value 225. The error bars of ordinate P of round dots represent the ranges of empirical data P in Table 1. Because 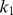 is unknown and
is unknown and  is undetermined, the bound for
is undetermined, the bound for 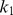 in the ith experiment is
in the ith experiment is 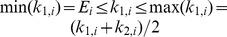 , and the bound for corresponding
, and the bound for corresponding 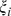 is
is 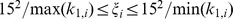 . Therefore, the ranges of abscissa
. Therefore, the ranges of abscissa 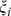 of round dots are relatively wide and the middle points lie in
of round dots are relatively wide and the middle points lie in 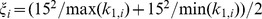 .
.
Figure 3. The relationship between the experimental data and analytical predictions in the log-log plots.

The red curve and the olive curve are obtained from (8), and the parameters of red curve are 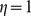 ,
, 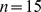 ; The parameters of olive curve are
; The parameters of olive curve are 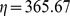 ,
, 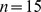 . The round dots represent the empirical data in Table 1. The
. The round dots represent the empirical data in Table 1. The 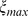 represents the maximum value 225 of
represents the maximum value 225 of  .
.
Figure 3 also shows when  is relatively small and corresponding
is relatively small and corresponding 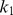 is big, all empirical data are enclosed between two curves; when
is big, all empirical data are enclosed between two curves; when  is relatively big and corresponding
is relatively big and corresponding 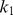 is small, some empirical data are enclosed between the two curves, but other empirical data lie above the red curve and the trend of the empirical data is opposite to the analytical predictions. The possible reasons are: on the one hand, organizers of some matchmaking fairs select only a few participants meeting their requirements from a large number of applicants, so a participant is easier to find the right man or woman; on the other hand, when the number of participants is small in a matchmaking fair, they understand the difficulty of finding an ideal object so compromise to a goodish choice. The two reasons above cause that the fewer the participants are, the higher the matching probability P is. Based on these effects, the deviation of experimental data from the model is acceptable.
is small, some empirical data are enclosed between the two curves, but other empirical data lie above the red curve and the trend of the empirical data is opposite to the analytical predictions. The possible reasons are: on the one hand, organizers of some matchmaking fairs select only a few participants meeting their requirements from a large number of applicants, so a participant is easier to find the right man or woman; on the other hand, when the number of participants is small in a matchmaking fair, they understand the difficulty of finding an ideal object so compromise to a goodish choice. The two reasons above cause that the fewer the participants are, the higher the matching probability P is. Based on these effects, the deviation of experimental data from the model is acceptable.
Conclusion
We propose a model of the two-way selection system and provide its analytical solution. Under several conditions, the compact approximations are derived analytically and verified by the simulation results. In the model, the parameter n that denotes the number of characters directly determines the probability of the successful match – due to its importance, we propose a rough method to estimate its value by fitting the empirical data collected via the Internet and the result is 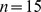 . Under some artificial assumptions, most of the experimental data fall into the range predicted by our model, so this model is helpful for understanding the dynamics mechanism of the real-world two-way selection systems, and provides a starting point for researching the nature of real-world two-way selection systems. We believe our model could enlighten readers in this rapidly developing field.
. Under some artificial assumptions, most of the experimental data fall into the range predicted by our model, so this model is helpful for understanding the dynamics mechanism of the real-world two-way selection systems, and provides a starting point for researching the nature of real-world two-way selection systems. We believe our model could enlighten readers in this rapidly developing field.
Funding Statement
This work was funded by the National Important Research Project (Grant No. 91024026), the National Natural Science Foundation of China (No. 11205040, 11105024, 11275186), the Major Important Project Fund for Anhui University Nature Science Research (Grant No. KJ2011ZD07) and the Specialized Research Fund for the Doctoral Program of Higher Education of China (Grant No. 20093402110032). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Oméro MJ, Dzierzawa M, Marsili M, Zhang YC (1997) Scaling behavior in the stable marriage problem. Journal de Physique I 7: 1723–1732. [Google Scholar]
- 2. Zanette DH, Manrubia SC (2001) Vertical transmission of culture and the distribution of family names. Physica A: Statistical Mechanics and its Applications 295: 1–8. [Google Scholar]
- 3. Zhang YC (2001) Happier world with more information. Physica A: Statistical Mechanics and its Applications 299: 104–120. [Google Scholar]
- 4. Caldarelli G, Capocci A (2001) Beauty and distance in the stable marriage problem. Physica A: Statistical Mechanics and its Applications 300: 325–331. [Google Scholar]
- 5. Laureti P, Zhang YC (2003) Matching games with partial information. Physica A: Statistical Mechanics and its Applications 324: 49–65. [Google Scholar]
- 6.Chakraborti A, Challet D, Chatterjee A, Marsili M, Zhang YC, et al.. (2013) Statistical mechanics of competitive resource allocation. arXiv preprint arXiv:13052121.
- 7. Lü L, Zhou T (2011) Link prediction in complex networks: A survey. Physica A: Statistical Mechanics and its Applications 390: 1150–1170. [Google Scholar]
- 8. Guimerà R, Sales-Pardo M (2009) Missing and spurious interactions and the reconstruction of complex networks. Proceedings of the National Academy of Sciences 106: 22073–22078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Lü L, Medo M, Yeung CH, Zhang YC, Zhang ZK, et al. (2012) Recommender systems. Physics Reports 519: 1–49. [Google Scholar]
- 10. Zhang CJ, Zeng A (2012) Behavior patterns of online users and the effect on information filtering. Physica A: Statistical Mechanics and its Applications 391: 1822–1830. [Google Scholar]
- 11. Guillaume JL, Latapy M (2004) Bipartite structure of all complex networks. Information processing letters 90: 215–221. [Google Scholar]
- 12. Shang MS, Lü L, Zhang YC, Zhou T (2010) Empirical analysis of web-based user-object bipartite networks. EPL (Europhysics Letters) 90: 48006. [Google Scholar]
- 13. Guimerà R, Sales-Pardo M, Amaral LAN (2007) Module identification in bipartite and directed networks. Physical Review E 76: 036102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Zhou YB, Lü L, Li M (2012) Quantifying the influence of scientists and their publications: distinguishing between prestige and popularity. New Journal of Physics 14: 033033. [Google Scholar]
- 15.Li L, Yang Z, Liu L, Kitsuregawa M (2008) Query-url bipartite based approach to personalized query recommendation. In: AAAI. volume 8, pp. 1189–1194.