

Abstract
The abnormal event detection problem is an important subject in real-time video surveillance. In this paper, we propose a novel online one-class classification algorithm, online least squares one-class support vector machine (online LS-OC-SVM), combined with its sparsified version (sparse online LS-OC-SVM). LS-OC-SVM extracts a hyperplane as an optimal description of training objects in a regularized least squares sense. The online LS-OC-SVM learns a training set with a limited number of samples to provide a basic normal model, then updates the model through remaining data. In the sparse online scheme, the model complexity is controlled by the coherence criterion. The online LS-OC-SVM is adopted to handle the abnormal event detection problem. Each frame of the video is characterized by the covariance matrix descriptor encoding the moving information, then is classified into a normal or an abnormal frame. Experiments are conducted, on a two-dimensional synthetic distribution dataset and a benchmark video surveillance dataset, to demonstrate the promising results of the proposed online LS-OC-SVM method.
Keywords: abnormal detection, optical flow, covariance matrix descriptor, online least squares one-class SVM
1. Introduction
Visual surveillance is one of the major research areas in computer vision. After recording events by a visual sensor, such as a camera, obtaining detailed information of individual or crowd behavior is a challenging object in this area; automatic abnormal event detection is required to provide convenience, safety and an efficient lifestyle for humanity [1]. An abnormal event is defined as behavior deviating from what one expects. For example, a pedestrian panic in a public region: the people are running in the plaza, where people are usually strolling. As shown in Figure 1a, a normal scene is illustrated, the people are walking. In Figure 1b, the people are suddenly running in different directions; this scene is considered abnormal. If a system can detect this event, which might imply a safety risk, security staff can be alerted to take emergency response procedures. The abnormal event detection is a content-based video analysis problem; it includes two technologies: a feature representation of an event model and an abnormal event detection approach.
Figure 1.

Examples of the normal and abnormal scenes. (a) A normal lawn scene: all the people are walking; (b) An abnormal lawn scene: all the people are running.
In [2–4], abnormal detection approaches with behavioral models were introduced. The behavior pattern modeled by adopting optical flow or pixel change history (PCH) was represented by Bayesian models. In [5], the motion feature, including the position, direction and velocity, was modeled by latent Dirichlet allocation. In [6], the abnormal vehicle behavior at intersections was detected via a stochastic graph model based on the Markovian approach. The behavior was labeled as abnormal when the current motion pattern cannot be recognized as any state of the system or a particular sequence of states cannot be parsed with the stochastic model. These works relied on an explicit signal statistical model, and the abnormal events were the ones interpreted as statistical model abrupt changes, maximum likelihood or Bayesian estimation theory [7]. The signal model together with probabilistic assumption techniques are usually extremely powerful insofar as an accurate model ex0ists; these methods are effective in several scenarios. However, there are various situations where a robust and tractable model cannot be obtained. This raises the need for model-free methods.
On the other hand, low-level motion features were employed. In [8], the authors presented an algorithm monitoring optical flow in a set of fixed spatial positions. The similarity of the model was computed to detect abnormal patches. In [9], the irregular behavior of images and videos was detected by comparing the likelihood of patches via a probabilistic graphical model. These methods based on separated patches, benefiting from the partial knowledge of the image, do not exploit the global information of the frame.
Trajectory information is also adopted to detect abnormal events. In [10,11], the authors presented a method for anomalous event detection by means of trajectory analysis. The trajectories were subsampled to a fixed-dimension vector representation and clustered with an one-class support vector machine (SVM). In [12], alarm detection of traffic was performed on the basis of the parameters of the moving objects and their trajectories by using semantic reasoning and ontologies. In [13], vision-based abnormal events for home healthcare systems were detected by using shape feature variation and 3D trajectory. Tracking-based algorithms are likely to fail in crowded scenes.
We consider the model-free approach, which does not require an explicit statistical model. To be accurate, the support vector machine (SVM) classification method is relied on in this paper. Inspired by the satisfactory performance of a covariance feature descriptor representing object in a tracking problem, a covariance descriptor characterizes the moving information of a global frame. In a tracking problem, the covariance descriptor is constructed of the blob intensity or color for template matching. In this paper, covariance encodes the optical flow of the global frame.
The rest of the paper is organized as follows. In Section 2, related works are briefly reviewed. In Section 3, the online least squares one-class support vector machine (online LS-OC-SVM) classification method is originally derived. In Section 4, a covariance matrix descriptor is described to provide feature vectors for the classification algorithm. In Section 5, we propose abnormal detection methods based on the online LS-OC-SVM. In Section 6, we present the results on synthetic data and real-world video scenes. Finally, Section 7 concludes the paper.
2. Related Work
SVM is usually trained in a batch model, i.e., all training data are given a priori and are learned together. If additional training data arrive afterward, the SVM must be retrained from scratch [14]. In the problem of abnormal event detection in video surveillance, the normal sequence for training may last for a long time. It is impractical to train the big training set of normal samples as one batch together. If a new datum is added to a large training set, it will likely have only a minimal effect on the previous decision surface. Resolving the problem from scratch seems computationally wasteful. Considering these two aspects, the online strategy is considered in our work to adapt to the computational and the memory requirement.
Some online learning algorithms for SVM were derived based on analyzing the change of Karush-Kuhn-Tucker (KKT) conditions while updating the classifier. In [15], new arrival data along with the data violating the KKT conditions, and the support vectors from the last iteration, were considered as a new training dataset to train the classifier at the current step. The iteration will be stopped when all data satisfy the KKT conditions. In [16,17], the authors analyzed the change of the KKT conditions when one datum was included into, or removed from, the training set; then, a so-called bookkeeping step was used to compute the new coefficients of the classifier to achieve an online update for a two-class SVM. Useful implementation issues on incremental SVM were presented in [18].
In [7], it was argued that the binary classification algorithm in [16] cannot be directly implemented for a one-class problem. In [7,19], the authors considered the change of the normal model over time and online identified outliers using previous data vectors in a sliding time window. Two one-class SVM classifiers, which preceded and followed the present instant, were compared. A change in the statistics of the time series was likely to occur when the resulting machines were different. The sliding time window approach was considered in [20], with an application on wireless sensor networks. This method, adopting sliding window formulation, is not inherently online, since it requires repeated batch training of new machines.
In [21], an online one-class SVM was presented following the idea of [22]: an exponential window was applied to the data to suit it to an adaptive scenario where the solution was able to track the changes of the data distribution and to forget old patterns. This algorithm is based on the slow-varying assumption.
Some online one-class SVM classification methods were proposed based on support vector data description (SVDD) [23,24], the hypersphere one-class SVM formulation. In [25], an online one-class classification method was proposed, a least squares optimization problem was considered and the model complexity was controlled by the coherence criterion. In [26], a method was proposed to reduce space and time complexities. It reduced the training set size during the training procedure by removing data having a high probability of becoming non-support-vectors.
In order to sidestep the difficulty in the nature of the constrained quadratic optimization problem, we derive an online version of the hyperplane one-class SVM [27] based on the least squares regularization. In the least squares SVM version, one finds the solution by solving a linear system instead of a quadratic programming problem. This advantage comes from the use of equality instead of inequality constraints in the problem formulation [28]. Least squares one-class SVM (LS-OC-SVM) was proposed in [29], without considering the sparsity of the hyperplane representation. It is thus inappropriate to detect abnormal events online. In the following, we shall derive an online version of the least squares one-class SVM, then propose a sparsification representation of the detector.
3. Classification
In this section, we introduce the derivation of the proposed online least square one-class support vector machine (online LS-OC-SVM). In abnormal detection problems, it is supposed that the samples from a positive class are obtainable. A density will only exist if the underlying probability measure possesses an absolutely continuous distribution function, but the general problem of estimating the measure for a large class of sets is not solvable [27,30]. The one-class SVM framework is then suitable to the specificity of the abnormal event detection where only normal scene data are available. Support vector machine (SVM) was initially proposed by Vapnik and Lerner [31], attempting to find a compromise between the minimization of empirical risk and the prevention of overfitting. By applying a kernel trick, SVM can handle nonlinear classification problems [10,32–34]. Based on the theoretical foundation of SVM and the soft-margin trick [35,36], one-class SVM is proposed to address the problem where only one-category (the positive) samples with a few outliers are available. In this section, after a brief review of one-class SVM and least squares one-class SVM on a batch model, an online training algorithm is proposed. A sparsified version of the algorithm will then be provided for further adapting to critical online requirements.
3.1. One-Class SVM
One-class SVM (OC-SVM) aims to determine a suitable region in the input data space, χ, which includes most of the samples drawn from an unknown probability distribution, P. It detects objects that resemble training samples. The hypersphere one-class SVM was proposed in [23,24]. It identified outliers by fitting a hypersphere with a minimal radius. The hyperplane one-class SVM was an extended version of the original SVM to one-class problems [27,36]. It identified outliers by fitting a hyperplane from the origin. In our work, we adopt the hyperplane one-class SVM, which is formulated as a constrained minimization optimization problem:
| (1) |
where xi ∈ χ, i ∈ {1…n}, are n training samples in the input data space, χ, and ξi is the slack variable for penalizing the outliers. The hyperparameter, C, is the weight for restraining the slack variable. It tunes the number of acceptable outliers and, thus, enables the analyzing of noisy data points. ‖·‖ denotes the Euclidean norm of a vector. The decision hyperplane is given by the equation:
| (2) |
The nonlinear function, Φ : χ
→
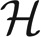 , maps datum xi from the input space, χ, into the feature space, , which allows us to solve a nonlinear classification problem by designing a linear classifier in the feature space. w defines a hyperplane in the feature space separating the projections of training data from the origin. A positive definite kernel function, κ, is defined as κ(x, x′) = <Φ(x), Φ(x′)〉, which implicitly maps the training or testing data, x, into a higher (possibly infinite) dimensional feature space. Introducing the Lagrangian multipliers, αi, the decision function in the input data space, χ, is given by:
, maps datum xi from the input space, χ, into the feature space, , which allows us to solve a nonlinear classification problem by designing a linear classifier in the feature space. w defines a hyperplane in the feature space separating the projections of training data from the origin. A positive definite kernel function, κ, is defined as κ(x, x′) = <Φ(x), Φ(x′)〉, which implicitly maps the training or testing data, x, into a higher (possibly infinite) dimensional feature space. Introducing the Lagrangian multipliers, αi, the decision function in the input data space, χ, is given by:
| (3) |
if f(x) = −1, the datum, x, is classified as abnormal; otherwise, x is classified as normal.
3.2. Least Squares One-Class SVM
Least squares SVM (LS-SVM) was proposed by Suykens in [37,38]. By using the quadratic loss function, Choi proposed least squares one-class SVM (LS-OC-SVM) [29]. LS-OC-SVM extracts a hyperplane as an optimal description of training objects in a regularized least squares sense. It can be written as the following objective function:
| (4) |
The condition for the slack variables in OC-SVM, ξi ≥ 0, is no longer in need. The variable, ξi, represents an error caused by a training object, xi, with respect to the hyperplane. The definitions of the other parameters in Equation (4) are the same as the ones in OC-SVM. The associated Lagrange is:
| (5) |
Setting derivatives of Equation (5) with respective to primal variables, w, ξi, ρ and αi, to zero, we have the following stationarity conditions:
| (6) |
| (7) |
| (8) |
| (9) |
Substituting Equations (6)–(8) into (9) yields:
| (10) |
For all I = 1, 2,…, n, we can rewrite Equation (10) in matrix form as:
| (11) |
where K is the Gram matrix with (i, j)-th entry κ(xi, xj), I is the identity matrix with the same dimension as Gram matrix K and α is the column vector with i-th entry αi for training sample xi. 1 and 0 are all-one and all-zero column vectors, respectively, with compatible lengths. The parameters, α and ρ, could be obtained by:
| (12) |
The hyperplane is then described by:
| (13) |
The distance, dis(x), of a datum, x, with respect to the hyperplane is calculated by:
| (14) |
where xi is a training sample, ‖α‖ is the two-norm of vector α. An object with a low dis(x) value lies close to the hyperplane thus resembles the training set better than other objects with high dix(x) values. The distance, dis(x), is used as a proximity measure to determine the normal and abnormal class of the data [29].
3.3. Online Least Squares One-Class SVM
In an online learning scheme, the training data continuously arrive. We thus need to tune hyperparameters in the objective function and the hypothesis class in an online manner [17]. Let αn, Kn and In denote the coefficient, Gram matrix and identity matrix at the time step, n, respectively. The parameters of LS-OC-SVM [αn – ρn ]T at the time step, n, could be calculated as:
| (15) |
In order to proceed, recall the matrix inverse identity for matrices A, B, C and D with suitable sizes [39]:
| (16) |
The matrix, Kn, with diagonal loading can be calculated recursively with respect to time step n by:
| (17) |
| (18) |
| (19) |
where κn+1 is the column vector with i-th entry κ(xi, xn+1), i ∈ {1, 2, …, n}, and κn+1 = κ(xn+1, xn+1). Based on Equations (15) and (17), we arrive at an online implementation of LS-OC-SVM.
3.4. Sparse Online Least Squares One-Class SVM
The procedures for calculating the parameters, α and ρ, of LS-OC-SVM in Section 3.3 lose sparseness, due to the quadratic loss function in the objective function Equation (4). This formulation is inappropriate for large-scale data and unsuitable for online learning, as the number of training samples grows infinitely [25]. We propose a sparse solution to provide a robust formulation. A dictionary is adopted to address the sparse approximation problem [40].
Instead of Equation (6), where w is expressed with all available data, we intend to approximate it by adopting a dictionary in a sparse way. Consider a dictionary, x ,
⊂ {l, 2, …, n}, of size D with elements xwj, j ∈
. Instead of Equation (6), we approximate w with these D dictionary elements:
,
⊂ {l, 2, …, n}, of size D with elements xwj, j ∈
. Instead of Equation (6), we approximate w with these D dictionary elements:
| (20) |
The hyperplane becomes:
| (21) |
In sparse online LS-OC-SVM, the distance, dis (x), of a datum, x, to the hyperplane is:
| (22) |
Where xwj is a dictionary element and β is the column vector with the entries, βj. Replacing Expression (20) into Lagrange Function (5), we have:
| (23) |
Taking the derivatives of the Function (23) with respect to primal variables, β, ξi, ρ and αi, yields:
| (24) |
| (25) |
| (26) |
| (27) |
The matrix form for Condition (27) is written:
| (28) |
Replacing Conditions (24) and (25) into (28) leads to:
| (29) |
Combining Equations (26) and (29), the equation for computing coefficients [α − ρ]T becomes:
| (30) |
After providing these relations with the dictionary, we now discuss the dictionary construction. The coherence criterion is adopted to characterize a dictionary in sparse approximation problems. It provides an elegant model reduction criterion with a less computationally-demanding procedure [25,40,41]. The coherence of a dictionary is defined as the largest correlation between the elements in the dictionary, i.e.,
| (31) |
In the online case, the coherence between a new datum and the current dictionary is calculated by:
| (32) |
Where xwj is the element in the dictionary, x. Presetting a threshold, μ0, the new arrival sample, xt, at the time step, t, is tested with the coherence criterion to judge whether the dictionary remains unchanged or is incremented by including the new element. For n training samples, the subset, which includes m (1 ≤ m ≪ n) samples, is considered the initial dictionary. Then, each remaining sample is tested with Equation (32) to determine the relation between itself and the previous dictionary. If ϵt ≤ μ0, it will be included into the dictionary. Concretely, the algorithm is performed with two cases described herein below.
-
First case:ϵt > μ0
In this case, at time step n + 1, the new data, xn+1, is not included into the dictionary. The Gram matrix, K, with the entries, κ(xi, xj), i, j ∈ {1, 2, …, D}, is unchanged. When a new sample, x, arrives, we need to compute:
where at time step n + 1, κ is the column vector with entries κ(xn+1,xwj), j ∈ {1, 2, …, D}. K(33) (x) is the matrix with the (i, j)-th entry κ(xi, xwj), i ∈ {1, 2, …, n}, j ∈ {1, 2, …, D}. -
Second case: ϵt ≤ μ0
In this case, the new data, xn+1, is added into the dictionary, x. Then, the Gram matrix should be changed by:
(34)
where K̅ is the Gram matrix of the dictionary, including the new arrival dictionary sample, xn+1, and K is the Gram matrix of the dictionary at the last time step, n. Let x = {xw1, xw2, …, xwD } denote the dictionary at time step n; d is the column vector with entries dj= κ(x,xwj), j ∈ {1, 2, …, D}, and d = κ(xn+1, xn+1). By adopting the matrix inverse identity Equation (16), we have:
| (35) |
where:
| (36) |
| (37) |
| (38) |
Because the dictionary changes, the value of K(x) and also
should be updated. Let the S denote the updated
at time step n + 1; we have:
| (39) |
| (40) |
where at time step n + 1, q is the column vector with entries qi = κ(xi, xD+1), i ∈ {1, 2, …, n}, and xD+1 is the new arrival datum xn+1, which is included into the dictionary. The matrix inverse in Equation (39) can be calculated by using four-times Woodbury identity:
| (41) |
with proper choices of matrices A, U, C and V, such that U and V should be chosen as two vectors, and A should be chosen as a scaler. Thus, the inverse, (C−1 + V A−1U), is a scaler; Equation (39) can be calculated very efficiently. For instance, for computing the inverse, including the term, (K(x)bq⊤), we regard two vectors, (K(x)b) and q⊤, as vector U and V, respectively, while C in Equation (41) is one.
Once knowing S, using Equation (33) to add the new κ with entries κ(xn+1, xwj), j ∈ {1, 2, …,D, D + 1}, xwj is an element of the dictionary.
4. Covariance Descriptor of Frame Behavior
The optical flow is chosen as the basic low-level feature to represent the movement direction and amplitude. We apply the Horn-Schunck (HS) method to compute optical flow in this paper. The optical flow can provide important information about the spatial arrangement of the object and the change rate of this arrangement [42]. The optical flow of a gray image is formulated as the minimization of the following global energy functional:
| (42) |
where I is the intensity of the image, Ix, Iy and It are the derivatives of the image intensity value along the x, y and time t dimension, u and υ are the components of the optical flow in horizontal and vertical direction and γ represents the weight of the regularization term.
The covariance feature descriptor was originally proposed by Tuzel [43] for pattern matching in a target tracking problem. Owing to its good performance, the covariance descriptor encoding the optical flow is introduced to represent the global movement of the frame. A feature is defined as:
| (43) |
where I is the image (which could be gray, red-green-blue (RGB), hue-saturation-value (HSV), hue-lightness-saturation (HLS), etc), ϕi is a mapping relating the image with the i – th feature, F is the W × H × d dimension feature, W is the image width, H is the image height and d is the number of the chosen features. For each frame, the feature, F, can be represented as the d × d covariance matrix:
| (44) |
where n is the number of the pixels sampled in the frame, μ is the mean of n feature vectors of the selected points and zk is the feature vector of the k – th point. C is the covariance matrix of the feature vector, F. The covariance matrix descriptor proposes a way to merge multiple features. Different choices of feature vectors are shown in Table 1, where u and υ are horizontal and vertical components of optical flow, ux and υx are the first derivatives of horizontal and vertical optical flow in the x direction, respectively, uy and υy are the first derivatives of the corresponding feature in the y direction, uxx and υxx are the second derivatives in x direction and uyy and υyy are the second derivatives in y direction. The flowchart of covariance matrix descriptor computation is shown in Figure 2. The optical flow and corresponding partial derivative characterize the inter-frame information or can be regarded as the movement information.
Table 1.
Different choices of feature F to construct the covariance descriptor.
| Feature VectorF | |
|---|---|
| F1(6 × 6) | [y x uυuxuy ] |
| F2(6 × 6) | [yxuυ υxυy ] |
| F3(8 × 8) | [y xuυuxuyυxυy ] |
| F4(12 × 12) | [y xuυuxuyυxυyuxxuyyυxxυyy ] |
Figure 2.

Covariance descriptor computation based on the features of a video frame.
If proper parameters are given, classical kernels, such as Gaussian, polynomial and sigmoidal kernels, have similar performances [44]. In our work, the Gaussian kernel is used. The covariance matrix is an element in the Lie group; the Gaussian kernel in Euclidean spaces is not suitable. The Gaussian kernel in the Lie group is defined as [45,46]:
| (45) |
where Xi and Xj are matrices in Lie group G; the parameter σ determines the scale at which the data is probed.
5. Abnormal Event Detection
In an abnormal event detection problem, it is assumed that a set of training frames, {I1, I2,…, In} (the positive class), describing the normal behavior is obtained. The abnormal detection strategies relative to the online algorithms proposed in Section 3.3 and Section 3.4 are introduced below.
5.1. Online LS-OC-SVM Strategy
The general architecture of the abnormal event detection method via online least squares one-class SVM (online LS-OC-SVM) proposed in Section 3.3 is summarized in Algorithm 1; the flowchart is shown in Figure 3 and explained below.
Figure 3.

Major processing states of the proposed abnormal frame event detection method. The covariance of the frame is computed.
|
| ||||||||||
| Algorithm 1: Visual abnormal event detection via online least squares one-class support vector machine (LS-OC-SVM) and sparse online LS-OC-SVM. | ||||||||||
|
| ||||||||||
| Require | ||||||||||
| n training frames and the corresponding optical flow . | ||||||||||
Compute the covariance matrix of each frame.
| ||||||||||
|
|
-
Step 1: The first step consists of calculating the covariance matrix descriptor of the training frames. The features could be chosen as any form shown in Table 1. This step can be generalized as:
(51) where {OP1,OP2,…, OPn} are the image optical flows of the 1st to n – th frames; {C1,C2,…, Cn} are the covariance matrix descriptors.
- Step 2: The second step is applying LS-OC-SVM on a small subset of the training samples to calculate the coefficient parameters, α and ρ, in Equation (11). Consider a subset , 1 ≤ m ≪ n of data selected from the training set . Without loss of generality, assume that the first m frames are chosen. These m samples are trained offline. This step can be described in the following equation:
where [K ] and [α − ρ ]T are defined in Equation (11).(52) - Step 3: After learning the first m samples, the coefficient matrices, K and [α − ρ ]T, are obtained. The online LS-OC-SVM method (Section 3.3) is applied to learn the remaining n – m samples {Cm+1,Cm+2…Cn}. This step can be expressed as:
(53) - Step 4: Based on the coefficient matrix, [α − ρ ]T, the distance of the training samples and the incoming test sample, Cn+l, with respect to the decision plane is computed. By comparing the distances of the samples, an abnormal event is detected:
(54) (55)
where Cn+l is the covariance matrix descriptor of the (n + l) – th frame needed to be classified, and Ci is the sample of the training data. “1” corresponds to an abnormal frame; “ − 1” corresponds to a normal frame. Tdis is the threshold of the distance, it is the maximum distance of the training samples to the hyperplane.
5.2. Sparse Online LS-OC-SVM Strategy
The abnormal event detection via sparse online least squares one-class SVM (sparse online LS-OC-SVM) is introduced below. A subset of the samples is chosen to form the dictionary, C, making a sparse representation of the training data. The initial dictionary, C, is learned offline. Each remaining training sample is learned one-by-one online. Meanwhile, it is checked to be included, or not, into the dictionary. The test datum is classified based on the dictionary. The feature extraction step (Step 1) and the detection step (Step 4) are the same as the ones presented in Section 5.1. Owing to the dictionary, the training steps are different.
Step 2-sparse: The second step is applying LS-OC-SVM to train the initial dictionary offline. The first m samples are the initial dictionary denoted as C. This step can be generalized as:
| (56) |
Step 3-sparse: After learning the initial dictionary, C, including the first m(1 ≤ m ≪n) samples, the remaining training samples, {Cm+1, Cm+2, …, Cn}, are learned via sparse online LS-OC-SVM described in Section 3.4. This step can be described in the following equations:
| (57) |
where C is the dictionary and Ck is a new incoming remaining sample in the training dataset. According to the coherence criterion introduced in Section 3.4, if the new sample, Ck, satisfies the dictionary updated condition, it will be included into the dictionary, C.
6. Abnormal Event Detection Results
This section presents the results of experiments conducted to illustrate the performance of the two proposed classification algorithms, online least square one-class SVM (online LS-OC-SVM) and sparse online least square one-class SVM (sparse online LS-OC-SVM). The two-dimensional synthetic distribution dataset and the University of Minnesota (UMN) [47] dataset are used.
6.1. Synthetic Dataset via Online LS-OC-SVM and Sparse Online LS-OC-SVM
Two synthetic data, “square” and “ring-line-square” [48], are used. The “square” consists of four lines, 2.2 in length and 0.2 in width. In the area of these lines, 400 points were randomly dispersed with a uniform distribution. The “ring-line-square” distribution is composed of three parts: a ring with an inner diameter of 1.0 and an outer diameter of 2.0, a line of 1.6 in length and 0.2 in width, and a square the same as dataset “square” introduced above. 850 points are randomly dispersed with a uniform distribution. These two data are shown in Figure 4.
Figure 4.

Synthetic dataset. (a) Square; (b) ring-line-square.
The first sample is used for initializing the online LS-OC-SVM proposed in Section 3.3; the 399 remaining samples in “square” and 849 remaining samples in “ring-ling-square” are learned in the online manner.
Via the sparse online LS-OC-SVM method proposed in Section 3.4, the first sample is trained offline, and this sample is considered the initial dictionary. Then, each arrival sample in 399 remaining samples in “square” and 849 remaining samples in “ring-ling-square” are checked by the coherence criterion to determine whether the dictionary should be retained or updated by including the new element.
The distances are shown in contours illustrating the boundary. The contours of “square” and “ring-line-square” are shown in Figures 5 and 6, respectively. Gaussian kernel was used in these two data, with bandwidth σ = 0.065. The preset threshold of the coherence criterion is μ0 = 0.08. The detection results obtained by these two online training algorithms are the same as the ones when training data were learned in a batch model.
Figure 5.

Offline, online LS-OC-SVM and sparse online LS-OC-SVM results of “square”. The figures might be viewed better electronically, in color and enlarged, (a) The contours when all the training data are learned as one batch offline; (b) The contours when the training data are learned via online LS-OC-SVM; (c) The blue circle (pointed out by the arrow) shows the original dictionary. The red points show the 232 new data included into the dictionary via sparse online LS-OC-SVM; (d) The contours when the training data are learned via sparse online LS-OC-SVM.
Figure 6.

Offline, online LS-OC-SVM and sparse online LS-OC-SVM results of “ring-line-square”, (a) The contours when all the training date are learned as one batch offline; (b) The contours when the training data are learned via online LS-OC-SVM; (c) The blue circle (pointed out by the arrow) shows the original dictionary. The red points show the 534 new data included into the dictionary via sparse online LS-OC-SVM; (d) The contours when the training data are learned via sparse online LS-OC-SVM.
6.2. Abnormal Visual Event Detection via Online LS-OC-SVM
UMN dataset detection results via online LS-OC-SVM proposed in Section 3.3 are shown below. The UMN dataset consists of eleven sequences of crowded panic escape events, which are recorded in a lawn, an indoor and a plaza scene. A frame where the people are walking in different directions is considered as a normal sample for training or for normal testing. A scene where the people are running is taken as an abnormal sample for testing. The detection results of the lawn scene, the indoor scene and the plaza scene are shown in Figures 7, Figure 8 and Figure 9, respectively. A Gaussian kernel for the covariance matrix in the Lie group is used. Various values of the variance, σ, in the Gaussian function and the penalty factor, C, are chosen to form the receiver operating characteristic (ROC) curve. In the indoor scene, time lags of the frame labels lead to the lower area under the ROC curve (AUC) value. In the last few frames, labeled as abnormal of abnormal sequences, there are no people, while, in the training samples, there are no people in the upper half of the image. The covariance of the training frame is similar to the covariance of the abnormal frame without people. Our covariance feature descriptor-based classification method cannot distinguish between these two situations. However, this issue can be resolved by utilizing the foreground information. For example, if there are no moving objects in the frame, this frame is immediately classified as abnormal. The results of these three scenes show that the covariance descriptor can distinguish between normal and abnormal events. The performance of online LS-OC-SVM is almost the same as that of the offline method.
Figure 7.

Detection results of the lawn scene, (a) The detection result of a normal frame; (b) The detection result of an abnormal panic frame; (c) Receiver operating characteristic (ROC) curve of covariance descriptors constructed from different features F of the lawn scene detection results via LS-OC-SVM. All the training samples are learned together offline. The biggest AUC value is 0.9874; (d) ROC curve of detection results via online LS-OC-SVM. The biggest AUC value is 0.9874.
Figure 8.

Detection results of the indoor scene. (a) The detection result of a normal frame; (b) The detection result of an abnormal panic frame; (c) ROC curve of covariance descriptors constructed from different features F of the indoor scene results via LS-OC-SVM. All the training samples are learned together offline. The biggest AUC value is 0.8900; (d) ROC curve of detection results via online LS-OC-SVM. The biggest AUC value is 0.8904.
Figure 9.

Detection results of the plaza scene. (a) The detection result of a normal frame; (b) The detection result of an abnormal panic frame; (c) ROC curve of covariance descriptors constructed from different features F of the plaza scene results via LS-OC-SVM. All the training samples are learned together offline. The biggest AUC value is 0.9800; (d) ROC curve of detection results via online LS-OC-SVM. The biggest AUC value is 0.9839.
6.3. Abnormal Visual Event Detection via Sparse Online LS-OC-SVM
UMN dataset abnormal event detection results via sparse online LS-OC-SVM proposed in Section 3.4 are presented. Taking the lawn scene as an example, the first normal covariance matrix descriptor from the training samples is included into the dictionary firstly; then, the remaining training covariance descriptors are learned online by the sparse online LS-OC-SVM method. The ROC curve of the detection results of the lawn scene, the indoor scene and the plaza scene are shown in Figure l0a–c, respectively.
Figure 10.

ROC curve of University of Minnesota (UMN) dataset. (a) Sparse online LS-OC-SVM results in the lawn scene. The biggest AUC value is 0.9510; (b) Sparse online LS-OC-SVM results in the indoor scene. The biggest AUC value is 0.8886; (c) Sparse online LS-OC-SVM results in the plaza scene. The biggest AUC value is 0.9515; (d) The ROC curve of the best performance of the lawn, plaza and indoor scene when the training samples are learned via LS-OC-SVM offline. The biggest AUC values of the lawn, indoor and plaza scene are 0.9874, 0.8900 and 0.9800.
The resulting performances when all training samples are learned offline via one-class SVM (OC-SVM), learned via least squares one-class SVM (LS-OC-SVM), learned via online least squares one-class SVM (online LS-OC-SVM) and learned via sparse online least squares one-class SVM (sparse LS-OC-SVM), are shown in Table 2. The LS-OC-SVM algorithm obtains better performance than the original OC-SVM. The performances of online and sparse online strategy results are similar to the resulting performances when all training samples are learned offline. The sparse online strategy can be computed efficiently and can adapt to the memory requirement.
Table 2.
AUC of the abnormal event detection method based on covariance descriptors constructed by different features F via OC-SVM (Section 3.1), original LS-OC-SVM learning training samples together offline (Section 3.2), online LS-OC-SVM (Section 3.3) and sparse online LS -OC-SVM (Section 3.4). The biggest value of each method is shown in bold.
| Features | Area under ROC | ||
| lawn | indoor | plaza | |
| offline OC-SVM | |||
| F1(6 × 6) | 0.9474 | 0.8381 | 0.9148 |
| F2(6 × 6) | 0.9583 | 0.8410 | 0.9192 |
| F3(8 × 8) | 0.9656 | 0.8483 | 0.9367 |
| F4(12 × 12) | 0.9798 | 0.8744 | 0.9782 |
| offline LS-OC-SVM | |||
| F1(6 × 6) | 0.9755 | 0.8605 | 0.9422 |
| F2(6 × 6) | 0.9738 | 0.8603 | 0.9489 |
| F3(8 × 8) | 0.9788 | 0.8662 | 0.9538 |
| F4(12 × 12) | 0.9874 | 0.8900 | 0.9800 |
| Online LS-OC-SVM | |||
| F1(6 × 6) | 0.9755 | 0.8616 | 0.9403 |
| F2(6 × 6) | 0.9720 | 0.8730 | 0.9517 |
| F3(8 × 8) | 0.9795 | 0.8670 | 0.9563 |
| F4(12 × 12) | 0.9874 | 0.8904 | 0.9839 |
| Sparse Online LS-OC-SV | M | ||
| F1(6 × 6) | 0.8840 | 0.8077 | 0.9245 |
| F2(6 × 6) | 0.9435 | 0.8886 | 0.9515 |
| F3(8 × 8) | 0.9269 | 0.8266 | 0.9428 |
| F4(12 × 12) | 0.9510 | 0.8223 | 0.9501 |
The resulting performances of the covariance matrix descriptor-based online least squares one-class SVM method, and of state-of-the-art methods, are shown in Table 3. The covariance matrix-based online abnormal frame detection method obtains competitive performance. In generally, our sparse online LS-OC-SVM method is better than others, except sparse reconstruction cost (SRC) [49]. In that paper, multi-scale histogram of optical flow (HOF) was taken as a feature and a testing sample was classified by its sparse reconstruction cost, through a weighted linear reconstruction of the over-complete normal basis set. However, the computation of the HOF takes more time than the computation of covariance. By adopting the integral image [43], the covariance matrix descriptor of the subimage can be computed conveniently. The covariance descriptor can appropriately be used to analyze partial image movement. In [49], the whole training dataset was saved in the memory in advance; then, the dictionary was chosen as an optimal subset for reconstructing. Our sparse online LS-OC-SVM strategy enables one to train the classifier with sequential inputs. This property makes our proposed method extremely suitable to handle large volumes of training data, while the method in [49] fails to work due to lack of memory.
Table 3.
The comparison of our proposed method with state-of-the-art methods for abnormal event detection in the UMN dataset. NN, nearest neighbor. SRC, sparse reconstruction cost. STCOG, spatial-temporal co-occurrence Gaussian mixture models.
7. Conclusions
In this paper, we proposed a method to detect abnormal events via online least squares one-class SVM (online LS-OC-SVM) and sparse online least squares one-class SVM (sparse online LS-OC-SVM). Online LS-OC-SVM learns training samples sequentially; sparse online LS-OC-SVM incorporates the coherence criterion to form the dictionary for a sparse representation of the detector. The covariance matrix descriptor encodes the movement feature of the frame to distinguish between normal and abnormal events. The proposed detection algorithms have been tested on a synthetic dataset and a real-world video dataset yielding successful results in detecting abnormal events.
Acknowledgments
This work is partially supported by the China Scholarship Council of Chinese Government and the SURECAP CPER project (fonction de surveillance dans les réseaux de capteurs sans fil via contrat de plan Etat-Région) and the Platform CAPSEC (capteurs pour la sécurité) funded by Région Champagne-Ardenne and FEDER (fonds européen de développement régional).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- 1.Suriani N.S., Hussain A., Zulkifley M.A. Sudden event recognition: A survey. Sensors. 2013;13:9966–9998. doi: 10.3390/s130809966. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Kosmopoulos D., Chatzis S.P. Robust visual behavior recognition. IEEE Signal Process. Mag. 2010;27:34–45. [Google Scholar]
- 3.Utasi Á., Czúni L. Detection of unusual optical flow patterns by multilevel hidden Markov models. Opt. Eng. 2010 doi: 10.1117/1.3280284. [DOI] [Google Scholar]
- 4.Xiang T., Gong S. Incremental and adaptive abnormal behaviour detection. Comput. Vis. Image Underst. 2008;111:59–73. [Google Scholar]
- 5.Kwak S., Byun H. Detection of dominant flow and abnormal events in surveillance video. Opt. Eng. 2011 doi: 10.1117/1.3542038. [DOI] [Google Scholar]
- 6.Jiménez-Hernández H., González-Barbosa J.J., Garcia-Ramírez T. Detecting abnormal vehicular dynamics at intersections based on an unsupervised learning approach and a stochastic model. Sensors. 2010;10:7576–7601. doi: 10.3390/s100807576. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Davy M., Desobry F., Gretton A., Doncarli C. An online support vector machine for abnormal events detection. Signal Process. 2006;86:2009–2025. [Google Scholar]
- 8.Adam A., Rivlin E., Shimshoni I., Reinitz D. Robust real-time unusual event detection using multiple fixed-location monitors. IEEE Trans. Pattern Anal. Mach. Intell. 2008;30:555–560. doi: 10.1109/TPAMI.2007.70825. [DOI] [PubMed] [Google Scholar]
- 9.Boiman O., Irani M. Detecting irregularities in images and in video. Int. J. Comput. Vis. 2007;74:17–31. [Google Scholar]
- 10.Piciarelli C., Micheloni C., Foresti G.L. Trajectory-based anomalous event detection. IEEE Trans. Circuits Syst. Video Technol. 2008;18:1544–1554. [Google Scholar]
- 11.Piciarelli C., Foresti G.L. On-line trajectory clustering for anomalous events detection. Pattern Recognit. Lett. 2006;27:1835–1842. [Google Scholar]
- 12.Calavia L., Baladrón C., Aguiar J.M., Carro B., Sánchez-Esguevillas A. A semantic autonomous video surveillance system for dense camera networks in smart cities. Sensors. 2012;12:10407–10429. doi: 10.3390/s120810407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Lee Y.S., Chung W.Y. Visual sensor based abnormal event detection with moving shadow removal in home healthcare applications. Sensors. 2012;12:573–584. doi: 10.3390/s120100573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Shilton A., Palaniswami M., Ralph D., Tsoi A.C. Incremental training of support vector machines. IEEE Trans. Neural Netw. 2005;16:114–131. doi: 10.1109/TNN.2004.836201. [DOI] [PubMed] [Google Scholar]
- 15.Lau K., Wu Q. Online training of support vector classifier. Pattern Recognit. 2003;36:1913–1920. [Google Scholar]
- 16.Cauwenberghs G., Poggio T. Incremental and decremental support vector machine learning. Adv. Neural Inf. Process. Syst. 2000;1:409–415. [Google Scholar]
- 17.Diehl C., Cauwenberghs G. SVM Incremental Learning, Adaptation and Optimization. Proceedings of International Joint Conference on Neural Networks (IJCNN); Portland, OR, USA. 20–24 July 2003; pp. 2685–2690. [Google Scholar]
- 18.Laskov P., Gehl C., Krüger S., Müller K.R. Incremental support vector learning: Analysis, implementation and applications. J. Mach. Learn. Res. 2006:7, 1909–1936. [Google Scholar]
- 19.Desobry F., Davy M., Doncarli C. An online kernel change detection algorithm. IEEE Trans. Signal Process. 2005:55, 2961–2974. [Google Scholar]
- 20.Zhang Y., Meratnia N., Havinga P. Adaptive and Online One-Class Support Vector Machine-Based Outlier Detection Techniques for Wireless Sensor Networks. Proceedings of International Conference on Advanced Information Networking and Applications Workshops (WAINA); Bradford, UK. 26–29 May 2009; pp. 990–995. [Google Scholar]
- 21.Gómez-Verdejo V., Arenas-García J., Lazaro-Gredilla M., Navia-Vazquez A. Adaptive one-class support vector machine. IEEE Trans. Signal Process. 2011:59, 2975–2981. [Google Scholar]
- 22.Kivinen J., Smola A.J., Williamson R.C. Online learning with kernels. IEEE Trans. Signal Process. 2004;52:2165–2176. [Google Scholar]
- 23.Tax D. Ph.D. Thesis. Delft University of Technology; Delft, The Netherlands: 2001. One-Class Classification. [Google Scholar]
- 24.Tax D.M., Duin R.P. Support vector data description. Mach. Learn. 2004;54:45–66. [Google Scholar]
- 25.Noumir Z., Honeine P., Richard C. Online One-Class Machines Based on the Coherence Criterion. Proceedings of the 20th European Signal Processing Conference (EUSIPCO); Bucharest, Romania. 27–31 August 2012; pp. 664–668. [Google Scholar]
- 26.Kim P.J., Chang H.J., Choi J.Y. Fast Incremental Learning for One-Class Support Vector Classifier Using Sample Margin Information. Proceedings of the 19th International Conference on Pattern Recognition (ICPR); Tampa, FL, USA. 8–11 December 2008; pp. 1–4. [Google Scholar]
- 27.Schölkopf B., Platt J.C., Shawe-Taylor J., Smola A.J., Williamson R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001;13:1443–1471. doi: 10.1162/089976601750264965. [DOI] [PubMed] [Google Scholar]
- 28.Suykens J., Lukas L., van Dooren P., de Moor B., Vandewalle J. Least Squares Support Vector Machine Classifiers: A Large Scale Algorithm. Proceedings of European Conference on Circuit Theory and Design (ECCTD); Stresa, Italy. 29 August-2 September 1999; pp. 839–842. [Google Scholar]
- 29.Choi Y.S. Least squares one-class support vector machine. Pattern Recognit. Lett. 2009;30:1236–1240. [Google Scholar]
- 30.Vapnik V.N. Statistical Learning Theory. Wiley; New York, NY, USA: 1998. [Google Scholar]
- 31.Vapnik V.N., Lerner A. Pattern recognition using generalized portrait method. Autom. Remote Control. 1963;24:774–780. [Google Scholar]
- 32.Boser B.E., Guyon I.M., Vapnik V.N. A Training Algorithm for Optimal Margin Classifiers. Proceedings of ACM the 5th Annual Workshop on Computational Learning Theory (COLT); Pittsburgh, PA, USA. 27–29 July 1992; pp. 144–152. [Google Scholar]
- 33.Cristianini N., Shawe-Taylor J. An Introduction to Support Vector Machines and other Kernel-Based Learning Methods. Cambridge University Press; Chambridge, UK: 2000. [Google Scholar]
- 34.Canu S., Grandvalet Y., Guigue V., Rakotomamonjy A. Perception Systemes et Information. INSA de Rouen; Rouen, France: 2008. SVM and Kernel Methods Matlab Toolbox, updated on 20 February 2008; A SVM Toolbox fully written in Matlab, even the QP solver. [Google Scholar]
- 35.Scholkopf B., Smola A.J., Williamson R.C., Bartlett P.L. New support vector algorithms. Neural Comput. 2000;12:1207–1245. doi: 10.1162/089976600300015565. [DOI] [PubMed] [Google Scholar]
- 36.Ben-Hur A., Horn D., Siegelmann H.T., Vapnik V. Support vector clustering. J. Mach. Learn. Res. 2002;2:125–137. [Google Scholar]
- 37.Suykens J.A., Vandewalle J. Least squares support vector machine classifiers. Neural Process. Lett. 1999;9:293–300. [Google Scholar]
- 38.Suykens J., Gestel T.V., Brabanter J.D., Moor B.D., Vandewalle J. Least Squares Support Vector Machines. World Scientific; Singapore: 2002. [Google Scholar]
- 39.Honeine P. Online kernel principal component analysis: A reduced-order model. IEEE Trans. Pattern Anal. Mack Intell. 2012;34:1814–1826. doi: 10.1109/TPAMI.2011.270. [DOI] [PubMed] [Google Scholar]
- 40.Tropp J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory. 2004;50:2231–2242. [Google Scholar]
- 41.Richard C., Bermudez J.C.M., Honeine P. Online prediction of time series data with kernels. IEEE Trans. Signal Process. 2009;57:1058–1067. [Google Scholar]
- 42.Horn B.K., Schunck B.G. Determining optical flow. Artif. Intell. 1981;17:185–203. [Google Scholar]
- 43.Tuzel O., Porikli F., Meer P. Region covariance: A fast descriptor for detection and classification. Lect. Notes Comput. Sci. 2006;3952:589–600. [Google Scholar]
- 44.Schölkopf B., Smola A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization and Beyond. MIT Press; Cambridge, MA, USA: 2002. [Google Scholar]
- 45.Hall B. Lie Groups, Lie Algebras, and Representations: An Elementary Introduction. Springer; Berlin, Germany: 2003. [Google Scholar]
- 46.Cong G., Fanzhang L., Cheng S. Research on Lie Group kernel learning algorithm. J. Front. Comput. Sci. Technol. 2012;6:1026–1038. [Google Scholar]
- 47.Detection of Events—Detection of Unusual Crowd Activity. [(accessed on 12 Dcember 2013)]. Available online: http://mha.cs.umn.edu/Movies/Crowd-Activity-All.avi.
- 48.Hoffmann H. Kernel PCA for novelty detection. Pattern Recognit. 2007;40:863–874. [Google Scholar]
- 49.Cong Y., Yuan J., Liu J. Sparse Reconstruction Cost for Abnormal Event Detection. Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR); Providence, RI, USA. 20–25 June 2011; pp. 3449–3456. [Google Scholar]
- 50.Mehran R., Oyama A., Shah M. Abnormal Crowd Behavior Detection Using Social Force Model. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Miami, FL, USA. 20–25 June 2009; pp. 935–942. [Google Scholar]
- 51.Shi Y., Gao Y., Wang R. Real-Time Abnormal Event Detection in Complicated Scenes. Proceedings of the 20th International Conference on Pattern Recognition (ICPR); Istanbul, Turkey. 23–26 August 2010; pp. 3653–3656. [Google Scholar]