

Abstract
The impact of cryptic relatedness (CR) on genomic association studies is well studied and known to inflate false-positive rates as reported by several groups. In contrast, conventional epidemiological studies for environmental risks, the confounding effect of CR is still uninvestigated. In this study, we investigated the confounding effect of unadjusted CR among a rural cohort in the relationship between environmental risk factors (body mass index, smoking status, alcohol consumption) and systolic blood pressure. We applied the methods of population-based whole-genome association studies for the analysis of the genome-wide single nucleotide polymorphism data in 1622 subjects, and detected 20.2% CR in this cohort population. In the case of the sample size, approximately 1000, the ratio of CR to the population was 20.2%, the population prevalence 25%, the prevalence in the CR 26%, heritability for liability 14.3% and prevalence in the subpopulation without CR 26%, the difference of estimated regression coefficient between samples with and without CR was not significant (P-value = 0.55). On the other hand, in another case with approximately >20% heritability for liability, we showed that confounding due to CR biased the estimation of exposure effects.
Keywords: confounding effect, cryptic relatedness, systolic blood pressure
Introduction
Cryptic relatedness (CR) is well known as a confounding factor in genome wide association study (GWAS) (Yu et al. 2006; Kang et al. 2008; Price et al. 2010), which inflates the false-positive rate. Voight and Pritchard (2005) developed a formal model of CR and studied its impact on genomic case–control association studies. They showed that the degree of confounding due to CR would usually be negligible. However, in contrast, they also reported on studies with sampling biases toward collecting relatives may indeed suffer from excessive rates of false positives. Typically, epidemiological designs in which individuals are ascertained nonrandomly from a closed population, the effect of the influence of close relatives might not be negligible. It is therefore important to correct or account for the confounding effect of CR in epidemiological cohort studies that have collected data from a limited or small-sized sample. However, the knowledge of the confounding effect of CR in epidemiological association studies is still unknown. Here, we examined the confounding effect of CR in the relationship between systolic blood pressure (SBP) and several environmental risk factors (body mass index [BMI], smoking status [daily smoker vs. nonsmoking], and alcohol consumption [drinking vs. abstention]).
It is also well known that being overweight and obese increases the risk of high blood pressure (Kannel 1967; World Health Organization 2000). However, interpreting the blood pressure–BMI relationship is further complicated by data from other studies, in which there appears to be no correlation between these variables (Roche and Siervogel 1991; Spiegelman et al. 1992; Bunker et al. 1995; Gallagher et al. 1996). In this article, we examined whether the confounding effect of CR might involve in the relationship between blood pressure and BMI. Additional goals of the study were to assess the confounding effect of CR in any potential relationship between blood pressure and the risk of other environmental factors; for example, smoking and alcohol consumption. There are several studies that examined the relationship between alcohol consumption or smoking and blood pressure in a Japanese population (Kiyohara et al. 1995; Minami et al. 2002; Ohmori et al. 2002). Ohira et al. (2009) looked into the effect of habitual alcohol intake on ambulatory blood pressure among Japanese men, which was associated with increased BP in the morning. Minami et al.(1999) studied the effects of smoking cessation on blood pressure in habitual smokers. However, there were no studies which examined the confounding effect of CR in the relationship between blood pressure and the risk of environmental factors. We aim to address the question of whether CR is likely to be a serious issue for inferring epidemiological relationship between these factors using the cohort study of Takahata residents. First, using the techniques to detect and correct for unrecognized population structure in GWAS, we examined how CR was presented in the sampling. Next, we tested the assumption of parallel regressions to examine whether its confounding effect as a covariate affected on environmental risk factors in difference setting (sample size, ratio of CR to the population, prevalence in CR, the population prevalence). Then, we applied multiple regression analysis to these data with and without CR in order to examine the differences obtained in estimating the regression coefficient.
Methods
Analysis of real data
We used the genome-wide 657,366 single nucleotide polymorphism (SNP) data and SBP as a phenotype in the cohort study of Takahata. We selected BMI, variables for smoking status (1: nonsmoking vs. 2: daily smoker), and alcohol consumption (1: abstention vs. 2: drinking) as environmental risk factors, and gender (1: male; 2: female) and age as covariates. Weight, height, and SBP were measured and standardized in the Takahata cohort design. We examined the relationship between individuals genetic background by the PLINK (Purcell et al. 2007) and the EIGENSTRAT methods (Price et al. 2006). We detected relationships between subjects using identity by descent (IBD) probability as a measurement.
Multiple regression analyses
We sampled our cohort population in a difference setting; sample size (approximately 1000, 400, or 500), the ratio of CR to the population (approximately 20%, 40%, or 50%), the prevalence in the subpopulation without CR (26%, 50%, or 76%), the prevalence in CR (26% fixed), the population prevalence (25%, 40%, or 50%), and heritability for liability (approximately 14%, 22%, or 32%) in our cohort population. Here, we estimated heritability for liability using the formula {(xp − xq)/ap}/ρ, where ρ denotes the expected proportion of alleles shared IBD (i.e., ρ = 2−R, where R denotes the degree of relationship), xp denotes the difference between mean value in the subpopulation without CR and threshold, xq denotes the difference between mean value in the subpopulation without CR and mean value in CR, and ap denotes the difference between population mean and mean value in the group of affected individuals (Yasuda 2007). In our context, ρ can be defined as the sum of expected proportion of allele shared IBD for all of the degree of relationship in our detected CR (i.e., R = 0, 1, 2). First, we tested the assumption of parallel regressions to examine whether the confounding effect of CR as a covariate affected on environmental risk factors; that is, the following test was performed,
Null hypothesis: bn1 = bn2, alternative hypothesis: bn1 ≠ bn2,
where k is the number of population (i.e., population with and without CR), and n is the number of independent variables and covariates. Then, we applied multiple regression analysis to these data with and without CR in order to examine the differences obtained in estimating the regression coefficient.
Cohort description
We performed an analysis of the data collected within a closed, small prospective study, concerned with various risk factors for common diseases.
Subject recruitment
The Takahata cohort was established for a baseline survey in a small rural town, Takahata in Yamagata Prefecture from 2006 to 2008. The total population size has been constant, approximately 25,000 throughout this period. The Takahata cohort has become part of our large genomic cohort initiative, the Yamagata cohort, which is now ongoing in the urban prefectural capital, Yamagata City, having approximately 250,000 residents. We used genomic DNAs from 1622 individuals who completed the questionnaire for environmental exposures and informed consent for our modern prospective genomic cohort study. This cohort study was performed under the approval by the Committee on Ethics at Yamagata University and all other institutions involved.
Genotyping
Using genomic DNAs from the Takahata population, we carried out genotyping for 657,366 SNPs using the Infinium Assay with Human660W-Quad BeadChip (Illumina, San Diego, CA) according to the standard procedure provided by Illumina.
Results
Figure 1 shows the relationship between total 1622 subjects with an IBD probability with regard to an identity by distance. First step, we removed individuals for low genotyping (P ≤ 0.05) from total 1622 sample using the PLINK method. By the PLINK and the EIGENSTRAT methods, we detected a relationship between subjects with an IBD probability >1/4 as a CR of 326 subjects (i.e., monozygotic twins, dizygotic twins, full-sibs, parent-offspring, half-siblings, grandparent, grandchild, aunt/uncle, and niece/nephew) in the sample of 1617 subjects. Figure 2 shows the relationship between 1291 subjects with an IBD probability with regard to an identity by distance after removed a CR of 326 subjects. Next, we removed subjects medically treated for blood pressure from samples with and without CR, respectively. Using the sample with and without CR, the sample sizes were 1039 and 829 individuals, respectively. We analyzed the data as described above. In this case, the heritability for liability was 14.3%. In the multiple regression analysis, the regression model found from the sampling data with CR was as follows:
Figure 1.
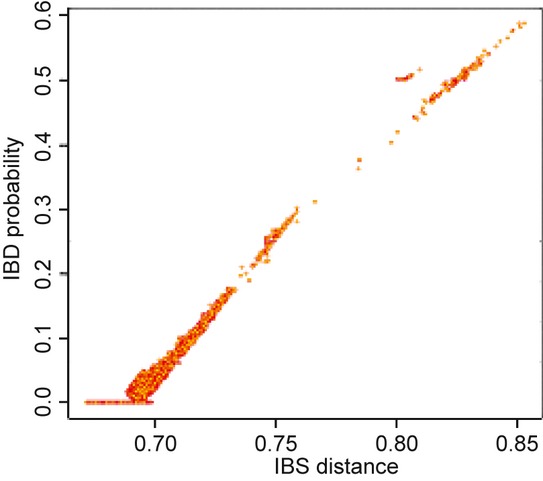
Plot of the relationship between total 1622 subjects with an identity by descent (IBD) probability with regard to an identity by state (IBS) distance; y-axis and x-axis describe IBD probability and IBS distance, respectively.
Figure 2.
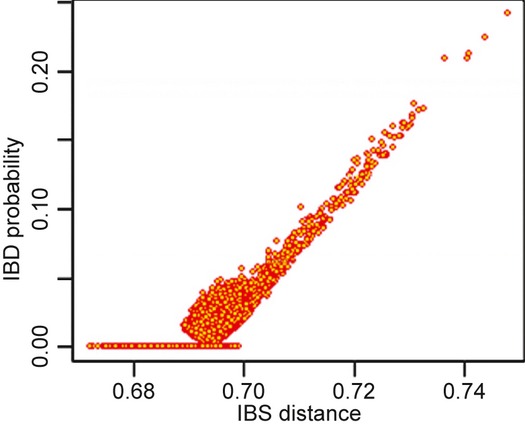
Plot of the relationship between 1291 subjects with an identity by descent (IBD) probability with regard to an identity by state (IBS) distance after which is removed a cryptic relatedness of 326 subjects with an IBD probability >1/4 (i.e., monozygotic twins, dizygotic twins, full-sibs, parent-offspring, half-siblings, grandparent, grandchild, aunt/uncle, and niece/nephew); y-axis and x-axis describe IBD probability and IBS distance, respectively.
| (1) |
where “Systolic” denotes systolic blood pressure and * indicates significant, P-values <0.05. Note that adjusted R-squared for equation (1) was 0.14.
The regression model found from the sampling data without CR was as follows:
| (2) |
Note that adjusted R-squared for equation (2) was 0.15.
Compared with equations (1) and (2), the results showed that the presence of CR is apparently not affected by estimating regression coefficient in regression modeling (Table 1). We tested the assumption of parallel regressions for equations (1) and (2). The difference between equations (1) and (2) was not significant (F-value = 0.35, P-value = 0.55).
Table 1.
Results of the regression coefficients between systolic blood pressure and environmental risk factors in the sample with and without cryptic relatedness (CR): sample size 1039, ratio of CR to the population 20.2%, population prevalence 25%, heritability for liability 14.3%, prevalence in the subpopulation without CR 26%, prevalence in CR 26%
| Estimated | Standard error | t-value | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | ||||
| Sample with CR1 | 82.52 | 5.15 | 16.03 | <2e−16 |
| Sample without CR2 | 77.11 | 5.49 | 14.06 | <2e−16 |
| BMI | ||||
| Sample with CR | 1.31 | 0.14 | 9.30 | <2e−16 |
| Sample without CR | 1.36 | 0.16 | 8.34 | 3.23e−16 |
| Alcohol consumption | ||||
| Sample with CR | −0.80 | 1.51 | −0.53 | 0.60 |
| Sample without CR | −0.42 | 1.61 | −0.26 | 0.79 |
| Smoking status | ||||
| Sample with CR | −0.66 | 0.71 | −0.93 | 0.35 |
| Sample without CR | −0.02 | 1.05 | −0.02 | 0.98 |
| Age | ||||
| Sample with CR | 0.38 | 0.07 | 5.43 | 6.86e−08 |
| Sample without CR | 0.41 | 0.05 | 7.99 | 4.62e−15 |
| Gender | ||||
| Sample with CR | −3.09 | 1.04 | −2.97 | 0.003 |
| Sample without CR | −2.46 | 1.01 | −2.44 | 0.01 |
Furthermore, as described in Methods, we analyzed under the following difference setting, conditional on the fixed prevalence in CR of 26%. The regression model found from the sampling data in the sample size of 400, the ratio of CR to the population 52.5%, prevalence in the population 40%, prevalence in the subpopulation without CR 55%, prevalence in CR 26%, the heritability for liability 24.2% was as follows:
| (3) |
Note that adjusted R-squared for equation (3) was 0.25. In contrast, the regression model found from the sampling without CR (sample size 190) was as follows:
| (4) |
Note that adjusted R-squared for equation (4) was 0.16. Compared with equations (3) and (4), the results showed that the presence of CR is apparently affected by estimating regression coefficient in regression modeling (Table 2). By testing the assumption of parallel regressions for equations (3) and (4), the difference between equations (3) and (4) was significant (F-value = 41.83, P-value = 2.103e−10).
Table 2.
Results of the regression coefficients between systolic blood pressure and environmental risk factors in the sample with and without cryptic relatedness (CR): sample size 400, ratio of CR to the population 52.5%, population prevalence 40%, heritability for liability 24.2%, prevalence in the subpopulation without CR 55%, prevalence in CR 26%
| Estimated | Standard error | t-value | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | ||||
| Sample with CR1 | 141.04 | 5.52 | 25.56 | <2e−16 |
| Sample without CR2 | 145.97 | 1.67 | 87.40 | <2e−16 |
| BMI | ||||
| Sample with CR | −0.12 | 0.15 | −0.76 | 0.45 |
| Sample without CR | 0.04 | 0.05 | 0.79 | 0.43 |
| Alcohol consumption | ||||
| Sample with CR | −6.11 | 1.81 | −3.37 | 0.0008 |
| Sample without CR | 1.28 | 0.56 | 2.30 | 0.022 |
| Smoking status | ||||
| Sample with CR | 5.34 | 0.71 | 7.57 | 2.69e−13 |
| Sample without CR | −0.39 | 0.25 | −1.59 | 0.11 |
| Age | ||||
| Sample with CR | −0.040 | 0.082 | −0.48 | 0.63 |
| Sample without CR | −0.13 | 0.02 | −5.47 | 1.44e−07 |
| Gender | ||||
| Sample with CR | −1.24 | 1.13 | −1.10 | 0.27 |
| Sample without CR | −0.92 | 0.32 | −2.86 | 0.004 |
The regression model found based on the sampling data in the sample size of 400, the ratio of CR to the population 52.5%, prevalence in the population 50%, prevalence in the subpopulation without CR 76.3%, prevalence in CR 26%, the heritability for liability 32.4% was as follows:
| (5) |
Note that adjusted R-squared for equation (5) was 0.24. In contrast, the regression model found from the sampling without CR (sample size 190) was as follows:
| (6) |
Note that adjusted R-squared for equation (6) was 0.42. Compared with equations (5) and (6), the results showed that the presence of CR is apparently affected by estimating regression coefficient in regression modeling (Table 3). By testing the assumption of parallel regressions for equations (5) and (6), the difference between equations (5) and (6) was significant (F-value = 39.74, P-value = 5.720e−10).
Table 3.
Results of the regression coefficients between systolic blood pressure and environmental risk factors in the sample with and without cryptic relatedness (CR): sample size 400, ratio of CR to the population 52.5%, population prevalence 50%, heritability for liability 14.3%, prevalence in the subpopulation without CR 76.3%, prevalence in CR 26%
| Estimated | Standard error | t-value | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | ||||
| Sample with CR1 | 135.37 | 5.77 | 23.47 | <2e−16 |
| Sample without CR2 | 136.68 | 2.09 | 65.34 | <2e−16 |
| BMI | ||||
| Sample with CR | 0.07 | 0.16 | 0.46 | 0.64 |
| Sample without CR | 0.06 | 0.05 | 1.11 | 0.27 |
| Alcohol consumption | ||||
| Sample with CR | −12.34 | 2.00 | −6.16 | 1.77e−09 |
| Sample without CR | −7.75 | 0.81 | −9.54 | <2e−16 |
| Smoking status | ||||
| Sample with CR | 4.15 | 0.74 | 5.62 | 3.60e−08 |
| Sample without CR | −2.32 | 0.32 | −7.23 | 1.24e−11 |
| Age | ||||
| Sample with CR | 0.17 | 0.09 | 1.89 | 0.06 |
| Sample without CR | 0.27 | 0.03 | 7.84 | 3.56e−13 |
| Gender | ||||
| Sample with CR | −1.13 | 1.18 | −0.95 | 0.34 |
| Sample without CR | 0.11 | 0.41 | 0.27 | 0.79 |
The regression model found from the sampling data in the sample size of 500, the ratio of CR to the population 42%, prevalence in the population 40%, prevalence in the subpopulation without CR 50%, prevalence in CR 26%, the heritability for liability 22.1% was as follows:
| (7) |
Note that adjusted R-squared for equation (7) was 0.19. In contrast, the regression model found from the sampling without CR (sample size 290) was as follows:
| (8) |
Note that adjusted R-squared for equation (8) was 0.16. Compared with equations (7) and (8), the results showed that the presence of CR is apparently affected by estimating regression coefficient in regression modeling (Table 4). By testing the assumption of parallel regressions for equations (7) and (8), the difference between equations (7) and (8) was significant (F-value = 24.96 P-value = 7.219e−07).
Table 4.
Results of the regression coefficients between systolic blood pressure and environmental risk factors in the sample with and without cryptic relatedness (CR): sample size 500, ratio of CR to the population 42%, population prevalence 40%, heritability for liability 22.1%, prevalence in the subpopulation without CR 50%, prevalence in CR 26%
| Estimated | Standard error | t-value | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | ||||
| Sample with CR1 | 137.18 | 4.91 | 27.92 | <2e−16 |
| Sample without CR2 | 141.55 | 2.99 | 47.26 | <2e−16 |
| BMI | ||||
| Sample with CR | 0.04 | 0.14 | 0.29 | 0.77 |
| Sample without CR | 0.09 | 0.08 | 1.11 | 0.27 |
| Alcohol consumption | ||||
| Sample with CR | −9.47 | 1.59 | −5.94 | 5.47e−09 |
| Sample without CR | −5.34 | 1.00 | −5.35 | 4.26e−07 |
| Smoking status | ||||
| Sample with CR | 3.47 | 0.64 | 5.45 | 8.10e−08 |
| Sample without CR | −2.30 | 0.44 | −5.18 | 4.26e−11 |
| Age | ||||
| Sample with CR | 0.10 | 0.07 | 1.34 | 0.18 |
| Sample without CR | 0.11 | 0.05 | 2.39 | 0.018 |
| Gender | ||||
| Sample with CR | −0.95 | 1.10 | −0.94 | 0.35 |
| Sample without vCR | −1.10 | 0.60 | −1.83 | 0.07 |
The regression model found from the sampling data in the sample size of 500, the ratio of CR to the population 42%, prevalence in the population 50%, prevalence in the subpopulation without CR 67.2%, prevalence in CR 26%, the heritability for liability 31.7% was as follows:
| (9) |
Note that size of sample with CR was 500 subjects and adjusted R-squared for equation (9) was 0.21. In contrast, the regression model found from the sampling without CR (sample size 290) was as follows:
| (10) |
Note that adjusted R-squared for equation (10) was 0.24. Compared with equations (9) and (10), the results showed that the presence of CR is apparently affected by estimating regression coefficient in regression modeling (Table 5). By testing the assumption of parallel regressions for equations (9) and (10), the difference between equations (9) and (10) was significant (F-value = 35.46 P-value = 3.915e−09).
Table 5.
Results of the regression coefficients between systolic blood pressure and environmental risk factors in the sample with and without cryptic relatedness (CR): sample size 500, ratio of CR to the population 42%, population prevalence 50%, heritability for liability 31.7%, prevalence in the subpopulation without CR 67.2%, prevalence in CR 26%
| Estimated | Standard error | t-value | Pr(>|t|) | |
|---|---|---|---|---|
| Intercept | ||||
| Sample with CR1 | 130.15 | 5.51 | 23.62 | <2e−16 |
| Sample without CR2 | 128.16 | 3.92 | 32.73 | <2e−16 |
| BMI | ||||
| Sample with CR | 0.17 | 0.15 | 1.13 | 0.26 |
| Sample without CR | 0.22 | 0.10 | 2.13 | 0.03 |
| Alcohol consumption | ||||
| Sample with CR | −16.61 | 1.67 | −9.95 | <2e−16 |
| Sample without CR | −8.11 | 1.24 | −6.53 | 2.99e−10 |
| Smoking status | ||||
| Sample with CR | 2.58 | 0.71 | 3.63 | 0.0003 |
| Sample without CR | −2.87 | 0.65 | −4.40 | 1.53e−05 |
| Age | ||||
| Sample with CR | 0.39 | 0.08 | 4.91 | 1.21e−06 |
| Sample without CR | 0.42 | 0.05 | 7.72 | 1.99e−13 |
| Gender | ||||
| Sample with CR | −1.44 | 1.09 | −1.33 | 0.19 |
| Sample without CR | −1.29 | 0.72 | −1.79 | 0.08 |
Discussion
We detected 20.2 % CR of the sample in Takahata cohort study. In our multiple regression models using sample size (N = 1000), there is no significant difference of regression coefficients in the sample with and without CR. In contrast, in the case that the population prevalence of SBP 40–50%, the prevalence in the subpopulation without CR 50–76%, the ratio of CR to the population 42–52%, sample size 400–500 and the heritability for liability 22–32%, the confounding effect of CR in the relationship between SBP and environmental risk factors is not negligible. In general, confounding is a major concern in causal studies because it results in biased estimation of exposure effects. In this respect, our study showed that confounding due to CR biased the estimation of exposure effects in the case of the heritability for liability by approximately >20%. On the other hand, although the number of predictors in the models were included enough (i.e., using independent variables for BMI, alcohol consumption, and smoking status, which were significantly correlated with blood pressure in several research groups (Kannel 1967; Minami et al. 1999; World Health Organization 2000; Ohira et al. 2009), adjusted R-square values of our regression equation models were not high. A possible explanation of low adjusted R-square values for our models is that other independent variables due to genetic factors might contribute to the SBP phenotype. Genetic factors that confer susceptibility to hypertension were identified in several populations (Jeunemaitre et al. 1992; Hata et al. 1994; Lifton 1996; Cusi et al. 1997). Theoretically, Fisher (1918) indicated that the impact of the effect on the phenotype was evaluated by comparing variances. Falconer and Mackay (1996) showed how the phenotypic variance can be partitioned into causal components of variance using the equation VP = VG + VE. In this sense, VP is the total phenotypic variance, VG is the total genetic variance consistent with the additive variance (VA), the dominance variance (VD), the interaction variance (VI) and VE as the environmental variance consistent with the special environmental variance (VEs) that refers to the within individual variance arising from localized circumstances, and general environmental variance VEg refers to the environmental variance contributing to between-individual component in origin. Note that the ratio VG = VP is the heritability of the character. Moreover, Falconer and Mackay (1996) revealed the existence of two coefficients for genetic variances; one is the coefficient r of the additive variance (VA) which called the coefficient of relationship between the relatives in question, and the other is the coefficient u of the dominance variance (VD) which represents the probability of the relatives having the same genotype through IBD. Using these two coefficients, the total genetic variance is given by VG = rVA + uVD + 2covAD, where covAD is the covariance of breeding values with dominance deviations (Falconer and Mackay 1996). According to this mathematical model, it is easily understood how factors associated with genetically close relatives in a sample of ostensibly unrelated individuals contribute to the effect of phenotype; that is, the phenotype is composed of both environmental and genetic elements that contribute to the relationship between relatives. Thus, some of the differences in the estimates of regression coefficients might be because of the adjustment strategies for concomitant confounding effect of CR. Rotimi et al. (1999) examined a familial pattern of blood pressure in a population of Nigerian families and clarified that heritability of <50% for both SBP and diastolic blood pressure (DBP) reinforced the importance of the nonshared familial environmental effects. Thus, one of the approaches to select the best model for the response variable using collected cohort data from a limited or small-sized sample is that the heritability of the blood pressure phenotype might be worth considering.
Historically, the most common statistical approach for dealing with confounding in epidemiology was based on stratification. Typically, given the importance of confounding in epidemiology, statistical methods recommend the removal of significantly confounding samples. However, the resulting removal of samples with confounding factors, the sample size is reduced. As with another possible approach, we are now extensively analyzing this issue by a method incorporating principal components of a large subset of GWAS SNPs as regression covariates. This approach does not waste resources; that is we can use the entire sample. There are some similarities between the approach by Price et al. (2006) and our method; however, in contrast we examine principal components of a large subset of GWAS SNPs to adjust the confounding effect of CR. On the other hand, they examined them only to adjust the population structure. Generally, principal components typically reflect genome-wide factors attributable to the demographic history of the populations studied (Price et al. 2006). In this respect, it still remains to be clarified whether principal components reflect genome-wide factors attributable to CR. We are now extensively analyzing under what condition such approach is plausible.
In conclusion, we found a confounding effect of CR in the relationship between SBP and environmental risk factors was not negligible. In our study, we showed that heritability for liability might reflect on the estimation of regression coefficients between SBP and environmental risk factors, because they vary with environmental risk factors that differ across some unsuspected relatedness. For the genetic case-control studies, test statistics are generally inflated relative to the expectation under the association of an independent sample and without genetic association to the disease. These false positives often are attributed to CR (Devlin and Roeder 1999). Thus, more or less in any other epidemiological investigations that were performed previously, a true effect might be hidden due to confounding arising from CR. In our study, we presented a simply modeling to illustrate the effect of CR on the estimation of coefficients. The size of the CR would have a big impact on the precision of the resulting estimates of coefficients. We are now extensively analyzing this issue in different settings. Various statistical methods have been proposed to take into account confounding factors such as linear mixed-effect models (Demidenko 2004) or methods that adjust data based on a principal components analysis (Price et al. 2006). Sturmer et al. (2005) proposed a method of adjusting for multiple unmeasured confounders in a cohort study. The amount of residual confounding due to unmeasured and poorly measured covariates was important enough to qualitatively change the association between NSAID (nonsteroidal anti-inflammatory drug) use and mortality (Sturmer et al. 2005). After data collection, using these techniques in an epidemiological association study, it might be important to adjust the cryptic relative pairs based on genetic data in the relationship between environmental risk factors and phenotypes.
Acknowledgments
This study was supported by JSPS KAKENHI Grant Number 24659316. This study was fully supported by a Grant-in-aid from the Global Center of Excellence program of the Japan Society for the Promotion of Science, “Formation of an International Network for Education and Research of Molecular Epidemiology (Project Leader: Takamasa KAYAMA).” We thank two reviewers for insightful suggestions.
Appendix
The following are the contributors of Yamagata University Genomic Cohort Consortium
Steering Committee: Takamasa Kayama1 (Chair), Hidetoshi Yamashita2 (Deputy chair), Akira Fukao3,4, Isao Kubota5,6, Takeo Kato7,8, Chifumi Kitanaka9,10, Shinya Sato1,5, Yoshiyuki Ueno11
Respiratory, Cardiovascular, and Renal Diseases and Related Traits: Isao Kubota5,6, Shinya Sato1,5, Tsuneo Konta6, Yoko Shibata6, Tetsu Watanabe6, Shuichi Abe6, Takuya Miyamoto6, Sumito Inoue6, Takehiko Miyashita6, Kazunobu Ichikawa6, Tetsuro Shishido6, Takanori Arimoto6, Hiroki Takahashi6, Satoshi Nishiyama6, and Ami Ikeda6
Metabolic and Neurodegenerative Diseases and Related Traits: Takeo Kato7,8, Makoto Daimon8, Toru Kawanami8, Manabu Wada8, Shigeki Arawaka8, Hidetoshi Oizumi8, Katsuro Kurokawa8, Shingi Susa8, Yuichi Katou8, Wataru Kameda8, Shingo Koyama8, Shigeru Karasawa8, Chifumi Iseki8, and Yoshimi Takahashi8
Cancer and Related Traits: Chifumi Kitanaka9,10, Yoshiyuki Ueno11
Gastrointestinal, Hepatic, and Pancreatic Diseases and Related Traits: Yoshiyuki Ueno11, Sumio Kawata11*, Takafumi Saito11, Naohiko Makino11,12, Kazuo Okumoto11, Hiroaki Haga11, Takeshi Sato11, Chikako Sato11, Hisayoshi Watanabe11, Yuko Nishise11, Rika Ishii11, Akiko Matsuda12, and Tomohiro Tozawa11,12
Eye Diseases and Related Traits: Hidetoshi Yamashita2 and Kei Honma2
Cohort Establishment: Akira Fukao3,4, Hiroto Narimatsu3, Kyoko Shibata3, Akiko Miura3, Rina Inoue3, Ai Numazawa3, Kahori Kudo3, Yoko Aita3, Noriko Umezawa3, Yuko Saito3, Yumi Takahashi3, Yuka Suzuki3, Katsumi Otani4, Atsushi Hozawa4, Li Shao4, Masatsugu Orui13, Atsuko Kobayashi14, Yuka Kanoya14, Takiko Hosoya14, Ikuko Suzuki14, Mariko Otake14, Yuko Morikagi14, Akiko Sekimata14, Manami Hiraka14, Yumi Matsuda14, Chika Sato14, Yoko Takeda14, Yoko Matsunami14, Tatsuya Horie14, Shiho Sato14, Mizue Inoue14, and Kaoru Baba14
Genetic, Genomic, and Statistical Analyses: Gen Tamiya15, Masao Ueki15, and Tomohiro Nakamura15
Genotyping: Gen Tamiya15, Jamiyansuren Jambaldorj16, and Satoko Araki16
DNA Extraction and Biobanking: Osamu Nakajima17,18
Database Construction: Kazuei Takahashi19 and Kazuo Goto19
Patent Control and Commercialization: Kimishige Ishizaka20
Yamagata University, Graduate School of Medicine, Department of Neurosurgery
Department of Ophthalmology
Advanced Molecular Epidemiology Research Institute (AMERI), Cohort Management Unit
Department of Public Health
AMERI, Respiratory and Cardiovascular Diseases Research Center
Department of Cardiology, Pulmonology, and Nephrology
AMERI, Metabolic and Degenerative Diseases Research Center
Department of Neurology, Hematology, Metabolism, Endocrinology and Diabetology
AMERI, Oncology Research Center
Department of Molecular Cancer Science
Department of Gastroenterology
Division of Endoscopy, Yamagata University Hospital
Yamagata Prefectural Tsuruoka Hospital
School of Nursing
AMERI, Genomic Information Analysis Unit
AMERI, Shared Laboratory
AMERI, Specimen Management Unit
Research Laboratory for Molecular Genetics
AMERI, Data Management Unit
COME center
*Present address: Hyogo Prefectural Nishinomiya Hospital.
Conflict of Interest
None declared.
References
- Bunker CH, Ukoli FA, Matthews KA, Kriska AM, Huston SL, Kuller LH. Weight threshold and blood pressure in a lean black population. Hypertension. 1995;143:1203–1218. doi: 10.1161/01.hyp.26.4.616. [DOI] [PubMed] [Google Scholar]
- Cusi D, Barlassina C, Azzani T, Casari G, Citterio L, Devoto M, et al. Polymorphisms of alpha-adducin and salt sensitivity in patients with essential hypertension. Lancet. 1997;349:1353–1357. doi: 10.1016/S0140-6736(97)01029-5. [DOI] [PubMed] [Google Scholar]
- Demidenko E. Mixed models: theory and applications. Hoboken, NJ: John Wiley and Sons, Inc; 2004. [Google Scholar]
- Devlin B, Roeder K. Genomic control for association studies. Biometrics. 1999;55:997–1004. doi: 10.1111/j.0006-341x.1999.00997.x. [DOI] [PubMed] [Google Scholar]
- Falconer DS, Mackay TFC. Introduction to quantitative genetics. London, U.K: Prentice Hall; 1996. [Google Scholar]
- Fisher RA. The correlation between relatives on the supposition of Mendelian inheritance. Trans. Roy. Soc. Edinburgh. 1918;52:399–433. [Google Scholar]
- Gallagher D, Visser M, Sepulveda D, Pierson RN, Harris T, Heymsfield SB. How useful is body mass index for comparison of body fatness across age, sex and ethnic groups. Am. J. Epidemiol. 1996;143:228–239. doi: 10.1093/oxfordjournals.aje.a008733. [DOI] [PubMed] [Google Scholar]
- Hata A, Namikawa C, Sasaki M, Sato K, Nakamura T, Tamura K, et al. Angiotensinogen as a risk factor for essential hypertension in Japan. J. Clin. Invest. 1994;93:1285–1287. doi: 10.1172/JCI117083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jeunemaitre X, Soubrier F, Kotelevtsev YV, Lifton RP, Williams CS, Charru A, et al. Molecular basis of human hypertension: role of angiotensinogen. Cell. 1992;71:169–180. doi: 10.1016/0092-8674(92)90275-h. [DOI] [PubMed] [Google Scholar]
- Kang HM, Zaitlen NA, Wade CM, Kirby A, Heckerman D, Daly MJ, et al. Efficient control of population structure in model organism association mapping. Genetics. 2008;178:1709–1723. doi: 10.1534/genetics.107.080101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kannel WB. The relation of adiposity to blood pressure and development of hyper tension. The Framingham study. Ann. Intern. Med. 1967;67:48–59. doi: 10.7326/0003-4819-67-1-48. [DOI] [PubMed] [Google Scholar]
- Kiyohara Y, Kato I, Iwamoto H, Nakayama K, Fukushima M. The impact of alcohol and hypertension on stroke incidence in a general Japanese population. The Hisayama study. Stroke. 1995;26:368–372. doi: 10.1161/01.str.26.3.368. [DOI] [PubMed] [Google Scholar]
- Lifton RP. Molecular genetics of human blood pressure variation. Science. 1996;272:676–680. doi: 10.1126/science.272.5262.676. [DOI] [PubMed] [Google Scholar]
- Minami J, Ishimitsu T, Matsuoka H. Effects of smoking cessation on blood pressure and heart rate variability in habitual smokers. Hypertension. 1999;33:586–590. doi: 10.1161/01.hyp.33.1.586. [DOI] [PubMed] [Google Scholar]
- Minami J, Yoshii M, Todoroki M, Nishikimi T, Ishimitsu T, Fukunaga T, et al. Effects of alcohol restriction on ambulatory blood pressure, heart rate, and heart rate variability in Japanese men. Am. J. Hypertens. 2002;15:125–129. doi: 10.1016/s0895-7061(01)02265-8. [DOI] [PubMed] [Google Scholar]
- Ohira T, Tanigawa T, Tabata M, Imano H, Kitamura A, Kiyama M, et al. Effects of habitual alcohol intake on ambulatory blood pressure, heart rate, and its variability among Japanese men. Hypertension. 2009;53:13–19. doi: 10.1161/HYPERTENSIONAHA.108.114835. [DOI] [PubMed] [Google Scholar]
- Ohmori S, Kiyohara Y, Kato I, Kubo M, Tanizaki Y, Iwamoto H, et al. Alcohol intake and future incidence of hypertension in a general Japanese population: the Hisayama study. Alcohol. Clin. Exp. Res. 2002;26:1010–1016. doi: 10.1097/01.ALC.0000021147.31338.C2. [DOI] [PubMed] [Google Scholar]
- Price AL, Patterson NJ, Plenge RM, Weinblatt ME, Shadick NA, Reich D. Principal components analysis corrects for stratification in genome-wide association studies. Nat. Genet. 2006;38:904–909. doi: 10.1038/ng1847. [DOI] [PubMed] [Google Scholar]
- Price AL, Zaitlen NA, Reich D, Patterson N. New approaches to population stratification in genome-wide association studies. Nat. Rev. Genet. 2010;11:459–463. doi: 10.1038/nrg2813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Purcell S, Neale B, Todda-Brown K, Thomas L, Ferreira MA, Bender D, et al. PLINK: a toolset for whole-genome association and population based linkage analysis. Am. J. Hum. Genet. 2007;81:559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Roche AF, Siervogel RM. Measures of body composition: their relationship to blood pressure and use in epidemiologic research. Ann. Epidemiol. 1991;1:313–320. doi: 10.1016/1047-2797(91)90042-b. [DOI] [PubMed] [Google Scholar]
- Rotimi CN, Cooper RS, Cao G, Ogunbiyi O, Ladipo M, Owoaje E, et al. Maximum-likelihood generalized heritability estimate for blood pressure in Nigerian families. Hypertension. 1999;33:874–878. doi: 10.1161/01.hyp.33.3.874. [DOI] [PubMed] [Google Scholar]
- Spiegelman D, Israel RG, Bouchard C, Willett WC. Absolute fat mass, percent body fat, and body-fat distribution: which is the real determinant of blood pressure and serum glucose? Am. J. Clin. Nutr. 1992;55:1033–1044. doi: 10.1093/ajcn/55.6.1033. [DOI] [PubMed] [Google Scholar]
- Sturmer T, Schneeweiss S, Avorn J, Glynn RJ. Adjusting effect estimates for unmeasured confounding with validation data using propensity score calibration. Am. J. Epidemiol. 2005;162:279–289. doi: 10.1093/aje/kwi192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Voight BF, Pritchard JK. Confounding from cryptic relatedness in case-control association studies. PLoS Genet. 2005;1:e32. doi: 10.1371/journal.pgen.0010032. [DOI] [PMC free article] [PubMed] [Google Scholar]
- World Health Organization. Obesity: preventing managing the global epidemic. Report of a WHO consultation. World Health Organ. Tech. Rep. Ser. 2000;894:1–253. [PubMed] [Google Scholar]
- Yasuda N. A primer of population genetics. Chiyoda-ku, Japan: Shokabo; 2007. [Google Scholar]
- Yu J, Pressoir G, Briqqs WH, Vroh Bi I, Yamasaki M, Doebley JF, et al. A unified mixed-model method for association mapping that accounts for multiple levels of relatedness. Nat. Genet. 2006;38:203–208. doi: 10.1038/ng1702. [DOI] [PubMed] [Google Scholar]