

Abstract
Two experiments employing an auditory priming paradigm were conducted to test predictions of the Neighborhood Activation Model of spoken word recognition (Luce & Pisoni, 1989, Neighborhoods of words in the mental lexicon. Manuscript under review). Acoustic–phonetic similarity, neighborhood densities, and frequencies of prime and target words were manipulated. In Experiment 1, priming with low frequency, phonetically related spoken words inhibited target recognition, as predicted by the Neighborhood Activation Model. In Experiment 2, the same prime-target pairs were presented with a longer inter-stimulus interval and the effects of priming were eliminated. In both experiments, predictions derived from the Neighborhood Activation Model regarding the effects of neighborhood density and word frequency were supported. The results are discussed in terms of competing activation of lexical neighbors and the dissociation of activation and frequency in spoken word recognition.
A fundamental problem in research on spoken word recognition concerns the processes by which stimulus information in the speech waveform is mapped onto lexical representations in long-term memory. Clearly, given the enormous size of the adult mental lexicon, isolating the sound pattern of one word from among tens of thousands of others in memory is no trivial matter for the listener. Nevertheless, word recognition normally appears to proceed effortlessly and with few errors. Given that one of the primary tasks of the word recognition system involves discrimination among lexical items, the study of the structural organization of words in memory takes on considerable importance for research in word recognition. In the present context, “structure” is defined specifically in terms of similarity relations among the sound patterns of words.
In a series of recent experiments, Luce and Pisoni (1989) investigated the effects that the number and nature of words activated in memory have on word recognition. Specifically, they examined the recognition of words in different similarity neighborhoods. A similarity neighborhood is defined as a collection of words that are phonetically similar to a given stimulus word. Two key structural characteristics have been used to describe similarity neighborhoods. Neighborhood density refers to the absolute number of words occurring in any given similarity neighborhood; neighborhood frequency refers to the frequencies of occurrence of the neighbors.
In order to determine the effects of similarity neighborhood structure on spoken word recognition, Luce and Pisoni performed experiments employing three paradigms: perceptual identification, auditory lexical decision, and auditory word naming. In these studies, the density and frequency characteristics of similarity neighborhoods were found to be important determinants of the speed and accuracy of stimulus identification. In brief, the major results of their study were the following:
First, words that came from sparse neighborhoods, that is, neighborhoods that contain few other phonetically similar words, were recognized more quickly and more accurately than words that came from more dense neighborhoods. Second, words having primarily low frequency neighbors were recognized more quickly and more accurately than words having primarily high frequency neighbors. In addition to neighborhood frequency effects, Luce and Pisoni also found word frequency effects—high frequency words were identified better than low frequency words. This was the case in both the perceptual identification and the auditory lexical decision studies, but not in the auditory word naming study. In the naming experiment, reliable effects of neighborhood density as described above were observed, but the effects of both neighborhood frequency and item frequency were largely attenuated.
To account for these findings, Luce and Pisoni (1989) have proposed the Neighborhood Activation Model (NAM) of spoken word recognition. A flow chart of NAM is shown in Fig. 1. The model states that upon presentation of stimulus input, a set of acoustic–phonetic patterns is activated in memory. It is assumed that all patterns similar to the input are activated regardless of whether they correspond to real words in the lexicon or not. These acoustic–phonetic patterns then activate a system of word decision units tuned to the patterns themselves. Only those acoustic–phonetic patterns corresponding to words in memory will activate word decision units. Neighborhood activation is therefore assumed to be identical to the activation of the word decision units.
Fig. 1.
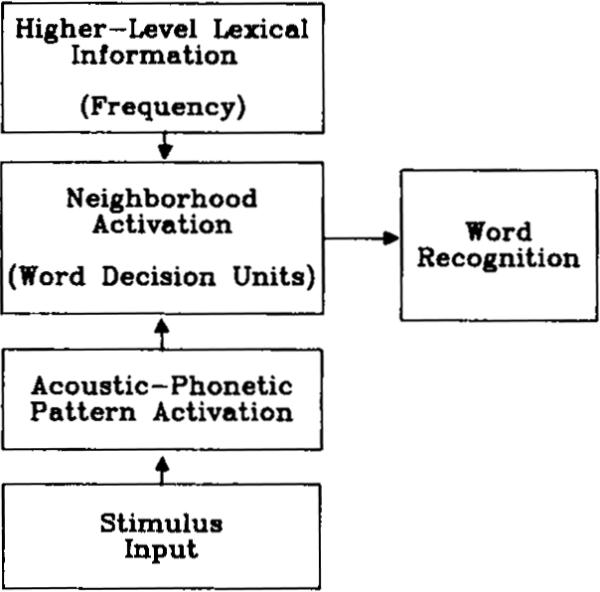
Flow diagram of the Neighborhood Activation Model (from Luce, 1986).
A diagram of a single word decision unit is shown in Fig. 2. Once activated, the decision units monitor the activation levels of the acoustic–phonetic patterns to which they correspond, as well as higher level lexical information. Word frequency is included in the higher level lexical information available to the decision units. These units therefore serve as the interface between acoustic–phonetic information in the speech waveform and higher level lexical information in long-term memory. Acoustic–phonetic information is assumed to drive the system by activating the word decision units, whereas higher level lexical information is assumed to operate by biasing these decision units. These biases operate by adjusting the activation levels represented within the word decision units.
Fig. 2.
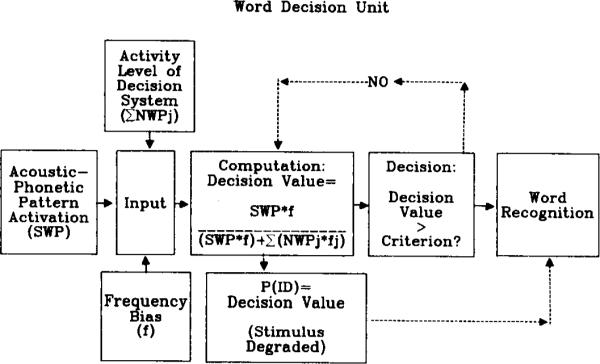
Diagram of a single word decision unit (from Luce, 1986).
The values computed by the word decision units for determining whether a particular pattern has been presented are given by the Neighborhood Probability Rule, which has the form
in which SWP is the probability of the stimulus word, freqs is the frequency of the stimulus word, NPWj is the probability of neighbor j, and freqj is the frequency of neighbor j.
This rule, based on R. D. Luce's (1959) choice rule, combines neighborhood density, neighborhood frequency, and stimulus word frequency to predict identification performance. The probability of identifying a stimulus word, p(ID), is therefore equal to the probability of the stimulus word divided by the probability of the word plus the combined probabilities of its neighbors. Neighborhood density and neighborhood frequency are represented in the denominator term of the rule as the summed weighted probabilities of all neighbors. (In the present experiments, all values of “neighborhood density” for any given word actually refer to the frequency-weighted neighborhood probability for the word (see Luce, 1986). Throughout this paper, we will be using the general term “density” to denote this joint metric, and we will not discuss neighborhood frequency as an explicit variable.) Frequency is represented as a weighting function on the stimulus and neighbor probabilities, biasing decisions in favor of higher frequency words.
As shown in Fig. 2, each decision unit is responsible for monitoring three sources of information that are simultaneously accounted for by the neighborhood probability rule: acoustic–phonetic pattern activation (SWP), higher level lexical information (freqs and freqj), and the overall level of activity in the system of units (the sum of the NPWs). As analysis of the stimulus input proceeds, the decision units continuously compute decision values via the neighborhood probability rule. As more information accumulates, the acoustic–phonetic pattern corresponding to the stimulus input is resolved. As the pattern is resolved, the activation levels of similar patterns steadily decrease and the decision values computed by the word decision unit monitoring the pattern of the actual stimulus steadily increase. Once the output of a given decision unit reaches some criterion, all information monitored by that decision unit is made available to working memory.
The neighborhood probability rule predicts reduced identification as a function of increased neighborhood density, which is represented in the denominator term of the rule. In terms of the on-line processing of the decision units, the presence of many similar neighbors serves to prolong the amount of processing time necessary to resolve the given input pattern. According to the model, frequency acts to bias decisions toward higher frequency items. Thus, the presence of high frequency words in the neighborhood is predicted by the rule to inhibit target identification. Note that NAM posits that activation in memory occurs independently of item frequencies and that the effects of frequency are not realized until the selection phase of the recognition process. Put another way, frequency is assumed to exert its influences after initial activation but before lexical access occurs. This claim regarding the role of frequency in word recognition is contrary to the claims of several other influential models of spoken word recognition, such as logogen theory (Morton, 1969), Forster's (1976) search model, and Marslen-Wilson's most recent version of cohort theory (1987).
Word recognition in NAM may be accomplished in a number of ways, depending on the requirements of the task. In situations in which the stimulus input is degraded, word recognition is accomplished by comparing the values computed by several word decision units and selecting the response corresponding to the highest value. When speeded responses are required, it is assumed that the subject sets a criterion for responding that, once exceeded by the output of a decision unit, results in the recognition of a word. Word recognition is defined explicitly as the choice of a particular pattern by the system of decision units.
One interesting prediction of NAM derives from the assumption of competition among lexical neighbors. As the neighborhood probability rule shows, increasing the activation level of a stimulus word's neighborhood is predicted to lower the probability of identifying the stimulus word itself. One means of experimentally manipulating the activation level of a stimulus word's neighborhood is to prime the stimulus word with one of its phonetically related neighbors. The model predicts that if a target stimulus presented for identification is immediately preceded by a phonetically related prime (a neighbor), residual activation from the prime should produce increased competition from the neighborhood and thereby inhibit stimulus word identification. In terms of the neighborhood probability rule, priming with a phonetically related word should increase the Σ[NPWj * freqj] term in the denominator of the rule and, therefore, reduce predicted identification performance for the target. In short, the model predicts inhibition priming from phonetically similar words.
In order to test this prediction, prime-target pairs related only by phonetic similarity were generated. In addition, as a baseline against which to evaluate predicted effects of inhibition priming, phonetically unrelated prime-target pairs were also generated. Thus, primes were either phonetically related or unrelated to the target words. None of the prime words were semantically related to the target words. Examples of targets with their related primes and their unrelated primes are: VEER-BULL, VEER-GUM; PAR-TALL, PAR-BASE; and HASH-ETCH, HASH-LAME.1
Phonetic similarity between primes and targets was determined from confusion matrices for individual consonants and vowels obtained in a previous study (see Luce, 1986). Based on these confusion matrices, primes were chosen that constituted the nearest neighbors of the target words, with the constraint that the primes and targets shared no common phonemes. The restriction against overlapping phonemes was imposed in order to prevent subjects from generating response strategies based on repeated overlap between prime-target pairs (for discussion, see Slowiaczek, Nusbaum, & Pisoni, 1987).2
In addition to the manipulation of prime type (related vs. unrelated), three other variables were examined: neighborhood density, prime frequency, and target frequency. Prime-target pairs were selected from dense, high frequency neighborhoods or from sparse, low frequency neighborhoods. Neighborhood density was manipulated, in part, to replicate previous findings and, in part, to determine if the predicted inhibition priming would be influenced by the structure of the neighborhoods from which the prime-target pairs were drawn.
The frequencies of the primes and targets were manipulated by orthogonally combining two levels of prime frequency (high and low) with two levels of target frequency (high and low). This manipulation was included as an important test of one aspect of NAM, namely, the assumption that frequency affects decision processes and is not directly coded in the activation levels of the word patterns. This assumption of the model directly follows from the results of the auditory word naming experiment discussed above. In the naming study, Luce and Pisoni found that while neighborhood density remained a powerful predictor of performance, word frequency did not. Similarly, Balota and Chumbley (1984) showed that word frequency effects may be greatly attenuated in certain experimental settings. Certainly, if word frequency information were so deeply ingrained in the activation coding of words, such effects should not be possible.
Assuming for the moment, however, that frequency directly modifies activation levels, one could argue that high frequency primes should produce relatively more inhibition of target recognition than low frequency primes, simply because high frequency primes should produce stronger competing activation levels in the neighborhood. However, this result is not predicted by NAM. Because NAM assumes that frequency does not directly affect activation levels, high frequency primes should not produce any more activation than low frequency primes. Thus, NAM does not predict substantial inhibition of target recognition for targets preceded by high frequency primes.
However, NAM does predict differential priming effects as a function of the frequency of the prime. In fact, the model predicts, somewhat counterintuitively, that low frequency primes should produce more inhibition than high frequency primes. The rationale for this prediction is as follows: All things being equal, NAM predicts that low frequency words should be identified less quickly and less accurately than high frequency words. Recall that this prediction is not based on the assumption that high frequency words have higher resting activation levels, lower recognition thresholds, or steeper activation functions than low frequency words. Instead, the word frequency advantage is assumed to arise because biased decisions regarding the stimulus input can be made more quickly and accurately for high frequency words. Therefore, activation levels for acoustic-phonetic patterns corresponding to high and low frequency words are assumed to rise and fall at the same rates. However, it is assumed that decisions in the word decision units can be made earlier for high frequency words than for low frequency words. If this is the case, the word decision unit for a high frequency word will surpass criterion for recognition sooner than a word decision unit for a low frequency word. This means that, in turn, the activation of an acoustic-phonetic pattern corresponding to a high frequency prime will begin to return to a resting level sooner than the activation of an acoustic-phonetic pattern corresponding to a low frequency prime. Thus, target items following high frequency primes should receive less competition from the residual activation of the prime than targets following low frequency primes.
In short, two main predictions were examined: First, it was predicted that phonetically related primes would inhibit target identification because of increased neighborhood competition. Second, it was predicted that, because frequency is assumed to affect decision processes and not activation levels, low frequency primes would produce relatively more inhibition than high frequency primes. This prediction is in contrast to predictions of several current models, discussed in detail below, that assume that frequency directly affects activation levels.
Experiment 1A
Method
Subjects
Sixty Indiana University undergraduate students participated in partial fulfillment of requirements of an introductory psychology course. All subjects were native speakers of English and reported no history of a speech or hearing disorder at the time of testing.
Stimuli
Two hundred forty phonetically related prime-target pairs were selected from a computerized lexical database based on Webster's pocket dictionary (1967). In addition, unrelated primes were selected for each of the 240 targets, for a total of 720 words. The related prime-target pairings were created by searching the database for each target's nearest neighbor with no common phonemes (see Footnote 2). As stated above, degree of similarity of a given prime to its target word was computed using confusion matrices for individual consonants and vowels (see Luce, 1986, for a complete description). The unrelated primes were selected by searching for words from neighborhoods that had the same density as their prospective targets, but were not phonetically confusable with the targets. From the original lists of words generated by these searches, the final 720 words selected were those which met the following constraints: (1) All targets and unrelated primes were three phonemes in length; related primes were either two or three phonemes in length; (2) all words were monosyllabic; (3) all words were listed in the Kucera and Francis (1967) corpus; and (4) all words had a rated familiarity of 6.0 or above on a 7-point scale. These familiarity ratings were obtained from a previous study by Nusbaum, Pisoni, and Davis (1984). In this study, all words from Webster's pocket dictionary were presented visually to subjects for familiarity ratings. The rating scale ranged from (1) “don't know the word” to (4) “recognize the word but don't know its meaning” to (7) "know the word and its meaning.“ The rating criterion of 6.0 and above was used to ensure that all prime and target words would be known by the subjects.
After all constraints were satisfied, the sets of primes and targets were divided into eight cells constructed by orthogonally combining two levels (high and low) of each of four variables: (1) prime-target relatedness, (2) neighborhood density, (3) prime frequency, and (4) target frequency. Once the prime-target pairs were assigned to their proper cells, the cell with the fewest pairs contained 30 items. Prime-target pairs with the lowest estimated phonetic confus-ability were removed from all other cells to leave 30 prime-target pairs in each of the eight cells, representing a virtually exhaustive set of all possible stimuli for the purposes of this experiment.
Once all the excess stimuli had been eliminated from the set of possible stimuli, the frequencies of the remaining words were as follows: Low frequency targets ranged in log frequency from 1.4241 to 1.5378, with a mean log frequency of 1.4891; high frequency targets ranged in log frequency from 2.8204 to 3.1207, with a mean log frequency of 2.9057. Low frequency related primes ranged in log frequency from 1.4365 to 1.5984, with a mean log frequency of 1.5102; high frequency related primes ranged in log frequency from 2.6972 to 3.0346 with a mean log frequency of 2.9685. Low frequency unrelated primes ranged in log frequency from 1.5012 to 1.8441, with a mean log frequency of 1.5990; high frequency unrelated primes ranged in log frequency from 2.1025 to 2.9361, with a mean log frequency of 2.6408.
Because every target item had two corresponding primes and no subject was to be presented the same target item twice, the stimuli were divided into two lists. Every subject responded to all 240 targets, but the primes and control items varied. For a given group, 120 of the targets were primed by related primes, the other 120 targets by control primes. The next group received the same targets paired with their primes in the reverse order. An equal number of subjects were presented with each list.
The stimuli were recorded in a sound-attenuated booth by a male talker of a mid-western dialect using an Ampex AG500 tape deck and an Electro-Voice D054 microphone. All words were spoken in isolation. The stimuli were then low-pass filtered at 4.8 kHz and digitized at a sampling rate of 10 kHz using a 12-bit analog-to-digital converter. All words were excised from the list using a digitally controlled speech waveform editor (WAVES) on a PDP 11/34 computer (Luce & Carrell, 1981). The mean duration of the targets was 691.99 ms; mean durations for the related and unrelated primes were 705.29 and 699.84 ms, respectively. Finally, all words were paired with their appropriate counterparts and stored digitally as stimulus files on a computer disk for later real-time presentation to subjects during the experiment.
To ensure that all stimuli could be identified accurately, 10 additional subjects were asked to identify all words in the absence of noise. Words which were not correctly identified by at least 8 of 10 subjects were re-recorded and replaced with more intelligible tokens.
Design
Two levels of four variables were examined: (1) prime type (related vs. unrelated); (2) neighborhood density (high vs. low); (3) prime frequency (high vs. low); and (4) target frequency (high vs. low). The dependent measure in all cases was the percentage of target words correctly identified.
Procedure
Subjects were tested in groups of five or fewer. Each subject was seated in a testing booth equipped with an ADM computer terminal and a pair of TDH-39 headphones. The presentation of stimuli was controlled by a PDP 11/34 computer. All stimuli were presented in random order.
A typical trial proceeded as follows: A prompt would appear on the CRT screen saying, “GET READY FOR NEXT TRIAL.” Five hundred milliseconds after this prompt appeared, a prime was presented over headphones at 75 dB (SPL) in the clear. Immediately upon the offset of the prime, 70 dB (SPL) of continuous white noise was presented. Fifty milliseconds after presentation of the noise, the target item was presented at 75 dB (SPL), yielding a + 5 dB signal-to-noise (S/N) ratio. The subjects' task was to identify each target word and type their responses on the ADM keyboard as accurately as possible following each trial. Subjects were under no time constraints to respond.
Each subject received 280 trials, the first 40 of which were practice and were not included in the final data analysis. There were equal numbers of trials in all 16 conditions, so each subject identified a target from each condition 15 times. Across 60 subjects, this procedure generated a total of 900 responses per condition.
Results
The percentage of words correctly identified was determined for each subject. For a response to be considered correct, the entire response had to match the target item exactly or be a homophone (e.g., there, their). Responses were corrected for simple spelling errors prior to analysis.
Figure 3 displays the results of the priming manipulation for all conditions. Light bars indicate conditions for unrelated primes, dark bars show performance for related primes. Mean percentage of correct target identification for high frequency targets is shown on the left; performance for low frequency targets is shown on the right. Performance for prime-target pairs selected from sparse neighborhoods is shown in the upper panel; performance for prime-target pairs from dense neighborhoods is shown in the lower panel.
Fig. 3.

Percent correct identification for high and low frequency target words as a function of neighborhood density and prime frequency for related and unrelated primes. Light bars show performance for unrelated primes, dark bars show performance for related primes.
A four-way analysis of variance (Prime Type × Neighborhood Density × Prime Frequency × Target Frequency) was performed on the mean percentages of correct responses. A significant main effect of prime type was obtained [F(1,59) = 8.11, MSe = .0146, p < .05]. (All results reported are p < .05 or beyond, unless specifically stated otherwise). Post-hoc Tukey's HSD analyses indicated that targets following related primes were identified significantly less accurately than targets following unrelated primes in three conditions. These conditions, denoted by asterisks in Fig. 3, are: (1) dense neighborhood/low frequency prime/high frequency target; (2) sparse neighborhood/low frequency prime/high frequency target; and (3) sparse neighborhood/low frequency prime/low frequency target. Thus, significant inhibition was obtained only when targets were preceded by low frequency primes.
The effects of neighborhood structure and target frequency are shown in Fig. 4. These results are collapsed across prime type to better illustrate the effects of neighborhood density and target frequency. Light bars indicate targets from sparse neighborhoods; dark bars indicate targets from dense neighborhoods. Mean percentage of correct target identification for high frequency targets is shown on the left, whereas performance for low frequency targets is shown on the right.
Fig. 4.

Percent correct identification for high and low frequency target words as a function of neighborhood density and prime frequency, averaged over prime type. Light bars show performance for targets from sparse neighborhoods, whereas dark bars show performance for targets from dense neighborhoods. The left panel shows the results for high frequency targets; the right panel shows the results for low frequency targets.
A significant main effect of neighborhood density was obtained [F(1,59) = 248.28, MSe = .0161]. In all conditions, target words occurring in sparse neighborhoods were recognized more accurately than target words from dense neighborhoods. A significant main effect of target frequency was also obtained [F(1,59) = 164.00, MSe = .0158]. In all conditions, high frequency targets were recognized more accurately than low frequency targets. There was no main effect of prime frequency [F(1,59) = 2.35, MSe = .0091, p = .1306].
The ANOVA based on subject performance showed several significant interactions. There were interactions of neighborhood density X target frequency [F(1,59) = 18.23, MSe = .0098], of neighborhood density X prime frequency [F(1,59) = 12.17, MSe = .0088], and of target frequency X prime frequency [F(1,59) = 21.22, MSe = .0087].
In addition to the ANOVA performed on the data grouped by subjects, an item analysis was performed to make sure that the results were not caused by idiosyncratic stimuli randomly assigned to certain cells in the design (Clark, 1973). This analysis was performed even though we considered our stimuli an exhaustive set of all possible pairs conforming to the constraints enumerated above. All the main effects obtained above were also obtained in the item analysis. Main effects were obtained for prime type [F(1,232) = 5.06, MSe = .0709], for neighborhood density [F(1,232) = 12.14, MSe = .1660], and for target frequency [F = 7.82, MSe = .1660]. No main effect of prime frequency was obtained in the item analysis [F(1,232) = 0.14, MSe = .1660, p = .7120] nor were any of the interactions obtained in the ANOVA performed on the subject data significant in the item analysis.
The basic pattern of results from this experiment is clear. In three of eight experimental conditions, priming with a phonetically related word significantly inhibited target recognition. A strong trend toward inhibition was also observed in four of the five remaining conditions. Furthermore, significant effects of neighborhood density and target frequency were observed across all conditions. Words occurring in sparse neighborhoods were identified more accurately than words occurring in dense neighborhoods. Also, high frequency words were identified more accurately than low frequency words. All three of these findings are consistent with the predictions outlined in the introduction. The results of the neighborhood density and frequency manipulations are consistent with the earlier findings of Luce and Pisoni (1989).
The three individual conditions in which significant inhibition effects were obtained shared a common property: All three conditions contained low frequency primes. Although there was no overall main effect of prime frequency, these findings demonstrate that low frequency primes do indeed inhibit target recognition more than high frequency primes, as predicted by NAM.
The inhibition demonstrated in Experiment 1A presumably was caused by increased competition in the target words' neighborhoods due to the lingering activation of the prime. When a target is presented only 50 ms after a low frequency prime, it is assumed that more residual activation is still in the neighborhood than when a target follows a high frequency prime. This occurs because decisions regarding low frequency words are made more slowly than decisions regarding high frequency words, thus allowing activation levels for low frequency primes to linger for more time. As a consequence, more lexical candidates remain activated when the target is presented, thereby producing greater competition between the target and possible alternatives.
Experiment IB
Although the results indicating inhibition priming obtained in Experiment 1A were statistically significant under both subject and item analyses, a replication of these findings was undertaken because of the potential theoretical importance of the present set of results. An exact replication of Experiment 1A was performed with 38 new subjects. The stimuli, experimental procedure, subject characteristics, and data analyses were identical to those used in Experiment 1A.
Results
Figure 5 displays the results of the priming manipulation for all conditions. As in Experiment 1A, a four-way analysis of variance (Prime Type × Neighborhood Density × Prime Frequency × Target Frequency) was performed on the mean percentages of correct responses.
Fig. 5.

Percent correct identification for high and low frequency target words as a function of neighborhood density and prime frequency for related and unrelated primes. Light bars show performance for unrelated primes, dark bars show performance for related primes.
A significant effect of prime type was again obtained [F(l,37) = 36.10, MSe = .0081, p < .05]. (All reported results are significant at the .05 level or beyond.) In addition, a significant main effect of prime frequency was obtained [F(l,37) = 4.27, MSe = .1193], such that low frequency primes produced more inhibition than high frequency primes. As in Experiment 1A, an item analysis was also conducted to ensure that the effects were not due to any idiosyncratic stimulus items. By the item analysis, main effects of prime type [F(l,224) = 8.51, MSe = .0375] and of prime frequency [F(l,224) = 8.43, MSe = .0357] were again obtained. Therefore, not only was the effect of inhibition priming significant in the replication, but the overall effect of prime frequency, which was not significant in Experiment 1A, was now found to be statistically reliable in the replication. These findings provide strong support to the validity of the results obtained in Experiment 1A.
The predictions for Experiments 1A and IB were based on the assumption that any priming effects obtained would arise purely from the increased amount of general activation in the primed similarity neighborhood. Incorporated into this assumption was the previously stated assumption that the primes and targets were related so subtly that subjects would not be able to apply any decision strategies due to learning during the course of the experiment. Experiment 2 was conducted to validate these assumptions and to further examine the time course of the observed priming effect. Experiments 1A and IB employed a 50 ms delay between primes and targets. Experiment 2 was a replication of the first two experiments; however, the inter-stimulus interval was increased to 500 ms.
It is generally accepted that following stimulus recognition, activation in memory drops, returning eventually to some resting level (Collins & Loftus, 1975; McClelland & Elman, 1986). If the priming effects demonstrated in the first experiment were due only to competition at an activation level, it should be possible to eliminate the inhibition effects simply by allowing the activation to fade over time. We predicted that increasing the inter-stimulus interval from 50 to 500 ms would eliminate the inhibition from priming observed in Experiments 1A and IB. We also predicted, however, that the pattern of results found in Experiments 1A and IB with regard to the effects of target frequencies and neighborhood densities would remain unchanged in Experiment 2.
Experiment 2
Method
The stimuli and experimental design were the same as Experiments 1A and 1B. The procedure was identical to that of Experiments 1A and 1B, with the exception of the increased inter-stimulus interval between prime and target items.
Subjects
Sixty new subjects participated in partial fulfillment of the requirements of an introductory psychology course. All subjects were native speakers of English and reported no history of a speech or hearing disorder at the time of testing.
Results
The percentage of words correctly identified was determined for each subject. As in Experiments 1A and 1B, for a response to be considered correct, the entire response had to match the target exactly or be a homophone (e.g., there, their). Responses were corrected for simple spelling errors prior to analysis.
Figure 6 displays the results of the priming manipulation for all conditions. The effects of neighborhood structure and target frequency are shown in Fig. 7. These results are collapsed across prime type to better illustrate the effects of neighborhood density and target frequency.
Fig. 6.

Percent correct identification for high and low frequency target words as a function of neighborhood density and prime frequency for related and unrelated primes. Light bars show performance for unrelated primes; dark bars show performance for related primes.
Fig. 7.

Percent correct identification for high and low frequency target words as a function of neighborhood density and prime frequency, averaged over prime type. Light bars show performance for targets from sparse neighborhoods, whereas dark bars show performance for targets from dense neighborhoods. The left panel shows the results for high frequency targets; the right panel shows the results for low frequency targets.
A four-way analysis of variance (Prime Type × Density × Target Frequency × Prime Frequency) was performed on the mean percentages of correct responses for each condition. Significant main effects were obtained for neighborhood density [F(1,59) = 435.53, MSe = .0123, p < .05] and target frequency [F(1,59) = 245.58, MSe = .0122, p < .05]. (Again, as in Experiment 1A, all results are p < .05, unless stated otherwise.) As in Experiments 1A and 1B, these main effects showed that target recognition was more accurate for words selected from sparse neighborhoods than for words selected from dense neighborhoods, and that target recognition was more accurate for high frequency targets than for low frequency targets. No main effects of prime type [F(1,59) = 1.45, MSe = .0149, p = .233] or prime frequency [F(1,59) = 3.01, MSe = .012, p = .088] were obtained. However, a significant interaction of target frequency × neighborhood density was observed [F(1,59) = 6.30, MSe = .0133].
In addition to the overall ANOVA, an item analysis was again performed to ensure that the results were not due to a few idiosyncratic stimulus items. Significant main effects were again obtained for neighborhood density [F(1,232) = 18.45, MSe = .1475] and target frequency [F(1,232) = 10.07, MSe = .1475]. No main effects were obtained for prime type [F(1,232) = 0.16, MSe = .0126, p = .6864] or prime frequency [F(1,232) = 0.02, MSe = .1475, p = .8783]. There were no significant interactions obtained in the item analysis.
The results of Experiment 2 closely resemble those of Experiments 1A and 1B with respect to the effects of neighborhood density and target frequency on target recognition. However, as expected, we did not find any effects of inhibition as observed in Experiments 1A and 1B. (Indeed, an analysis of variance performed across Experiments 1A and 2 revealed a significant interaction of prime type × inter-stimulus interval [F(1,118) = 6.80, MSe = .0124, p < .05)].) Our hypothesis was that the inhibition obtained in Experiments 1A and 1B was caused by increased activation of words in the target's neighborhood resulting from previous recognition of the prime item. Following this reasoning, we predicted that this inhibition would not occur when a longer inter-stimulus interval was used because the residual activation in the neighborhood produced by the prime would have more time to drop to its resting level. The results obtained supported these predictions and lend credence to our interpretation of Experiments 1A and 1B.
General Discussion
The present experiments were undertaken in order to test several predictions of the Neighborhood Activation Model using a priming paradigm. We were specifically interested in directly testing the Neighborhood Probability Rule. Recall that the rule states that as activation of a neighborhood increases, the probability of recognizing a given stimulus word in that neighborhood will decrease. Exploiting this property of the rule, we predicted that priming a lexical neighborhood with a word phonetically similar to a subsequent target word would inhibit target recognition. Indeed, in Experiments 1A and 1B, we found that priming with a phonetically related neighbor inhibited target recognition, relative to a baseline determined by priming with an unrelated word. The short-lived effect of inhibition from priming observed in Experiments 1A and 1B appears to arise purely from the competing activation among phonetically similar lexical neighbors. This is evident by the null result of Experiment 2, in which the effects of priming were eliminated entirely by increasing the inter-stimulus interval from 50 to 500 ms.
In addition to the effects of priming, we also found that both neighborhood densities and item frequencies influenced target identification accuracy. Target words from sparse neighborhoods were identified better than target words from dense neighborhoods, and high frequency target words were identified better than low frequency target words.
The present experiments replicate the earlier findings of Luce and Pisoni (1989). Using perceptual identification, lexical decision, and naming paradigms, Luce and Pisoni obtained consistent results indicating that neighborhood density, neighborhood frequency, and item frequency are primary determinants of spoken word recognition performance. The present study, employing an auditory priming paradigm, has again demonstrated reliable effects of these same structural properties of similarity neighborhoods. When subjects were presented with low frequency targets from dense neighborhoods, performance was worst, whereas when they were presented with high frequency targets from sparse neighborhoods, performance was best. The inhibition effects, as well as the neighborhood effects observed here were all predicted by NAM.
Most contemporary models of word recognition, such as logogen theory (Morton, 1969), Forster's search theory (Forster, 1976), and cohort theory (Marslen-Wilson & Welsh, 1978; Marslen-Wilson & Tyler, 1980; Marslen-Wilson, 1987) assume that word frequency is directly represented in the resting activation levels, or in the relative speed of activation of words in long-term memory. In contrast, NAM does not make this assumption. Rather, in NAM, decision units that are sensitive to frequency information operate after activation has occurred and bias the decision units toward higher frequency words. In the priming paradigm, the effect of the prime on the identification of the target item is generally believed to arise from residual activation in long-term memory (e.g., Collins & Loftus, 1975; McClelland & Rumelhart, 1981; Slowiaczek, Nusbaum, & Pisoni, 1987). If activation arises directly from presentation of the prime, and if frequency information directly affects the level of activation, one would expect to find a reliable trend for high frequency primes to exert the largest influences on target identification. In the present experiment, we found that low frequency primes produce greater inhibition of target recognition than high frequency primes, a result that may be problematic for several current models that assert that frequency is coded in the activation levels themselves. In contrast, we predicted that low frequency primes would be recognized more slowly than high frequency primes. Consequently, low frequency primes would leave more residual activation and competition in the neighborhood than high frequency primes. This unresolved activation would produce added competition among phonetically similar words, making low frequency primes inhibit subsequent target items more than high frequency primes. This prediction was, in fact, confirmed in Experiments 1A and IB.
If word frequency were directly represented in the activation levels of words, however, high frequency primes should have produced stronger inhibition effects. This was clearly not the case, thus lending additional support to NAM's characterization of the role of frequency information in the decision stage of spoken word recognition.
In contrast to the present results demonstrating inhibition priming, numerous examples of facilitation priming in many different kinds of studies and different modalities of presentation have been reported in the literature (e.g., Collins & Loftus, 1975; Hillinger, 1980; Jakimik, Cole, & Rud-nicky, 1985; Slowiaczek, Nusbaum, & Pisoni, 1987). All of these studies obtained facilitation from priming whether presentation was visual or auditory and whether the relations between primes and targets were semantic or phonological. In one recent experiment, Slowiaczek, Nusbaum, and Pisoni (1987) presented prime-target pairs which overlapped by zero, one, two, or three phonemes. Their results showed that accuracy of target identification improved significantly as the number of overlapping phonemes between primes and targets increased. The contrasting results of the Slowiaczek et al. study and the present study raise two important questions. First, we must ask whether or not the current finding of inhibition from priming is supported in the literature. Second, we must ask why some priming procedures produce inhibition while others produce facilitation.
Just as one can find numerous examples of priming studies resulting in facilitation of target identification, one can also cite examples of priming studies demonstrating inhibition. The majority of these findings have been observed in semantic priming experiments using visual presentation (e.g., Meyer, Schvaneveldt, & Ruddy, 1974; Neely, Schmidt, & Roediger, 1983; Taraban & McClelland, 1987), but there have been some findings in auditory priming as well (e.g., Tanenhaus, Flanigan, & Seiden-berg, 1980; Slowiaczek & Pisoni, 1986). Especially interesting are the recent findings of Taraban & McClelland (1987). These researchers used a primed naming paradigm and measured latency of onset to pronounce visually presented target words and obtained results that were similar to the results of the present study. The authors discuss “conspiracy models” of word pronunciation and note that visually presented words with many orthographically similar neighbors are pronounced more slowly than words with few similar neighbors. This effect is analogous to the effects of neighborhood density found by Luce and Pisoni (1989) and replicated in the present study of spoken word recognition. Furthermore, Taraban and McClelland found that visually similar words presented as prime-target pairs produced longer latencies to pronounce and more mispronunciations than dissimilar words used as prime-target pairs. This effect is analogous to the effect of inhibition from priming obtained in the present study. In another study, Slowiaczek and Pisoni (1986) employed a phonological priming paradigm in a lexical decision task. Although their primary results showed facilitation, the authors did note that in certain instances of high phonological similarity between primes and targets, some evidence of inhibition was observed. They speculated that these effects might arise from competition among phonologically similar lexical candidates.
Thus, examples of both inhibition and facilitation from priming may be found in the literature. It is of interest to consider what the fundamental differences are between studies like the present one and those such as Slowiaczek et al. (1987) that give rise to these differential effects. The only dimension distinguishing the studies is the level of priming—Slowiaczek et al. primed at a phonological level whereas we primed at a lower acoustic-phonetic level. Luce (1986) has suggested that the facilitation effects found by Slowiaczek et al. may have been due to expectancies generated by subjects during the course of the experiment. It is not unreasonable to make such an assertion; although the primes and targets in the Slowiaczek et al. study shared as little as one common phoneme, subjects may have easily noticed the consistent phonological relationships and generated their responses from a strategically restricted set of response alternatives.3
A number of studies have suggested that facilitation produced by priming arises from biases. These biases may not necessarily exert their influences at a conscious response level as active decisions, but may be present as perceptual biases. For example, Becker and Killion (1977) reported facilitation in a primed lexical decision task. Upon examining their results, the authors speculated that if subjects are induced to expect targets to occur from a small set of possibilities, they may be able to bypass a process of feature extraction, but only if the presented stimulus matches properties of the expected set. The stimuli for the present study were selected specifically to avoid this possible confounding. Our primes and targets shared no identical segments at all, making it very unlikely that subjects could learn any meaningful relations and strategically modify their guessing to take advantage of any cross-trial regularities.
The results of the present study strongly support the theoretical predictions of NAM. However, it is appropriate to examine alternate models of word recognition and to apply their predictions to the present data. As noted in Slowiaczek et al., (1987) several contemporary models of spoken word recognition cannot adequately account for effects of acoustic-phonetic priming. For instance, neither Forster's (1976) search theory,4 nor Klatt's LAFS model (1980) can explain the present results, or those of Slowiaczek et al. This is the case because these models include no mechanisms for comparing previously recognized words to new inputs; they only compare inputs to stored lexical representations in memory. Similarly, Morton's (1969) logogen theory is not equipped to account for the present results because logogens are not supposed to affect the thresholds of other logogens in the system.
In a recent chapter, Marslen-Wilson (1987) has proposed a modified version of cohort theory. Because the original version of the theory never directly addressed issues of word frequency, Marslen-Wilson has conducted several cross-modal semantic priming lexical decision experiments with gated words equated for recognition points. From his results, Marslen-Wilson argues that frequency effects arise early in the perceptual process. Specifically, he claims that high frequency words are activated relatively faster than low frequency words in the same cohort, so they are recognized faster. Additionally, he has recently added some competitive processes to cohort theory which are similar to those proposed in NAM, stating that low frequency words are not only activated more slowly than high frequency words, but that they cannot be recognized until their higher frequency competitors have dropped below some criterial level of activation. These latest assumptions make it very difficult, however, to determine whether or not cohort theory can now account for the differential results of prime frequency obtained in the present study. The implication that high frequency words receive immediate strong activation may lead one to predict that high frequency primes would tend to overshadow subsequent targets more than low frequency primes. Experiments 1A and IB of the present study obtained exactly the opposite results. This disparity suggests that prime frequency may not be represented as a simple coding of an item's activation level. Low frequency primes seem to leave greater residual activation in the target's similarity neighborhood, and this extra activation translates into greater inhibition of target recognition performance. It may be necessary to employ sophisticated simulation analyses to adequately determine what cohort theory's predictions should be in this kind of situation.
In summary, the present study has demonstrated that priming a stimulus word with a phonetically related word will inhibit stimulus recognition. This effect is particularly robust when the prime items are low frequency words. The present study has also demonstrated that structural properties of lexical similarity neighborhoods are powerful predictors of spoken word recognition performance. These findings, taken together with the earlier findings of Luce and Pisoni (1989), provide additional support for the Neighborhood Activation Model. This model assumes that spoken words are recognized by initially activating a set of acoustically similar words in memory and then selecting from this set the item that is most consistent with the acoustic-phonetic information in the speech waveform. Word frequency is assumed to operate in the decision process to bias responses toward the more frequent lexical items in the activated neighborhood. We believe these attributes are primarily responsible for the speed, accuracy, and efficiency of the human word recognition system.
Acknowledgments
This research was supported by National Institutes of Health grant NS-12179 to Indiana University. We thank Jan Charles-Luce and Michael Cluff for their assistance in evaluating the stimuli, Richard Shiffrin, Gabriel Frommer, Denise Beike, and two anonymous reviewers for comments and suggestions, and Michael Dedina for his technical advice.
Footnotes
The authors may be contacted for complete lists of the stimuli used.
Phonetic similarities between primes and targets were computed by determining the values of SWP and NWP in the neighborhood probability rule. The actual values of SWP and NWP in the neighborhood probability rule were computed as follows: Individual confusion matrices for all initial and final consonants and vowels were obtained under appropriate S/N ratios. The stimulus word probabilities (SWPs) were then computed by multiplicatively combining the probabilities of the initial consonants, vowels and final consonants of the target stimulus words to render estimates of the SWPs based on the confusion matrices. For example, for the stimulus word /kot/ (“coat”), the stimulus word probability was computed as follows: SWP(/kot/) = p(k|k) * p(o|o) * p(t|t). This product expresses the probability of the /k/ in /kot/ given that /k/ was actually presented, the probability of /o/ given /o/ was actually presented, and the probability of /t/ given /t/ was actually presented. Using the confusion matrices in this manner, it was thus possible to obtain an estimate of p(/kot/|/kot/). In this manner, SWPs for all the target words were computed.
In order to obtain estimates of the NWPs, a similar procedure was employed. For example, in order to determine the NWP for /bæt/ (“bat”) given presentation of the stimulus word /kot/, the confusion matrices were again consulted. However, in this instance, an estimate of p(/bæt/|/kot/) was computed by multiplicatively combining the p(b|k), p(æ|o), and p(t|t). Thus, in the present study, those neighbors having the highest values for NWP that had no phonemic overlap with the target items were selected as primes.
If one considers these differential effects of priming in the context of an interactive activation model (e.g., McClelland & Rumelhart, 1987) another explanation is suggested. These models predict that a prime will have the effect of encouraging recognition of items that share their particular features. If this were indeed the case, easily recognized primes which share common phonemes with targets should increase the probability of target identification a priori, simply because the prime encourages guesses that share its features. It is not clear, therefore, whether facilitation from priming in an interactive activation model would represent a system in which activation from the prime actually facilitates activation of the target or if the experimental context of similar primes and targets simply correctly biases guessing.
Hillinger (1980) has pointed out that Forster's (1976) search model predicts that a “trail” of residual activation will be left after searching the peripheral access files. This feature of the model makes priming predictions possible. However, since Forster's access files are organized by frequency, one would expect that low frequency words could prime high frequency words, but not vice versa. The present study obtained priming effects despite frequency ordering (low frequency primes affected both high and low frequency targets).
References
- Balota DA, Chumbley JI. Are lexical decisions a good measure of lexical access? The role of word frequency in the neglected decision stage. Journal of Experimental Psychology: Human Perception and Performance. 1984;10:340–357. doi: 10.1037//0096-1523.10.3.340. [DOI] [PubMed] [Google Scholar]
- Becker CA, Killion TH. Interaction of visual and cognitive effects in word recognition. Journal of Experimental Psychology: Human Perception and Performance. 1977;3:389–401. [Google Scholar]
- Clark HH. The language-as-fixed-effect fallacy: A critique of language statistics in psychological research. Journal of Verbal Learning and Verbal Behavior. 1973;12:335–359. [Google Scholar]
- Collins A, Loftus E. A spreading activation theory of semantic processing. Psychological Review. 1975;82:407–428. [Google Scholar]
- Forster KI, Wales RJ, Walker E. New approaches to language mechanisms. North Holland; Amsterdam: 1976. Accessing the mental lexicon. [Google Scholar]
- Hillinger ML. Priming effects with phone-mically similar words: The encoding-bias hypothesis reconsidered. Memory & Cognition. 1980;8:115–123. doi: 10.3758/bf03213414. [DOI] [PubMed] [Google Scholar]
- Jakimik J, Cole RA, Rudnicky AI. Sound and spelling in spoken word recognition. Journal of Memory and Language. 1985;24:165–178. [Google Scholar]
- Klatt DH. Speech perception: A model of acoustic–phonetic analysis and lexical access. Journal of Phonetics. 1979;79:279–312. [Google Scholar]
- Kučera F, Francis W. Computational analysis of present day American English. Brown University Press; Providence, R.I.: 1967. [Google Scholar]
- Luce PA. Unpublished Doctoral dissertation. Indiana University; Bloomington, IN: 1986. Neighborhoods of words in the mental lexicon. [Google Scholar]
- Luce PA, Carrell TD. Creating and editing waveforms using WAVES. Speech Research Laboratory, Department of Psychology, Indiana University; Bloomington, IN: 1981. Research on Speech Perception, Progress Report No. 7. [Google Scholar]
- Luce PA, Pisoni DB. Neighborhoods of words in the mental lexicon. 1989. Manuscript under review. [Google Scholar]
- Luce RD. Individual choice behavior. New York; Wiley: 1959. [Google Scholar]
- Marslen-Wilson WD. Functional parallelism in spoken word recognition. Cognition. 1987;25:71–102. doi: 10.1016/0010-0277(87)90005-9. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson WD, Tyler LK. The temporal structure of spoken language understanding. Cognition. 1980;8:1–71. doi: 10.1016/0010-0277(80)90015-3. [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson WD, Welsh A. Processing interactions and lexical access during word recognition in continuous speech. Cognitive Psychology. 1978;10:29–63. [Google Scholar]
- McClelland JL, Elman JL. The TRACE model of speech perception. Cognitive Psychology. 1986;18:1–86. doi: 10.1016/0010-0285(86)90015-0. [DOI] [PubMed] [Google Scholar]
- McClelland JL, Rumelhart DE. An interactive activation model of context effects in letter perception: Part 1. An account of basic findings. Psychological Review. 1981;88:375–407. [PubMed] [Google Scholar]
- Meyer DE, Schvaneveldt RW, Ruddy MG. Functions of graphemic and phonemic codes in visual word recognition. Memory & Cognition. 1974;2:309–321. doi: 10.3758/BF03209002. [DOI] [PubMed] [Google Scholar]
- Morton J. Interaction of information in word recognition. Psychological Review. 1969;76:165–178. [Google Scholar]
- Neely JH, Schmidt SR, Roediger HL., III Inhibition from related primes in recognition memory. Journal of Experimental Psychology: Learning, Memory & Cognition. 1983;9:196–211. [Google Scholar]
- Nusbaum HC, Pisoni DB, Davis CK. Sizing up the Hoosier mental lexicon: Measuring the familiarity of 20,000 words. Speech Research Laboratory, Psychology Department, Indiana University; Bloomington, IN: 1984. Research on Speech Perception Progress Report No. 10. [Google Scholar]
- Slowiaczek LM, Nusbaum HC, Pisoni DB. Phonological priming in auditory word recognition. Journal of Experimental Psychology: Learning, Memory and Cognition. 1987;13:64–75. doi: 10.1037//0278-7393.13.1.64. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Slowiaczek LM, Pisoni DB. Effects of phonological similarity on priming in auditory lexical decision. Memory & Cognition. 1986;14:230–237. doi: 10.3758/bf03197698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanenhaus MK, Flanigan HP, Seidenberg MS. Orthographic and phonological activation in auditory and visual word recognition. Memory & Cognition. 1980;8:513–520. doi: 10.3758/bf03213770. [DOI] [PubMed] [Google Scholar]
- Taraban R, McClelland JL. Conspiracy effects in word pronunciation. Journal of Memory and Language. 1987;26:608–631. [Google Scholar]
- Webster's Seventh Collegiate Dictionary. Library Reproduction Service; Los Angeles: 1967. [Google Scholar]