

Abstract
We propose a shrinkage method to estimate the coefficient function in a functional linear regression model when the value of the coefficient function is zero within certain sub-regions. Besides identifying the null region in which the coefficient function is zero, we also aim to perform estimation and inferences for the nonparametrically estimated coefficient function without over-shrinking the values. Our proposal consists of two stages. In stage one, the Dantzig selector is employed to provide initial location of the null region. In stage two, we propose a group SCAD approach to refine the estimated location of the null region and to provide the estimation and inference procedures for the coefficient function. Our considerations have certain advantages in this functional setup. One goal is to reduce the number of parameters employed in the model. With a one-stage procedure, it is needed to use a large number of knots in order to precisely identify the zero-coefficient region; however, the variation and estimation difficulties increase with the number of parameters. Owing to the additional refinement stage, we avoid this necessity and our estimator achieves superior numerical performance in practice. We show that our estimator enjoys the Oracle property; it identifies the null region with probability tending to 1, and it achieves the same asymptotic normality for the estimated coefficient function on the non-null region as the functional linear model estimator when the non-null region is known. Numerically, our refined estimator overcomes the shortcomings of the initial Dantzig estimator which tends to under-estimate the absolute scale of non-zero coefficients. The performance of the proposed method is illustrated in simulation studies. We apply the method in an analysis of data collected by the Johns Hopkins Precursors Study, where the primary interests are in estimating the strength of association between body mass index in midlife and the quality of life in physical functioning at old age, and in identifying the effective age ranges where such associations exist.
Key words and phrases: B-spline basis function, functional linear regression, group smoothly clipped absolute deviation approach, null region
1. Introduction
We study the functional linear regression (FLR) model
| (1.1) |
where Yi denotes the ith response, Xid(t) are realizations of random processes Xd(t), βd(t) are the corresponding smooth coefficient functions on [0, T], and ei ~ N(0, σ2) are random errors independent of Xid(t), i = 1, 2, …, n. The response Y reflects the weighted cumulative effects of functional predictors Xd(t), and the coefficient functions βd(t) represent the corresponding weights. In practice, it is often of interest to know which areas of Xd(t) contribute to the value of Y and in what magnitude. That is, we are interested in learning the null region in which βd(t) = 0, and in estimating the values of βd(t) when they are non-zero.
Regression models with functional predictors have application in functional data analysis (FDA), and lately in longitudinal data analysis (LDA) when the longitudinal covariate measurements are collected intensively. Ramsay and Silverman (2005) and Ferraty and Vieu (2006) reviewed theoretical and methodological developments and gave many examples. A non-exhaustive list of recent works includes the followings. Estimation of βd(t) with a spline approach was proposed by Cardot, Ferraty, and Sarda (2003). Crambes, Kneip, and Sarda (2009) proposed a smoothing spline estimator of βd(t) with a new penalty term to ensure existence of the estimator, and studied its asymptotic behavior. Fan and Zhang (2000) studied the FLR problem with a functional response. Cai and Hall (2006) investigated prediction issues in FLR. With an additional link function in model (1.1), Müller and Stadtmüller (2005) studied the generalized functional linear model. Yao, Müller, and Wang (2005) extended the scope of the problem to cover longitudinal data. James, Wang, and Zhu (2009) emphasized the importance of the interpretability of βd(t) and proposed to use a version of the Dantzig selector (Candes and Tao (2007)) for this purpose. They equated the problem of identifying zero-value regions of the corresponding order derivative of βd(t) to that of variable selection in a multiple linear regression setting; however, to precisely identify the null region of βd(t), the Dantzig selector needs to use a large number of knots, and the quality of the estimated βd(t) deteriorates on the non-null region with the increasing number of knots. It is known that with the number of parameters increasing and increasing with sample size, the variation of estimation increases. We illustrate this phenomenon in our specific setting in Section 4. Further, the asymptotic distribution, a property tends to be desired by a functional data analysis approach, is not reported for their estimator. We derived the asymptotic distribution for our proposed estimator in Section 3.
In this paper, we propose a two-stage estimator to simultaneously identify the null region of βd(t) and estimate βd(t) on the non-null region. The goal behind this approach is to avoid having a large number of parameters in either stage and still maintain a high quality of estimation performance. We roughly identify the null region at stage one, and adaptively regularize the estimate of βd(t) on the null and non-null regions at stage two, applying different group penalties. At stage one, an initial estimator identifies and preferably over-estimates the null region; the desired precision is reached at the second stage. When the number of parameters is large, a direct implementation of the Dantzig selector gives poor estimation of the coefficient function in the non-null region. Our two-stage procedure simplifies the problem, naturally reduces over-shrinking of the coefficient functions in the non-null region, and achieves superior numerical performance.
We structure the paper as follows. In Section 2, we present our proposed method as a B-spline approximation coupled with shrinkage, which takes the advantage of the local property of B-spline basis functions. In Section 3, we show that the proposed estimator enjoys the Oracle property and we give its asymptotic distribution. Simulation studies are reported in Section 4. In Section 5, we apply the proposed method to data from the Johns Hopkins Precursors Study to investigate the effect of body mass index at midlife on a quality of life index for physical functioning at old age. Concluding remarks are given in Section 6. Assumptions for the theoretical properties and sketch of the proofs are provided in the Appendix. The exact algorithms to implement the proposed method, detailed proofs, and additional numerical results are reported in a supplementary document.
2. Estimation of Coefficient Functions and Their Null Regions
To simplify the notation and presentation, we take D = 1, suppress the subscript d in model (1.1), and write
| (2.1) |
We assume ei ~ N (0, σ2) and μ = 0. Without loss of generality, we let σ = 1. Generalization of the method to the cases D > 1 is discussed in Section 2.3. The asymptotic properties under (2.1) can be extended to model (1.1).
As in James, Wang, and Zhu (2009), we assume that the processes Xi(t) are known while, in practice, Xi(t) are usually not completely observable. Instead, the observations (Yi, tij, Xij) are available for i = 1, …, n and j = 1, …, mi, where Xij = Xi(tij). In practice, Xi(t) are measured at discrete and perhaps irregular time points and it is common to include a pre-smoothing step. See Ramsay and Silverman (2005) for insight and illustrations, and Hall and Van Keilegom (2008) for theoretical considerations. We report the effects of pre-smoothing in the numerical studies.
For estimating the coefficient function, β(t), as well as identifying its null region, denoted by
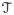 , we use B-splines. Given k0,n + 1 evenly-spaced knots, 0 = τ0 < τ1 < τ2 < … < τk0,n−1< τk0,n = T, let Ij = [τj−1, τj] for j = 1, …, k0,n. Associated with this set of knots, there are (k0,n + h) B-spline basis functions, B0(t) = (B0,1(t), …, B0,k0,n+h(t))T, each of which is a piecewise polynomial of degree h with support on at most h+1 subintervals Ij. The upper panel of Figure 1 shows the seven basis functions with h = 2 and knots {0.0, 0.2, 0.4, 0.6, 0.8, 1.0}. Given the sample size n and the k0,n + 1 knots, the coefficient function can be expressed as
, we use B-splines. Given k0,n + 1 evenly-spaced knots, 0 = τ0 < τ1 < τ2 < … < τk0,n−1< τk0,n = T, let Ij = [τj−1, τj] for j = 1, …, k0,n. Associated with this set of knots, there are (k0,n + h) B-spline basis functions, B0(t) = (B0,1(t), …, B0,k0,n+h(t))T, each of which is a piecewise polynomial of degree h with support on at most h+1 subintervals Ij. The upper panel of Figure 1 shows the seven basis functions with h = 2 and knots {0.0, 0.2, 0.4, 0.6, 0.8, 1.0}. Given the sample size n and the k0,n + 1 knots, the coefficient function can be expressed as
Figure 1.

Local support of B-spline basis function.
| (2.2) |
where b0 = (b0,1, …, b0,k0,n+h)T is the B-spline approximation coefficient, e0(t) is an approximation error that is uniformly bounded on [0, T] with the bound going to 0 as k0,n goes to infinity. For details on B-spline approximation, see Schumaker (1981). Using the B-spline approximation for β(t) in (2.2), (2.1) can be re-written as
| (2.3) |
where z0,i is a (k0,n + h) × 1 vector with the jth element , and Y and Z0 are, respectively, the n × 1 vector and n × (k0,n + h) matrix that contain Yi and z0,i as entries.
Note that the choices of B0(t), Ij, and consequently, the values of b0, e0(t), ε0,i and z0,i, vary with the sample size n. To simplify notation, the subscript n is suppressed; we use the subscript 0 to indicate the association with the initial stage.
2.1. Initial estimate of the null region
It is convenient to let the end points of
fall on the end points of certain subintervals Ij. With the initial knots
, assume each Ij is entirely contained either in
or in
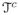 , the complement of
. Having no prior information on the location of
, we use a moderate number of evenly-spaced internal knots on [0, T]. The initial location of
can be roughly established through Ij and an estimate of b0 in (2.3).
, the complement of
. Having no prior information on the location of
, we use a moderate number of evenly-spaced internal knots on [0, T]. The initial location of
can be roughly established through Ij and an estimate of b0 in (2.3).
We use the Dantzig selector to estimate b0 at this stage, argminb||b||l1 subject to , with being the kth column of Z0, , and ||b||l1 denoting the L1 norm of b. We denote this initial estimate of b0 by b̃0. The conditions of equivalence between the Dantzig selector and LASSO have been reported in James, Radchenko, and Lv (2009), Bickel, Ritov, and Tsybakov (2009), and references therein. It is not essential to have high precision during this stage, so other regularization estimators such as LASSO or SCAD can be used here, even though the simulation outcomes from James, Wang, and Zhu (2009) imply numerical advantages of the Dantzig selector over LASSO. For further details on the Dantzig selector, see Candes and Tao (2007).
With the B-spline basis supported on at most h + 1 subintervals, the value of
on a single subinterval Ij is determined by h +1 coefficients in b0. For example, in Figure 1, the estimated β(t) for any t ∈ [0.4, 0.6] depends only on the coefficients of the three basis functions in the lower panel. When the h + 1 coefficients associated with Ij are all 0, the subinterval Ij is contained in the null region of
; otherwise, it is in the non-null region. In practice, even if Ij ⊂
, its associated h + 1 coefficients in b0 might not all be 0, but we only need a rough estimate of null region at this stage. We simply use a small threshold value at the initial stage to identify the subintervals within the null region of β(t). Thus, if the absolute values of all h + 1 coefficients are smaller than dn, we classify the corresponding Ij as part of
. The union of all identified subintervals is taken as the initial estimate of
, denoted by
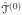 . We let the threshold value dn go to 0 as n goes to infinity. The rates of dn and k0,n are given and discussed in Section 3, and their numerical determination is in Section 4.
. We let the threshold value dn go to 0 as n goes to infinity. The rates of dn and k0,n are given and discussed in Section 3, and their numerical determination is in Section 4.
2.2. Null region refinement and function estimation
The second stage of our estimator refines the estimated location of
and the estimate of β(t) on
. We develop a grouped smoothly-clipped absolute deviation (SCAD) method and a boundary grid-search algorithm at the second stage to refine the null region and to achieve the estimate of β(t) on
. The asymptotic distribution of the estimated β(t) can be naturally established. Our estimator overcomes the concerns of large numbers of parameters, maintains the sparse property, readily adopts the existing efficient computation algorithm, and achieves desired numerical and theoretical qualities.
In Stage 1, k0,n+1 evenly-spaced internal knots are placed in [0, T] to identify the initial estimate of
; in Stage 2, we use a grid-search based algorithm to find the refined null region within
by examining a sequence of working null regions
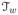 ⊆
. We let the search algorithm and the penalty determination in grouped SCAD share the same objective function so that we can conduct the evaluation jointly. A practical algorithm of specifying a sequence of
’s is given in the supplementary document.
⊆
. We let the search algorithm and the penalty determination in grouped SCAD share the same objective function so that we can conduct the evaluation jointly. A practical algorithm of specifying a sequence of
’s is given in the supplementary document.
Having
, we remove all initial knots within
, and place k1,n +1 evenly-spaced knots on
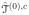 , with k1,n < k0,n in general. With the grid size in the boundary search procedure not related to k1,n, the determination of grid size is a numerical decision. The smaller grid size gives more precise boundary but can lead to a computationally more demanding task. In our simulation studies, we used a grid size of 0.02T, where T is the range of t.
, with k1,n < k0,n in general. With the grid size in the boundary search procedure not related to k1,n, the determination of grid size is a numerical decision. The smaller grid size gives more precise boundary but can lead to a computationally more demanding task. In our simulation studies, we used a grid size of 0.02T, where T is the range of t.
Using the new set of knots corresponding to each
, we generate a new set of B-spline basis functions
and the corresponding new variables,
following the same procedure described below (2.3). Moreover, (2.1) can be rewritten as
| (2.4) |
where and are equivalently defined as b0, z0,i and Z0, respectively, in (2.3), and the ith entry of is , with the approximation error . As in (2.3), , and vary with the sample size n. The subscript n is suppressed to simplify the notation, and the subscript 1 indicates the association with the refinement stage.
To estimate
, we propose a group penalized least squares method. According to
, the coefficients in b are divided into groups bN,w (null) and bS,w (signal). Specifically, if a subinterval is part of
, then all coefficients bi that are associated with this subinterval are put into bN,w; the group bS,w contains the remainder.
Different penalty functions are available in the literature, including the L2 penalty of ridge regression, the L1 penalty of LASSO regression (Tibshirani (1996)), and the SCAD penalty function (Fan and Li (2001)). We use the SCAD penalty function with coefficients in the two groups bN,w and bS,w penalized separately. Using the L2 penalty does not help us to identify
, and Zou (2006) pointed out that the LASSO estimator is not consistent, which prevented us from considering the group LASSO (Yuan and Lin (2006)). That SCAD penalizes less on coefficients with large absolute values allows the non-zero coefficient functions to be better estimated. With the division of b into bN,w and bS,w,
is estimated as the minimizer of the objective function
where pλ(·) is the SCAD penalty of Fan and Li (2001), defined through its derivative
; a is usually taken as 3.7, and λ is a tuning parameter selected by the criterion C(
, λ), which can be the generalized cross validation criterion (GCV), Akaike’s information criterion (AIC), the Bayesian information criterion (BIC; Schwarz), or the residual information criterion (RIC), as specified in the supplementary document. By calculating a criterion for each working
, we simultaneously select the
and λ, that minimize it. Penalizing the coefficients, b, in groups helps to shrink the coefficients in bN,w to zero, simultaneously.
Given an initial value of , the local quadratic approximation (LQA) is used in the algorithm of Fan and Li (2001) to approximate the penalty function. However, as pointed out in Zou and Li (2008), the LQA estimator does not provide a sparse representation. Instead, Zou and Li (2008) proposed a one-step local linear approximation (LLA) and converted the SCAD problem to a LASSO regression that utilized the LARS algorithm of Efron et al. (2004) to get the sparse estimate. We use the LLA for the group penalty in our method for the same reason.
Let b̃1 be the initial estimate, which can be the ordinary least squares estimator, and b̃1N,w and b̃1S,w be the coefficients inside and outside the working null region
, respectively. We approximate the group penalty pλ(||bN,w||l1) by
The penalty pλ(||bS,w||l1) is approximated equivalently. Using these approximations, we estimate by minimizing the objective function
| (2.5) |
With ||bN,l||lwand ||bS,l||lw as the L1 norms of bN,w and bS,w and and as weights, the task of minimizing Qn(b) can be carried out using the adaptive LASSO of Zou (2006) and the efficient LARS algorithm of Efron et al. (2004). By the LLA, the coefficients within the same group are penalized with the weights according to their group memberships. When as λ → 0, the coefficients in bS,w are barely penalized. As a result, the estimation bias of β(t) on , induced by the shrinkage penalty, can be greatly reduced.
For a fixed dimension of the regression parameters, we note that Wang, Chen, and Li (2007) developed an alternative group SCAD estimator using the L2-norm and the local quadratic approximation. Their estimator does not have a sparse representation, so our procedure is more suitable here.
To summarize, we take the refined estimate of the null region,
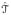 , as
, as
| (2.6) |
With
| (2.7) |
the refined estimate of β(t) is
where B1(t) are the B-spline basis functions associated with
.
2.3. Generalization to D > 1
We have taken D = 1 in (1.1). When D > 1, all steps can be carried out without much modification, as follows. After obtaining variables z0,i for each βd(t), the Dantzig selector can be applied to obtain initial estimates simultaneously for each βd(t) by including the variables z0,i of all βd(t) in (2.3). The adaptive knots and the variables z1,i in (2.4) can then be obtained one by one for each d. Finally, after having the variables
of all βd(t) in (2.4), the refinement procedure with group SCAD is performed with the coefficient b in Qn(
, λ,
b) partitioned into 2D groups, two groups being associated with each βd(t).
3. Oracle Property
In this section, we show that, under certain conditions, our estimator enjoys the Oracle property for identifying
and for estimating β(t) on
. The conditions and the proofs of the theorems are deferred to the Appendix or to the supplementary document.
Recall that the parameters b0 and b1 in (2.3) and (2.4) vary with the sample size n. In the asymptotic studies, we denote them as b0(n) and b1(n), respectively. Similarly, B1(t) is denoted as B1(n, t), the initial estimator of b0(n) as b̃0(n), and the refined estimator of b1(n) as b̂1(n). The tuning parameter λ is denoted as λn.
For the estimator in the initial stage, we have an asymptotic result.
Theorem 1
Let b̃0(n) = (b̃0,1(n), …, b̃0,k0,n+h(n))T be the Dantzig estimate of b0(n), with ei ~ N (0, 1) and μ = 0. For the tuning parameter in the Dantzig selector, and under the conditions A1–A6 in the Appendix, we have
||b̃0(n)− b0(n)||l2 = Op{n−1/2k0,n(logk0,n)1/2};
sup|b̃0,j(n)| = Op{n−1/2k0,n(logk0,n)1/2}for b0,j(n) associated with
;-
With probability tending to 1,
where, with r ≥ 3 as in the condition A1, is a sub-region of [0, T], converging to the empty set as n → ∞.
Theorem 1 shows that the Dantzig selector estimate of b0(n) is consistent. The L2 convergence rate follows from Bickel, Ritov, and Tsybakov (2009); see also Raskutti, Wainwright, and Yu (2010); The sup-norm convergence rate can be derived following Lounici (2008); proof of part (iii) is given in the supplementary document.
Let the n × (k1,n + h) matrix Z1(n) = (z1,1,
z1,2, …,
z1,n)T, where z1,i is defined in (2.4). Recall that the estimate of the coefficient function is
, where B1(n, t) contains the B-spline basis functions at the refinement stage. Further, divide the basis functions B1(n, t) into B1N (n, t) and B1S(n, t) and the matrix Z1(n) into Z1N (n) and Z1S(n), according to the membership of their corresponding coefficients b1N (n), related to the null region
, and b1S(n).
For the estimator in the refinement stage, we have an asymptotic result.
Theorem 2
Assume the conditions A1–A8 in the Appendix and an initial estimator with the rate ||b̃1(n) − b1(n)||l2= Op(n−1/2k1,n), with ei ~ N(0, 1) and μ = 0.
for t ∈
, we have β̂(t) = 0, with probability tending to 1.-
for t ∈, we have
where
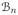 (t) denotes the estimation bias,
is the B-spline approximation error, and
(t) denotes the estimation bias,
is the B-spline approximation error, and
- With in A5, we have
The assumed rate for the initial estimator b̃1(n) is verified for the ordinal least squares estimator in the supplementary document.
Properties in Theorems 1 and 2 correspond to the Oracle properties reported in Zou (2006). Precisely, with a large n, we are able to identify the correct subregions in which the coefficient functions are non-zero; furthermore, we are able to estimate the values of the coefficient functions on the non-null regions as if we knew their exact locations.
4. Finite Sample Numerical Performances
We conducted simulation studies to evaluate the finite sample performance of our estimators.
Study 1
In this simulation study, we considered two covariate functions and the model
for i = 1, 2, …, n, with random errors ei ~ N(0, 1). The covariate functions Xi1(t) and Xi2(t) were quadratic spline functions on [0, 10] with 50 equally-spaced knots and the corresponding coefficients were generated uniformly from [−5, 5]. We took m = 50 observations within [0, 10] from the true functions as the observed data and re-constructed Xi1(t) and Xi2(t) by B-spline approximations. We used coefficient functions β1(t) and β2(t) as follows.
β1(t) was a piecewise quadratic function generated from quadratic B-spline functions with evenly-spaced knots at {0.0, 0.5, …, 9.5, 10.0}, while its coefficients were from a 22×1 vector with the last eight entries (2.0, 2.3, 2.5, 2.7, 2.7, 2.7, 2.6, 2.6)T, and the rest of the entries zero.
- The non-zero part of β2(t) was a Trigonometric function:
These coefficient functions are plotted in Figure 2. The shape of the function β1(t) is commonly observed in biological studies; it indicates the pattern of growing into a stable state. As shown in the figure, β1(t) = 0 on [0, 6] and β2(t) = 0 on [0, 7].
Figure 2.

Plots of β1(t) and β2(t) for Study 1.
In each study, we generated 250 data sets with sample size n = 150. To evaluate the performance of the estimator, the estimated functions β̂1(t) and β̂2(t) were compared to the corresponding true functions. For the comparison, we report two quantities,
For β1(t),
= [0, 6],
= (6, 10], and l0 = 6, l1 = 4. For β2(t),
= [0, 7],
= (7, 10], and l0 = 7, l1 = 3. The quantity A0 measures the integrated absolute differences between the estimated coefficient functions and the true functions on the null regions, while A1 measures it on the non-null regions.
We first evaluate the performance of the Dantzig estimates of βd(t) (d = 1, 2) with different numbers of knots. Ideally, in order to reach high precision in determining the null region with a direct application of the Dantzig selector, one would need a very large number of knots. However, performance also deteriorates when the number of parameters is very large. Here, we can decide the number of variables in our problem, and design the procedure to improve numerical performance. Below, we show the effect of the total number of knots, k0,n + 1, on the performance of the Dantzig estimator of βd(t), varying the number of knots among k0,n = 50, 100, 200, and 300.
The performances of the estimated coefficient functions by least squares with k0,n = 50, and the Dantzig selector with k0,n = 50, 100, 200, and 300, are summarized in Table 1. The entries of the table give the Monte Carlo averages of A0 and A1 over the 250 generated data sets, while the corresponding standard deviation is reported in parentheses. Since the same Xi1(t) and Xi2(t) were generated for each value of k0,n, the results of the Dantzig estimator in Table 1 differ only by k0,n. Table 1 shows that the least square estimator performed poorly on both regions, even with 50 knots. The Dantzig estimator performed well on the null region throughout, which is indicated by the small values of A0. However, its estimation of βd(t) on the non-null regions was increasingly worse with growth in the number of knots. The poor performance of the Dantzig estimator on the non-null regions in Table 1 indicates the necessity of a refining stage.
Table 1.
Integrated absolute biases of the least squares and the Dantzig estimates for Study 1. Each entry is the Monte Carlo average of Aj, j = 0 or 1; the corresponding standard deviation is reported in parentheses.
| β1(t) | β2(t) | |||||
|---|---|---|---|---|---|---|
|
| ||||||
| Estimator | k0;n | A0 | A1 | A0 | A1 | |
|
|
||||||
| Least Squares | 50 | 2.220 (1.414) | 3.272 (2.150) | 1.905 (1.253) | 3.982 (2.783) | |
| Dantzig Selector | 50 | 0.005 (0.010) | 0.695 (0.090) | 0.004 (0.007) | 0.792 (0.114) | |
| Dantzig Selector | 100 | 0.010 (0.019) | 1.416 (0.100) | 0.009 (0.014) | 1.687 (0.136) | |
| Dantzig Selector | 200 | 0.008 (0.021) | 2.318 (0.102) | 0.006 (0.013) | 2.661 (0.141) | |
| Dantzig Selector | 300 | 0.007 (0.020) | 2.724 (0.104) | 0.004 (0.011) | 3.120 (0.133) | |
We next evaluate the performance of the proposed one-step group SCAD estimator. The method, as described in Sections 2.1 to 2.3 with D = 2, refined the initial null region estimates and estimated βd(t) on the non-null regions simultaneously, using the proposed algorithm. Based on the theoretical rates in Section 3, we let k0,n = ck0n0.23, k1,n = ck1n0.20, and dn = cdn−0.25. We used a 10-fold cross validation on five data sets to choose the c’s, and then fixed them throughout the simulation. With the grid-search algorithm to determine the boundary of null regions, we do not expect outcomes to be sensitive to the choices of ck0 and cd, and a bad choice could simply lead to more computation in locating the boundaries at the second stage. This is indeed the case. The 10-fold CV results are indifferent over the range of cd we tried, cd varying from 0.05 to 0.5 (dn varying between 0.014 and 0.143). The CV values varied near their minimums for k0,n between 35 and 55 for all five data sets. We used k0,n = 50 ≈ 13n0.23, k1,n = 12 ≈ 4.5n0.20, and dn = 0.2n−0.25. For comparison, we calculated the adaptive LASSO estimates of βd(t) by estimating the B-spline coefficients associated with the same adaptive knots, with the adaptive weights (Zou (2006)) being the inverse of absolute values of initial estimates by least squares. The criterion C(
, λ) was specified as GCV, AIC, BIC, or RIC, defined in the supplementary document. The same set of criteria were also used to select the tuning parameter in adaptive LASSO. The performances of estimated coefficient functions with AIC and BIC criteria, as well as the Oracle estimates that used the known null regions, are summarized in Table 2. The results with GCV and RIC, which are comparable to those with AIC and BIC, are reported in the supplementary document. The outcomes show that the criteria work about equally well. We tried different k0,n values but, as expected, they do not play much of a role in our procedure.
Table 2.
Integrated absolute biases of the least squares, the Dantzig selector, the adaptive LASSO (adpLASSO), and the one-step group SCAD (gSCAD) estimates for Study 1. Each entry is the Monte Carlo average of Aj, j = 0 or 1; the corresponding standard deviation is reported in parentheses.
| β1(t) | β2(t) | |||
|---|---|---|---|---|
|
| ||||
| Estimator | A0 | A1 | A0 | A1 |
|
|
||||
| Oracle Estimator | - | 0.157 (0.041) | - | 0.166 (0.046) |
| Least Squares | 2.205 (1.432) | 3.283 (2.549) | 1.963 (1.256) | 4.088 (2.716) |
| Dantizig Selector | 0.006 (0.013) | 0.692 (0.094) | 0.006 (0.010) | 0.821 (0.132) |
| adpLASSO AIC | 0.041 (0.030) | 0.193 (0.059) | 0.036 (0.028) | 0.214 (0.069) |
| adpLASSO BIC | 0.031 (0.031) | 0.212 (0.059) | 0.025 (0.029) | 0.240 (0.074) |
| gSCAD AIC | 0.024 (0.033) | 0.143 (0.038) | 0.024 (0.030) | 0.155 (0.048) |
| gSCAD BIC | 0.004 (0.013) | 0.140 (0.037) | 0.003 (0.009) | 0.154 (0.049) |
It may seem surprising that the Oracle estimator gives slightly larger A1 values than the proposed estimators. This is due to the fact that the proposed estimators shrink the small non-zero values on the boundary toward zero, and consequently achieve less varied and better estimated outcomes near the null boundary.
The initial null regions of β1(t) and β2(t) identified by the Dantzig selector and the refined null regions of the one-step group SCAD method are shown in Table 3, where the averages of the lower and upper limits of the estimated null regions over the 250 generated data sets, as well as the corresponding standard deviations in parentheses, are summarized. The true null regions are [0, 6] for β1(t) and [0, 7] forβ2(t), respectively.
Table 3.
Null region estimates for Study 1. Each entry is the Monte Carlo average of estimated boundary of the null region; the corresponding standard deviation is reported in parentheses.
| β1(t) | β2(t) | |||
|---|---|---|---|---|
|
| ||||
| Estimator | lower | upper | lower | upper |
|
|
||||
| Dantzig Selector | 0.008 (0.064) | 6.230 (0.175) | 0.002 (0.038) | 7.123 (0.202) |
| gSCAD AIC | 0.011 (0.091) | 5.773 (0.479) | 0.004 (0.063) | 6.666 (0.528) |
| gSCAD BIC | 0.010 (0.082) | 6.058 (0.171) | 0.003 (0.051) | 6.951 (0.181) |
As shown in Tables 2 and 3, the least squares estimates of βd(t) are poor on both null and non-null regions of βd(t). The Dantzig selector tends to have less favorable performance on the non-null regions of βd(t). Moreover, the initial null region identified by it tends to be larger than the true region. The one-step group SCAD method seems to satisfactorily estimate the coefficient functions on both null and non-null regions. Furthermore, by refining the null region initial estimates, our method, particularly using the BIC or RIC criterion, tends to identify the null regions of βd(t) with a greater accuracy than the Dantzig selector. The one-step group SCAD method also outperforms adaptive LASSO on both null and non-null regions.
The full simulation results with GCV, AIC, BIC, and RIC criteria, reported in the supplementary document, show that the performances of the criteria in the method are, in general, satisfactory; see Wang, Li, and Tsai (2007) for another report of using these four criteria in comparison of performances of SCAD methods. The results show that BIC and RIC are less conservative in identifying the null regions. This is expected because the BIC and RIC criteria put heavier penalty on the effective number of parameters than the AIC criterion (Shi and Tsai (2002)).
One advantage of the proposed estimators is that they readily provide inferences for non-zero coefficient functions. Here, we computed the variance of the point estimator given in Theorem 2 and constructed the pointwise 95% confidence interval according to the asymptotic normality results in Theorem 2 for t in the non-null regions. At each point, the true value of coefficient function β1(t) or β2(t) was compared with the computed pointwise 95% confidence interval, and the coverage probabilities (CP) of the confidence intervals were computed over the 250 generated data sets. Besides CP, we also calculated the Monte Carlo biases, standard deviations (SD), and mean square errors (MSE) for points in the non-null regions. For β1(t), we took t = 6.1, 6.2, ···, 10.0, and for β2(t), t = 7.1, 7.2, ···, 10.0. Using AIC and BIC, the entries of Table 4 give the averages of Monte Carlo biases, SDs, MSEs, and CP over these points, while the corresponding standard deviation is reported in parentheses. The coverage probabilities of the confidence intervals, computed over the 250 generated data sets at these points in the non-null regions of β1(t) and β2(t), are plotted in Figure 3, for AIC and BIC. Table 4 shows that the estimators based on AIC and BIC perform similarly on the non-null regions and all yield coverage probabilities of the pointwise confidence intervals close to the nominal level 0.95. The slightly lower coverage probabilities than the nominal level is due to the shrinkage of the estimates for t close to the boundary of the null regions, as shown in Figure 3. The GCV and RIC criteria have similar performances to AIC and BIC; their results are reported in the supplementary document.
Table 4.
Monte Carlo bias, standard deviation (SD), mean squared error (MSE), and empirical coverage probability (CP) of 95% pointwise confidence intervals of group SCAD (gSCAD) estimates for Study 1. Each entry is the average over the selected points in the non-null region of β1(t) or β2(t); the corresponding standard deviation is reported in parentheses.
|
β1(t)
|
||||
|---|---|---|---|---|
| Estimator | Ave. MC Bias | Ave. MC SD | Ave. MC MSE | CP |
|
|
||||
| gSCAD AIC | 0.004 (0.013) | 0.201 (0.213) | 0.085 (0.331) | 0.932 (0.047) |
| gSCAD BIC | −0.001 (0.019) | 0.195 (0.218) | 0.084 (0.339) | 0.928 (0.094) |
|
β2(t)
|
||||
| Estimator | Ave. MC Bias | Ave. MC SD | Ave. MC MSE | CP |
|
|
||||
| gSCAD AIC | −0.006 (0.031) | 0.224 (0.247) | 0.110 (0.394) | 0.924 (0.053) |
| gSCAD BIC | −0.012 (0.043) | 0.221 (0.242) | 0.107 (0.378) | 0.915 (0.098) |
Figure 3.

Empirical coverage probabilities (CP) of 95% pointwise confidence intervals for coefficient estimate over non-null region of β1(t) and β2(t) for Study 1, by AIC and BIC. For β1(t), the points are taken at t = 6.1, 6.2, ···, 10.0, for β2(t), the points are taken at t = 7.1, 7.2, ···, 10.0.
We also briefly investigated the effects of having irregularly spaced time points by dropping 10% and 20% of the observations on Xi1(t) and Xi2(t) at random from the simulated data, followed by a pre-smoothing step. Our procedure was then applied to the pre-smoothed data. The relative performance of least squares, the Dantzig selector, the adaptive LASSO, and the one-step group SCAD, were similar to what is seen in Tables 1–4. We noted a slight decrease in the average coverage probabilities. For example, for group SCAD with the AIC criterion, the coverage probabilities for β1(t) and β2(t) were 90.6% and 88.7% for 10% dropped, and 87.7% and 85.6% for 20% dropped. A further investigation indicated that the decrease in average coverage probabilities mainly occurred near the boundary of null regions. This observation implies that the performance of our estimators near the boundary of null regions tends to be subject to the influence of the locations and numbers of observations on the covariate functions Xi1(t) and Xi2(t).
Study 2
We conducted a second simulation study with
and ei ~ N(0, 0.25). The covariate functions Xi(t) were generated and reconstructed on [0, 1] by the same methods as in Study 1. The coefficient function was β(t) = max[0, 8log(t + 1) sin{3.5π(t − 0.2)}], shown in Figure 4. Its null region is
= [0.0, 0.2]∪[0.486, 0.771].
Figure 4.

Plot of β(t) for Study 2.
We generated 250 data sets with sample size n = 500. The 10-fold CV results suggested the use of a much smaller k0,n; we took k0,n = 20, k1,n = 10, and dn = n−0.25. The equivalent results to those in Study 1 are reported in Tables 5 to 7. The 95% CI overage probabilities (CP) are reported over t = 0.21, 0.22, …, 0.48, 0.78, 0.79, …, 1.00 within
. Tables 5 and 6 show that the method has better performance overall in estimating β(t) and identifying the null region of β(t) than the other methods, and behaves similarly as the oracle estimator. The Dantzig estimator tends to yield larger A1, as usual. We repeated the simulation with k0,n = 50 while keeping the rest of the setup unchanged. The Monte Carlo averages of A0 for least-squares, Dantzig, adaptive LASSO (AIC), and grouped SCAD (AIC) were 3.755, 0.001, 0.198, and 0.043, respectively, while the corresponding values for A1 were 3.840, 0.849, 0.268, and 0.246. Similar performances were obtained using other criteria. We note that the outcomes for adaptive LASSO and our method change little, mainly due to the slight changes of boundaries and the knot locations at the second stage. The least-squares and Dantzig estimators again suffered from the large number of parameters.
Table 5.
Integrated absolute biases of the least squares, the Dantzig selector, the adaptive LASSO (adpLASSO), and the one-step group SCAD (gSCAD) estimates for Study 2. Each entry is the Monte Carlo average of Aj, j = 0 or 1; the corresponding standard deviation is reported in parentheses.
| Estimator | A0 | A1 |
|---|---|---|
|
|
||
| Oracle Estimator | - | 0.257 (0.054) |
| Least Squares | 0.246 (0.060) | 0.240 (0.054) |
| Dantzig Selector | 0.006 (0.007) | 0.485 (0.069) |
| adpLASSO AIC | 0.066 (0.063) | 0.246 (0.063) |
| adpLASSO BIC | 0.023 (0.041) | 0.278 (0.079) |
| gSCAD AIC | 0.038 (0.076) | 0.230 (0.054) |
| gSCAD BIC | 0.009 (0.020) | 0.226 (0.056) |
Table 7.
Monte Carlo bias, standard deviation (SD), mean squared error (MSE), and empirical coverage probability (CP) of 95% pointwise confidence intervals of group SCAD (gSCAD) estimates for Study 2. Each entry is the average over the selected points in the non-null region of β1(t) or β2(t); the corresponding standard deviation is reported in parentheses.
|
β1(t)
|
||||
|---|---|---|---|---|
| Estimator | Ave. MC Bias | Ave. MC SD | Ave. MC MSE | CP |
|
|
||||
| gSCAD AIC | −0.012 (0.055) | 0.296 (0.173) | 0.120 (0.265) | 0.950 (0.016) |
| gSCAD BIC | −0.020 (0.072) | 0.286 (0.183) | 0.120 (0.272) | 0.951 (0.020) |
Table 6.
Null region estimates for Study 2. Each entry is the Monte Carlo average of estimated boundary of the null region; the corresponding standard deviation is reported in parentheses.
| [0.000, 0.200] | [0.486, 0.771] | |||
|---|---|---|---|---|
|
| ||||
| Estimator | lower | upper | lower | upper |
|
|
||||
| Dantzig Selector | 0.001 (0.009) | 0.199 (0.016) | 0.502 (0.014) | 0.749 (0.008) |
| gSCAD AIC | 0.001 (0.009) | 0.194 (0.021) | 0.507 (0.019) | 0.744 (0.016) |
| gSCAD BIC | 0.001 (0.009) | 0.199 (0.016) | 0.502 (0.014) | 0.749 (0.008) |
5. The Johns Hopkins Precursors Study
The impact of cumulative lifelong risk exposure on quality of life (QoL) in old age is of great interest to researchers. We applied our method to data from the Johns Hopkins Precursors Study to investigate the effect of body mass index (BMI) at midlife on the quality of life at older ages. In this, we focused on the outcome of physical functioning (PF), an important QoL measure among the elderly, collected through the SF-36 health survey questionnaires (Ware and Sherbourne (1992)), with a score that ranged from 0 to 100. We restricted our analysis to data from 107 participants who had their PF scores assessed between 70 and 76 years of age. The age range of interest for the BMI was 40 to 70 years. The transformed PF score, was used as the response in model (2.1).
To obtain each participant’s trajectory of BMI on [40, 70], we first pre-smoothed the available BMI records for each subject (Ramsay and Silverman (2005)). The pre-smoothed and centered BMI trajectories on [38, 72] were then fitted by quadratic B-splines with evenly-spaced knots of {38, 40, ···, 70, 72}. In the initial stage of the method, the functional coefficient on [40, 70] was approximated by quadratic splines with evenly-spaced knots of {40, 42, ···, 68, 70}. The Dantzig selector, with the tuning parameter selected by leave-one-out cross validation, yielded the initial null region [40, 52] ∪ [58, 70]. The initial estimate of β(t) by the Dantzig selector is plotted in Figure 6.
Figure 6.

The estimated coefficient function for BMI in the Johns Hopkins Precursors Study. The upper panel shows the initial estimate by Dantzig selector. The lower panel shows the refined estimate by the proposed one-step group SCAD estimator with the dotted lines being the 95% pointwise CI for it in the refined non-null region [46, 64]. The AIC and RIC criteria yield the same refined estimates.
During the refining stage, we specified the working null regions as [40, 52 − l] ∪ [58 + l, 70] and let l = 0, 1, 2,···, 10. Using the method proposed in Section 2.2, the refined null region selected by both AIC and RIC was [40, 46] ∪ [64, 70]. The two criteria also led to identical refined estimates of β(t) on [40, 70], as well as the same pointwise 95% confidence intervals; they are plotted in Figure 6.
Figure 6 shows that greater values of BMI between ages 46 and 64 seem to be associated with greater decrease in the PF scores in early to mid 70 years of age. The 95% pointwise confidence intervals of β(t) on [46, 64], albeit not significant, are almost all in the negative range. In contrast to our approach, the Dantzig selector identified a larger null region and shrunk the estimated coefficient function on the non-null region toward zero. This is consistent with what we observed in the simulation study. The zero coefficient function in the mid-forties and younger implies that a greater BMI at this age range does not contribute much to additional risk of decreasing PF scores, after factoring in body weight patterns in the subsequent two decades. On the other hand, the zero coefficient function after the mid-sixties could be due to a mixture of two forces; high BMI is harmful in general, but being too thin may not be a good sign among the elderly either.
The non-significant finding could be due to the relatively small number of participants in our sample and the modest association between BMI and the PF scores, not uncommon in this kind of study. To better understand whether we had sufficient power to confirm a modest association, we conducted a small power analysis. In the analysis, we specified the true coefficient function as the curve estimated by the proposed method. Then, conditional on the available BMI records, we generated new PF scores according to the fitted model and applied the method to calculate 95% confidence intervals. The proportions of pointwise 95% confidence intervals that were completely negative at ages 50, 55, and 60, with the λ in SCAD penalty being fixed at the value selected in the data analysis, were 0.496, 0.256, and 0.522, respectively. The finding from the Precursors Study data nevertheless suggests the potential for added benefit of slower decline in physical functioning at old age in keeping a healthy body weight in midlife.
6. Concluding Remarks
With the development in variable selection when the number of predictors is large, we advance a method to estimate coefficient functions in functional linear model when the values of the functions are zero in certain sub-regions. Our aim is a functional data analysis (FDA) tool in which the final estimator on the non-null region behaves just like a regular FDA solution. Our estimator successfully attains the properties we desire: it maintains the sparsity and Oracle properties in the estimated coefficient functions, asymptotic normality applies, and it achieves superior numerical performances compared to existing alternatives in both identification of
and the estimation of β(t). The proposed procedure borrows strength from existing efficient algorithms and can be easily carried out.
An additional point is that in functional data analysis, we select the number of basis functions and determine the number of parameters needed. When the number is unavoidably large, as in the variable selection problems in genomic studies, even the best estimator can be poor. When we reduce the number of parameters, we simplify the nature of the problem and consequently obtain improved results. There are alternatives to what we have proposed. In our method, as indicated in the supplementary document, we shrank the limits of each null interval in a symmetric way with a grid size of 0.02T. More effective search ideas, such as a combination of shrinking and expanding around the limits, could be conducted and should lead to some improvement. The performance of the estimates on the non-null region can be further improved by an adaptive selection of knots, as in the regular B-spline smoothing estimation. We have not pursued these directions here.
Supplementary Material
Figure 5.

Empirical coverage probabilities (CP) of 95% pointwise confidence intervals for coefficient estimate over non-null region of β(t) for Study 2, by AIC and BIC. The points are taken at t = 0.21, 0.22, ···, 0.48, 0.78, 0.79, ···, 0.99, 1.00.
Acknowledgments
Zhou’s research was supported by the National Science Foundation (DMS-0906665). N.-Y. Wang’s research was supported by grants from the National Institutes of Health (UL1 RR025005 and P60 DK79637). N. Wang’s research was supported by a grant from the National Cancer Institute (CA74552). The Johns Hopkins Precursors Study is supported by a grant from the National Institute on Aging (R01 AG01760).
Appendix: Assumptions and Technical Details
We provide the assumptions behind the theoretical properties and sketch their proofs in the Appendix; refer to the supplementary document for further details.
A.1. Notation and assumptions
Recall that k0,n + 1, k1,n + 1 are the numbers of knots, and Z0(n) and Z1(n) are the design matrices in models (2.3) and (2.4) for the two stages, respectively.
Let
be a standardized version of Z0(n) such that
has its diagonal elements, Ψz0*(j, j) ≡ 1, for all j. Take δb0(n) = b̃0(n) − b0(n), and let δb0,
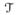 (n) and δb0,
(n) and δb0,
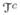 (n) be δb0(n), corresponding to null and signal regions, respectively, with s(n) the number of non-zero coefficients in b0(n). Recall the definitions of Z1N (n) and Z1S(n) in Section 3. To show the Oracle properties of the proposed estimator, consider the following conditions.
(n) be δb0(n), corresponding to null and signal regions, respectively, with s(n) the number of non-zero coefficients in b0(n). Recall the definitions of Z1N (n) and Z1S(n) in Section 3. To show the Oracle properties of the proposed estimator, consider the following conditions.
A1: β (t) has rth (r ≥ 3) bounded derivative on [0, T].
A2: , for i = 1, 2, …, n and some constant M′ < ∞.
- A3: For some integers less than k0,n + h and non-zero δbo(n),
- A4: For a constant γ > 1 and s ≥ s(n),
A5: For k0,n, and . For k1,n, .
A6: For the threshold value dn, and .
A7: For the tuning parameter λn, λn → 0 and .
-
A8: There are constants such thatwhere λmin(A) and λmax(A) denote the smallest and largest eigenvalues of the matrix A. The same eigenvalue condition as for holds for the matrices and . In addition,
for a constant c3 > 0.
Condition A2 is weaker than one assumed in James, Wang, and Zhu (2009). The restricted eigenvalue condition A3 from Bickel, Ritov, and Tsybakov (2009) controls the singularity of the first stage design matrix to ensure the L2 rate, while A4 is required to warrant the sup-norm rate in Theorem 1. The rate of the threshold value dn given in condition A6 guarantees that, with probability tending to 1 as n → ∞,
is correctly identified by
. Condition A8 is analogous to one in Fan and Peng (2004) when the number of predictors increases with n. It appears as lemmas in Zhou, Shen and Wolfe (1998) and Zhu, Fung and He (2008); to avoid redundancy, we simply use it as a condition.
A.2. Sketch Proof of Theorem 2
We use an > Op(bn) and an ≥ Op(bn) to denote that, as n → ∞ with probability tending to 1, bn/an → 0 and bn/an is bounded from above, respectively. Here we sketch the key steps in the proof of Theorem 2. Recall that b1N (n) and b1S(n) are the division of b1(n) according to
. Since b1N (n) contains the coefficients associated with
, by Theorem 1 (iii), these coefficients are either associated with
or with Ω(k0,n). Consequently, by A5,
. Following the proof of Part (iii) of Theorem 1 in the supplementary document, it is easy to see that ||b1S(n)||l1 ≥ Op(1).
We assume the initial value b̃1(n) satisfies ||b̃1(n) − b1(n)||l2 = Op(n−1/2
k1,n). Note that b̃1N (n) and b̃1S(n) are the division of b̃1(n) according to
. Given ||b̃1N (n) − b1N (n)||l1 ≤ C||b̃1N (n) − b1N (n)||l2= Op(n−1/2k1,n),
, and A5, we have that
and ||b̃1S (n)||l2 ≥ Op(1). Given A7, with probability tending to 1, we have that
and
.
Let Qn be Qn(
, λ,
b) in (2.5), and focus on the expansion of Qn{b̂1(n)} − Qn{b1(n)}as
where b̂1N (n),
b̂1S(n) and b1N (n),b
b1S(n) are the divisions of b̂1(n) and b1(n), respectively, according to their association with
. Handling the null and non-null coefficients separately, we show, with some detailed derivation, that a non-optimal bound for the convergence rate of b̂1(n) holds as
; this rate is sufficient for us to use in the proof of Theorem 2. The proof of b̂1,j(n) = 0, with probability tending to 1, for any b̂1,j(n) associated with
, is a direct consequence of this convergence. Part (i) is proved.
We have
and
with probability tending to 1. We now give the key steps that lead to the asymptotic distribution of β̂(t) for t ∈
. For large n, we have
By Huang (1998), Un(t) is the asymptotic normal component, is the estimation bias, and Wn(t) contains the spline approximation error.
Given that e(n)~ N(0, In), we have that, for t ∈
,
where .
By A8, . Thus, we have for some constant C, and for some constant C′. Then
Also by A8, we have
By A5, each coefficient in b1N (n) is bounded by for some constant C′. Combined with the fact that by A7, we can show that
Therefore, we have
The term
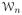 (t) is the B-spline approximation error at β(t). Given A1 and the B-spline approximation property, we have
(t) is the B-spline approximation error at β(t). Given A1 and the B-spline approximation property, we have
Therefore we have, for t ∈
,
Part (ii) is proved.
Assuming the additional stronger condition
in A5, it follows that (n/k1,n)1/2|
(t)| = op(1) and (n/k1,n)1/2|
(t)| = op(1). Therefore we have, for t ∈
,
Part (iii) is proved.
Footnotes
SuppDoc.pdf describes the aglorithms, the technical proofs, and provides additional tables and figures for the outcomes of the numerical studies.
Contributor Information
Jianhui Zhou, Email: jz9p@virginia.edu.
Nae-Yuh Wang, Email: naeyuh@jhmi.edu.
Naisyin Wang, Email: nwangaa@umich.edu.
References
- Bickel PJ, Ritov Y, Tsybakov AB. Simultaneous analysis of LASSO and Dantzig selector. The Annals of Statistics. 2009;37:1705–1732. [Google Scholar]
- Cai T, Hall P. Prediction in functional linear regression. The Annals of Statistics. 2006;34:2159–2179. [Google Scholar]
- Candes E, Tao T. The Dantzig selector: Statistical estimation when p is much larger than n. The Annals of Statistics. 2007;35:2313–2351. [Google Scholar]
- Cardot H, Ferraty F, Sarda P. Spline estimators for the functional linear model. Statistica Sinica. 2003;13:571–591. [Google Scholar]
- Crambes C, Kneip A, Sarda P. Smoothing spline estimators for functional linear regression. The Annals of Statistics. 2009;37:35–72. [Google Scholar]
- Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression (with discussion) The Annals of Statistics. 2004;32:407–499. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Fan J, Peng H. Nonconcave penalized likelihood with a diverging number of parameters. The Annals of Statistics. 2004;32:928–961. [Google Scholar]
- Fan J, Zhang J. Two-step estimation of functional linear models with application to longitudinal data. Journal of the Royal Statistical Society B. 2000;62:303–322. [Google Scholar]
- Ferraty F, Vieu P. Nonparametric Functional Data Analysis: Theory and Practice. Springer-Verlag; New York: 2006. [Google Scholar]
- Hall P, Van Keilegom I. Two-sample tests in functional data analysis starting from discrete data. Statistica Sinica. 2008;17:1511–1531. [Google Scholar]
- Huang JZ. Projection estimation in multiple regression with application to functional anova models. The Annals of Statistics. 1998;26:242–272. [Google Scholar]
- James G, Radchenko P, Lv J. DASSO: Connections Between the Dantzig Selector and Lasso. Journal of the Royal Statistical Society B. 2009;71:127–142. [Google Scholar]
- James G, Wang J, Zhu J. Functional linear regression that’s interpretable. The Annals of Statistics. 2009;37:2083–2108. [Google Scholar]
- Lounici K. Sup-norm convergence rate and sign concentration property of Lasso and Dantzig estimators. Electronic Journal of Statistics. 2008;2:90–102. [Google Scholar]
- Müller HG, Stadtmüller U. Generalized functional linear models. The Annals of Statistics. 2005;22:774–805. [Google Scholar]
- Ramsay JO, Silverman BW. Functional Data Analysis. Springer; New York: 2005. [Google Scholar]
- Raskutti G, Wainwright MJ, Yu B. Restricted eigenvalue conditions for correlated Gaussian designs. Journal of Machine Learning Research. 2010;11:22412259. [Google Scholar]
- Schumaker LL. Spline Functions: Basic Theory. John Wiley & Sons; New York: 1981. [Google Scholar]
- Shi P, Tsai CL. Regression model selection{a residual likelihood approach. Journal of the Royal Statistical Society B. 2002;64:237–252. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society B. 1996;58:267–288. [Google Scholar]
- Wang H, Li R, Tsai CL. Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika. 2007;94:553–568. doi: 10.1093/biomet/asm053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang L, Chen G, Li H. Group SCAD regression analysis for microarray time course gene expression data. Bioinformatics. 2007;23:1486–1494. doi: 10.1093/bioinformatics/btm125. [DOI] [PubMed] [Google Scholar]
- Ware JE, Sherbourne CD. The MOS 36-item short-form health survey (SF-36): I. conceptual framework and item selection. Med Care. 1992;30:473–483. [PubMed] [Google Scholar]
- Yao F, Müller HG, Wang JL. Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association. 2005;100:577–590. [Google Scholar]
- Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society B. 2006;68:49–67. [Google Scholar]
- Zhou S, Shen X, Wolfe DA. Local asymptotics for regression splines and confidence regions. The Annals of Statistics. 1998;26:1760–1782. [Google Scholar]
- Zhu Z, Fung WK, He X. On the asymptotics of marginal regression splines with longitudinal data. Biometrika. 2008;94:907–917. [Google Scholar]
- Zou H. The adaptive LASSO and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models (with discussion) The Annals of Statistics. 2008;36:1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.