

Abstract
We propose a generalized double Pareto prior for Bayesian shrinkage estimation and inferences in linear models. The prior can be obtained via a scale mixture of Laplace or normal distributions, forming a bridge between the Laplace and Normal-Jeffreys’ priors. While it has a spike at zero like the Laplace density, it also has a Student’s t-like tail behavior. Bayesian computation is straightforward via a simple Gibbs sampling algorithm. We investigate the properties of the maximum a posteriori estimator, as sparse estimation plays an important role in many problems, reveal connections with some well-established regularization procedures, and show some asymptotic results. The performance of the prior is tested through simulations and an application.
Keywords: Heavy tails, high-dimensional data, LASSO, maximum a posteriori estimation, relevance vector machine, robust prior, shrinkage estimation
1. Introduction
There has been a great deal of work in shrinkage estimation and simultaneous variable selection in the frequentist framework. The LASSO of Tibshirani (1996) has drawn much attention to the area, particularly after the introduction of LARS (Efron et al. (2004)) due to its superb computational performance. There is a rich literature analyzing the LASSO and related approaches (Fu (1998), Knight and Fu (2000), Fan and Li (2001), Yuan and Lin (2005), Zhao and Yu (2006), Zou (2006), Zou and Li (2008)), with a number of articles considering asymptotic properties.
Bayesian approaches to the same problem became popular with the works of Tipping (2001) and Figueiredo (2003). By expressing Student’s t priors for basis coefficients as scale mixtures of normals (West (1987)), and relying on type II maximum likelihood estimation (Berger (1985)), Tipping (2001) developed the relevance vector machine for sparse estimation in kernel regression. In this setting, however, exact sparsity comes with the price of forfeiting propriety of the posterior by driving the scale parameter of the Student’s t distribution toward zero. In fact, driving both the scale parameter and the degrees of freedom to zero yields the so-called Normal-Jeffreys’ prior, π(θ) ∝ 1|θ|. The name emerges due to the fact that the hierarchy follows as θ ~ N(0, τ), π(τ) ∝ 1/τ, where the latter is the Jeffreys’ prior on the prior variance of θ. Figueiredo (2003) proposed an expectation-maximization algorithm for maximum a posteriori estimation under Laplace and Normal-Jeffreys’ priors, with estimates under the Laplace corresponding to the LASSO. The Normal-Jeffreys’ prior leads to substantially improved performance with finite samples due to the property of strongly shrinking small coefficients to zero while minimally shrinking large coefficients due to the heavy tails; however, it has no meaning from an inferential aspect as it leads to an improper posterior.
A Bayesian LASSO was proposed by Park and Casella (2008) and Hans (2009). However, these procedures inherit the problem of over-shrinking large coefficients due to the relatively light tails of the Laplace prior. Strawderman-Berger priors (Strawderman (1971), Berger (1980)) have some desirable properties yet lack a simple analytic form. Recently proposed priors have been designed to have high density near zero and heavy tails without the impropriety problem of Normal-Jeffreys. The horseshoe prior of Carvalho, Polson, and Scott (2009, 2010) is induced through a carefully-specified mixture of normals, leading to such desirable properties as an infinite spike at zero and very heavy tails. They studied sparse shrinkage estimation properties of the horseshoe in a normal means problem. Griffin and Brown (2007, 2010) proposed an alternative class of hierarchical priors for shrinkage with some similarities to the prior we propose, but it lacks a simple analytic form that facilitates the study of some properties.
There is a need for alternative shrinkage priors that lead to sparse point estimates if desired, do not over-shrink coefficients that are not close to zero, facilitate straight-forward computation even in large p cases, and result in a joint posterior distribution that does a good job of quantifying uncertainty. We propose the generalized double Pareto prior which independently finds mention in Cevher (2009). It has a simple analytic form, yields a proper posterior, and possesses such appealing properties as a spike at zero, Student’s t-like tails, and a simple characterization as a scale mixture of normals that leads to a straightforward Gibbs sampler for posterior inferences. We consider both fully Bayesian and frequentist penalized likelihood approaches based on this prior. We show that the induced penalty in the regularization framework yields a consistent thresholding rule having the continuity property in the orthogonal case, with a simple expectation-maximization algorithm described for sparse estimation in non-orthogonal cases. In another independent work motivated by applications to genome wide associations studies, Lee et al. (2011) consider a generalized t prior (McDonald and Newey (1988)) that includes the generalized double Pareto as a special case. Similarities to previous work are limited and our contributions beyond them are (i) the formal introduction of a generalized Pareto density, thresholded and folded at zero, as a shrinkage prior in Bayesian analysis, (ii) the scale mixture representation of the generalized double Pareto in Proposition 1 which is central to our work, (iii) its connection to the Laplace and Normal-Jeffreys’ priors as limiting cases in Proposition 2, (iv) the resulting fully conditional posteriors in a linear regression setting along with a simple Gibbs sampling procedure, (v) a detailed discussion on the hyper-parameters α and η and their treatment, along with the incorporation of a griddy sampling scheme into the Gibbs sampler, (vi) a detailed analysis of the induced penalty by the generalized double Pareto prior and the properties of the resulting thresholding rule, (vii) an explicit analytic form for the maximum a posteriori estimator in orthogonal cases, (viii) an expectation-maximization procedure to obtain the maximum a posteriori estimate in non-orthogonal cases using the normal mixture representation, (ix) the one-step estimator (Zou and Li (2008)) resulting from the Laplace mixture representation, revealing the connection of the resulting procedure to the adaptive LASSO of Zou (2006), and (x) the oracle properties of the resulting estimators.
2. Generalized Double Pareto Prior
The generalized double Pareto density is
| (2.1) |
where ξ > 0 is a scale parameter and θ > 0 is a shape parameter. In contrast to (2.1), the generalized Pareto density of Pickands (1975) is parametrized in terms of a location parameter , a scale parameter ξ > 0, and a shape parameter as
| (2.2) |
with θ ≥ μ for α > 0 and μ ≤ θ ≤ μ − ξα for α < 0. The mean and variance for the generalized Pareto distribution are for α ∉ [0, 1] and for α ∉ [0, 2]. If we let μ = 0, (2.2) becomes an exponential density as α → ∞ with mean ξ and variance ξ2.
To modify the generalized Pareto density to be a shrinkage prior, we let μ = 0 and reflect the positive part about the origin, assuming α > 0, for a density that is symmetric about zero. The mean and variance for the generalized double Pareto distribution are for α > 1 and for α > 2. The dispersion is controlled by ξ and α, with α controlling the tail heaviness and α = 1 corresponding to Cauchy-like tails and no finite moments.
Figure 2.1 compares the density in (2.1) to Cauchy and Laplace densities for the special case ξ = α = 1, so that f(θ) = 1/{2(1 + |θ|)2}. We refer to this form as the standard double Pareto. Near zero, the standard double Pareto resembles the Laplace density, suggesting similar sparse shrinkage properties of small coefficients in maximum a posteriori estimation. It also has Cauchy-like tails, which is appealing in avoiding over-shrinkage away from the origin. This is illustrated in Figure 2.1(a). Figure 2.1(b) illustrates how the density in (2.1) changes for different values of ξ and α.
Figure 2.1.

(a) Probability density functions for standard double Pareto (solid line), standard Cauchy (dashed line) and Laplace (dot-dash line) (λ = 1) distributions. (b) Probability density functions for the generalized double Pareto with (ξ, α) values of (1, 1) (solid line), (0.5, 1) (dashed line), (1, 3) (long-dashed line), and (3, 1) (dot-dash line).
Prior (2.1) can be represented as a scale mixture of normal distributions leading to computational simplifications. As shorthand notation, let θ ~ GDP(ξ, α) denote that θ has density (2.1).
Proposition 1. Let θ ~ N(0, τ), τ ~ Exp(λ2/2), and λ ~ Ga(α, η), where α > 0 and η > 0. The resulting marginal density for θ is GDP(ξ = η/α, α).
Proposition 1 reveals a relationship between the prior in (2.1) and the prior of Griffin and Brown (2007), with the difference being that Griffin and Brown (2007) place a mixing distribution on λ2 leading to a marginal density on θ with no simple analytic form.
In Proposition 2 we show that the prior in (2.1) forms a bridge between two limiting cases – Laplace and Normal-Jeffreys’ priors.
Proposition 2. Given the representation in Proposition 1, θ GDP(ξ = η/α, α) implies
f(θ) ∝ 1/|θ| for α = 0 and η = 0,
f(θ|λ′) = (λ′/2) exp (−λ′|θ|) for α → ∞, α/η = λ′ and 0 < λ′ < ∞
Proof. For the first item, setting α = η = 0 implies placing a Jeffreys’ prior on λ, π(λ) ∝ 1/λ. Integration over λ yields π(τ) ∝ 1/τ, which implies the Normal-Jeffreys’ prior on θ. For the second item, notice that π(λ) = δ(λ − λ′), where δ(.) denotes the Dirac delta function, since and . Thus, .
As noted in Polson and Scott (2010), if π(τ) has exponential or lighter tails, observations are shrunk towards zero by some non-diminishing amount, regardless of size. This phenomenon is well-understood and commonly observed in estimation under the Laplace prior, where an exponential density mixes a normal density. The higher-level mixing (over λ) in Proposition 1 allows π(τ) to have heavier tails, remedying the unwanted bias.
As α grows, the density becomes lighter tailed, more peaked and the variance becomes smaller, while as η grows, the density becomes flatter and the variance increases. Hence if we increase α, we may cause unwanted bias for large signals, though causing stronger shrinkage for noise-like signals; if we increase η we may lose the ability to shrink noise-like signals, as the density is not as pronounced around zero; and finally, if we increase α and η at the same rate, the variance remains constant but the tails become lighter, converging to a Laplace density in the limit. This leads to over-shrinking of coefficients that are away from zero. As a typical default specification for the hyperparameters, one can take α = η = 1. This choice leads to Cauchy-like tail behavior, which is well-known to have desirable Bayesian robustness properties.
To motivate this default choice, we assess the behavior of the prior shrinkage factor κ = 1/(1 + τ) ∈ (0, 1), where θ ~ N(0, τ) is the parameter of interest (Carvalho et al. (2010)). As κ → 0, the prior imposes no shrinkage, while as κ → 1 it has a strong pull towards zero. The generalized double Pareto distribution implies a prior π(κ) on κ upon integration over λ in Proposition 1. For the standard double Pareto, this is
where Erfc(.) denotes the complementary error function. In Figure 2.2, we compare π(κ) under the standard double Pareto, Strawderman-Berger, horseshoe, and Cauchy priors, which may all be considered default choices. The priors behave similarly for κ ≈ 0, implying similar tail behavior. The behavior of π(κ) for κ ≈ 1 governs the strength of shrinkage of small signals. As κ → 1, π(κ) tends towards zero for the Cauchy, implying weak shrinkage, while π(κ) is unbounded for the horseshoe, suggesting a strong pull towards zero for small signals. The Strawderman-Berger and standard double Pareto priors are a compromise between these extremes, with π(κ) bounded for κ → 1 in both cases. The standard double Pareto assigns higher density close to one than the Strawderman-Berger prior, and has the advantage of a simple analytic form over the Strawderman-Berger and horseshoe priors.
Figure 2.2.

Prior density of κ implied by the standard double Pareto prior (solid line), Strawderman–Berger prior (dashed line), horseshoe prior (dot-dash line) and standard Cauchy prior (dotted line).
Of course it is best to adjust α and η according to any available prior information pertaining to the sparsity structure of the estimated vector. For general α > 0 and η > 0 values, the prior on κ is
| (2.3) |
where denotes the confluent hypergeometric function. Note that π(κ|α, η) takes a “horseshoe” shape when α = η = 0. Carvalho, Polson, and Scott (2010) show that π(κ) ∝ κ−1(1−κ)−1 implies a Normal-Jeffreys’ prior on θ, which can also be observed by setting α = η = 0 in (2.3) in conjunction with Proposition 1. Hence π(κ|α, η) is unbounded at κ = 1 forcing π(θ|α, η) to be unbounded at 0 only if η = 0. The effects of α and η are now observed with better clarity from Figure 2.3. As η increases, less and less density is assigned to the neighborhood of κ ≈ 1, repressing shrinkage. On the other hand, increasing α values place more and more density in the neighborhood of κ ≈ 1 promoting further shrinkage. This notion is later reinforced by Proposition 3, such that the prior induces a thresholding rule under maximum a posteriori estimation if . Hence, we need to carefully pick these hyper-parameters, in particular α, as there is a trade-off between the magnitude of shrinkage and tail robustness.
Figure 2.3.

Prior density of κ (a) when α = 1 and η = 0.5 (dashed), η = 1 (solid), η = 2 (dot-dash) (b) when η = 1 and α = 1 (solid), α = 2 (dashed), α = 3 (dot-dash).
3. Bayesian Inference in Linear Models
Consider the linear regression model y = Xβ + ∊, where y is an n-dimensional vector of responses, X is the n × p design matrix and ∊ ~ N (0, σ2In). Letting βj|σ ~ GDP(ξ = ση/α, α) independently for j = 1, …, p,
| (3.1) |
From Proposition 1, this prior is equivalent to βj|σ ~ N(0, σ2τj), with and λj ~ Ga(α, η). We place the Jeffreys’ prior on the error variance, π(σ) ∝ 1/σ.
Using the scale mixture of normals representation, we obtain a simple data augmentation Gibbs sampler having the conditional posteriors (β|σ2, T, y) ~ N (X′X + T−1)−1X′y, σ2 (X′X + T−1)−1, (σ2|β, T, y) ~ IG{(n + p)/2, (y − Xβ)′(y − Xβ)/2}, (λj|βj, σ2) ~ Ga(α + 1, |βj|/σ + η), , where T = diag(τ1, …, τp) and Inv-Gauss denotes the inverse Gaussian distribution with location and scale parameters μ and ρ. In our experience, this Gibbs sampler is efficient with fast rates of convergence and mixing.
In the absence of any prior information on α and η, one may either set them to their default values or, as an alternative, choose hyper-priors to allow the data to inform about the values of α and η. We use π(α) = 1/(1+α)2 and π(η) = 1/(1+η)2 to correspond to generalized Pareto hyper-priors with location parameter 0, scale parameter 1 and shape parameter 1. The median value of the resulting distribution for α and η is 1, centered at the default choices suggested earlier, while the mean and variance do not exist.
For sampling purposes, let a = 1/(1+α) and e = 1/(1+η). These transformations suggest a uniform prior on a and e in (0, 1) given the generalized Pareto priors on α and η. Consequently, the conditional posteriors for a and e are
We propose the embedded griddy Gibbs (Ritter and Tanner (1992)) sampling scheme:
Form a grid of m points a(1), …, a(m) in the interval (0, 1).
Calculate w(k) = π(a(k)|β, η).
Normalize the weights, .
Draw a sample from the set {a(1), …, a(m)} with probabilities {}, and set α = 1/a − 1 to be used at the current iteration of the Gibbs sampler.
Repeat the same procedure for e and obtain a random draw for η. We also experiment with fixing η as 1 while treating α as unknown. In this case, the prior variance of β|σ2 is determined by α.
In what follows we establish the ties between the Bayesian approach we have taken and some frequentist regularization approaches. The simple analytic structure of the generalized double Pareto prior facilitates analyses while its hierarchical formulation leads to straight-forward computation.
4. Sparse Maximum a Posteriori Estimation
The generalized double Pareto distribution can be used not only as a prior in a Bayesian analysis, but also to induce a sparsity-favoring penalty in regularized least squares:
| (4.1) |
where X is initially assumed to have orthonormal columns and p(.) denotes the penalty function implied by the prior on the regression coefficients. Following Fan and Li (2001), let , and denote the minimization problem in (4.1) for a component of β as
| (4.2) |
with the penalty function p(|βj|) = (α + 1) log (ση + |βj|) that simply retains the term in −log π(βj|α, η) that depends on βj.
From Fan and Li (2001), a good penalty function should result in an estimator that is (i) nearly unbiased when the true unknown parameter is large, (ii) a thresholding rule that automatically sets small estimated coefficients to zero to reduce model complexity, and (iii) continuous in data () to avoid instability in model prediction. In the following, we show that the penalty function induced by prior (3.1) may achieve these properties.
4.1. Near-unbiasedness
The first order derivative of (4.2) with respect to βj is , where p′(|βj|) = ∂p(|βj|)/∂|βj| is the term causing bias in estimation. Although it is appealing to introduce bias in small coefficients to reduce the mean squared error and model complexity, it is also desirable to limit the shrinkage of large coefficients with p′(|βj|) → 0 as |βj| → ∞. In addition, it is desirable for p′(|βj|) to approach zero rapidly, implying shrinkage, and the associated introduction of bias rapidly decreases as coefficients get further away from zero. In fact, the rate of convergence of p′(|βj|) to zero is of the same order under the generalized double Pareto and Normal-Jeffreys’ priors, with . As α controls the tail heaviness in the generalized double Pareto prior, with lighter tails for larger values of α, convergence of the ratio to (α + 1) is intuitive. In the case of LASSO, the bias, p′(|βj|), remains constant regardless of |βj|, which can also be observed in Figure 4.4(b).
Figure 4.4.

Thresholding functions for (a) generalized double Pareto prior with , α = {1, 3, 7}, (b) Hard thresholding, generalized double Pareto prior with η = 2, α = 3 and LASSO with σ = 1.
4.2. Sparsity
As noted in Fan and Li (2001), a sufficient condition for the resulting estimator to be a thresholding rule is that the minimum of the function |βj| + σ2p′(|βj|) is positive.
Proposition 3. Under the formulation in Proposition 1, prior (3.1) implies a penalty yielding an estimator that is a thresholding rule if .
This result is obtained by finding the minimum of |βj| + σ2p′(|βj|) and taking it greater than zero. The thresholding is a direct consequence of the fact that when , which requires that , the derivative of (4.2) is positive for all positive βj and negative for all negative βj. In this case, the penalized least squares estimator is zero. When , two roots may exist. The larger one (in absolute value) or zero is the penalized least squares estimator. To elaborate more on this, the root(s) may exist for only when . A helpful illustration is Figure 3 of Fan and Li (2001).
4.3. Continuity
Continuity in data is important if an estimator is to avoid instabilities in prediction. As in Breiman (1996), “a regularization procedure is unstable if a small change in data can make large changes in the regularized estimator”. Discontinuities in the thresholding rule may result in inclusion or dismissal of a signal with minor changes in the data used (see Figure 4.4(b)). Hard-thresholding, the “usual” variable selection, is an unstable procedure, while ridge and LASSO estimates are considered stable.
A necessary and sufficient condition for continuity is that the minimum of the function |βj| + σ2p′(|βj|) is at zero (Fan and Li (2001)). For our prior, the minimum of this function is obtained at . Therefore yields an estimator with this property.
Proposition 4. Under the formulation in Proposition 1, a subfamily of prior (2.1) with yields an estimator with the continuity property.
In this particular case, the penalized likelihood estimator is set to zero if . When
| (4.3) |
As can be observed in Figure 4.4(a), ensuring continuity by letting creates a trade-off between sparsity and tail-robustness. As the thresholding region becomes wider, the larger values are penalized further, yet not nearly at the level of LASSO.
4.4. Maximum a Posteriori Estimation via Expectation-Maximization
We assume a normal likelihood to formulate the procedure for non-orthogonal linear regression. Estimation is carried out via the expectation-maximization (EM) algorithm.
4.4.1. Exploiting the Normal Mixture Representation
We take the expectation of the log-posterior with respect to the conditional posterior distributions of (, ) and (, σ2(k)) at the kth step, then maximize with respect to βj and σ2 to get the values for the (k + 1)th step.
- E-step:
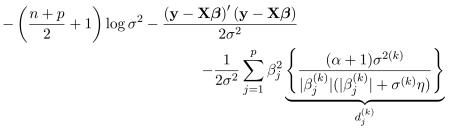
- M-step: Letting , we have
We refer to this estimator as GDP(MAP).
4.4.2. Exploiting the Laplace Mixture Representation and the One-step Estimator
In the proof of Proposition 1, the integration over τ leads to a Laplace mixture representation of the prior. Since the mixing distribution of the Laplace is a known distribution the required expectation is obtained with ease, resulting in the maximization step,
| (4.4) |
Where a = −(n + p +2), , and . The component-specific multiplier on |βj| is obtained from the expectation of λj with respect to its conditional posterior distribution, π(λj|βj, σ2). Similar results to (4.4) are in Candes, Wakin and Boyd (2008), Cevher (2009), and Garrigues (2009).
An intuitive relationship to the adaptive LASSO of Zou (2006) and the one-step sparse estimator of Zou and Li (2008) can be seen via the Laplace mixture representation. As a computationally fast alternative to estimating the exact mode via the above EM algorithm, we can obtain a “one-step estimator” and exploit the LARS algorithm as in Zou and Li (2008). The one-step estimator is
| (4.5) |
with α† = 2σ2(0)(α + 1) and η† = σ(0)η. This estimator resembles the adaptive LASSO. The LARS algorithm can be used to obtain β(1) very quickly. We refer to this estimator as GDP(OS).
Remark 1. For η† = 0, the GDP(OS) solution path for varying α† is identical to the adaptive LASSO solution path with γ = 1 (see (4) in Zou (2006)) using identical β(0).
Remark 2. GDP(OS) forms a bridge between the LASSO and the adaptive LASSO: as η† → ∞ and α†/η† → λ† < ∞, GDP(OS) gives the LASSO solution with penalty parameter λ†.
We derive the GDP(OS) estimator only to reveal a close connection with the adaptive LASSO of Zou (2006) and do not use it in our experiments.
4.4.3. Normal vs. Laplace Representations in Computation
As pointed out by an anonymous referee, it is appropriate to compare the convergence behavior of the EM algorithms that exploit different mixture representations. We generated n = {200, 400, 600, 800, 1000} observations from , where the xij were independent standard normals for p = {20, 40, 60, 80, 100}, ∊ ~ N(0, σ2), and σ = 3. We set the first p/4 components of β* to be 1 and the rest to 0. For each (n, p) combination we simulated 100 data sets and ran the EM algorithms obtained from normal and Laplace scale mixture representations. Figure 4.5 illustrates the number of iterations taken by the two algorithms until ∥β(k+1) − β(k)∥2 < 10−6. As expected, the convergence under the Laplace mixture representation was much faster with the intermediary mixing parameter τj integrated out rather than using the expectation step in the EM algorithm.
Figure 4.5.

Number of iterations until convergence of the EM algorithms under normal and Laplace representations.
4.5. Oracle Properties
Following Zou (2006) and Zou and Li (2008), we show that the GDP(MAP) and GDP(OS) estimators possess oracle properties. Relaxing the normality assumption on the error term leads to two conditions for Theorem 2 and Theorem 3.
-
(A1)
yi = xiβ* + ∊i where ∊1, …, ∊n are independent and identically distributed with mean 0 and variance σ2.
-
(A2)
, where C is a positive definite matrix.
In what follows, , retains the entries of β indexed by , and retains the rows and columns of C indexed by .
Theorem 1. Let
denote the GDP(MAP) estimator, where and . Let . Suppose that , and, . Then is
consistent in variable selection in that ;
asymptotically normal with .
Remark 3. More generally, the above results hold if and .
Theorem 2. Let denote the GDP(OS) estimator in (4.5) and . Suppose that , , and . Then is
consistent in variable selection in that ;
asymptotically normal with .
The proofs are deferred to Section 8.
5. Experiments
5.1. Simulation
In this section, we compare the proposed estimators to the posterior means obtained under the normal, Laplace, and horseshoe priors, to the Bayesian model averaged (BMA) estimator, as well as to the sparse estimates resulting from LASSO (Tibshirani (1996)) and SCAD (Fan and Li (2001)). GDP(PM) and GDP(MAP) denote the posterior mean and the MAP estimates, respectively, under the generalized double Pareto prior. Hyper-parameter values are provided in footnotes of Tables 5.1 and 5.2 when fixed in advance and are otherwise treated as random with the priors specified in Section 3. When not fixed, we first obtain the posterior means of the hyper-parameters from an initial Bayesian analysis, then use them in the calculation of the MAP estimates.
Table 5.1.
Model error comparisons.
| n = 50 | |||||
|---|---|---|---|---|---|
|
| |||||
| Method | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 |
| Normal | 2.2990.085 | 4.8790.263 | 2.5850.134 | 4.9720.385 | 2.8860.150 |
| Laplace | 2.6340.137 | 3.6620.233 | 2.8370.126 | 4.3260.211 | 3.4580.120 |
| Horseshoe | 2.2640.086 | 2.3160.167 | 3.2050.140 | 3.9290.218 | 4.4090.130 |
| BMA | 2.4510.123 | 1.6470.126 | 4.0430.233 | 3.0620.194 | 6.0150.301 |
| GDP(PM)1 | 2.3060.114 | 2.4050.192 | 3.1930.215 | 4.1230.304 | 4.2830.142 |
| GDP(PM)2 | 2.3030.095 | 2.3090.195 | 3.1240.153 | 3.9100.237 | 4.4510.109 |
| GDP(PM) | 2.2710.085 | 2.6060.167 | 3.0470.147 | 4.3480.171 | 3.6400.134 |
| GDP(MAP)1 | 3.4140.148 | 1.6190.150 | 5.6050.298 | 2.9700.168 | 8.7690.403 |
| GDP(MAP)2 | 4.2500.354 | 1.6180.153 | 6.3310.300 | 3.0400.163 | 9.3080.377 |
| GDP(MAP) | 4.8760.355 | 2.0910.182 | 4.2990.222 | 3.7400.284 | 5.7240.177 |
| LASSO | 2.1830.124 | 2.6180.152 | 3.2580.194 | 3.5310.172 | 5.6460.229 |
| SCAD | 3.7320.214 | 2.1320.229 | 5.2490.239 | 3.1790.193 | 8.5050.387 |
|
| |||||
| n = 400 | |||||
|
| |||||
| Normal | 0.3950.014 | 0.4550.019 | 0.4260.016 | 0.4550.024 | 0.4120.013 |
| Laplace | 0.3150.016 | 0.3740.014 | 0.3880.016 | 0.4220.015 | 0.4570.014 |
| Horseshoe | 0.2190.016 | 0.2050.010 | 0.3410.014 | 0.3460.009 | 0.5140.023 |
| BMA | 0.1510.011 | 0.1250.005 | 0.2400.016 | 0.2110.009 | 0.6460.037 |
| GDP(PM)1 | 0.2330.016 | 0.2060.009 | 0.3260.015 | 0.2840.014 | 0.6250.031 |
| GDP(PM)2 | 0.2280.017 | 0.2150.009 | 0.3320.013 | 0.3030.010 | 0.5790.027 |
| GDP(PM) | 0.2480.017 | 0.1820.007 | 0.3770.016 | 0.3620.012 | 0.4660.016 |
| GDP(MAP)1 | 0.1540.014 | 0.1110.011 | 0.2860.016 | 0.2100.011 | 0.7390.043 |
| GDP(MAP)2 | 0.1610.013 | 0.1110.010 | 0.2840.016 | 0.2100.009 | 0.6520.035 |
| GDP(MAP) | 0.1850.017 | 0.1190.010 | 0.3260.016 | 0.3360.010 | 0.4780.020 |
| LASSO | 0.2510.014 | 0.2760.014 | 0.3390.020 | 0.3480.011 | 0.4850.021 |
| SCAD | 0.1210.010 | 0.1180.008 | 0.2330.011 | 0.2060.017 | 0.4690.019 |
α = 1, η = 1
η = 1
Table 5.2.
Posterior means of the hyper-parameters and the resulting model error.
| n = 50 | n = 400 | ||||
|---|---|---|---|---|---|
|
| |||||
| GDP(PM) | GDP(PM)2 | GDP(PM) | GDP(PM)2 | ||
| Model 2 | α | 2.464 | 1.165 | 0.688 | 0.870 |
| η | 4.181 | – | 0.614 | ||
| ME | 2.443 | 2.219 | 0.149 | 0.181 | |
|
| |||||
| Model 5 | α | 5.262 | 1.200 | 9.400 | 0.560 |
| η | 9.476 | – | 51.735 | – | |
| ME | 6.290 | 7.019 | 0.518 | 0.614 | |
η = 1
We generated n = {50, 400} observations from , where the xij were standard normals with Cov(xj, xj′) = 0.5|j−j′|, ∊i ~ N(0, σ2), and σ = 3. We used the following β* configurations:
Model 1: 5 randomly chosen components of β* set to 1 and the rest to 0.
Model 2: 5 randomly chosen components of β* set to 3 and the rest to 0.
Model 3: 10 randomly chosen components of β* set to 1 and the rest to 0.
Model 4: 10 randomly chosen components of β* set to 3 and the rest to 0.
Model 5: β* = (0.85, …, 0.85)′.
In our experiments y and the columns of X were centered and the columns of X scaled to have unit length. For the calculation of competing estimators we used lars (Hastie and Efron (2011)), SIS (Fan et al. (2010)), monomvn (Gramacy (2010)) and BAS (Clyde and Littman (2005), Clyde, Ghosh, and Littman (2010)) packages in R. We mainly followed the default settings provided by the packages. Under the normal prior, the so-called “ridge” parameter was given an inverse gamma prior with shape and scale parameters 10−3. Under the Laplace prior, as a default choice, a gamma prior was placed on the “LASSO parameter” λ2, as given in (6) of Park and Casella (2008), with shape and rate parameters 2 and 0.1, respectively. Under the horseshoe prior, the monomvn package uses the hierarchy given in Section 1.1 of Carvalho, Polson, and Scott (2010). For BMA, we used the default settings of the BAS package that employs the Zellner-Siow prior given in Section 3.1 of Liang et al. (2008). The tuning for LASSO and SCAD were carried out by the criteria given in Yuan and Lin (2005) and Wang, Li, and Tsai (2007), respectively, avoiding cross-validation.
100 data sets were generated for each case. In Table 5.1, we report the median model error. Model error was calculated as , where C is the variance-covariance matrix that generated X and denotes the estimator in use. The values in the subscripts give the bootstrap standard error of the median model error values obtained. The bootstrap standard error was calculated by generating 500 bootstrap samples from 100 model error values, finding the median model error for each case, and then calculating the standard error for it. Under each model, the best three performances are boldfaced in the tables.
GDP(PM) estimates showed a similar performance to that of horseshoe under sparse setups. GDP(PM) (with α and η unknown) also showed great flexibility in adapting to dense models with small signals. GDP(MAP) estimates performed similarly to SCAD and much better than LASSO, particularly so with increasing sparsity, signal and/or sample size. The GDP(PM) and GDP(MAP) calculations are straightforward and computationally inexpensive due to the normal (and Laplace) scale mixture representation used. Being able to use a simple Gibbs sampler (especially when α = η = 1) makes the procedure attractive for the average user.
Letting α = η = 1 may be somewhat restrictive if the underlying model is very dense or very sparse, but in the cases we considered, it performed comparably to others and we believe that it constitutes a good default prior similar to standard Cauchy with the added advantage of thresholding ability. Although we do not take up p ⪢ n cases in this paper, in such situations much larger values of would need to be chosen to adjust for multiplicity.
5.2. Inferences on Hyper-parameters
Here we take a closer look at the inferences on the hyper-parameters obtained from an individual data set for Models 2 and 5 from Section 5.1. This gives us some insight into how α and η are inferred with changing sample size and sparsity structure. Note that GDP(PM)2 is more restrictive than GDP(PM) as η is fixed, treating only α as unknown. Figure 5.6 gives the marginal posteriors of α and η in cases of GDP(PM)2 and GDP(PM) as described in Section 5.1, while Table 5.2 reports the posterior means for α and η, as well as model error (ME) performance (as calculated in Section 5.1) on the particular data set used. We clearly observe the adaptive nature and higher flexibility of GDP(PM) moving from a sparse to a dense model with a big increase, particularly in η, flattening the prior on β. There is not quite as much wiggle room in the case of GDP(PM)2. All it can do is to drive α smaller to allow heavier tails to accommodate a dense structure. As observed in Table 5.1, however, GDP(PM)2 performs comparably in sparse cases.
Figure 5.6.

Inferences for (a) GDP(PM) for n = 50 under Model 2, (b) GDP(PM)2 for n = 50 under Model 2, (c) GDP(PM) for n = 400 under Model 2, (b) GDP(PM)2 for n = 400 under Model 2, (e) GDP(PM) for n = 50 under Model 5, (f) GDP(PM)2 for n = 50 under Model 5, (g) GDP(PM) for n = 400 under Model 5, (h) GDP(PM)2 for n = 400 under Model 2.
6. Data Example
We consider the ozone data analyzed by Breiman and Friedman (1985) and by Casella and Moreno (2006). The original data set contains 13 variables and 366 observations. The modeled response is the daily maximum one-hour averaged ozone reading in Los Angeles over 330 days in 1976. There are p = 12 predictors considered and deleting incomplete observations leaves n = 203 observations. For validation, the data were split into a training set containing 180 observations and a test set containing 23 observations. We considered models including main effects, quadratic, and two-way interaction terms resulting in 290 possible subsets. The complex correlation structure of the data is illustrated in Figure 6.7.
Figure 6.7.

The correlation structure of the Ozone data.
Figure 6.8 summarizes the performance of the proposed estimators and their competitors. Median values for and the ±2 standard error intervals were obtained by running the methods on 100 different random training-test splits. Standard errors were computed via bootstrapping the medians 500 times.
Figure 6.8.

Out-of-sample performance comparisons for Ozone data. (×) denotes the median value for while the lines represent the ±2 standard error regions. 1α = 1, η = 1; 2η = 1.
The median number of predictors retained in the model by all three GDP(MAP) estimates was only 4 while it was 14 and 9 for LASSO and SCAD. Hence GDP(MAP) promoted much sparser models. In terms of prediction, GDP(PM)1 yielded the second best results after BMA, with GDP(PM)2, GDP(PM), and the horseshoe estimator all having somewhat worse performance. These shrinkage priors are designed to mimic model averaging behavior, so we expected to obtain results that were competitive with, but not better than, BMA. The improved performance for GDP(PM)1 may be attributed to the use of default hyper-parameter values that were fixed in advance at values thought to produce good performance in sparse settings. Treating the hyper-parameters as unknown is appealing from the standpoint of flexibility, but in practice the data may not inform sufficiently about their values to outperform a good default choice. GDP(MAP)1 and SCAD both performed within the standard error range of LASSO, while retaining a smaller number of variables in the model. As it is important to account for model uncertainty in prediction, the posterior mean estimator under the GDP prior is appealing in mimicking BMA. In addition, obtaining a simple model containing a relatively small number of predictors is often important, since such models are more likely to be used in fields in which predictive black boxes are not acceptable and practitioners desire interpretable predictive models.
7. Discussion
We have proposed a hierarchical prior obtained through a particular scale mixture of normals where the resulting marginal prior has a folded generalized Pareto density thresholded at zero. This prior combines the best of both worlds in that fully Bayes inferences are feasible through its hierarchical representation, providing a measure of uncertainty in estimation, while the resulting marginal prior on the regression coefficients induces a penalty function that allows for the analysis of frequentist properties under maximum a posteriori estimation. The resulting posterior mean estimator can be argued to be mimicking a Bayesian model averaging behavior through mixing over higher level hyper-parameters. Although Bayesian model averaging is appealing, it can be argued that allowing parameters to be arbitrarily close to zero instead of exactly equal to zero may be more natural in some problems. Hence we have a procedure that not only bridges two paradigms – Bayesian shrinkage estimation and regularization – but also yields three useful tools: a sparse estimator with good frequentist properties through maximum a posteriori estimation, a posterior mean estimator that mimics a model averaging behavior, and a useful measure of uncertainty around the observed estimates. In addition, the proposed methods have substantial computational advantages in relying on simple block-updated Gibbs sampling, while BMA requires sampling from a model space with 2p models. Given the simple and fast computation and the excellent performance in small sample simulation studies, the generalized double Pareto should be useful as a shrinkage prior in a broad variety of Bayesian hierarchical models, while also suggesting close relationships with frequentist penalized likelihood approaches. The proposed prior can be used in generalized linear models, shrinkage of basis coefficients in non-parametric regression, and in such settings as factor analysis and nonparametric Bayes modeling.
8. Technical Details
Proof of Theorem 1. The proof follows along similar lines as does the proof of Theorem 2 in Zou (2006). We first prove asymptotic normality. Let and
Let , suggesting . Now
and we know that X′X/n → C and . Consider the limiting behavior of the third term, noting that . If , then . If , then which is 0 if uj = 0, and diverges otherwise. By Slutsky’s Theorem
Vn(u)−Vn(0) is convex and the unique minimum of the right hand side is . By epiconvergence (Geyer (1994), Knight and Fu (2000)),
| (8.1) |
Since , this proves asymptotic normality.
Now ; thus . Hence for consistency, it is sufficient to show that . Consider the event . By the KKT optimality conditions, . Noting that by (8.1), , while
By (8.1) and Slutsky’s Theorem, we know that both terms in the brackets converge in distribution to some normal, so
This concludes the proof.
Proof of Theorem 2. We modify the proof of Theorem 2 in Zou (2006). Here denotes the least squares estimator. We first prove asymptotic normality. Let and
Let , suggesting . Now
and we know that X′X/n → C and . Consider the limiting behavior of the third term. If then, by the Continuous Mapping Theorem, and . By Slutsky’s Theorem, . If , then and , where . Again by Slutsky’s Theorem,
Vn(u)−Vn(0) is convex and the unique minimum of the right hand side is . By epiconvergence (Geyer (1994), Knight and Fu (2000)),
| (8.2) |
Since , this proves the asymptotic normality.
Now ; thus . We show that for all , . Consider the event . By the KKT optimality conditions, . We know that , while
By (8.2) and Slutsky’s Theorem, we know that both terms in the brackets converge in distribution to some normal, so
which proves consistency.
Acknowledgments
This work was supported by Award Number R01ES017436 from the National Institute of Environmental Health Sciences. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institute of Environmental Health Sciences or the National Institutes of Health. Jaeyong Lee was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (20110027353).
Contributor Information
Artin Armagan, SAS Institute Inc., Durham, NC 27513, USA, artin.armagan@sas.com.
David B. Dunson, Department of Statistical Science, Duke University, Durham, NC 27708, USA, dunson@stat.duke.edu
Jaeyong Lee, Department of Statistics, Seoul National University, Seoul, 151-747, Korea, leejyc@gmail.com.
References
- Berger J. A robust generalized Bayes estimator and confidence region for a multivariate normal mean. The Annals of Statistics. 1980;8:716–761. [Google Scholar]
- Berger J. Statistical Decision Theory and Bayesian Analysis. Springer; New York: 1985. [Google Scholar]
- Breiman L. Heuristics of instability and stabilization in model selection. The Annals of Statistics. 1996;24:2350–2383. [Google Scholar]
- Breiman L, Friedman JH. Estimating optimal transformations for multiple regression and correlation. Journal of the American Statistical Association. 1985:80. [Google Scholar]
- Candes EJ, Wakin MB, Boyd SP. Enhancing sparsity by reweighted ℓ1 minimization. Journal of Fourier Analysis and Applications. 2008;14:877–905. [Google Scholar]
- Carvalho C, Polson N, Scott J. Handling sparsity via the horseshoe. JMLR: W&CP. 2009:5. [Google Scholar]
- Carvalho C, Polson N, Scott J. The horseshoe estimator for sparse signals. Biometrika. 2010;97:465–480. [Google Scholar]
- Casella G, Moreno E. Objective Bayesian variable selection. Journal of the American Statistical Association. 2006:101. [Google Scholar]
- Cevher V. Learning with compressible priors. Advances in Neural Information Processing Systems. 2009:22. [Google Scholar]
- Clyde M, Ghosh J, Littman ML. Bayesian adaptive sampling for variable selection and model averaging. Journal of Computational and Graphical Statistics. 2010;20:80–101. [Google Scholar]
- Clyde M, Littman M. Bayesian model averaging using Bayesian adaptive sampling – BAS package manual. 2005. [Google Scholar]
- Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression. The Annals of Statistics. 2004;32:407–499. [Google Scholar]
- Fan J, Feng Y, Samworth R, Wu Y. SIS package manual. 2010 [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Figueiredo MAT. Adaptive sparseness for supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2003;25:1150–1159. [Google Scholar]
- Fu W. Penalized regressions: The bridge versus the lasso. Journal of Computational and Graphical Statistics. 1998;7:397–416. [Google Scholar]
- Garrigues PJ, University of California . PhD Thesis. Berkeley: 2009. Sparse coding models of natural images: Algorithms for efficient inference and learning of higher-order structure. [Google Scholar]
- Geyer CJ. On the asymptotics of constrained M-estimation. The Annals of Statistics. 1994;22:1993–2010. [Google Scholar]
- Gramacy RB. Estimation for multivariate normal and Student-t data with monotone missingness – Monomvn package manual. 2010. [Google Scholar]
- Griffin JE, Brown PJ. Technical Report. 2007. Bayesian adaptive lassos with non-convex penalization. [Google Scholar]
- Griffin JE, Brown PJ. Inference with normal-gamma prior distributions in regression problems. Bayesian Analysis. 2010;5:171–188. [Google Scholar]
- Hans C. Bayesian lasso regression. Biometrika. 2009;96:835–845. [Google Scholar]
- Hastie T, Efron B. Lars package manual. 2011. [Google Scholar]
- Knight K, Fu W. Asymptotics for lasso-type estimators. The Annals of Statistics. 2000;28:1356–1378. [Google Scholar]
- Lee A, Caron F, Doucet A, Holmes C. Bayesian sparsity-path-analysis of genetic association signal using generalized t priors. Statistical Applications in Genetics and Molecular Biology. 2012;11 doi: 10.2202/1544-6115.1712. [DOI] [PubMed] [Google Scholar]
- Liang F, Paulo R, Molina G, Clyde M, Berger J. Mixtures of g priors for Bayesian variable selection. Journal of the American Statistical Association. 2008;103:410–423. [Google Scholar]
- McDonald JB, Newey WK. Partially adaptive estimation of regression models via the generalized t distribution. Econometric Theory. 1988;4:428–457. [Google Scholar]
- Park T, Casella G. The Bayesian lasso. Journal of the American Statistical Association. 2008;103:681–686. [Google Scholar]
- Pickands J. Statistical inference using extreme order statistics. The Annals of Statistics. 1975;3:119–131. [Google Scholar]
- Polson NG, Scott JG. Bayesian Statistics. Oxford University Press; 2010. Shrink globally, act locally: Sparse Bayesian regularization and prediction; p. 9. [Google Scholar]
- Ritter C, Tanner MA. Facilitating the Gibbs sampler: The Gibbs stopper and the griddy-Gibbs sampler. Journal of the American Statistical Association. 1992;97:861–868. [Google Scholar]
- Strawderman WE. Proper Bayes minimax estimators of the multivariate normal mean. The Annals of Mathematical Statistics. 1971;42:385–388. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. 1996;58:267–288. [Google Scholar]
- Tipping ME. Sparse Bayesian learning and the relevance vector machine. Journal of Machine Learning Research. 2001:1. [Google Scholar]
- Wang H, Li R, Tsai CL. Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika. 2007;94:553–568. doi: 10.1093/biomet/asm053. [DOI] [PMC free article] [PubMed] [Google Scholar]
- West M. On scale mixtures of normal distributions. Biometrika. 1987;74:646–648. [Google Scholar]
- Yuan M, Lin Y. Efficient empirical Bayes variable selection and estimation in linear models. Journal of the American Statistical Association. 2005;100:1215–1225. [Google Scholar]
- Zhao P, Yu B. On model selection consistency of lasso. Journal of Machine Learning Research. 2006:7. [Google Scholar]
- Zou H. The adaptive lasso and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models. The Annals of Statistics. 2008;36:1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]