

Abstract
Ankyrin (ANK) repeats are one of the most common amino acid sequence motifs that mediate interactions between proteins of myriad sizes, shapes and functions. We assess their widespread abundance in Bacteria and Archaea for the first time and demonstrate in Bacteria that lifestyle, rather than phylogenetic history, is a predictor of ANK repeat abundance. Unrelated organisms that forge facultative and obligate symbioses with eukaryotes show enrichment for ANK repeats in comparison to free-living bacteria. The reduced genomes of obligate intracellular bacteria remarkably contain a higher fraction of ANK repeat proteins than other lifestyles, and the number of ANK repeats in each protein is augmented in comparison to other bacteria. Taken together, these results reevaluate the concept that ANK repeats are signature features of eukaryotic proteins and support the hypothesis that intracellular bacteria broadly employ ANK repeats for structure-function relationships with the eukaryotic host cell.
Keywords: Protein domains, Symbiosis, Archaea, Bacteria, Ankyrin repeat domains
Introduction
Ankyrin (ANK) repeats are ubiquitous structural motifs in eukaryotic proteins. They function as scaffolds to facilitate protein-protein interactions involved in signal transduction, cell cycle regulation, vesicular trafficking, inflammatory response, cytoskeleton integrity, transcriptional regulation, among others (Mosavi et al., 2004). Consistent with the necessity of their function, amino acid substitutions in the ANK repeats of a protein (ANK-containing proteins) are associated with a number of human diseases including cancer (p16 protein) (Tang, Fersht & Itzhaki, 2003), neurological disorders such as CADASIL (Notch protein) (Joutel et al., 1996), and skeletal dysplasias (TRPV4 protein) (Inada et al., 2012; Mosavi et al., 2004). In addition, variations in the amino acid sequence of the human ANKK1 are associated with addictive behaviors such as alcoholism and nicotine addiction (Ponce et al., 2008; Suraj Singh, Ghosh & Saraswathy, 2013).
The structure of each individual 33 amino acid ANK repeat begins with a β-turn that precedes two antiparallel α-helices and ends with a loop that feeds into the next repeat. These interconnected protein motifs stack one upon another to form an ANK domain (Gorina & Pavletich, 1996; Sedgwick & Smerdon, 1999). The prevalence and varied functionality of ANK-containing proteins in eukaryotes can be attributed to (i) the strong degeneracy of the 33 amino acid repeat that allows for the specificity of individual molecular interactions, and (ii) the variability in the number of individual repeats in an ANK domain, which provides a platform for protein interactions (Li, Mahajan & Tsai, 2006; Sedgwick & Smerdon, 1999).
Because the ANK repeat was discovered in Saccharomyces cerevisiae, Schizosaccharomyces pombe, and Drosophila melanogaster (Breeden & Nasmyth, 1987), they were quickly prescribed as a signature feature of eukaryotic proteins. Despite the conventional wisdom (until recently) and frequent citations in the literature that ANK repeats are taxonomically restricted to eukaryotes, there has been no systematic investigation to assess their distribution across the diversity of life. Several related questions on the comparative biology of ANK repeats can be addressed: Are ANK-containing proteins more prevalent in the domains Eukarya than Bacteria and Archaea and to what extent? What is the typical fraction of a proteome dedicated to proteins containing ANK repeats across the three domains of life? Are ANK-containing proteins distributed non-randomly with respect to taxonomy or lifestyle?
In this study, we establish a new threshold on the distribution of ANK repeats across the tree of life. Further, the enrichment of ANK-containing proteins in symbiotic bacteria provides comprehensive support to experimental cases in which ANK-containing proteins promote interactions between bacterial and eukaryotic cells.
Materials and methods
ANK data acquisition and analysis
All genome information was obtained from the SUPERFAMILY v1.75 database (SUPERFAMILY; Wilson et al., 2009), including the taxonomy, and number of ANK-containing proteins (Table S1). The SUPERFAMILY database currently contains protein domain information on 2,489 strains, where there can be more than one strain representing a single phylogenetic species. This database is an archive of structural and functional domains in proteins of sequenced genomes (Wilson et al., 2009), which are annotated using hidden Markov models through the SCOP (Structural Classification of Proteins) SUPERFAMILY protein domain classification (Gough et al., 2001; SUPERFAMILY). We note appropriate caution that ANK-containing proteins are identified based on a computational framework and are not experimentally confirmed. We used NCBI’s Genome resource (NCBI Genome resource) to obtain total gene and protein numbers for each strain in the analysis. To determine the percent of a strain’s total protein number (proteome) that is composed of ANK-containing proteins, the number of ANK-containing proteins was divided by the total number of proteins and multiplied by a factor of 100. Only strains with available total protein information were used in this analysis. For the bacterial class and lifestyle analysis, an average of the number and/or percent of ANK-containing proteins for all strains of the same species were used for these analyses. For the lifestyle analysis, ANK-containing protein information on Cardinium hertigii was added to the analysis because detailed information regarding its ANK-containing proteins was recently published (Penz et al., 2012).
To analyze the amino acid sequence of ANK repeats and generate the consensus sequence for Archaea, we obtained the sequence ID of ANK-containing proteins from SUPERFAMILY v1.75 (SUPERFAMILY) and the amino acid sequence from NCBI’s Proteins database (NCBI Protein resource). We used SMART (Letunic, Doerks & Bork, 2012) to identify the number and location of each individual ANK repeat in the protein (Letunic, Doerks & Bork, 2012; Schultz et al., 1998). For the amino acid sequence identity analysis, individual ANK repeat sequences were aligned using MUSCLE using default parameters (Edgar, 2004) and the percent identity of the sequences was calculated in Geneious Pro 5.6.2 (Biomatters, 2010). To generate the archaeal ANK consensus sequence, all 132 ANK repeat sequences from the ANK-containing proteins identified in the SUPERFAMILY database were utilized. To generate the eukaryotic ANK consensus sequence, ANK repeat sequences from one ANK-containing protein from each phylum was identified in the SUPERFAMILY database, the ANK repeat was identified by SMART and utilized, resulting in a total of 153 ANK-repeat sequences (Table S2). When comparing ANK repeat sequences from two strains, the average of all combinations of ANK repeat comparisons was used. For the eukaryotic and archaeal consensus sequence, all indels and ends were trimmed after the ANK repeats were aligned by MUSCLE. The consensus sequence was generated by Geneious.
16S rRNA phylogenetic tree and independence analysis
We selected one representative 16S rRNA sequence from each bacterial class and aligned them by MUSCLE in Geneious Pro 5.6.2 (Table S3). This alignment was then used to reconstruct a phylogenetic tree that reflects the well-established ancestry of the bacterial classes for a phylogenetic independence test of the abundance of ANK-containing proteins. Prior to building the tree, a DNA substitution model for the alignment was selected by using jModelTest, version 2.1.3 using default parameters (Darriba et al., 2012; Guindon & Gascuel, 2003) A Bayesian phylogenetic tree was generated by MrBayes using the HKY85 IG model of DNA sequence evolution using default parameters (Huelsenbeck & Ronquist, 2001; Ronquist & Huelsenbeck, 2003; Hasegawa, Kishino & Yano, 1985). For testing phylogenetic independence of ANK-containing proteins, the PDAP program in Mesquite vs 2.75 was used to generate independent contrasts for the data in Fig. 3B using default parameters (Maddison & Maddison, 2006; Midford, Garland & Maddison, 2005) Phylogenetic Independence version 2.0 (Reeve & Abouheif, 2003) performed the Test For Serial Independence (TFSI) using default parameters based on the Bayesian tree.
Figure 3. Analysis of ANK-containing proteins in Bacteria.

(A) Bar graph of the percent of bacterial strains analyzed (y axis) with the specified number of ANK-containing proteins (x axis). The number above the bars on the graph lists the number of strains with the specified number of ANK-containing proteins. (B) Consensus phylogeny of 16S rRNA sequences from one species (randomly selected) in each class. (C) Species analysis of bacterial classes that contain four or more ANK-containing protein encoding genes (only classes with 5 or more represented species were included in this analysis). The fraction in parentheses represents the number of species with four or more ANK-containing proteins in the bacterial class over the total number of species in that bacterial class.
Results
ANK-containing proteins across the tree of life
The consensus amino acid sequences for the ANK repeats in each domain of life are shown in Fig. 1 (Al-Khodor et al., 2010; Mosavi et al., 2004) (Table S2). There is a notable correspondence in amino acid identity and similarity across the domains, with the highest values between Eukarya and Bacteria (76.7% identity), followed by Archaea and Bacteria (73.3% identity), and then Eukarya and Archaea (66% identity). Despite the conservation of the domain-specific consensus sequences, there can be substantial amino acid sequence diversity at each position of the ANK repeat. For example, this variation is evident in the Archaea, where the mean % of the sequences ± standard deviation that establishes each consensus amino acid is 49.6 ± 24.7% (Table S4). Indeed, seven amino acid positions form a consensus from less than one quarter of the sequences.
Figure 1. ANK repeat consensus sequence across all domains of life.
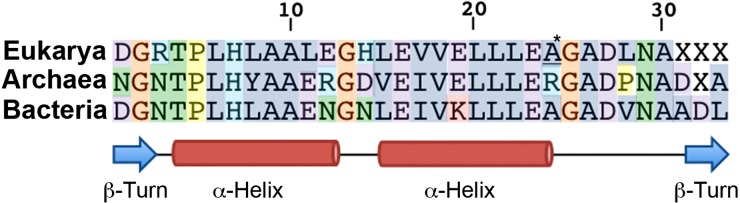
Comparison of consensus sequences previously derived from (i) 153 Eukarya ANK repeat sequences (Table S2), (ii) 132 Archaea ANK repeat sequences and (iii) Bacteria ANK repeat sequences (Al-Khodor et al., 2010). The amino acid color scheme indicates that the amino acids share similar biochemical properties (polar uncharged, green; positively charged, light blue; negatively charged, purple; hydrophobic, dark blue; glycine, orange; proline, yellow). [* This alanine (A) appears in equal proportions (16%) to lysine (K)].
Of the 2,489 strains analyzed here, 1,912 are from the domain Bacteria, 444 are from the domain Eukarya, and 133 are from the domain Archaea. All 444 eukaryotic strains except one (Saccharomyces cerevisiae CLIB382, which lacks a completely annotated genome) contain at least one ANK-containing protein (Fig. 2, Table S1). 51% of bacterial strains (981/1912) and 11% of archaeal strains (15/133) harbor at least one ANK-containing protein (Fig. 2A). When strains are grouped into genera, we similarly find that 56% of bacterial genera (308/549) and 9% of archaeal genera (6/69) contain species that encode at least one protein with an ANK repeat.
Figure 2. ANK-containing protein analysis across all domains of life.

(A) Bar graph of the average percent of the strains in each domain that have one or more ANK-containing proteins. The total number of strains analyzed and the number of strains with more than one ANK-containing protein are listed below the graph. (B) Bar graph of the average number of ANK containing proteins in strains of each domain. The average number of ANK-containing proteins in each domain is listed below the graph. Error bars represent standard deviation. (*P < 0.05, ** P < 0.000001, Two-tailed Mann-Whitney U; ANOVA P < 0.000001). (C) Bar graph showing the average percent of the proteome composed of ANK-containing proteins in each domain. Error bars represent standard deviation. (*P < 0.000001, Two-tailed Mann-Whitney U; ANOVA, P < 0.000001).
For those strains with at least one ANK-containing protein, the average number and normalized percent of ANK-containing proteins per strain are shown for each major domain of life in Fig. 2B and 2C. The differences in the relative fraction of the proteome dedicated to proteins with ANK repeats are significant between the domains (Mann-Whitney U p < 0.00001).
ANK-containing proteins in bacteria
The percent of bacterial strains that contain multiple ANK-containing proteins rapidly declines as the cutoff number of ANK-containing proteins per proteome increases to four and higher (Fig. 3A). To glean which phylogenetic groups of bacteria harbor an enriched fraction of ANK-containing proteins, 24 bacterial classes spanning 202 bacterial strains encoding ≥ four predicted ANK-containing proteins were analyzed.
The class with the highest fraction of ≥ four ANK-containing proteins was Sphingobacteria (Fig. 3B and 3C). To our knowledge, it is the first report that this class of typically free-living bacteria putatively encode ANK-containing proteins. Interestingly, many of the classes with a high percentage of ANK-containing proteins in Fig. 3B and 3C cluster with lineages that form symbioses with hosts, including Spirochetes, Chlamydia, and various sub-groups of Proteobacteria. As endosymbioses have independently evolved across the tree of Bacteria, the taxa are, as expected, scattered across the bacterial tree such that the relative abundance of ANK-containing proteins across the 24 classes of Bacteria is independent of phylogenetic history (p = 0.32, PI test, Reeve & Abouheif, 2003).
Enrichment of ANK-containing proteins in bacterial symbionts
To corroborate the enrichment of ANK-containing proteins in symbiotic bacteria, we categorized each taxon with four or more ANK-containing proteins into three bacterial lifestyles: (i) free-living species that solely replicate outside of host cells, (ii) facultative host-associated (intracellular and extracellular) species that can use a host for replication, and (iii) obligate intracellular species that replicate strictly within host cells. We assigned these three lifestyles following our previous annotations (Newton & Bordenstein, 2011) and searching the primary literature (Table S5).
Our comparisons reveal a striking correlation between replication strategy and abundance of proteins containing ANK repeats. Both obligate intracellular and facultative host-associated bacteria contain, on average, a significantly, higher absolute number of ANK-containing proteins than those that are free-living (Fig. 4A, Mann-Whitney U p < 0.001, ANOVA p < 0.00003), despite the notable fact that free-living species have significantly larger proteomes (Fig. 4C, Mann-Whitney U p < 0.01 for all comparisons, ANOVA p < 0.00001). Facultative host-associated strains have the most expansive repertoire of ANK-containing proteins based on absolute protein numbers (Fig. 4A and 4D), likely owing to their dual capacity to interact with eukaryotic host cells as well as retain a large genome. Consistent with these findings, a majority of the bacterial strains that contained 20 or more ANK-containing proteins are obligate intracellular or facultative host-associated microbes, while only one is free-living (Table 1).
Figure 4. Lifestyle analysis of bacterial species with four of more ANK-containing proteins.

An average of the number or percent of ANK-containing proteins for all strains of the same species was used for these analyses. FL, FHA and O denote free-living, facultative host-associated and obligate intracellular bacteria, respectively. (A) Bar graph of the average number of ANK-containing proteins in species with four of more ANK-containing proteins. Error bars represent standard deviation. (*P < 0.001, **P < 0.00001, Two-tailed Mann-Whitney U; ANOVA, P < 0.00003). (B) Bar graph of the average percent of the proteome composed of ANK-containing proteins in species with four of more ANK-containing proteins. Error bars represent standard deviation. (*P 0.001, **P < 0.0001, ***P < 0.00001, Two-tailed Mann-Whitney U; ANOVA, P < 0.00001). (C) Bar graph of the average total number of proteins in the proteomes of species with four of more ANK-containing proteins. Error bars represent standard deviation. (*P < 0.01, **P < 0.00001, ***P < 0.000001, Two-tailed Mann-Whitney U; ANOVA, P < 0.00001). (D) Bar graph of percent of species in each lifestyle that contain the specified number of ANK-containing proteins (example: 74% of obligate intracellular species, 58% of facultative host associated species, and 28% of free-living species of bacteria contain six ANK-containing proteins). (E) Bar graph of the percent of species in each lifestyle that contain the specified percent of ANK-containing proteins.
Table 1. Bacterial species with 20 or more ANK-containing proteins in our analysis.
| Species | Lifestyle | Class | # ANK-containing proteins | Total Gene # | % Genes with ANK domains | Total Protein # | % Proteins with ANK domains |
|---|---|---|---|---|---|---|---|
| Desulfomonile tiedjei DSM 6799 | FL | Deltaproteobacteria | 42 | 5664 | 0.742 | 5494 | 0.764 |
| Brachyspira hyodysenteriae WA1 | FHA | Spirochaetia | 60 | 2680 | 2.239 | 2642 | 2.271 |
| Brachyspira intermedia PWS/A | FHA | Spirochaetia | 57 | 2926 | 1.948 | 2872 | 1.985 |
| Brachyspira murdochii DSM 12563 | FHA | Spirochaetia | 48 | 2894 | 1.659 | 2809 | 1.709 |
| Burkholderia vietnamiensis G4 | FHA | Betaproteobacteria | 37 | 7861 | 0.471 | 7617 | 0.486 |
| Brachyspira pilosicoli 95/1000 | FHA | Spirochaetia | 32 | 2336 | 1.370 | 2299 | 1.392 |
| Legionella longbeachae NSW150 | FHA | Gammaproteobacteria | 26 | 3739 | 0.695 | 3470 | 0.749 |
| Legionella pneumophila str. Paris | FHA | Gammaproteobacteria | 21 | 3278 | 0.641 | 3166 | 0.663 |
| Turneriella parva DSM 21527 | FHA | Spirochaetia | 21 | 4214 | 0.498 | 4139 | 0.507 |
| Wolbachia sp. wPip Pel | O | Alphaproteobacteria | 58 | 1423 | 4.076 | 1275 | 4.549 |
| Orientia tsutsugamushi str. Ikeda | O | Alphaproteobacteria | 47 | 2005 | 2.344 | 1967 | 2.389 |
| Candidatus Amoebophilus asiaticus 5a2 | O | Bacteroidetes | 46 | 1597 | 2.880 | 1334 | 3.448 |
| Orientia tsutsugamushi str. Boryong | O | Alphaproteobacteria | 37 | 2216 | 1.670 | 1182 | 3.130 |
| Wolbachia sp. wRi | O | Alphaproteobacteria | 31 | 1303 | 2.379 | 1150 | 2.696 |
| Rickettsia bellii OSU 85-389 | O | Alphaproteobacteria | 28 | 1511 | 1.853 | 1475 | 1.898 |
| Rickettsia bellii RML369-C | O | Alphaproteobacteria | 27 | 1469 | 1.838 | 1429 | 1.889 |
| Rickettsia felis URRWXCal2 | O | Alphaproteobacteria | 24 | 1551 | 1.547 | 1512 | 1.587 |
After normalizing the dataset by the total number of proteins, the fraction of the proteome containing ANK-containing proteins is highest in obligate intracellular species (Fig. 4B and 4E). The percentage of ANK-containing proteins is inversely related to proteome size across bacterial lifestyle. In fact, a significant difference in the abundance of proteins with ANK repeats is broadly evident between the lifestyles (Mann-Whitney U p <0.001 for all comparisons, ANOVA p < 0.00001). When considering both the abundance of proteins with ANK repeats and limited proteome size, obligate intracellular bacteria have a remarkably high composition of ANK-containing proteins that not only exceeds that of other bacterial lifestyles, but also is comparable to the composition of eukaryotes in Fig. 2C.
Enrichment of repeats in ANK-containing proteins in bacterial symbionts
Obligate intracellular bacteria also harbor significantly more ANK repeats per protein (Fig. 5A; Table S6). On average, an obligate intracellular microbe contains 6.1 ANK repeats per ANK-containing protein, while free-living and facultative host-associated microbes only contain 4.6 and 4.3 ANK repeats, respectively (ANOVA p = 0.012, pairwise tests between the lifestyles, t-test p < 0.012). As discussed below, these differences likely affect protein stability.
Figure 5. Individual ANK repeat number and amino acid sequence identity analysis.

(A) Bar graph of the average number of ANK repeats in ANK-containing proteins for free-living (FL), facultative host-associated (FHA) and obligate intracellular (O) bacteria. Error bars represent standard deviation (*p = 0.0127, **p = 0.0036, t-test). For a list of strains analyzed, refer to Table S6. (B) Bar graph of the average percent of amino acid identity of the ANK repeats from the listed species with Wolbachiaw Mel ANK repeats. Strains analyzed listed in Table S8. Error bars represent standard error.
Effect of symbiont transmission on ANK-containing proteins
To determine if the mode of transmission of obligate intracellular bacteria associates with the abundance of ANK-containing proteins, we employed a previously published list of vertically and horizontally transmitted obligate intracellular bacteria (Table S7) (Newton & Bordenstein, 2011). Based on the mean of all strains from the same species (a species average), horizontally transmitted taxa (n = 24) contain more ANK-containing proteins than vertically transmitted ones (n = 6) (5.33 vs. 1.66, Mann-Whitney U p = 0.174), and have a higher percentage of their proteome dedicated to ANK-containing proteins (0.41% vs. 0.12%, Mann-Whitney U p = 0.191). However, these differences are not statistically different likely owing to the small sample size in the vertically transmitted group. If we analyze the data from each strain, the differences between horizontally (n = 31) and vertically transmitted taxa (n = 8) are marginally insignificant for the abundance of ANK-containing proteins (5.13 vs. 0.88, Mann-Whitney U p = 0.062) and proportion of ANK-containing proteins (0.39% vs. 0.11%, Mann-Whitney U p = 0.08).
ANK amino acid sequence identity across bacterial lifestyles
Two explanations for why obligate intracellular bacteria have a greater fraction of proteins with ANK repeats and ANK repeats per ANK-containing protein than facultative host-associated and free-living bacteria are: (i) ANK-containing proteins are adaptive to bacteria with an intracellular lifestyle or (ii) ANK-containing proteins experience frequent horizontal transfer between co-infecting, obligate intracellular microbes.
Fig. 5B demonstrates that there is no conservation in the ANK repeat amino acid sequence between species of the same lifestyle. For instance, when comparing the amino acid sequence of Wolbachia (strain wMel) ANK repeats to the ANK repeat sequences from other obligate intracellular, facultative host-associated and free-living microbes, there are no significant differences in the amount of sequence identity between lifestyles (Fig. 5B; Table S8). Surprisingly, Wolbachia ANK repeats are no more or less similar in sequence to each other than ANK repeats from other obligate intracellular, facultative host-associated and free-living species. Even the ANK repeat amino acid sequences of species in the same order have very little sequence identity (Fig. S1). This low level of sequence identity within and between unrelated taxa may be due to degeneracy in the ANK repeat amino acid sequence itself (Li, Mahajan & Tsai, 2006) and does not permit a demarcation of the two explanations above.
ANK-containing proteins in archaea
Of the 133 archaeal strains, 11% contain ANK-containing proteins (Fig. 2). Of these strains, the average number of ANK repeats per protein was 5.25, and four species contained more than one ANK-containing protein in their proteome (Fig. 6A). Interestingly, the ANK-containing proteins in some archaeal genera are conserved, while others are not. In the Methanosarcina genus, two species have one ANK-containing proteins with 66.9% amino acid identity. However, the three species with ANK-containing proteins from the Pyrobaculum genus have very different amino acid sequences (Fig. 6B). Other archaeal genera with ANK-containing proteins include Acidianus, Halogeometricum, Metallosphaera, Methanocella, Methanococcus, Methanothermococcus, Sulfolobus, Thermofilum, and Thermoplasma (Table S9).
Figure 6. Analysis of ANK-containing proteins in archaeal strains.

(A) Bar graph of the percent of archaeal strains analyzed with the specified number of ANK-containing proteins. The number above the bars on the graph lists the number of strains with the specified number of ANK-containing proteins. (B) Chart of the percent amino acid identity between the amino acid sequences of Pyrobaculum ANK-containing proteins.
Discussion
A central finding of this comparative study is that ANK repeats are more prevalent in bacterial species than generally recognized in the current literature, with over half of all of the 1,912 bacterial strains analyzed containing ANK-containing proteins. Far from being rare or even exclusive to certain phylogenetic groups of related bacteria, ANK repeats in Bacteria are widely distributed protein motifs. We do note that this analysis is limited to the strain information present in the SUPERFAMILY database (SUPERFAMILY). While not exhaustive, this database and our analysis spans a broad spectrum of bacterial domains, including 1912 bacterial strains, representing 992 species and 52 phylogenetic classes. Since certain strains of Bacteria that have relevance to human health naturally receive attention and have been well sampled, it is possible that the SUPERFAMILY dataset is not representative of the microbial diversity of the natural world, but rather is enriched in bacterial species that affect human health. Nonetheless, this analysis is the most comprehensive survey of ANK repeat distribution and abundance to date, leading us to conclude that previous assumptions about the rarity of ANK repeats outside of eukaryotes are exaggerated.
Evolutionary theories on the origins of the ANK repeat have evolved over time. Originally, it was assumed that prokaryotic ANK-containing proteins were obtained via horizontal gene transfer (HGT) from eukaryotic hosts, indicating that the ANK repeat originated in eukaryotic proteins (Bork, 1993). While the short sequence and divergence levels of the repeat motif between taxa precludes a clear inference of the origin of ANK repeats, there are several reasons why a single, common ancestor may be just as likely as horizontal transfer of the ANK repeat between the phylogenetic domains. First, we showed that the consensus sequences between the three domains are roughly similar, thus making it difficult to rule out that ANK repeat evolution follows the phylogeny of the domains. Second, there are several species of Archaea and non-host associated microbes that have ANK-containing proteins, which may be indicative of an older origin of the ANK repeat. Finally, although the results indicate that host-associated microbes have an increased fraction of ANK-containing proteins in comparison to free-living microbes, all lifestyles can harbor such proteins, specifying that they provide broader advantages to the cell. Whether or not these proteins were inherited by HGT or evolved by descent with modification from a common ancestor, the distribution for these proteins in Bacteria and Archaea has been unknown and warrants functional and evolutionary analyses.
While ANK repeats in eukaryotes are ubiquitous structural motifs that facilitate a myriad of protein-protein interactions, our analysis reveals that ANK repeats cluster to some degree in symbiotic bacteria involved in microbial-host interactions. Recent studies of host-associated bacterial species, including, Legionella pneumophila (Al-Khodor et al., 2010; de Felipe et al., 2008), Anaplasma phagocytophilum (IJdo, Carlson & Kennedy, 2007), and Ehrlichia chaffeenis (Zhu et al., 2009), show that ANK-containing proteins can be secreted through a type IV secretion system into the cytoplasm of their host and alter host gene expression and interfere with its hosts’ microtubule directed vesicular transport, respectively (Garcia-Garcia et al., 2009; Pan et al., 2008; Zhu et al., 2009). Based on our data, bacterial ANK-containing proteins may play a significant role in ensuring the pathogen’s survival within the host cell.
Protein folding studies indicate that higher numbers of ANK repeats in a protein results in increased structural stability (Hagai et al., 2012; Mello et al., 2005; Wetzel et al., 2008). We observed that obligate intracellular microbes, on average, have 6.1 ANK repeats per protein, in comparison to 4.6 and 4.55 in bacteria with free-living and facultative host associated replication, respectively (Fig. 5A). This significant difference suggests that the proteins with ANK repeats in obligate intracellular bacteria have a more stable structure than those from bacteria in the other two lifestyles. Furthermore, a study on the folding dynamics and stability of DARPins (designed ankyrin repeat proteins) composed of identical ANK repeats designed from a consensus ANK repeat found that when the number of ANK repeats was reduced from 7 to 4, the stability of the protein was substantially reduced (Wetzel et al., 2008). Coincidentally, this difference in the number of ANK repeats is similar to that observed between obligate intracellular bacteria and free-living/facultative host associated lifestyles in our analysis. Taken together, we suggest that the ANK-containing proteins in obligate intracellular species have, on average, a more stable structure that could potentially underlie more effective interactions between bacterial effector proteins and host proteins. Interestingly, recent proteomic evidence has indicated that some obligate intracellular bacteria, including Blochmonnia chromaiodes and Buchnera, express an abundance of chaperones, such as GroEL, in an effort to provide greater stability for proteins that have accumulated deleterious mutations (Fan et al., 2013; Poliakov et al., 2011). It is possible that enhanced stability of the ANK domain conferred by the accumulation of additional ANK repeats is not required to provide stability for protein interactions, but is rather part of an overall effort to increase protein stability.
On a related note, a comparative study on ANK domain-encoding genes (ANK genes) present in species of Wolbachia pipientis that inhabit Drosophila found that these ANK genes are rapidly evolving due to homologous and illegitimate recombination via the short direct repeat sequences (Siozios et al., 2013). The authors speculated that since stress-related genes also contain these types of direct repeats, which allows for rapid change in challenging environmental conditions, ANK-containing proteins may be used in similar stressful conditions such as directly interacting with host tissues or proteins (Rocha, Matic & Taddei, 2002; Siozios et al., 2013). This inference complements the findings of our analysis because the enriched repertoire of ANK-containing proteins and ANK repeats per protein in obligate bacteria may aid intimate host-microbe interactions.
A number of pathogenic microbes that contain ANK-containing proteins have been identified in this study. For instance, the microbe with the greatest number is the spirochete, Brachyspira hyodysenteriae,which remarkably has 60 ANK-containing proteins. B. hyodysenteriae is a classic gastrointestinal pathogen and the causative agent of a wide range of diarrheal diseases in pigs that naturally leads to significant economic ramifications (ter Huurne & Gaastra, 1995). Of B. hyodysenteriae’s 60 ANK-containing proteins, 34 contain a signal sequence for secretion (Table S10) suggesting that many of these proteins, if expressed, are exported from the microbe into its host that may facilitate pathogenesis (Bellgard et al., 2009; Mappley et al., 2012).
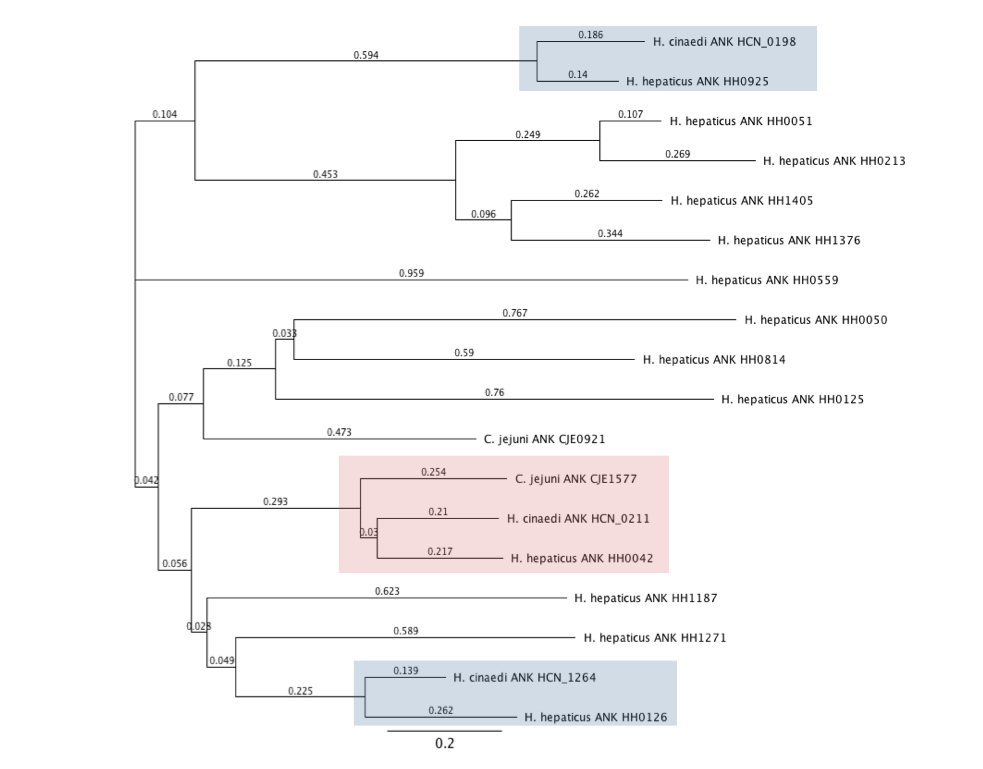
The number of ANK-containing proteins within a group of closely related taxa can be extremely variable. In the order Campylobacterales, Helicobacter hepaticus has 13 such proteins, Helicobacter mustelae has two proteins and Helicobacter cinaedi has three. The remaining five Helicobacter species in our analysis do not have any ANK-containing proteins (Table S11). The related Campylobacter species, including Campylobacter jejuni, have two to three (Table S11), and some ANK-containing proteins in Helicobacter and Campylobacter are probable orthologs (Fig. S2). Interestingly, one ANK-containing protein present in both H. cinaedi and C. jejuni is required for C. jejuni colonization due to its capacity to reduce levels of reactive oxygen species (ROS) in the cell (Flint, Sun & Stintzi, 2012). Finally, the increased repertoire of ANK-containing proteins in H. hepaticus, particularly the three proteins with secretion signal sequence and the two proteins with transmembrane domains (Table S12), may associate with this species’ unique infection of the lower bowel and liver of its host, resulting in inflammatory bowel disease, chronic hepatitis, and liver cancer (Suerbaum et al., 2003).
Although the vast majority of the species with the highest number of ANK-containing proteins are host associated, Desulfomonile tiedjei is an outlier because it harbors 42 such proteins (Table 1). D. teidjei is an anaerobic, free-living bacteria that dechlorinates hydrocarbons, such as tetrachloroethylene (PCE) and trichloroethylene (TCE) (Deweerd & Suflita, 1990). The fact that D. tiedjei also harbors 42 ANK-containing proteins, 19 of which also contain signal sequences, has, to our knowledge, not been reported nor discussed in this microbe’s bioremediation capabilities (Table S13). Although it dechlorinates PCE and TCE, D. teidjei cannot use these chemicals as a carbon source. Instead, D. teidjei lives syntrophically with other anaerobic microbes and relies on them for nutrients (Shelton & Tiedje, 1984). We speculate based on widespread enrichment of ANK-containing proteins in symbionts that these ANK-containing proteins could play a role in this interaction.
Conclusions
Our analysis of the ANK protein motif, augmented with the taxon lifestyles and phylogeny, upgrades the magnitude of ANK repeat biology across the diversity of life. The enrichment of ANK-containing proteins in host-associated bacteria signifies that they are not evolutionarily restricted to unique types of Bacteria or Archaea, but instead can independently thrive in diverse taxa. The functional roles of ANK-containing proteins in Bacteria and Archaea remain understudied and will be an exciting frontier for future investigations of protein interactions between the different domains of life.
Supplemental Information
{kind=link}
All ANK repeat sequences from the following species were analyzed: Legionella pneumophila Philadelphia 1, Coxiella burnetii Dugway 7E9-12, Wolbachia pipientis wMel, Ralstonia solanacearum PSI07, Burkholderia vietnamiensis G4, Leptospira biflexa serovar Patoc strain ’Patoc 1 (Paris), Treponema pallidum pallidum Nichols. To analyze the individual ANK repeats, the ANK-containing proteins sequence ID was obtained from SUPERFAMILY v1.75 and the amino acid sequence information was obtained from NCBIs Proteins database (http://www.ncbi.nlm.nih.gov/protein/). SMART (http://smart.embl-heidelberg.de/) was used to identify the number and location of each individual ANK repeat in the ANK-containing protein. For the amino acid sequence identity analysis, individual ANK repeat sequences were aligned using MUSCLE and the percent identity of the sequences was calculated in Geneious Pro 5.6.2. When comparing ANK repeat sequences from two strains, the average of all combinations of ANK repeat comparisons was used. All species ANK repeat sequences were compared to Wolbachia pipientis wMel to show that the level of identity was the same between species of the same order, and that of a different order (Wolbachia).
{kind=link}
TM, transmemebrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART.
SMART was used to identify ANK repeats, and the ANK domain contained all ANK repeats and some internal linker sequences. MUSCLE alignment was used to align amino acid sequences. INDELS and ends of amino acid sequences were removed after being aligned. Geneious builder was used to build the Neighbor-Joining tree. Blue boxes; Helicobacter hepaticus & Helicobacter cidaedi orthologs Red Box: Helicobacter hepaticus, Helicobacter cidaedi, and C. jejuni orthologs.
{kind=link}
TM, transmembrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART.
TM, transmemebrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART. * Desti_0449 has a HPT (Histidine Phosphotransfer), a REC (cheY-homologous receiver) and a GGDEF(diguanylate cyclase) domain. **Desti_1504 has a Peptidase C14 (Caspase domain) domain.
Funding Statement
This research was made possible by NIH awards F32 GM 100778 and 5T32HD007043-34 to KKJ, and R01 GM085163 to S.R.B. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Additional Information and Declarations
Competing Interests
The authors declare that they have no competing interests.
Author Contributions
Kristin Jernigan conceived and designed the experiments, performed the experiments, analyzed the data, wrote the paper.
Seth R Bordenstein conceived and designed the experiments, analyzed the data, wrote the paper.
References
- Al-Khodor et al. (2010).Al-Khodor S, Price CT, Kalia A, Abu Kwaik Y. Functional diversity of ankyrin repeats in microbial proteins. Trends in Microbiology. 2010;18:132–139. doi: 10.1016/j.tim.2009.11.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bellgard et al. (2009).Bellgard MI, Wanchanthuek P, La T, Ryan K, Moolhuijzen P, Albertyn Z, Shaban B, Motro Y, Dunn DS, Schibeci D, Hunter A, Barrero R, Phillips ND, Hampson DJ. Genome sequence of the pathogenic intestinal spirochete brachyspira hyodysenteriae reveals adaptations to its lifestyle in the porcine large intestine. PLoS ONE. 2009;4:e4641. doi: 10.1371/journal.pone.0004641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Biomatters (2010). Biomatters. 2010. Geneious version 5.6.2. Available fromhttp://www.geneious.com/
- Bork (1993).Bork P. Hundreds of ankyrin-like repeats in functionally diverse proteins: mobile modules that cross phyla horizontally? Proteins. 1993;17:363–374. doi: 10.1002/prot.340170405. [DOI] [PubMed] [Google Scholar]
- Breeden & Nasmyth (1987).Breeden L, Nasmyth K. Similarity between cell-cycle genes of budding yeast and fission yeast and the Notch gene of Drosophila. Nature. 1987;329:651–654. doi: 10.1038/329651a0. [DOI] [PubMed] [Google Scholar]
- Darriba et al. (2012).Darriba D, Taboada GL, Doallo R, Posada D. jModelTest 2: more models, new heuristics and parallel computing. Nature Methods. 2012;9:772. doi: 10.1038/nmeth.2109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Felipe et al. (2008).de Felipe KS, Glover RT, Charpentier X, Anderson OR, Reyes M, Pericone CD, Shuman HA. Legionella eukaryotic-like type IV substrates interfere with organelle trafficking. PLoS Pathogens. 2008;4:e1000117. doi: 10.1371/journal.ppat.1000117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deweerd & Suflita (1990).Deweerd KA, Suflita JM. Anaerobic aryl reductive dehalogenation of halobenzoates by cell extracts of “Desulfomonile tiedjei”. Applied and Environmental Microbiology. 1990;56:2999–3005. doi: 10.1128/aem.56.10.2999-3005.1990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Edgar (2004).Edgar RC. MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Reseach. 2004;32:1792–1797. doi: 10.1093/nar/gkh340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan et al. (2013).Fan Y, Thompson JW, Dubois LG, Moseley MA, Wernegreen JJ. Proteomic analysis of an unculturable bacterial endosymbiont (Blochmannia) reveals high abundance of chaperonins and biosynthetic enzymes. Journal of Proteome Research. 2013;12:704–718. doi: 10.1021/pr3007842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Flint, Sun & Stintzi (2012).Flint A, Sun YQ, Stintzi A. Cj1386 is an ankyrin-containing protein involved in heme trafficking to catalase in Campylobacter jejuni. Journal of Bacteriology. 2012;194:334–345. doi: 10.1128/JB.05740-11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garcia-Garcia et al. (2009).Garcia-Garcia JC, Barat NC, Trembley SJ, Dumler JS. Epigenetic silencing of host cell defense genes enhances intracellular survival of the rickettsial pathogen Anaplasma phagocytophilum. PLoS Pathogens. 2009;5:e1000488. doi: 10.1371/journal.ppat.1000488. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gorina & Pavletich (1996).Gorina S, Pavletich NP. Structure of the p53 tumor suppressor bound to the ankyrin and SH3 domains of 53BP2. Science. 1996;274:1001–1005. doi: 10.1126/science.274.5289.1001. [DOI] [PubMed] [Google Scholar]
- Gough et al. (2001).Gough J, Karplus K, Hughey R, Chothia C. Assignment of homology to genome sequences using a library of hidden Markov models that represent all proteins of known structure. Journal of Molecular Biology. 2001;313:903–919. doi: 10.1006/jmbi.2001.5080. [DOI] [PubMed] [Google Scholar]
- Guindon & Gascuel (2003).Guindon S, Gascuel O. A simple, fast, and accurate algorithm to estimate large phylogenies by maximum likelihood. Systematic Biology. 2003;52:696–704. doi: 10.1080/10635150390235520. [DOI] [PubMed] [Google Scholar]
- Hagai et al. (2012).Hagai T, Azia A, Trizac E, Levy Y. Modulation of folding kinetics of repeat proteins: interplay between intra- and interdomain interactions. Biophysical Journal. 2012;103:1555–1565. doi: 10.1016/j.bpj.2012.08.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hasegawa, Kishino & Yano (1985).Hasegawa M, Kishino H, Yano T. Dating of the human-ape splitting by a molecular clock of mitochondrial DNA. Journal of Molecular Evolution. 1985;22:160–174. doi: 10.1007/BF02101694. [DOI] [PubMed] [Google Scholar]
- Huelsenbeck & Ronquist (2001).Huelsenbeck JP, Ronquist F. MRBAYES: Bayesian inference of phylogenetic trees. Bioinformatics. 2001;17:754–755. doi: 10.1093/bioinformatics/17.8.754. [DOI] [PubMed] [Google Scholar]
- Inada et al. (2012).Inada H, Procko E, Sotomayor M, Gaudet R. Structural and biochemical consequences of disease-causing mutations in the ankyrin repeat domain of the human TRPV4 channel. Biochemistry. 2012;51:6195–6206. doi: 10.1021/bi300279b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Joutel et al. (1996).Joutel A, Corpechot C, Ducros A, Vahedi K, Chabriat H, Mouton P, Alamowitch S, Domenga V, Cecillion M, Marechal E, Maciazek J, Vayssiere C, Cruaud C, Cabanis EA, Ruchoux MM, Weissenbach J, Bach JF, Bousser MG, Tournier-Lasserve E. Notch3 mutations in CADASIL, a hereditary adult-onset condition causing stroke and dementia. Nature. 1996;383:707–710. doi: 10.1038/383707a0. [DOI] [PubMed] [Google Scholar]
- IJdo, Carlson & Kennedy (2007).JW IJdo, Carlson AC, Kennedy EL. Anaplasma phagocytophilum AnkA is tyrosine-phosphorylated at EPIYA motifs and recruits SHP-1 during early infection. Cellular Microbiology. 2007;9:1284–1296. doi: 10.1111/j.1462-5822.2006.00871.x. [DOI] [PubMed] [Google Scholar]
- Letunic, Doerks & Bork (2012).Letunic I, Doerks T, Bork P. SMART 7: recent updates to the protein domain annotation resource. Nucleic Acids Research. 2012;40(D1):D302–D305. doi: 10.1093/nar/gkr931. doi: 10.1093/nar/gkr931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li, Mahajan & Tsai (2006).Li J, Mahajan A, Tsai MD. Ankyrin repeat: a unique motif mediating protein-protein interactions. Biochemistry. 2006;45:15168–15178. doi: 10.1021/bi062188q. [DOI] [PubMed] [Google Scholar]
- Maddison & Maddison (2006).Maddison WP, Maddison DR. 2006. Mesquite: A modular system for evolutionary analysis. Version 1.1.
- Mappley et al. (2012).Mappley LJ, Black ML, AbuOun M, Darby AC, Woodward MJ, Parkhill J, Turner AK, Bellgard MI, La T, Phillips ND, La Ragione RM, Hampson DJ. Comparative genomics of Brachyspira pilosicoli strains: genome rearrangements, reductions and correlation of genetic compliment with phenotypic diversity. BMC Genomics. 2012;13:454. doi: 10.1186/1471-2164-13-454. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mello et al. (2005).Mello CC, Bradley CM, Tripp KW, Barrick D. Experimental characterization of the folding kinetics of the notch ankyrin domain. Journal of Molecular Biology. 2005;352:266–281. doi: 10.1016/j.jmb.2005.07.026. [DOI] [PubMed] [Google Scholar]
- Midford, Garland & Maddison (2005).Midford PE, Garland T, Jr, Maddison WP. 2005. PDAP Package of Mesquite. Version 1.07.
- Mosavi et al. (2004).Mosavi LK, Cammett TJ, Desrosiers DC, Peng ZY. The ankyrin repeat as molecular architecture for protein recognition. Protein Science. 2004;13:1435–1448. doi: 10.1110/ps.03554604. [DOI] [PMC free article] [PubMed] [Google Scholar]
- NCBI Genome resource. NCBI Genome resource. Available at:http://www.ncbi.nlm.nih.gov/genome .
- NCBI Protein resource. NCBI Protein resource. Available at:http://www.ncbi.nlm.nih.gov/protein .
- Newton & Bordenstein (2011).Newton IL, Bordenstein SR. Correlations between bacterial ecology and mobile DNA. Current Microbiology. 2011;62:198–208. doi: 10.1007/s00284-010-9693-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pan et al. (2008).Pan X, Luhrmann A, Satoh A, Laskowski-Arce MA, Roy CR. Ankyrin repeat proteins comprise a diverse family of bacterial type IV effectors. Science. 2008;320:1651–1654. doi: 10.1126/science.1158160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Penz et al. (2012).Penz T, Schmitz-Esser S, Kelly SE, Cass BN, Muller A, Woyke T, Malfatti SA, Hunter MS, Horn M. Comparative genomics suggests an independent origin of cytoplasmic incompatibility in Cardinium hertigii. PLoS Genetics. 2012;8:e1003012. doi: 10.1371/journal.pgen.1003012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poliakov et al. (2011).Poliakov A, Russell CW, Ponnala L, Hoops HJ, Sun Q, Douglas AE, van Wijk KJ. Large-scale label-free quantitative proteomics of the pea aphid-Buchnera symbiosis. Molecular & Cellular Proteomics. 2011;10:M110 007039. doi: 10.1074/mcp.M110.007039. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ponce et al. (2008).Ponce G, Hoenicka J, Jimenez-Arriero MA, Rodriguez-Jimenez R, Aragues M, Martin-Sune N, Huertas E, Palomo T. DRD2 and ANKK1 genotype in alcohol-dependent patients with psychopathic traits: association and interaction study. The British Journal of Psychiatry. 2008;193:121–125. doi: 10.1192/bjp.bp.107.041582. [DOI] [PubMed] [Google Scholar]
- Reeve & Abouheif (2003).Reeve J, Abouheif E. 2003. Phylogenetic Independence. Version 2.0, Department of Biology, McGill University.
- Rocha, Matic & Taddei (2002).Rocha EP, Matic I, Taddei F. Over-representation of repeats in stress response genes: a strategy to increase versatility under stressful conditions? Nucleic Acids Research. 2002;30:1886–1894. doi: 10.1093/nar/30.9.1886. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ronquist & Huelsenbeck (2003).Ronquist F, Huelsenbeck JP. MrBayes 3: Bayesian phylogenetic inference under mixed models. Bioinformatics. 2003;19:1572–1574. doi: 10.1093/bioinformatics/btg180. [DOI] [PubMed] [Google Scholar]
- Schultz et al. (1998).Schultz J, Milpetz F, Bork P, Ponting CP. SMART, a simple modular architecture research tool: identification of signaling domains. Proceedings of National Academy of Sciences of United States of America. 1998;95:5857–5864. doi: 10.1073/pnas.95.11.5857. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sedgwick & Smerdon (1999).Sedgwick SG, Smerdon SJ. The ankyrin repeat: a diversity of interactions on a common structural framework. Trends in Biochemical Sciences. 1999;24:311–316. doi: 10.1016/s0968-0004(99)01426-7. [DOI] [PubMed] [Google Scholar]
- Shelton & Tiedje (1984).Shelton DR, Tiedje JM. General method for determining anaerobic biodegradation potential. Applied and Environmental Microbiology. 1984;47:850–857. doi: 10.1128/aem.47.4.850-857.1984. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Siozios et al. (2013).Siozios S, Ioannidis P, Klasson L, Andersson SG, Braig HR, Bourtzis K. The diversity and evolution of Wolbachia ankyrin repeat domain genes. PLoS ONE. 2013;8:e55390. doi: 10.1371/journal.pone.0055390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suerbaum et al. (2003).Suerbaum S, Josenhans C, Sterzenbach T, Drescher B, Brandt P, Bell M, Droge M, Fartmann B, Fischer HP, Ge Z, Horster A, Holland R, Klein K, Konig J, Macko L, Mendz GL, Nyakatura G, Schauer DB, Shen Z, Weber J, Frosch M, Fox JG. The complete genome sequence of the carcinogenic bacterium Helicobacter hepaticus. Proceedings of National Academy of Sciences of United States of America. 2003;100:7901–7906. doi: 10.1073/pnas.1332093100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- SUPERFAMILY. SUPERFAMILY. HMM library and genome assignments server. Available athttp://supfam.org/SUPERFAMILY/
- Suraj Singh, Ghosh & Saraswathy (2013).Suraj Singh H, Ghosh PK, Saraswathy KN. DRD2 and ANKK1 Gene polymorphisms and alcohol dependence: a case-control study among a mendelian population of east asian ancestry. Alcohol and Alcoholism. 2013;48:409–414. doi: 10.1093/alcalc/agt014. [DOI] [PubMed] [Google Scholar]
- Tang, Fersht & Itzhaki (2003).Tang KS, Fersht AR, Itzhaki LS. Sequential unfolding of ankyrin repeats in tumor suppressor p16. Structure. 2003;11:67–73. doi: 10.1016/s0969-2126(02)00929-2. [DOI] [PubMed] [Google Scholar]
- ter Huurne & Gaastra (1995).ter Huurne AA, Gaastra W. Swine dysentery: more unknown than known. Veterinary Microbiology. 1995;46:347–360. doi: 10.1016/0378-1135(95)00049-g. [DOI] [PubMed] [Google Scholar]
- Wetzel et al. (2008).Wetzel SK, Settanni G, Kenig M, Binz HK, Pluckthun A. Folding and unfolding mechanism of highly stable full-consensus ankyrin repeat proteins. Journal of Molecular Biology. 2008;376:241–257. doi: 10.1016/j.jmb.2007.11.046. [DOI] [PubMed] [Google Scholar]
- Wilson et al. (2009).Wilson D, Pethica R, Zhou Y, Talbot C, Vogel C, Madera M, Chothia C, Gough J. SUPERFAMILY–sophisticated comparative genomics, data mining, visualization and phylogeny. Nucleic Acids Research. 2009;37:D380–386. doi: 10.1093/nar/gkn762. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu et al. (2009).Zhu B, Nethery KA, Kuriakose JA, Wakeel A, Zhang X, McBride JW. Nuclear translocated Ehrlichia chaffeensis ankyrin protein interacts with a specific adenine-rich motif of host promoter and intronic Alu elements. Infection and Immunity. 2009;77:4243–4255. doi: 10.1128/IAI.00376-09. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
All ANK repeat sequences from the following species were analyzed: Legionella pneumophila Philadelphia 1, Coxiella burnetii Dugway 7E9-12, Wolbachia pipientis wMel, Ralstonia solanacearum PSI07, Burkholderia vietnamiensis G4, Leptospira biflexa serovar Patoc strain ’Patoc 1 (Paris), Treponema pallidum pallidum Nichols. To analyze the individual ANK repeats, the ANK-containing proteins sequence ID was obtained from SUPERFAMILY v1.75 and the amino acid sequence information was obtained from NCBIs Proteins database (http://www.ncbi.nlm.nih.gov/protein/). SMART (http://smart.embl-heidelberg.de/) was used to identify the number and location of each individual ANK repeat in the ANK-containing protein. For the amino acid sequence identity analysis, individual ANK repeat sequences were aligned using MUSCLE and the percent identity of the sequences was calculated in Geneious Pro 5.6.2. When comparing ANK repeat sequences from two strains, the average of all combinations of ANK repeat comparisons was used. All species ANK repeat sequences were compared to Wolbachia pipientis wMel to show that the level of identity was the same between species of the same order, and that of a different order (Wolbachia).
TM, transmemebrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART.
SMART was used to identify ANK repeats, and the ANK domain contained all ANK repeats and some internal linker sequences. MUSCLE alignment was used to align amino acid sequences. INDELS and ends of amino acid sequences were removed after being aligned. Geneious builder was used to build the Neighbor-Joining tree. Blue boxes; Helicobacter hepaticus & Helicobacter cidaedi orthologs Red Box: Helicobacter hepaticus, Helicobacter cidaedi, and C. jejuni orthologs.
TM, transmembrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART.
TM, transmemebrane domain. The number in the parentheses in the TM domain column refers to the number of TM domains the protein is predicted to have by SMART. * Desti_0449 has a HPT (Histidine Phosphotransfer), a REC (cheY-homologous receiver) and a GGDEF(diguanylate cyclase) domain. **Desti_1504 has a Peptidase C14 (Caspase domain) domain.