

Significance
Attention has recently focused on a basic yet unresolved problem in statistics: How can one quantify the strength of a statistical association between two variables without bias for relationships of a specific form? Here we propose a way of mathematically formalizing this “equitability” criterion, using core concepts from information theory. This criterion is naturally satisfied by a fundamental information-theoretic measure of dependence called “mutual information.” By contrast, a recently introduced dependence measure called the “maximal information coefficient” is seen to violate equitability. We conclude that estimating mutual information provides a natural and practical method for equitably quantifying associations in large datasets.
Abstract
How should one quantify the strength of association between two random variables without bias for relationships of a specific form? Despite its conceptual simplicity, this notion of statistical “equitability” has yet to receive a definitive mathematical formalization. Here we argue that equitability is properly formalized by a self-consistency condition closely related to Data Processing Inequality. Mutual information, a fundamental quantity in information theory, is shown to satisfy this equitability criterion. These findings are at odds with the recent work of Reshef et al. [Reshef DN, et al. (2011) Science 334(6062):1518–1524], which proposed an alternative definition of equitability and introduced a new statistic, the “maximal information coefficient” (MIC), said to satisfy equitability in contradistinction to mutual information. These conclusions, however, were supported only with limited simulation evidence, not with mathematical arguments. Upon revisiting these claims, we prove that the mathematical definition of equitability proposed by Reshef et al. cannot be satisfied by any (nontrivial) dependence measure. We also identify artifacts in the reported simulation evidence. When these artifacts are removed, estimates of mutual information are found to be more equitable than estimates of MIC. Mutual information is also observed to have consistently higher statistical power than MIC. We conclude that estimating mutual information provides a natural (and often practical) way to equitably quantify statistical associations in large datasets.
This paper addresses a basic yet unresolved issue in statistics: How should one quantify, from finite data, the association between two continuous variables? Consider the squared Pearson correlation R2. This statistic is the standard measure of dependence used throughout science and industry. It provides a powerful and meaningful way to quantify dependence when two variables share a linear relationship exhibiting homogenous Gaussian noise. However, as is well known, R2 values often correlate badly with one’s intuitive notion of dependence when relationships are highly nonlinear.
Fig. 1 provides an example of how R2 can fail to sensibly quantify associations. Fig. 1A shows a simulated dataset, representing a noisy monotonic relationship between two variables x and y. This yields a substantial R2 measure of dependence. However, the R2 value computed for the nonmonotonic relationship in Fig. 1B is not significantly different from zero even though the two relationships shown in Fig. 1 are equally noisy.
Fig. 1.

Illustration of equitability. (A and B)  data points simulated for two noisy functional relationships that have the same noise profile but different underlying functions. (Upper) Mean ± SD values, computed over 100 replicates, for three statistics: Pearson’s R2, mutual information I (in bits), and MIC. Mutual information was estimated using the KNN algorithm (18) with
data points simulated for two noisy functional relationships that have the same noise profile but different underlying functions. (Upper) Mean ± SD values, computed over 100 replicates, for three statistics: Pearson’s R2, mutual information I (in bits), and MIC. Mutual information was estimated using the KNN algorithm (18) with  . The specific relationships simulated are both of the form
. The specific relationships simulated are both of the form  , where η is noise drawn uniformly from
, where η is noise drawn uniformly from  and x is drawn uniformly from one of two intervals, (A)
and x is drawn uniformly from one of two intervals, (A)  or (B)
or (B)  . Both relationships have the same underlying mutual information (0.72 bits).
. Both relationships have the same underlying mutual information (0.72 bits).
It is therefore natural to ask whether one can measure statistical dependencies in a way that assigns “similar scores to equally noisy relationships of different types.” This heuristic criterion has been termed “equitability” by Reshef et al. (1, 2), and its importance for the analysis of real-world data has been emphasized by others (3, 4). It has remained unclear, however, how equitability should be defined mathematically. As a result, no dependence measure has yet been proved to have this property.
Here we argue that the heuristic notion of equitability is properly formalized by a self-consistency condition that we call “self-equitability.” This criterion arises naturally as a weakened form of the well-known Data Processing Inequality (DPI). All DPI-satisfying dependence measures are thus proved to satisfy self-equitability. Foremost among these is “mutual information,” a quantity of central importance in information theory (5, 6). Indeed, mutual information is already widely believed to quantify dependencies without bias for relationships of one type or another. And although it was proposed in the context of modeling communications systems, mutual information has been repeatedly shown to arise naturally in a variety of statistical problems (6–8).
The use of mutual information for quantifying associations in continuous data is unfortunately complicated by the fact that it requires an estimate (explicit or implicit) of the probability distribution underlying the data. How to compute such an estimate that does not bias the resulting mutual information value remains an open problem, one that is particularly acute in the undersampled regime (9, 10). Despite these difficulties, a variety of practical estimation techniques have been developed and tested (11, 12). Indeed, mutual information is now routinely computed on continuous data in many real-world applications (e.g., refs. 13–17).
Unlike R2, the mutual information values I of the underlying relationships in Fig. 1 A and B are identical (0.72 bits). This is a consequence of the self-equitability of mutual information. Applying the kth nearest-neighbor (KNN) mutual information estimation algorithm of Kraskov et al. (18) to simulated data drawn from these relationships, we see that the estimated mutual information values agree well with the true underlying values.
However, Reshef et al. claim in their paper (1) that mutual information does not satisfy the heuristic notion of equitability. After formalizing this notion, the authors also introduce a new statistic called the “maximal information coefficient” (MIC), which, they claim, does satisfy their equitability criterion. These results are perhaps surprising, considering that MIC is actually defined as a normalized estimate of mutual information. However, no mathematical arguments were offered for these assertions; they were based solely on the analysis of simulated data.
Here we revisit these claims. First, we prove that the definition of equitability proposed by Reshef et al. is, in fact, impossible for any (nontrivial) dependence measure to satisfy. MIC is then shown by example to violate various intuitive notions of dependence, including DPI and self-equitability. Upon revisiting the simulations of Reshef et al. (1), we find the evidence offered in support of their claims about equitability to be artifactual. Indeed, random variations in the MIC estimates of ref. 1, which resulted from the small size of the simulated datasets used, are seen to have obscured the inherently nonequitable behavior of MIC. When moderately larger datasets are used, it becomes clear that nonmonotonic relationships have systematically reduced MIC values relative to monotonic ones. The MIC values computed for the relationships in Fig. 1 illustrate this bias. We also find that the nonequitable behavior reported for mutual information by Reshef et al. does not reflect inherent properties of mutual information, but rather resulted from the use of a nonoptimal value for the parameter k in the KNN algorithm of Kraskov et al. (18).
Finally we investigate the power of MIC, the KNN mutual information estimator, and other measures of bivariate dependence. Although the power of MIC was not discussed by Reshef et al. (1), this issue is critical for the kinds of applications described in their paper. Here we find that, when an appropriate value of k is used, KNN estimates of mutual information consistently outperform MIC in tests of statistical power. However, we caution that other nonequitable measures such as “distance correlation” (dCor) (19) and Hoeffding’s D (20) may prove to be more powerful on some real-world datasets than the KNN estimator.
In the text that follows, uppercase letters ( ) are used to denote random variables, lowercase letters
) are used to denote random variables, lowercase letters  denote specific values for these variables, and tildes
denote specific values for these variables, and tildes  signify bins into which these values fall when histogrammed. A “dependence measure,” written
signify bins into which these values fall when histogrammed. A “dependence measure,” written  , refers to a function of the joint probability distribution
, refers to a function of the joint probability distribution  , whereas a “dependence statistic,” written
, whereas a “dependence statistic,” written  , refers to a function computed from finite data
, refers to a function computed from finite data  that has been sampled from
that has been sampled from  .
.
Results
R2-Equitability.
In their paper, Reshef et al. (1) suggest the following definition of equitability. This makes use of the squared Pearson correlation measure  , so for clarity we call this criterion “R2-equitability.”
, so for clarity we call this criterion “R2-equitability.”
Definition 1.
A dependence measure
 is R2-equitable if and only if, when evaluated on a joint probability distribution
is R2-equitable if and only if, when evaluated on a joint probability distribution
 that corresponds to a noisy functional relationship between two real random variables
X
and
Y, the following relation holds:
that corresponds to a noisy functional relationship between two real random variables
X
and
Y, the following relation holds:
Here, g is a function that does not depend on
 and
f
is the function defining the noisy functional relationship, i.e.,
and
f
is the function defining the noisy functional relationship, i.e.,
for some random variable
η.
The noise term
η
may depend on
 as long as
η
has no additional dependence on
X, i.e., as long
as
as long as
η
has no additional dependence on
X, i.e., as long
as
 is a Markov chain.†
is a Markov chain.†
Heuristically this means that, by computing the measure  from knowledge of
from knowledge of  , one can discern the strength of the noise η, as quantified by
, one can discern the strength of the noise η, as quantified by  , without knowing the underlying function
, without knowing the underlying function  . Of course this definition depends strongly on what properties the noise η is allowed to have. In their simulations, Reshef et al. (1) considered only uniform homoscedastic noise: η was drawn uniformly from some symmetric interval
. Of course this definition depends strongly on what properties the noise η is allowed to have. In their simulations, Reshef et al. (1) considered only uniform homoscedastic noise: η was drawn uniformly from some symmetric interval  . Here we consider a much broader class of heteroscedastic noise: η may depend arbitrarily on
. Here we consider a much broader class of heteroscedastic noise: η may depend arbitrarily on  , and
, and  may have arbitrary functional form.
may have arbitrary functional form.
Our first result is this: No nontrivial dependence measure can satisfy R2-equitability. This is due to the fact that the function f in Eq. 2 is not uniquely specified by  . For example, consider the simple relationship
. For example, consider the simple relationship  . For every invertible function h there also exists a valid noise term ξ such that
. For every invertible function h there also exists a valid noise term ξ such that  (SI Text, Theorem 1). R2-equitability then requires
(SI Text, Theorem 1). R2-equitability then requires  . However,
. However,  is not invariant under invertible transformations of X. The function g must therefore be constant, implying that
is not invariant under invertible transformations of X. The function g must therefore be constant, implying that  does not depend on
does not depend on  and is therefore trivial.
and is therefore trivial.
Self-Equitability and Data Processing Inequality.
Because R2-equitability cannot be satisfied by any (interesting) dependence measure, it cannot be adopted as a useful mathematical formalization of Reshef et al.’s heuristic (1). Instead we propose formalizing the notion of equitability as an invariance property we term self-equitability, which is defined as follows.
Definition 2.
A dependence measure
 is self-equitable if and only if it is symmetric (
is self-equitable if and only if it is symmetric ( ) and
satisfies
) and
satisfies
whenever f is a deterministic function, X
and
Y
are variables of any type, and
 forms a Markov chain.
forms a Markov chain.
The intuition behind this definition is similar to that behind Eq. 1, but instead of using R2 to quantify the noise in the relationship we use D itself. An important advantage of this definition is that the Y variable can be of any type, e.g., categorical, multidimensional, or non-Abelian. By contrast, the definition of R2-equitability requires that Y and  must be real numbers.
must be real numbers.
Self-equitability also employs a more general definition of “noisy relationship” than does R2-equitability: Instead of positing additive noise as in Eq. 2, one simply assumes that Y depends on X only through the value of  . This is formalized by the Markov chain condition
. This is formalized by the Markov chain condition  . As a result, any self-equitable measure
. As a result, any self-equitable measure  must be invariant under arbitrary invertible transformations of X or Y (SI Text, Theorem 2). Self-equitability also has a close connection to DPI, a fundamental criterion in information theory (6) that we briefly restate here.
must be invariant under arbitrary invertible transformations of X or Y (SI Text, Theorem 2). Self-equitability also has a close connection to DPI, a fundamental criterion in information theory (6) that we briefly restate here.
Definition 3.
A dependence measure
 satisfies DPI if and only if
satisfies DPI if and only if
whenever the random variables
 form a Markov chain
form a Markov chain
 .
.
DPI formalizes our intuitive notion that information is generally lost, and is never gained, when transmitted through a noisy communications channel. For instance, consider a game of telephone involving three children, and let the variables X, Y, and Z represent the words spoken by the first, the second, and the third child, respectively. The criterion in Eq. 4 is satisfied only if the measure D upholds our intuition that the words spoken by the third child will be more strongly dependent on those said by the second child (as quantified by  ) than on those said by the first child (quantified by
) than on those said by the first child (quantified by  ).
).
It is readily shown that all DPI-satisfying dependence measures are self-equitable (SI Text, Theorem 3). Moreover, many dependence measures do satisfy DPI (SI Text, Theorem 4). This begs the question of whether there are any self-equitable measures that do not satisfy DPI. The answer is technically “yes”: For example, if  satisfies DPI, then a new measure defined as
satisfies DPI, then a new measure defined as  will be self-equitable but will not satisfy DPI. However, DPI enforces an important heuristic that self-equitability does not, namely that adding noise should not increase the strength of a dependency. So although self-equitable measures that violate DPI do exist, there is good reason to require that sensible measures also satisfy DPI.
will be self-equitable but will not satisfy DPI. However, DPI enforces an important heuristic that self-equitability does not, namely that adding noise should not increase the strength of a dependency. So although self-equitable measures that violate DPI do exist, there is good reason to require that sensible measures also satisfy DPI.
Mutual Information.
Among DPI-satisfying dependence measures, mutual information is particularly meaningful. Mutual information rigorously quantifies, in units known as “bits,” how much information the value of one variable reveals about the value of another. This has important and well-known consequences in information theory (6). Perhaps less well known, however, is the natural role that mutual information plays in the statistical analysis of data, a topic we now touch upon briefly.
The mutual information between two random variables X and Y is defined in terms of their joint probability distribution  as
as
 |
 is always nonnegative and
is always nonnegative and  only when
only when  . Thus, mutual information will be greater than zero when X and Y exhibit any mutual dependence, regardless of how nonlinear that dependence is. Moreover, the stronger the mutual dependence is, the larger the value of
. Thus, mutual information will be greater than zero when X and Y exhibit any mutual dependence, regardless of how nonlinear that dependence is. Moreover, the stronger the mutual dependence is, the larger the value of  . In the limit where Y is a (nonconstant) deterministic function of X (over a continuous domain),
. In the limit where Y is a (nonconstant) deterministic function of X (over a continuous domain),  .
.
Mutual information is intimately connected to the statistical problem of detecting dependencies. From Eq. 5 we see that, for data drawn from the distribution  ,
,  quantifies the expected per-datum log-likelihood ratio of the data coming from
quantifies the expected per-datum log-likelihood ratio of the data coming from  as opposed to
as opposed to  . Thus,
. Thus,  is the typical amount of data one needs to collect to get a twofold increase in the posterior probability of the true hypothesis relative to the null hypothesis [i.e., that
is the typical amount of data one needs to collect to get a twofold increase in the posterior probability of the true hypothesis relative to the null hypothesis [i.e., that  ]. Moreover, the Neyman–Pearson lemma (21) tells us that this log-likelihood ratio,
]. Moreover, the Neyman–Pearson lemma (21) tells us that this log-likelihood ratio,  , has the maximal possible statistical power for such a test. The mutual information
, has the maximal possible statistical power for such a test. The mutual information  therefore provides a tight upper bound on how well any test of dependence can perform on data drawn from
therefore provides a tight upper bound on how well any test of dependence can perform on data drawn from  .
.
Accurately estimating mutual information from finite continuous data, however, is nontrivial. The difficulty lies in estimating the joint distribution  from a finite sample of N data points
from a finite sample of N data points  . The simplest approach is to “bin” the data—to superimpose a rectangular grid on the
. The simplest approach is to “bin” the data—to superimpose a rectangular grid on the  scatter plot and then assign each continuous x value (or y value) to the column bin
scatter plot and then assign each continuous x value (or y value) to the column bin  (or row bin
(or row bin  ) into which it falls. Mutual information can then be estimated from the data as
) into which it falls. Mutual information can then be estimated from the data as
 |
where  is the fraction of data points falling into bin
is the fraction of data points falling into bin  . Estimates of mutual information that rely on this simple binning procedure are commonly called “naive” estimates (22). The problem with such naive estimates is that they systematically overestimate
. Estimates of mutual information that rely on this simple binning procedure are commonly called “naive” estimates (22). The problem with such naive estimates is that they systematically overestimate  . As was mentioned above, this has long been recognized as a problem and significant attention has been devoted to developing alternative methods that do not systematically overestimate mutual information. We emphasize, however, that the problem of estimating mutual information becomes easy in the large data limit, because
. As was mentioned above, this has long been recognized as a problem and significant attention has been devoted to developing alternative methods that do not systematically overestimate mutual information. We emphasize, however, that the problem of estimating mutual information becomes easy in the large data limit, because  can be determined to arbitrary accuracy as
can be determined to arbitrary accuracy as  .
.
The Maximal Information Coefficient.
In contrast to mutual information, Reshef et al. (1) define MIC as a statistic, not as a dependence measure. At the heart of this definition is a naive mutual information estimate  computed using a data-dependent binning scheme. Let
computed using a data-dependent binning scheme. Let  and
and  , respectively, denote the number of bins imposed on the x and y axes. The MIC binning scheme is chosen so that (i) the total number of bins
, respectively, denote the number of bins imposed on the x and y axes. The MIC binning scheme is chosen so that (i) the total number of bins  does not exceed some user-specified value B and (ii) the value of the ratio
does not exceed some user-specified value B and (ii) the value of the ratio
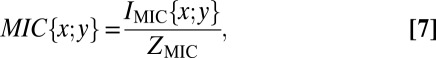 |
where  , is maximized. The ratio in Eq. 7, computed using this data-dependent binning scheme, is how MIC is defined. Note that, because
, is maximized. The ratio in Eq. 7, computed using this data-dependent binning scheme, is how MIC is defined. Note that, because  is bounded above by
is bounded above by  , MIC values will always fall between 0 and 1. We note that
, MIC values will always fall between 0 and 1. We note that  (1) and
(1) and  (2) have been advocated, although no mathematical rationale for these choices has been presented.
(2) have been advocated, although no mathematical rationale for these choices has been presented.
In essence the MIC statistic  is defined as a naive mutual information estimate
is defined as a naive mutual information estimate  , computed using a constrained adaptive binning scheme and divided by a data-dependent normalization factor
, computed using a constrained adaptive binning scheme and divided by a data-dependent normalization factor  . However, in practice this statistic often cannot be computed exactly because the definition of MIC requires a maximization step over all possible binning schemes, a computationally intractable problem even for modestly sized datasets. Rather, a computational estimate of MIC is typically required. Except where noted otherwise, MIC values reported in this paper were computed using the software provided by Reshef et al. (1).
. However, in practice this statistic often cannot be computed exactly because the definition of MIC requires a maximization step over all possible binning schemes, a computationally intractable problem even for modestly sized datasets. Rather, a computational estimate of MIC is typically required. Except where noted otherwise, MIC values reported in this paper were computed using the software provided by Reshef et al. (1).
Note that when only two bins are used on either the x or the y axis in the MIC binning scheme,  . In such cases the MIC statistic is identical to the underlying mutual information estimate
. In such cases the MIC statistic is identical to the underlying mutual information estimate  . We point this out because a large majority of the MIC computations reported below produced
. We point this out because a large majority of the MIC computations reported below produced  . Indeed it appears that, except for highly structured relationships, MIC typically reduces to the naive mutual information estimate
. Indeed it appears that, except for highly structured relationships, MIC typically reduces to the naive mutual information estimate  (SI Text).‡
(SI Text).‡
Analytic Examples.
To illustrate the differing properties of mutual information and MIC, we first compare the exact behavior of these dependence measures on simple example relationships  .§ We begin by noting that MIC is completely insensitive to certain types of noise. This is illustrated in Fig. 2 A–C, which provides examples of how adding noise at all values of X will decrease
.§ We begin by noting that MIC is completely insensitive to certain types of noise. This is illustrated in Fig. 2 A–C, which provides examples of how adding noise at all values of X will decrease  but not necessarily decrease
but not necessarily decrease  . This pathological behavior results from the binning scheme used in the definition of MIC: If all data points can be partitioned into two opposing quadrants of a 2 × 2 grid (half the data in each), a relationship will be assigned
. This pathological behavior results from the binning scheme used in the definition of MIC: If all data points can be partitioned into two opposing quadrants of a 2 × 2 grid (half the data in each), a relationship will be assigned  regardless of the structure of the data within the two quadrants. Mutual information, by contrast, has no such limitations on its resolution.
regardless of the structure of the data within the two quadrants. Mutual information, by contrast, has no such limitations on its resolution.
Fig. 2.

MIC violates multiple notions of dependence that mutual information upholds. (A–J) Example relationships between two variables with indicated mutual information values (I, shown in bits) and MIC values. These values were computed analytically and checked using simulated data (Fig. S1). Dark blue blocks represent twice the probability density of light blue blocks. (A–C) Adding noise everywhere to the relationship in A diminishes mutual information but not necessarily MIC. (D–F) Relationships related by invertible nonmonotonic transformations of X and Y. Mutual information is invariant under these transformations but MIC is not. (G–J) Convolving the relationships shown in G–I along the chain  produces the relationship shown in J. In this case MIC violates DPI because
produces the relationship shown in J. In this case MIC violates DPI because  . Mutual information satisfies DPI here because
. Mutual information satisfies DPI here because  .
.
Furthermore,  is not invariant under nonmonotonic transformations of X or Y. Mutual information, by contrast, is invariant under such transformations. This is illustrated in Fig. 2 D–F. Such reparameterization invariance is a necessary attribute of any dependence measure that satisfies self-equitability or DPI (SI Text, Theorem 2). Fig. 2 G–J provides an explicit example of how the noninvariance of MIC causes DPI to be violated, whereas Fig. S2 shows how noninvariance can lead to violation of self-equitability.
is not invariant under nonmonotonic transformations of X or Y. Mutual information, by contrast, is invariant under such transformations. This is illustrated in Fig. 2 D–F. Such reparameterization invariance is a necessary attribute of any dependence measure that satisfies self-equitability or DPI (SI Text, Theorem 2). Fig. 2 G–J provides an explicit example of how the noninvariance of MIC causes DPI to be violated, whereas Fig. S2 shows how noninvariance can lead to violation of self-equitability.
Equitability Tests Using Simulated Data.
The key claim made by Reshef et al. (1) in arguing for the use of MIC as a dependence measure has two parts. First, MIC is said to satisfy not just the heuristic notion of equitability, but also the mathematical criterion of R2-equitability (Eq. 1). Second, Reshef et al. (1) argue that mutual information does not satisfy R2-equitability. In essence, the central claim made in ref. 1 is that the binning scheme and normalization procedure that transform mutual information into MIC are necessary for equitability. As mentioned in the Introduction, however, no mathematical arguments were made for these claims; these assertions were supported entirely through the analysis of limited simulated data.
We now revisit this simulation evidence. To argue that MIC is R2-equitable, Reshef et al. simulated data for various noisy functional relationships of the form  . A total of 250, 500, or 1,000 data points were generated for each dataset; see Table S1 for details.
. A total of 250, 500, or 1,000 data points were generated for each dataset; see Table S1 for details.  was computed for each data set and was plotted against
was computed for each data set and was plotted against  , which was used to quantify the inherent noise in each simulation.
, which was used to quantify the inherent noise in each simulation.
Were MIC to satisfy R2-equitability, plots of MIC against this measure of noise would fall along the same curve regardless of the function f used for each relationship. At first glance Fig. 3A, which is a reproduction of figure 2B of ref. 1, suggests that this may be the case. These MIC values exhibit some dispersion, of course, but this is presumed in ref. 1 to result from the finite size of the simulated datasets, not any inherent f-dependent bias of MIC.
Fig. 3.

Reexamination of the R2-equitability tests reported by Reshef et al. (1). MIC values and mutual information values were computed for datasets simulated as described in figure 2 B–F of ref. 1. Specifically, each simulated relationship is of the form  . Twenty-one different functions f and twenty-four different amplitudes for the noise η were used. Details are provided in Table S1. MIC and mutual information values are plotted against the inherent noise in each relationship, as quantified by
. Twenty-one different functions f and twenty-four different amplitudes for the noise η were used. Details are provided in Table S1. MIC and mutual information values are plotted against the inherent noise in each relationship, as quantified by  . (A) Reproduction of figure 2B of ref. 1.
. (A) Reproduction of figure 2B of ref. 1.  was calculated on datasets comprising 250, 500, or 1,000 data points, depending on f. (B) Same as A but using datasets comprising 5,000 data points each. (C) Reproduction of figure 2D of ref. 1. Mutual information values
was calculated on datasets comprising 250, 500, or 1,000 data points, depending on f. (B) Same as A but using datasets comprising 5,000 data points each. (C) Reproduction of figure 2D of ref. 1. Mutual information values 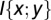 were computed (in bits) on the datasets from A, using the KNN estimator with smoothing parameter
were computed (in bits) on the datasets from A, using the KNN estimator with smoothing parameter  . (D) KNN estimates of mutual information, made using
. (D) KNN estimates of mutual information, made using  , computed for the datasets from B. (E) Each point plotted in A–D is colored (as indicated here) according to the monotonicity of f, which is quantified using the squared Spearman rank correlation between X and
, computed for the datasets from B. (E) Each point plotted in A–D is colored (as indicated here) according to the monotonicity of f, which is quantified using the squared Spearman rank correlation between X and  (Fig. S3).
(Fig. S3).
However, as Fig. 3B shows, substantial f-dependent bias in the values of MIC become evident when the number of simulated data points is increased to 5,000. This bias is particularly strong for noise values between 0.6 and 0.8. To understand the source of this bias, we colored each plotted point according to the monotonicity of the function f used in the corresponding simulation. We observe that MIC assigns systematically higher scores to monotonic relationships (colored in blue) than to nonmonotonic relationships (colored in orange). Relationships of intermediate monotonicity (purple) fall in between. This bias of MIC for monotonic relationships is further seen in analogous tests of self-equitability (Fig. S4A).
MIC is therefore seen, in practice, to violate R2-equitability, the criterion adopted by Reshef et al. (1). However, this nonequitable behavior of MIC is obscured in figure 2B of ref. 1 by two factors. First, scatter due to the small size of the simulated datasets obscures the f-dependent bias of MIC. Second, the nonsystematic coloring scheme used in figure 2B of ref. 1 masks the bias that becomes apparent with the coloring scheme used here.
To argue that mutual information violates their equitability criterion, Reshef et al. (1) estimated the mutual information in each simulated dataset and then plotted these estimates  against noise, again quantified by
against noise, again quantified by  . These results, initially reported in figure 2D of ref. 1, are reproduced here in Fig. 3C. At first glance, Fig. 3C suggests a bias of mutual information for monotonic functions that is significantly worse than the bias exhibited by MIC. However, these observations are artifacts resulting from two factors.
. These results, initially reported in figure 2D of ref. 1, are reproduced here in Fig. 3C. At first glance, Fig. 3C suggests a bias of mutual information for monotonic functions that is significantly worse than the bias exhibited by MIC. However, these observations are artifacts resulting from two factors.
First, Reshef et al. (1) did not compute the true mutual information of the underlying relationship; rather, they estimated it using the KNN algorithm of Kraskov et al. (18). This algorithm estimates mutual information based on the distance between kth nearest-neighbor data points. In essence, k is a smoothing parameter: Low values of k will give estimates of mutual information with high variance but low bias, whereas high values of k will lessen this variance but increase bias. Second, the bias due to large values of k is exacerbated in small datasets relative to large datasets. If claims about the inherent bias of mutual information are to be supported using simulations, it is imperative that mutual information be estimated on datasets that are sufficiently large for this estimator-specific bias to be negligible.
We therefore replicated the analysis in figure 2D of ref. 1, but simulated 5,000 data points per relationship and used the KNN mutual information estimator with  instead of
instead of  . The results of this computation are shown in Fig. 3D. Here we see nearly all of the nonequitable behavior cited in ref. 1 is eliminated; this observation holds in the large data limit (Fig. S4D).
. The results of this computation are shown in Fig. 3D. Here we see nearly all of the nonequitable behavior cited in ref. 1 is eliminated; this observation holds in the large data limit (Fig. S4D).
Of course mutual information does not exactly satisfy R2-equitability because no meaningful dependence measure does. However, mutual information does satisfy self-equitability, and Fig. S4E shows that the self-equitable behavior of mutual information is seen to hold approximately for KNN estimates made on the simulated data from Fig. 3D. Increasing values of k reduce the self-equitability of the KNN algorithm (Fig. S4 E–G).
Statistical Power.
Simon and Tibshirani (24) have stressed the importance of statistical power for measures of bivariate association. In this context, “power” refers to the probability that a statistic, when evaluated on data exhibiting a true dependence between X and Y, will yield a value that is significantly different from that for data in which X and Y are independent. MIC was observed (24) to have substantially less power than a statistic called dCor (19), but KNN mutual information estimates were not tested. We therefore investigated whether the statistical power of KNN mutual information estimates could compete with dCor, MIC, and other non–self-equitable dependence measures.
Fig. 4 presents the results of statistical power comparisons performed for various statistics on relationships of five different types.¶ As expected, R2 was observed to have optimal power on the linear relationship, but essentially negligible power on the other (mirror symmetric) relationships. dCor and Hoeffding’s D (20) performed similarly to one another, exhibiting nearly the same power as R2 on the linear relationship and retaining substantial power on all but the checkerboard relationship.
Fig. 4.

Assessment of statistical power. Heat maps show power values computed for R2; dCor (19); Hoeffding’s D (20); KNN estimates of mutual information, using k = 1, 6, or 20; and MIC. Full power curves are shown in Fig. S6. Simulated datasets comprising 320 data points each were generated for each of five relationship types (linear, parabolic, sinusoidal, circular, or checkerboard), using additive noise that varied in amplitude over a 10-fold range; see Table S2 for simulation details. Asterisks indicate, for each relationship type, the statistics that have either the maximal noise-at-50%-power or a noise-at-50%-power that lies within 25% of this maximum. The scatter plot above each heat map shows an example dataset having noise of unit amplitude.
Power calculations were also performed for the KNN mutual information estimator using  , 6, and 20. KNN estimates computed with
, 6, and 20. KNN estimates computed with  exhibited the most statistical power of these three; indeed, such estimates exhibited optimal or near-optimal statistical power on all but the linear relationship.
exhibited the most statistical power of these three; indeed, such estimates exhibited optimal or near-optimal statistical power on all but the linear relationship.
However, R2, dCor, and Hoeffding’s D performed substantially better on the linear relationship (Fig. S6). This is important to note because the linear relationship is likely to be more representative of many real-world datasets than are the other four relationships tested. The KNN mutual information estimator also has the important disadvantage of requiring the user to specify k without any mathematical guidelines for doing so. The choices of k used in our simulations were arbitrary, and, as shown, these choices can greatly affect the power and equitability of one’s mutual information estimates.
MIC, computed using  , was observed to have relatively low statistical power on all but the sinusoidal relationship. This is consistent with the findings of ref. 24. Interestingly, MIC actually exhibited less statistical power than the mutual information estimate
, was observed to have relatively low statistical power on all but the sinusoidal relationship. This is consistent with the findings of ref. 24. Interestingly, MIC actually exhibited less statistical power than the mutual information estimate  on which it is based (Figs. S5 and S6). This argues that the normalization procedure in Eq. 7 may actually reduce the statistical utility of MIC.
on which it is based (Figs. S5 and S6). This argues that the normalization procedure in Eq. 7 may actually reduce the statistical utility of MIC.
We note that the power of the KNN estimator increased substantially with k, particularly on the simpler relationships, whereas the self-equitability of the KNN estimator was observed to decrease with increasing k (Fig. S4 E–G). This trade-off between power and equitability, observed for the KNN estimator, appears to reflect the bias vs. variance trade-off well known in statistics. Indeed, for a statistic to be powerful it must have low variance, but systematic bias in the values of the statistic is irrelevant. By contrast, our definition of equitability is a statement about the bias of a dependence measure, not the variance of its estimators.
Discussion
We have argued that equitability, a heuristic property for dependence measures that was proposed by Reshef et al. (1), is properly formalized by self-equitability, a self-consistency condition closely related to DPI. This extends the notion of equitability, defined originally for measures of association between one-dimensional variables only, to measures of association between variables of all types and dimensionality. All DPI-satisfying measures are found to be self-equitable, and among these mutual information is particularly useful due to its fundamental meaning in information theory and statistics (6–8).
Not all statistical problems call for a self-equitable measure of dependence. For instance, if data are limited and noise is known to be approximately Gaussian, R2 (which is not self-equitable) can be a much more useful statistic than estimates of mutual information. On the other hand, when data are plentiful and noise properties are unknown a priori, mutual information has important theoretical advantages (8). Although substantial difficulties with estimating mutual information on continuous data remain, such estimates have proved useful in a variety of real-world problems in neuroscience (14, 15, 25), molecular biology (16, 17, 26–28), medical imaging (29), and signal processing (13).
In our tests of equitability, the vast majority of MIC estimates were actually identical to the naive mutual information estimate  . Moreover, the statistical power of MIC is noticeably reduced relative to
. Moreover, the statistical power of MIC is noticeably reduced relative to  in situations where the denominator
in situations where the denominator  in Eq. 7 fluctuates (Figs. S5 and S6). This suggests that the normalization procedure at the heart of MIC actually decreases MIC's statistical utility.
in Eq. 7 fluctuates (Figs. S5 and S6). This suggests that the normalization procedure at the heart of MIC actually decreases MIC's statistical utility.
We briefly note that the difficulty of estimating mutual information has been cited as a reason for using MIC instead (3). However, MIC is actually much harder to estimate than mutual information due to the definition of MIC requiring that all possible binning schemes for each dataset be tested. Consistent with this we have found the MIC estimator from ref. 1 to be orders of magnitude slower than the mutual information estimator of ref. 18.
In addition to its fundamental role in information theory, mutual information is thus seen to naturally solve the problem of equitably quantifying statistical associations between pairs of variables. Unfortunately, reliably estimating mutual information from finite continuous data remains a significant and unresolved problem. Still, there is software (such as the KNN estimator) that can allow one to estimate mutual information well enough for many practical purposes. Taken together, these results suggest that mutual information is a natural and potentially powerful tool for making sense of the large datasets proliferating across disciplines, both in science and in industry.
Materials and Methods
MIC was estimated using the “MINE” suite of ref. 1 or the “minepy” package of ref. 23 as described. Mutual information was estimated using the KNN estimator of ref. 18. Simulations and analysis were performed using custom Matlab scripts; details are given in SI Text. Source code for all of the analysis and simulations reported here is available at https://sourceforge.net/projects/equitability/.
Supplementary Material
Acknowledgments
We thank David Donoho, Bud Mishra, Swagatam Mukhopadhyay, and Bruce Stillman for their helpful feedback. This work was supported by the Simons Center for Quantitative Biology at Cold Spring Harbor Laboratory.
Footnotes
The authors declare no conflict of interest.
*This Direct Submission article had a prearranged editor.
Data deposition: All analysis code reported in this paper have been deposited in the SourceForge database at https://sourceforge.net/projects/equitability/.
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1309933111/-/DCSupplemental.
†The Markov chain condition  means that
means that  . Chapter 2 of ref. 6 gives a good introduction to Markov chains relevant to this discussion.
. Chapter 2 of ref. 6 gives a good introduction to Markov chains relevant to this discussion.
‡As of this writing, code for the MIC estimation software described by Reshef et al. in ref. 1 has not been made public. We were therefore unable to extract the  values computed by this software. Instead,
values computed by this software. Instead,  values were extracted from the open-source MIC estimator of Albanese et al. (23).
values were extracted from the open-source MIC estimator of Albanese et al. (23).
§Here we define the dependence measure  as the value of the statistic
as the value of the statistic  in the
in the  limit.
limit.
¶These five relationships were chosen to span a wide range of possible qualitative forms; they should not be interpreted as being equally representative of real data.
References
- 1.Reshef DN, et al. Detecting novel associations in large data sets. Science. 2011;334(6062):1518–1524. doi: 10.1126/science.1205438. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Reshef DN, Reshef Y, Mitzenmacher M, Sabeti P. 2013. Equitability analysis of the maximal information coefficient with comparisons. arXiv:1301.6314v1 [cs.LG]
- 3.Speed T. Mathematics. A correlation for the 21st century. Science. 2011;334(6062):1502–1503. doi: 10.1126/science.1215894. [DOI] [PubMed] [Google Scholar]
- 4.Anonymous Finding correlations in big data. Nat Biotechnol. 2012;30(4):334–335. doi: 10.1038/nbt.2182. [DOI] [PubMed] [Google Scholar]
- 5.Shannon CE, Weaver W. The Mathematical Theory of Communication. Urbana, IL: Univ of Illinois; 1949. [Google Scholar]
- 6.Cover TM, Thomas JA. Elements of Information Theory. New York: Wiley; 1991. [Google Scholar]
- 7.Kullback S. Information Theory and Statistics. Mineola, NY: Dover; 1959. [Google Scholar]
- 8.Kinney JB, Atwal GS. Parametric inference in the large data limit using maximally informative models. Neural Comput. 2013 doi: 10.1162/NECO_a_00568. 10.1162/NECO_a_00568. [DOI] [PubMed] [Google Scholar]
- 9.Miller G. Note on the bias of information estimates. In: Quastler H, editor. Information Theory in Psychology II-B. Glencoe, IL: Free Press; 1955. pp. 95–100. [Google Scholar]
- 10.Treves A, Panzeri S. The upward bias in measures of information derived from limited data samples. Neural Comput. 1995;7(2):399–407. [Google Scholar]
- 11.Khan S, et al. Relative performance of mutual information estimation methods for quantifying the dependence among short and noisy data. Phys Rev E Stat Nonlin Soft Matter Phys. 2007;76(2 Pt 2):026209. doi: 10.1103/PhysRevE.76.026209. [DOI] [PubMed] [Google Scholar]
- 12.Panzeri S, Senatore R, Montemurro MA, Petersen RS. Correcting for the sampling bias problem in spike train information measures. J Neurophysiol. 2007;98(3):1064–1072. doi: 10.1152/jn.00559.2007. [DOI] [PubMed] [Google Scholar]
- 13.Hyvärinen A, Oja E. Independent component analysis: Algorithms and applications. Neural Netw. 2000;13(4–5):411–430. doi: 10.1016/s0893-6080(00)00026-5. [DOI] [PubMed] [Google Scholar]
- 14.Sharpee T, Rust NC, Bialek W. Analyzing neural responses to natural signals: Maximally informative dimensions. Neural Comput. 2004;16(2):223–250. doi: 10.1162/089976604322742010. [DOI] [PubMed] [Google Scholar]
- 15.Sharpee TO, et al. Adaptive filtering enhances information transmission in visual cortex. Nature. 2006;439(7079):936–942. doi: 10.1038/nature04519. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Kinney JB, Tkacik G, Callan CG., Jr Precise physical models of protein-DNA interaction from high-throughput data. Proc Natl Acad Sci USA. 2007;104(2):501–506. doi: 10.1073/pnas.0609908104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Kinney JB, Murugan A, Callan CG, Jr, Cox EC. Using deep sequencing to characterize the biophysical mechanism of a transcriptional regulatory sequence. Proc Natl Acad Sci USA. 2010;107(20):9158–9163. doi: 10.1073/pnas.1004290107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kraskov A, Stögbauer H, Grassberger P. Estimating mutual information. Phys Rev E Stat Nonlin Soft Matter Phys. 2004;69(6 Pt 2):066138. doi: 10.1103/PhysRevE.69.066138. [DOI] [PubMed] [Google Scholar]
- 19.Szekely G, Rizzo M. Brownian distance covariance. Ann Appl Stat. 2009;3(4):1236–1265. doi: 10.1214/09-AOAS312. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hoeffding W. A non-parametric test of independence. Ann Math Stat. 1948;19(4):546–557. [Google Scholar]
- 21.Neyman J, Pearson ES. On the problem of the most efficient tests of statistical hypotheses. Philos Trans R Soc A. 1933;231:289–337. [Google Scholar]
- 22.Paninski L. Estimation of entropy and mutual information. Neural Comput. 2003;15(6):1191–1253. [Google Scholar]
- 23.Albanese D, et al. Minerva and minepy: A C engine for the MINE suite and its R, Python and MATLAB wrappers. Bioinformatics. 2013;29(3):407–408. doi: 10.1093/bioinformatics/bts707. [DOI] [PubMed] [Google Scholar]
- 24.Simon N, Tibshirani R. 2011. Comment on ‘Detecting novel associations in large data sets’ by Reshef et al., Science Dec 16, 2011. arXiv:1401.7645.
- 25.Rieke F, Warland D, de Ruyter van Steveninck R, Bialek W. Spikes: Exploring the Neural Code. Cambridge, MA: MIT Press; 1997. [Google Scholar]
- 26.Elemento O, Slonim N, Tavazoie S. A universal framework for regulatory element discovery across all genomes and data types. Mol Cell. 2007;28(2):337–350. doi: 10.1016/j.molcel.2007.09.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Goodarzi H, et al. Systematic discovery of structural elements governing stability of mammalian messenger RNAs. Nature. 2012;485(7397):264–268. doi: 10.1038/nature11013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Margolin AA, et al. ARACNE: An algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinformatics. 2006;7(Suppl 1):S7. doi: 10.1186/1471-2105-7-S1-S7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Pluim JPW, Maintz JBA, Viergever MA. Mutual-information-based registration of medical images: A survey. IEEE Trans Med Imaging. 2003;22(8):986–1004. doi: 10.1109/TMI.2003.815867. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.