

Abstract
We present an asymptotic treatment of errors involved in point-based image registration where control point (CP) localization is subject to heteroscedastic noise; a suitable model for image registration in fluorescence microscopy. Assuming an affine transform, CPs are used to solve a multivariate regression problem. With measurement errors existing for both sets of CPs this is an errors-in-variable problem and linear least squares is inappropriate; the correct method being generalized least squares. To allow for point dependent errors the equivalence of a generalized maximum likelihood and heteroscedastic generalized least squares model is achieved allowing previously published asymptotic results to be extended to image registration. For a particularly useful model of heteroscedastic noise where covariance matrices are scalar multiples of a known matrix (including the case where covariance matrices are multiples of the identity) we provide closed form solutions to estimators and derive their distribution. We consider the target registration error (TRE) and define a new measure called the localization registration error (LRE) believed to be useful, especially in microscopy registration experiments. Assuming Gaussianity of the CP localization errors, it is shown that the asymptotic distribution for the TRE and LRE are themselves Gaussian and the parameterized distributions are derived. Results are successfully applied to registration in single molecule microscopy to derive the key dependence of the TRE and LRE variance on the number of CPs and their associated photon counts. Simulations show asymptotic results are robust for low CP numbers and non-Gaussianity. The method presented here is shown to outperform GLS on real imaging data.
Keywords: Errors-in-variable, fluorescence microscopy, generalized least squares, image registration
I. Introduction
Image registration is the process of overlaying two or more images of the same scene [1]. From a theoretical stance, registration is the process of establishing the geometric transformations between two or more data sets such that they can be viewed in a single coordinate system. These images could arise from different times (multitemporal), different viewpoints (multiview), or different sensors (multimodal).
Broadly speaking, image registration techniques can be divided into two categories. The first is intensity-based registration where gray scale values in both images are correlated to match the images, e.g. [2], [3]. Here we are concerned with the alternative method, feature-based registration, whereby correspondence between the two images is determined through the matching of distinct features common in both images e.g. [4], [5], (although there exist methods that combine both feature and intensity-based approaches to registration e.g. [6]). Specifically we are concerned with the case where the features used for matching are points in the image where pair correspondence is certain. In this case they are known as control points (CPs). It is common that these points are created with the use of fiducial markers, e.g. beads in microscopy [7], [8], or infrared emitting diodes in computer aided surgery [9].
We consider an image to capture a subset of the space ℝd, d = 2 or 3. Given two image spaces ℐ1 ⊆ ℝd and ℐ2 ⊆ ℝd, say, registration is concerned with estimating the mapping T : ℐ1 → ℐ2. It is typical to consider T to be an affine transformation e.g. [10]–[13]. In this circumstance, for x ∈ ℐ1, T(x) = Ax + s where A ∈ ℝd×d is a square invertible matrix and s ∈ ℝd is a translation vector. This includes the well studied subclass of rigid transformations where the matrix A is a rotation transformation [11], [12], [14], [15]. Registration involves using the CP locations in ℐ1 and their corresponding mapped positions in ℐ2 to find T.
In general, due to noisy signals, the location of the CPs in at least one of the images can not be measured exactly and instead are perturbed by random errors. Commonly these error terms are not identically distributed (heteroscedastic) and/or directional (anisotropic). Consequently it is not possible to exactly match the CPs in both images. With this problem in mind, two key questions arise. Firstly; what is the procedure for estimating A and s that correctly accounts for the measurement errors in localizing the CPs? Secondly; how accurately can we determine the transformation and hence what errors arise from the registration process? In response to the second of these questions, it has been common in the literature to define the target registration error (TRE) as a measure of accuracy for a registration and its distributional properties are of keen interest e.g. [10]–[12], [14]–[16].
One of the most widely researched and applied methods of image registration has been the traditional least squares estimator [13], [14], [17]. Given that the CP locations are precisely known without error in one of the images, and the errors in their localization in the second image are independent and identically distributed (iid) then this provides a proper method of registration. In the case of rigid transformations (A represents rotation only) [14] provides an approximation to the root mean square of the TRE that has been corroborated with simulated data. This was extended to an approximate distribution of the TRE in [15] and [16]. For rigid transforms when errors are only present in one set of CPs then several papers have attempted to extend distributional results for the TRE to the case where errors are heteroscedastic and anisotropic based on a number of different approaches, including maximum likelihood procedures [12], and a spatial stiffness model [10].
In most registration scenarios measurement errors will exist in both sets of CP locations rendering these methods insufficient. In this circumstance the problem is known as an errors-in-variables (EIV) problem and it is well known the that traditional least square method provides inconsistent estimators [18]. If all measurement errors are iid then the total least squares (TLS) method (see [19]–[21]) is the correct procedure and [22] provides distributional results for the parameter estimators in the Gaussian case. Under the assumption that measurement errors are iid and white then [23] (corrected by [24]) takes a maximum likelihood (ML) approach to the EIV problem associated with image registration and Cramér-Rao lower bounds are derived for the variance of parameter estimators. However the reality is iid is a rare luxury and any deviation from this render the TLS and ML methods inconsistent. It is therefore necessary to consider the broader class of model called heteroscedastic EIV (HEIV).
In this paper we will use fluorescence microscopy as a motivating example. Using fiducial markers to perform image registration is an important pre-processing step when correcting for drift between successive frames (multitemporal) e.g. [7], or combining a pair of different colored monochromatic images captured through different sensors (multimodal) e.g. [8], [25]. Localization accuracy depends on the brightness of the light emitting object (see [26]–[30]) and hence each fiducial marker is localized with varying degrees of accuracy. This presents us with a typical HEIV model. It is useful to define a new measure of registration error that we will call the localization registration error (LRE). Recent advances in microscopy have made it possible to detect single molecules in a cellular environment, e.g. [31]–[33]. Localizing a feature (e.g. a single molecule) in ℐ1 typically has its own errors associated with it. The LRE measures the combined effect of this localization error and the registration error to give the localization error of the feature registered in the second image, and is of importance to researchers [8], [25].
There have been recent attempts to tackle the EIV approach to rigid image registration for heteroscedastic errors in [34], [35] with the heteroscedastic EIV (HEIV) algorithm; an iterative procedure that finds an optimal solution to the HEIV model. Numerical Monte Carlo estimates of the TRE for the HEIV algorithm are considered in [11] and compared with a spatial stiffness model approach to the HEIV problem.
In this paper we consider the HEIV model for CP registration, the most general form of the registration problem (under the affine assumption). In Section II we rigorously formulate CP based image registration and formally define the TRE and LRE measures. In Section III, by taking the generalized maximum likelihood approach introduced in [36] as a starting point, we are able to show its equivalence to a heteroscedastic formulation of generalized least squares (GLS) and an EIV analogy of the least squares approach, here called ordinary least squares (OLS) in keeping with the terminology of [22] for iid EIV. In the case where error covariance matrices for each CP are a scalar multiple of a known matrix (e.g. multiples of the identity), we derive the closed form solution. In Section IV, asymptotic results derived in [36] are used to derive distributions for the registration parameters. In Section V these distributions are used to derive asymptotic distributions for the TRE and LRE. In Section VI we derive the asymptotic second order moments of the TRE and LRE in a microscopy setting, giving neat closed form expressions in terms of photon counts and experimental parameters. We verify these results in Section VII with numerical simulations and show asymptotic results are appropriate for relatively low (realistic) numbers of CPs. The method presented here is shown in Section VIII to outperform the traditional GLS method (that assumes homoscedastic measurement errors) when applied to real fluorescence microscopy imaging data. This paper represents a significant development upon the preliminary results first reported in [37].
A comprehensive list of abbreviations and notations used in this paper can be found in Tables II–V in Appendix A.
Table II. Abbreviations.
| CP(s) | control point(s) |
| TRE | target registration error - Definition II. 1 |
| EIV | errors-in- variables - (1) |
| TLS | total least squares |
| ML | maximum likelihood |
| HEIV | heteroscedastic errors-in-variables |
| LRE | localization registration error - Definition II.2 |
| GLS | generalized least squares - Definition III. 1 |
| OLS | ordinary least squares - Definition III.l |
| SPD | symmetric positive definite |
| WCGLS | weighted covariance generalized least squares - Section III-A |
II. Formulating the Problem
Suppose K CPs are located in at true locations in ℐ1 ⊆ ℝd at true locations {x1,k ∈ ℐ1,k = 1, …, K}, and in ℐ2 ⊆ ℝd at true locations, such that {x2,k ∈ ℐ2,k = 1, …, K}, such that x2,k = T(x1,k) = Ax1,k + s, k = 1, …, K, where A ∈ ℝd × d and s ∈ ℝd. In reality the positions of the CPs cannot be known exactly and must instead be measured. Consequently we observe the CP locations as {y1,k ∈ ℐ1,k = 1, …, K} and {y2,k ∈ ℐ2,k = 1, …, K}, where yj,k = xj,k + ∊j,k, k = 1, …, K, j = 1, 2. The term ∊j,k ∈ ℝd is a random variable known as the measurement error. Each measurement error is assumed zero mean and to have individual symmetric positive definite covariance matrix Ωj,k. It is assumed that all measurement errors are pairwise independent across the CPs.
We define the ℝd × K matrices Xj ≡ [xj,1, …, xj,K], Yj ≡ [yj,1, …, yj,K] and ℰj ≡ [∊j,1, …, ∊j,K], j = 1,2, and further define the stacked ℝ2d × K matrices , and . With this notation the system of equations can be conveniently represented as the single matrix equation
| (1) |
where T is the matrix transpose, α = [0T, sT]T, Λ = [Id, AT]T and 1K is a column vector of length K with every element taking the value 1. The columns of X1 are known as the independent variables and the columns of X2 are the dependent variables. Models of type (1) where observations of both the dependent and independent variables contain measurement errors are EIV models.
If covariance matrices differ across CPs then they must be known [36]. (In [34] the covariance matrices are unknown, but still require estimation through bootstrapping methods). It is convenient at this point to assume the errors in model (1) follow two possible, but different statistical frameworks. The first shall be called the second-order framework
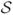 .
.
Assumption I
Under
, the columns of ℰ are independent with kth column
having mean zero and known symmetric positive definite (SPD) covariance matrix
| (2) |
where cov{v} denotes the covariance matrix of a vector v.
The alternative framework shall be called the distributional framework
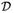 .
.
Assumption II
Under
, the columns of ℰ are independent and of known distribution with the kth column
where the SPD covariance matrix Ωk is again known and of form (2). (Notation
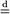 means ‘equal in distribution’ and Np(μ, Σ) denotes the p-variate normal distribution with mean μ and covariance Σ.)
means ‘equal in distribution’ and Np(μ, Σ) denotes the p-variate normal distribution with mean μ and covariance Σ.)
With both
and
, matrices {Ωk, k = 1, …, K} are in general not equal. In this circumstance (1) is a HEIV model.
Given measurements Y, and assuming (1) models the system, the image registration process involves constructing estimators  and ŝ for parameters A and s, respectively. The method of estimation will be discussed in Section III.
A. Image Registration Errors
Suppose we have registered the pair of images with estimators  and ŝ, we need a measure of how successful the registration procedure has been. We begin by defining the commonly used target registration error [10]–[12], [14]–[16]. For anisotropic noise it is important to consider the error as a vector, rather than just its magnitude.
Definition II.1
The target registration error (TRE) τ : ℐ1 → ℝd for an arbitrary point x1 ∈ ℐ1 with corresponding mapped position in ℐ2 of x2 = Ax1 + s is given as τ(x1) ≡ x2−(Âx1 + ŝ) = Ax1 + s − (Âx1 + ŝ).
We may find it more helpful to consider a related measure. Suppose we are interested in registering a specific feature (e.g. a single molecule) in ℐ1 with true position x1,F ∈ ℐ1, in the second image the true position of this feature is x2,F ∈ ℐ2, with x2,F = Ax1,F + s. However, as with the CPs, the position of the feature in ℐ1 is actually measured to be at y1,F = x1,F + ∊1,F, where ∊1,F is a measurement error with zero mean and covariance Ω1,F. Therefore our estimator for the position of the feature in ℐ2 is Ây1,F + ŝ. A key question is; what is the error associated with localizing the feature in ℐ2? To quantify this we define a new measure that we will call the localization registration error.
Definition II.2
For a feature in ℐ1 with true and measured locations x1,F and y1,F = x1,F + ∊1,F respectively, the localization registration error (LRE) ℓF is defined as the difference between the true position and the registered position, i.e. ℓF ≡ x2,F − (Ây1,F + ŝ) = Ax1,F + s − (Ây1,F + ŝ).
Let us define the difference between the true and estimated values of the transform parameters as ΔA ≡ Â − A and Δs ≡ ŝ − s. It can be shown that
| (3) |
| (4) |
We can connect the two as ℓF = −Aε1,F − ΔAε1,F + τ(x1,F). When localization of the feature in ℐ1 can be achieved exactly, i.e. ∊1,F = 0, then ℓF = τ(x1,F). To derive the distribution of the TRE and LRE, and importantly their respective covariance matrices Ωτ and Ωℓ, it is necessary to know the distributional properties of the terms ΔA and Δs.
III. Parameter Estimation
Parameter estimation for EIV models of type (1) when the columns of the measurement error matrix ℰ are iid is well established. The multivariate total least squares (TLS) (see [19]–[21]) or the multivariate generalized least squares (GLS) method [22] solve different but equivalent minimization problems. The parameter estimators that solve the respective minimization problems are exactly known and [22] also derived their asymptotic distributions for Gaussian measurement errors.
The reality is that the covariance matrices {Ωk, k = 1, …, K} for the stacked measurement errors {∊k, k = 1, …, K} are, in general, not identical and as such the iid assumption is invalid (although pointwise independence is still assumed). Hence, these estimators and the distributional results derived for the iid case are unsuitable for the image registration problem posed here. It is therefore necessary to take a more general approach to formulating the minimization problem and parameter estimation that can take into account heteroscedastic measurement errors. Definition III.1(i) is given in [36] and Definitions III.1(ii)–(iii) are given here as a generalization to the minimization problems considered in [22].
Definition III.1
Consider the observation matrix Y of measured CP locations that is assumed to arise from model (1) under Assumption I (second-order framework
).
Define likelihood function ℒ(A, s, X1; Y) ≡ p(Y; A, s, X1), where is the joint probability density function (pdf) for the columns of observation matrix Y = [y1, …, yK]. The ML estimators ŝml, Âml and are defined as .
For any given A and s, the residual vectors rk ≡ yk − Λx1,k − α are zero mean and have covariance matrix Ωk, k = 1, …, K. Let and let ║ · ║F represent the Frobenius matrix norm, the ordinary least squares (OLS) estimators ŝols, Âols and are defined as .
For any given A and s, the residual vectors qk ≡ y2,k − Ay1,k − s are zero mean and have covariance matrix Φk = UΩkUT, k = 1, …, K, where U = [−A, Id]. Let , the generalized least squares (GLS) estimators ŝgls, Âgls are defined as .
The maximum likelihood solutions for models of type (1) are discussed in [36]. The number of unknown nuisance parameters {x1,k, k = 1, …, K} increases linearly with the number of observations {yk, k = 1, …, K} and are known as incidental parameters [38]. [36] adopts the generalized likelihood approach of [39] to estimate the structural parameters A and s in models containing incidental parameters and an iterative procedure for computing the estimators is given. Let vec(Z) for a r × s matrix Z = [z1, …, zs] be defined as the rs × 1 vector and define β ≡ [sT, vec(A)T]T.
Assumption III
Let D be a matrix with (m, n)th element given as E{∂2 ℒ(A, s, X; Y)/∂βm∂βn}. All elements of D exist and D is non-singular.
Under Assumption III, these estimators of A and s are consistent [36], [40]. We now present the key result of this section, the proof of which is found in Appendix B.
Theorem III.2
Consider model (1) under Assumption I (second-order framework
), where the random vectors {∊k, k = 1, …, K} are pairwise independent and vector ∊k has covariance Ωk, k = 1, …, K, then the solutions to the OLS and GLS minimization problems (see Definitions III.1(ii) and III.1(iii)) are identical to the ML estimators for the likelihood function under Assumption II (distributional framework
) (i.e. Âml = Âols = Âgls, ŝml = ŝols = ŝgls and
), where
.
We note the OLS and GLS estimators do not depend on having Gaussian distributed measurement errors.
A. Weighted Covariance Generalized Least Squares
While iterative procedures are required to compute the ML/OLS/GLS estimators—see Definitions III.1(i),(ii) and (iii)—in the general case of heteroscedastic noise it is possible to derive an exact closed form expression for the ML/OLS/GLS estimators when we consider the following special case, which we term weighted covariance.
Assumption IV
For all k = 1, …, K, the SPD covariance matrix Ωk of ∊k—the kth column of the measurement error matrix ℰ—is given by Ωk = ηkΩ0 where Ω0 is a known SPD matrix and ηk ∈ ℝ+ is known.
Assumption IV will be shown to be suitable in fluorescence microscopy image registration—see Section VI-A—and from a theoretical stance includes the important case of . We introduce a further set of assumptions that are necessary for consistency of the estimators presented in Theorem III.3.
Assumption V
Define the scalar , vector and matrix , then we assume exists, and there exists ȳ and W such that and with probability one (wp1).
Define vectors , matrix and matrix , then we assume there exists Ψ such that wp1.
The proof of the following theorem is found in Appendix C.
Theorem III.3
Consider the multivariate EIV model (1) under Assumption I (second-order framework
) and Assumption IV (weighted covariance). Define
, vector
and matrix
. The eigendecomposition of
is represented as
with E = diag{e1, e2, …, e2d} where e1 ≥ … ≥ e2d are the ordered eigenvalues of
and the columns of G are the corresponding eigenvectors. Making the partition
, and assuming
exists, the ML/OLS/GLS estimators A of s and are given as
| (5) |
where Û = [−Â, Id]. Furthermore, provided Assumption V additionally holds then  and ŝ are consistent estimators of A and s, respectively.
IV. Asymptotic Distributions for Parameter Estimators
For the most general case where the covariance matrices {Ωk, k = 1, …, K} are unrelated and unequal SPD matrices, [36] also derived the asymptotic distributions for the ML estimators of s and A under distributional framework
. These estimators form the elements of the estimator β̂ for the parameter vector β ≡ [sT, vec(A)T]T. Provided Assumption II (statistical framework
) holds, i.e. measurement errors are Gaussian, the result will also be appropriate for the OLS and GLS estimators as given in Definitions III.1(ii) and III.1(iii). We introduce
to denote asymptotically equal in distribution with respect to K. The following is from [36].
Theorem IV.1
Consider the multivariate EIV model (1) under Assumption II (distributional framework
), then given β̂ ≡ [ŝT, vec(Â)T]T is a consistent estimator of β ≡ [sT, vec(A)T]T, defining Δβ ≡ β̂ − β we have
, where
, with B(K) = H(K)−1
P(K)(H(K)−1)T,
| (6) |
and
| (7) |
where Φk = UΩkUT, U = [−A, Id], and ⊗ denotes the Kronecker product. Given β̂ is a consistent estimator of β, then H and P are consistently estimated by Ĥ(K) and P̂(K) respectively, calculated by substituting X̂1 = [x̂1,1, …, x̂1,K] for X1, and then  and ŝ into (6) and (7).1
Using this result we are able to present the following corollary for the asymptotic distributions of the estimators in the special case of the weighted covariance property—see Section III-A. We introduce the notation [M]mn for the (m, n)th element of a matrix M, and specifically use Δamn as short-hand for [ΔA]mn. The proof of the following is found in Appendix D.
Corollary IV.2
Consider the multivariate EIV model (1) under Assumption II (distributional framework
) and Assumption IV (weighted covariance). Define vector
, matrix
, matrix
, matrix Φ0 = UΩ0UT (where U = [−A, Id]), and matrix
. Let β̂ ≡ [ŝT, vec(ÂT)]T be constructed from the estimators in (5), then under Assumption V (consistency)
, where
where
| (8) |
| (9) |
This gives the following key asymptotic identities as K → ∞
where we define and the limits and (which both exist under Assumption V).
We note that in the iid case where Ωk = σ2I2d for all k = 1, …, K then the parameter estimation procedures (as outlined in Theorem III.3) and the asymptotic results (as outlined in Corollary IV.2) reduce to the results presented in [22] and thus forms a natural extension to well established GLS results.
V. A symptotic Distributions for TRE and LRE
Given the distributional results of Theorem IV.1 and Corollary IV.2 it is now possible to derive asymptotic distributions for the TRE and LRE—see Definitions II.1 and II.2, respectively. The proof of the following is omitted but follows directly from the linear combination of Gaussian random variables being itself Gaussian. The covariance matrix follows directly from (3), Theorem IV.1 and Corollary IV.2.
Corollary V.1
Under model (1), Assumption II (distributional framework
) and Assumption III (consistency), for a point x1,F ∈ ℐ1 then
with (m, n)th element given as
| (10) |
with B as defined in Theorem IV.1. Further to this, under Assumption IV (weighted covariance) and Assumption V (consistency), where Θ and Φ0 are as defined in Corollary IV.2
| (11) |
To consider distributional results for the LRE, it is necessary to decompose ℓF into two parts, ℓF = − Aε1,F + zF where zF = − ΔAε1,F − Δs − ΔAx1,F. The term −Aε1,F is a random variable with no dependency on the image registration process, being independent of ΔA and Δs (and hence K, CP locations and CP measurement errors). By contrast, each term in zF is dependent on the image registration process, being a function of ΔA and Δs. It is important to note zF and −Aε1,F are independent. We can now provide the following asymptotic result for zF, the proof of which is omitted but follows directly from the linear combination of Gaussian random variables being itself Gaussian. The covariance matrix follows directly from (4), Theorem IV.1 and Corollary IV.2.
Corollary V.2
Under model (1), Assumption II (distributional framework
) and Assumption III (consistency) provided
where ε1,F is the measurement error associated with localizing a feature in ℐ1 with true location x1,F, then
with (m, n)th element of Z given as
| (12) |
Further to this, under Assumption IV (weighted covariance) and Assumption V (consistency),
| (13) |
While the asymptotic distributions presented here are mathematically elegant, experimenters are keen to know the covariance matrices Ωτ and Ωℓ of the TRE τ and LRE ℓF, respectively, in their registration procedure. It is therefore necessary to have results for finite K. Consider model (1) under Assumptions II (distributional framework
) and III (consistency), or Assumptions II, IV (weighted covariance) and V (consistency). Let x1,F ∈ ℐ1 be the true position of a feature that is localized at y1,F = x1,F + ∊1,F, where
. For “large K” we assume the asymptotics have been approximately met and hence from Corollaries V.1 and V.2, together with the independence of zF and −Aε1,F, the TRE τ(x1,F) and LRE ℓF are both approximately d-dimensional normally distributed with zero mean and have respective approximate covariance matrices
| (14) |
| (15) |
These approximations will be used in Sections VI and VII to investigate in more detail registration problems in single molecule microscopy.
VI. Image Registration Error Analysis for Single Molecule Microscopy
We apply the theory presented thus far in this paper to the important problem of assessing localization errors due to the registration process in a fluorescence microscopy setup. Registration is a common pre-processing step in microscopy experiments. Fiducial markers are used as CPs, these are bright, light emitting objects (e.g. fluorescent beads [8], [42]) that require estimation of their location. One example of a fluorescence microscopy experimental setup is to register a pair of different colored monochromatic images, for example to see if two different protein molecules colocalize e.g. [8], [25], [43], [44]. This is a multimodal registration problem. Fiducial markers are also used for drift correction between successive image frames [7]. This is a multitemporal registration problem.
As will now be discussed, the covariance matrix associated with localizing each CP/fiducial marker in each image is dependent on the number of photons associated with it that are detected at the sensor, and therefore presents us with a HEIV problem of type (1).
A. Measurement Errors
In [26] and [30] are lower bound expressions for the covariance matrix of the error in localizing an isolated point source emitting photons as an inhomogeneous Poisson process in the presence of background and readout noise, which in turn is shown in [26] to be a reasonable estimate for the true covariance matrix. These general expressions can be used with the estimation procedure of [36]—see Section III—for parameter estimation and TRE and LRE second-order moments can be computed with the generalized expressions of (10) and (12), respectively.
When imaging in the absence of background noise and readout noise the covariance matrix for the error in localizing a point source in the object space is given as N−1 J, where N is the number of photons collected from the point source at the detector, and J is a SPD matrix that can be computed from experimental parameters including photon wavelength, numerical aperture and the point spread function of the optical system. For a non-pixelated detector J is diagonal, with pixels introducing off-diagonal terms. In the image space this covariance matrix becomes N−1 ℳ2 J, where ℳ is the known system magnification between the object space and the image space (a distance r in the object space is measured as ℳr in the image space). Further to this, it is shown in [45] that even in the presence of typical levels of background and readout noise the covariance matrix N−1 ℳ2 J is a suitable approximation to the covariance matrix for errors in localizing a bright (high signal to noise ratio) point source. Conventional fiducial markers used in fluorescence microscopy are typically bright and hence for the purposes of this paper we assume that they can be treated in this way.
We assume the image registration formulation of Section II and model (1) with the use of K fiducial markers for the CPs. The matrix J and system magnification ℳ are specific to the image and hence labeled Jj and ℳj, respectively, j = 1, 2. Suppose Nj,k photons are detected at the detector for fiducial marker k in ℐj, k = 1, …, K, j = 1,2. The measurement errors ∈j,k, k = 1, …, K, j = 1, 2, are therefore assumed to have covariance Ωj,k of the form Ωj,k = (1/Nj,k)Ωj,0, where is a SPD matrix and universal for all CPs in ℐj. This gives the covariance matrix of as the block diagonal matrix Ωk = diag{(1/N1,k)Ω1,0,(1/N2,k)Ω2,0}.
Consider the two common image registration scenarios described at the beginning of this section. The first is in registering two monochromatic images captured at the same time with two different sensors (multimodal). While the photon count associated with a single fiducial marker at two different wavelengths (i.e. in separate monochromatic images) will be different, it is reasonable to assume that there is a linear relation between the brightness of the marker in each image i.e. a marker that is bright in ℐ1 is also bright in ℐ2. Mathematically we say N2,k = cN1,k for all k = 1, …, k, where c > 0 is a constant of proportionality, suitable for all k = 1, …, k. The second scenario is performing drift correction by registering two images taken by the same sensor at different times (multitemporal). In this case, provided the brightness of the marker remains constant in the time between captures, then we assume N1,k ≈ N2,k (which is mathematically equivalent to the multimodal scenario with c = 1). The constant c need not be known to derive expressions for Ωτ and Ωℓ, we just assume it exists.
With this assumption we have the situation where the covariance matrices of the measurement errors have the weighted co-variance property, i.e. they are scalar multiples of
| (16) |
with ηk = 1/N1,k providing the scaling factor. This gives , the mean photon count for the K CPs in ℐ1. Fig. 1 summarizes the key steps involved in registering a pair of fluorescence microscopy images.
Fig. 1.
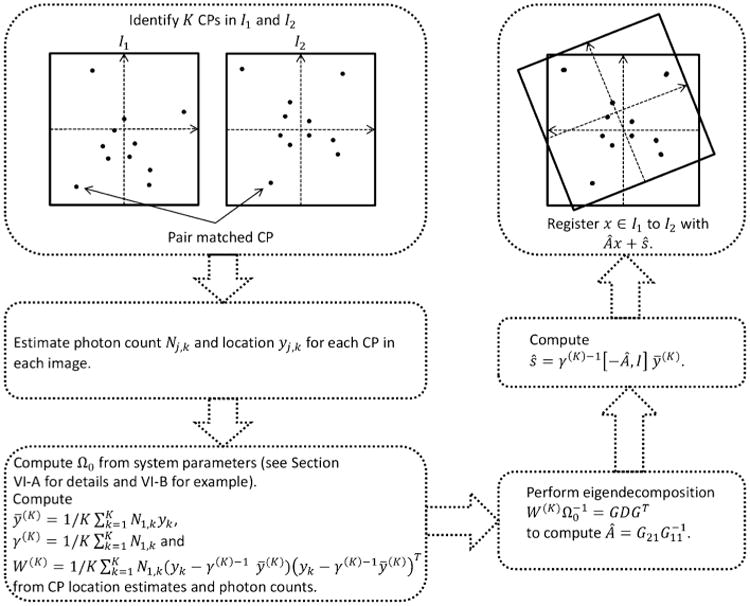
Flow chart summarizing the key steps in registering a pair of fluorescence microscopy images.
B. Microscopy LRE
We now consider the expressions for the TRE and LRE covariance matrices, Ωτ and Ωℓ, respectively. Consider localizing a single molecule in ℐ1 at point y1,F, where y1,F = x1,F+∈1,F with the measurement error having covariance Ω1,F estimable from [26], and x1,F being the true positional vector. We estimate its location (the registered position) in ℐ2 as Ây1,F + ŝ.
We begin by considering the following 2D model.
Assumption (i)
We model the CP measurement errors where Ωk is given in (2) with where Nj,k is the photon count at the detector associated with CP k in ℐj, k = 1, …, K, j = 1, 2. ℳj is the known system magnification associated with ℐj. ζj is a known function of the point spread function, photon wavelength and numerical aperture. In multimodal registration ℳj and ζj will be different for each image, while in multitemporal registration they will be identical for both images. Ω0 is of form (16) where .
Assumption (ii)
Consider the CP true positions {x1,k, k = 1, …, K} to be K realizations of a random variable
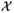 ∈ ℝ2 with mean zero and covariance κ2
I2, and let associated photon counts be non-zero, finite and independent of CP positions.
∈ ℝ2 with mean zero and covariance κ2
I2, and let associated photon counts be non-zero, finite and independent of CP positions.
Assumption (iii)
The affine transformation parameter A = SR represents a scaling S = ςI2, ς ∈ ℝ+, combined with a unitary rotation or reflection (or a combination of both)R, i.e. RT R = RRT = I2.
We will make use of the following Lemma, the proof of which is found in Appendix E.
Lemma VI.1
Let CP positions {x1,k,k = 1, …, K} be K realizations of a random variable
∈ ℝd with finite mean μ and SPD covariance II, and let weights{ηk, k = 1, …, K} be K realizations of a random variable  with finite non-zero mean and finite variance independent of CP position. Let
and
where
and
, then
and
, each wp1.
with finite non-zero mean and finite variance independent of CP position. Let
and
where
and
, then
and
, each wp1.
From Assumption (ii) and Lemma VI.1 x̄1 = 0 and N̄1 κ2 I2 will provide our estimate of Ψ, where . We introduce . Using these expressions for x̄1 and Ψ and with the covariance matrix in Assumption (i) and the form of the transformation parameters in Assumption (iii), then from the definitions in Corollary IV.2 we have the identities Φ0 = (ς2ζ1 + c−1 ζ2)I2 and . Substituting these expressions into (11) and (13) gives
where rF ≡ ║x1,F║ is the radial distance of the feature/single molecule from the origin. Given the spread of the CPs (represented by κ) is much greater than the localization accuracy of the individual CPs (represented by σ̄1 and σ̄2) and the localization accuracy of the feature (represented by σF)—as is typical in microscopy—then the term and (both in the order of 10−6 for a typical microscopy experiment) can be considered negligible. From Corollaries V.1 and V.2 and assuming approximations (14) and (15) we state the following key result:
Proposition VI.2
For large K, under Assumptions (i)–(iii) the (m, n)th element of the covariance matrix of the TRE can be approximated as
| (17) |
The (m, n) th element of the covariance matrix of the LRE can be approximated as
| (18) |
If the covariance Ω1,F is itself representable as , where N1,F is the photon count associated with the feature (molecule) imaged in ℐ1, then in (18) we replace with . The covariance matrices Ωτ and Ωℓ are both given with respect to image space ℐ2. To express these matrices with respect to the object space coordinates we use and .
Consider (17). We immediately notice that the TRE has an inverse dependence the number of CPs (denoted by K). Given extra CPs have similar localization errors to those already deployed, then increasing the number of CPs will improve the TRE covariance and it vanishes to zero as the number of CPs tends to infinity. It will be the case that for relatively small numbers of CPs the TRE improvements are significant by attempting to introduce more of them into the registration process. However, if we already have a large number of CPs then there is no significant gain in registration performance by small increases in their numbers. Specifically to microscopy, the TRE covariance will also vanish as the mean photon counts tend to infinity. Therefore extending exposure time will improve registration. Diagonal terms of the TRE covariance have dependency on CP measurement errors in both images, while off diagonal terms of the TRE covariance depend only on measurement errors in ℐ2. In relation to the parameters A and s, the LRE and TRE covariance matrices are independent of rotation and translation and exhibit dependence only on scaling factor ς. The diagonal terms of the Ωℓ have lower bound .
Localization accuracy is defined as the standard deviation of the molecule's object space localization error. One derivable quantity of interest to researchers will be the amount by which the registration process affects localization of a feature (single molecule) in object space.
Definition VI.3
Let be the covariance matrix for the measurement error in localizing a feature at true location x1,F ∈ ℐ1 and let Ωℓ be the covariance matrix of the LRE, then the localization loss ratio, ΔF say, has (m, n)th element .
From (18) we now give the following result for the registration induced error ratio:
Proposition VI.4
Under Assumptions (i)–(iii) the diagonal terms of the registration induced error ratio matrix, ΔF, for a feature at true location x1,F ∈ ℐ1 are given as (for n = 1, 2)
| (19) |
Proposition VI.5
If we wish the localization accuracy of a registered feature in ℐ2 to be restricted to p% more than the localization accuracy in ℐ1, i.e. [ΔF] ≤ 1 + (p/100), assuming strict equality in (19), we require the following inequality is satisfied:
| (20) |
Consider a multitemporal registration scenario, i.e. point spread functions, numerical aperture and photon wavelengths can be considered identical ζ1 = ζ2, ℳ1 = ℳ2 and N1,k ≈ N2,k for all k = 1, …, K. Assume A is a rotation with no scaling (i.e ς = 1) and we have an arbitrary translation s. Inequality (20) becomes . For example, suppose we image a single molecule in ℐ1 with a photon count of N1,F = 200 on the outer corner of a square ℐ1 of dimensions l × l, then . Consider CPs that are uniformly distributed in ℐ1, then κ2 = l2/12 and (rF/κ)2 = 6. To restrict the loss in localization accuracy of the single molecule due to the registration process to within 10% then we require K−1((1/N̄1) + (1/N̄2)) ≤ 1.5 × 10−4. In such a scenario, 10 CPs with a mean photon count of 1350 would be sufficient. A single molecule at the center of ℐ1 would undergo a loss in localization accuracy of only 0.71%.
C. Non-Diagonal Ω0
Let us now consider the case where there exists off-diagonal terms in the matrices Ω1,0 and Ω2,0—see Section VI-A. Ω0 is still of form (16) with . Assuming the analysis in Section VI-B on the order of magnitude of relative terms still holds, and matrix
| (21) |
represents a rotation by angle φ, we have the following
| (22) |
| (23) |
| (24) |
where , j = 1, 2, and ρ̄1 = ρ1,0/N̄1. Equations (22), (23) and (24) show that when the covariance of the CP measurement errors contain off-diagonal terms, the covariance matrices of the TRE and LRE are dependent on the amount of rotation in the transform. For example, for φ ∈ (0, π/4) then [Ωτ]11 < [Ωτ]22, and for φ ∈ (−π/4, 0) we have [Ωτ]11 > [Ωτ]22. However, for small rotation angles φ the effect of off diagonal terms is negligible and the results in Propositions VI.2 and VI.4 will still be appropriate.
D. Geometrically Regular Control Point Configurations
In addition to control points that appear to the experimenter at random locations in the image space, it is also useful to consider the use of deterministic, geometrically regular CP locations set by the experimenter. These could take the form of a grid or ellipse (which includes the special case of a circle, provided pair correspondence between the CPs in both images can be guaranteed). We once again take the weighting factor for the covariance matrix (the reciprocal of the photon count) associated with a CP to be a realization of a random variable
and is completely independent of CP location.
Consider a square grid of side length a centered at the origin, where CPs are evenly spaced including positioning at each vertex (i.e. K is always square). It can be shown Ψ = E{
−1} (a2/3)I2. In this situation (18) is valid, replacing κ with a2/3.
We also consider an ellipse centered at the origin with the major axis running along the x axis with major radius a and minor radius b, then it can the shown that Ψ = (1/2) E{
−1} diag {a2,b2}. Equation (18) is still valid, however for the case n = m = 1 then κ should be replaced by a. When n = m = 2, k is replaced b. With a > b, this implies that image registration is better resolved in the direction of the major axis as opposed to the direction of the minor axis.
VII. Simulations
Here we seek verification of the results in Section VI through Monte Carlo simulations. We consider a multitemporal registration scenario. ℐ1 and ℐ2 each comprise of 512 × 512 pixels, with each pixel being of dimensions 16 μm × 16 μm. The system magnification is ℳ1 = ℳ2 = 100, so in object space each pixel corresponds to a square of 0.16 μm × 0.16 μm. We consider the affine transformation T : ℐ1 → ℐ2, T(x) = Ax + s with A being a rotation of form (21) with φ = π/6 and s = [480, 480]T (corresponding to 30 pixels in each direction).
We assume the measurement errors for the bead positions in ℐj have mean zero and covariance matrix (ℳjζj/Nj,k)I2 where [26]. λj,em is the wavelength of the photons observed in the jth image and is set as 0.520 μm for j = 1 and 2. nF is the numerical aperture of the optical system and set to a typical value of 1.4 for both images. Nj,k is the photon count associated with the kth CP in the jth image. We consider a single molecule in ℐ1 with true position x1,F = (1600,1200) (giving rF = ║x1,F║ = 2000 μm), assuming localization is subject to measurement error with covariance , where σF = 0.186 μm. Estimators  and ŝ were computed as outlined in Theorem III.3.
Simulations for a multimodal scenario would be carried out in an analogous manner. However, instead of the system parameters (photon wavelength, numerical aperture, system magnification) being the same for both images, they would in general differ between ℐ1 and ℐ2. These different values can be easily accounted for by calculating the covariance matrix Ω0 appropriately and generating measurement errors with this covariance. LRE and TRE covariance terms can be calculated by substituting the system parameters into (17) and (18). Affine transformation parameters A and s are then estimated in an identical way.
A. Distributional Analysis
Fig. 2 is a quantile-quantile (Q-Q) plot for the distribution of the first element of the TRE. The curve is produced by ordering 10000 independent and normalized estimates (with respect to the theoretical variance) into increasing order of the size. The probability of a value less than the jth ordered estimate (or sample quantile) is pj = j/10001 to a close approximation. The corresponding theoretical quantile of the normal distribution is the value υj such that pj = F(υj), where F(·) is the cumulative distribution function of the normal distribution. The values υ1, …, υ10000 are plotted on the x-axis against the ordered estimates for (a) K = 6, (b) 10, (c) 15, (d) 20 uniformly distributed CPs. Even for low numbers of CPs the fit to the derived “large K” distribution is striking, and similar results were seen for the second element of the TRE.
Fig. 2.
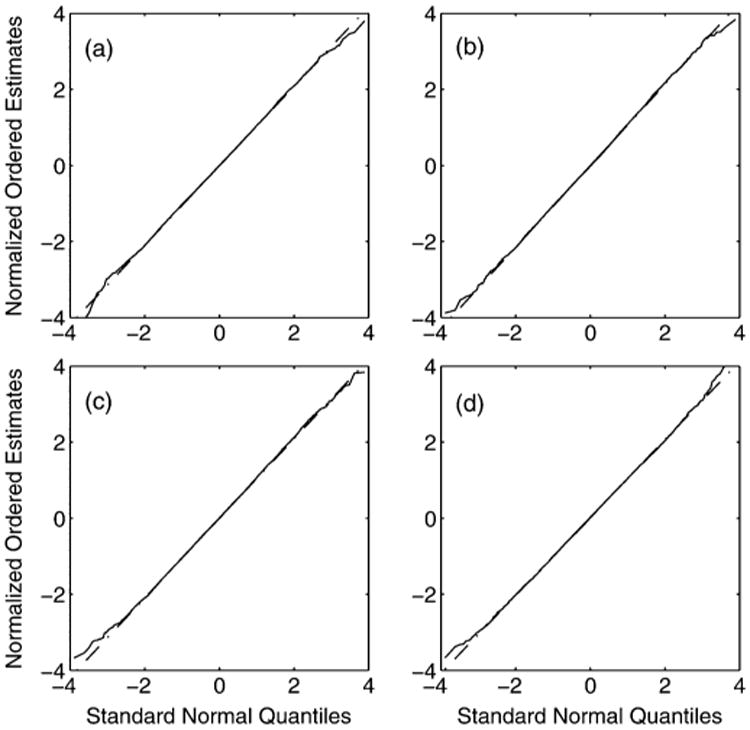
Q-Q plot for the first element of the TRE vector with normally distributed CP measurement errors, for (a) K = 6, (b) 10, (c) 15, (d) 20 CPs uniformly distributed in the image space. The (mostly obscured) dashed straight line marks the line of perfect fit.
We note that the LRE ℓF is comprised of contributions from the TRE τ and the measurement error ∊1,F. The elements of the TRE have standard deviation of order nm, whereas the elements of ∊1,F have standard deviation of order 2 nm. The is therefore dominated by the Gaussian measurement error ∊1,F. For this reason it is more meaningful to focus analysis on the distribution of the TRE.
B. Localization Analysis
We now consider four different CP configurations; CP locations are (a) normally distributed about the center of ℐ1 with covariance κ2I2, κ = 1350 μm, (b) uniformly distributed in ℐ1, (c) arranged in an ellipse with major radius 4000 μm and minor radius 3000 μm, and (d) arranged in a square grid of side 8100 μm. Due to restrictions on the possible values of K in (d) we consider simulations where K takes the value of the square numbers from 4 to 64 inclusive. For configurations (a)–(d) the sample standard deviation of [ℓF]1 for 100000 Monte Carlo simulations is computed for each value of K, while keeping the same uniform distribution that the CP photon counts are sampled from. The results are plotted in Fig. 3, as are the values predicted by (18). The dashed line marks the theoretical lower bound of the LRE standard deviation.
Fig. 3.
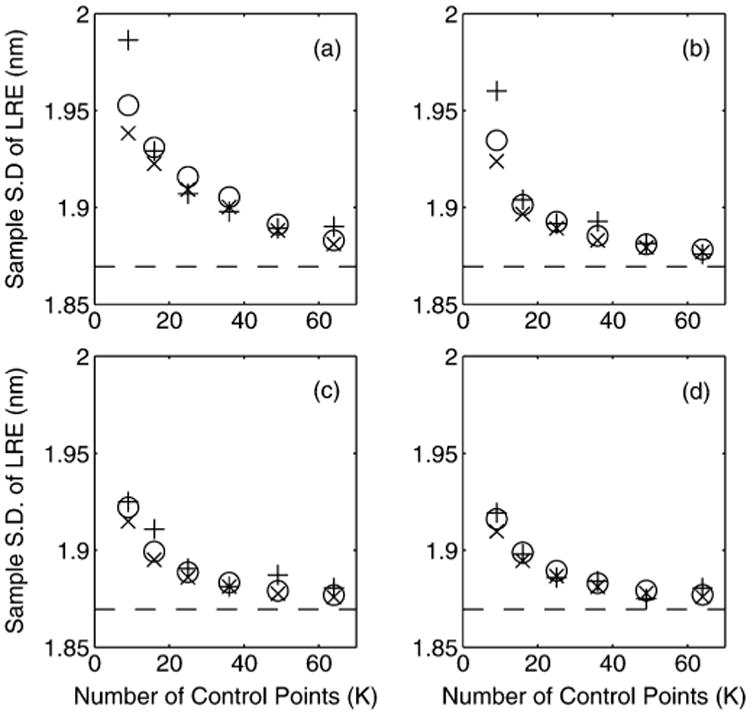
The sample standard deviation of ℓF (from 100000 simulations) in object space dimensions is plotted as a function of the number of CPs K for (a) normally distributed, (b) uniformly distributed, (c) elliptical and (d) grid CP configurations (see Section VII-B for more details). The ‘+’ represents the sample standard deviation of the LRE (in units nanometers). The circles represent the standard deviation as predicted by Corollary V.2. The ‘×’ shows the standard deviation as predicted with (18). The dashed line marks the theoretical bound σF.
The accuracy for normally and uniformly distributed CPs (scenarios (a) and (b)) shows some deviation from the large sample results for small K ∼ 9, and in such a circumstance (20) is not totally appropriate. A better interpretation is; at the very least this inequality must be satisfied. However, for larger values of K this provides an excellent guide to experimenters. The elliptical and grid configurations (scenarios (c) and (d)) show a much closer fit for small K compared to the random configurations (secnarios (a) and (b)). This is most likely due to the random positioning of the CPs adding to the overall variance of the parameter estimators. In the deterministic case (20) is an excellent guide to experimenters.
In Fig. 4 we keep the number of CPs constant at K = 16 and change the mean of the uniform distribution from which the photon counts are sampled. For configurations (a)–(d), the sample standard deviation of the first element of the LRE for ℒF 100000 Monte Carlo simulations is computed. We also plot the values as predicted by (18). The dashed line marks the theoretical lower bound of the LRE standard deviation. By increasing the photon count, the asymptotic results can be readily achieved and the key results presented in this paper provide an excellent guide.
Fig. 4.
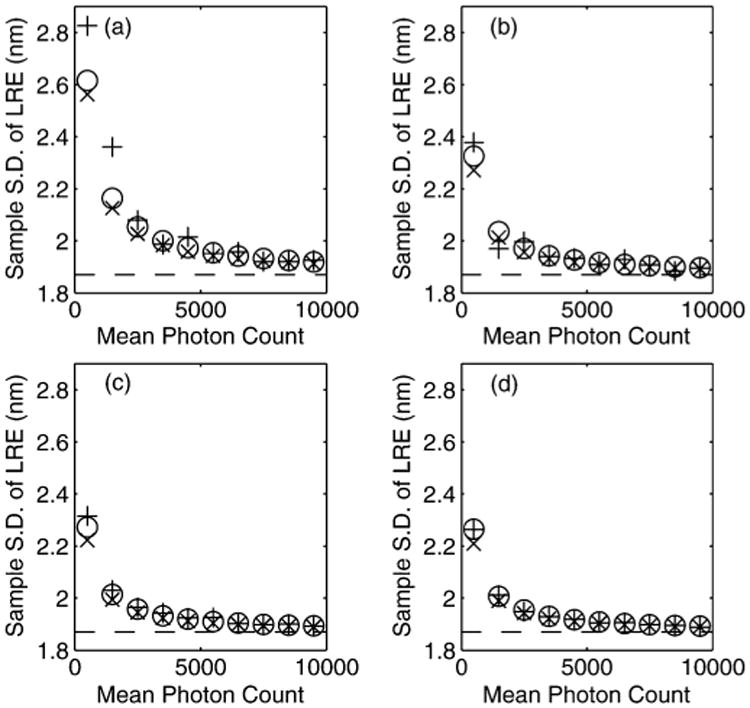
The sample standard deviation of ℓF (from 100000 simulations) in object space dimensions is plotted as a function of N̄1, the mean photon count for the CPs in I1, for a constant K = 16 with (a) normally distributed, (b) uniformly distributed, (c) elliptical and (d) grid CP configurations (see Section VII-B for more details). The ‘+’ represents the sample standard deviation of the LRE (in units nanometers). The circles represent the standard deviation as predicted by Corollary V.2. The ‘×’ shows the standard deviation as predicted with (18). The dashed line marks the theoretical bound σF.
We have shown in Section VI-B that for a diagonal covariance matrix Ω0, as is the case in our simulations, then the LRE and TRE are independent of rotation angle and translation in the affine transformation. In Fig. 5 we keep the number of CPs constant at K = 16, the mean of the uniform distribution from which the photon counts are sampled is kept constant and with affine transformation parameter A = R of form (21) change the angle of rotation φ. For each rotation angle the translation is by a random amount. For configurations (a)–(d), the sample standard deviation of the first element of the LRE ℒF for 100000 Monte Carlo simulations is computed. We also plot the values as predicted by (18). The dashed line marks the theoretical lower bound of the LRE standard deviation. It is clear that the standard deviation of the LRE is invariant to rotation angle and translation, as predicted.
Fig. 5.
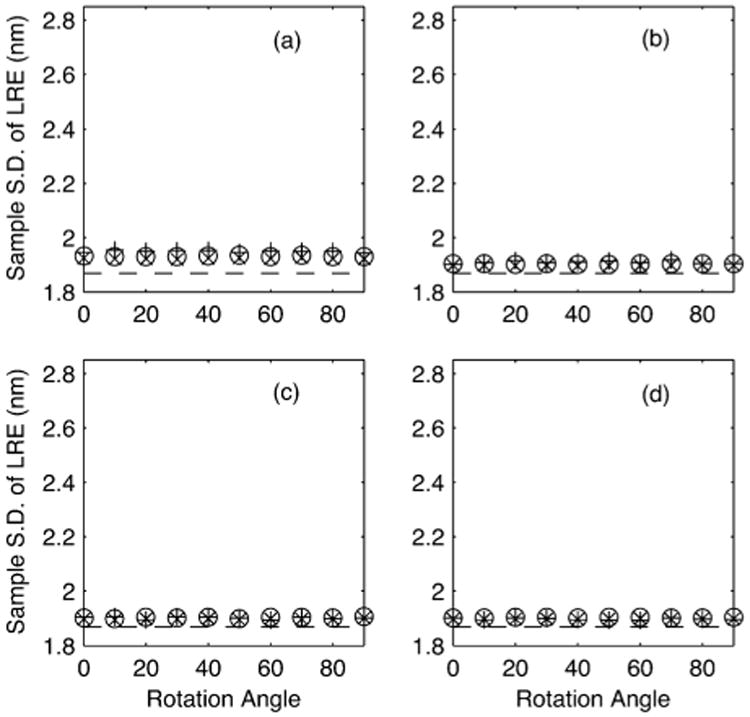
The sample standard deviation of ℓF (from 100000 simulations) in object space dimensions is plotted as a function of rotation angle φ (in degrees) when A = R with R of form (21), for a constant K = 16 with (a) normally distributed, (b) uniformly distributed, (c) elliptical and (d) grid CP configurations (see Section VII-B for more details). The ‘+’ represents the sample standard deviation of the LRE (in units nanometers). The circles represent the standard deviation as predicted by Corollary V.2. The ‘×’ shows the standard deviation as predicted with (18). The dashed line marks the theoretical bound σF.
C. Non-Gaussian Measurement Errors
The derived Gaussian distribution for the TRE presented in this paper is given under the assumption that measurement errors in localizing CPs are themselves Gaussian distributed. The measurement errors in a microscopy experiment are often assumed to be Gaussian—which is justified by large sample results and evidence based on the analysis of experimental and simulated data—it is nevertheless useful to know how robust the results of this paper are under deviations away from this Gaussian assumption. We therefore consider the TRE when measurement errors are uniformly distributed, an extreme deviation from Gaussianity.
Fig. 6 gives Q-Q plots to compare the first element of the TRE against the normal distribution. Labels (a)–(d) refer to the same values of K as with Fig. 2. Even with such a pronounced change in the distribution of the CP measurement errors the plots show the normal distribution is still an appropriate approximation for the TRE, although the exact distribution is unknown.
Fig. 6.
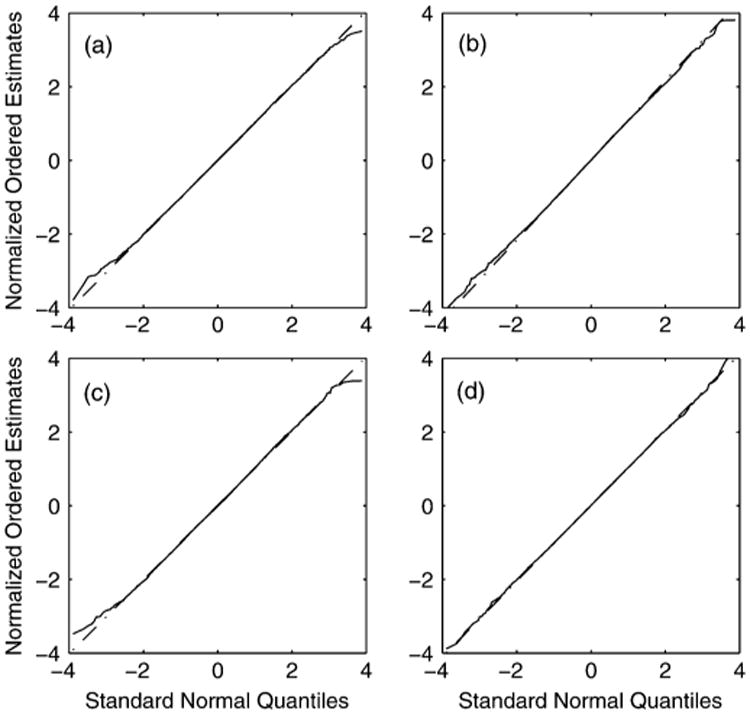
Q-Q plot for the first element of the TRE vector with uniformly distributed CP measurement errors, for (a) K = 6, (b) 10, (c) 15, (d) 20 CPs uniformly distributed in the image space. The (mostly obscured) dashed straight line marks the line of perfect fit.
VIII. Imaging Data and Method Comparison
We now apply the algorithm presented in this paper to real imaging data. Analysis has been conducted by performing image registration between a pair of images of the same object space taken by two separate cameras (multimodal registration). We have 599 repeat captures, resulting in 599 pairs of images to register. The registration was performed using 27 TetraSpeck fluorescent beads visible in both fields of view. System parameters were identical for each image, with system magnifications of 63, numerical apertures equal to 1.45 and the photon wavelength distributions peaking at 638 nm.
To calculate the TRE for each of the 599 registrations we need to know the exact coordinates of a point in each image that perfectly map to one another under the affine transformation. Without knowledge of the true transformation parameters this is not available and we instead isolate one of the beads and average its location over the 599 images for each camera. This will give a very high precision estimate of its true location in each image and these coordinates are used as the reference points for the TRE. The TRE is then calculated for each of the 599 registration experiments using two different methods.
The first method is the weighted covariance GLS method presented in this paper (developed in Section III-A and implemented on simulations in Section VII). This method uses the system parameters quoted above and the point spread function to calculate covariance matrix Ω0 and takes into account both the photon count and location estimates for each bead to compute estimates of the affine transformation parameters A and s—see Fig. 1 for details.
The second method used is the traditional GLS method presented in [22, page 28] (that assumes homoscedastic measurement errors and is equivalent to the ML approach to image registration used by [23]). This method uses just the location estimates for each bead in estimating A and s.
For both methods, the sample standard deviation of the TRE for the x- and y-direction is computed and displayed in Table I. This was repeated 27 times, each time isolating a different bead to act as the reference point.
Table I.
Sample standard deviations of TRE in the x- and y-directions from 599 registration experiments (units: nm), each row is for one of 27 different coordinate points. ‘WCGLS’ columns are using the New weighted covariance generalized least squares presented in This paper. ‘GLS’ columns are using traditional generalized least Squares that assumes homoscedastic measurement errors. ‘GAIN’ Columns give the precentage improvement in the WCGLS method Over the GLS method
| WCGLS (x) - nm | GLS (x) - nm | Gain (%) | WCGLS (y) - nm | GLS (y) - nm | Gain (%) |
|---|---|---|---|---|---|
| 4.142 | 4.283 | 3.399 | 4.003 | 4.342 | 8.478 |
| 3.942 | 4.039 | 2.446 | 3.762 | 4.095 | 8.873 |
| 4.030 | 4.736 | 17.517 | 4.111 | 4.531 | 10.208 |
| 3.657 | 4.238 | 15.880 | 3.640 | 4.001 | 9.926 |
| 2.972 | 3.073 | 3.393 | 2.659 | 2.906 | 9.292 |
| 2.709 | 2.896 | 6.916 | 2.361 | 2.581 | 9.331 |
| 3.124 | 3.187 | 2.026 | 2.846 | 3.156 | 10.886 |
| 3.913 | 4.082 | 4.326 | 3.801 | 4.256 | 11.954 |
| 2.338 | 2.436 | 4.206 | 1.842 | 2.021 | 9.717 |
| 3.436 | 3.844 | 11.897 | 3.194 | 3.573 | 11.851 |
| 3.743 | 4.207 | 12.382 | 3.555 | 3.984 | 12.055 |
| 4.279 | 4.684 | 9.461 | 4.355 | 4.896 | 12.426 |
| 3.363 | 3.660 | 8.850 | 3.302 | 3.692 | 11.811 |
| 2.865 | 3.053 | 6.555 | 2.441 | 2.693 | 10.343 |
| 2.472 | 2.566 | 3.796 | 1.976 | 2.145 | 8.554 |
| 3.623 | 3.865 | 6.699 | 3.300 | 3.657 | 10.842 |
| 3.404 | 3.772 | 10.812 | 3.403 | 3.789 | 11.352 |
| 2.757 | 2.853 | 3.484 | 2.364 | 2.536 | 7.276 |
| 2.896 | 3.146 | 8.623 | 2.733 | 2.974 | 8.800 |
| 3.154 | 3.274 | 3.800 | 2.859 | 3.053 | 6.791 |
| 4.674 | 4.857 | 3.929 | 4.401 | 4.840 | 9.985 |
| 3.449 | 3.831 | 11.060 | 3.462 | 3.750 | 8.318 |
| 3.282 | 3.537 | 7.774 | 3.162 | 3.390 | 7.187 |
| 3.282 | 3.465 | 5.592 | 3.085 | 3.292 | 6.717 |
| 3.687 | 3.985 | 8.074 | 3.572 | 3.870 | 8.349 |
| 3.987 | 4.043 | 1.401 | 3.799 | 4.201 | 10.595 |
| 2.590 | 2.832 | 9.359 | 2.183 | 2.412 | 10.514 |
The results show the weighted covariance GLS methods presented here consistently outperforms the traditional GLS method. Comparisons with the theoretical results would be misleading because of a lack of access to the ground truth and photon counts significantly differ across the 599 samples.
IX. Concluding Remarks
We have used a heteroscedastic generalized least squares approach to point-based image registration. This has allowed an asymptotic analysis of the distributional properties of the TRE and the LRE; a new measure of registration success that is of interest in microscopy. By considering the weighted covariance we have derived closed form expressions for both the registration estimators and the large sample TRE/LRE distributions. These distributions can be used for determining confidence intervals of errors induced by registration.
Fluorescence microscopy image registration was used as a motivating example. Here we have derived the TRE and LRE covariance matrices in terms of the number of CPs, their spread in the object space, and associated photon counts. The relative loss in localization accuracy of a imaged single molecule was further derived. When the covariance matrices of the CP measurement errors are multiples of the identity then there is no dependence on the translation or rotation components of the affine transformation. When they have off-diagonal terms then the TRE/LRE are dependent on the rotation part of the affine transformation but still remain independent of the translation. Theoretical results have been verified with Monte Carlo simulations and even for relatively small values of K simulations show excellent agreement with the theory. However, small but notice able discrepancies between the simulations and large sample expressions do occur for small K and in such a situation the results presented here should be considered a useful guide rather than exact.
Using real imaging data the weighted covariance GLS method presented here has been shown to consistently outperform the traditional GLS method.
Acknowledgments
The authors would like to thank Dr. S. Ram, D. Kim and Prof. E. Sally Ward for the data analyzed in Section VIII.
The associate editor coordinating the review of this manuscript and approving it for publication was Dr. Yufei Huang. This work was supported in part by the National Institute of Health grant R01 GM085575.
Biographies

E. A. K. Cohen received the M.Phys. degree in mathematics and physics from the University of Warwick, Coventry, U.K., in 2005 and the Ph.D. degree in 2011 from Imperial College London, U.K., in statistics. He worked as a Signal Processing Scientist at QinetiQ, Malvern, U.K., before starting his Ph.D. in 2007. In 2011, he joined the University of Texas (UT), Dallas, in the Ward-Ober lab based at UT Southwestern Medical Center at Dallas as a Postdoctoral Research Scholar. He is currently a Lecturer in Statistics at Imperial College London. His research interests include multivariate signal and image processing, and their applications to the natural sciences.

R. J. Ober (S'87-M'88-SM'95) received the Ph.D. degree in electrical engineering from the University of Cambridge, U.K., in 1987.
From 1987 to 1990, he was a Research Fellow at Girton College and the Engineering Department, University of Cambridge. In 1990, he joined the University of Texas at Dallas, Richardson, where he is currently a Professor with the Department of Electrical Engineering and the Department of Bioengineering. He is also Adjunct Professor at the University of Texas Southwestern Medical Center, Dallas. His research interests include signal and imaging processing, and their applications to biological problems, fluorescence microscopy and biosensors.
Appendix A.
Table II gives a list of standard abbreviations. Table III gives a list of common operators and functions. Table IV gives a list of standard notations. Table V gives a list of fluorescence microscopy notations.
Table III. Operators and Functions.
| cov{·} | covariance matrix of a random vector |
| Np(μ, Σ) | p-dimensional multivariate normal distribution with mean μ and covariance matrix Σ |
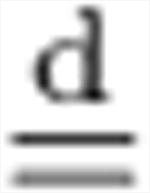
|
equal in distribution |
| ℒ(·) | likelihood function |
| p(·) | probability density function |
| vec(·) | vec(Z) of a r × a matrix Z = [z1, …, zs] is the rs × 1 vector |
| E{·} | expectation operator |
| ⊗ | Kronecker product |
| δij | δij equals zero for i ≠ j and equals one for i = j. |
Table IV. Key Notation.
| Notation | Type | Definition | ||
|---|---|---|---|---|
| d | d ∈ {2,3} | dimension of image space | ||
| ℐj | subset of ℝd | image space j, j = 1,2 | ||
| A | ℝd × d | matrix valued affine transformation parameter | ||
| s | ℝd | vector valued affine transformation parameter | ||
| K | ℕ | number of CPs | ||
| xj,k | ℝd | true location of kth CP (k = 1, …K) in ℐj | ||
| ∊j,k | ℝd | random measurement error associated with localizing kth CP in ℐj | ||
| yj,k | ℝd | measured location of kth CP in ℐj, yj,k = xj,k + ∊j,k | ||
| Ωj,k | ℝd × d | Ωj,k = cov{∊j,k} | ||
| Xj | ℝd × K | Xj = [xj, 1, …, xj,k] | ||
| ℰj | ℝd × K | ℰj = [∊j, 1, …, ∊j,k] | ||
| Yj | ℝd × K | Yj = [ yj, 1, …, yj,k] | ||
| X | ℝ2d × K |
|
||
| ℰ | ℝ2d × K |
|
||
| Y | ℝ2d × K |
|
||
| Λ | ℝ2d × d | Λ = [Id, AT]T | ||
| 0 | ℝd | 0 = [0, 0]T or [0, 0, 0]T | ||
| α | ℝ2d | α [0T, sT]T | ||
| 1K | ℝK | 1 = [1, 1, …, 1]T | ||
| ∊k | ℝ2d |
|
||
| Ωk | ℝ2d × 2d | Ωk = cov{∊k} | ||
| τ(·) | ℝd ↦ ℝd | TRE | ||
| xj,F | ℝd | true location of a feature in ℐj | ||
| ∊j,F | ℝd | random measurement error associated with localizing a feature in ℐj | ||
| yj,F | ℝd | measured location of a feature in ℐj, yj,F = xj,F + ∊j,F | ||
| Ω1,F | ℝd × d | ΩF = cov{∊1,F} | ||
| Â | ℝd × d | estimator of A | ||
| ŝ | ℝd | estimator of s | ||
| ℓF | ℝd | LRE for a feature | ||
| ΔA | ℝd × d | ΔA = Â − A | ||
| Δs | ℝd | Δs = ŝ − s | ||
| Ωτ | ℝd × d | Ωτ = cov{τ} | ||
| Ωℓ | ℝd × d | Ωℓ = cov{ℓF} | ||
| yk | ℝ2d |
|
||
| U | ℝd×2d | U = [−A, Id] | ||
| Φk | ℝd×d | Φk = UΩkUT | ||
| β | ℝ(d+d2) | β = [sT, vec(A)T]T | ||
| ηk | ℝ+ | scalar and matrix valued quantities when we have the property Ωk = ηkΩ0 | ||
| Ω0 | ℝ2d × 2d | |||
| γ(K) | ℝ+ |
|
||
| γ | γ = limK → ∞ γ(K) | |||
| ȳ(K) | ℝ2d |
|
||
| ȳ | ȳ = limK → ∞ ȳ(K) | |||
| W(K) | ℝ2d × 2d |
|
||
| W | W = limK → ∞ W(K) | |||
|
|
ℝd |
|
||
| Ξ(K) | ℝd × d |
|
||
| Ψ(K) | ℝd × d |
|
||
| Ψ | Ψ = limK → ∞ Ψ(K) | |||
| Θ(K) | ℝd × d |
|
||
| Θ | Θ = limK → ∞ Θ(K) | |||
| θ | ℝ |
|
||
| Φ0 | ℝd × d | Φ0 = UΩ0UT |
Table V. Fluorescence Microscopy Notation.
| Notation | Type | Definition | ||
|---|---|---|---|---|
| Nj,k | ℕ | photon count associated with kth CP in ℐj | ||
| Nj | ℤ+ | mean photon count for CPs in ℐj | ||
| ℳj | ℝ+ | system magnification for ℐj | ||
| λj,em | ℝ+ | photon wavelength associated with ℐj | ||
| ζj | ℝ+ | known function of the point spread function, photon wavelength and numerical aperture for ℐj | ||
| κ2 | ℝ+ | x/y-direction variance of randomly positioned CPs | ||
| R | ℝd ×d | a rotation matrix | ||
| ς | ℝ+ | scaling constant for A of the form ςR | ||
|
|
ℝ+ |
|
||
| rF | ℝ+ | radial distance of single molecule from origin of ℐ1 |
Appendix B.
Proof of Theorem III.2
Under Assumption II, the 4D multivariate Gaussian pdf for measurement vector is given as
where μk = Λx1, k + α, k = 1, …, K, Λ = [Id, AT]T. The likelihood function ℒ(A, s, X1; Y) for A, s and X1 is given as
The parameter values that maximize ℒ(A, s, X1; Y) are those that minimize the term . Noticing
it follows that Âml = Âols, ŝml = ŝols and .
Lemma B.1
Let the kth column of X̂1 be given as
| (25) |
then for any fixed A and s, r(s, A, X̂1; Y) ≤ r(s, A, X1; Y) and ℒ(A, s, X̂1; Y) ≥ ℒ(A, s, X1; Y).
Proof
Let , then . The conditional estimator x̂1, k is the value of x1, k that gives . This gives and the result follows.
The ML estimators (under Assumption II) and OLS estimators (under Assumption I) for A and s are the values that minimize where . Substituting in (25) gives
| (26) |
We note that is a non-singular square matrix and .
Lemma B.2
Let F and G be equal dimension n × p matrices such that the matrix [F, G] is square nonsingular and FT G = 0, then In = F(FT F)−1 FT + G(GT G) −1 GT.
Lemma (B.2) gives
| (27) |
Substituting (27) into (26) gives r̃k = Γk(A)T q̃k where and is a row orthogonal matrix. Hence Γk(A) Γk(A)T = I2d and , giving
under Assumption I.
Appendix C.
Proof of Theorem III.3
This proof borrows from [22]. Consider the Frobenius norm
Then
and consequently by setting equal to zero we conclude for any fixed where
| (28) |
Under Assumption IV we have Φk = ηkΦ0 and we can simplify (28) to give ŝ = γ(K)−1Uȳ(K),where and .
Define vk ≡ yk − γ(K)−1ȳ, k = 1, …, K and the matrix V ≡ [v1, …, vK], then it can be shown for any fixed A that
| (29) |
where
with equality in (29) holding if and only if
We now note that under Assumption IV
where
and hence we can write with . We note ṼṼT = W(K).
We are required to minimize
with respect to A.
Lemma C.1
Let M ∈ ℝm × n with m ≥ n and rank(M) = r and let P ∈ ℝn × q, q ≤ r, be a matrix with q orthonormal columns. Then
is minimized for given M, when P = G̃k where
 G̃T is a singular value decomposition (svd) of M and G̃k = [gm−k+1, …, gm] denotes the matrix k of orthonormal right singular vectors of M corresponding to the k smallest singular values.
G̃T is a singular value decomposition (svd) of M and G̃k = [gm−k+1, …, gm] denotes the matrix k of orthonormal right singular vectors of M corresponding to the k smallest singular values.
We note that
and ΓT(A) is a 2d × d matrix with orthonormal columns. Let
G̃T be the svd of
where we partition the matrix of right singular vectors
From Lemma C.1 we have
with equality reached when  is such that . From the svd of we have
the eigendecomposition of where the columns of are the eigenvectors of , with inverse
| (30) |
We have which gives , resulting in
with the final equality coming from (30), where we make the partition
With
we have and  = −([G−1]22)−1[G−1]21. Using the block inverse of G we have and , and it follows that . We have now shown
for all A and s.
We are left with showing consistency. Let
and consider eigendecomposition with E(K) = diag{e1, e2, …, e2d} where e1 ≥ … ≥ e2d are the ordered eigenvalues of and the columns of G(K) are the corresponding eigenvectors. Under Assumptions I, IV and V(i) it can be shown exists and is equal to wp1, where and Λ = [Id, AT]T. Further to this, Assumption V(ii) implies is positive definite. Under these conditions we give the following as a summary to the results found in [22, Section 3].
Lemma C.2
will have eigendecomposition where and each wp1.
Let γ1 ≥ γ2 ≥ … γd ≥ 0 be the eigenvalues of is symmetric hence there exists d × d matrix ψ such that where Dγ = diag{γ1, γ2, …, γd}. We therefore have
and hence
Consequently, we conclude that Λψ are ordered eigenvectors of
with eigenvalues E = (Id + Dγ). By also considering
we see that the columns of Λψ are the d eigenvectors with the largest corresponding eigenvalues, and the columns of ΓT(A) are the eigenvectors with the smallest eigenvalues (each equal to one). As such, if we define
 to be a matrix whose columns are the eigenvectors of
, ordered by descending size of their corresponding eigenvalues, then
to be a matrix whose columns are the eigenvectors of
, ordered by descending size of their corresponding eigenvalues, then
for some unitary matrix
. From Lemma C.2 this gives
wp1.
Using this result and under Assumption V where and . By the strong law of large numbers (SLLN), wp1, and hence ȳ = x̄ where with . Therefore, with Uxk = x2, k − Ax1, k = s for all k = 1, …, K, γ−1Uȳ = γ−1Ux̄ = γ−1 γs and wp1.
Appendix D.
Proof of Corollary IV.2
Under Assumptions II, IV, V and IV, and from Theorems III.3 and IV.1, we have that asymptotically in K, where H and P are given by (6) and (7), respectively. Let us define scalar , vector and matrix . Under Assumption IV it can be shown
and
Considering the forms of and in (8) and (9), respectively, we write and . Using the mixed-product property of the Kronecker product and the symmetry of H, then
and
Using the block matrix inverse
where . Results follow by computing , forming the Kronecker product with Φ0 and taking limits as K → ∞ under Assumption V.
Appendix E.
Proof of Lemma VI.1
. With weighting factors {ηk, k = 1, …, K} being independent of points {x1, k, k = 1, …, K} by SLLN
wp1. Let us consider the matrix
where
and
. By SLLN γ = E{
−1}. By SLLN and independence
Hence
wp1.
Footnotes
Contributor Information
E. A. K. Cohen, Email: e.cohen@imperial.ac.uk, Eric Jonsson School of Electrical Engineering and Computer Science, University of Texas at Dallas, Richardson, TX 75083 USA. He is also with the Department of Mathematics, Imperial College London, SW7 2AZ U.K.
R. J. Ober, Email: ober@utdallas.edu, Eric Jonsson School of Electrical Engineering and Computer Science, University of Texas at Dallas, Richardson, TX 75083 USA.
References
- 1.Zitová B, Flusser J. Image registration methods: A survey. Image Vis Comput. 2003;21:977–1000. [Google Scholar]
- 2.Chumchob N, Chen K. A robust affine image registration method. Int J Numer Anal Mod. 2009;6:311–334. [Google Scholar]
- 3.Myronenko A, Song X. Intensity-based image registration by minimizing residual complexity. IEEE Trans Med Imag. 2010;29, no. 11:1882–1891. doi: 10.1109/TMI.2010.2053043. [DOI] [PubMed] [Google Scholar]
- 4.Liao S, Chung ACS. Feature based nonrigid brain MR image registration with symmetric alpha stable filters. IEEE Trans Med Imag. 2010;29, no. 1:106–119. doi: 10.1109/TMI.2009.2028078. [DOI] [PubMed] [Google Scholar]
- 5.Yasein MS, Agathoklis P. A feature-based image registration technique for images of different scales. IEEE Int Symp Circ. 2008:3558–3560. [Google Scholar]
- 6.Li W, Leung H. A maximum likelihood approach for image registration using control point and intensity. IEEE Trans Image Process. 2004;13, no. 8:1115–1127. doi: 10.1109/tip.2004.828435. [DOI] [PubMed] [Google Scholar]
- 7.Bates M, Huang B, Dempsey GT, Zhuang X. Multicolor super-resolution imaging with photo-switchable fluorescent probes. Sci. 2007;317:1749–1753. doi: 10.1126/science.1146598. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Stirling Churchman L, Ökten RS, Rock J, Dawson JF, Spudich JA. Single molecule high-resolution colocalization of Cy3 and Cy5 attached to macromolecules measures intramolecular distances through time. PNAS. 2005;102:1419–1423. doi: 10.1073/pnas.0409487102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.West JB, Maurer CR. Designing optically tracked instruments for image-guided surgery. IEEE Trans Med Imag. 2004;23, no. 5:533–545. doi: 10.1109/tmi.2004.825614. [DOI] [PubMed] [Google Scholar]
- 10.Ma B, Ellis RE. Analytic expressions for fiducial and surface target registration error. Med Image Comput Comput-Assist Intervention (MICCAI) 2006;4191:637–644. doi: 10.1007/11866763_78. [DOI] [PubMed] [Google Scholar]
- 11.Ma B, Moghari MH, Ellis RE, Abolmaesumi P. Estimation of optimal fiducial target registration error in the presence of heteroscedastic noise. IEEE Trans Med Imag. 2010;29, no. 3:708–723. doi: 10.1109/TMI.2009.2034296. [DOI] [PubMed] [Google Scholar]
- 12.Moghari MH, Abolmaesumi P. Distribution of target registration error for anisotropic and inhomogeneous fiducial localization error. IEEE Trans Med Imag. 2009;28, no. 6:799–813. doi: 10.1109/TMI.2009.2020751. [DOI] [PubMed] [Google Scholar]
- 13.Umeyama S. Least-squares estimation of transformation parameters between two point patterns. IEEE Trans Pattern Anal. 1991;13, no. 4:376–380. [Google Scholar]
- 14.Fitzpatrick JM, West JB, Maurer CR. Predicting error in rigid-body point-based registration. IEEE Trans Med Imag. 1998;17, no. 9:694–702. doi: 10.1109/42.736021. [DOI] [PubMed] [Google Scholar]
- 15.Fitzpatrick JM, West JB. The distribution of target registration error in rigid-body point-based registration. IEEE Trans Med Imag. 2001;20:917–927. doi: 10.1109/42.952729. [DOI] [PubMed] [Google Scholar]
- 16.West JB, Fitzpatrick JM, Toms SA, Maurer CR, Maciunas RJ. Fiducial point placement and the accuracy of point-based, rigid body registration. Neurosurg. 2001;48:810–817. doi: 10.1097/00006123-200104000-00023. [DOI] [PubMed] [Google Scholar]
- 17.Arun KS, Huang TS, Blostein SD. Least-squares fitting of two 3D point sets. IEEE Trans Pattern Anal. 1987;9, no. 5:698–700. doi: 10.1109/tpami.1987.4767965. [DOI] [PubMed] [Google Scholar]
- 18.Davies RB, Hutton B. The effect of errors in the independent variables in linear regression. Biometrika. 1975;62:383–391. [Google Scholar]
- 19.Van Huffel S. The Total Least Squares Problem: Computational Aspects and Analysis. Philadelphia, PA, USA: SIAM; 1991. [Google Scholar]
- 20.Van Huffel S, Lemmerling P, editors. Total Least Squares and Errors-in-Variables Modeling. Boston, MA, USA: Kluwer Academic; 2002. [Google Scholar]
- 21.Markovsky I, Van Huffel S. Overview of total least-squares methods. Signal Process. 2007;87:2283–2302. [Google Scholar]
- 22.Gleser LJ. Estimation in a multivariate “errors in variable” regression model: Large sample results. Ann Statist. 1981;9:24–44. [Google Scholar]
- 23.Yetik IS, Nehorai A. Performance bounds on image registration. IEEE Trans Signal Process. 2006;54, no. 5:1737–1749. [Google Scholar]
- 24.Li J, Huang P. A comment on “performance bounds on image registration”. IEEE Trans Signal Process. 2009;57, no. 6:2432–2433. [Google Scholar]
- 25.Koyama-Honda I, Ritchie K, Iion R, Murakoshi H, Kasai RS, Kusumi A. Fluorescence imaging for monitoring the colocalization of two single molecules in living cells. Biophys J. 2005;88:2126–2136. doi: 10.1529/biophysj.104.048967. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Ober RJ, Ram S, Ward ES. Localization accuracy in single-molecule microscopy. Biophys J. 2004;86:1185–1200. doi: 10.1016/S0006-3495(04)74193-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Ram S, Ward ES, Ober RJ. Beyond Rayleigh's criterion: a resolution measure with application to single-molecule microscopy. PNAS. 2006;103:4457–4462. doi: 10.1073/pnas.0508047103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Ram S, Ward ES, Ober RJ. A stochastic analysis of distance estimation approaches in single molecule microscopy: Quantifying the resolution limits of photon-limited imaging systems. Multidim Syst Signal Process. 2012;3:503–542. doi: 10.1007/s11045-012-0175-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Shen Z, Andersson SB. Bias and precision of the fluoroBrancroft algorithm for single particle localization in fluorescence microscopy. IEEE Trans Signal Process. 2011;59, no. 8:4041–4046. [Google Scholar]
- 30.Wong Y, Lin Z, Ober RJ. Limit of the accuracy of parameter estimation for moving single molecules imaged by fluorescence microscopy. IEEE Trans Signal Process. 2011;59, no. 3:895–911. doi: 10.1109/TSP.2010.2098403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Chalfie M, Tu Y, Euskirchen G, Ward WW, Prasher DC. Green fluorescent protein as a marker for gene expression. Sci. 1994;263:802–805. doi: 10.1126/science.8303295. [DOI] [PubMed] [Google Scholar]
- 32.Pierce DW, Hom-Booher N, Vale RD. Imaging individual green fluorescent proteins. Nature. 1997;388:338. doi: 10.1038/41009. [DOI] [PubMed] [Google Scholar]
- 33.Schmidt T, Schútz GJ, Baumgartner W, Gruber HJ, Schindler H. Characterization of photophysics and mobility of single molecules in a fluid lipid membrane. J Phys Chem -US. 1995;99:17662–17668. [Google Scholar]
- 34.Matei B, Meer P. Optimal rigid motion estimation and performance evaluation with bootstrap. Proc IEEE Comput Vis Pattern Recogn. 1999;1:1339–1342. [Google Scholar]
- 35.Matei B, Meer P. A general method for errors-in-variables problems in computer vision. Proc IEEE Comput Vis Pattern Recogn. 2000;2:2018–2021. [Google Scholar]
- 36.Chan NN, Mak TK. Heteroscedastic errors in a linear-functional relationship. Biometrika. 1984;71:212–215. [Google Scholar]
- 37.Cohen EAK, Ober RJ. Image registration error analysis with applications in single molecule microscopy. Proc I S Biomed Imag. 2012:996–999. doi: 10.1109/ISBI.2012.6235725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Neyman J, Scott EL. Consistent estimates based on partially consistent observations. Econometrica. 1948;19:1–32. [Google Scholar]
- 39.Morton R. Efficiency of estimating equations and the use of pivots. Biometrika. 1981;68:227–233. [Google Scholar]
- 40.Foutz RV. On the unique consistent solution to the likelihood equations. J Amer Stat Assoc. 1977;72:147–148. [Google Scholar]
- 41.Chan NN, Mak TK. Estimation in multivariate errors-in-variables models. Linear Algebra Appl. 1985;70:197–207. [Google Scholar]
- 42.Ram S, Prabhat P, Ward ES, Ober RJ. Improved single particle localization accuracy with dual objective multifocal plane microscopy. Opt Express. 2009;17:6881–6898. doi: 10.1364/oe.17.006881. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.French AP, Mills S, Swarup R, Bennett MJ, Pridmore TP. Colocalization of fluorescent markers in confocal microscope images of plant cells. Nat Protoc. 2008;3:619–628. doi: 10.1038/nprot.2008.31. [DOI] [PubMed] [Google Scholar]
- 44.Lachmanovich E, Shvartsman DE, Malka Y, Botvin C, Henis YI, Weiss AM. Co-localization analysis of complex formation among membrane proteins by computerized fluorescence microscopy: Application to immunofluorescence co-patching studies. J Microsc. 2003;212, no. 2:122–131. doi: 10.1046/j.1365-2818.2003.01239.x. [DOI] [PubMed] [Google Scholar]
- 45.Cohen EAK, Ober RJ. Measurement errors in fluorescence microscopy experiments. in Conf Rec Asilomar C. 2012:1602–1606. doi: 10.1109/ACSSC.2012.6489300. [DOI] [PMC free article] [PubMed] [Google Scholar]