

Abstract
Six candidate height-diameter models were used to analyze the height-diameter relationships. The common methods for estimating the height-diameter models have taken the classical (frequentist) approach based on the frequency interpretation of probability, for example, the nonlinear least squares method (NLS) and the maximum likelihood method (ML). The Bayesian method has an exclusive advantage compared with classical method that the parameters to be estimated are regarded as random variables. In this study, the classical and Bayesian methods were used to estimate six height-diameter models, respectively. Both the classical method and Bayesian method showed that the Weibull model was the “best” model using data1. In addition, based on the Weibull model, data2 was used for comparing Bayesian method with informative priors with uninformative priors and classical method. The results showed that the improvement in prediction accuracy with Bayesian method led to narrower confidence bands of predicted value in comparison to that for the classical method, and the credible bands of parameters with informative priors were also narrower than uninformative priors and classical method. The estimated posterior distributions for parameters can be set as new priors in estimating the parameters using data2.
1. Introduction
Forests play a very important role not only in timber, mining, and recreational sectors, but also in global carbon cycles and climate change [1]. One of the most important elements of forest structure is the relationship between tree height and diameter. Individual tree height and diameter are the most commonly measured variables for estimating tree volume, site index, and other important variables in forest growth and yield, succession, and carbon budget models [2–4]. Tree diameter is relatively easy to measure accurately in the field at little cost. Conversely, tree height is not commonly measured for several reasons, which include (1) being time consuming to obtain; (2) chance of observer error; (3) visual obstructions [5]. Consequently, many foresters only subsample tree heights or do not measure heights at all. Often tree heights are estimated from observed diameter at breast-height (DBH) outside bark. The estimation of tree volume and site index, as well as the description of stand dynamics and succession over time, heavily relies on accurate height-diameter models [6]. A number of tree height-diameter models have been developed for various tree species [7–10]. These height-diameter models can be used to predict “missing” tree heights from measured DBHs [11, 12], indirectly predict height growth [13], and also estimate individual tree biomass using individual tree biomass equations [14]. Chave et al. [15] found that the most important parameters in predicting biomass of tropical forest tree species were in decreasing order of importance, diameter, wood density, height, and forest type (classified as dry, moist, or wet forest). The inclusion of height was reported to reduce the standard error of biomass estimates from 19.2 to 12.5%. Thus, accurate prediction of tree heights is essential for forest inventory, model simulation, and management decision making [2, 6].
Curtis [6] summarized a great many available height-diameter equations and used Furnival's index of fit to compare the performance of 13 linear functions fitted to second-growth Douglas-fir (Pseudotsuga menziesii (Mirb.) Franco) data. Since then, with the relative ease of fitting nonlinear functions, many nonlinear functions have been developed for height predictions [16, 17]. However, as tree form and allometry are influenced by both environmental and competitive factors [18–20], temporal changes in these conditions are likely to affect the height-diameter relationship. This may cause varied uncertainty in estimating height-diameter relationships at any given time. A major limitation of these equations is that they produce very different results when applied to different stands where the equations were originally developed [21, 22]. The height-diameter relationship is also not stable over time even within the same stand [23, 24]. Such differences could hold important implications for biomass and carbon storage potential.
This uncertainty resulting from temporal changes needs to be accounted for when interpreting height-diameter relationships in natural stands. Available methods do not apply to this problem. Bayesian inference is an alternative method of statistical inference that is frequently being used to evaluate ecological models [25–28]. In forestry, Bayesian methods have been adopted in several applications such as aboveground tree biomass [29], diameter distribution [30, 31], tree growth [32], individual tree mortality [33, 34], stand-level height and volume growth models [35, 36], and stand basal distribution [37]. Despite aforementioned studies, there is still a shortage of publications about application of the Bayesian methods in forestry, compared with other fields. Furthermore, to our knowledge, we found that there are no reports about the use of Bayesian methods in height-diameter curves.
In this study, we developed height-diameter models with nonlinear equations often used and selected the best nonlinear model for describing the height-diameter relationships. Based on the “best” model, we formulated a Bayesian modeling framework for exploring uncertainty of height-diameter relationships. Finally, we also compared the Bayesian method with classical method.
2. Data
The Chinese fir (Cunninghamia lanceolata (Lamb.) Hook.) stands are located in Fenyi County, Jiangxi Province, southern China. The longitude is 114°30′E, latitude 27°30′N. Mean annual temperature, precipitation, and evaporation are 16.8°C, 1656 mm, and 1503 mm, respectively.
The plots were established in 1981, planted in a random block arrangement with the following tree spacings: N1: 2 m × 3 m (1667 trees/ha); N2: 2 m × 1.5 m (3333 trees/ha); N3: 2 m × 1 m (5000 trees/ha); N4: 1 m × 1.5 m (6667 trees/ha); N5: 1 m × 1 m (10,000 trees/ha). Each spacing level was replicated three times. Each plot comprised an area of 20 m × 30 m and a buffer zone of similarly treated trees surrounded each plot. Layout of the sample plots is shown in Figure 1. The tree diameter measurements in all of the plots were conducted after the tree height reached 1.3 m. More than 50 trees in each plot were tagged and measured for total height. Sampling was performed in each winter from 1983 to 1988 and then every two years until 2007. The forest structure of Chinese fir is stable when the forest is 25 years old. In this study, two data sets, data1 (24 years old) and data2 (26 years old), were used for modeling height-diameter relationships. The data1 was used for selecting the “best” model for analyzing the relationships of height-diameter and generating prior distributions of parameters for Bayesian method. The data2 was used for comparing the classical method with Bayesian method with uninformative priors and informative priors. The two data sets are described in Figure 2 and summary statistics are shown in Table 1.
Figure 1.
Layout of the sample plots for Chinese fir in this study.
Figure 2.
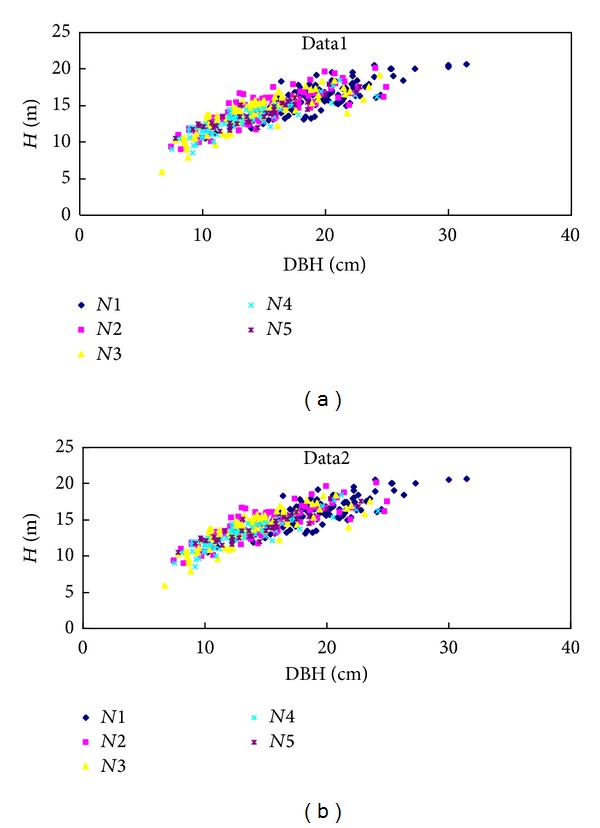
Scatter plot of tree height (H) against diameter at breast (DBH) for different densities. N1 = 2 m × 3 m (1667 trees/ha), N2 = 2 m × 1.5 m (3333 trees/ha), N3 = 2 m × 1 m (5000 trees/ha), N4 = 1 m × 1.5 m (6667 trees/ha), and N5 = 1 m × 1 m (10,000 trees/ha).
Table 1.
Summary statistics of tree diameter and height for two data sets.
| Attributes | Data1 (24 years old, n = 445 trees) | Data2 (26 years old, n = 424 trees) | ||
|---|---|---|---|---|
| DBH | H | DBH | H | |
| Min. | 6.7 | 6 | 7.5 | 8.1 |
| Max. | 31.5 | 20.7 | 32.4 | 21.3 |
| Mean | 15.73 | 14.52 | 16.41 | 15.04 |
| SD | 4.28 | 2.39 | 4.40 | 2.37 |
SD: standard deviation.
3. Method
3.1. Base Height-Diameter Equations
Many nonlinear models have been used to model tree height-diameter relationships. Six nonlinear models (Table 2) were selected as candidate height-diameter models based on their appropriate mathematical features (e.g., typical sigmoid shape, flexibility) and possible biological interpretation of parameters (e.g., upper asymptote, maximum, or minimum growth rate) described in the literature [4, 38, 39].
Table 2.
Nonlinear height-diameter equations selected in the study.
3.2. Bayes' Rule
Let y = (y 1, y 2, y 3, …) represent a vector of data and let θ = (θ 1, θ 2, θ 3, …) be a vector of parameters to be estimated. Bayes' rule is then expressed as
| (1) |
where p represents the probability distribution or density function. Values for θ can be obtained by minimum least squares (MLS) or maximum likelihood estimation (MLE) in the classical approach. In the Bayesian framework, it uses probability distributions to describe uncertainty in the parameters being estimated. θ had a probability distribution that can be calculated as the rearranged form of (1):
| (2) |
where p(y) = ∫p(y | θ)p(θ)dθ for continuous θ. Since it is the integration of admissible values of θ, p(y) does not depend on θ and can be viewed as a constant for fixed y, which yields the following [36]:
| (3) |
We should note that the conditional distribution of θ given data y (p(θ | y)) is what we are interested in estimating and represents the posterior probability distribution (simply called posterior) in the Bayesian framework. p(y | θ) tells us the distribution of y assuming that θ is known, which is the likelihood function when regarded as a function of the parameters [40]. p(θ) is called the prior probability distribution for the parameters (simply called prior) and reflects information available about the hypothesis. Therefore, (3) indicates that the posterior distribution of θ is proportional to the likelihood of y given θ and the prior distribution of θ. The important characteristic of Bayesian method is that the parameters are treated as random variables [36, 41]. This is a very different assumption from that of classical method, which treats parameters as true, fixed (if unknown) quantities [40, 42].
3.3. Prior Distribution Specification
The choice of prior distribution is critical for Bayesian method [43]. In the above several nonlinear equations, we need to choose appropriate prior distributions for all parameters, including a, b, and c. Many researchers choose to use uninformative normal (Gaussian) priors that reflect prior “ignorance,” which would not have a strong influence on the parameters. Such priors typically arise in the form of a parametric distribution with large or infinite variance. Alternatively, if prior information is available from external knowledge (reported parameters from the literatures), this information can be used to construct a prior distribution. Often, there is little prior information regarding model unknowns, in which case an uninformative or vague prior distribution can be employed. In this study, we initially used uninformative for data1, Gaussian priors on all parameters (a, b, c): a ~ N (0, 1000), b ~ N (0, 1000), c ~ N (0, 1000). We set the previously estimated posterior distribution for data1 as the new prior distribution for data2.
3.4. Model Selection
The root mean square error (RMSE) was calculated for classical model performance evaluation. And deviance information criterion (DIC) was used to evaluate the Bayesian models. It is very useful in the Bayesian model selection [44]; DIC is characterized as
| (4) |
where Dbar refers to the posterior mean of the deviance and pD is the effective number of parameters in the model. The posterior mean of the deviance Dbar = E θ(−2log(p(y | θ))) and pD = Dbar − Dhat. Dhat is a point estimate of deviance given by . As with RMSE, the model with the smallest DIC is selected to the “best” model.
In the Bayesian analysis, we set the previously estimated posterior distribution of parameters as the new prior distribution using data2. Mean relative deviation (MD), fit index (similar to R-square), and RMSE were used to compare the classical model with Bayesian model in the estimation stage. MD is given as
| (5) |
where Y i represents the observed tree height of tree i, is the corresponding predicted value, and n is the number of observations.
Bayesian parameters were estimated using the WinBUGS version 1.4 [45], which implements Markov chain Monte Carlo algorithms using a Gibbs sampler [46]. Classical model parameters were estimated by use of the NLIN procedure (DUD method) in SAS.
4. Results
We set 300 000 iterations to run to ensure that maximum convergence and satisfied posterior distributions of estimated parameters for Bayesian method are obtained. Among those 300 000 iterations, the initial 20 000 iterations were discarded from analysis as burn-in iterations. To reduce the correlation between neighbouring iterations, the thinning parameters in the six models were all set to 3. After iterating, the mean, standard deviation (Std.), and 95% credible intervals with data1 can be obtained. The credible intervals of most parameters of the classical method were nearly equal to Bayesian method with uninformative priors (Table 3). In this study, based on RMSE (Table 3), we also found that Weibull model was the “best” model for describing height-diameter relationships of Chinese fir both for classical method and Bayesian method.
Table 3.
Parameter estimates of six models using classical and Bayesian methods with uninformative priors using data1.
| Classical method | Bayesian method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Parameter estimate | 95% interval | RMSE | Parameter estimate | 95% interval | DIC | |||||
| Mean | Std. error | Lower | Higher | Mean | Std. | Lower | Higher | ||||
| Chapman-Richards | a | 22.95 | 2.472 | 18.10 | 27.81 | 1.1554 | 21.15 | 0.988 | 19.56 | 23.96 | 1398.34 |
| b | 0.05 | 0.016 | 0.02 | 0.08 | 0.06 | 0.009 | 0.04 | 0.08 | |||
| c | 0.87 | 0.126 | 0.62 | 1.12 | 1.01 | 0.082 | 0.83 | 1.18 | |||
|
| |||||||||||
| Weibull | a | 23.59 | 3.315 | 17.07 | 30.10 | 1.1551 | 26.58 | 4.619 | 20.86 | 38.67 | 1368.38 |
| b | 0.07 | 0.006 | 0.06 | 0.08 | 0.07 | 0.005 | 0.06 | 0.08 | |||
| c | 0.90 | 0.100 | 0.71 | 1.10 | 0.85 | 0.080 | 0.71 | 0.99 | |||
|
| |||||||||||
| Logistic | a | 19.12 | 0.661 | 17.82 | 20.42 | 1.1644 | 19.25 | 0.797 | 17.99 | 21.02 | 1406.18 |
| b | 3.24 | 0.233 | 2.78 | 3.70 | 3.27 | 0.226 | 2.88 | 3.73 | |||
| c | 0.13 | 0.012 | 0.11 | 0.15 | 0.13 | 0.012 | 0.11 | 0.15 | |||
|
| |||||||||||
| Gompertz | a | 28.53 | 2.322 | 23.97 | 33.10 | 1.1556 | 26.58 | 0.721 | 25.23 | 27.96 | 1399.03 |
| b | −15.48 | 3.258 | −21.88 | −9.08 | −12.74 | 0.875 | −14.38 | −11.07 | |||
| c | 4.92 | 2.053 | 0.89 | 8.96 | 3.13 | 0.604 | 1.87 | 4.22 | |||
|
| |||||||||||
| Bertalanffy | a | 16.58 | 0.164 | 16.26 | 16.91 | 1.2421 | 16.59 | 0.172 | 16.31 | 16.87 | 1462.49 |
| b | 0.18 | 0.003 | 0.17 | 0.19 | 0.18 | 0.003 | 0.18 | 0.19 | |||
|
| |||||||||||
| Power law | a | 2.78 | 0.122 | 2.54 | 3.02 | 1.1658 | 2.80 | 0.123 | 2.57 | 3.04 | 1406.01 |
| b | 0.57 | 0.016 | 0.54 | 0.60 | 0.57 | 0.016 | 0.54 | 0.59 | |||
Based on the Bayesian method, the posterior probability distributions of the three parameters of Weibull model for data2 were obtained. The posterior probability distributions based on Bayesian method with informative priors were more concentrated than uninformative priors (Figure 3). Estimates of a, b, and c using Bayesian method and classical method were numerically identical in height-diameter model. The intervals of the three parameters estimates using classical method and Bayesian method with uninformative priors also had similar range, while they were wider than the intervals from Bayesian method with informative priors. The interval of asymptote parameter a using Bayesian method with informative prior was 68.4% narrower than the one of classical method, 66.7% narrower for b, and 59% narrower for c (Table 4).
Figure 3.
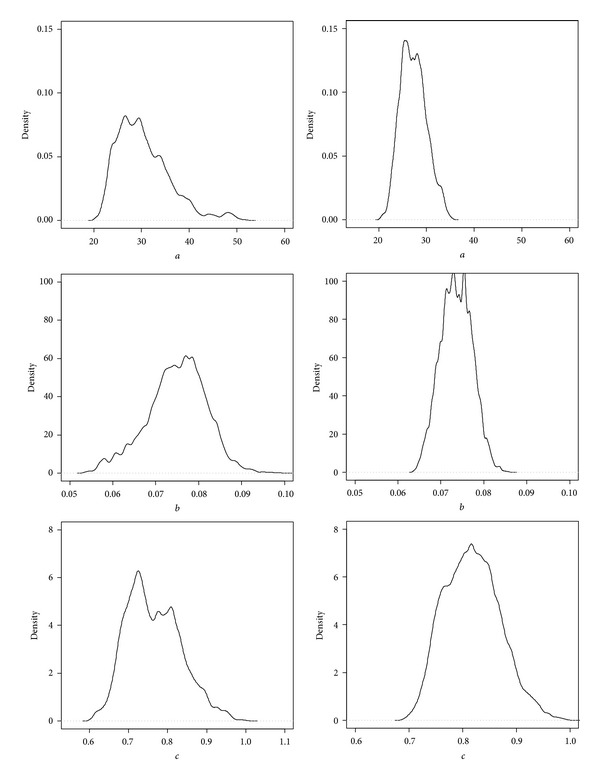
Posterior density curves of Weibull parameters based on Bayesian method with uninformative priors and informative priors using data2. The left row is for uninformative priors; the right row is for informative priors.
Table 4.
Parameter estimates of Weibull model using classical and Bayesian methods with data2.
| Method | Parameter estimate | 95% interval | |||
|---|---|---|---|---|---|
| Mean | Std. error | Lower | Higher | ||
| Classical method | a | 29.14 | 8.446 | 12.54 | 45.74 |
| b | 0.08 | 0.009 | 0.06 | 0.09 | |
| c | 0.77 | 0.116 | 0.54 | 1.00 | |
|
| |||||
| Bayesian with informative priors | a | 27.28 | 2.722 | 22.6 | 33.1 |
| b | 0.07 | 0.004 | 0.07 | 0.08 | |
| c | 0.82 | 0.052 | 0.73 | 0.92 | |
|
| |||||
| Bayesian with uninformative priors | a | 30.41 | 5.56 | 22.59 | 44.84 |
| b | 0.07 | 0.007 | 0.06 | 0.09 | |
| c | 0.76 | 0.070 | 0.65 | 0.92 | |
We also found that RMSE and fit index for Bayesian method and classical method were nearly equal, and Bayesian method with informative priors was slightly better than uninformative priors (Table 5). Despite the numerically equal evaluation statistics using classical method and Bayesian method, the credible bands of predicted values with Bayesian method were narrower than classical method, and the ones with informative priors were slightly narrower than uninformative priors (Figure 4).
Table 5.
Evaluation statistics of classical and Bayesian method using data2.
| Statistics | Classical method | Bayesian with uninformative priors | Bayesian with informative priors |
|---|---|---|---|
| MD | −0.0003 | −0.0033 | −0.0017 |
| Fit index | 0.7407 | 0.7407 | 0.7406 |
| RMSE | 1.2063 | 1.2063 | 1.2064 |
Figure 4.

Predicted tree height values against observed values with data2. From up to down, the predicted values were obtained from classical method, Bayesian method with uninformative priors, and informative priors, respectively. The “error bars” were 95% confidence bands.
5. Discussion and Conclusion
The curves generated with empirical models were checked with respect to their biological meaning; for example, height-diameter curves were assumed to demonstrate an approximately a sigmoid shape with clear inflection point that occurred in an early stage and other height increment should be more than zero [47]. In this study, the values of the evaluation statistics of the models showed that Weibull model most accurately estimated the tree height. Zhang [38] evaluated the prediction performance of six nonlinear height-diameter models for ten conifer species and found that Weibull function gave more accurate results than other model forms. Considering the model mathematical features, biological realism, and accurate prediction, we recommend the Weibull model as the base model in this case for further study.
Comparing the evaluation statistics from Bayesian method and classical method, we found that they were quite close (Table 5). However, we cannot only rely on the evaluations statistics for assessing a method, the prediction accuracy should also be taken into account. The improvement in prediction accuracy with Bayesian method led to narrower confidence bands of predicted value in comparison to that for the classical method (Figure 4). Bayesian method is an important statistical tool that is increasingly being used by ecologists [48, 49] and differs from classical method in main two ways. Firstly, Bayesian methods are fully consistent with mathematical logic, while classical methods are only logical when making probabilistic statements about long-run averages obtained from hypothetical replicates of sample data [50, 51]. Secondly, relevant prior knowledge about the data can be incorporated naturally into Bayesian analyses whereas classical methods ignore the relevant prior knowledge other than the sample data [41, 52]. Bayesian credible interval and classical confidence are usually numerically identical if the Bayesian prior is uninformative. An uninformative prior is one in which the data (by the likelihood, which is p(y | θ) in Bayes' rule) dominates the posterior, and the prior probabilities of all reasonable parameter values are approximately equal. Thus the posterior distribution has the same form as the likelihood. Since the posterior distribution with uninformative prior is less precise, the credible interval was wider (Table 4) [52].
With data2, the estimated posterior distributions for parameters can be treated as new priors in predicting the parameters. That is, informative new priors obtained from data1 are used in the estimation process of data2 to incorporate results from previously fitted models. It is the advantage of Bayesian method to update a model with new data. Therefore, not only are the data considered to be samples from a random variable, but the parameters to be estimated are regarded as random variables [40]. Thus, informative priors increased the precision of Bayesian estimates.
It is also noted that there are chances to improve the research. Additional variables, such as site index, age, and stand density, can be included in the analysis and develop hierarchical Bayesian models that can yield more accurate priors for new data. For example, it would be possible to develop procedures in which the prior information adapts to specific site and age. For more comprehensive and accurate relationships of height-diameter, additional variables describing stand density (e.g., stand basal area or number of trees) and site quality (e.g., site index) should be incorporated into the models [53, 54].
Height-diameter equations are crucial for estimating vertical forest structure [55], biomass, and carbon storage. Since collecting height data is costly and time consuming, the Bayesian method is valuable when data are limited, because it exploits prior information that can be obtained from other sources, for example, the fitted models, and it explicitly accommodates parameter variability. In conclusion, the Bayesian method is an alternatively feasible method for analyzing height-diameter relationships.
Acknowledgments
The authors are grateful to the editor and two anonymous reviewers for their valuable suggestions and comments on the paper. Funding for the study was provided by National Natural Science Foundation of China (no. 31300537 and no. 31370629), the Research Institute of Forestry, Chinese Academy of Forestry, for fund support for young scholars (no. RIF2013-09), and collaborative innovation plan of Jiangsu Higher Education.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Authors' Contribution
Xiongqing Zhang and Aiguo Duan contributed equally to the work.
References
- 1.FAO. Scientific facts on forests. 2006, http://www.greenfacts.org/en/forests/forests-greenfacts-level2.pdf. [Google Scholar]
- 2.Botkin DB, Jamak JF, Wallis JR. Some ecological consequences of a computer model of forest growth. Journal of Ecology. 1972;60:849–873. [Google Scholar]
- 3.Vanclay JK. Modelling Forest Growth and Yield: Applications to Mixed Tropical Forests. London, UK: CAB International; 1994. [Google Scholar]
- 4.Peng C, Zhang L, Liu J. Developing and validating nonlinear height-diameter models for major tree species of ontario’s boreal forests. Northern Journal of Applied Forestry. 2001;18(3):87–94. [Google Scholar]
- 5.Colbert KC, Larsen DR, Lootens JR. Height-diameter equations for thirteen midwestern bottomland hardwood species. Northern Journal of Applied Forestry. 2002;19(4):171–176. [Google Scholar]
- 6.Curtis RO. Height-diameter and height-diameter-age equations for second-growth Douglas-fir. Forest Science. 1967;13:365–375. [Google Scholar]
- 7.Fang Z, Bailey RL. Height-diameter models for tropical forests on Hainan Island in southern China. Forest Ecology and Management. 1998;110(1–3):315–327. [Google Scholar]
- 8.Lóopez-Sánchez CA, Varela GG, Dorado FC, et al. A height-diameter model for Pinus radiate D. Don in Galicia (Northwest Spain) Annals of Forest Science. 2003;60:237–245. [Google Scholar]
- 9.Peng C, Zhang L, Zhou X, Dang Q, Huang S. Developing and evaluating tree height-diameter models at three geographic scales for black spruce in Ontario. Northern Journal of Applied Forestry. 2004;21(2):83–92. [Google Scholar]
- 10.Temesgen H, Hann DW, Monleon VJ. Regional height-diameter equations for major tree species of southwest Oregon. Western Journal of Applied Forestry. 2007;22(3):213–219. [Google Scholar]
- 11.Shongming Huang SH, Titus SJ, Wiens DP. Comparison of nonlinear height-diameter functions for major Alberta tree species. Canadian Journal of Forest Research. 1992;22(9):1297–1304. [Google Scholar]
- 12.Hann DW. ORGANON User’s Manual Edition 8.0. Corvallis, Ore, USA: Department of Forest Resources, Oregon State University; 2005. [Google Scholar]
- 13.Larsen DR, Hann DW. Height-Diameter Equations for Seventeen Tree Species in Southwest Oregon. Oregon State University, Forest Research Lab; 1987. [Google Scholar]
- 14.Penner M, Power C, Muhairve C, et al. Information Report. BC-X-370. Victoria, Canada: Canadian Forest Service, Pacific Forestry Centre; 1997. Canada’s forest biomass resources: deriving estimates from Canada’s forest inventory. [Google Scholar]
- 15.Chave J, Andalo C, Brown S, et al. Tree allometry and improved estimation of carbon stocks and balance in tropical forests. Oecologia. 2005;145(1):87–99. doi: 10.1007/s00442-005-0100-x. [DOI] [PubMed] [Google Scholar]
- 16.Fekedulegn D, Mac Siurtain MP, Colbert JJ. Parameter estimation of nonlinear growth models in forestry. Silva Fennica. 1999;33(4):327–336. [Google Scholar]
- 17.Sharma M, Parton J. Height-diameter equations for boreal tree species in Ontario using a mixed-effects modeling approach. Forest Ecology and Management. 2007;249(3):187–198. [Google Scholar]
- 18.Krumland BE, Wensel LC. A generalized height-diameter equation for coastal California species. Western Journal of Applied Forestry. 1988;3:113–115. [Google Scholar]
- 19.Holbrook NM, Putz FE. Influence of neighbors on tree form: effects of lateral shade and prevention of sway on the allometry of Liquidambar styraciflua (sweet gum) American Journal of Botany. 1989;76(12):1740–1749. [Google Scholar]
- 20.King DA. Tree allometry, leaf size and adult tree size in old-growth forests. Tree Physiology. 1991;9(3):369–381. doi: 10.1093/treephys/9.3.369. [DOI] [PubMed] [Google Scholar]
- 21.Calama R, Montero G. Interregional nonlinear height-diameter model with random coefficients for stone pine in Spain. Canadian Journal of Forest Research. 2004;34(1):150–163. [Google Scholar]
- 22.Nogueira EM, Nelson BW, Fearnside PM, França MB, Oliveira ÁCAD. Tree height in Brazil’s “arc of deforestation”: shorter trees in south and southwest Amazonia imply lower biomass. Forest Ecology and Management. 2008;255(7):2963–2972. [Google Scholar]
- 23.Flewelling JW, de Jong R. Considerations in simultaneous curve fitting for repeated height-diameter measurements. Canadian Journal of Forest Research. 1994;24(7):1408–1414. [Google Scholar]
- 24.Lappi J. Calibration of height and volume equations with random parameters. Forest Science. 1991;37:781–801. [Google Scholar]
- 25.Dixon P, Ellison AM. Introduction: ecological applications of bayesian inference. Ecological Applications. 1996;6(4):1034–1035. [Google Scholar]
- 26.Anholt BR, Werner E, Skelly DK. Effect of food and predators on the activity of four larval ranid frogs. Ecology. 2000;81(12):3509–3521. [Google Scholar]
- 27.Toivonen HTT, Mannila H, Korhola A, Olander H. Applying Bayesian statistics to organism-based environmental reconstruction. Ecological Applications. 2001;11(2):618–630. [Google Scholar]
- 28.Shen T-J, Chao A, Lin C-F. Predicting the number of new species in further taxonomic sampling. Ecology. 2003;84(3):798–804. [Google Scholar]
- 29.Zapata-Cuartas M, Sierra CA, Alleman L. Probability distribution of allometric coefficients and Bayesian estimation of aboveground tree biomass. Forest Ecology and Management. 2012;277:173–179. [Google Scholar]
- 30.Green EJ, Roesch FA, Jr., Smith AFM, Strawderman WE. Bayesian estimation for the three-parameter Weibull distribution with tree diameter data. Biometrics. 1994;50(1):254–269. [Google Scholar]
- 31.Bullock BP, Boone EL. Deriving tree diameter distributions using Bayesian model averaging. Forest Ecology and Management. 2007;242(2-3):127–132. [Google Scholar]
- 32.Clark JS, Wolosin M, Dietze M, et al. Tree growth inference and prediction from diameter censuses and ring widths. Ecological Applications. 2007;17(7):1942–1953. doi: 10.1890/06-1039.1. [DOI] [PubMed] [Google Scholar]
- 33.Wyckoff PH, Clark JS. Predicting tree mortality from diameter growth: a comparison of maximum likelihood and Bayesian approaches. Canadian Journal of Forest Research. 2000;30(1):156–167. [Google Scholar]
- 34.Metcalf CJE, McMahon SM, Clark JS. Overcoming data sparseness and parametric constraints in modeling of tree mortality: a new nonparametric Bayesian model. Canadian Journal of Forest Research. 2009;39(9):1677–1687. [Google Scholar]
- 35.Green EJ, Strawderman WE. Predictive posterior distributions from a Bayesian version of a slash pine yield model. Forest Science. 1996;42(4):456–464. [Google Scholar]
- 36.Li R, Stewart B, Weiskittel A. A Bayesian approach for modelling non-linear longitudinal/hierarchical data with random effects in forestry. Forestry. 2012;85(1):17–25. [Google Scholar]
- 37.Nyström K, Ståhl G. Forecasting probability distributions of forest yield allowing for a Bayesian approach to management planning. Silva Fennica. 2001;35(2):185–201. [Google Scholar]
- 38.Zhang L. Cross-validation of non-linear growth functions for modelling tree height-diameter relationships. Annals of Botany. 1997;79(3):251–257. [Google Scholar]
- 39.Huang S. Ecoregion-based individual tree height-diameter models for lodgepole pine in Alberta. Western Journal of Applied Forestry. 1999;14(4):186–193. [Google Scholar]
- 40.Edwards AWF. Likelihood. Baltimore, Md, USA: Johns Hopkins University Press; 1992. [Google Scholar]
- 41.Ellison AM. Bayesian inference in ecology. Ecology Letters. 2004;7(6):509–520. [Google Scholar]
- 42.De Valpine P, Hastings A. Fitting population models incorporating process noise and observation error. Ecological Monographs. 2002;72(1):57–76. [Google Scholar]
- 43.Gelman A, Carlin JB, Stern HS, et al. Bayesian Data Analysis. 2nd edition. Boca Raton, Fla, USA: Chapman and Hall/CRC; 2004. [Google Scholar]
- 44.Spiegelhalter DJ, Best NG, Carlin BP, Van Der Linde A. Bayesian measures of model complexity and fit. Journal of the Royal Statistical Society B. 2002;64(4):583–616. [Google Scholar]
- 45.Spiegelhalter DJ, Thomas A, Best N, Lunn D. WinBUGS user manual. 2003, http://www.mrc-bsu.cam.ac.uk/bugs.
- 46.Chib S, Greenberg E. Understanding the metropolis-hastings algorithm. The American Statistician. 1995;49:327–335. [Google Scholar]
- 47.Sharma RP. Modelling height-diameter relationships for Chir pine trees. Banko Janakari. 2009;19:3–9. [Google Scholar]
- 48.Hui C, McGeoch MA, Warren M. A spatially explicit approach to estimating species occupancy and spatial correlation. Journal of Animal Ecology. 2006;75(1):140–147. [Google Scholar]
- 49.Hui C, Foxcroft LC, Richardson DM, Macfadyen S. Defining optimal sampling effort for large-scale monitoring of invasive alien plants: a Bayesian method for estimating abundance and distribution. Journal of Applied Ecology. 2011;48(3):768–776. [Google Scholar]
- 50.Berger JO, Berry DA. Statistical analysis and the illusion of objectivity. American Scientist. 1988;76:159–165. [Google Scholar]
- 51.Jaynes ET. Probability Theory: The Logic of Science. New York, NY, USA: Cambridge University Press; 2003. [Google Scholar]
- 52.McCarthy MA. Bayesian Methods for Ecology. Cambridge, UK: Cambridge University Press; 2007. [Google Scholar]
- 53.Temesgen H, Gadow KV. Generalized height-dimater models—an application for major tree species in complex stands of interior British Columbia. European Journal of Forest Research. 2004;123(1):45–51. [Google Scholar]
- 54.Newton PF, Amponsah IG. Comparative evaluation of five height-diameter models developed for black spruce and jack pine stand-types in terms of goodness-of-fit, lack-of-fit and predictive ability. Forest Ecology and Management. 2007;247(1–3):149–166. [Google Scholar]
- 55.Ritchie MW, Hann DW. Development of a tree height growth model for Douglas-fir. Forest Ecology and Management. 1986;15(2):135–145. [Google Scholar]
- 56.Richards FJ. A flexible growth function for empirical use. Journal of Experimental Botany. 1959;10(2):290–301. [Google Scholar]
- 57.Yang RC, Kozak A, Smith JHG. The potential of Weibull-type functions as a flexible growth curve. Canadian Journal of Forest Research. 1978;8:424–431. [Google Scholar]
- 58.Zeide B. Analysis of growth equation. Forest Science. 1993;39:594–616. [Google Scholar]
- 59.Ratkowsky DA. Handbook of Nonlinear Regression. New York, NY, USA: Marcel Dekker; 1990. [Google Scholar]
- 60.Von Bertalanffy L. Problems of organic growth. Nature. 1949;163(4135):156–158. doi: 10.1038/163156a0. [DOI] [PubMed] [Google Scholar]
- 61.Arabatzis AA, Burkhart HE. An evaluation of sampling methods and model forms for estimating height-diameter relationships in loblolly pine plantations. Forest Science. 1992;38:192–198. [Google Scholar]