

Summary
Dynamic treatment regimes operationalize the clinical decision process as a sequence of functions, one for each clinical decision, where each function maps up-to-date patient information to a single recommended treatment. Current methods for estimating optimal dynamic treatment regimes, for example Q-learning, require the specification of a single outcome by which the ‘goodness’ of competing dynamic treatment regimes is measured. However, this is an over-simplification of the goal of clinical decision making, which aims to balance several potentially competing outcomes, e.g., symptom relief and side-effect burden. When there are competing outcomes and patients do not know or cannot communicate their preferences, formation of a single composite outcome that correctly balances the competing outcomes is not possible. This problem also occurs when patient preferences evolve over time. We propose a method for constructing dynamic treatment regimes that accommodates competing outcomes by recommending sets of treatments at each decision point. Formally, we construct a sequence of set-valued functions that take as input up-to-date patient information and give as output a recommended subset of the possible treatments. For a given patient history, the recommended set of treatments contains all treatments that produce non-inferior outcome vectors. Constructing these set-valued functions requires solving a non-trivial enumeration problem. We offer an exact enumeration algorithm by recasting the problem as a linear mixed integer program. The proposed methods are illustrated using data from the CATIE schizophrenia study.
Keywords: Dynamic Treatment Regimes, Personalized Medicine, Composite Outcomes, Competing Outcomes, Preference Elicitation
1. Introduction
Dynamic treatment regimes (DTRs) operationalize the clinical decision-making process wherein a clinician selects a treatment based on current patient characteristics and then continues to adjust treatment over time in response to the evolving health status of the patient. A DTR is a sequence of decision rules, one for each decision point. Each rule takes as input current patient information and gives as output a recommended treatment. There is growing interest in estimating “optimal” DTRs from randomized or observational data. A DTR is said to be optimal if, when applied in the population of interest, it maximizes the average clinical outcome. Optimal DTRs have been estimated for chronic conditions including ADHD (Laber et al., 2011; Nahum-Shani et al., 2010, 2012), depression (Schulte et al., 2012; Song et al., 2012), HIV infection (Moodie et al., 2007), schizophrenia (Shortreed et al., 2011), and cigarette addiction (Strecher et al., 2006). Approaches for estimating optimal DTRs from data include Q-learning (Watkins and Dayan, 1992; Nahum-Shani et al., 2010), A-learning (Murphy, 2003; Blatt et al., 2004; Robins, 2004), regret regression (Henderson et al., 2010), and direct value maximization (Orellana et al., 2010; Zhang et al., 2012; Zhao et al., 2012).
To estimate a DTR from data using any of the above methods, one must specify a single outcome and neglect all others. For example, one might seek the most effective DTR without regard for side-effects. Alternatively, one could form a linear combination of two outcomes, e.g., side effects and effectiveness, yielding a single composite outcome. Forming this outcome requires the elicitation of a trade-off between two outcomes; for example, one would need to know that a gain of 1 unit of effectiveness is worth a cost of 3 units of side-effects. However, for some illnesses, e.g., severe schizophrenia, preferences across outcomes can vary widely across patients (Kinter, 2009). Thus, even if one could elicit this trade-off at an aggregate level, assuming that a particular trade-off holds for all decision-makers is not reasonable since each will have his or her own individual preferences which cannot be known a priori. Furthermore, patients may not know their preferences, they may be unable to communicate them, or they may have preferences which evolve over time (Strauss et al., 2011).
Lizotte et al. (2012) present one approach to dealing with this problem using a method that estimates an optimal DTR for all possible linear trade-offs simultaneously. Their method can also be used to explore what range of trade-offs is consistent with each available treatment. Nonetheless, their method assumes that any outcome preference can be expressed by a composite outcome that is a linear combination of the outcomes under consideration. They still (perhaps implicitly) require the decision-maker to assess and reason about the space of linear composite outcomes. In addition, their approach suggests actions based on the assumption that preferences remain fixed over time.
We propose set-valued Dynamic Treatment Regimes (SVDTRs) as an alternative to DTRs that accommodates competing outcomes and preference heterogeneity both across patients and time, but avoids eliciting trade-offs between outcomes. Like a DTR, an SVDTR is a sequence of decision rules. However, the decision rules that compose an SVDTR take as input current patient information and give as output a set of recommended treatments. This set is a singleton when there exists a treatment that is best across all outcomes but contains multiple treatments otherwise. Treatments that are inferior according to all outcomes are eliminated. By presenting multiple reasonable treatments, our proposed method still allows for the incorporation of clinical judgment, individual patient preferences (to the extent that they are known), cost, and local availability, when deciding among the non-inferior treatments. Our approach does not require any individual preference information from the decision maker; however, in its most general form, our approach makes use of an elicited ‘clinically significant’ difference on each outcome scale to help decide if one treatment is clearly inferior to another (see Friedman et al., 2010, for example).
This work is motivated by the Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) study (Stroup et al., 2003), in which schizophrenic patients were randomized up to two times to different treatments. CATIE has three features that make it amenable to our proposed approach: i) It contains data we can use to individualize treatment. ii) It follows patients over multiple treatment phases. iii) It contains data on important competing outcomes. The CATIE data include both measures of symptoms and side-effects, and it is well-established that treatments that provide some of the best symptom relief have the worst side-effects (Breier et al., 2005; Allison et al., 1999). Thus, to illustrate our approach we present an SVDTR-based analysis of CATIE in Section 4.
Our primary contribution is the introduction of SVDTRs, which offer a new approach to operationalizing sequential clinical decision making that is informed by predicted competing outcomes and by clinical judgment. We also provide a novel mathematical programming formulation which gives a computationally efficient method to estimate SVDTRs from data. In Section 2, we review the Q-learning algorithm for estimating optimal DTRs from data. In Section 3 we propose an SVDTR for the two decision point problem, and in Section 3.1 we describe our mathematical programming approach for estimating an SVDTR from data. Section 4 presents our analysis of CATIE. For clarity, the main body of the paper considers only binary treatment decisions; we give an extension to an arbitrary number of treatments in Web Appendix A.
2. Single outcome decision rules
In this section we review the Q-learning algorithm for estimating an optimal DTR when there is a single outcome of interest. For simplicity, we consider the case in which there are two decision points and two treatment options at each decision point. In this setting the data available to estimate an optimal DTR consists of n trajectories (H1, A1, H2, A2, Y), one for each patient, drawn i.i.d. from some unknown distribution. We use capital letters like H1 and A1 to denote random variables and lower case letters like h1 and a1 to denote realized values of these random variables. The components of each trajectory are as follows: Ht ∈ ℝpt denotes patient information collected prior to the assignment of the tth treatment, and thus is information the decision maker can use to inform the tth treatment decision (note that H2 may contain some or all of the vector ); At ∈ {−1, 1} denotes the tth treatment assignment; Y ∈ ℝ denotes the outcome of interest which is assumed to be coded so that higher values are more desirable than lower values. The outcome Y is commonly a measure of treatment effectiveness, but could also be a composite measure attempting to balance different objectives. Given the definition of Y, the goal is to construct a pair of decision rules π = (π1, π2) where πt(ht) denotes a decision rule for assigning treatment at time t to a patient with history ht in such a way that the expected response Y, given such treatment assignments, is maximized. Formally, if Eπ denotes the joint expectation over Ht, At, and Y under the restriction that At = πt(Ht), then the optimal decision rule πopt satisfies Eπopt Y = supπ Eπ Y. Note this definition of optimality ignores the impact of the DTR πopt on any outcome not incorporated into Y.
One method for estimating an optimal DTR is the Q-learning algorithm (Watkins and Dayan, 1992). Q-learning is an approximate dynamic programming procedure that relies on regression models to approximate the conditional expectations , and . The function Qt is termed the stage-t Q-function. The function Q2(h2, a2) measures the quality of assigning treatment a2 at the second decision point to a patient with history h2. The function Q1(h1, a1) measures the quality of assigning treatment a1 at the first decision point to a patient with history h1, assuming optimal treatment decisions will be made at the second decision point. Hence, it follows that , t = 1, 2. This is the dynamic programming solution to finding the optimal sequence of decision rules (Bellman, 1957).
In practice, the Q-functions are not known and must be estimated from data. We consider linear working models of the form , where ht,1 and ht,2 are (possibly the same) vector summaries of ht. Note that ht,j, j = 1, 2 might contain polynomial terms or other basis expansions as appropriate. The Q-learning algorithm proceeds in three steps:
Estimate the parameters of the working model for the stage-2 Q-function using least squares. Let β̂2 and ψ̂2 denote these estimates, and let Q̂2(h2, a2) denote the fitted model.
- Define the predicted future outcome Ỹ following the estimated optimal decision rule at stage two as .
- Estimate the parameters indexing the working model for the stage-1 Q-function using least squares. That is, regress Ỹ on H1 and A1 using the working model to obtain β̂1 and ψ̂1. Let Q̂1(h1, a1) denote the fitted model.
The Q-learning estimate of πopt is π̂ = (π̂1, π̂2) where π̂t (ht) = arg maxat∈{−1,1} Q̂(ht, at).
The Q-learning algorithm is simple to implement and easy to interpret given its connections to regression. Therefore, we use Q-learning as the basis for developing SVDTRs. Alternatives to Q-learning are listed in Section 1.
3. Set-valued dynamic treatment regimes
In a DTR, the optimal decision rule at time t = 1 depends critically on the decision rule that will be used at time t = 2, which in turn depends on the Q-functions at time t = 2. This is why Q-learning and related methods use backwards recursive estimation beginning at the final stage. Thus, if we cannot estimate the Q-function at t = 2 for any reason, existing recursive approaches like Q-learning cannot be applied. It follows that if the optimal rule for t = 2 depends on preference, but preference information is unavailable, Q-learning cannot be directly applied and we must devise a new strategy.
In some populations, e.g., severe schizophrenics, high quality preference elicitation may not be possible (Kinter, 2009; Strauss et al., 2011), which can lead to misspecification of the composite outcome needed to estimate Q-functions (see Web Appendix B for an illustration of how composite outcome misspecification can impact the quality of a decision rule). Furthermore, preference may evolve unpredictably over time so even if patient preferences were known exactly at the time of each treatment decision, future treatment preferences are unknown, and this precludes backwards recursive estimation.
Table 1 illustrates the foregoing problems in simplified setting with two hypothetical subjects drawn from different populations, no subject covariates, and two competing outcomes generically termed ‘side-effects’ and ‘efficacy.’ For Subject A, an initial preference for efficacy suggests treatment 1 at the first stage. Suppose, however, that during the course of the first treatment Subject A develops a strong aversion to side-effects. Because the initial treatment was chosen assuming a static preference for efficacy, Subject A is left with poor and very poor choices in terms of their current preference at the second stage. Given the information provided in the table the decision maker may recommend treatment -1 initially to allow for better second stage treatment choices; however, it is important to note that once estimates of outcomes and viable treatment strategies are provided to the decision maker (see below) treatment choice is no longer a statistical problem. An alternative strategy would be to apply the Q-learning algorithm with respect to each outcome. In the case of Subject A, the Q-learning algorithm for side-effects would recommend treatment -1, whereas the Q-learning algorithm for efficacy would recommend treatment 1. The disagreement between the output of these algorithms could serve as signal to the decision maker that other external factors (e.g., clinical judgment, past treatment preferences, etc.) should be incorporated as ‘tie-breakers.’ However, Subject B in Table 1 demonstrates that this strategy will not work in general. The Q-learning algorithm for side-effects and efficacy both recommend treatment 1 at the first stage for Subject B. However, treatment 1 at the first stage leads to extreme and potentially undesirable trade-offs at the second stage.
Table 1.
Illustrative example for competing outcomes generically called ‘side-effects’ and ‘efficacy’ and no patient covariates. In both cases the set {−1, 1} should be recommended at the first stage. Subject A illustrates the impact of preference evolution. If Subject A is initially concerned only with efficacy then they will choose treatment 1 at the first stage. However, if at the time of the second decision Subject A is concerned with side-effects, having initially chosen treatment 1 they are only left with poor choices. Subject B illustrates a potential problem with applying Q-learning separately to each outcome and then checking for agreement. Both Q-learning applied to efficacy and side-effects recommend treatment 1 at the first stage for Subject B. However, the Q-learning algorithm applied to efficacy assumes treatment -1 will be chosen at the second stage, and the Q-learning algorithm applied to side-effects assumes treatment 1 will be applied at the second stage. Yet, for Subject B applying treatment 1 at the first stage leads to extreme and potentially undesirable trade-offs at the second stage.
| Stage 1 Txt | Stage 2 Txt | Subject A | Subject B | ||
|---|---|---|---|---|---|
| Side-effects | Efficacy | Side-effects | Efficacy | ||
| 1 | 1 | Very poor | Very good | Very good | Very poor |
| 1 | -1 | Poor | Poor | Poor | Very good |
| -1 | 1 | Good | Good | Good | Good |
| -1 | -1 | Very good | Poor | Fair | Very poor |
In this section we propose set-valued DTRs for two decision points and two competing outcomes. An extension to an arbitrary number of treatments is given in Web Appendix A. The data available to estimate a pair of decision rules, one for each patient, comprises n trajectories (H1, A1, H2, A2, Y, Z) drawn i.i.d. from a fixed but unknown distribution. The first four elements in each trajectory are the same as the Q-learning setup and Z, Y ∈ ℝ denote competing outcomes observed sometime after the assignment of the second treatment A2. We assume that both Y and Z are coded so that higher values are preferred.
Our method can make use of clinically significant differences ΔY ≥ 0 and ΔZ ≥ 0 for outcomes Y and Z respectively, to differentiate between treatment outcomes. We call a difference in outcome clinically significant if a clinician would be willing to change her treatment strategy given that this change was expected to yield a difference of at least ΔY (ΔZ) in the outcome Y (Z), all else being equal. These differences may be elicited from a panel of experts, estimated from historical data, or taken from existing clinical guidelines. Importantly, in eliciting ΔY there is no need to reference the competing outcome Z, and vice versa when eliciting ΔZ. They may be patient-independent and constant over time. We believe the incorporation of clinically significant differences adds to the utility and interpretability of our approach in many domains; nevertheless, they are not necessary for the validity of our algorithms and could be taken to both equal zero. Furthermore, our algorithms do not preclude clinical significances being functions of individual patient characteristics, being different at each time point, or allowing dependence between ΔY and ΔZ, however, we do not incorporate these generalizations into our notation. To avoid having to repeatedly qualify our discussion, we will assume that both ΔY > 0 and ΔZ > 0.
The goal is to construct a pair of decision rules π = (π1, π2) where πt : ℝpt → {{−1, 1}, {−1}, {1}} maps up-to-date patient information to a subset of the possible decisions. Ideally, for a patient presenting with h2 at the second stage the set-valued decision rule would recommend a single treatment if that treatment is expected to yield a clinically significant improvement (relative to the alternative treatment) in at least one of the outcomes and, in addition, that treatment is not expected to lead to a significant detriment in the other outcome. If the preceding condition does not hold for one of the treatments then the decision rule should return the set {−1, 1} and leave the ‘tie-breaking’ to the decision maker. Define the (non-normalized) second stage treatment effects as , and likewise . Then, the ideal second stage decision rule, say , is given by
| (1) |
where sgn denotes the signum function. Figure 1 illustrates how depends on r2Y (h2) and r2Z (h2), ΔY, and ΔZ. If we consider the (r2Y (h2), r2Z (h2)) ∈ ℝ2, its location relative to the points (ΔY, ΔZ), (−ΔY, ΔZ), (ΔY, −ΔZ) and (−ΔY, −ΔZ) determines whether we prefer treatment 1, prefer treatment −1, or are undecided according to the foregoing criteria.
Figure 1.
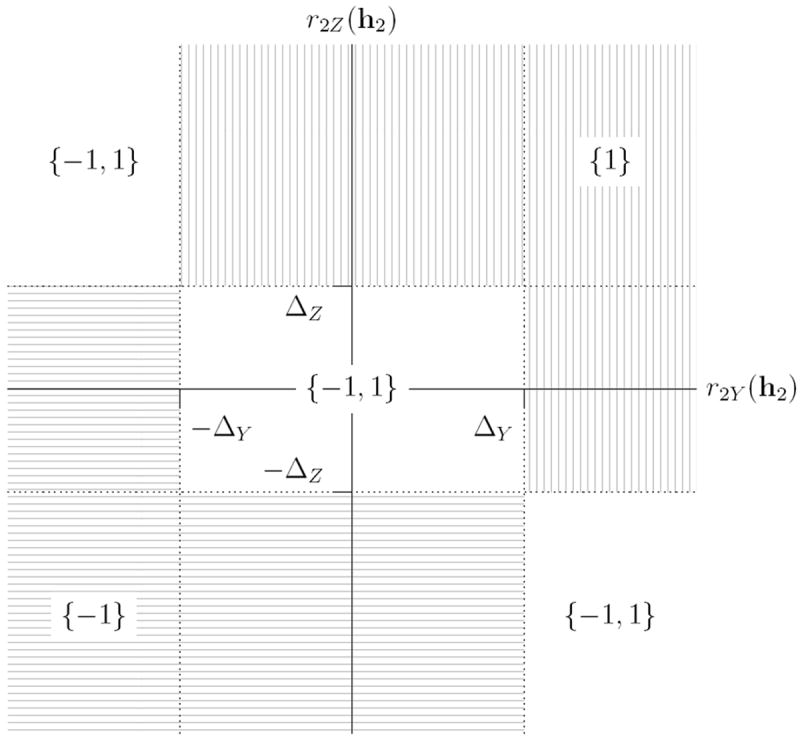
Diagram showing how the output of depends on ΔY and ΔZ, and on the location of the point (r2Y(h2), r2Z(h2)).
We now define given that a clinician always selects treatments from the set-valued decision rule at the second stage. This problem is complicated by the fact that, unlike in the standard setting, there exists a set of histories h2 at the second stage—those for which —where we do not know which treatment would be chosen. To address this, we begin by assuming that some non-set-valued decision rule τ2 will be used at the second stage, we will then consider an appropriate set of possible τ2 in order to define .
Suppose a non-set-valued decision rule τ2 : ℝp2 → {−1, 1} is used to assign treatments at the second stage. That is, a patient presenting with history h2 would be assigned treatment τ2(h2). Define . Furthermore, define so that Q1Y (h1, a1, τ2) is the expected outcome for a patient with first stage history H1 = h1 treated at the first stage with A1 = a1 and the decision rule τ2 at the second stage. Replacing Y with Z yields Q2Z(h2, τ2) and Q1Z(h1, a1, τ2). Thus, if it is known that a clinician will follow τ2 at the second decision point, then the ideal decision rule at the first decision point is given by
| (2) |
where , and similarly . Note that assigns a single treatment if that treatment is expected to yield a clinically significant improvement on one or both the outcomes while not causing clinically significant loss in either outcome assuming the clinician will follow τ2 at the second decision point.
We now describe how to construct the ideal decision rule at the first decision point when the rule at the second decision point is set-valued. We say a non-set-valued rule τ2 is compatible with a set-valued decision rule τ2 if and only if
| (3) |
Let be the set of all rules that are compatible with . We define to be the set-valued decision rule
| (4) |
Our motivation for this definition is a desire to maintain as much choice as possible at stage 1, while making as few assumptions about future behaviour as possible. The definition in (4) assumes only that in the future some τ2 in accordance with π2 will be followed. Therefore at stage 1 we would only eliminate treatments for which there exists no compatible future decision rule that makes that treatment a desirable choice.
However, if we do not impose some smoothness constraints on τ2, the set can be very large, and computing the union (4) can become intractable. Furthermore, may contain unreasonable future policies. Suppose that for all h2 in some non-null set H2. Then the policy that assigns 1 to rational-valued histories in H2 and −1 to irrational-valued histories in H2 belongs to even though it is clearly not a reasonable policy to follow. We will see that the modelling choices made to estimate Q2Y and Q2Z suggest a sensible subset of over which to take the union (4) instead. We provide a mathematical programming formulation that allows us to use existing optimization algorithms to efficiently compute the union over this much smaller subset (see below).
We now turn to the estimation of and from data. As in the Q-learning setup, let ht,j j = 1, 2 denote vector summaries of the history at time t. To estimate the ideal second stage decision rule we postulate linear models for second stage Q-functions, say, of the form , , which we estimate using least squares. In a slight abuse of notation, we write ht,j,i to denote the jth vector summary (j = 1, 2) of history ht (t = 1, 2) for subject i (i = 1, …, n), and ht,·,i to denote the history at time t for subject i. The estimated ideal second stage set-valued decision rule π̂2Δ is the plug-in estimate of (1). In order to estimate the ideal decision rule at the first decision point we must characterize how a clinician might assign treatments at the second decision point. We begin by assuming that clinicians’ behavior, denoted by τ2, is compatible with π̂2Δ as defined in (3), and we further assume that τ2 can be expressed as a thresholded linear function of h2. We call such decision rules feasible for π̂2Δ, and we define the set of feasible decision rules at stage 2 by . Here, p2,2 = dim(h2,2). This is exactly the set of all stage 2 decision rules that would be output by Q-learning for some outcome on the given space of histories.
Thus, F(π̂2Δ) denotes the set of second stage non-set-valued decision rules that a clinician might follow if they were presented with π̂2Δ. This set is indexed by the vector ρ ∈ ℝp2,2. It can be verified that F(π̂2Δ) is non-empty since belongs to F(π̂2Δ). For an arbitrary τ2 ∈ F(π̂2Δ), define the working models
| (5) |
where β1Y (τ2), ψ1Y (τ2), β1Z (τ2), and ψ1Z (τ2) are coefficient vectors specific to τ2. For a fixed τ2 one can estimate these coefficients by regressing and on H1 and A1 using the working models in (5). Let Q̂1Y (h1, a1, τ2) and Q̂1Z (h1, a1, τ2) denote these fitted models, and let , and . Define
| (6) |
and
| (7) |
Thus, π̂1Δ is a set-valued decision rule that assigns a single treatment if only that treatment leads to an (estimated) expected clinically significant improvement on one or both outcomes and does not lead to a clinically significant loss in either outcome across all the treatment rules in F(π̂2Δ) that a clinician might consider at the second stage. Alternatives to this definition of π̂1Δ are discussed in Section 5.
Remark 1
In addition to providing a set of recommended treatments it is useful to provide decision makers with information regarding outcomes which are likely to be realized under feasible regimes. At the second stage, estimates (Q̂2Y (h2, 1), Q̂2Z(h2, 1)) and (Q̂2Y (h2, −1), Q̂2Z (h2, −1) should accompany π̂2Δ(h2). At the first stage, π̂1Δ(h1) should be accompanied by a plot of Q̂1Y (h1, a1, τ2) against Q̂1Z(h1, a1, τ2) across values of τ2 ∈ F(π̂2Δ) with separate plotting symbols and colors for a1 = ±1. Such a plot shows, for each potential first stage treatment, expected outcomes following feasible second stage treatment rules given current patient information as captured by h1. An example of such a plot is given in Figure 3.
Figure 3.
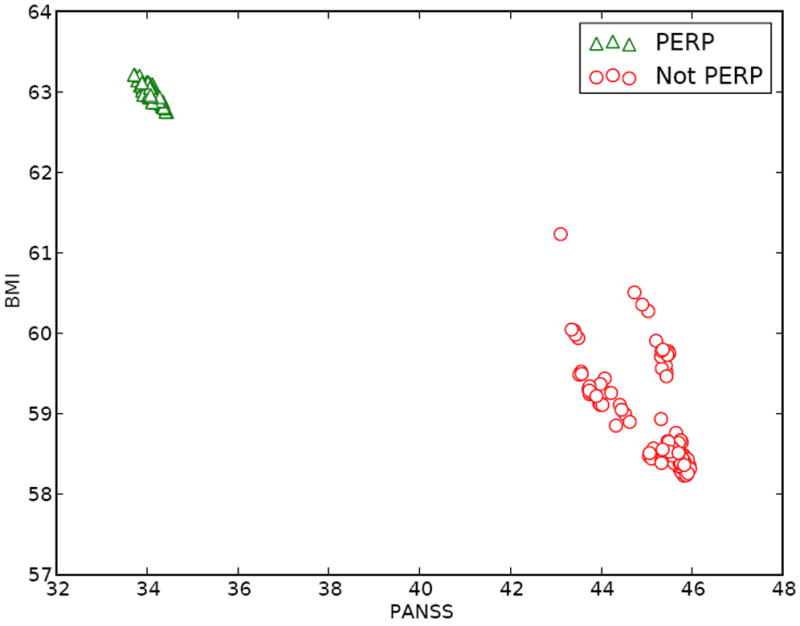
Q̂1B(h1, a1, τ2) against Q̂1P(h1, a1, τ2) across τ2 ∈ F̃ (π̂2Δ) for a single patient with history (panss = −25.5, bmi = −15.6) in the CATIE data. Note, that while there are 61,659 polices in F̃(π̂2Δ) many of these yield similar predicted values for Q̂1B(h1, a1, τ2) and Q̂1P(h1, a1, τ2); we have plotted a random subset to make individual points more clearly visible. This display suggests that a patient presenting with H1 = h1, choosing perphenazine (PERP) is associated with better expected outcomes on BMI but worse on PANSS under feasible second stage rules.
3.1 Computation
Computing π̂1Δ(h1) requires solving a seemingly difficult enumeration problem. Nevertheless, exact computation of π̂1Δ(h1) is possible and (7) can be solved quickly when p2,2 is small.
First, note that if τ2 and are decision rules at the second stage that agree on the observed data, that is, if for i = 1, …, n, then and . It follows that . Thus, if we consider a finite subset F̃(π̂2Δ) of F(π̂2Δ) that contains one decision rule for each possible “labeling” of the stage 2 histories contained in the observed data, then we have
| (8) |
We use the term “labeling” by analogy with classification: each stage 2 history h2,·,i is given a binary “label” ℓi ∈ {−1, 1} by some τ2. Rather than taking a union over the potentially uncountable F(π̂2Δ) indexed by ρ ∈ ℝp2,2, we will instead enumerate the finite set of all feasible labelings of the observed data, place a corresponding τ2 for each one into the set F̃(π̂2Δ), and take the union over F̃(π̂2Δ).
We say that a labeling ℓ1, …, ℓn is compatible with a set-valued decision rule π̂2Δ if ℓi ∈ π̂2Δ(h2,·,i), i = 1, …, n, and feasible if it furthermore can be induced by a feasible decision rule τ2 ∈ F(π̂2Δ). (Recall that in our terminology, feasible decision rules are compatible.) Equivalently, the labeling is feasible if it is both compatible with π̂2Δ and if the two sets {h2,2,i∣ℓi = 1} and {h2,2,i∣ℓi = −1} are linearly separable in ℝp2,2. Our algorithm for computing F̃(π̂2Δ) works by specifying a linear mixed integer program with indicator constraints whose solutions correspond to the linearly separable labelings of the observed data that are compatible with π̂2Δ.
First, we note that determining whether or not a given π̂2Δ-compatible labeling ℓ1, …, ℓn is feasible is equivalent to checking the following set of constraints:
| (9) |
The constant 1 in the above inequalities is arbitrary since one can rescale both sides by any positive constant. Given a particular labeling, the existence of a ψ2 that satisfies (9) can be proved or disproved in polynomial time using a linear program solver (see, e.g., Megiddo (1987) and references therein). The existence of such a ψ2 implies a feasible τ2 given by that produces the labeling ℓ1, …, ℓn when applied to the stage 2 data.
To find all possible feasible labelings, we treat the ℓi as variables in an optimization, we formulate a linear mixed integer program with constraints given by
and we find all unique feasible solutions. We present the feasibility problem as a minimization because it is the natural form for modern optimization software packages like CPLEX (www.ibm.com/software/integration/optimization/cplex-optimizer/), which are capable of handling the integer constraints on ℓi. Note that if we simply want to recover the feasible ℓi then the choice of f does not matter, and we may choose f = 0 for simplicity and efficiency in practice. CPLEX is capable of enumerating all feasible labelings efficiently (the examples considered in this paper take less than one minute to run on a laptop with 8GB DDR3 RAM and a 2.67GHz dual core processor). If we wanted to also recover the maximum margin separators for the feasible labelings, for example, we could use the quadratic objective f = ∥ψ2∥2.
Let F̃ (π̂2Δ) denote the collection of feasible decision rules defined by for each feasible ψ2. Then for any h1 ∈ ℝp1 we define π̂1Δ (h1) using (8). Note that F̃(π̂2Δ) does not depend on the h1 and hence is computed only once for a given dataset.
4. CATIE
We now consider the application of our method to data from the Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) Schizophrenia study. The CATIE study was designed to compare sequences of antipsychotic drug treatments for the care of schizophrenia patients. The full study design is quite complex (Stroup et al., 2003); we will make several simplifications in order to more clearly illustrate the potential of our method. CATIE was an 18-month sequential randomized trial that was divided into two main phases of treatment. Upon entry into the study, most patients began “Phase 1,” in which they were randomized uniformly to one of five possible treatments: olanzapine, risperidone, quetiapine, ziprasidone, or perphenazine. As they progressed through the study, patients were given the opportunity at each monthly visit to discontinue their Phase 1 treatment and begin “Phase 2” on a new treatment. The set of possible Phase 2 treatments depended on the reason for discontinuing Phase 1 treatment. If the Phase 1 treatment was deemed to produce unacceptable side-effects, they entered the tolerability group and their Phase 2 treatment was chosen randomly as follows: ziprasidone with probability 1/2, or uniformly randomly from the set {olanzapine, risperidone, quetiapine} with probability 1/2. If the Phase 1 treatment was deemed ineffective at reducing symptoms, they entered the efficacy group and their Phase 2 treatment was chosen randomly as follows: clozapine with probability 1/2, or uniformly randomly from the set {olanzapine, risperidone, quetiapine} with probability 1/2.
Although CATIE was designed to compare several treatments within each stage, there are natural groupings at each stage that allow us to collapse the data in a meaningful way and consider only binary treatments. We can therefore directly apply our method as described. In the Phase 2 Tolerability group, it is natural to compare olanzapine against the other three drugs since it is known a priori to be efficacious (Breier et al., 2005), but is also known to cause significant weight gain as a side-effect. In the Phase 2 Efficacy group, it is natural to compare clozapine against the rest of the potential treatments, both because the randomization probabilities called for having 50% of patients in that group on clozapine, and because clozapine is substantively different from the other three drugs: it is known to be highly effective at controlling symptoms, but it is also known to have significant side-effects and its safe administration requires very close patient monitoring. In Phase 1, it is natural to compare perphenazine, the only typical antipsychotic, against the other four drugs which are atypical antipsychotics. (Typical-versus-atypical was an important comparison in CATIE.)
For our first outcome, which we denote P, we use the Positive and Negative Syndrome Scale (PANSS) which is a numerical representation of the level of psychotic symptoms experienced by a patient (Kay et al., 1987). A higher value of PANSS indicates more severe symptoms. PANSS is a well-established measure that we have used in previous work (Shortreed et al., 2011). Since having larger PANSS is worse, we use 100 minus the percentile of a patient’s PANSS at the end of their time in the study. We use the distribution of PANSS at the beginning of the study as the reference distribution for the percentile.
For our second outcome, which we denote B, we use Body Mass Index (BMI), a measure of obesity. Weight gain is a clinically important side-effect of many antipsychotic drugs (Allison et al., 1999). Because in this population having a larger BMI is worse, we use 100 minus the percentile of a patient’s BMI at the end of their time in the study. Again, we use the distribution of BMI at the beginning of the study as the reference distribution.
We transformed both outcomes into percentiles to match Lizotte et al. (2012); we also include an analysis using the raw BMI and PANSS scores in Web Appendix C. Regression diagnostics for both analyses as well as baseline distributions are given in Web Appendix D.
In all of our models, we include two baseline covariates. The first, TD, is an indicator of “tardive dyskinesia,” a motor side-effect that can be caused by previous treatment. The second, EXACER, an indicator that the patient has been recently hospitalized, thus indicating an exacerbation of his or her condition. These do not interact with treatment in our models.
For our covariates h2 that interact with treatment, we choose the patients most recently recorded PANSS score percentile in our model for PANSS, and the most recently recorded BMI percentile in our model for BMI. These percentiles were shifted by −50 so that a patient at the median has h2 = 0. This was done so that in each model, the coefficient for the main effect of treatment can be directly interpreted as the treatment effect for a patient with median PANSS (resp. BMI). Treatments were coded −1, 1. For both outcomes we chose 5 percentile points as our indifference range, that so ΔP = ΔB = 5.
4.0.1 Phase 2 Tolerability
Web Appendix D gives the models estimated from the Phase 2 tolerability data. In summary, olanzapine appears to be beneficial if one considers the PANSS (P) outcome, but detrimental if one considers the BMI (B) outcome. This is evident in the center panel of Figure 2, where we see that the predictions of (r2P, r2B) for all of the patient histories in our dataset fall in the lower-right region of the plot, where both treatments are recommended because they conflict with each other according to the two outcomes.
Figure 2.
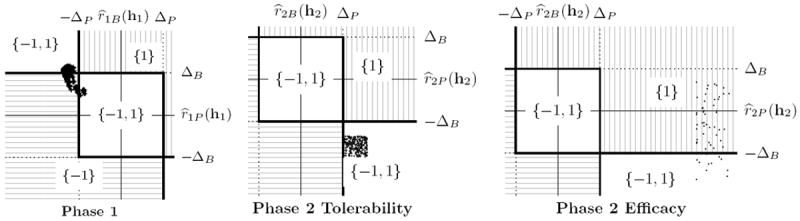
Left: Diagram showing how the output of π̂1Δ(h1) depends on ΔP (clinically significant difference in PANSS) and ΔB (clinically significant difference in BMI), and on the joint treatment effect, at Phase 1. The cloud of points shows the possible joint treatment effects that can be realized by a single patient with history (panss = −25.5, bmi = −15.6) if the patient follows some feasible decision rule at Phase 2. That is, each point is associated with a different choice of Phase 2 decision rule. Note that for some future decision rules, the point lies in the {−1, 1} region, and for others it lies in the {−1} region; taking the union we have π̂1Δ(h1) = {−1, 1} for this patient. Center: Diagram showing how the output of π̂2Δ(h2) depends on ΔP and ΔB, and on the location of the point (r̂2P(h2), r̂2B(h2)) for all patients in the Phase 2 Tolerability group. Each plotted point shows the estimated joint treatment effect for a different patient in the dataset. Since Phase 2 is the last phase, there are no future decision rules to consider and each history is associated with a unique joint treatment effect. Right: Analogous plot for the Phase 2 Efficacy group.
4.0.2 Phase 2 Efficacy
Web Appendix D gives the models estimated from the Phase 2 efficacy data. Clozapine appears to be beneficial if one considers the PANSS (P) outcome. Furthermore, there is weak evidence that clozapine is detrimental if one considers the BMI (B) outcome. This is evident in the rightmost panel of Figure 2, where the predictions of (r2P, r2B) for all of the patient histories are to the right of r̂2P = ΔP, indicating that clozapine is predicted to be the better choice for all patients when considering only the PANSS outcome. Furthermore, for most subjects, clozapine is not significantly worse than the other (aggregate) treatment according to BMI; thus, for most of the histories only clozapine (i.e., {1}) would be recommended. However, we found that for patients with a BMI covariate greater than about 24 (i.e., those among the top best 25 percent according to BMI), clozapine is predicted to perform clinically significantly worse according to the BMI outcome, and both treatments (i.e., {−1, 1}) would be recommended for these patients.
4.0.3 Phase 1
Recall that given any history h1 at Phase 1, our predicted values (r̂1P, r̂1B) for that history depend not only on the history itself but on the future decision rule that will be followed subsequently. For illustrative purposes, Web Appendix D gives a particular model estimated from the Phase 1 data assuming a particular feasible decision rule for Phase 2 chosen from the 61, 659 feasible Phase 2 decision rules enumerated by our algorithm. (The estimated coefficients would be different had we used a different Phase 2 decision rule.) For this particular future decision rule, perphenazine performs somewhat worse according to PANSS than the atypical antipsychotics, and somewhat better according to BMI.
Whereas for the Phase 2 analyses we showed plots of different (r̂2P, r̂2B) for different histories, for Phase 1, we will show different (r̂1P, r̂1B) for a fixed history at Phase 1 as we vary the Phase 2 decision rule. Recall that our treatment recommendation for Phase 1 is the union over all feasible future decision rules of the treatments recommended for each future decision rule. The leftmost panel in Figure 2 shows the possible values of (r̂1P, r̂1B); for some future decision rules only treatment −1 is recommended, but for others the set {−1, 1} is recommended. Taking the union, we recommend the set {−1, 1} for this history at Phase 1. Figure 3 shows, for a fixed first stage history h1, a plot of Q̂1B(h1, a1, τ2) against Q̂1P (h1, a1, τ2) across all τ2 ∈ F̃(π̂2Δ) for a single subject in the CATIE data. Note, that while there are 61,659 polices in F̃(π̂2Δ) many of these yield similar predicted values for Q̂1B(h1, a1, τ2) and Q̂1P(h1, a1, τ2). This display suggests that a patient presenting with H1 = h1, choosing perphenazine (PERP) is associated with better expected outcomes on BMI but worse on PANSS under feasible second stage rules.
5. Discussion
We proposed set-valued dynamic treatment regimes as a method for adapting treatment recommendations to the evolving health status of a patient in the presence of competing outcomes. Our proposed methodology deals with the reality that there is typically no universally best treatment for chronic illnesses like depression or schizophrenia by identifying when a trade-off between efficacy and side-effects must be made. Although computation of the set-valued dynamic treatment regimes requires solving a difficult enumeration problem, we offered an efficient algorithm that uses existing linear mixed integer programming software.
Our proposed methodology avoids the construction of composite outcomes, a process which may be undesirable: constructing a composite outcome requires combining outcomes that are on different scales, the ‘optimal trade-off’ between two (or more) outcomes is likely to be patient-specific, evolving over time, and the assumption that a linear trade-off is sufficient to describe all possible patient preferences may be unrealistic.
There are a number of directions in which this work can be extended. Web Appendix A provides an extension to the case with two decision points but an arbitrary number of treatment choices available at each stage. Interestingly, our enumeration problem is closely related to transductive learning, a classification problem setting where only a subset of the available training data is labeled, and the task is to predict labels at the unlabeled points in the training data. By finding a minimum-norm solution for ψ2 subject to our constraints, we could produce the transductive labeling that induces the maximum margin linear separator. Our algorithm would then correspond to a linear separable transductive support vector machine (SVM) (Cortes and Vapnik, 1995). This observation leads to a possible criterion for evaluating feasible decision rules: we hypothesize that the greater the induced margin, the more “attractive” the decision rule, because large-margin decision rules avoid giving very similar patients different treatments. If the number of feasible future decision rules becomes impractically large, we may wish to keep only the most “separable” ones when computing the union at the first stage. We are currently pursuing this line of research.
Supplementary Material
Acknowledgments
The authors acknowledge invaluable comments and criticisms from the Editor, Associate Editor, and two anonymous referees. Eric Laber acknowledges support from NIH grant P01 CA142538. Data used in the preparation of this article were obtained from the limited access datasets distributed from the NIH-supported “Clinical Antipsychotic Trials of Intervention Effectiveness in Schizophrenia” (CATIE-Sz). The study was supported by NIMH Contract #N01MH90001 to the University of North Carolina at Chapel Hill. The ClinicalTrials.gov identifier is NCT00014001. This manuscript reflects the views of the authors and may not reflect the opinions or views of the CATIE-Sz Study Investigators or the NIH.
Footnotes
Supplementary Materials
Web Appendix A, referenced in Sections 1, 3, and 5, Web Appendix B, referenced in Section 3, Web Appendix C, referenced in Section 4, Web Appendix D, referenced in Section 4, and computer code implementing the SVDTR algorithm described in Section 3.1, are available with this paper at the Biometrics website on Wiley Online Library.
References
- Allison DB, Mentore JL, Heo M, Chandler LP, Cappelleri JC, Infante MC, Weiden PJ. Antipsychotic-induced weight gain: A comprehensive research synthesis. American Journal of Psychiatry. 1999 Nov;156:1686–1696. doi: 10.1176/ajp.156.11.1686. [DOI] [PubMed] [Google Scholar]
- Bellman R. Dynamic Programming. Princeton University Press; 1957. [Google Scholar]
- Blatt D, Murphy SA, Zhu J. Technical Report 04-63. The Methodology Center, Penn. State University; 2004. A-learning for approximate planning. [Google Scholar]
- Breier A, Berg PH, Thakore JH, Naber D, Gattaz WF, Cavazzoni P, Walker DJ, Roychowdhury SM, Kane JM. Olanzapine versus ziprasidone: Results of a 28-week double-blind study in patients with schizophrenia. American Journal of Psychiatry. 2005;162:1879–1887. doi: 10.1176/appi.ajp.162.10.1879. [DOI] [PubMed] [Google Scholar]
- Cortes C, Vapnik V. Support-vector networks. Machine Learning. 1995;20:273–297. [Google Scholar]
- Friedman LM, Furberg CD, DeMets DL. Fundamentals of clinical trials. Springer; 2010. [Google Scholar]
- Henderson R, Ansell P, Alshibani D. Regret-regression for optimal dynamic treatment regimes. Biometrics. 2010;66:1192–1201. doi: 10.1111/j.1541-0420.2009.01368.x. [DOI] [PubMed] [Google Scholar]
- Kay SR, Fiszbein A, Opler LA. The Positive and Negative Syndrome Scale (PANSS) for schizophrenia. Schizophrenia Bulletin. 1987;13(2):261–276. doi: 10.1093/schbul/13.2.261. [DOI] [PubMed] [Google Scholar]
- Kinter ET. Identifying Treatment Preferences of Patients with Schizophrenia in Germany: An Application of Patient-centered Care. ProQuest; 2009. [Google Scholar]
- Laber EB, Lizotte DJ, Qian M, Murphy SA. Statistical inference in dynamic treatment regimes. Pre-print, arXiv:1006.5831v1. 2011 [Google Scholar]
- Lizotte DJ, Bowling M, Murphy S. Linear fitted-Q iteration with multiple reward functions. Journal of Machine Learning Research. 2012 Accepted. [PMC free article] [PubMed] [Google Scholar]
- Megiddo N. On the complexity of linear programming. Advances in economic theory. 1987:225–268. [Google Scholar]
- Moodie EEM, Richardson TS, Stephens DA. Demystifying optimal dynamic treatment regimes. Biometrics. 2007;63(2):447–455. doi: 10.1111/j.1541-0420.2006.00686.x. [DOI] [PubMed] [Google Scholar]
- Murphy SA. Optimal dynamic treatment regimes (with discussion) Journal of the Royal Statistical Society: Series B. 2003;58:331–366. [Google Scholar]
- Nahum-Shani I, Qian M, Almirall D, Pelham WE, Gnagy B, Fabiano G, Waxmonsky J, Yu J, Murphy SA. Q-learning: A data analysis method for constructing adaptive interventions. Technical Report. 2010 doi: 10.1037/a0029373. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nahum-Shani I, Qian M, Almirall D, Pelham WE, Gnagy B, Fabiano G, Waxmonsky J, Yu J, Murphy SA. Experimental design and primary data analysis methods for comparing adaptive interventions. To appear, Psychological Methods. 2012 doi: 10.1037/a0029372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Orellana L, Rotnitzky A, Robins J. Dynamic regime marginal structural mean models for estimation of optimal dynamic treatment regimes, part i: Main content. Int Jrn of Biostatistics. 2010;6(2) [PubMed] [Google Scholar]
- Robins J. Optimal structural nested models for optimal sequential decisions. Proceedings of the second seattle Symposium in Biostatistics; Springer; 2004. pp. 189–326. [Google Scholar]
- Schulte P, Tsiatis A, Laber E, Davidian M. Q-and a-learning methods for estimating optimal dynamic treatment regimes. Statistical Science. 2012 doi: 10.1214/13-STS450. In Press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shortreed S, Laber EB, Lizotte DJ, Stroup TS, Pineau J, Murphy SA. Informing sequential clinical decision-making through reinforcement learning: an empirical study. Machine Learning. 2011;84(1–2):109–136. doi: 10.1007/s10994-010-5229-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Song R, Wang W, Zeng D, Kosorok MR. Penalized q-learning for dynamic treatment regimes. Pre-Print, arXiv:1108.5338v1. 2012 [Google Scholar]
- Strauss GP, Robinson BM, Waltz JA, Frank MJ, Kasanova Z, Herbener ES, Gold JM. Patients with schizophrenia demonstrate inconsistent preference judgments for affective and nonaffective stimuli. Schizophrenia bulletin. 2011;37(6):1295–1304. doi: 10.1093/schbul/sbq047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strecher VJ, Shiffman S, West R. Moderators and mediators of a web-based computer-tailored smoking cessation program among nicotine patch users. Nicotine & tobacco research. 2006;8(S. 1):S95. doi: 10.1080/14622200601039444. [DOI] [PubMed] [Google Scholar]
- Stroup TS, McEvoy JP, Swartz MS, Byerly MJ, Glick ID, Canive JM, McGee MF, Simpson GM, Stevens MC, Lieberman JA. The National Institute of Mental Health Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) project: Schizophrenia trial design and protocol development. Schizophrenia Bulletin. 2003;29(1):15–31. doi: 10.1093/oxfordjournals.schbul.a006986. [DOI] [PubMed] [Google Scholar]
- Watkins CJCH, Dayan P. Q-learning. Machine Learning. 1992;8:279–292. [Google Scholar]
- Zhang B, Tsiatis A, Laber E, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012 doi: 10.1111/j.1541-0420.2012.01763.x. To appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y, Zeng D, Rush JA, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. 2012 doi: 10.1080/01621459.2012.695674. Submitted. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.