

Abstract
In this paper, we consider the Minimum Reaction Insertion (MRI) problem for finding the minimum number of additional reactions from a reference metabolic network to a host metabolic network so that a target compound becomes producible in the revised host metabolic network in a Boolean model. Although a similar problem for larger networks is solvable in a flux balance analysis (FBA)-based model, the solution of the FBA-based model tends to include more reactions than that of the Boolean model. However, solving MRI using the Boolean model is computationally more expensive than using the FBA-based model since the Boolean model needs more integer variables. Therefore, in this study, to solve MRI for larger networks in the Boolean model, we have developed an efficient Integer Programming formalization method in which the number of integer variables is reduced by the notion of feedback vertex set and minimal valid assignment. As a result of computer experiments conducted using the data of metabolic networks of E. coli and reference networks downloaded from the Kyoto Encyclopedia of Genes and Genomes (KEGG) database, we have found that the developed method can appropriately solve MRI in the Boolean model and is applicable to large scale-networks for which an exhaustive search does not work. We have also compared the developed method with the existing connectivity-based methods and FBA-based methods, and show the difference between the solutions of our method and the existing methods. A theoretical analysis of MRI is also conducted, and the NP-completeness of MRI is proved in the Boolean model. Our developed software is available at “http://sunflower.kuicr.kyoto-u.ac.jp/~rogi/minRect/minRect.html.”
Introduction
Metabolism is one of the most important biological processes in organisms. Relations between reactions and chemicals in the metabolism are often represented by metabolic networks [1]. Since many of these metabolic processes can produce commodity and specialty chemicals, the manipulation of metabolisms has been extensively studied in the field of metabolic engineering. One of the most successful applications of metabolic engineering is production of industrially valuable products using a microbial host with recombinant technologies [2]–[4]. Techniques for production of desired chemicals using a microbial host are roughly classified into the following three types [5]: (a)combinations of existing pathways, (b)engineering of existing pathways, and (c) de novo pathway design. In (a), partial pathways can be recruited from independent organisms and co-localized in a single host. For example, 1,3-propanediol is synthesized by Nakamura et al. in which pathways from Saccharomyces cerevisiae and Klebsiella pneumonia were assembled in E. coli [6] and another example is the production of artemisinic acid, a precursor to the plant-based anti-malarial drug artemisinin in yeast [7]. In (b), new non-natural chemicals can be produced by engineering existing routes [8], [9]. (c) is realized by the combination of (a) and (b), that is, the recruitment of partial pathways from different species and the use of engineered enzymes for extensions of pathways. It is to be noted that (a) focuses on the topology of the given metabolic networks, while (b) and (c) utilize the information of the structures of chemicals as well.
The “pathway prediction system” (PPS) of the University of Minnesota Biocatalysis and Biodegradation Database (UM-BBD) is designed to predict routes for the biodegradation of xenobiotic compounds [10]–[12]. From a set of previously defined biotransformation rules, the PPS guides the user through potential pathways one step at a time, requiring the selection of a new target metabolite at each step [5]. Biochemical Network Integrated Computational Explorer (BNICE) is a computational framework for generating every possible biochemical reaction from a given set of enzyme reaction rules and source or target compounds [13], [14]. However, since the number of predicted novel pathways is huge in many cases, some prioritization is necessary to choose the most promiscuous ones [15]. For example, one measure of such prioritization is to minimize the number of enzymatic steps [16].
In the type (a) problem, it seems that there are three major models for judging the producibility of target compounds, that is, connectivity model, flow model, and Boolean model. For each of them, Minimum Reaction Insertion (MRI) problem can be defined for finding the minimum number of additional reactions from a reference metabolic network to a host metabolic network so that a target compound becomes producible in the revised host metabolic network. In the connectivity model such as [16], the producibility of target compounds is judged by the connectivity between the source and the target compounds. After the source and the target compounds are connected by the additional reactions, the producibility is often evaluated by such a flow model as flux balance analysis (FBA) or an elementary mode [17], in which the sum of incoming flows must be equal to the sum of outgoing flows for each compound and the ratio of the amount of substrates and products must satisfy the coefficients given in each chemical reaction formula. In the Boolean model, each reaction occurs if all its substrates are producible whereas each compound is producible if one of its producing reactions occurs [18]. The source compounds are called seeds and the producible compounds are called the scope of the seed. In this model, a Boolean function of “AND” is attached to each reaction node and “OR” is attached to each compound node in the metabolic networks.
For example, suppose that there is a chemical reaction “A+B→C+D”, where A and B are called substrates whereas C and D are called products. In the connectivity model, either A or B is necessary to produce C and D, whereas both A and B are necessary for the Boolean model. In the flow model including FBA, in addition to the condition that both A and B must exist, both C and D are necessary to be consumed by other reactions. Thus, each model outputs a different solution for producing desired compounds.
From the view point of computational complexity, although the connectivity model is very simple and then applicable even to very large networks, its logical analysis ability is not strong since it cannot detect the lack of necessary substrates. The good point of the flow model is its computational efficiency since problems in the flow model can often be formalized by linear programming, for which there exist polynomial time algorithms [19]. However, these polynomial time algorithms are not applicable for MRI since discrete variables are necessary for representing additional reactions, although it is solvable by mixed integer programming [20].
Although the computational time of the FBA-based method for MRI is very small and scalable for genome-scale metabolic reconstruction [20], Boolean methods also have attractive features and are expected to complement the FBA-based method. Indeed, for the analysis of metabolic networks, many studies have been conducted to develop Boolean models. For example, Lemke et al. [21] studied the effect of deletion of each enzyme in the metabolic network of a Boolean model, and Smart et al. [22] considered almost the same problem from the viewpoint of the Boolean aspect of the flux balance model. Li et al. [23] and Sridhar et al. [24] have developed methods for finding a set of enzymes whose inhibition stops the production of the target compounds with a minimum elimination of the non-target compounds. Lee et al. [25] and Takemoto et al. [26] estimated the distribution of the size of the effect of the deletions of enzymes using a branching process.
As for the shortcoming of the FBA-based method for MRI, it tends to be considerably affected by the redundancy of the given metabolic network since each node is affected not only by the incoming flows but also by the outgoing flows. For example, suppose that a metabolic network of Fig. 1 (A) is given, where circles and rectangles represent compounds and reactions respectively. In order to produce the target compound from the source compounds, {R1, R2, R3, R4} is necessary in the flow model including FBA, whereas either {R1, R4} or {R1, R2, R3} is sufficient for the Boolean model. Moreover, in the metabolic network of Fig. 1 (B), {R1,R2,R3} is necessary for FBA whereas {R2} is sufficient for the Boolean model.
Figure 1. A problem of how to produce a target compound from the source nodes.

In the Boolean model, either {R1, R4} or {R1, R2, R3} is sufficient, whereas {R1, R2, R3, R4, R5} is necessary for the flow model including FBA.
Therefore, in this research, we study the problem of designing a pathway for producing target compounds in metabolic networks of the Boolean model since its logical analysis ability is more stable than that of the FBA, particularly when the flexible parts of the metabolic networks are large. Our approach is based on (a), that is, the combination of existing pathways. In our problem setting, a base metabolic network of a host organism, which we call the host network, is given; it cannot produce the target compound in its initial form. However, an integrated metabolic network of many other organisms are given as the reference network from which we should find the minimum number of additional reactions so that the target compound becomes producible. We prove that this problem is NP-complete.
Although both the FBA-based model and the Boolean model for MRI are considered to be NP-complete, the former is likely to have a faster exponential time algorithm than the latter since FBA has fewer integer variables. Although the computational complexity of the Boolean model is large, we develop an efficient method based on integer programming (IP) [27], [28], which is often used as a formalization of NP-complete problems and there is an efficient free solver for IP called CPLEX [29]. We also conducted four computer experiments in which the metabolic network of E. coli is used as the host network and the reference pathway of the KEGG database [30] is used as the reference network, and propanol, butanol, sedoheptulose 7-phosphate, and maleic acid are used as the target compound in each experiment. The results of the experiments show that (1) our IP-based method can appropriately solve MRI in the Boolean model; (2) solutions of MRI in the Boolean model are more suitable than those by connectivity based methods; (3) our IP-based method is applicable to large-scale networks where an exhaustive search does not work; and (4) solutions of MRI in the Boolean model tend to be smaller than those in the FBA-based model based on [31]. Our developed software is available at “http://sunflower.kuicr.kyoto-u.ac.jp/~rogi/minRect/minRect.html”.
Materials and Methods
Problem Definition
In this section, the main problem Minimum Reaction Insertion (MRI) in a Boolean model is first explained with an example and then mathematical formalization is described.
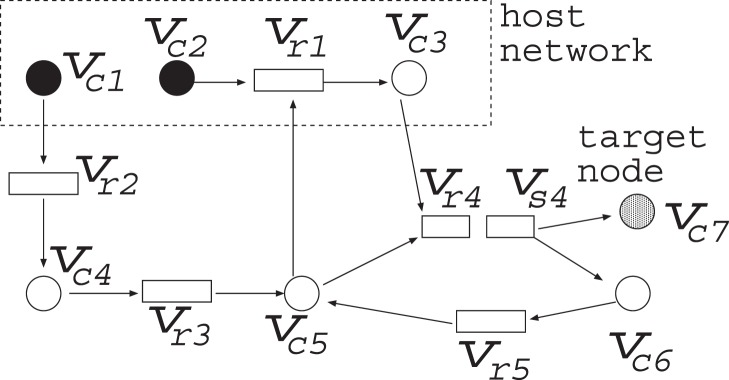
Suppose that a metabolic network shown in Fig. 2 is given, where each rectangle (resp., circle) corresponds to a reaction (resp., chemical compound). For example, 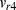 is a reaction, its substrates are
is a reaction, its substrates are 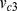 and
and 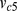 and its products are
and its products are 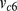 and
and 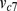 . Black circles
. Black circles 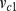 and
and 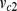 denote the source nodes and are assumed to be provided by the external environment. On the other hand, a gray circle
denote the source nodes and are assumed to be provided by the external environment. On the other hand, a gray circle 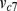 represents a target compound and the purpose of MRI is to make the target compound producible. However, initially only the host network, which is shown by the dotted rectangle, is available. Since only
represents a target compound and the purpose of MRI is to make the target compound producible. However, initially only the host network, which is shown by the dotted rectangle, is available. Since only 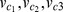 and
and 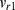 are included in the host network, the target compound
are included in the host network, the target compound 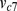 is not producible. Instead the entire network is called the reference network and reactions not included in the host network can be added later. In MRI, the minimum number of additional reactions should be determined to make the target compound producible. In this example, the addition of
is not producible. Instead the entire network is called the reference network and reactions not included in the host network can be added later. In MRI, the minimum number of additional reactions should be determined to make the target compound producible. In this example, the addition of 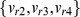 is the optimal solution. The difficult point of MRI is how to deal with the effect of cycles. In the example of Fig. 2, the addition of
is the optimal solution. The difficult point of MRI is how to deal with the effect of cycles. In the example of Fig. 2, the addition of 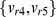 looks like the optimal solution. However, this solution is not appropriate since it relies on the cycle consisting of
looks like the optimal solution. However, this solution is not appropriate since it relies on the cycle consisting of 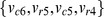 and
and 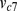 is not producible unless the initial amount of
is not producible unless the initial amount of 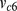 is sufficiently large.
is sufficiently large.
Figure 2. An example of MRI.
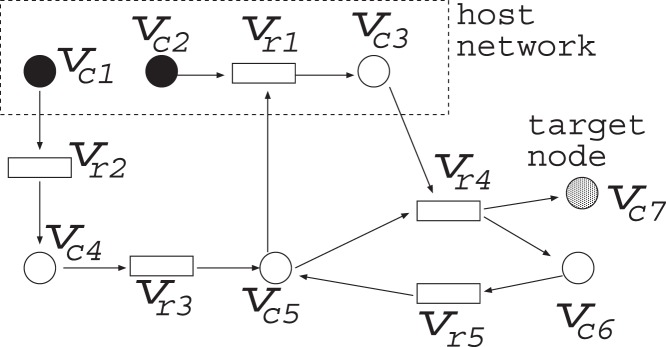
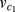 and
and 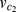 are the source nodes.
are the source nodes.
MRI is mathematically defined as follows: A metabolic network can be represented by a directed graph  . There are two types of node sets
. There are two types of node sets 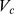 and
and 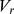 , where
, where 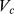 denotes a set of compound nodes and
denotes a set of compound nodes and 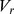 represents a set of reaction nodes.
represents a set of reaction nodes. 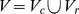 and
and 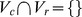 hold. The neighbors of compound nodes must be reaction nodes, and the neighbors of reaction nodes must be compound nodes. Let
hold. The neighbors of compound nodes must be reaction nodes, and the neighbors of reaction nodes must be compound nodes. Let 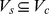 be a set of source nodes and
be a set of source nodes and 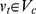 be a target node. Source nodes have no incoming edges and correspond to the seed compounds of [18]. In this study, we assume that source nodes are producible at any time.
be a target node. Source nodes have no incoming edges and correspond to the seed compounds of [18]. In this study, we assume that source nodes are producible at any time.
Suppose that a host network
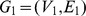 and a reference network
and a reference network
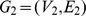 are given where
are given where 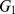 and
and 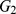 are metabolic networks, and
are metabolic networks, and 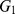 is a subgraph of
is a subgraph of 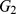 induced by
induced by 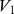 .
. 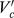 (resp.,
(resp., 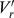 ) is a set of compound nodes (resp., reaction nodes) in
) is a set of compound nodes (resp., reaction nodes) in  and is called the set of additional compound nodes (resp., additional reaction nodes).
and is called the set of additional compound nodes (resp., additional reaction nodes).
Let 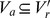 be a set of additional reaction nodes. In the Boolean model, each node is assigned either “0” or “1”. For a compound node, “1” means producible and “0” means not producible. As for a reaction node, “1” means active and “0” means inactive. Let
be a set of additional reaction nodes. In the Boolean model, each node is assigned either “0” or “1”. For a compound node, “1” means producible and “0” means not producible. As for a reaction node, “1” means active and “0” means inactive. Let 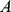 be such an assignment (that is
be such an assignment (that is  is a function from
is a function from 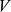 to
to 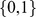 ). For each node
). For each node 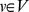 , we write
, we write 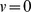 (resp.,
(resp., 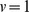 ) if
) if  (resp.,
(resp.,  ) is assigned to
) is assigned to  .
. 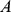 is called a valid assignment if the following conditions are satisfied: (i) for each
is called a valid assignment if the following conditions are satisfied: (i) for each 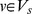 ,
, 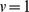 . (ii) for each
. (ii) for each 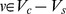 ,
, 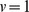 if and only if there is
if and only if there is  such that
such that 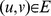 and
and 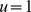 . (iii) for each
. (iii) for each 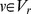 ,
, 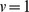 if and only if
if and only if 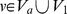 and
and 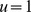 holds for all
holds for all  such that
such that 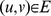 . This implies that each reaction node corresponds to an “AND” node and each compound node corresponds to an “OR” node.
. This implies that each reaction node corresponds to an “AND” node and each compound node corresponds to an “OR” node.
If 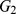 has no directed cycles, a valid assignment is uniquely determined for each
has no directed cycles, a valid assignment is uniquely determined for each 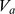 . However, if
. However, if 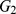 has a directed cycle, multiple valid assignments may exist. Let us call
has a directed cycle, multiple valid assignments may exist. Let us call 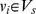 and
and 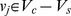 source connected if there is a directed path from
source connected if there is a directed path from 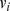 to
to 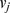 , and the values of the nodes included in the path are all 1. There exist valid assignments where the values of nodes in a directed cycle are 1 even if these nodes are not source connected. In order to avoid such a case, we use the notion of minimal valid assignment, which is similar to the notion of maximal valid assignment defined in [32]. A valid assignment
, and the values of the nodes included in the path are all 1. There exist valid assignments where the values of nodes in a directed cycle are 1 even if these nodes are not source connected. In order to avoid such a case, we use the notion of minimal valid assignment, which is similar to the notion of maximal valid assignment defined in [32]. A valid assignment 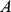 is called minimal if
is called minimal if 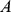 is valid and
is valid and 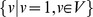 is minimal with respect to the inclusion relationships for sets.
is minimal with respect to the inclusion relationships for sets.
Now we define the Minimum Reaction Insertion as follows:
Input: A host metabolic network
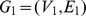 , a reference metabolic network
, a reference metabolic network 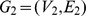 , and a target compound
, and a target compound 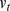 .
.Output: A minimum cardinality set of
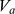 for which
for which 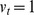 is satisfied in the minimal valid assignment of the induced subgraph of
is satisfied in the minimal valid assignment of the induced subgraph of 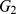 by
by 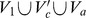 .
.
As mentioned in the section of Theoretical Results, a minimal valid assignment is uniquely determined if 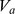 is given. However, solving MRI is not easy since the number of candidate
is given. However, solving MRI is not easy since the number of candidate 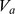 is
is 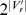 and MRI is proved to be NP-complete. Since utilizing software packages of Integer Programming (IP) is efficient for solving NP-complete problems, we develop a method of IP formalization for solving MRI. Since the computational time of the IP-based method is considered to be exponential in terms of the number of variables, it is important to develop an IP formalization of MRI with a small number of variables. To do so, our previously developed method for Minimum Reaction Cut (MRC) [32] may be useful although many modifications are necessary.
and MRI is proved to be NP-complete. Since utilizing software packages of Integer Programming (IP) is efficient for solving NP-complete problems, we develop a method of IP formalization for solving MRI. Since the computational time of the IP-based method is considered to be exponential in terms of the number of variables, it is important to develop an IP formalization of MRI with a small number of variables. To do so, our previously developed method for Minimum Reaction Cut (MRC) [32] may be useful although many modifications are necessary.
MRC is a problem to find a minimum set of reactions that interfere with the production of target compounds [32] and is known to be NP-complete. Let  (resp.,
(resp.,  ) be the number of compound (resp., reaction) nodes. If we use
) be the number of compound (resp., reaction) nodes. If we use 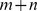 time steps to calculate the maximal valid assignment in MRC, the number of variables in IP is
time steps to calculate the maximal valid assignment in MRC, the number of variables in IP is 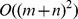 . The feedback vertex set (FVS) is a node set whose removal makes a network cycle-free. In [32], we succeeded in reducing the number of variables to
. The feedback vertex set (FVS) is a node set whose removal makes a network cycle-free. In [32], we succeeded in reducing the number of variables to 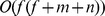 , where
, where 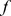 is the size of the feedback vertex set and
is the size of the feedback vertex set and 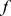 is considerably smaller than
is considerably smaller than  or
or  . If use of
. If use of 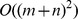 variables is allowed in MRI, almost the same method as in MRC can be used. However, to reduce the number of variables in IP to
variables is allowed in MRI, almost the same method as in MRC can be used. However, to reduce the number of variables in IP to 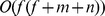 , many modifications are necessary since minimal valid assignment and maximal valid assignment have different features.
, many modifications are necessary since minimal valid assignment and maximal valid assignment have different features.
Integer Programming-Based Method for Minimum Reaction Insertion
Here, we show IP formalization methods for MRI in the Boolean model. To apply IP, problems must be formalized to maximize or minimize a given objective function which is a linear function of integer variables and constraints must also be given as linear equations or inequations of integer variables.
Suppose that the host network and the reference network are given as shown in Fig. 2. The simplest IP formalization IP-MRI-A for solving Minimum Reaction Insertion is as follows where the time step increases by 1 when the Boolean calculation is synchronously conducted for every node:
IP-MRI-A
Minimize
| (1) |
Subject to
| (2) |
for all

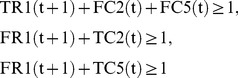 |
(3) |
| (4) |
| (5) |
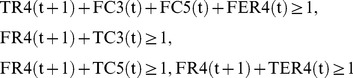 |
(6) |
| (7) |
| (8) |
| (9) |
| (10) |
| (11) |
| (12) |
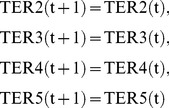 |
(13) |
| (14) |
| (15) |
| (16) |
| (17) |
where every variable takes either 0 or 1. 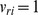 (resp.,
(resp., 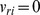 ) at time step
) at time step  is represented by TR
is represented by TR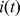 = 1 (resp. FR
= 1 (resp. FR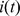 = 1) and TR
= 1) and TR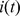 +FR
+FR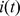 = 1 holds for any
= 1 holds for any  and
and  . For example, TR
. For example, TR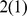 = 0 means that
= 0 means that 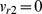 at time step 1, and FR
at time step 1, and FR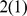 = 1 automatically holds at the same time. In the implementation, FR
= 1 automatically holds at the same time. In the implementation, FR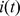 is replaced with 1-TR
is replaced with 1-TR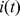 to reduce the number of variables. Similarly, the values of compound nodes are represented by TC
to reduce the number of variables. Similarly, the values of compound nodes are represented by TC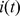 and FC
and FC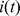 . For example, FC
. For example, FC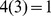 means that
means that 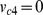 at time step 3.
at time step 3.
(3) represents the Boolean relation 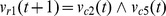 . Since Boolean relations such as “
. Since Boolean relations such as “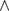 ” or “
” or “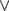 ” cannot directly be used in IP, it is necessary to convert them into linear equations and/or inequations. Since
” cannot directly be used in IP, it is necessary to convert them into linear equations and/or inequations. Since 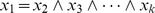 can be represented by
can be represented by 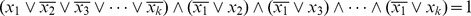 ,
, 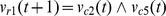 can be converted into
can be converted into 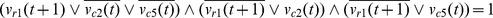 , and then (3) is obtained.
, and then (3) is obtained.
For a compound node with indegree 1, the value of the predecessor node is just copied. For example, since 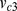 has only one predecessor
has only one predecessor 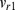 ,
, 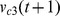 is just copied from
is just copied from 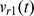 as shown in (8). Similarly,
as shown in (8). Similarly, 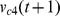 is just copied from
is just copied from 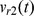 as shown in (9).
as shown in (9).
For a compound node with indegree more than 1, it is necessary to convert the “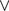 ” relation into linear equations or equations. (10) represents the Boolean relation
” relation into linear equations or equations. (10) represents the Boolean relation 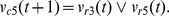 Since
Since 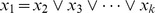 is represented by
is represented by 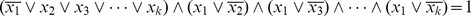 ,
, 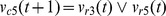 can be converted into
can be converted into 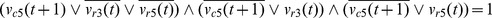 , and then (10) is obtained.
, and then (10) is obtained.
As for the reaction nodes not included in the host network, TER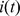 and FER
and FER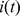 are used to represent whether
are used to represent whether 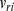 is activated. We use a virtual node
is activated. We use a virtual node 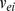 as one of the predecessors of
as one of the predecessors of 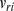 . Since
. Since 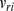 is represented by an AND node,
is represented by an AND node, 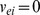 keeps
keeps 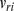 inactive even if all other predecessors of
inactive even if all other predecessors of 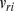 are 1. For example,
are 1. For example, 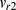 in Fig. 2 has only one predecessor
in Fig. 2 has only one predecessor 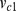 . However, since
. However, since 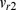 is not included in the host network and
is not included in the host network and 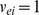 is necessary for
is necessary for 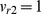 ,
, 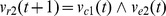 must hold, and then (4) is obtained.
must hold, and then (4) is obtained.
Since we assume minimal valid assignment, at 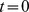 , the source compound nodes are assigned 1, but the other compound nodes and reaction nodes are assigned 0.
, the source compound nodes are assigned 1, but the other compound nodes and reaction nodes are assigned 0.
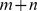 is the largest number of time steps necessary for the 0–1 assignment to converge. (1) means that the number of additional reactions should be minimized. (2) means that the target compound
is the largest number of time steps necessary for the 0–1 assignment to converge. (1) means that the number of additional reactions should be minimized. (2) means that the target compound 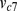 should become 1 after the 0–1 assignment converges. (3)–(7) represent the constraints by
should become 1 after the 0–1 assignment converges. (3)–(7) represent the constraints by 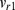 to
to 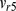 respectively. Note that
respectively. Note that 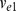 does not exist since
does not exist since 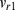 is included in the host network and then
is included in the host network and then 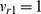 holds for any
holds for any 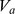 . (8)–(12) represent the constraints by
. (8)–(12) represent the constraints by 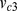 to
to 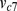 respectively. (13) represents that
respectively. (13) represents that 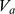 does not change by time transition. (14) means that
does not change by time transition. (14) means that 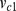 and
and 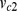 are source nodes. (15)–(16) represent that all nodes but source nodes are assigned 0 in the initial state. (17) means that “T” and “F” represent “true (1)” and “false (0)” respectively, and complement each other.
are source nodes. (15)–(16) represent that all nodes but source nodes are assigned 0 in the initial state. (17) means that “T” and “F” represent “true (1)” and “false (0)” respectively, and complement each other.
The above formalization can clearly solve MRI and obtain the correct solution 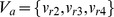 , however
, however 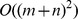 variables are necessary. To reduce the number of variables, it is necessary to reduce the number of time steps. If time is not taken into account at all, the following inappropriate IP formalization IP-MRI-B is obtained.
variables are necessary. To reduce the number of variables, it is necessary to reduce the number of time steps. If time is not taken into account at all, the following inappropriate IP formalization IP-MRI-B is obtained.
IP-MRI-B
Minimize
| (18) |
Subject to
| (19) |
 |
(20) |
| (21) |
| (22) |
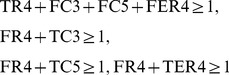 |
(23) |
| (24) |
| (25) |
| (26) |
| (27) |
| (28) |
| (29) |
| (30) |
| (31) |
When compared to IP-MRI-A, (18),(19),(20)–(24), (25)–(29), (30), and (31) correspond to (1),(2),(3)–(7), (8)–(12), (14), and (17) respectively although the notion of time is not used in IP-MRI-B. (13) in IP-MRI-A means that the value of 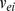 does not change in the time transition, but this constraint is not necessary for IP-MRI-B since it does not have the notion of time. Moreover, neither (15) nor (16) of IP-MRI-A is used in IP-MRI-B.
does not change in the time transition, but this constraint is not necessary for IP-MRI-B since it does not have the notion of time. Moreover, neither (15) nor (16) of IP-MRI-A is used in IP-MRI-B.
In IP-MRI-B, the solution of IP is 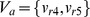 since
since 
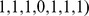 is a valid assignment and satisfies
is a valid assignment and satisfies 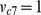 . Note that
. Note that 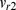 and
and 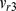 are forced to be 0 since they are not included in either the host network or
are forced to be 0 since they are not included in either the host network or 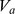 . Although it satisfies all constraints and
. Although it satisfies all constraints and 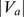 is minimum, this assignment is not appropriate since
is minimum, this assignment is not appropriate since 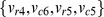 forms a cycle and all of them are assigned 1 without the influence of source nodes. To avoid such an inappropriate assignment, it is necessary to consider minimal valid assignment with respect to the number of 1 s for each
forms a cycle and all of them are assigned 1 without the influence of source nodes. To avoid such an inappropriate assignment, it is necessary to consider minimal valid assignment with respect to the number of 1 s for each 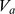 . As shown in the section of Theoretical Results, the minimal valid assignment is uniquely determined for each
. As shown in the section of Theoretical Results, the minimal valid assignment is uniquely determined for each 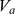 .
.
Thus, IP-MRI-A can solve MRI, but 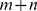 time steps are necessary, while IP-MRI-B, which does not use the notion of time, cannot solve MRI. The feedback vertex set (FVS) is a set of nodes whose removal makes the network acyclic. Since IP-MRI-B can solve MRI if there is no cycle, it is reasonable to apply IP-MRI-B for the acyclic network obtained by the deletion of FVS and use the notion of time as in IP-MRI-A to nodes included in
time steps are necessary, while IP-MRI-B, which does not use the notion of time, cannot solve MRI. The feedback vertex set (FVS) is a set of nodes whose removal makes the network acyclic. Since IP-MRI-B can solve MRI if there is no cycle, it is reasonable to apply IP-MRI-B for the acyclic network obtained by the deletion of FVS and use the notion of time as in IP-MRI-A to nodes included in  based on the idea developed in [32].
based on the idea developed in [32].
In the improved method, IP-MRI-C, we firstly find an FVS  consisting of reaction nodes and then decompose each
consisting of reaction nodes and then decompose each  into two nodes
into two nodes 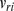 and
and 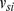 so that
so that 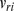 has only in-edges and
has only in-edges and 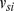 has only out-edges. For example, in the network of Fig. 2, since
has only out-edges. For example, in the network of Fig. 2, since 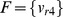 is a feedback vertex set,
is a feedback vertex set, 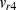 is decomposed into
is decomposed into 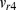 and
and 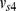 as shown in Fig. 3. Furthermore, we put an additional constraint that
as shown in Fig. 3. Furthermore, we put an additional constraint that 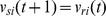 . The number of time steps of IP-MRI-C is
. The number of time steps of IP-MRI-C is 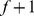 while that of IP-MRI-A is
while that of IP-MRI-A is 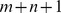 , where
, where 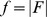 . Therefore, the numbers of variables in IP-MRI-C and IP-MRI-A are
. Therefore, the numbers of variables in IP-MRI-C and IP-MRI-A are 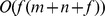 and
and 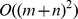 respectively. Since
respectively. Since 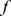 is considerably smaller than
is considerably smaller than 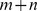 in most metabolic networks and the computational time of IP exponentially increases with the number of variables, we can expect a significant improvement from the view point of the computational time.
in most metabolic networks and the computational time of IP exponentially increases with the number of variables, we can expect a significant improvement from the view point of the computational time.
Figure 3. The cycles are decomposed in the FVS-based method.
Although finding the minimum FVS is known to be NP-complete, it is not necessary to use the minimum FVS in our problem setting. We use a simple greedy algorithm to choose FVS as follows:
Procedure
 , where
, where  and
and 
for
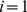 to
to  do
do
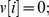
for
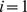 to
to  do
do
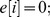
while there exists
 such that
such that 
if there exists
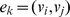 such that
such that 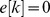 and
and 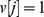 then
then
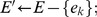
for all
 do
do
else if there exists
 such that
such that  and
and  do
do
else if there exists
 such that
such that  do
do
 for the minimum
for the minimum 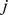 ;
;return
 ;
;
Since the reaction nodes for FVS are chosen by a greedy algorithm, the size of FVS is not always optimal. However, it is important to note that even if the size of FVS is not optimal, the solution of MRI calculated by IP-MRI-C is always optimal. If there are multiple optimal solutions in MRI, there is a possibility that the solutions are different since IP outputs only one solution. However, it may be possible to enumerate all optimal solutions of MRI by iteratively solving IP with a constraint to avoid the already chosen solutions.
For example, IP-MRI-C for Fig. 2 is as follows, where  is decomposed into
is decomposed into  and
and 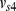 , and time step increases by 1 only when the value of
, and time step increases by 1 only when the value of 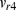 is copied to
is copied to 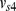 .
.
IP-MRI-C
Minimize
| (32) |
Subject to
| (33) |
for all
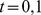
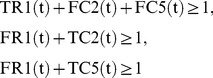 |
(34) |
| (35) |
| (36) |
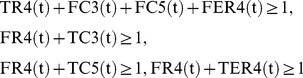 |
(37) |
| (38) |
| (39) |
| (40) |
| (41) |
| (42) |
| (43) |
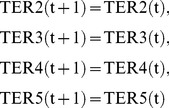 |
(44) |
| (45) |
| (46) |
| (47) |
| (48) |
| (49) |
where each variable takes either 0 or 1.
When compared to IP-MRI-A, (32),(33),(34)–(38), (39)–(43), (44), (46), and (49) correspond to (1),(2),(3)–(7), (8)–(12), (13), (14), and (17), respectively. 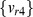 is chosen as a feedback vertex set, and then decomposed into
is chosen as a feedback vertex set, and then decomposed into 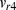 and
and 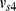 as shown in Fig. 3.
as shown in Fig. 3.
Note that the number of time steps is 2 = 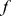 +1, and TSR4
+1, and TSR4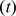 = 1 represents
= 1 represents 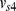 = 1. In (42)–(43), the constraints for
= 1. In (42)–(43), the constraints for 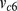 and
and 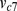 are represented by the variable corresponding to
are represented by the variable corresponding to 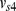 instead of that to
instead of that to 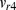 . (45) represents that the time step increases by 1 when the value of
. (45) represents that the time step increases by 1 when the value of 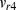 is copied to
is copied to 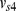 in Fig. 3. (48) represents
in Fig. 3. (48) represents 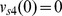 to obtain the minimal valid assignment.
to obtain the minimal valid assignment.
Additionally, if we use the FVS-based method and no cycles are included in 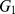 and
and 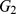 , the number of necessary time steps is only one. For example, suppose that
, the number of necessary time steps is only one. For example, suppose that 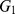 and
and 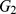 are as shown in Fig. 4 (A). In this case, the correct solution of MRI is
are as shown in Fig. 4 (A). In this case, the correct solution of MRI is 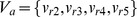 . However, if we set TC1(0) = 1 and TC6(0) = 0, IP can output no solution since the condition TC6(0) = 1 is never satisfied. On the other hand, if we set TC1(0) = 1 and TC6(0) = 1, an inappropriate solution
. However, if we set TC1(0) = 1 and TC6(0) = 0, IP can output no solution since the condition TC6(0) = 1 is never satisfied. On the other hand, if we set TC1(0) = 1 and TC6(0) = 1, an inappropriate solution 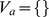 is obtained by IP. To avoid such a case, in our method, if one of the predecessors of an additional reaction node
is obtained by IP. To avoid such a case, in our method, if one of the predecessors of an additional reaction node 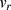 is included in the host network, we decompose
is included in the host network, we decompose 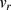 as if it were included in FVS. For example, in the network of Fig. 4 (A),
as if it were included in FVS. For example, in the network of Fig. 4 (A), 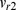 is decomposed into
is decomposed into 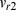 and
and 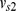 as shown in Fig. 4 (B) so that the values of the source nodes and the target node are calculated in different time steps.
as shown in Fig. 4 (B) so that the values of the source nodes and the target node are calculated in different time steps.
Figure 4. A special case where there is no cycle.

(A) An example where a contradiction occurs if the notion of time is not used. (B) Decomposition of a border node to avoid the contradiction.
Results
Computer Experiments
We conducted computer experiments for solving MRI with data downloaded from the KEGG database. The experiment was conducted on a PC with an Intel(R) Xeon(R) 3.33 GHz CPU and 10 GB RAM having the SUSE Linux (version 12.2) operating system, where CPLEX (version 12.4.0.0) was used as the solver of integer programming.
In this study, a reference network consists of the central metabolism and the related modules necessary for producing the target compound. A map of the KEGG PATHWAY is a minimum unit, and three or four maps of the KEGG PATHWAY are chosen and integrated as the reference network in each of our experiments. As for species, a reference network includes the chemical reactions of all species, whereas the metabolic networks of E. coli are used for the host networks. The major difference between the pathway alignment methods by KEGG and our developed method is that our method is based on a Boolean model, whereas the pathway alignment methods consider only the topology of networks.
In synthetic biology, it is of great interest to construct a minimal genome that realizes the desired functions [33]–[35]. Since glycolysis, gluconeogenesis, citrate cycle and pentose phosphate pathway are considered to be essential even in artificial organisms, it is reasonable to assume that the host networks in the computer experiments have some of these pathways in one of the simplest organisms, E. coli. Because the purpose of this study is not focused on the reconstruction of genome-scale metabolic network model, but the design of a minimal genome in addition to the existing pathways to produce a desired compound, each reference network consists of the maps of the KEGG pathway located between the central metabolism and each target compound.
In the first computer experiment, the target compound is propanol (C00479 in KEGG ID), the host network is glycolysis and gluconeogenesis of E. coli (eco00010.xml), and the reference network covers glycolysis, gluconeogenesis and glycerolipid metabolism of other species (ko00010.xml and ko00561.xml). The numbers of compound and reaction nodes are 58 and 85, respectively, where 30 reactions are reversible. The source nodes are D-glucose (C00031), oxaloacetate (C00036), salicin (C01451), arbutin (C06186), UDP-glucose (C00029), acyl-CoA (C00040), and diglucosyl-diacylglycerol (C06040), which are represented by black circles in Fig. 5. It took 0.19 s to solve MRI. The obtained additional reactions are 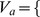 R01514, R01752, R01036, R01048, R02577, R02376
R01514, R01752, R01036, R01048, R02577, R02376 , where these reactions produce propanol from 3-phospho-D-glycerate (C00197) via glycerol (C00116) as shown in Fig. 5. Since 3-phospho-D-glycerate (C00197) is producible by glycolysis and gluconeogenesis of E. coli and works as a connection between glycolysis and glycerolipid metabolism, the obtained
, where these reactions produce propanol from 3-phospho-D-glycerate (C00197) via glycerol (C00116) as shown in Fig. 5. Since 3-phospho-D-glycerate (C00197) is producible by glycolysis and gluconeogenesis of E. coli and works as a connection between glycolysis and glycerolipid metabolism, the obtained 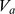 can be considered an appropriate solution of MRI.
can be considered an appropriate solution of MRI.
Figure 5. Propanol (C00479) becomes producible from glycolysis and gluconeogenesis by the addition of Va = {R01514, R01752, R01036, R01048, R02577, R02376}.

Difference between Developed Model and Shortest Path-Based Model
To show the difference between the developed model and the shortest path-based models, we conducted the second experiment where PathComp of KEGG (“http://www.genome.jp/tools/pathcomp/”) was used to calculate the solution of the shortest path-based model. In the experiment, the host network consists of glycolysis, gluconeogenesis and citrate cycle of E. coli (eco00010.xml and eco00020.xml), and the reference network consists of glycolysis, gluconeogenesis, citrate cycle and pentose phosphate pathway of other species (ko00010.xml, ko00020.xml and ko00030.xml). The numbers of compound and reaction nodes are 64 and 108, respectively, where 59 reactions are reversible. There are four source nodes, D-glucose(C00031), arbutin(C06186), salicin(C01451), and acetate (C00033), and the number of candidates for the additional reactions is 66. When the target compound is sedoheptulose 7-phosphate (C05382), as shown in Fig. 6, the solution of MRI is 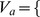 R01827, R01830
R01827, R01830 , where the substrates of R01827 are beta-D-fructose 6-phosphate (C05345) and D-erythrose 4-phosphate (C00279). It took 32.58 s to obtain the solution. Since D-erythrose 4-phosphate (C00279) is not included in the host network, it is necessary to add R01830 in which substrates are beta-D-fructose 6-phosphate (C05345) and D-glyceraldehyde 3-phosphate (C00118) and the products are D-xylulose 5-phosphate (C00231) and D-erythrose 4-phosphate (C00279). It is to be noted that both beta-D-fructose 6-phosphate (C05345) and D-glyceraldehyde 3-phosphate (C00118) are producible by the host network.
, where the substrates of R01827 are beta-D-fructose 6-phosphate (C05345) and D-erythrose 4-phosphate (C00279). It took 32.58 s to obtain the solution. Since D-erythrose 4-phosphate (C00279) is not included in the host network, it is necessary to add R01830 in which substrates are beta-D-fructose 6-phosphate (C05345) and D-glyceraldehyde 3-phosphate (C00118) and the products are D-xylulose 5-phosphate (C00231) and D-erythrose 4-phosphate (C00279). It is to be noted that both beta-D-fructose 6-phosphate (C05345) and D-glyceraldehyde 3-phosphate (C00118) are producible by the host network.
Figure 6. When the target compound was C05382, MRI selected R01827 and R01830 from 66 candidates for the additional reactions whereas the shortest path-based method (PathComp) selected only R01827.

On the other hand, PathComp just connects the producible compounds and the target compound adds only R01827 since R01827 is adjacent to both beta-D-fructose 6-phosphate (C05345) and sedoheptulose 7-phosphate (C05382). However, it is clear that R01827 does not occur if D-erythrose 4-phosphate (C00279) does not exist. Thus the difference between the shortest path-based method and the developed method is that the developed method considers Boolean constraints for each reaction and compound whereas the shortest path-based method only considers the connectivity of nodes.
Scalability
Next, we conducted the third experiment to show the scalability of our method. The host network consists of the source nodes of glycolysis and gluconeogenesis of E. coli (eco00010.xml), that is, D-glucose(C00031), arbutin(C06186), salicin(C01451), oxaloacetate(C00036) and acetate (C00033). The reference network consists of glycolysis, gluconeogenesis, citrate cycle, pentose phosphate pathway and butanol metabolism of other species (ko00010.xml, ko00020.xml, ko00030.xml and ko00650.xml), where R01172 is treated as a reversible reaction. The target compound is butanol (C06142). The numbers of compound and reaction nodes are 93 and 150, respectively, where 87 reactions are reversible. It took 919.79 s (15m19s) for the developed method to solve MRI and the solution was 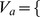 R00235, R00238, R01977, R03027, R01171, R01172, R03545
R00235, R00238, R01977, R03027, R01171, R01172, R03545 . These seven reactions form a path from acetate to 1-butanol via acetyl-CoA, acetoacetyl-CoA, crotonoyl-CoA and butanoyl-CoA, which satisfies the Boolean constraints. Since the number of reactions in the reference network is 150, it is necessary to examine
. These seven reactions form a path from acetate to 1-butanol via acetyl-CoA, acetoacetyl-CoA, crotonoyl-CoA and butanoyl-CoA, which satisfies the Boolean constraints. Since the number of reactions in the reference network is 150, it is necessary to examine 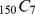 cases if an exhaustive search is conducted. Since examining
cases if an exhaustive search is conducted. Since examining 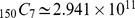 cases is almost impossible, it is seen that the IP-based method is useful for solving MRI, particularly when the given networks are not small.
cases is almost impossible, it is seen that the IP-based method is useful for solving MRI, particularly when the given networks are not small.
Difference between Developed Model and FBA-Based Model
Finally, we conducted an experiment to show the difference between the developed model and the FBA-based model. We assume that the reference network consists of glycolysis, gluconeogenesis, citrate cycle, pentose phosphate pathway and butanol metabolism of other species (ko00010.xml, ko00020.xml, ko00030.xml and ko00650.xml), and the host network includes only one reaction R04394 between salicin (C01451) and salicin 6-phosphate (C06188) as shown in Fig. 7. Therefore, the source node is only salicin (C01451). Note that reversible reactions are decomposed into two reactions, and denoted by P and Q. The target compound is maleic acid (C01384). The numbers of compound and reaction nodes are 93 and 150, respectively, where 87 reactions are reversible.
Figure 7. The comparison between the Boolean model and the FBA-based model [20].

More reactions are necessary for the FBA-based model to produce the target compound than the Boolean-based model.
Then, the solution of MRI in our Boolean model is {R05134, R02736, R02035, R02036, R05605, R00344, R00342, R01082, R01087}, whereas the solution of FBA-based model is {R05134, R02736, R02035, R02036, R05605, R01058, R01518, R00658, R00200, R00344, R00342, R01082, R01087}. It is to be noted that {R01058, R01518, R00658, R00200} is not necessary for the Boolean model, but necessary for the FBA-based model. In the Boolean model, R01058 is not necessary to produce C01384 since the lack of reactions in downstream does not affect. However, in the FBA model, R01058 is necessary. Otherwise, C00118 is not consumed and then R05605 (denoted as Q05605 in Fig. 7) cannot occur. Thus, the solution of MRI in the FBA-based model tends to include more reactions than that in the Boolean model. It took 7896.46 s (2h11m36s) to solve the Boolean model of MRI.
Theoretical Results
Although solving IP is NP-complete, a problem that can be formalized as IP is not always NP-complete. Therefore, in the following paragraphs, we prove that MRI is NP-complete and show the appropriateness of formalizing MRI of the Boolean model as IP.
Theorem 1: Minimum Reaction Insertion is NP-complete even when the maximum indegree and outdegree are bounded by 2.
Proof: Since the problem is clearly in NP, it suffices to show NP-hardness. The proof is by a polynomial time reduction from minimum vertex cover (MVC), which is a problem for a given graph to find the minimum number of nodes so that each edge is incident to at least one of the selected nodes. For example, for the graph shown in Fig. 8(A) , 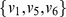 is an optimal solution of MVC.
is an optimal solution of MVC.
Figure 8. The polynomial time reduction from minimum vertex cover (MVC) problem to minimum reaction insertion (MRI) problem.

(A) An instance of MVC. (B) The corresponding instance of MRI.
Let 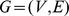 be an instance of MVC, where
be an instance of MVC, where 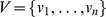 and
and 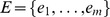 . We construct the corresponding MRI as follows. The host network
. We construct the corresponding MRI as follows. The host network 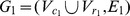 is given by
is given by
The reference network 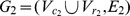 is given by
is given by
For example, MVC for the graph shown in Fig. 8 (A) is converted into MRI shown in Fig. 8 (B). It is clear that this conversion can be done in polynomial time.
In the following paragraphs, we show that MVC for 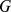 has a solution of size
has a solution of size  if and only if MRI has a solution in which
if and only if MRI has a solution in which 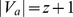 holds. When
holds. When 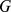 has a vertex cover of size
has a vertex cover of size  ,
, 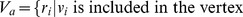
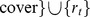 satisfies
satisfies 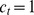 in the minimal valid assignment and
in the minimal valid assignment and 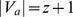 holds. On the other hand, suppose that
holds. On the other hand, suppose that 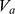 satisfies
satisfies 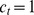 in the minimal valid assignment and
in the minimal valid assignment and 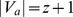 . Since
. Since 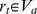 is necessary for
is necessary for 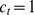 ,
,  nodes are included in
nodes are included in 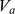 from
from  . Since each
. Since each 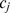 must be 1 to satisfy
must be 1 to satisfy 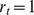 , at least one predecessor of each
, at least one predecessor of each 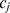 must be included in
must be included in 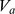 for each
for each 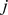 . Since there is an edge between
. Since there is an edge between 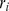 and
and 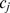 if and only if
if and only if 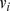 is incident to
is incident to 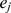 ,
, 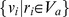 is a vertex cover of size
is a vertex cover of size  . Nodes whose degrees are more than 2 can be converted by the methods shown in Fig. 9.
. Nodes whose degrees are more than 2 can be converted by the methods shown in Fig. 9.
Figure 9. The conversion of nodes with the indegree and the outdegree more than 2.

Theorem 2: Given a host network, a reference network and a set of additional reactions, a minimal valid assignment is uniquely determined.
Proof: For any valid assignment 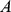 , the assignment obtained by assigning 0 to all nodes that are not source connected is also a valid assignment. On the other hand, for any valid assignment
, the assignment obtained by assigning 0 to all nodes that are not source connected is also a valid assignment. On the other hand, for any valid assignment 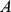 , the assignment obtained by assigning 0 to a source connected node is not a valid assignment. Since source connected nodes
, the assignment obtained by assigning 0 to a source connected node is not a valid assignment. Since source connected nodes 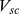 are uniquely determined for
are uniquely determined for 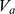 ,
, 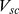 is a minimal valid assignment and uniquely determined.
is a minimal valid assignment and uniquely determined.
Discussion
In this paper, we formalized an optimization problem MRI in a Boolean model with a notion of minimal valid assignment. We proved that MRI in the Boolean model is NP-complete and the minimal valid assignment is uniquely determined when 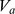 is given. Since an exhaustive search cannot be used to solve MRI when the given networks are not small, we developed an IP-based method for MRI. To improve the scalability of the developed method, it is necessary to reduce the number of variables appearing in IP formalization since the computational time of IP is considered to be exponential to the number of variables. Although the simple IP formalization with the notion of time is useful for solving MRI, it needs
is given. Since an exhaustive search cannot be used to solve MRI when the given networks are not small, we developed an IP-based method for MRI. To improve the scalability of the developed method, it is necessary to reduce the number of variables appearing in IP formalization since the computational time of IP is considered to be exponential to the number of variables. Although the simple IP formalization with the notion of time is useful for solving MRI, it needs 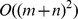 variables in IP formalization. If the notion of FVS is used, the number of necessary time steps reduces to
variables in IP formalization. If the notion of FVS is used, the number of necessary time steps reduces to 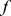 , where
, where 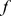 denotes the size of FVS, and the number of variables in IP is
denotes the size of FVS, and the number of variables in IP is 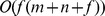 . Although the idea of using FVS is similar to [32], many modifications are necessary since the minimal valid assignment and the maximal valid assignment have many different properties.
. Although the idea of using FVS is similar to [32], many modifications are necessary since the minimal valid assignment and the maximal valid assignment have many different properties.
We also conducted four computer experiments in which data were downloaded from the KEGG database, CPLEX was used as the IP solver, and propanol, butanol, sedoheptulose 7-phosphate, and maleic acid were used as the target compound for each experiment. The host network was a metabolic network of E. coli and the reference network of KEGG was used as the reference network. The results of the computer experiments confirmed the correctness and the scalability of the developed method, and the appropriateness of the problem setting of MRI.
An important advantage of our Boolean model is its capability of detecting the lack of substrates, whereas the connectivity-based methods cannot appropriately handle this point. An extended type of connectivity-based method is BNICE, which enumerates all possible pathways from the source nodes to the target compound, and uses thermodynamical feasibility and pathway length to evaluate each candidate pathway. In contrast, the developed method evaluates each candidate pathway based on the number of additional reactions. Another advantage of the developed model is its capability of handling branches and/or cycles in a pathway from the source compounds to the target compound, whereas BNICE considers only the non-branching paths. However, since BNICE nicely evaluates each pathway by the thermodynamic free energy of the included compounds and length, considering the thermodynamic free energy in a Boolean model represents an important direction of our future work.
It is to be noted that the solution of MRI in the FBA-based model is different from that in the Boolean model. In particular, if the reference network includes a large redundant part, the FBA-based model tends to output a larger solution than the Boolean model, although the FBA-based model is very fast when compared to the Boolean model. Therefore, one of our future works is to develop a hybrid method combining the FBA-based method and the Boolean-based method. Petri-net-based methods [36] are also interesting since they may extract the good points of both Boolean-based methods and FBA-based methods.
Funding Statement
TT was partially supported by JSPS, Japan (Grant-in-Aid for Young Scientists (B)25730005 and Grant-in-Aid for Scientific Research (A) 25250028). JS is an Australian National Health and Medical Research Council (NHMRC) Peter Doherty Fellow and a recipient of the Hundred Talents Program of the Chinese Academy of Sciences (CAS). TA was partly supported by the Chinese Academy of Sciences Visiting Professorship for Senior International Scientists, China, and Grant-in-Aid #22240009 from JSPS, Japan. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Soh KC, Hatzimanikatis V (2010) Dreams of metabolism. Trends in Biotechnology 28(10): 501–508. [DOI] [PubMed] [Google Scholar]
- 2. Bro C, Regenberg B, Forster J, Nielsen J (2006) In silico aided metabolic engineering of saccharomyces cerevisiae for improved bioethanol production. Metabolic Engineering 8(2): 102–111. [DOI] [PubMed] [Google Scholar]
- 3. Lee SK, Chou H, Ham TS, Lee TS, Keasling JD (2008) Metabolic engineering of microorganisms for biofuels production: from bugs to synthetic biology to fuels. Current Opinion in Biotechnology 19(6): 556–563. [DOI] [PubMed] [Google Scholar]
- 4. Alper H, Jin YS, Moxley J, Stephanopoulos G (2005) Identifying gene targets for the metabolic engineering of lycopene biosynthesis in escherichia coli. Metabolic Engineering 7(3): 155–164. [DOI] [PubMed] [Google Scholar]
- 5. Prather K, Martin C (2008) De novo biosynthetic pathways: rational design of microbial chemical factories. Current Opinion in Biotechnology 19(5): 468–474. [DOI] [PubMed] [Google Scholar]
- 6. Nakamura CE, Whited GM (2003) Metabolic engineering for the microbial production of 1,3- propanediol. Current Opinion in Biotechnology 14(5): 454–459. [DOI] [PubMed] [Google Scholar]
- 7. Ro DK, Paradise EM, Ouellet M, Fisher KJ, Newman KL, et al. (2006) Production of the antimalarial drug precursor artemisinic acid in engineered yeast. Nature 440(7086): 940–943. [DOI] [PubMed] [Google Scholar]
- 8. de Boer AL, Schmidt-Dannert C (2003) Recent efforts in engineering microbial cells to produce new chemical compounds. Current Opinion in Chemical Biology 7(2): 273–278. [DOI] [PubMed] [Google Scholar]
- 9. Mijts BN, Schmidt-Dannert C (2003) Engineering of secondary metabolite pathways. Current Opinion in Biotechnology 14(6): 597–602. [DOI] [PubMed] [Google Scholar]
- 10.Ellis LBM, Roe D, Wackett LP (2006) The university of minnesota biocatalysis/biodegradation database: the first decade. Nucleic Acids Research (suppl 1): D517–D521. [DOI] [PMC free article] [PubMed]
- 11. Hou B, Ellis L, Wackett L (2004) Encoding microbial metabolic logic: predicting biodegradation. Journal of Industrial Microbiology and Biotechnology 31(6): 261–272. [DOI] [PubMed] [Google Scholar]
- 12. Hou BK, Wackett LP, Ellis LBM (2003) Microbial pathway prediction: A functional group approach. Journal of Chemical Information and Computer Sciences 43(3): 1051–1057. [DOI] [PubMed] [Google Scholar]
- 13. Hatzimanikatis V, Li C, Ionita JA, Henry CS, Jankowski MD, et al. (2005) Exploring the diversity of complex metabolic networks. Bioinformatics 21(8): 1603–1609. [DOI] [PubMed] [Google Scholar]
- 14. Gonzalez-Lergier J, Broadbelt LJ, Hatzimanikatis V (2005) Theoretical considerations and computational analysis of the complexity in polyketide synthesis pathways. Journal of the American Chemical Society 127(27): 9930–9938. [DOI] [PubMed] [Google Scholar]
- 15. Cho A, Yun H, Park J, Lee S, Park S (2010) Prediction of novel synthetic pathways for the production of desired chemicals. BMC Systems Biology 4(1): 35. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Noor E, Eden E, Milo R, Alon U (2010) Central carbon metabolism as a minimal biochemical walk between precursors for biomass and energy. Molecular Cell 39(5): 809–820. [DOI] [PubMed] [Google Scholar]
- 17. Haus UU, Klamt S, Stephen T (2008) Computing knock-out strategies in metabolic networks. Journal of Computational Biology 15(3): 259–268. [DOI] [PubMed] [Google Scholar]
- 18. Handorf T, Ebenhoh O, Heinrich R (2005) Expanding metabolic networks: Scopes of compounds, robustness, and evolution. Journal of Molecular Evolution 61(4): 498–512. [DOI] [PubMed] [Google Scholar]
- 19.Karmarkar N (1984) A new polynomial-time algorithm for linear programming. In: Proceedings of the sixteenth annual ACM symposium on Theory of computing. New York, NY, USA: ACM, STOC ’84, 302–311. doi:10.1145/800057.808695. Available: http://doi.acm.org/10.1145/800057.808695.
- 20. Henry CS, DeJongh M, Best AA, Frybarger PM, Linsay B, et al. (2010) High-throughput generation, optimization and analysis of genome-scale metabolic models. Nature Biotechnology 9: 977–982. [DOI] [PubMed] [Google Scholar]
- 21. Lemke N, Herédia F, Barcellos CK, Dos Reis AN, Mombach JC (2004) Essentiality and damage in metabolic networks. Bioinformatics 20(1): 115–119. [DOI] [PubMed] [Google Scholar]
- 22. Smart AG, Amaral LAN, Ottino JM (2008) Cascading failure and robustness in metabolic networks. Proceedings of the National Academy of Sciences 105(36): 13223–13228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Li Z, Wang RS, Zhang XS, Chen L (2009) Detecting drug targets with minimum side effects in metabolic networks. Systems Biology, IET 3(6): 523–533. [DOI] [PubMed] [Google Scholar]
- 24.Sridhar P, Song B, Kahveci T, Ranka S (2008) Mining metabolic networks for optimal drug targets. In: Pacific Symposium on Biocomputing. volume 13, 291–302. [PubMed]
- 25. Lee D, Goh KI, Kahng B (2012) Branching process approach for boolean bipartite networks of metabolic reactions. Physical Review E 86(2): 027101. [DOI] [PubMed] [Google Scholar]
- 26. Takemoto K, Tamura T, Akutsu T (2013) Theoretical estimation of metabolic network robustness against multiple reaction knockouts using branching process approximation. Physica A: Statistical Mechanics and its Applications 392(21): 5525–5535. [Google Scholar]
- 27.Schrijver A (1986) Theory of linear and integer programming. New York, NY, USA: John Wiley & Sons, Inc.
- 28. Li Z, Zhang S, Wang Y, Zhang XS, Chen L (2007) Alignment of molecular networks by integer quadratic programming. Bioinformatics 23(13): 1631–1639. [DOI] [PubMed] [Google Scholar]
- 29.IBM (2010) IBM ILOG CPLEX Optimizer. Available: http://www-01.ibm.com/software/integration/optimization/cplex-optimizer/.
- 30. Kanehisa M, Goto S (2000) Kegg: Kyoto encyclopedia of genes and genomes. Nucleic Acids Research 28(1): 27–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Suthers PF, Dasika MS, Kumar VS, Denisov G, Glass JI, et al. (2009) A genome-scale metabolic reconstruction of mycoplasma genitalium, ips189. PLoS Computational Biology 5(2). [DOI] [PMC free article] [PubMed]
- 32. Tamura T, Takemoto K, Akutsu T (2010) Finding minimum reaction cuts of metabolic networks under a boolean model using integer programming and feedback vertex sets. IJKDB 1(1): 14–31. [Google Scholar]
- 33.Lee JH, Sung BH, Kim MS, Blattner FR, Yoon BH, et al.. (2009) Metabolic engineering of a reduced-genome strain of escherichia coli for l-threonine production. Microb Cell Fact 8(2). [DOI] [PMC free article] [PubMed]
- 34. Ara K, Ozaki K, Nakamura K, Yamane K, Sekiguchi J, et al. (2007) Bacillus minimum genome factory: effective utilization of microbial genome information. Biotechnology and Applied Biochemistry 46(3): 169–178. [DOI] [PubMed] [Google Scholar]
- 35. Mizoguchi H, Mori H, Fujio T (2007) Escherichia coli minimum genome factory. Biotechnology and Applied Biochemistry 46(3): 157–167. [DOI] [PubMed] [Google Scholar]
- 36. Jin G, Zhao H, Zhou X, Wong STC (2011) An enhanced petri-net model to predict synergistic effects of pairwise drug combinations from gene microarray data. Bioinformatics 27(13): i310–i316. [DOI] [PMC free article] [PubMed] [Google Scholar]