

Abstract
Gastric cancer, as one of the leading causes of cancer related deaths worldwide, causes about 800,000 deaths per year. Up to now, the mechanism underlying this disease is still not totally uncovered. Identification of related genes of this disease is an important step which can help to understand the mechanism underlying this disease, thereby designing effective treatments. In this study, some novel gastric cancer related genes were discovered based on the knowledge of known gastric cancer related ones. These genes were searched by applying the shortest path algorithm in protein-protein interaction network. The analysis results suggest that some of them are indeed involved in the biological process of gastric cancer, which indicates that they are the actual gastric cancer related genes with high probability. It is hopeful that the findings in this study may help promote the study of this disease and the methods can provide new insights to study various diseases.
1. Introduction
Gastric carcinogenesis is a multistep process involving genetic and epigenetic alteration of protein-coding protooncogenes and tumor-suppressor genes. Gastric cancer (GC) is the fourth most commonly diagnosed cancer and is estimated to be the second most common cause of cancer related death and causes about 800,000 deaths worldwide per year [1, 2]. Because of the improvement of the dietary structure, the mortality rate shows a declining trend worldwide [3]. However, the incidences of gastric cancer are still remarkable in areas where infection by Helicobacter pylori is prevalent [4]. Besides H. pylori, smoking and alcohol consumption also increase the risk of developing gastric cancer significantly [5, 6]. Compared with women, men have a higher incidence, while estrogen may protect women against the gastric cancer [7].
In the previous cases, over 90% gastric cancers are adenocarcinomas, which could be divided into two major types in terms of the histopathology [8]. Intestinal type gastric cancer is often related to environmental factors such as H. pylori, while diffuse type gastric cancer is more often associated with genetic abnormalities. Caldas et al. reviewed that the diffuse type gastric cancer tended to occur in female and young individuals [9]. Besides adenocarcinomas, other types of gastric cancers like lymphomas occurred in a very low incidence [10]. Since the gastric cancer leads to high mortality, the early diagnose especially the molecular diagnose is particularly important for the therapy.
So far, numerous genes have been found involved in gastric tumorigenesis. Among the reported gastric cancer related genes, most of them could have also been found in other types of carcinomas. p53, famous for its tumor-suppressing role, has a mutated rate ranging from 0 to 21% in diffuse type GC and 36–43% in intestinal type GC [11]; E-cadherin, which plays a pivotal role in EMT (Epithelial Mesenchymal Transition), is predisposed to mutagenesis in sporadic diffuse type GC (33–50%) [12]; another star gene harboring high correlation with gastric cancer is RNUX3, which manifests to be a tumor-suppressor gene of GC [13]. Although dozens of genes have been found related to gastric cancer, they are insufficient to elucidate the tumorigenesis of GC unless more relevant genes being uncovered.
It is time-consuming to discover novel gastric cancer related genes by experiment alone, because the search space is very large. Computational approach is an alternative way which can help investigators screen out some related genes. On the other hand, lots of computational approaches have been developed to settle various biological problems, such as drug design [14–19] and analysis of complicated biological network [20–24]. In this study, a computational method was built to discover novel gastric cancer related genes based on some known related ones retrieved from Gastric Cancer Database, UniProtKB, and TSGene Database. After applying the shortest path algorithm in protein-protein interaction network to search the shortest path connecting any pair of known gastric cancer related genes, the candidate genes were found. Further analysis suggests that some of them are related to the formation and development of gastric cancer. We hope that this contribution may give help to uncover the mechanism of this disease, thereby designing effective treatments.
2. Materials and Methods
2.1. Materials
Gastric cancers related genes are collected from the following three datasets: (1) 102 genes are picked up from Gastric Cancer Database (http://www.gastric-cancer.site40.net/); (2) 128 reviewed gastric cancer related genes were found in the UniProtKB (Protein Knowledgebase, http://www.uniprot.org/uniprot/) by setting the keyword as human gastric cancer oncogene/suppressor gene, where 86 are oncogenes and 42 are suppressor genes; (3) 9 genes were obtained from TSGene Database (Tumor Suppressor Gene Database, http://bioinfo.mc.vanderbilt.edu/TSGene/) by searching the human gastric cancer in the Literature Search box. After combining these genes, we obtained 150 gastric cancer related genes, which were available in Supplementary Material I (available online at http://dx.doi.org/10.1155/2014/371397).
2.2. Protein-Protein Interaction (PPI) Network
It is known that interactions of proteins are important for the majority of biological functions. Many studies have shown that proteins in one interaction always share similar functions [25–29]. Since gastric cancers related genes may have some common features, it is feasible to discover novel gastric cancers related genes based on known related ones and PPI network. In this study, the PPI network was constructed based on the protein interaction information retrieved from STRING (Search Tool for the Retrieval of Interacting Genes/Proteins, http://string.embl.de/) (version 9.0) [30], a well-known database integrating known and predicted protein interactions. In the obtained file, each interaction consists of two protein IDs and a score measuring the likelihood of the interaction's occurrence. For later formulation, the score of the interaction between proteins p 1 and p 2 was denoted by I(p 1, p 2). To construct the weighted network, proteins in the STRING were taken as nodes and two nodes were adjacent if and only if the score of the interaction between the corresponding proteins was greater than zero. In addition, the score of the interaction was used to label the weight of the corresponding edge as follows:
| (1) |
where p i (i = 1,2) was the corresponding protein of node v i.
2.3. Shortest Path Genes
As described in Section 2.1, 150 gastric cancer related genes were collected, which must have some common features related to gastric cancer. On the other hand, according to Section 2.2, two proteins in one interaction, that is, they are adjacent in the constructed PPI network, always share common features. It can be further deduced that proteins in the shortest path connecting two known gastric cancer related genes may share some common features that the two known gastric cancer related genes have. Therefore, we searched the shortest path between any pair of known gastric cancer related genes by Dijkstra's algorithm, the most famous shortest path algorithm proposed by Dijkstra in 1956 [31].
After collecting the shortest paths connecting any pair of known gastric cancer related genes, we found that some nodes/genes occurred in many paths, while the majority of nodes/genes in PPI network were not in any path. To distinguish these nodes/genes, the betweenness of each node/gene was calculated, which is defined as the number of the shortest paths containing the node/gene as an inner node. Since the concept of betweenness accounts for direct and indirect influences of proteins at distant network [32], it has been employed in the study of various natural and man-made networks [33–38].
It is easy to see that genes with high betweenness may share more features related to gastric cancer than those with low betweenness, while the likelihood of gene with betweenness equal to 0 to be the novel gastric cancer related gene is zero. Accordingly, we picked out genes with betweenness greater than 0 and termed them as the shortest path genes. Since the main purpose of this study is to discover novel gastric cancer related genes, the known gastric cancer related genes were not included in the set of shortest path genes.
2.4. Further Filtering Based on Permutation Test
As described in Section 2.3, some of the shortest path genes can be obtained based on their betweenness. However, the betweenness of some nodes may be strongly influenced by the essential structure of the network. For example, the cut-vertex of the network may always receive high betweenness easier than other vertices. To control this false discovery, a permutation test was conducted to further filter these shortest path genes as follows.
-
(i)
Randomly select 1,000 gene sets G 1, G 2,…, G 1000 in PPI network with the same size of known gastric cancer related gene set.
-
(ii)
Calculate the betweenness of each shortest path gene on each gene set G i (1 ≤ i ≤ 1000).
-
(iii)The permutation FDR of the shortest path gene p was computed by
(2)
where δ i was defined to be 1 if the betweenness of p on G i was greater than that of p on the known gastric cancer related gene set.
It is obvious that smaller permutation FDR of one shortest path gene indicates that it is the actual gastric cancer related gene with high possibility.
2.5. Gene Set Enrichment Analysis
DAVID [39] is a functional annotation tool, which has been widely used to analyze gene lists derived from different biological problems [40–45]. Here, it was also employed for KEGG pathway and GO enrichment analysis of the obtained gene set. The enrichment P value was corrected to control family-wise false discovery rate under certain rate (e.g., ≤0.05) with Benjamin multiple testing correction method [46]. During the enrichment analysis, all genes in the human genome were considered. 13 items in the output of DAVID and their meanings are listed in Table 1. For detailed description, please see Huang et al.'s study [39].
Table 1.
Items in the output of DAVID and their meanings.
| Item | Meaning |
|---|---|
| Category | DAVID category, that is, KEGG or GO |
| Term | Gene set name |
| Count | The number of genes associated with this gene set |
| Percentage | Calculated by “gene associated with this gene set”/“total number of query genes” |
| P value | Modified Fisher Exact P value |
| Genes | The list of genes from your query set that are annotated to this gene set |
| List total | The number of genes in your query list mapped to any gene set in this ontology |
| Pop hits | The number of genes annotated to this gene set on the background list |
| Pop total | The number of genes on the background list mapped to any gene set in this ontology |
| Fold enrichment | The ratio of the proportions on query genes and the background information which are associated with the gene set |
| Bonferroni | Bonferroni adjusted P value |
| Benjamini | Benjamini adjusted P value |
| FDR | FDR adjusted P value |
3. Results and Discussion
3.1. Candidate Genes
Of the 150 known gastric cancer related genes, the shortest path connecting any pair of them was searched in PPI network constructed in Section 2.2. After counting the betweenness of each gene in PPI network, 466 shortest path genes with betweenness greater than zero were retrieved. These 466 genes and their betweenness can be found in Supplementary Material II. To exclude the false discovery, the permutation test was conducted. The permutation FDRs of 466 shortest path genes were calculated by (2) and also listed in Supplementary Material II. It can be observed that 144 genes were with permutation FDRs no more than 0.1. These genes were considered to have a strong relationship with gastric cancer.
3.2. Results of Gene Set Enrichment Analysis
DAVID, as a functional annotation tool, was employed to analyze the 144 shortest path genes. The analysis results included two categories: GO and KEGG. These results were available in Supplementary Materials III and IV, respectively. The detailed discussion based on these results was as follows.
From Supplementary Material III, 294 GO terms were enriched by the 144 genes. We investigated the first 10 GO terms in the list, which were shown in Figure 1. The “Count” items in the output of DAVID for these 10 GO terms were also shown in Figure 1. Among these 10 GO terms, 5 out of the 10 GO terms are cellular component (CC) GO terms including (1) GO:0005654: nucleoplasm (“count” = 30); (2) GO:0031981: nuclear lumen (“count” = 34); (3) GO:0043233: organelle lumen (“count” = 37); (4) GO:0031974: membrane-enclosed lumen (“count” = 37); (5) GO:0005829: cytosol (“count” = 30). As we know, tumorigenesis is a very complicated biological process which means the transform processes could take place everywhere in the cells [47]. In our analysis results, the related proteins distribute both in nuclear and cytosol which is in accordance with the characters of the gastric cancer. The remaining 5 GO terms are biological process (BP) GO terms: (1) GO:0032268: regulation of cellular protein metabolic process (“count” = 20); (2) GO:0009725: response to hormone stimulus (“count” = 17); (3) GO:0031399: regulation of protein modification process (“count” = 15); (4) GO:0009719: response to endogenous stimulus (“count” = 17); (5) GO:0010604: positive regulation of macromolecule metabolic process (“count” = 25). Liu et al. reported that the cancer cells usually harbor abnormal metabolic status [48]. In our results 80% (4/5) BP are relative to the metabolic stress response by means of direct regulation of the metabolic process or indirect regulation by altering the stimulus-related pathways. Besides, protein modification, which is also enriched in our results, plays an important role in the carcinogenesis by altering the pivotal proteins [49]. Although these genes may not be the indispensable factors in gastric cancer, the common points among them would give us the hints about the tumorigenesis of the gastric cancer.
Figure 1.
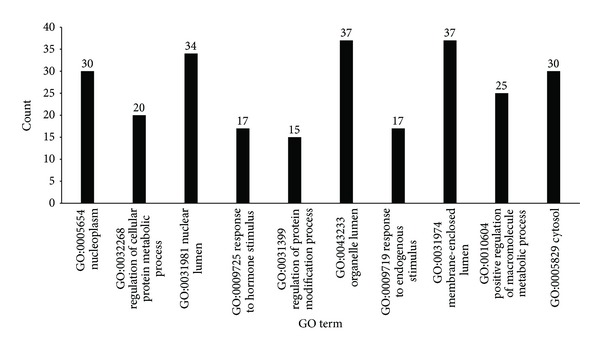
The top 10 GO terms enriched by 144 genes. The x-axis lists GO's ID and name, while the y-axis represents the number of genes that shared the GO term among the 144 genes.
From Supplementary Material IV, 8 KEGG pathways were enriched by 144 genes, which were shown in Figure 2. It can be observed that 6 out of 8 KEGG pathways were with P value less than 0.05, which were investigated as follows. The first pathway was hsa04110: cell cycle pathway (“count” = 10). 10 genes including PCNA, MYC, and CCND1 are enriched in this pathway. One of the significant characters of gastric cancer is the abnormal activated cell cycle [50]. Among these genes, PCNA is responsible for the DNA synthesis and CCND1 could alter cell cycle by regulating the CDK kinases [51, 52]. Other 2 pathways found in our study are related to the DNA repair which are also very critical for the carcinogenesis. Hsa03450: nonhomologous end joining (NHEJ) (“count” = 3) is a pathway that repairs double-strand breaks in DNA and base excision repair (BER) is a cellular mechanism that repairs damaged DNA throughout the cell cycle [53, 54]. Another intriguing pathway is hsa03040: spliceosome pathway (“count” = 7) which was always abnormal in cancer cells [55]. We speculate that the spliceosome could modify the expression of the oncogenes or tumor-suppress genes which eventually lead to the tumorigenesis. Finally, we also find the hsa05221: acute myeloid leukemia (AML) pathway (“count” = 7) and cancer related pathways in our list. The results imply that the gastric cancer has the common mechanism as well as other cancers especially the AML. Look has reviewed that RUNX1 is the key factor in the hematopoietic development and highly correlated with AML [56]. However, its homologous protein RUNX3 that shares 70% similarity has been reported playing pivotal role in gastric cancer [57]. The finding unravels that cancer normally has the common molecular mechanism as well as the specific pathway with type-dependent pattern. Although several reported pathways are included in our study, the novel pathways with gastric cancer would expand our views of mechanisms about the tumorigenesis of gastric cancer. On the other hand, we have observed that some genes in these pathways could play a very important role in the carcinogenesis of gastric cancer.
Figure 2.
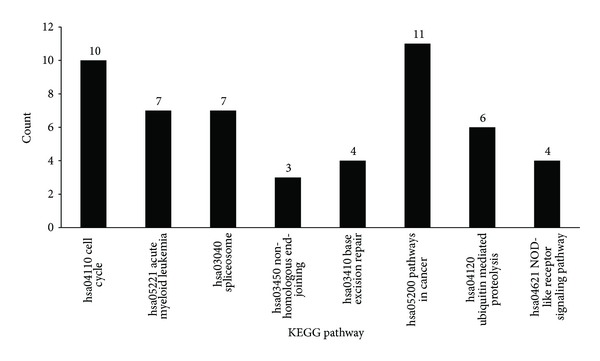
The 8 KEGG pathways enriched by 144 genes. The x-axis lists pathway's ID and name, while the y-axis represents the number of genes that shared the pathway among the 144 genes.
3.3. Analysis of the Relationship of Some Candidate Genes and Gastric Cancer
As described in Section 3.1, 144 genes were discovered by our method. Some of them may have strong relationship with gastric cancer and were discussed as follows. Table 2 listed these genes and their betweenness and permutation FDRs.
Table 2.
Important candidate shortest path genes and their betweenness and permutation FDRs.
| Ensemble ID of shortest path genes | Gene name | Betweenness | Permutation FDR |
|---|---|---|---|
| ENSP00000368438 | PCNA | 454 | 0.083 |
| ENSP00000227507 | CCND1 | 594 | 0.02 |
| ENSP00000367207 | MYC | 779 | 0.01 |
| ENSP00000306245 | FOS | 318 | 0.035 |
| ENSP00000300305 | RUNX1 | 224 | 0.002 |
| ENSP00000262887 | XRCC1 | 152 | 0.094 |
| ENSP00000352516 | DNMT1 | 169 | 0.093 |
| ENSP00000379110 | CXCL1 | 107 | 0.033 |
Proliferating Cell Nuclear Antigen (PCNA) (see row 2 of Table 2), also known as cyclin, is an auxiliary protein of DNA polymerase-δ that plays important roles both in DNA synthesis and DNA repair [51, 58]. PCNA could act as a homotrimer and helps increase the processivity of leading strand synthesis during DNA replication [59, 60]. In response to DNA damage, this protein is ubiquitinated and is involved in the RAD6-dependent DNA repair pathway [61, 62]. As we know, DNA repair is the main way to remove the carcinogenic lesions caused by UV or other common mutagens [63]. Pascucci et al. have reviewed that the NER (nucleotide excision repair) was highly correlated with skin cancer and intestinal cancer [64]. Intriguingly, numerous works have considered PCNA labeling rate as the prognostic indicator of gastric cancer because its expression was consistent with malignant potential of gastric cancer [65–67]. Ji et al. have found the abnormal increase of PCNAexpression in 58 gastric carcinoma tissues [68]. Similar conclusion was also achieved by Takamura et al. who have performed immunohistochemical study on 164 patients with gastric carcinomas [69]. Although the strong correlation is observed between PCNAand gastric cancer, the detailed mechanism of how PCNA promotes the gastric cancer needs further elucidation.
Besides PCNA, another protein in highly conserved cyclin family was also found in our study. CCND1 (see row 3 of Table 2), with official full name of cyclin D1, was firstly described by Motokura et al. in 1991 [70]. In the following decades, the importance of CCND1 in cell cycle and tumorigenesis was underlined by different labs. Because of the amplification of the 11q13 region where CCND1 locates, CCND1 is frequently overexpressed in human cancers accompanied with abnormalities that are driven by multiple mechanisms including genomic alternations, posttranscriptional regulation and posttranslational protein stabilization [71–73]. On one hand, cyclin D1 could increase CDK activity and consequently result in continuous proliferation which is necessary for tumorigenesis [74, 75]. On the other hand, cyclin D1 may induce the tumorigenesis in certain types of cancers by means of its nuclear receptor-agonistic activity in the CDK-independent way [52, 76].
MYC (see row 4 of Table 2) is a regulator gene that codes for a transcription factor, and it is frequently mutated in many cancers. In Myc-related cancers, Myc is constitutively expressed and leads to the abnormal expression of many genes which may be involved in cell proliferation, differentiation and apoptosis, and these uncontrolled biological processes finally underlie the cancer. Myc is believed to regulate expression of 15% of all genes [77]. Similar with CCND1, Myc expression could be regulated transcriptionally, posttranscriptionally, or posttranslationally [78]. Chung and Levens have reviewed that the deregulated expression of Myc is sufficient to lead to cellular transformation in vitro and tumorigenesis in vivo [79]. Besides the transforming role, Myc could also promote chromosomal instability by means of its function as a transcriptional regulator [80]. In the previous reports, Myc overexpression has been described in over 40% of gastric cancer [81]. Among nearly half the gastric cancer, copy number gains are frequently detected along chromosome 8 where Myc locates [82, 83]. As the key factor of tumorigenesis, Myc could provide potential target for therapy for gastric cancer [84].
FOS (see row 5 of Table 2), well known as c-fos, encodes a 62 kDa protein, which forms heterodimer with c-jun and subsequently results in the formation of AP-1 complex. FOS has been found to be overexpressed in a variety of cancers. Bakin and Curran have found that c-fos could change DNA methylation pattern by regulating DNMT1 and thereby cause the downregulation of tumor suppressor genes [85]. In addition, c-fos could lead to the loss of cell polarity and EMT which is critical for the metastatic and invasive growth of cancer cells [86]. Hu et al. also found that c-fos is required for the expression of matrix metalloproteinases that are indispensable for invasive growth of cancer cells [87]. However, some recent studies have unraveled the tumor suppressor activity of c-fos, including prohibition of the cell cycle progression, promotion of cell death, or repressing the anchorage-independent growth [88]. In coincidence with the negative role of c-fos in tumorigenesis, Jin et al. analyzed 625 consecutive gastric cancers; 388 cases (62.1%) showed loss of nuclear c-fos expression [89]. Consistent results were concluded by Zhou et al. in 58 patients with gastric cancer [90]. However, Mazurenko et al. reported that high level of c-fos expression was observed in stomach carcinomas [91]. The discordance may be caused by the different stages of progression in different studies. In conclusion, c-fos is a double-edged sword, which could promote or suppress tumorigenesis of gastric cancer.
RUNX1 (see row 6 of Table 2), better known as AML1, plays a critical role in hematopoietic development [92]. RUNX1 belongs to the RUNX family whose 3 members (RUNX1, RUNX2, and RUNX3) share 70% resemblance. Unlike its familial protein RUNX3 that is a strong candidate as a gastric cancer tumor suppressor. RUNX1 is always considered as a tumor suppressor for acute lymphoblastic leukemia (AML) [56]. Usui et al. have examined mRNA expression of all three RUNX genes in the gastric mucosa, and they found that RUNX1 was coexpressed with RUNX3 in pit cells [93]. Sakakura et al. observed remarkable downregulation of RUNX1 and RUNX3 in 9 gastric cancer cell lines and 56 primary gastric cancer specimens [94]. Although RUNX1 is famous for its involving in AML, more lines of evidence shed light to its anticarcinogenesis activity in other carcinoma including gastric cancer.
Other genes found in our study have also been reported relating with gastric cancer. Specific SNPs (Single Nucleotide Polymorphism) in XRCC1 (X-ray repair cross-complementing 1) (see row 7 of Table 2) are highly associated with gastric cancer [95]. DNMT1 (DNA methyltransferase 1) (see row 8 of Table 2), which is overexpressed in gastric cancer, is associated with increased risks of gastric atrophy with its abnormal polymorphisms [96]. The expression of CXCL1 (chemokine (C-X-C motif) ligand 1) (see row 9 of Table 2) is higher in gastric cancer tissues and endows the cancer cells with more powerful migration and invasion ability [97]. Beyond these genes, more genes associated with gastric tumorigenesis require more evidences for validation or further exploration.
4. Conclusion
Identification of disease genes is one of the most important problems in biomedicine and genomics. For gastric cancer, as one of the leading causes of cancer related deaths worldwide, it is eager to discover its related genes, which can help to uncover its mechanism and design effective treatments. This contribution presented a computational method to identify novel gastric cancer related genes based on known related ones by shortest path algorithm and PPI network. The analysis implies that some genes discovered in this study have direct or indirect relationship with gastric cancer. It is hopeful that this contribution would give a new insight to study this disease and other diseases.
Supplementary Material
The Supplementary Material consists of four files. In detail, Supplementary Material 1 lists 150 gastric cancer related genes; Supplementary Material 2 lists the shortest path genes and their permutation FDRs; Supplementary Material 3 lists GO enrichment results of 144 genes; Supplementary Material 4 lists KEGG enrichment results of 144 genes.
Acknowledgments
This paper is supported by Natural Science Fund Projects of Jilin province (201215059), Development of Science and Technology Plan Projects of Jilin province (20100733, 201101074), SRF for ROCS, SEM (2009-36), Scientific Research Foundation (Jilin Department of Science & Technology, 200705314, 20090175, 20100733), Scientific Research Foundation (Jilin Department of Health, 2010Z068), and SRF for ROCS (Jilin Department of Human Resource & Social Security, 2012–2014).
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Author's Contribution
Yang Jiang and Yang Shu contributed equally to this work.
References
- 1.Parkin DM, Bray F, Ferlay J, Pisani P. Estimating the world cancer burden: globocan 2000. International Journal of Cancer. 2001;94(2):153–156. doi: 10.1002/ijc.1440. [DOI] [PubMed] [Google Scholar]
- 2.Ferlay J, Shin H-R, Bray F, Forman D, Mathers C, Parkin DM. Estimates of worldwide burden of cancer in 2008: globocan 2008. International Journal of Cancer. 2010;127(12):2893–2917. doi: 10.1002/ijc.25516. [DOI] [PubMed] [Google Scholar]
- 3.Palli D. Epidemiology of gastric cancer: an evaluation of available evidence. Journal of Gastroenterology. 2000;35(supplement 12):84–89. [PubMed] [Google Scholar]
- 4.El-Omar EM, Carrington M, Chow W-H, et al. Interleukin-1 polymorphisms associated with increased risk of gastric cancer. Nature. 2000;404(6776):398–402. doi: 10.1038/35006081. [DOI] [PubMed] [Google Scholar]
- 5.Nomura A, Grove JS, Stemmermann GN, Severson RK. Cigarette smoking and stomach cancer. Cancer Research. 1990;50(article 7084) [PubMed] [Google Scholar]
- 6.Sung NY, Choi KS, Park EC, et al. Smoking, alcohol and gastric cancer risk in Korean men: the National Health Insurance Corporation Study. British Journal of Cancer. 2007;97(5):700–704. doi: 10.1038/sj.bjc.6603893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Chandanos E, Lagergren J. Oestrogen and the enigmatic male predominance of gastric cancer. European Journal of Cancer. 2008;44(16):2397–2403. doi: 10.1016/j.ejca.2008.07.031. [DOI] [PubMed] [Google Scholar]
- 8.Lauren P. The two histological main types of gastric carcinoma: diffuse and so-called intestinal-type carcinoma. An attempt at a histo-clinical classification. Acta Pathologica et Microbiologica Scandinavica. 1965;64:31–49. doi: 10.1111/apm.1965.64.1.31. [DOI] [PubMed] [Google Scholar]
- 9.Caldas C, Carneiro F, Lynch HT, et al. Familial gastric cancer: overview and guidelines for management. Journal of Medical Genetics. 1999;36(12):873–880. [PMC free article] [PubMed] [Google Scholar]
- 10.Kumar V, Abbas AK, Fausto N, Aster JC. Robbins & Cotran Pathologic Basis of Disease. Philadelphia, Pa, USA: Elsevier Health Sciences; 2009. [Google Scholar]
- 11.Maesawa C, Tamura G, Suzuki Y, et al. The sequential accumulation of genetic alterations characteristic of the colorectal adenoma-carcinoma sequence does not occur between gastric adenoma and adenocarcinoma. The Journal of Pathology. 1995;176(3):249–258. doi: 10.1002/path.1711760307. [DOI] [PubMed] [Google Scholar]
- 12.Becker K-F, Atkinson MJ, Reich U, et al. E-cadherin gene mutations provide clues to diffuse type gastric carcinomas. Cancer Research. 1994;54(14):3845–3852. [PubMed] [Google Scholar]
- 13.Li Q-L, Ito K, Sakakura C, et al. Causal relationship between the loss of RUNX3 expression and gastric cancer. Cell. 2002;109(1):113–124. doi: 10.1016/s0092-8674(02)00690-6. [DOI] [PubMed] [Google Scholar]
- 14.Chen L, Zeng W-M, Cai Y-D, Feng K-Y, Chou K-C. Predicting anatomical therapeutic chemical (ATC) classification of drugs by integrating chemical-chemical interactions and similarities. PLoS ONE. 2012;7(4) doi: 10.1371/journal.pone.0035254.e35254 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Yamanishi Y, Araki M, Gutteridge A, Honda W, Kanehisa M. Prediction of drug-target interaction networks from the integration of chemical and genomic spaces. Bioinformatics. 2008;24(13):i232–i240. doi: 10.1093/bioinformatics/btn162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Yamanishi Y, Kotera M, Kanehisa M, Goto S. Drug-target interaction prediction from chemical, genomic and pharmacological data in an integrated framework. Bioinformatics. 2010;26(12):i246–i254. doi: 10.1093/bioinformatics/btq176. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Padhy BM, Gupta YK. Drug repositioning: re-investigating existing drugs for new therapeutic indications. Journal of Postgraduate Medicine. 2011;57(2):153–160. doi: 10.4103/0022-3859.81870. [DOI] [PubMed] [Google Scholar]
- 18.Chen L, Lu J, Luo X, Feng K-Y. Prediction of drug target groups based on chemical-chemical similarities and chemical-chemical/protein connections. Biochimica et Biophysica Acta. 2014;1844(1, part B):207–213. doi: 10.1016/j.bbapap.2013.05.021. [DOI] [PubMed] [Google Scholar]
- 19.Chen L, Lu J, Zhang N, Huang T, Cai -D Y. A hybrid method for prediction and repositioning of drug Anatomical Therapeutic Chemical classes. Molecular BioSystems. 2014 doi: 10.1039/c3mb70490d. [DOI] [PubMed] [Google Scholar]
- 20.Ma H-W, Zeng A-P. The connectivity structure, giant strong component and centrality of metabolic networks. Bioinformatics. 2003;19(11):1423–1430. doi: 10.1093/bioinformatics/btg177. [DOI] [PubMed] [Google Scholar]
- 21.Dale JM, Popescu L, Karp PD. Machine learning methods for metabolic pathway prediction. BMC Bioinformatics. 2010;11, article 15 doi: 10.1186/1471-2105-11-15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Chen L, Huang T, Shi X-H, Cai Y-D, Chou K-C. Analysis of protein pathway networks using hybrid properties. Molecules. 2010;15(11):8177–8192. doi: 10.3390/molecules15118177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Huang T, Chen L, Cai Y-D, Chou K-C. Classification and analysis of regulatory pathways using graph property, biochemical and physicochemical property, and functional property. PLoS ONE. 2011;6(9) doi: 10.1371/journal.pone.0025297.e25297 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Chen L, Zeng W-M, Cai Y-D, Huang T. Prediction of metabolic pathway using graph property, chemical functional group and chemical structural set. Current Bioinformatics. 2013;8(2):200–207. [Google Scholar]
- 25.Gao YF, Chen L, Cai YD, Feng KY, Huang T, Jiang Y. Predicting metabolic pathways of small molecules and enzymes based on interaction information of chemicals and proteins. PLoS ONE. 2012;7(9) doi: 10.1371/journal.pone.0045944.e45944 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Hu L, Huang T, Shi X, Lu W-C, Cai Y-D, Chou K-C. Predicting functions of proteins in mouse based on weighted protein-protein interaction network and protein hybrid properties. PLoS ONE. 2011;6(1) doi: 10.1371/journal.pone.0014556.e14556 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Sharan R, Ulitsky I, Shamir R. Network-based prediction of protein function. Molecular Systems Biology. 2007;3(1, article 88) doi: 10.1038/msb4100129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Ng K-L, Ciou J-S, Huang C-H. Prediction of protein functions based on function-function correlation relations. Computers in Biology and Medicine. 2010;40(3):300–305. doi: 10.1016/j.compbiomed.2010.01.001. [DOI] [PubMed] [Google Scholar]
- 29.Bogdanov P, Singh AK. Molecular function prediction using neighborhood features. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2010;7(2):208–217. doi: 10.1109/TCBB.2009.81. [DOI] [PubMed] [Google Scholar]
- 30.Jensen LJ, Kuhn M, Stark M, et al. STRING 8—a global view on proteins and their functional interactions in 630 organisms. Nucleic Acids Research. 2009;37(supplement 1):D412–D416. doi: 10.1093/nar/gkn760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Gormen TH, Leiserson CE, Rivest RL, Stein C, editors. Introduction to Algorithms. Cambridge, Mass, USA: The MIT Press; 1990. [Google Scholar]
- 32.Craven JBM. Markov Networks for Detecting Overlapping Elements in Sequence Data. Cambridge, Mass, USA: The MIT Press; 2005. [Google Scholar]
- 33.Davis J, Goadrich M. The relationship between precision-recall and ROC curves. Proceedings of the 23rd International Conference on Machine Learning (ICML '06); June 2006; pp. 233–240. [Google Scholar]
- 34.Bunescu R, Ge R, Kate RJ, et al. Comparative experiments on learning information extractors for proteins and their interactions. Artificial Intelligence in Medicine. 2005;33(2):139–155. doi: 10.1016/j.artmed.2004.07.016. [DOI] [PubMed] [Google Scholar]
- 35.Johnson DE, Wolfgang GHI. Predicting human safety: screening and computational approaches. Drug Discovery Today. 2000;5(10):445–454. doi: 10.1016/s1359-6446(00)01559-2. [DOI] [PubMed] [Google Scholar]
- 36.Li B-Q, Niu B, Chen L, et al. Identifying chemicals with potential therapy of HIV based on protein-protein and protein-chemical interaction network. PLoS ONE. 2013;8(6) doi: 10.1371/journal.pone.0065207.e65207 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Chen L, Li B-Q, Zheng M-Y, Zhang J, Feng K-Y, Cai Y-D. Prediction of effective drug combinations by chemical interaction, protein interaction and target enrichment of KEGG pathways. BioMed Research International. 2013;2013:10 pages. doi: 10.1155/2013/723780.723780 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Zhang J, Jiang M, Yuan F, et al. Identification of age-related macular degeneration related genes by applying shortest path algorithm in protein-protein interaction network. BioMed Research International. 2013;2013:8 pages. doi: 10.1155/2013/523415.523415 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Huang DW, Sherman BT, Lempicki RA. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nature Protocols. 2009;4(1):44–57. doi: 10.1038/nprot.2008.211. [DOI] [PubMed] [Google Scholar]
- 40.Clark MJ, Homer N, O’Connor BD, et al. U87MG decoded: the genomic sequence of a cytogenetically aberrant human cancer cell line. PLoS Genetics. 2010;6(1) doi: 10.1371/journal.pgen.1000832.e1000832 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Teekakirikul P, Eminaga S, Toka O, et al. Cardiac fibrosis in mice with hypertrophic cardiomyopathy is mediated by non-myocyte proliferation and requires Tgf-β . The Journal of Clinical Investigation. 2010;120(10):3520–3529. doi: 10.1172/JCI42028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Chu C, Qu K, Zhong F, Artandi S, Chang H. Genomic maps of long noncoding RNA occupancy reveal principles of RNA-chromatin interactions. Molecular Cell. 2011;44(4):667–678. doi: 10.1016/j.molcel.2011.08.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Kalverda B, Pickersgill H, Shloma VV, Fornerod M. Nucleoporins directly stimulate expression of developmental and cell-cycle genes inside the nucleoplasm. Cell. 2010;140(3):360–371. doi: 10.1016/j.cell.2010.01.011. [DOI] [PubMed] [Google Scholar]
- 44.Mayshar Y, Ben-David U, Lavon N, et al. Identification and classification of chromosomal aberrations in human induced pluripotent stem cells. Cell Stem Cell. 2010;7(4):521–531. doi: 10.1016/j.stem.2010.07.017. [DOI] [PubMed] [Google Scholar]
- 45.Sanders SJ, Ercan-Sencicek AG, Hus V, et al. Multiple recurrent de novo CNVs, including duplications of the 7q11.23 Williams syndrome region, are strongly associated with autism. Neuron. 2011;70(5):863–885. doi: 10.1016/j.neuron.2011.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. The Annals of Statistics. 2001;29(4):919–1188. [Google Scholar]
- 47.Hohenberger P, Gretschel S. Gastric cancer. The Lancet. 2003;362(9380):305–315. doi: 10.1016/s0140-6736(03)13975-x. [DOI] [PubMed] [Google Scholar]
- 48.Liu R, Li Z, Bai S, et al. Mechanism of cancer cell adaptation to metabolic stress: proteomics identification of a novel thyroid hormone-mediated gastric carcinogenenic signaling pathway. Molecular and Cellular Proteomics. 2009;8(1):70–85. doi: 10.1074/mcp.M800195-MCP200. [DOI] [PubMed] [Google Scholar]
- 49.Sun DF, Zhang YJ, Tian XQ, Chen YX, Fang JY. Inhibition of mTOR signalling potentiates the effects of trichostatin A in human gastric cancer cell lines by promoting histone acetylation. Cell Biology International. 2014;38(1):50–63. doi: 10.1002/cbin.10179. [DOI] [PubMed] [Google Scholar]
- 50.Tahara E. Genetic pathways of two types of gastric cancer. IARC Scientific Publications. 2004;(157):327–349. [PubMed] [Google Scholar]
- 51.Essers J, Theil AF, Baldeyron C, et al. Nuclear dynamics of PCNA in DNA replication and repair. Molecular and Cellular Biology. 2005;25(21):9350–9359. doi: 10.1128/MCB.25.21.9350-9359.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Coqueret O. Linking cyclins to transcriptional control. Gene. 2002;299(1-2):35–55. doi: 10.1016/s0378-1119(02)01055-7. [DOI] [PubMed] [Google Scholar]
- 53.Moore JK, Haber JE. Cell cycle and genetic requirements of two pathways of nonhomologous end-Joining repair of double-strand breaks in Saccharomyces cerevisiae . Molecular and Cellular Biology. 1996;16(5):2164–2173. doi: 10.1128/mcb.16.5.2164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Liu Y, Prasad R, Beard WA, et al. Coordination of steps in single-nucleotide base excision repair mediated by apurinic/apyrimidinic endonuclease 1 and DNA polymerase β . The Journal of Biological Chemistry. 2007;282(18):13532–13541. doi: 10.1074/jbc.M611295200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Naro C, Sette C. Phosphorylation-mediated regulation of alternative splicing in cancer. International Journal of Cell Biology. 2013;2013:15 pages. doi: 10.1155/2013/151839.151839 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Look AT. Oncogenic transcription factors in the human acute leukemias. Science. 1997;278(5340):1059–1064. doi: 10.1126/science.278.5340.1059. [DOI] [PubMed] [Google Scholar]
- 57.Li Q-L, Ito K, Sakakura C, et al. Causal relationship between the loss of RUNX3 expression and gastric cancer. Cell. 2002;109(1):113–124. doi: 10.1016/s0092-8674(02)00690-6. [DOI] [PubMed] [Google Scholar]
- 58.Shivji MKK, Kenny MK, Wood RD. Proliferating cell nuclear antigen is required for DNA excision repair. Cell. 1992;69(2):367–374. doi: 10.1016/0092-8674(92)90416-a. [DOI] [PubMed] [Google Scholar]
- 59.Moldovan G-L, Pfander B, Jentsch S. PCNA, the maestro of the replication fork. Cell. 2007;129(4):665–679. doi: 10.1016/j.cell.2007.05.003. [DOI] [PubMed] [Google Scholar]
- 60.Prelich G, Tan C-K, Kostura M. Functional identity of proliferating cell nuclear antigen and a DNA polymerase-δ auxiliary protein. Nature. 1987;326(6112):517–520. doi: 10.1038/326517a0. [DOI] [PubMed] [Google Scholar]
- 61.Hoege C, Pfander B, Moldovan G-L, Pyrowolakis G, Jentsch S. RAD6-dependent DNA repair is linked to modification of PCNA by ubiquitin and SUMO. Nature. 2002;419(6903):135–141. doi: 10.1038/nature00991. [DOI] [PubMed] [Google Scholar]
- 62.Shivji MKK. Nucleotide excision repair DNA synthesis by DNA polymerase ε in the presence of PCNA, RFC, and RPA. Biochemistry. 1995;34(15):5011–5017. doi: 10.1021/bi00015a012. [DOI] [PubMed] [Google Scholar]
- 63.de Boer J, Hoeijmakers JHJ. Nucleotide excision repair and human syndromes. Carcinogenesis. 2000;21(3):453–460. doi: 10.1093/carcin/21.3.453. [DOI] [PubMed] [Google Scholar]
- 64.Pascucci B, D’Errico M, Parlanti E, Giovannini S, Dogliotti E. Role of nucleotide excision repair proteins in oxidative DNA damage repair: an updating. Biochemistry. 2011;76(1):4–15. doi: 10.1134/s0006297911010032. [DOI] [PubMed] [Google Scholar]
- 65.Ohyama S, Yonemura Y, Miyazaki I. Proliferative activity and malignancy in human gastric cancers: significance of the proliferation rate and its clinical application. Cancer. 1992;69(2):314–321. doi: 10.1002/1097-0142(19920115)69:2<314::aid-cncr2820690207>3.0.co;2-9. [DOI] [PubMed] [Google Scholar]
- 66.Kuang RG, Wu HX, Hao GX, Wang JW, Zhou CJ. Expression and significance of IGF-2, PCNA, MMP-7, and α-actin in gastric carcinoma with Lauren classification. The Turkish Journal of Gastroenterology. 2013;24(2):99–108. doi: 10.4318/tjg.2013.0571. [DOI] [PubMed] [Google Scholar]
- 67.Jain S, Filipe MI, Hall PA, Waseem N, Lane DP, Levison DA. Prognostic value of proliferating cell nuclear antigen in gastric carcinoma. Journal of Clinical Pathology. 1991;44(8):655–659. doi: 10.1136/jcp.44.8.655. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Ji J, Zhao P, Huang B. Study of gastric carcinoma and PCNA and c-met gene abnormality. Wei Sheng Yan Jiu. 2008;37(4):479–482. [PubMed] [Google Scholar]
- 69.Takamura H, Yonemura Y, Fonseca L, et al. Correlation of DNA ploidy, c-erB-2 protein tissue status, level of PCNA expression and clinical outcome in gastric carcinomas. Nihon Geka Gakkai Zasshi. 1995;96(4):213–222. [PubMed] [Google Scholar]
- 70.Motokura T, Bloom T, Kim HG, et al. A novel cyclin encoded by a bcl1-linked candidate oncogene. Nature. 1991;350(6318):512–515. doi: 10.1038/350512a0. [DOI] [PubMed] [Google Scholar]
- 71.Jiang W, Kahn SM, Tomita N, Zhang Y-J, Lu S-H, Weinstein IB. Amplification and expression of the human cyclin D gene in esophageal cancer. Cancer Research. 1992;52(10):2980–2983. [PubMed] [Google Scholar]
- 72.Buckley MF, Sweeney KJE, Hamilton JA, et al. Expression and amplification of cyclin genes in human breast cancer. Oncogene. 1993;8(8):2127–2133. [PubMed] [Google Scholar]
- 73.Kim JK, Diehl JA. Nuclear cyclin D1: an oncogenic driver in human cancer. Journal of Cellular Physiology. 2009;220(2):292–296. doi: 10.1002/jcp.21791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Malumbres M, de Castro IP, Hernández MI, Jiménez M, Corral T, Pellicer A. Cellular response to oncogenic ras involves induction of the Cdk4 and Cdk6 inhibitor p15(INK4b) Molecular and Cellular Biology. 2000;20(8):2915–2925. doi: 10.1128/mcb.20.8.2915-2925.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Serrano M, Gomez-Lahoz E, DePinho RA, Beach D, Bar-Sagi D. Inhibition of ras-induced proliferation and cellular transformation by p16(INK4) Science. 1995;267(5195):249–252. doi: 10.1126/science.7809631. [DOI] [PubMed] [Google Scholar]
- 76.Zwijsen RML, Wientjens E, Klompmaker R, van der Sman J, Bernards R, Michalides RJAM. CDK-independent activation of estrogen receptor by cyclin D1. Cell. 1997;88(3):405–415. doi: 10.1016/s0092-8674(00)81879-6. [DOI] [PubMed] [Google Scholar]
- 77.Fernandez PC, Frank SR, Wang L, et al. Genomic targets of the human c-Myc protein. Genes and Development. 2003;17(9):1115–1129. doi: 10.1101/gad.1067003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 78.Sears RC. The life cycle of c-Myc: from synthesis to degradation. Cell Cycle. 2004;3(9):1133–1137. [PubMed] [Google Scholar]
- 79.Chung H-J, Levens D. c-myc expression: keep the noise down! Molecules and Cells. 2005;20(2):157–166. [PubMed] [Google Scholar]
- 80.Prochownik EV, Li Y. The ever expanding role for c-Myc in promoting genomic instability. Cell Cycle. 2007;6(9):1024–1029. doi: 10.4161/cc.6.9.4161. [DOI] [PubMed] [Google Scholar]
- 81.Milne AN, Sitarz R, Carvalho R, Carneiro F, Offerhaus GJA. Early onset gastric cancer: on the road to unraveling gastric carcinogenesis. Current Molecular Medicine. 2007;7(1):15–28. doi: 10.2174/156652407779940503. [DOI] [PubMed] [Google Scholar]
- 82.Sakakura C, Mori T, Sakabe T, et al. Gains, losses, and amplifications of genomic materials in primary gastric cancers analyzed by comparative genomic hybridization. Genes Chromosomes Cancer. 1999;24(4):299–305. doi: 10.1002/(sici)1098-2264(199904)24:4<299::aid-gcc2>3.0.co;2-u. [DOI] [PubMed] [Google Scholar]
- 83.Yang S, Jeung H-C, Jeong HJ, et al. Identification of genes with correlated patterns of variations in DNA copy number and gene expression level in gastric cancer. Genomics. 2007;89(4):451–459. doi: 10.1016/j.ygeno.2006.12.001. [DOI] [PubMed] [Google Scholar]
- 84.Vita M, Henriksson M. The Myc oncoprotein as a therapeutic target for human cancer. Seminars in Cancer Biology. 2006;16(4):318–330. doi: 10.1016/j.semcancer.2006.07.015. [DOI] [PubMed] [Google Scholar]
- 85.Bakin AV, Curran T. Role of DNA 5-methylcytosine transferase in cell transformation by fos. Science. 1999;283(5400):387–390. doi: 10.1126/science.283.5400.387. [DOI] [PubMed] [Google Scholar]
- 86.Fialka I, Schwarz H, Reichmann E, Oft M, Busslinger M, Beug H. The estrogen-dependent c-JunER protein causes a reversible loss of mammary epithelial cell polarity involving a destabilization of adherens junctions. Journal of Cell Biology. 1996;132(6):1115–1132. doi: 10.1083/jcb.132.6.1115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Hu E, Mueller E, Oliviero S, Papaioannou VP, Johnson R, Spiegelman BM. Targeted disruption of the c-fos gene demonstrates c-fos-dependent and -independent pathways for gene expression stimulated by growth factors or oncogenes. The EMBO Journal. 1994;13(13):3094–3103. doi: 10.1002/j.1460-2075.1994.tb06608.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Mikula M, Gotzmann J, Fischer ANM, et al. The proto-oncoprotein c-Fos negatively regulates hepatocellular tumorigenesis. Oncogene. 2003;22(42):6725–6738. doi: 10.1038/sj.onc.1206781. [DOI] [PubMed] [Google Scholar]
- 89.Jin SP, Kim JH, Kim MA, et al. Prognostic significance of loss of c-fos protein in gastric carcinoma. Pathology and Oncology Research. 2007;13(4):284–289. doi: 10.1007/BF02940306. [DOI] [PubMed] [Google Scholar]
- 90.Zhou L, Zhang J-S, Yu J-C, et al. Negative association of c-fos expression as a favorable prognostic indicator in gastric cancer. Archives of Medical Research. 2010;41(3):201–206. doi: 10.1016/j.arcmed.2010.04.009. [DOI] [PubMed] [Google Scholar]
- 91.Mazurenko NN, Kogan EA, Sukhova NM, Zborovskaia IB. Synthesis and distribution of oncoproteins in tumor tissue. Voprosy Meditsinskoj Khimii. 1991;37(6):53–59. [PubMed] [Google Scholar]
- 92.Song W-J, Sullivan MG, Legare RD, et al. Haploinsufficiency of CBFA2 causes familial thrombocytopenia with propensity to develop acute myelogenous leukaemia. Nature Genetics. 1999;23(2):166–175. doi: 10.1038/13793. [DOI] [PubMed] [Google Scholar]
- 93.Usui T, Aoyagi K, Saeki N, et al. Expression status of RUNX1/AML1 in normal gastric epithelium and its mutational analysis in microdissected gastric cancer cells. International Journal of Oncology. 2006;29(4):779–784. [PubMed] [Google Scholar]
- 94.Sakakura C, Hagiwara A, Miyagawa K, et al. Frequent downregulation of the runt domain transcription factors RUNX1, RUNX3 and their cofactor CBFB in gastric cancer. International Journal of Cancer. 2005;113(2):221–228. doi: 10.1002/ijc.20551. [DOI] [PubMed] [Google Scholar]
- 95.Xue H, Ni P, Lin B, Xu H, Huang G. X-ray repair cross-complementing group 1 (XRCC1) genetic polymorphisms and gastric cancer risk: a HuGe review and meta-analysis. The American Journal of Epidemiology. 2011;173(4):363–375. doi: 10.1093/aje/kwq378. [DOI] [PubMed] [Google Scholar]
- 96.Jiang J, Jia Z, Cao D, et al. Polymorphisms of the DNA methyltransferase 1 associated with reduced risks of Helicobacter pylori infection and increased risks of gastric atrophy. PLoS ONE. 2012;7(9) doi: 10.1371/journal.pone.0046058.e46058 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97.Cheng W-L, Wang C-S, Huang Y-H, Tsai M-M, Liang Y, Lin K-H. Overexpression of CXCL1 and its receptor CXCR2 promote tumor invasion in gastric cancer. Annals of Oncology. 2011;22(10):2267–2276. doi: 10.1093/annonc/mdq739. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The Supplementary Material consists of four files. In detail, Supplementary Material 1 lists 150 gastric cancer related genes; Supplementary Material 2 lists the shortest path genes and their permutation FDRs; Supplementary Material 3 lists GO enrichment results of 144 genes; Supplementary Material 4 lists KEGG enrichment results of 144 genes.