

Abstract
Meta-analysis methods that combine  -values into a single unified
-values into a single unified 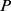 -value are frequently employed to improve confidence in hypothesis testing. An assumption made by most meta-analysis methods is that the
-value are frequently employed to improve confidence in hypothesis testing. An assumption made by most meta-analysis methods is that the 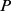 -values to be combined are independent, which may not always be true. To investigate the accuracy of the unified
-values to be combined are independent, which may not always be true. To investigate the accuracy of the unified 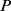 -value from combining correlated
-value from combining correlated 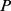 -values, we have evaluated a family of statistical methods that combine: independent, weighted independent, correlated, and weighted correlated
-values, we have evaluated a family of statistical methods that combine: independent, weighted independent, correlated, and weighted correlated 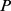 -values. Statistical accuracy evaluation by combining simulated correlated
-values. Statistical accuracy evaluation by combining simulated correlated 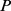 -values showed that correlation among
-values showed that correlation among 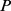 -values can have a significant effect on the accuracy of the combined
-values can have a significant effect on the accuracy of the combined 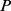 -value obtained. Among the statistical methods evaluated those that weight
-value obtained. Among the statistical methods evaluated those that weight 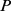 -values compute more accurate combined
-values compute more accurate combined 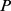 -values than those that do not. Also, statistical methods that utilize the correlation information have the best performance, producing significantly more accurate combined
-values than those that do not. Also, statistical methods that utilize the correlation information have the best performance, producing significantly more accurate combined 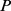 -values. In our study we have demonstrated that statistical methods that combine
-values. In our study we have demonstrated that statistical methods that combine  -values based on the assumption of independence can produce inaccurate
-values based on the assumption of independence can produce inaccurate 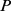 -values when combining correlated
-values when combining correlated 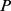 -values, even when the
-values, even when the 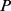 -values are only weakly correlated. Therefore, to prevent from drawing false conclusions during hypothesis testing, our study advises caution be used when interpreting the
-values are only weakly correlated. Therefore, to prevent from drawing false conclusions during hypothesis testing, our study advises caution be used when interpreting the 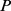 -value obtained from combining
-value obtained from combining 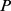 -values of unknown correlation. However, when the correlation information is available, the weighting-capable statistical method, first introduced by Brown and recently modified by Hou, seems to perform the best amongst the methods investigated.
-values of unknown correlation. However, when the correlation information is available, the weighting-capable statistical method, first introduced by Brown and recently modified by Hou, seems to perform the best amongst the methods investigated.
Introduction
Meta-analysis methods that combine 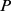 -values into a single unified
-values into a single unified  -value are commonly used to rank or score a list of hypotheses [1]. For each hypothesis tested, the
-value are commonly used to rank or score a list of hypotheses [1]. For each hypothesis tested, the 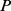 -values to be combined are often acquired from studying different features associated with the hypothesis or from using different data analysis methods (DAM) to analyze a chosen feature. Either approaches conducted to test the same list of hypotheses assign an overall
-values to be combined are often acquired from studying different features associated with the hypothesis or from using different data analysis methods (DAM) to analyze a chosen feature. Either approaches conducted to test the same list of hypotheses assign an overall 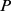 -value to each hypothesis tested. These
-value to each hypothesis tested. These  -values are then usually sorted, with the most significant result ranking first in the list. Given that different features may not be completely independent and that different DAMs may share protocols and use similar information, it is likely that the
-values are then usually sorted, with the most significant result ranking first in the list. Given that different features may not be completely independent and that different DAMs may share protocols and use similar information, it is likely that the 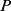 -values obtained for a hypothesis are correlated.
-values obtained for a hypothesis are correlated.
Most 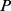 -value combining methods assume that the
-value combining methods assume that the 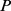 -values to be combined are independent or weakly correlated [2], [3]. When the unified
-values to be combined are independent or weakly correlated [2], [3]. When the unified 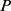 -value is computed by combining correlated
-value is computed by combining correlated 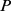 -values, without properly taking into account the correlation, there can be notable effects in the significance assignment of the hypothesis tested. As the
-values, without properly taking into account the correlation, there can be notable effects in the significance assignment of the hypothesis tested. As the 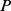 -values to be combined are possibly correlated, it is important to investigate the effect that correlation has on the unified
-values to be combined are possibly correlated, it is important to investigate the effect that correlation has on the unified 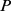 -value. The current study is designed to evaluate the accuracy of the unified
-value. The current study is designed to evaluate the accuracy of the unified 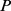 -value computed by combining (positively) correlated
-value computed by combining (positively) correlated 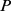 -values using some commonly applied statistical methods. By
-values using some commonly applied statistical methods. By 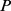 -value accuracy, we mean how well on average does reported
-value accuracy, we mean how well on average does reported 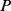 -value agree with the one-sided cumulative distribution function of the random variable (associated with the null hypotheses tested) at the critical region. In other words, accurate
-value agree with the one-sided cumulative distribution function of the random variable (associated with the null hypotheses tested) at the critical region. In other words, accurate 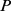 -value means that when one controls type-I error rate at a level
-value means that when one controls type-I error rate at a level  , the type-I error rate is really controlled at the level
, the type-I error rate is really controlled at the level  . To keep this paper focused, we will not provide a lengthy introduction. For methods that we will evaluate, more details are provided in the Methods sections. For others, we will only provide the readers with appropriate references.
. To keep this paper focused, we will not provide a lengthy introduction. For methods that we will evaluate, more details are provided in the Methods sections. For others, we will only provide the readers with appropriate references.
Several studies have been performed to evaluate methods that combine independent 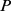 -values [4]–[10]. For example, Rosenthal has evaluated nine methods for combining
-values [4]–[10]. For example, Rosenthal has evaluated nine methods for combining 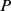 -values and has summarized advantages, limitations and applications for each method [4]. Loughin [5] has also conducted a systematic comparison of methods for combining
-values and has summarized advantages, limitations and applications for each method [4]. Loughin [5] has also conducted a systematic comparison of methods for combining 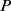 -values and recommended practitioners to choose a method based on the structure and expectation for the problem being studied. Recently, Whitlock [6] has showed that the weighted Z-method has more power and precision than Fisher's test. In other studies, Chen [8] as well as Chen and Nadarajah [9], have shown that either the generalized Fisher method due to Lancaster or a special case of Lancaster's test outperform the weighted Z-method, while Zaykin [10] has shown that the weighted Z-method has similar power to Lancaster's method when the weights are selected to be the square roots of sample sizes.
-values and recommended practitioners to choose a method based on the structure and expectation for the problem being studied. Recently, Whitlock [6] has showed that the weighted Z-method has more power and precision than Fisher's test. In other studies, Chen [8] as well as Chen and Nadarajah [9], have shown that either the generalized Fisher method due to Lancaster or a special case of Lancaster's test outperform the weighted Z-method, while Zaykin [10] has shown that the weighted Z-method has similar power to Lancaster's method when the weights are selected to be the square roots of sample sizes.
As for combining correlated 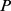 -values, only few studies have been conducted to evaluate the accuracy of the unified
-values, only few studies have been conducted to evaluate the accuracy of the unified 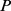 -value computed by existing statistical methods [11], [12]. Evidently, more comprehensive investigations that incorporate different methods, encompass a wide range of correlation strength, and have a large number of simulations can further our understanding on the effect of correlation has on computing a unified
-value computed by existing statistical methods [11], [12]. Evidently, more comprehensive investigations that incorporate different methods, encompass a wide range of correlation strength, and have a large number of simulations can further our understanding on the effect of correlation has on computing a unified  -value. To advance towards this direction, we systematically investigate a family of statistical methods for combining
-value. To advance towards this direction, we systematically investigate a family of statistical methods for combining  -values. Because we are interested in combining
-values. Because we are interested in combining  -values obtained from the right-tailed tests, we have limited our study to methods that combine
-values obtained from the right-tailed tests, we have limited our study to methods that combine  -values based on the normal distribution (e.g. Stouffer's method) and on the Chi-square distribution (e.g. Fisher's method), the general purpose method and the right-tail method recommended by Loughin [5]. The two aforementioned methods, aside from being frequently used to combine
-values based on the normal distribution (e.g. Stouffer's method) and on the Chi-square distribution (e.g. Fisher's method), the general purpose method and the right-tail method recommended by Loughin [5]. The two aforementioned methods, aside from being frequently used to combine 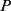 -values, are useful and important to study for the following reason. Both methods mentioned have variations that weight
-values, are useful and important to study for the following reason. Both methods mentioned have variations that weight 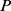 -values while computing the combined
-values while computing the combined  -value: Lipták, Good and Bhoj methods [13]–[15], and variations that take into account the correlation among
-value: Lipták, Good and Bhoj methods [13]–[15], and variations that take into account the correlation among 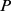 -values: Hartung and Hou methods [16], [17]. In addition, all methods mentioned above either have closed-form formulas, i.e., distribution functions, or approximation formulas that can provide the unified
-values: Hartung and Hou methods [16], [17]. In addition, all methods mentioned above either have closed-form formulas, i.e., distribution functions, or approximation formulas that can provide the unified 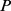 -value with minimum computation cost.
-value with minimum computation cost.
In summary, our study presents an accuracy evaluation of the unified 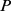 -value obtained from statistical methods designed to combine independent, weighted independent, correlated, and weighted correlated
-value obtained from statistical methods designed to combine independent, weighted independent, correlated, and weighted correlated 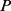 -values. We have evaluated the accuracy of the unified
-values. We have evaluated the accuracy of the unified  -value from combining positively correlated
-value from combining positively correlated 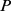 -value vectors with correlation among
-value vectors with correlation among 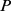 -value vectors in the range
-value vectors in the range  . Our results show that methods designed to combine independent
. Our results show that methods designed to combine independent 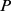 -values but with the capability of assigning weights to
-values but with the capability of assigning weights to 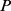 -values perform better than methods that combine independent
-values perform better than methods that combine independent 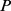 -values without weights. Also methods that take into account the correlation between
-values without weights. Also methods that take into account the correlation between 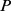 -values perform significantly better than methods designed to combine independent
-values perform significantly better than methods designed to combine independent 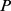 -values. Based on this study, the method first introduced by Brown [18] to combine correlated
-values. Based on this study, the method first introduced by Brown [18] to combine correlated 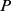 -values and later adapted to include weights by Hou [17] is the best performing one amongst the methods investigated.
-values and later adapted to include weights by Hou [17] is the best performing one amongst the methods investigated.
Methods
The main task of combining 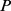 -values is described below. Given a list of hypotheses
-values is described below. Given a list of hypotheses  , let each hypothesis have
, let each hypothesis have 
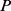 -values associated with it. These
-values associated with it. These 
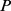 -values can be organized as
-values can be organized as 
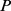 -value vectors,
-value vectors,  , each having
, each having  components. Each
components. Each 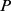 -value vector may result from analyzing one out of
-value vector may result from analyzing one out of  different features of every hypothesis or may be from analyzing a single feature using one of the
different features of every hypothesis or may be from analyzing a single feature using one of the  different DAMs. The
different DAMs. The 
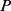 -values associated with hypothesis
-values associated with hypothesis  are
are 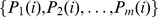 . Given those values, one needs to combine them to form a single unified
. Given those values, one needs to combine them to form a single unified 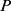 -value. This scenario can occur in many applications. As an example, when different studies are performed to test a set of genetic loci for allelic imbalance [19], the number of genetic regions tested will correspond to the number of hypotheses
-value. This scenario can occur in many applications. As an example, when different studies are performed to test a set of genetic loci for allelic imbalance [19], the number of genetic regions tested will correspond to the number of hypotheses 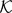 and each region will carry with them
and each region will carry with them 
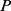 -values, one from each of the
-values, one from each of the  studies. To fairly rank these possible
studies. To fairly rank these possible  regions, for each region one would need a unified
regions, for each region one would need a unified 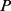 -value resulting from combining the
-value resulting from combining the 
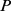 -values associated with it. For database search based peptide identification using mass spectrometry, it is possible to analyze the data using multiple analysis methods. Here for each experimental spectrum, the number of hypotheses tested
-values associated with it. For database search based peptide identification using mass spectrometry, it is possible to analyze the data using multiple analysis methods. Here for each experimental spectrum, the number of hypotheses tested  equals the number of scored peptides in the database and each peptide receives a
equals the number of scored peptides in the database and each peptide receives a 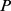 -value from each of the
-value from each of the  analysis methods. To fairly rank the candidate peptides, it is again natural to combine the
analysis methods. To fairly rank the candidate peptides, it is again natural to combine the 
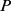 -values associated with each scored peptide [3] to reach a unified
-values associated with each scored peptide [3] to reach a unified 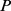 -value. In the sequence homology detection where multiple motifs are used as a query to a sequence database, it is often needed to combine the
-value. In the sequence homology detection where multiple motifs are used as a query to a sequence database, it is often needed to combine the 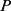 -values, each from one of the
-values, each from one of the  motifs, to assign the statistical significance to a sequence in the sequence database [2]. In this case,
motifs, to assign the statistical significance to a sequence in the sequence database [2]. In this case,  is the number of sequences in the database, while
is the number of sequences in the database, while  is the number of motifs used as the query.
is the number of motifs used as the query.
To make the notation uniform, we will use  and
and  to represent the cumulative distribution and inverse cumulative distribution. When the subscript
to represent the cumulative distribution and inverse cumulative distribution. When the subscript 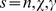 ,
,  represents respectively the cumulative Normal, Chi-squared, and Gamma distributions. All the parameters of these distributions will be shown as arguments enclosed by a pair of parentheses following the symbol
represents respectively the cumulative Normal, Chi-squared, and Gamma distributions. All the parameters of these distributions will be shown as arguments enclosed by a pair of parentheses following the symbol  .
.
Combining Independent P-values
We begin this subsection with a brief introduction of Stouffer's (Z-transform test) and Fisher's (Chi-square test) methods. Generalizations of both methods to combine weighted 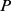 -values are also described.
-values are also described.
Method 1
The combined Z-transform test was first used by Stouffer et al. [20] and later generalized to include weights by Lipták [13]. Under the null hypothesis, the 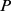 -values are uniformly distributed between [0,1]. Given a list of
-values are uniformly distributed between [0,1]. Given a list of 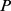 -values
-values 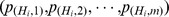 associated with a given
associated with a given  , one transforms the
, one transforms the 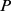 -values to a new variable
-values to a new variable 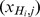 by a simple transformation
by a simple transformation
where  stands for the inverse of the cumulative normal distribution. For the Z-transform test the distribution function used is the standard Normal (Gaussian) distribution with probability density function given by
stands for the inverse of the cumulative normal distribution. For the Z-transform test the distribution function used is the standard Normal (Gaussian) distribution with probability density function given by
with parameters  and
and  .
.
Stouffer's way to combine the above 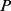 -values is by defining a new variable
-values is by defining a new variable
 |
which is also Gaussian distributed with 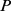 -value given by the formula
-value given by the formula
| (1) |
A generalization of the above equation that assigns weights ( ) to the variable
) to the variable  is know as the weighted Z-transform test [13]
is know as the weighted Z-transform test [13]
 |
The variable of the weighted Z-transform  also follows Normal distribution, and the formula for the
also follows Normal distribution, and the formula for the 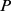 -value is also given by eq. (1).
-value is also given by eq. (1).
Method 2
Fisher's method [21] is one of the most used method to combine independent 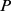 -values. The combined Fisher
-values. The combined Fisher 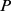 -value is obtained through the following variable:
-value is obtained through the following variable:
which follows a Chi-squared distribution  with 2
with 2 degrees of freedom. Computing the unified
degrees of freedom. Computing the unified 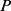 -value using the Chi-squared distribution is not the most efficient approach because of the significant computational cost in calculating the cumulative distribution
-value using the Chi-squared distribution is not the most efficient approach because of the significant computational cost in calculating the cumulative distribution  . A more efficient way to obtain the unified
. A more efficient way to obtain the unified 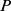 -value has been proposed [2], [3], where the unified
-value has been proposed [2], [3], where the unified 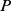 -value of
-value of  has a closed form given by
has a closed form given by
| (2) |
or in terms of the  variable
variable
| (3) |
Note that as  increases
increases  decreases and vice versa.
decreases and vice versa.
Fisher's method does not assign weights to the 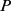 -values to be combined. However, when information is available regarding how
-values to be combined. However, when information is available regarding how 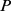 -values were obtained, it might be beneficial to weight
-values were obtained, it might be beneficial to weight 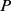 -values. Lancaster et al. [22] addresses this issue by replacing the random variable
-values. Lancaster et al. [22] addresses this issue by replacing the random variable 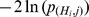 with
with  , a variable following a Chi-squared distribution with
, a variable following a Chi-squared distribution with  degrees of freedom not necessarily equal to two.
degrees of freedom not necessarily equal to two.
In Lancaster's procedure, summarized below, one can exploit the equivalence between the Chi-squared distribution  and the gamma distribution
and the gamma distribution 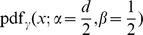 to reach a different weighting generalization. For hypothesis
to reach a different weighting generalization. For hypothesis  , the variable
, the variable  can now be written as
can now be written as
which evidently follows a Chi-squared distribution with  degrees of freedom. In the expression above, Fisher's method is recovered by setting
degrees of freedom. In the expression above, Fisher's method is recovered by setting  for all
for all  . Another way to incorporate weights is to keep
. Another way to incorporate weights is to keep 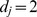 while retaining a general
while retaining a general  value. Specifically, one may choose, with
value. Specifically, one may choose, with  being the weight factor, to use the following new variable
being the weight factor, to use the following new variable
The 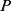 -value for
-value for  can be easily evaluated using the same technique as that in [3] and is given below
can be easily evaluated using the same technique as that in [3] and is given below
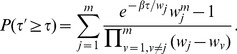 |
(4) |
Interestingly, with  , eq. (4) corresponds to the unified
, eq. (4) corresponds to the unified 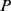 -value of multiplying weighted independent
-value of multiplying weighted independent 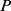 -values obtained earlier by Good [14]. This can be seen by the following observation. Good defined his variable
-values obtained earlier by Good [14]. This can be seen by the following observation. Good defined his variable
and the corresponding 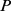 -value is given by
-value is given by
 |
(5) |
When expressed in the variable  , we easily see that
, we easily see that
 |
in agreement with eq. (4) when  .
.
A question that arises naturally when using methods such as the weighted Z-transform's test, Good's test, and Lancaster's test is how to obtain the optimal weights ( )? This difficult question has been raised and it was suggested that the choice of weights may vary by cases [23]. Existing methods to assign/estimate the weights include, but are not limited to: (1) weight in proportion to the reciprocal of the variance estimated from each study [6], (2) estimate the weights from one's prior belief about a method or feature [24], (3) select weights to stabilize the variance of the combined test statistics [25], and (4) use weights that improve the testing power [26]. Because there is no universal procedure to compute the optimal weights to be used, in this study the weights, when used, were randomly generated and normalized to sum to one (see Table 1).
)? This difficult question has been raised and it was suggested that the choice of weights may vary by cases [23]. Existing methods to assign/estimate the weights include, but are not limited to: (1) weight in proportion to the reciprocal of the variance estimated from each study [6], (2) estimate the weights from one's prior belief about a method or feature [24], (3) select weights to stabilize the variance of the combined test statistics [25], and (4) use weights that improve the testing power [26]. Because there is no universal procedure to compute the optimal weights to be used, in this study the weights, when used, were randomly generated and normalized to sum to one (see Table 1).
Table 1. Breakdown of Methods Used to Combine 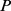 -values Investigated.
-values Investigated.
| Method Name | Ref. number | Eq. number | Acc. weights | Nor. weights | Account for corr. |
| Fisher | [21] | 3 | no | none | no |
| Stouffer | [20] | 1 | no | none | no |
| Bhoj | [15] | 6 | yes |

|
no |
| Good | [14] | 5 | yes |

|
no |
| Lipták | [13] | 1 | yes |

|
no |
| Hartung | [16] | 9 | yes |

|
yes |
| Hou | [17] | 14 | yes |

|
yes |
The first column of the table provides the names of the methods used to combine 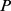 -values investigated in our study. The second column lists the reference number cited in this paper for the publication (Ref) corresponding to the method used. The third column provides the equation number for the method distribution function used to compute the formula
-values investigated in our study. The second column lists the reference number cited in this paper for the publication (Ref) corresponding to the method used. The third column provides the equation number for the method distribution function used to compute the formula 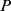 -value. The fourth column indicates if a method equation can accommodate (acc.) weight when combining
-value. The fourth column indicates if a method equation can accommodate (acc.) weight when combining 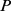 -value. The fifth column gives the normalization (nor.) procedure used to normalize the weights. Finally, the last column conveys the information about a method's capability to account for correlation (corr.) between
-value. The fifth column gives the normalization (nor.) procedure used to normalize the weights. Finally, the last column conveys the information about a method's capability to account for correlation (corr.) between 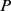 -values.
-values.
There are also two apparent problems with Lancaster's eq. (4) and Good's eq. (5). The first problem is that the weights used can't be identical, otherwise singularities can occur [14], [15]. Second, if the difference between some of the weights are small, numerical instability can occur [15], [17], [27]. In order to address the problem of numerical instability associated with identical and almost identical weights, Bhoj [15] suggested an approximation using a linear combination of  gamma density functions (with
gamma density functions (with  )
)
 |
(6) |
where  is the incomplete gamma function and
is the incomplete gamma function and  is the gamma function. Although the approximation provided by Bhoj does reduce to Fisher's distribution when the weights are all equal and does not encounter singularities when weights are identical or nearly identical, this approximation does not lead to Good's distribution when the weights are all different. A recent publication [27] has provided an analytical formula that not only is numerically stable when combining
is the gamma function. Although the approximation provided by Bhoj does reduce to Fisher's distribution when the weights are all equal and does not encounter singularities when weights are identical or nearly identical, this approximation does not lead to Good's distribution when the weights are all different. A recent publication [27] has provided an analytical formula that not only is numerically stable when combining 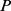 -values with nearly degenerate or identical weights but also correctly reproduces Fisher's and Good's results as limiting cases.
-values with nearly degenerate or identical weights but also correctly reproduces Fisher's and Good's results as limiting cases.
Combining Dependent P-values
In this subsection we summarize two statistical methods that are generalizations of Stouffer's test (Z-transform test) and Fisher's test (Chi-square test) that attempt to account for the correlation among 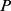 -values to be combined.
-values to be combined.
Method 3
Hartung [16] incorporates the correlation among 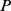 -values via introducing in the Z-transform test (eq. (1)) the correlation-matrix, with elements
-values via introducing in the Z-transform test (eq. (1)) the correlation-matrix, with elements 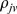 computed from the variable pairs
computed from the variable pairs  , and by defining a new variable
, and by defining a new variable
 |
where
| (7) |
and
| (8) |
where  is the average value of
is the average value of  ,
,  is the total number of hypotheses tested, and
is the total number of hypotheses tested, and  is the variance of
is the variance of  .
.
The 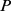 -value for
-value for  is then approximated by the standard Normal distribution
is then approximated by the standard Normal distribution
| (9) |
which nevertheless becomes exact in the two extreme limits of 
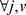 and
and 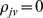
 . Although in general the distribution of
. Although in general the distribution of  is only approximately normal, it is arguable that ignoring correlation can cause more damage to the combined
is only approximately normal, it is arguable that ignoring correlation can cause more damage to the combined 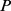 -value than the deviations from normality. Applications and extensions of Hartung's idea can also be found in more recent publications [12], [28].
-value than the deviations from normality. Applications and extensions of Hartung's idea can also be found in more recent publications [12], [28].
Method 4
Following Satterthwaite's procedure [29], there have been some attempts, when combining correlated 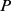 -values, to obtain approximate unified
-values, to obtain approximate unified 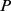 -value for the Fisher's variable (no weight) [18], [30] and for the Good's variable (unequal weights) [17]. The main idea of Satterthwaite's procedure is to equate the first two moments of the uncharacterized distribution to that of a Chi-squared distribution. Brown [18] and Kost et al. [30] tried to approximate the distribution of the Fisher's variable
-value for the Fisher's variable (no weight) [18], [30] and for the Good's variable (unequal weights) [17]. The main idea of Satterthwaite's procedure is to equate the first two moments of the uncharacterized distribution to that of a Chi-squared distribution. Brown [18] and Kost et al. [30] tried to approximate the distribution of the Fisher's variable
and Hou [17] the distribution of Good's variable
to that of a Chi-squared distribution  , with
, with  being a scale factor to be determined.
being a scale factor to be determined.
The expectation value ( ) the variance (
) the variance ( ) of
) of  by formal operation are given respectively by
by formal operation are given respectively by
| (10) |
 |
(11) |
On the other hand, the expectation value and variance of  using
using  yields
yields
| (12) |
| (13) |
Equating (10) to (12) and (11) to (13) yields
 |
and
 |
The covariance (cov) term used above was first estimated by Brown [18] and recently an improved estimation (through numerically tabulating the covariance as a function of the correlation and then performing polynomial fits) was provided by Kost and McDermott [30]
where  above is the correlation between
above is the correlation between  and
and  . The
. The 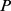 -value for
-value for  is then approximated by that of a Chi-squared distribution
is then approximated by that of a Chi-squared distribution
| (14) |
Equation (14) reduces to Fisher's formula eq. (3) when the 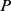 -values are independent and the weights are all same. However, the above equation does not reduces to Good's formula eq. (5) when the
-values are independent and the weights are all same. However, the above equation does not reduces to Good's formula eq. (5) when the 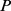 -values are independent and each carries a different weight.
-values are independent and each carries a different weight.
Generating Correlated P-value Vectors
By definition, the  -values of null hypotheses should be uniformly distributed between
-values of null hypotheses should be uniformly distributed between  and
and  , which is often assumed by methods of combining
, which is often assumed by methods of combining 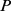 -values. However, the uniformity of
-values. However, the uniformity of  -values, when assigned by available statistical tools to a group of null hypotheses, is often lost. This would handicap the efficacy of methods for combining
-values, when assigned by available statistical tools to a group of null hypotheses, is often lost. This would handicap the efficacy of methods for combining 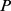 -values from the start. To eliminate the effect of nonuniform null
-values from the start. To eliminate the effect of nonuniform null  -values from our evaluation, we enforce the quasi-uniformity of null
-values from our evaluation, we enforce the quasi-uniformity of null  -values by first constructing a starter
-values by first constructing a starter 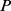 -value vector
-value vector  of size
of size  with the
with the  th element
th element 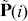 =
=  , for
, for  . (See next paragraph for more details.) This guarantees an even sample of the
. (See next paragraph for more details.) This guarantees an even sample of the 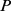 -values (in the range from
-values (in the range from  to
to  ). To achieve correlations of various strengths, we have used
). To achieve correlations of various strengths, we have used 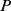 -value vectors, each of which is obtained via permuting (pairwise) the elements of a fixed vector, the starter vector with a small perturbation, by a randomly chosen number. The basic idea is that when the number of pairwise permutations is not large, the resulting
-value vectors, each of which is obtained via permuting (pairwise) the elements of a fixed vector, the starter vector with a small perturbation, by a randomly chosen number. The basic idea is that when the number of pairwise permutations is not large, the resulting 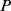 -value vectors will be correlated to the fixed vector and will be correlated among one another. It is worth pointing out that this approach does not generate correlations with a prescribed strength: even with the same number of random pairwise permutations of the vector elements, the correlation between any pair of such permuted vectors does not have a fixed strength. We believe this is closer to the real-world scenario than having a fixed correlation strength among the
-value vectors will be correlated to the fixed vector and will be correlated among one another. It is worth pointing out that this approach does not generate correlations with a prescribed strength: even with the same number of random pairwise permutations of the vector elements, the correlation between any pair of such permuted vectors does not have a fixed strength. We believe this is closer to the real-world scenario than having a fixed correlation strength among the 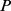 -value vectors. The value of
-value vectors. The value of  should not matter in terms of testing whether a method can provide accurate combined
should not matter in terms of testing whether a method can provide accurate combined 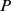 -value. If a small
-value. If a small  is used, however, the combined
is used, however, the combined 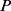 -value will have a large statistical fluctuation that may reduce the resolution of the comparison. On the other hand, making
-value will have a large statistical fluctuation that may reduce the resolution of the comparison. On the other hand, making  large causes a long computational time. We find that using
large causes a long computational time. We find that using  yields enough separations among methods tested without significantly slowing down the computation.
yields enough separations among methods tested without significantly slowing down the computation.
For each method investigated, we have performed a simulation of 500,000 realizations, each of which was conducted as follows. First, pick a random positive integer  with
with  . Second, generate the first
. Second, generate the first 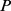 -value vector
-value vector  by adding a small random perturbation (
by adding a small random perturbation ( ) between 0 and
) between 0 and  to each vector element of
to each vector element of  :
:  . Evidently, by increasing the upper bound for
. Evidently, by increasing the upper bound for  , one will produce
, one will produce  -values with larger variations from exactly uniform distribution. In the third step, generate more size-
-values with larger variations from exactly uniform distribution. In the third step, generate more size-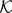 vectors
vectors 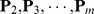 and initialize them to
and initialize them to  . For each vector generated, its vector elements are pairwise permuted
. For each vector generated, its vector elements are pairwise permuted  (chosen at the first step) times. After that using
(chosen at the first step) times. After that using 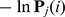 in place of
in place of 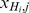 the pairwise correlation
the pairwise correlation  was computed using eq. (8) and the average correlation E
was computed using eq. (8) and the average correlation E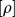 among vectors was computed using eq. (7). This work flow is illustrated in Figure 1 with
among vectors was computed using eq. (7). This work flow is illustrated in Figure 1 with  for simplicity. The constructed random
for simplicity. The constructed random  -value vectors
-value vectors  were then combined to obtain a unified
were then combined to obtain a unified 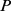 -value vector (
-value vector ( ) using the various methods listed in Table 0. Once the unified
) using the various methods listed in Table 0. Once the unified 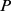 -value vector (
-value vector ( ) was calculated, its elements were sorted in increasing order and it was then compared against the rank (
) was calculated, its elements were sorted in increasing order and it was then compared against the rank ( ) vector, whose element is obtained by dividing the rank of a
) vector, whose element is obtained by dividing the rank of a  element by
element by  , i.e.,
, i.e.,  for
for  ranging from 1 to
ranging from 1 to  . We shall call
. We shall call  , the
, the  th element of the rank vector, the normalized rank of rank
th element of the rank vector, the normalized rank of rank  .
.
Figure 1. Example workflow of generating correlated 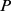 -values and pairwise correlations.
-values and pairwise correlations.

In this example figure,  is
is 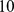 , the number of
, the number of 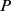 -value vectors is
-value vectors is  , the number of pairwise permutations
, the number of pairwise permutations 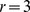 , and the perturbations
, and the perturbations  s are set to zero for clarity and simplicity. The resulting pairwise correlations by using
s are set to zero for clarity and simplicity. The resulting pairwise correlations by using  in place of
in place of  are displayed in a symmetric matrix form.
are displayed in a symmetric matrix form.
Statistical Accuracy Evaluation of the Combined P-value ( )
)
If a method yields a unified 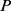 -value vector
-value vector  agreeing with
agreeing with  , the scatter plot of
, the scatter plot of  versus
versus 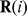 should produce a straight line with slope one and intercept zero [31]. It is also important to mention that the smallest computed
should produce a straight line with slope one and intercept zero [31]. It is also important to mention that the smallest computed 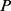 -value is expected to be inversely proportional to the sample size, which for the current case is of the order of
-value is expected to be inversely proportional to the sample size, which for the current case is of the order of  . An example of a logarithmic plot of
. An example of a logarithmic plot of  versus
versus  generated from a single iteration of our simulation is shown in Figure 2. Using the textbook definition of
generated from a single iteration of our simulation is shown in Figure 2. Using the textbook definition of 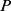 -value, the linear slope obtained from the logarithmic plot of
-value, the linear slope obtained from the logarithmic plot of  versus
versus  should be approximately one for methods with accurate statistics. To quantify how well
should be approximately one for methods with accurate statistics. To quantify how well  agrees with
agrees with  we use four measures: (1) the average weighted sum of squares error (
we use four measures: (1) the average weighted sum of squares error ( ), (2) the distance (
), (2) the distance ( ) between
) between  and
and  , (3) the expected rank E
, (3) the expected rank E , and (4)the expected error of
, and (4)the expected error of  . Figure 2 also illustrates what is being computed by the above four measures.
. Figure 2 also illustrates what is being computed by the above four measures.
Figure 2. Log-log plot of the unified 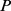 -value vector
-value vector  versus the rank vector
versus the rank vector 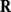 .
.

The curves in panels (A) and (B) were obtained from combining the 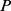 -values of four
-values of four 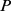 -value vectors, each of size 10,000, using Stouffer's method. In panel (A), the red circles show the scatter plot of normalized rank versus computed
-value vectors, each of size 10,000, using Stouffer's method. In panel (A), the red circles show the scatter plot of normalized rank versus computed 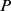 -value from a randomly picked iteration (realization) of very weak average correlation. It is through curves like the one displayed in panel (A) that enables one to calculate the average sum of squares error using eq. (15) and the distance measure using eq. (16). Panel (B) shows 1000 curves, each of which is obtained from performing the same task as that leads to the curve in (A) but with different average correlation strengths. The lines that go significantly above
-value from a randomly picked iteration (realization) of very weak average correlation. It is through curves like the one displayed in panel (A) that enables one to calculate the average sum of squares error using eq. (15) and the distance measure using eq. (16). Panel (B) shows 1000 curves, each of which is obtained from performing the same task as that leads to the curve in (A) but with different average correlation strengths. The lines that go significantly above  line are from cases with stronger average correlations. They yield unified
line are from cases with stronger average correlations. They yield unified 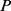 -values that are much exaggerated perhaps due to the fact that the Stouffer's method does not account for correlations. By averaging the normalized rank
-values that are much exaggerated perhaps due to the fact that the Stouffer's method does not account for correlations. By averaging the normalized rank  along the blue line (
along the blue line ( ) yields the value
) yields the value 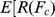 (see eq. (17)). By shifting the blue line to different
(see eq. (17)). By shifting the blue line to different  values renders the entire
values renders the entire  versus
versus  curve. The red horizontal line illustrates the case when
curve. The red horizontal line illustrates the case when  (or normalized rank
(or normalized rank 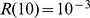 ). By averaging the
). By averaging the 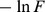 values along this line, the
values along this line, the  value is obtained for
value is obtained for  by simply adding
by simply adding  to the averaged value (see eq. (18)).
to the averaged value (see eq. (18)).
Average Weighted Sum of Squares Error
We define the average weighted sum of squares error as
| (15) |
The weight factor ( ),
), 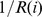 , in the above equation was chosen so that each point in the transformed variable domain carries the same contribution to the
, in the above equation was chosen so that each point in the transformed variable domain carries the same contribution to the  . By construction, the
. By construction, the 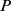 -values in the random vector
-values in the random vector  are uniformly distributed between
are uniformly distributed between  . However, once we make the logarithmic transformation,
. However, once we make the logarithmic transformation,  , we find the new variable
, we find the new variable  to be exponentially distributed, i.e.,
to be exponentially distributed, i.e.,  . One may thus introduce
. One may thus introduce  , a weight factor making
, a weight factor making  , to compensate the non-uniformity in
, to compensate the non-uniformity in  . This leads to
. This leads to  , the weight factor used in eq. (15).
, the weight factor used in eq. (15).
Angular Distance Between F and R
To compute the distance between  and
and  , we began by first computing the slope (
, we began by first computing the slope ( ) of the logarithmic plot of
) of the logarithmic plot of 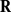 versus
versus  using a weighted least-square regression, which aims to minimize the weighted sum of squares error (
using a weighted least-square regression, which aims to minimize the weighted sum of squares error ( )
)
Taking the derivative of the above expression with respect to  and
and  and setting them equal to zero gives the following equations:
and setting them equal to zero gives the following equations:
and
 |
Solving the above two equations simultaneously for a and b gives
 |
where  and
and  are the weighted average of
are the weighted average of  and
and  respectively and
respectively and
 |
From  and
and  , a normalized vector
, a normalized vector  was computed using the points
was computed using the points  and
and  along the regression line. Similarly another normalized vector
along the regression line. Similarly another normalized vector  was obtained using the points
was obtained using the points  and
and  along the ideal line. Finally, the (angular)distance between the two unit vectors
along the ideal line. Finally, the (angular)distance between the two unit vectors  and
and 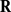 was computed
was computed
 |
(16) |
Methods with accurate statistics are expected to have  and
and 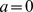 . Evidently,
. Evidently,  leads to
leads to  (see eq. (16)). The independence of the angular distance
(see eq. (16)). The independence of the angular distance  on the intercept parameter
on the intercept parameter  implies that
implies that  only measures the relative accuracy of the
only measures the relative accuracy of the 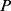 -value, not the absolute accuracy. For example, if
-value, not the absolute accuracy. For example, if  , even when the positive constant
, even when the positive constant  is different from
is different from  ,
,  is still zero.
is still zero.
Expected Rank E[ ]
]
For iteration 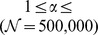 , we denote by
, we denote by  the largest normalized rank whose corresponding reported
the largest normalized rank whose corresponding reported 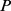 -value is less than or equal to a selected cutoff
-value is less than or equal to a selected cutoff 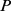 -value
-value  . The expected rank E[
. The expected rank E[ ] is computed by averaging
] is computed by averaging  over all realizations and can be written as
over all realizations and can be written as
| (17) |
In the ideal case of absolute accuracy, 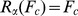 . In reality, this is hardly the case and that is why we use the expectation value of
. In reality, this is hardly the case and that is why we use the expectation value of  versus
versus  as the measure. For methods with accurate statistics a plot of E[
as the measure. For methods with accurate statistics a plot of E[ ] versus
] versus  should trace closely the line
should trace closely the line  .
.
Expected Error of 
The expected error of  relative to
relative to  (for
(for  ) is defined as
) is defined as
| (18) |
and the standard deviation
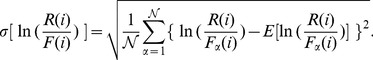 |
(19) |
For methods with accurate statistics, plotting 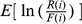 versus
versus  should track the line
should track the line  well and have small standard deviations for various
well and have small standard deviations for various  .
.
Results and Discussion
The four measures mentioned in the methods section are used to evaluate the accuracy of the unified 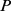 -value computed. In Figures 3, 4, 5 and 6, we show the results of combining a list of
-value computed. In Figures 3, 4, 5 and 6, we show the results of combining a list of 
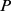 -values. The layout of each of these figure is identical. For each method considered, our simulation includes a total of
-values. The layout of each of these figure is identical. For each method considered, our simulation includes a total of 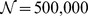 iterations. At each iteration, we generated
iterations. At each iteration, we generated  lists, within which the
lists, within which the  th list is obtained by taking the
th list is obtained by taking the  entry of each of the 12
entry of each of the 12 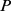 -value vectors,
-value vectors,  . By computing the pairwise correlation (see eq. (8)) among the
. By computing the pairwise correlation (see eq. (8)) among the 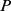 -value vectors, one obtains the average pairwise correlation E
-value vectors, one obtains the average pairwise correlation E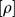 given by eq. (7). Each iteration, generating a
given by eq. (7). Each iteration, generating a  -tuples of
-tuples of  -value vectors, thus yields an average correlation
-value vectors, thus yields an average correlation  .
.
Figure 3. Methods that combine independent  -values: Fisher, Stouffer and Bhoj.
-values: Fisher, Stouffer and Bhoj.

The curves plotted above are the curves for the four different measures used to evaluate the accuracy of the computed  -value from combining the
-value from combining the  -values of 12
-values of 12 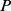 - value vectors.In panel C, note that the Fisher curve (red) is almost completely covered by the Bhoj curve (green). See text for more details.
- value vectors.In panel C, note that the Fisher curve (red) is almost completely covered by the Bhoj curve (green). See text for more details.
Figure 4. Methods that combine weighted independent 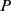 -values: Good, Lipták and Bhoj.
-values: Good, Lipták and Bhoj.

The curves plotted above are the curves for the four different measures used to evaluate the accuracy of the computed 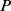 -value from combining the
-value from combining the 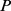 -values of 12
-values of 12  -value vectors. See text for more details.
-value vectors. See text for more details.
Figure 5. Methods that combine correlated  -values: Hartung and Hou.
-values: Hartung and Hou.

The curves plotted above are the curves for the four different measures used to evaluate the accuracy of the computed  -value from combining the
-value from combining the  -values of 12
-values of 12  -value vectors. See text for more details.
-value vectors. See text for more details.
Figure 6. Methods that combine weighted correlated  -values: Hartung and Hou.
-values: Hartung and Hou.

The curves plotted above are the curves for the four different measures used to evaluate the accuracy of the computed  -value from combining the
-value from combining the  -values of 12
-values of 12 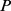 -value vectors. See text for more details.
-value vectors. See text for more details.
For Figures 3, 4, 5, 6, the data points in panels A and B respectively display the expected average sums of square errors (E ) and expected distances (E
) and expected distances (E ) versus E
) versus E . More specifically, every data point plotted with
. More specifically, every data point plotted with  -axis value
-axis value  represents an average of 25,000 iterations, each of which has its
represents an average of 25,000 iterations, each of which has its  -tuple's average correlation
-tuple's average correlation  fall in the range of
fall in the range of  . For panels C, D, E and F, each data point plotted is computed using all the
. For panels C, D, E and F, each data point plotted is computed using all the  iterations from our simulation. The curves in panel C show the expected number of events with unified
iterations from our simulation. The curves in panel C show the expected number of events with unified 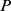 -value computed less than or equal to a cutoff value
-value computed less than or equal to a cutoff value 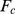 . For methods with accurate statistics, by the definition of
. For methods with accurate statistics, by the definition of 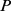 -value, a plot of E
-value, a plot of E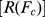 versus
versus  should follow the line
should follow the line  . Panels D and E (and F for Figures 3 and 4) display the expected
. Panels D and E (and F for Figures 3 and 4) display the expected  value together with its standard deviation as a function of
value together with its standard deviation as a function of  . Similar plots for the combination of 4 and 8
. Similar plots for the combination of 4 and 8 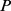 -value vectors can be found in File S1.
-value vectors can be found in File S1.
Figure 3 displays the results for methods that assume the the 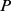 -values to be combined are independent: Fisher's (eq. 3), Stouffer's (eq. 1) and Bhoj's (eq. 6) methods. These methods are expected to compute accurate combined
-values to be combined are independent: Fisher's (eq. 3), Stouffer's (eq. 1) and Bhoj's (eq. 6) methods. These methods are expected to compute accurate combined 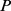 -values for E
-values for E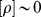 , corresponding to the first few data points of panels A and B. The data points in panels A and B show that as E
, corresponding to the first few data points of panels A and B. The data points in panels A and B show that as E increases so does the E
increases so does the E and E
and E , indicating the methods' inadequacy for handling correlation among
, indicating the methods' inadequacy for handling correlation among 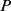 -values. All three curves in panel C lie above the
-values. All three curves in panel C lie above the 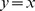 line, indicating that all three methods exaggerate significance when combining correlated
line, indicating that all three methods exaggerate significance when combining correlated 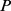 -values. The curves in panels D, E and F show that the average value (red solid curve) of
-values. The curves in panels D, E and F show that the average value (red solid curve) of  can deviate significantly from
can deviate significantly from  axis with wild fluctuations (error bars shown in blue). Also, a comparison with the plots obtained from combining 4, 8, and 12
axis with wild fluctuations (error bars shown in blue). Also, a comparison with the plots obtained from combining 4, 8, and 12  -value vectors indicates that the accuracy of the unified
-value vectors indicates that the accuracy of the unified  -value decreases as the number of
-value decreases as the number of 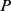 -values combined increases from 4 to 12.
-values combined increases from 4 to 12.
Figure 4 shows the results for methods that combine weighted independent 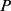 -values: Good's (eq. 5), Lipták's (eq. 1) and Bhoj's (eq. 6) methods. These three methods may be viewed as extensions of the previous three methods with
-values: Good's (eq. 5), Lipták's (eq. 1) and Bhoj's (eq. 6) methods. These three methods may be viewed as extensions of the previous three methods with 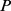 -value weighting enabled. Comparison of the panels of Figure 4 with that of Figure 3 shows noticeable improvement on the accuracy of the combined
-value weighting enabled. Comparison of the panels of Figure 4 with that of Figure 3 shows noticeable improvement on the accuracy of the combined 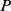 -values. Although the accuracy has improved by weighting the
-values. Although the accuracy has improved by weighting the 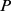 -values, the computed
-values, the computed 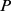 -value still differs significantly from the expected value. The observed improvement suggests that weighting
-value still differs significantly from the expected value. The observed improvement suggests that weighting 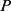 -values might weaken the effect of correlation by promoting one
-values might weaken the effect of correlation by promoting one  -value over the rest in the list of
-value over the rest in the list of  -values to be combined. Other studies have also recommended [32], [33] weighting
-values to be combined. Other studies have also recommended [32], [33] weighting  -values to improve statistical power. Even though weighting
-values to improve statistical power. Even though weighting 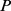 -values is recommended, there exists no consensus on how to determine the optimal weights [6], [24]-[26]. This is why in our simulation we have assigned random weights to the
-values is recommended, there exists no consensus on how to determine the optimal weights [6], [24]-[26]. This is why in our simulation we have assigned random weights to the 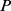 -values to be combined. In principle, the accuracy of the computed
-values to be combined. In principle, the accuracy of the computed 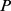 -value from the three methods above could be improved by using a different procedure to compute the weights. Such an investigation, although worth pursuing in its own right, is beyond the scope of the current study.
-value from the three methods above could be improved by using a different procedure to compute the weights. Such an investigation, although worth pursuing in its own right, is beyond the scope of the current study.
Figure 5 shows the results from using methods designed to combine correlated 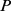 -values: Hartung's (eq. 9) and Hou's (eq. 14) methods. The curves in Figure 5 when compared with the curves of Figure 3 and 4 show a significant improvement in the accuracy of the combined
-values: Hartung's (eq. 9) and Hou's (eq. 14) methods. The curves in Figure 5 when compared with the curves of Figure 3 and 4 show a significant improvement in the accuracy of the combined 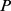 -value computed. From the curves of Figure 5 Hou's method seems to be the better performing one, it has a smaller expected error and standard deviation when compared with the curves obtained from Hartung's method. As shown in panel C of Fig. 6, Hou's E
-value computed. From the curves of Figure 5 Hou's method seems to be the better performing one, it has a smaller expected error and standard deviation when compared with the curves obtained from Hartung's method. As shown in panel C of Fig. 6, Hou's E vs
vs  curve also traces reasonable well the line
curve also traces reasonable well the line  , deviating from it only by a factor of about 4.0 for
, deviating from it only by a factor of about 4.0 for  .
.
Finally, in Figure 6 we have the evaluation results of methods that combine weighted correlated  -values: Hartung's (eq. 9) and Hou's (eq. 14) methods. When the curves of Figure 6 are compared with that of Figure 5, as before it shows that weighting
-values: Hartung's (eq. 9) and Hou's (eq. 14) methods. When the curves of Figure 6 are compared with that of Figure 5, as before it shows that weighting  -values tends to improve the accuracy of the the computed
-values tends to improve the accuracy of the the computed  -value The curves also show that Hou's method has a larger improvement in accuracy by using weights in comparison to Hartung's method. As articulated earlier and supported by the observed results, there is a possibility that the accuracy of the combined
-value The curves also show that Hou's method has a larger improvement in accuracy by using weights in comparison to Hartung's method. As articulated earlier and supported by the observed results, there is a possibility that the accuracy of the combined  -value could be further improved by having a statistically and mathematically rigorous procedure that could render the optimal weights to be used.
-value could be further improved by having a statistically and mathematically rigorous procedure that could render the optimal weights to be used.
In a brief summary, methods designed for combining independent
 -values tend to yield exaggerated
-values tend to yield exaggerated  -values when used to combining correlated
-values when used to combining correlated  -values. On the other hand, most methods designed to handle correlated
-values. On the other hand, most methods designed to handle correlated 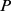 -values tend to provide conservative estimates for the unified
-values tend to provide conservative estimates for the unified 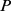 -values. The first case can be understood easily since one is effectively using nearly identical evidences to corroborate one another. For the latter case, however, we can not provide an intuitive interpretation except that it might result from the heuristics those methods employed. Weighting
-values. The first case can be understood easily since one is effectively using nearly identical evidences to corroborate one another. For the latter case, however, we can not provide an intuitive interpretation except that it might result from the heuristics those methods employed. Weighting 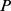 -values seems to weaken the effect of correlation. This can be roughly understood as follows. By weighting each of the
-values seems to weaken the effect of correlation. This can be roughly understood as follows. By weighting each of the 
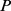 -values, only the
-values, only the 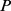 -values assigned the highest weights play a role. This increase the likelihood of having the highest weighted
-values assigned the highest weights play a role. This increase the likelihood of having the highest weighted  -values be nearly independent, thereby reducing the effect of correlations. Not only does it help the methods designed for combining independent
-values be nearly independent, thereby reducing the effect of correlations. Not only does it help the methods designed for combining independent 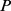 -values, it also helps the ones for combining correlated
-values, it also helps the ones for combining correlated 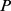 -values as most of these methods are heuristic-based and get more accurate results when the correlation is weaker. Based on these results, when the lists of the
-values as most of these methods are heuristic-based and get more accurate results when the correlation is weaker. Based on these results, when the lists of the 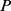 -value vectors are complete, it is best to calculate the corresponding pairwise correlations between any two
-value vectors are complete, it is best to calculate the corresponding pairwise correlations between any two  -value vectors, introduce weights, and then assign the final unified statistical significance to each hypothesis.
-value vectors, introduce weights, and then assign the final unified statistical significance to each hypothesis.
In real applications, however, one is often faced with incomplete lists of  -values. That is, one only has the
-values. That is, one only has the  -values for the highest ranking hypotheses, not for all hypotheses tested. This prevents one from computing the correlations needed for the formalism for combining correlated
-values for the highest ranking hypotheses, not for all hypotheses tested. This prevents one from computing the correlations needed for the formalism for combining correlated  -values. In this case, i.e., when combining
-values. In this case, i.e., when combining 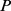 -values of unknown correlation, one should exercise caution. Absent the correlation information, a better option might be to use the smallest of the
-values of unknown correlation, one should exercise caution. Absent the correlation information, a better option might be to use the smallest of the 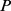 -values to be combined and then apply the Bonferroni correction by multiplying the smallest
-values to be combined and then apply the Bonferroni correction by multiplying the smallest 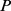 -value by
-value by  , the number of
, the number of 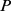 -values to be combined. This will guarantee a conserved statistics. However, under this approach, one might run into cases where the smallest
-values to be combined. This will guarantee a conserved statistics. However, under this approach, one might run into cases where the smallest 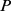 -values considered is larger than
-values considered is larger than  , thereby obtaining a corrected
, thereby obtaining a corrected 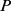 -value that is larger than
-value that is larger than  . Even if each of the
. Even if each of the 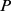 -value lists is complete, there are still scenarios not covered in this paper. For example, it is possible that higher order correlations (such as the three-body or four-body) exist among the
-value lists is complete, there are still scenarios not covered in this paper. For example, it is possible that higher order correlations (such as the three-body or four-body) exist among the 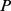 -value vectors. We did not consider these cases since we are not aware of any readily available methods designed to deal with such type of higher order correlations.
-value vectors. We did not consider these cases since we are not aware of any readily available methods designed to deal with such type of higher order correlations.
In conclusion our study recommends that the unified 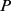 -value obtained from combining
-value obtained from combining 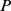 -values of unknown correlation should be used with caution to prevent from drawing false conclusions. Results from our study agree with previous investigations [6], [8], [10], supporting the hypothesis that weighting
-values of unknown correlation should be used with caution to prevent from drawing false conclusions. Results from our study agree with previous investigations [6], [8], [10], supporting the hypothesis that weighting 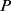 -values has the potential to improve the accuracy of the combined
-values has the potential to improve the accuracy of the combined 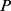 -value. However, the important issues of choosing the weights to optimize a method's power and estimating the correlation matrix elements among
-value. However, the important issues of choosing the weights to optimize a method's power and estimating the correlation matrix elements among 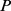 -values from small sample sizes remain challenging [34], [35]. Our results also show that when combining independent or weighted independent
-values from small sample sizes remain challenging [34], [35]. Our results also show that when combining independent or weighted independent 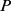 -values, Bhoj's method produces more accurate
-values, Bhoj's method produces more accurate 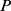 -values than other methods tested. In the case when the correlation information is available, among the methods investigated, Hou's method, able to accommodate
-values than other methods tested. In the case when the correlation information is available, among the methods investigated, Hou's method, able to accommodate 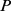 -value weighting, seems to be the best performing method.
-value weighting, seems to be the best performing method.
Supporting Information
This pdf file contains eight figures showing 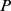 -value accuracy evaluation of methods considered in this manuscript when combining 4 and 8
-value accuracy evaluation of methods considered in this manuscript when combining 4 and 8  -value vectors.
-value vectors.
(PDF)
Acknowledgments
We thank the administrative group of the National Institutes of Health Biowulf Clusters, where all the computational tasks were carried out. We also thank the National Institutes of Health Fellows Editorial Board for editorial assistance.
Funding Statement
This work was supported by the Intramural Research Program of the National Library of Medicine at the National Institutes of Health/Department of Health and Human Services. Funding for Open Access publication charges for this article was provided by the National Institutes of Health. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Olkin I (1995) Statistical and theoretical considerations in meta-analysis. J Clin Epidemiol 48: 133–146. [DOI] [PubMed] [Google Scholar]
- 2. Bailey TL, Gribskov M (1998) Combining evidence using p-values: application to sequence homology searches. Bioinformatics 14: 48–54. [DOI] [PubMed] [Google Scholar]
- 3. Alves G, Wu WW, Wang G, Shen RF, Yu YK (2008) Enhancing peptide identification confidence by combining search methods. J Proteome Res 7: 3102–3113. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Rosenthal R (1978) Combining Results of Independent studies. Psychological Bulletin 85: 185–193. [Google Scholar]
- 5. Loughin TM (2004) A systematic comparison of methods for combining p-values from independent tests. Computational Statistics & Data Analysis 47: 467–485. [Google Scholar]
- 6. Whitlock MC (2005) Combining probability from independent tests: the weighted Z-method is superior to Fisher's approach. J Evol Biol 18: 1368–1373. [DOI] [PubMed] [Google Scholar]
- 7. Won S, Morris N, Lu Q, Elston RC (2009) Choosing an optimal method to combine P-values. Stat Med 28: 1537–1553. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Chen Z (2011) Is the weighted z-test the best method for combining probabilities from independent tests? J Evol Biol 24: 926–930. [DOI] [PubMed] [Google Scholar]
- 9. Chen Z, Nadarajah S (2014) On the optimally weighted -test for combining probabilities from independent studies. Computational Statistics & Data Analysis 70: 387–394. [Google Scholar]
- 10.Zaykin DV (2011) Optimally weighted Z-test is a powerful method for combining probabilities in meta-analysis. J Evol Biol. [DOI] [PMC free article] [PubMed]
- 11. Dudbridge F, Koeleman BP (2003) Rank truncated product of P-values, with application to genomewide association scans. Genet Epidemiol 25: 360–366. [DOI] [PubMed] [Google Scholar]
- 12. Demetrescu M, Hassler U, Tarcolea AI (2006) Combining significance of correlated statistics with application to panel data. Oxford Bulletin of Economics and Statistics 68: 647–663. [Google Scholar]
- 13. Lipták P (1958) On the combination of independent tests. Magyar Tud Akad Nat Kutato int Kozl 3: 171–197. [Google Scholar]
- 14. Good IJ (1955) On the weighted combination of significance tests. Journal of the Royal Statistical Society Series B (Methodological) 17: 264–265. [Google Scholar]
- 15. Bhoj DS (1992) On the distribution of the weighted combination of independent probabilities. Statistics & Probability Letters 15: 37–40. [Google Scholar]
- 16. Hartung J (1999) A note on combining dependent tests of significance. Biometrical Journal 41: 849–855. [Google Scholar]
- 17. Hou CD (2005) A simple approximation for the distribution of the weighted combination of nonindependent or independent probabilities. Statistics & Probability Letters 73: 179–187. [Google Scholar]
- 18. Brown MB (1975) A method for combining non-independent, one-sided tests of significance. Biometrics 31: 987–992. [Google Scholar]
- 19. Vattathil S, Scheet P (2013) Haplotype-based profiling of subtle allelic imbalance with SNP arrays. Genome Res 23: 152–158. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Stouffer S, Suchman E, DeVinney L, Star S, Williams RMJ (1949) The American Soldier, Vol. 1: Adjustment during Army Life. Princeton: Princeton University Press.
- 21.Fisher RA (1932) Statistical Methods for Research Workers, vol. II. Edinburgh: Oliver and Boyd.
- 22. Lancaster HD (1961) The combination of probabilities: an application of orthogonal functions. Austr J Statist 3: 20–33. [Google Scholar]
- 23.Hedges L, Olkin I (1985) Statistical methods for meta-analysis. New York: Academic Press.
- 24.Zelen M, Joel LS (1959) The weighted compounding of two independent significance tests. The Annals of Mathematical Statistics 30 : pp. 885–895. [Google Scholar]
- 25. Pepe MS, Fleming TR (1989) Weighted Kaplan-Meier statistics: a class of distance tests for censored survival data. Biometrics 45: 497–507. [PubMed] [Google Scholar]
- 26. Loesgen S, Dempfle A, Golla A, Bickeboller H (2001) Weighting schemes in pooled linkage analysis. Genet Epidemiol 21 Suppl 1S142–147. [DOI] [PubMed] [Google Scholar]
- 27. Alves G, Yu YK (2011) Combining independent, weighted p-values: Achieving computational stability by a systematic expansion with controllable accuracy. PLoS ONE 6: e22647. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Delongchamp R, Lee T, Velasco C (2006) A method for computing the overall statistical significance of a treatment effect among a group of genes. BMC Bioinformatics 7 Suppl 2S11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Satterthwaite FE (1946) An approximate distribution of estimates of variance components. Biometrics Bulletin 2: 110–114. [PubMed] [Google Scholar]
- 30. Kost JT, McDermott MP (2002) Combining dependent p-values. Statistics & Probability Letters 60: 183–190. [Google Scholar]
- 31. Schweder T, Spjotvoll E (1982) Plots of p-values to evaluate many tests simultaneously. Biometrika 69: 493–502. [Google Scholar]
- 32. Genovese CR, Roeder K, Wasserman L (2006) False discovery control with p-value weighting. Biometrika 93: 509–524. [Google Scholar]
- 33. Hu JX, Zhao H, Zhou HH (2010) False Discovery Rate Control With Groups. J Am Stat Assoc 105: 1215–1227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Liechty JC, Liechty MW, Muller P (2004) Bayesian correlation estimation. Biometrika 91: 1–14. [Google Scholar]
- 35. Peng J, Wang P, Zhou N, Zhu J (2009) Partial correlation estimation by joint sparse regression models. Journal of the American Statistical Association 104: 735–746. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
This pdf file contains eight figures showing -value accuracy evaluation of methods considered in this manuscript when combining 4 and 8 -value vectors.
(PDF)