

Significance
Science is an activity with far-reaching implications for modern society. Understanding how the social organization of science and its fundamental unit, the research team, forms and evolves is therefore of critical significance. Previous studies uncovered important properties of the internal structure of teams, but little attention has been paid to their most basic property: size. This study fills this gap by presenting a model that successfully explains how team sizes in various fields have evolved over the past half century. This model is based on two principles: (i) smaller (core) teams form according to a Poisson process, and (ii) larger (extended) teams begin as core teams but consequently accumulate new members through the process of cumulative advantage based on productivity.
Keywords: team science, cumulative advantage
Abstract
Research teams are the fundamental social unit of science, and yet there is currently no model that describes their basic property: size. In most fields, teams have grown significantly in recent decades. We show that this is partly due to the change in the character of team size distribution. We explain these changes with a comprehensive yet straightforward model of how teams of different sizes emerge and grow. This model accurately reproduces the evolution of empirical team size distribution over the period of 50 y. The modeling reveals that there are two modes of knowledge production. The first and more fundamental mode employs relatively small, “core” teams. Core teams form by a Poisson process and produce a Poisson distribution of team sizes in which larger teams are exceedingly rare. The second mode employs “extended” teams, which started as core teams, but subsequently accumulated new members proportional to the past productivity of their members. Given time, this mode gives rise to a power-law tail of large teams (10–1,000 members), which features in many fields today. Based on this model, we construct an analytical functional form that allows the contribution of different modes of authorship to be determined directly from the data and is applicable to any field. The model also offers a solid foundation for studying other social aspects of science, such as productivity and collaboration.
Contemporary science has undergone major changes in the last half century at all levels: institutional, intellectual, and social, as well as in its relationship with society at large. Science has been changing in response to increasingly complex problems of contemporary society and the inherently challenging nature of unresolved questions, with an expectation to serve as a major driver for economic growth. Consequently, the contemporary science community has adopted a problem-driven approach to knowledge production that often blurs the lines between pure and applied, and is more permeable around disciplinary borders, leading to cross-/multi/inter/transdisciplinarity (1). The major staple of this approach is team effort (2–5). The increased prominence of scientific teams has recently led to a formation of research area, “science of team science,” which is “centered on examination of the processes by which scientific teams organize, communicate, and conduct research” (6). If we want not only to understand contemporary science but also to create and promote viable science policies, we need to uncover principles that lead to the formation and subsequent evolution of scientific research teams.
Studies of collaboration in science, and coauthorship as its most visible form, have a long history (7–11). The collaborative mode of knowledge production is often perceived as being in contrast to the individualistic mode of the past centuries (12, 13). Previous studies have established that the fraction of coauthored papers has been growing with respect to single-authored papers (5), that in recent decades teams have been growing in size (14), and that interinstitution and international teams are becoming more prevalent (15, 16). In addition, high-impact research is increasingly attributed to large teams (5, 6), as is research that features more novel combination of ideas (17). The reasons for an increase in collaborative science have been variously explained as due to the shifts in the types of problems studied (1) and the related need for access to more complex instruments and broader expertise (15, 18, 19).
A research team is a group of researchers collaborating to produce scientific results, which are primarily communicated in the form of research articles. Researchers who appear as authors on a research article represent a visible and easily quantifiable manifestation of a collaborative, team science effort. We refer to such a group of authors as an “article team.” In this study, we focus on one of the most fundamental aspects of team science: “article team size distribution” and its change/evolution over time. (In the rest of the article, we will refer to an article team simply as “the team.”) Many studies focused only on the mean or the median sizes of teams, implicitly assuming that the character of the distribution of team sizes does not change. Relatively few studies examined full team size distribution, albeit for rather limited datasets (10, 20, 21), with some of them noticing the changing character of this distribution (10). The goal of the current study is to present a more accurate characterization and go beyond empirical observations to provide a model of scientific research team formation and evolution that leads to the observed team size distributions.
Despite a large number of studies of coauthorship and scientific teams, there are few explanatory models. One such exception is the model by Guimerà et al. (2) of the self-assembly of teams, which is based on the role that newcomers and repeated collaborations play in the emergence of large connected communities and the success of team performance. Although their model features team size as a parameter, its values were not predicted by the model but were taken as input from the list of actual publications. The objective of the current study is to go beyond the internal composition of teams to explain the features of team size distribution and its change over the past half century. Thus, the model we propose in this paper is complementary to the efforts by Guimerà et al. Our model is based on several simple principles that govern team formation and its evolution. The validity of the model is confirmed by constructing simulated team size distributions that closely match the empirical ones based on 150,000 articles published in the field of astronomy since the 1960s. We reveal the existence of two principal modes of knowledge production: one that forms small core teams based on a Poisson process, and the other that leads to large, extended teams that grow gradually on the principle of cumulative advantage.
Empirical Team Size Distributions
The significant change in the character of team size distribution is the key insight underlying the proposed model. Previous studies have shown a marked increase in the mean team size in recent decades, not only in astronomy (e.g., refs. 2 and 22), but in all scientific fields (5). Specifically, the average team size in astronomy grew from 1.5 in 1961–1965 to 6.7 in 2006–2010 (marked by arrows in Fig. 1, which shows, on a log-log scale, team size distributions in the field of astronomy in two time periods). However, Fig. 1 reveals even more: a recent distribution (2006–2010) is not just a scaled-up version of the 1961–1965 distribution shifted toward larger values; it has a profoundly different shape. Most notably, although in 1961–1965 the number of articles with more than five authors was falling precipitously, and no article featured more than eight authors, now there exists an extensive tail of large teams, extending to team sizes of several hundred authors. The tail closely follows the power-law distribution (red line in Fig. 1). The power-law tail is seen in recent team size distributions of other fields as well (25). In contrast, the “original” 1961–1965 distribution did not feature a power-law tail. Instead, most team sizes were in the vicinity of the mean value. The shape of this original distribution can instead be described with a simple Poisson distribution (blue curve in Fig. 1), an observation made in some previous works (10, 20). Note that the time when the distribution stopped being Poisson would differ from field to field.
Fig. 1.

Distribution of article team sizes in astronomy in two time periods separated by 45 y. The distribution from 1961 to 1965 is well described by a Poisson distribution (blue curve). This is in contrast to 2006–2010 distribution, which features an extensive power-law tail (red line). The arrows mark the mean values of each distribution. For 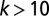 (
(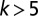 for 1961–1965), the data are binned in intervals of 0.1 decades, thus revealing the behavior far in the tail, where the frequency of articles of a given size is up to million times lower than in the peak. All distributions in this and subsequent figures are normalized to the 2006–2010 distribution in astronomy. Error bars in this and subsequent figures correspond to 1 SD. The full dataset consists of 154,221 articles published between 1961 and 2010 in four core astronomy journals (listed in SI Materials and Methods), which publish the majority of research in this field (23). Details on data collection are given elsewhere (24).
for 1961–1965), the data are binned in intervals of 0.1 decades, thus revealing the behavior far in the tail, where the frequency of articles of a given size is up to million times lower than in the peak. All distributions in this and subsequent figures are normalized to the 2006–2010 distribution in astronomy. Error bars in this and subsequent figures correspond to 1 SD. The full dataset consists of 154,221 articles published between 1961 and 2010 in four core astronomy journals (listed in SI Materials and Methods), which publish the majority of research in this field (23). Details on data collection are given elsewhere (24).
We interpret the fact that the distribution of team sizes in astronomy in the 1960s is well described as a stochastic variable drawn from a Poisson distribution to mean that initially the production of a scientific paper used to be governed by a “Poisson process” (26, 27). This is an intuitively sound explanation because many real-world phenomena involving low rates arise from a Poisson process. Examples include pathogen counts (28), highway traffic statistics (29), and even sports scores (30). Team assembly can be viewed as a low-rate event, because its realization involves few authors out of a very large possible pool of researchers. Poisson rate (λ) can be interpreted as a characteristic number of authors that are necessary to carry out a study. The actual realization of the process will produce a range of team sizes, distributed according to a Poisson distribution with the mean being this characteristic number.
In contrast, the dynamics behind the power-law distribution that features in team sizes in recent times is fundamentally different from a simple Poisson process, and instead suggests the operation of a process of “cumulative advantage.” Cumulative advantage, also known as the Yule process, and as preferential attachment in the context of network science (31, 32), has been proposed as an explanation for the tails of collaborator and citation distributions (25, 32–38). Unlike the Poisson process, cumulative advantage is a dynamic process in which the properties of a system depend on its previous state. How did a distribution characterized by a Poisson function evolve into one that follows a power law? Does this evolution imply a change in the mode of the team assembly? Does a Poisson process still operate today? Fig. 1 shows that, for smaller team sizes 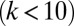 , the power law breaks down, forming instead a “hook.” This small-k behavior must not be neglected because the great majority of articles (90%) are still published in teams with fewer than 10 authors. The hook, peaking at teams with two or three authors, may represent a vestige of what was solely the Poisson distribution in the past. This simple assumption is challenged by the fact that no single Poisson distribution can adequately fit the small-k portion of the 2006–2010 team size distribution. Namely, the high ratio of two-author papers to single-author papers in the 2006–2010 distribution would require a Poisson distribution with
, the power law breaks down, forming instead a “hook.” This small-k behavior must not be neglected because the great majority of articles (90%) are still published in teams with fewer than 10 authors. The hook, peaking at teams with two or three authors, may represent a vestige of what was solely the Poisson distribution in the past. This simple assumption is challenged by the fact that no single Poisson distribution can adequately fit the small-k portion of the 2006–2010 team size distribution. Namely, the high ratio of two-author papers to single-author papers in the 2006–2010 distribution would require a Poisson distribution with 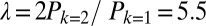 . Such distribution produces a peak at
. Such distribution produces a peak at 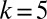 , which is significantly offset compared with its actual position. Evidently, the full picture involves some additional elements.
, which is significantly offset compared with its actual position. Evidently, the full picture involves some additional elements.
In the following section, we present a model that combines the aforementioned processes and provides answers to the questions raised in this section, demonstrating that knowledge production occurs in two principal modes.
Model of Team Formation and Evolution
We next lay out a relatively simple model that incorporates principles of team formation and its evolution. We produce simulated team size distributions based on the model and validate them by testing how well they “predict” empirical distributions in the field of astronomy. This model is universally applicable to other fields, as will be discussed later.
The model consists of authors who write papers over time. Each paper has a “lead” author who is responsible for putting together a team and producing a paper. Each lead author is associated with two types of teams: “core” and “extended.” Core teams consist of the lead author and coauthors. Their size is drawn from a Poisson distribution with some rate λ. If the drawing yields the number 1, the core team consists of the lead author alone. We allow λ, the characteristic size of core teams, to grow with time. Existing authors, when they publish again, retain their original core teams. The probability of publishing by an author who has published previously is 0.8. Unlike core teams, extended teams evolve dynamically. Initially, the extended team has the same members as the core team. However, the extended team is allowed to add new members in proportion to the aggregate productivity of its current members. New extended team members are randomly chosen from core teams of existing members, or from a general pool if no such candidates are available. The cumulative advantage principle that governs the growth of extended teams will mean that teams that initially happen to have more members in their core teams and/or whose members have published more frequently as lead authors, will accrete more new members than the initially smaller and/or less productive teams. (We have tested several flavors of cumulative advantage and found that the empirical distributions are best reproduced when the growth follows the aggregate productivity of all members as lead authors, rather than their productivity that includes coauthorships.) This process allows some teams to grow very large, beyond the size that can be achieved with a Poisson process. The process is gradual, so very large teams appear only when some time has passed. It is important that extended teams do not replace core teams; they coexist, and the lead author can choose to publish with one or the other at any time. This choice is presumably based on the type or complexity of a research problem. In simulation, we assume a fixed probability 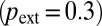 for an article to require an extended team. Core and extended teams correspond to traditional and team-oriented modes of knowledge production, respectively.
for an article to require an extended team. Core and extended teams correspond to traditional and team-oriented modes of knowledge production, respectively.
We also incorporate several additional elements to this basic outline that brings the model closer to reality. First, the empirical data indicate that in recent times there is an excess of two-author papers over single-author papers, especially from authors who have just started publishing. Apparently, such authors tend not to publish alone, probably because they include their mentors as coauthors. To reproduce such behavior, we posit in the model that some fraction of lead authors will form their core teams by adding an additional member to the number drawn from a Poisson distribution. We call such teams “core +1 teams,” as opposed to “standard core teams.” Furthermore, we assume that repeat publications are more likely from authors who started publishing more recently. Finally, we assume that certain authors retire and their teams are dissolved. However, the process of retirement is not essential to reproduce the empirical team size distribution.
The model is implemented through a simulation of 154,221 articles, each with a list of “authors.” The number of articles is set to match the empirical number of articles published within the field of astronomy in the period 1961–2010. The sequence in which the articles are produced in the simulation allows us to match them to actual publication periods (e.g., articles with sequential numbers 51,188–69,973 correspond to articles published from 1991 to 1995). In Fig. 2, we show a compelling match between the real data (dots with error bars) and the predictions of our model (values connected by colored lines) for three time periods (1961–1965, 1991–1995, and 2006–2010). The model correctly reproduces the emergence of the power-law tail and its subsequent increased prominence, as well as the change in the shape of the low-k distribution (the hook), and the shift of the peak from single-author papers to those with two or three authors. The strongest departure of the model from the empirical distribution is the bump in the far tail of the 2006–2010 distribution (around k = 200). We have identified this “excess” to be due to several papers that were published by a Fermi collaboration (39) over a short period. Note, however, that only 0.6% of all 2006–2010 papers were published by teams with more than 100 authors.
Fig. 2.

Comparison between article team size distributions based on model simulation (values connected by colored lines) and the empirical data (points) for the field of astronomy in three time periods. Our model for the formation and evolution of teams reproduces the observed distributions remarkably well. The model assumes that each lead author forms a core team through a Poisson process. Additionally, extended teams arise from core teams by adding new members in proportion to the productivity of the team. Team growth of productive teams then facilitates further team growth. This process of cumulative advantage leads to the appearance of the power-law component of large teams at later times. In the model, each time a paper is produced the lead author can choose to work with his/her core team or the extended team, thus leading to two main modes of knowledge production. Interestingly, in our simulation, the probability of choosing core or extended teams does not need to change over time to match the data. Kolmogorov–Smirnov (KS) tests were run to formally assess the match between the model and data. For the three time periods shown, the maximum deviations are D = 0.11, 0.06, and 0.17, corresponding to 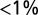 of chance match. All distributions are normalized to the 2006–2010 distribution.
of chance match. All distributions are normalized to the 2006–2010 distribution.
In addition to predicting the distribution of team sizes, the model also produces good predictions for other, author-centric distributions. Fig. S1 compares model and empirical distributions for article per author (productivity), collaborator per author, and team per author distributions, as well as the trend in the size of the largest connected component. The latter correctly predicts that the giant component forms in the early 1970s. Distributions and trends based on the implementation of the team assembly principles of Guimerà et al. (2) are also shown in Fig. S1 for comparison (with team sizes supplanted from our model). They yield predictions of similar quality. Collaborator distribution has been the focus of numerous studies (34–38). Here, we follow the usual determination of collaborators based on coauthorship. In the limiting case in which each author appears on only one article (which is true for the majority of authors over time periods of a few years), the collaborator distribution, 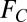 , is related to team size distribution as follows:
, is related to team size distribution as follows: 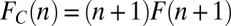 , where F is the team size distribution. Therefore, the power-law tail in the collaborator distributions, which has been traditionally explained in the network context as the manifestation of the “preferential attachment” in which authors with many collaborators [“star scientists” (40)] have a higher probability of acquiring new collaborators (nodes that join the network), may alternatively be interpreted as authors (not necessarily of “star” status) belonging to extended teams that grow through the mechanism of cumulative advantage.
, where F is the team size distribution. Therefore, the power-law tail in the collaborator distributions, which has been traditionally explained in the network context as the manifestation of the “preferential attachment” in which authors with many collaborators [“star scientists” (40)] have a higher probability of acquiring new collaborators (nodes that join the network), may alternatively be interpreted as authors (not necessarily of “star” status) belonging to extended teams that grow through the mechanism of cumulative advantage.
Interestingly, the model predicts the empirical distribution quite well (Fig. 2), even though we assumed that the propensity to publish with the extended team has remained constant over the 50-y period 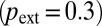 . This suggests a hypothesis that (at least in astronomy) there always existed a similar proportion of problems that would have required nonindividualistic effort, but it took time for such an approach of conducting research to become conspicuous because of the gradual growth of extended teams.
. This suggests a hypothesis that (at least in astronomy) there always existed a similar proportion of problems that would have required nonindividualistic effort, but it took time for such an approach of conducting research to become conspicuous because of the gradual growth of extended teams.
The model allows us to assess the relative contribution of different modes of authorship. In Fig. 3, we separately show the distribution of articles produced by both types of core teams and the extended teams. By definition, “core +1” teams and extended teams start at 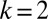 , and therefore single-author papers can only be produced in a standard-core team mode. Two-author teams are almost exclusively the result of core teams with equal shares of standard and “core +1” teams. The contribution of “core +1” teams drops significantly for three or more authors, which is not surprising if such teams are expected to be primarily composed of student–mentor pairs. Standard core teams dominate as the production mechanism in articles containing up to eight authors, i.e., they make up most of the hook. Extended teams become the dominant mode of production of articles that include 10 or more authors; thus, they are responsible for the power-law tail of large teams.
, and therefore single-author papers can only be produced in a standard-core team mode. Two-author teams are almost exclusively the result of core teams with equal shares of standard and “core +1” teams. The contribution of “core +1” teams drops significantly for three or more authors, which is not surprising if such teams are expected to be primarily composed of student–mentor pairs. Standard core teams dominate as the production mechanism in articles containing up to eight authors, i.e., they make up most of the hook. Extended teams become the dominant mode of production of articles that include 10 or more authors; thus, they are responsible for the power-law tail of large teams.
Fig. 3.

Distribution of article team sizes according to the generating authorship mode (for astronomy, 2006–2010). A lead author can choose to publish with his/her core team or the extended team. The mode that involves core teams dominates in articles with fewer than 10 authors. Furthermore, to accurately reproduce the empirical distribution, it is necessary to assume two types of core teams: standard and “core +1” teams. The latter type is also drawn from a Poisson distribution but includes an extra member. The majority of such articles are presumably produced by teams based around student–mentor pairs.
Analytical Decomposition of Team Size Distributions
Deriving the relative contribution of different types of teams as performed in the previous section and shown in Fig. 3 requires a model simulation and is therefore not practical as a means of interpreting empirical distributions. Fortunately, we find (by testing candidate functions using the maximum-likelihood method) that the distribution of the articles produced by each of the three types of teams can be approximated by the following functional form equivalents: standard core and “core +1” teams are well described by Poisson functions, 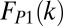 and
and 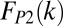 , whereas the distribution of articles produced by extended teams is well described by a power-law function with a low-end exponential cutoff,
, whereas the distribution of articles produced by extended teams is well described by a power-law function with a low-end exponential cutoff, 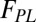 . Therefore, the following analytical function can be fit to the empirical team size distribution to obtain its decomposition:
. Therefore, the following analytical function can be fit to the empirical team size distribution to obtain its decomposition:
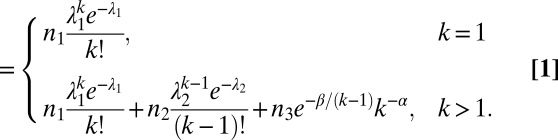 |
In the above expression, 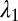 and
and 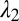 are the Poisson rates for
are the Poisson rates for 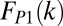 and
and 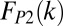 , α is the power-law slope, and β determines the strength of the exponential truncation. Relative normalization of the three components is given by
, α is the power-law slope, and β determines the strength of the exponential truncation. Relative normalization of the three components is given by 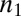 ,
, 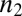 , and
, and 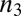 . This expression features six independent parameters. Although other analytical functions can, in principle, also provide a good fit to the overall size distribution, Eq. 1 is constructed so that each component corresponds to a respective authorship mode. Furthermore, as shown in Fig. S2, removing various components of Eq. 1 leads to decreased ability to fit the empirical distribution.
. This expression features six independent parameters. Although other analytical functions can, in principle, also provide a good fit to the overall size distribution, Eq. 1 is constructed so that each component corresponds to a respective authorship mode. Furthermore, as shown in Fig. S2, removing various components of Eq. 1 leads to decreased ability to fit the empirical distribution.
The best-fitting functional form 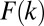 for the most recent team size distribution in astronomy is shown in Fig. 4. The fitting was performed using
for the most recent team size distribution in astronomy is shown in Fig. 4. The fitting was performed using 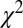 minimization. The overall fit is very good and the individual components of Eq. 1 match the different modes of authorship, as derived by the model (Fig. 3). By integrating these components, we find that currently 57% of articles belong to
minimization. The overall fit is very good and the individual components of Eq. 1 match the different modes of authorship, as derived by the model (Fig. 3). By integrating these components, we find that currently 57% of articles belong to 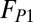 and can therefore be attributed to standard core teams. Another 12% are due to “core +1” teams
and can therefore be attributed to standard core teams. Another 12% are due to “core +1” teams 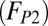 , whereas the remaining 31% of articles are fit by the truncated power-law component
, whereas the remaining 31% of articles are fit by the truncated power-law component 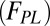 and can therefore be interpreted as originating from extended teams.
and can therefore be interpreted as originating from extended teams.
Fig. 4.

Functional decomposition of the empirical article team size distribution (for astronomy, 2006–2010). Different modes of authorship identified by the model have their functional equivalents, thus allowing the empirical determination of the contribution of each mode to the team size distribution. Core teams are well fit by Poisson functions, whereas the extended teams are well fit by an exponentially truncated power-law component. Based on the best-fitting function given in Eq. 1, for 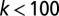 . KS test yields
. KS test yields 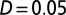 , corresponding to
, corresponding to 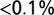 of chance match.
of chance match.
The principles that underlie the proposed model are universal and not field dependent. Only the parameters that specify the rate of growth or the relative strength of the processes will differ from field to field. Consequently, the analytical decomposition given by Eq. 1 can be applied to other fields. Fig. 5 shows the best-fitting functions (Eq. 1) to the empirical team size distributions in the following fields: mathematics, ecology, social psychology, literature, and for articles from arXiv, all for the current period (2006–2010). Core journals used for these fields are listed in SI Materials and Methods. All of the distributions are well described by our model-based functional decomposition. Parameters for the fit and contributions of different authorship modes are given in Table 1. There is much variety. In literature, the standard core team mode accounts for nearly the entire output (99%) with very small teams. Mathematics also features relatively small teams and a steep decline of larger teams. Nevertheless, the functional decomposition implies that 9% of articles are produced in the extended-team mode (see also Fig. S3), but these teams are still not much larger than core teams (2.9 vs. 1.8 members on average). Mathematics and social psychology feature the largest share of “core +1” teams. Team size distributions for ecology and social psychology both have more prominent power-law tails than mathematics 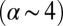 , but they are not yet as extensive as in astronomy
, but they are not yet as extensive as in astronomy 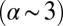 . Both fields feature a hook at low k similar to that of astronomy. Finally, articles from arXiv (mostly belonging to the field of physics) have a power-law slope very similar to that of astronomy.
. Both fields feature a hook at low k similar to that of astronomy. Finally, articles from arXiv (mostly belonging to the field of physics) have a power-law slope very similar to that of astronomy.
Fig. 5.

Functional fits (Eq. 1) to the article team size distribution in the fields of mathematics, ecology, literature, social psychology, and for arXiv (for 2006–2010). All distributions are well fitted by the functional form that is a sum of two Poisson functions and a truncated power law (Eq. 1), demonstrating that the proposed analytical description is universal. Distributions are normalized to the 2006–2010 distribution in astronomy, which is also shown with its best-fitting function for comparison (without data points, for clarity). A KS test yields D = 0.06, 0.17, 0.08, and 0.05 for ecology, mathematics, social psychology, and arXiv, respectively, which all correspond to 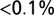 probability of chance match. Literature has too few points for a KS test.
probability of chance match. Literature has too few points for a KS test.
Table 1.
Characteristics of different fields obtained from analytical decomposition
| Field | Articles (2006–2010) | 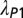 |
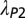 |
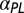 |
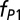 |
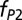 |
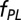 |
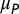 |
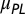 |
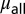 |
| Astronomy | 31,473 | 3.25 | 0.67 | 2.8 | 0.52 | 0.11 | 0.37 | 3.21 | 11.20 | 6.14 |
| Ecology | 5,420 | 3.23 | 0.83 | 3.8 | 0.62 | 0.13 | 0.25 | 3.20 | 4.58 | 3.54 |
| Mathematics | 3,244 | 0.87 | 0.75 | 13.4 | 0.57 | 0.33 | 0.09 | 1.84 | 2.87 | 1.93 |
| Social psychology | 4,122 | 2.24 | 1.58 | 4.5 | 0.46 | 0.36 | 0.18 | 2.72 | 3.89 | 2.93 |
| Literature | 725 | 0.06 | 0.02 | 5.0 | 0.99 | 0.00 | 0.01 | 1.03 | 3.75 | 1.05 |
| arXiv | 235,414 | 1.80 | 4.93 | 2.6 | 0.72 | 0.05 | 0.23 | 2.38 | 6.56 | 3.36 |
The meaning of the columns is given in the legend of Fig. 6.
Application of Analytical Decomposition for Describing Trends in Team Evolution
Analytical decomposition, introduced in the previous section, allows us to empirically derive the contribution of different modes of authorship over time and to explore the characteristics of teams as they evolve. We now fit Eq. 1 to article teams in astronomy for all 5-y time periods, from 1961 to 2010. Fig. 6, Left, shows the change in the best-fit Poisson rates of both types of core teams as well as the evolution of the slope of the power-law component. As previously suggested, the Poisson rate of core teams has gradually increased from close to zero in the early 1960s to a little over three recently. However, the slope of the power-law component has gradually been flattening, from 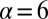 to
to 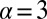 , i.e., the power-law component has been gaining in prominence.
, i.e., the power-law component has been gaining in prominence.
Fig. 6.
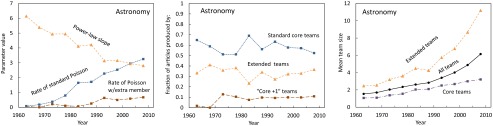
Trends in team evolution in astronomy from 1961 to 2010. (Left) Fifty-year trend of parameters characterizing the three components of the distribution, derived from a functional fit (Eq. 1). The characteristic size (i.e., Poisson rate) of standard core teams has 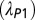 been rising throughout this period, whereas that of “core +1” teams
been rising throughout this period, whereas that of “core +1” teams 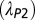 has remained constant in the last two decades. The power-law slope
has remained constant in the last two decades. The power-law slope 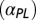 has been getting shallower, i.e., the significance of the power-law component has been increasing. (Center) Fraction of articles produced by different modes of authorship (team types): standard core
has been getting shallower, i.e., the significance of the power-law component has been increasing. (Center) Fraction of articles produced by different modes of authorship (team types): standard core 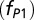 , “core +1”
, “core +1” 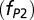 , and extended
, and extended 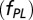 . (Right) Trends in the mean team size, overall
. (Right) Trends in the mean team size, overall 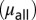 and by team type (both types of core teams,
and by team type (both types of core teams, 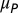 , and extended teams,
, and extended teams, 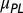 ). The increase in the overall mean team size in astronomy is primarily the result of the rapid growth of power-law (extended) teams.
). The increase in the overall mean team size in astronomy is primarily the result of the rapid growth of power-law (extended) teams.
Fig. 6, Center, shows the relative contributions of the three modes of authorship in astronomy over the time period of 50 y, obtained by integrating the best-fit functional components. Remarkably, the contributions have remained relatively stable, with articles in the power-law component (i.e., articles produced by extended teams) making ∼30%. This stability in the fraction of power-law articles is directly connected to the fixed propensity of authors to write articles with extended teams, as indicated in the model simulation. In all time periods, most papers (∼60%) have been published by standard core teams (the Poisson component). Core teams with an extra member seem to appear in the early 1970s, but their contribution has remained at around 10%.
As pointed out earlier, many studies have emphasized the impressive growth of “mean” team sizes. We can now explore this trend in the light of the various authorship modes. In Fig. 6, Right, we show the change in the mean size of all teams, and separately of core teams (standard and “core +1” teams together) and of power-law (extended) teams. In the early 1960s, both the core and the extended teams were relatively small (1.1 and 2.5 members, respectively). Subsequently, the mean size of core teams has increased linearly to 3.2 members. However, the mean size of extended teams has grown exponentially, and most recently averages 11.2 members. The exponential increase in the size of extended teams is affecting the overall mean, despite the fact that the extended teams represent the minority mode of authorship. Although the growth of core teams is more modest, it nevertheless indicates that the level of collaboration, as measured by article team size, increases for this traditional mode of producing knowledge as well. Whether this increase is a reflection of a real change in the level of collaborative work or simply a change in the threshold for a contributor to be considered a coauthor is beyond the scope of this work.
In a similar fashion, we explored the evolution of fit parameters, mode contributions, and team sizes for mathematics and ecology (Figs. S3 and S4). Mathematics features a small extended-team component (10%) that emerged in the mid-1980s. Extended teams in mathematics are still only slightly larger in size than the core teams. The share of “core +1” teams is increasing. The mean size of all core teams has increased, albeit moderately (from 1.2 to 1.8 members). In ecology, the overall increase in mean team size mostly reflects the increase of the characteristic size of standard core teams in the 1980s. The observed increase of the share of extended teams appears to come at the expense of standard core teams.
Implications and Conclusions
The model proposed in this paper successfully explains the evolution of the sizes of scientific teams as manifested in author lists of research articles. It demonstrates that team formation is a multimodal process. Primary mode leads to relatively small core teams, the size of which may represent the typical number of researchers required to produce a research paper. The secondary mode results in teams that expand in size, and which are presumably used to carry out research that requires expertise or resources from outside of the core team. These two modes are responsible for producing the hook and the power law-tail in team size distribution, respectively.
This two-mode character may not be exclusive to team sizes. Interestingly, a similarly shaped distribution consisting of a hook and a power-law tail is characteristic of another bibliometric distribution, that of the number of citations that an article receives. Recently, a model was proposed that successfully explained this distribution (33) by proposing the existence of two modes of citation, direct and indirect, where the latter is subject to cumulative advantage.
Understanding the distribution of the number of coauthors in a publication is of fundamental importance, as it is one of the most basic distributions that underpin our notions of scientific collaboration and the concept of “team science.” The principles of team formation and evolution laid out in this work have the potential to illuminate many questions in the study of scientific collaboration and communication, and may have broader implications for research evaluation.
Supplementary Material
Acknowledgments
I thank the two anonymous reviewers for their constructive comments and Colleen Martin and John McCurley for copyediting.
Footnotes
The author declares no conflict of interest.
This article is a PNAS Direct Submission.
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1309723111/-/DCSupplemental.
References
- 1.Gibbons M, et al. The New Production of Knowledge: The Dynamics of Science and Research in Contemporary Societies. London: Sage; 1994. [Google Scholar]
- 2.Guimerà R, Uzzi B, Spiro J, Amaral LA. Team assembly mechanisms determine collaboration network structure and team performance. Science. 2005;308(5722):697–702. doi: 10.1126/science.1106340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Jones BF, Wuchty S, Uzzi B. Multi-university research teams: Shifting impact, geography, and stratification in science. Science. 2008;322(5905):1259–1262. doi: 10.1126/science.1158357. [DOI] [PubMed] [Google Scholar]
- 4.Newman MEJ. In: Who is the Best Connected Scientist? A Study of Scientific Coauthorship Networks. Complex Networks. Ben-Naim E, Frauenfelder H, Toroczkai Z, editors. Berlin: Springer; 2004. pp. 337–370. [Google Scholar]
- 5.Wuchty S, Jones BF, Uzzi B. The increasing dominance of teams in production of knowledge. Science. 2007;316(5827):1036–1039. doi: 10.1126/science.1136099. [DOI] [PubMed] [Google Scholar]
- 6.Börner K, et al. A multi-level systems perspective for the science of team science. Sci Transl Med. 2010;2(49):49cm24. doi: 10.1126/scitranslmed.3001399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Price DJdS. Little Science, Big Science. New York: Columbia Univ Press; 1963. [Google Scholar]
- 8.Dd B. Possible relationships between the history and sociology of science. Sociol Inq. 1978;48(3-4):140–161. [Google Scholar]
- 9.Babchuk N, Keith B, Peters G. Collaboration in sociology and other scientific disciplines: A comparative trend analysis of scholarship in the social, physical, and mathematical sciences. Am Sociol. 1999;30(3):5–21. [Google Scholar]
- 10.Glänzel W. Coauthorship patterns and trends in the sciences (1980–1998): A bibliometric study with implications for database indexing and search strategies. Libr Trends. 2002;50(3):461–473. [Google Scholar]
- 11.Kretschmer H. Patterns of behaviour in coauthorship networks of invisible colleges. Scientometrics. 1997;40(3):579–591. [Google Scholar]
- 12.Cronin B. Hyperauthorship: A postmodern perversion of evidence of a structural shift in scholarly communication practices? J Am Soc Inf Sci Technol. 2001;52(7):558–569. [Google Scholar]
- 13.Cronin B, Shaw D, La Barre K. A cast of thousands: Co-authorship and sub-authorship collaboration in the twentieth century as manifested in the scholarly literature of psychology and philosophy. J Am Soc Inf Sci Technol. 2003;54(9):855–871. [Google Scholar]
- 14.Bordons M, Gomez I. Collaboration networks in science. In: Cronin B, Atkins HB, editors. The Web of Knowledge: A Festschrift in Honor of Eugene Garfield. Medford, NJ: Information Today; 2000. pp. 197–213. [Google Scholar]
- 15.Shrum W, Genuth J, Chompalov I. Structures of Scientific Collaboration. Cambridge, MA: MIT; 2007. [Google Scholar]
- 16.Wagner CS. The New Invisible College: Science for Development. Washington, DC: Brookings Institution; 2008. [Google Scholar]
- 17.Uzzi B, Mukherjee S, Stringer M, Jones B. Atypical combinations and scientific impact. Science. 2013;342(6157):468–472. doi: 10.1126/science.1240474. [DOI] [PubMed] [Google Scholar]
- 18.Hagstrom WO. The Scientific Community. New York: Basic Books; 1965. [Google Scholar]
- 19.Melin G. Pragmatism and self-organization: Research collaboration on the individual level. Res Policy. 2000;29(1):31–40. [Google Scholar]
- 20.Price DJ, Beaver DD. Collaboration in an invisible college. Am Psychol. 1966;21(11):1011–1018. doi: 10.1037/h0024051. [DOI] [PubMed] [Google Scholar]
- 21.Epstein RJ. Six authors in search of a citation: Villains or victims of the Vancouver convention? BMJ. 1993;306(6880):765–767. doi: 10.1136/bmj.306.6880.765. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Fernández JA. The transition from an individual science to a collective one: The case of astronomy. Scientometrics. 1998;42(1):61–74. [Google Scholar]
- 23.Henneken EA, et al. E-print journals and journal articles in astronomy: A productive co-existence. Learn Publ. 2007;20(1):16–22. [Google Scholar]
- 24.Milojević S. How are academic age, productivity and collaboration related to citing behavior of researchers? PLoS One. 2012;7(11):e49176. doi: 10.1371/journal.pone.0049176. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Milojević S. Modes of collaboration in modern science—beyond power laws and preferential attachment. J Am Soc Inf Sci Technol. 2010;61(7):1410–1423. [Google Scholar]
- 26.Kingman JFC. Poisson Processes. Oxford: Oxford Univ Press; 1993. [Google Scholar]
- 27.Ross SM. Stochastic Processes. 2nd Ed. New York: Wiley; 1995. [Google Scholar]
- 28.Feller W. An Introduction to Probability Theory and Its Applications. 3rd Ed. New York: Wiley; 1968. [Google Scholar]
- 29.Gerlough DL, Andre S. Use of Poisson Distribution in Highway Traffic. The Probability Theory Applied to Distribution of Vehicles on Two-Lane Highways. Saugatuck, CT: Eno Foundation for Highway Traffic Control; 1955. [Google Scholar]
- 30.Karlis D, Ntzoufras I. Analysis of sports data by using bivariate Poisson models. Statistician. 2003;52(3):381–393. [Google Scholar]
- 31.Newman MEJ. Power laws, Pareto distributions and Zipf’s law. Contemp Phys. 2005;46(5):323–351. [Google Scholar]
- 32.Clauset A, Shalizi CR, Newman MEJ. Power-law distributions in empirical data. SIAM Rev Soc Ind Appl Math. 2009;51(4):661–703. [Google Scholar]
- 33.Peterson GJ, Pressé S, Dill KA. Nonuniversal power law scaling in the probability distribution of scientific citations. Proc Natl Acad Sci USA. 2010;107(37):16023–16027. doi: 10.1073/pnas.1010757107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Barabási A-L, Albert R. Emergence of scaling in random networks. Science. 1999;286(5439):509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 35.Barabási A-L, et al. Evolution of the social network of scientific collaborations. Physica A. 2002;311(3-4):590–614. [Google Scholar]
- 36.Newman MEJ. Clustering and preferential attachment in growing networks. Phys Rev E Stat Nonlin Soft Matter Phys. 2001;64(2 Pt 2):025102. doi: 10.1103/PhysRevE.64.025102. [DOI] [PubMed] [Google Scholar]
- 37.Newman MEJ. The structure of scientific collaboration networks. Proc Natl Acad Sci USA. 2001;98(2):404–409. doi: 10.1073/pnas.021544898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Börner K, Maru JT, Goldstone RL. The simultaneous evolution of author and paper networks. Proc Natl Acad Sci USA. 2004;101(Suppl 1):5266–5273. doi: 10.1073/pnas.0307625100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Abdo AA, et al. Fermi large area telescope first source catalog. Astrophys J Suppl Ser. 2010;188(2):405–436. [Google Scholar]
- 40.Moody J. The structure of a social science collaboration network: Disciplinary cohesion from 1963 to 1999. Am Sociol Rev. 2004;69(2):213–238. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.