


Abstract
IntAct (freely available at http://www.ebi.ac.uk/intact) is an open-source, open data molecular interaction database populated by data either curated from the literature or from direct data depositions. IntAct has developed a sophisticated web-based curation tool, capable of supporting both IMEx- and MIMIx-level curation. This tool is now utilized by multiple additional curation teams, all of whom annotate data directly into the IntAct database. Members of the IntAct team supply appropriate levels of training, perform quality control on entries and take responsibility for long-term data maintenance. Recently, the MINT and IntAct databases decided to merge their separate efforts to make optimal use of limited developer resources and maximize the curation output. All data manually curated by the MINT curators have been moved into the IntAct database at EMBL-EBI and are merged with the existing IntAct dataset. Both IntAct and MINT are active contributors to the IMEx consortium (http://www.imexconsortium.org).
INTRODUCTION
Experimental approaches to determine molecular interactions often require that interactions are determined in non-physiological conditions which can result in significant false positive and false negative rates. Knowledge of experimental details, such as the experimental technology used, cellular context, protein modifications and expression systems are essential to evaluate the reliability of an interaction report, or to combine multiple reports into an overall reliability assessment. Experiments often determine additional valuable biological information in addition to the identity of the interaction partners, for example, interacting domains or sites of post-translational modifications. Curating interactions to the required level of detail to capture this information requires both a relatively complex data structure and frequent updates, including the mapping of binding regions, point mutations and post-translational modification to a specified sequence within a reference protein sequence database. An update to a predictive gene model may result in a corresponding change to the protein sequence(s) derived from it. Interactions involving domains and/or residues of that protein sequence within an interaction database will then require a corresponding update to ensure the mapping to the updated sequence is correct. Update pipelines need to be run regularly, in line with the release cycle of the sequence database, namely every 4 weeks in the case of UniProtKB (1). Similarly, controlled vocabularies (CVs) used to annotate interaction data need to be refreshed with every new release. The systematic capture of detailed information requires both a complex underlying data model and a curator-friendly, efficient data capture system using web services to provide on-demand data import from external resources and frequently updated CVs. Such complex curation environments are much more expensive in terms of development and operational cost than the public facing, read-only website components of a typical molecular interaction database.
The IntAct molecular interaction database has existed since 2002 to serve richly curated molecular interaction data provided in community accepted standard formats to a broad user community (2). Data users range from cell biologists exploring the fine details of the mechanism by which a specific protein binds to protein partners to analysts utilizing the entire known interactome of a particular model organism to perform network analysis on the results of a large-scale ‘Omics experiment. The IntAct database is based on a relational database management system (Oracle; Postgres version available), Hibernate object-relational mapping, Java-based middleware, Lucene/SOLR indexing and a web-based front end for public search, visualization and download of the data. From its earliest implementations in 2002 onwards, the IntAct curation system has been developed as a web-based platform, to allow collaborative curation by physically remote partners, originally mainly a small group of UniProtKB/Swiss-Prot curators based in Geneva, Switzerland. While the IntAct data model is capable of describing interactions between any biomolecule type, the primary curation focus has always been on experimentally verified protein–protein interactions. IntAct curators capture this data from the literature, in a series of curation projects directed by grant funding and the requirements of collaborating experimental groups. In addition, the direct submission of experimental data as part of the publication process is actively encouraged by an increasing number of journals and is supported by the IntAct curation team. Any submitted data are kept confidential until the accompanying publication is released but formatted data files can be provided to the submitter directly from the editorial tool to ease input into tools such as Cytopscape (3). IntAct is released at least monthly, and all existing publications are available from the IntAct ftp site in PSI-MI XML and MITAB 2.5, 2.6 and 2.7 formats as well as via direct download from the website where data are additionally available in RDF and XGMML formats (2,4,5). Data can also be queried using the PSICQUIC web service, and IntAct IMEx data are also accessible via the IMEx website (6). All IntAct software, including the web-based curation tool, is free and open source, and can be used, modified and redistributed under the terms of the Apache Software License.
The MINT (Molecular INTeraction) database was created in 2002 at the University of Tor Vergata, Rome (7), independent of IntAct in funding and organization, but with very similar aims, curating experimentally derived protein interactions, with specific curation targets determined by the requirements of the large experimental activity of the group, for example, SH3 domain-based interactions (8). A major activity was and is the close collaboration with the FEBS Letters Journal, where MINT curates all protein interactions published in the journal (9,10). MINT developed its own software infrastructure for curation as well as data dissemination, but already in 2006 decided to adapt the IntAct relational database implementation to reduce the overhead of database development and maintenance. The MINT web interface remained distinct and based on an IntAct-independent code base.
Unlike protein structure or sequence databases, where single, collaborative database projects such as PDBe (11) and UniProt (1) provide the vast majority of public data, curation of molecular interaction data is mainly performed by a relatively large number of small to medium, independently funded projects (12). Often the driver for a curation effort is not general resource provision, but local expertise in a specific scientific domain, which is exploited for the curation of reference datasets, often in direct support of experimental activities in the same group. As an example, MatrixDB (Universite de Lyon, France) (13) is highly specialized in the curation of extracellular domain interactions. While domain-specific, expert-curated interaction datasets are likely to be of high quality and scientific relevance, this distributed approach also has significant risks. Recognizing the risks of data fragmentation, redundant curation and redundant software development, many leading interaction databases, including IntAct, MINT and DIP (14), have since 2002 (15) engaged in increasingly closer collaboration, moving from definition of common data representation [Human Proteome Organisation Proteomics Standards Initiative (HUPO PSI)-MI] (4) to co-ordinated curation strategies (IMEx) (6) and common computational query interfaces (PSICQUIC) (5). It is an essential part of the IMEx Consortium agreement that, should a member database lose funding or cease activities due to transfer of group interests, the data be passed to another IMEx member database for long-term data stewardship. As of January 2012, the MPIDB database (16) ceased active curation and since that date the IMEx records for that database are present within and updated by IntAct. These additional 363 publications significantly increased the IntAct support for microbial interactions.
COMMUNITY ACCESS TO A WEB-BASED CURATION TOOL
As previously described (2), IntAct has invested heavily in the development of a sophisticated web-based editorial tool, enabling the systematic capture of the complexities of a molecular interaction experiment to either IMEx (6) or MIMIx-level (17) as determined by the curator. Part of the motivation for providing the entire IntAct code base as open source was to reduce redundant development of interaction database platforms. It was originally envisaged that individual groups would emulate the original MINT model and locally install versions of IntAct to curate and maintain their own interaction data. However, as described earlier, this still leaves such groups with a heavy data maintenance overhead to keep records synchronized with sequence database and CV updates. Over the last few years, several groups have therefore preferred to curate directly into IntAct and make use of the existing IntAct data maintenance pipeline. This is not ‘community annotation’ per se, as these all represent highly trained M.Sc. and Ph.D. level curators, with IntAct staff providing the appropriate level of training and also quality control of all records produced to ensure curation standards and data quality remain consistent across the entire dataset. When requested, IntAct makes interaction records available in specific download formats for each contributing group, and indeed for other databases wishing to display interaction data. For example, a number of UniProtKB/Swiss-Prot curators at both the Swiss Institute of Bioinformatics and EBI have for several years annotated molecular interactions directly into IntAct. IntAct then scores and filters all interaction evidences in the database and exports a high confidence subset, with a high degree of probability that the molecule pairs described physically interact with each other, back to UniProtKB (1), neXtProt (18) and the Gene Ontology annotation project (19) in a distinct format for each. Other databases such as I2D (Interologous Interaction Database) (20), which curates interaction protein interaction data relevant to the development of cancer and InnateDB (21), capturing both protein and gene interactions relevant to the process of innate immunity, choose to select appropriate records directly from the ftp site for subsequent import into their own resources. Both databases use the IntAct editor to perform IMEx-level curation (6). The contract curation company, Molecular Connections (www.molecularconnections.com/), perform pro bono public domain data curation via the IntAct database. AgBase, a curated resource of animal and plant gene products, captures data subsequently imported into their host–pathogen database (http://www.agbase.msstate.edu/hpi/main.html). The Cardiovascular Gene Ontology Annotation Initiative at University College London is building an interactome of cardiovascular associated proteins (http://www.ucl.ac.uk/cardiovasculargeneontology/).
Several of the groups contributing data to IntAct are interested in molecule types other than proteins. MatrixDB (13) database focuses on interactions established by both extracellular proteins and polysaccharides, and uses the IntAct curation tool to input interaction data which is subsequently downloaded and transferred into their own database environment. Similarly, a very new collaboration with the Norwegian University of Science and Technology, Trondheim is further extending the initial efforts of the IntAct curators into capturing transcription factor interactions with the genes to which they bind. To meet both these additional use cases, the IntAct editorial tool has been extended to facilitate access to both small molecule data from ChEBI (22) and information on the gene derived from Ensembl (23). In each case, web services enable key information to be downloaded from an appropriate reference database and stored internally within IntAct, enabling curators to annotate interaction data relevant to those entities. In the near future, the increasing amount of RNA-based interaction data will also present new challenges to the molecular interaction curation community and the development of reference resources such as RNAcentral (24) will be critical to the capture of these important interactomes.
Each group is provided with its own PSICQUIC web service (5) running from within the IntAct database so that each data provider can choose to embed its own web service within a web page or tool, completely independently of other data present in the database. IntAct has also made several changes to enable additional credit to be given to external contributors. In addition to minor cosmetic changes to the website, such as displaying the logos of these groups and also the source of each data entry in the database, a new Institute Manager facility has been added to the editorial tool, to enable each set of curators to be linked and statistics generated on request, to enable each institute to support internal and grant-driven data requirements.
The model of a shared curation environment and common data dissemination formats minimizes the development of redundant curation platforms and ensures compatibility of the curated data generated by all partners, while each partner can contribute their domain-specific curation expertise. On the other hand, the option of separate web interfaces for partners allows them to develop domain-specific websites for their communities, based on their own as well as other partners’ data (see Figure 1).
Figure 1.
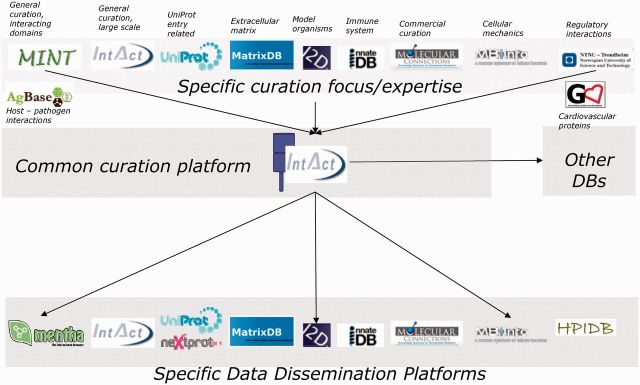
The web-based IntAct curation environment is used by currently 11 independent organizations, most of which re-export the data and present it through their own web interfaces.
THE MINTACT PROJECT
The use of IntAct as a shared curation platform has been boosted in Summer 2013, when IntAct and MINT joined forces to optimize curation and software development efforts. IntAct and MINT shared many commonalities and much of the basic maintenance and, as described earlier, update work to the underlying database infrastructure was largely redundant between the two groups. The two databases collaborated closely to work on the data formats and standards produced in collaboration with other members of the Molecular Interaction work group of the HUPO-PSI. This also included the development of curation standards and CV terms in addition to tools and services such as the PSICQUIC Web service. However, despite these shared efforts and their common infrastructure, both databases existed as physically separate entities and independently improved and updated their respective installations. It was therefore agreed, early in 2013, to merge this common effort, with a view to making optimal use of limited developer resources and maximize the curation output. To achieve this, the entire set of experimentally derived data manually curated from published literature was transferred from MINT to IntAct at EMBL-EBI. Locally maintained CVs such as the cell line and tissue lists used to describe the host organism in which experiments are undertaken, were manually aligned and merged into a single reference list. Centrally maintained CVs, for example, the PSI-MI CV were refreshed (4). Underlying protein sequences, and features mapped to them, were updated to the latest UniProtKB release before the two datasets were merged. Although the IMEx Consortium rules now prevent redundant curation of the same publication by multiple member databases, there were many examples of papers curated prior to 2006 which were present in both databases. In each case, the most richly annotated paper was selected as the dataset retained within the combined dataset. A new tagged data subset, Virus, was created to tag the manually curated papers from VirusMINT (25), and supplemented by additional papers containing virus–virus or virus–host interactions already present in the IntAct database. The final merged dataset (11 879 publications, 430 134 binary interactions) was released in August 2013, resulting in a huge increase in the data available. As detailed in Figure 2, the number of publications in IntAct almost doubled from 6600 to 12 000. While the joining of the two datasets was a huge effort for all involved curators and developers, it ultimately took only a little over 1 month from the original transfer of the MINT dataset end of August to the first joint release in early September. Taking into account the huge size of the MINT dataset, this is an impressive demonstration of the usefulness of common curation strategies and data representation between independent databases in the same or closely related domain.
Figure 2.
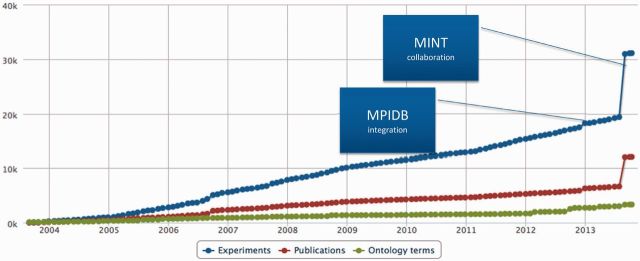
Growth of the IntAct database.
As from June 2013, the MINT curators curate new publications directly into the IntAct database, and the input into ongoing MINT projects has been transferred to the IntAct platform. This includes the creation of the Structured Digital Abstracts for FEBS letters which are now generated by IntAct, with the agreement of the editorial board of that journal. The MENTHA interactome browser (26) will continue to be built on the PSICQUIC web services of IMex databases (6) and BioGRID (27), as before. The merger of curation activities gives users access to an improved and continually updated single dataset, and the European tax payer gets an improved return on investment as improvement to the underlying database structure and website development efforts need only be funded once, at a single site with both groups contributing to long term data maintenance efforts. Future software developments, such as upgrades to new versions of data formats, will be undertaken jointly by the two groups, maximizing resources in a time of restricted funding in Europe.
FUTURE PLANS
Over the last few years, IntAct has focused very much on data input, developing a sophisticated curation tool, curation life cycle and working with many other groups to extend the effective coverage of the literature achieved by the database. While this will continue, it is intended in the immediate future to focus on the presentation of the resulting data to those members of the IntAct user community who access the data via the website—improving search, filtering and graphical capabilities. New ways to display data need to be explored to cope with the ever-growing volume available. It is estimated that the volume of data held by the IntAct database alone may grow to 750 000 binary interaction evidences in the next 5 years, and while this can be presented using current simplistic network views, it is almost impossible to derive useful information directly from the resulting graphic. Novel methods of merging data and displaying clustered by pathway, process or subcellular location have to be considered.
Interaction data are becoming ever-more sophisticated and new ways of visualizing data need to be developed to capture this. One example of this is the generation of dynamic interaction data, in which changes in protein complex composition in response to stimuli, be these biochemical (e.g. in response to increasing concentrations of an agonist such as a growth factor), temporal (such as different phases of the cell cycle) or environmental (dark versus light). IntAct has developed an extension of the CytoscapeWeb viewer (28) to present such dynamic changes as an animation driven by radio-buttons, provided data are entered into the database under appropriate annotation topic headings. The entire potential protein complex is displayed in the viewer, with those interactions relevant under a particular condition, or set of conditions, highlighted with the edge colour in red (http://www.ebi.ac.uk/intact/interaction/EBI-6263088). Future plans include extending this viewer, and indeed the underlying database model, to cope with concomitant changes in expressed protein level within the complex as improvements in mass spectrometry-based quantitative proteomics techniques means that such data become available.
We are constantly trying to improve our databases and services in terms of accuracy and representation and actively encourage user feedback. Please contact IntAct if you have any questions via http://www.ebi.ac.uk/support/index.php or email us directly at intact-help@ebi.ac.uk. Information about curation is provided at http://www.ebi.ac.uk/intact/pages/documentation/data_curation.xhtml and at http://www.ebi.ac.uk/intact/pages/documentation/data_submission.xhtml about data submissions. Extensive documentation and training material on how to best use our resource is available at http://www.ebi.ac.uk/training/networks. Curation groups interested in capturing interaction data who would like access to the editorial tool are encouraged to contact the IntAct molecular interaction database to discuss this further (intact-help@ebi.ac.uk).
FUNDING
European Commission under PSIMEx, contract [FP7-HEALTH-2007-223411], SyBoSS [FP7-HEALTH-2009-242129] and Affinomics [FP7-241481]; IntAct is additionally supported by The Michael J. Fox Foundation for Parkinson's Research LRRK2 Biology LEAPS and NHLBI Proteomics Center Award [HHSN268201000035C]; MINT is supported by AIRC [10360], ERC [322749-DEPTH] and Telethon [GGP09243]. The Cardiovascular Gene Annotation Initiative is supported by British Heart Foundation grant [RG/13/5/30112]; SIB Swiss Institute of Bioinformatics receives financial support from the Swiss Federal Government through the State Secretariat for Education, Research and Innovation (SERI). Funding for open access charge: European Commission grant Affinomics [FP7-241481].
Conflict of interest statement. Arathi Raghunath is an employee of Molecular Connections, a contract annotation company.
REFERENCES
- 1. The UniProt Consortium. (2013) Update on activities at the Universal Protein Resource (UniProt) in 2013. Nucleic Acids Res., 41, D43–D47. [DOI] [PMC free article] [PubMed]
- 2.Kerrien S, Aranda B, Breuza L, Bridge A, Broackes-Carter F, Chen C, Duesbury M, Dumousseau M, Feuermann M, Hinz U, et al. The IntAct molecular interaction database in 2012. Nucleic Acids Res. 2013;41:D43–D47. doi: 10.1093/nar/gkr1088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Saito R, Smoot ME, Ono K, Ruscheinski J, Wang PL, Lotia S, Pico AR, Bader GD, Ideker T. A travel guide to Cytoscape plugins. Nat. Methods. 2012;9:1069–1076. doi: 10.1038/nmeth.2212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Kerrien S, Orchard S, Montecchi-Palazzi L, Aranda B, Quinn AF, Vinod N, Bader GD, Xenarios I, Wojcik J, Sherman D, et al. Broadening the horizon—level 2.5 of the HUPO-PSI format for molecular interactions. BMC Biol. 2007;5:44. doi: 10.1186/1741-7007-5-44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.del-Toro N, Dumousseau M, Orchard S, Jimenez RC, Galeota E, Launay G, Goll J, Breuer K, Ono K, Salwinski L, et al. A new reference implementation of the PSICQUIC web service. Nucleic Acids Res. 2013;41:W601–W606. doi: 10.1093/nar/gkt392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Orchard S, Kerrien S, Abbani S, Aranda B, Bhate J, Bidwell S, Bridge A, Briganti L, Brinkman FS, Cesareni G, et al. Protein interaction data curation: the International Molecular Exchange (IMEx) consortium. Nat. Methods. 2012;9:345–350. doi: 10.1038/nmeth.1931. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Licata L, Briganti L, Peluso D, Perfetto L, Iannuccelli M, Galeota E, Sacco F, Palma A, Nardozza AP, Santonico E, et al. MINT, the molecular interaction database: 2012 update. Nucleic Acids Res. 2012;40:D857–D861. doi: 10.1093/nar/gkr930. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Carducci M, Perfetto L, Briganti L, Paoluzi S, Costa S, Zerweck J, Schutkowski M, Castagnoli L, Cesareni G. The protein interaction network mediated by human SH3 domains. Biotechnol. Adv. 2012;30:4–15. doi: 10.1016/j.biotechadv.2011.06.012. [DOI] [PubMed] [Google Scholar]
- 9.Ceol A, Chatr-Aryamontri A, Licata L, Cesareni G. Linking entries in protein interaction database to structured text: the FEBS Letters experiment. FEBS Lett. 2008;582:1171–1177. doi: 10.1016/j.febslet.2008.02.071. [DOI] [PubMed] [Google Scholar]
- 10.Leitner F, Chatr-aryamontri A, Mardis SA, Ceol A, Krallinger M, Licata L, Hirschman L, Cesareni G, Valencia A. The FEBS Letters/BioCreative II.5 experiment: making biological information accessible. Nat. Biotechnol. 2010;28:897–899. doi: 10.1038/nbt0910-897. [DOI] [PubMed] [Google Scholar]
- 11.Berman HM, Kleywegt GJ, Nakamura H, Markley JL. The future of the protein data bank. Biopolymers. 2013;99:218–222. doi: 10.1002/bip.22132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Orchard S. Molecular interaction databases. Proteomics. 2012;12:1656–1662. doi: 10.1002/pmic.201100484. [DOI] [PubMed] [Google Scholar]
- 13.Chautard E, Fatoux-Ardore M, Ballut L, Thierry-Mieg N, Ricard-Blum S. MatrixDB, the extracellular matrix interaction database. Nucleic Acids Res. 2011;39:D235–D240. doi: 10.1093/nar/gkq830. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Xenarios I, Salwínski L, Duan XJ, Higney P, Kim SM, Eisenberg D. DIP, the Database of Interacting Proteins: a research tool for studying cellular networks of protein interactions. Nucleic Acids Res. 2002;30:303–305. doi: 10.1093/nar/30.1.303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Orchard S, Hermjakob H. Preparing molecular interaction data for publication. Methods Mol. Biol. 2011;694:229–236. doi: 10.1007/978-1-60761-977-2_15. [DOI] [PubMed] [Google Scholar]
- 16.Goll J, Rajagopala SV, Shiau SC, Wu H, Lamb BT, Uetz P. MPIDB: the microbial protein interaction database. Bioinformatics. 2008;24:1743–1744. doi: 10.1093/bioinformatics/btn285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Orchard S, Salwinski L, Kerrien S, Montecchi-Palazzi L, Oesterheld M, Stümpflen V, Ceol A, Chatr-aryamontri A, Armstrong J, Woollard P, et al. The minimum information required for reporting a molecular interaction experiment (MIMIx) Nat. Biotechnol. 2007;25:894–898. doi: 10.1038/nbt1324. [DOI] [PubMed] [Google Scholar]
- 18.Gaudet P, Argoud-Puy G, Cusin I, Duek P, Evalet O, Gateau A, Gleizes A, Pereira M, Zahn-Zabal M, Zwahlen C, et al. neXtProt: organizing protein knowledge in the context of human proteome projects. J. Proteome Res. 2013;12:293–298. doi: 10.1021/pr300830v. [DOI] [PubMed] [Google Scholar]
- 19.The Gene Ontology Consortium. Gene Ontology annotations and resources. Nucleic Acids Res. 2013;41:D530–D535. doi: 10.1093/nar/gks1050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Niu Y, Otasek D, Jurisica I. Evaluation of linguistic features useful in extraction of interactions from PubMed; application to annotating known, high-throughput and predicted interactions in I2D. Bioinformatics. 2010;26:111–119. doi: 10.1093/bioinformatics/btp602. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Breuer K, Foroushani AK, Laird MR, Chen C, Sribnaia A, Lo R, Winsor GL, Hancock RE, Brinkman FS, Lynn DJ. InnateDB: systems biology of innate immunity and beyond—recent updates and continuing curation. Nucleic Acids Res. 2013;41:D1228–D1233. doi: 10.1093/nar/gks1147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Hastings J, de Matos P, Dekker A, Ennis M, Harsha B, Kale N, Muthukrishnan V, Owen G, Turner S, Williams M, et al. The ChEBI reference database and ontology for biologically relevant chemistry: enhancements for 2013. Nucleic Acids Res. 2013;41:D456–D463. doi: 10.1093/nar/gks1146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Fernández-Suárez XM, Schuster MK. Using the Ensembl genome server to browse genomic sequence data. Curr. Protoc. Bioinformatics. 2010 doi: 10.1002/0471250953.bi0115s30. Chapter 1, unit1.15. [DOI] [PubMed] [Google Scholar]
- 24.Bateman A, Agrawal S, Birney E, Bruford EA, Bujnicki JM, Cochrane G, Cole JR, Dinger ME, Enright AJ, Gardner PP, et al. RNAcentral: a vision for an international database of RNA sequences. RNA. 2011;17:1941–1946. doi: 10.1261/rna.2750811. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Chatr-aryamontri A, Ceol A, Peluso D, Nardozza A, Panni S, Sacco F, Tinti M, Smolyar A, Castagnoli L, Vidal M, et al. VirusMINT: a viral protein interaction database. Nucleic Acids Res. 2009;37:D669–D673. doi: 10.1093/nar/gkn739. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Calderone A, Castagnoli L, Cesareni G. mentha: a resource for browsing integrated protein-interaction networks. Nat. Methods. 2013;10:690–691. doi: 10.1038/nmeth.2561. [DOI] [PubMed] [Google Scholar]
- 27.Chatr-Aryamontri A, Breitkreutz BJ, Heinicke S, Boucher L, Winter A, Stark C, Nixon J, Ramage L, Kolas N, O'Donnell L, et al. The BioGRID interaction database: 2013 update. Nucleic Acids Res. 2013;41:D816–D823. doi: 10.1093/nar/gks1158. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Lopes CT, Franz M, Kazi F, Donaldson SL, Morris Q, Bader GD. Cytoscape Web: an interactive web-based network browser. Bioinformatics. 2010;26:2347–2348. doi: 10.1093/bioinformatics/btq430. [DOI] [PMC free article] [PubMed] [Google Scholar]