

Abstract
One might assume that familiarity with a scene or previous encounters with objects embedded in a scene would benefit subsequent search for those items. However, in a series of experiments we show that this is not the case: When participants were asked to subsequently search for multiple objects in the same scene, search performance remained essentially unchanged over the course of searches despite increasing scene familiarity. Similarly, looking at target objects during previews, which included letter search, 30 seconds of free viewing, or even 30 seconds of memorizing a scene, also did not benefit search for the same objects later on. However, when the same object was searched for again memory for the previous search was capable of producing very substantial speeding of search despite many different intervening searches. This was especially the case when the previous search engagement had been active rather than supported by a cue. While these search benefits speak to the strength of memory-guided search when the same search target is repeated, the lack of memory guidance during initial object searches – despite previous encounters with the target objects - demonstrates the dominance of guidance by generic scene knowledge in real-world search.
Introduction
Imagine meeting a friend for breakfast. You sit down and, as you are exchanging the latest news, you have already started searching for the bread. Once found, you look for some butter and then reach for the knife that you expect to find next to your plate. We perform numerous of these kinds of searches every day in which we search multiple times through the same real-world scene. In contrast, the bulk of research on the guidance of attention in visual search has used simple displays that change trial after trial (Treisman, 1993; Wolfe, 1998; Wolfe & Reynolds, 2008). Even those studies that aim to investigate more realistic search behavior by using real-world scenes, typically involve search for objects in scenes that the observers have never seen before and that change from trial to trial (e.g., Castelhano & Henderson, 2007; Eckstein, Drescher, & Shimozaki, 2006; Henderson, Brockmole, Catslehano, & Mack, 2007; Hollingworth, 2006; Malcolm & Henderson, 2010; Võ & Henderson, 2010). Unsurprisingly, models that aim to explain the deployment of visual attention during real-world search, have focused on search behavior in novel scenes (e.g., Ehinger, Hidalgo-Sotelo, Torralba & Oliva, 2009; Hwang, Higgins, & Pomplun, 2009; Torralba, Oliva, Castelhano, & Henderson, 2006). By recording eye movements as observers searched multiple times through the same scene, the current study moves us a step closer to an understanding of these most common search tasks.
Memory for previously attended objects
One would assume that repeated exposure to a scene increases search performance for objects in that scene. Imagine making breakfast in the kitchen of Figure 1, a kitchen that you have not seen before. You start by searching for the pan, then the eggs, followed by the onions and baguettes, etc. When your friend asks you to pass the kitchen towel, you would assume that you would be faster now that you have already looked for other objects and therefore familiarized yourself with the kitchen. It seems even more likely that you would retrieve the second onion from the basket more rapidly than the first.
Figure 1.

A kitchen scene in which one might search for onions, baguettes, kitchen towels, etc.
These intuitions are backed by findings from contextual cueing studies, where repeated exposure to the same target distractor arrangements increases response times (Chun & Jiang, 1998; for a review see Chun & Turk-Browne, 2008). Using real-world scenes, Brockmole and Henderson (2006a, b) have shown that contextual cueing in scenes can reduce response times and also guides eye movements to targets. Moreover, Hollingworth (2005) demonstrated that participants can remember both the spatial context of a scene and the specific positions of local objects after being exposed to a 20 second preview of a scene.
The ease with which one learns about objects and scenes is also illustrated by studies that have demonstrated massive memory for objects (Brady, Konkle, Alvarez & Oliva 2008; Hollingworth, 2004; Konkle, Brady, Alvarez & Oliva, 2010; Tatler & Melcher, 2007) and scenes (Konkle, Brady, Alvarez & Oliva, in press; Standing, 1973). The ability to learn quite detailed information about object in scenes is documented in studies that show that previously fixated (and therefore attended) objects embedded in scenes can be retained in visual long-term memory for hours or even days (e.g., Hollingworth, 2004; Hollingworth & Henderson, 2002; Hollingworth, Williams, & Henderson, 2001; for a review see Hollingworth, 2006). For example, Hollingworth and Henderson (2002) used a saccade-contingent change detection paradigm to investigate memory for previously attended objects. They found that changes to previously fixated objects were detected at a higher rate than changes to objects that had not been fixated. Additionally, longer gaze durations led to increased change detection performance. Even incidental fixations on objects during search improved subsequent recognition memory (e.g., Castelhano & Henderson, 2005; Võ, Schneider, & Matthias, 2008). These studies support the conclusion that looking at an object provides the observer with considerable information regarding its appearance and position within the scene. However, there has been some dispute on whether such stored information actually helps when looking for target items. When does looking at an object actually help looking for it?
Does visual search need memory?
Wolfe, Klempen, and Dahlen (2000) conducted a series of experiments in which observers search repeatedly through an unchanging set of letters. Search through a random set of letters that are large enough not to require foveation, proceeds at a rate of about 35 msec/letter. Interestingly, this search efficiency did not change even after hundreds of searches through the same small set of letters. Response times were reduced but, since the slope of the RT × set size functions did not change, this reduction was attributed to non-search components (e.g. response speeding).
After several hundred searches through the same sets of 3 or 6 letters, there is no doubt that observers had memorized the letters. However, that memory was not used to make search more efficient. Oliva, Wolfe, and Arsenio (2004) found similar results with small sets of realistic objects in scenes. They could force observers to use their memory for objects but, given a choice between using memory and doing the visual search over again, observers seemed to choose repeated visual search.
These results seem to fly in the face of logic and experience. It seems obvious that search is more efficient in a familiar scene than in an unfamiliar one. You remember where you put that receipt in the mess that is your desk. That memory obviously guides search in a way that it would not if you were searching your colleague’s desk (an experiment we do not suggest). However, the failure to improve search efficiency with repeated search is not quite as odd as it first sounds. These failures occur in tasks where the “effective set size” of the display (Neider & Zelinsky, 2008) is fixed. The effective set size is the number of items that are task-relevant. In the Wolfe et al. (2000) studies, Os searched through the same small set of letters for hundreds of trials and obtained no increase in search efficiency because the number of task-relevant items remains fixed. If, on the other hand, Os begin a block of trials searching through 18 letters but come to learn that only 6 are ever queried, search becomes more efficient because the effective set size is reduced from 18 to 6. While Os may still need to search, they learn to restrict that search to the 6 task-relevant items (Kunar, Flusberg, & Wolfe, 2008). In real world searches, many effects of memory will be due to reductions in effective set size.
It remains interesting that memorization of a small effective set size does not lead to further improvements in search efficiency. Consider the example of an effective set size of 6. Once memorized, if asked about the presence of an item, observers could search through the visual set or search through the memory set. Kunar, Flusberg, and Wolfe (2008) found that search through the visual set was more efficient than search through the memory set for the letter stimuli described above and so it turns out to be more efficient to search the same scene again rather than reactivating stored display representations.
Repeated search in scenes
Real scenes complicate this analysis. We do not know the set size of a real scene. It is clear, however, that, once the target is specified, the effective set size is much smaller than the real set size, whatever it may be. Returning to the kitchen in the opening example, if you are looking for the eggs, there are only certain places where eggs might be. They will not be hanging on the wall, no matter how many other objects hang there. Exposure to a scene, as in Hollingworth (2006) is likely to make the reduction in effective set size more dramatic for the average target item. Once you have looked at the scene, the plausible locations of eggs are further reduced by your increased knowledge of the structure of the scene.
You might also memorize the locations of some objects. Let us suppose that includes the eggs. The speed of a subsequent search for the eggs might represent a race between a search through memory for the remembered location of the eggs and a visual search through the plausible egg locations.
The current study
Knowledge about a scene can speed search. The current study asks about the acquisition of that knowledge. In these experiments, observers search multiple times through the same scene. The preceding discussion has described two sources of information that might make later searches faster than previous searches. First, observers might learn more about the scene structure and might be able to use that to limit the effective set size. Second, in searching for one item, observers might incidentally learn the location of other items and be able to use that information on a subsequent search.
In Experiment 1, participants first search for 15 different objects in each of 10 different scenes amounting to 150 different object searches. After this first block, they are asked to search for the same 150 objects in the same locations within the same, unaltered scenes in a second block, and yet again in a third. Note that, during the first search through the 15 items in a scene, familiarity with the scene grows and the opportunities for incidental learning abound since the scene remains visible and unchanged during the 15 repeated searches. The resulting reduction in effective set size and the resulting memory could each speed search during block 1. However, we find that search performance is largely unchanged over those initial searches. On the second search through the scene for the same objects, we find a substantial improvement in search time, suggesting that something about searching for and finding specific objects speeds subsequent search for that object. Experiments 2–5 employ different ways of familiarizing Os with a scene and its contents other than having Os search for the specific objects. In Experiment 2, participants search for 15 different letters, superimposed on future target objects. This forces participants to look at the eventual target objects without looking for them. In Experiment 3, participants view each scene for 30 seconds and are asked to decide whether a male or a female person lives in the depicted room. In Experiment 4, they are explicitly instructed to memorize each object in the scene and their locations for a subsequent memory test (Hollingworth, 2006). Finally, in Experiment 5, on half of the initial searches, participants are given a spatial cue that allows them to find the target without the need to search. In each of these experiments, we can ask if previous encounters with a scene improve search performance in subsequent search blocks. To anticipate our main finding, merely looking at objects does not speed search for these on subsequent blocks. The effects of structural understanding of the scenes seems to reach asymptote on first exposure. Those effects are large enough to render insignificant the role of incidental memories for one item, developed while looking for another item or otherwise interacting with a scene. The development of a memory that is useful for search seems to require that the observers search for and find the objects. Other forms of exposure are insufficient.
General Methods
Participants
In each of the five experiments, fifteen observers were tested (Exp.1: Mean Age=26, SD=6, 9 female; Exp.2: M=27 SD=6, 9 female; Exp.3: M=27, SD=10, 9 female; Exp.4: M=25, SD=9, 11 female, Exp.5: M=26, SD=5, 12 female). All were paid volunteers who had given informed consent. Each had at least 20/25 visual acuity and normal color vision as assessed by the Ishihara test.
Stimulus Material
Ten full-color images of indoor scenes were presented in all experiments of this study. An additional image was used for practice trials. Images were carefully chosen to include 15 singleton targets, i.e., when searching for a wine glass only one object resembling a wine glass would be present in the scene. Scenes were displayed on a 19-inch computer screen (resolution 1024 × 768 pixel, 100 Hz) subtending visual angles of 37° (horizontal) and 30° (vertical) at a viewing distance of 65 cm.
Apparatus
Eye movements were recorded with an EyeLink1000 tower system (SR Research, Canada) at a sampling rate of 1000 Hz. Viewing was binocular but only the position of the right eye was tracked. Experimental sessions were carried out on a computer running OS Windows XP. Stimulus presentation and response recording were controlled by Experiment Builder (SR, Research, Canada).
Procedure
Each experiment was preceded by a randomized 9-point calibration and validation procedure. Before each new scene, a drift correction was applied or - if necessary – a recalibration was performed.
In all experiments, participants would search, one after another, for 15 different objects in the same unchanging scene. The object of search was identified at the start of each search by presenting a target word (font: Courier, font size: 25, color: white with black borders, duration: 750 ms) in the center of the scene. Participants were instructed to search for the object as fast as possible and, once found, to press a button while fixating the object. This triggered auditory feedback. The scene remained continuously visible. The next search was started with the appearance of a new target word (see Figure 2).
Figure 2.
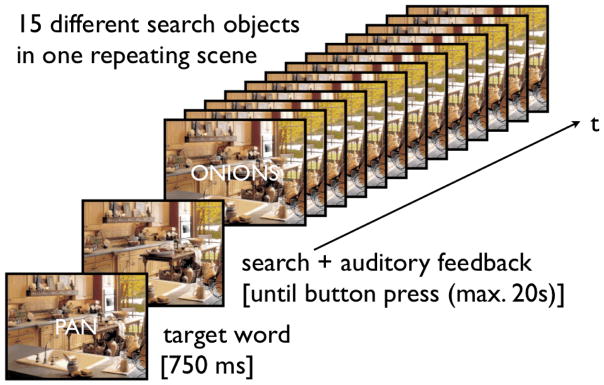
Fifteen repeated searches through a single, unchanging display. Target words at the center of the display designated the object of search for each search.
After 15 searches in the same scene, a drift check (or recalibration if necessary) was performed before starting search in a different scene. One block consisted of 15 searches through each of 10 different scenes (150 trials). After the first block of searches (during which no target was searched for twice), the same targets in the same positions in the same scenes would be searched for again in a second block (order of searches was randomized). Participants were not told in advance that they would search for the same objects again in subsequent blocks of the experiment.
Experiment 1 consisted of three such blocks. In Experiments 2–4, participants only looked for objects in Block 1 and 2, but performed different tasks that required them to look at the scenes in a preceding Block 0. More detailed descriptions of these tasks can be found in the method sections for each experiment. In Experiment 5 participants repeatedly searched for objects in three successive blocks. However, half of the target objects in the first block were cued with a valid spatial cue so that search was not necessary. In effect, we told them where the target item was. The goal was to differentiate between the effects of actively searching for a target and having attention summoned to that target.
An additional scene was used for practice trials at the beginning of each experiment, which was not included in the final analyses. Each experiment lasted for about 30 minutes.
Eye movement data analysis
The interest area for each target object was defined by a rectangular box that was large enough to encompass that object. Trials with response times of more than 7 seconds were excluded as outliers [in all experiments < 6%]. This reduced variance, while the pattern of data essentially remained the same as it would with all trials included.
Raw data was filtered using SR Research Data Viewer. In order to investigate search performance and eye movement behavior, a set of measures was calculated: Response time was defined as the time elapsed from target word offset until button press. Response time was further divided into Time to target fixation - measured from target word offset until the first fixation of the target object – and Decision Time – recorded from the first fixation of the target object until button press. Number of fixations was defined as the number of discrete fixations until the target object was first fixated. The value does not include the initial scene fixation centered on the screen, but does include the first fixation on the target object. Scan path ratio was calculated as the sum of all saccade lengths until first target fixation divided by the shortest distance from the scene center to the center of the target interest area. A perfectly efficient search would yield a ratio of 1 with increasing values for increasing deviations from the optimal path to the target. For the interpretation of these measures it is important to note that the decision time will give us information on the time it takes to make a decision upon target fixation, while all other measures reflect the strength of guidance to the search target prior to its fixation, For most of the analyses we performed ANOVAs with block (Block 1 vs. Block 2 vs. Block 3) and search epoch (Epoch 1: searches 1–5 vs. Epoch 2: searches 6–10 vs. Epoch 3: searches 11–15) as within-subject factors. For the investigation of effects of epoch, we restricted ANOVAs to the first exposure to the scene in Block1 (15 searches).
The order of object searches was Latin-square randomized such that across participants each of the 150 objects was equally often target in each of the three search epochs.
We also calculated the Total gaze duration, defined as the amount of time spent fixating on an object while it was not the object of search. Thus, in Experiment 1, this would be the time that an observer happened to spend fixating on one item while searching for another on all the trials before that item became a target, itself. It is a measure of the incidental attention to the object. In Experiments 3 and 4, observers were engaged in 30 seconds of free viewing during Block 0. The total gaze duration for an object was calculated as the sum of all fixation durations on that object during those 30 seconds of free viewing.
Experiment 1
Previous research on repeated search has had observers searching the same scene for the same objects multiple times (e.g., Kunar, Flusberg, & Wolfe, 2008; Oliva, Wolfe, & Arsenio, 2004; Wolfe, Klempen, & Dahlen, 2000; Wolfe, Alvarez, Rosenholtz, & Kuzmova, in prep). In this first experiment, we dissociate repeated search for the same object from extended exposure to the same scene. In the first block, observers search for a different object on each of 15 trials. Thus, they get many seconds of exposure to the scene but they do not repeat a specific search until the second block. By recording eye movements we were able to distinguish between effects on the time to guide, i.e., to first target fixation, versus decision time once the target was fixated. Moreover, we can use fixation as a conservative measure of incidental attention to non-target objects during search for the designated target. This allows us to ask if attention to an object on earlier trials, speeds search for that object on a subsequent trial. Wolfe et al. (in prep) found that the second search for a target was much faster than the first search. Eye movement data can be used to determine if the increased speed of the second search reflects more efficient search – as seen in eye movement measures before target fixation – or faster decision processes - as seen in eye movement measures upon target fixation, or both.
Methods
Procedure
As already described in the General Methods section, participants were asked to search for 15 different objects in the same, unchanging scene. In Experiment 1, participants searched for each item three times, once in each of three blocks. That is, while participants searched for 150 different objects across 10 scenes in Block 1, they looked for the same objects again in Blocks 2 and 3.
Results
For purposes of analysis, the data from the 15 searches in each scene are grouped into 3 epochs: searches 1–5, 6–10, and 11–15. Figure 3 shows overall response time, mean time to first target fixation, and decision time (total RT time to fixation) as a function epoch for each of the three blocks. Note that, while the absolute values vary, the range of the y-axis is the same 1000 msec in all three panels.
Figure 3.
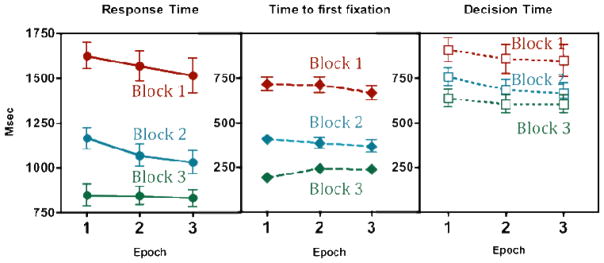
Total response time, mean time to first target fixation, and decision time as a function of epoch for each block of Experiment One. Error bars are +/− 1 s.e.m. The y-axis covers 1000 msec in all three panels.
Similar data for other measures (# of fixation, scan path ratio, etc) can be found in Table 1. The effects of epoch are modest compared to the effects of block and are sometimes statistically non-existent. Thus, searching repeatedly for different items in the same scene produces no main effect of search epochs on the time to first fixation (Fig. 3b) or on number of fixations or scan path ratio until target fixation (Table 1). All F’s < 1.62, all p’s>.21, all partial eta-squares <.11. There is a small decrease in decision time (Fig. 3c) and response time (Fig. 3a): F(2,14)=3.92, p=.03, pη2=.22 and F(2,14)=2.72, p=.08, pη2=.16, respectively. However, when we focus on the analyses on Block 1, the first exposure to the scene, we find no main effects of epoch in any of the measures: (RT: F(2,14)=1.08, p=.35, pη2=.07; time and fixations to target fixation: Fs<1; decision time: F(2,14)=1.16, p=.32, pη2=.08; scan path ratio: F(2,14)=1.40, p=.26, pη2=.09). In contrast, there are large effects of block. All measures show substantial search improvement when observers search for the same object again in blocks 2 and 3 (all F’s > 26.26, all p’s<.01, all pη2>.65). For example, time to target fixation decreased by about 300 ms from Block 1 to Block 2, but only by about 50 ms from Epoch 1 to Epoch 3 within Block 1. Similarly, decision time decreased by about 170ms from Block 1 to Block 2, and only 60ms from Epoch 1 to Epoch 3. These results imply that increasing familiarity with the scene did not speed search, while a repetition of the same search target greatly reduced both search and decision time.
Table 1.
| Dependent Variables | Blocks | Search Epochs | ANOVAs | |||||
|---|---|---|---|---|---|---|---|---|
| Response time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 1623 [73] | 1568 [83] | 1514 [96] | Block | 124.80 | ** | .90 | |
| Bl. 2 | 1164 [59] | 1070 [61] | 1032 [63] | Epoch | 2.72 | .08 | .16 | |
| Bl. 3 | 832 [62] | 849 [51] | 845 [46] | B × E | 1.21 | .32 | .08 | |
|
| ||||||||
| Time to target fixation in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 716 [38] | 711 [42] | 668 [41] | Block | 183.27 | ** | .93 | |
| Bl. 2 | 409 [29] | 386 [31] | 369 [35] | Epoch | .56 | .58 | .04 | |
| Bl. 3 | 194 [29] | 245 [24] | 239 [26] | B × E | 1.05 | .39 | .07 | |
|
| ||||||||
| Decision time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 907 [68] | 857 [81] | 846 [91] | Block | 26.42 | ** | .65 | |
| Bl. 2 | 756 [48] | 684 [59] | 664 [61] | Epoch | 3.92 | .03 | .22 | |
| Bl. 3 | 637 [50] | 604 [51] | 605 [51] | B × E | .58 | .69 | .04 | |
|
| ||||||||
| Fixations to target fixation | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 3.10 [.14] | 3.06 [.16] | 2.86 [.15] | Block | 175.88 | ** | .93 | |
| Bl. 2 | 1.84 [.11] | 1.81 [.13] | 1.72 [.12] | Epoch | .61 | .55 | .04 | |
| Bl. 3 | 1.04 [.12] | 1.18 [.10] | 1.20 [.11] | B × E | .89 | .48 | .06 | |
|
| ||||||||
| Scan path Ratio | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 2.90 [.16] | 2.94 [.15] | 2.64 [.12] | Block | 153.59 | ** | .92 | |
| Bl. 2 | 1.95 [.10] | 2.07 [.18] | 1.81 [.12] | Epoch | 1.61 | .22 | .10 | |
| Bl. 3 | 1.36 [.11] | 1.60 [.15] | 1.49 [.12] | B × E | 1.12 | .36 | .07 | |
|
| ||||||||
| Error rates in % | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 15.83 [2.61] | 17.53 [2.54] | 13.71 [2.04] | Block | 15.71 | ** | .53 | |
| Bl. 2 | 10.03 [2.09] | 11.10 [2.07] | 8.31 [1.28] | Epoch | 1.56 | .23 | .10 | |
| Bl. 3 | 7.90 [1.25] | 6.17 [1.01] | 6.80 [1.43] | B × E | 1.83 | .14 | .12 | |
Because the range on the y-axis in each of the three panels of Figure 3 is 1000 msec, it is possible to compare the size of differences between blocks for overall RTs and time to fixation and decision time individually. Thus we can see that the Block 1 to Block 2 improvement in RT comes mostly from improvements in the time to first fixation on the target. However, there is still substantial improvement in the time spent after that fixation.
Error rate
A search was regarded as correct, when the participant looked at the target object while pressing a button. Errors could be made by looking at a location outside the target interest area, while pressing the button or by failing to find the target object within 7 seconds. In Experiment 1, the overall error rate averaged 11 %. While error rates declined across blocks, F(2,14)=15.71, p<.01, pη2=.53, there was no main effect of search epoch, F(2,14)=1.56, p=.23 pη2=.10, and no significant interaction, F(4,14)=1.83, p=.14 pη2=.12.
Incidental gaze duration and response time
It seems counterintuitive that search performance does not increase across more than a dozen searches through the same scene. If looking for an object really creates a memory representation that can speed subsequent searches for the same object in Block 2, one would assume that the same memory representation should also lead to increased search efficiency within Block 1 by avoiding refixations on former search targets. We therefore computed incidental gaze durations on objects in Block 1 to test whether objects were fixated to a different degree before and after they had become targets. For each object, we calculated the sum of all fixation durations on that object prior to and after the time that it became a target. Note that for this calculation of incidental gaze durations we included all trials; those with RTs longer than 7 seconds and those where the response was incorrect, because the course of those searches contributes to the participants incidental exposure to subsequent targets. Excluding error trials yielded essentially the same results. We found a small, but significant decrease in gaze durations from 295 ms before to 220 ms after the target had been fixated, t(14)= 5.45, p < .01. Similarly, the probability of fixating an object that had previously been a target decreased from 67% to 64%, t(14)= 2.86, p = .01. This does imply some degree of memory for previous search targets that influences search behavior. However, in the context of ongoing search this target memory does not seem to be strong enough to yield search benefits for other objects in the same scene.
While there is no significant effect of epoch in Block 1, there is some indication of modest improvement. Perhaps we would see clearer evidence for improvement specifically for those targets that had been fixated incidentally before becoming search targets. We therefore used incidental gaze durations on an object prior to being a target to test whether fixating a distractor object (let’s say a toaster) during search for the target (maybe a tea pot) would help find the toaster when it subsequently becomes a target. These mean incidental gaze durations were then correlated with mean RTs for each of the 150 objects. As can be seen in Figure 4, incidental gaze duration and RT did not significantly correlate (R=.04, p=.61). Moreover, additional analyses showed that the slightly positive correlation was due to one object that was hardly ever found (a watering can that you can search for in Figure 1). Interestingly, this failure occurred even though observers looked at the watering can while it was a distractor for about a second on average. Without this object, the correlation further drops down to R=.02, p=.79. Whether an object had been looked at for many hundreds of ms on prior trials had no influence on the time it took to look for that object once it became the target of search.
Figure 4.
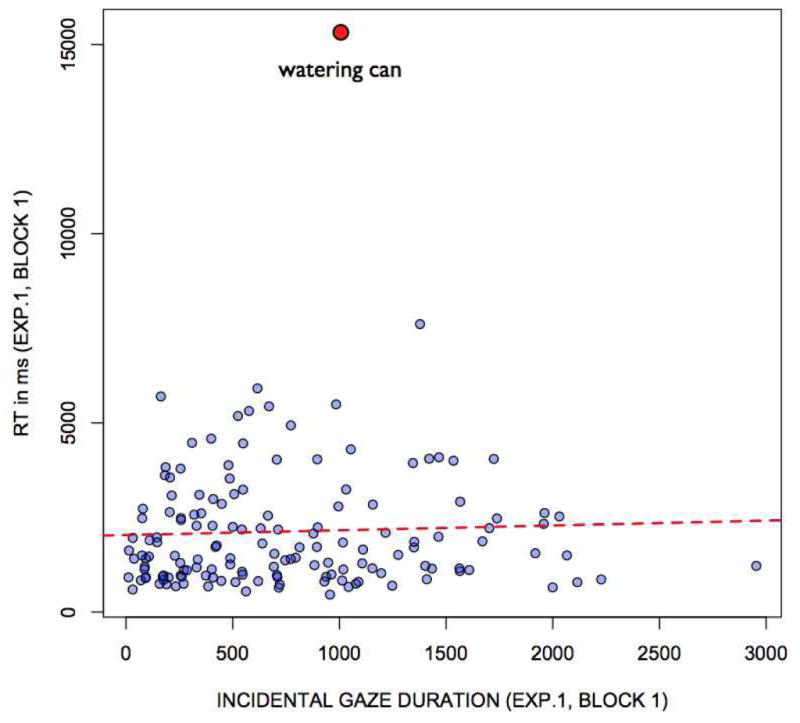
Response time for a target item as a function of the amount of time that target was incidentally fixated on previous trials.
Similar to findings by Oliva et al. (2004) and Wolfe et al. (in prep), we found very weak improvement across repeated searches for different objects in an unchanging scene. The failure to find a behavioral benefit of incidental fixation seems curious, since we know from previous work that we have a stunning ability to memorize scenes and their objects (for a review see, Hollingworth 2006). Moreover, incidental distractor fixations during search have been shown to increase recognition memory for them (e.g., Castelhano & Henderson, 2005; Võ et al., 2008) and changes to objects are detected at a higher rate when they had been previously fixated (Hollingworth & Henderson, 2002). Moreover, our data show that memory for previous search targets reduces the probability of refixating these objects when searching for new targets. Indeed, it is possible that the unreliable improvement that we did see is related to memory for targets that were found, rather than other objects that were incidentally encountered (Gibson, Li, Skow, Brown, & Cooke, 2000). Obviously object information is acquired and stored during search, but does not seem to be functional for guiding initial searches. In contrast, we find clear evidence for memory guidance when the search target is repeated (see also Brockmole & Henderson, 2006a, b). By Block 3 search seems to be entirely guided by search target memory and guided well enough that the first saccade generally goes to the target. We will defer until the General Discussion further consideration of the nature of the drastic improvement in search performance between blocks.
When does looking at an object help us looking for it? Apparently, incidental exposure during search for something else makes rather little difference. In Experiments 2–4, we try three different ways to induce observers to preview objects in scenes. To anticipate the results, when observers subsequently search for the target objects, prior fixations from these various previews also fail to speed search.
Experiment 2
Experiment 1 showed a strong search benefit for objects that had previously been target of a prior search. What happens if an object shared the location of an earlier search target, but was not the search target itself? When that object later became the search target, would we observe a search benefit arising from having looked at the shared location? In Experiment 2, the first block of object search was preceded by a block of a letter search task in which letters were superimposed on each object in the scene that would later become a search target (see Figure 5). Thus, participants would look at each of the future target objects without looking for them. This attention to the target location, if not the to the target object, might produce effects that would fall between actual search for the object and merely incidental fixation on the objects.
Figure 5.

An example of a search display used in Experiment 2, Block 0, consisting of 15 letters superimposed on the 15 search targets of Block 1 and Block 2. Note that we took care to ensure that letters were visible and did not completely cover target objects.
Procedure
Letter search displays consisted of 15 different letters randomly chosen from the alphabet and superimposed on objects in Block 0 that would subsequently be targets during object search in Blocks 1 and 2. Thus, the images used in both letter and object search were identical. Participants were not informed that there would be a second, object search, portion of the task and, thus, they had no idea that the placement of the letters was significant. Together with the scene, all letters remained visible for all 15 searches within a scene. At the beginning of each trial, a letters cue was presented in the center of the screen (font: Courier, font size: 25, color: white with black borders, duration: 750 ms) to indicate which letter to look for. To avoid confusion between target cue and target letters and to minimize masking of objects by letters, target letters were smaller and of different font (font: Arial, font size: 18, color: white). Participants were instructed to search for the letters as fast as possible and once found to press a button while fixating the letter. Auditory feedback was given. After completing 150 letter searches in 10 different scenes, participants performed object searches (without superimposed letters) similar to Block 1 and 2 in Experiment 1.
Results
Figure 6 shows the critical results for Experiment 2. Our interest in performance on the letter search task (call this Block 0) is confined to evidence that participants did what they were told. We therefore analyzed search performance for letters in Block 0 and objects in Blocks 1 and 2 separately. Since search for these letters superimposed on scenes is more difficult than object search, we allowed RTs up to 15 seconds. Error rates for letter search in Block 0 were 18%. RT for the letter search averaged 2607 ms and significantly decreased across epochs (Epoch 1: 3053 ms, Epoch 2: 2378, Epoch 3: 2389 ms; F(2,14)=12.26, p<.01, pη2=.47). Essentially, all of the decline occurs over the course of the first 3 letter search trials. The important question is whether exposure to the scene and fixation on the location of each object in Block 0 produce any savings in Block 1, the first object search block. As is clear from Figure 6, performance on Block 1 of Experiment 2 is very similar to performance on Block 1 of Experiment 1. An ANOVA with search epochs as within and experiment as between-subject factor showed no significant RT differences between experiments, all F’s <1. Previous scene exposure during letter search did not speed search for objects.
Figure 6.
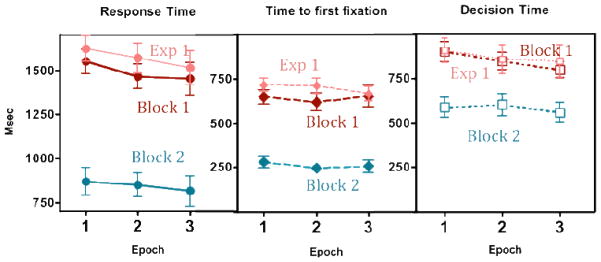
Response time, mean time to first target fixation, and decision time as a function of epoch for each block of Experiment Two. Note that Block 1 is the first block of object search. Block 1 from Exp. 1 is shown for comparison. Error bars are +/− 1 s.e.m.
While Block 0 had no effect on Block 1, Block 1 had a strong effect on Block 2, similar to the effects in Experiment 1. As can be seen in Table 2, all eye measures showed a similar pattern of results: There was no significant speeding of eye movements towards the target as a function of search epochs, all Fs<1.09, all ps>.34, all pη2<.08. Only upon fixation did decision time significantly decrease across epochs, F(1,14)=3.63, p<.05, pη2=.21. As in Experiment 1, there seems to be modest speeding of response over 15 searches through the same scene, but it is much smaller than the decrease in RT that is seen the second time that a participant searches for the same object in Block 2, all Fs>18.92, all ps<.01, all pη2>.57.
Table 2.
| Dependent Variables | Blocks | Search Epochs | ANOVAs | |||||
|---|---|---|---|---|---|---|---|---|
| Response time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 1549 [68] | 1466 [70] | 1452 [90] | Block | 51.19 | ** | .79 | |
| Bl. 2 | 869 [79] | 850 [69] | 815 [84] | Epoch | 1.08 | .35 | .07 | |
| B × E | .35 | .71 | .02 | |||||
|
| ||||||||
| Time to target fixation in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 650 [41] | 620 [50] | 654 [62] | Block | 66.67 | ** | .83 | |
| Bl. 2 | 282 [33] | 248 [25] | 257 [35] | Epoch | .45 | .64 | .03 | |
| B × E | .15 | .86 | .01 | |||||
|
| ||||||||
| Decision time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 899 [58] | 846 [49] | 798 [44] | Block | 18.92 | ** | .57 | |
| Bl. 2 | 587 [56] | 603 [61] | 558 [56] | Epoch | 3.63 | * | .21 | |
| B × E | 1.22 | .31 | .08 | |||||
|
| ||||||||
| Fixations to target fixation | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 2.77 [.20] | 2.67 [.21] | 2.73 [.22] | Block | 64.10 | ** | .82 | |
| Bl. 2 | 1.35 [.13] | 1.15 [.09] | 1.24 [.14] | Epoch | .66 | .57 | .04 | |
| B × E | .10 | .90 | .00 | |||||
|
| ||||||||
| Scan path Ratio | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 2.75 [.16] | 2.79 [.18] | 2.72 [.18] | Block | 69.05 | ** | .83 | |
| Bl. 2 | 1.65 [.08] | 1.72 [.16] | 1.53 [.10] | Epoch | .33 | .72 | .02 | |
| B × E | .15 | .87 | .01 | |||||
|
| ||||||||
| Error rates in % | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 11.84 [1.43] | 12.93 [1.43] | 11.02 [1.77] | Block | 10.54 | ** | .68 | |
| Bl. 2 | 8.68 [2.09] | 8.69 [2.29] | 8.29 [2.05] | Epoch | .40 | .67 | .06 | |
| B × E | .51 | .32 | .73 | |||||
Error rates
Average error rates for object searches in Experiment 2 was 10%. These differed only across blocks, F(1,14)=10.54, p<.01, pη2=.68, but not across search epochs, F<1, nor was there an interaction, F<1.
Discussion
The letter search task of Block 0 produced an average of nearly 30 seconds of exposure to each scene along with a fixation of the location of each eventual target object. However, this preview produced no transfer to the object search task. Block 1 of Experiment 2 looked essentially identical to Block 1 of Experiment 1. Experiment 2 did replicate the main findings of Experiment 1 in finding large benefits between Blocks 1 and 2 and little or no benefit of continued time within a block. Thus, merely looking at an object does not automatically generate a representation that can be used to guide gaze. Given that knowledge of a scene’s composition will guide search, the failure to find any effect between Block 0 and Block 1 indicates that the effects of this sort of scene understanding reach asymptote very quickly on first exposure to a scene. Thereafter, essentially full generic information is available about where eggs might be in this kitchen and so forth.
While intriguing, this experiment had some drawbacks: While we took care that the letters did not hide the underlying target objects, these might have nevertheless distracted attention away from the objects rather than to them. Even worse, observers could have done the letter search without at all paying attention to the scene background and its objects basically searching on a different, superimposed level. Also, compared to free viewing, search instructions can override the influence of, for example, visual salience (Foulsham & Underwood, 2007) and might therefore also inhibit the uptake and storage of object information, which do not fit the current goals, but could be used for future searches. To overcome these limitations of Experiment 2, we increased engagement with the scenes by asking participants in Experiment 3 to initially view the scene for a purpose other than searching.
Experiment 3
Procedure
Participants in Experiment 3 were instructed to simply view a scene for 30 seconds. In order to engage them with the scene, they had to indicate after each scene via a button press, whether a male or a female person usually lived in the scene. This ensured that participants had to look at the scene, as a whole, as well as at individual objects, e.g., a shaving brush or a perfume bottle. Thirty seconds roughly corresponded to the time spent in the scene when performing 15 individual searches. Before each new scene, a drift check was performed. Participants were not told that they would subsequently be asked to search the same scenes for objects. Object searches in Block 1 and 2 were the same as Blocks 1 and 2 in Experiments 1 and 2.
Results
During 30 seconds of previewing the scene participants on average fixated 91% of the objects that would later become search targets.
Looking at Figure 7, it is obvious that 30 seconds of examination of the scene in Block 0 did not speed subsequent search in Block 1. Indeed, the first block of Experiment 3 has response times that are actually somewhat slower than the equivalent block from Experiment 1 (F(1,28)=6.09, p<.05, pη2=.18). Similar to the previous experiments, search benefits were substantial when the search target was repeated in Block 2 (all Fs>29.98, all p<.01, all pη2>.67). In Experiment 3, there were significant effects of epoch. Except for the scan path ratio, search performance increased slightly across search epochs (all Fs>3.61, all p<.05, all pη2>.20). These effects are on the order of 1/4th the size of the Block effect. That is, overall RT is about 150 msec faster in Epoch 3 than in Epoch 1. Note, however, that in what we could call Epoch 4 — the first Epoch of Block 2, some minutes after Block 1 — overall RTs are over 600 msec faster. A summary of all measures can be seen in Table 3. Additionally, we also provide analyses on the contribution of memory for target locations below (see Incidental gaze duration and response time).
Figure 7.
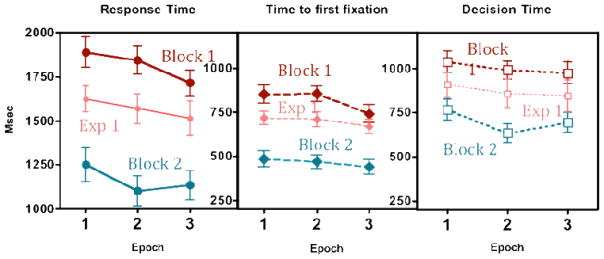
Response time, mean time to first target fixation, and decision time as a function of epoch for each block of Experiment 3. Note that Block 1 is the first block of object search. Block 1 from Exp. 1 is shown for comparison. Error bars are +/− 1 s.e.m.
Table 3.
| Dependent Variables | Blocks | Search Epochs | ANOVAs | |||||
|---|---|---|---|---|---|---|---|---|
| Response time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 1888 [85] | 1844 [81] | 1715 [73] | Block | 61.61 | ** | .81 | |
| Bl. 2 | 1250 [96] | 1103 [86] | 1134 [83] | Epoch | 5.53 | ** | .28 | |
| B × E | 1.56 | .23 | .10 | |||||
|
| ||||||||
| Time to target fixation in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 853 [54] | 854 [44] | 741 [52] | Block | 86.43 | ** | .86 | |
| Bl. 2 | 484 [44] | 469 [40] | 440 [43] | Epoch | 3.63 | * | .21 | |
| B × E | .68 | .52 | .05 | |||||
|
| ||||||||
| Decision time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 1036 [59] | 990 [51] | 974 [62] | Block | 29.98 | ** | .68 | |
| Bl. 2 | 766 [60] | 634 [55] | 693 [57] | Epoch | 5.70 | * | .29 | |
| B × E | 1.60 | .22 | .10 | |||||
|
| ||||||||
| Fixations to target fixation | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 3.19 [.22] | 3.15 [.21] | 2.74 [.18] | Block | 76.08 | ** | .84 | |
| Bl. 2 | 1.72 [.14] | 1.72 [.13] | 1.64 [.15] | Epoch | 3.61 | * | .20 | |
| B × E | 1.10 | .34 | .07 | |||||
|
| ||||||||
| Scan path ratio | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 2.77 [.18] | 2.72 [.19] | 2.52 [.13] | Block | 52.65 | ** | .79 | |
| Bl. 2 | 1.78 [.14] | 1.88 [.15] | 1.74 [.11] | Epoch | .82 | .45 | .06 | |
| B × E | .37 | .69 | .03 | |||||
|
| ||||||||
| Error rates in % | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 16.95 [1.68] | 13.64 [1.62] | 15.46 [1.84] | Block | 14.80 | ** | .51 | |
| Bl. 2 | 8.17 [1.36] | 11.36 [2.28] | 10.69 [1.76] | Epoch | .09 | .92 | .00 | |
| B × E | 8.43 | * | .38 | |||||
Error rates
Average error rates for object searches in Experiment 3 averaged 13%. These differed across blocks, F(1,14)=14.80, p<.01, pη2=.51, but not across search epochs, F<1. There was a significant interaction, F(2,14)=8.43, p<.05, pη2=.38, due to slightly decreasing error rates in Block 1 and increasing error rates in Block 2.
Incidental gaze duration and response time
Before looking at correlations between incidental gaze durations during the preview Block 0 and response times in Block 1, we want to take a closer look at the significant decline of RTs across epochs observed in Block 1. Note that contrary to Experiment 1, Block 1 in this experiment is not the first exposure to the scene. Therefore, the effects of epoch should be treated with caution. Nevertheless, we conducted additional analyses to test whether objects were fixated to a different degree before and after they had become targets. As in Experiment 1, we found a significant decrease in target gaze durations, i.e. from 341 ms before to 246 ms after the target had been fixated, t(14)= 3.90, p < .01. Similarly, the probability of fixating an object that had previously been a target decreased from 69% to 64%, t(14) = 3.57, p < .01, a slightly greater decrease than what we observed in Experiment 1. This again suggests that memory for target objects might play a role in the observed decrease of RTs across epochs. This decrease is more pronounced than the decrease of RTs within Block 1 in Experiment 1, which did not reach significance. Target memory might therefore have been stronger in Experiment 3. In line with this assumption, the speeding of search from Block 1 to Block 2 was also more pronounced in Experiment 3 (650 ms benefit) than in Experiment 1 (<500 ms). While we can only speculate about the reasons for this stronger target memory in Experiment 3, it is clear that despite an extended scene preview in Block 0, overall search performance in Block 1 was no better than Block 1 performance in Experiment 1.
To directly test the influence of the preview on initial searches, we looked into whether more time spent looking at an object during the preview in Block 0 would produce a benefit in subsequent search. Participants fixated 91% of the target objects that would later become search targets. We correlated the mean fixation durations on each of the 150 objects during the scene preview with response times for each of these objects during the first block of searches. As can be seen in Figure 8, we found a significant correlation, R=−.23, p<.01. However, additional analysis of individual objects showed that the correlation was mainly driven by some objects, that were specifically large in size (e.g., comforter, chair, chest, mirror). Also, one object was never looked at during scene inspection, a window shade. It seems that this object was not relevant for solving our male/female question. Nevertheless, Figure 7 shows that it was among the fastest to be found. Figure 7 appears to be an illustration of a correlation driven by a common variable. Large objects are fixated more often and found more rapidly.
Figure 8.

Mean RTs of 150 object searches in Block 1 plotted against mean gaze durations on 150 objects during the scene preview in Block 0. Objects of large sizes are depicted in red. Note the shade that was never looked at, but among the fastest to be found.
Discussion
It seems odd that despite inspecting a scene for 30 seconds, observers were no faster at finding objects compared to Experiment 1, where the scene had never been scene before. While one might have thought that participants in Experiment 2 had simply ignored the scene background during letter search, we specifically asked participants to engage with the scene in Experiment 3. Nevertheless, it seems that looking at the bulk of the objects did not produce a benefit when subsequently looking for the same objects. Though this comparison of Block 1 on two different experiments is a between-subjects comparison, had there been anything like the 650 msec improvement — seen from Block 1 to Block 2 — we would have been able to see it. Recall that Block 1 search times were actually slower than the comparable block in Experiment 1. We do not have a convincing explanation for that effect, but it does show that these methods are capable of registering a significant difference of about 200 msec, albeit in an unexpected direction. For further analysis of this point, see the results section of Experiment 4. In any case, it is clear is that the familiarity with a scene and its objects, produced by 30 seconds of viewing, does not necessarily lead to search benefits. Negative results always lead to the suspicion that one just has not found the right conditions. In that spirit, Experiment 4 was another attempt to create a situation in which looking at objects helps looking for them.
Experiment 4
Maybe participants in Experiment 3 were too occupied looking at objects that were related to the task of discriminating between a male or female scene. In Experiment, we explicitly instructed participants to memorize the scene and the location of its objects for a later recognition memory test. Now, would looking at objects in a scene benefit subsequent search?
Procedure
The procedure was essentially identical to Experiment 3 except that participants were asked to memorize the scenes, especially the location of embedded objects for a later memory task (which was not given). Participants were not told that they would be searching the same scenes later on. Object searches in Block 1 and 2 were again similar to Experiments 1–3.
Results
As can be seen in Figure 9, Experiment 4 repeats the pattern established in Experiments 2 and 3. The preview, this time an explicit instruction to memorize the scene, had no benefit on the subsequent search for objects in the scene. Block 1 did not significantly differ from Block 1 of Experiment 1, F(1,28)=1.59, p>.21, pη2=.05 and, in fact, Experiment 1 was, if anything, faster than Block 1 of Experiment 4. Block 2 was significantly faster than Block 1 on all measures (all Fs>26.03, all p<.01, all pη2>.64). There was a significant speeding of decision time, F(2,14)=7.30, p<.01, pη2=.34, while all other measures showed no effect of epoch, all Fs<1.92, all p>.15, all pη2<.13. A summary of other measures can be seen in Table 4.
Figure 9.
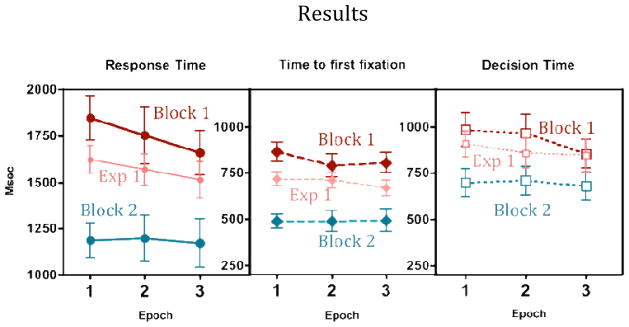
Response time, mean time to first target fixation, and decision time as a function of epoch for each block of Experiment Four. Note that Block 1 is the first block of object search. Block 1 from Exp 1. is shown for comparison. Error bars are +/− 1 s.e.m.
Table 4.
| Dependent Variables | Blocks | Search Epochs | ANOVAs | |||||
|---|---|---|---|---|---|---|---|---|
| Response time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 1847 [121] | 1754 [153] | 1659 [120] | Block | 50.26 | ** | .78 | |
| Bl. 2 | 1188 [94] | 1199 [122] | 1173 [132] | Epoch | 1.93 | .16 | .12 | |
| B × E | 2.64 | .09 | .16 | |||||
|
| ||||||||
| Time to target fixation in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 864 [53] | 789 [62] | 805 [56] | Block | 57.38 | ** | .80 | |
| Bl. 2 | 489 [37] | 490 [55] | 493 [62] | Epoch | .45 | .65 | .03 | |
| B × E | 1.49 | .24 | .10 | |||||
|
| ||||||||
| Decision time in ms | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 982 [90] | 965 [100] | 853 [76] | Block | 26.04 | ** | .65 | |
| Bl. 2 | 698 [75] | 710 [77] | 679 [77] | Epoch | 7.30 | ** | .34 | |
| B × E | 2.70 | .08 | .16 | |||||
|
| ||||||||
| Fixations to target fixation | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 3.29 [.16] | 3.03 [.18] | 3.03 [.15] | Block | 65.53 | ** | .82 | |
| Bl. 2 | 1.90 [.13] | 1.85 [.17] | 1.88 [.21] | Epoch | .50 | .61 | .03 | |
| B × E | 1.13 | .33 | .07 | |||||
|
| ||||||||
| Scan path ratio | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 2.95 [.15] | 2.72 [.09] | 2.76 [.11] | Block | 60.97 | ** | .81 | |
| Bl. 2 | 1.92 [.12] | 1.71 [.13] | 1.96 [.17] | Epoch | 1.48 | .25 | .10 | |
| B × E | .67 | .52 | .05 | |||||
|
| ||||||||
| Error rates in % | Epoch 1 | Epoch 2 | Epoch 3 | Factor | Fs | ps | pη2 | |
| Bl. 1 | 15.85 [1.60] | 18.64 [2.07] | 16.63 [1.85] | Block | 18.40 | ** | .57 | |
| Bl. 2 | 12.84 [1.97] | 11.91 [2.11] | 12.16 [2.08] | Epoch | .69 | .51 | .05 | |
| B × E | 1.65 | .21 | .11 | |||||
To ensure that the lack of significant differences of Block 1 performance across experiments is not due to a potential weakness of our between-subject comparisons, we cross-validated these analyses by comparing Block 1 performance of Experiment 1 with the second blocks of Experiments 2–4. For all these comparisons, our between-subject ANOVAs on RTs revealed significant effects: Experiment 1 vs. 2: F(1,28)=49.30, p<.01, pη2=.64, Experiment 1 vs. 3: F(1,28)=13.67, p<.01, pη2=.33, and Experiment 1 vs. 4: F(1,28)=8.28, p<.01, pη2=.23. Thus, our between-subject analysis is capable of registering the substantial improvements produced by the experience of searching for an object. No such improvements are seen following the Block 0 experiences of Experiments 2, 3, and 4.
Error rates
The average error rate for object searches in Experiment 4 was 15%. These only differed across blocks, F(1,14)=18.40, p<.01, pη2=.57, but not across search epochs, F<1. There was also no interaction, F(2,14)=1.65, p=.21, pη2=.11.
Incidental gaze duration and response time
During 30 seconds of scene memorizing participants fixated on average 93% of all future target objects in a scene. We again correlated the mean gaze durations on each object during scene memorization in Block 0 with response times for these objects during initial searches. One object, a serving pot, was never found within the 7-second time limit and was therefore excluded from these analyses. Compared to scene inspection of Experiment 3, the correlation seems stronger, R=.-30, p<.01. However, as can be seen in Figure 10, this correlation again seems to be driven by a few large objects (e.g., comforter, chair, or chest). These might attract attention during scene memorization, and, independent of any specific memory traces for them, large objects are also found faster than smaller items. In an additional item analysis we found that while the mean size of all target regions of interest was about 29° squared visual angle, interest areas of these larger objects ranged between 79 and 158° squared visual angle.
Figure 10.
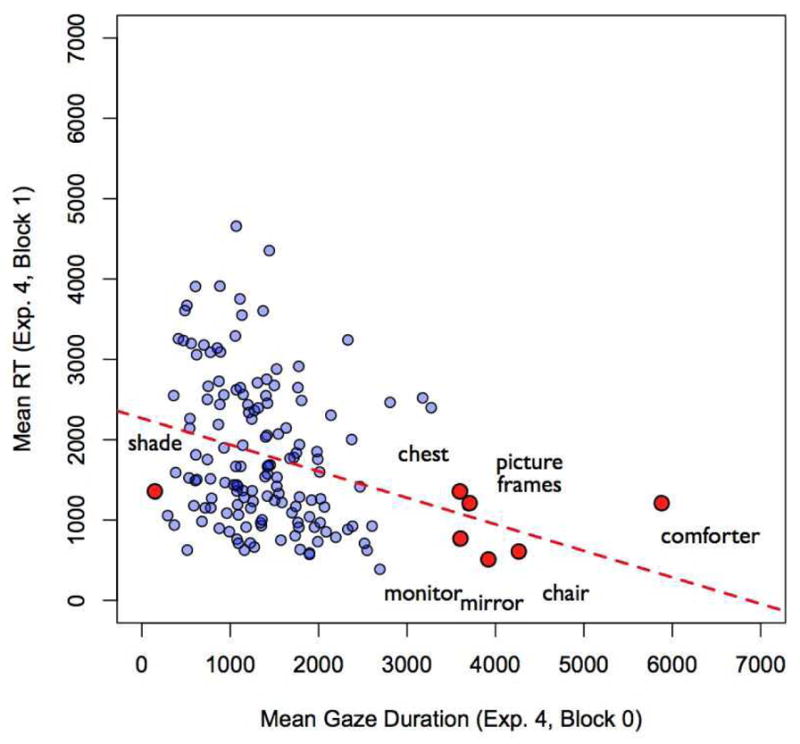
Mean RTs of 150 initial object searches in Block 1 plotted against mean gaze durations on 150 objects during the scene memorization in Block 0. Some objects of large sizes are depicted in red. Note that, as previously, the shade was rarely fixated incidentally, and was found relatively quickly.
In order to test whether the correlation was a function of a stimulus property like size rather than under the influence of memory processes, we ran another analysis in which we correlated the gaze durations in Experiment 4 with the response times of the previous Experiment 3. Note that this tested two different groups of participants against each other. Any correlation should therefore be mediated by stimulus properties rather than memory processes. There is a significant correlation for gaze durations and response times across different experiments and participant groups which was very similar to the correlation found for gaze durations and RTs within Experiment 4, R=.-22, p<.01 (see Fig. 11).
Figure 11.

Between-experiment correlation: Mean RTs of 150 initial object searches in Experiment 3 plotted against mean gaze durations on 150 objects during the scene memorization in Experiment 4. Again, objects of large sizes are depicted in red.
Discussion
Experiment 4 provided further evidence for the surprising inability to use information gathered during scene preview to speed subsequent search. Even when explicitly asked to memorize the scene and the location of its objects, participants were no faster during their first object searches after viewing each scene for 30 seconds than participants in Experiment 1 who had never seen the scenes before. This runs counter to our intuition that looking at something out in the world would help us look for that exact same object in the exact same environment later on. This is all the more striking, given the clear evidence for robust memory for scenes and for the objects in those scenes (for a review see Hollingworth, 2006).
Why are observers unable to use information gathered during scene viewing for the benefit of search? Could it be that active, successful search for the target is necessary if one is to improve the speed of a subsequent search for that target? Experiment 5 tests the hypothesis that the searching component is necessary and that mere finding is not sufficient. In Experiment 5, participants searched for the 15 different objects in each of 10 different scenes in a preview block (designated Block 0) before conducting the same searches as in the previous four experiments in Block 1 and Block 2. In the preview block, a valid spatial cue was presented on half of the searches, shortly after target word presentation. For those trials, participants found the target without the need for active search. The other targets required active search in Block 0. In this way, we can determine if the act of search is critical for search improvement.
Experiment 5
Procedure
At the beginning of the experiment, participants were told that they would be searching for 15 different objects in the same scene. Similar to the previous experiments, a target word was presented in the center of the screen for 750 ms at the beginning of each new search. However, in half of the searches they were told that they would be given a completely valid, spatial cue that would indicate the target location. A red rectangular frame, surrounding the object appeared after target word offset. It was present for only 100 ms to avoid masking effects once the object was fixated. In both cued and uncued trials, participants responded by pressing a button while fixating the target object.
Results
In the preview, Block 0, cued trials were much faster (1136 ms) than uncued, active search trials (1946 ms). Indeed, the active search trials are notably slower than first searches for the same objects in the previous four experiments. It may be that the presence of valid cues on some trials caused observers to hesitate or wait in vain for a cue before commencing search on active search trials. The critical question, for present purposes is whether these two types of experience on Block 0 had different effects when observers performed the same, uncued search for all objects on Blocks 1 and 2.
Figure 12 shows that active search on Block 0 does, indeed, make a difference to the response times on Block 1. Response time is about 150 msec faster in Block 1 when observers had actively searched for the target in Block 0 than if that target’s location had been cued. Paired, two-way t-tests show that this difference is significant, T(14)= 2.76, p<.05, and is maintained even in the 2nd block, T(14)= 2.61, p<.05. This benefit for active search is mainly due to speeded decision times in Block 1, T(14)= 5.45, p<.01, but is also marginally evident in the scan path ratio, T(14)= 1.57, p=.07. The time and fixations to target fixations show no effect of active search in Block 1, Fs<1, but tendencies for a benefit in Block 2. The benefit of active search on subsequent search in Block 2 is observable in all measures, all Ts>1.19, all ps<.08, except for decision time, T<1 (see Table 5 for all measures). It seems that active search has its strongest effect on decision time and RTs immediately in Block 1, while its affect on guidance to the target is mostly evident in Block 2. In all cases, values for active searches are consistently below values for passive searches throughout Blocks 1 and 2.
Figure 12.
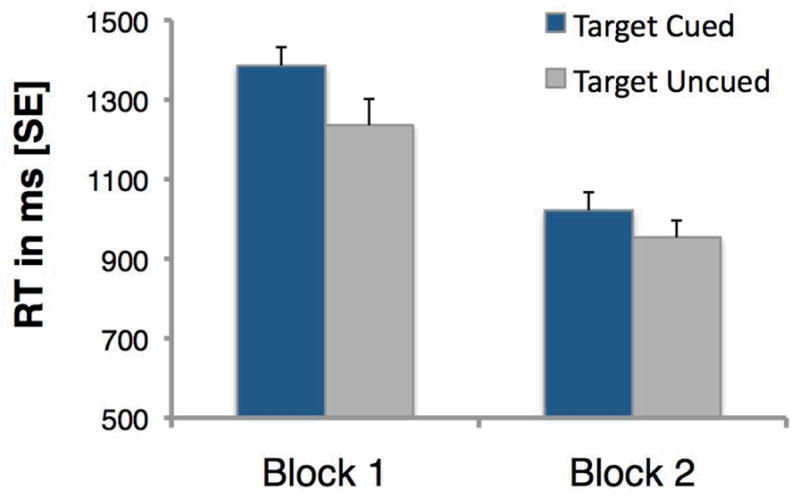
Response time as a function of block and of the type of experience (active search or target cued) in Block 0. Error bars are 1 s.e.m.
Table 5.
| Dependent Variables | Blocks | Cue conditions | ANOVAs | |||||
|---|---|---|---|---|---|---|---|---|
| Response time in ms | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 1136 [62] | 1948 [50] | Block | 60.07 | ** | .81 | ||
| Bl. 1 | 1385 [47] | 1235 [66] | Cue | 57.15 | ** | .80 | ||
| Bl. 2 | 1022 [45] | 954 [42] | B × C | 115.82 | ** | .89 | ||
|
| ||||||||
| Time to target fixation in ms | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 454 [13] | 1006 [38] | Block | 54.49 | ** | .80 | ||
| Bl. 1 | 603 [28] | 572 [51] | Cue | 36.01 | ** | .72 | ||
| Bl. 2 | 449 [36] | 395 [33] | B × C | 83.95 | ** | .86 | ||
|
| ||||||||
| Decision time in ms | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 681 [52] | 941 [47] | Block | 31.07 | ** | .69 | ||
| Bl. 1 | 782 [39] | 664 [43] | Cue | 9.99 | ** | .42 | ||
| Bl. 2 | 573 [32] | 559 [29] | B × C | 55.08 | ** | .80 | ||
|
| ||||||||
| Fixations to target fixation | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 1.56 [.05] | 3.62 [.20] | Block | 46.01 | ** | .77 | ||
| Bl. 1 | 2.33 [.12] | 2.22 [.19] | Cue | 30.65 | ** | .69 | ||
| Bl. 2 | 1.77 [.14] | 1.54 [.12] | B × C | 71.80 | ** | .84 | ||
|
| ||||||||
| Scan path ratio | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 1.40 [.06] | 3.05 [.19] | Block | 12.59 | ** | .47 | ||
| Bl. 1 | 2.36 [.12] | 2.10 [.13] | Cue | 8.99 | * | .39 | ||
| Bl. 2 | 2.01 [.16] | 1.69 [.11] | B × C | 50.25 | ** | .78 | ||
|
| ||||||||
| Error rates in % | Cue | No Cue | Factor | Fs | ps | pη2 | ||
| Bl. 0 | 3.82 [.81] | 12.72 [1.42] | Block | .57 | .57 | .04 | ||
| Bl. 1 | 7.10 [.68] | 8.27 [1.37] | Cue | 15.36 | ** | .52 | ||
| Bl. 2 | 6.10 [1.61] | 7.84 [1.66] | B × C | 18.19 | ** | .56 | ||
Error rates
The average error rate for object searches in Experiment 5 was 8%. Error rates were higher for uncued trials, F(1,14)=15.36, p<.01, pη2=.52. There was no reduction of error rates across blocks, F<1, but a significant interaction, F(2,14)=18.19, pη2=.56, in that cued produced fewer errors than uncued trials in Block 0, T(14)= 6.15, p<.01, where the cue was actually present, which is not the case in Blocks 1 and 2, T<1 and T(14)= 1.48, p>.05, respectively.
Discussion
During the initial search of Experiment 5 (Block 0) we occasionally presented a spatial cue that provided observers with valid information on the appearance as well as location of objects within a scene. Therefore, only in half of the trials participants were actively searching, while in the other half the spatial cue would greatly diminish the need to engage in active search. Interestingly, we found that uncued, active search for a target in Block 0 was associated with shorter RTs on Block 1 and Block 2 of subsequent search when compared to cued search on Block 0.
Note that the difference between cued and uncued in Block 1 of Experiment 5, while substantial, is markedly smaller than the differences between first searches and second searches for the same target in Experiments 1–4. For example, the RT difference between Block 1 and Block 2 of Experiment 4 (Fig. 8) is about 500 msec compared to 150 msec between cued and uncued in Block 1 of Experiment 5. Apparently, the cued search of Experiment 5, while not as useful as the uncued search, is more useful than letter search (Exp. 2), or 30 seconds of exposure to the scene with various instructions (Exp. 3 & 4). It is possible that some of this benefit involves learning what a “bowl” or a “pillow” looks like in this specific scene. In all of the experiments, targets are identified to the observer by a printed word. After that first exposure, the observer knows that “bowl” refers to that bowl. Knowing precisely what a target looks like makes a significant difference to RT (Castelhano & Heaven, 2010; Malcolm & Henderson, 2009; Wolfe, Horowitz, Kenner, Hyle, & Vasan, 2004). If this is the case, it is interesting that even the act of attempting to memorize the scene does not bring much useful knowledge about the appearance of this bowl. In addition, during initial searches participants learn which of the objects are relevant, and where these are located in the scene. Note, however, that this cannot be the whole account of the effects presented here because both the cued and the uncued conditions of Experiment 5 provide all this information. Any difference between these conditions in Block 0 must therefore be due to the degree of engagement in search. The results of Experiment 5 show that active search conveys the greatest search benefit.
General Discussion
Memory plays an unexpectedly ambiguous role in visual search. We know from previous work that memory can guide search: When it is used to discourage revisitation of previously visited distractors (e.g., Boot et al., 2004; Klein, 2009; Kristjansson, 2000; Peterson et al., 2007; Peterson et al., 2001; Takeda & Yagi, 2000), when future targets are memorized (e.g., Korner & Gilchrist, 2007, 2008; Gilchrist & Harvey, 2000), or when scene context is memorized (e.g., Hollingworth, 2009). On the other hand, studies on repeated search have shown that, simply because memory is available, this does not mean that it will play a role in search. Searches through the same unchanging scene seem to rely more on vision than memory (Kunar et al., 2008; Oliva et al., 2004; Wolfe et al., 2000, in prep).
What does it take to create a memory representation that speeds subsequent search for an object in a scene? In a series of five experiments, we explored how various ways of looking at objects influence how we look for them when repeatedly searching the same unchanging scene. We found that some interactions with an object are far more effective than others. Prior search for a specific object in a real scene has a substantial effect on subsequent search for that object. However, various forms of exposure to the same object from incidental (Exp. 2) to quite directed (Exp.4) do not have this effect. The effect of prior search on subsequent search seems to be more marked in real scenes than it is with more restricted stimuli (e.g. letter arrays) used in other repeated search experiments (Wolfe et al., 2000).
Guidance of repeated search in scenes
When visual search is ‘unguided’, attention is directed at random from item to item until a target is found. When it is guided, some source or sources of information reduce the effective set size to a subset of the objects in the display. Thus, in a search for a red letter, “T”, among black and red distractor letters, the effective set size is reduced from the set of all letters to the set of red letters (Egeth, Virzi, & Garbart, 1984). Searches for objects in scenes are strongly guided from the outset in ways that searches for targets in random arrays of objects are not (Wolfe, Võ, Evans, & Greene, 2011). For example, in a search for a person, scene priors guide search to the most probable locations of people (e.g., Torralba et al., 2006). Despite their complexity, natural scenes provide a huge amount of information that can be readily used to guide search and/or gaze even if the scene has never been viewed before. This information includes the scene’s basic level category (Greene & Oliva, 2009), its spatial layout (Oliva & Torralba 2001), and an estimate of the distribution of basic visual features like color and orientation (Chong & Treisman, 2003). Combined with general scene knowledge, this fund of information, inherent to a scene, can be used essentially instantaneously to guide search. A short glimpse of a scene – even as short as 50 ms – can be used to guide gaze to probable target locations (Võ & Henderson, 2010).
As a way to appreciate the power of this scene-based guidance, consider Figure 13. The figure shows gaze distributions during the first search for an object – here a jam jar in a kitchen scene. The colors of the heat maps are based on summed gaze durations during search across all participants assuming a 1° visual angle fovea for each fixation. The warmer the color, the longer was the scene location looked at. About 20% of the image is visited by the eyes on the first search, suggesting that this rapid scene guidance immediately eliminates some 80% of the scene from consideration. Strikingly, the figure shows that the gaze distributions were essentially identical whether observers had never seen the scene before (Exp. 1), had searched for superimposed letters in the same scene for several dozen seconds (Exp. 2), had viewed the scene for 30 seconds to decide whether this is more a male or a female scene (Exp. 3), or even had worked to memorize the scene for 30 seconds (Exp. 4). The additional information provided by the previews in Experiments 2–4 do not seem to have been able to do better than the 80% reduction in effective set size provided by the scene on its first appearance.
Figure 13.

Gaze distributions of all observers during their initial search for a jam jar in Block 1 across Experiments 1–4. Note that despite different ways of previewing each scene in Experiments 2–4, gaze distributions are almost identical to initial searches in Experiment 1, where the scene was encountered for the first time.
Why do we seem to search for each new object as if we have never seen the scene before rather than to draw on stored memory representations? One reason might be that in an unchanging scene, information can be easily accessed “just-in-time”, according to the current demands. This strategy is commonly observed in real-world behavior, where observers acquire the specific information they need just at the point it is required in the task (Ballard, Hayhoe, & Pelz, 1995; Triesch, Ballard, Hayhoe, & Sullivan, 2003). Incidental memory for things observed certainly exists (see Hollingworth, 2006) – but it might not be worth cluttering working memory with such representations “just-in-case” the incidentally encountered item becomes the object of search. Instead, the scene itself can serve as an “outside memory” (O’Regan, 1992), which reduces the dependence on memory representations that may be costly and can become faulty over time (Dukas, 1999). Contrary to the original notion of an “outside memory” that renders memory useless, we propose that a scene provides a wealth of easily accessible information which can be updated and refined over time and across searches. As noted, the scene and generic knowledge about the behavior of objects in such scenes will guide attention quite effectively. Thus, when the task is to search for an object for the first time, scene guidance will usually deliver the object quite efficiently. It may be faster and less error prone to simply search again rather than to retrieve and reactivate stored memory traces.
Memory guidance for previous search targets
While the various forms of incidental preview do not seem to reduce the search space, Figure 14 shows that prior search does have this effect. Figure 14 depicts the distribution of eye movements for the first, second, and third searches for the jam jar and clearly demonstrates how the search space, averaged across all participants, was cut in half after each repeated jam jar search (from 16% in Block 1, to 8% in Block 2, to 4% in Block 3).
Figure 14.

Gaze distributions of all observers searching for a jam jar in Experiment 1. Search space substantially decreased from Block 1 over Block 2 to Block 3 (left to right).
What is it about prior search that is so much more effective than other exposure to the scene? There are a few obvious candidates: For instance, participants were given feedback on whether their search had been correct or not in their initial searches. Successfully completing a search therefore provided explicit information on the target appearance and location. Wolfe et al., (Experiment 5, in prep) also found evidence that knowledge of the exact appearance of a target mattered. They found a speeding of response times when picture cues were used instead of word cues (see also Castelhano & Heaven, 2010; Malcolm & Henderson, 2009). However, this is not able to account for the whole search benefit. Recall that the cued and uncued conditions of Experiment 5 involve the same feedback and the same precise information about which objects are relevant, what they look like, and where they are located. Arguably, in fact, the cued condition information is more precise and yet the prior search benefit is greater in the uncued condition.
More than an effect of merely learning what the target looks like, the substantial benefit from prior searches we have observed across all experiments may reflect knowledge of how to search for a specific object. That is, we might become more skilled in applying general scene knowledge to a specific scene if we have accomplished that exact act of search before. We found benefits of prior search on different components of this “skill”. Thus, there was a reduction in the time spent fixating the target, a measure of decision time as well as on eye movement measures that reflect processes prior to target fixation (e.g., time, number of fixations, and scan path ratio to target fixation). In Block 2 of all experiments, targets were found with fewer intervening fixations in a more direct scan path. This implies that in addition to speeding decision times, guidance to the search target is also facilitated in the second search.
Finally, the degree of focused attention directed to a scene or a particular object might play an important role in forming memory representations that can be used for search in scenes. Forty years ago, Loftus (1972) demonstrated that recognition memory for pictures increased with the number of fixations directed to the picture. More recently, Tatler, Gilchrist, and Land (2005) found that the detection of position changes depends on the fixation of the moved object (see also Hollingworth & Henderson, 2002). Fixation seems to be a prerequisite for associating object position information to the scene representation. The results of this study, however, show that not all fixations are created equal. Fixations of an object for the purpose of scrutinizing or memorization were less beneficial for subsequent search than fixations that resulted from a successfully completed search activity. Binding object identities to scene locations might only result in stored scene representations that are able to guide search from memory rather than simply searching again, when such object-scene binding was the result of a previous search.
The role of active engagement in repeated visual search
To summarize our argument, incidental exposure and/or preview failed to provide the observer with anything more useful than the powerful scene-based guidance that was available immediately after the scene first appeared. On the other hand, prior search did provide an aid to subsequent search and this aid was even greater when observers had to actively search in the uncued condtions of Experiment 5 than when we provided observers with a spatial cue that marked the position of the search object. In both the cued and uncued cases, the initial search block provided observers with information regarding the 15 relevant items, their appearance and their location within each scene. However, something more is acquired when active search is required. The differences between preview, cued, and active uncued search conditions have their parallels in other tasks. The finding that people are better able to remember items that were produced than items that were simply viewed is known as the generation effect (Jacoby, 1978; Slamecka & Graf, 1978). Furthermore, self-performed tasks are more often recognized and recalled than those that are just observed (e.g., Hornstein & Mulligan, 2001, 2004). Our results clearly show that these findings translate to the search domain where target object information acquired through active search engagement serves as a crucial and efficient guide when the same target is searched for a second time.
Conclusion
In the routine pursuit of our lives, we search repeatedly through scenes, move on to other scenes, and then return to search again. We are very good at this. Over the course of our lives (and/or the course of evolution), we have learned enough about the way the world works that we search a scene intelligently for items that we have never had occasion to search for before. The present experiments suggest that this intelligence is rather generic. Our knowledge of the plausible locations of jam jars is more useful on that first search than any incidental knowledge about a jam jar that we happened to have seen in this particular scene before. However, having once searched for that jam jar, we have learned something about that particular object that will provide us with more than generic guidance the next time we search for it.
Table 6.
| Dependent Variables | Block | Cue condition | Planned Contrasts | ||
|---|---|---|---|---|---|
|
| |||||
| Cue | No Cue | Ts | ps | ||
| Response time in ms | Block 1 | 1385 [47] | 1235 [66] | 2.76 | * |
| Block 2 | 1022 [45] | 954 [42] | 2.61 | * | |
|
| |||||
| Time to target fixation in ms | Block 1 | 603 [28] | 572 [51] | .67 | .51 |
| Block 2 | 449 [36] | 395 [33] | 1.20 | .07 | |
|
| |||||
| Decision time in ms | Block 1 | 782 [39] | 664 [43] | 5.45 | ** |
| Block 2 | 573 [32] | 559 [29] | .64 | .53 | |
|
| |||||
| Fixations to target fixation | Block 1 | 2.33 [.12] | 2.22 [.19] | .67 | .52 |
| Block 2 | 1.77 [.14] | 1.54 [.12] | 2.05 | .06 | |
|
| |||||
| Scan path ratio | Block 1 | 2.36 [.12] | 2.10 [.13] | 1.57 | .07 |
| Block 2 | 2.01 [.16] | 1.69 [.11] | 1.91 | * | |
Acknowledgments
This work was supported by grants to MV (DFG: VO 1683/1-1) and JMW (NEI EY017001, ONR N000141010278). We also want to thank Erica Kreindel for assistance in data acquisition.
References
- Ballard DH, Hayhoe MM, Pelz JB. Memory Representations in natural tasks. Cognitive Neuroscience. 1995;7:66–80. doi: 10.1162/jocn.1995.7.1.66. [DOI] [PubMed] [Google Scholar]
- Biederman I, Glass AL, Stacy EW. Searching for objects in real-world scenes. Journal of Experimental Psychology. 1973;97:22–27. doi: 10.1037/h0033776. [DOI] [PubMed] [Google Scholar]
- Boot WR, McCarley JM, Kramer AF, Peterson MS. Automatic and intentional memory processes in visual search. Psychonomic Bulletin & Review. 2004;5:854–861. doi: 10.3758/bf03196712. [DOI] [PubMed] [Google Scholar]
- Brady TF, Konkle T, Alvarez GA, Oliva A. Visual long-term memory has a massive storage capacity for object details. Proceedings of the National Acadademy of Science U S A. 2008;105(38):14325–14329. doi: 10.1073/pnas.0803390105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brockmole JR, Henderson JM. Recognition and attention guidance during contextual cuing in real-world scenes: Evidence from eye movements. Quarterly Journal of Experimental Psychology. 2006a;59:1177–1187. doi: 10.1080/17470210600665996. [DOI] [PubMed] [Google Scholar]
- Brockmole JR, Henderson JM. Using real-world scenes as contextual cues for search. Visual Cognition. 2006b;13:99–108. [Google Scholar]
- Castelhano M, Henderson JM. Incidental visual memory for objects in scenes. Visual Cognition. 2005;12(6):1017–1040. [Google Scholar]
- Castelhano M, Henderson JM. Initial Scene Representations Facilitate Eye Movement Guidance in Visual Search. Journal of Experimental Psychology: Human Perception and Performance. 2007;33:753–763. doi: 10.1037/0096-1523.33.4.753. [DOI] [PubMed] [Google Scholar]
- Castelhano MS, Heaven C. The Relative Contribution of Scene Context and Target Features to Visual Search in Real-world Scenes. Attention, Perception, & Psychophysics. 2010;72(5):1283–1297. doi: 10.3758/APP.72.5.1283. [DOI] [PubMed] [Google Scholar]
- Chong SC, Treisman A. Representation of statistical properties. Vision Research. 2003;43:393–404. doi: 10.1016/s0042-6989(02)00596-5. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Contextual cuing: Implicit learn- ing and memory of visual context guides spatial attention. Cognitive Psychology. 1998;36:28–71. doi: 10.1006/cogp.1998.0681. [DOI] [PubMed] [Google Scholar]
- Chun MM, Turk-Browne NB. Associative learning mechanisms in vision. In: Luck SJ, Hollingworth AR, editors. Visual memory. Oxford: Oxford University Press; 2008. pp. 209–245. [Google Scholar]
- Droll J, Eckstein M. Expected object position of two hundred fifty observers predicts first fixations of seventy seven separate observers during search. Journal of Vision. 2008;8(6):320–320. [Google Scholar]
- Dukas R. Costs of Memory: Ideas and Predictions. Journal of Theoretical Biology. 1999;197(1):41–50. doi: 10.1006/jtbi.1998.0856. [DOI] [PubMed] [Google Scholar]
- Eckstein MP, Drescher BA, Shimozaki SS. Attentional cues in real scenes, saccadic targeting, and Bayesian priors. Psychological Science. 2006;17(11):973–980. doi: 10.1111/j.1467-9280.2006.01815.x. [DOI] [PubMed] [Google Scholar]
- Egeth HE, Virzi RA, Garbart H. Searching for conjunctively defined targets. Journal of Experimental Psychology: Human Perception and Performance. 1984;10:32–39. doi: 10.1037//0096-1523.10.1.32. [DOI] [PubMed] [Google Scholar]
- Ehinger KA, Hidalgo-Sotelo B, Torralba A, Oliva A. Modelling search for people in 900 scenes: A combined source model of eye guidance. Visual Cognition. 2009;17(6):945–978. doi: 10.1080/13506280902834720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gibson BS, Li L, Skow E, Brown K, Cooke L. Searching for one versus two identical targets: When visual search has a memory. Psychological Science. 2000;11(4):324–327. doi: 10.1111/1467-9280.00264. [DOI] [PubMed] [Google Scholar]
- Gilchrist ID, Harvey M. Refixation frequency and memory mechanisms in visual search. Current Biology. 2000;10:1209–1212. doi: 10.1016/s0960-9822(00)00729-6. [DOI] [PubMed] [Google Scholar]
- Greene MR, Oliva A. The Briefest of Glances: The Time Course of Natural Scene Understanding. Psychological Science. 2009;20:464–472. doi: 10.1111/j.1467-9280.2009.02316.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henderson JM, Brockmole JR, Castelhano MS, Mack M. Visual saliency does not account for eye movements during visual search in real-world scenes. In: van Gompel R, Fischer M, Murray W, Hill R, editors. Eye movements: A window on mind and brain. Oxford: Elsevier; 2007. pp. 537–562. [Google Scholar]
- Hollingworth A. Two forms of scene memory guide visual search: Memory for scene context and memory for the binding of target object to scene location. Visual Cognition. 2009;17:273–291. [Google Scholar]
- Hollingworth A. Visual memory for natural scenes: Evidence from change detection and visual search. Visual Cognition. 2006;14:781–807. [Google Scholar]
- Hollingworth A. Constructing visual representations of natural scenes: The roles of short- and long-term visual memory. Journal of Experimental Psychology: Human Perception and Performance. 2004;30:519–537. doi: 10.1037/0096-1523.30.3.519. [DOI] [PubMed] [Google Scholar]
- Hollingworth A, Henderson JM. Accurate visual memory for previously attended objects in natural scenes. Journal of Experimental Psychology: Human Perception and Performance. 2002;28:113–136. [Google Scholar]
- Hollingworth A, Williams CC, Henderson JM. To see and remember: Visually specific information is retained in memory from previously attended objects in natural scenes. Psychonomic Bulletin & Review. 2001;8:761–768. doi: 10.3758/bf03196215. [DOI] [PubMed] [Google Scholar]
- Hornstein SL, Mulligan NW. Memory for action events: The role of objects in memory for self- and other-performed tasks. American Journal of Psychology. 2001;114:199–217. [PubMed] [Google Scholar]
- Hornstein SL, Mulligan NW. Memory for actions: Enactment and source memory. Psychonomic Bulletin & Review. 2004;11(2):367–372. doi: 10.3758/bf03196584. [DOI] [PubMed] [Google Scholar]
- Horowitz TS, Wolfe JM. Visual search has no memory. Nature. 1998;394:575–577. doi: 10.1038/29068. [DOI] [PubMed] [Google Scholar]
- Hwang AD, Higgins EC, Pomplun M. A model of top-down attentional control during visual search in complex scenes. Journal of Vision. 2009;9(5):25, 1–18. doi: 10.1167/9.5.25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacoby LL. On interpreting the effects of repetition: Solving a problem versus remembering a solution. Journal of Verbal Learning and Verbal Behavior. 1978;17:649–667. [Google Scholar]
- Klein RM. On the Control of Attention. Canadian. Journal of Experimental Psychology. 2009;63(3):240–252. doi: 10.1037/a0015807. [DOI] [PubMed] [Google Scholar]
- Konkle T, Brady TF, Alvarez GA, Oliva A. Conceptual distinctiveness supports detailed visual long-term memory. Journal of Experimental Psychology: General. 2010;139(3):558–78. doi: 10.1037/a0019165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Konkle T, Brady TF, Alvarez GA, Oliva A. Scene memory is more detailed than you think: the role of scene categories in visual long-term memory. Psychological Science. doi: 10.1177/0956797610385359. in press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Körner C, Gilchrist ID. Memory processes in multiple-target visual search. Psychological Research. 2008;72:99–105. doi: 10.1007/s00426-006-0075-1. [DOI] [PubMed] [Google Scholar]
- Körner C, Gilchrist ID. Finding a new target in an old display: Evidence for a memory recency effect in visual search. Psychonomic Bulletin & Review. 2007;14(5):846–851. doi: 10.3758/bf03194110. [DOI] [PubMed] [Google Scholar]
- Kristjansson A. In search of remembrance: Evidence for memory in visual search. Psychological Science. 2000;11:328–332. doi: 10.1111/1467-9280.00265. [DOI] [PubMed] [Google Scholar]
- Kunar MA, Flusberg SJ, Wolfe JM. The role of memory and restricted context in repeated visual search. Perception and Psychophysics. 2008;70(2):314–328. doi: 10.3758/pp.70.2.314. [DOI] [PubMed] [Google Scholar]
- Loftus GR. Eye fixations and recognition memory for pictures. Cognitive Psychology. 1972;3:525–551. [Google Scholar]
- Malcolm GL, Henderson JM. Combining top-down processes to guide eye movements during real-world scene search. Journal of Vision. 2010;10(2):4, 1–11. doi: 10.1167/10.2.4. [DOI] [PubMed] [Google Scholar]
- Neider MB, Zelinsky GJ. Exploring set size effects in scenes: Identifying the objects of search. Visual Cognition. 2008;16(1):1–10. [Google Scholar]
- Oliva A, Torralba A. Modeling the shape of the scene: A holistic representation of the spatial envelope. International Journal of Computer Vision. 2001;42:145–175. [Google Scholar]
- Oliva A, Wolfe JM, Arsenio HC. Panoramic search: The interaction of memory and vision in search through a familiar scene. Journal of Experimental Psychology: Human Perception and Performance. 2004;30(6):1132–1146. doi: 10.1037/0096-1523.30.6.1132. [DOI] [PubMed] [Google Scholar]
- O’Regan KJ. Solving the” real” mysteries of visual perception: The world as an outside memory. Canadian Journal of Psychology. 1992;46(3):461–488. doi: 10.1037/h0084327. [DOI] [PubMed] [Google Scholar]
- Peterson MS, Beck MR, Vomela M. Visual search is guided by prospective and retrospective memory. Perception & Psychophysics. 2007;69(1):123–135. doi: 10.3758/bf03194459. [DOI] [PubMed] [Google Scholar]
- Peterson MS, Kramer AF, Wang RF, Irwin DE, McCarley JS. Visual search has memory. Psychological Science. 2001;12:287–292. doi: 10.1111/1467-9280.00353. [DOI] [PubMed] [Google Scholar]
- Slamecka NJ, Graf P. The generation effect: Delineation of a phenomenon. Journal of Experimental Psychology: Human Learning and Memory. 1978;4:592–604. [Google Scholar]
- Standing L. Learning 10,000 pictures. Quarterly Journal of Experimental Psychology. 1973;25:207–222. doi: 10.1080/14640747308400340. [DOI] [PubMed] [Google Scholar]
- Takeda Y, Yagi A. Inhibitory tagging in visual search can be found if search stimuli remain visible. Perception & Psychophysics. 2000;62(5):927–934. doi: 10.3758/bf03212078. [DOI] [PubMed] [Google Scholar]
- Tatler BW, Melcher D. Pictures in mind: Initial encoding of object properties varies with the realism of the scene stimulus. Perception. 2007;36:1715–1729. doi: 10.1068/p5592. [DOI] [PubMed] [Google Scholar]
- Tatler BW, Gilchrist ID, Land MF. Visual memory for objects in natural scenes: From fixations to object files. Quarterly Journal of Experimental Psychology. 2005;58A:931–960. doi: 10.1080/02724980443000430. [DOI] [PubMed] [Google Scholar]
- Torralba A, Oliva A, Castelhano MS, Henderson JM. Contextual guidance of eye movements and attention in real-world scenes: The role of global features on object search. Psychological Review. 2006;113(4):766–786. doi: 10.1037/0033-295X.113.4.766. [DOI] [PubMed] [Google Scholar]
- Treisman A. The perception of features and objects. In: Baddeley A, Weiskrantz L, editors. Attention: Selection, awareness, and control. Oxford: Clarendon Press; 1993. pp. 5–35. [Google Scholar]
- Triesch J, Ballard DH, Hayhoe MM, Sullivan BT. What you see is what you need. Journal of Vision. 2003;3:86–94. doi: 10.1167/3.1.9. [DOI] [PubMed] [Google Scholar]
- Võ MLH, Henderson JM. Does Gravity Matter? Effects of Semantic and Syntactic Inconsistencies on the Allocation of Attention during Scene Perception. Journal of Vision. 2009;9(3):24, 1–15. doi: 10.1167/9.3.24. [DOI] [PubMed] [Google Scholar]
- Võ MLH, Henderson JM. The Time Course of Initial Scene Processing for Guidance of Eye Movements When Searching Natural Scenes. Journal of Vision. 2010;10(3):14, 1–13. doi: 10.1167/10.3.14. [DOI] [PubMed] [Google Scholar]
- Võ MLH, Schneider WX, Matthias E. Transsaccadic Scene Memory Revisited: A ‘Theory of Visual Attention (TVA)’ based Approach to Recognition Memory and Con dence for Objects in Naturalistic Scenes. Journal of Eye-Movement Research. 2008;2(2):7, 1–13. [Google Scholar]
- Wolfe JM. Visual search. In: Pashler H, editor. Attention. Hove, East Sussex, UK: Psychology Press Ltd; 1998. pp. 13–74. [Google Scholar]
- Wolfe JM, Reynolds JH. Visual Search. In: Basbaum AI, Kaneko A, Shepherd GM, Westheimer G, editors. The Senses: A Comprehensive Reference. Vol. 2. San Diego: Academic Press; 2008. pp. 275–280. VIsion II. [Google Scholar]
- Wolfe JM, Klempen N, Dahlen K. Post-attentive vision. Journal of Experimental Psychology: Human Perception & Performance. 2000;26(2):693–716. doi: 10.1037//0096-1523.26.2.693. [DOI] [PubMed] [Google Scholar]
- Wolfe JM, Võ ML-H, Evans KK, Greene MR. Visual search in scenes involves selective and non-selective pathways. Trends in Cognitive Sciences. 2011;15(2):77–84. doi: 10.1016/j.tics.2010.12.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolfe JM, Horowitz TS, Palmer EM, Michod KO, VanWert MJ. Getting in to Guided Search. In: Coltheart V, editor. Tutorials in Visual Cognition. Hove, Sussex: Psychology Press; 2010. pp. 93–120. [Google Scholar]
- Wolfe JM, Horowitz TS, Kenner N, Hyle M, Vasan N. How fast can you change your mind? The speed of top-down guidance in visual search. Vision Research. 2004;44:1411–1426. doi: 10.1016/j.visres.2003.11.024. [DOI] [PubMed] [Google Scholar]
- Wolfe JM, Alvarez GA, Rosenholtz R, Kuzmova YI. Visual search for arbitrary objects in real scenes. doi: 10.3758/s13414-011-0153-3. in prep. [DOI] [PMC free article] [PubMed] [Google Scholar]