

Abstract
Neural decoding is an important approach for extracting information from population codes. We previously proposed a novel transductive neural decoding paradigm and applied it to reconstruct the rat’s position during navigation based on unsorted rat hippocampal ensemble spiking activity. Here, we investigate several important technical issues of this new paradigm using one data set of one animal. Several extensions of our decoding method are discussed.
I. INTRODUCTION
Neural decoding, as an inverse problem to neural encoding analysis, aims to infer sensory stimuli or motor kinematics based on recorded ensemble neuronal spiking activity. Neural decoding is important not only for understanding neural codes (i.e., neural response features capable of representing all information that neurons carry about the stimuli of interest), but also for extracting maximal information from population neurons in engineering applications, such as brain-machine interfaces [13]. Traditional neural decoding methods based on spiking activity [3], [21], [20], [12] rely on spike sorting, a process that is computationally expensive, time-consuming, and prone to errors [8], [18], [19]. To overcome this drawback, we have proposed a novel transductive neural decoding paradigm and applied it to unsorted rat hippocampal population codes [10].1 Unlike traditional neural encoding/decoding methods, the proposed paradigm does not require estimating tuning curves (TCs) for individual sorted single units. Our paradigm is also different from other spike-sorting-free decoding methods in the literature [6], [17] in that spike waveform features are used in decoding analysis.
In this paper, we first briefly review the transductive, spike sorting-free decoding method [10], before discussing in greater detail several technical issues related to application of the method to neural data. Next, we discuss extensions to the proposed method. From an information-theoretic perspective, we also propose a practical way to assess the mutual information between sensory stimuli and neural spiking responses, which are mathematically characterized by a spatio-temporal Poisson process (STPP).
II. METHOD: TRANSDUCTIVE NEURAL DECODING
The basic idea of transductive neural decoding described in [10] is to model ensemble neuronal spiking activity as a spatio-temporal point process [15], in which the timing of spike events is defined with a random measure in time, and the “mark” associated with the spike events is defined with another random measure in real space.
A. Spatio-temporal Poisson Process (STPP)
Let us consider a STPP, which is the simplest spatio-temporal point process in which events are independent in time. Let λ(t, a) denote the rate function, and a ∈ S (where S is a vector space). For any subset Sj ∈ S in the space, the number of the events occurring inside the region is also a temporal Poisson process with associate rate function λSj(t):
| (1) |
The expected number of events in any spatio-temporal region is also Poisson distributed with the mean rate given by
| (2) |
In the special case where the generalized rate function is a separable function of space and time such that
| (3) |
where p(a) represents the spatial probability density function (pdf) of the random variable a, and . The interpretation of the separable STPP is as follows: To generate random Poisson events in space-time, the first step is to sample a Poisson process with a rate function λS(t), and the second step, is to draw a random vector a (associated with each event) from p(a). Therefore, the spatio-temporal point process may be viewed as a purely temporal marked point process, with spatial marks at each time point of event occurrence from the ground process, and the marked space is defined by a random probability measure [15]. Detailed technical backgrounds are referred to [10].
B. Bayesian Decoding
In the context of neural decoding, let random variable a ≡ {a1, … ad} ∈ ℝd denote the measured d-dimensional feature extracted from the spike waveform (e.g., peak amplitude, waveform derivative, principal components, or any features that are used in spike sorting process), let x ∈ ℝq denote the sensory stimulus or motor covariate (such as the animal’s position, head direction, velocity, etc.) that is being decoded. Furthermore, let n denote the number of spike events in the complete d-dimensional space within a time interval [t, t + Δt), and let a1:n denote the associated n d-dimensional spike waveform features. The d-dimensional feature space is divided evenly into J non-overlapping regions S ≡ (S1 ∪ S2 … ∪ SJ), and a1:n ∈ S.
To infer the probability of the unknown variable of interest xt at time t, we resort to the Bayes rule
| (4) |
where P(xt) denotes the prior probability, P(a1:n|xt) denotes the likelihood, and the denominator denotes a normalizing constant. Provided that a non-informative temporal prior for P(xt) is used (for this reason, from now on we will drop the subscript t on xt; the extension of using a temporal prior is discussed later), then Bayesian decoding is aimed to maximize the product of the likelihood and spatial prior P(x):
| (5) |
To compute the likelihood, we assume that the spike events follow a time-homogeneous STPP with a generalized rate function λ(a, x). It follows that the number of events occurring within a time window [t, t + Δt) and subregion Sj in the d-dimensional spike feature space also follows a Poisson distribution with the rate function , which can be viewed as a spatial TC with respect to the covariate space x. By dividing the spike feature space into J non-overlapping spatial subregions , we can factorize the likelihood function into a product of Poisson likelihoods of all J subregions
| (6) |
where n(Sj) denotes the number of spike events within the region Sj. In the limiting case when the subregion becomes sufficiently small such that n(Sj) is equal to 0 or 1 within the time interval Δt, simplifying (6) and replacing it into (5) yields the posterior
| (7) |
where λ(x) denotes the rate of spike events occurring in the covariate space x.
To compute (7), we need to compute or establish a representation for the generalized rate function λ(a, x) and its marginal rate function λ(x). In practice, these rate functions are estimated a priori by recording spike events and their associated features while sampling over the covariate space. Note that the generalized rate function used in (6) can be written as
| (8) |
where N denotes the total number of spike events recorded within time interval (0, T], μ is the mean spiking rate defined in (2), π(x) denotes the occupancy probability of x during the complete time interval, and p(a, x) denotes the joint pdf of a and x. Furthermore, we have , and , where p(a|x) denotes the conditional pdf.
In the decoding phase, in order to compute the likelihood (6), we would need to evaluate the target point in the functions λ(a, x) and λ(x), or equivalently in p(a, x) and p(x). Finally, to choose the maximum a posteriori (MAP) estimate of x, denoted by xMAP we simply evaluate the log-posterior (7) among all candidates in the x space, and choose the one that has the highest value.
C. Density Estimation: Parametric vs. Nonparametric Methods
In our decoding paradigm, the essential task is to estimate the joint pdf p(a, x) and its marginal p(x). Multivariate density estimation has been well studied in statistics [14]. Common methods include (i) parametric approaches, which model the data by a finite mixture model (a process similar to spike sorting at the first place); and (ii) nonparametric approaches, such as the histogram or kernel density estimation (KDE). Parametric representation is compact but less flexible; nonparametric approaches are model-free but more computationally expensive.
We investigate two methods here: one is based on an ℓ-mixtures of Gaussians (MoG) model, another based on Gaussian KDE, using a non-isotropic multivariate Gaussian kernel K
| (9) |
| (10) |
where , (mr, Hr) denote the r-th mean vector and diagonal (yet non-isotropic) covariance matrix, respectively, in the mixture model for the augmented vector denotes the m-th source data point from the training set, and σi and hj denote the kernel bandwidth (BW) parameters for the i-th and j-th element in a and x, respectively.
For the MoG model, the unknown parameters are estimated from the expectation-maximization (EM) algorithm. For the KDE, the BW parameters are estimated from [2].
III. MUTUAL INFORMATION BETWEEN STIMULUS AND NEURAL RESPONSES
Let X denote the sensory stimuli, and let R denote the raw neuronal responses (spike waveform). Any feature extraction from raw data (such as spike count, PCA) can be modeled as a generic nonlinear function f. According to the Data Processing Inequality, post-processing of R never increases the mutual information between X and R [13]
| (11) |
This inequality is also applicable to spike sorting. In comparison to spike sorting-based decoding, spike sorting-free decoding sidesteps the sorting (clustering) process and reduces information loss, and prevents accumulating sorting error into decoding analysis.
The mutual information between the sensory input x and spike waveform features a is written as [4]
| (12) |
where the marginal and joint entropy functions can be estimated from KDE. For instance, given the multivariate kernel density estimator of an unknown pdf p(x), a simple plug-in resubstitution estimator for differential entropy can be written as [1]: , where denotes a kernel density estimator based on M data samples.
In the presence of multi-electrode recording, given the spike waveform feature (a1, …, aℓ) from ℓ electrodes, the mutual information is given by [4]
| (13) |
where the second step follows from the conditional independence assumption between the covariate x and the neural response ar from each electrode. The conditional entropy H(ar|x) = H(x) − H(ar, x) can be estimated directly from KDE, and the joint entropy H(a1, …, aℓ) may be estimated with a resampling method.
IV. RESULTS: POSITION RECONSTRUCTION WITH UNSORTED RAT HIPPOCAMPAL ENSEMBLE SPIKING ACTIVITY
A. Experimental Data
For experimental protocol and details, the reader is referred to [10]. Animals were traveling in a 3.1-m linear track environment, which was binned with 0.1-m bin size resulting in 31 position bins. Simultaneous tetrode recordings were collected from the CA1 area of rat hippocampus. In each recording recording session, the waveforms of all unsorted spikes were re-thresholded at 75 μV. Next, for unsorted spike events, the spikes with a peak to trough width of greater than 150 μs are considered as originating from pyramidal cells and are included in the decoding analysis. For each tetrode, the peak amplitudes from 4 channels are used to construct a ∈ ℝ4 (see the left panel of Fig. 1 for illustration). In one selected data set studied here, we collect 48 putative pyramidal cells from 18 tetrodes within about 30-min recordings. The first half of the data is used as the training set. The temporal bin size is chosen as Δt = 250 ms, and only run periods (velocity filter 0.15 m/s) are chosen in encoding and decoding analyses. The decoding error is defined as |xtrue − xMAP| (x ∈ ℝ) for each temporal bin.
Fig. 1.
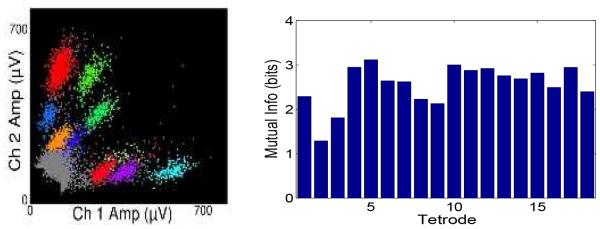
Left: Raw spike amplitudes from one tetrode (shown in 2 channels). Right: Estimated mutual information (bits) between the position (x) and spike amplitude (a) in each tetrode (computed from Eq. 12); note that they are all bounded by the entropy of stimulus (3.36 bits).
B. Experimental Results
1) Transductive Decoding with Sorted vs. All Spikes
For the selected data set, we show the number of spikes per tetrode based on sorted (10664) spikes or all recorded (39383) spikes (Fig. 2, left panel). As seen, nearly 73% recorded spikes are discarded in spike sorting. Potentially, many non-clusterable spikes contain tuning information; and traditional spike sorting-based decoding methods may suffer an information loss by discarding those spikes. The decoding error cumulative distribution function (cdf) curve (Fig. 2, right panel) indicates a statistically significant improvement in decoding accuracy (two-sample KS test: P < 0.001). The median (mean) statistics of decoding error are 0.1111 (0.1920) m for using all spikes, and 0.1172 (0.2051) m for using only sorted spikes. This result also confirms our previous finding [10].
Fig. 2.
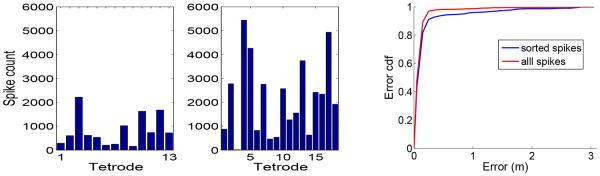
Left: Numbers of spike counts per tetrode for sorted vs. all spikes. Right: Decoding error cdf curves from using sorted and all spikes.
2) Parametric vs. Nonparametric Density Estimation
Next, we compare two density estimators (Eqs. 9 and 10) in our proposed transductive neural decoding paradigm. For the nonparmetric method, we use Gaussian KDE with non-isotropic BW parameters. For the parametric method, we use various numbers (4, 6, 8, 10, 12) of MoG for each tetrode, resulting in a maximum of 216 multivariate Gaussians for 18 tetrodes. Note that using a Gaussian mixture for density estimation is in spirit similar to the clustering process during spike sorting, except that we estimate (a, x) jointly (instead of a alone in spike sorting), and that the spread of the kernels is allowed to be overlapping (without making hard decisions). The decoding results are shown in Fig. 3 (left panel). As seen, the decoding accuracy also improves as the number of the Gaussian mixtures increases. The nonparametric method has a better decoding performance due to its more accurate representation of the density. Besides, for the decoding purpose, a local density representation is more preferable to a global characterization.
Fig. 3.
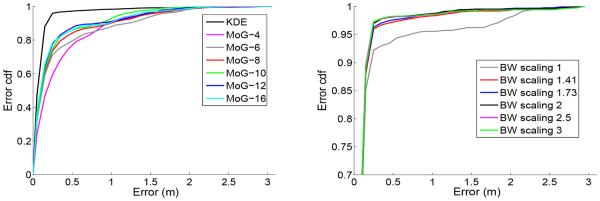
Decoding error cdf curves from both mixtures of Gaussians (MoG) and KDE methods (left), and from using various BW scalings (right).
3) Reduction of Source Samples
In KDE representation, the density is represented by M source data points (at one electrode). Obviously, the storage requirement and computational complexity of decoding is linearly proportional to M. To reduce the computational burden, we attempt to reduce the source samples by two methods. The first method uses a higher threshold (in our case, greater than 75 μV) to exclude low-amplitude spike events. Generally, the low-amplitude spikes have less recoverable information of the stimulus. The second method aims to compress source samples using some computational methods [11], [7], [9]. Here we use a computationally efficient KD-tree method (http://www.ics.uci.edu/~ihler/code/kde.html).
The results of the decoding error statistics are summarized in Table I. As seen from the mean/median error statistics, the decoding accuracy degrades while using a very high threshold; however, better performance can also be expected using a slightly higher threshold (e.g., 100 μV). On the other hand, reducing source sample size using a computational method always degrades decoding accuracy, regardless of the data source (sorted spikes or all spikes).
TABLE I.
STATISTICS OF THE MEAN/MEDIAN DECODING ERROR (UNIT: METER) USING VARIOUS THRESHOLDS OR VARIOUS COMPRESSED SAMPLE SIZE M FOR OUR TRANSDUCTIVE AMPLITUDE-BASED DECODING.
| threshold (μV) | sorted spikes | all spikes |
|---|---|---|
| 100 | 0.2056/0.1159 | 0.1928/0.1009 |
| 125 | 0.2174/0.1176 | 0.2057/0.1116 |
| 150 | 0.2347/0.1197 | 0.2132/0.1154 |
|
| ||
| M (per tetrode) | sorted spikes | all spikes |
|
| ||
| 500 | 0.4536/0.1876 | N/A |
| 1000 | 0.3283/0.1307 | N/A |
| 2000 | 0.2444/0.1194 | 0.5642/0.1598 |
| 3000 | 0.2051/0.1172 | 0.3960/0.1279 |
| ALL data | 0.2051/0.1172 | 0.1920/0.1111 |
4) Scaling the BW Parameters
In the presence of noisy spikes (in the low-amplitude space), it is common to use a larger kernel BW to smooth the noise-contaminated samples. To test this idea, we fix the position BW (0.05 m) and scale the initial amplitude BW (estimated from [2]) by different scalars in all four dimensions. The decoding error cdf curves are shown in Fig. 3 (right panel). For this data set, the optimal scaling parameter is 2, achieving the median (mean) decoding error of 0.1043 (0.1346) m. Note that the mean decoding error is greatly reduced.
V. DISCUSSION
A. Curse of Dimensionality
In a general setting, the dimensionality of the covariate space can be very large: either q is large, or the range for individual univariate dimension is large (with a relatively small bin size). For MAP estimation, a naive even binning of the covariate space can be extremely inefficient, since the occupancy density π(x) may be very sparse. To tackle the “curse of dimensionality” problem, we may use a divide-and-conquer approach by constructing q independent decoders, each one equipped with its own density estimator. Another way is to use informative cues to draw candidate samples from an informative covariate space (an idea similar to importance sampling) [5]. Here we discuss two sampling approaches.
1) Sampling from a Temporal Prior
Within the state-space framework, we can sample the current covariate x from a transition prior of the covariate at the previous discrete time step [3], [21]:
| (14) |
where p(xt|xt−1) denotes a transition probability density. The posterior can be estimated used a recursive Bayesian filtering rule (for notation simplicity, we have ignored the subscript 1:n for a)
| (15) |
where P(at|xt, a1:t−1) = P(at|xt) (because of the statistical independence between at and a1:t−1 in the spike waveform feature space) denotes the data likelihood at the t-th time step.
2) Kernel Regression
Since at every time step t, we observe the current spike waveform feature at; ideally, the candidate sample is drawn from the mode of the posterior P(x|at). However, searching for the mode in a high-dimensional covariate space is a very challenging problem. Instead, we can search for the mean in the sample space, which may be computed by a continuous multi-input multi-ouput mapping through nonparametric regression x = g(a), where g(·) is a locally smooth multivariate function
| (16) |
Eq. (16) is known as Nadaraya-Watson kernel regression. However, in the presence of noisy spikes and multi-modes in P(x|a), this scheme might not be effective. Alternatively, we may draw candidate samples from P(a|x) using an auxiliary variable [5].
B. Other Issues
Several remaining issues are worth mentioning. First, region-dependent kernel BW parameters can be considered in KDE. For instance, in the low spike-amplitude space, we may use a small BW for the dense noisy spikes, while a large BW is preferred in the median-to-high amplitude space. In addition, finding a meaningful representation of the feature (e.g., by nonlinear transformation) and selecting an appropriate kernel function (in either parametric or nonparametric density estimation) would help separate different feature clusters and improve the decoding accuracy. Second, we have assumed that each sample point contributes equally in KDE. Alternatively, samples can be merged (according to certain similarity measure) and assigned with unequal weights [22], which also helps reduce the sample size.
All of above-mentioned topics will be the subject of our future decoding analysis investigation, using recordings not only from the rat hippocampus, but also from other brain regions (e.g., primate primary motor cortex). In addition, real-time implementations of our transductive neural decoding paradigm using online (parametric or nonparametric) density estimation is currently under investigation.
Acknowledgments
Supported by NIH Grants DP1-OD003646 and MH061976.
Footnotes
The term “transductive” is motivated by “transductive inference” initiated in the machine learning literature [16], which aims to avoid solving a more general problem. In the context of neural decoding, we aim to infer input stimuli from population codes without resorting to spike sorting.
REFERENCES
- 1.Beirlant J, Dudewicz E, Gyor L, Van Der Meulen E. Nonparametric entropy estimation: An overview. 1997;6:17–39. [Google Scholar]
- 2.Botev ZI, Grotowski JF, Kroese DP. Kernel density estimation via diffusion. 2010;38:2916–2957. [Google Scholar]
- 3.Brown EN, Frank LM, Tang D, Quirk MC, Wilson MA. A statistical paradigm for neural spike train decoding applied to position prediction from ensemble firing patterns of rat hippocampal place cells. 1998;18:7411–7425. doi: 10.1523/JNEUROSCI.18-18-07411.1998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Cover TM, Thomas JA. Wiley; 1991. [Google Scholar]
- 5.Doucet A, de Freitas N, Gordon N. Springer; 2001. [Google Scholar]
- 6.Fraser G, Chase SM, Whitford A, Schwartz AB. Control of a brain-computer interface without spike sorting. 2009;6:055004. doi: 10.1088/1741-2560/6/5/055004. [DOI] [PubMed] [Google Scholar]
- 7.Girolami M, He C. Probability density estimation from optimally condensed data samples. 2003;25:1253–1264. [Google Scholar]
- 8.Harris KD, Henze DA, Csicsvari J, Hirase H, Buzsaki G. Accuracy of tetrode spike separation as determined by simultaneous intracellular and extracellular measurements. 2000;84:401–414. doi: 10.1152/jn.2000.84.1.401. [DOI] [PubMed] [Google Scholar]
- 9.Huang D, Chow TWS. Enhancing density-based data reduction using entropy. 2006;18:470–495. doi: 10.1162/089976606775093927. [DOI] [PubMed] [Google Scholar]
- 10.Kloosterman F, Layton S, Chen Z, Wilson MA. Bayesian decoding of unsorted spikes in the rat hippocampus. under review. [DOI] [PMC free article] [PubMed]
- 11.Mitra P, Murthy CA, Pal SK. Density-based multiscale data condensation. 2002;24:1–14. [Google Scholar]
- 12.Pillow JW, Ahmadian Y, Paninski L. Model-based decoding, information estimation, and change-point detection techniques for multineuron spike trains. 2010;23:1–45. doi: 10.1162/NECO_a_00058. [DOI] [PubMed] [Google Scholar]
- 13.Quiroga RQ, Panzeri S. Extracting information from neuronal populations: information theory and decoding approaches. 2009;10:173–185. doi: 10.1038/nrn2578. [DOI] [PubMed] [Google Scholar]
- 14.Scott DW. John Wiley & Sons; New York: 1992. [Google Scholar]
- 15.Snyder DL, Miller MI. Springer; New York: 1991. [Google Scholar]
- 16.Vapnik VN. Wiley; New York: 1998. [Google Scholar]
- 17.Ventura V. Spike train decoding without spike sorting. 2008;20:923–963. doi: 10.1162/neco.2008.02-07-478. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Won DS, Tiesinga PHE, Henriquez CS, Wolf PD. Analytical comparison of the information in sorted and non-sorted cosine-tuned spike activity. 2007;4:322–335. doi: 10.1088/1741-2560/4/3/017. [DOI] [PubMed] [Google Scholar]
- 19.Wood F, Fellows M, Vargas-Irwin C, Black MJ, Donoghue JP. On the variability of manual spike sorting. 2004;51:912–918. doi: 10.1109/TBME.2004.826677. [DOI] [PubMed] [Google Scholar]
- 20.Zemel RS, Dayan P, Pouget A. Probabilistic interpretation of population codes. 1998;10:403–430. doi: 10.1162/089976698300017818. [DOI] [PubMed] [Google Scholar]
- 21.Zhang K, Ginzburg I, McNaughton BL, Sejnowski TJ. Interpreting neuronal population activity by reconstruction: unified framework with application to hippocampal place cells. 1998;79:1017–1044. doi: 10.1152/jn.1998.79.2.1017. [DOI] [PubMed] [Google Scholar]
- 22.Zhou A, Cai Z, Wei L, Qian W. M-kernel merging: Towards density estimation over data streams; 2003. pp. 285–292. [Google Scholar]