

Abstract
Purpose
This study evaluated child-adult differences for consonant identification in a noise or a two-talker masker. Error patterns were compared across age and masker type to test the hypothesis that errors with the noise masker reflect limitations in the peripheral encoding of speech, whereas errors with the two-talker masker reflect target-masker confusions within the central auditory system.
Method
A repeated-measures design compared the performance of children (5–13 years) and adults in continuous speech-shaped noise or a two-talker masker. Consonants were identified from a closed set of 12 using a picture-pointing response.
Results
In speech-shaped noise, children under 10 years of age performed more poorly than adults, but performance was adult-like for 11- to 13-year-olds. In the two-talker masker significant child-adult differences were observed in even the oldest group of children. Systematic clusters of consonant errors were observed for children in the noise masker and for adults in both maskers, but not for children in the two-talker masker.
Conclusions
These results suggest a more prolonged time course of development for consonant identification in a two-talker than in a noise masker. Differences in error patterns between the maskers support the hypothesis that errors with the two-talker masker reflect failures of sound segregation.
INTRODUCTION
Children require a more advantageous signal-to-noise ratio (SNR) compared to adults to achieve similar levels of performance on speech detection, identification, or recognition when tested in the presence of competing noise (e.g., Elliott et al., 1979; Nishi, Lewis, Hoover, Choi, & Stelmachowicz, 2010; Nittrouer & Boothroyd, 1990). For example, Nittrouer and Boothroyd (1990) observed poorer syllable and sentence recognition for young children (4–6 years) compared to adults (18–30 years) in the presence of speech-shaped noise. Age-related improvements in performance have also been reported across childhood (e.g., Eisenberg, Shannon, Martinez, Wygonski, & Boothroyd, 2000; Elliot et al., 1979; Nishi et al., 2010). That is, preschoolers and kindergarteners are often more susceptible to the masking effects of noise than older children. In a recent study, Nishi and her colleagues (2010) examined child-adult differences in the ability to recognize nonsense syllables embedded in speech-shaped noise. Syllable recognition was measured for three age groups of children (4–5, 6–7, and 8–9 year-olds) as well as for adults. Overall recognition performance was significantly poorer for the group of 4- to 5-year-olds compared to the three older age groups. Moreover, adult-like performance in the speech-shaped noise masker was observed only for the oldest group of children tested (8–9 year-olds).
Relative to noise maskers, prolonged and more pronounced child-adult differences have been observed for measures of speech perception in the presence of competing speech (e.g., Elliot et al., 1979; Fallon, Trehub, & Schneider, 2000; Hall, Grose, Buss, & Dev, 2002; Wightman & Kistler, 2005; Wilson, Farmer, Gandhi, Shelburne, & Weaver, 2010). For example, Hall et al. (2002) observed a larger child-adult difference in the ability to identify spondee words embedded in a two-talker masker than in speech-shaped noise. The observation of poorer speech perception in a two-talker masker than a spectrally matched noise masker was termed ‘perceptual masking’ by Carhart, Tillman, and Greetis (1969), and this effect was argued to reflect contributions of central auditory processes.
More recent studies have described the relatively poor speech perception observed in maskers composed of a small number of talkers as ‘informational masking’ (e.g., Brungart, Simpson, Ericson, & Scott, 2001; Freyman, Balakrishnan, & Helfer, 2004; Wightman & Kistler, 2005). Based on terminology introduced to describe results from psychoacoustic experiments using multi-tonal stimuli (e.g., Kidd, Mason, Deliwala, Woods, and Colburn, 1994; Oh & Lutfi, 1998), informational masking in the context of speech-on-speech masking generally refers to masking produced even though the peripheral auditory system provides the brain with sufficient detail to adequately encode the spectral and temporal properties of the target and masker speech. More specifically, it has been suggested that maskers comprised of two or three competing talkers are easily confused with the target speech tokens. This target-masker similarity reduces the listener’s ability to perceptually segregate the target speech from the competing speech masker and/or selectively attend to the target speech while disregarding the irrelevant masker streams (e.g., Brungart, 2001; Brungart et al., 2001; Freyman et al., 2004; Hall et al., 2002).
Informational masking is often contrasted with traditional energetic masking, believed to reflect limitations in peripheral processing (e.g., Fletcher, 1940). Several laboratories have developed techniques and stimuli aimed at isolating the effects of informational and energetic masking for speech-on-speech masking (e.g., Arbogast, Mason, & Kidd, 2002; Brungart, Chang, Simpson, & Wang, 2006; Festen & Plomp, 1990). Although separating the independent contributions of informational and energetic masking is complex and challenging, converging evidence using different approaches indicates that energetic masking plays a relatively small role in speech perception in the presence of a two-talker masker (e.g., Brungart et al., 2006; Freyman et al., 2004). Energetic masking effects become larger as the number of talkers comprising the masker is increased, dominating performance when the multi-talker babble approximates noise (e.g., Freyman et al., 2004). Presumably, the role of informational masking decreases as the number of masker talkers increases because the resulting masker babble becomes less speech-like and thus, less easily confused with the target speech.
The current study evaluated child-adult differences in the ability to identify phonemes embedded in a speech-shaped noise or a two-talker masker. A phoneme identification task was used to facilitate comparisons in error patterns across both age and masker type. Beginning with the seminal study by Miller and Nicely (1955), investigators have consistently shown that adults identify some consonants more accurately than others in the presence of noise (e.g., Benki, 2003; Boothroyd & Nittrouer, 1988; Phatak & Allen, 2007; Phatak, Lovitt, & Allen, 2008; Woods, Yund, Herron, & Ua Cruadhlaoich, 2010; Wang & Bilger 1973). These consonant error patterns can be influenced by the type of masking noise (e.g., Phatak et al., 2008), the SNR (e.g., Miller & Nicely, 1955; Phatak & Allen, 2007; Woods et al., 2010), and the linguistic context in which the consonant is presented (e.g., Dubno & Levitt, 1981; Nittrouer & Boothroyd, 1990; Wang & Bilger, 1973; Woods et al., 2010). Nonetheless, several common patterns are evident across the many studies reported in the literature. For example, place confusions are generally the most common single-feature error made by adults in noise, followed by manner, and then voicing confusions (e.g., Dubno & Levitt, 1981; Miller & Nicely, 1955; Woods et al., 2010). Error patterns also tend to be similar across subjects within a given study. This between-subject consistency is in agreement with Miller and Nicely’s interpretation that information transmission is determined primarily by the stimulus and the peripheral encoding of that stimulus, rather than by more central factors.
Despite the large number of adult studies available in the literature, relatively few studies have reported children’s consonant confusion patterns in noise (Danhauer, Abdala, Johnson, & Asp, 1986; Johnson, 2000; Nishi et al., 2010; Neuman & Hochberg, 1983). Recently, Nishi et al. (2010) compared consonant confusion patterns between 4- to 9-year-old children and adults in the presence of a speech-shaped noise at three different SNRs (0, 5, and 10 dB SNR). Although similar error patterns were generally observed across children and adults, the youngest group of children made some types of errors more frequently than older children and adults. Specifically, 4- to 5-year-olds tended to have relatively more difficulty perceiving stop consonants in the front place. Despite these subtle age effects in the rate of feature errors, consistent error patterns were observed across the large number of children tested (n=72). Similar to the adult findings, these systematic confusions suggest that the speech-shaped noise limits the transmission of information to a greater extent for some consonant features than for others.
The goal of the current study was to evaluate child-adult differences in the ability to identify phonemes presented in a speech-shaped noise or a two-talker masker. One benefit of this approach is that it provides an opportunity to compare consonant confusions and feature error patterns across age and across the two maskers. The studies discussed in the previous paragraphs focused on consonant identification in the presence of a noise masker, but there is a paucity of data describing consonant identification in competing speech maskers for any age group. Extending the work of Hall et al. (2002), who used a spondee identification task, it was predicted that larger child-adult differences in overall consonant identification would be observed with the two-talker than with the noise masker. Unlike word recognition, the use of a consonant identification task provides an opportunity to compare error patterns across listener age groups and across the two maskers. Whereas speech-shaped noise is expected to mask identification cues via energetic masking, the two-talker masker creates the additional problem of determining which components of the acoustic waveform belong to the target and which belong to the masker. Thus, it was hypothesized that systematic and similar consonant confusions would be observed across subjects in the speech-shaped noise. Moreover, it was predicted that the majority of consonant confusions in the speech-shaped noise would be the result of a single-feature error. This pattern of results would be consistent with previous studies of both children (e.g., Nishi et al., 2010) and adults (e.g., Miller and Nicely, 1955), demonstrating that noise interferes with the peripheral encoding of speech to a greater extent for some features than for others. In contrast, it was hypothesized that error patterns with the two-talker masker would be inconsistent both within and across subjects, with incorrect responses being unrelated to the target phoneme in many cases. This could occur if segregation of the target and masker streams failed, and the listener reported a phoneme from the masker stream.
II. METHOD
A. Subjects
A total of sixty-two children (5–13 years) and twenty-eight adults (19–34 years) participated. Subject recruitment was aimed at sampling a wide age range of children, across which many complex auditory abilities are thought to develop (e.g., Wightman, Kistler, & O’Bryan, 2010; Moore, Cowan, Riley, Edmondson-Jones, & Ferguson, 2011). To that end, children were recruited in three groups: 5- to 7 year-olds, 8- to 10 year-olds, and 11- to 13 year-olds. All subjects were native speakers of English, with a self or parental report of normal hearing, speech, and language. Subjects were required to pass a hearing screening prior to testing, with thresholds less than or equal to 20 dB HL for octave frequencies between 250 and 8000 Hz (ANSI, 2010).
Child subjects belonged to one of two comparison groups, and adult subjects belonged to one of three comparison groups. Comparison group A was tested at an SNR of 0; this group allowed an assessment of age effects at a fixed SNR. Comparison groups B and C were tested at SNRs expected to produce more comparable performance across age group; these groups allowed comparisons to be made across both age and masker type for data that were approximately matched in performance (instead of SNR). The number and mean age of listeners in each age group and comparison group are reported in Table 1, with the associated SNR for each masker.
Table 1.
Subject groups and associated SNR for each masker. The absence of value in the column associated with the two-talker masker for comparison group B reflects the fact that this masker was not tested for this comparison group.
| SNR | |||||
|---|---|---|---|---|---|
| comparison group |
age group | n | mean age (yrs) |
speech-shaped noise |
two-talker masker |
| A | 5–7 yrs | 8 | 6.7 | 0 dB | 0 dB |
| 8–10 yrs | 11 | 9.4 | 0 dB | 0 dB | |
| 11–13 yrs | 8 | 12.5 | 0 dB | 0 dB | |
| adult | 8 | 24.2 | 0 dB | 0 dB | |
| B | 5–7 yrs | 11 | 6.0 | −5 dB | |
| 8–10 yrs | 12 | 9.2 | −5 dB | ||
| 11–13 yrs | 12 | 12.5 | −5 dB | ||
| adult | 12 | 23.2 | −5 dB | ||
| C | adult | 8 | 25.4 | −10 dB | −10 dB |
B. Stimuli and conditions
Based loosely on the Audiovisual Feature Test for Young Children (Tyler, Fryauf-Bertschy, & Kelsay, 1991), the target stimuli were consonant-vowel (CV) tokens consisting of one of 12 American English consonants (/b, s, d, h, k, m, n, p, ∫, t, v, z/) in the initial position, followed by the vowel /i/. The tokens were recorded in isolation from an adult female speaker in a sound-treated booth (IAC) using a condenser microphone (AKG-C1000S). The microphone was mounted approximately six inches from the speaker’s mouth. Productions were amplified (TDT MA3) and digitized at a resolution of 32 bits and a sampling rate of 44.1 kHz (CARDDELUXE). Both authors reviewed the complete set of CV tokens prior to subject recruitment to ensure that each sample was intelligible and free of audible distortion. Token durations ranged from 458 to 678 ms (mean = 532 ms). Prior to the experiment, the 12 tokens were scaled to have equal total root-mean-square (rms) level and were resampled at a rate of 24.414 kHz using MATLAB.
The masker was either two-talker speech or speech-shaped noise. The two-talker masker consisted of continuous, meaningful speech produced by two different adult females speaking separate passages from familiar children’s books. One sample was 3 min 8 sec, and the other was 3 min 28 sec. Both samples were manually edited to remove silent pauses greater than approximately 300 ms, and then repeated without discontinuity to create a “seamless” 60-minute stream for each talker. The streams from the two talkers were balanced for overall rms level, mixed, and digitized using a resolution of 32 bits and a sampling rate of 24.414 kHz. The speech-shaped noise masker was created based on the spectral envelope of the two-talker masker. This envelope was obtained by calculating the magnitude spectrum based on a 95.1-sec sample of the two-talker masker. A Gaussian noise of equal duration was then transformed into the frequency domain, multiplied by the spectral envelope, and the result was transformed back into the time domain. This procedure generated a 95.1-sec sample of noise that could be repeated without discontinuities at the beginning and end of the array.
The selection and presentation of stimuli were controlled using custom MATLAB software. The CV tokens and masker were mixed (TDT SM3), amplified (Techtron 5507), sent to a headphone buffer (TDT HB6), and presented in the sound field using a loudspeaker (Monitor Audio, Monitor 4). The loudspeaker was positioned at a distance of 1 m from the subject at 0-degree azimuth.
C. Procedure
Subjects were tested individually in a double-walled, sound-attenuated room (IAC). During the experiment, subjects identified the CV tokens from the closed set of 12 using a picture-pointing response. The average rms level of each token was 65 dB SPL. One of the CV tokens was randomly presented on each trial, and the subject was asked to identify the perceived token by pointing to the corresponding image on a handheld, 8 × 11 inch response board. Each CV token was represented by a distinct and visually unambiguous picture (e.g., a bumble bee for /bi/) on the 12-alternative response board. An experimenter sat behind the subject in the booth beside a computer monitor. The experimenter entered the subject’s identification responses using a mouse and initiated each new presentation. Subjects were encouraged to make their best guess based on what they heard. The maximum response window was 10 seconds. A “no response” was registered after this response window if the subject failed to point to one of the 12 phonemes on the response board. No feedback was provided about token identity.
Subjects completed a practice phase in quiet prior to testing to ensure task comprehension and familiarity with the response illustrations. First, the tester provided a live-voice production of each of the 12 consonants while pointing at the corresponding picture on the response board. Next, tokens were played in isolation from the loudspeaker at 65 dB SPL in the order they appeared on the picture board. Finally, each of the 12 tokens was presented in random order from the loudspeaker at 65 dB SPL in quiet. Subjects were asked to point to the correct picture on the response board; spoken responses were not required. All children who were recruited completed this practice phase with ease, correctly identifying all 12 consonants in quiet (100%).1
Following training, subjects completed separate testing conditions in the presence of each masker. Data were collected in 60-token blocks, each with five repetitions of the 12 CV tokens in random order. Comparison group A was tested at a masker level of 65 dB SPL (SNR of 0 dB). Comparison group B was tested only in the speech-shaped noise condition at a masker level of 70 dB SPL (SNR of −5 dB). Comparison group C, consisting of adults only, was tested in both masker conditions at a masker level of 75 dB SPL (SNR of −10 dB). Subjects were tested in a single session; children took approximately 20–30 minute to complete each masker condition, whereas adults took 15–20 minutes.. The order of the two masker conditions was counterbalanced across subjects in comparison groups A and C.
III. RESULTS
Two sets of analyses were performed. In the first analysis, percent correct identification performance was computed for individual subjects based on responses for all 60 presentations of the CV tokens. Overall percent correct scores are discussed and presented in corresponding figures. However, percent correct performance was converted to rationalized arcsine units (RAUs) prior to statistical analyses to prevent bias due to non-uniformity of variance (Studebaker, 1985). In the second series of analyses, confusion matrices were constructed for individual listeners for each masker condition. These matrices were used to compute feature transmission following Miller and Nicely (1955).
A. Overall consonant identification performance
The left panel of Figure 1 presents average percent correct scores for both masker conditions with standard deviations (SDs) across subjects in comparison group A, tested at 0 dB SNR. The right panel of Figure 1 presents average percent scores (with SDs) for comparison group B, tested in the speech-shaped noise masker at −5 dB SNR. Open bars indicate performance for 5- to 7-year-olds, patterned bars indicate performance for 8- to 10-year-olds, grey bars indicate performance for 11- to 13-year-olds, and black bars indicate performance for adults. Results for the two-talker masker at 0 dB SNR are plotted to the left, results for the speech-shaped noise masker at 0 dB SNR are plotted in the middle, and results for the speech-shaped noise masker at −5 dB SNR are plotted to the right.
Figure 1.
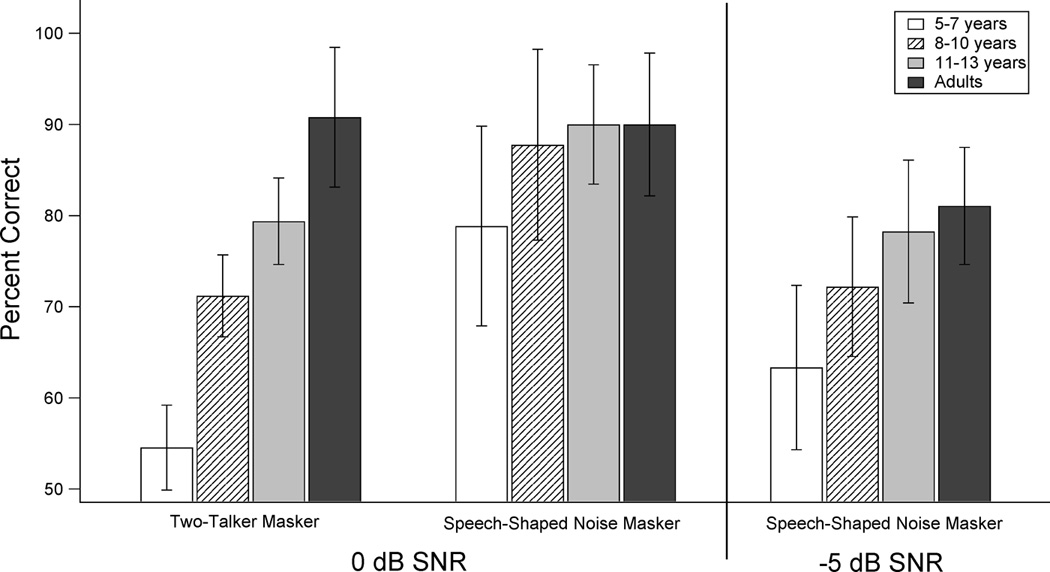
Average percent correct scores (with SDs) are shown for 5- to 7-year-olds (open bars), 8- to 10-year-olds (patterned bars), 11- to 13-year-olds (grey bars), and adults (black bars) in the presence of the two-talker masker at 0 dB SNR (left, comparison group A), the speech-shaped noise masker at 0 dB SNR (middle, comparison group A), and the speech-shaped noise masker at −5 dB SNR (right, comparison group B).
Identification performance at 0 dB SNR was better for adults than for the youngest group of children (5–7 years) for both masker conditions. However, child-adult differences appear to be larger and more persistent for the two-talker compared to the noise masker at 0 dB SNR. For the noise masker at 0 dB SNR, average performance for 5- to 7-year-olds was nine percentage points lower than for 8- to 10-year-olds. Average performance was only two percentage points lower for 8- to 10-year-olds compared to 11- to 13-year-olds, and no difference in average performance was observed between 11- to 13-year-olds and adults. For the two-talker masker at 0 dB SNR, the largest average difference in performance across age groups was observed between 5- to 7-year-olds and 8- to 10-year-olds (16 percentage points), but a substantial difference in performance was also observed between 8- to 10-year-olds and 11- to 13-year-olds (eight percentage points). In contrast to the pattern of results observed in the presence of the noise, child-adult differences in overall consonant identification were evident between 11- to 13-year-olds and adults (12 percentage points) in the presence of the two-talker masker.
A repeated-measures analysis of variance (ANOVA) on these scores represented in RAUs was consistent with the trends observed in the left panel of Figure 1. This analysis indicated significant effects of Masker Type [F(1,31) = 79.2; p < 0.001; ηp2 = 0.72], Age Group [F(3,31) = 26.4; p < 0.001; ηp2 = 0.52], and Masker Type X Age Group [F(3,31) = 11.2; p < 0.001; ηp2 = 0.72]. Paired comparisons (with Bonferroni adjustments, using a criterion of α = 0.05) were performed to examine this interaction. For the speech-shaped noise condition at 0 dB SNR, performance was poorer for 5- to 7-year-olds than for any of three older groups. There were no significant differences between the remaining three age group comparisons (p = 1.0 for all three comparisons). For the two-talker masker condition at 0 dB SNR, performance was significantly poorer for 5- to 7-year-olds compared to each of the three older groups, for 8- to 10-year-olds compared to adults, and for 11- to 13-year-olds compared to adults. There was no significant difference in performance between 8- to 10-year-olds and 11- to 13-year-olds in the presence of the two-talker masker (p = 0.3).
The rationale for testing all subjects at a uniform SNR in comparison group A was to compare developmental effects in susceptibility to masking across the speech-shaped noise and two-talker masker conditions. The decision to use an SNR of 0 dB was based on extensive pilot data, as well as previous studies showing near-chance speech-in-noise performance for young children when target speech is presented at a negative SNR relative to the masker (e.g., Stuart, Givens, Walker, & Elangovan, 2006). Estimates of performance in the two-talker masker are consistent with these previous data. However, average overall identification performance in the speech-shaped noise masker at 0 dB SNR was close to 90% for the two oldest groups of children and the group of adults. Thus, potential ceiling effects limit the interpretation of child-adult differences in masking for the speech-shaped noise condition. In comparison group B, data were collected from children and adults in the speech-shaped noise masker at −5 dB SNR. These data are shown in the right panel of Figure 1. As in previous conditions, there was a trend for better performance with increasing age for the speech-shaped noise masker at −5 dB SNR. The 5- to 7-year-olds and 8- to 10-year-olds differed by nine percentage points, the 8- to 10-year-olds and 11- to 13-year-olds differed by six percentage points, and the 11- to 13-year-olds and adults differed by three percentage points. A one-way ANOVA was conducted to test the statistical reliability of these trends. The main effect of Age Group was significant [F(3,43) = 11.5; p < 0.001]. Consistent with the results obtained in the noise masker at 0 dB SNR, paired comparisons (with Bonferroni adjustments, using a criterion of α = 0.05) indicated that the average identification performance for 5- to 7-year-olds in the speech-shaped noise at −5 dB SNR was significantly poorer than for 8- to 10-year-olds, for 11- to 13-year-olds, or for adults. There were no significant differences between 8- to 10-year-olds and 11- to 13-year-olds (p = 0.4) or between 11- to 13-year-olds and adults (p = 1.0). In contrast to the results obtained in noise at 0 dB SNR, however, identification performance for 8- to 10-year-olds in the speech-shaped noise masker at −5 dB SNR was significantly poorer than for adults.
Figure 2 presents overall consonant identification performance for individual subjects, plotted as a function of subject age, in comparison groups for which data at a fixed SNR are available in both masker conditions. Circles show percent correct scores at 0 dB SNR (comparison group A), and triangles show scores at −10 dB SNR (comparison group C). Open symbols indicate scores for the noise masker, and filled symbols indicate scores for the two-talker masker. Considerable between-subjects variability in overall performance was observed, but the individual data for comparison group A are generally consistent with the group data summarized in the left portion of Figure 1. For the noise condition at 0 dB SNR, overall identification performance appears to be poorer for the younger children, but similar across older children and adults. For example, scores below 85% correct were observed for all of the children in the 5- to 7-year-old group. In contrast, only the two youngest children in the 8- to 10-year-olds group and one child in the 11- to 13-year-old group had an identification score lower than 85%. For the two-talker condition at 0 dB SNR, child-adult differences in overall performance appear to be present throughout the age range of children tested in the current study. Identification scores ranged from 38 to 72% for 5- to 7-year-olds, from 58 to 87% for 8- to 10-year-olds, from 70 to 90% for 11- to 13-year-olds, and from 87 to 93% for adults. Combining the three groups of children, age was a significant predictor of RAU score at 0 dB SNR for both the noise (r = 0.66, p < 0.001) and two-talker (r= 0.75, p < 0.00001) masker conditions.
Figure 2.
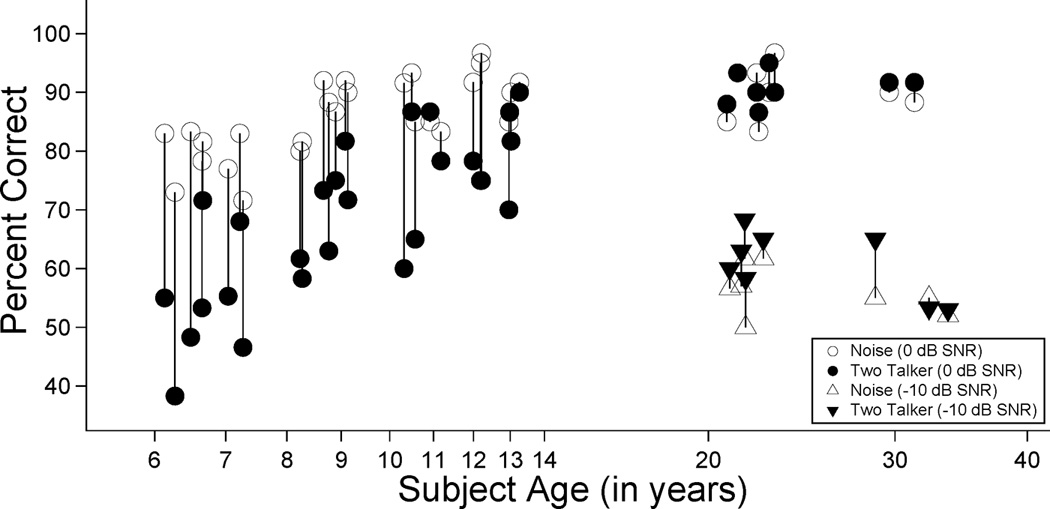
Individual percent correct data are plotted as a function of subject age. Open symbols indicate overall consonant identification performance in the speech-shaped noise masker, and filled symbols indicate performance in the two-talker masker. Circles show scores obtained at 0 dB SNR (comparison group A), and the triangles show scores obtained at −10 dB SNR (comparison group C). Vertical lines indicate the magnitude of the perceptual masking effect (performance in the noise masker minus performance in the two-talker masker).
The perceptual masking effect, defined as the difference in performance between the noise and two-talker conditions (Carhart et al., 1969), is shown by the length of the vertical line connecting symbols for each subject in Figure 2. At 0 dB SNR, this difference ranged from 10 to 35 percentage points (mean = 24) for 5- to 7-year-olds, from −2 to 32 percentage points (mean = 17) for 8- to 10-year-olds, from 0 to 22 percentage points (mean = 11) for 11- to 13-year-olds, and from −5 to 7 percentage points (mean = −1) for adults. Considering all three age groups of children tested at 0 dB SNR, 24 of 27 children showed a decrease in the accuracy of consonant identification of 5 percentage points or greater in the two-talker compared to the noise masker. The remaining three children (ages 10.9, 13.0 and 13.3 years) performed similarly in presence of the noise and two-talker maskers. In sharp contrast to the children, only one adult showed a decrease of 5 percentage points or greater in the two-talker compared to the two-talker masker at 0 dB SNR. The remaining six adults showed similar or better performance across the two-talker and noise conditions. The difference in performance (in RAUs) between the two-talker and noise masker was negatively correlated with age across the three groups of children (r = −0.60, p < 0.001), suggesting an age-related decrease in perceptual masking with increasing age during childhood.
Data collected from adults in comparison group C, tested at −10 dB SNR, were used to further evaluate perceptual masking in adults. As shown by the triangles in Figure 2, overall identification performance was poorer for the adults tested at −10 dB SNR than those tested at 0 dB SNR. Despite poorer performance at the lower SNR, comparison group C also failed to show a systematic perceptual masking effect. Two separate repeated-measures ANOVAs were conducted to test the statistical reliability of these trends, with performance represented in RAUs. Adults tested at 0 dB SNR showed no significant difference between the noise and two-talker maskers [F(1,7) = 0.148; p = 0.7]. However, adults tested at −10 dB SNR showed better performance in the presence of the two-talker masker than in the noise [F(1,7) = 11.5; p < 0.05]. In summary, these data indicate that adults showed limited or no perceptual masking as defined by Carhart et al. (1969), using the current stimuli at either 0 or −10 dB SNR. These results should not be interpreted as indicating that adults are fully segregating the speech and masker speech streams, as spectro-temporal modulations in speech could support performance that is substantially better than that observed for speech-shaped noise (Brungart et al., 2006). However, these results do support the more conservative conclusion that adults are better than young children at segregating the signal and masker speech stimuli.
B. Consonant confusion patterns for 5–7 year-olds and adults
The approach used in the analyses of consonant confusions and feature errors was to approximately match overall performance across the two masker types, as well as across children and adults. For 5- to 7-year-olds, data were taken from comparison group B (−5 dB SNR) for the speech-shaped noise masker and comparison group A (0 dB SNR) for the two-talker masker. These datasets were associated with 63% and 54% percent correct, respectively. For adults, data were taken from comparison group C (−10 dB SNR) for both the speech-shaped noise and the two-talker maskers. These datasets were associated with 56% and 60% correct, respectively.
Figure 3 shows contour plots indicating the consonant confusions associated with 5- to 7-year-olds (top row) and adults (bottom row), with the left column showing results for the speech-shaped noise masker and the right panel showing results for the two-talker masker. These plots were generated by compiling all of the errors for each group and masker type, and summing complementary errors. For example, the number of /p/ responses to /h/ targets was summed with the number of /h/ responses to /p/ targets. The results were normalized to the peak error value, such that the resulting values ranged from 0 (no errors) to 1 (most common error). These values are associated with white and black shading in Figure 3, respectively, with intermediate values represented by shades of grey. In the noise masker, 5- to 7-year-old children and adults tended to make consistent errors. In children and in adults, the most commonly confused consonant pairs were /m, n/, /h, p/, /b, v/ and /m, b/. The normalized error rate for these confusions spanned 0.6–1.0 for both age groups. The next mostly likely error had a normalized rate of 0.4 (/v, m/ in children). In contrast to the noise masker, data for the two-talker masker were less consistent within and across datasets. Both groups commonly confused the pair /m, n/, but error rates for other pairs differed for children and adults. Other consonant pairs associated with normalized error rates of 0.5 or greater included /p, h/ and /b,v/ for adults and /n, v/ for children. The consistency of error rates within each dataset can be characterized in terms of the median normalized error; small values indicate that most errors occur for a restricted set of confusions, whereas a larger value indicates a more uniform distribution of errors across consonant pairs. For the two-talker masker, the median normalized error rate was the 0.13 for children and 0.05 for adults. In contrast, for the speech-shaped noise, the median normalized error rate was 0.03 for both age groups. Visually, this is reflected as more grey shading in the plots associated with the two-talker compared to the speech-shaped noise masker.
Figure 3.
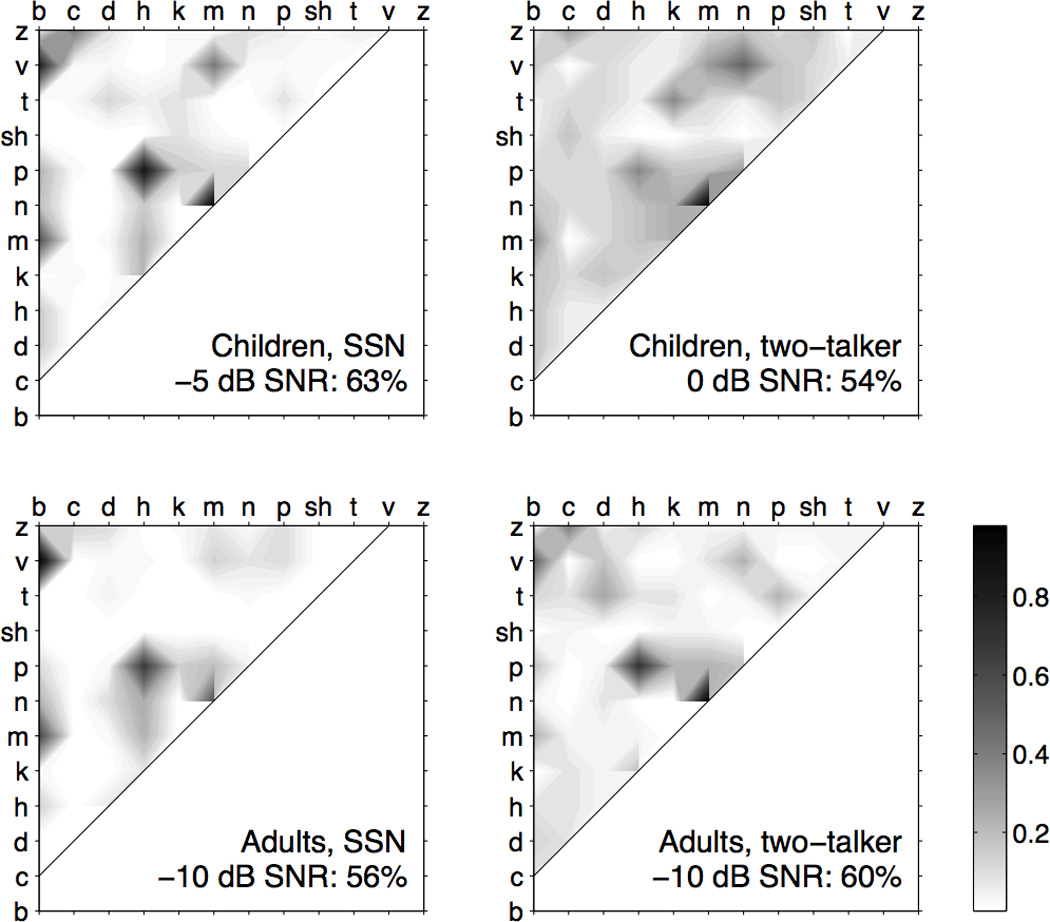
Consonant confusions associated with the speech-shaped noise masker (left column) and the two-talker masker (right column) are shown for 5- to 7-year-olds are shown in the top row and for adults are shown in the bottom row. Values ranged from 0 (no errors) to 1 (most common error), associated with white and black shading, respectively. Intermediate error values are shown by the grey shading.
Individual data were used to compute feature transmission, based on the theoretical analysis described first described by Miller and Nicely (1955). In the primary analysis, speech errors related to the linguistic features of voicing, place of articulation, and manner of articulation were identified and compared across children and adults for each masker. Information transmission was evaluated for each dataset (age group and masker type) following the methods described by Miller and Nicely (1955); the results (in bits) were divided by the maximum information transfer possible for each feature in the present paradigm. The result supports a comparison of the relative information transfer in each of the three features. The proportions of information received for each feature (voicing, place, and manner) are shown in Figure 4 for each of the four groups. The proportion of voicing, place, and manner errors are shown by the open, patterned, and grey bars, respectively. Error bars show ± 1 SD of the mean. The pattern of information received for voicing, place, and manner features appears to be similar across 5- to 7-year-olds and adults for both masker conditions. However, the pattern of feature errors appears to differ across the speech-shaped noise and two-talker masker conditions. For the noise masker, there is a trend in both age groups for greater proportional information transfer for voicing, slightly less for place, and less still for manner. For the two-talker masker, there is less of a difference between the proportional information transfer across features. Another notable trend observed in children’s data shown in Figure 4 is the increase in individual variability for each of the three features in the two-talker masker compared to the noise. Unlike children, greater individual variability in the proportion of information received for the features of voicing, place and manner is not evident in the two-talker compared to the noise masker for adults. Although the features are not independent, the consequences feature dependence are mediated in the current study by the comparison across the two masker conditions. Thus, analyses of the scores were performed to test the statistical significance of the trends observed in Figure 4. A single analysis was not applied to the whole dataset because adult data were from a single group, whereas child data were taken from two groups. Further, the assumption of homogeneity of variance was violated. A repeated-measures ANOVA of Feature (voicing, place, manner) was performed separately for each masker type and age group. For children in the noise condition, this analysis revealed a significant main effect of Feature [F(2, 20) = 8.2; p < 0.01; ηp2 = 0.45], indicating differences across the three features in the proportion of information received. Pairwise comparisons (adjusted Bonferroni, using a criterion of α = 0.05) showed that a greater proportion of information was received for voicing than for manner. The proportion of information received was not significantly different between voicing and place (p = 0.06) or between place and manner (p = 0.5). A significant main effect of Feature [F(2, 14) = 17.9; p < 0.0001; ηp2 = 0.72] was also observed for adults in the noise masker. Pairwise comparisons (adjusted Bonferroni, using a criterion of α = 0.05) indicated that the proportion of voicing information received was significantly higher than for manner information. In addition, the proportion of place information was significantly higher than for manner information. There was no significant difference between voicing and place (p = 0.7). In contrast to the results observed with the noise masker, no significant main effect of Feature was observed for children in the two-talker masker [F(2, 14) = 2.3; p = 0.14]. Consistent with the results observed with the noise masker, statistical analysis for the adults in the two-talker masker indicated a significant main effect of Feature [F(2, 14) = 3.9; p < 0.05]. However, pairwise comparisons failed to show a significant difference in the information received across voicing and place (p = 0.2), voicing and manner (p = 0.1), or place and manner (p = 0.7) when Bonferroni adjustments were applied.
Figure 4.

The proportion of information (with SDs) received for the linguistic features of voicing (open bars), place of articulation (patterned bars) and manner of articulation (shaded bars) is shown for two subject groups and two masker types. The 5- to 7-year-olds were tested in the speech-shaped noise masker at −5 dB SNR (comparison group B) and in the two-talker masker at 0 dB SNR (comparison group A). The adults were tested at −10 dB SNR for both maskers (comparison group C).
In addition to the analyses of single-feature errors, it is of interest to examine the proportion of incorrect responses resulting from an error in one feature compared to the proportion of incorrect responses that are the result of errors in multiple features or no-response trials. These error rates are shown in Figure 5. For 5- to 7-year-olds, there was a trend for the proportion of single-feature errors to decrease in the two-talker relative to the noise masker. Results of a one-way ANOVA confirmed a significant effect of masker type for the children [F(1,17) = 32.0; p < 0.001]. In contrast to the children’s data, a repeated-measures ANOVA of the proportion of single feature errors for adults failed to show a significant main effect of masker type [F(1,7) = 2.3; p = 0.2]. Another striking trend was the difference in the proportion of “no response” errors between the two-talker and noise maskers. In the noise condition, an average of 6% of errors made by children and 1% of errors made by adults were no-response errors. In contrast, an average of 22% of children’s errors and 16% of adults’ errors in the two-talker masker were no-response errors. This pattern of results is consistent with the idea that when subjects made errors in the noise masker, they heard some but not all features of the consonant, due to energetic masking. In the two-talker masker, in contrast, subjects may have had difficulty identifying any of the features of the consonant, perhaps due to a failure to segregate the signal from the masker.
Figure 5.

The proportion of incorrect responses (with SDS) resulting from a single-feature error, multiple errors, and no-responses is shown for 5–7 year-olds and adults. Bars indicate data for the 5- to 7-year-olds tested at −5 dB SNR in the speech-shaped noise masker (open bars), adults tested at −10 dB SNR in the speech-shaped noise masker (grey bars), 5- to 7-year-olds tested at 0 dB SNR in the two-talker masker (patterned bars), and adults tested at −10 dB SNR in the two-talker masker (black bars).
IV. DISCUSSION
The aims of the current study were twofold. The first goal was to evaluate child-adult differences in overall consonant identification performance across a speech-shaped noise and a two-talker masker. Consistent with previous studies of children using a spondee identification task (e.g., Hall et al., 2002), the current results indicate larger child-adult differences in the presence of a two-talker compared to a speech-shaped noise masker. The second goal of this study was to test the hypothesis that the speech-shaped noise masker interferes with identification cues via energetic masking, whereas the two-talker masker interferes with the perceptual segregation of the target and masker speech. Comparisons of both feature errors and the number of features missed across the two masker types are consistent with this hypothesis.
Child-adult differences in overall consonant identification performance in the speech-shaped noise masker are in general agreement with the age-related changes observed by Nishi et al. (2010). Although Nishi et al. observed a similar improvement across age in overall performance with increasing SNR, adult-like performance was not observed for the two youngest groups of children (4–5 and 6–7 years) at any of the three SNRs examined (0, 5 and 10 dB). The current results indicate mature performance for most 8- to 10-year-olds in the noise masker at 0 dB SNR. Although potential ceiling effects limit the interpretation of child-adult differences in the noise masker at 0 dB SNR, data obtained at a more challenging SNR of −5 dB also show mature consonant identification performance in the presence of a speech-shaped noise by 11 to 13 years of age. Whereas overall identification performance in the presence of speech-shaped noise was significantly poorer for both 5- to 7-year-olds and 8- to 10-year-olds compared to adults tested at −5 dB SNR, adult-like performance was observed for the oldest group of children tested (11–13 years).
One striking finding of the present study is the prolonged child-adult differences in masking observed for phoneme identification in the presence of the two-talker masker. In contrast to the results with the noise masker, age effects in overall identification performance persisted beyond the first decade of life. Mounting evidence supports the idea that masking effects extend into the teenage years for complex listening tasks using target words or sentences (e.g., Wightman et al. 2010). Given that the oldest group of children tested in the present study (11–13 years) performed significantly more poorly than the adults in the two-talker masker, future research aimed at determining the age at which consonant identification performance reaches mature levels in the presence of complex speech maskers should include subjects between the ages of 13 and 18 years, as well as testing at multiple SNRs.
The pronounced child-adult differences observed in the two-talker compared to the noise masker here and in previous studies (e.g., Bonino et al., 2012; Hall et al., 2002) may reflect immaturity in how children perceptually segregate the target consonants from the two competing masker streams of speech. Most researchers agree that the peripheral auditory system provides the brain with a fairly precise representation of the basic spectral, temporal, and intensity properties of sound by about six months of age (reviewed by Werner & Leibold, 2010). However, the ability to use the information that the ear provides the brain develops over a much longer time course. Extensive experience with speech may be required before children fully learn important features of sound across different talkers and listening environments, an idea supported here by the observation of a statistically significant correlation between children’s overall identification performance in the two-talker masker and their age.
Evidence supporting the hypothesis that children’s relatively poor performance in the presence of the two-talker masker reflects difficulties performing sound segregation comes from studies that have measured the benefit in speech recognition performance associated with the introduction of stimulus cues thought to facilitate sound segregation (e.g., Bonino et al., 2012; Brungart et al., 2001; Freyman, Helfer, McCall, & Clifton, 1999; Freyman et al., 2004; Wightman & Kistler, 2005). These cues include spatial separation, frequency separation, asynchronous temporal onsets, difference in harmonic structure, and dissimilar temporal modulations (e.g., Bregman, 1990). Substantial reductions in the informational masking of speech have been observed for most adults when these cues are provided (e.g., Brungart et al., 2001; Freyman et al., 1999; Freyman et al., 2004). In contrast, the extent to which children benefit from these acoustic cues appears to depend on the specific cue that is introduced (e.g., Bonino et al., in press; Garadat & Litovsky, 2007; Wightman & Kistler, 2005). For example, word recognition scores improve for both children and adults in the presence of a continuous two-talker masker when subjects are provided with a carrier phrase (i.e., “say the word” prior to the presentation of target words) compared to scores obtained when the target words are presented in isolation (Bonino et al., 2012). One explanation for this finding is that the carrier phrase promotes the formation of an auditory stream based on the common spectral fluctuations of the target talker’s voice over time. Children do not appear to benefit as much as adults when a video representation of the target talker is provided at the same time as the auditory signal; this manipulation results in a large release from informational masking for adults in the presence of a single stream of competing stream of speech, but provides little benefit for children under 8 years of age (Wightman, Kistler, & Brungart, 2006). There is also evidence that harmonicity may have different effects on auditory stream segregation for speech perception in children and adults (e.g., Nittrouer & Tarr, 2011).
A related possible explanation for the larger child-adult differences observed in the two-talker compared to the speech-shaped noise masker is that children are immature in their ability to correctly segregate and attend to target signals on the basis of spectro-temporal modulation patterns. It has been well documented that adults’ speech recognition performance improves in temporally-modulated noise compared to steady noise (e.g., Cooke, 2006; Wilson & Carhart, 1969). A portion of the benefit observed for normal-hearing adults in fluctuating maskers is the result of improvements in the SNR at the “dips” in the fluctuating speech masker. However, this benefit also relies on the ability to utilize envelope cues to perform sound segregation (e.g., Brungart et al., 2006; Oxenham, 2008). In contrast to adults, young children appear to be less efficient than adults in taking advantage of the improved SNR at the “dips” in the fluctuating speech masker (Stuart, 2008; Hall, Grose, Buss, & Roush, 2012). For example, Hall et al. (2012) examined sentence recognition for younger children (4.6 to 6.7 years), older children (7.3 to 11.1 years), and adults in the presence of steady speech-shaped noise or temporally-modulated noise. Both groups of children performed more poorly than adults in the presence of both the steady and modulated maskers, but a larger masking release was observed for adults than for the younger children. Given children’s mature peripheral representation of sound (reviewed by Werner and Leibold, 2010), the present results may reflect children’s difficulties in combining speech information that are distributed across temporal and spectral gaps in the masker.
Whereas speech-shaped noise was expected to mask some identification cues via energetic masking, the two-talker masker was expected to produce both informational and energetic masking. Thus, it was hypothesized that the error patterns with the two-talker masker would be less systematic than the error patterns with the speech-shaped noise masker. The current data are in agreement with this hypothesis. As in previous studies (e.g., Nishi et al., 2010; Woods et al., 2010), a significantly greater proportion of voicing information was received by both the 5- to 7-year-olds and the adults in the noise masker relative to manner information. Adults, but not children, received significantly more place than manner information in the noise masker. In contrast to the results with the noise masker, there was no significant difference in the proportion of information received across the three features of manner, place and voicing for the 5- to 7-year-olds in the presence of the two-talker masker. Although a significant main effect of feature was observed for the adults in the two-talker masker, adjusted post-hoc testing failed to identify systematic differences across the three features.
In addition to the differences in error patterns across the two maskers, the proportion of single-feature errors was significantly greater in the noise than in the two-talker masker for both age groups. Considered together, these observations are consistent with the idea that errors made in the two-talker masker result from more central factors than errors made in the noise masker. A series of studies by Wightman and his colleagues using a coordinate-response measure (e.g., Wightman & Kistler, 2005; Wightman et al., 2010) provides additional support for this interpretation. For example, Wightman and Kistler (2005) reported that many of the errors made by children were the result of intrusions from the masker stream and may reflect children’s difficulties in the segregation process.
The results from the present study may have implications for the application of speech-in-noise testing in the pediatric audiology clinic. Despite a growing clinical interest in obtaining more realistic measures of functional auditory skills, it would be premature to begin using speech maskers for diagnostic purposes without first developing a greater understanding of the typical time course of development for these stimuli and collecting comprehensive normative data. The observation of large individual differences in performance with complex maskers and the finding of differences across tokens produced by different speakers (e.g., Phatak & Allen, 2007; Phatak et al., 2008) further complicate efforts to determine the range of typical performance. Moreover, the time course of development is likely to depend on several factors, including the competing masker. For complex listening tasks, such as the perception of speech embedded in a speech masker containing only a few talkers, it is clear that the maturation of hearing follows an extended course of development.
ACKNOWLEDGMENTS
This work was supported from the National Institute of Deafness and Other Communication Disorders (R01 DC011038). Portions of these results were presented to the American Auditory Society Annual Meeting in Scottsdale, AZ in March 2011. We are grateful to the members of the Human Auditory Development Laboratory for their assistance with data collection.
Footnotes
Pilot data were collection from seven children (5–9 years) in quiet prior to the start of data collection for the current study. Perfect performance (100%) was observed for five of these children, with the remaining two children each making one error.
REFERENCES
- American National Standards Institute. Specifications for audiometers. New York, NY: 2010. (ANSI/ASA S3.6-2010). [Google Scholar]
- Arbogast T, Mason C, Kidd G. The effect of spatial separation on information and energetic masking of speech. The Journal of the Acoustical Society of America. 2002;112:2086–2098. doi: 10.1121/1.1510141. [DOI] [PubMed] [Google Scholar]
- Benki JR. Analysis of English nonsense syllable recognition in noise. Phonetica. 2003;60:129–157. doi: 10.1159/000071450. [DOI] [PubMed] [Google Scholar]
- Bonino AY, Leibold LJ, Buss E. Release from perceptual masking in children and adults: Benefit of a carrier phrase. Ear and Hearing. doi: 10.1097/AUD.0b013e31825e2841. (in press). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boothroyd A, Nittrouer S. Mathematical treatment of context effects in phoneme and word recognition. The Journal of the Acoustical Society of America. 1988;84:101–114. doi: 10.1121/1.396976. [DOI] [PubMed] [Google Scholar]
- Bregman AS. Auditory Scene Analysis. Cambridge, MA: MIT; 1990. [Google Scholar]
- Brungart DS. Informational and energetic masking effects in the perception of two simultaneous talkers. The Journal of the Acoustical Society of America. 2001;109:1101–1109. doi: 10.1121/1.1345696. [DOI] [PubMed] [Google Scholar]
- Brungart DS, Chang PS, Simpson BD, Wang D. Isolating the energetic component of speech-on-speech masking with ideal time-frequency segregation. The Journal of the Acoustical Society of America. 2006;120:4007–4018. doi: 10.1121/1.2363929. [DOI] [PubMed] [Google Scholar]
- Brungart DS, Simpson BD, Ericson MA, Scott KR. Informational and energetic masking effects in the perceptual of multiple simultaneous talkers. The Journal of the Acoustical Society of America. 2001;110:2527–2538. doi: 10.1121/1.1408946. [DOI] [PubMed] [Google Scholar]
- Carhart R, Tillman TW, Greetis ES. Perceptual masking in multiple sound backgrounds. The Journal of the Acoustical Society of America. 1969;45:694–703. doi: 10.1121/1.1911445. [DOI] [PubMed] [Google Scholar]
- Cooke M. A glimpsing model of speech perception in noise. The Journal of the Acoustical Society of America. 2006;119:1562–1573. doi: 10.1121/1.2166600. [DOI] [PubMed] [Google Scholar]
- Danhauer JL, Abdala C, Johnson C, Asp C. Perceptual features from normal-hearing and hearing impaired children’s errors on the NST. Ear and Hearing. 1986;5:318–322. doi: 10.1097/00003446-198610000-00005. [DOI] [PubMed] [Google Scholar]
- Dubno JR, Levitt H. Predicting consonant confusions from acoustic analysis. The Journal of the Acoustical Society of America. 1981;69:249–261. doi: 10.1121/1.385345. [DOI] [PubMed] [Google Scholar]
- Eisenberg LS, Shannon RV, Martinez AS, Wygonski J, Boothroyd A. Speech recognition with reduced spectral cues as a function of age. The Journal of the Acoustical Society of America. 2000;107:2704–2710. doi: 10.1121/1.428656. [DOI] [PubMed] [Google Scholar]
- Elliott LL, Connors S, Kille E, Levin S, Ball K, Katz D. Children’s understanding of monosyllabic nouns in quiet and noise. The Journal of the Acoustical Society of America. 1979;66:12–21. doi: 10.1121/1.383065. [DOI] [PubMed] [Google Scholar]
- Fallon M, Trehub SE, Schneider BA. Children perception of speech in multitalker babble. The Journal of the Acoustical Society of America. 2000;108:3023–3029. doi: 10.1121/1.1323233. [DOI] [PubMed] [Google Scholar]
- Feston J, Plomp R. Effects of fluctuating noise and interfering speech on the speech reception threshold for impaired and normal hearing. The Journal of the Acoustical Society of America. 1990;88:1725–1736. doi: 10.1121/1.400247. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Balakrishnan U, Helfer KS. Effect of number of masking talkers and auditory priming on informational masking in speech recognition. The Journal of the Acoustical Society of America. 2004;115:2246–2256. doi: 10.1121/1.1689343. [DOI] [PubMed] [Google Scholar]
- Freyman RL, Helfer KS, McCall DD, Clifton RK. The role of perceived spatial separation in the unmasking of speech. The Journal of the Acoustical Society of America. 1999;106:3578–3588. doi: 10.1121/1.428211. [DOI] [PubMed] [Google Scholar]
- Garadat SN, Litovsky RY. Speech intelligibility in free field: Spatial unmasking in preschool children. The Journal of the Acoustical Society of America. 2007;121:1047–1055. doi: 10.1121/1.2409863. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hall JW, III, Grose JH, Buss E, Dev MB. Spondee recognition in a two-talker masker and a speech-shaped noise masker in adults and children. Ear and Hearing. 2002;23:159–165. doi: 10.1097/00003446-200204000-00008. [DOI] [PubMed] [Google Scholar]
- Hall JW, III, Grose JH, Buss E, Roush PA. Effects of Age and Hearing Impairment on the Ability to Benefit from Temporal and Spectral Modulation. Ear and Hearing. 2012;33:340–348. doi: 10.1097/AUD.0b013e31823fa4c3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson CE. Children’s phoneme identification in reverberation and noise. Journal of Speech, Language, and Hearing Research. 2000;43:144–157. doi: 10.1044/jslhr.4301.144. [DOI] [PubMed] [Google Scholar]
- Kidd G, Mason CR, Deliwala PA, Woods WS, Coburn HS. Reducing informational masking by sound segregation. The Journal of the Acoustical Society of America. 1994;95:3475–3480. doi: 10.1121/1.410023. [DOI] [PubMed] [Google Scholar]
- Miller GA, Nicely PE. An analysis of the perceptual confusions among some English consonants. The Journal of the Acoustical Society of America. 1955;27:338–352. [Google Scholar]
- Moore DR, Cowan JA, Riley A, Edmondson-Jones AM, Ferguson MA. Development of auditory processing in 6- to 11-year-old children. Ear and Hearing. 2011;32:269–285. doi: 10.1097/AUD.0b013e318201c468. [DOI] [PubMed] [Google Scholar]
- Neuman AC, Hochberg I. Children’s perception of speech in reverberation. The Journal of the Acoustical Society of America. 1983;73:2145–2149. doi: 10.1121/1.389538. [DOI] [PubMed] [Google Scholar]
- Nishi K, Lewis DE, Hoover BM, Choi S, Stelmachowicz PG. Children’s recognition of American English consonants in noise. The Journal of the Acoustical Society of America. 2010;127:3177–3188. doi: 10.1121/1.3377080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nittrouer S, Boothroyd A. Context effects in phoneme and word recognition by young children and older adults. The Journal of the Acoustical Society of America. 1990;87:2705–2715. doi: 10.1121/1.399061. [DOI] [PubMed] [Google Scholar]
- Oh EL, Lutfi RA. Nonmonotonicity of informational masking. The Journal of the Acoustical Society of America. 1998;104:3489–3499. doi: 10.1121/1.423932. [DOI] [PubMed] [Google Scholar]
- Phatak SA, Allen JB. Consonant and vowel confusions in speech-weighted noise. The Journal of the Acoustical Society of America. 2007;121:2312–2326. doi: 10.1121/1.2642397. [DOI] [PubMed] [Google Scholar]
- Phatak SA, Lovitt A, Allen JB. Consonant confusions in white noise. The Journal of the Acoustical Society of America. 2008;124:1220–1233. doi: 10.1121/1.2913251. [DOI] [PubMed] [Google Scholar]
- Stuart A. Reception thresholds for sentences in quiet, continuous noise, and interrupted noise in school-age children. Journal of the American Academy of Audiology. 2008;19:135–146. doi: 10.3766/jaaa.19.2.4. [DOI] [PubMed] [Google Scholar]
- Stuart A, Givens GD, Walker LJ, Elangovan S. Auditory temporal resolution in normal-hearing preschool children revealed by word recognition in continuous and interrupted noise. The Journal of the Acoustical Society of America. 2006;119:1946–1949. doi: 10.1121/1.2178700. [DOI] [PubMed] [Google Scholar]
- Studebaker GA. A “rationalized” arcsine transform. Journal of Speech and Hearing Research. 1985;28:455–462. doi: 10.1044/jshr.2803.455. [DOI] [PubMed] [Google Scholar]
- Tyler RS, Fryauf-Bertschy H, Kelsay D. The University of Iowa Hospitals, Department of Otolaryngology - Head and Neck Surgery. Iowa City: Iowa; 1991. Audiovisual feature test for young children. [Google Scholar]
- Wang MD, Bilger RC. Consonant confusions in noise: a study of perceptual features. The Journal of the Acoustical Society of America. 1973;54:1248–1266. doi: 10.1121/1.1914417. [DOI] [PubMed] [Google Scholar]
- Werner LA, Leibold LJ. Auditory development in normal-hearing children (Ch. 4) In: Seewald R, Tharpe AM, editors. Comprehensive Handbook of Pediatric Audiology. San Diego (CA): Plural Publishing; 2010. pp. 63–82. [Google Scholar]
- Wightman FL, Kistler DJ. Informational masking of speech in children: Effects of ipsilateral and contralateral distracters. The Journal of the Acoustical Society of America. 2005;118:3164–3176. doi: 10.1121/1.2082567. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wightman FL, Kistler DJ, Brungart D. Informational masking of speech in children: Auditory-visual integration. The Journal of the Acoustical Society of America. 2005;119:3940–3949. doi: 10.1121/1.2195121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wightman FL, Kistler DJ, O’Bryan A. Individual differences and age effects in a dichotic informational masking paradigm. The Journal of the Acoustical Society of America. 2010;128:270–279. doi: 10.1121/1.3436536. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wilson RH, Carhart R. Influence of pulsed masking on the threshold for spondees. The Journal of the Acoustical Society of America. 1969;46:998–1010. doi: 10.1121/1.1911820. [DOI] [PubMed] [Google Scholar]
- Wilson RH, Farmer NM, Gandhi A, Shelburne E, Weaver J. Normative data for the Words-in-Noise test for 6- to 12-year-old children. Journal of Speech, Language, and Hearing Research. 2010;53:1111–1121. doi: 10.1044/1092-4388(2010/09-0270). [DOI] [PubMed] [Google Scholar]
- Woods DL, Yund EW, Herron TJ, Ua Cruadhlaoich MAI. Consonant identification in consonant-vowel-consonant syllables in speech-spectrum noise. The Journal of the Acoustical Society of America. 2010;127:1609–1623. doi: 10.1121/1.3293005. [DOI] [PubMed] [Google Scholar]