

Abstract
Multiple hypothesis testing is a fundamental problem in high dimensional inference, with wide applications in many scientific fields. In genome-wide association studies, tens of thousands of tests are performed simultaneously to find if any SNPs are associated with some traits and those tests are correlated. When test statistics are correlated, false discovery control becomes very challenging under arbitrary dependence. In the current paper, we propose a novel method based on principal factor approximation, which successfully subtracts the common dependence and weakens significantly the correlation structure, to deal with an arbitrary dependence structure. We derive an approximate expression for false discovery proportion (FDP) in large scale multiple testing when a common threshold is used and provide a consistent estimate of realized FDP. This result has important applications in controlling FDR and FDP. Our estimate of realized FDP compares favorably with Efron (2007)’s approach, as demonstrated in the simulated examples. Our approach is further illustrated by some real data applications. We also propose a dependence-adjusted procedure, which is more powerful than the fixed threshold procedure.
Keywords: Multiple hypothesis testing, high dimensional inference, false discovery rate, arbitrary dependence structure, genome-wide association studies
1 Introduction
Multiple hypothesis testing is a fundamental problem in the modern research for high dimensional inference, with wide applications in scientific fields, such as biology, medicine, genetics, neuroscience, economics and finance. For example, in genome-wide association studies, massive amount of genomic data (e.g. SNPs, eQTLs) are collected and tens of thousands of hypotheses are tested simultaneously to find if any of these genomic data are associated with some observable traits (e.g. blood pressure, weight, some disease); in finance, thousands of tests are performed to see which fund managers have winning ability (Barras, Scaillet & Wermers 2010).
False Discovery Rate (FDR) has been introduced in the celebrated paper by Benjamini & Hochberg (1995) for large scale multiple testing. By definition, FDR is the expected proportion of falsely rejected null hypotheses among all of the rejected null hypotheses. The classification of tested hypotheses can be summarized in Table 1:
Table 1.
Classification of tested hypotheses
| Number of | Number not rejected | Number rejected | Total |
|---|---|---|---|
| True Null | U | V | p0 |
| False Null | T | S | p1 |
|
| |||
| p – R | R | p | |
Various testing procedures have been developed for controlling FDR, among which there are two major approaches. One is to compare the P-values with a data-driven threshold as in Benjamini & Hochberg (1995). Specifically, let p(1) ≤ p(2) ≤ · · · ≤ p(p) be the ordered observed P-values of p hypotheses. Define k = max {i: p(i) ≤ iα/p} and reject , where α is a specified control rate. If no such i exists, reject no hypothesis. The other related approach is to fix a threshold value t, estimate the FDR, and choose t so that the estimated FDR is no larger than α (Storey 2002). Finding such a common threshold is based on a conservative estimate of FDR. Specifically, let , where R(t) is the number of total discoveries with the threshold t and p̂0 is an estimate of p0. Then solve t such that . The equivalence between the two methods has been theoretically studied by Storey, Taylor & Siegmund (2004) and Ferreira & Zwinderman (2006).
Both procedures have been shown to control the FDR for independent test statistics. However, in practice, test statistics are usually correlated. Although Benjamini & Yekutieli (2001) and Clarke & Hall (2009) argued that when the null distribution of test statistics satisfies some conditions, dependence case in the multiple testing is asymptotically the same as independence case, multiple testing under general dependence structures is still a very challenging and important open problem. Efron (2007) pioneered the work in the field and noted that correlation must be accounted for in deciding which null hypotheses are significant because the accuracy of false discovery rate techniques will be compromised in high correlation situations. There are several papers that show the Benjamini-Hochberg procedure or Storey’s procedure can control FDR under some special dependence structures, e.g. Positive Regression Dependence on Subsets (Benjamini & Yekutieli 2001) and weak dependence (Storey, Taylor & Siegmund 2004). Sarkar (2002) also shows that FDR can be controlled by a generalized stepwise multiple testing procedure under positive regression dependence on subsets. However, even if the procedures are valid under these special dependence structures, they will still suffer from efficiency loss without considering the actual dependence information. In other words, there are universal upper bounds for a given class of covariance matrices.
In the current paper, we will develop a procedure for high dimensional multiple testing which can deal with any arbitrary dependence structure and fully incorporate the covariance information. This is in contrast with previous literatures which consider multiple testing under special dependence structures, e.g. Sun & Cai (2009) developed a multiple testing procedure where parameters underlying test statistics follow a hidden Markov model, and Leek & Storey (2008) and Friguet, Kloareg & Causeur (2009) studied multiple testing under the factor models. More specifically, consider the test statistics
where Σ is known and p is large. We would like to simultaneously test H0i: μi = 0 vs H1i: μi ≠ 0 for i = 1, · · ·, p. Note that Σ can be any non-negative definite matrix. Our procedure is called Principal Factor Approximation (PFA). The basic idea is to first take out the principal factors that derive the strong dependence among observed data Z1, · · ·, Zp and to account for such dependence in calculation of false discovery proportion (FDP). This is accomplished by the spectral decomposition of Σ and taking out the largest common factors so that the remaining dependence is weak. We then derive the asymptotic expression of the FDP, defined as V/R, that accounts for the strong dependence. The realized but unobserved principal factors that derive the strong dependence are then consistently estimated. The estimate of the realized FDP is obtained by substituting the consistent estimate of the unobserved principal factors.
We are especially interested in estimating FDP under the high dimensional sparse problem, that is, p is very large, but the number of μi ≠ 0 is very small. In section 2, we will explain the situation under which Σ is known. Sections 3 and 4 present the theoretical results and the proposed procedures. In section 5, the performance of our procedures is critically evaluated by various simulation studies. Section 6 is about the real data analysis. All the proofs are relegated to the Appendix and the Supplemental Material.
2 Motivation of the Study
In genome-wide association studies, consider p SNP genotype data for n individual samples, and further suppose that a response of interest (i.e. gene expression level or a measure of phenotype such as blood pressure or weight) is recorded for each sample. The SNP data are conventionally stored in an n × p matrix X = (xij), with rows corresponding to individual samples and columns corresponding to individual SNPs. The total number n of samples is in the order of hundreds, and the number p of SNPs is in the order of tens of thousands.
Let Xj and Y denote, respectively, the random variables that correspond to the jth SNP coding and the outcome. The biological question of the association between genotype and phenotype can be restated as a problem in multiple hypothesis testing, i.e., the simultaneous tests for each SNP j of the null hypothesis Hj of no association between the SNP Xj and Y. Let be the sample data of Xj, be the independent sample random variables of Y. Consider the marginal linear regression between and :
| (1) |
We wish to simultaneously test the hypotheses
| (2) |
to see which SNPs are correlated with the phenotype.
Recently statisticians have increasing interests in the high dimensional sparse problem: although the number of hypotheses to be tested is large, the number of false nulls (βj ≠ 0) is very small. For example, among 2000 SNPs, there are maybe only 10 SNPs which contribute to the variation in phenotypes or certain gene expression level. Our purpose is to find these 10 SNPs by multiple testing with some statistical accuracy.
Because of the sample correlations among , the least-squares estimators for in (1) are also correlated. The following result describes the joint distribution of . The proof is straightforward.
Proposition 1
Let β̂j be the least-squares estimator for βj in (1) based on n data points, rkl be the sample correlation between Xk and Xl and skk be the sample variance of Xk. Assume that the conditional distribution of Yi given is . Then, conditioning on , the joint distribution of is (β̂1, · · ·, β̂p)T ~ N((β1, · · ·, βp)T, Σ*), where the (k, l)th element in Σ* is .
For ease of notation, let Z1, · · ·, Zp be the standardized random variables of β̂1, · · ·, β̂p, that is,
| (3) |
In the above, we implicitly assume that σ is known and the above standardized random variables are z-test statistics. The estimate of residual variance σ2 will be discussed in Section 6 via refitted cross-validation (Fan, Guo & Hao, 2011). Then, conditioning on { },
| (4) |
where and Σ has the (k, l)th element as rkl. Simultaneously testing (2) based on (β̂1, · · ·, β̂p)T is thus equivalent to testing
| (5) |
based on (Z1, · · ·, Zp)T.
In (4), Σ is the population covariance matrix of (Z1, · · ·, Zp)T, and is known based on the sample data { }. The covariance matrix Σ can have arbitrary dependence structure. We would like to clarify that Σ is known and there is no estimation of the covariance matrix of X1, · · ·, Xp in this set up.
3 Estimating False Discovery Proportion
From now on assume that among all the p null hypotheses, p0 of them are true and p1 hypotheses (p1 = p − p0) are false, and p1 is supposed to be very small compared to p. For ease of presentation, we let p be the sole asymptotic parameter, and assume p0 → ∞ when p → ∞. For a fixed rejection threshold t, we will reject those P-values no greater than t and regard them as statistically significance. Because of its powerful applicability, this procedure has been widely adopted; see, e.g., Storey (2002), Efron (2007, 2010), among others. Our goal is to estimate the realized FDP for a given t in multiple testing problem (5) based on the observations (4) under arbitrary dependence structure of Σ. Our methods and results have direct implications on the situation in which Σ is unknown, the setting studied by Efron (2007, 2010) and Friguet et al (2009). In the latter case, Σ needs to be estimated with certain accuracy.
3.1 Approximation of FDP
Define the following empirical processes:
where t ∈ [0, 1]. Then, V (t), S(t) and R(t) are the number of false discoveries, the number of true discoveries, and the number of total discoveries, respectively. Obviously, R(t) = V (t) + S(t), and V (t), S(t) and R(t) are all random variables, depending on the test statistics (Z1, · · ·, Zp)T. Moreover, R(t) is observed in an experiment, but V (t) and S(t) are both unobserved.
By definition, FDP(t) = V (t)/R(t) and FDR(t) = E [ V (t)/R(t)]. One of interests is to control FDR(t) at a predetermined rate α, say 15%. There are also substantial research interests in the statistical behavior of the number of false discoveries V (t) and the false discovery proportion FDP(t), which are unknown but realized given an experiment. One may even argue that controlling FDP is more relevant, since it is directly related to the current experiment.
We now approximate V (t)/R(t) for the high dimensional sparse case p1 ≪ p. Suppose (Z1, · · ·, Zp)T ~ N((μ1, · · ·, μp)T, Σ) in which Σ is a correlation matrix. We need the following definition for weakly dependent normal random variables; other definitions can be found in Farcomeni (2007).
Definition 1
Suppose (K1, · · ·, Kp)T ~ N((θ1, · · ·, θp)T, A). Then K1, · · ·, Kp are called weakly dependent normal variables if
| (6) |
where aij denote the (i, j)th element of the covariance matrix A.
Our procedure is called principal factor approximation (PFA). The basic idea is to decompose any dependent normal random vector as a factor model with weakly dependent normal random errors. The details are shown as follows. Firstly apply the spectral decomposition to the covariance matrix Σ. Suppose the eigenvalues of Σ are λ1, · · ·, λp, which have been arranged in decreasing order. If the corresponding orthonormal eigenvectors are denoted as γ1, · · ·, γp, then
| (7) |
If we further denote for an integer k, then
| (8) |
where ||·||F is the Frobenius norm. Let , which is a p × k matrix. Then the covariance matrix Σ can be expressed as
| (9) |
and Z1, · · ·, Zp can be written as
| (10) |
where bi = (bi1, · · ·, bik)T, , the factors are W = (W1, · · ·, Wk)T ~ Nk(0, Ik) and the random errors are (K1, · · ·, Kp)T ~ N(0, A). Furthermore, W1, · · ·, Wk are independent of each other and independent of K1, · · ·, Kp. The joint distribution of (Z1, …, Zp) in (10) is the same as that in (4) and the FDP is only a function of Z1, · · ·, Zp. Thus, we can assume (10) is the data generation process. In expression (10), {μi = 0} correspond to the true null hypotheses, while {μi ≠ 0} correspond to the false ones. Note that although (10) is not exactly a classical multifactor model because of the existence of dependence among K1, · · ·, Kp, we can nevertheless show that (K1, · · ·, Kp)T is a weakly dependent vector if the number of factors k is appropriately chosen.
We now discuss how to choose k such that (K1, · · ·, Kp)T is weakly dependent. Denote by aij the (i, j)th element in the covariance matrix A. If we have
| (11) |
then by the Cauchy-Schwartz inequality
Note that , so that (11) is self-normalized. Note also that the left hand side of (11) is bounded by p−1/2λk+1 which tends to zero whenever λk+1 = o(p1/2). In particular, if λ1 = o(p1/2), the matrix Σ is weak dependent and k = 0. In practice, we always choose the smallest k such that
holds for a predetermined small ε, say, 0.01. When such a minimum k0 > 0, λk0 ≥ εp1/2. In other words, the remaining eigenvalues (if any) are large.
Theorem 1
Suppose (Z1, · · ·, Zp)T ~ N((μ1, · · ·, μp)T, Σ). Choose an appropriate k such that
Let for j = 1, · · ·, k. Then,
| (12) |
where with bi = (bi1, · · ·, bik)T and W ~ Nk(0, Ik) in (10), and Φ(·) and zt/2 = Φ−1(t/2) are the cumulative distribution function and the t/2 lower quantile of a standard normal distribution, respectively.
Note that condition (C0) implies that K1, · · ·, Kp are weakly dependent random variables, but (11) converges to zero at some polynomial rate of p.
Theorem 1 gives an asymptotic approximation for FDP(t) under general dependence structure. To the best of our knowledge, it is the first result to explicitly spell out the impact of dependence. It is also closely connected with the existing results for independence case and weak dependence case. Let bih = 0 for i = 1, · · ·, p and h = 1, · · ·, k in (10) and K1, · · ·, Kp be weakly dependent or independent normal random variables, then it reduces to the weak dependence case or independence case, respectively. In the above two specific cases, the numerator of (12) is just p0t. Storey (2002) used an estimate for p0, resulting an estimator of FDP(t) as p̂0t/R(t). This estimator has been shown to control the false discovery rate under independency and weak dependency. However, for general dependency, Storey’s procedure will not work well because it ignores the correlation effect among the test statistics, as shown by (12). Further discussions for the relationship between our result and the other leading research for multiple testing under dependence are shown in Section 3.4.
The results in Theorem 1 can be better understood by some special dependence structures as follows. These specific cases are also considered by Roquain & Villers (2010), Finner, Dickhaus & Roters (2007) and Friguet, Kloareg & Causeur (2009) under somewhat different settings.
Example 1: [Equal Correlation]
If Σ has ρij = ρ ∈ [0, 1) for i ≠ j, then we can write
where W ~ N(0, 1), Ki ~ N (0, 1), and W and all Ki’s are independent of each other. Thus, we have
where d = (1 − ρ) −1/2.
Note that Delattre & Roquain (2011) studied the FDP in a particular case of equal correlation. They provided a slightly different decomposition of in the proof of Lemma 3.3 where the errors Ki’s have a sum equal to 0. Finner, Dickhaus & Roters (2007) in their Theorem 2.1 also shows a result similar to Theorem 1 for equal correlation case.
Example 2: [Multifactor Model]
Consider a multifactor model:
| (13) |
where ηi and ai are defined in Theorem 1 and Ki ~ N (0, 1) for i = 1, · · ·, p. All the Wh’s and Ki’s are independent of each other. In this model, W1, · · ·, Wk are the k common factors. By Theorem 1, expression (12) holds.
Note that the covariance matrix for model (13) is
| (14) |
When {aj} is not a constant, columns of L are not necessarily eigenvectors of Σ. In other words, when the principal component analysis is used, the decomposition of (9) can yield a different L and condition (11) can require a different value of k. In this sense, there is a subtle difference between our approach and that in Friguet, Kloareg & Causeur (2009) when the principal component analysis is used. Theorem 1 should be understood as a result for any decomposition (9) that satisfies condition (C0). Because we use principal components as approximated factors, our procedure is called principal factor approximation. In practice, if one knows that the test statistics comes from a factor model structure (13), multiple testing procedure based on the factor analysis (14) is preferable, since formula (12) becomes exact. In this case, the matrices L from the principal analysis (9) and from the factor analysis (14) are approximately the same when p is large, under some mild conditions. On the other hand, when such factor structure is not granted, the principal component analysis is more advantageous, due in part, to computational expediency and theoretical support (Theorem 1).
In Theorem 1, since FDP is bounded by 1, taking expectation on both sides of the equation (12) and by the Portmanteau lemma, we have the convergence of FDR:
Corollary 1
Under the assumptions in Theorem 1,
| (15) |
The expectation on the right hand side of (15) is with respect to standard multivariate normal variables (W1, · · ·, Wk)T ~ Nk(0, Ik).
The proof of Theorem 1 is based on the following result.
Proposition 2
Under the assumptions in Theorem 1,
| (16) |
| (17) |
The proofs of Theorem 1 and Proposition 2 are shown in the Appendix.
3.2 Estimating Realized FDP
In Theorem 1 and Proposition 2, the summation over the set of true null hypotheses is unknown. However, due to the high dimensionality and sparsity, both p and p0 are large and p1 is relatively small. Therefore, we can use
| (18) |
as a conservative surrogate for
| (19) |
Since only p1 extra terms are included in (18), the substitution is accurate enough for many applications.
Recall that FDP(t) = V (t)/R(t), in which R(t) is observable and known. Thus, only the realization of V (t) is unknown. The mean of V (t) is E[Σi∈{true null}I(Pi ≤ t)] = p0t, since the P-values corresponding to the true null hypotheses are uniformly distributed. However, the dependence structure affect the variance of V (t), which can be much larger than the binomial formula p0t(1 − t). Owen (2005) has theoretically studied the variance of the number of false discoveries. In our framework, expression (18) is a function of i.i.d. standard normal variables. Given t, the variance of (18) can be obtained by simulations and hence variance of V (t) is approximated via (18). Relevant simulation studies will be presented in Section 5.
In recent years, there have been substantial interests in the realized random variable FDP itself in a given experiment, instead of controlling FDR, as we are usually concerned about the number of false discoveries given the observed sample of test statistics, rather than an average of FDP for hypothetical replications of the experiment. See Genovese & Wasserman (2004), Meinshausen (2005), Efron (2007), Friguet et al (2009), etc. In our problem, by Proposition 2 it is known that V (t) is approximately
| (20) |
Let
if R(t) ≠ 0 and FDPA(t) = 0 when R(t) = 0. Given observations z1, · · ·, zp of the test statistics Z1, · · ·, Zp, if the unobserved but realized factors W1, · · ·, Wk can be estimated by Ŵ1, · · ·, Ŵk, then we can obtain an estimator of FDPA(t) by
| (21) |
when R(t) ≠ 0 and when R(t) = 0. Note that in (21), is an estimator for .
The following procedure is one practical way to estimate W = (W1, · · ·, Wk)T based on the data. For observed values z1, · · ·, zp, we choose the smallest 90% of |zi|’s, say. For ease of notation, assume the first m zi’s have the smallest absolute values. Then approximately
| (22) |
The approximation from (10) to (22) stems from the intuition that large |μi|’s tend to produce large |zi|’s as Zi ~ N (μi, 1) 1 ≤ i ≤ p and the sparsity makes approximation errors negligible. Finally we apply the robust L1-regression to the equation set (22) and obtain the least-absolute deviation estimates Ŵ1, · · ·, Ŵk. We use L1-regression rather than L2-regression because there might be nonzero μi involved in (22) and L1 is more robust to the outliers than L2. Other possible methods include using penalized method such as LASSO or SCAD to explore the sparsity. For example, one can minimize
with respect to and W, where pλ(·) is a folded-concave penalty function (Fan and Li, 2001).
The estimator (21) performs significantly better than Efron (2007)’s estimator in our simulation studies. One difference is that in our setting Σ is known. The other is that we give a better approximation as shown in Section 3.4.
Efron (2007) proposed the concept of conditional FDR. Consider E(V (t))/R(t) as one type of FDR definitions (see Efron (2007) expression (46)). The numerator E(V (t)) is over replications of the experiment, and equals a constant p0t. But if the actual correlation structure in a given experiment is taken into consideration, then Efron (2007) defines the conditional FDR as E(V (t)|A)/R(t) where A is a random variable which measures the dependency information of the test statistics. Estimating the realized value of A in a given experiment by Â, one can have the estimated conditional FDR as E(V (t)|Â)/R(t). Following Efron’s proposition, Friguet et al (2009) gave the estimated conditional FDR by E(V (t)|Ŵ)/R(t) where Ŵ is an estimate of the realized random factors W in a given experiment.
Our estimator in (21) for the realized FDP in a given experiment can be understood as an estimate of conditional FDR. Note that (19) is actually . By Proposition 2, we can approximate V (t) by . Thus the estimate of conditional FDR is directly an estimate of the realized FDP V (t)/R(t) in a given experiment.
3.3 Asymptotic Justification
Let w = (w1, · · ·, wk)T be the realized values of , and ŵ be an estimator for w. We now show in Theorem 2 that in (21) based on a consistent estimator ŵ has the same convergence rate as ŵ under some mild conditions.
Theorem 2
If the following conditions are satisfied:
-
(C1)
R(t)/p > H for H > 0 as p → ∞,
-
(C2)
,
-
(C3)
||ŵ − w||2 = Op(p−r) for some r > 0,
then .
In Theorem 2, (C2) is a reasonable condition because zt/2 is a large negative number when threshold t is small and is a realization from a normal distribution with . Thus or is unlikely close to zero.
Theorem 3 shows the asymptotic consistency of L1–regression estimators under model (22). Portnoy (1984b) has proven the asymptotic consistency for robust regression estimation when the random errors are i.i.d. However, his proof does not work here because of the weak dependence of random errors. Our result allows k to grow with m, even at a faster rate of o(m1/4) imposed by Portnoy (1984b).
Theorem 3
Suppose (22) is a correct model. Let ŵ be the L1–regression estimator:
| (23) |
where bi = (bi1, · · ·, bik)T. Let w = (w1, · · ·, wk)T be the realized values of . Suppose k = O(mκ) for 0 ≤ κ < 1 − δ. Under the assumptions
-
(C4)
for η = O(m2κ),
-
(C5)
for a constant d > 0.
-
(C6)
amax/amin ≤ S for some constant S when m → ∞ where 1/ai is the standard deviation of Ki,
-
(C7)
amin = O(m(1−κ)/2).
We have .
(C4) is stronger than (C0) in Theorem 1 as (C0) only requires . (C5) ensures the identifiability of β, which is similar to Proposition 3.3 in Portnoy (1984a). (C6) and (C7) are imposed to facilitate the technical proof.
We now briefly discuss the role of the factor k. To make the approximation in Theorem 1 hold, we need k to be large. On the other hand, to make the realized factors estimable with reasonably accuracy, we hope to choose a small k as demonstrated in Theorem 3. Thus, the practical choice of k should be done with care.
Since m is chosen as a certain large proportion of p, combination of Theorem 2 and Theorem 3 thus shows the asymptotic consistency of based on L1–regression estimator of w = (w1, · · ·, wk)T in model (22):
The result in Theorem 3 are based on the assumption that (22) is a correct model. In the following, we will show that even if (22) is not a correct model, the effects of misspecification are negligible when p is sufficiently large. To facilitate the mathematical derivations, we instead consider the least-squares estimator. Suppose we are estimating W = (W1, · · ·, Wk)T from (10). Let X be the design matrix of model (10). Then the least-squares estimator for W is ŴLS = W + (XTX)−1XT(μ + K), where μ = (μ1, · · ·, μp)T and K = (K1, · · ·, Kp)T. Instead, we estimate W1, · · ·, Wk based on the simplified model (22), which ignores sparse {μi}. Then the least-squares estimator for W is , in which we utilize the orthogonality between X and var(K). The following result shows that the effect of misspecification in model (22) is negligible when p → ∞, and consistency of the least-squares estimator.
Theorem 4
The bias due to ignoring non-nulls is controlled by
In Theorem 1, we can choose appropriate k such that λk > cp1/2 as noted proceeding Theorem 1. Therefore, as p → ∞ is a reasonable condition. When are truly sparse, it is expected that ||μ||2 grows slowly or is even bounded so that the bound in Theorem 4 is small. For L1–regression, it is expected to be even more robust to the outliers in the sparse vector .
3.4 Dependence-Adjusted Procedure
A problem of the method used so far is that the ranking of statistical significance is completely determined by the ranking of the test statistics {|Zi|}. This is undesirable and can be inefficient for the dependent case: the correlation structure should also be taken into account. We now show how to use the correlation structure to improve the signal to noise ratio.
Note that by (10), where ai is defined in Theorem 1. Since , the signal to noise ratio increases, which makes the resulting procedure more powerful. Thus, if we know the true values of the common factors W = (W1, · · ·, Wk)T, we can use as the test statistics. The dependence-adjusted p-values can then be used. Note that this testing procedure has different thresholds for different hypotheses based on the magnitude of Zi, and has incorporated the correlation information among hypotheses. In practice, given Zi, the common factors are realized but unobservable. As shown in section 3.2, they can be estimated. The dependence adjusted p-values are then given by
| (24) |
for ranking the hypotheses where Ŵ = (Ŵ1, · · ·, Ŵk)T is an estimate of the principal factors. We will show in section 5 by simulation studies that this dependence-adjusted procedure is more powerful. The “factor adjusted multiple testing procedure” in Friguet et al (2009) shares a similar idea.
3.5 Relation with Other Methods
Efron (2007) proposed a novel parametric model for V (t):
| (25) |
where A ~ N(0, α2) for some real number α and φ(·) stands for the probability density function of the standard normal distribution. The correlation effect is explained by the dispersion variate A. His procedure is to estimate A from the data and use
| (26) |
as an estimator for realized FDP(t). Note that the above expressions are adaptations from his procedure for the one-sided test to our two-sided test setting. In his simulation, the above estimator captures the general trend of the FDP, but it is not accurate and deviates from the true FDP with large amount of variability. Consider our estimator in (21). Write η̂i = σiQi where Qi ~ N (0, 1). When σi → 0 for ∀i ∈ {true null}, by the second order Taylor expansion,
| (27) |
By comparison with Efron’s estimator, we can see that
| (28) |
Thus, our method reduces to Efron’s one when {η̂i} are small.
Leek & Storey (2008) considered a general framework for modeling the dependence in multiple testing. Their idea is to model the dependence via a factor model and reduces the multiple testing problem from dependence to independence case via accounting the effects of common factors. They also provided a method of estimating the common factors. In contrast, our problem is different from Leek & Storey’s and we estimate common factors from principal factor approximation and other methods. In addition, we provide the approximated FDP formula and its consistent estimate.
Friguet, Kloareg & Causeur (2009) followed closely the framework of Leek & Storey (2008). They assumed that the data come directly from a multifactor model with independent random errors, and then used the EM algorithm to estimate all the parameters in the model and obtained an estimator for FDP(t). In particular, they subtract ηi out of (13) based on their estimate from the EM algorithm to improve the efficiency. However, the ratio of estimated number of factors to the true number of factors in their studies varies according to the dependence structures by their EM algorithm, thus leading to inaccurate estimated FDP(t). Moreover, it is hard to derive theoretical results based on the estimator from their EM algorithm. Compared with their results, our procedure does not assume any specific dependence structure of the test statistics. What we do is to decompose the test statistics into an approximate factor model with weakly dependent errors, derive the factor loadings and estimate the unobserved but realized factors by L1-regression. Since the theoretical distribution of V (t) is known, estimator (21) performs well based on a good estimation for W1, · · ·, Wk.
4 Approximate Estimation of FDR
In this section we propose some ideas that can asymptotically control the FDR, not the FDP, under arbitrary dependency. Although their validity is yet to be established, promising results reveal in the simulation studies. Therefore, they are worth some discussion and serve as a direction of our future work.
Suppose that the number of false null hypotheses p1 is known. If the signal μi for i ∈ {false null} is strong enough such that
| (29) |
then asymptotically the FDR is approximately given by
| (30) |
which is the expectation of a function of W1, · · ·, Wk. Note that FDR(t) is a known function and can be computed by Monte Carlo simulation. For any predetermined error rate α, we can use the bisection method to solve t so that FDR(t) = α. Since k is not large, the Monte Carlo computation is sufficiently fast for most applications.
The requirement (29) is not very strong. First of all, Φ(3) ≈ 0.9987, so (29) will hold if any number inside the Φ(·) is greater than 3. Secondly, is usually very small. For example, if it is 0.01, then , which means that if either zt/2 + ηi + μi or zt/2 − ηi − μi exceed 0.3, then (29) is approximately satisfied. Since the effect of sample size n is involved in the problem in Section 2, (29) is not a very strong condition on the signal strength {βi}.
Note that Finner et al (2007) considered a “Dirac uniform model”, where the p-values corresponding to a false hypothesis are exactly equal to 0. This model might be potentially useful for FDR control. The calculation of (30) requires the knowledge of the proportion p1 of signal in the data. Since p1 is usually unknown in practice, there is also future research interest in estimating p1 under arbitrary dependency.
5 Simulation Studies
In the simulation studies, we consider p = 2000, n = 100, σ = 2, the number of false null hypotheses p1 = 10 and the nonzero βi = 1, unless stated otherwise. We will present 6 different dependence structures for Σ of the test statistics (Z1, · · ·, Zp)T ~ N((μ1, · · ·, μp)T, Σ). Following the setting in section 2, Σ is the correlation matrix of a random sample of size n of p–dimensional vector Xi = (Xi1, · · ·, Xip), and , j = 1, · · ·, p. The data generating process vector Xi’s are as follows.
[Equal correlation] Let XT = (X1, · · ·, Xp)T ~ Np(0, Σ) where Σ has diagonal element 1 and off-diagonal element 1/2.
-
[Fan & Song’s model] For X = (X1, · · ·, Xp), let be i.i.d. N(0, 1) and
where are standard normally distributed.
[Independent Cauchy] For X = (X1, · · ·, Xp), let be i.i.d. Cauchy random variables with location parameter 0 and scale parameter 1.
-
[Three factor model] For X = (X1, · · ·, Xp), let
where W(1) ~ N(−2, 1), W(2) ~ N(1, 1), W(3) ~ N(4, 1), are i.i.d. U(−1, 1), and Hj are i.i.d. N (0, 1).
-
[Two factor model] For X = (X1, · · ·, Xp), let
where W(1) and W(2) are i.i.d. N(0, 1), and are i.i.d. U(−1, 1), and Hj are i.i.d. N(0, 1).
-
[Nonlinear factor model] For X = (X1, · · ·, Xp), let
where W(1) and W(2) are i.i.d. N(0, 1), and are i.i.d. U(−1, 1), and Hj are i.i.d. N(0, 1).
Fan & Song’s Model has been considered in Fan & Song (2010) for high dimensional variable selection. This model is close to the independent case but has some special dependence structure. Note that although we have used the term “factor model” above to describe the dependence structure, it is not the factor model for the test statistics Z1, · · ·, Zp directly. The covariance matrix of these test statistics is the sample correlation matrix of X1, · · ·, Xp.
The effectiveness of our method is examined in several aspects. We first examine the goodness of approximation in Theorem 1 by comparing the marginal distributions and variances. We then compare the accuracy of FDP estimates with other methods. Finally, we demonstrate the improvement of the power with dependence adjustment.
Distributions of FDP and its approximation
Without loss of generality, we consider a dependence structure based on the two factor model above. Let n = 100, p1 = 10 and σ = 2. Let p vary from 100 to 1000 and t be either 0.01 or 0.005. The distributions of FDP(t) and its approximated expression in Theorem 1 are plotted in Figure 1. The convergence of the distributions are self-evidenced. Table 2 summarizes the total variation distance between the two distributions.
Figure 1.

Comparison for the distribution of the FDP with that of its approximated expression, based on the two factor model over 10000 simulations. From the top row to the bottom, p = 100, 500, 1000 respectively. The first two columns correspond to t = 0.01 and the last two correspond to t = 0.005.
Table 2.
Total variation distance between the distribution of FDP and the limiting distribution of FDP in Figure 1. The total variation distance is calculated based on “TotalVarDist” function with “smooth” option in R software.
| p = 100 | p = 500 | p = 1000 | |
|---|---|---|---|
| t = 0.01 | 0.6668 | 0.1455 | 0.0679 |
| t = 0.005 | 0.6906 | 0.2792 | 0.1862 |
Variance of V (t)
Variance of false discoveries in the correlated test statistics is usually large compared with that of the independent case which is p0t(1 − t), due to correlation structures. Thus the ratio of variance of false discoveries in the dependent case to that in the independent test statistics can be considered as a measure of correlation effect. See Owen (2005). Estimating the variance of false discoveries is an interesting problem. With approximation (17), this can easily be computed. In Table 3, we compare the true variance of the number of false discoveries, the variance of expression (19) (which is infeasible in practice) and the variance of expression (18) under 6 different dependence structures. It shows that the variance computed based on expression (18) approximately equals the variance of number of false discoveries. Therefore, we provide a fast and alternative method to estimate the variance of number of false discoveries in addition to the results in Owen (2005). Note that the variance for independent case is merely less than 2. The impact of dependence is very substantial.
Table 3.
Comparison for variance of number of false discoveries (column 2), variance of expression (19) (column 3) and variance of expression (18) (column 4) with t = 0.001 based on 10000 simulations.
| Dependence Structure | var(V (t)) | var(V ) | var(V.up) |
|---|---|---|---|
| Equal correlation | 180.9673 | 178.5939 | 180.6155 |
| Fan & Song’s model | 5.2487 | 5.2032 | 5.2461 |
| Independent Cauchy | 9.0846 | 8.8182 | 8.9316 |
| Three factor model | 81.1915 | 81.9373 | 83.0818 |
| Two factor model | 53.9515 | 53.6883 | 54.0297 |
| Nonlinear factor model | 48.3414 | 48.7013 | 49.1645 |
Comparing methods of estimating FDP
Under different dependence structures, we compare FDP values using our procedure PFA in equation (30) without taking expectation and with p1 known, Storey’s procedure with p1 known ((1 − p1)t/R(t)) and Benjamini-Hochberg procedure. Note that Benjamini-Hochberg procedure is a FDR control procedure rather than a FDP estimating procedure. The Benjamini-Hochberg FDP is obtained by using the mean of “True FDP” in Table 4 as the control rate in B-H procedure. Table 4 shows that our method performs much better than Storey’s procedure and Benjamini-Hochberg procedure, especially under strong dependence structures (rows 1, 4, 5, and 6), in terms of both mean and variance of the distribution of FDP. Recall that the expected value of FDP is the FDR. Table 3 also compares the FDR of three procedures by looking at the averages. Note that the actual FDR from B-H procedure under dependence is much smaller than the control rate, which suggests that B-H procedure can be quite conservative under dependence.
Table 4.
Comparison of FDP values for our method based on equation (30) without taking expectation (PFA) with Storey’s procedure and Benjamini-Hochberg’s procedure under six different dependence structures, where p = 2000, n = 200, t = 0.001, and βi = 1 for i ∈ {false null}. The computation is based on 10000 simulations. The means of FDP are listed with the standard deviations in the brackets.
| True FDP | PFA | Storey | B-H | |
|---|---|---|---|---|
| Equal correlation | 6.67% (15.87%) | 6.61% (15.88%) | 2.99% (10.53%) | 3.90% (14.58%) |
| Fan & Song’s model | 14.85% (11.76%) | 14.85% (11.58%) | 13.27% (11.21%) | 14.46% (13.46%) |
| Independent Cauchy | 13.85% (13.60%) | 13.62% (13.15%) | 11.48% (12.39%) | 13.21% (15.40%) |
| Three factor model | 8.08% (16.31%) | 8.29% (16.39%) | 4.00% (11.10%) | 5.46% (16.10%) |
| Two factor model | 8.62% (16.44%) | 8.50% (16.27%) | 4.70% (11.97%) | 5.87% (16.55%) |
| Nonlinear factor model | 6.63% (15.56%) | 6.81% (15.94%) | 3.20% (10.91%) | 4.19% (15.31%) |
Comparison with Efron’s Methods
We now compare the estimated values of our method PFA (21) and Efron (2007)’s estimator with true values of false discovery proportion, under 6 different dependence structures. Efron (2007)’s estimator is developed for estimating FDP under unknown Σ. In our simulation study, we have used a known Σ for Efron’s estimator for fair comparisons. The results are depicted in Figure 2, Figure 3 and Table 5. Figure 2 shows that our estimated values correctly track the trends of FDP with smaller amount of noise. It also shows that both our estimator and Efron’s estimator tend to overestimate the true FDP, since FDPA(t) is an upper bound of the true FDP(t). They are close only when the number of false nulls p1 is very small. In the current simulation setting, we choose p1 = 50 compared with p = 1000, therefore, it is not a very sparse case. However, even under this case, our estimator still performs very well for six different dependence structures. Efron (2007)’s estimator is illustrated in Figure 2 with his suggestions for estimating parameters, which captures the general trend of true FDP but with large amount of noise. Figure 3 shows that the relative errors of PFA concentrate around 0, which suggests good accuracy of our method in estimating FDP. Table 5 summarizes the relative errors of the two methods.
Figure 2.

Comparison of true values of False Discovery Proportion with estimated FDP by Efron (2007)’s procedure (grey crosses) and our PFA method (black dots) under six different dependence structures, with p = 1000, p1 = 50, n = 100, σ = 2, t = 0.005 and βi = 1 for i ∈ {false null} based on 1000 simulations. The Z-statistics with absolute value less than or equal to x0 = 1 are used to estimate the dispersion variate A in Efron (2007)’s estimator. The unconditional estimate of FDR(t) is p0t/R(t) shown as green triangles.
Figure 3.

Histograms of the relative error (RE) between true values of FDP and estimated FDP by our PFA method under the six dependence structures in Figure 2. RE is defined as if FDP(t) ≠ 0 and 0 otherwise.
Table 5.
Means and standard deviations of the relative error between true values of FDP and estimated FDP under the six dependence structures in Figure 2. REP and REE are the relative errors of our PFA estimator and Efron (2007)’s estimator, respectively. RE is defined in Figure 3.
| REP | REE | |||
|---|---|---|---|---|
|
| ||||
| mean | SD | mean | SD | |
| Equal correlation | 0.0241 | 0.1262 | 1.4841 | 3.6736 |
| Fan & Song’s model | 0.0689 | 0.1939 | 1.2521 | 1.9632 |
| Independent Cauchy | 0.0594 | 0.1736 | 1.3066 | 2.1864 |
| Three factor model | 0.0421 | 0.1657 | 1.4504 | 2.6937 |
| Two factor model | 0.0397 | 0.1323 | 1.1227 | 2.0912 |
| Nonlinear factor model | 0.0433 | 0.1648 | 1.3134 | 4.0254 |
Dependence-Adjusted Procedure
We compare the dependence-adjusted procedure described in section 3.4 with the testing procedure based only on the observed test statistics without using correlation information. The latter is to compare the original z-statistics with a fixed threshold value and is labeled as “fixed threshold procedure” in Table 6. With the same FDR level, a procedure with smaller false nondiscovery rate (FNR) is more powerful, where FNR = E[T/(p − R)] using the notation in Table 1.
Table 6.
Comparison of Dependence-Adjusted Procedure with Fixed Threshold Procedure under six different dependence structures, where p = 1000, n = 100, σ = 1, p1 = 200, nonzero βi simulated from U (0, 1) and k = n − 3 over 1000 simulations.
| Fixed Threshold Procedure | Dependence-Adjusted Procedure | |||||
|---|---|---|---|---|---|---|
|
| ||||||
| FDR | FNR | Threshold | FDR | FNR | Threshold | |
|
| ||||||
| Equal correlation | 17.06% | 4.82% | 0.06 | 17.34% | 0.35% | 0.001 |
| Fan & Song’s model | 6.69% | 6.32% | 0.0145 | 6.73% | 1.20% | 0.001 |
| Independent Cauchy | 7.12% | 0.45% | 0.019 | 7.12% | 0.13% | 0.001 |
| Three factor model | 5.46% | 3.97% | 0.014 | 5.53% | 0.31% | 0.001 |
| Two factor model | 5.00% | 4.60% | 0.012 | 5.05% | 0.39% | 0.001 |
| Nonlinear factor model | 6.42% | 3.73% | 0.019 | 6.38% | 0.68% | 0.001 |
In Table 6, without loss of generality, for each dependence structure we fix threshold value 0.001 and reject the hypotheses when the dependence-adjusted p-values (24) is smaller than 0.001. Then we find the corresponding threshold value for the fixed threshold procedure such that the FDR in the two testing procedures are approximately the same. The FNR for the dependence-adjusted procedure is much smaller than that of the fixed threshold procedure, which suggests that dependence-adjusted procedure is more powerful. Note that in Table 6, p1 = 200 compared with p = 1000, implying that the better performance of the dependence-adjusted procedure is not limited to sparse situation. This is expected since subtracting common factors out make the problem have a higher signal to noise ratio.
6 Real Data Analysis
Our proposed multiple testing procedures are now applied to the genome-wide association studies, in particular the expression quantitative trait locus (eQTL) mapping. It is known that the expression levels of gene CCT8 are highly related to Down Syndrome phenotypes. In our analysis, we use over two million SNP genotype data and CCT8 gene expression data for 210 individuals from three different populations, testing which SNPs are associated with the variation in CCT8 expression levels. The SNP data are from the International HapMap project, which include 45 Japanese in Tokyo, Japan (JPT), 45 Han Chinese in Beijing, China (CHB), 60 Utah residents with ancestry from northern and western Europe (CEU) and 60 Yoruba in Ibadan, Nigeria (YRI). The Japanese and Chinese population are further grouped together to form the Asian population (JPTCHB). To save space, we omit the description of the data pre-processing procedures. Interested readers can find more details from the websites: http://pngu.mgh.harvard.edu/purcell/plink/res.shtml and ftp://ftp.sanger.ac.uk/pub/genevar/, and the paper Bradic, Fan & Wang (2010).
We further introduce two sets of dummy variables (d1, d2) to recode the SNP data, where d1 = (d1,1, · · ·, d1,p) and d2 = (d2,1, · · ·, d2,p), representing three categories of polymorphisms, namely, (d1,j, d2,j) = (0, 0) for SNPj = 0 (no polymorphism), (d1,j, d2,j) = (1, 0) for SNPj = 1 (one nucleotide has polymorphism) and (d1,j, d2,j) = (0, 1) for SNPj = 2 (both nucleotides have polymorphisms). Let be the independent sample random variables of Y, and be the sample values of d1,j and d2,j respectively. Thus, instead of using model (1), we consider two marginal linear regression models between and :
| (31) |
and between and :
| (32) |
For ease of notation, we denote the recoded n × 2p dimensional design matrix as X. The missing SNP measurement are imputed as 0 and the redundant SNP data are excluded. Finally, the logarithm-transform of the raw CCT8 gene expression data are used. The details of our testing procedures are summarized as follows.
To begin with, consider the full model Y = α + Xβ + ε, where Y is the CCT8 gene expression data, X is the n × 2p dimensional design matrix of the SNP codings and εi ~ N (0, σ2), i = 1, · · ·, n are the independent random errors. We adopt the refitted cross-validation (RCV) (Fan, Guo & Hao 2010) technique to estimate σ by σ̂, where LASSO is used in the first (variable selection) stage.
Fit the marginal linear models (31) and (32) for each (recoded) SNP and obtain the least-squares estimate β̂j for j = 1, · · ·, 2p. Compute the values of Z-statistics using formula (3), except that σ is replaced by σ̂.
Calculate the P-values based on the Z-statistics and compute R(t) = #{Pj: Pj ≤ t} for a fixed threshold t.
Apply eigenvalue decomposition to the population covariance matrix Σ of the Z-statistics. By Proposition 1, Σ is the sample correlation matrix of (d1,1, d2,1, · · ·, d1,p, d2,p)T. Determine an appropriate number of factors k and derive the corresponding factor loading coefficients .
Order the absolute-valued Z-statistics and choose the first m = 95% × 2p of them. Apply L1-regression to the equation set (22) and obtain its solution Ŵ1, · · ·, Ŵk. Plug them into (21) and get the estimated FDP(t).
For each intermediate step of the above procedure, the outcomes are summarized in the following figures. Figure 4 illustrates the trend of the RCV-estimated standard deviation σ̂ with respect to different model sizes. Our result is similar to that in Fan, Guo & Hao (2010), in that although σ̂ is influenced by the selected model size, it is relatively stable and thus provides reasonable accuracy. The empirical distributions of the Z-values are presented in Figure 5, together with the fitted normal density curves. As pointed out in Efron (2007, 2010), due to the existence of dependency among the Z-values, their densities are either narrowed or widened and are not N(0, 1) distributed. The histograms of the P -values are further provided in Figure 6, giving a crude estimate of the proportion of the false nulls for each of the three populations. The main results of our analysis are presented in Figures 7, which depicts the number of total discoveries R(t), the estimated number of false discoveries V̂(t) and the estimated False Discovery Proportion as functions of (the minus log10-transformed) thresholding t for the three populations. As can be seen, in each case both R(t) and V̂(t) are decreasing when t decreases, but exhibits zigzag patterns and does not always decrease along with t, which results from the cluster effect of the P-values. A closer study of the outputs further shows that for all populations, the estimated FDP has a general trend of decreasing to the limit of around 0.1 to 0.2, which backs up the intuition that a large proportion of the smallest P-values should correspond to the false nulls (true discoveries) when Z-statistics is very large; however, in most other thresholding values, the estimated FDPs are at a high level. This is possibly due to small signal-to-noise ratios in eQTL studies.
Figure 4.
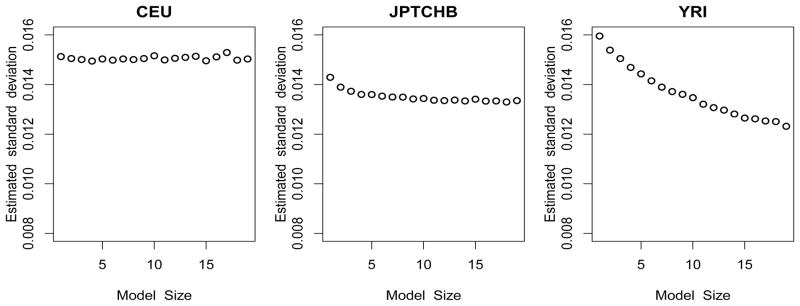
σ̂ of the three populations with respect to the selected model sizes, derived by using refitted cross-validation (RCV).
Figure 5.
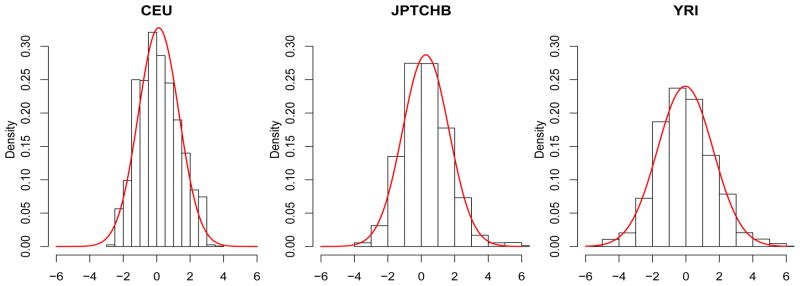
Empirical distributions and fitted normal density curves of the Z-values for each of the three populations. Because of dependency, the Z-values are no longer N(0, 1) distributed. The empirical distributions, instead, are N(0.12, 1.222) for CEU, N(0.27, 1.392) for JPT and CHB, and N(−0.04, 1.662) for YRI, respectively. The density curve for CEU is closest to N(0, 1) and the least dispersed among the three.
Figure 6.
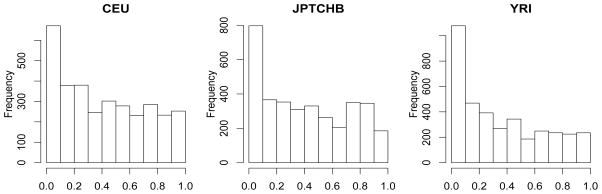
Histograms of the P -values for each of the three populations.
Figure 7.

Number of total discoveries, estimated number of false discoveries and estimated False Discovery Proportion as functions of thresholding t for CEU population (row 1), JPT and CHB (row 2) and YRI (row 3). The x-coordinate is −log t, the minus log10-transformed thresholding.
The results of the selected SNPs, together with the estimated FDPs, are depicted in Table 7. It is worth mentioning that Deutsch et al. (2005) and Bradic, Fan & Wang (2010) had also worked on the same CCT8 data to identify the significant SNPs in CEU population. Deutsch et al. (2005) performed association analysis for each SNP using ANOVA, while Bradic, Fan & Wang (2010) proposed the penalized composite quasi-likelihood variable selection method. Their findings were different as well, for the first group identified four SNPs (exactly the same as ours) which have the smallest P-values but the second group only discovered one SNP rs965951 among those four, arguing that the other three SNPs make little additional contributions conditioning on the presence of rs965951. Our results for CEU population coincide with that of the latter group, in the sense that the false discovery rate is high in our findings and our association study is marginal rather than joint modeling among several SNPs.
Table 7.
Information of the selected SNPs and the associated FDP for a particular threshold. Note that the density curve of the Z-values for CEU population is close to N(0, 1), so the approximate equals pt/R(t) ≈ 0.631. Therefore our high estimated FDP is reasonable.
| Population | Threshold | # Discoveries | Estimated FDP | Selected SNPs |
|---|---|---|---|---|
| JPTCHB | 1.61 × 10−9 | 5 | 0.1535 | rs965951 rs2070611 rs2832159 rs8133819 rs2832160 |
| YRI | 1.14 × 10−9 | 2 | 0.2215 | rs9985076 rs965951 |
| CEU | 6.38 × 10−4 | 4 | 0.8099 | rs965951 rs2832159 rs8133819 rs2832160 |
Table 8 lists the SNP selection based on the dependence-adjusted procedure. For JPTCHB, with slightly smaller estimated FDP, the dependence-adjusted procedure selects the same SNPs with the group selected by the fixed-threshold procedure, which suggests that these 5 SNPs are significantly associated with the variation in gene CCT8 expression levels. For YRI, rs965951 is selected by the both procedures, but the dependence-adjusted procedure selects other three SNPs which do not appear in Table 7. For CEU, the selections based on the two procedures are quite different. However, since the estimated FDP for CEU is much smaller in Table 8 and the signal-to-noise ratio of the test statistics is higher from the dependence-adjusted procedure, the selection group in Table 8 seems more reliable.
Table 8.
Information of the selected SNPs for a particular threshold based on the dependence-adjusted procedure. The number of factors k in (24) equals 10. The estimated FDP is based on estimator (21) by applying PFA to the adjusted Z-values.
| Population | Threshold | # Discoveries | Estimated FDP | Selected SNPs |
|---|---|---|---|---|
| JPTCHB | 2.89 × 10−4 | 5 | 0.1205 | rs965951 rs2070611 rs2832159 rs8133819 rs2832160 |
| YRI | 8.03 × 10−5 | 4 | 0.2080 | rs7283791 rs11910981 rs8128844 rs965951 |
| CEU | 5.16 × 10−2 | 6 | 0.2501 | rs464144* rs4817271 rs2832195 rs2831528* rs1571671* rs6516819* |
is the indicator for SNP equal to 2 and otherwise is the indicator for 1.
7 Discussion
We have proposed a new method (principal factor approximation) for high dimensional multiple testing where the test statistics have an arbitrary dependence structure. For multivariate normal test statistics with a known covariance matrix, we can express the test statistics as an approximate factor model with weakly dependent random errors, by applying spectral decomposition to the covariance matrix. We then obtain an explicit expression for the false discovery proportion in large scale simultaneous tests. This result has important applications in controlling FDP and FDR. We also provide a procedure to estimate the realized FDP, which, in our simulation studies, correctly tracks the trend of FDP with smaller amount of noise.
To take into account of the dependence structure in the test statistics, we propose a dependence-adjusted procedure with different threshold values for magnitude of Zi in different hypotheses. This procedure has been shown in simulation studies to be more powerful than the fixed threshold procedure. An interesting research question is how to take advantage of the dependence structure such that the testing procedure is more powerful or even optimal under arbitrary dependence structures.
While our procedure is based on a known correlation matrix, we would expect that it can be adapted to the case with estimated covariance matrix. The question is then how accuracy the covariance matrix should be so that a simple substitution procedure will give an accurate estimate of FDP.
We provide a simple method to estimate the realized principal factors. A more accurate method is probably the use of penalized least-squares method to explore the sparsity and to estimate the realized principle factor.
Supplementary Material
8 Appendix
Lemma 1 is fundamental to our proof of Theorem 1 and Proposition 2. The result is known in probability, but has the formal statement and proof in Lyons (1988).
Lemma 1 (Strong Law of Large Numbers for Weakly Correlated Variables)
Let be a sequence of real-valued random variables such that E|Xn|2 ≤ 1. If Xn| ≤ 1 a.s. and , then a.s..
Proof of Proposition 2
Note that Pi = 2Φ(−|Zi|). Based on the expression of (Z1, · · ·, Zp)T in (10), are dependent random variables. Nevertheless, we want to prove
| (33) |
Letting Xi = I(Pi ≤ t|W1, · · ·, Wk) − P (Pi ≤ t|W1, · · ·, Wk), by Lemma 1 the conclusion (33) is correct if we can show
To begin with, note that
Since , the first term in the right-hand side of the last equation is Op(p−1). For the second term, the covariance is given by
To simplify the notation, let be the correlation between Ki and Kj. Without loss of generality, we assume (for , the calculation is similar). Denote by
Then, from the joint normality, it can be shown that
| (34) |
Next we will use Taylor expansion to analyze the joint probability further. We have shown that (K1, · · ·, Kp)T ~ N(0, A) are weakly dependent random variables. Let denote the covariance of Ki and Kj, which is the (i, j)th element of the covariance matrix A. We also let . By the Hölder inequality,
as p → ∞. For each Φ(·), we apply Taylor expansion with respect to ,
where is the Lagrange residual term in the Taylor’s expansion, and in which f(z) is a polynomial function of z with the highest order as 6.
Therefore, we have (34) equals
where we have used the fact that and the finite moments of standard normal distribution are finite. Now since P(|Zi| < −Φ−1(t/2)|W1, · · ·, Wk) = Φ(c1,i) − Φ(c2,i), we have
In the last line, (φ(c1,i) − φ(c2,i))(φ(c1,j) − φ(c2,j))aiaj is bounded by some constant except on a countable collection of measure zero sets. Let Ci be defined as the set {zt/2 + ηi + μi = 0} ∪ {zt/2 − ηi − μi = 0}. On the set ,(φ{c1,i) − φ (c2,i))ai converges to zero as ai → ∞. Therefore, (φ(c1,i) − φ(c2,i))(φ(c1,j) − φ(c2,j))aiaj is bounded by some constant on .
By the Cauchy-Schwartz inequality and (C0) in Theorem 1, . Also we have . On the set , we conclude that
Hence by Lemma 1, for fixed (w1, · · ·, wk)T,
| (35) |
If we define the probability space on which (W1, · · ·, Wk) and (K1, · · ·, Kp) are constructed as in (10) to be (Ω,
 , ν), with
and ν the associated σ–algebra and (Lebesgue) measure, then in a more formal way, (35) is equivalent to
, ν), with
and ν the associated σ–algebra and (Lebesgue) measure, then in a more formal way, (35) is equivalent to
for each fixed (w1, · · ·, wk)T and almost every ω ∈ Ω, leading further to
for almost every ω ∈ Ω, which is the definition for
Therefore,
With the same argument we can show
for the high dimensional sparse case. The proof of Proposition 2 is now complete.
Proof of Theorem 1
For ease of notation, denote as R̃(t) and Σi∈{true null} [Φ(ai(zt/2 + ηi)) + Φ(ai(zt/2 − ηi))] as Ṽ(t), then
by the results in Proposition 2 and the fact that both and p−1R(t) are bounded random variables. The proof of Theorem 1 is complete.
Proof of Theorem 2
Letting
we have
Consider . By the mean value theorem, there exists ξi in the interval of ( ), such that where φ(·) is the standard normal density function.
Next we will show that φ(ai(zt/2 + ξi))ai is bounded by a constant. Without loss of generality, we discuss about the case in (C2) when . By (C3), we can choose sufficiently large p such that zt/2 + ξi < −τ/2. For the function g(a) = exp(−a2x2/8)a, g(a) is maximized when a = 2/x. Therefore,
For we have the same result. In both cases, we can use a constant D such that φ(ai(zt/2 + ξi))ai ≤ D.
By the Cauchy-Schwartz inequality, we have . Therefore, by the Cauchy-Schwartz inequality and the fact that , we have
By (C1) in Theorem 2, R(t)/p > H for H > 0 when p → ∞. Therefore, |Δ1/R(t)| = O(||ŵ − w||2). For Δ2, the result is the same. The proof of Theorem 2 is now complete.
Proof of Theorem 3
The proof is technical. To save space, it is relegated to the Supplemental Material.
Proof of Theorem 4
Note that . By the definition of X, we have XTX = Λ, where λ = diag(λ1, · · ·, λk). Therefore, by the Cauchy-Schwartz inequality,
The proof is complete.
Footnotes
The paper was completed while Xu Han was a postdoctoral fellow at Princeton University. This research was partly supported by NSF Grants DMS-0704337 and DMS-0714554 and NIH Grants R01-GM072611 and R01GM100474. The authors are grateful to the editor, associate editor and referees for helpful comments.
Proof of Theorem 3. (pdf)
Contributor Information
Jianqing Fan, Email: jqfan@princeton.edu, Department of Operations Research & Financial Engineering, Princeton University, Princeton, NJ 08544, USA and honorary professor, School of Statistics and Management, Shanghai University of Finance and Economics, Shanghai, China.
Xu Han, Email: xhan@princeton.edu, Department of Statistics, University of Florida, Florida, FL 32606.
Weijie Gu, Email: wgu@princeton.edu, Department of Operations Research & Financial Engineering, Princeton University, Princeton, NJ 08544.
References
- Barras L, Scaillet O, Wermers R. False Discoveries in Mutual Fund Performance: Measuring Luck in Estimated Alphas. Journal of Finance. 2010;65:179–216. [Google Scholar]
- Benjamini Y, Hochberg Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. Journal of the Royal Statistical Society, Series B. 1995;57:289–300. [Google Scholar]
- Benjamini Y, Yekutieli D. The Control of the False Discovery Rate in Multiple Testing Under Dependency. The Annals of Statistics. 2001;29:1165–1188. [Google Scholar]
- Bradic J, Fan J, Wang W. Penalized Composite Quasi-Likelihood For Ultrahigh-Dimensional Variable Selection. Journal of the Royal Statistical Society, Series B. 2010;73(3):325–349. doi: 10.1111/j.1467-9868.2010.00764.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clarke S, Hall P. Robustness of Multiple Testing Procedures Against Dependence. The Annals of Statistics. 2009;37:332–358. [Google Scholar]
- Delattre S, Roquain E. On the False Discovery Proportion Convergence under Gaussian Equi-Correlation. Statistics and Probability Letters. 2011;81:111–115. [Google Scholar]
- Deutsch S, Lyle R, Dermitzakis ET, Attar H, Subrahmanyan L, Gehrig C, Parand L, Gagnebin M, Rougemont J, Jongeneel CV, Antonarakis SE. Gene expression variation and expression quantitative trait mapping of human chromosome 21 genes. Human Molecular Genetics. 2005;14:3741–3749. doi: 10.1093/hmg/ddi404. [DOI] [PubMed] [Google Scholar]
- Efron B. Correlation and Large-Scale Simultaneous Significance Testing. Journal of the American Statistical Association. 2007;102:93–103. [Google Scholar]
- Efron B. Correlated Z-Values and the Accuracy of Large-Scale Statistical Estimates. Journal of the American Statistical Association. 2010;105:1042–1055. doi: 10.1198/jasa.2010.tm09129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Guo S, Hao N. Variance Estimation Using Refitted Cross-Validation in Ultrahigh Dimensional Regression. Journal of the Royal Statistical Society: Series B. 2010 doi: 10.1111/j.1467-9868.2011.01005.x. to appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Fan J, Song R. Sure Independence Screening in Generalized Linear Models with NP-Dimensionality. Annals of Statistics. 2010;38:3567–3604. [Google Scholar]
- Ferreira J, Zwinderman A. On the Benjamini-Hochberg Method. Annals of Statistics. 2006;34:1827–1849. [Google Scholar]
- Farcomeni A. Some Results on the Control of the False Discovery Rate Under Dependence. Scandinavian Journal of Statistics. 2007;34:275–297. [Google Scholar]
- Friguet C, Kloareg M, Causeur D. A Factor Model Approach to Multiple Testing Under Dependence. Journal of the American Statistical Association. 2009;104:1406–1415. [Google Scholar]
- Finner H, Dickhaus T, Roters M. Dependency and False Discovery Rate: Asymptotics. Annals of Statistis. 2007;35:1432–1455. [Google Scholar]
- Genovese C, Wasserman L. A Stochastic Process Approach to False Discovery Control. Annals of Statistics. 2004;32:1035–1061. [Google Scholar]
- Leek JT, Storey JD. A General Framework for Multiple Testing Dependence. PNAS. 2008;105:18718–18723. doi: 10.1073/pnas.0808709105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lyons R. Strong Laws of Large Numbers for Weakly Correlated Random Variables. The Michigan Mathematical Journal. 1988;35:353–359. [Google Scholar]
- Meinshausen N. False Discovery Control for Multiple Tests of Association under General Dependence. Scandinavian Journal of Statistics. 2006;33(2):227–237. [Google Scholar]
- Owen AB. Variance of the Number of False Discoveries. Journal of the Royal Statistical Society, Series B. 2005;67:411–426. [Google Scholar]
- Portnoy S. Robust and Nonlinear Time Series Analysis. Springer-Verlag; New York: 1984a. Tightness of the sequence of c.d.f. processes defined from regression fractiles; pp. 231–246. [Google Scholar]
- Portnoy S. Asymptotic behavior of M-estimators of p regression parameters when p2/n is large; I. Consistency. Annals of Statistics. 1984b;12:1298–1309. [Google Scholar]
- Roquain E, Villers F. Exact Calculations For False Discovery Proportion With Application To Least Favorable Configurations. Annals of Statistics. 2011;39:584–612. [Google Scholar]
- Sarkar S. Some Results on False Discovery Rate in Stepwise Multiple Testing Procedures. Annals of Statistics. 2002;30:239–257. [Google Scholar]
- Storey JD. A Direct Approach to False Discovery Rates. Journal of the Royal Statistical Society, Series B. 2002;64:479–498. [Google Scholar]
- Storey JD, Taylor JE, Siegmund D. Strong Control, Conservative Point Estimation and Simultaneous Conservative Consistency of False Discovery Rates: A Unified Approach. Journal of the Royal Statistical Society, Series B. 2004;66:187–205. [Google Scholar]
- Sun W, Cai T. Large-scale multiple testing under dependency. Journal of the Royal Statistical Society, Series B. 2009;71:393–424. doi: 10.1111/rssb.12064. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.