

Abstract
Multiple imputation is a popular way to handle missing data. Automated procedures are widely available in standard software. However, such automated procedures may hide many assumptions and possible difficulties from the view of the data analyst. Imputation procedures such as monotone imputation and imputation by chained equations often involve the fitting of a regression model for a categorical outcome. If perfect prediction occurs in such a model, then automated procedures may give severely biased results. This is a problem in some standard software, but it may be avoided by bootstrap methods, penalised regression methods, or a new augmentation procedure.
Keywords: Missing data, Multiple imputation, Perfect prediction, Separation
1. Introduction
Multiple imputation (MI) is a popular way to handle missing data under the missing at random assumption (MAR) (Little and Rubin, 2002). Briefly, the missing data are stochastically imputed times. In the commonest approach, the completed data sets are then analysed using methods appropriate for complete data, and the results are combined using Rubin’s rules (Rubin, 1987a).
The main difficulty in MI lies in designing a suitable method to perform the imputations. In particular, Rubin’s rules will only give valid standard errors if the imputations adequately reflect the uncertainty in the data (i.e. they are “proper” (Rubin, 1987a)). Three main methods are available in standard software: a multivariate normal procedure and two procedures based on univariate regressions.
First, a multivariate normal distribution may be assumed for the data, and a Monte Carlo Markov Chain (MCMC) procedure may be used to draw samples of the missing data from their posterior distribution given the observed data. This is implemented in SAS (SAS Institute Inc., 2004) and Stata (StataCorp, 2009), as user-written software in S-PLUS (Schafer, 2008), and in stand-alone software (Schafer, 2008). It is also advocated for data including categorical variables (Schafer, 1997), but a normal distribution for such variables is unlikely to perform well in general (Bernaards et al., 2007).
Second, if the missing data have a monotone pattern, then it is possible to impute the variables in increasing order of amount of missing data, using appropriate generalised linear models of each variable on the previous variables. This method avoids the normality assumption in the first approach and has been implemented in SAS (SAS Institute Inc., 2004) and Stata (StataCorp, 2009).
A third option is multiple imputation by chained equations (MICE) (van Buuren et al., 1999), also known as fully conditional specification (van Buuren, 2007) and sequential regression multivariate imputation (Raghunathan et al., 2001). This starts by filling in missing values in any convenient way and then imputes each variable in turn, using a regression of the observed values of that variable on the observed and currently imputed values of all other variables. As with the monotone method, appropriate generalised linear models (GLMs) are used. This method has been implemented as user-written software in Stata (Royston, 2004, 2005, 2007, 2009), S-PLUS or R (van Buuren and Oudshoorn, 2000) and SAS (Raghunathan et al., 2001, 2007).
In order for imputations to be proper, the imputation procedure must account for uncertainty in the parameters of the imputation model. This is achieved automatically in the MCMC procedure, but the regression-based approaches require a two-step procedure: (1) draw the regression parameters from their posterior distribution, and (2) draw the imputed values from the regression model using the sampled regression parameters. The first step is computationally straightforward in linear regression. With other GLMs, the posterior is commonly approximated by a multivariate normal distribution, from which it is easy to draw parameters: we call this the “Normal-approximation draw” method. This technique will clearly run into difficulties if the Normal approximation is poor.
This paper focuses on a situation where the Normal approximation is very poor: when imputing a discrete variable for which “perfect prediction” (or “separation” (Heinze and Schemper, 2002)) occurs. For example, in logistic regression, perfect prediction occurs if there is a level of a categorical explanatory variable for which the observed values of the outcome are all one (or all zero). In this case, the likelihood increases to a limit as one or more model coefficients go to plus or minus infinity.
The paper explores the implications of perfect prediction for MI using monotone or MICE imputation with the “Normal-approximation draw” method, and proposes several solutions. Section 2 introduces a trial in dental pain with a repeated binary outcome, in which different software packages, apparently implementing the same algorithm, give very different results. Section 3 describes proper imputation and perfect prediction. Section 4 shows possible pitfalls with the aid of a simple artificial data set. Section 5 proposes a way round the problem that may be included in an automated procedure. Section 6 returns to the analysis of the dental pain trial. Section 7 reports a simulation study, and Section 8 discusses broader issues.
2. Dental pain data
Our example comes from a clinical trial exploring the treatment of moderate or severe pain in patients who have had their third molar extracted. These data were also analysed by Carpenter and Kenward (2008). 366 patients were randomly assigned to one of seven treatment groups: an active drug A at 5 different doses, a control drug C, or placebo. The outcome to be analysed is a binary measure of pain relief, 1 indicating some or complete relief from pain and 0 indicating no relief, measured 0.25, 0.5, 0.75, 1, 1.5, 2, 3, 4, 5 and 6 h after tooth extraction.
We define as the outcome at the th occasion for the th individual randomised to treatment , where and for the 5 doses of drug A, for drug C and for placebo. The aim of the present analysis is to compare the prevalence of pain relief at the final time-point across the 7 treatments, so we are interested in contrasts of the in the simple analysis model
| (1) |
Although it would be more usual to have a model with an intercept and 6 contrasts, having one parameter per arm makes it easier to explore the impact of perfect prediction.
Unfortunately, only 216 patients had observed, because 87, 34, 10, 8 and 11 patients were lost to follow-up after the 5th, 6th, 7th, 8th and 9th observations respectively. Loss to follow-up was strongly associated with previous lack of pain relief, so the missing data are a likely source of bias in a complete cases (CC) analysis, which excludes individuals with missing . The missing data pattern was very nearly monotone; to simplify analysis, we made it completely monotone by replacing 5 intermittent missing values at the 4th, 5th and 6th observations with the previously observed values. We do not advocate such a procedure in general, but the handling of the intermittent missing values is unimportant in these data: alternative procedures, imputing the 5 intermittent missing values all as 0 or all as 1, produced results differing by less than 1% of a standard error from those shown.
Constructing an imputation model for these data is problematic because outcomes change very little over time: over 40% of patients were never observed to change their outcome, and only 10% changed their response more than once during follow-up. We therefore follow Carpenter and Kenward (2008) and allow each outcome to depend on the previous outcome but not on earlier outcomes, with the associations between outcomes being allowed to vary over time and between treatment groups. This yields the imputation model
| (2) |
for and .
We analysed these data using monotone multiple imputation to impute the missing outcomes. Following Eq. (2), the imputation model for each outcome was a logistic regression on the previous outcome, treatment group and their interaction. We performed the imputation using SAS PROC MI and R. In R, the MICE software library (van Buuren and Oudshoorn, 2000) is not explicitly designed for monotone imputation, but was made to implement it by suitable specification of the imputation models and setting the number of cycles to 1. Programs are available as supplementary material in the electronic version of this paper. In anticipation of instability (due to the lack of variation in the outcomes and the high dropout rate), and in order to reduce Monte Carlo error, in each method we use a relatively large number of 100 imputations.
The results (Table 1) show that the point estimates (estimated log odds of outcome) and their standard errors vary substantially between the two MI methods, especially for . The observed differences are not attributable to Monte Carlo error in the MI procedure, because Monte Carlo standard errors were no more than 0.08; these were computed by a jackknife method using the mim command in Stata (Royston et al., 2009). Substantial differences are also seen between the MI and CC analyses. These are not expected to agree precisely, because they make different assumptions about the missing data mechanism, but it is a cause for concern that the standard errors for some of the parameters are substantially larger for the MI analyses than for the CC analysis. Further, the fractions of missing information, which measure the increase in variance of the parameter estimates due to the missing data (Schafer, 1997), are unreasonably large, reaching 0.95 for .
Table 1.
Dental pain trial: comparison of complete cases and 2 different MI procedures for the logistic regression of outcome on treatment group at the final timepoint. Figures are estimated log odds of pain relief (standard error) and fraction of missing information (FMI) in model (1).
| Parameter | MI with 100 imputations |
Complete cases | |||
|---|---|---|---|---|---|
| SAS/PROC MI |
R/MICE |
||||
| Estimate (s.e.) | FMI | Estimate (s.e.) | FMI | ||
| 0.37 (0.74) | 0.84 | 0.43 (0.71) | 0.83 | 0.83 (0.45) | |
| 1.21 (0.53) | 0.59 | 1.19 (0.78) | 0.80 | 1.72 (0.49) | |
| 1.04 (0.47) | 0.53 | 1.10 (0.58) | 0.67 | 1.46 (0.42) | |
| 2.04 (0.59) | 0.44 | 1.29 (1.02) | 0.85 | 2.71 (0.73) | |
| 2.32 (0.65) | 0.41 | 1.59 (0.70) | 0.69 | 2.48 (0.60) | |
| 1.00 (0.45) | 0.51 | 0.90 (0.35) | 0.23 | 1.30 (0.38) | |
| 1.52 (1.85) | 0.92 | 0.23 (1.65) | 0.95 | 1.39 (0.79) | |
The sparseness of the data implies that some parameter estimates in model (2) are infinite. The differences between procedures may therefore be a consequence of different ways of handling perfect prediction. We return to these data in Section 6 where we explore to what extent handling of perfect prediction can explain the differences.
3. Theory
3.1. Imputation model
We assume that the data for individual are where multivariate is complete but univariate is incomplete. We focus on the case where is discrete. Our aim is to impute the missing values of : this may either be the whole imputation task, part of a monotone imputation procedure, or part of a MICE algorithm. Assuming individuals are independent, the imputation model is . If is discrete then our model could be the saturated model . More commonly, includes discrete and continuous components, and modelling assumptions are required. We will consider the three models most commonly used in practice. When is binary, we consider the logistic model
| (3) |
where and are vectors. When is an ordered categorical variable with levels for , we consider the ordered logistic model
| (4) |
When is a nominal categorical variable, we consider the multinomial model
| (5) |
where .
3.2. Proper imputation
In order for Rubin’s rules to produce valid results, multiple imputation must allow for uncertainty in the parameters of the imputation model. We first consider three ways of doing this (Rubin and Schenker, 1986).
3.2.1. Explicitly Bayesian methods
Much of the literature concerns the problem of imputing a binary (or other discrete) incomplete variable within strata defined by one or more other discrete variables (Rubin and Schenker, 1986). In this case, a prior such as Beta(1,1) may be used for the stratum-specific probability of the incomplete variable. A draw from the posterior distribution of is easily obtained and directly leads to a set of proper imputations. This method is applicable to the dental pain trial but does not extend easily to a more general regression situation.
3.2.2. Bootstrap
Rubin and Schenker (1986) propose a method that they call the approximate Bayesian bootstrap (Rubin, 1981) to draw proper imputations in the discrete case. This may be generalised by drawing a bootstrap sample of the observed data and re-fitting the imputation model to the bootstrap sample, yielding a parameter and hence imputations drawn from (Royston, 2004, 2005).
3.2.3. Normal-approximation draw
This method is widely used in multiple imputation software. Let the maximum likelihood estimate from fitting the imputation model be with variance-covariance matrix . If the log-likelihood is approximately quadratic and the prior is weak, then the posterior is approximately . We therefore draw from this distribution and obtain imputations from . For linear regression, this method is exact, provided it is modified by first drawing the variance from its exact inverse-gamma posterior.
3.3. Perfect prediction
Perfect prediction may occur in any GLM with a categorical outcome. In this case, the likelihood tends to a limit as one or more regression parameters go to plus or minus infinity: loosely, these parameters have maximum likelihood estimate (MLE) equal to plus or minus infinity. It is arguable whether this is in itself a problem, since odds ratios of 0 or infinity should be no more surprising than estimated probabilities of zero or one. However, a problem definitely arises with standard errors computed from the information matrix: these are extremely large, reflecting the near-flat nature of the likelihood.
Software packages differ in their handling of perfect prediction in usual modelling situations. SAS PROC LOGISTIC, for example, prints a warning message but does not modify its estimation procedure, so that extremely large standard errors are reported. Stata’s logistic procedure (StataCorp, 2009), by contrast, attempts to detect perfect prediction before fitting the model. If perfect prediction is detected, the perfectly predicting covariate and the perfectly predicted observations are dropped from the analysis. If perfect prediction is not detected, the singular information matrix is taken to imply a non-identifiable model, and standard errors are computed via a generalised inverse approach.
4. Proper imputation in the presence of perfect prediction
We now show how the Normal-approximation draw method of Section 3.2.3 fails if perfect prediction arises. We use an artificial data set comprising a complete binary variable and an incomplete binary variable (Table 2). In this section we focus on imputing the missing values of when . The relevant observed data are 100 failures and no successes, so under the MAR assumption, we would assume that the missing values are all (or almost all) failures.
Table 2.
Artificial data used to illustrate the perfect prediction problem.
|
|
|||
|---|---|---|---|
| 0 | 1 | Missing | |
| 0 | 100 | 0 | 100 |
| 1 | 100 | 100 | 100 |
When we fit the logistic regression to the complete cases, there is no finite MLE (Fig. 1), reflecting perfect prediction. If no corrections are made, then the software will report a very large estimate of and an even larger standard error. If this standard error is taken at face value and the Normal-approximation draw method is applied, then will be drawn from a very wide and flat posterior distribution, in such a way that most draws will be either very large and positive or very large and negative. In our data, the 100 missing observations will thus typically be imputed either correctly as 100 failures, or incorrectly as 100 successes. This will downwardly bias the point estimate of and inflate its standard error by the large between-imputation variability. We call this method “Normal/allow”.
Fig. 1.

Profile log-likelihood for model fitted to the data in Table 2.
One alternative to “Normal/allow” arises if the software detects the large standard errors and adopts a generalised inverse approach. A large between-imputation variability is avoided, but the precise consequences depend on the generalised inverse method used. A second alternative arises if the software detects perfect prediction before model fitting and drops the perfectly predicting covariate and the perfectly predicted observations from the analysis. Then we are left with the simple model for which the MLE is clearly (i.e. ). It would be an error to apply this model to observations with .
5. Solutions
The perfect prediction problem can occur whenever a Normal-approximation draw method is used. The alternatives suggested in Section 3, the explicitly Bayesian method and the bootstrap, therefore avoid the perfect prediction problem. Here we propose two more solutions within the Normal-approximation draw method.
5.1. Penalised regression
Firth (1993) proposed a general penalised regression procedure which eliminates the first-order bias of the parameter estimates; more importantly for the present work, it also avoids infinite parameter estimates. For logistic regression, this procedure can be expressed as a modification of the iteratively reweighted least squares algorithm (McCullagh and Nelder, 1989). The th observation is augmented with one success and one failure, both carrying weight , where is the th diagonal element of the weighted hat matrix is the diagonal matrix of true variances which depends on the parameters , and is the design matrix. Penalised regression gives more appropriate standard errors and more symmetrical log-likelihoods than unpenalised regression (Bull et al., 2007) so that a Normal-approximation draw is more appropriate than for “Normal/allow”. We call this method “Normal/penalise”. Depending on the implementation, it can be markedly slower than unpenalised regression, and hence computationally unrealistic in the MICE context where the regression must be performed repeatedly. Also, implementation for the ordered logistic and multinomial regression models is harder (Bull et al., 2002).
5.2. Regression with augmented data
We propose an ad hoc but computationally convenient way to avoid the problems associated with perfect prediction: we augment the data with a few extra observations that avert perfect prediction. This is done for each predictor variable by adding observations at two design points differing only on that predictor. The added observations are assigned a small weight to limit their impact on the estimated imputation model. This augmentation method has been implemented in our Stata software, ice (Royston, 2004, 2005).
Our algorithm is as follows. We first compute the mean and SD of each predictor . We then add 2 records to the data, where is either or takes its first observed level; and other variables are fixed to their mean . We then repeat this procedure for each level of and for each predictor variable . If there are predictors and has levels then this adds a total of records to the data. The same method is used whether the predictor is quantitative or a dummy for a categorical variable; it is therefore not exactly invariant to the choice of reference category for categorical variables with more than 2 levels.
We now assign a small weight to each of these added observations. We propose so that the total added weight is , the total number of parameters in the imputation model. This agrees with the method of Firth (1993) which eliminates first-order bias in parameter estimates, with the method of Clogg et al. (1991), and with standard practice in the 2-by-2 table where 0.5 is added to all cells if any cell is zero (Cox and Snell, 1989; Sweeting et al., 2004). Again, a Normal-approximation draw is more appropriate than for “Normal/allow”. We call this method “Normal/augment”.
To support the above choice of , we performed a small comparison of assigning different weights to the added observations. We focus on a single group with successes and failures. The group in Table 2 has and , and we also explored the cases and . When the Normal approximation draw method is used with added to all cells, the mean number of imputed successes is where , and . This expectation was computed using Gauss–Hermite quadrature; a low value is desirable. Fig. 2 shows that the mean number of imputed successes is near 1 if , with only weak dependence on , but it increases as moves away from . By comparison, the Bayesian approach with Beta(1,1) prior would impute a mean number of successes of or just under 1. Thus , which corresponds to , appears to be a good choice.
Fig. 2.

Mean number of imputed successes in data in Table 2 using “Normal/augment” method: comparison of different values added to all cells, for three different numbers of failures .
5.3. Method comparison
Fig. 3 shows the distribution of the number of imputed successes in each of 100 imputed data sets for the data in Table 2. Recall that imputed successes should be very few in the group and about half of the group.
Fig. 3.

Artificial data of Table 2: number of imputed successes in 100 individuals with (left panels) and in 100 individuals with (right panels), using various analysis methods and software packages.
The first three rows of Fig. 3 show methods that do not work satisfactorily. The Normal/allow method performs very badly in the group with perfect prediction (). Imputation with R/MICE appears to be using the Normal/allow method. The code used was
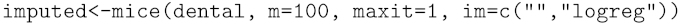
Surprisingly, imputation with SAS gives over-variable imputations in the group without perfect prediction (). These results presumably result from an unsuccessful attempt to correct the singular variance-covariance matrix. The SAS code was:

The next four rows of Fig. 3 show the methods proposed, which all perform satisfactorily. They differ slightly in that the bootstrap method imputes no successes in whereas the other methods impute a small number of successes in this group. We return to this point in the discussion. The Normal/augment method was implemented in Stata using
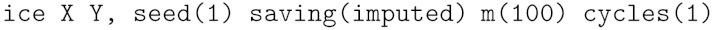
The last row of Fig. 3 shows results using IVEware in SAS (Raghunathan et al., 2001, 2007). This performed well for these data, but it appeared to achieve this by replacing very large standard errors with zero.
5.4. More than two levels
We also considered the case of an incomplete variable with 3 levels, by adding to Table 2 100 observations with and , and 100 observations with and . This leads to perfect prediction when is imputed using the multinomial model (5). The average fraction of the 100 observations with and missing that were imputed as 1 was 42% using Normal/allow, 0.7% using Normal/augment, and 0% using the bootstrap.
6. Revisiting the dental pain data
We now return to the dental pain data. Further exploration of the data shows that perfect prediction occurred at some point in every treatment group except group 6. This suggests that the results from SAS and R/MICE, seen in Table 1, are likely to be wrong. We compare those results with results using the explicitly Bayesian, penalised, bootstrap and augmentation methods (Fig. 4). The Bayesian method was done both with beta (0.5, 0.5) and beta (1, 1) priors. The augmentation method was implemented in Stata using code available as supplementary material in the electronic version of this paper.
Fig. 4.

Dental pain data: estimated log odds of pain relief at 10th occasion (with 95% confidence interval) for various analysis methods.
It is clear from Fig. 4 that Normal/allow, R/MICE and SAS can give seriously misleading results. The newly introduced methods are reasonably consistent with one another, although differences are noticeable even between the Bayesian methods with different priors, presumably because of the extreme sparseness of the data. Estimated fractions of missing information with the newly introduced methods ranged from 0.73 to 0.85 for and were lower for the other parameters.
The complete cases analysis gives larger point estimates than the newly introduced methods. The difference is not unexpected, since complete cases analysis makes a different assumption from MI analysis. In these data, missing data almost always occur when there was no pain relief at the previous outcome, so complete cases analysis tends to exclude individuals with worse outcomes: this explains the differences seen.
7. Simulation study
We finally perform a small simulation study to explore the properties of the proposed methods in a more realistic setting with three covariates (two binary and one continuous) and a continuous outcome. 1000 data sets were simulated, each with a sample size . was binary with . was binary with and so that perfect prediction always occurred. was continuous with . was continuous with . was missing completely at random with probability ; the other variables were complete. We fixed , and . The missing values of were imputed from a logistic regression on and , and perfect prediction was handled by the Normal/allow, Normal/augment, Normal/penalise and Bootstrap methods. Five imputed data sets were created, although more would be needed for definitive results in any particular data set (Bodner, 2008). The imputed data were used to estimate and .
The results (Table 3) confirm the poor performance of Normal/allow for all parameters except : the estimated prevalence of is biased upwards and estimated associations are weakened. Coverages for Normal/allow are reasonable, but only because bias is accompanied by inflated standard errors. The other three methods perform equally well, with negligible bias, similar empirical standard errors, appropriate model-based standard errors, appropriate coverage and similar power.
Table 3.
Results of simulation study to compare Normal/allow, Bootstrap, Normal/penalise and Normal/augment methods for handling perfect prediction. EmpSE is the empirical standard error, ModSE is the relative error in the model standard error compared with the empirical standard error, Coverage is coverage of a nominal 95% confidence interval, and Power is the power to reject parameter = 0.
| Parameter | Method | Bias | EmpSE | ModSE (%) | Coverage (%) | Power (%) |
|---|---|---|---|---|---|---|
| = 0.1 | Normal/allow | 0.07 | 0.05 | 130 | 99 | 23 |
| Bootstrap | 0.00 | 0.02 | 1 | 95 | 100 | |
| Normal/penalise | 0.00 | 0.02 | 3 | 95 | 100 | |
| Normal/augment | 0.00 | 0.02 | 3 | 95 | 100 | |
| = 1 | Normal/allow | −0.22 | 0.36 | 47 | 93 | 20 |
| Bootstrap | 0.02 | 0.43 | 1 | 94 | 65 | |
| Normal/penalise | 0.00 | 0.42 | 2 | 94 | 65 | |
| Normal/augment | −0.02 | 0.42 | 3 | 95 | 63 | |
| = 1 | Normal/allow | −0.11 | 0.24 | 26 | 96 | 90 |
| Bootstrap | 0.01 | 0.25 | 1 | 96 | 98 | |
| Normal/penalise | 0.00 | 0.25 | 1 | 95 | 97 | |
| Normal/augment | 0.00 | 0.25 | 2 | 96 | 97 | |
| = 0.5 | Normal/allow | 0.00 | 0.09 | −3 | 94 | 100 |
| Bootstrap | 0.00 | 0.09 | −3 | 94 | 100 | |
| Normal/penalise | 0.00 | 0.09 | −3 | 94 | 100 | |
| Normal/augment | 0.00 | 0.09 | −3 | 94 | 100 | |
| Maximum Monte Carlo error | 0.01 | 0.01 | 5 | 1 | 2 | |
8. Discussion
We have shown that implementations of imputation procedures for categorical variables can go seriously wrong if perfect prediction occurs. This was a problem in earlier versions of our own software, ice, and at the time of writing it remains a problem in at least two other major software packages. It can apply in any setting where an imputation procedure involves a categorical data regression and where the uncertainty about the imputation model parameters is allowed for by sampling from a Normal approximation to a posterior distribution.
General advice is that imputation models should aim to include as many relevant variables as possible in order to make the missing at random assumption more plausible (Collins et al., 2001; Zhou et al., 2001). While we agree with this argument, it does increase the probability of perfect prediction occurring. Further research is needed to be sure that there are no other hidden problems that can arise with large imputation models.
Various approaches to perfect prediction are possible. The simplest is to abandon proper imputation if perfect prediction is detected — that is, to use the estimated parameter rather than a draw from the posterior. This certainly avoids the traps we have described, but it somewhat underestimates the uncertainty in the data if Rubin’s rules are applied. We have proposed three general alternatives: drawing approximately from the posterior via a bootstrap procedure, using penalised regression, and augmentation. A fourth alternative, the explicitly Bayesian method, appears to be used by the new mi package for R (Gelman et al., 2008), which uses a default “minimal-information” prior distribution via Gelman’s bayesglm function. The bootstrap procedure and augmentation are probably the most straightforward of these alternatives.
Perfect prediction may be regarded as logical (“ always implies ”) or as random (“ can occur with , but this was not observed in our data”). The bootstrap procedure implicitly views perfect prediction as a logical phenomenon, whereas the augmentation procedure implicitly views it as random (the group in Fig. 3 has a few successes imputed by Normal/augment, but none by Bootstrap). This distinction could help in choosing which method to use.
One way to detect problems with a Normal approximation to the log likelihood is to compare the values of from the true and approximated likelihoods (Raghunathan et al., 2001). The ratio of the two values should be close to 1 but can be very large (more than 1000) when perfect prediction is inappropriately handled. We suggest that values outside the range (0.1,10) should be a cause for concern. One way to improve the approximation is to use importance sampling in which several values of are drawn from the Normal approximation, and the values of are computed and used in choosing one of the values (Rubin, 1987b, 2003).
We have implemented the augmentation method in version 1.4.1 and later of the ice command for Stata. Users should be aware that (unlike in methods such as penalised likelihood) different parameterisations–for example, different choices of reference category for a categorical variable–can give somewhat different answers. However, in our experience, such differences are of no practical importance, and the main problem that can arise is upward bias in the prevalence of rare levels of categorical variables. Prevalences will be biased when the number of augmented events in a level (approximately ) is not small compared with the number of observed events.
In summary, awareness of the perfect prediction problem is important for users of MI routines, since these may not always handle the problem appropriately. It is also essential for anyone programming an MI routine.
Footnotes
Code for implementing the analyses described in Sections 2 and 6 in SAS, R and Stata is available as supplementary material in the electronic version of this paper.
Supplementary data associated with this article can be found, in the online version, at doi:10.1016/j.csda.2010.04.005.
Appendix. Supplementary data
Supplementary data for “Avoiding bias due to perfect prediction in multiple imputation of incomplete categorical variables”.
References
- Bernaards C.A., Belin T.R., Schafer J.L. Robustness of a multivariate normal approximation for imputation of incomplete binary data. Statistics in Medicine. 2007;26:1368–1382. doi: 10.1002/sim.2619. [DOI] [PubMed] [Google Scholar]
- Bodner T.E. What improves with increased missing data imputations? Structural Equation Modeling: A Multidisciplinary Journal. 2008;15:651–675. [Google Scholar]
- Bull S.B., Lewinger J.P., Lee S.S.F. Confidence intervals for multinomial logistic regression in sparse data. Statistics in Medicine. 2007;26:903–918. doi: 10.1002/sim.2518. [DOI] [PubMed] [Google Scholar]
- Bull S.B., Mak C., Greenwood C.M.T. A modified score function estimator for multinomial logistic regression in small samples. Computational Statistics and Data Analysis. 2002;39:57–74. [Google Scholar]
- Carpenter, J.R., Kenward, M.G., 2008. Missing data in clinical trials—a practical guide. Birmingham: National Institute for Health Research, Publication RM03/JH17/MK. Available at: http://www.pcpoh.bham.ac.uk/publichealth/methodology/projects/RM03_JH17_MK.shtml.
- Clogg C.C., Rubin D.B., Schenker N., Schultz B., Weidman L. Multiple imputation of industry and occupation codes in census public-use samples using Bayesian logistic regression. Journal of the American Statistical Association. 1991;86:68–78. [Google Scholar]
- Collins L.M., Schafer J.L., Kam C.M. A comparison of inclusive and restrictive strategies in modern missing data procedures. Psychological Methods. 2001;6:330–351. [PubMed] [Google Scholar]
- Cox D.R., Snell E.J. Chapman & Hall/CRC; 1989. Analysis of Binary Data. [Google Scholar]
- Firth D. Bias reduction of maximum likelihood estimates. Biometrika. 1993;80:27–38. [Google Scholar]
- Gelman, A., Hill, J., Yajima, M., Su, Y.-S., Pittau, M.G., 2008. mi: missing data imputation and model checking.http://cran.r-project.org/web/packages/mi/index.html.
- Heinze G., Schemper M. A solution to the problem of separation in logistic regression. Statistics in Medicine. 2002;21:2409–2419. doi: 10.1002/sim.1047. [DOI] [PubMed] [Google Scholar]
- Little R.J.A., Rubin D.B. 2nd ed. Wiley; Hoboken, NJ: 2002. Statistical Analysis with Missing Data. [Google Scholar]
- McCullagh P., Nelder J.A. 2nd ed. Chapman and Hall; London: 1989. Generalized Linear Models. [Google Scholar]
- Raghunathan T.E., Lepkowski J.M., Hoewyk J.V., Solenberger P. A multivariate technique for multiply imputing missing values using a sequence of regression models. Survey Methodology. 2001;27:85–95. [Google Scholar]
- Raghunathan, T.E., Solenberger, P.W., Hoewyk, J.V., 2007. IVEware: imputation and variance estimation software. http://www.isr.umich.edu/src/smp/ive.
- Royston P. Multiple imputation of missing values. Stata Journal. 2004;4:227–241. [Google Scholar]
- Royston P. Multiple imputation of missing values: update. Stata Journal. 2005;5:188–201. [Google Scholar]
- Royston P. Multiple imputation of missing values: further update of ice, with an emphasis on interval censoring. Stata Journal. 2007;7:445–464. [Google Scholar]
- Royston P. Multiple imputation of missing values: further update of ice, with an emphasis on categorical variables. Stata Journal. 2009;9:466–477. [Google Scholar]
- Royston P., Carlin J.B., White I.R. Multiple imputation of missing values: new features for mim. Stata Journal. 2009;9:252–264. [Google Scholar]
- Rubin D.B. The Bayesian bootstrap. The Annals of Statistics. 1981;9:130–134. [Google Scholar]
- Rubin D.B. John Wiley and Sons; New York: 1987. Multiple Imputation for Nonresponse in Surveys. [Google Scholar]
- Rubin D.B. A noniterative sampling/importance resampling alternative to the data augmentation algorithm for creating a few imputations when fractions of missing information are modest: the SIR algorithm. Journal of the American Statistical Association. 1987;82:543–546. [Google Scholar]
- Rubin D.B. Nested multiple imputation of NMES via partially incompatible MCMC. Statistica Neerlandica. 2003;57:3–18. [Google Scholar]
- Rubin D.B., Schenker N. Multiple imputation for interval estimation from simple random samples with ignorable nonresponse. Journal of the American Statistical Association. 1986;81:366–374. [Google Scholar]
- SAS Institute Inc., 2004. SAS/STAT 9.1 User’s Guide. SAS Institute Inc., Cary, NC (Chapter 46).
- Schafer J.L. Chapman and Hall; London: 1997. Analysis of Incomplete Multivariate Data. [Google Scholar]
- Schafer, J.L., 2008. Software for multiple imputation. http://www.stat.psu.edu/~jls/misoftwa.html.
- StataCorp . Stata Press; College Station, TX: 2009. Stata Statistical Software: Release 11. [Google Scholar]
- Sweeting M.J., Sutton A.J., Lambert P.C. What to add to nothing? Use and avoidance of continuity corrections in meta-analysis of sparse data. Statistics in Medicine. 2004;23:1351–1375. doi: 10.1002/sim.1761. [DOI] [PubMed] [Google Scholar]
- van Buuren S. Multiple imputation of discrete and continuous data by fully conditional specification. Statistical Methods in Medical Research. 2007;16(3):219–242. doi: 10.1177/0962280206074463. [DOI] [PubMed] [Google Scholar]
- van Buuren S., Boshuizen H.C., Knook D.L. Multiple imputation of missing blood pressure covariates in survival analysis. Statistics in Medicine. 1999;18:681–694. doi: 10.1002/(sici)1097-0258(19990330)18:6<681::aid-sim71>3.0.co;2-r. [DOI] [PubMed] [Google Scholar]
- van Buuren, S., Oudshoorn, C.G.M., 2000. Multivariate imputation by Chained equations: MICE V1.0 user’s manual. TNO Report PG/VGZ/00.038, Leiden: TNO preventie en gezondheid. Available at: http://www.multiple-imputation.com/.
- Zhou X.-H., Eckert G.J., Tierney W.M. Multiple imputation in public health research. Statistics in Medicine. 2001;20:1541–1549. doi: 10.1002/sim.689. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary data for “Avoiding bias due to perfect prediction in multiple imputation of incomplete categorical variables”.