

Abstract
We study the effect of additive noise on integro-differential neural field equations. In particular, we analyze an Amari-type model driven by a Q-Wiener process, and focus on noise-induced transitions and escape. We argue that proving a sharp Kramers’ law for neural fields poses substantial difficulties, but that one may transfer techniques from stochastic partial differential equations to establish a large deviation principle (LDP). Then we demonstrate that an efficient finite-dimensional approximation of the stochastic neural field equation can be achieved using a Galerkin method and that the resulting finite-dimensional rate function for the LDP can have a multiscale structure in certain cases. These results form the starting point for an efficient practical computation of the LDP. Our approach also provides the technical basis for further rigorous study of noise-induced transitions in neural fields based on Galerkin approximations.
Mathematics Subject Classification (2000): 60F10, 60H15, 65M60, 92C20.
Keywords: Stochastic neural field equations, Nonlocal equations, Large deviation principle, Galerkin approximation
1 Introduction
Starting from the classical works of Wilson/Cowan [64] and Amari [1], there has been considerable interest in the analysis of spatiotemporal dynamics of mesoscale models of neural activity. Continuum models for neural fields often take the form of nonlinear integro-differential equations where the integral term can be viewed as a nonlocal interaction term; see [37] for a derivation of neural field models. Stationary states, traveling waves, and pattern formation for neural fields have been studied extensively; see, e.g., [20,29] or the recent review by Bressloff [14] and references therein.
In this paper, we are going to study a stochastic neural field model. There are several motivations for our approach. In general, it is well known that intra and interneuron [27] dynamics are subject to fluctuations. Many meso or macroscale continuum models have stochastic perturbations due to finite-size effects [38,61]. Therefore, there is certainly a genuine need to develop new techniques to analyze random neural systems [50]. For stochastic neural fields, there is also the direct motivation to understand the relation between noise and short-term working memory [52] as well as noise-induced phenomena [54] in perceptual bistability [62]. Although an eventual goal is to match results from stochastic neural fields to actual cortex data [35], we shall not attempt such a comparison here. However, the techniques we develop could have the potential to make it easier to understand the relation between models and experiments; see Sect. 10 for a more detailed discussion.
There is a relatively small amount of fairly recent work on stochastic neural fields, which we briefly review here. Brackley and Turner [11] study a neural field with a gain function, which has a random firing threshold. Fluctuating gain functions are also considered by Coombes et al. [22]. Bressloff and Webber [15] analyze a stochastic neural field equation with multiplicative noise while Bressloff and Wilkinson [16] study the influence of extrinsic noise on neural fields. In all these works, the focus is on the statistics of traveling waves such as front diffusion and the effects of noise on the wave speed. Hutt et al. [41] study the influence of external fluctuations on Turing bifurcation in neural fields. Kilpatrick and Ermentrout [43] are interested in stationary bump solutions. They observe numerically a noise-induced passage to extinction as well as noise-induced switching of bump solutions and conjecture that “a Kramers’ escape rate calculation” [[43], p. 16] could be applied to stochastic neural fields, but they do not carry out this calculation. In particular, the question is whether one can give a precise estimate of the mean transition time between metastable states for stochastic neural field equations; for a precise statement of the classical Kramers’ law; see Sect. 5, Eq. (32). However, to the best of our knowledge, there seems to be no general Kramers’ law or large deviation principle (LDP) calculation available for continuum neural field models although large deviations have been of recent interest in neuroscience applications [13,33]. It is one of the main goals of this paper to provide the basic steps toward a general theory.
Although Kramers’ law [5] and LDPs [26,34] are well understood for finite-dimensional stochastic differential equations (SDEs), the work for infinite-dimensional evolution equations is much more recent. In particular, it has been shown very recently that one may extend Kramers’ law to certain stochastic partial differential equations (SPDEs) [4,6,7] driven by space-time white noise. The work of Berglund and Gentz [7] provides a quite general strategy how to “lift” a finite-dimensional Kramers’ law to the SPDE setting using a Galerkin approximation due to Blömker and Jentzen [8]. Since the transfer of PDE techniques to neural fields has been very successful, either directly [51] or indirectly [14,21], one may conjecture that the same strategy also works for SPDEs and stochastic neural fields.
In this paper, we consider a rate-based (or Amari) neural field model driven by a Q-Wiener process W
| (1) |
for a trace-class operator Q, nonlinear gain function f, and an interaction kernel w; the technical details and definitions are provided in Sect. 2. Observe that (1) is a relatively general formulation of a nonlocal neural field. Hence, we expect that the techniques developed in this paper carry over to much wider classes of neural fields beyond (1) such as activity-based models.
Remark 1.1 To avoid confusion, we alert readers familiar with neural fields that the nonlinear gain function f in (1) is sometimes also called a “rate function.” However, we reserve “rate function” for a functional, to be denoted later by I, arising in the context of an LDP as this convention is standard in the context of LDPs.
Our main goal in the study of (1) is to provide estimates on the mean first passage times between metastable states. In particular, we develop the basic analytical tools to approximate equation (1) as well as its rate function using a finite-dimensional Galerkin approximation. By making the rate function as explicit as possible, we do not only provide a starting point for further analytical work, but also provide a framework for efficient numerical methods to analyze metastable states.
The paper is structured as follows: The motivation for (1) is given in Sect. 3 where a formal calculation shows that a space-time white noise perturbation of the gain function in a deterministic neural field leads to (1). In Sect. 4, we briefly describe important features of the deterministic dynamics for (1) where . In particular, we collect several examples from the literature where the classical Kramers’ stability configuration of bistable stationary states separated by an unstable state occurs for Amari-type neural fields. In Sect. 5, we introduce the notation for Kramers’ law and LDPs and state the main theorem on finite-dimensional rate functions. In Sect. 6, we argue that a direct approach to Kramers’ law via “lifting” for (1) is likely to fail. Although the Amari model has a hidden energy-type structure, we have not been able to generalize the gradient-structure approach for SPDEs to the stochastic Amari model. This raises doubt whether a Kramers’ escape rate calculation can actually be carried out, i.e., whether one may express the prefactor of the mean first-passage in the bistable case explicitly. Based on these considerations, we restrict ourselves to just derive an LDP. In Sect. 7, the LDP is established by a direct transfer of a result known for SPDEs. The disadvantage of this approach is that the resulting rate function is difficult to calculate, analytically or numerically, in practice. Therefore, we establish in Sect. 8 the convergence of a suitable Galerkin approximation for (1). Using this approximation, one may apply results about the LDP for SDEs, which we carry out in Sect. 9. In this context, we also notice that the trace-class noise can induce a multiscale structure of the rate function in certain cases. The last two observations lead to a tractable finite-dimensional approximation of the LDP and hence also an associated finite-dimensional approximation for first-exit time problems. We conclude the paper in Sect. 10 with implications of our work and remarks about future problems.
2 Amari-Type Models
In this study, we consider stochastic neural field models with additive noise of the form
| (2) |
for , a small parameter , and , where ℬ is bounded and closed. In (2) the solution U models the averaged electrical potential generated by neurons at location x in an area of the brain ℬ. Neural field equations of the form (2) are called Amari-type equations or a rate-based neural field models. The equation is driven by an adapted space-time stochastic process on a filtered probability space . The precise definition of the process W will be given below.
The parameter is the decay rate for the potential, is a kernel that models the connectivity of neurons at location x to neurons at location y. Positive values of w model excitatory connections and negative values model inhibitory connections. The gain function relates the potential of neurons to inputs into other neurons. Typically, the gain functions are chosen sigmoidal, for example, (up to affine transformations of the argument) or . These examples of gain functions are bounded, infinitely often differentiable with bounded derivatives. However, throughout the paper, we only make the standing assumption that
(H1) the gain function f is globally Lipschitz continuous on ℝ.
We may transfer Eq. (2) into the Hilbert space setting of infinite-dimensional stochastic evolution equations [23,56] for the Hilbert space . Subsequently, brackets always denote the inner product on this Hilbert space. Moreover, we introduce the following notation. Firstly, F denotes the nonlinear Nemytzkii-operator defined from f, i.e., for any function . The condition (H1) implies that is a Lipschitz continuous operator. Often, spatially continuous solutions to (2) are also of interest, and thus we note that the Nemytzkii-operator also preserves its Lipschitz continuity on the Banach space with its norm due to ℬ being bounded.a Secondly, the linear operator K is the integral operator defined by the kernel w
| (3) |
Throughout the paper, we assume that
(H2) the kernel w is such that K is a compact, self-adjoint operator on .
We note that an integral operator is self-adjoint if and only if the kernel is symmetric, i.e., for all . A sufficient condition for the compactness of K is, e.g., in which case the operator is called a Hilbert–Schmidt operator. Since ℬ is bounded, the continuity of the kernel w on implies the compactness of K considered an integral operator on .
Then we rewrite Eq. (2) as an Hilbert space-valued stochastic evolution equation
| (4) |
where W is an -valued stochastic process. Interpreting the original equation in this form, we now give a definition of the noise process assuming that
(H3) W is a Q-Wiener process on , where the covariance operator Q is a nonnegative, symmetric trace class operator on .
For a detailed explanation of a Hilbert space-valued Q-Wiener process and its covariance operator, we refer to, e.g., [23,56]. As the operator Q is nonnegative, symmetric, and of trace class there exists an orthonormal basis of consisting of eigenfunctions and corresponding non-negative real eigenvalues , which satisfy . It then holds that the Q-Wiener process W satisfies
| (5) |
where are a sequence of independent scalar Wiener processes (cf. [[56], Proposition 2.1.10]). The series (5) converges in the mean-square on . Furthermore, a straightforward adaptation of the proof of [[56], Proposition 2.1.10] shows that convergence in the mean-square also holds in the space for every if for all i (corresponding to nonzero eigenvalues) and .
The existence and uniqueness of mild solutions to (4) with trace class noise for given initial condition is guaranteed under the Lipschitz condition on f, cf. [23], and we can write the solution in its mild form
| (6) |
The solution possesses a modification in and from now on we always identify the solution (6) with its continuous modification. It is worthwhile to note that for cylindrical Wiener processes—and thus in particular space-time white noise—there does not exist a solution to (4). This contrasts with other well-studied infinite-dimensional stochastic evolution equations, e.g., the stochastic heat equation. Due to the representation of the solution (6), it follows that a solution can only be as spatially regular as the stochastic convolution . In the present case, the semigroup generated by the linear operator is not smoothing in contrast to, e.g., the semigroup generated by the Laplacian in the heat equation. Thus, the stochastic convolution is only as smooth as the noise which for space-time white noise is not even a well-defined function. To be more specific, for cylindrical Wiener noise, the series representation of the stochastic convolution (cf. see Eq. (8) below) does not converge in a suitable probabilistic sense.
We next aim to strengthen the spatial regularity of the solution (6), which will be required later on. According to [[23], Theorem 7.10] the solution (6) is a continuous process taking values in the Banach space if the initial condition satisfies , the linear part in the drift of (4) generates a strongly continuous semigroup on , the nonlinear term KF is globally Lipschitz continuous on , and finally, if the stochastic convolution is a continuous process taking values in . It is easily seen that the first conditions are satisfied and sufficient conditions for the latter property are given in the following lemma.
Lemma 2.1Assume that the orthonormal basis functionsare Lipschitz continuous with Lipschitz constantssuch that
| (7) |
for a. Then the process
| (8) |
possesses a modification withγ-Hölder continuous paths infor all.
Proof We prove the lemma applying the Kolmogorov–Centsov theorem (cf. [[23], Theorem 3.3 and Theorem 3.4]). Throughout the proof, C is some finite constant, which may change from line to line, but is independent of and . We start showing that the process O is Hölder continuous in the mean-square in each direction. As are assumed continuous these are pointwise uniquely given and each is for fixed and a Gaussian random variable due to . Hence, for all and all , we obtain
using
for every and . Next, for the temporal regularity we obtain
As the exponential function on the negative half-axis is Hölder continuous for every , it holds
Thus, overall Jensen’s inequality yields . Since the difference is centered Gaussian, it further holds that
Now, the Kolmogorov–Centsov theorem implies the statement of the lemma. □
We present an example to illustrate the type of noise we are generally interested in. Further motivation is provided in Sect. 3.
Example 2.1 Consider the neural field equation on a d-dimensional cube with noise based on trigonometric basis functions of . This type of noise is almost ubiquitous in applications as for the stochastic heat equations the basis functions can be chosen such that the usual (Dirichlet, Neumann or periodic) boundary conditions are preserved. For the example of noise preserving homogeneous Neumann boundary conditions, the basis functions are
| (9) |
where , is a multi-index in and the functions are given by
The functions are for all pointwise bounded by and Lipschitz continuous with Lipschitz constants given by (cf. [[8], Lemma 5.3]). Next, we construct a trace class Wiener process from these basis functions. A particular important example of spatiotemporal noise is smooth noise with exponentially decaying spatial correlation length [15,36,43], i.e.,
| (10) |
for a parameter modeling the spatial correlation length. Note that for this noise process approximates space-time white noise. Following [60], we can calculate under the assumption that the coefficients such that the Q-Wiener process (5) possesses the correlation function (10) and obtain
| (11) |
Now, it is easy to see that for this choice of eigenvalues the noise is of trace class and moreover the additional conditions of Lemma 2.1 are satisfied: As the functions are bounded, we obtain
and the second condition of (7) is satisfied as
3 Gain Function Perturbation
Another motivation for the considered additive noise neural field equations stems from a (formal) perturbation of the gain function f with space-time white noise. Let denote space time white noise and consider the randomly perturbed Amari equation
| (12) |
Recall that, by assumption (H2), the integral operator K defined by the kernel w is a self-adjoint compact operator. Thus, the spectral theorem implies that K possess only real eigenvalues , , and the corresponding eigenfunctions form an orthonormal basis of . If additionally we assume that
(H4) K is a Hilbert–Schmidt operator on , that is, ,
then the eigenvalues satisfy . Hence, K possesses the series representation
which yields for the perturbed equation (12) the representation
Next, note that the random variables form a sequence of independent scalar white noise processes in time. Therefore, the perturbed equation becomes
Rewriting this equation in the usual notation of stochastic differential equations we obtain
| (13) |
where
is a trace-class Wiener process on the Hilbert space . Note, when comparing to (5) here the coefficients may be negative, however, as is also a Wiener process this slight inconsistency can be neglected.
We next want to discuss spatial continuity of the solution to this equation with its particular noise structure. It is clear that this should translate into smoothing conditions of the kernel w. Due to Lemma 2.1, it is sufficient to establish conditions (7): First, it holds that
due to Parseval’s identity. Hence, the first condition of (7) becomes
| (14) |
Next, the basis functions are continuous if the kernel is continuous in x and as the minimal Lipschitz constant is given by the supremum on the derivatives we obtain
due to the Cauchy–Schwarz inequality. Therefore, the second condition in (7) is satisfied if
| (15) |
for a and a . The condition (14) and the first part of (15) are easily checked but for the second part of (15) usually theoretical results on the speed of decay of the eigenvalues have to be obtained. We note that (15) is certainly satisfied with if K is a trace class operator and the eigenfunctions are pointwise bounded independently of i; see, e.g., Example 2.1.
4 Deterministic Dynamics
The classical deterministic Amari model, obtained for in (2), is
| (16) |
where . Note that we may allow ℬ to be unbounded for the deterministic case as solutions of (16) do exist in this case [55]. Suppose there exists a stationary solution of (16). To determine the stability of consider . Substituting into (16) and Taylor-expanding around yields the linearized problem
| (17) |
Hence, the standard ansatz leads to the eigenvalue problem
| (18) |
The linear stability condition is equivalent to where . The stability analysis can be reduced to the understanding of the operator ℒ. However, this is a highly nontrivial problem as the behavior depends upon ℬ, , , and .
An LDP and Kramers’ law are of particular interest in the case of bistability. Therefore, we point out that there are many situations where (16) does have three stationary solutions: , which are stable and which is unstable. The following three examples make this claim more precise.
Example 4.1 The first example is presented by Ermentrout and McLeod [29]. Let , , and assume that . Furthermore, suppose that with and
| (19) |
has precisely three zeros with . The additional conditions and guarantee stability of the stationary solutions and . As an even more explicit assumption [[29], p. 463], one may consider a Dirac δ-distribution for w in (16), which yields
| (20) |
Suppose there are precisely three solutions for given by with . If , and then (20) has an unstable stationary solution between the two stable stationary solutions.
Example 4.2 An even more concrete example is given by Guo and Chow [39,40]. They assume , , and fix two functions
where is the Heaviside function and b, a, A, and are parameters. Depending on parameter values, one may obtain three constant stationary solutions exhibiting bistability as expected from Example 4.1. However, there are also parameter values so that three stationary pulses exhibiting bistability exist.
Note that the choice is not essential to obtain two deterministically-stable stationary states and one deterministically-unstable stationary state . The important aspect is that certain algebraic equations, such as and in Example 4.1, have the correct number of solutions. Furthermore, one has to make sure that the sign of the nonlinearity f is chosen correctly to obtain the desired deterministic stability results for the stationary solutions. Hence, we expect that a similar situation also holds for bounded domains; see also [63].
Examples 4.1–4.2 are typical for many similar cases with or . Many results on existence and stability of stationary solutions are available; see, e.g., [1,46,51,52], and references therein.
Example 4.3 As a higher-dimensional example, one may consider the work by Jin, Liang, and Peng [42] who assume that , , , and
where κ is the Lipschitz constant of . Furthermore, suppose is uniformly continuous and
for . Then [[42], Proposition 11] the conditions
yield three stationary solutions , and . The solutions are stable and satisfy and . The solution is unstable.
Although we only focus on stationary solutions, it is important to remark that the techniques developed here could—in principle—also be applied to traveling waves for . The existence and stability of traveling waves for (16) has been investigated for many different situations; see, e.g. [12,14,21,29], and references therein. However, it seems reasonable to restrict ourselves here to the stationary case as even for this simpler case an LDP and Kramers’ law are not yet well understood.
5 Large Deviations and Kramers’ Law
Here, we briefly introduce the background and notation for LDPs and Kramers’ law needed through the remaining part of the paper; see [26,34] for more details. Consider a topological space 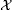 with Borel σ-algebra . A mapping is called a good rate function if it is lower semicontinuous and the level set is compact for each . Sometimes the term action functional is used instead of rate function. Consider a family of probability measures on . The measures satisfy an LDP with good rate function I if
with Borel σ-algebra . A mapping is called a good rate function if it is lower semicontinuous and the level set is compact for each . Sometimes the term action functional is used instead of rate function. Consider a family of probability measures on . The measures satisfy an LDP with good rate function I if
| (21) |
holds for any measurable set ; often infima over the interior and closure coincide so that lim inf and lim sup coincide at a common limit. One of the most classical cases is the application of (21) to finite-dimensional SDEs
| (22) |
where , , , is a vector of k independent Brownian motions and we shall assume that the initial condition is deterministic. If we want to emphasize that depends on ϵ, we shall also use the notation . The topological space is chosen as a path space
To state the next result, we also need the Sobolev space
| (23) |
Furthermore, we are going to assume that the diffusion matrix is positive definite.
The SDE (22) satisfies the LDP (21) given by
| (24) |
for any measurable set of pathswith good rate function
| (25) |
An important application of the LDP (24) is the so-called first-exit problem. Suppose that starts near a stable equilibrium of the deterministic system given by setting in (22), where 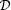 is a bounded domain with smooth boundary. Define the first-exit time
is a bounded domain with smooth boundary. Define the first-exit time
| (26) |
To formalize the application of the LDP, define the mapping
| (27) |
which is the cost for a path starting at u to reach v in time s. Next, assume that is properly contained inside the (deterministic) basin of attraction of . Then one can show [[34], Theorem 4.1, p. 124] that
| (28) |
To get more precise information on the exit distribution, one defines the function
which is called the quasipotential for . It is natural to minimize the quasipotential over and define
Theorem 5.2 ([[34], Theorem 4.2, p. 127], [[26], Theorem 5.7.11])
For all initial conditionsand all, the following two limits hold:
| (29) |
| (30) |
If the SDE (22) has a gradient structure with identity diffusion matrix, i.e.,
| (31) |
then one can show [[34], Sect. 4.3] that the quasipotential is given by . If the potential has precisely two local minima and a saddle point with stable directions so that the Hessian has eigenvalues
then one can even refine Theorem 5.2. Suppose then the mean first passage time to satisfies
| (32) |
where denotes the usual Euclidean norm in . The formula (32) is also known as Kramers’ law [5] or Arrhenius–Eyring–Kramers’ law [2,31,45]. Note that the key differences with the general LDP (29) for the first-exit problem are that (32) yields a precise prefactor for the exponential transition time and uses the explicit form of the good rate function for gradient systems. It is interesting to note that a rigorous proof of (32) has only been obtained quite recently [9,10].
6 Gradient Structures in Infinite Dimensions
The finite-dimensional Kramers’ formula (32) applies to SDEs (22) with a gradient-structure where is the potential. A generalization of Kramers’ law has been carried over to the infinite-dimensional case of SPDEs given by
| (33) |
for , , a bounded interval, for suitably large and denotes space-time white noise and either Dirichlet or Neumann boundary conditions are used [4,6,7]. A crucial reason why this generalization works is that the SPDE (33) has a gradient-type structure [32] given by the energy functional
| (34) |
More precisely, when one obtains from (33) a PDE, say with Dirichlet boundary conditions,
| (35) |
for a given sufficiently smooth initial condition . Standard parabolic regularity [[30], Sect. 7.1] implies that solutions U of (35) lie in the Sobolev spaces . Computing the Gâteaux derivative in this space yields
| (36) |
The Gâteaux derivative is equal to the Fréchet derivative by a standard continuity result [[25], p. 47]. Hence, (36) shows that the stationary solutions of (35) are critical points of the gradient functional V. Since the gradient structure of the deterministic PDE (35) is a key structure to obtain a Kramers’-type estimate for the SPDE (33), we would like to check whether there is an analogue available for the deterministic Amari model (16).
We shall assume for simplicity that for the calculations in this section. Although this is a slightly stronger assumption than (H1), we shall see below that even with this assumption we are not able to obtain an immediate generalization of (36). Using a direct modification of the results in [55], it follows that the deterministic Amari model (16) has solutions in the Hölder space for and is the usual domain we use for the Amari model. Now consider the analogous naive guess to (36) given by
| (37) |
Computing the derivative in yields
| (38) |
Therefore, setting is not equivalent to the solution of the stationary problem
Due to the presence of the different terms and in (38), one may guess that the modified functional
| (39) |
could work. However, another direct computation shows that
Hence, f and its derivative Df both appear instead of the desired formulation; by a similar computation one can show that replacing in (39) by fails as well. Hence, there does not seem to be a natural generalization for the guess for the gradient functional (34). However, one has to consider possible coordinate changes. The idea to apply a preliminary transformation has been discussed, e.g., in [[28], p. 2] and [[51], p. 488]. Assume that
| (40) |
Define as the mean action-potential generating rate so that . Observe that
| (41) |
For this equation, the problem observed in (39) should disappear as the integral only contains linear terms. One may define an energy-type functional
Calculating the derivative yields
This shows that there is hidden energy-type flow structure in the Amari model for the assumptions (40) so that
| (42) |
However, even with this variable transformation, there seems to be little hope to derive a precise Kramers’ rule for the stochastic Amari model (2) by generalizing the approach for SPDE systems [4,6,7]. The problems are as follows:
– There is still a space-time dependent nonlinear prefactor in (42) for the deterministic system, so the system is not an exact gradient flow for a potential.
– Applying the change-of-variable for the stochastic Amari model (2) requires an Itô-type formula so that
| (43) |
where is now a multiplicative noise term; see [24], and references therein for more details on infinite-dimensional Itô-type formulas. The higher-order term in the drift part of (43) is not expected to cause difficulties but a multiplicative noise structure definitely excludes the direct application of Kramers’ law.
– Even if we would just assume—without any immediate physical motivation—that the noise term in (43) is purely additive , there is a problem to apply Kramers’ law since we do not have a structure like in (22) with as is a Q-Wiener process defined in (5) and driving space-time white noise in (4) is particularly excluded due to the nonexistence of a solution.
Based on these observations, an immediate approach to generalize a sharp Kramers’ formula to neural fields seems unlikely. Hence we try to understand an LDP for the stochastic Amari-type model (2).
7 Direct Approach to an LDP
A general direct approach for the derivation of an LDP for infinite-dimensional stochastic evolution equations is presented in [23] and further results have been obtained for certain additional classes of SPDEs [17-19,57]. The results in [23] are valid for semilinear equations with suitable Lipschitz assumptions on the nonlinearity and with solutions taking values in . We state the available results applied to continuous solutions of the Amari equation (4) assuming that the conditions of Lemma 2.1 are satisfied.
For the following, we assume that there exists an open neighborhood containing a stable equilibrium state of the deterministic Amari equation (16) such that is contained in the basin of attraction of . We are interested in the rate function and the first-exit time of the process from given by
if U starts in the deterministic equilibrium state . In order to state the quasipotential for u, we consider the control system
| (44) |
for controls for all and denote by its unique mild solutionb taking values in for all . Then we define
| (45) |
where this quasipotential relates to the minimal energy necessary to move the control system (44) started at the equilibrium state to z.
Theorem 7.1 ([[23], Theorem 12.18])
It holds that
Following further the exposition in [[23], Sect. 12] explicit formulae for the rate function I are only available in the special case of the drift possessing gradient structure and space-time white noise. As we have argued above, this structure is particularly not satisfied for neural field equations. Hence, the same observations as presented at the end of the last section prevent a further direct analytic approach to the LDP. Therefore, we try to understand the LDP problem for a discretized approximate finite-dimensional version of the neural field equation.
8 Galerkin Approximation
Throughout the section, we assume that the assumptions (H1)–(H3) are satisfied. As a discretized version of the neural field equation (2), we consider its spectral Galerkin approximations; recall that the solution of (2) lies in as discussed in Sect. 2. In order to decouple the noise, we define the spectral representation of the solution
| (46) |
Here, the orthonormal basis functions are given by the eigenfunctions of the covariance operator of the noise with corresponding eigenvalues , see Eq. (5). To obtain a equation for the coefficients , we take the inner product of Eq. (4) with the basis functions , which yields
After plugging in (46), we obtain for the countable Galerkin system
| (47) |
Here, the nonlinearities coupling all the equations are given by
due to the symmetry of the kernel w. If, in addition, we assume that (H4) holds and K and Q possess the same eigenfunctions and the eigenvalues are related as discussed in Sect. 3 the nonlinearities become
| (48) |
The Nth Galerkin approximation to U is obtained truncating the spectral representation (46), and thus given by
| (49) |
where are the solutions to the N-dimensional Galerkin SDE system
| (50) |
where the nonlinearities are given by
| (51) |
or, in the special case of Sect. 3, by
| (52) |
respectively. The following theorem establishes the almost sure convergence of the Galerkin approximations to the solution of (4). Therefore, we may be able to infer properties of the behavior of paths of the solution from the path behavior of the Galerkin approximations. We have deferred the proof of the theorem to the Appendix.
Theorem 8.1It holds for allthat
If, in addition, the seriesconverges inand the functionsare Lipschitz continuous with Lipschitz constantssuch thatfor a (i.e., the conditions of Lemma 2.1 are satisfied), such thatandKis compact on, then it holds for allthat
9 Approximating the LDP
The LDP in Theorem 7.1 is not immediately computable. Here, we show that a finite-dimensional approximation can be made and what the structure of this approximation entails. For simplicity, consider the case when the diagonal diffusion matrix 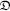 with entries is positive definite, i.e., for all . Observe that the inverse of induces an inner product on for via
with entries is positive definite, i.e., for all . Observe that the inverse of induces an inner product on for via
where is understood as the projection onto if . We are also going to use the notation introduced in Sect. 8 for the Galerkin approximation, i.e., denotes the vector
| (53) |
where denotes the solutions of the N-dimensional system (50). Note that throughout this section we shall always work with the Galerkin coefficients, e.g., refers to the vector
Furthermore, for arbitrary functions , which are used in the formulation of the rate function, we use the notation to denote the projection onto the first N Galerkin coefficients. Theorem 5.1 immediately implies the following:
Proposition 9.1For the finite-dimensional Galerkin system (50) the rate function is given by
| (54) |
where.
Recall from Sect. 7 that Theorem 7.1 provides a large deviation principle. For the case when Q is a positive operator, we may formally rewrite the control system (44) as
| (55) |
so that the rate function for the Amari model can be expressed as
| (56) |
where and . Therefore, the next result just implies that the Galerkin approximation is consistent for the LDP.
Proposition 9.2For eachwe have.
Proof Considering the finite-dimensional rate function (54) it suffices to notice that
by orthonormality of the basis in . □
Hence, we may work with the finite-dimensional Galerkin system and its LDP for computational purposes. However, the truncation N may still be very large. We are going to show, using a formal analysis for a certain case, that there is an intrinsic multiscale structure of the rate function. We assume that we are in the special case considered in Sect. 3 where K and Q have the same eigenfunctions and the corresponding eigenvalues are given by and , respectively.
Lemma 9.1For each, the first part of the rate function (54) can be rewritten as
| (57) |
where the three terms are given by
and.
Proof For notational simplicity, we shall temporarily omit in this proof the subscript for the inner product as well as the Galerkin index, e.g., as it is understood that we work with N-dimensional vectors in this proof. Consider the following general calculation:
and observe that the result is independent of N. □
It is important to point out that the LDP from Theorem 5.1 requires the infimum of the rate function. From Lemma 9.1, we know that the rate function splits into three terms. The three terms are interesting in the asymptotic limit . Suppose
as for some nonnegative functions κ, η. Then Lemma 9.1 yields
Lemma 9.2Suppose there exists a positive constantsuch that
| (58) |
then.
Proof A direct estimate yields
Since and , the last integral is uniformly bounded over by . □
We remark that several typical functions f discussed in Sect. 2 such as and are globally bounded so that Lemma 9.2 does apply to many practical cases. In this situation, we get that
We make a case distinction between the different relative asymptotics of and . Note that the following asymptotic relations are purely formal:
– If or as , then we can conclude that , i.e.,
| (59) |
since for trace-class noise we know that . If we formally require that for N sufficiently large, then the higher-order Galerkin modes decays exponentially in time
– If as , then and the first term dominates the asymptotics. But for all N so that the rate function only has a finite infimum if as . This implies again that (59) holds for the case of a finite infimum.
Hence, we get in many reasonable first-exit problems for the Amari model with trace-class noise that there is a finite set for of “slow” or “center-like” directions and an infinite set of “fast” or “stable” directions for . Although we have made this observation from the rate function alone, it is entirely natural considering the structure of the Galerkin approximation. Indeed, for the case when the eigenvalues of K and Q are related, we may write (50) as
| (60) |
so that for bounded nonlinearity f, which is represented in the terms in (60), the higher-order modes should really just be governed by .
Hence, Propositions 9.1–9.2 and the multiscale nature of the problem induced by the trace-class noise suggests a procedure how to approximate the rate function and the associated LDP in practice. In particular, we may compute the eigenvalues and eigenfunctions of K and Q up to a sufficiently large given order . This yields an explicit representation of the Galerkin system and the associated rate function. Then one may apply any finite-dimensional technique to understand the rate function. One may even find a better truncation order based on the knowledge that the minimizer of the rate function must have components that decay (almost) exponentially in time for orders bigger than N.
10 Outlook
In this paper, we have discussed several steps toward a better understanding of noise-induced transitions in continuum neural fields. Although we have provided the main basic elements via the LDP and finite-dimensional approximations, there are still several very interesting open problems.
We have demonstrated that a sharp Kramers’ rate calculation for neural fields with trace-class noise is very challenging as the techniques for white-noise gradient-structure SPDEs cannot be applied directly. However, we have seen in Sect. 4 that the deterministic dynamics for neural fields frequently exhibits a classical bistable structure with a saddle-state between stable equilibria. This suggests that there should be a Kramers’ law with exponential scaling in the noise intensity as well as a precisely computable pre-factor. It is interesting to ask how this pre-factor depends on the eigenvalues of the trace-class operator Q defining the Q-Wiener process. We expect that new technical tools are needed to answer this question.
From the viewpoint of experimental data, the exponential scaling for the LDP is relevant as it shows that noise-induced transitions have exponential interarrival times. This leads to the possibility that working memory as well as perceptual bistability could be governed by a Poisson process. However, the same phenomena could also be governed by a slowly varying variable, i.e., by an adaptive neural field [14]; the “fast” activity variable U in the Amari model is augmented by one or more “slow” variables. In this context, the required assumptions on the equilibrium structure in Sect. 4 and the noise in Sect. 3 is not necessary to produce a bistable switch and the fast variable U can, e.g., just have a single deterministically unstable equilibrium and bistable, nonrandom switching between metastable states may occur. Of course, there is also the possibility that an intermediate regime between noise-induced and deterministic escape is relevant [53].
It is interesting to note that the same problem arises generically across many natural sciences in the study of critical transitions (or “tipping points”) [48,59]. The question which escape mechanism from a metastable state matches the data is often discussed very controversially and we shall not aim to provide a discussion here. However, our main goal to make the LDP and its associated rate functional as explicit as possible should definitely help to simplify comparison between models and experiment. For example, a parameter study or data assimilation for the finite-dimensional Galerkin system considered in Theorem 8.1 and the associated rate function in Proposition 9.1 are often easier than working directly with the abstract solutions of the stochastic Amari model in .
To study the parameter dependence is an interesting open question, which we aim to address in future work. In particular, the next step is to use the Galerkin approximations in Sect. 8 and the associated LDP in Sect. 9 for numerical purposes [49]. Recent work for SPDEs [8] suggests that a spectral method can also be efficient for stochastic neural fields. Results on numerical continuation and jump heights for SDEs [47] can also be immediately transferred to the spectral approximation, which would allow for studies of bifurcations and associated noise-induced phenomena.
One may also ask how far the technical assumptions we make in this paper can be weakened. It is not clear which parts of the global Lipschitz assumptions may be replaced by local assumptions or removed altogether. Similar remarks apply to the multiscale nature of the problem induced by the decay of the eigenvalues of Q. How far this observation can be exploited to derive more efficient analytical as well as numerical techniques remains to be investigated.
On a more abstract level, it would certainly be desirable to extend our basic framework to other topics that have been considered already for deterministic neural fields. A generalization to activity based models with nonlinearity seems possible. Furthermore, it may be highly desirable to go beyond stationary solutions and investigate noise-induced switching and transitions for traveling waves and patterns.
Appendix: Convergence of the Galerkin Approximation
Proof of Theorem 8.1 We fix a . Throughout the proof an unspecified norm or operator norm , respectively, are either for the Hilbert space or the Banach space and estimates using the unspecified notation are valid in both cases. Furthermore, denotes an arbitrary deterministic constant, which may change from line to line but depend only on T. We begin the proof obtaining an a priori growth bound on the solution of the Amari equation (4). Using the linear growth condition on F implied by its Lipschitz continuity, we obtain the estimate
Due to Gronwall’s inequality, there exists a deterministic constant C such that it holds almost surely
| (61) |
Note that O is an Ornstein–Uhlenbeck process, and it thus holds
almost surely and under the assumptions of Lemma 2.1 in addition
almost surely.
Let denote the projection operator from to the subspace spanned by the first N basis functions. Then we find that in Hilbert space notation the Nth Galerkin approximation satisfies
Here, we use to be shorthand for the truncated stochastic convolution
| (62) |
Hence, we obtain for the error of the Galerkin approximation
Adding and subtracting the obvious terms yields for the norm the estimate
where and as a consequence of [[3], Lemma 11.1.4] (cf. the application of this result below). Next, using the Lipschitz and linear growth conditions on F, applying Gronwall’s inequality, taking the supremum over all and estimating using the bound (61) yield
| (63) |
It remains to show that the individual terms in the right-hand side converge to zero for almost surely.
– It clearly holds that and the convergence holds by assumption.
– Next, as argued above is a.s. finite and the compactness of the operator K implies for , see [[3], Lemma 12.1.4].
– Finally, the third error term vanishes if the Galerkin approximations of the Ornstein–Uhlenbeck process O converge almost surely in the spaces and , respectively. This convergence is proven in Lemma A.1 below.
The proof is completed. □
The following lemma contains the convergence of the Galerkin approximation of the Ornstein–Uhlenbeck process necessary for proving Theorem 8.1.
Lemma A.1There exists a sequencewithsuch that for alland allthere exists a random variablewithfor allsuch that
almost surely. If, in addition, the seriesconverges inand the functionsare Lipschitz continuous with Lipschitz constantssuch thatfor a, then it further holds that
almost surely.
Remark A.1 Assumptions on the speed of convergence of the series and and readily yield a rate of convergence for the Galerkin approximation due to the definition of the constants in the proof of the lemma.
Proof of Lemma A.1 As in the proof Theorem 8.1 the unspecified norm denotes either the norm in or in and estimates are valid in both cases. We fix , and a with . Throughout the proof denotes a constant that changes from line to line, but depends only on the fixed parameters T, p, ρ, α and the domain .
Then we obtain for all with using the factorization method (cf. [[23], Sect. 5.3]) similarly to the proof of [[8], Lemma 5.6] the estimate
where is the process defined by
In order to estimate the pth mean of the process , we proceed separately for the two cases and .
The case of: Due to the orthogonality of the basis functions and employing Hölder’s inequality, one obtains
Next, as the stochastic integrals in the right-hand side are centered Gaussian random variables [[8], Lemma 5.2]c yields for all
Therefore, we obtain for all with
| (64) |
where the final upper bound decreases to zero for by assumption.
The case of: In this case the estimates get a bit more involved. As The continuous embedding of the Sobolev–Slobodeckij space into (cf. [[58], Sect. 2.2.4 and 2.4.4]) and [[8], Lemma 5.2] yield the estimates
| (65) |
We proceed estimating the two expectation terms in the right-hand side. Then we obtain for all and all for the first term
| (66) |
for any and for the second term
| (67) |
Next applying the estimates (67) and (66) to the right-hand side of (65) yields, note that ,
for any . Due to the assumptions of the lemma the two summations in the right hand side converge for , and thus we obtain for all with the estimate
| (68) |
where the right-hand side decreases to zero for .
Overall, we infer from the estimates (64) and (68) that is a Cauchy-sequence in the two spaces and with respect to convergence in the pth mean and the limit is given by the process O. Moreover, it holds that
| (69) |
where the constant C depends only on p but is independent of N and the sequence is independent of p and . As we fixed sufficiently large at the beginning of the proof, the result (69) holds for all sufficiently large . Then, however, Jensen’s inequality implies that (69) holds for all . Proceeding as in the proof of [[44], Lemma 2.1] using the Chebyshev–Markov inequality and the Borel–Cantelli lemma, one obtains that there exists for all a random variable with for all such that
| (70) |
The proof is completed. □
Competing Interests
The authors declare that they have no competing interests.
Authors’ Contributions
Both authors contributed equally to the paper.
Contributor Information
Christian Kuehn, Email: ck274@cornell.edu.
Martin G Riedler, Email: martin.riedler@jku.at.
Acknowledgements
CK would like to thank the European Commission (EC/REA) for support by a Marie-Curie International Reintegration Grant and the Austrian Academy of Sciences (ÖAW) for support via an APART fellowship. We also would like to thank two anonymous referees whose comments helped to improve the manuscript.
References
- We note that the boundedness assumption on the domain ℬ in this study is only necessary when dealing with results in the space as is the appropriate space for the LDP results. All other results in this paper which only deal with the space , e.g., existence of solutions and convergence of the Galerkin approximation, are also valid for unbounded spatial domains.
- The existence of such a solution is guaranteed by standard results on deterministic equations (cf. [[23], Sect. A.3]) as long as maps continuously into . This is easily established. The unique square root of Q is the Hilbert–Schmidt operator given by for all and in order to show that it remains to establish that the functions converge uniformly on ℬ. This holds as for all
Hence, the upper bound, which is finite due to (7), is in independent of x and converges to zero for . Moreover, we further find that implies . - For a centered Gaussian random variable Z, it holds for all .
References
- Amari S. Dynamics of pattern formation in lateral-inhibition type neural fields. Biol Cybern. 1977;4:77–87. doi: 10.1007/BF00337259. [DOI] [PubMed] [Google Scholar]
- Arrhenius S. Über die Reaktionsgeschwindigkeit bei der Inversion von Rohrzucker durch Säuren. Z Phys Chem. 1889;4:226–248. [Google Scholar]
- Atkinson K, Han W. Theoretical Numerical Analysis. 2. Springer, Berlin; 2005. [Google Scholar]
- Barret F: Sharp asymptotics of metastable transition times for one-dimensional SPDEs. arXiv:1201.4440; 2012.1201.4440
- Berglund N: Kramers’ law: validity, derivations and generalisations. arXiv:1106.5799v1; 2011.1106.5799v1
- Berglund N, Gentz B. Anomalous behavior of the Kramers rate at bifurcations in classical field theories. J Phys A, Math Theor. 2009;4 Article ID 052001. [Google Scholar]
- Berglund N, Gentz B: Sharp estimates for metastable lifetimes in parabolic SPDEs: Kramers’ law and beyond. arXiv:1202.0990; 2012.1202.0990
- Blömker D, Jentzen A. Galerkin approximations for the stochastic Burgers equation. SIAM J Numer Anal. 2013. [DOI]
- Bovier A, Eckhoff M, Gayrard V, Klein M. Metastability in reversible diffusion processes. I. Sharp asymptotics for capacities and exit times. J Eur Math Soc. 2004;4(4):399–424. [Google Scholar]
- Bovier A, Gayrard V, Klein M. Metastability in reversible diffusion processes. II. Precise estimates for small eigenvalues. J Eur Math Soc. 2005;4:69–99. [Google Scholar]
- Brackley CA, Turner MS. Random fluctuations of the firing rate function in a continuum neural field model. Phys Rev E. 2007;4 doi: 10.1103/PhysRevE.75.041913. Article ID 041913. [DOI] [PubMed] [Google Scholar]
- Bressloff PC. Traveling fronts and wave propagation failure in an inhomogeneous neural network. Physica D. 2001;4:83–100. doi: 10.1016/S0167-2789(01)00266-4. [DOI] [Google Scholar]
- Bressloff PC. Metastable states and quasicycles in a stochastic Wilson–Cowan model. Phys Rev E. 2010;4 doi: 10.1103/PhysRevE.82.051903. Article ID 051903. [DOI] [PubMed] [Google Scholar]
- Bressloff PC. Spatiotemporal dynamics of continuum neural fields. J Phys A, Math Theor. 2012;4 Article ID 033001. [Google Scholar]
- Bressloff PC, Webber MA. Front propagation in stochastic neural fields. SIAM J Appl Dyn Syst. 2012;4(2):708–740. doi: 10.1137/110851031. [DOI] [Google Scholar]
- Bressloff PC, Wilkerson J. Traveling pulses in a stochastic neural field model of direction selectivity. Front Comput Neurosci. 2012;4 doi: 10.3389/fncom.2012.00090. Article ID 90. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cardon-Weber C. Large deviations for a Burgers’-type SPDE. Stoch Process Appl. 1999;4(1):53–70. doi: 10.1016/S0304-4149(99)00047-2. [DOI] [Google Scholar]
- Cerrai S, Röckner M. Large deviations for invariant measures of general stochastic reaction-diffusion systems. C R Math Acad Sci. 2003;4:597–602. doi: 10.1016/j.crma.2003.09.015. [DOI] [Google Scholar]
- Cerrai S, Röckner M. Large deviations for stochastic reaction-diffusion systems with multiplicative noise and non-Lipschitz reaction term. Ann Probab. 2004;4:1–40. doi: 10.1214/aop/1078415827. [DOI] [Google Scholar]
- Coombes S. Waves, bumps, and patterns in neural field theories. Biol Cybern. 2005;4:91–108. doi: 10.1007/s00422-005-0574-y. [DOI] [PubMed] [Google Scholar]
- Coombes S, Owen MR. Evans functions for integral neural field equations with Heaviside firing rate function. SIAM J Appl Dyn Syst. 2004;4:574–600. [Google Scholar]
- Coombes S, Laing CR, Schmidt H, Svanstedt N, Wyller JA. Waves in random neural media. Discrete Contin Dyn Syst, Ser A. 2012;4:2951–2970. [Google Scholar]
- Da Prato G, Zabczyk J. Stochastic Equations in Infinite Dimensions. Cambridge University Press, Cambridge; 1992. [Google Scholar]
- Da Prato G, Jentzen A, Röckner M: A mild Itô formula for SPDEs. arXiv:1009.3526v4; 2012.1009.3526v4
- Deimling K. Nonlinear Functional Analysis. Dover, Mineola; 2010. [Google Scholar]
- Dembo A, Zeitouni O. Large Deviations Techniques and Applications. Springer, Berlin; 1998. (Applications of Mathematics 38). [Google Scholar]
- Destexhe A, Rudolph-Lilith M. Neuronal Noise. Springer, Berlin; 2012. [Google Scholar]
- Enculescu M, Bestehorn M. Liapunov functional for a delayed integro-differential equation model of a neural field. Europhys Lett. 2007;4 Article ID 68007. [Google Scholar]
- Ermentrout GB, McLeod JB. Existence and uniqueness of travelling waves for a neural network. Proc R Soc Edinb A. 1993;4(3):461–478. doi: 10.1017/S030821050002583X. [DOI] [Google Scholar]
- Evans LC. Partial Differential Equations. 2. Am Math Soc, Providence; 2010. [Google Scholar]
- Eyring H. The activated complex in chemical reactions. J Chem Phys. 1935;4:107–115. doi: 10.1063/1.1749604. [DOI] [Google Scholar]
- Faris WG, Jona-Lasinio G. Large fluctuations for a nonlinear heat equation with noise. J Phys A, Math Gen. 1982;4:3025–3055. doi: 10.1088/0305-4470/15/10/011. [DOI] [Google Scholar]
- Faugeras O, MacLaurin J: A large deviation principle for networks of rate neurons with correlated synaptic weights. arXiv:1302.1029v3; 2013.1302.1029v3
- Freidlin MI, Wentzell AD. Random Perturbations of Dynamical Systems. Springer, Berlin; 1998. [Google Scholar]
- Funahashi S, Bruce CJ, Goldman-Rakic PS. Mnemonic coding of visual space in the monkey’s dorsolateral prefrontal cortex. J Neurophysiol. 1989;4(2):331–349. doi: 10.1152/jn.1989.61.2.331. [DOI] [PubMed] [Google Scholar]
- García-Ojalvo J, Sancho MJ. Noise in Spatially Extended Systems. Springer, New York; 1999. [DOI] [PubMed] [Google Scholar]
- Gerstner W, Kistler W. Spiking Neuron Models. Cambridge University Press, Cambridge; 2002. [Google Scholar]
- Ginzburg I, Sompolinsky H. Theory of correlations in stochastic neural networks. Phys Rev E. 1994;4:3171–3191. doi: 10.1103/PhysRevE.50.3171. [DOI] [PubMed] [Google Scholar]
- Guo Y, Chow CC. Existence and stability of standing pulses in neural networks: I. Existence. SIAM J Appl Dyn Syst. 2005;4(2):217–248. doi: 10.1137/040609471. [DOI] [Google Scholar]
- Guo Y, Chow CC. Existence and stability of standing pulses in neural networks: II. Stability. SIAM J Appl Dyn Syst. 2005;4(2):249–281. doi: 10.1137/040609483. [DOI] [Google Scholar]
- Hutt A, Longtin A, Schimansky-Geier L. Additive noise-induced Turing transitions in spatial systems with application to neural fields and the Swift–Hohenberg equation. Physica D. 2008;4:755–773. doi: 10.1016/j.physd.2007.10.013. [DOI] [Google Scholar]
- Jin D, Liang D, Peng J. Existence and properties of stationary solution of dynamical neural field. Nonlinear Anal, Real World Appl. 2011;4:2706–2716. doi: 10.1016/j.nonrwa.2011.03.016. [DOI] [Google Scholar]
- Kilpatrick ZP, Ermentrout B. Wandering bumps in stochastic neural fields. SIAM J Appl Dyn Syst. 2013. [DOI] [PMC free article] [PubMed]
- Kloeden PE, Neuenkirch A. The pathwise convergence of approximation schemes for stochastic differential equations. LMS J Comput Math. 2007;4:235–253. [Google Scholar]
- Kramers HA. Brownian motion in a field of force and the diffusion model of chemical reactions. Physica. 1940;4(4):284–304. doi: 10.1016/S0031-8914(40)90098-2. [DOI] [Google Scholar]
- Kubota S, Hamaguchi K, Aihara K. Local excitation solutions in one-dimensional neural fields by external input stimuli. Neural Comput Appl. 2009;4:591–602. doi: 10.1007/s00521-009-0246-2. [DOI] [Google Scholar]
- Kuehn C. Deterministic continuation of stochastic metastable equilibria via Lyapunov equations and ellipsoids. SIAM J Sci Comput. 2012;4(3):A1635–A1658. doi: 10.1137/110839874. [DOI] [Google Scholar]
- Kuehn C. A mathematical framework for critical transitions: normal forms, variance and applications. J Nonlinear Sci. 2013. [DOI]
- Kuehn C, Riedler MG: Spectral approximations for stochastic neural fields. In preparation; 2013.
- Laing C, Lord G, editor. Stochastic Methods in Neuroscience. Oxford University Press, London; 2009. [Google Scholar]
- Laing CR, Troy WC. PDE methods for nonlocal models. SIAM J Appl Dyn Syst. 2003;4(3):487–516. doi: 10.1137/030600040. [DOI] [Google Scholar]
- Laing CR, Troy WC, Gutkin B, Ermentrout B. Multiple bumps in a neuronal model of working memory. SIAM J Appl Math. 2002;4(1):62–97. doi: 10.1137/S0036139901389495. [DOI] [Google Scholar]
- Meisel C, Kuehn C. On spatial and temporal multilevel dynamics and scaling effects in epileptic seizures. PLoS ONE. 2012;4(2) doi: 10.1371/journal.pone.0030371. Article ID e30371. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moreno-Bote R, Rinzel J, Rubin N. Noise-induced alternations in an attractor network model of perceptual bistability. J Neurophysiol. 2007;4(3):1125–1139. doi: 10.1152/jn.00116.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Potthast R, Beim Graben P. Existence and properties of solutions for neural field equations. Math Methods Appl Sci. 2010;4(8):935–949. [Google Scholar]
- Prévôt C, Roeckner M. A Concise Course on Stochastic Partial Differential Equations. Springer, Berlin; 2007. [Google Scholar]
- Röckner M, Wang F-Y, Wu L. Large deviations for stochastic generalized porous media equations. Stoch Process Appl. 2006;4:1677–1689. doi: 10.1016/j.spa.2006.05.007. [DOI] [Google Scholar]
- Runst T, Sickel W. Sobolev Spaces of Fractional Order, Nemytskij Operators, and Nonlinear Partial Differential Equations. de Gruyter, Berlin; 1996. [Google Scholar]
- Scheffer M, Bascompte J, Brock WA, Brovkhin V, Carpenter SR, Dakos V, Held H, van Nes EH, Rietkerk M, Sugihara G. Early-warning signals for critical transitions. Nature. 2009;4:53–59. doi: 10.1038/nature08227. [DOI] [PubMed] [Google Scholar]
- Shardlow T. Numerical simulation of stochastic PDEs for excitable media. J Comput Appl Math. 2005;4(2):429–446. doi: 10.1016/j.cam.2004.06.020. [DOI] [Google Scholar]
- Soula H, Chow CC. Stochastic dynamics of a finite-size spiking neural network. Neural Comput. 2007;4(12):3262–3292. doi: 10.1162/neco.2007.19.12.3262. [DOI] [PubMed] [Google Scholar]
- van Ee R. Dynamics of perceptual bi-stability for stereoscopic slant rivalry and a comparison with grating, house-face, and Necker cube rivalry. Vis Res. 2005;4:29–40. doi: 10.1016/j.visres.2004.07.039. [DOI] [PubMed] [Google Scholar]
- Veltz R, Faugeras O. Local/global analysis of the stationary solutions of some neural field equations. SIAM J Appl Dyn Syst. 2010;4(3):954–998. doi: 10.1137/090773611. [DOI] [Google Scholar]
- Wilson H, Cowan J. A mathematical theory of the functional dynamics of cortical and thalamic nervous tissue. Biol Cybern. 1973;4(2):55–80. doi: 10.1007/BF00288786. [DOI] [PubMed] [Google Scholar]